diff --git a/docs/handbook/engineering/incident-response.mdx b/docs/handbook/engineering/incident-response.mdx
deleted file mode 100644
index 202ab5557f..0000000000
--- a/docs/handbook/engineering/incident-response.mdx
+++ /dev/null
@@ -1,60 +0,0 @@
----
-title: "Incident Response"
-icon: 'bell-ring'
----
-
-Incident.io is our primary tool for managing and responding to urgent issues and service disruptions. This guide explains how we use incident.io to coordinate our on-call rotations and emergency response procedures.
-
-## Setup and Notifications
-
-### Personal Setup
-1. Download the incident.io mobile app from your device's app store
-2. Ask your team to add you to the incident.io workspace
-3. Configure your notification preferences:
- - Phone calls for critical incidents
- - Push notifications for high-priority issues
- - Slack notifications for standard updates
-
-### On-Call Rotations
-Our team operates on a weekly rotation schedule through incident.io, where every team member participates. When you're on-call:
-- You'll receive priority notifications for all urgent issues
-- Phone calls will be placed for critical service disruptions
-- Rotations change every week, with handoffs occurring on Monday mornings
-- Response is expected within 15 minutes for critical incidents
-
-
-
- If you are unable to respond to an incident, please escalate to the engineering team.
-
-
-
-## Creating an Incident
-
-There are three ways to create an incident:
-
-### Channel 1: Fire Emoji Reaction through Slack
-
-1. When a customer reports an issue in Slack
-2. React to the message with the 🔥 emoji
-3. This will automatically:
- - Create a new incident
- - Page the on-call engineer
- - Create a dedicated incident channel
- - Link the original message for context
-
-### Channel 2: GitHub Issue
-
-1. Create a new issue in the GitHub repository
-2. Add the `high priority` label
-3. This for immediate attention from the on-call engineer
-
-### Channel 3: Outage Notification through Digital Ocean / Checkly
-
-1. Digital Ocean will automatically notify us when there is an outage in CPU, Memory or Disk
-2. Checkly will automatically notify us when the e2e test fails and the website is down
-
-
-## Best Practices
-- Always acknowledge incident notifications
-- Update the incident status regularly
-- Document any actions taken in the incident channel
\ No newline at end of file
diff --git a/docs/handbook/engineering/on-call.mdx b/docs/handbook/engineering/on-call.mdx
deleted file mode 100644
index c716461f6e..0000000000
--- a/docs/handbook/engineering/on-call.mdx
+++ /dev/null
@@ -1,43 +0,0 @@
----
-title: 'On-Call'
-icon: 'phone'
----
-
-The on-call rotation is a simple strategy to ensure there is always someone available to fix the issue for the users, each engineer is responsible for a week and the rotation is done by the team.
-
-## Why On-Call?
-
-We need to ensure there is **exactly one person** at the same time who is the main point of contact for the users and the **first responder** for the issues. It's also a great way to learn about the product and the users and have some fun.
-
-
- You can listen to [Queen - Under Pressure](https://www.youtube.com/watch?v=a01QQZyl-_I) while on-call, it's fun and motivating.
-
-
-
- If you ever feel burn out in middle of your rotation, please reach out to the team and we will help you with the rotation or take over the responsibility.
-
-
-## When you are on-call
-
-The primary objective of being on-call is to triage issues and assist users. It is not about fixing the issues or coding missing features. Delegation is key whenever possible.
-
-You are responsible for the following:
-
-* Respond to Slack messages as soon as possible, referring to the [customer support guidelines](./customer-support.mdx).
-
-* Check [community.activepieces.com](https://community.activepieces.com) for any new issues or to learn about existing issues.
-
-
- **Friendly Tip #1**: always escalate to the team if you are unsure what to do.
