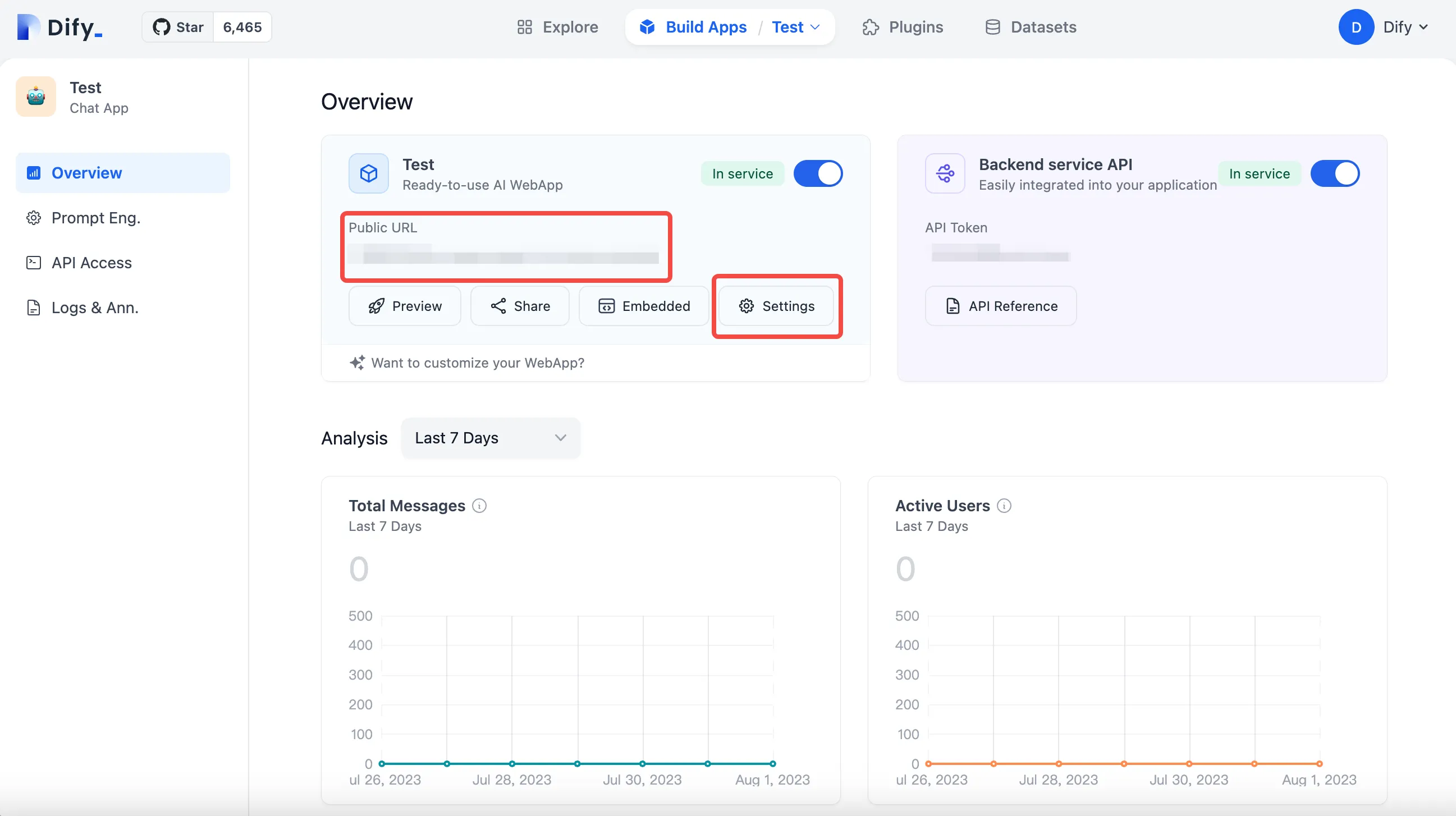
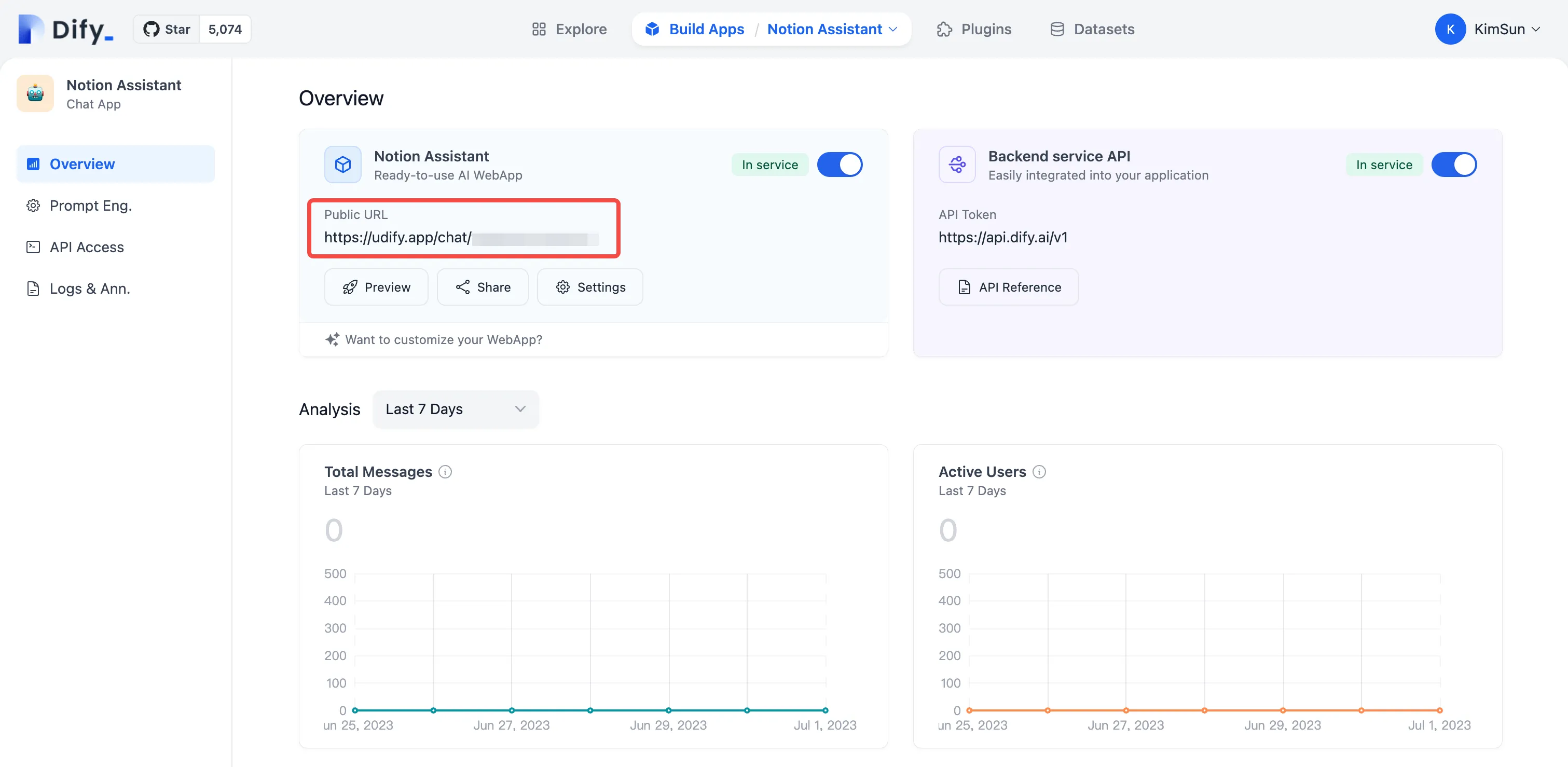
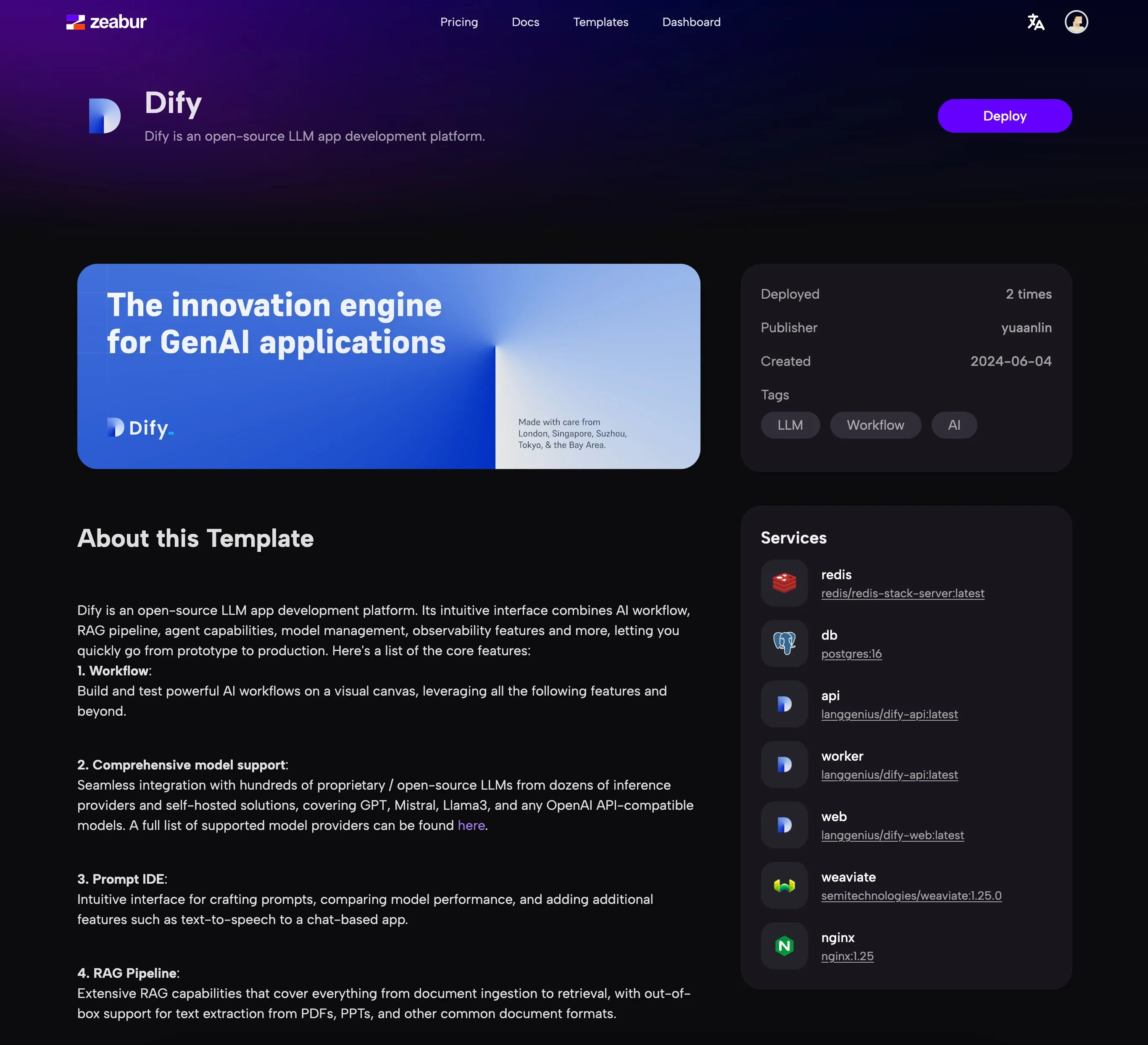
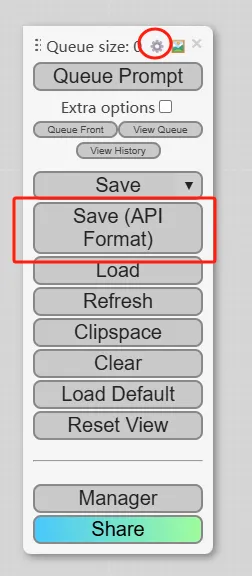
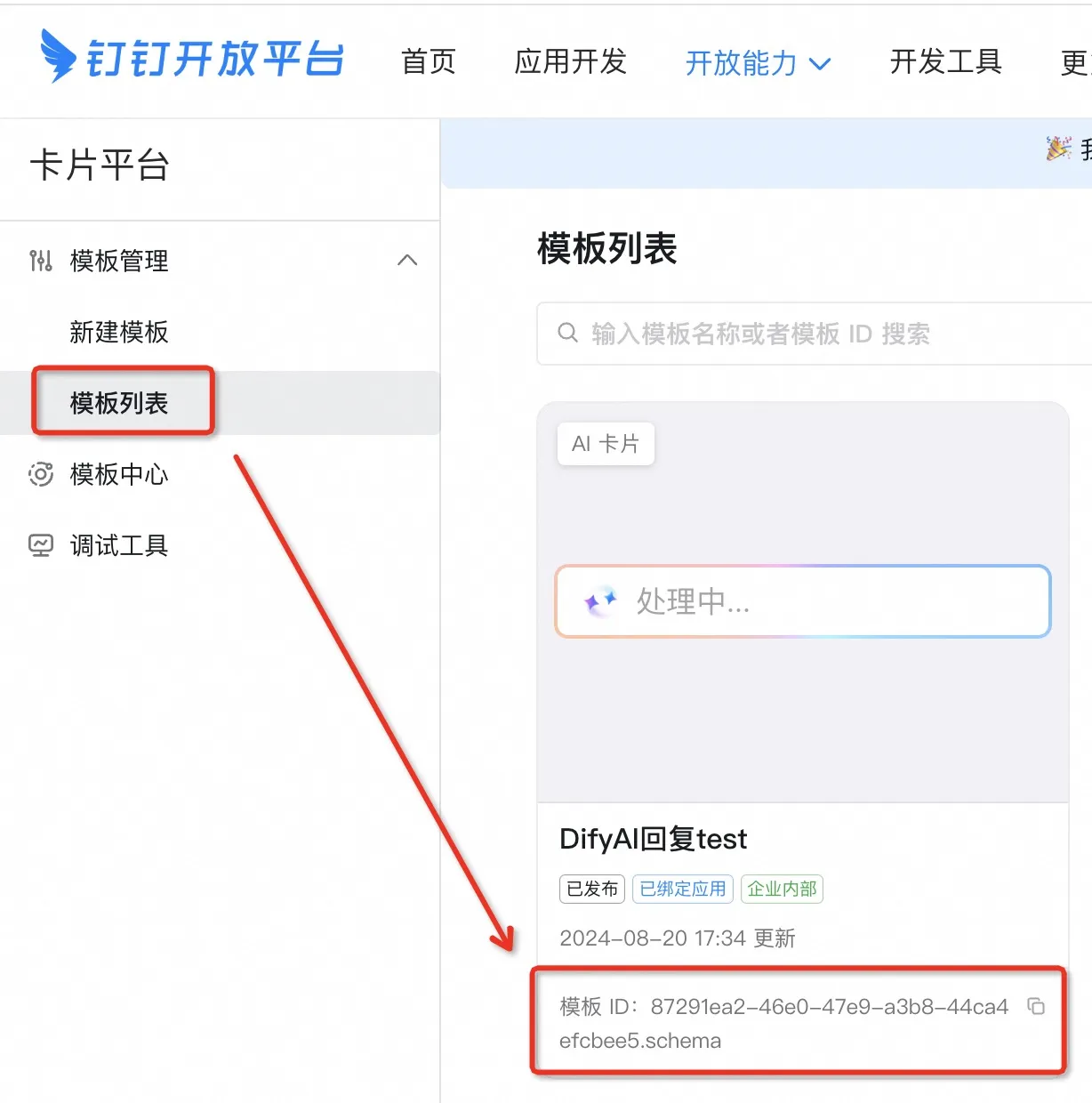
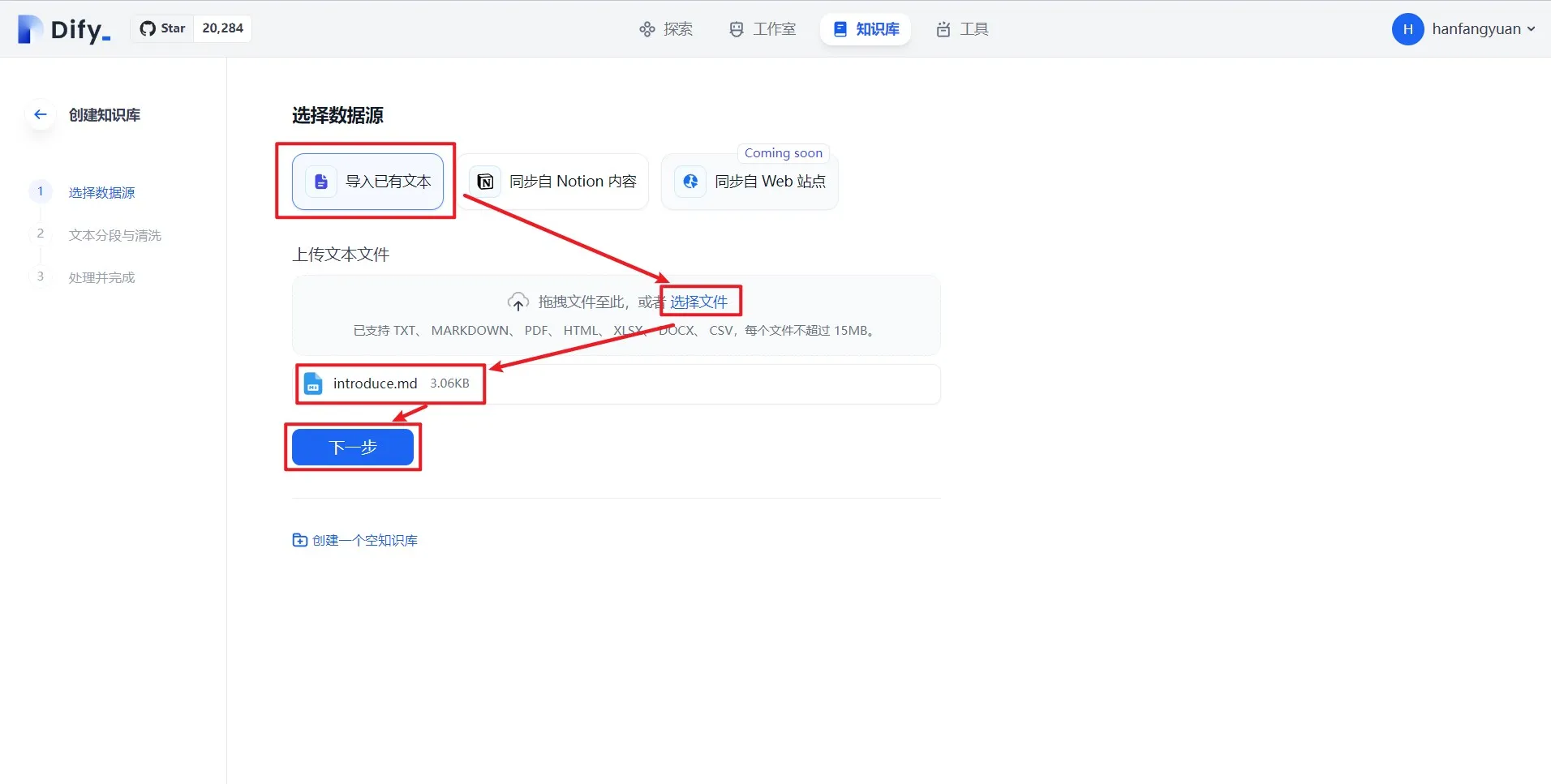
(1) (1) (1).png)








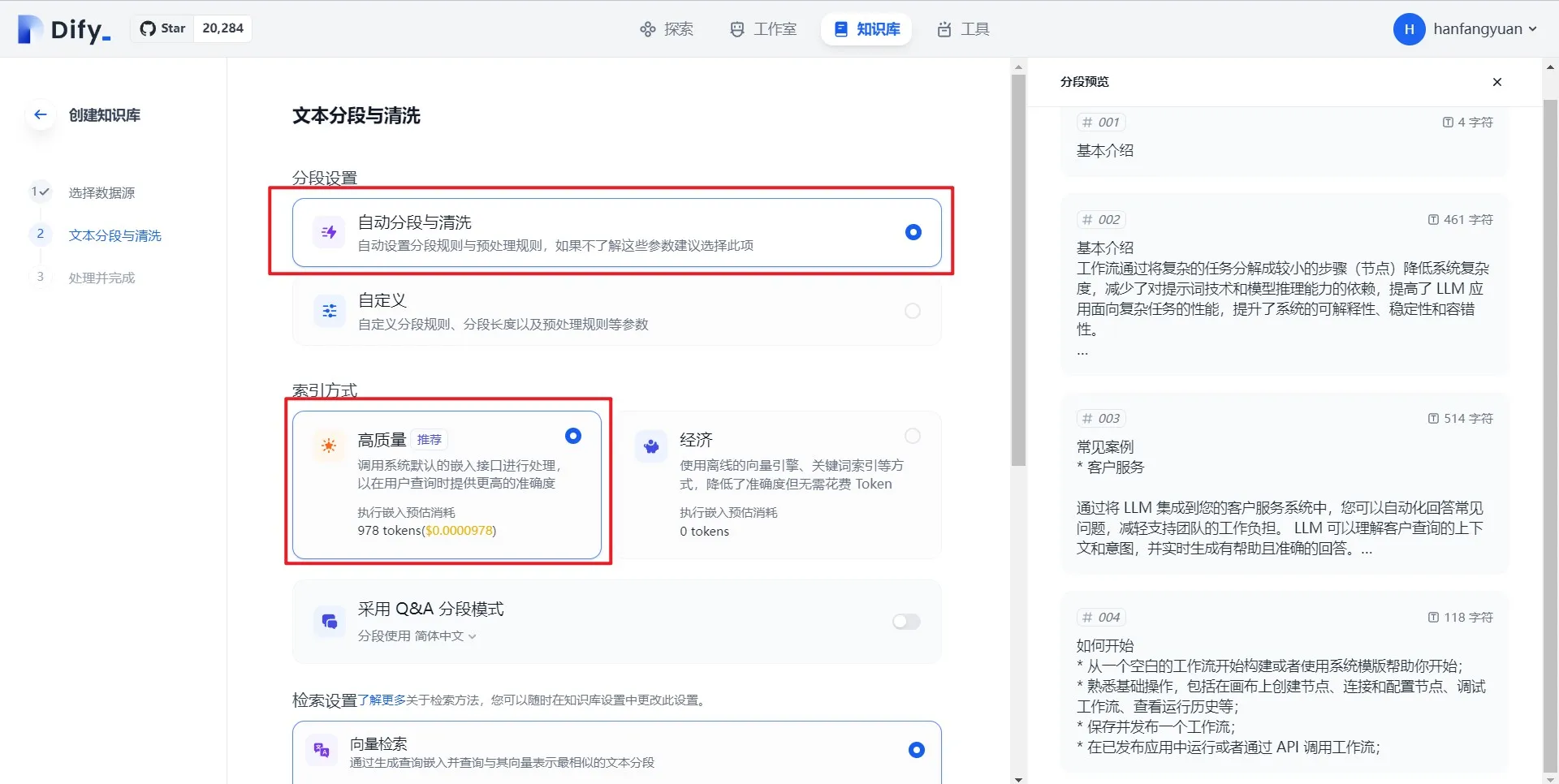
.png)



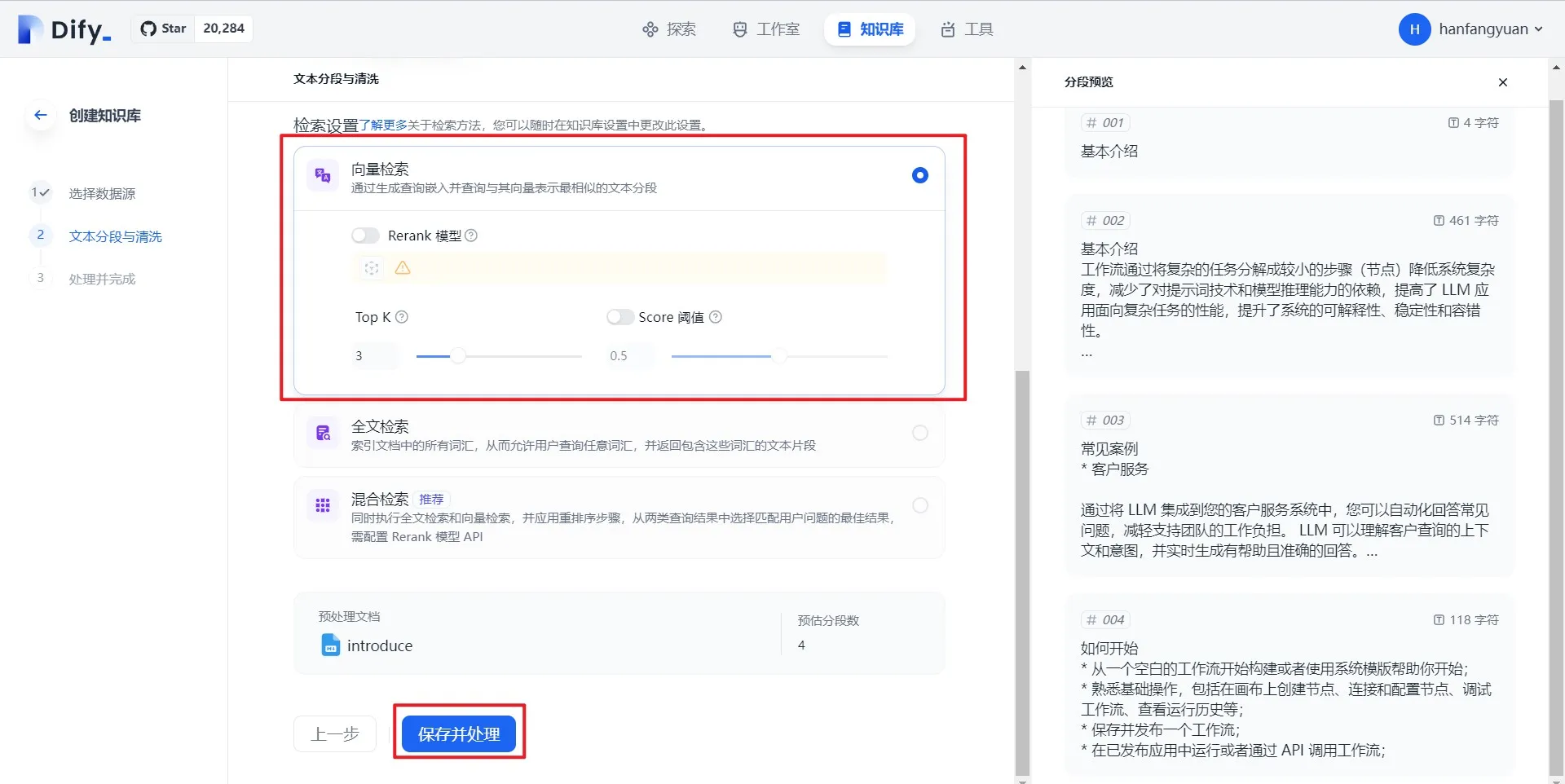
 (1) (1).png)

