Releases: databricks/koalas
Version 1.0.1
Critical bug fix
We fixed a critical bug introduced in Koalas 1.0.0 (#1609).
If we call DataFrame.rename with columns parameter after some operations on the DataFrame, the operations will be lost:
>>> kdf = ks.DataFrame([[1, 2, 3, 4], [5, 6, 7, 8]], columns=["A", "B", "C", "D"])
>>> kdf1 = kdf + 1
>>> kdf1
A B C D
0 2 3 4 5
1 6 7 8 9
>>> kdf1.rename(columns={"A": "aa", "B": "bb"})
aa bb C D
0 1 2 3 4
1 5 6 7 8This should be:
>>> pdf1.rename(columns={"A": "aa", "B": "bb"})
aa bb C D
0 2 3 4 5
1 6 7 8 9Other improvements
Version 1.0.0
Better pandas API coverage
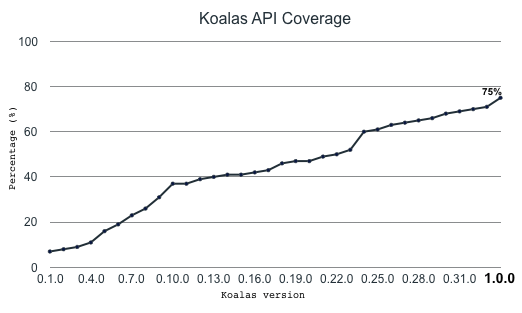
We implemented many APIs and features equivalent with pandas such as plotting, grouping, windowing, I/O, and transformation, and now Koalas reaches the pandas API coverage close to 80% in Koalas 1.0.0.
Apache Spark 3.0
Apache Spark 3.0 is now supported in Koalas 1.0 (#1586, #1558). Koalas does not require any change to use Spark 3.0. Apache Spark has more than 3400 fixes landed in Spark 3.0 and Koalas shares the most of fixes in many other components.
It also brings the performance improvement in Koalas APIs that execute Python native functions internally via pandas UDFs, for example, DataFrame.apply and DataFrame.apply_batch (#1508).
Python 3.8
With Apache Spark 3.0, Koalas supports the latest Python 3.8 which has many significant improvements (#1587), see also Python 3.8.0 release notes.
Spark accessor
spark accessor was introduced from Koalas 1.0.0 in order for the Koalas users to leverage the existing PySpark APIs more easily (#1530). For example, you can apply the PySpark functions as below:
import databricks.koalas as ks
import pyspark.sql.functions as F
kss = ks.Series([1, 2, 3, 4])
kss.spark.apply(lambda s: F.collect_list(s))Better type hint support
In the early versions, it was required to use Koalas instances as the return type hints for the functions that return a pandas instances, which looks slightly awkward.
def pandas_div(pdf) -> koalas.DataFrame[float, float]:
# pdf is a pandas DataFrame,
return pdf[['B', 'C']] / pdf[['B', 'C']]
df = ks.DataFrame({'A': ['a', 'a', 'b'], 'B': [1, 2, 3], 'C': [4, 6, 5]})
df.groupby('A').apply(pandas_div)In Koalas 1.0.0 with Python 3.7+, you can also use pandas instances in the return type as below:
def pandas_div(pdf) -> pandas.DataFrame[float, float]:
return pdf[['B', 'C']] / pdf[['B', 'C']]In addition, the new type hinting is experimentally introduced in order to allow users to specify column names in the type hints as below (#1577):
def pandas_div(pdf) -> pandas.DataFrame['B': float, 'C': float]:
return pdf[['B', 'C']] / pdf[['B', 'C']]See also the guide in Koalas documentation (#1584) for more details.
Wider support of in-place update
Previously in-place updates happen only within each DataFrame or Series, but now the behavior follows pandas in-place updates and the update of one side also updates the other side (#1592).
For example, the following updates kdf as well.
kdf = ks.DataFrame({"x": [np.nan, 2, 3, 4, np.nan, 6]})
kser = kdf.x
kser.fillna(0, inplace=True)kdf = ks.DataFrame({"x": [np.nan, 2, 3, 4, np.nan, 6]})
kser = kdf.x
kser.loc[2] = 30kdf = ks.DataFrame({"x": [np.nan, 2, 3, 4, np.nan, 6]})
kser = kdf.x
kdf.loc[2, 'x'] = 30If the DataFrame and Series are connected, the in-place updates update each other.