-
-
-## On-Call Schedule
-
-| Week | Engineer |
-| --------------------------------- | ---------------------------------------------------------------- |
-| 25th September - 1st October 2024 | [@abuaboud](https://github.com/abuaboud) |
-| 2nd - 9th October 2024 | [@abuaboud](https://github.com/abuaboud) |
-| 9th - 13th October 2024 | [@AbdulTheActivePiecer](https://github.com/AbdulTheActivePiecer) |
-| 13th - 20th October 2024 | [@hazemadelkhalel](https://github.com/hazemadelkhalel) |
-| 20th - 27th October 2024 | [@anasbarg](https://github.com/anasbarg) |
-| 27th October - 3rd November 2024 | [@abuaboud](https://github.com/abuaboud) |
\ No newline at end of file
diff --git a/docs/handbook/engineering/how-we-work.mdx b/docs/handbook/engineering/onboarding/how-we-work.mdx
similarity index 98%
rename from docs/handbook/engineering/how-we-work.mdx
rename to docs/handbook/engineering/onboarding/how-we-work.mdx
index 832d157b64..6bfb29df90 100644
--- a/docs/handbook/engineering/how-we-work.mdx
+++ b/docs/handbook/engineering/onboarding/how-we-work.mdx
@@ -1,5 +1,5 @@
---
-title: "How We Work?"
+title: "Engineering Workflow"
icon: 'lightbulb'
---
diff --git a/docs/handbook/engineering/onboarding/on-call.mdx b/docs/handbook/engineering/onboarding/on-call.mdx
new file mode 100644
index 0000000000..9f8eb327fa
--- /dev/null
+++ b/docs/handbook/engineering/onboarding/on-call.mdx
@@ -0,0 +1,64 @@
+---
+title: 'On-Call'
+icon: 'phone'
+---
+
+## Prerequisites:
+- [Setup Incident IO](../playbooks/setup-incident-io)
+
+## Why On-Call?
+
+We need to ensure there is **exactly one person** at the same time who is the main point of contact for the users and the **first responder** for the issues. It's also a great way to learn about the product and the users and have some fun.
+
+
+ You can listen to [Queen - Under Pressure](https://www.youtube.com/watch?v=a01QQZyl-_I) while on-call, it's fun and motivating.
+
+
+
+ If you ever feel burn out in middle of your rotation, please reach out to the team and we will help you with the rotation or take over the responsibility.
+
+
+## On-Call Schedule
+
+The on-call rotation is managed through Incident.io, with each engineer taking a one-week shift. You can:
+- View the current schedule and upcoming rotations on [Incident.io On-Call Schedule](https://app.incident.io/activepieces/on-call/schedules)
+- Add the schedule to your Google Calendar using [this link](https://calendar.google.com/calendar/r?cid=webcal://app.incident.io/api/schedule_feeds/cc024d13704b618cbec9e2c4b2415666dfc8b1efdc190659ebc5886dfe2a1e4b)
+
+
+Make sure to update the on-call schedule in Incident.io if you cannot be available during your assigned rotation. This ensures alerts are routed to the correct person and maintains our incident response coverage.
+
+To modify the schedule:
+1. Go to [Incident.io On-Call Schedule](https://app.incident.io/activepieces/on-call/schedules)
+2. Find your rotation slot
+3. Click "Override schedule" to mark your unavailability
+4. Coordinate with the team to find coverage for your slot
+
+
+
+## What it means to be on-call
+
+The primary objective of being on-call is to triage issues and assist users. It is not about fixing the issues or coding missing features. Delegation is key whenever possible.
+
+You are responsible for the following:
+
+* Respond to Slack messages as soon as possible, referring to the [customer support guidelines](./customer-support.mdx).
+
+* Check [community.activepieces.com](https://community.activepieces.com) for any new issues or to learn about existing issues.
+
+* Monitor your Incident.io notifications and respond promptly when paged.
+
+
+ **Friendly Tip #1**: always escalate to the team if you are unsure what to do.
+
+
+## How do you get paged?
+
+Monitor and respond to incidents that come through these channels:
+
+#### Slack Fire Emoji (🔥)
+When a customer reports an issue in Slack and someone reacts with 🔥, you'll be automatically paged and a dedicated incident channel will be created.