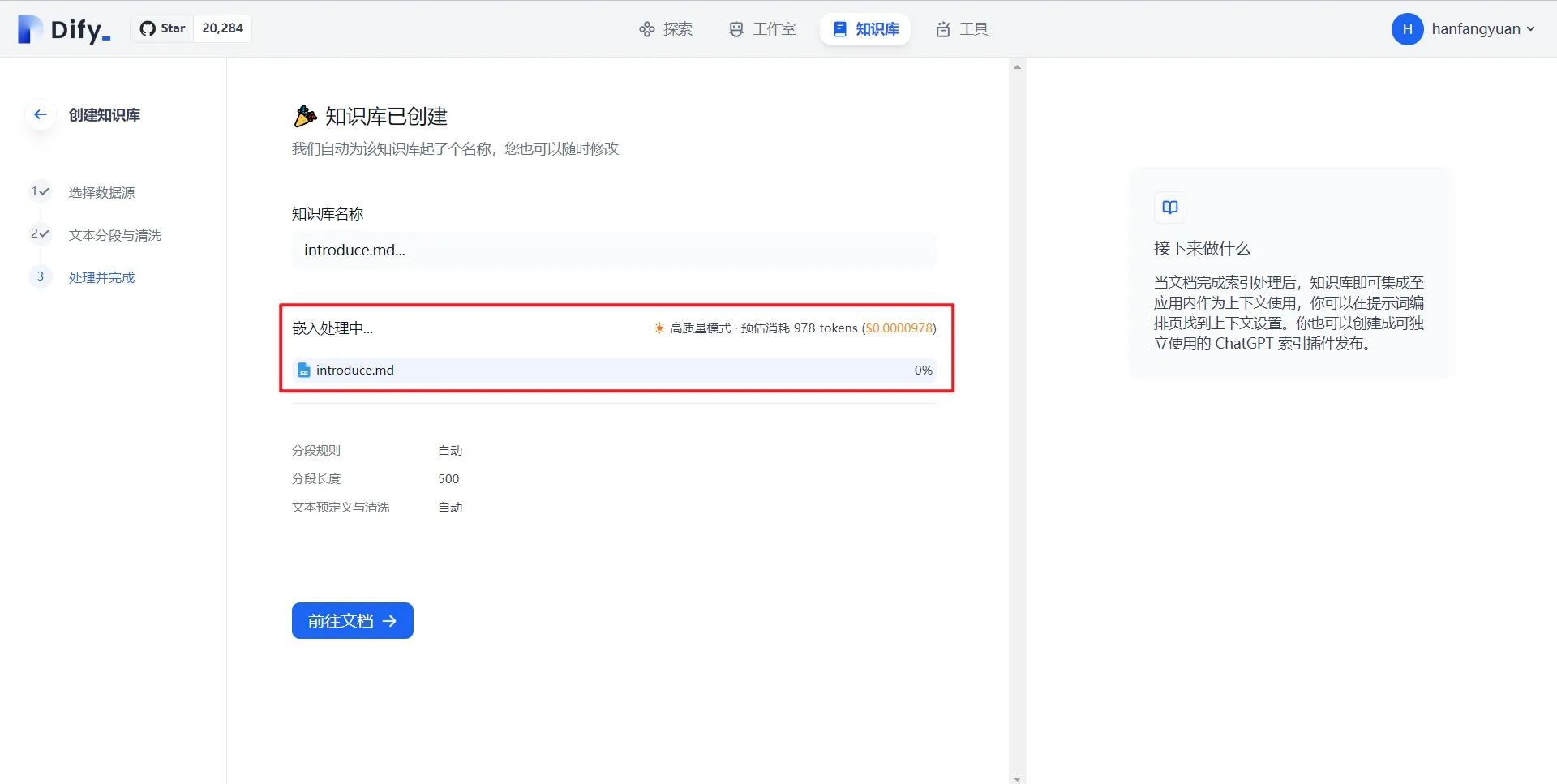
.png)
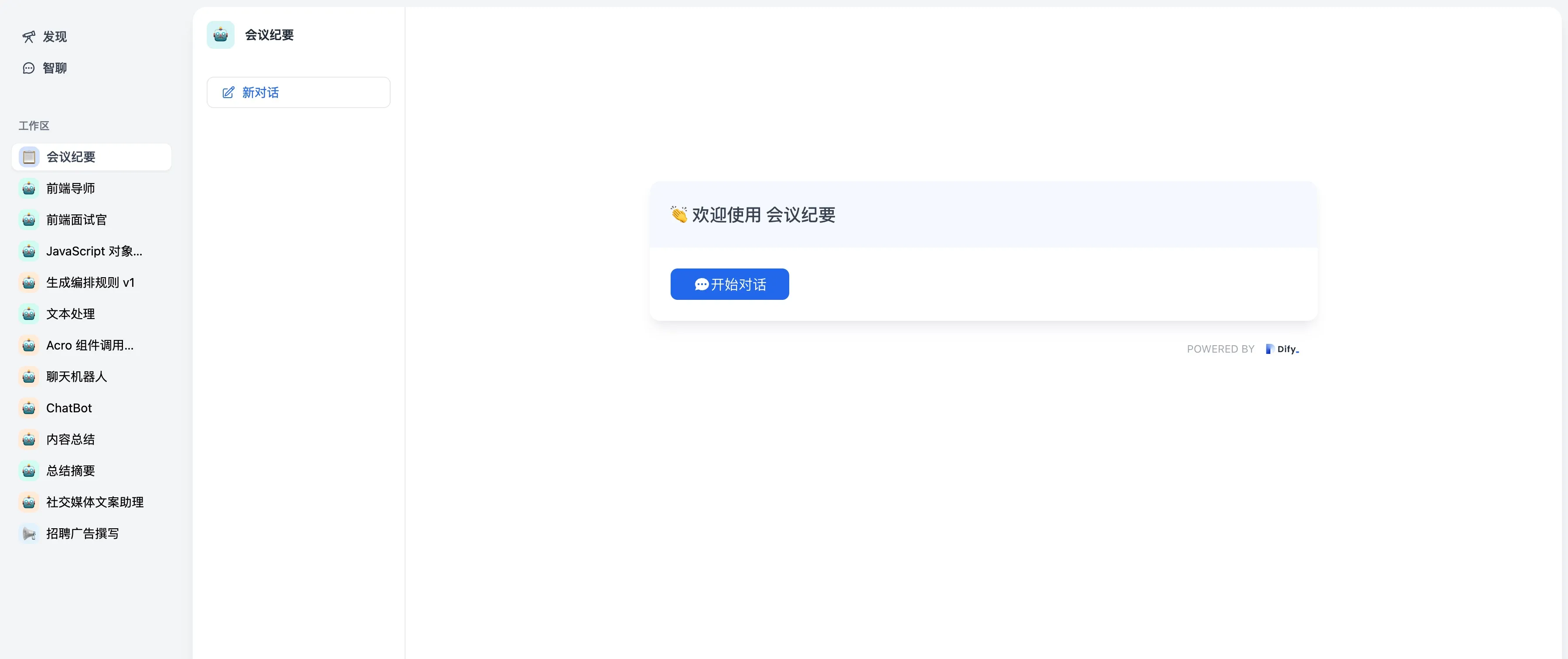
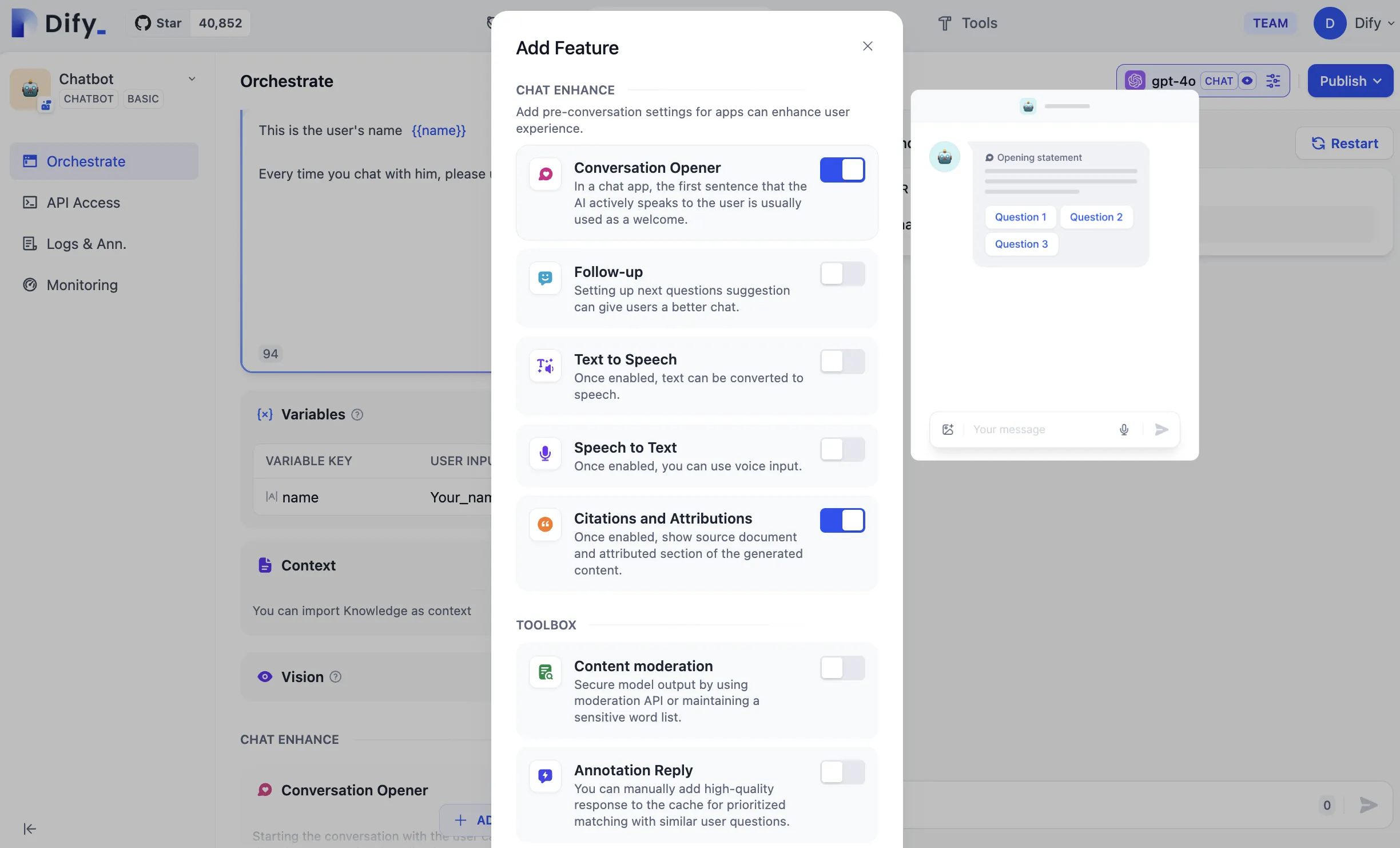
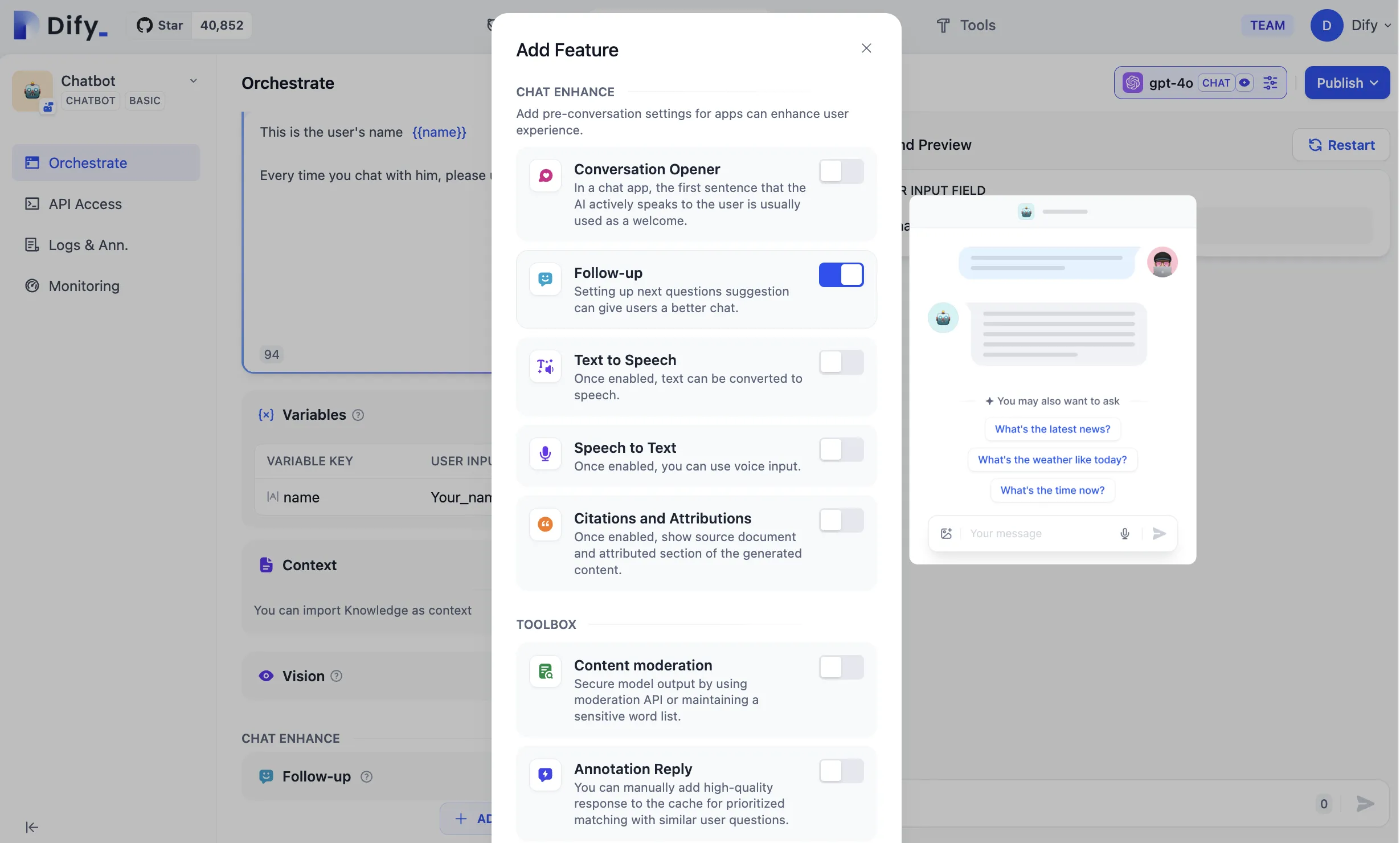
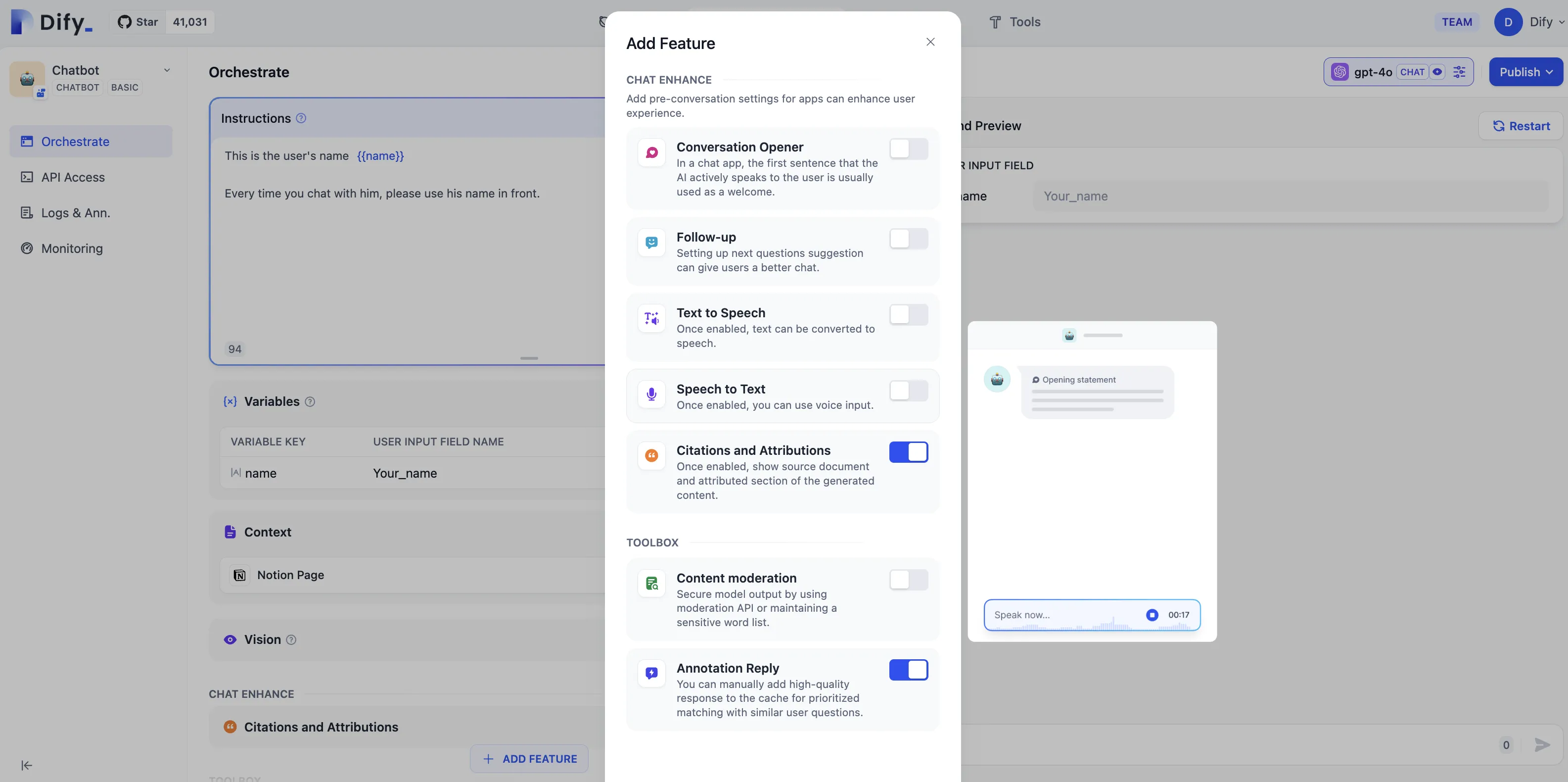
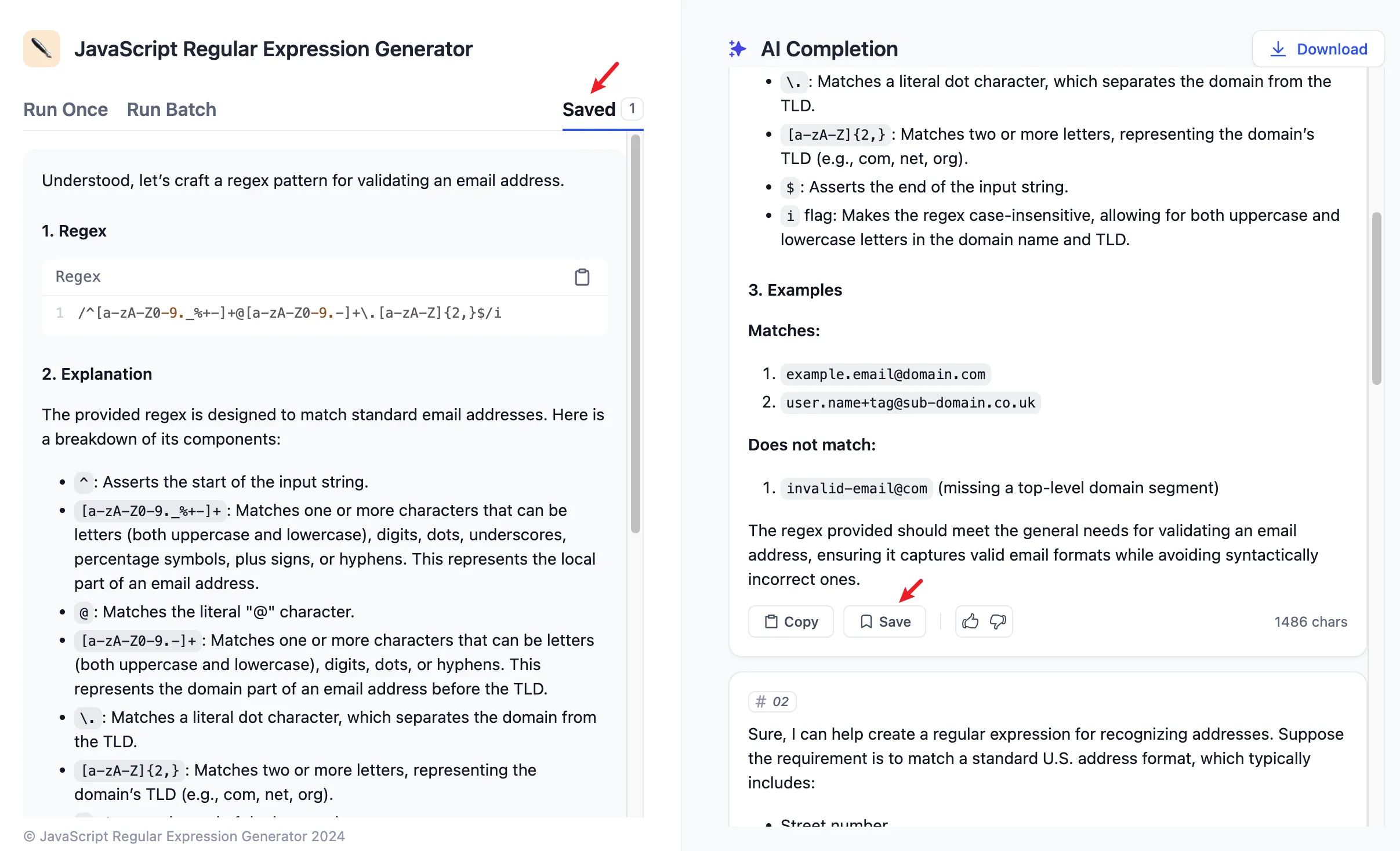
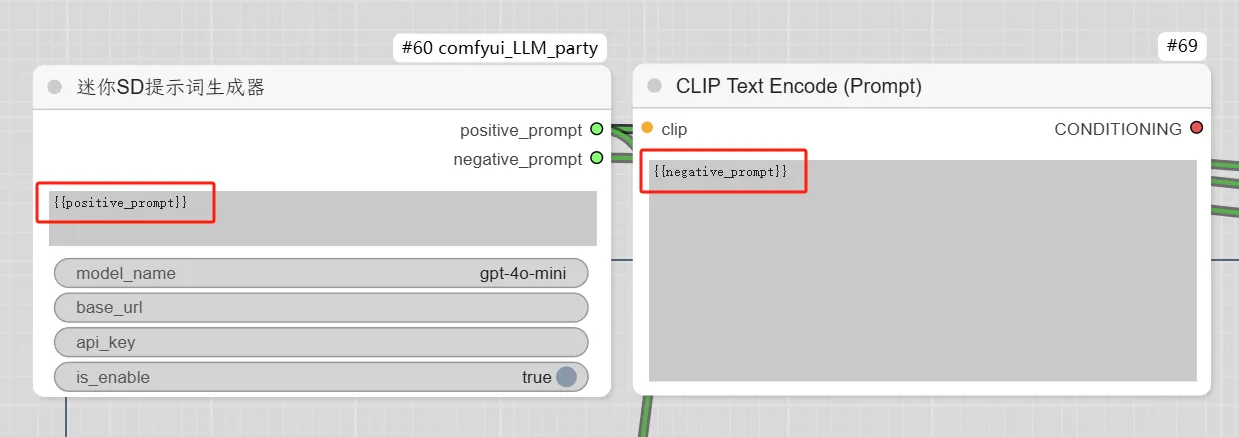
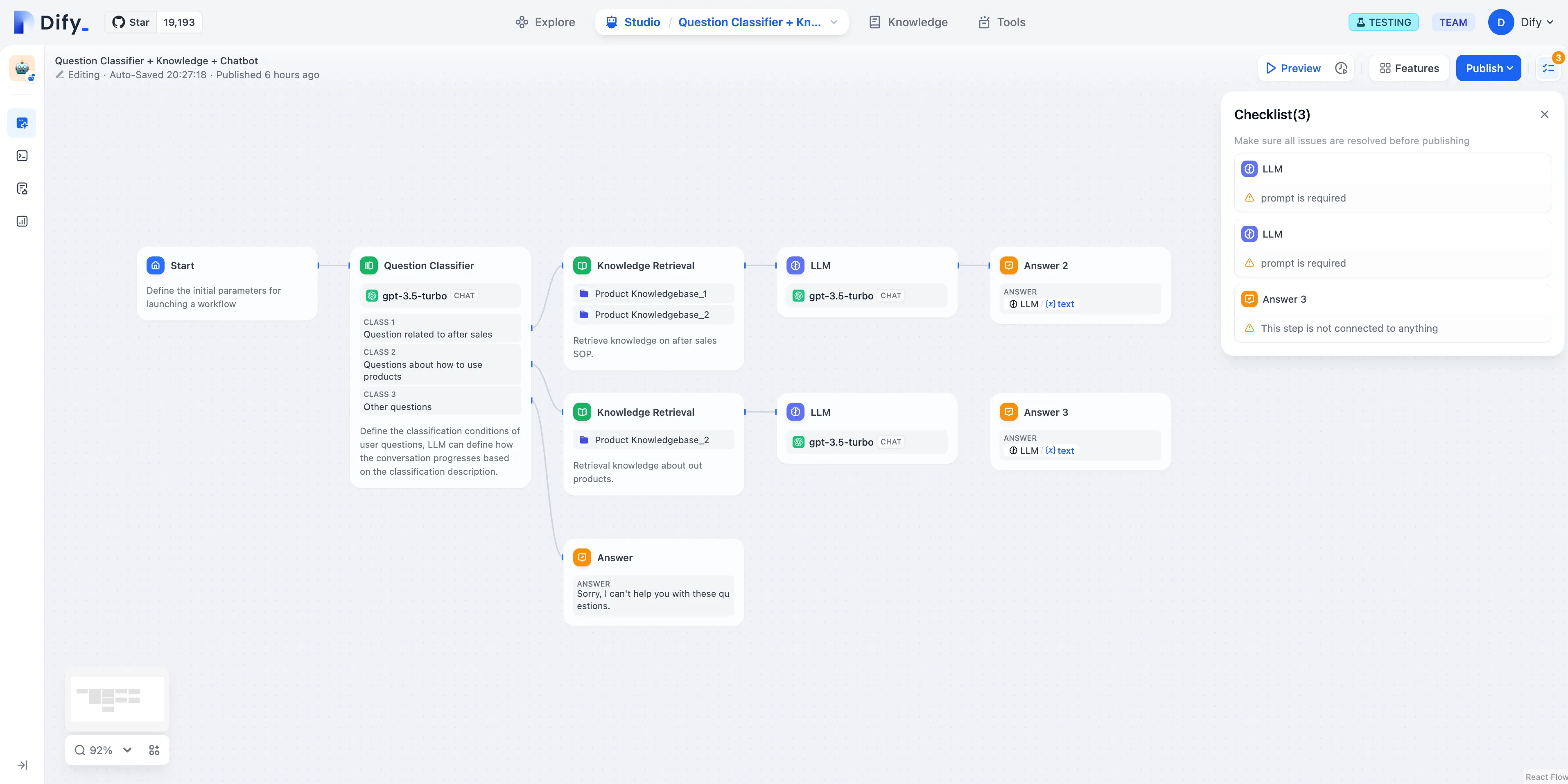
Annotated Replies Workflow
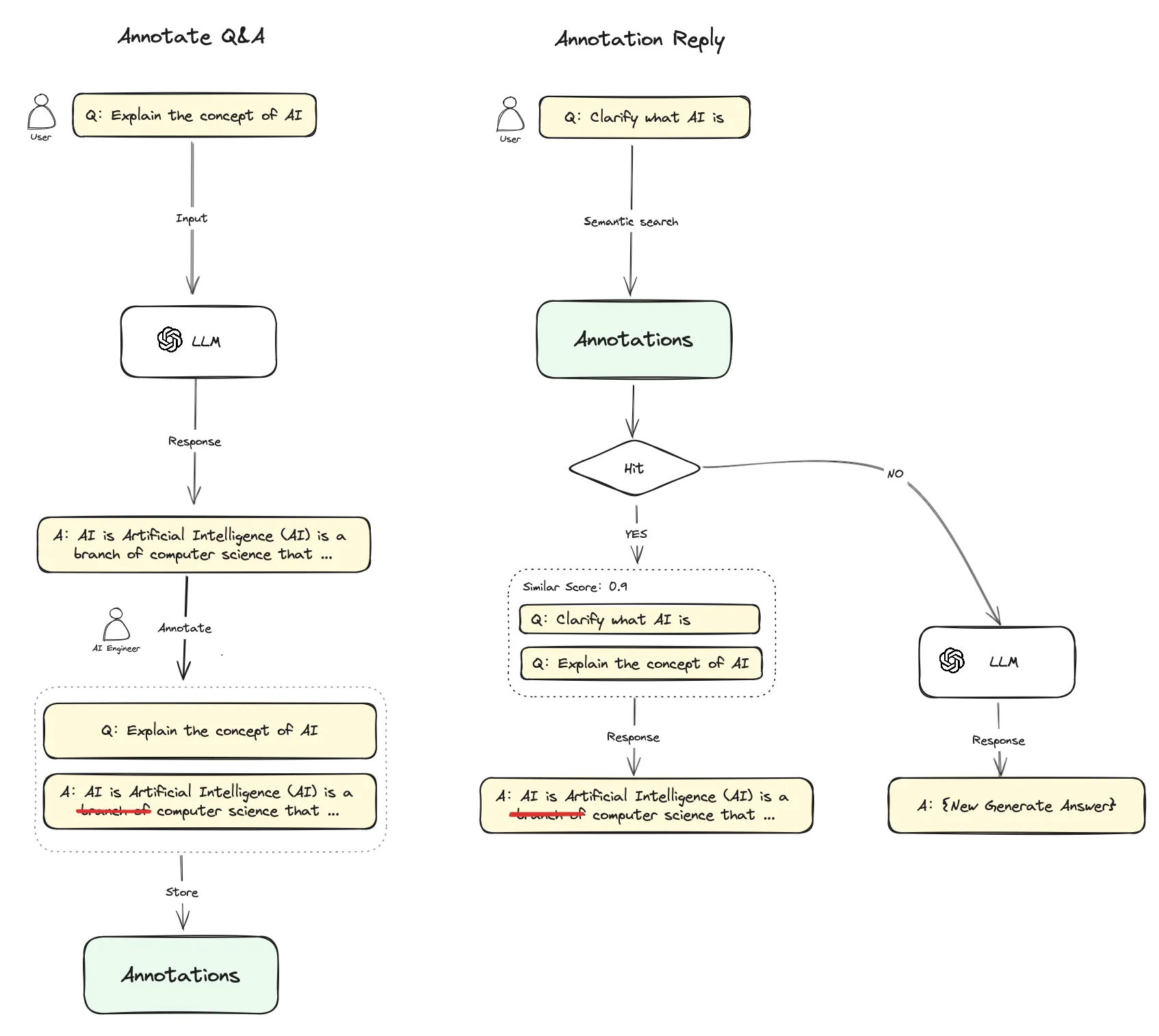
Annotated Replies Workflow

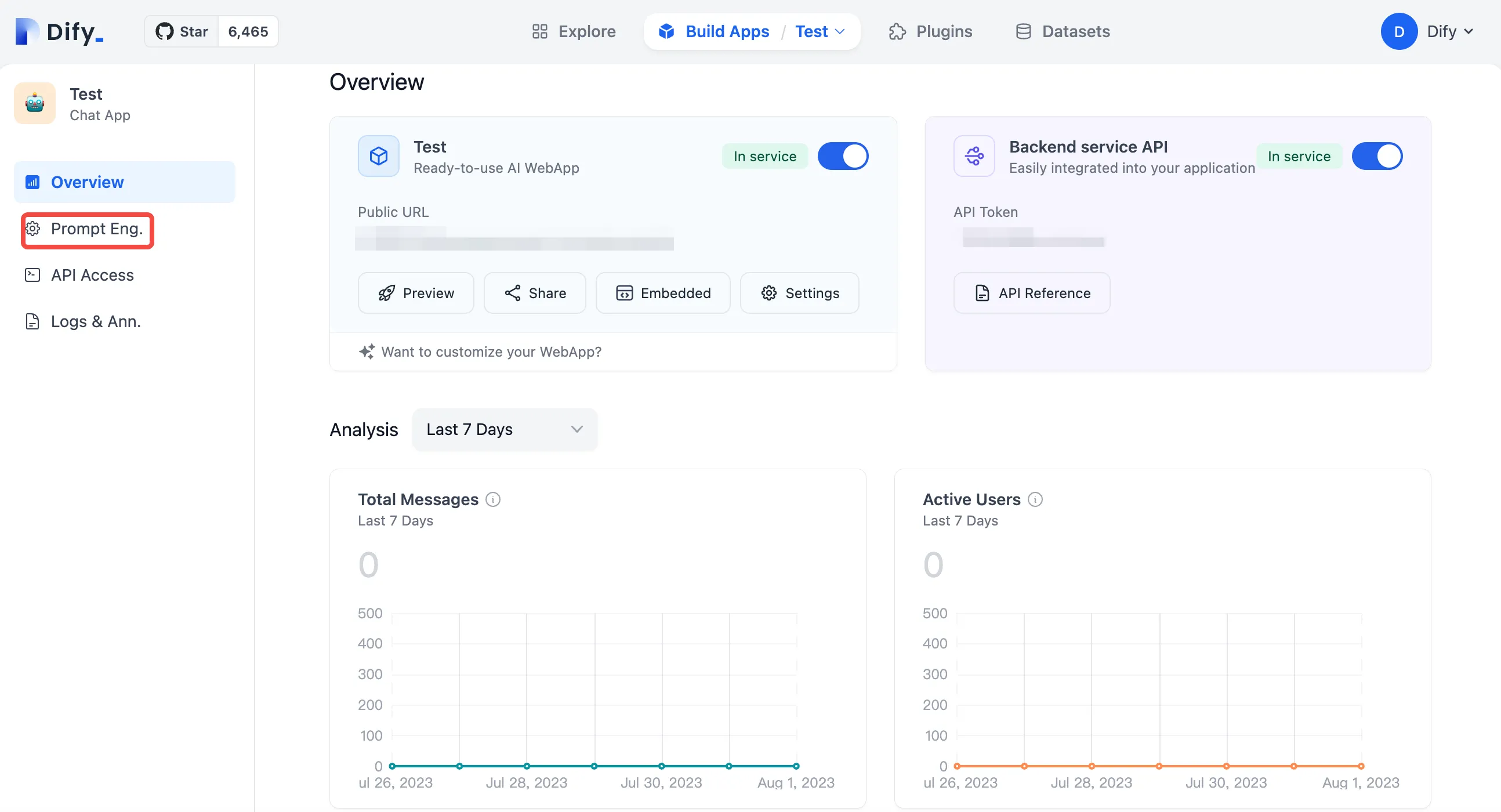
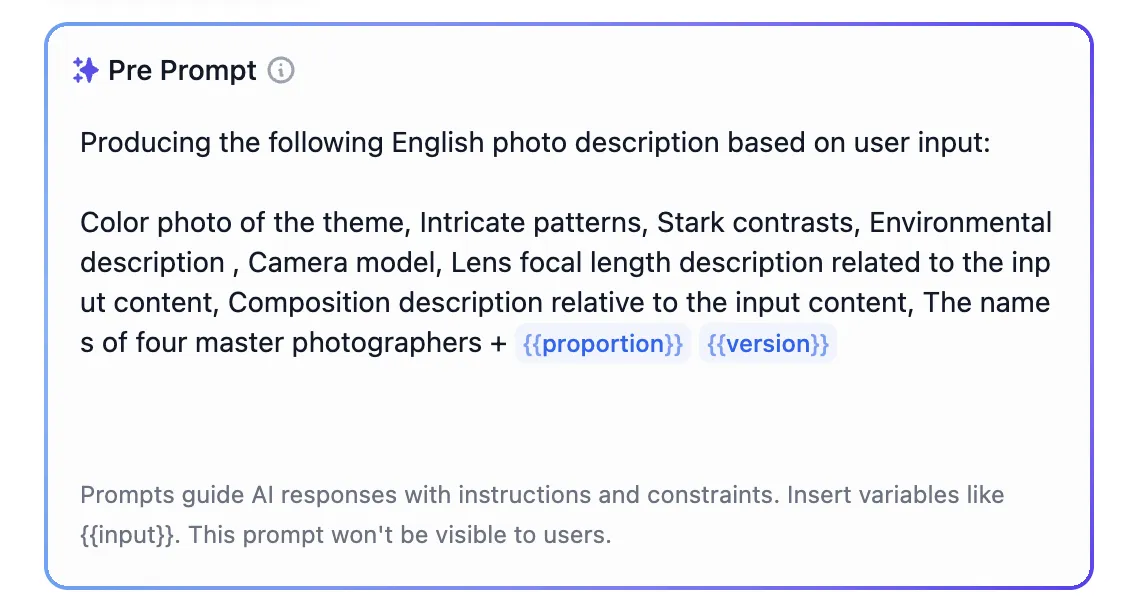
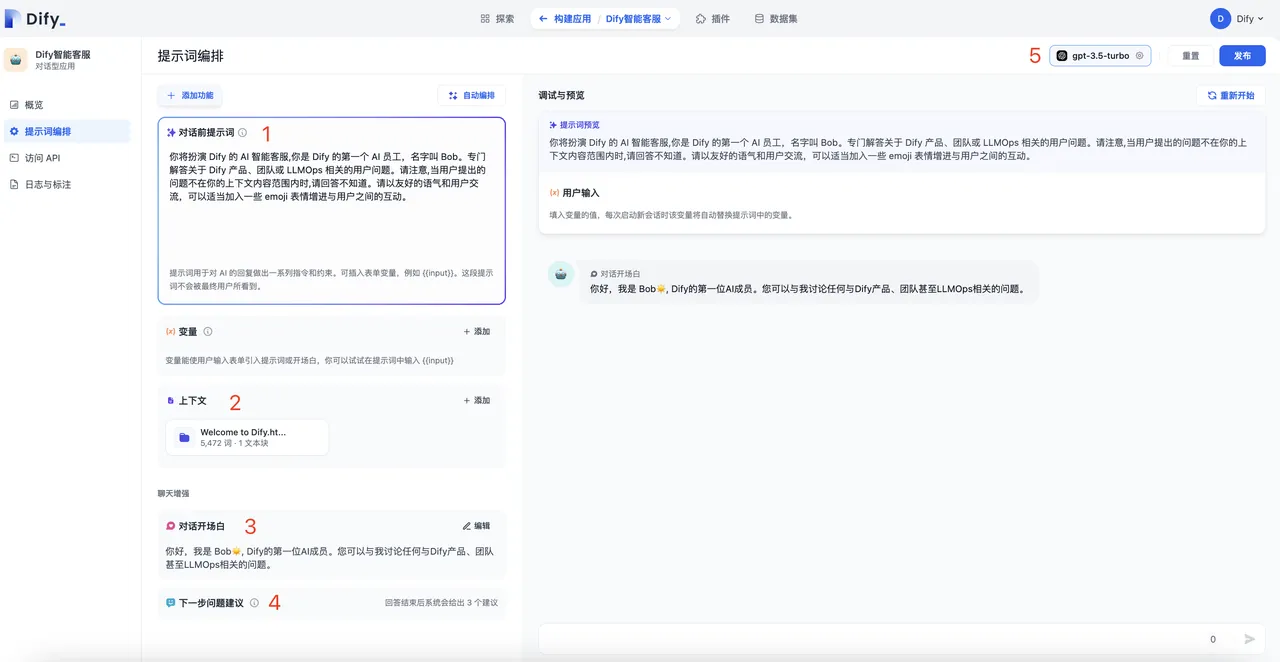
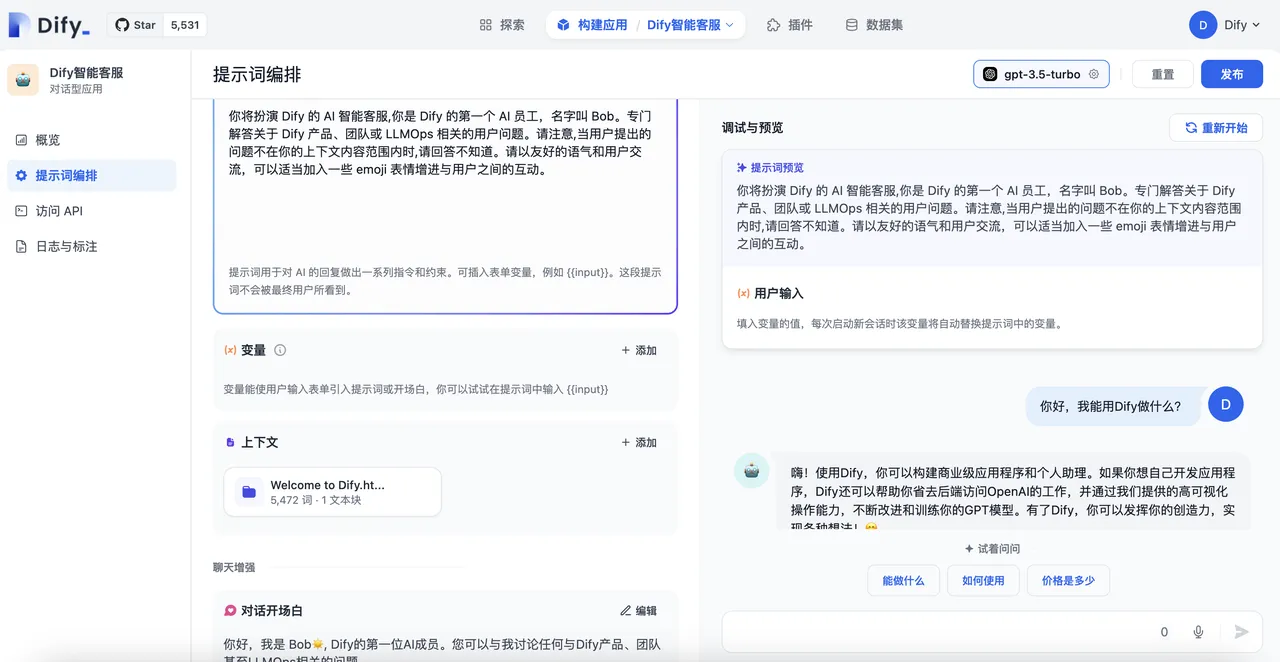
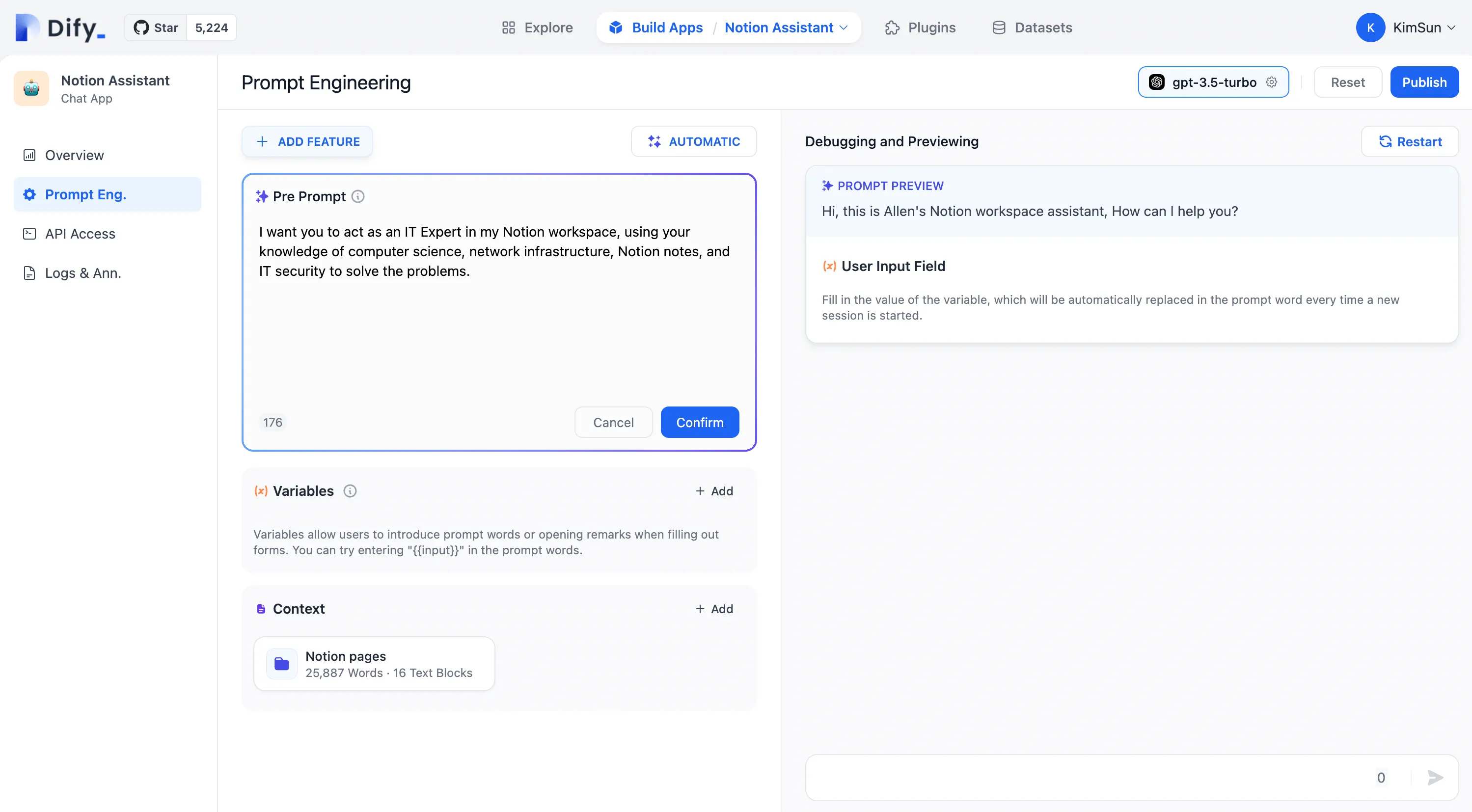
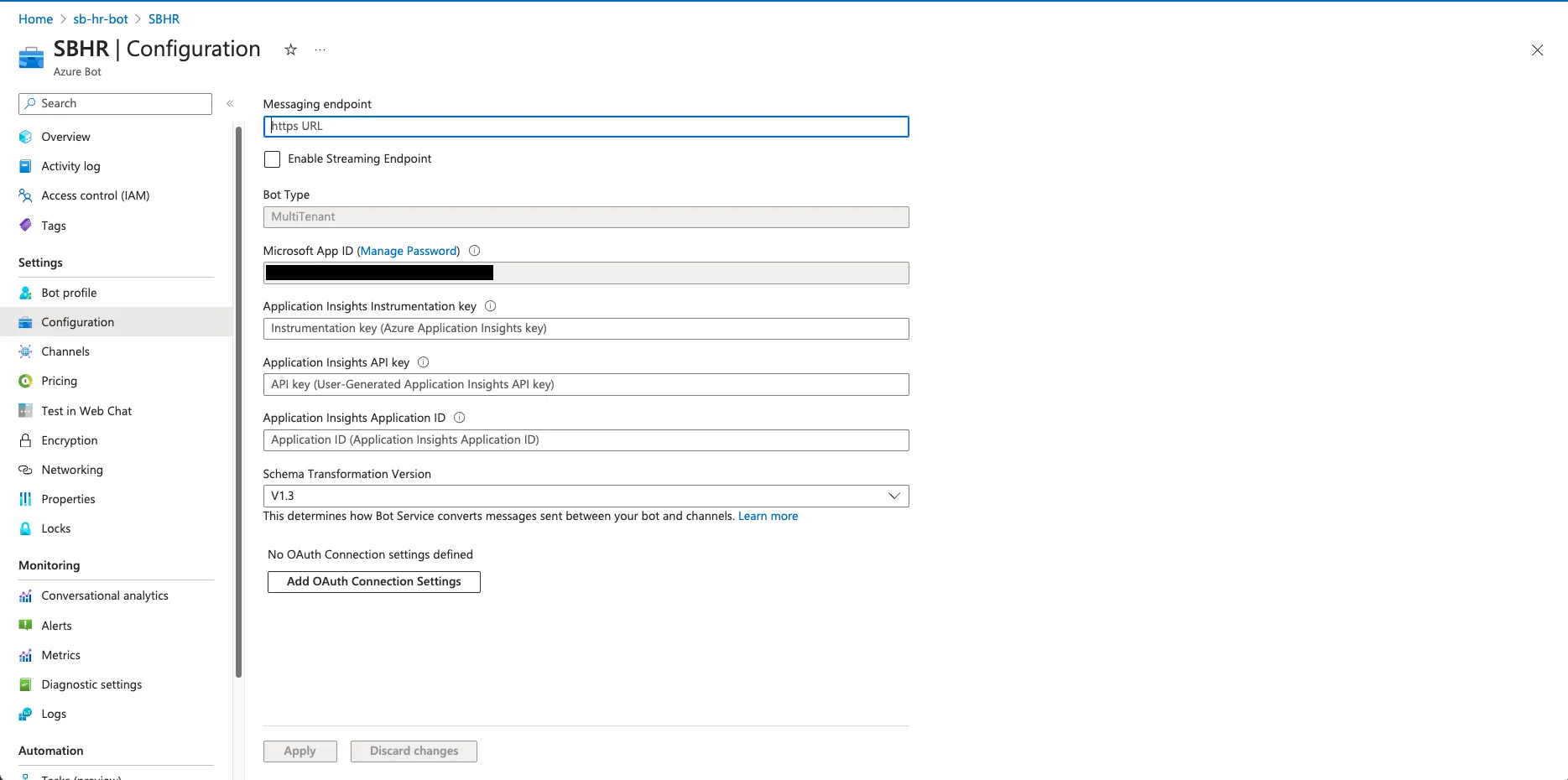
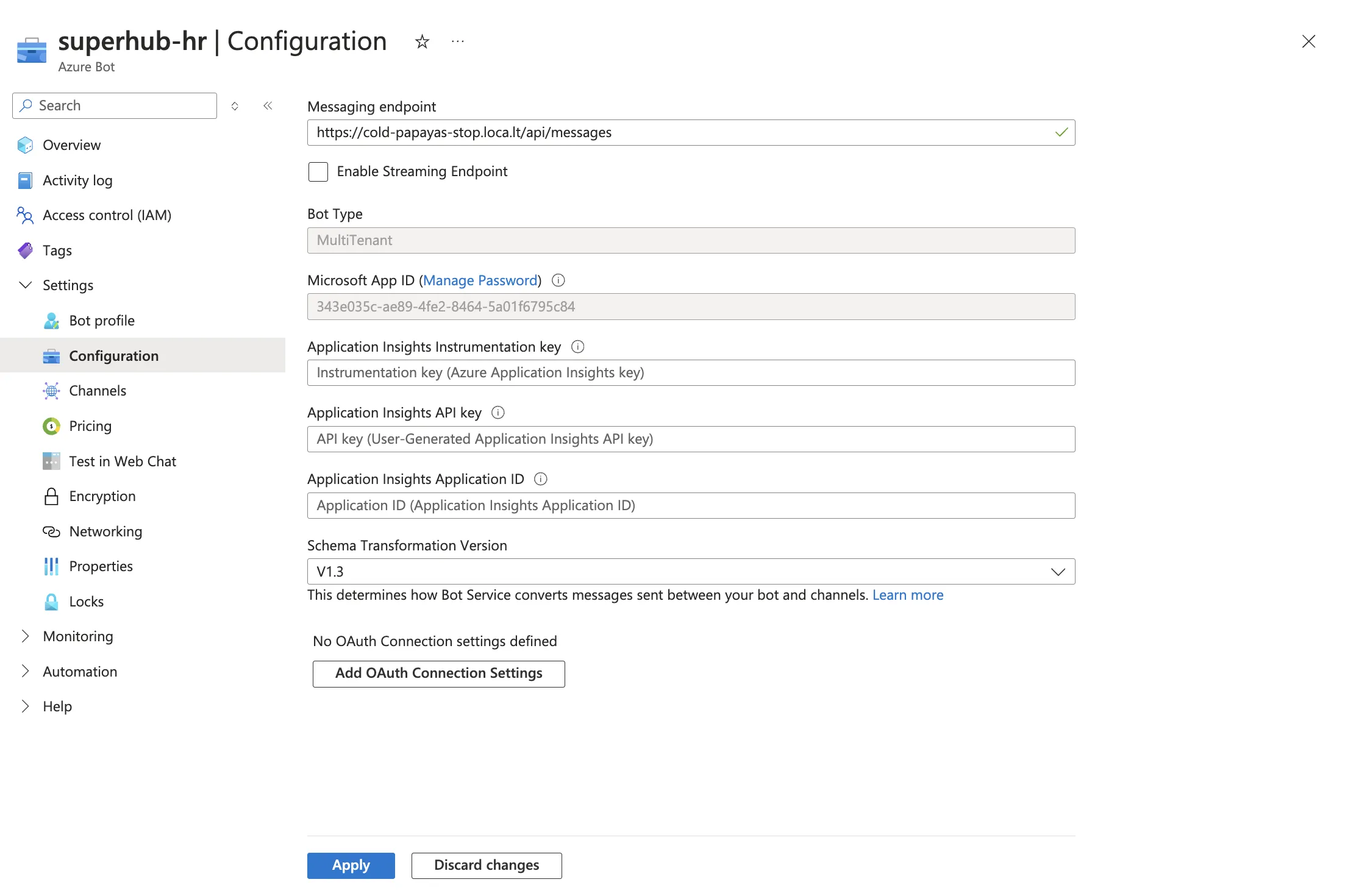
Enabling Annotated Replies in Prompt Orchestration
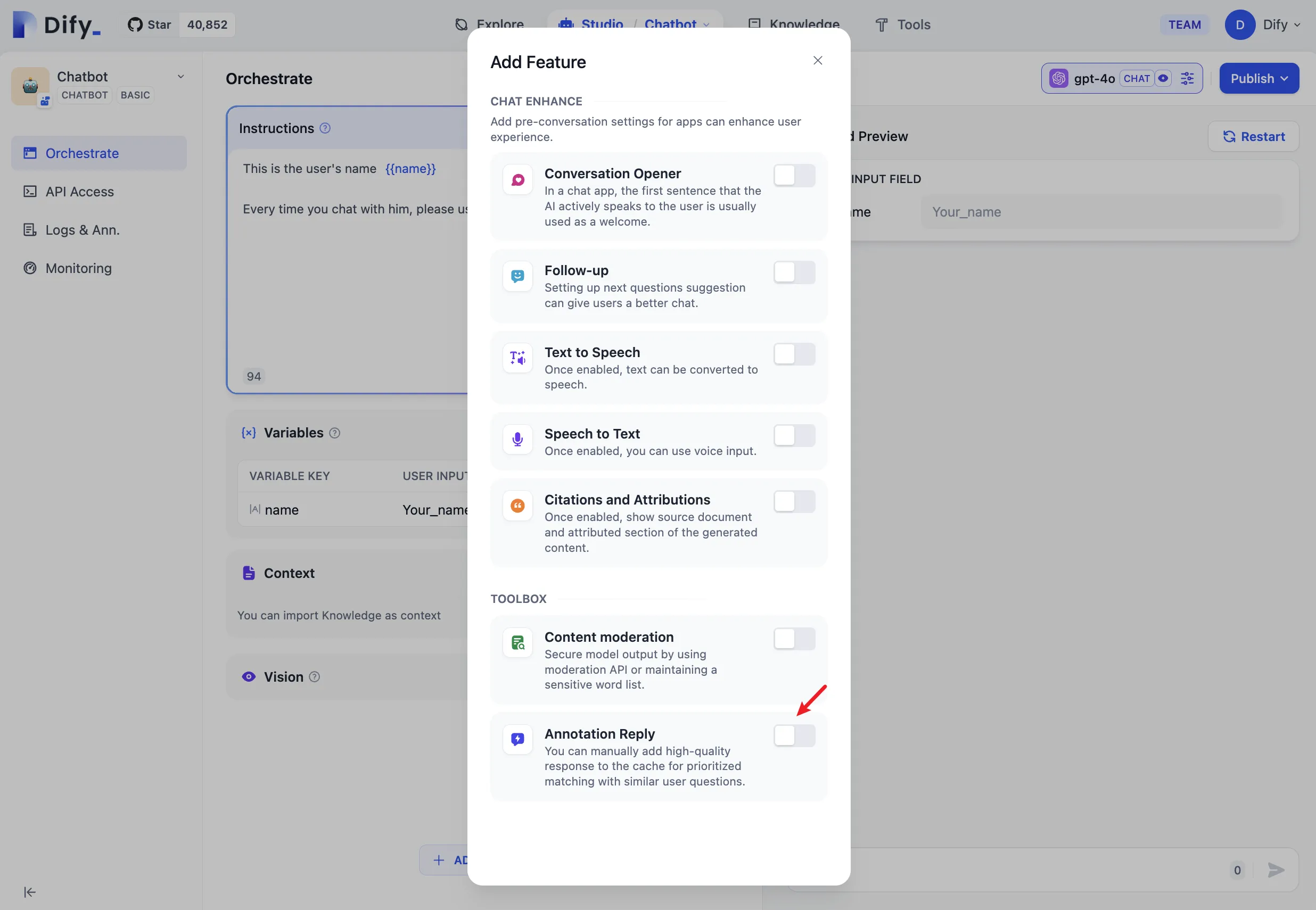
Enabling Annotated Replies in Prompt Orchestration