Less restriction on compute.ops_on_diff_frames
In Koalas 1.0.0, the restriction of compute.ops_on_diff_frames became much more loosened (#1522, #1554). For example, the operations such as below can be performed without enabling compute.ops_on_diff_frames, which can be expensive due to the shuffle under the hood.
df + df + df
df['foo'] = df['bar']['baz']
df[['x', 'y']] = df[['x', 'y']].fillna(0)Other new features and improvements
DataFrame:
__bool__(#1526)explode(#1507)spark.apply(#1536)spark.schema(#1530)spark.print_schema(#1530)spark.frame(#1530)spark.cache(#1530)spark.persist(#1530)spark.hint(#1530)spark.to_table(#1530)spark.to_spark_io(#1530)spark.explain(#1530)spark.apply(#1530)mad(#1538)__abs__(#1561)
Series:
item(#1502, #1518)divmod(#1397)rdivmod(#1397)unstack(#1501)mad(#1503)__bool__(#1526)to_markdown(#1510)spark.apply(#1536)spark.data_type(#1530)spark.nullable(#1530)spark.column(#1530)spark.transform(#1530)filter(#1511)__abs__(#1561)bfill(#1580)ffill(#1580)
Index:
__bool__(#1526)spark.data_type(#1530)spark.column(#1530)spark.transform(#1530)get_level_values(#1517)delete(#1165)__abs__(#1561)holds_integer(#1547)
MultiIndex:
__bool__(#1526)spark.data_type(#1530)spark.column(#1530)spark.transform(#1530)get_level_values(#1517)delete(#1165__abs__(#1561)holds_integer(#1547)
Along with the following improvements:
- Fix Series.clip not to create a new DataFrame. (#1525)
- Fix combine_first to support tupled names. (#1534)
- Add Spark accessors to usage logging. (#1540)
- Implements multi-index support in Dataframe.filter (#1512)
- Fix Series.fillna to avoid Spark jobs. (#1550)
- Support DataFrame.spark.explain(extended: str) case. (#1563)
- Support Series as repeats in Series.repeat. (#1573)
- Fix fillna to handle NaN properly. (#1572)
- Fix DataFrame.replace to avoid creating a new Spark DataFrame. (#1575)
- Cache an internal pandas object to avoid run twice in Jupyter. (#1564)
- Fix Series.div when div/floordiv np.inf by zero (#1463)
- Fix Series.unstack to support non-numeric type and keep the names (#1527)
- Fix hasnans to follow the modified column. (#1532)
- Fix explode to use internal methods. (#1538)
- Fix RollingGroupby and ExpandingGroupby to handle agg_columns. (#1546)
- Fix reindex not to update internal. (#1582)
Backward Compatibility
Version 0.33.0
apply and transform Improvements
We added supports to have positional/keyword arguments for apply, apply_batch, transform, and transform_batch in DataFrame, Series, and GroupBy. (#1484, #1485, #1486)
>>> ks.range(10).apply(lambda a, b, c: a + b + c, args=(1,), c=3)
id
0 4
1 5
2 6
3 7
4 8
5 9
6 10
7 11
8 12
9 13>>> ks.range(10).transform_batch(lambda pdf, a, b, c: pdf.id + a + b + c, 1, 2, c=3)
0 6
1 7
2 8
3 9
4 10
5 11
6 12
7 13
8 14
9 15
Name: id, dtype: int64>>> kdf = ks.DataFrame(
... {"a": [1, 2, 3, 4, 5, 6], "b": [1, 1, 2, 3, 5, 8], "c": [1, 4, 9, 16, 25, 36]},
... columns=["a", "b", "c"])
>>> kdf.groupby(["a", "b"]).apply(lambda x, y, z: x + x.min() + y + z, 1, z=2)
a b c
0 5 5 5
1 7 5 11
2 9 7 21
3 11 9 35
4 13 13 53
5 15 19 75Spark Schema
We add spark_schema and print_schema to know the underlying Spark Schema. (#1446)
>>> kdf = ks.DataFrame({'a': list('abc'),
... 'b': list(range(1, 4)),
... 'c': np.arange(3, 6).astype('i1'),
... 'd': np.arange(4.0, 7.0, dtype='float64'),
... 'e': [True, False, True],
... 'f': pd.date_range('20130101', periods=3)},
... columns=['a', 'b', 'c', 'd', 'e', 'f'])
>>> # Print the schema out in Spark’s DDL formatted string
>>> kdf.spark_schema().simpleString()
'struct<a:string,b:bigint,c:tinyint,d:double,e:boolean,f:timestamp>'
>>> kdf.spark_schema(index_col='index').simpleString()
'struct<index:bigint,a:string,b:bigint,c:tinyint,d:double,e:boolean,f:timestamp>'
>>> # Print out the schema as same as DataFrame.printSchema()
>>> kdf.print_schema()
root
|-- a: string (nullable = false)
|-- b: long (nullable = false)
|-- c: byte (nullable = false)
|-- d: double (nullable = false)
|-- e: boolean (nullable = false)
|-- f: timestamp (nullable = false)
>>> kdf.print_schema(index_col='index')
root
|-- index: long (nullable = false)
|-- a: string (nullable = false)
|-- b: long (nullable = false)
|-- c: byte (nullable = false)
|-- d: double (nullable = false)
|-- e: boolean (nullable = false)
|-- f: timestamp (nullable = false)GroupBy Improvements
We fixed many bugs of GroupBy as listed below.
