New Workflow Submit: Distributed Data Stream Aggregator – No-Lambda, Low-Code 3-Tier Architecture for Scalable Data Processing #405
Description
Description
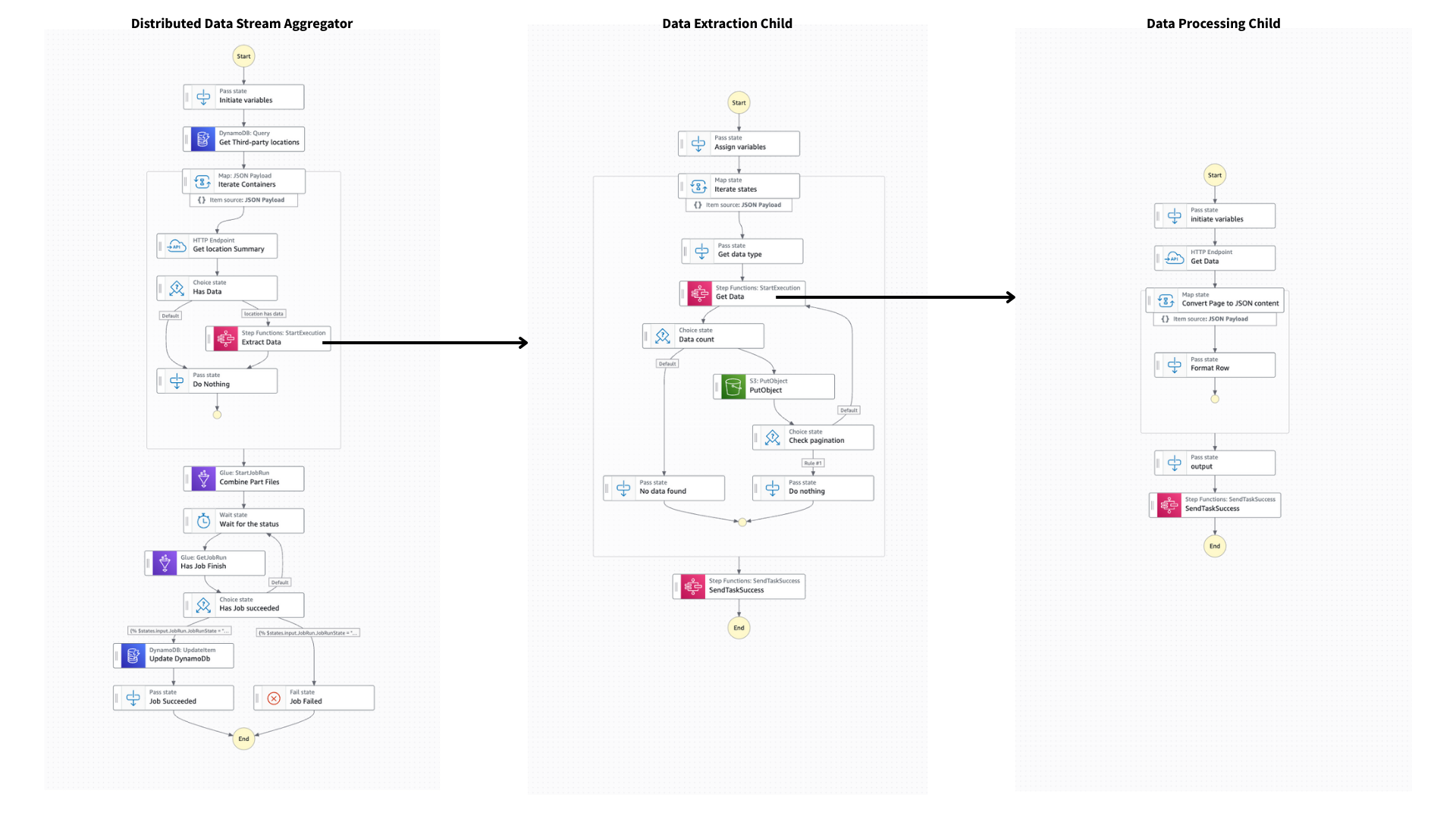
This workflow demonstrates how to orchestrate large-scale data aggregation from multiple third-party sources using AWS Step Functions with a no-Lambda, low-code approach. By relying exclusively on Step Functions’ native integrations, JSONata expressions, and AWS managed services, this workflow provides a cost-optimized, scalable, and production-ready solution for high-throughput data ingestion and processing.
The architecture is composed of three coordinated state machines, each serving a specific role in the data lifecycle. The main workflow (Standard) manages the overall orchestration, including querying metadata from DynamoDB, launching distributed processing tasks with the Distributed Map state, and handling lifecycle events. A child workflow (Standard) focuses on data extraction, managing paginated retrieval of large datasets from external APIs. Finally, a child workflow (Express) executes high-frequency third-party API calls at scale, designed to handle bursty traffic patterns with millisecond-level latency.
Partial results from each branch execution are stored in Amazon S3, ensuring durability and scalability. Once all data segments are available, an AWS Glue job consolidates these intermediate outputs into a unified dataset, which can then be used for downstream analytics or machine learning workloads. This approach minimizes custom code—limited to a small Glue ETL script—while keeping orchestration logic declarative and transparent within Step Functions.
Key features include robust retry and error-handling strategies, ensuring fault tolerance in the face of throttling, transient errors, or third-party outages. The architecture leverages advanced Step Functions patterns such as 3-tier orchestration, Distributed Map for parallelization, and JSONata for payload manipulation, making it suitable for enterprise-scale workloads. By avoiding Lambda functions entirely, the workflow reduces cold-start latency, lowers operational costs, and simplifies IAM/security auditing.
This pattern is ideal for organizations that need to consolidate data from multiple external providers or APIs, particularly where volume, reliability, and cost-efficiency are critical. It provides a reference for teams seeking to maximize Step Functions’ native service integrations while minimizing the operational burden of managing custom compute.
Simplicity
3 - Application
Diagram
Type
Standard (Main workflow)
(Child workflows include one Standard and one Express for demonstration.)
Resources
- AWS Step Functions Developer Guide – Service Integrations
- Using Distributed Map for Large-Scale Parallel Processing
- AWS Glue Documentation
- Error Handling in AWS Step Functions
Framework
SAM
Author Bio
Aparna Saha – Cloud Architect focused on serverless data processing.