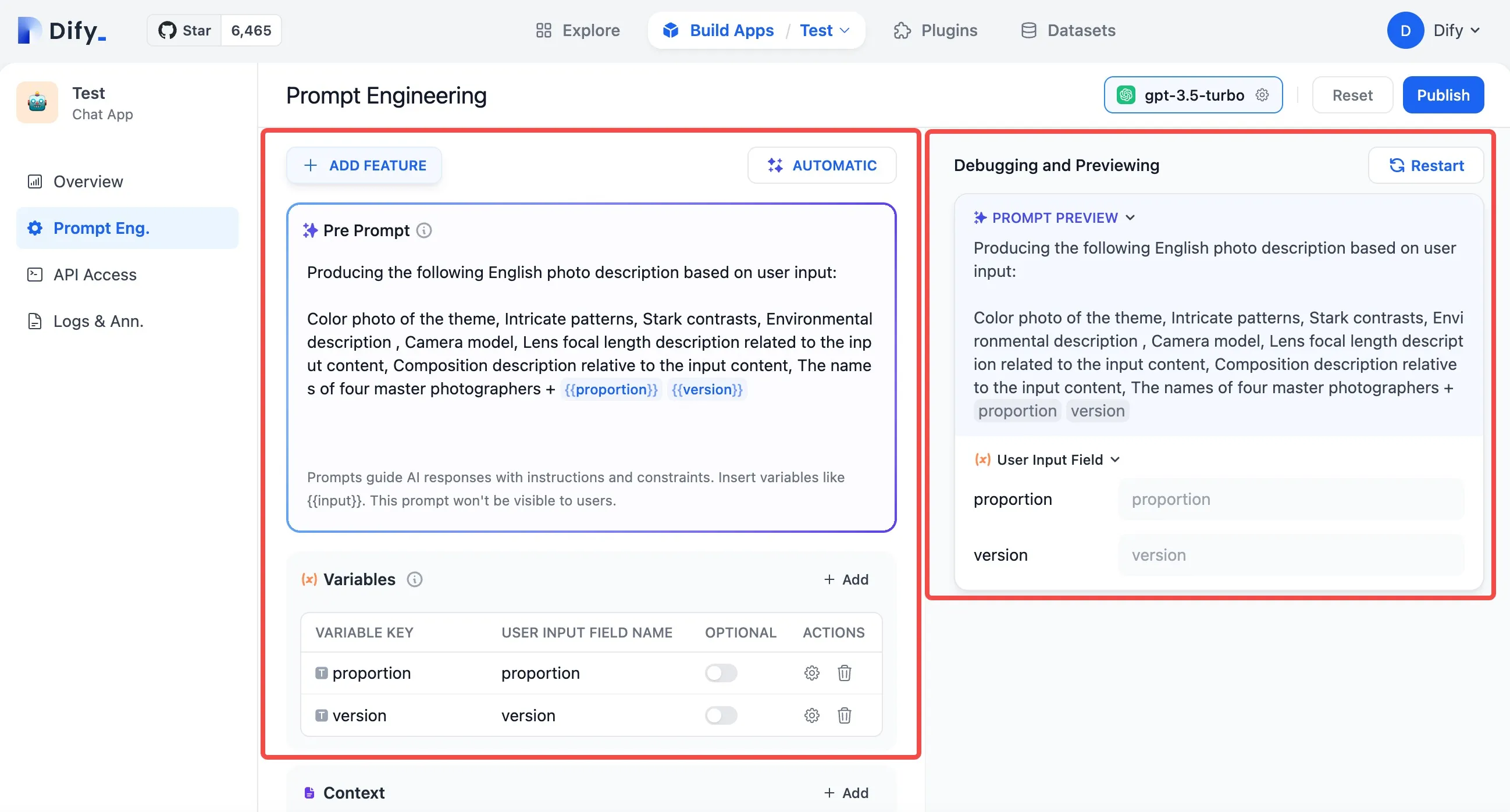
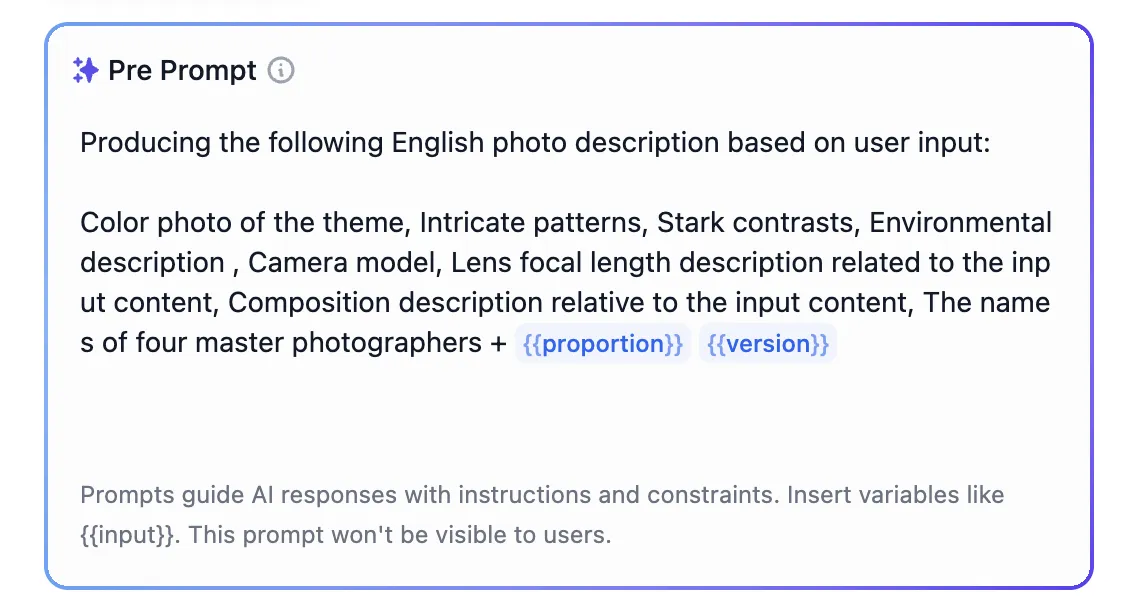
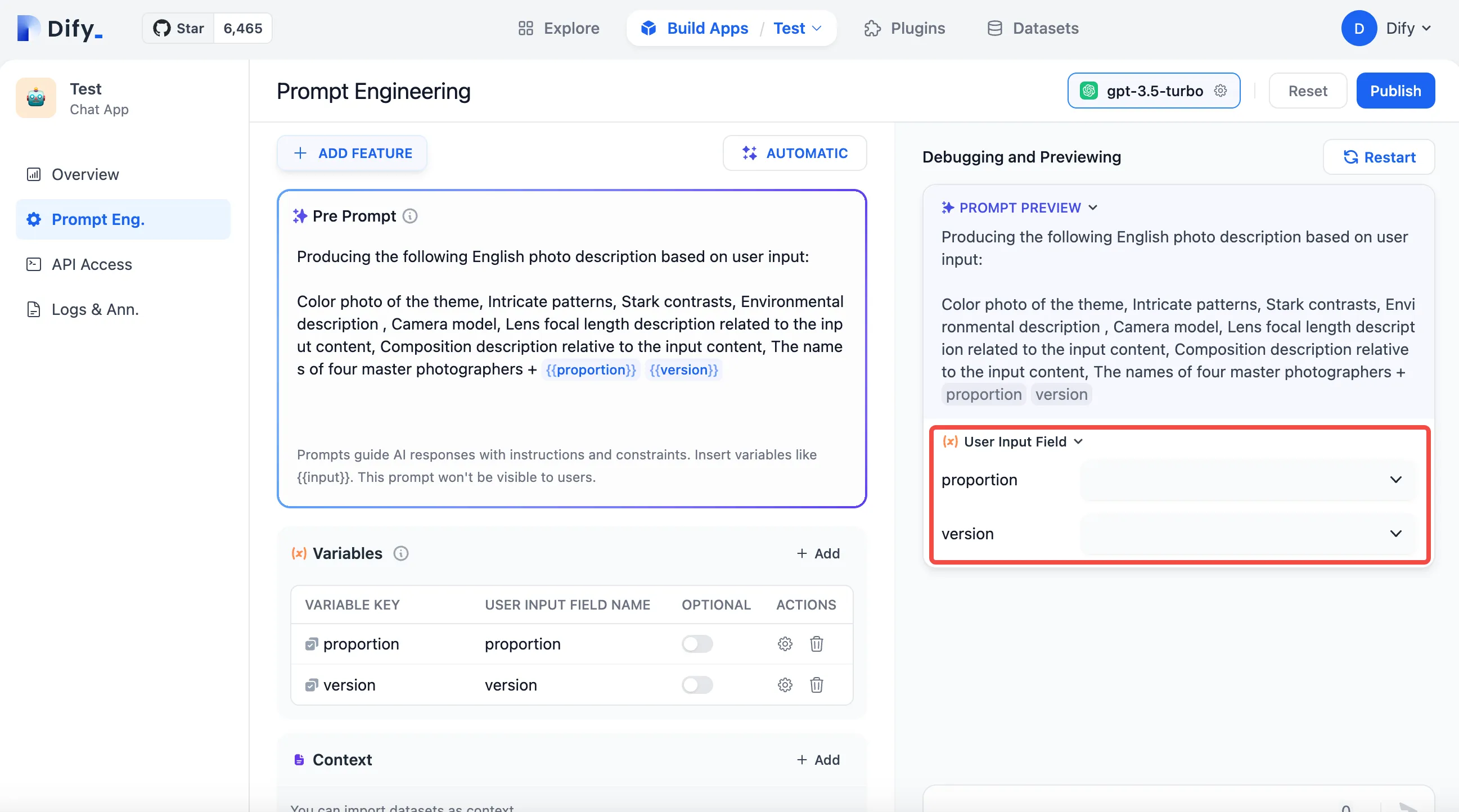
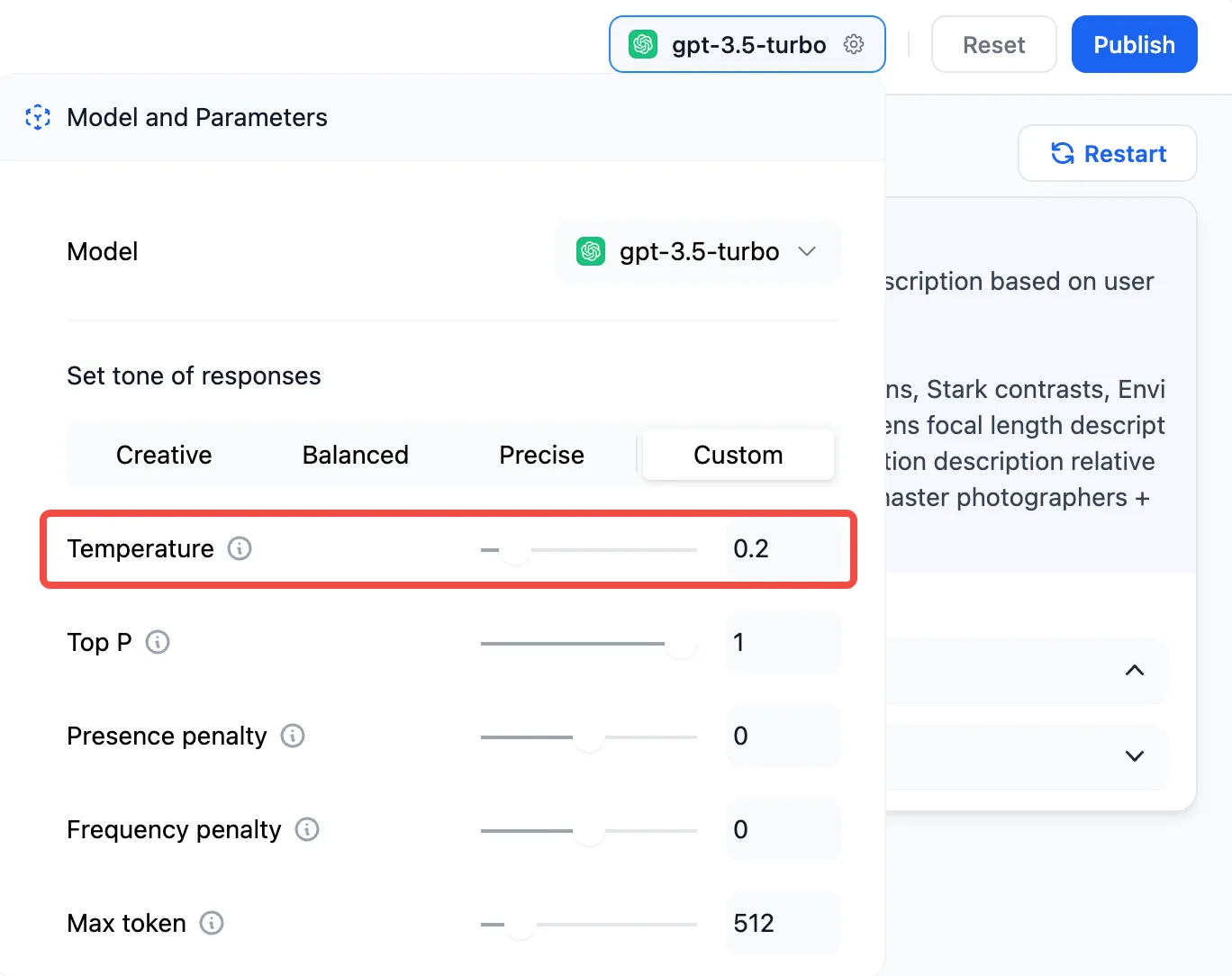
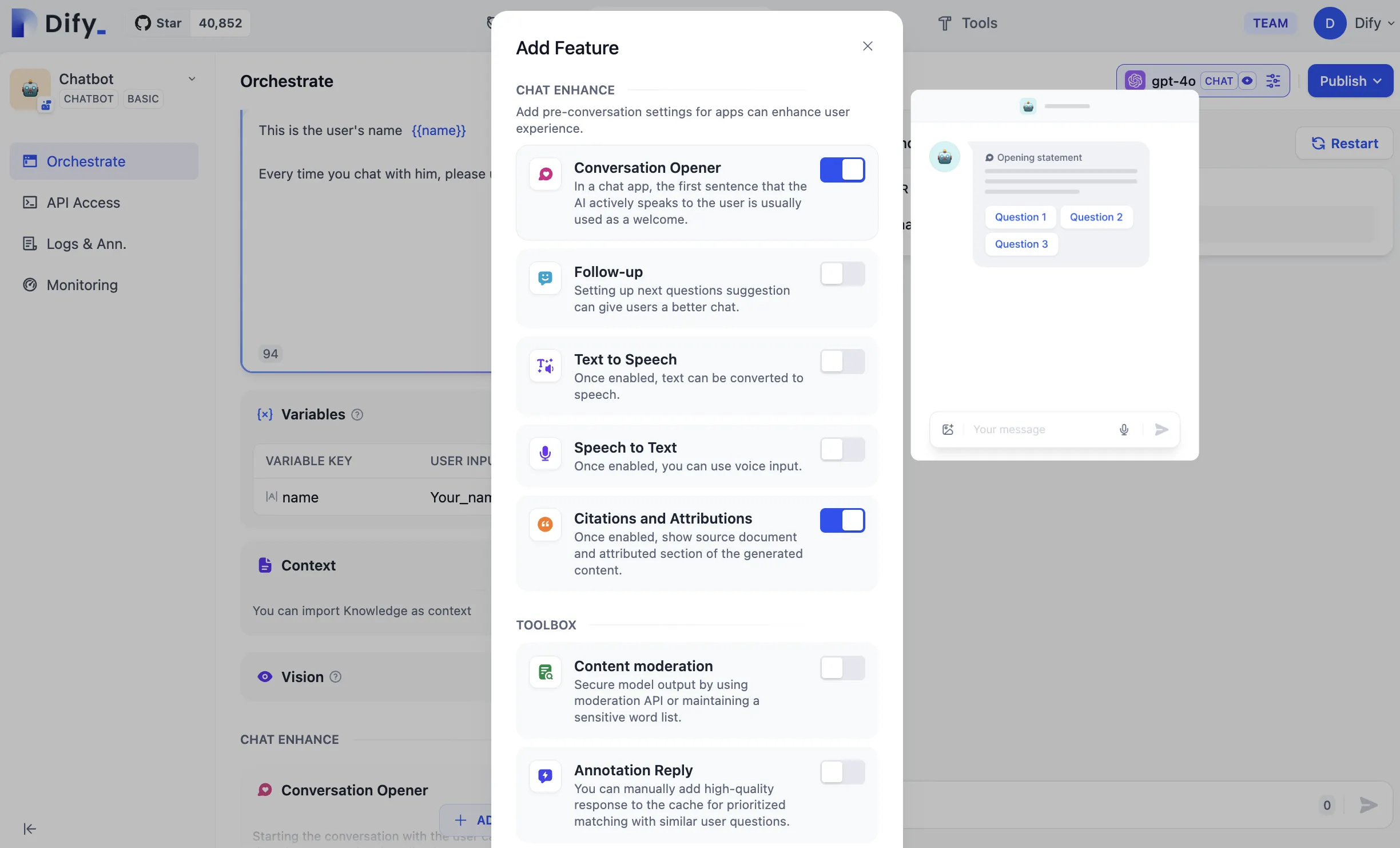
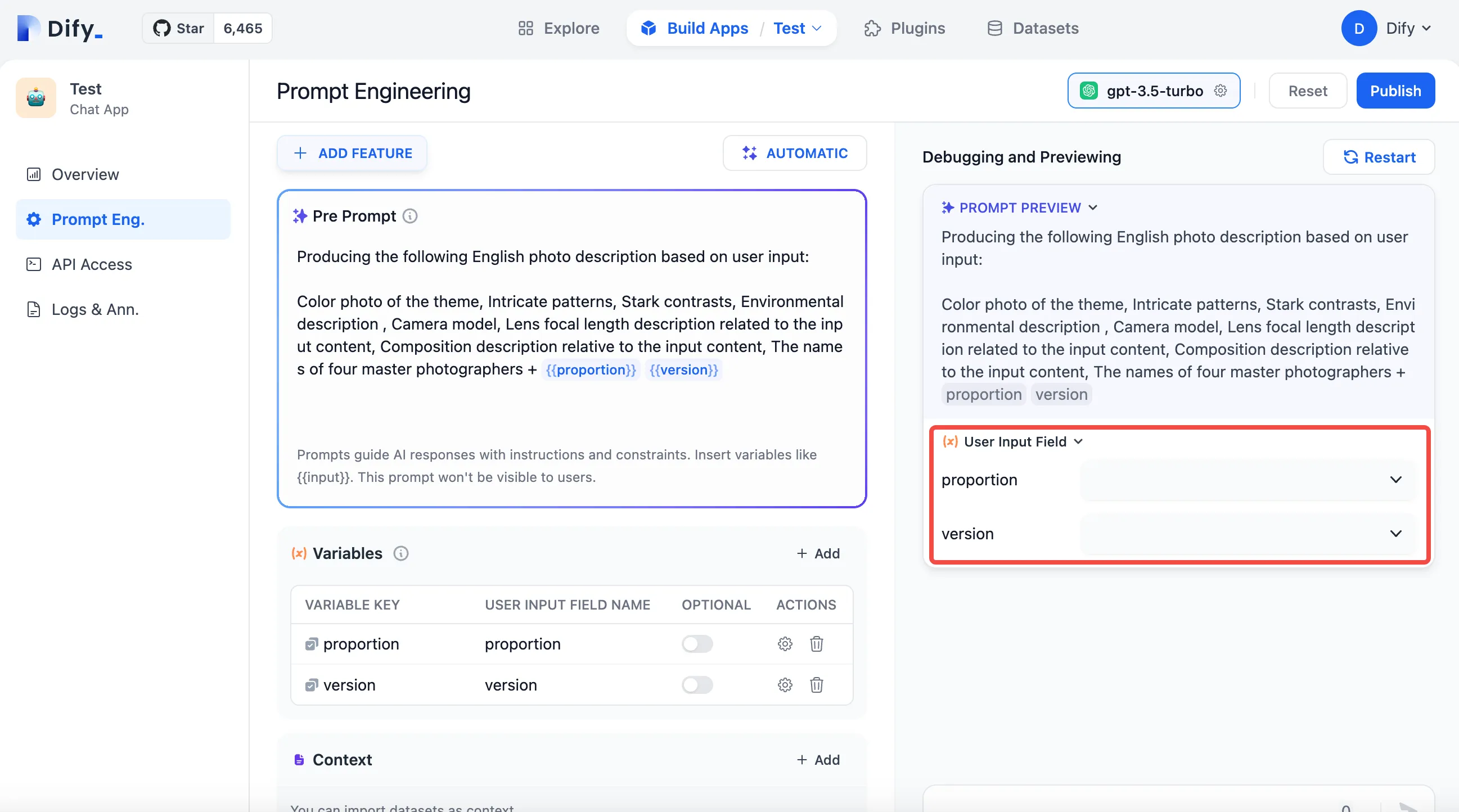
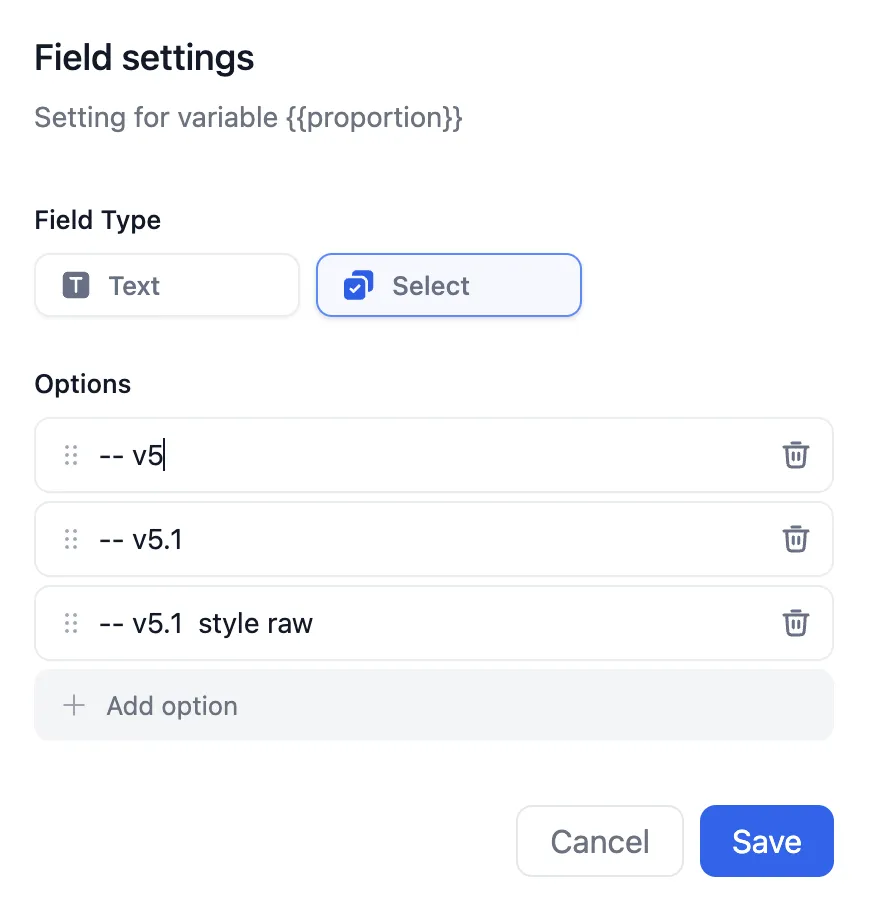
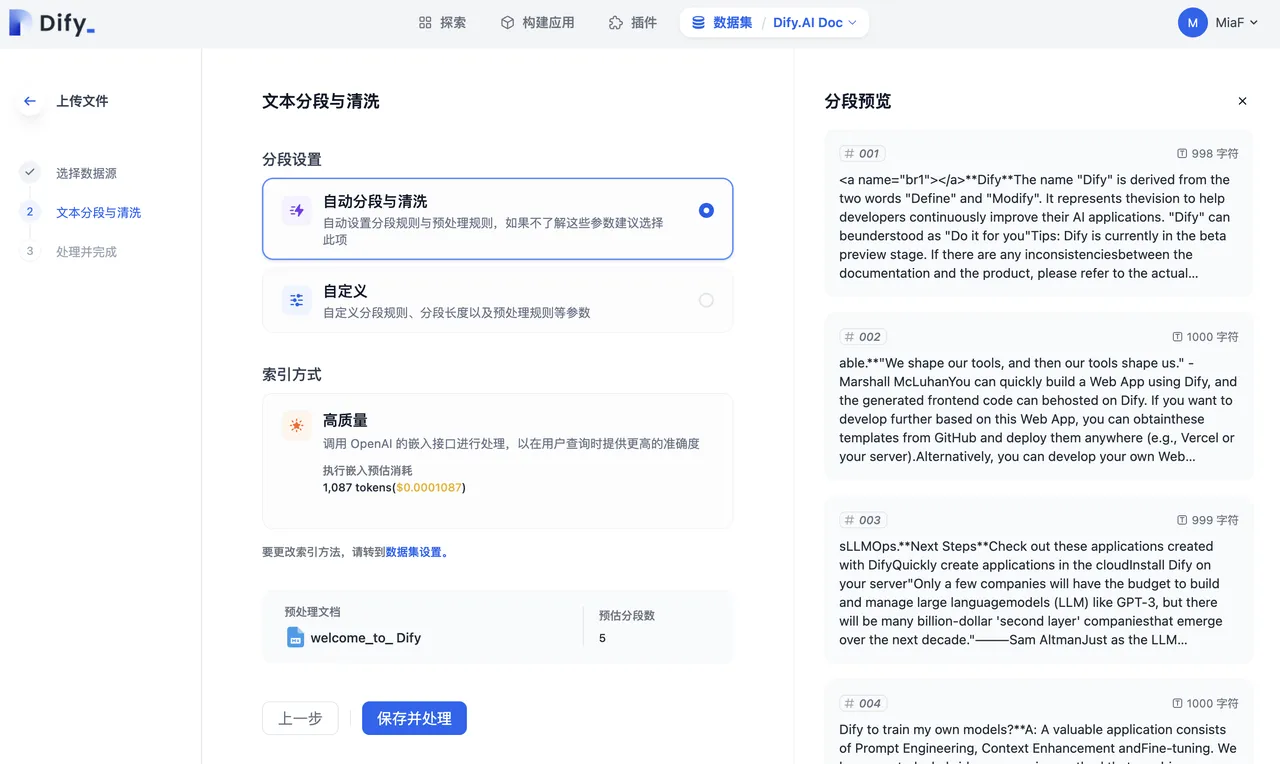
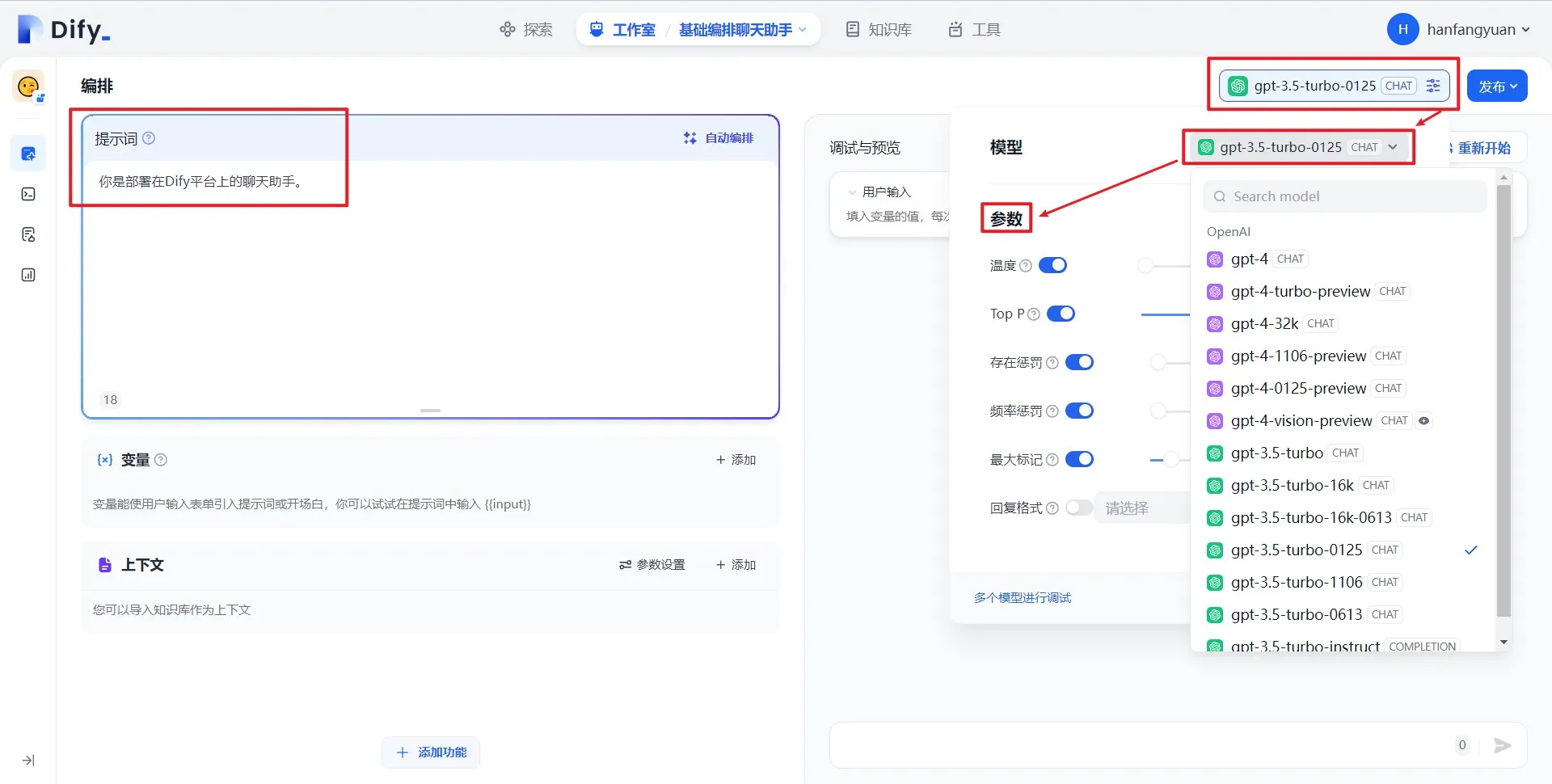
Setting Parameters for Annotated Replies
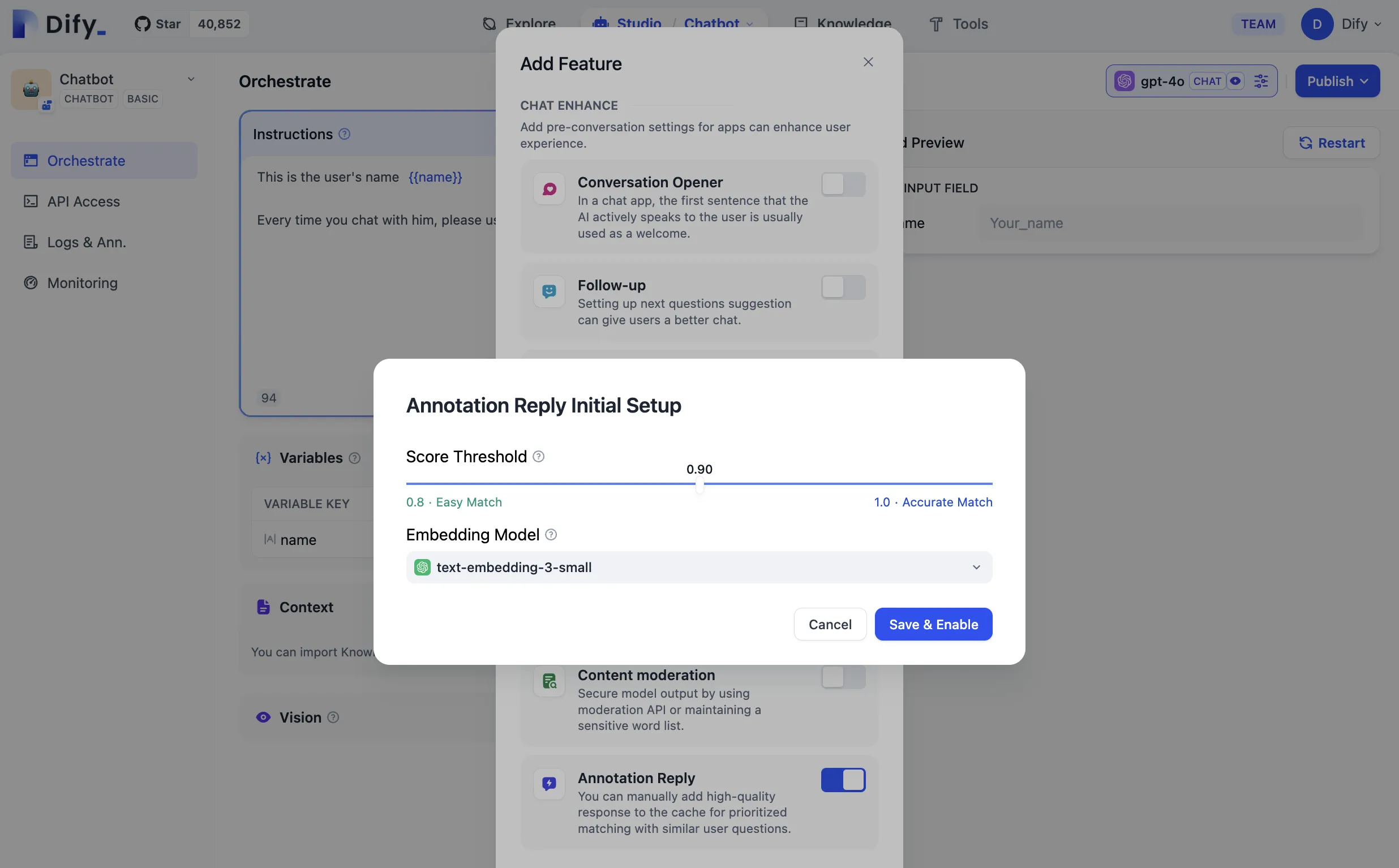
Setting Parameters for Annotated Replies