+
+#### Automated Alerts
+Watch for notifications from:
+ - Digital Ocean about CPU, Memory, or Disk outages
+ - Checkly about e2e test failures or website downtime
diff --git a/docs/handbook/engineering/overview.mdx b/docs/handbook/engineering/overview.mdx
new file mode 100644
index 0000000000..c035fdf20b
--- /dev/null
+++ b/docs/handbook/engineering/overview.mdx
@@ -0,0 +1,8 @@
+---
+title: "Overview"
+icon: "code"
+---
+
+Welcome to the engineering team! This section contains essential information to help you get started, including our development processes, guidelines, and practices. We're excited to have you on board.
+
+
diff --git a/docs/handbook/engineering/playbooks/bullboard.mdx b/docs/handbook/engineering/playbooks/bullboard.mdx
new file mode 100644
index 0000000000..c6158864d2
--- /dev/null
+++ b/docs/handbook/engineering/playbooks/bullboard.mdx
@@ -0,0 +1,91 @@
+---
+title: "Queues Dashboard"
+icon: "gauge-high"
+---
+
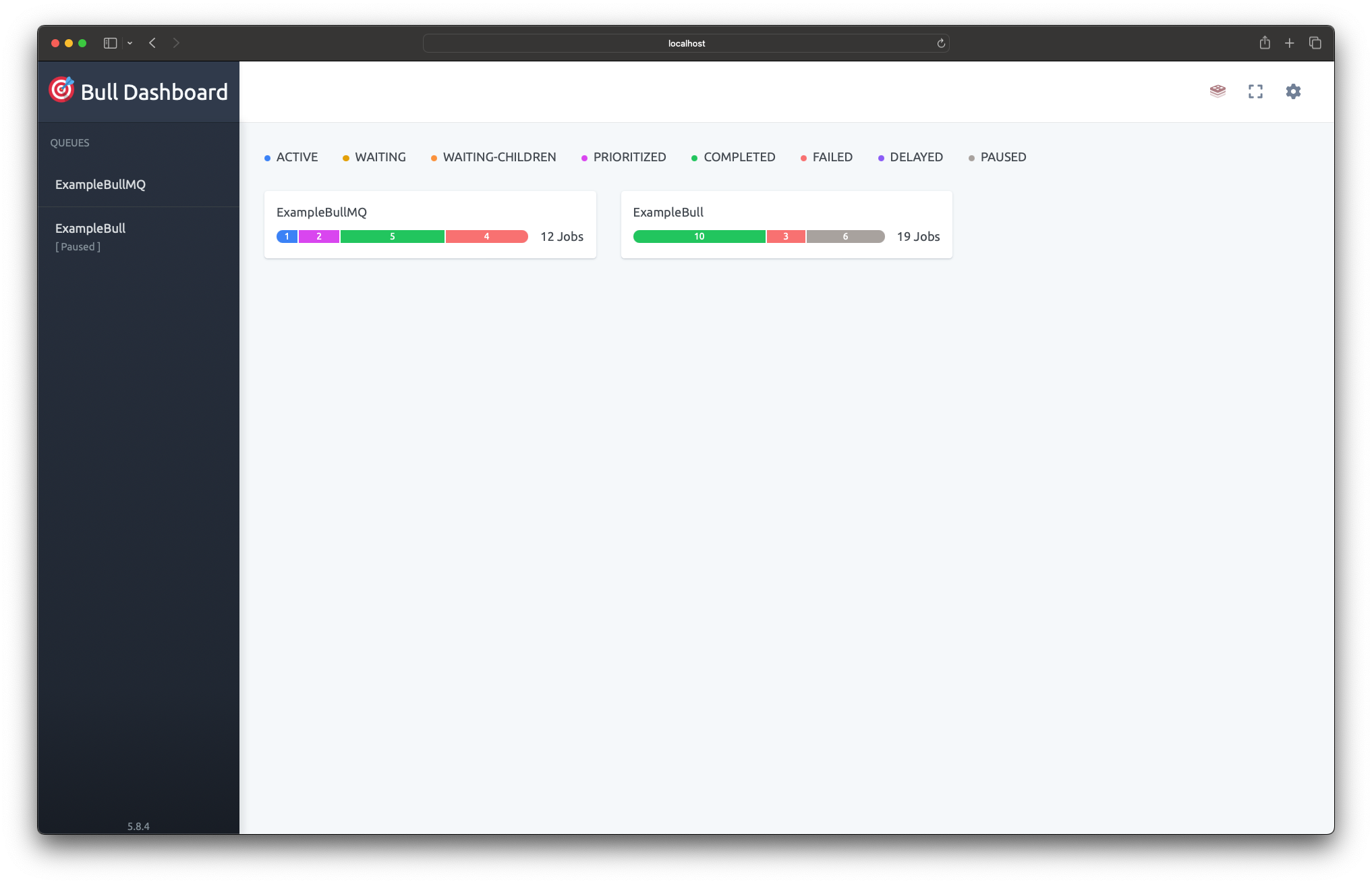
+The Bull Board is a tool that allows you to check issues with scheduling and internal flow runs issues.
