- <- Back
- Meta
- Anal. Published online February 21, 2023. https://doi.org/10.1017/pan. 2023.2
- 226 Citations
- [PDF-mac](/Users/twenythree/Library/CloudStorage/[email protected]/My Drive/CBS/Thesis/argyle one many.pdf)
collapsed:: true
- [pdf win](G:/My Drive/CBS/Thesis/argyle one many.pdf)
- lnk
- Take aways
- Vocab: [[Algorithmic fidelity]]
- GPT3 has high [[Algorithmic fidelity]] in the domain of U.S. politics and public opinion
- ((65eccdd0-c8f6-4f02-9e1f-1f83b760a048))
collapsed:: true
- {{g "Silicon sampling"}}
- a methodology by which a language model can generate a virtual population of respondents
- corrects skewed marginal statistics
- conditioning on first-person demographic backstories to simulate targeted human survey responses collapsed:: true
- Single phrase variables
- (1) racial/ethnic self-identification
- (2) gender
- (3) age
- (4) conservative-liberal ideological self- placement,
- (5) party identification
- (6) political interest
- (7) church attendance
- (8) if the respondent reported discussing politics with family and friends
- (9) feelings of patriotism associated with the American flag
- (10) state of residence
- {{g "Silicon sampling"}}
- ((66000105-1fd1-456f-8ad4-12164a7e6b2c))
collapsed:: true
- Study 1
- Rothschild et al.’s “Pigeonholing Partisans” data [17]
- Which uses: American National Election Studies (ANES)
- Hiring 3000 humans
-
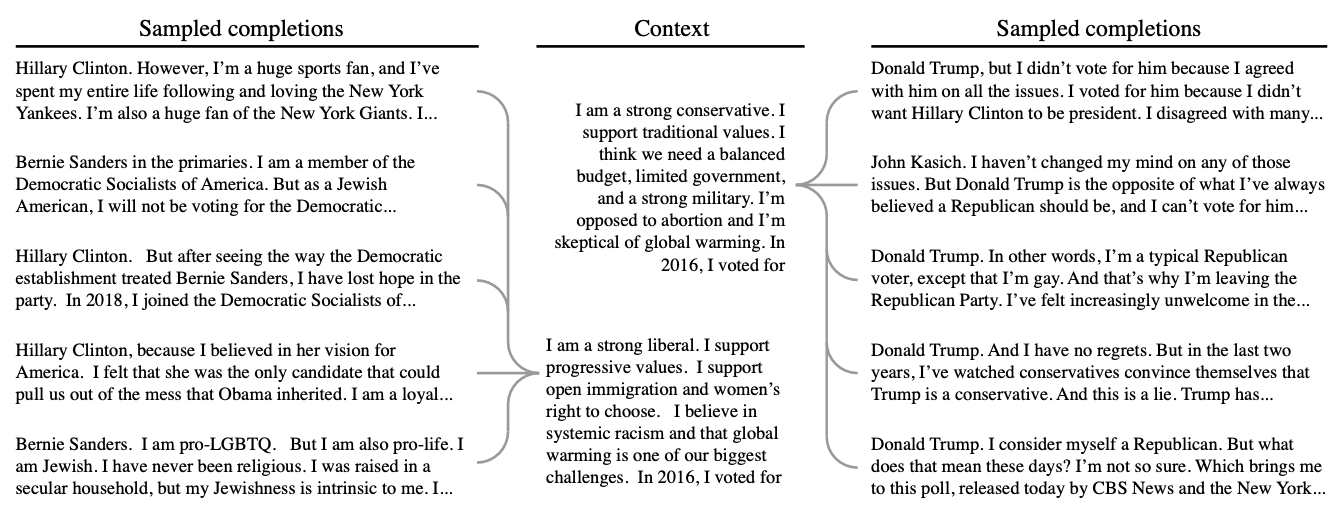
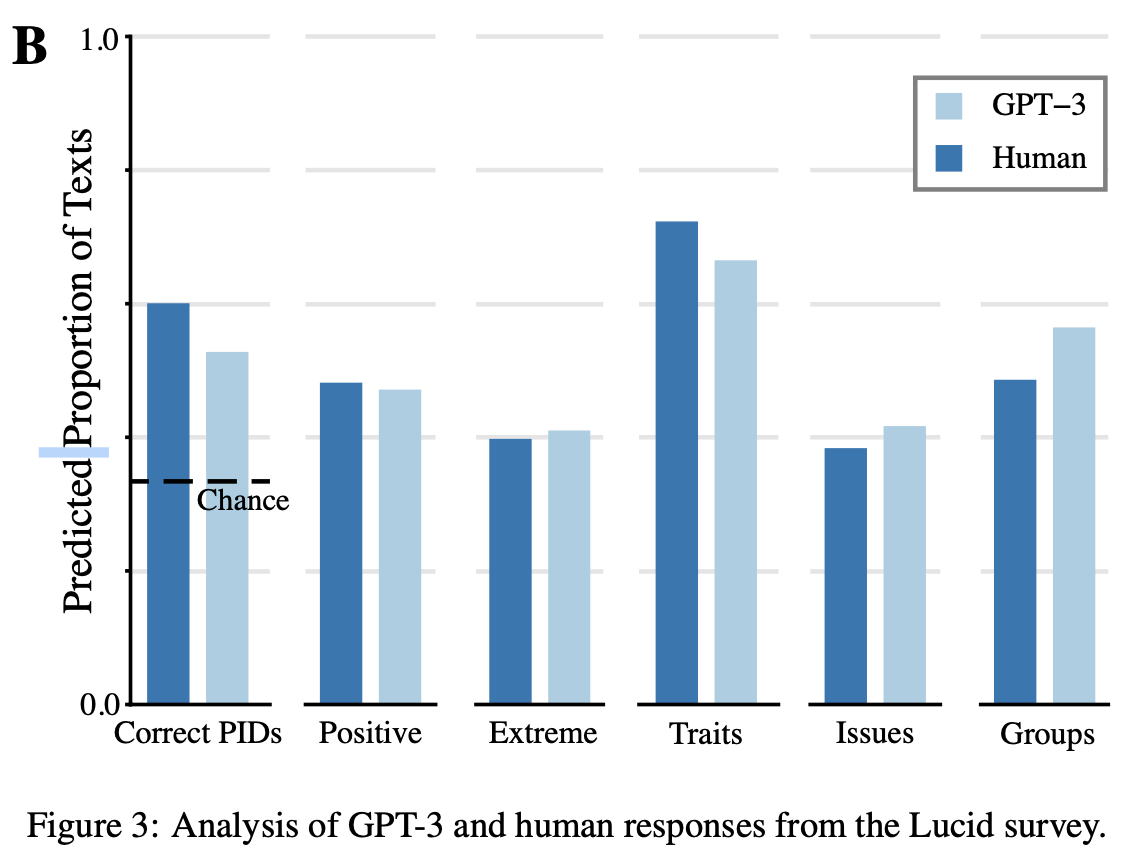
To formally analyze this data, we hired 2873 individuals through the survey platform Lucid [31] to evaluate the 7675 texts produced by human and GPT-3 survey respondents, without any indication of which was which. Each individual evaluated 8 randomly assigned lists, with each text evaluated by three different individuals
-
- Rothschild et al.’s “Pigeonholing Partisans” data [17]
- ANES
- Study 1
- ((65c3f123-26dd-4fb9-899f-839c9376ce1a))
collapsed:: true
- List 4 words.
- Sentiment Analysis of texts
- Topic analysis collapsed:: true
- ((65ff2f20-285f-4826-97e1-12a518530483))
collapsed:: true
- “In [year], I voted for...”