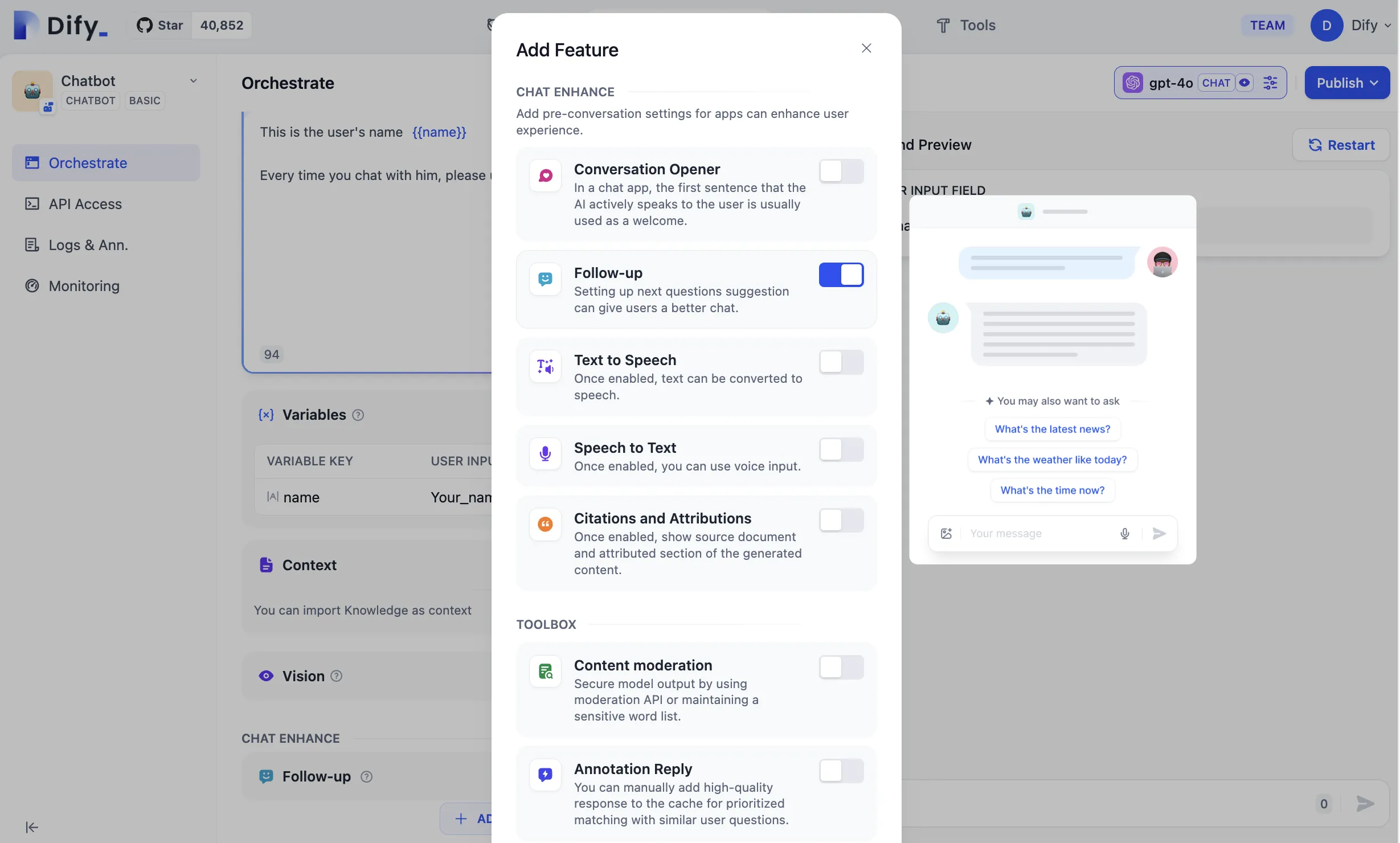
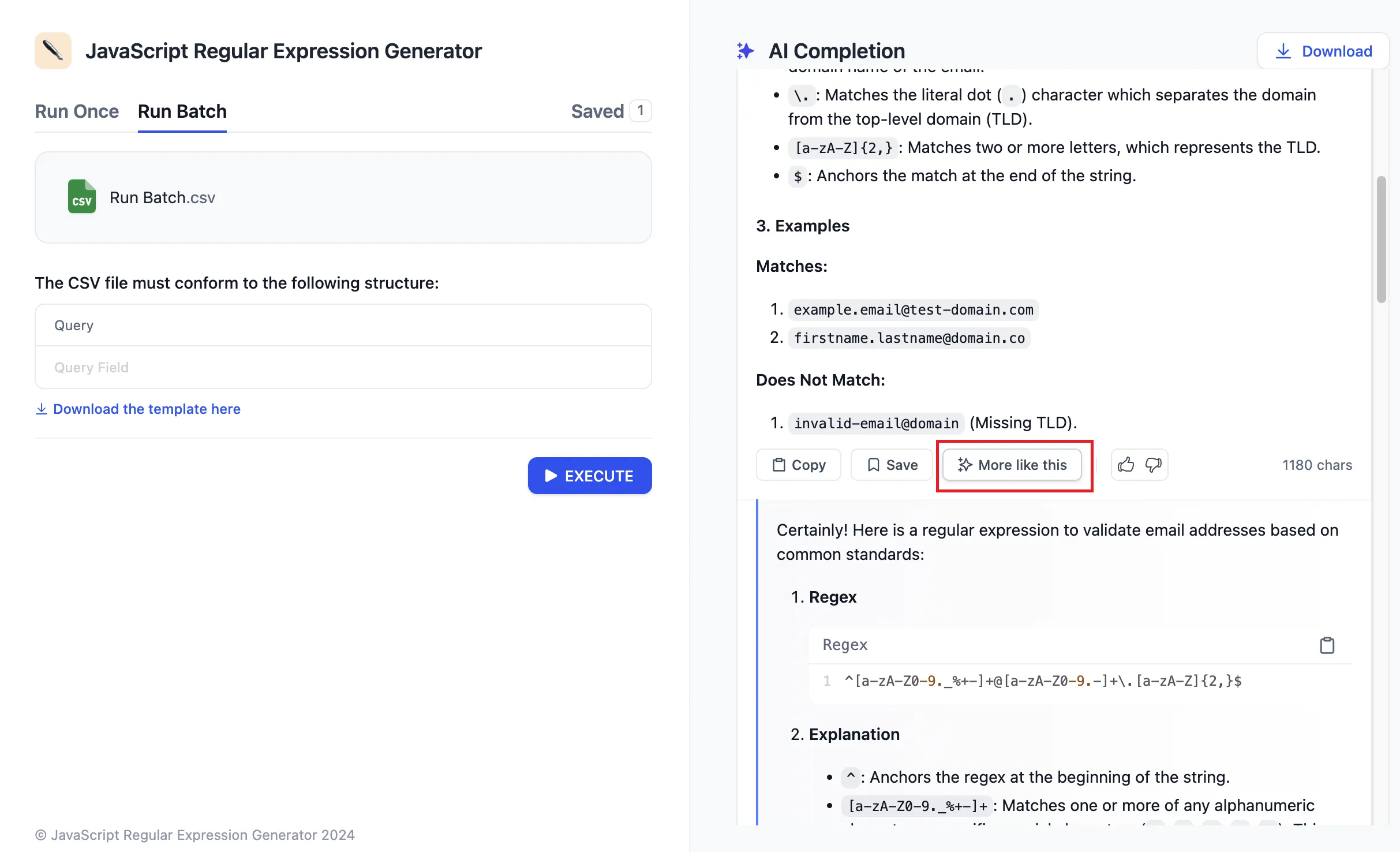
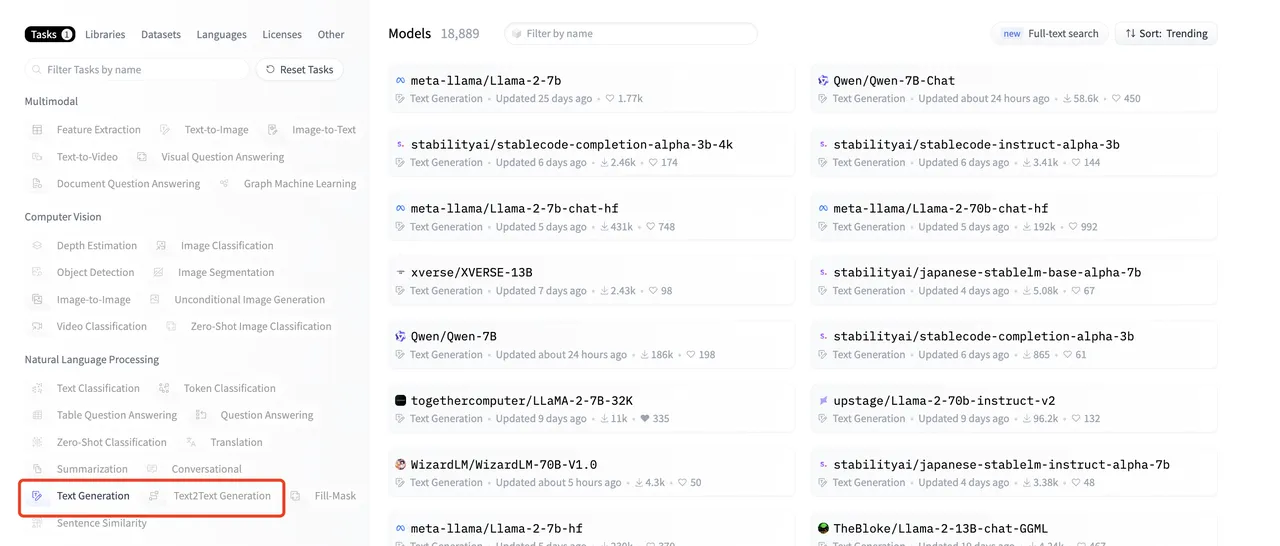
Adding Annotated Replies
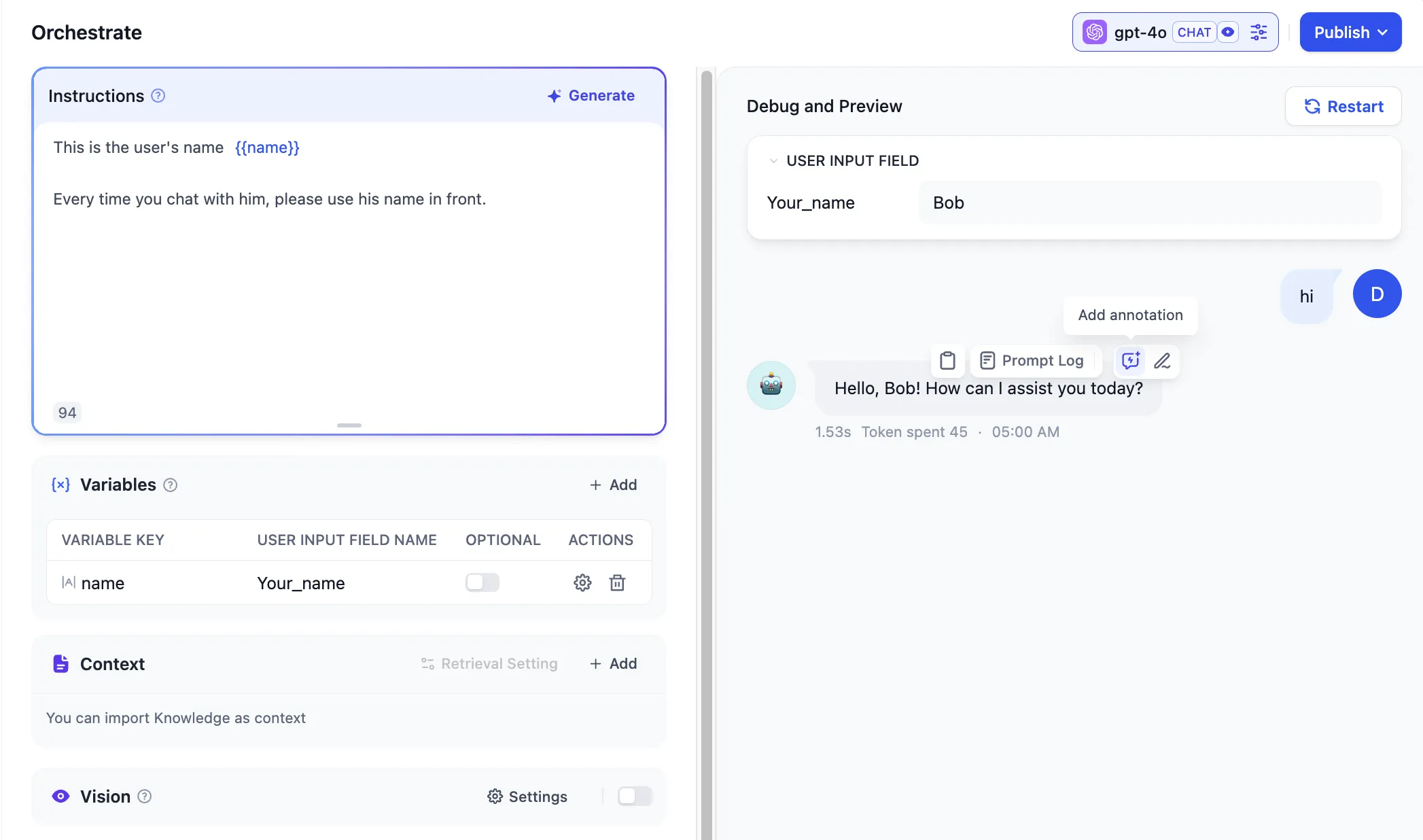
Adding Annotated Replies

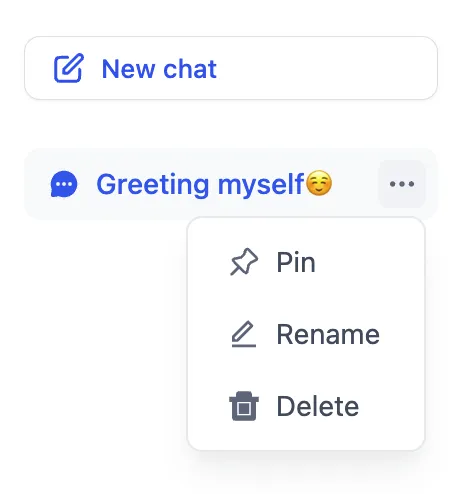
Editing Annotated Replies
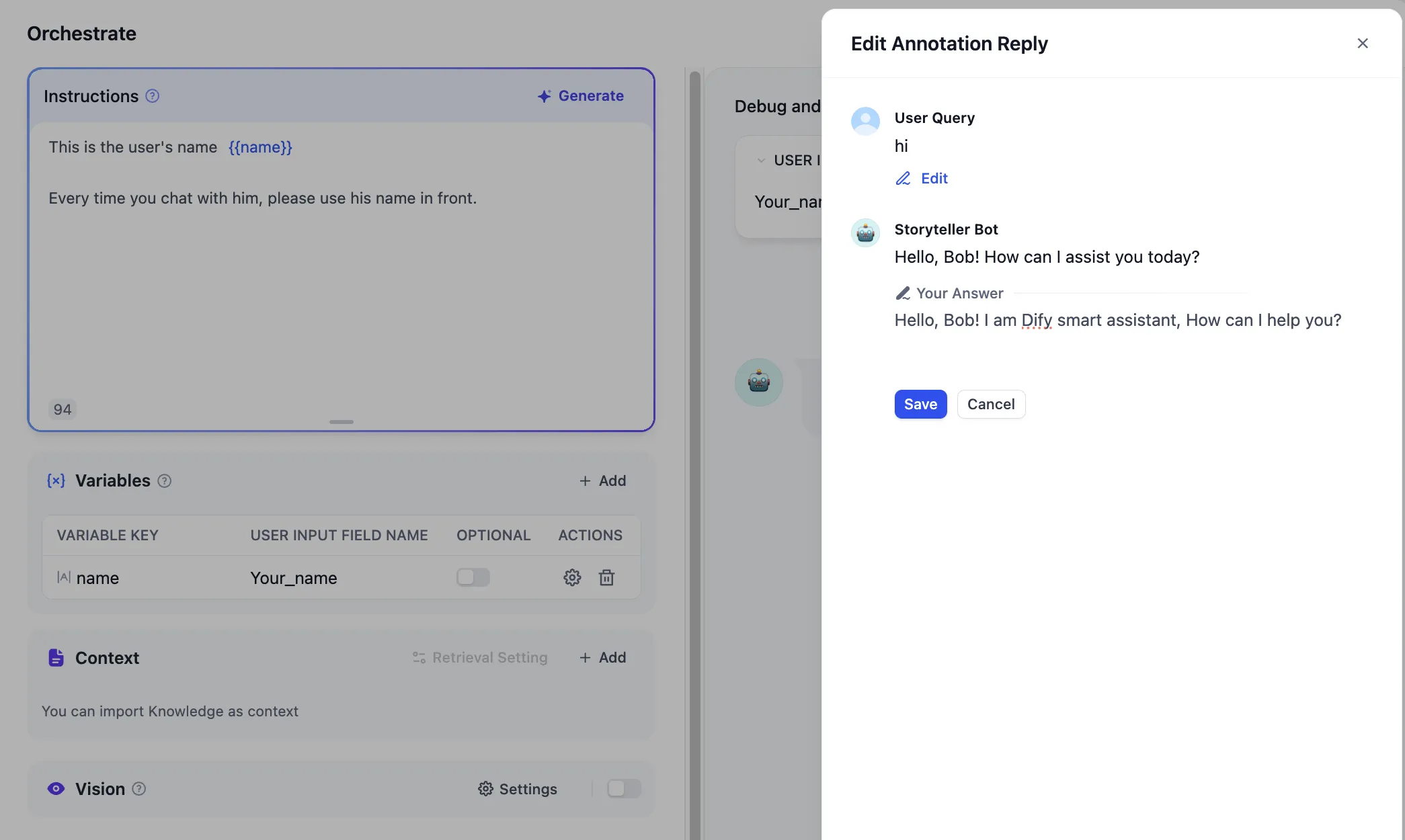
Editing Annotated Replies

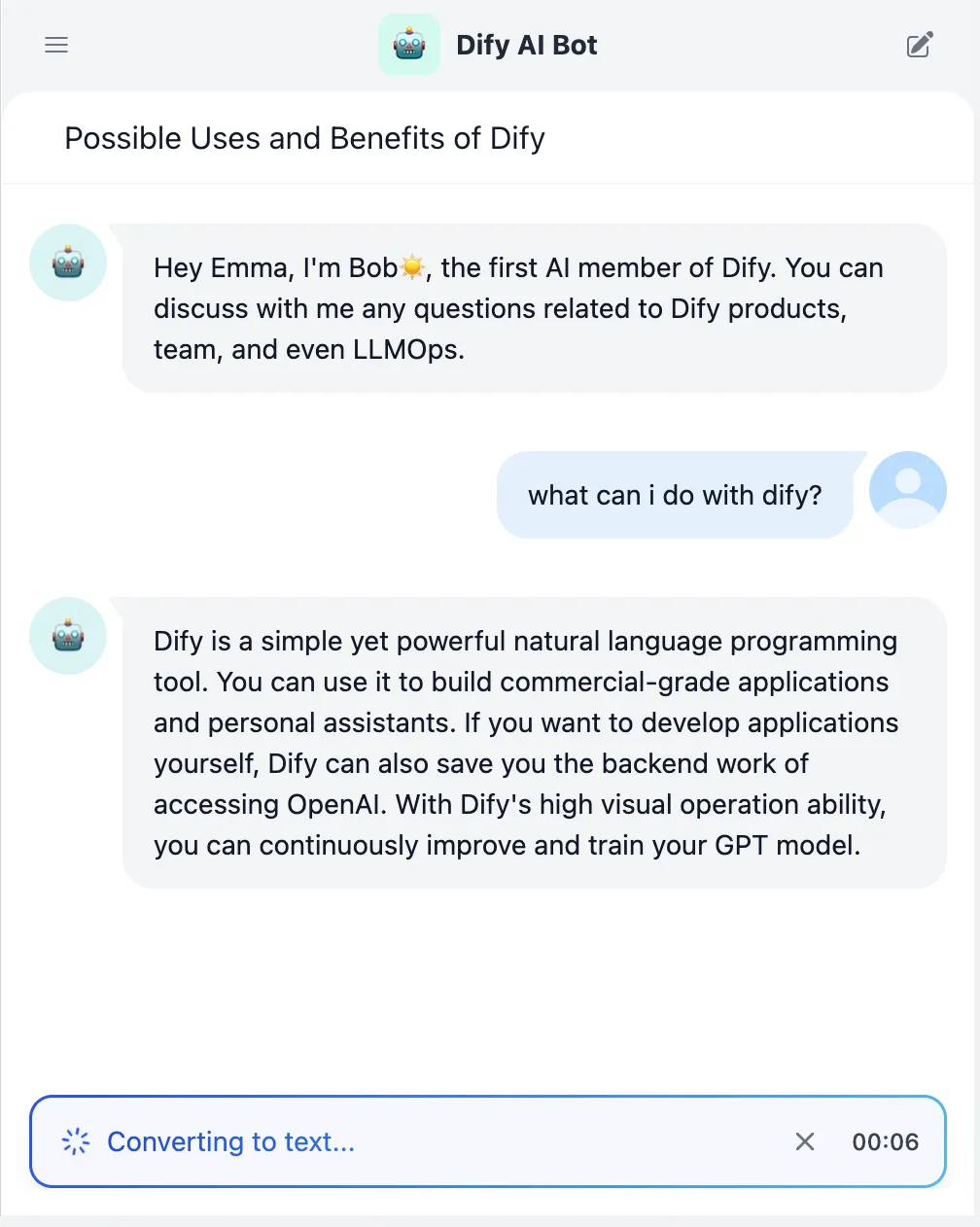
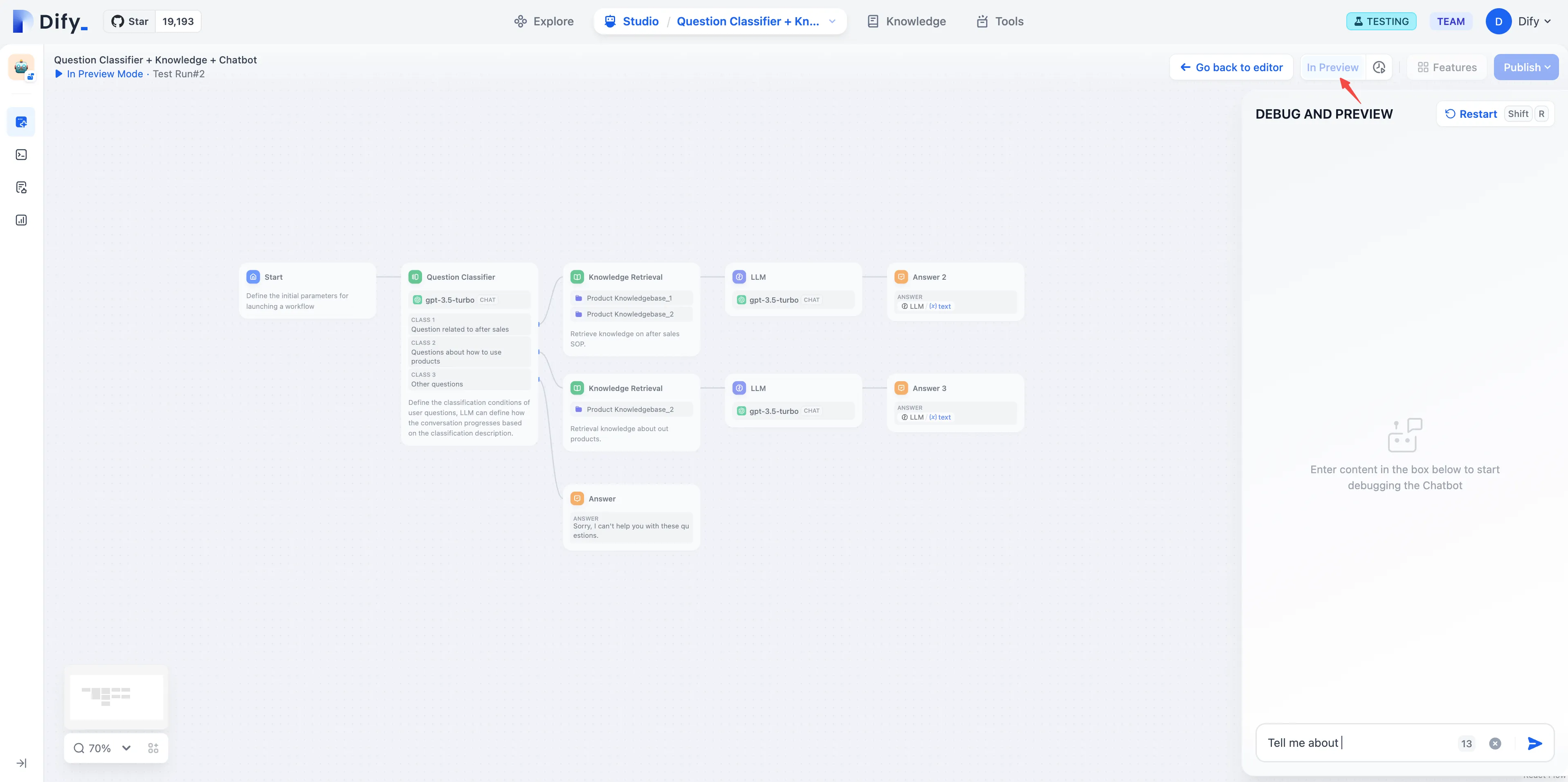
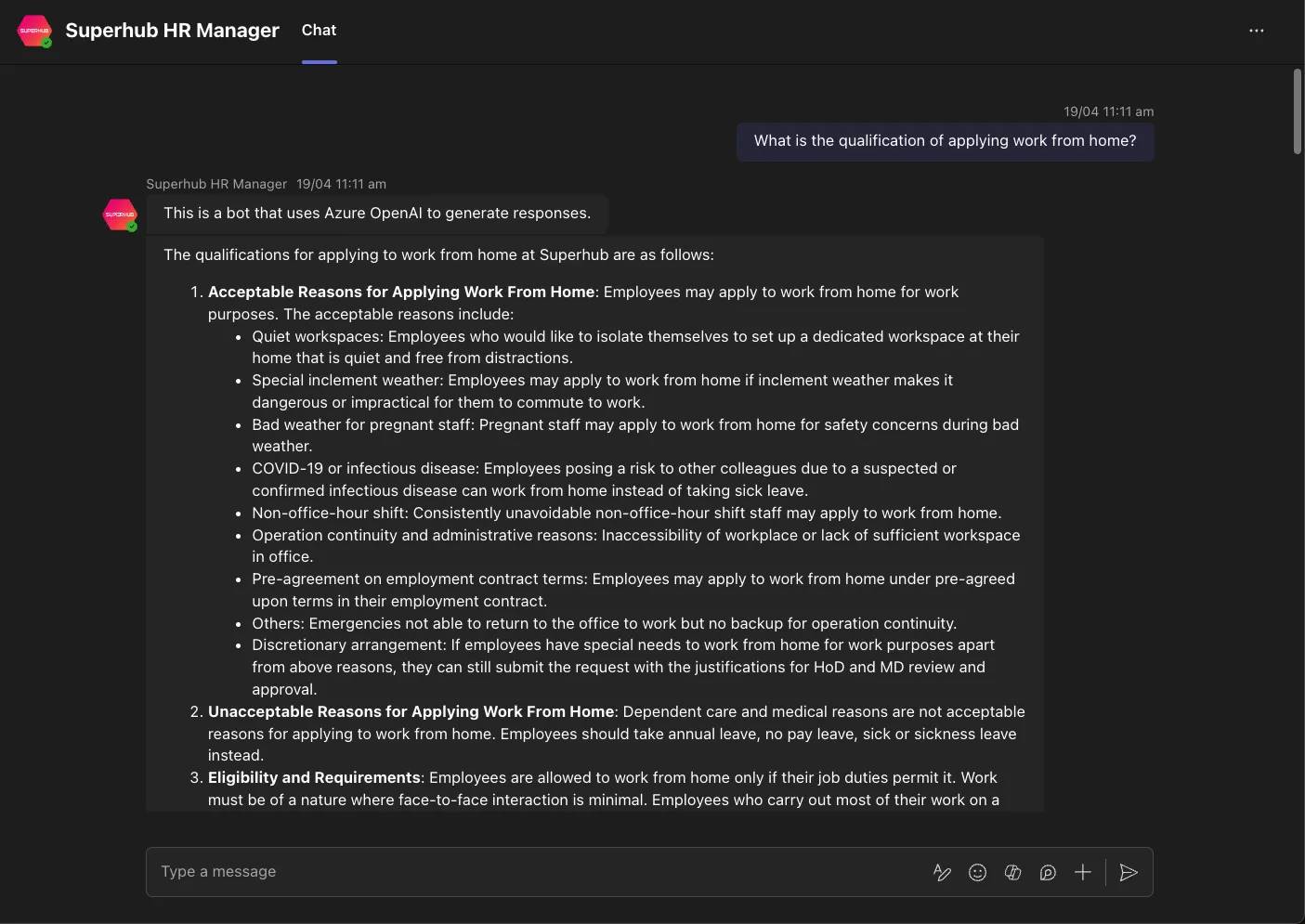
Replying to User Questions with Saved Annotations
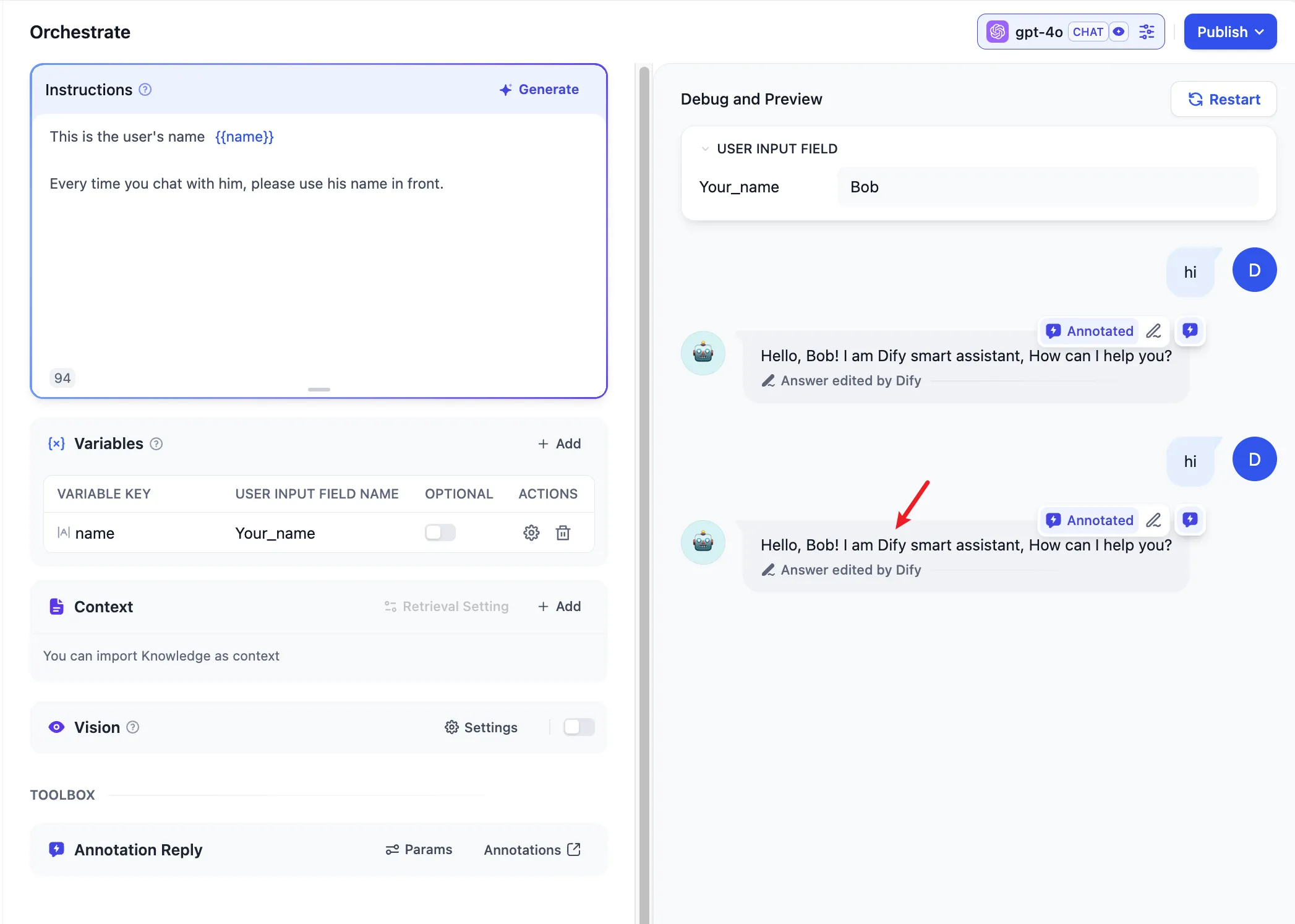
Replying to User Questions with Saved Annotations

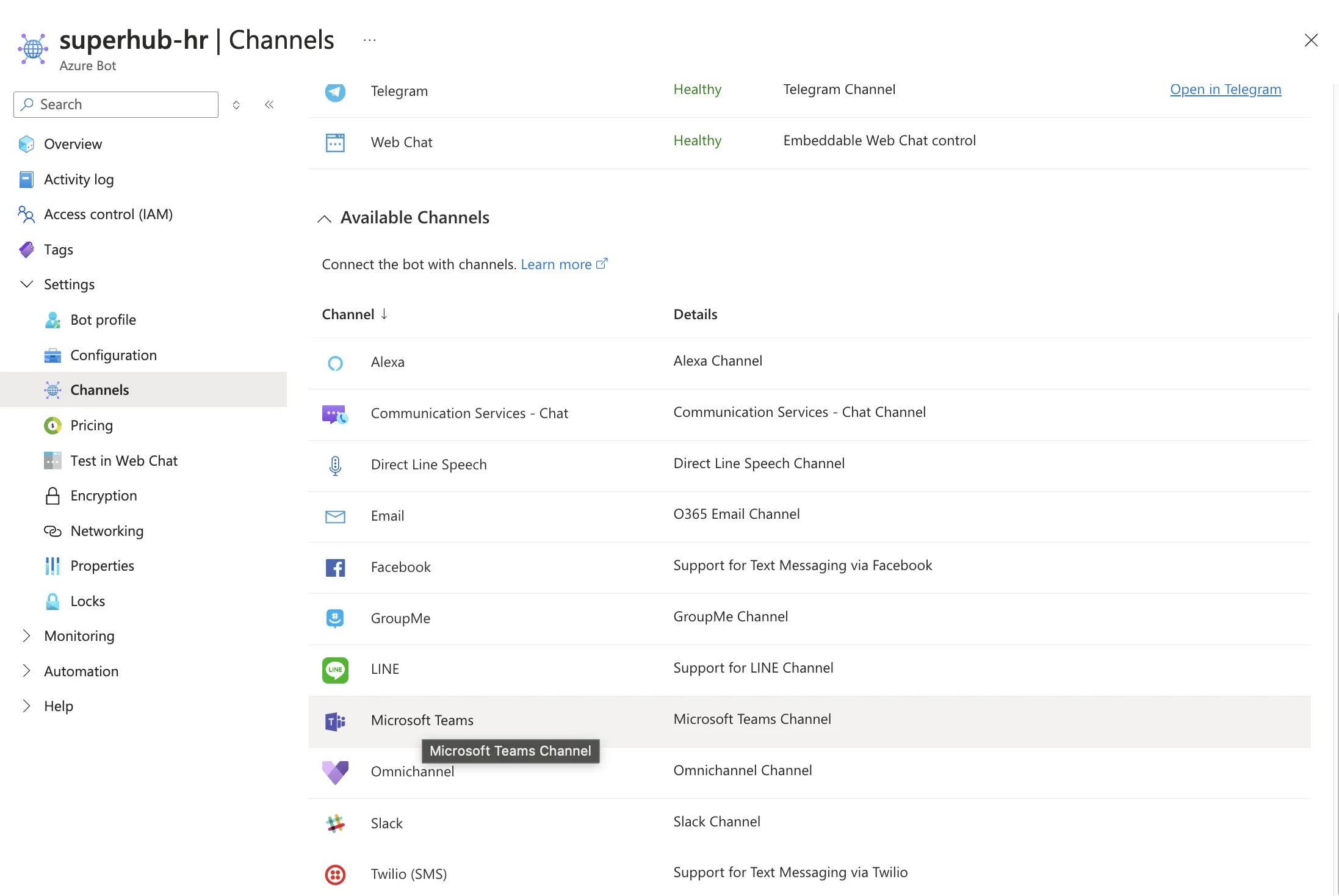
Enabling Annotated Replies in Logs and Annotations
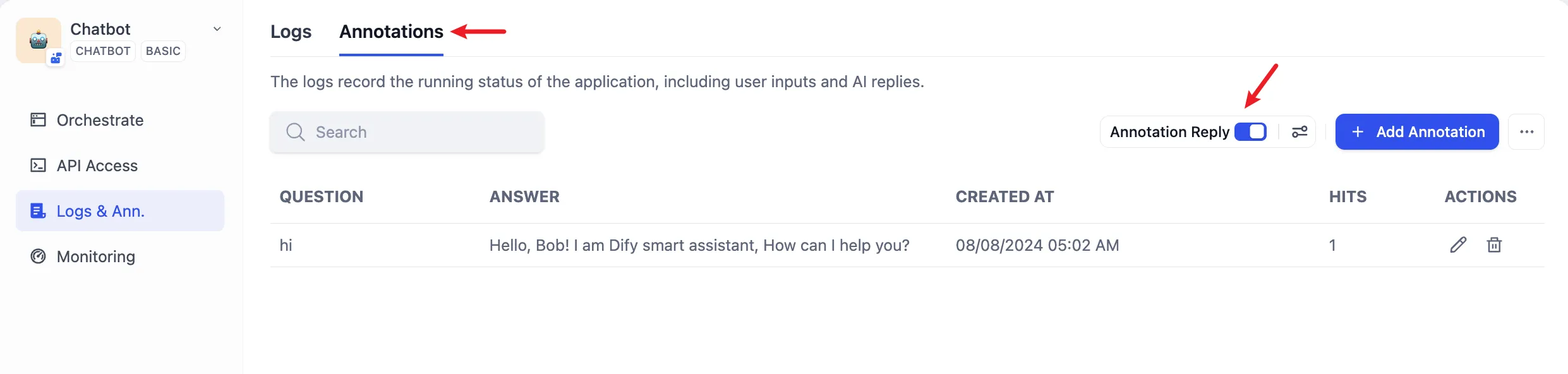
Enabling Annotated Replies in Logs and Annotations