+
+
+
+## Setup BullBoard
+
+To enable the Bull Board UI in your self-hosted installation:
+
+1. Define these environment variables:
+ - `AP_QUEUE_UI_ENABLED`: Set to `true`
+ - `AP_QUEUE_UI_USERNAME`: Set your desired username
+ - `AP_QUEUE_UI_PASSWORD`: Set your desired password
+
+2. Access the UI at `/api/ui`
+
+
+
+For cloud installations, please ask your team for access to the internal documentation that explains how to access BullBoard.
+
+
+## Common Issues
+
+### Scheduling Issues
+
+If a scheduled flow is not triggering as expected:
+
+1. Check the `repeatableJobs` queue in BullBoard to verify the job exists
+2. Verify the job status is not "failed" or "delayed"
+3. Check that the cron expression or interval is configured correctly
+4. Look for any error messages in the job details
+
+### Flow Stuck in "Running" State
+
+If a flow appears stuck in the running state:
+
+1. Check the `oneTimeJobs` queue for the corresponding job
+2. Look for:
+ - Jobs in "delayed" state (indicates retry attempts)
+ - Jobs in "failed" state (indicates execution errors)
+3. Review the job logs for error messages or timeouts
+4. If needed, you can manually remove stuck jobs through the BullBoard UI
+
+## Queue Overview
+
+We maintain four main queues in our system:
+
+#### Scheduled Queue (`repeatableJobs`)
+
+Contains both polling and delayed jobs.
+
+
+Failed jobs are not normal and need to be checked right away to find and fix what's causing them.
+
+
+
+Delayed jobs represent either paused flows scheduled for future execution or upcoming polling job iterations.
+
+
+#### One-Time Queue (`oneTimeJobs`)
+Handles immediate flow executions that run only once
+
+
+- Delayed jobs indicate an internal system error occurred and the job will be retried automatically according to the backoff policy
+- Failed jobs require immediate investigation as they represent executions that failed for unknown reasons that could indicate system issues
+
+
+#### Webhook Queue (`webhookJobs`)
+
+Handles incoming webhook triggers
+
+
+- Delayed jobs indicate an internal system error occurred and the job will be retried automatically according to the backoff policy
+- Failed jobs require immediate investigation as they represent executions that failed for unknown reasons that could indicate system issues
+
+
+#### Users Interaction Queue (`usersInteractionJobs`)
+
+Handles operations that are directly initiated by users, including:
+• Installing pieces
+• Testing flows
+• Loading dropdown options
+• Executing triggers
+• Executing actions
+
+Failed jobs in this queue are not retried since they represent real-time user actions that should either succeed or fail immediately
+
diff --git a/docs/handbook/engineering/playbooks/database-migration.mdx b/docs/handbook/engineering/playbooks/database-migration.mdx
new file mode 100644
index 0000000000..7cc945bd10
--- /dev/null
+++ b/docs/handbook/engineering/playbooks/database-migration.mdx
@@ -0,0 +1,94 @@
+---
+title: "Database Migrations"
+description: "Guide for creating database migrations in Activepieces"
+icon: "database"
+---
+
+Activepieces uses TypeORM as its database driver in Node.js. We support two database types across different editions of our platform.