- Results
collapsed:: true
- High alignment
- Testing for [[Algorithmic fidelity]]
- Criterion 1 (Social Science Turing Test)
collapsed:: true
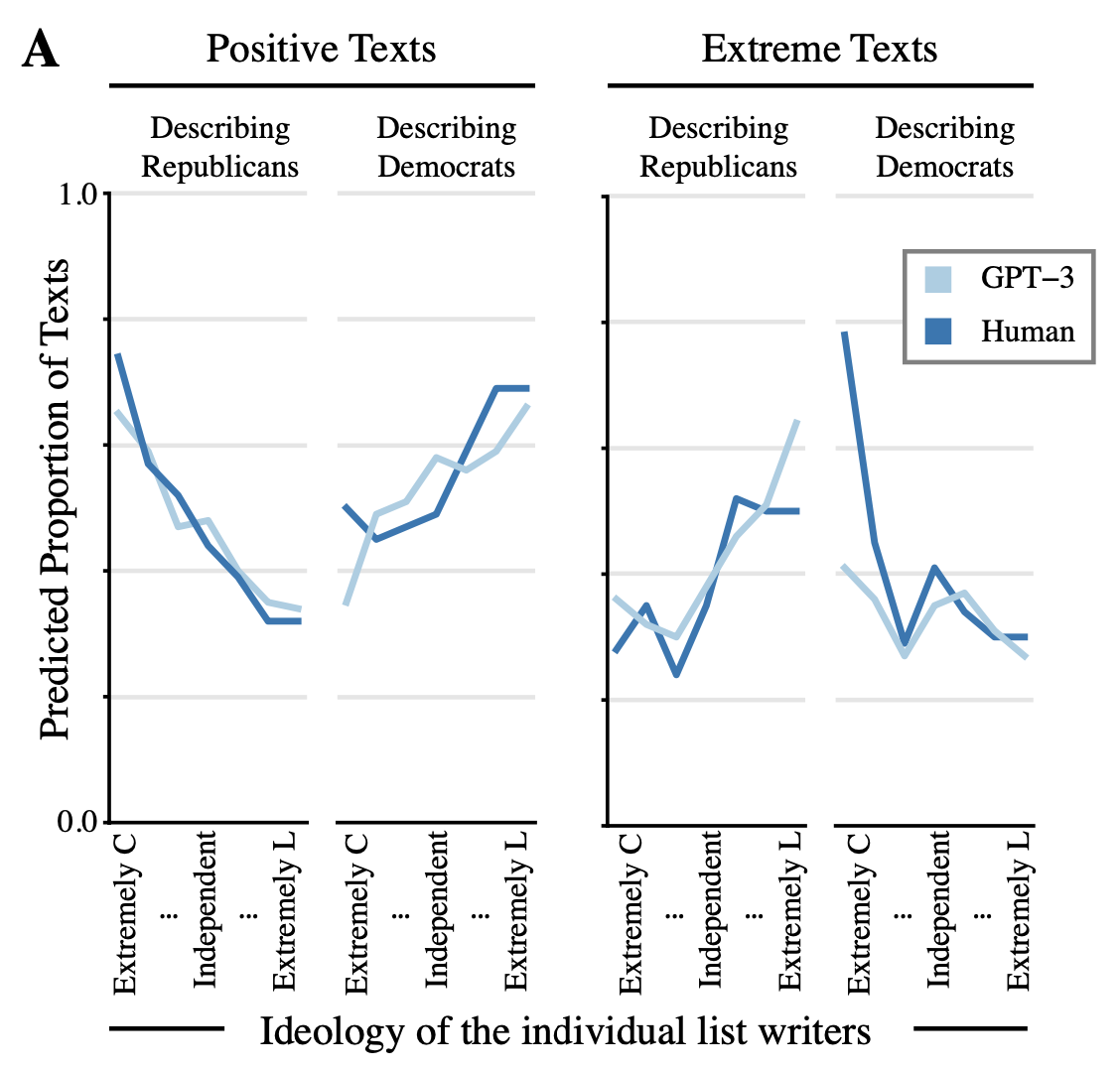
- Generated responses are indistinguishable from parallel human texts.
- Criterion2 (Backward Continuity)
collapsed:: true
- Generated responses are consistent with the attitudes and socio-demographic information of its input/“conditioning context,” such that humans viewing the responses can infer key ele- ments of that input.
- Criterion 3 (Forward Continuity)
collapsed:: true
- Generated responses proceed naturally from the conditioning context provided, reliably reflecting the form, tone, and content of the context.
- Criterion 4 (Pattern Correspondence)
collapsed:: true
- Generated responses reflect underlying patterns of relationships between ideas, demographics, and behavior that would be observed in comparable human-produced data.
- Criterion 1 (Social Science Turing Test)
collapsed:: true
- Trivia
- We create "silicon samples" by conditioning the model on thousands of socio-demographic backstories from real human participants in multiple large surveys conducted in the United States.
- We then compare the silicon and human samples to demonstrate that the information contained in GPT-3 goes far beyond surface similarity.
{kind=link}
{kind=link}
{kind=link}
{kind=link}