Setting Parameters for Annotated Replies
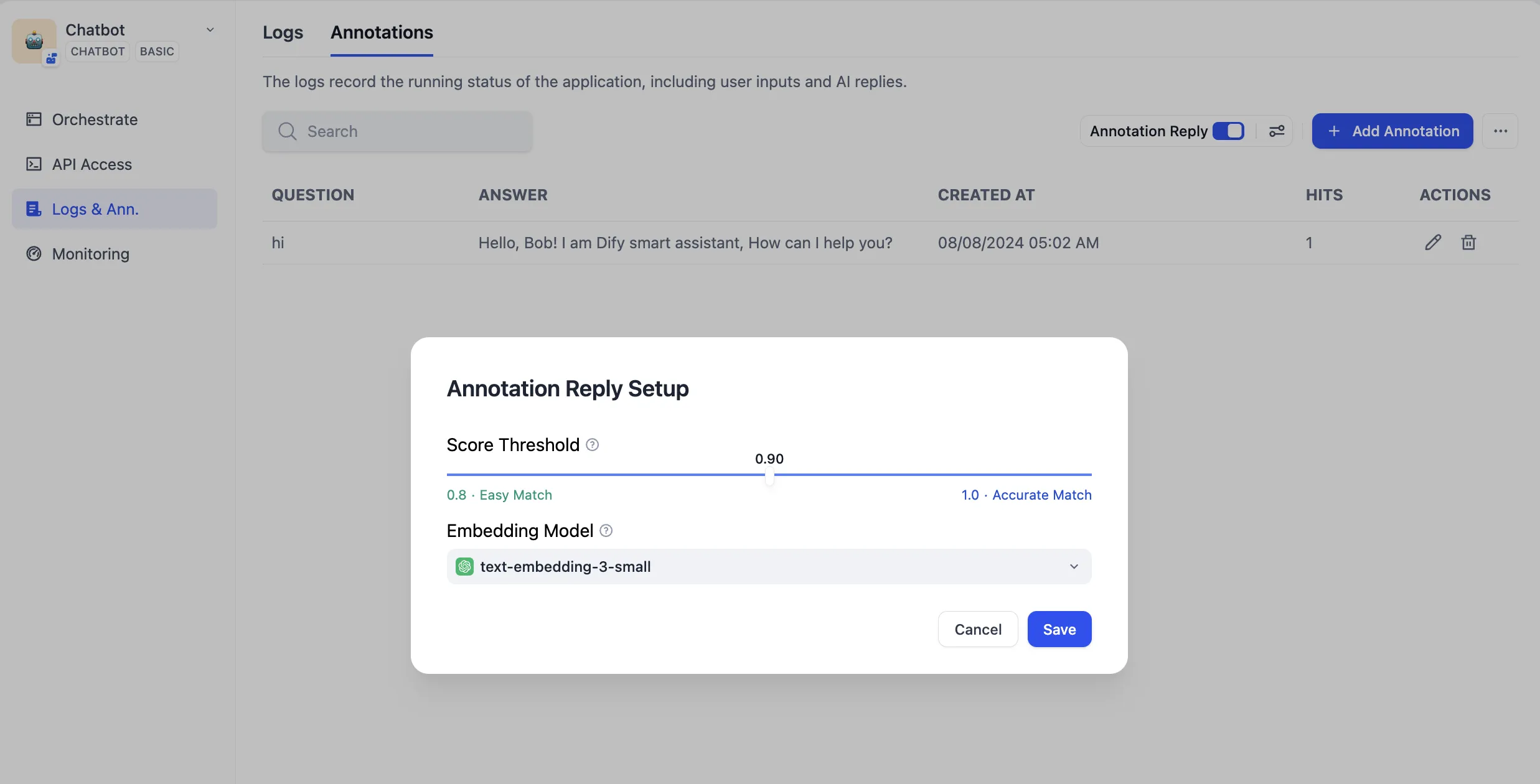
Setting Parameters for Annotated Replies

Bulk Import of Annotated Q&A Pairs
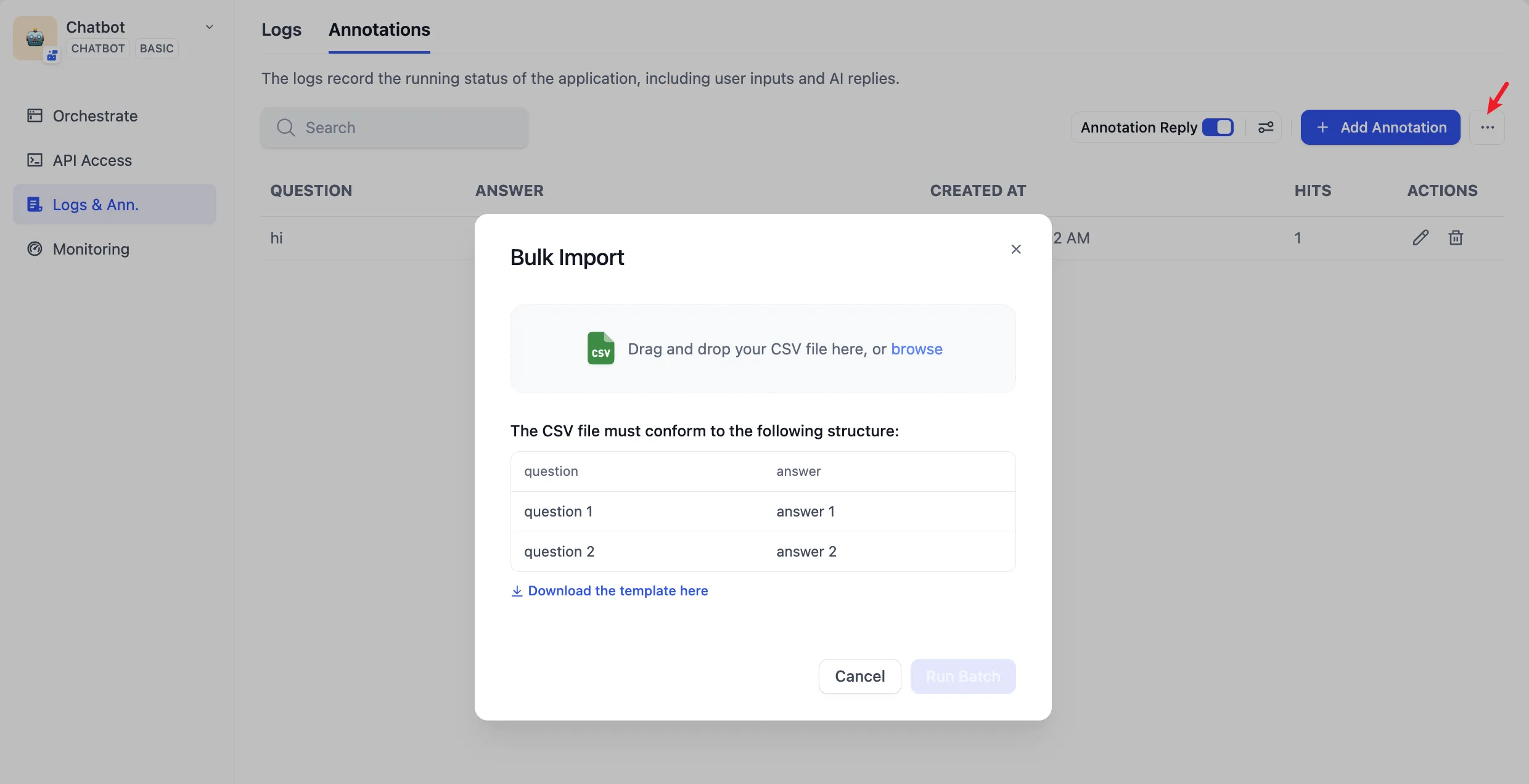
Bulk Import of Annotated Q&A Pairs

Bulk Export of Annotated Q&A Pairs
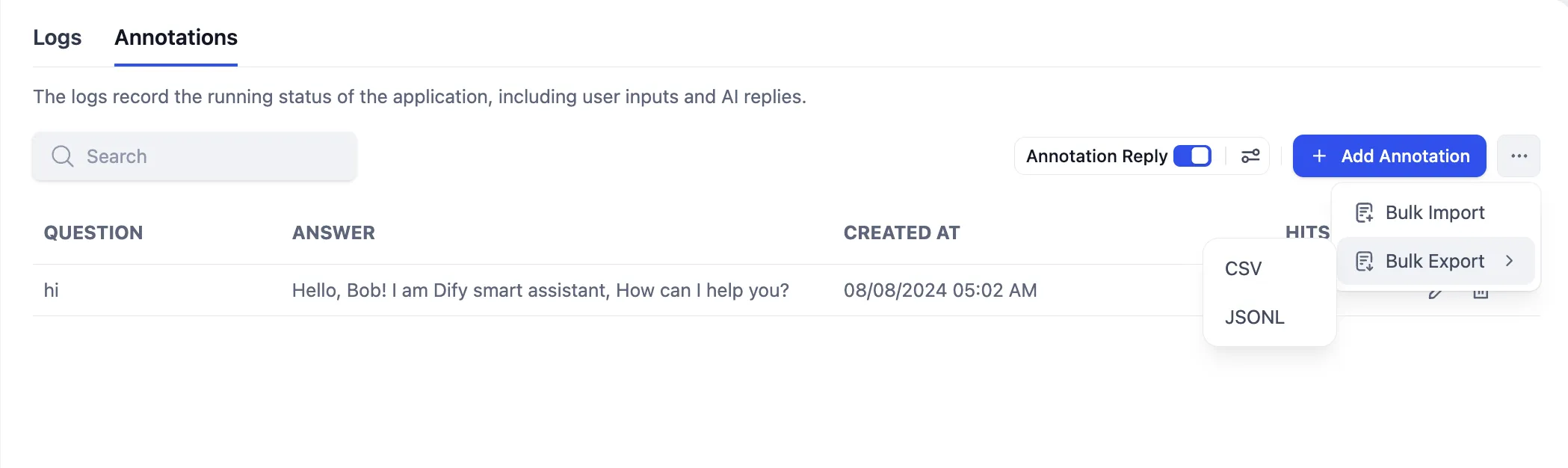
Bulk Export of Annotated Q&A Pairs

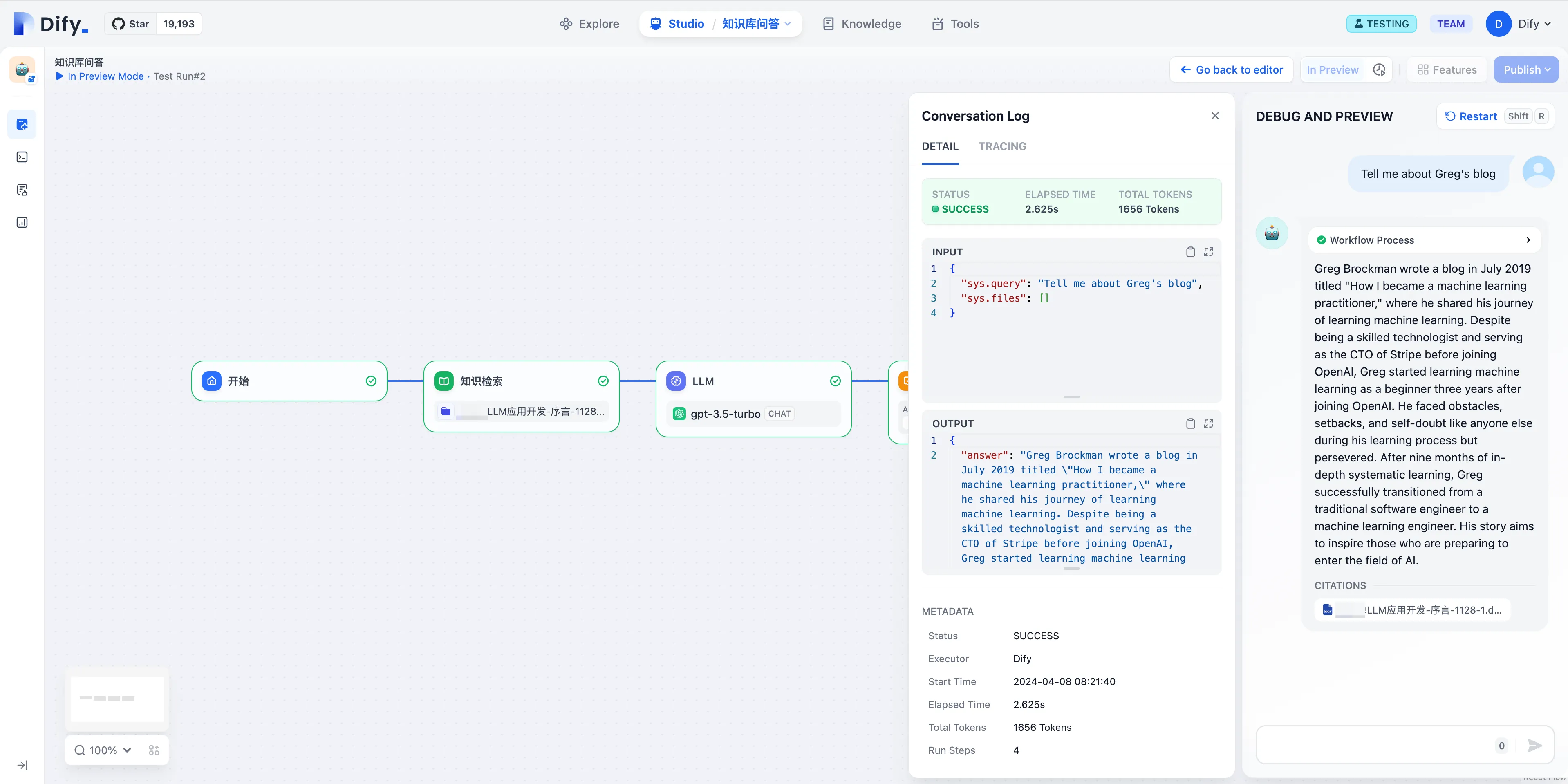
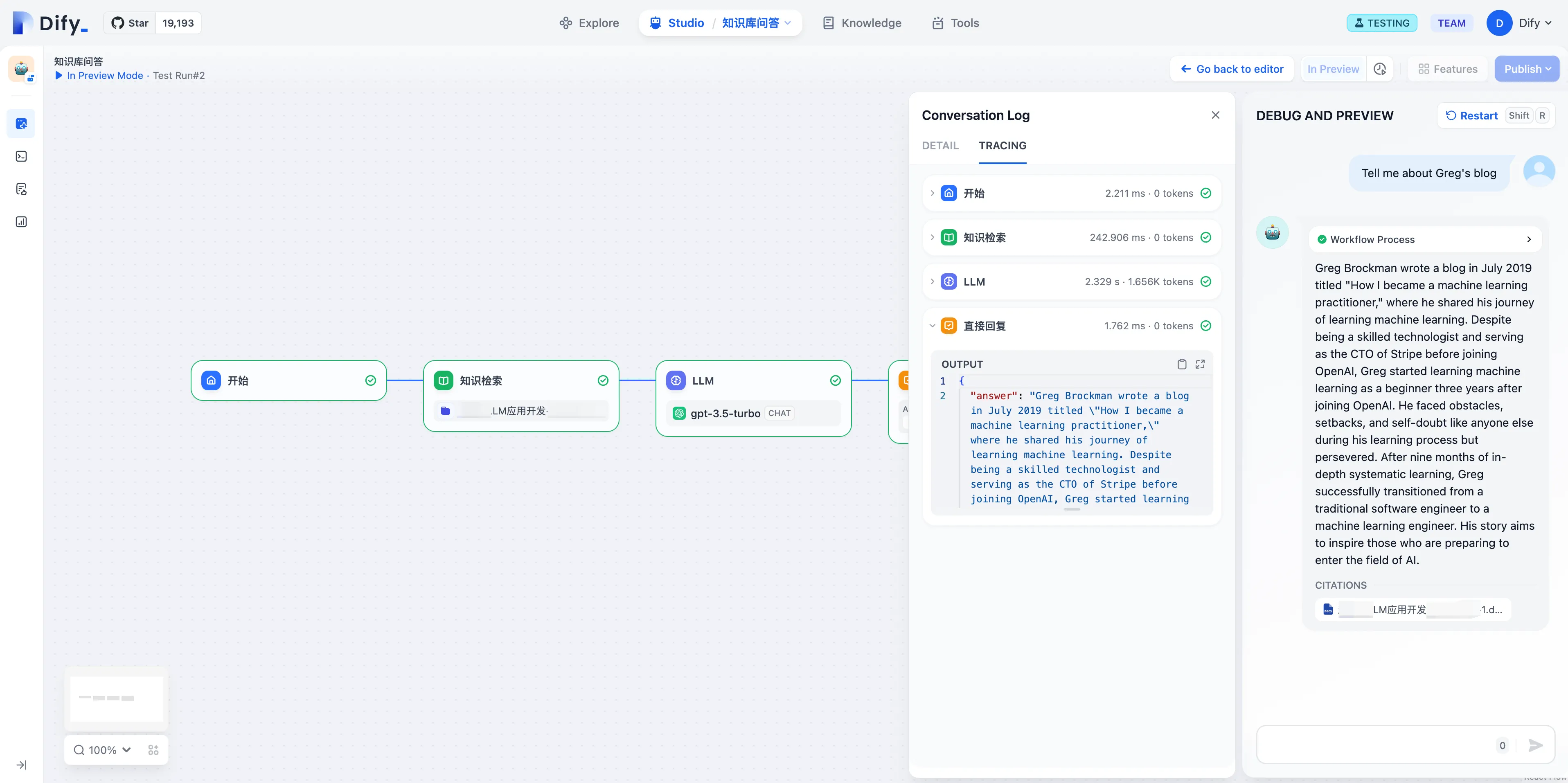
Viewing Annotation Hit History
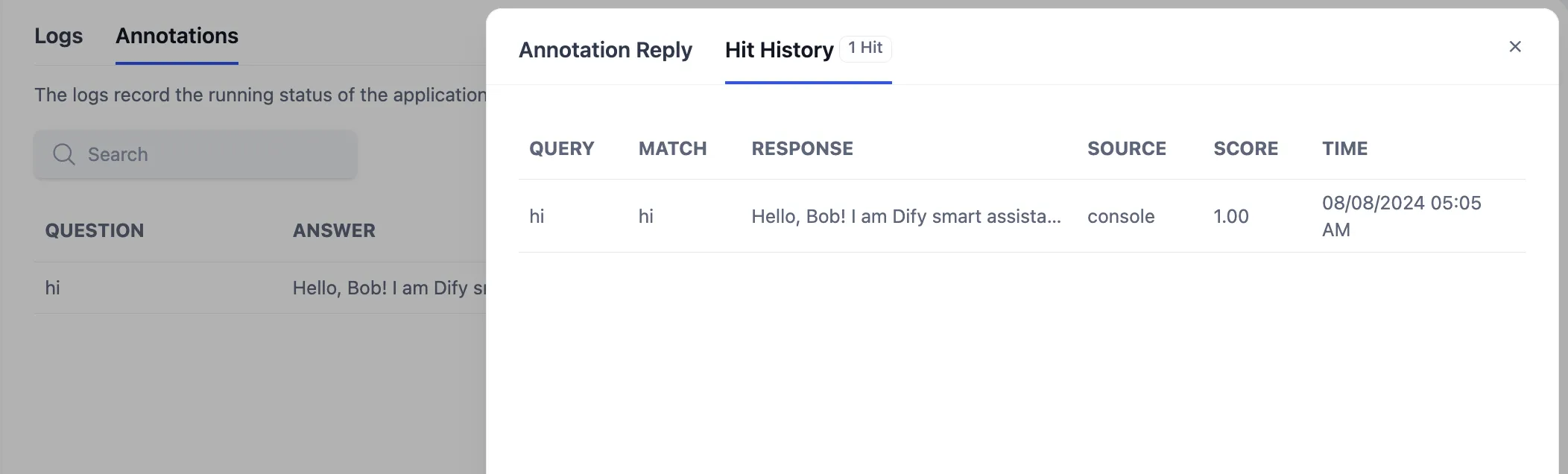
Viewing Annotation Hit History