+
+The database migration files contain both what to do to migrate (up method) and what to do when rolling back (down method).
+
+
+Read more about TypeORM migrations here:
+https://orkhan.gitbook.io/typeorm/docs/migrations
+
+
+## Database Support
+
+- PostgreSQL
+- SQLite
+
+
+**Why Do we have SQLite?**
+We support SQLite to simplify development and self-hosting. It's particularly helpful for:
+
+- Developers creating pieces who want a quick setup
+- Self-hosters using platforms to manage docker images but doesn't support docker compose.
+
+
+## Editions
+
+- **Enterprise & Cloud Edition** (Must use PostgreSQL)
+- **Community Edition** (Can use PostgreSQL or SQLite)
+
+
+If you are generating a migration for an entity that will only be used in Cloud & Enterprise editions, you only need to create the PostgreSQL migration file. You can skip generating the SQLite migration.
+
+
+
+### How To Generate
+
+
+
+ Uncomment the following line in `packages/server/api/src/app/database/database-connection.ts`:
+ ```typescript
+ export const exportedConnection = databaseConnection()
+ ```
+
+
+
+ Edit your `.env` file to set the database type:
+
+ ```env
+ # For SQLite migrations (default)
+ AP_DATABASE_TYPE=SQLITE
+ ```
+
+ For PostgreSQL migrations:
+ ```env
+ AP_DATABASE_TYPE=POSTGRES
+ AP_POSTGRES_DATABASE=activepieces
+ AP_POSTGRES_HOST=db
+ AP_POSTGRES_PORT=5432
+ AP_POSTGRES_USERNAME=postgres
+ AP_POSTGRES_PASSWORD=password
+ ```
+
+
+
+ Run the migration generation command:
+ ```bash
+ nx db-migration server-api name=
+ ```
+ Replace `` with a descriptive name for your migration.
+
+
+
+ The command will generate a new migration file in `packages/server/api/src/app/database/migrations`.
+ Review the generated file and:
+
+ - For PostgreSQL migrations: Move it to `postgres-connection.ts`
+ - For SQLite migrations: Move it to `sqlite-connection.ts`
+
+
+
+ After moving the file, remember to re-comment the line from step 1:
+ ```typescript
+ // export const exportedConnection = databaseConnection()
+ ```
+
+
+
+
+Always test your migrations by running them both up and down to ensure they work as expected.
+
diff --git a/docs/handbook/engineering/playbooks/infrastructure.mdx b/docs/handbook/engineering/playbooks/infrastructure.mdx
new file mode 100644
index 0000000000..eb6aa51653
--- /dev/null
+++ b/docs/handbook/engineering/playbooks/infrastructure.mdx
@@ -0,0 +1,26 @@
+---
+title: "Cloud Infrastructure"
+icon: "server"
+---
+
+
+ The playbooks are private, Please ask your team for an access.
+
+
+
+Our infrastructure stack consists of several key components that help us monitor, deploy, and manage our services effectively.
+
+## Hosting Providers
+
+We use two main hosting providers:
+
+- **DigitalOcean**: Hosts our databases including Redis and PostgreSQL
+- **Hetzner**: Provides the machines that run our services
+
+## Grafana (Loki) for Logs
+
+We use Grafana Loki to collect and search through logs from all our services in one centralized place.
+
+## Kamal for Deployment
+
+Kamal is a deployment tool that helps us deploy our Docker containers to production with zero downtime.
diff --git a/docs/handbook/engineering/pre-releases.mdx b/docs/handbook/engineering/playbooks/releases.mdx
similarity index 98%
rename from docs/handbook/engineering/pre-releases.mdx
rename to docs/handbook/engineering/playbooks/releases.mdx
index 820f754738..eda2ddecb7 100644
--- a/docs/handbook/engineering/pre-releases.mdx
+++ b/docs/handbook/engineering/playbooks/releases.mdx
@@ -1,5 +1,5 @@
---
-title: 'Pre-Releases'
+title: 'How to create Release'
icon: 'flask'
---
diff --git a/docs/handbook/engineering/playbooks/setup-incident-io.mdx b/docs/handbook/engineering/playbooks/setup-incident-io.mdx
new file mode 100644
index 0000000000..3ced699f9a
--- /dev/null
+++ b/docs/handbook/engineering/playbooks/setup-incident-io.mdx
@@ -0,0 +1,30 @@
+---
+title: "Setup Incident.io"
+icon: 'bell-ring'
+---
+
+Incident.io is our primary tool for managing and responding to urgent issues and service disruptions.
