You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
We launched our [Hacker News search and RAG engine](https://hn.trieve.ai) with a half-baked typo correction system. Our first draft took 30+ms which was slow enough that we defaulted it to off. Our latest version is 100 times faster and you can try it at [hn.trieve.ai](https://hn.trieve.ai). Heres the story of how we did it:
16
+
We launched our [Hacker News search and RAG engine](https://hn.trieve.ai) with a half-baked typo correction system. Our first draft took 30+ms which was slow enough that we defaulted it to off. Our latest version is 100 times faster and you can try it at [hn.trieve.ai](https://hn.trieve.ai). We tell you exactly how we did it in this post!
15
17
16
18
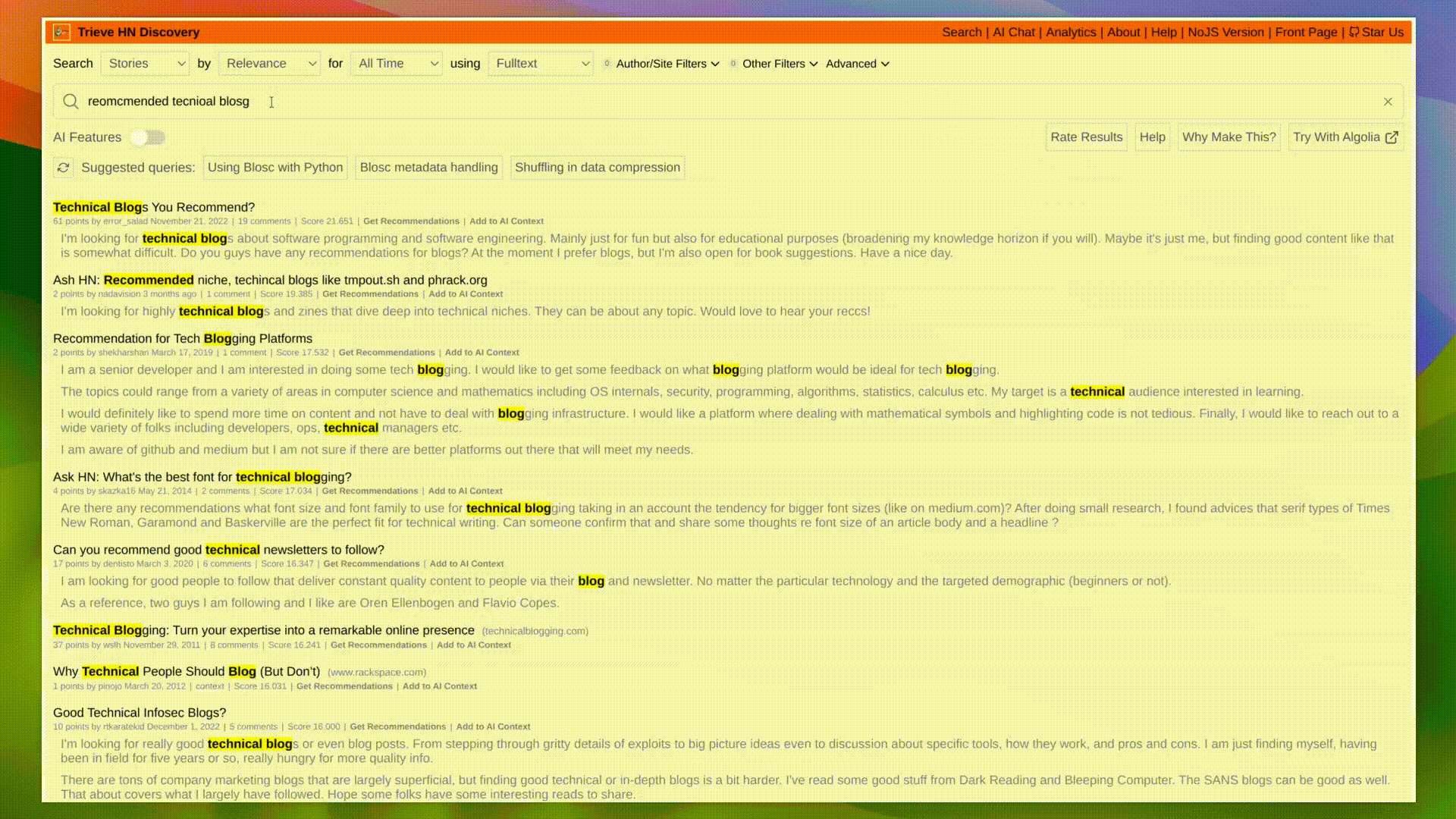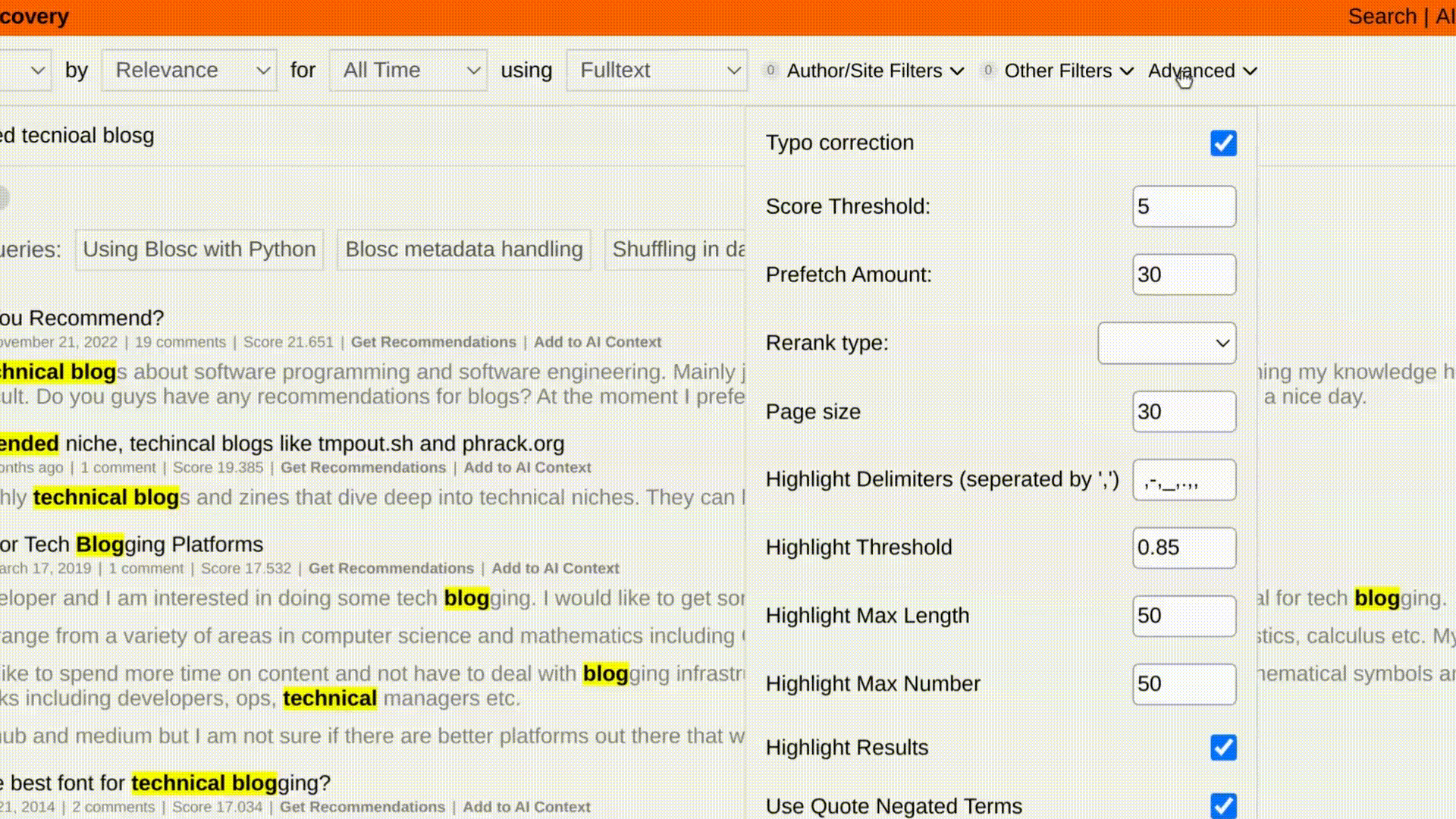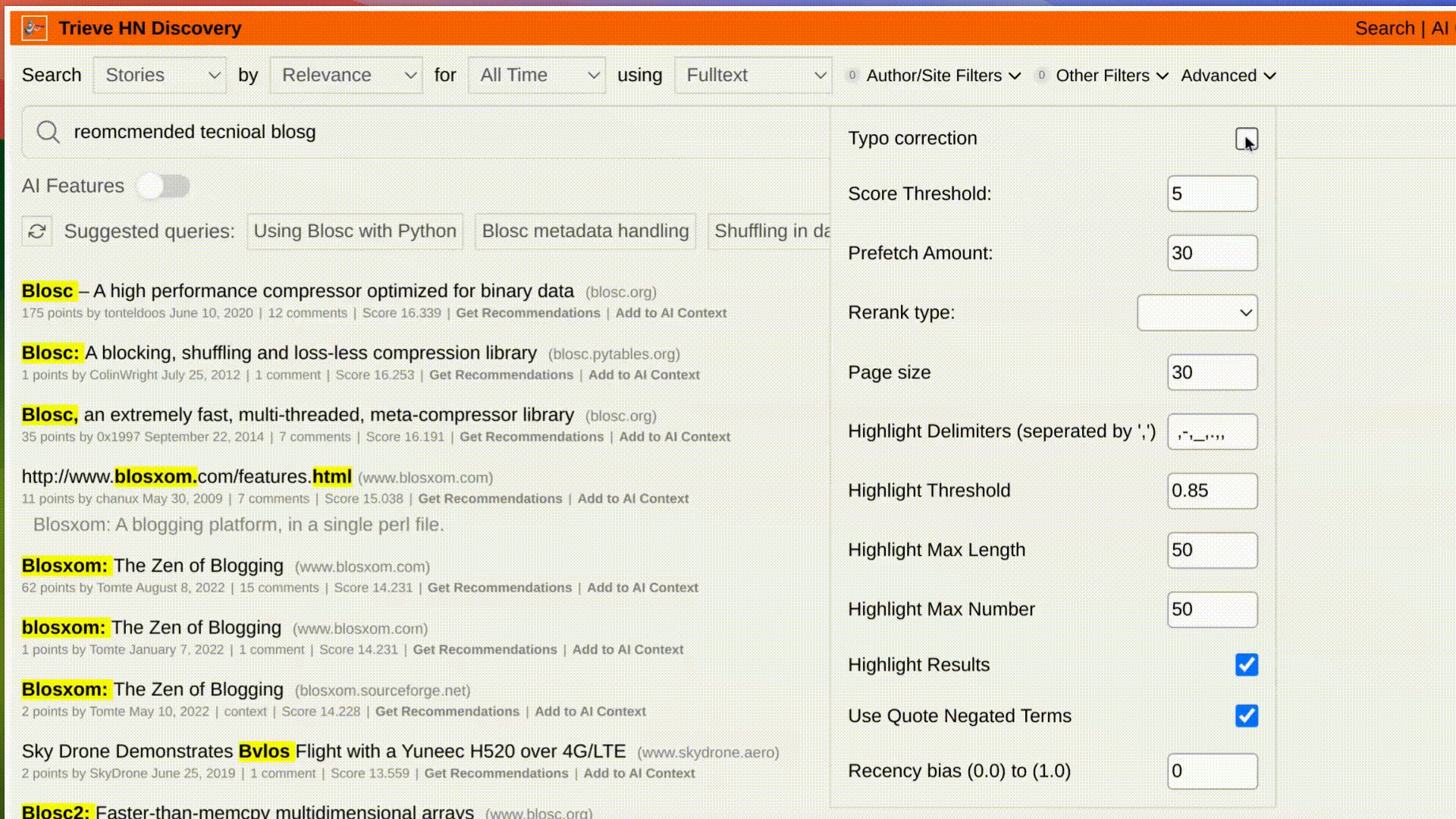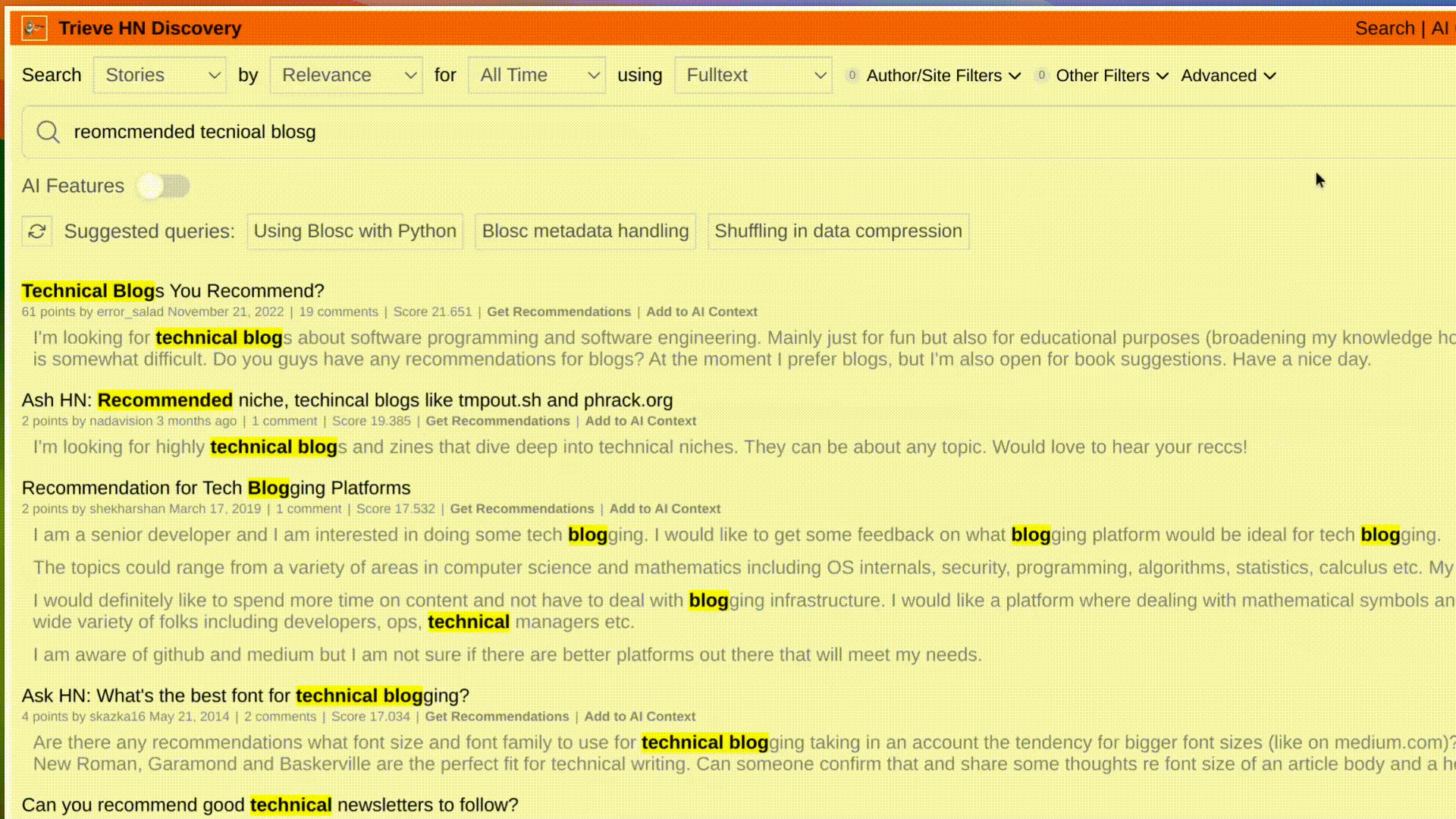
For small datasets, this is an easy task. You can scroll ~1000 HN post size text blobs in 10 seconds with one worker and basic word splitting. However, as you scale to the size of our [Hacker News Demo (38M+ posts)](https://hn.trieve.ai), work needs to be distributed.