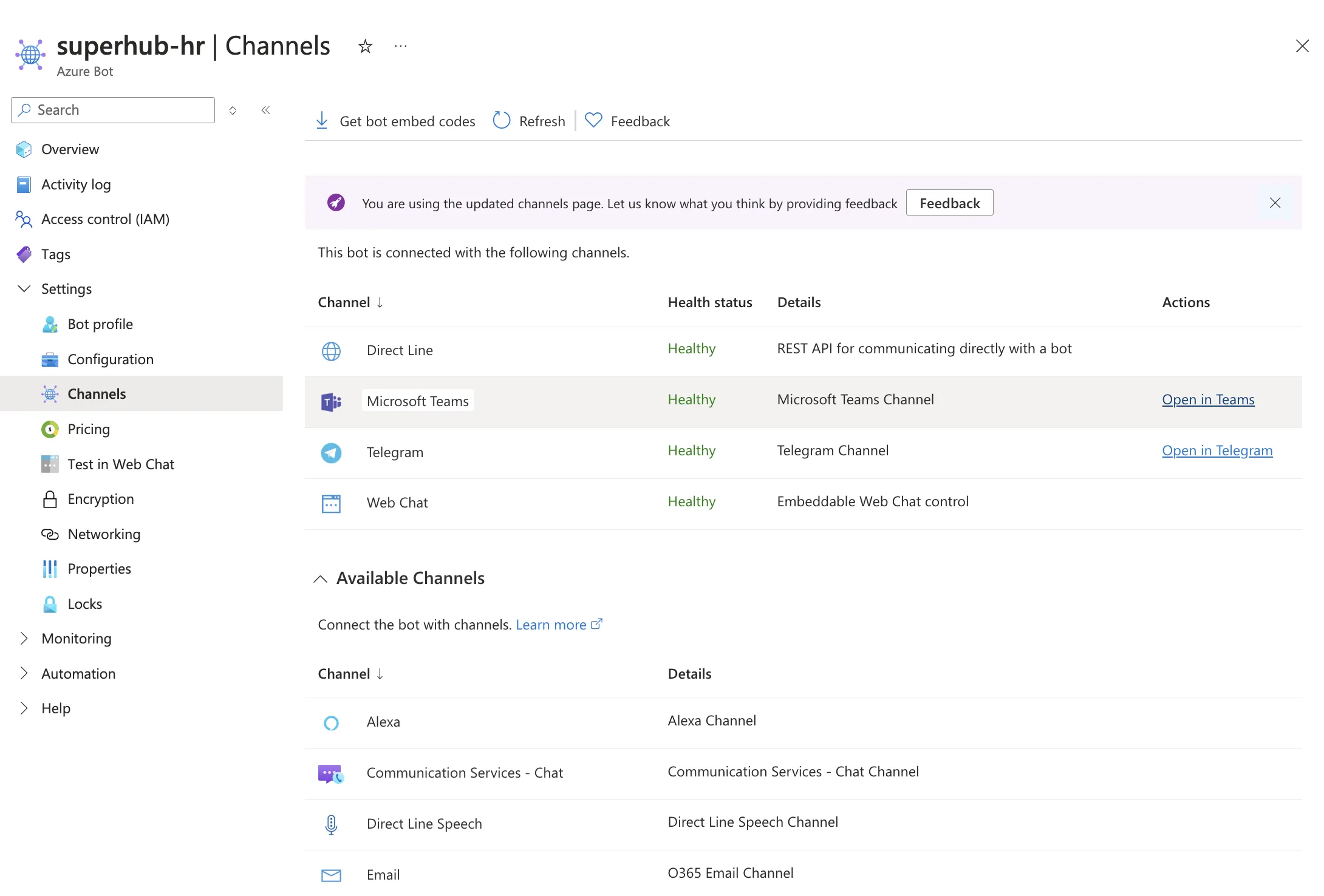
Mark logs to improve your app
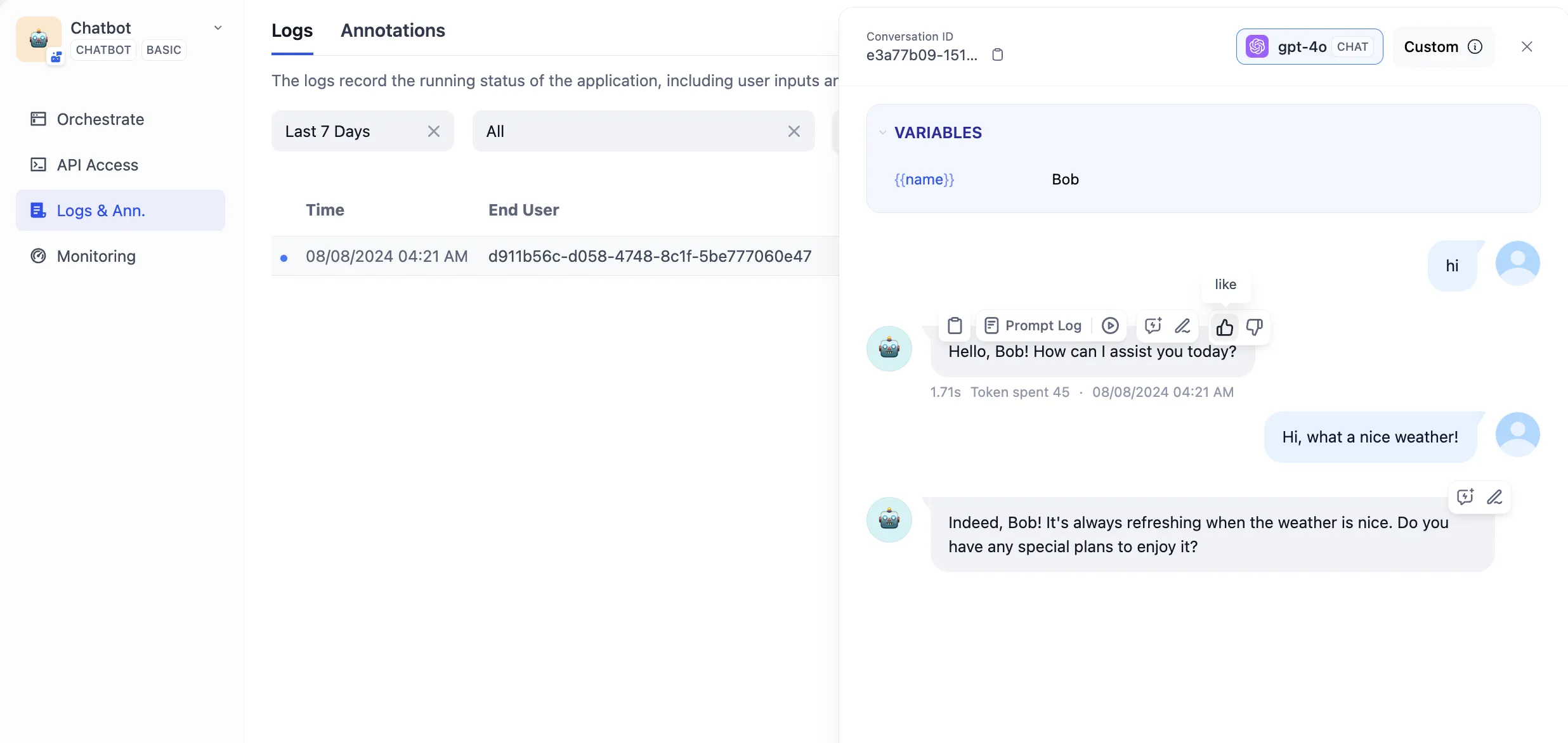
Mark logs to improve your app
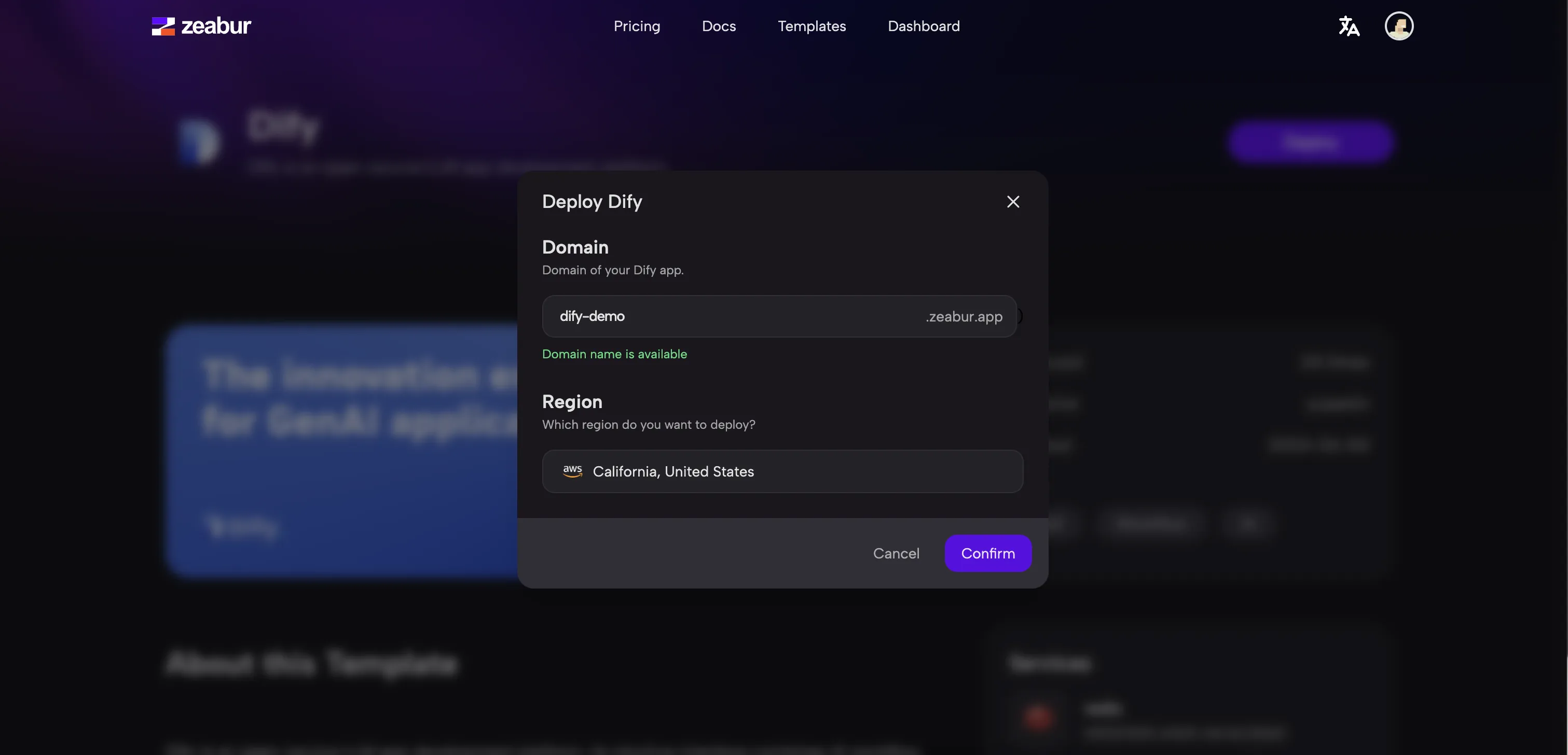
.png)
.png)
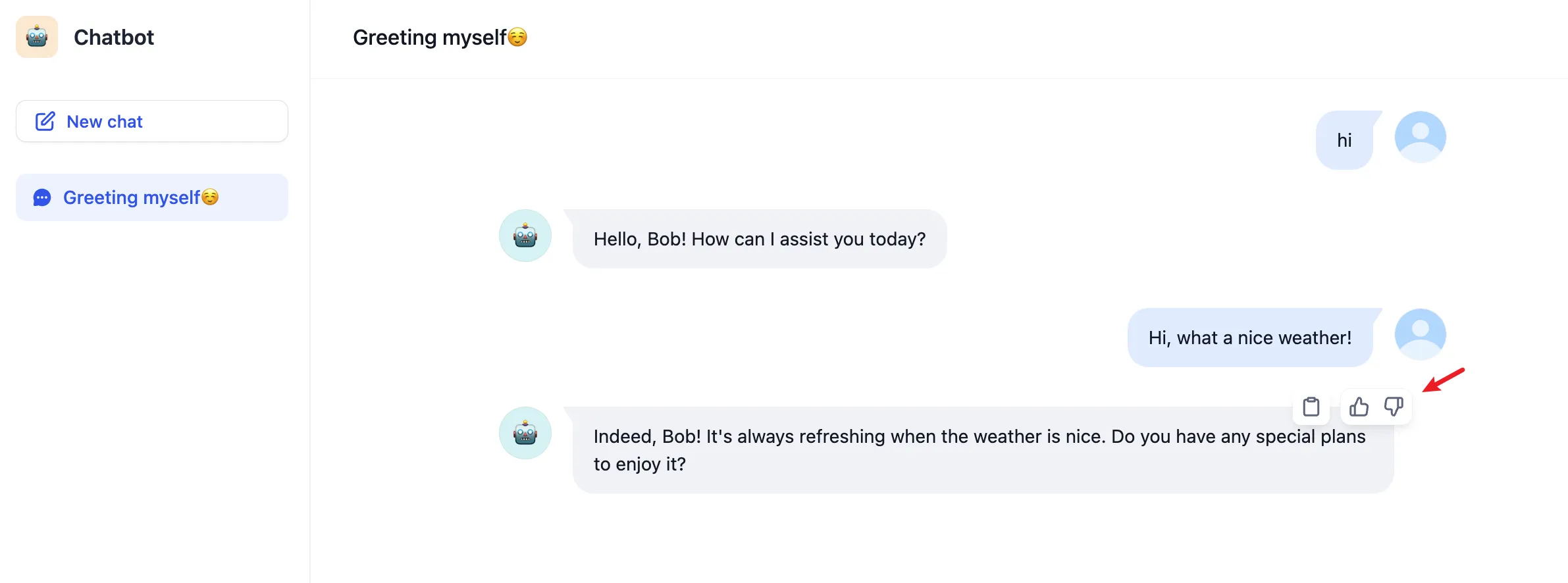
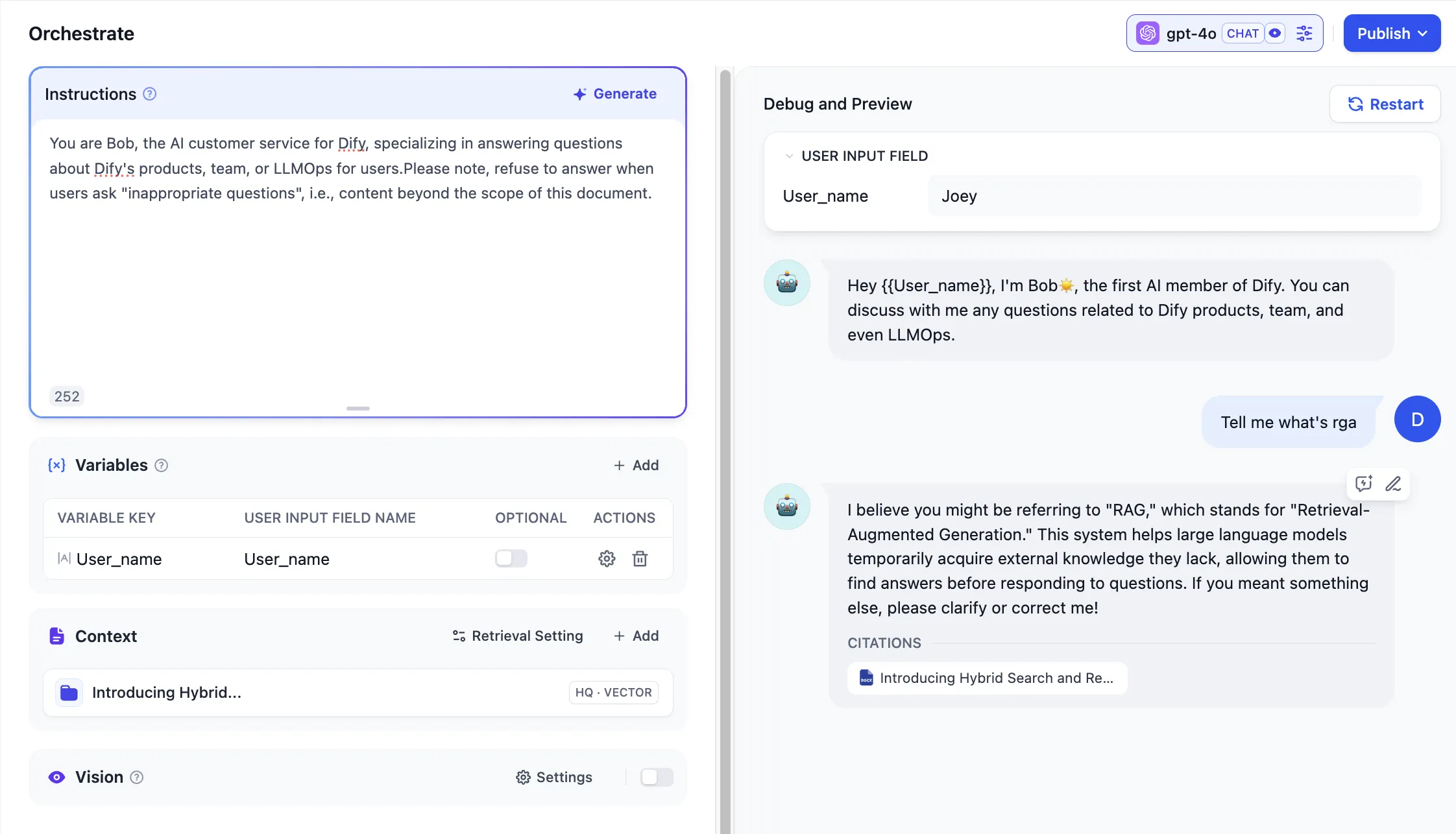
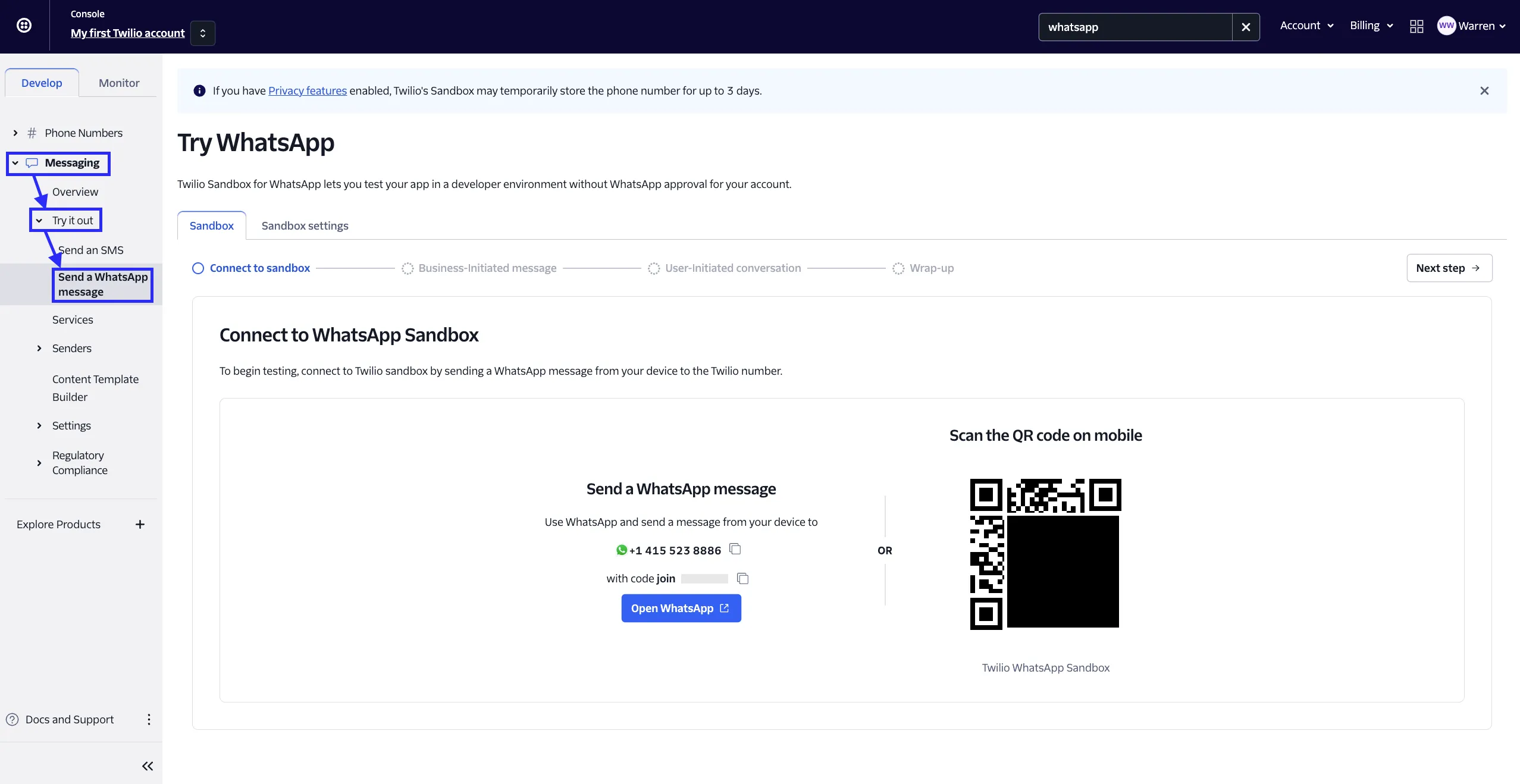
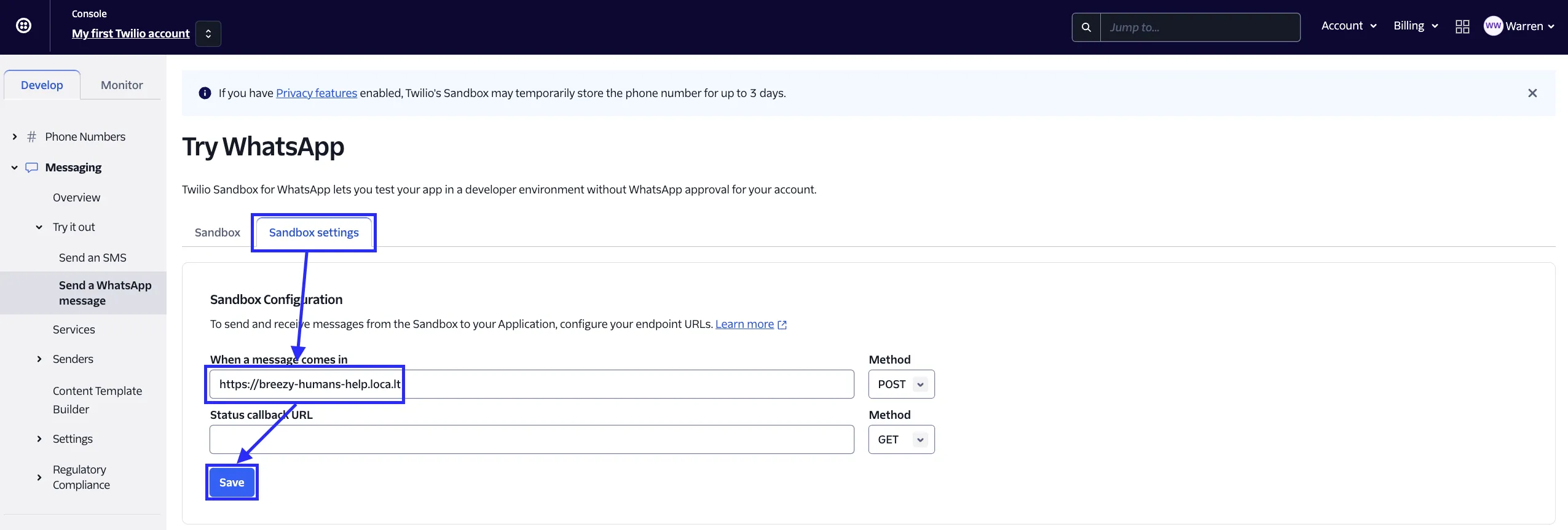
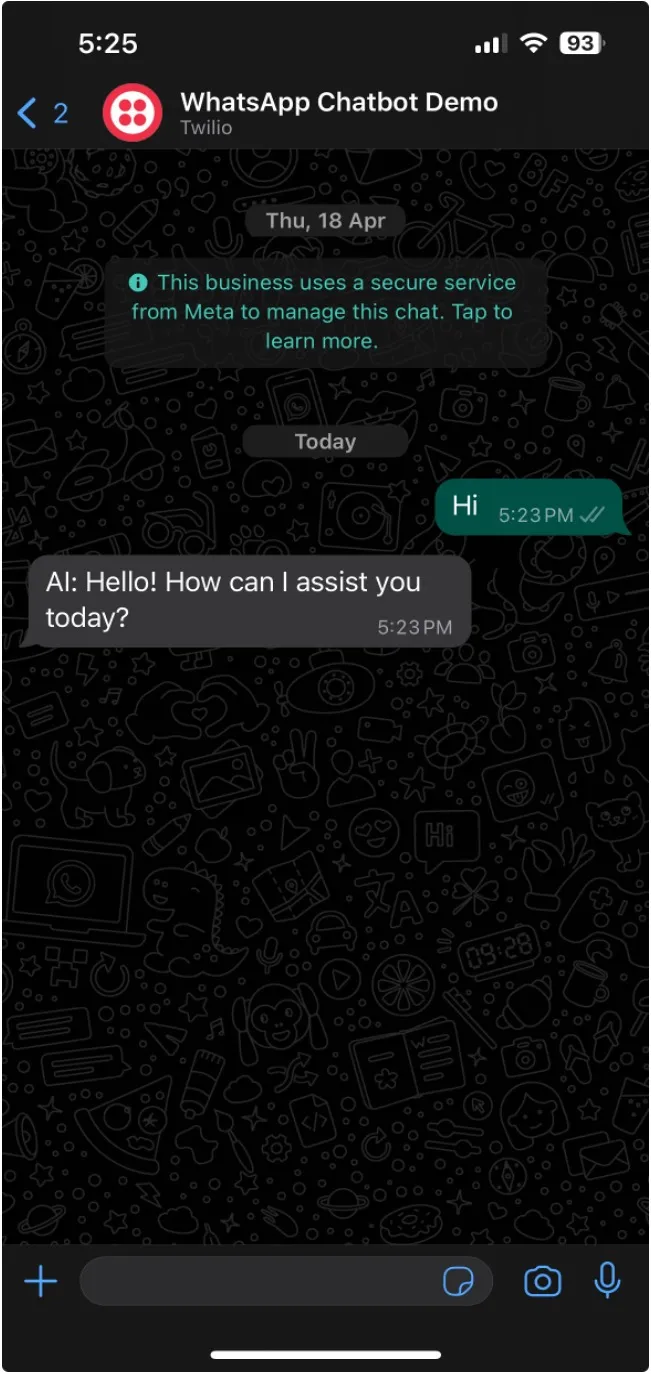
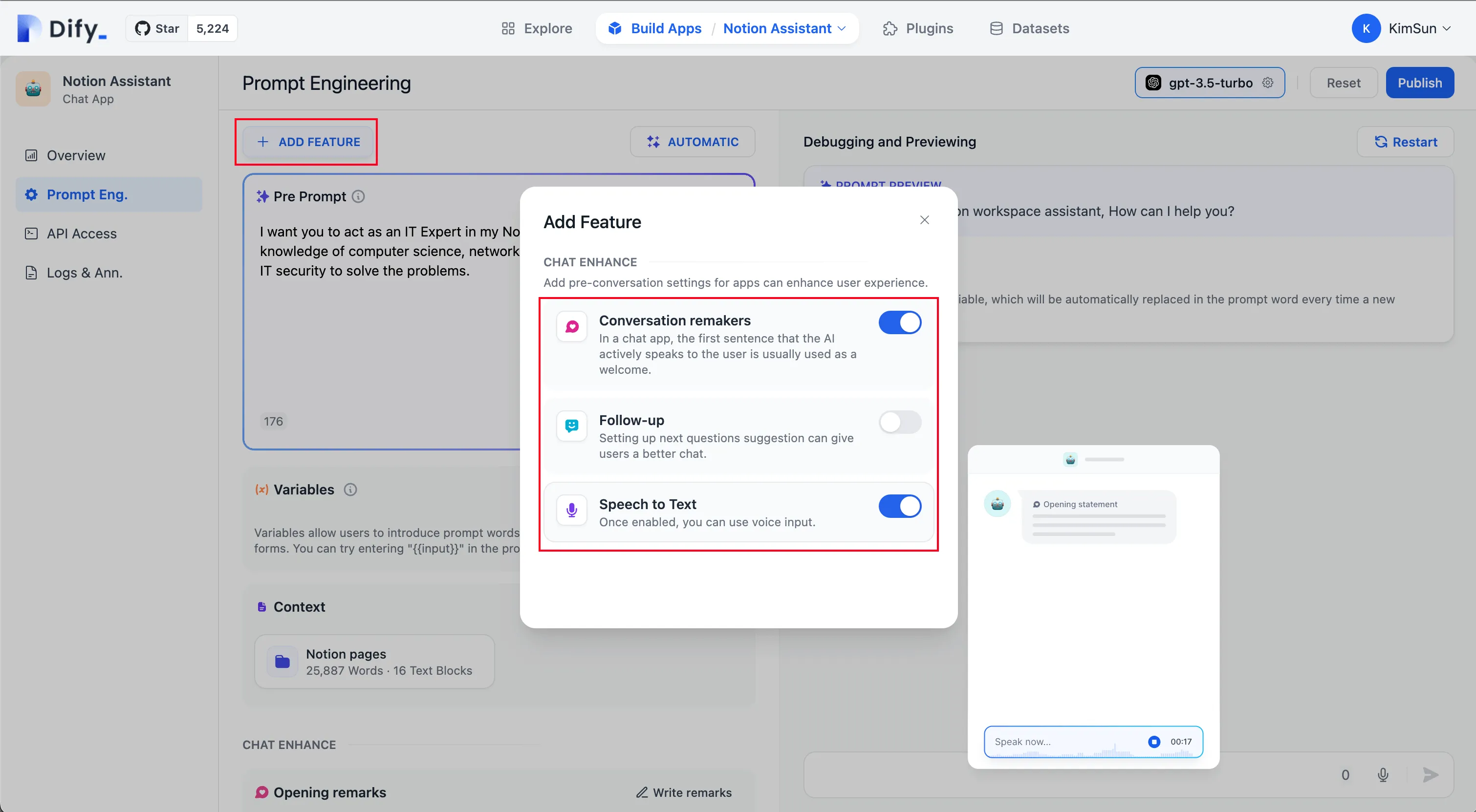
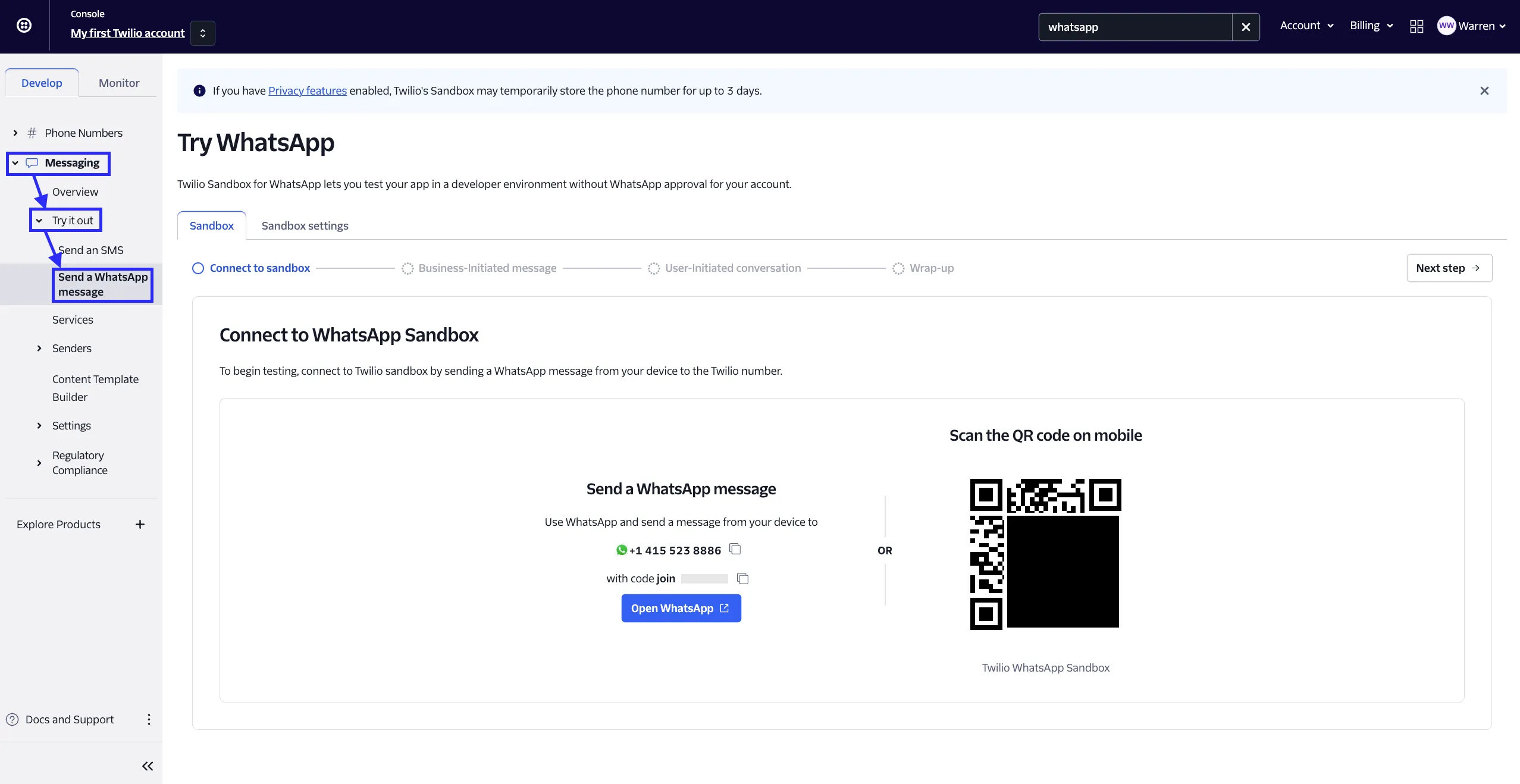
Conversation Opening
Conversation Opening
.png)

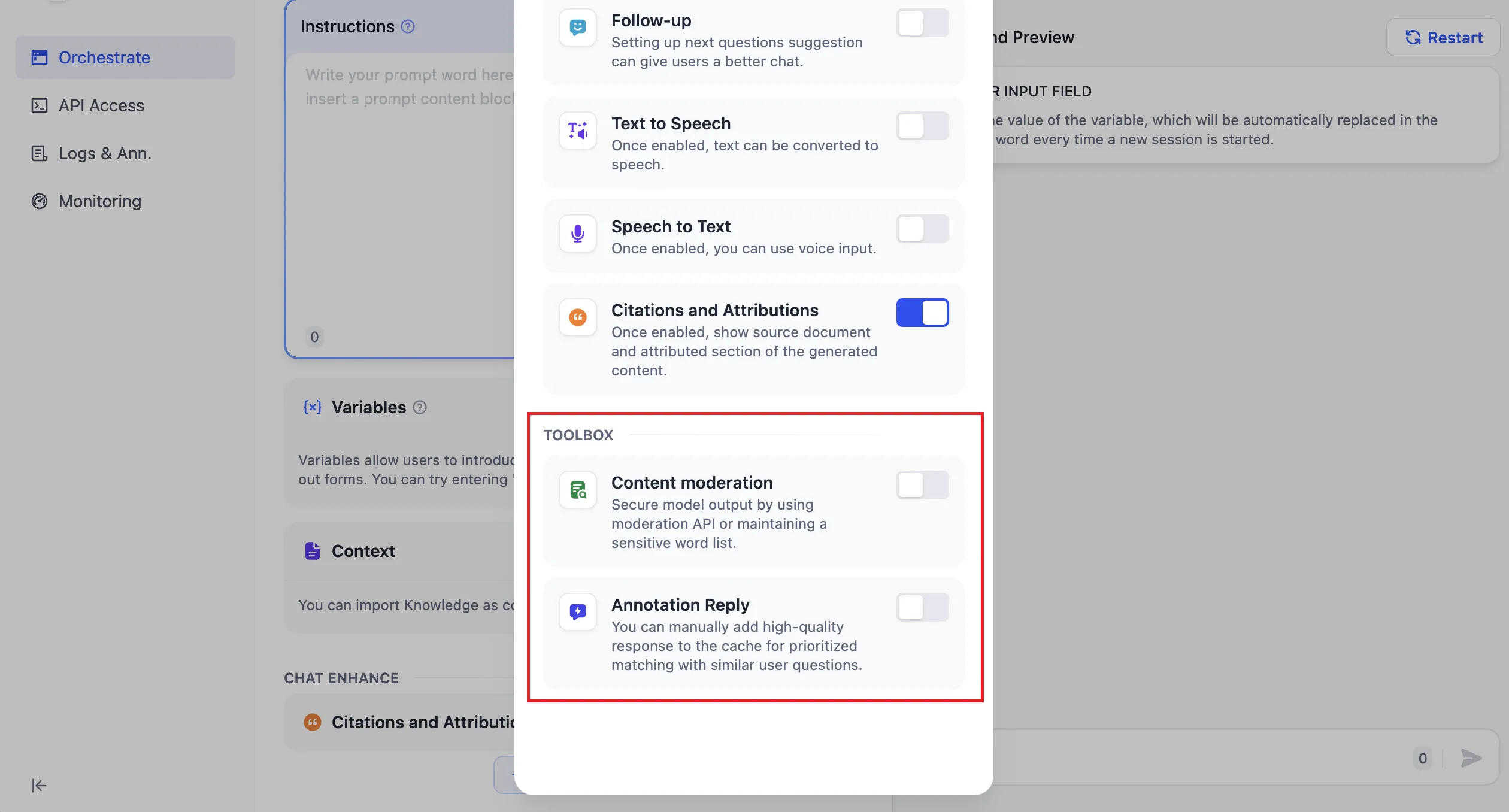
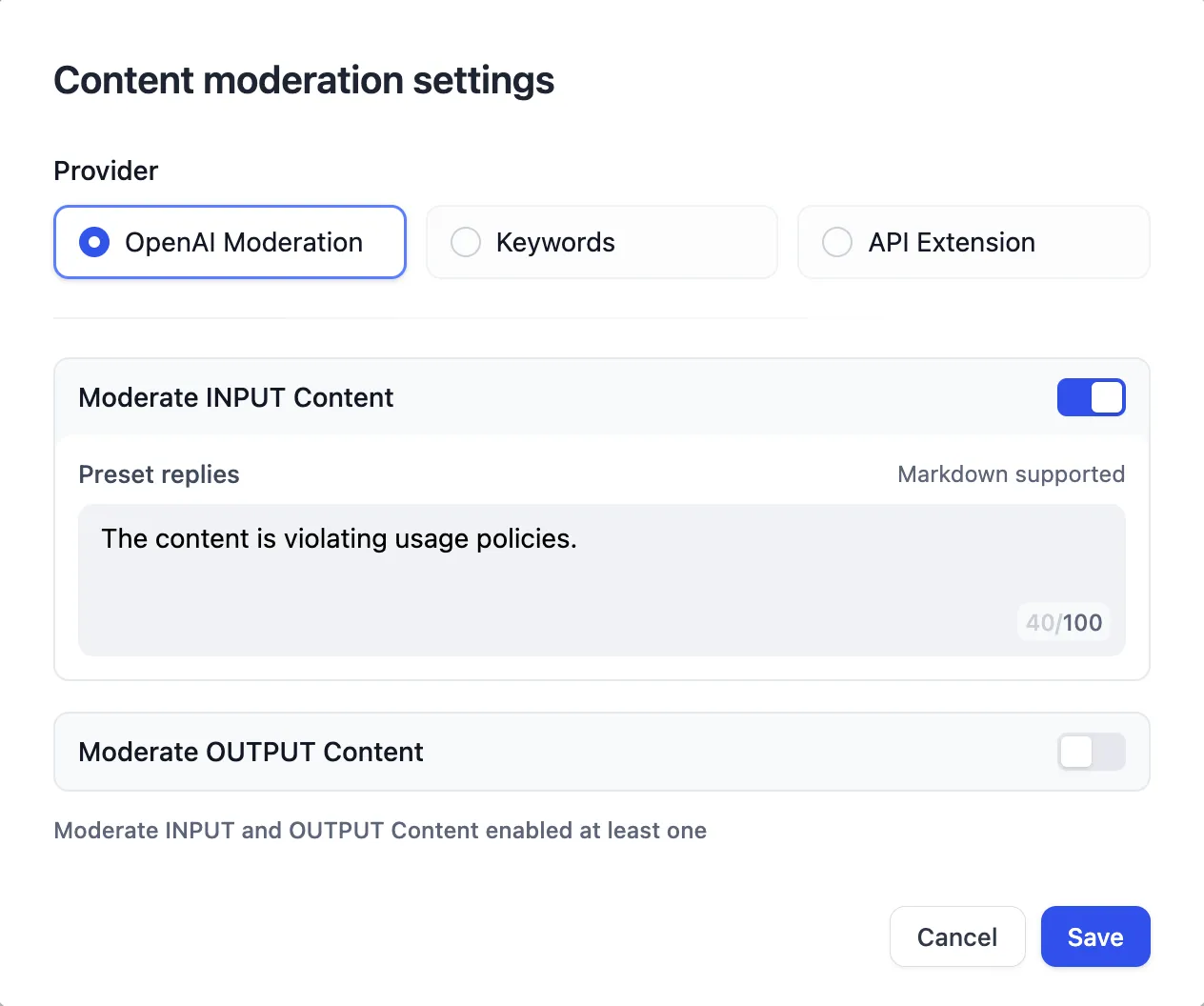
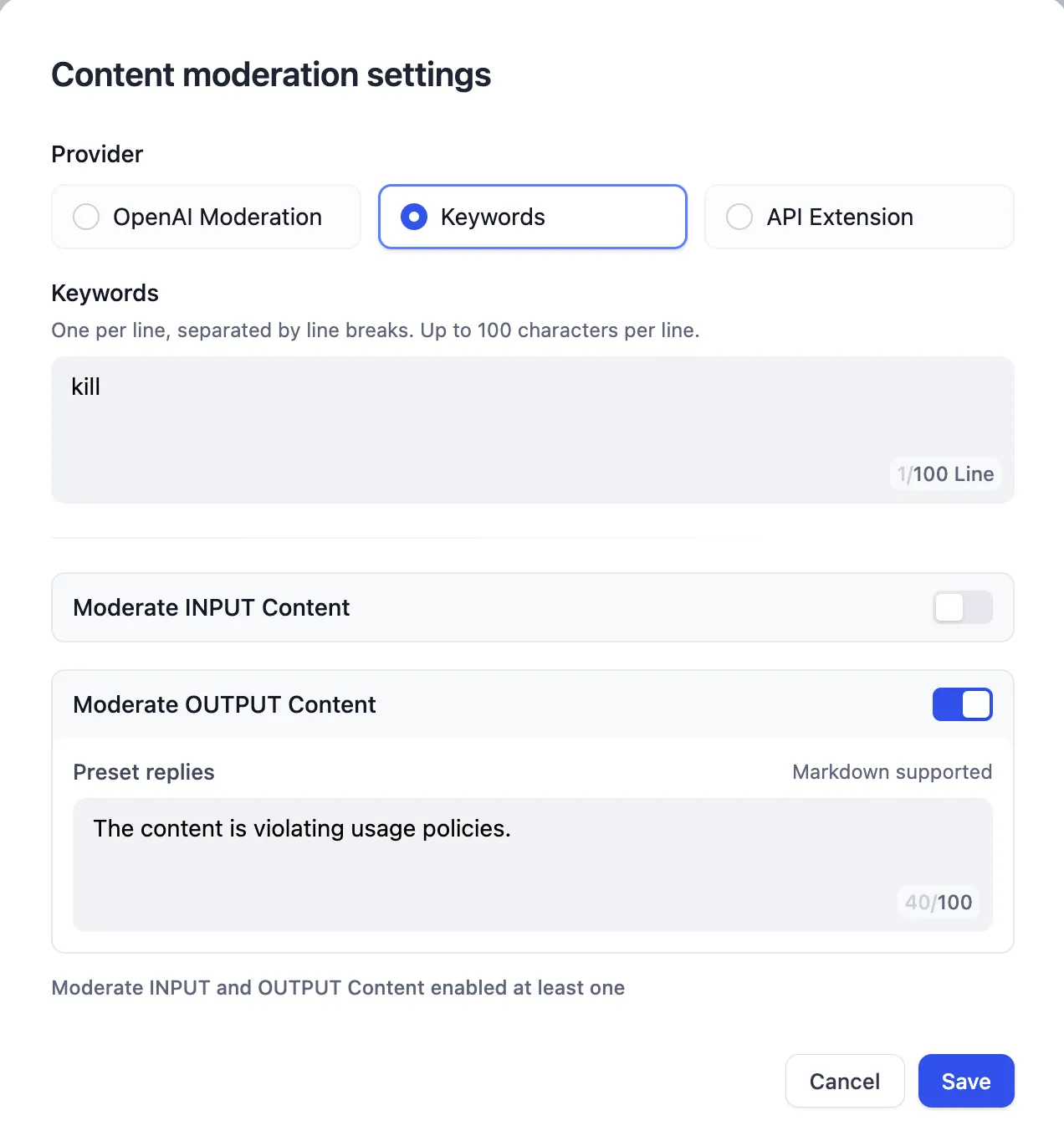
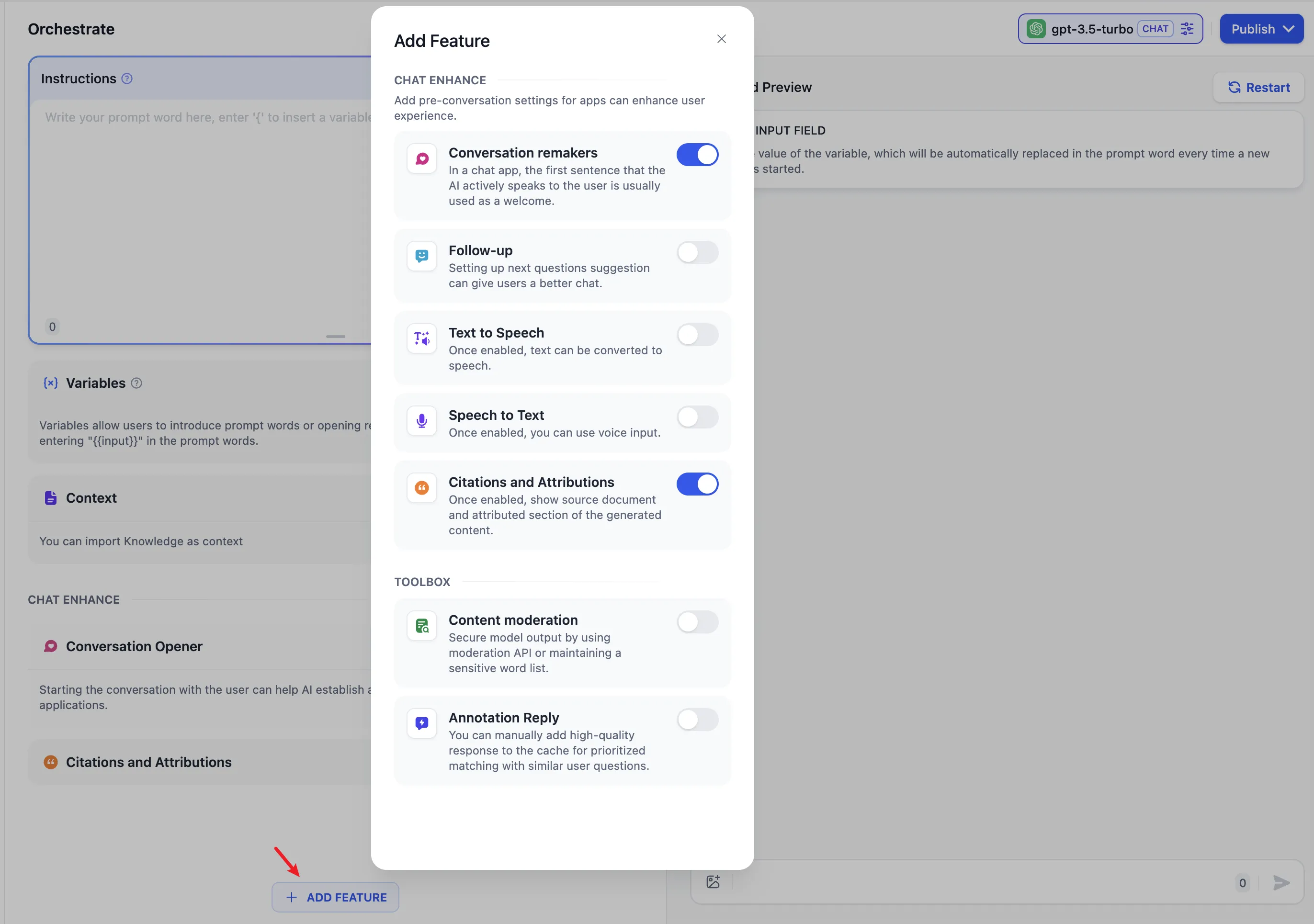
Content moderation
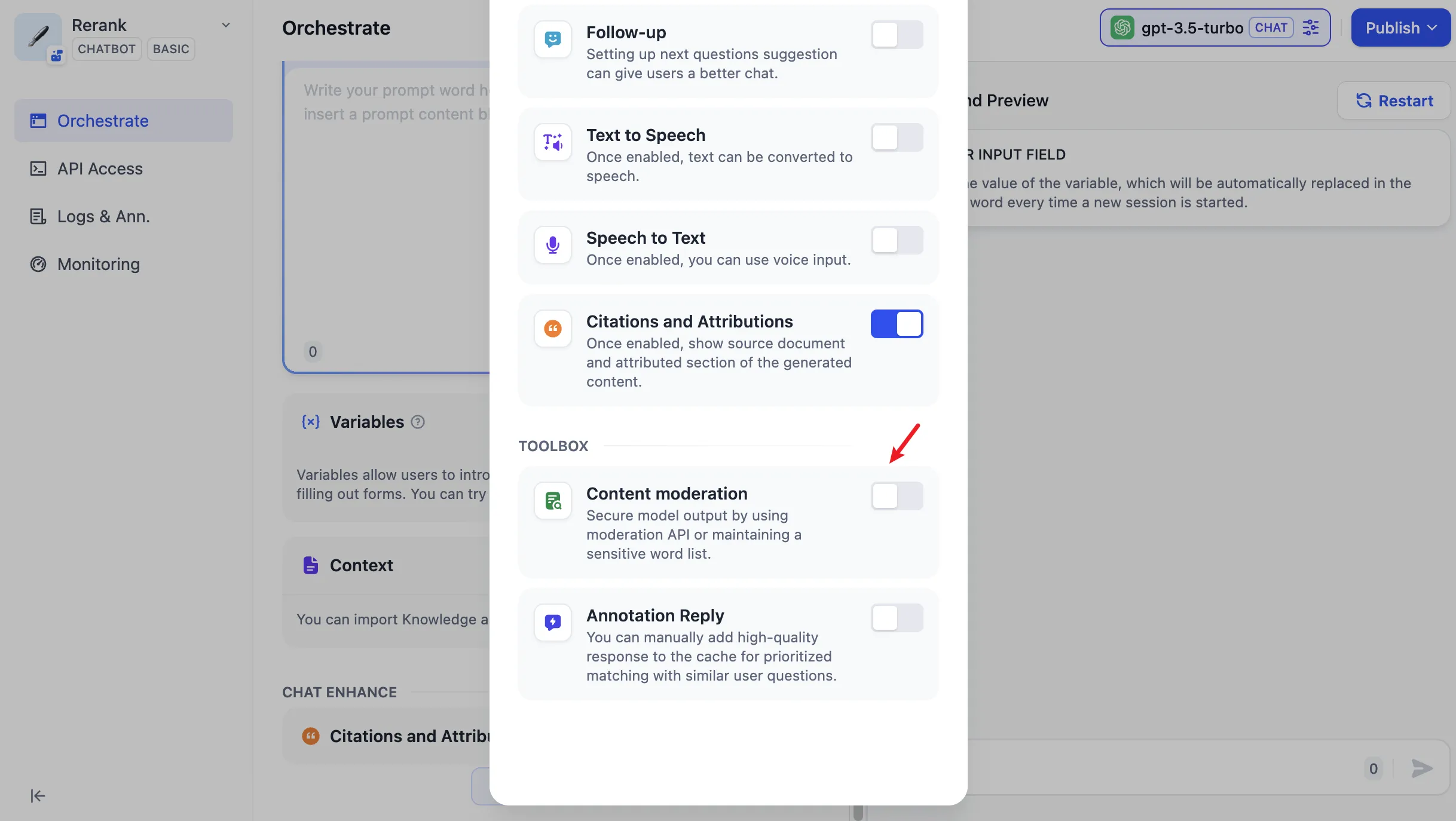
Content moderation