- Fix groupby when as_index=False. (#1457)
- Make groupby.apply in pandas<0.25 run the function only once per group. (#1462)
- Fix Series.groupby on the Series from different DataFrames. (#1460)
- Fix GroupBy.head to recognize agg_columns. (#1474)
- Fix GroupBy.filter to follow complex group keys. (#1471)
- Fix GroupBy.transform to follow complex group keys. (#1472)
- Fix GroupBy.apply to follow complex group keys. (#1473)
- Fix GroupBy.fillna to use GroupBy._apply_series_op. (#1481)
- Fix GroupBy.filter and apply to handle agg_columns. (#1480)
- Fix GroupBy apply, filter, and head to ignore temp columns when ops from different DataFrames. (#1488)
- Fix GroupBy functions which need natural orderings to follow the order when opts from different DataFrames. (#1490)
Other new features and improvements
We added the following new feature:
SeriesGroupBy:
filter(#1483)
Other improvements
- dtype for DateType should be np.dtype("object"). (#1447)
- Make reset_index disallow the same name but allow it when drop=True. (#1455)
- Fix named aggregation for MultiIndex (#1435)
- Raise ValueError that is not raised now (#1461)
- Fix get dummies when uses the prefix parameter whose type is dict (#1478)
- Simplify DataFrame.columns setter. (#1489)
Version 0.32.0
Koalas documentation redesign
Koalas documentation was redesigned with a better theme, pydata-sphinx-theme. Please check the new Koalas documentation site out.

transform_batch and apply_batch
We added the APIs that enable you to directly transform and apply a function against Koalas Series or DataFrame. map_in_pandas is deprecated and now renamed to apply_batch.
import databricks.koalas as ks
kdf = ks.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf + 1 # should always return the same length as input.
kdf.transform_batch(pandas_plus)import databricks.koalas as ks
kdf = ks.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf[pdf.a > 1] # allow arbitrary length
kdf.apply_batch(pandas_plus)Please also check Transform and apply a function in Koalas documentation.
Other new features and improvements
We added the following new feature:
DataFrame:
SeriesGroupBy:
unique(#1426)
Index:
spark_column(#1438)
Series:
spark_column(#1438)
MultiIndex:
spark_column(#1438)
Other improvements
- Fix from_pandas to handle the same index name as a column name. (#1419)
- Add documentation about non-Koalas APIs (#1420)
- Hot-fixing the lack of keyword argument 'deep' for DataFrame.copy() (#1423)
- Fix Series.div when divide by zero (#1412)
- Support expand parameter if n is a positive integer in Series.str.split/rsplit. (#1432)
- Make Series.astype(bool) follow the concept of "truthy" and "falsey". (#1431)
- Fix incompatible behaviour with pandas for floordiv with np.nan (#1429)
- Use mapInPandas for apply_batch API in Spark 3.0 (#1440)
- Use F.datediff() for subtraction of dates as a workaround. (#1439)
Version 0.31.0
PyArrow>=0.15 support is back
We added PyArrow>=0.15 support back (#1110).
Note that, when working with pyarrow>=0.15 and pyspark<3.0, Koalas will set an environment variable ARROW_PRE_0_15_IPC_FORMAT=1 if it does not exist, as per the instruction in SPARK-29367, but it will NOT work if there is a Spark context already launched. In that case, you have to manage the environment variable by yourselves.
Spark specific improvements
Broadcast hint
We added broadcast function in namespace.py (#1360).
We can use it with merge, join, and update which invoke join operation in Spark when you know one of the DataFrame is small enough to fit in memory, and we can expect much more performant than shuffle-based joins.
For example,
>>> merged = df1.merge(ks.broadcast(df2), left_on='lkey', right_on='rkey')
>>> merged.explain()
== Physical Plan ==
...
...BroadcastHashJoin...
...persist function and storage level
We added persist function to specify the storage level when caching (#1381), and also, we added storage_level property to check the current storage level (#1385).