+This guide explains how we use Incident.io to coordinate our on-call rotations and emergency response procedures.
+
+## Setup and Notifications
+
+### Personal Setup
+
+1. Download the Incident.io mobile app from your device's app store
+2. Ask your team to add you to the Incident.io workspace
+3. Configure your notification preferences:
+ - Phone calls for critical incidents
+ - Push notifications for high-priority issues
+ - Slack notifications for standard updates
+
+### On-Call Rotations
+
+Our team operates on a weekly rotation schedule through Incident.io, where every team member participates. When you're on-call:
+- You'll receive priority notifications for all urgent issues
+- Phone calls will be placed for critical service disruptions
+- Rotations change every week, with handoffs occurring on Monday mornings
+- Response is expected within 15 minutes for critical incidents
+
+
+ If you are unable to respond to an incident, please escalate to the engineering team.
+
diff --git a/docs/install/configuration/troubleshooting.mdx b/docs/install/configuration/troubleshooting.mdx
index 67fc8b9027..2c96b05817 100644
--- a/docs/install/configuration/troubleshooting.mdx
+++ b/docs/install/configuration/troubleshooting.mdx
@@ -20,28 +20,9 @@ To resolve these issues:
### Runs with Internal Errors or Scheduling Issues
-The Bull Board is a tool that allows you to check runs for issues.
-It is accessible when you are using Redis as the queue system. In production mode, you can access it at `/api/ui`, and in development mode, it is located at `/ui`.
-
-To enable the Bull Board UI, follow these steps:
-
-1. Define the following environment variables:
- - `AP_QUEUE_UI_ENABLED`: Set it to `true`.
- - `AP_QUEUE_UI_USERNAME`: Set it to your desired username.
- - `AP_QUEUE_UI_PASSWORD`: Set it to your desired password.
-
-Make sure to change the username and password to your preferred values.
-
-You will be able to access the Bull Board UI at `/api/ui` (production) or `/ui` (development) depending on your environment.
-
-
-
-There are two queues that you can monitor:
-- oneTimeJobs: This queue is used for currently pending runs.
-- repeatableJobs: This queue is used for polling triggers.
-
-In case you have flows with internal errors, please go to the oneTimeJobs queue and click on the failed run. You can see the error message in the data section and retry the flow by clicking on the retry button.
+If you're experiencing issues with flow runs showing internal errors or scheduling problems:
+[BullBoard dashboard](/handbook/engineering/playbooks/bullboard)
### Truncated logs
diff --git a/docs/mint.json b/docs/mint.json
index 58b43d60ee..ebfa80c69a 100644
--- a/docs/mint.json
+++ b/docs/mint.json
@@ -116,13 +116,23 @@
]
},
{
- "group": "Engineering",
+ "group": "Engineering Onboarding",
"icon": "code",
"pages": [
- "handbook/engineering/how-we-work",
- "handbook/engineering/on-call",
- "handbook/engineering/incident-response",
- "handbook/engineering/pre-releases"
+ "handbook/engineering/overview",
+ "handbook/engineering/onboarding/how-we-work",
+ "handbook/engineering/onboarding/on-call"
+ ]
+ },
+ {
+ "group": "Engineering Playbooks",
+ "icon": "code",
+ "pages": [
+ "handbook/engineering/playbooks/setup-incident-io",
+ "handbook/engineering/playbooks/releases",
+ "handbook/engineering/playbooks/infrastructure",
+ "handbook/engineering/playbooks/bullboard",
+ "handbook/engineering/playbooks/database-migration"
]
},
{