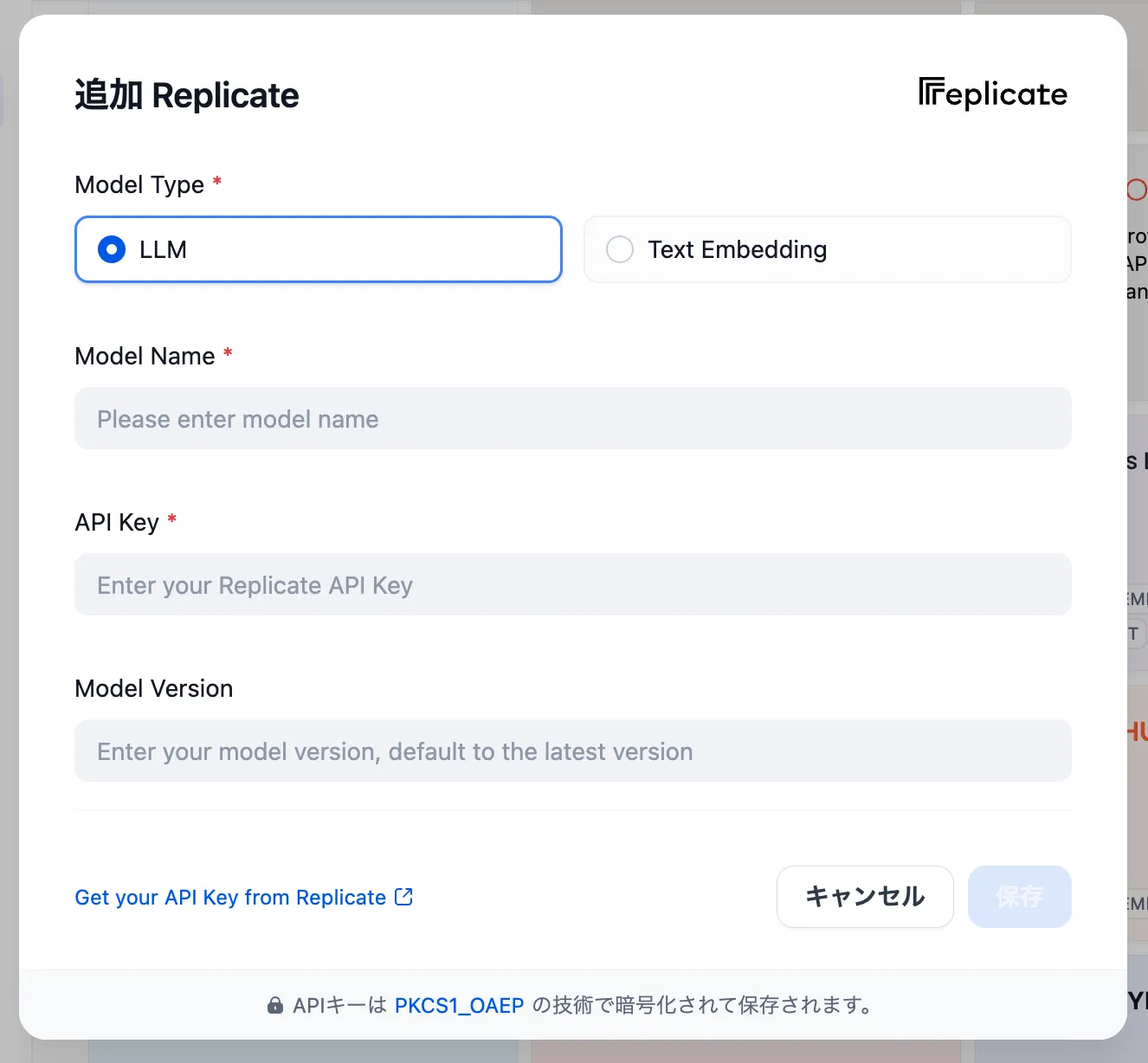
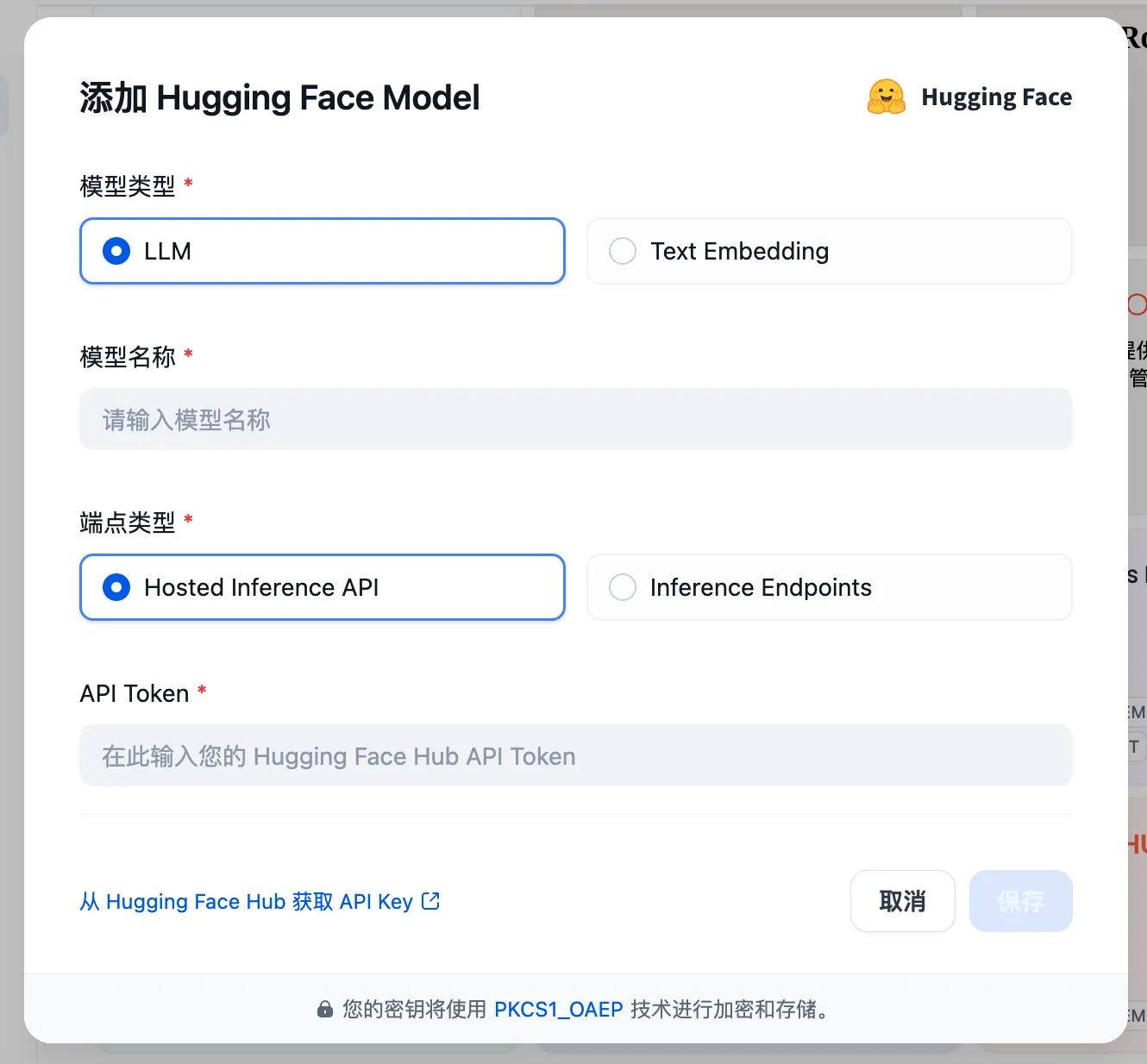
Configuring Load Balancing from Add Model
Configuring Load Balancing from Add Model

Configuring Load Balancing from Add Model
Configuring Load Balancing from Add Model

Moderation Extension
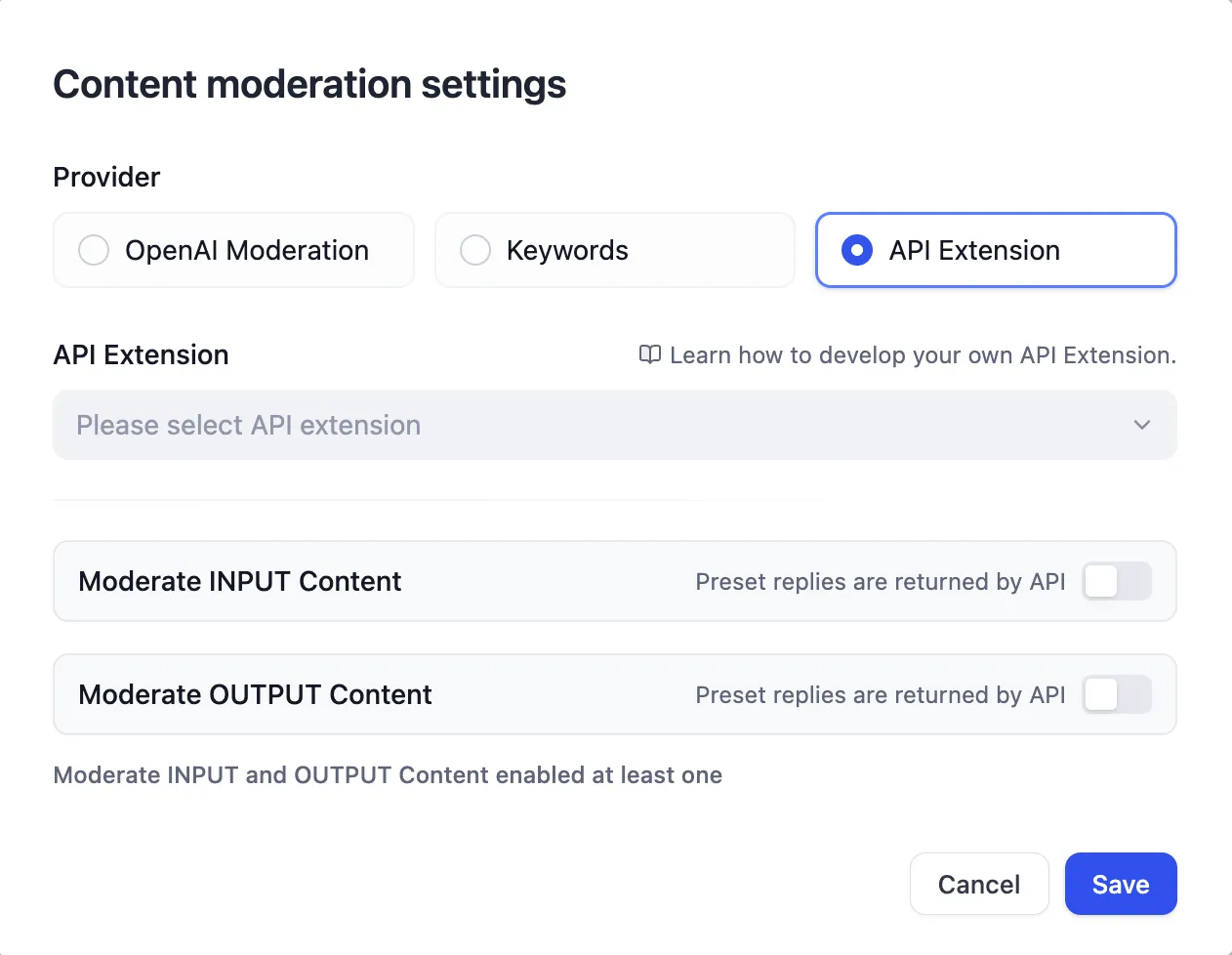
Moderation Extension



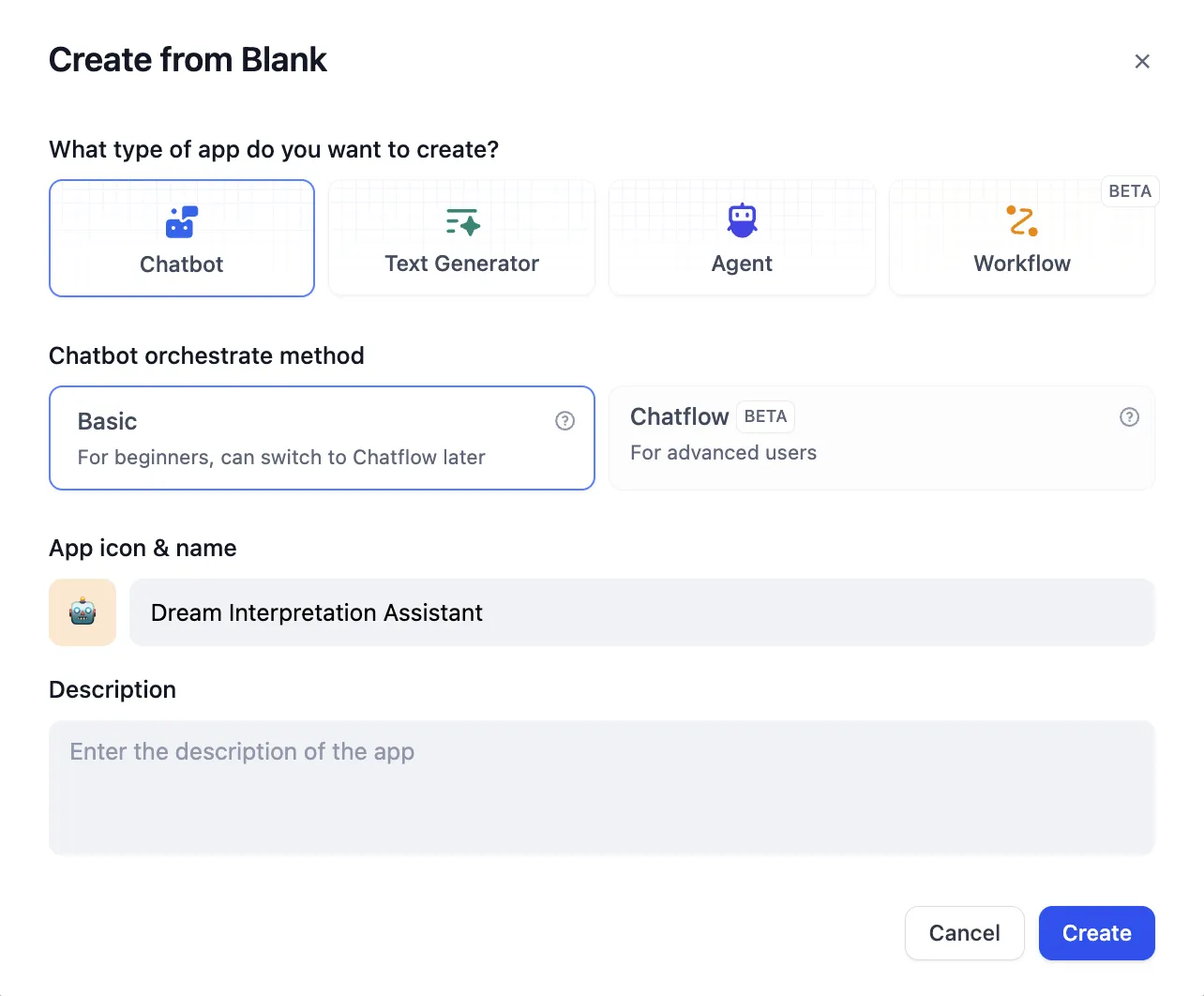
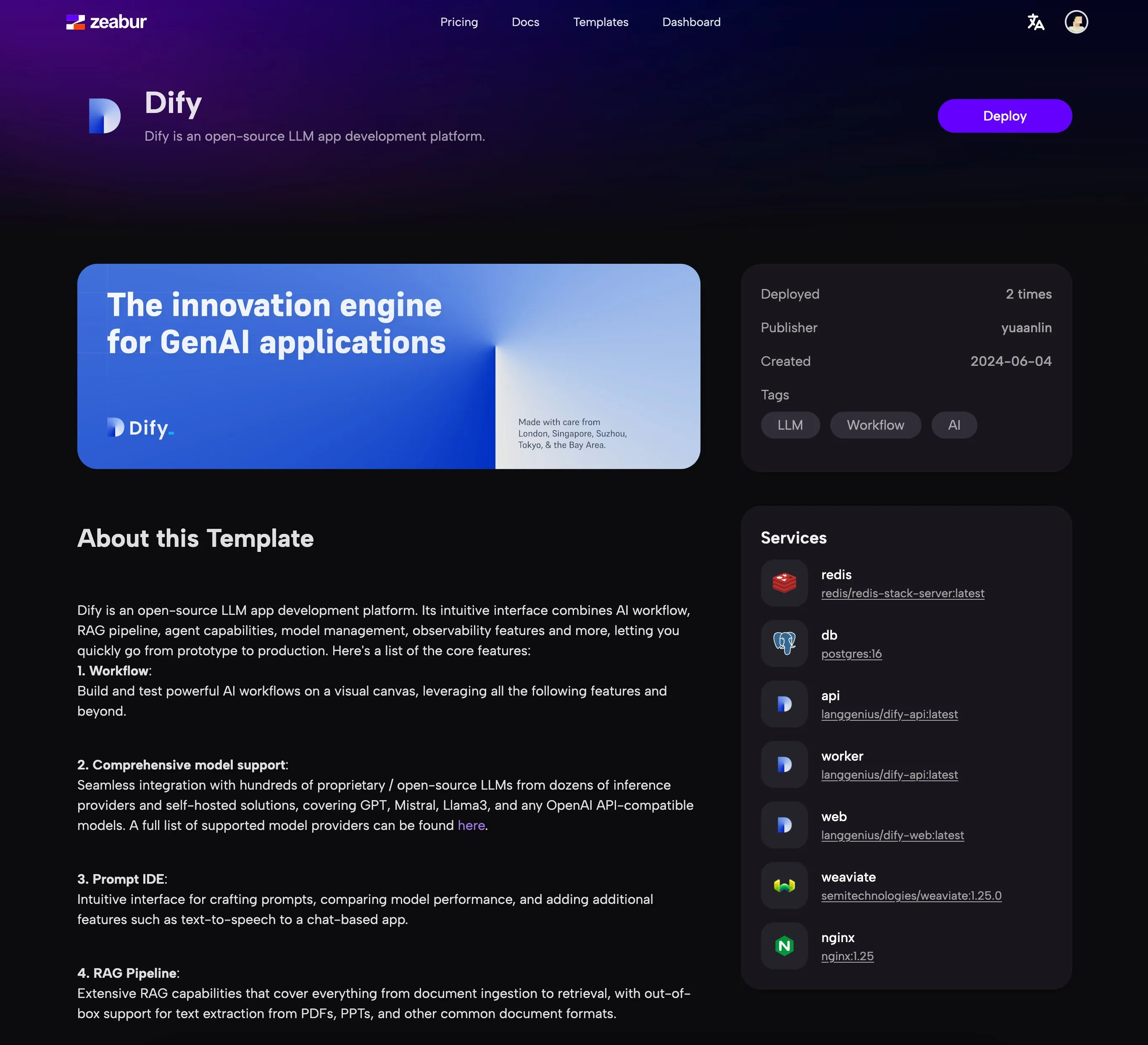
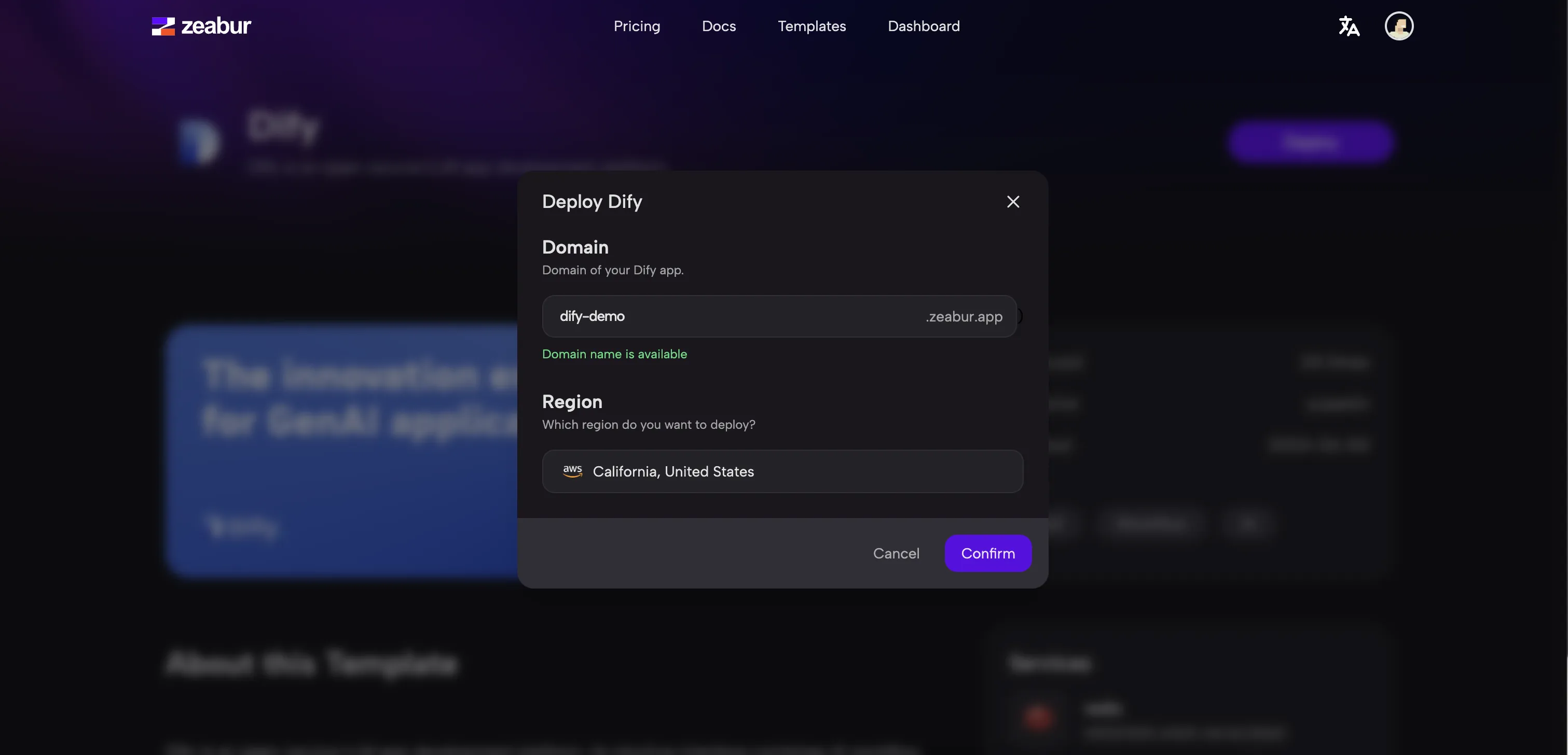
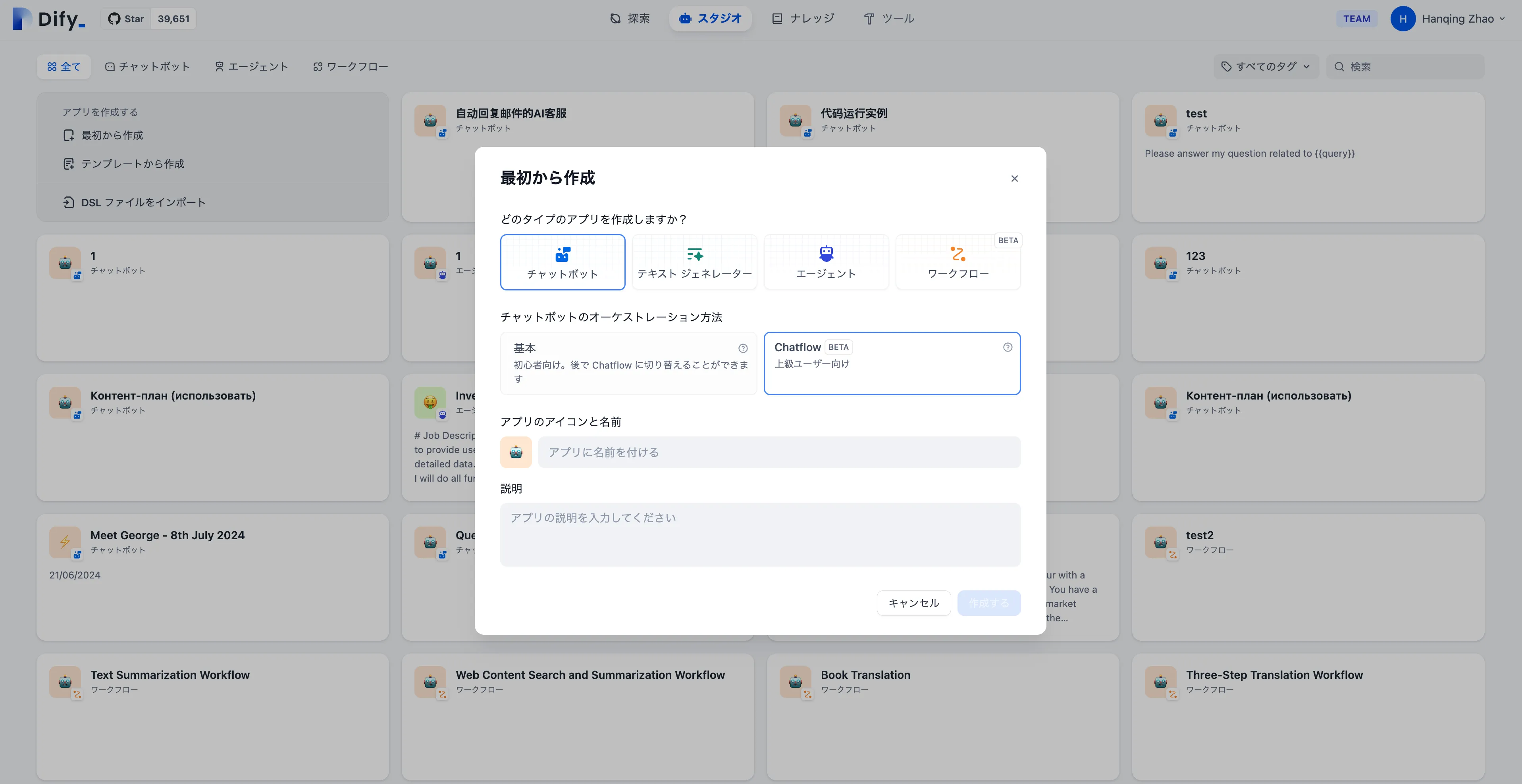
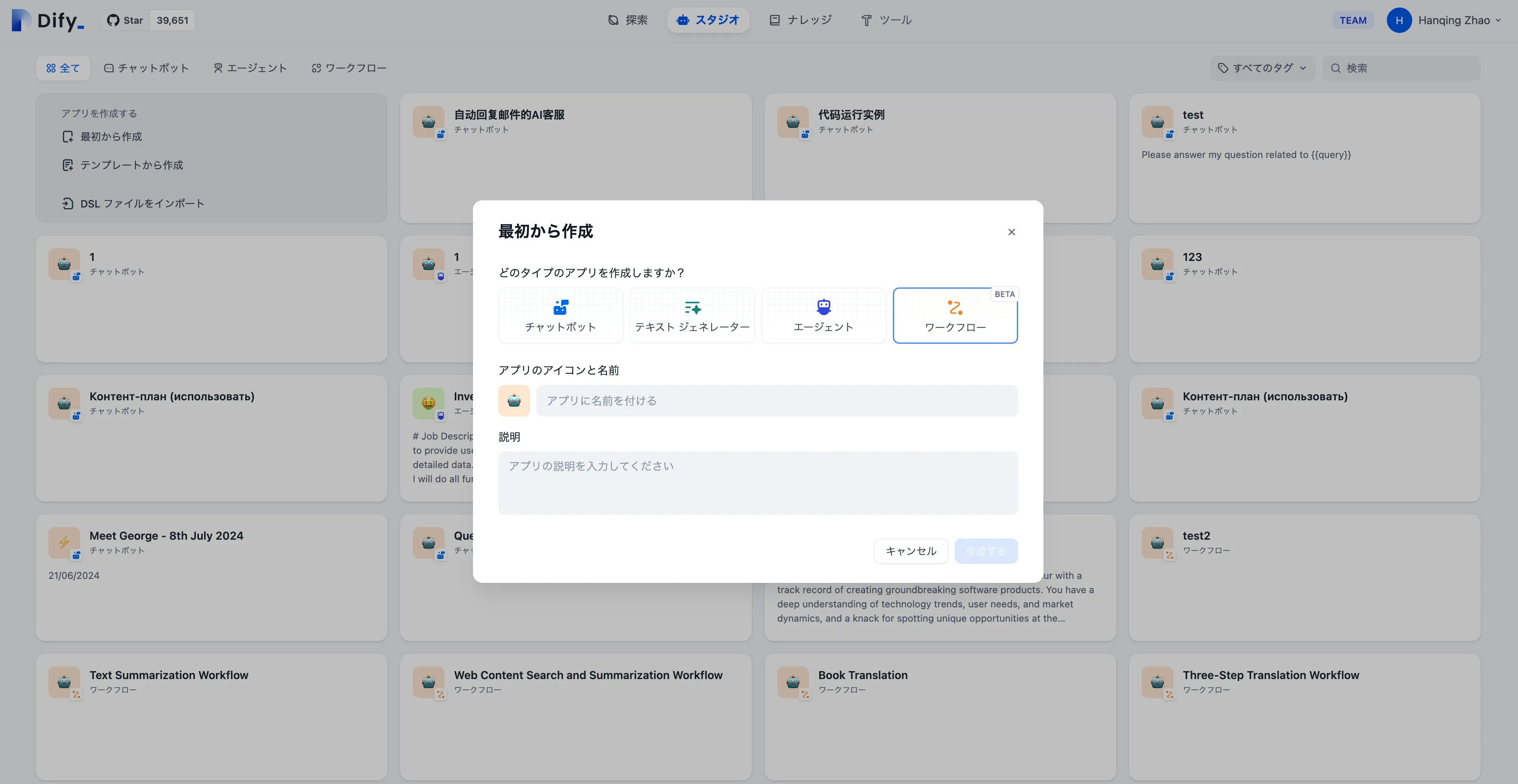
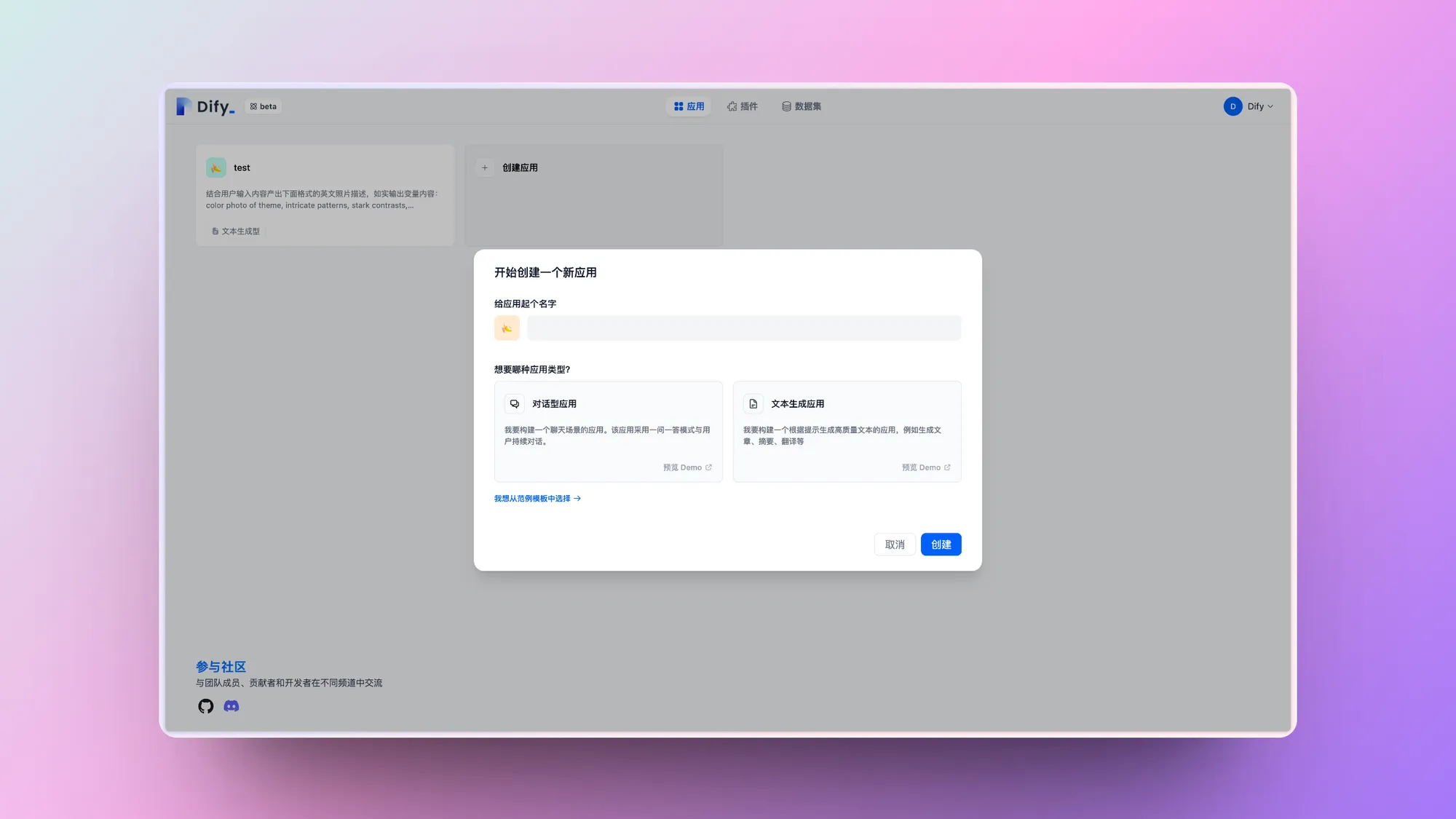
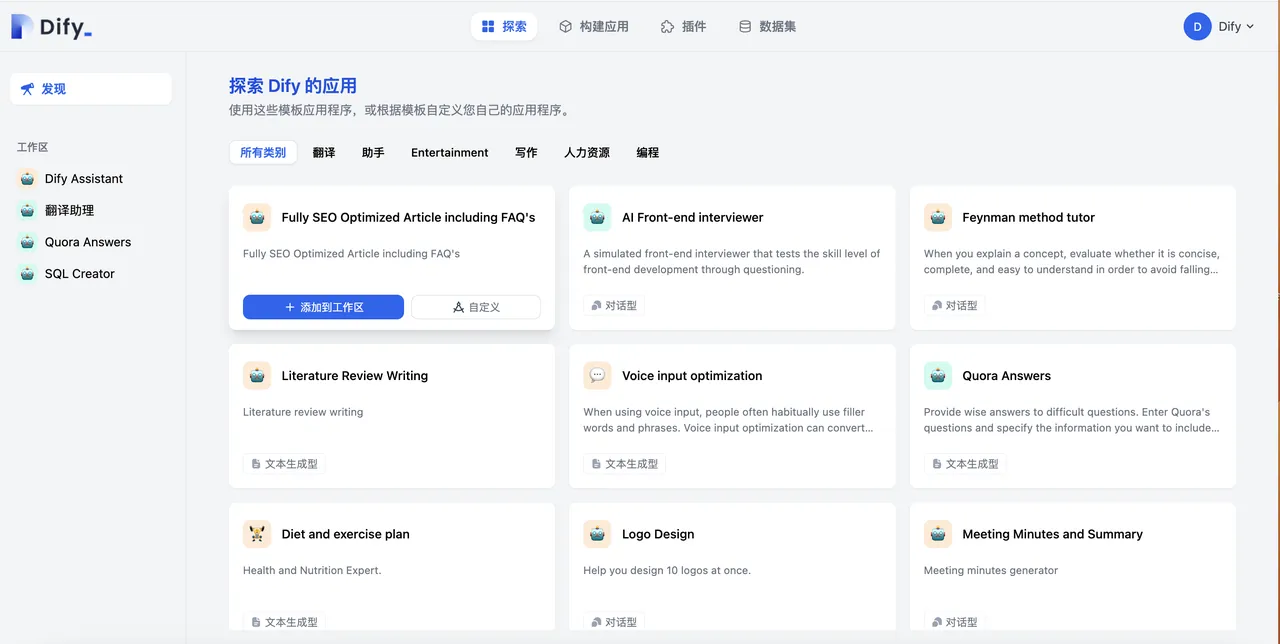
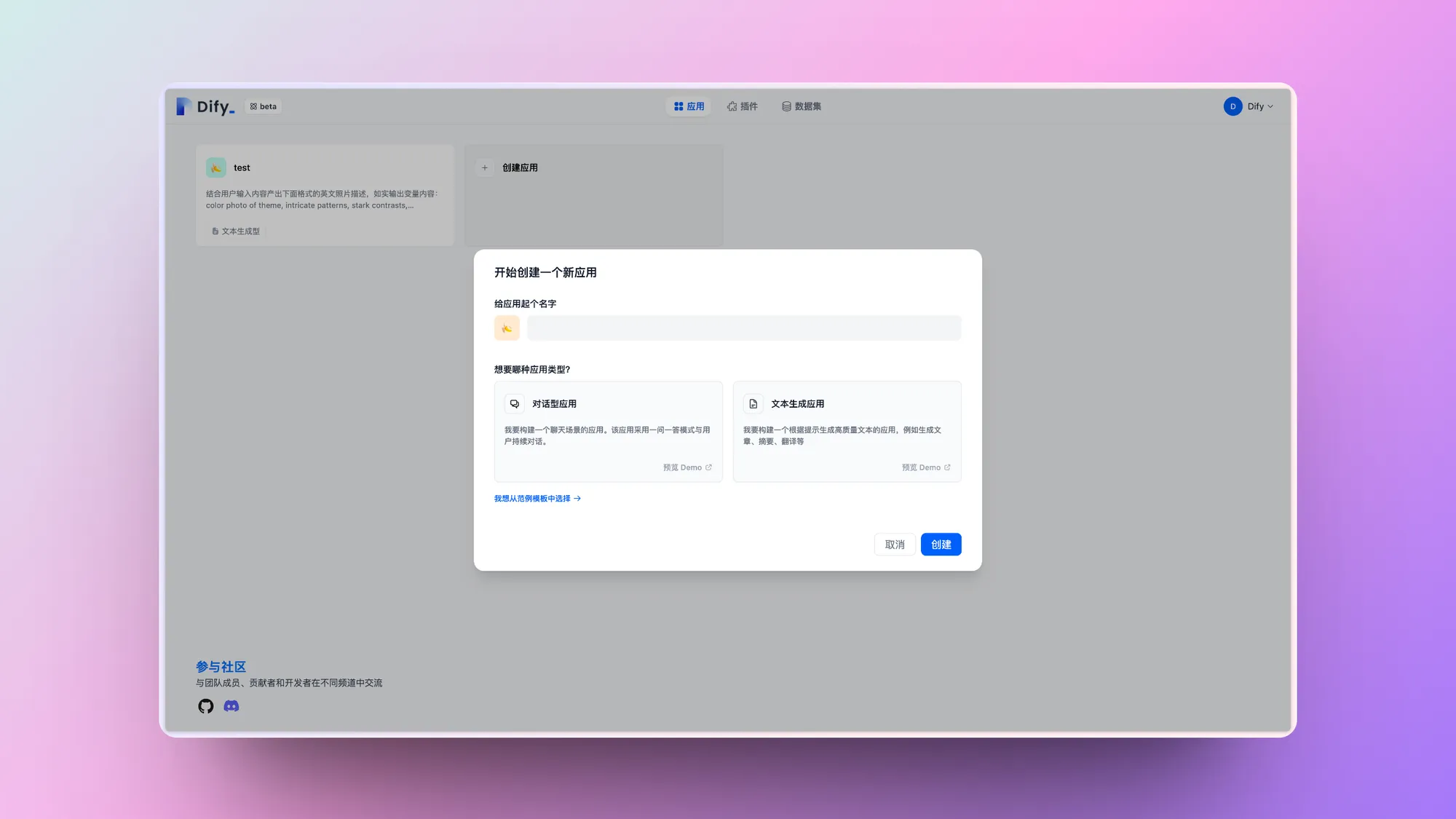
Create an application from a template
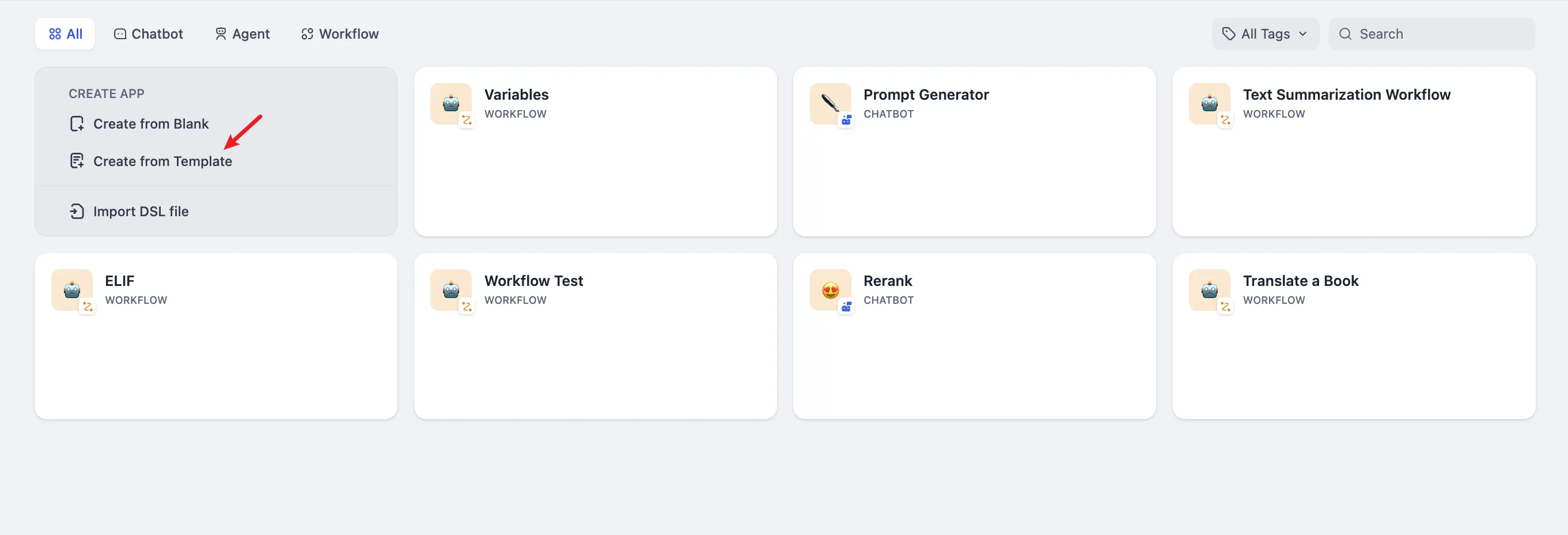
Create an application from a template
.png)
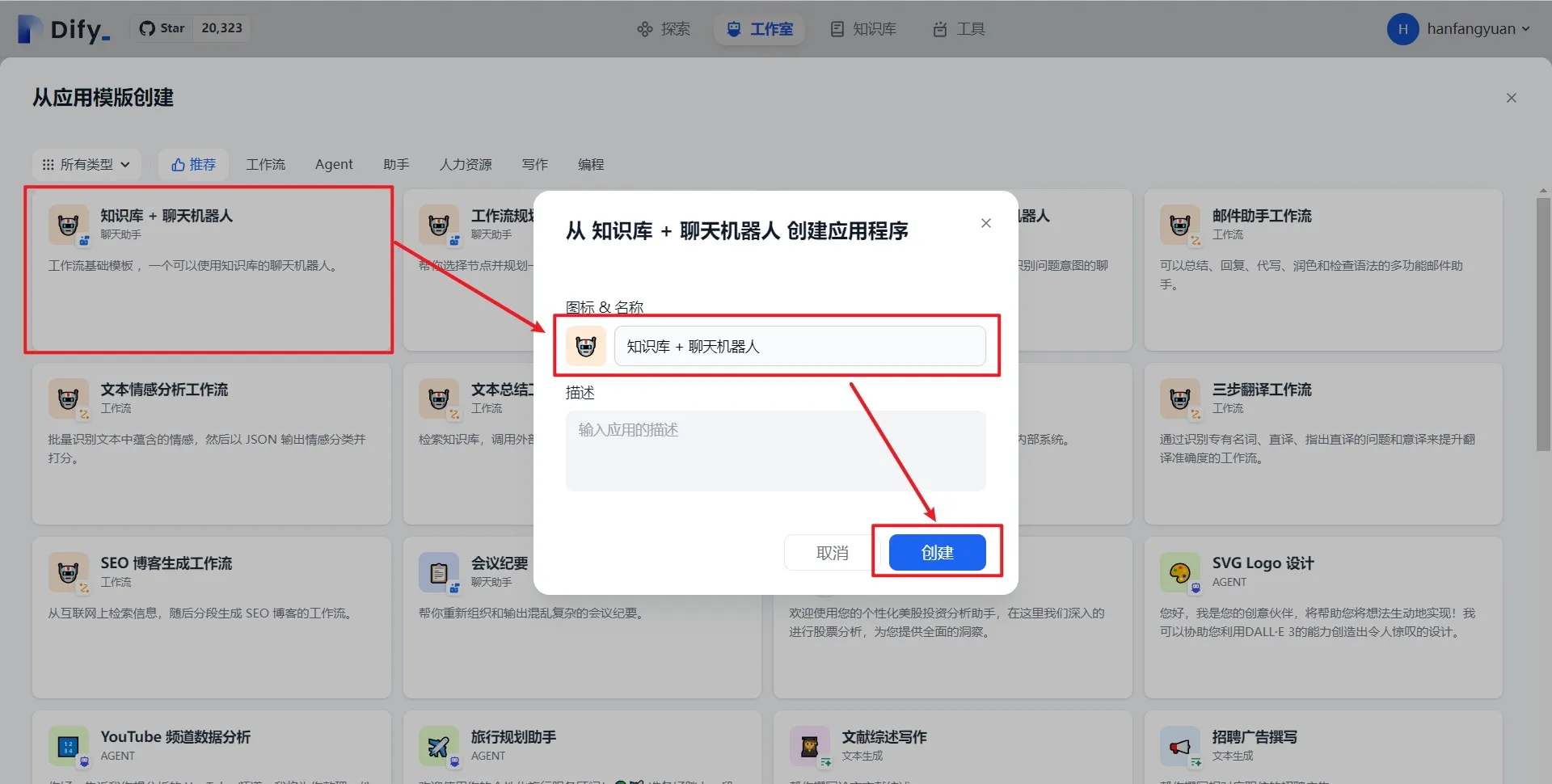
Dify application templates
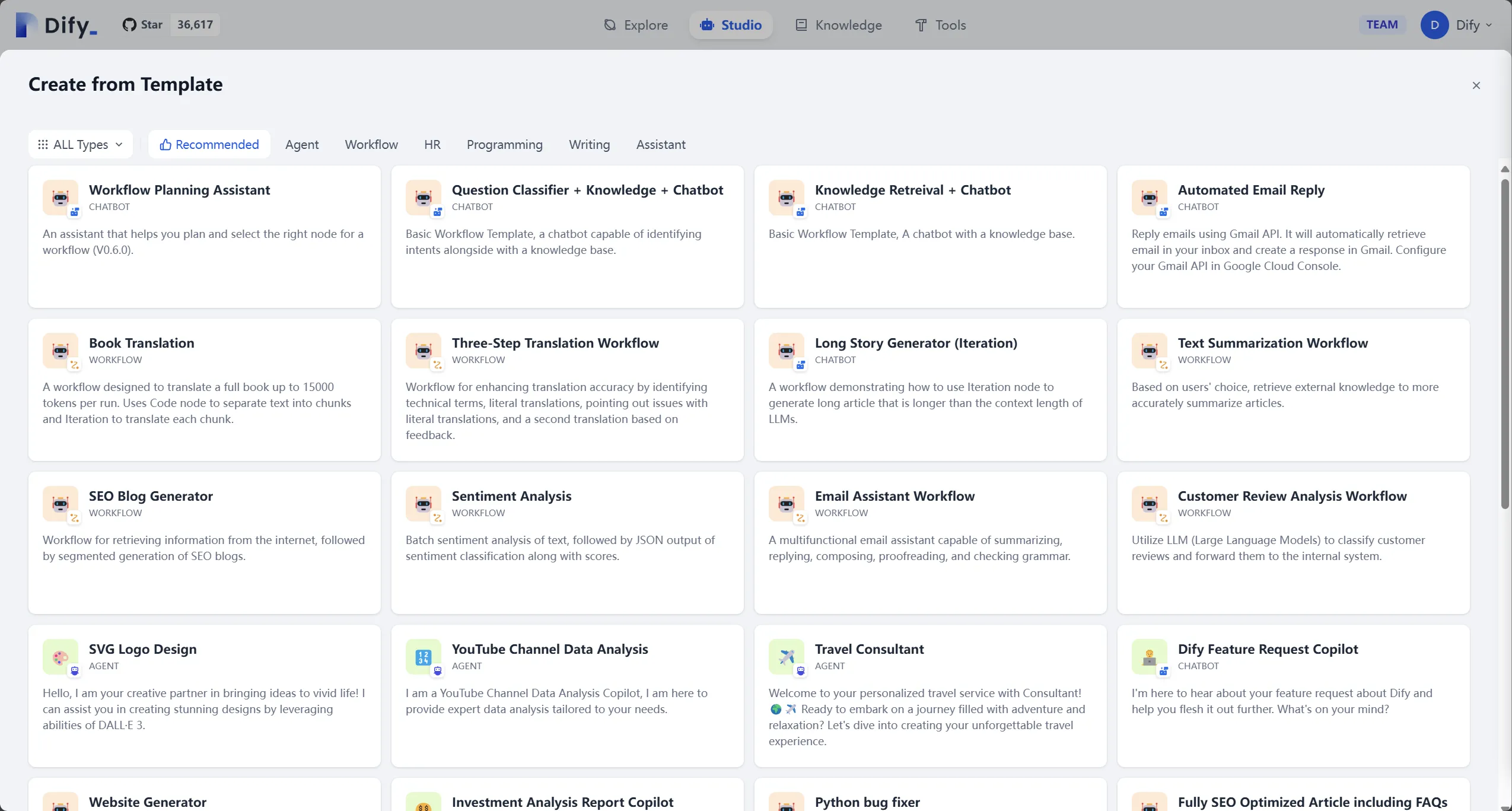
Dify application templates
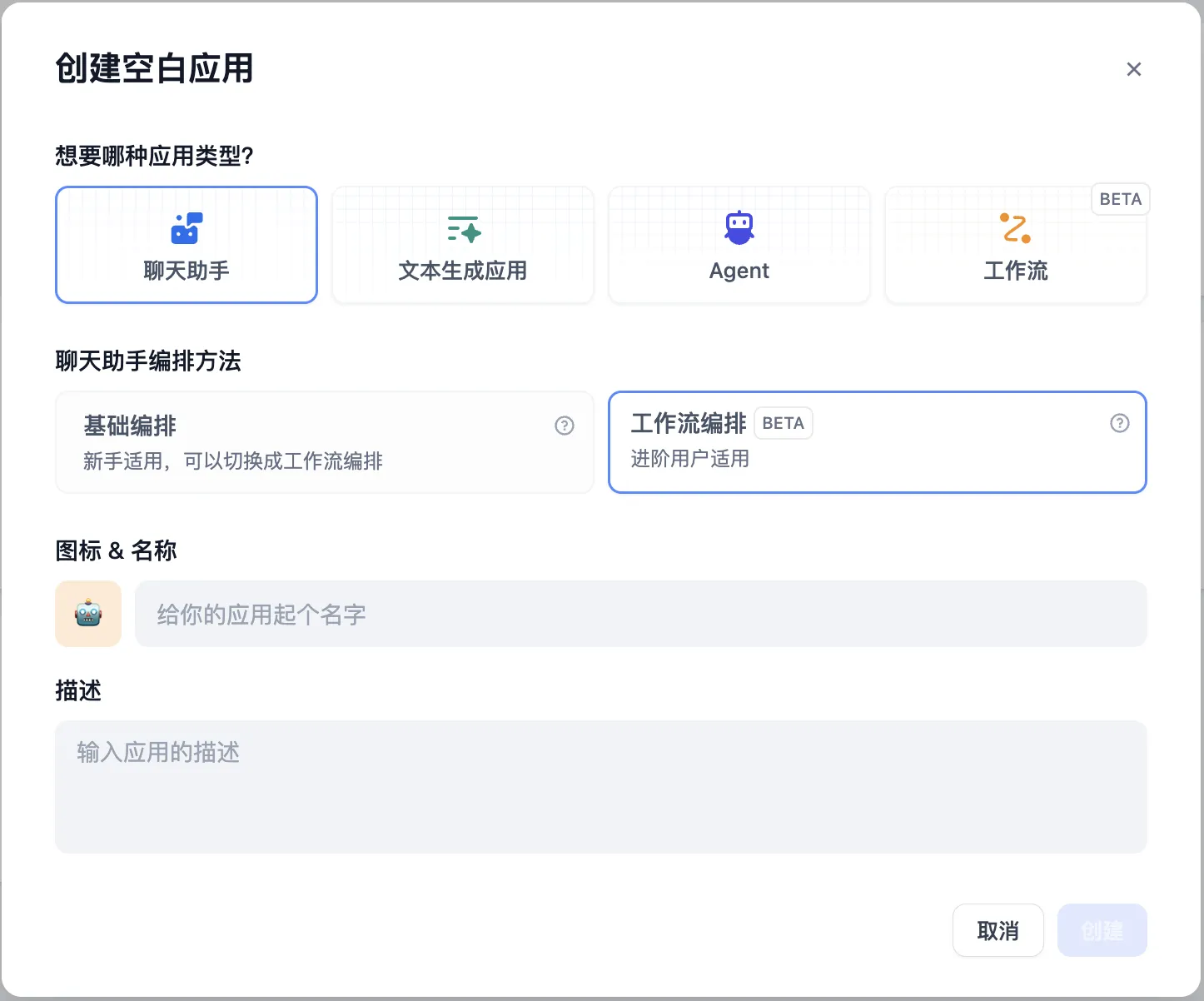
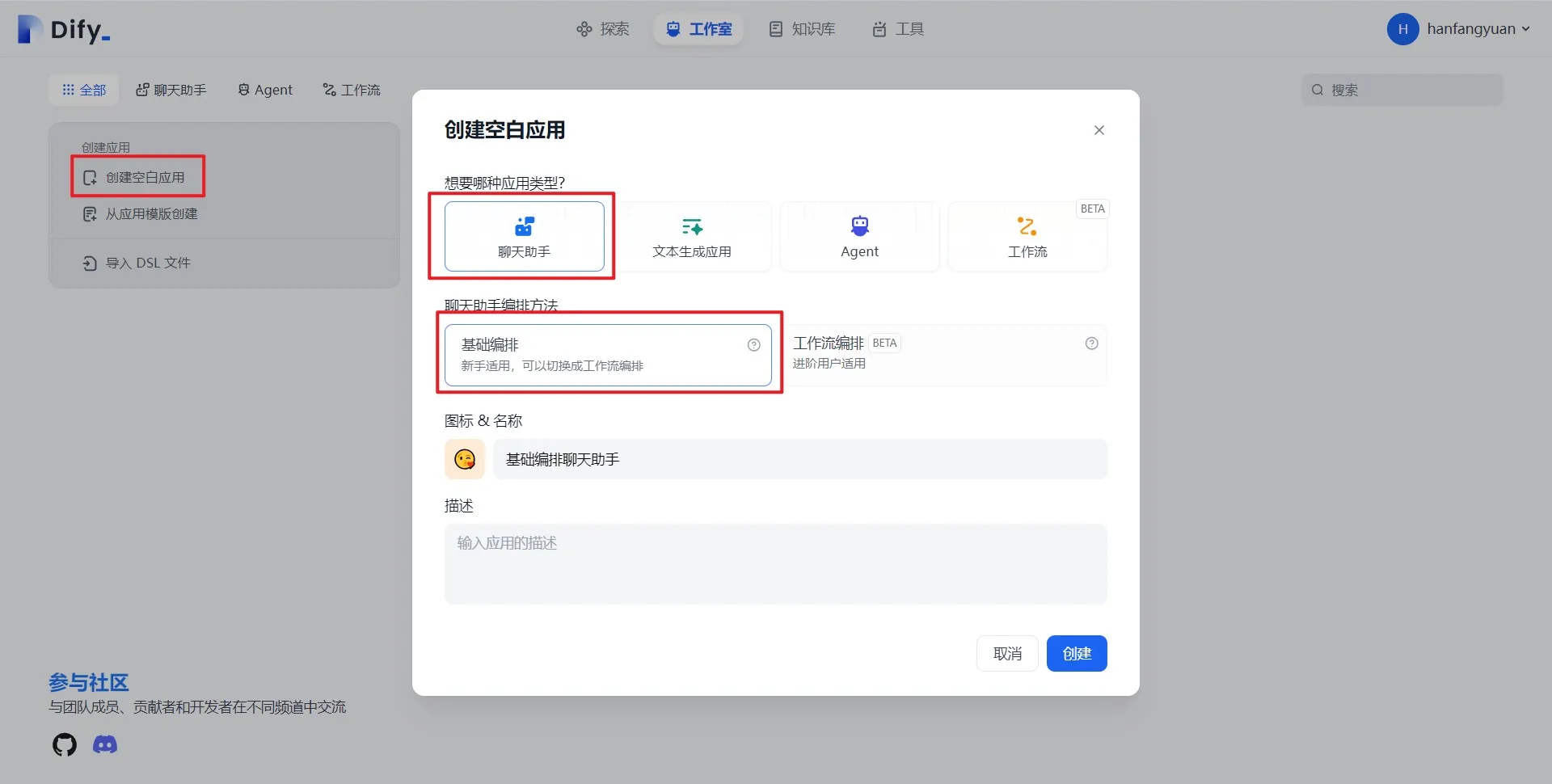
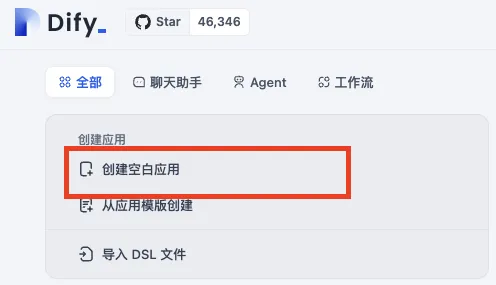
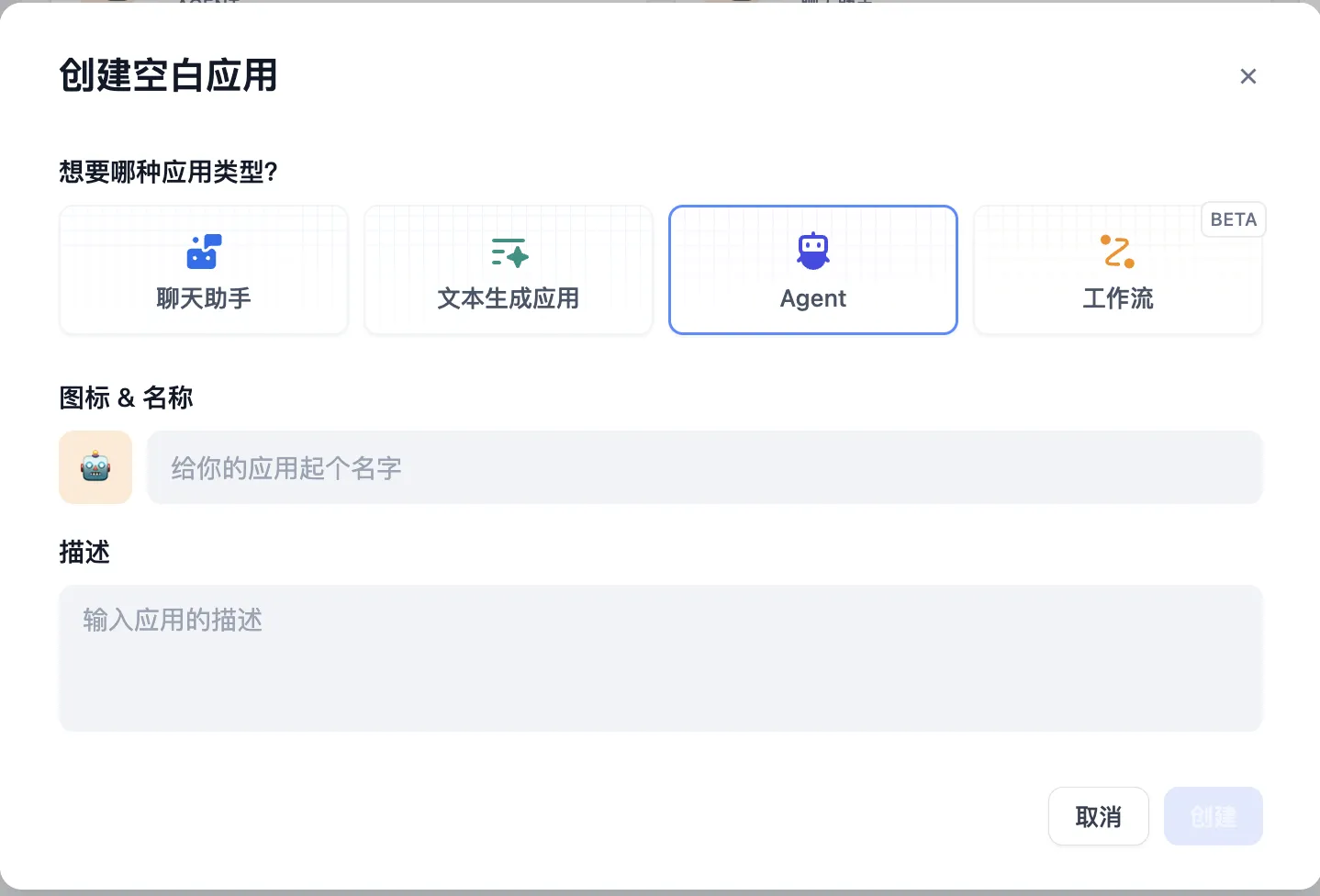
Create a blank application
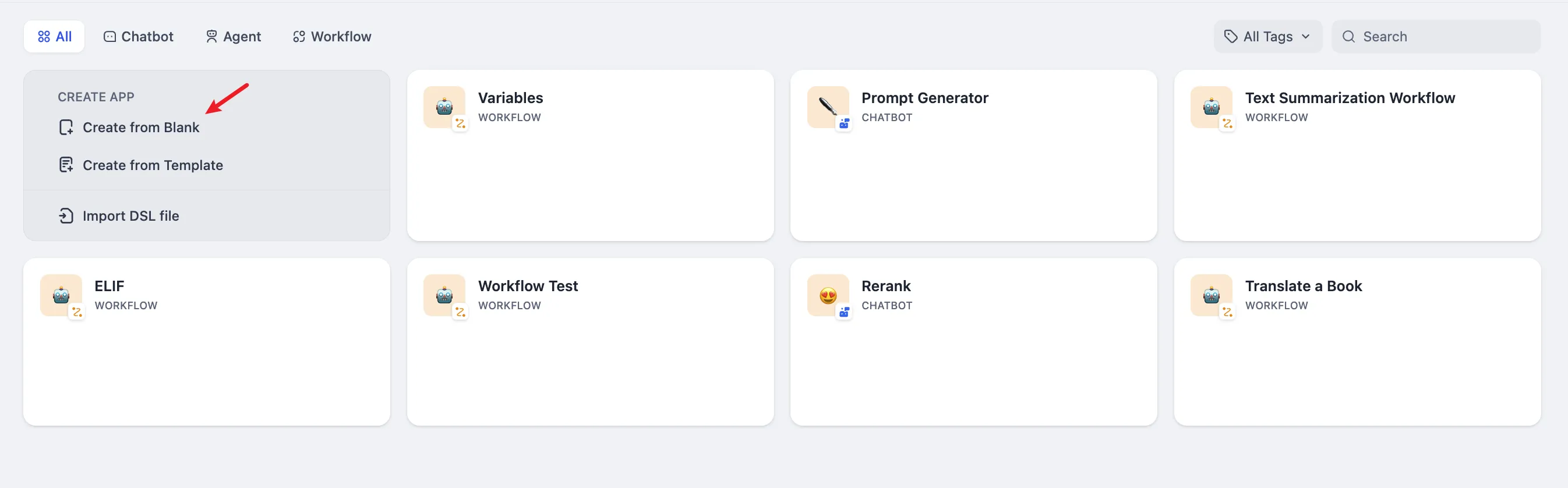
Create a blank application