>>> with df.cache() as cached_df:
... print(cached_df.storage_level)
...
Disk Memory Deserialized 1x Replicated
>>> with df.persist(pyspark.StorageLevel.MEMORY_ONLY) as cached_df:
... print(cached_df.storage_level)
...
Memory Serialized 1x ReplicatedOther new features and improvements
We added the following new feature:
DataFrame:
Series:
Other improvements
- Add a way to specify index column in I/O APIs (#1379)
- Fix
iloc.__setitem__with the other Series from the same DataFrame. (#1388) - Add support Series from different DataFrames for
loc/iloc.__setitem__. (#1391) - Refine
__setitem__for loc/iloc with DataFrame. (#1394) - Help misuse of options argument. (#1402)
- Add blog posts in Koalas documentation (#1406)
- Fix mod & rmod for matching with pandas. (#1399)
Version 0.30.0
Slice column selection support in loc
We continue to improve loc indexer and added the slice column selection support (#1351).
>>> from databricks import koalas as ks
>>> df = ks.DataFrame({'a':list('abcdefghij'), 'b':list('abcdefghij'), 'c': range(10)})
>>> df.loc[:, "b":"c"]
b c
0 a 0
1 b 1
2 c 2
3 d 3
4 e 4
5 f 5
6 g 6
7 h 7
8 i 8
9 j 9Slice row selection support in loc for multi-index
We also added the support of slice as row selection in loc indexer for multi-index (#1344).
>>> from databricks import koalas as ks
>>> import pandas as pd
>>> df = ks.DataFrame({'a': range(3)}, index=pd.MultiIndex.from_tuples([("a", "b"), ("a", "c"), ("b", "d")]))
>>> df.loc[("a", "c"): "b"]
a
a c 1
b d 2Slice row selection support in iloc
We continued to improve iloc indexer to support iterable indexes as row selection (#1338).
>>> from databricks import koalas as ks
>>> df = ks.DataFrame({'a':list('abcdefghij'), 'b':list('abcdefghij')})
>>> df.iloc[[-1, 1, 2, 3]]
a b
1 b b
2 c c
3 d d
9 j jSupport of setting values via loc and iloc at Series
Now, we added the basic support of setting values via loc and iloc at Series (#1367).
>>> from databricks import koalas as ks
>>> kser = ks.Series([1, 2, 3], index=["cobra", "viper", "sidewinder"])
>>> kser.loc[kser % 2 == 1] = -kser
>>> kser
cobra -1
viper 2
sidewinder -3Other new features and improvements
We added the following new feature:
DataFrame:
Series:
Index:
MultiIndex:
Other improvements
- Compute Index.is_monotonic/Index.is_monotonic_decreasing in a distributed manner (#1354)
- Fix SeriesGroupBy.apply() to respect various output (#1339)
- Add the support for operations between different DataFrames in groupby() (#1321)
- Explicitly don't support to disable numeric_only in stats APIs at DataFrame (#1343)
- Fix index operator against Series and Frame to use iloc conditionally (#1336)
- Make nunique in DataFrame to return a Koalas DataFrame instead of pandas' (#1347)
- Fix MultiIndex.drop() to follow renaming et al. (#1356)
- Add column axis in ks.concat (#1349)
- Fix iloc for Series when the series is modified. (#1368)
- Support MultiIndex for duplicated, drop_duplicates. (#1363)
Version 0.29.0
Slice support in iloc
We improved iloc indexer to support slice as row selection. (#1335)
For example,
>>> kdf = ks.DataFrame({'a':list('abcdefghij')})
>>> kdf
a
0 a
1 b
2 c
3 d
4 e
5 f
6 g
7 h
8 i
9 j
>>> kdf.iloc[2:5]
a
2 c
3 d
4 e
>>> kdf.iloc[2:-3:2]
a
2 c
4 e
6 g
>>> kdf.iloc[5:]
a
5 f
6 g
7 h
8 i
9 j
>>> kdf.iloc[5:2]
Empty DataFrame
Columns: [a]
Index: []Documentation
We added links to the previous talks in our document. (#1319)
You can see a lot of useful talks from the previous events and we will keep updated.
https://koalas.readthedocs.io/en/latest/getting_started/videos.html
Other new features and improvements
We added the following new feature:
DataFrame:
stack(#1329)
Series:
repeat(#1328)
Index:
MultiIndex:
Other improvements
- DataFrame.pivot should preserve the original index names. (#1316)
- Fix _LocIndexerLike to handle a Series from index. (#1315)
- Support MultiIndex in DataFrame.unstack. (#1322)
- Support Spark UDT when converting from/to pandas DataFrame/Series. (#1324)
- Allow negative numbers for head. (#1330)
- Return a Koalas series instead of pandas' in stats APIs at Koalas DataFrame (#1333)
Version 0.28.0
pandas 1.0 support
We added pandas 1.0 support (#1197, #1299), and Koalas now can work with pandas 1.0.