21
29
22
-
Eventually, we decided on 2 distinct workers for dictionary building:
30
+
Eventually, we decided on 2 distinct workers for dictionary building:
23
31
24
32
1.[Cronjob](https://github.com/devflowinc/trieve/blob/main/server/src/bin/word-id-cronjob.rs) to scroll all of the documents present in each of our users' search indices and add chunk ids from our database into a Redis queue 500 at a time.
25
33
2.[Word worker](https://github.com/devflowinc/trieve/blob/main/server/src/bin/word-worker.rs) that pops off the queue and procesesses 500 chunks at a time. Text for each chunk is pulled, split into words, and each word is then loaded into Clickhouse.
@@ -28,17 +36,9 @@ We chose [ClickHouse](https://clickhouse.com/) to store the dictionary as we ran
28
36
29
37
## Using a BKTree data structure to identify and correct typos
30
38
31
-
We take the [standard approach to typo correction](https://nullwords.wordpress.com/2013/03/13/the-bk-tree-a-data-structure-for-spell-checking/) and build per-dataset Burkhard-Keller Trees (BKTrees) for efficient comparision of words in the search query and the dataset's dictionary in O(log N) time complexity. Read more on the data structure at [wikipedia.org/BKTree](https://en.wikipedia.org/wiki/BK-tree).
32
-
33
-
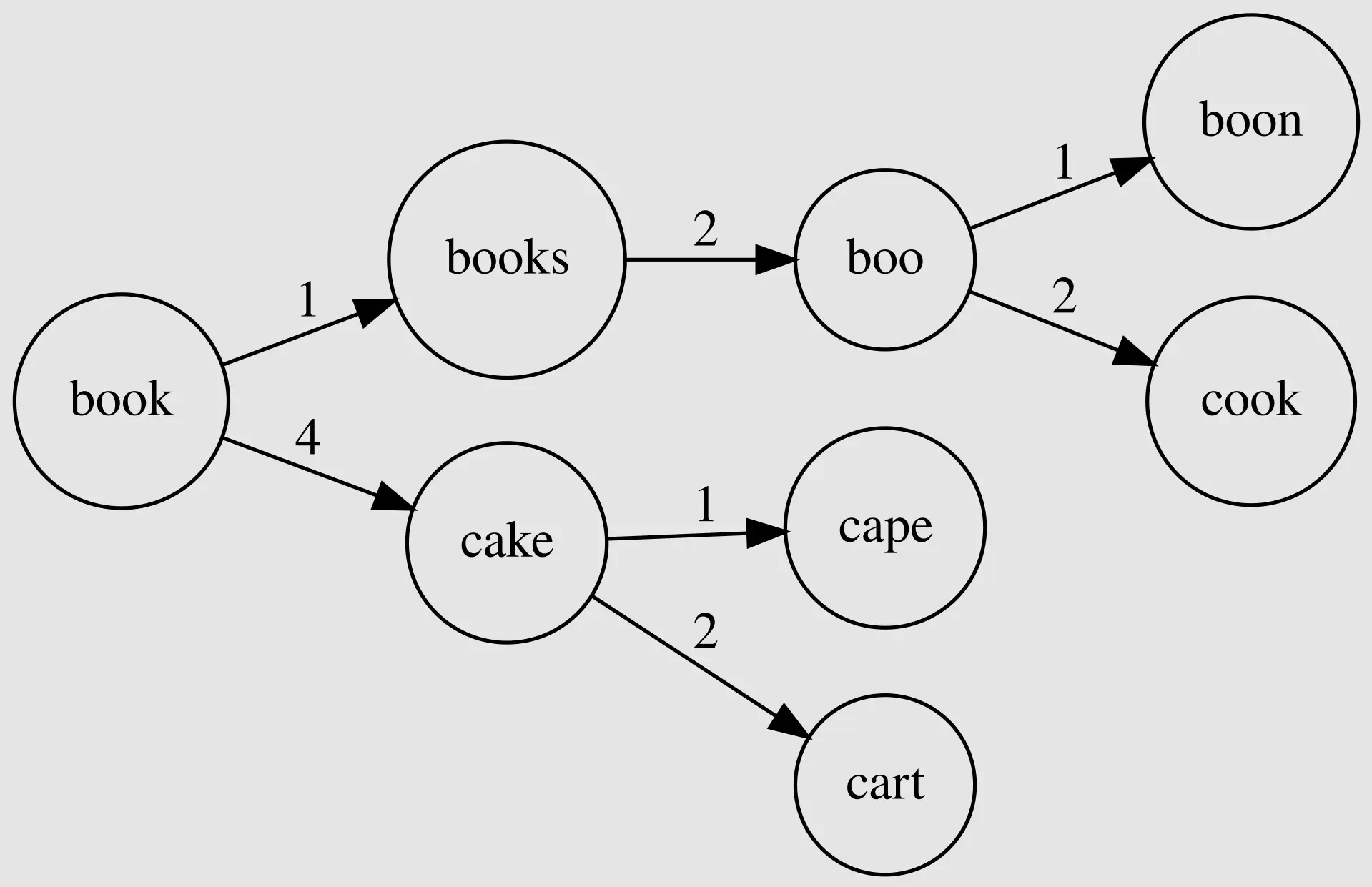
34
-
35
-
BKTrees are a type of metric tree whose nodes are the word (and frequency in our case) and edges are the edit distance between the node and its children.
