Static output feedback and fixed order controller design package for Python
SOF is the simplest feedback controller structure. More precisely, it redirects the system output to the system input after multiplying by a constant gain matrix. You can find brief information about SOF in this page.
The algorithm implemented in this package can calculate a stabilizing SOF gain which also minimizes the
However, this algorithm works when some sufficient conditions are satisfied. If the problem parameters (listed below) is not appropriate, the algorithm fails and prints an error message. Please see the article, and the PhD thesis, for detailed information and analysis.
The algorithm is mainly developed for discrete time systems, but it may also compute similar SOF gains for continuous time systems when this algorithm is applied to the zero-order hold (ZOH) discretized versions with a sufficiently large sampling frequency.
Furthermore, the algorithm can be used to calculate fixed-order controllers. Please, check tests for examples and docs for detailed information.
python3 -m venv venv
source venv/bin/activate
pip install -e '.[dev]'
pytest
It can be installed via pip.
pip install focont
Consider this highly simplified real life example below which is a naively discretized version of the ideal Newton motion equations. It is a model of a ball's motion on an inclined plane.
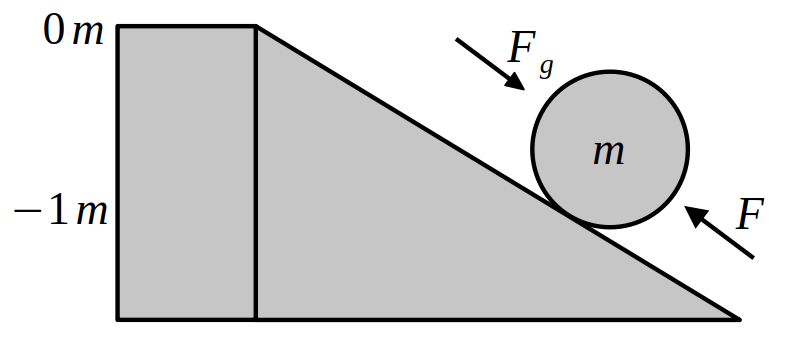
In the model, the top of plane is assumed to be the origin and force
where
where
With this information, the system matrices can be written as
where
Problem:
Calculate a static output feedback (SOF) gain
where force is a function of measurment
In other terms, how can I use the measurment
from focont import foc, system
def main():
A = [
[ 1.01, 0.10 ],
[ 0.00, 0.99 ],
]
B = [
[ 0 ],
[ 1 ],
]
C = [ [ 1, 1 ] ]
Q = [
[ 1, 0 ], # Weight of p_t
[ 0, 0 ],
]
R = [ [ 1 ] ] # Weight of u_t
data = { "A": A, "B": B, "C": C, "Q": Q, "R": R }
pdata = system.load(data)
foc.solve(pdata)
foc.print_results(pdata)
if __name__ == "__main__":
main()Prints out:
Progress: 10%, dP=0.4662574448312318
Iterations converged, a solution is found
- Stabilizing SOF gain:
[[-0.6147]]
- Eigenvalues of the closed loop system:
[0.8907 0.4946]
|e|:
[0.8907 0.4946]Meaning that,
For this problem, the closed loop system
is stable when rlocus method. When
the cost
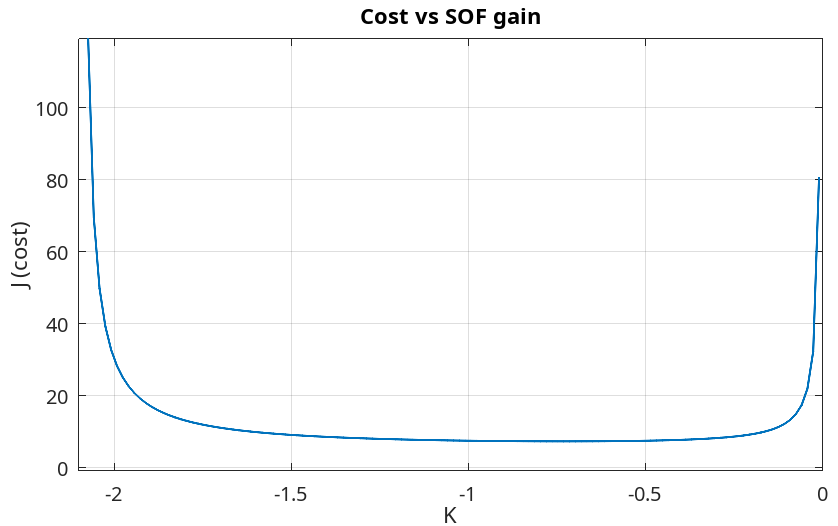
In this plot, the minimum cost is
Let us modify the cost function and assign a higher weight to the consumed energy. Meaning that, we do not care much about how quickly the ball is transported but we want to spend less energy.
In this case, the SOF gain
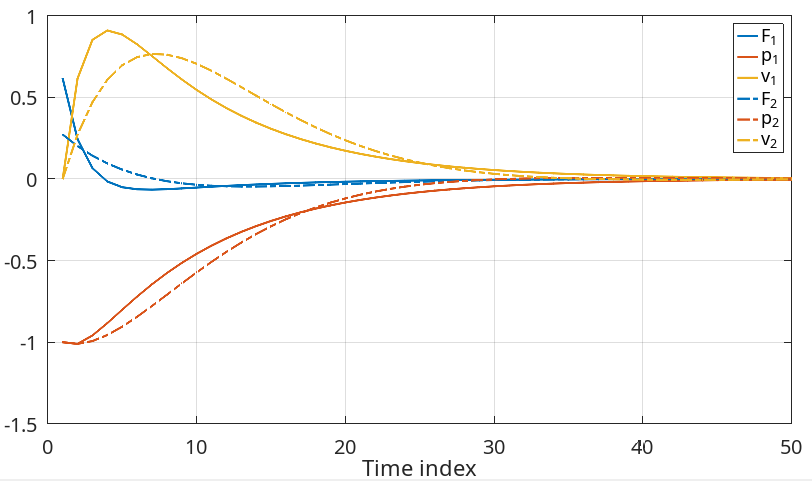
Results for different cost weigths. Position (red), velocity (yellow), force
$u_t$ (blue),$J = \sum_{t=0}^{\infty} p_t^2+ u_t^2$ (solid),$J = \sum_{t=0}^{\infty} p_t^2+10 u_t^2$ (dashed)
The dashed lines are obtained when the consumed energy is largely penalized in the cost function. As it can be seen, it gets closer to the origin slower (red), but consumed energy (blue) is smaller.
Comments: First, I should emphasize that this is a very simplified, naive model of the actual physical system. How strange, in the problem's story the guy pushing the ball upwards can measure the sum of position and velocity. Assume that, you are driving a car and the front dashboard only shows the sum of how many kilometers you have traveled and the current velocity, instead of showing them separately. How would you avoid getting speeding tickets?
In many real life control problems, similar to this hypothetical example you can not be aware of the system's all internal states but can only measure a combination (a function) of them.
In the hypothetical example above, if both state variables,
However, being able to measure a combination of the state variables makes the optimization problem more complicated (possibly non-convex) which is the reason of undershooting blue lines in the plot above. Negative values in blue lines mean, the guy stops pushing and leaves the work to the gravity time by time, because of the lack of full information of the system's state.
Measuring a combination of the states turns the problem into a static output feedback (SOF) problem. Focont implements an approximate dynamic programming based approach to the SOF problem and comes up with the solution above.