map_in_pandas
We implemented DataFrame.map_in_pandas API (#1276) so Koalas can allow any arbitrary function with pandas DataFrame against Koalas DataFrame. See the example below:
>>> import databricks.koalas as ks
>>> df = ks.DataFrame({'A': range(2000), 'B': range(2000)})
>>> def query_func(pdf):
... num = 1995
... return pdf.query('A > @num')
...
>>> df.map_in_pandas(query_func)
A B
1996 1996 1996
1997 1997 1997
1998 1998 1998
1999 1999 1999Standardize code style using Black
As a development only change, we added Black integration (#1301). Now, all code style is standardized automatically via running ./dev/reformat, and the style is checked as a part of ./dev/lint-python.
Other new features and improvements
We added the following new feature:
DataFrame:
Other improvements
- Fix
DataFrame.describe()to support multi-index columns. (#1279) - Add util function validate_bool_kwarg (#1281)
- Rename data columns prior to filter to make sure the column names are as expected. (#1283)
- Add an faq about Structured Streaming. (#1298)
- Let extra options have higher priority to allow workarounds (#1296)
- Implement 'keep' parameter for
drop_duplicates(#1303) - Add a note when type hint is provided to DataFrame.apply (#1310)
- Add a util method to verify temporary column names. (#1262)
Version 0.27.0
head ordering
Since Koalas doesn't guarantee the row ordering, head could return some rows from distributed partition and the result is not deterministic, which might confuse users.
We added a configuration compute.ordered_head (#1231), and if it is set to True, Koalas performs natural ordering beforehand and the result will be the same as pandas'.
The default value is False because the ordering will cause a performance overhead.
>>> kdf = ks.DataFrame({'a': range(10)})
>>> pdf = kdf.to_pandas()
>>> pdf.head(3)
a
0 0
1 1
2 2
>>> kdf.head(3)
a
5 5
6 6
7 7
>>> kdf.head(3)
a
0 0
1 1
2 2
>>> ks.options.compute.ordered_head = True
>>> kdf.head(3)
a
0 0
1 1
2 2
>>> kdf.head(3)
a
0 0
1 1
2 2GitHub Actions
We started trying to use GitHub Actions for CI. (#1254, #1265, #1264, #1267, #1269)
Other new features and improvements
We added the following new feature:
DataFrame:
- apply (#1259)
Other improvements
- Fix identical and equals for the comparison between the same object. (#1220)
- Select the series correctly in SeriesGroupBy APIs (#1224)
- Fixes
DataFrame/Series.clipfunction to preserve its index. (#1232) - Throw a better exception in
DataFrame.sort_valueswhen multi-index column is used (#1238) - Fix
fillnanot to change index values. (#1241) - Fix
DataFrame.__setitem__with tuple-named Series. (#1245) - Fix
corrto support multi-index columns. (#1246) - Fix output of
print()matches with pandas of Series (#1250) - Fix fillna to support partial column index for multi-index columns. (#1244)
- Add as_index check logic to groupby parameter (#1253)
- Raising NotImplementedError for elements that actually are not implemented. (#1256)
- Fix where to support multi-index columns. (#1249)
Version 0.26.0
iat indexer
We continued to improve indexers. Now, iat indexer is supported too (#1062).
>>> df = ks.DataFrame([[0, 2, 3], [0, 4, 1], [10, 20, 30]],
... columns=['A', 'B', 'C'])
>>> df
A B C
0 0 2 3
1 0 4 1
2 10 20 30
>>> df.iat[1, 2]
1Other new features and improvements
We added the following new features:
koalas.Index
koalas.MultiIndex:
equals(#1216)identical(#1215)swaplevel(#1105)is_all_dates(#1205)is_monotonic_increasing(#1183)is_monotonic_decreasing(#1183)append(#1163)to_frame(#1187)
koalas.DataFrameGroupBy
describe(#1168)
Other improvements
- Change default write mode to overwrite to be consistent with pandas (#1209)
- Prepare Spark 3 (#1211, #1181)
- Fix
DataFrame.idxmin/idxmax. (#1198) - Fix reset_index with the default index is "distributed-sequence". (#1193)
- Fix column name as a tuple in multi column index (#1191)
- Add favicon to doc (#1189)