36
-
This type of tree implements a trait known as the triangle inequality.
37
-
38
-
Let's say we're at a node n in the BKtree, and we know the distance `d(n, q)` between `n` and our query `q`. For any child `c` of `n`, we know `d(n, c)` (it's stored in the tree). The triangle inequality tells us:
39
-
`d(q, c) ≥ |d(q, n) - d(n, c)|`. This means if `|d(q, n) - d(n, c)| > k`, we can safely skip the entire subtree rooted at `c`, as no string in that subtree can be within distance `k` of `q`.
39
+
We take the [standard approach to typo correction](https://nullwords.wordpress.com/2013/03/13/the-bk-tree-a-data-structure-for-spell-checking/) and build per-dataset Burkhard-Keller Trees (BKTrees) for efficient comparision of words in the search query and the dataset's dictionary in O(log N) time complexity. Explaining this data structure in depth is outside the scope of this blog, but you can read our [Rust implementation here]((https://github.com/devflowinc/trieve/blob/6e114abdca5683440e2834eccacf3f850dff810f/server/src/operators/typo_operator.rs#L35-112)) or read its [wiki](https://en.wikipedia.org/wiki/BK-tree).
40
40
41
-
We utilized a third[ bktree-worker](https://github.com/devflowinc/trieve/blob/main/server/src/bin/bktree-worker.rs) to build the BKTrees. It takes datasets with completed dictonaries stored in Clickhouse then uses their words and frequencies to construct a tree.
41
+
We utilized a third[ bktree-worker](https://github.com/devflowinc/trieve/blob/main/server/src/bin/bktree-worker.rs) to build the BKTrees. It takes datasets with completed dictonaries stored in Clickhouse then uses their words and frequencies to construct a tree.
42
42
43
43
Once the BKTree is constructed, the worker then stores it in Redis such that it can be efficiently loaded into the API server's memory when needed at first query time for a given dataset.
44
44
@@ -73,7 +73,7 @@ lazy_static! {
73
73
}
74
74
```
75
75
76
-
On the first search with typo-tolerance enabled, we initiate a ~200-400ms cold start to pull the BKTree for the dataset being queried from Redis into server memory. Searches following this operation then use the BKTree to check for typos which only takes 100-300μs.
76
+
On the first search with typo-tolerance enabled, we initiate a ~200-400ms cold start to pull the BKTree for the dataset being queried from Redis into server memory. Searches following this operation then use the BKTree to check for typos which only takes 100-300μs.
We plan to leverage this same system to implement query splitting and concatenation as those features share the same requirement of quickly looking up words in a dictionary as does typo tolerance.
233
+
We plan to leverage this same system to implement query splitting and concatenation as those features share the same requirement of quickly looking up words in a dictionary.
234
234
235
235
Trieve will always pursue the best possible relevance out of the box! Try it on our [HN search engine](https://hn.trieve.ai), [sign up for a free cloud account](https://dashboard.trieve.ai), or [see our self-hosting guides](https://docs.trieve.ai/self-hosting/aws).
0 commit comments