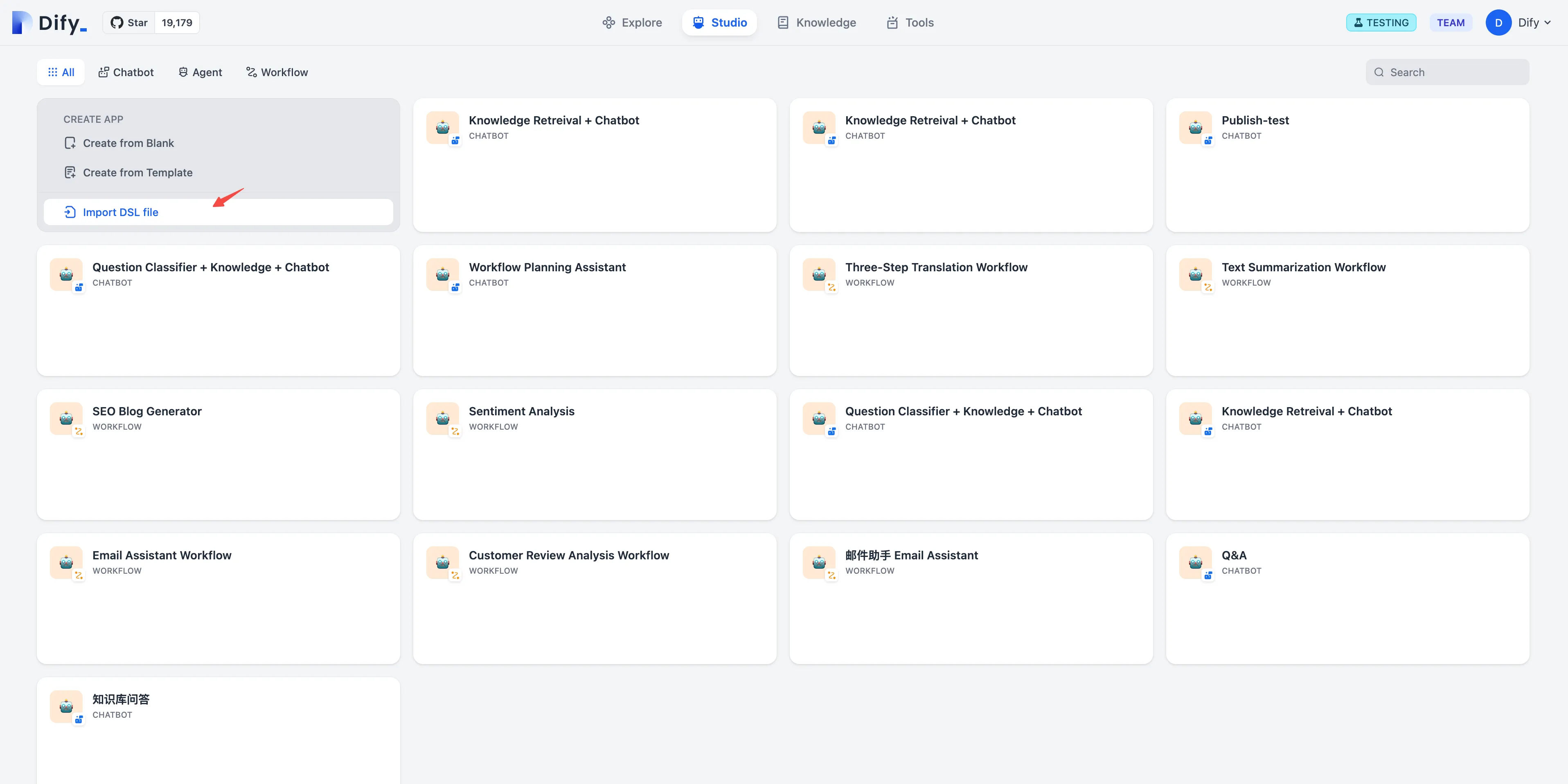
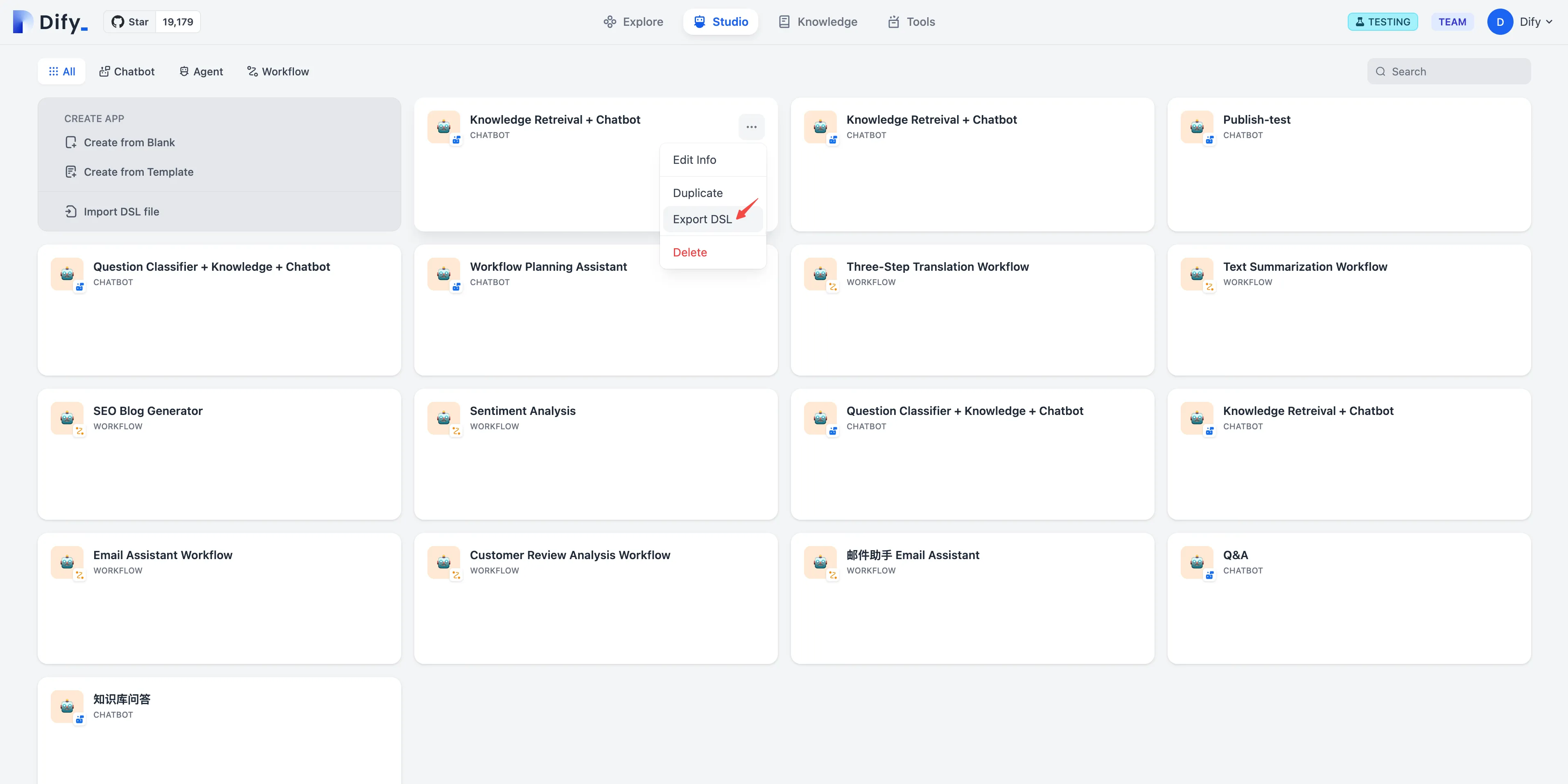
Create an application by importing a DSL file
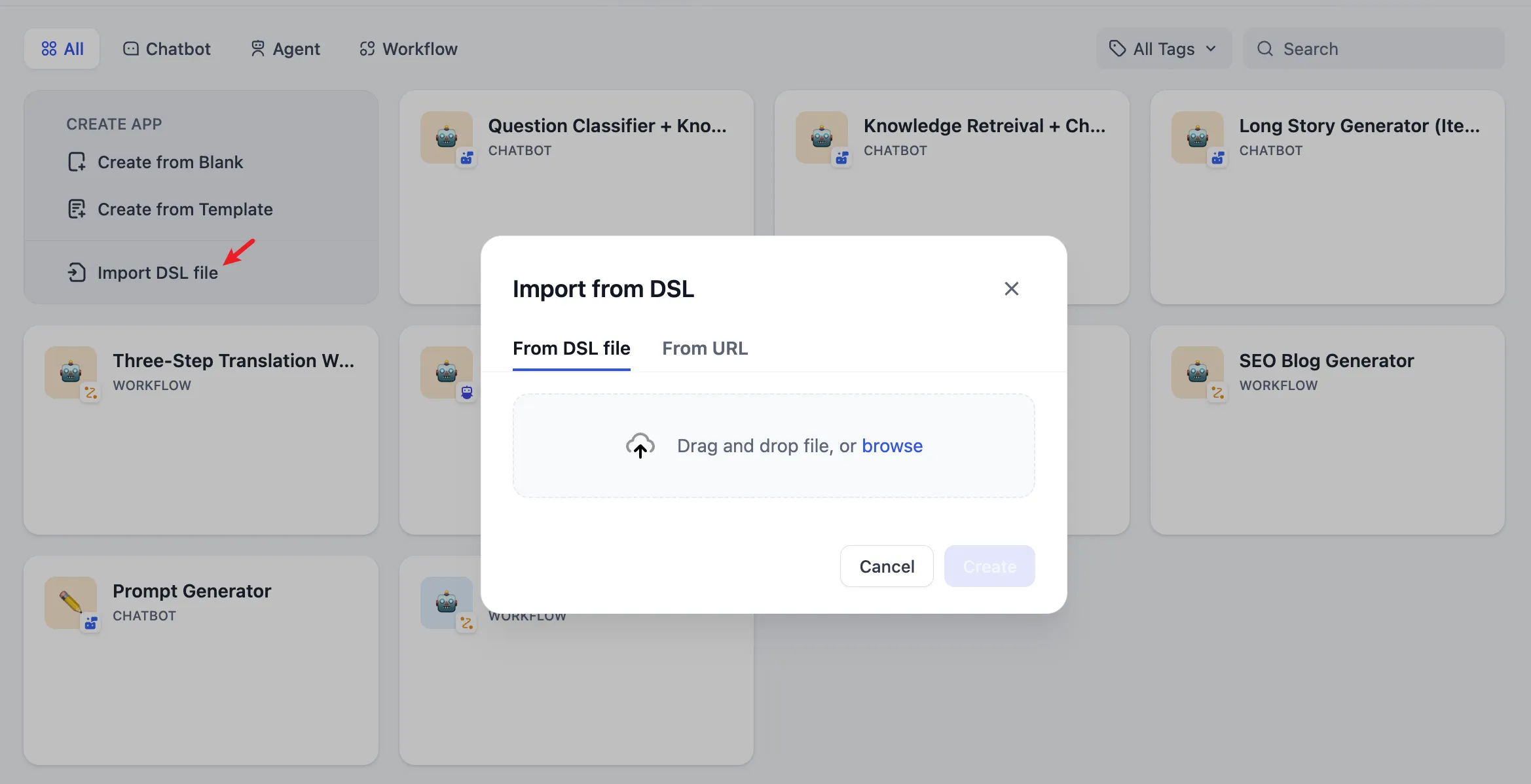
Create an application by importing a DSL file

Create an application by importing a DSL file
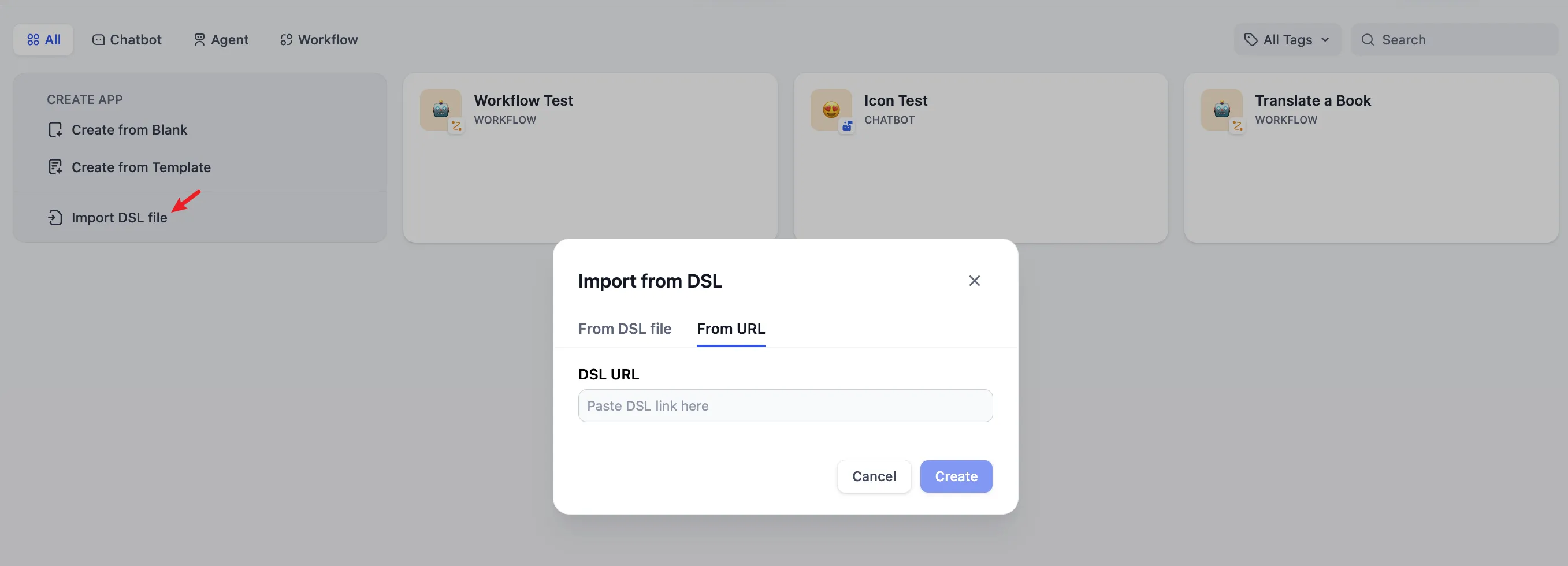
Create an application by importing a DSL file






 (1).png)




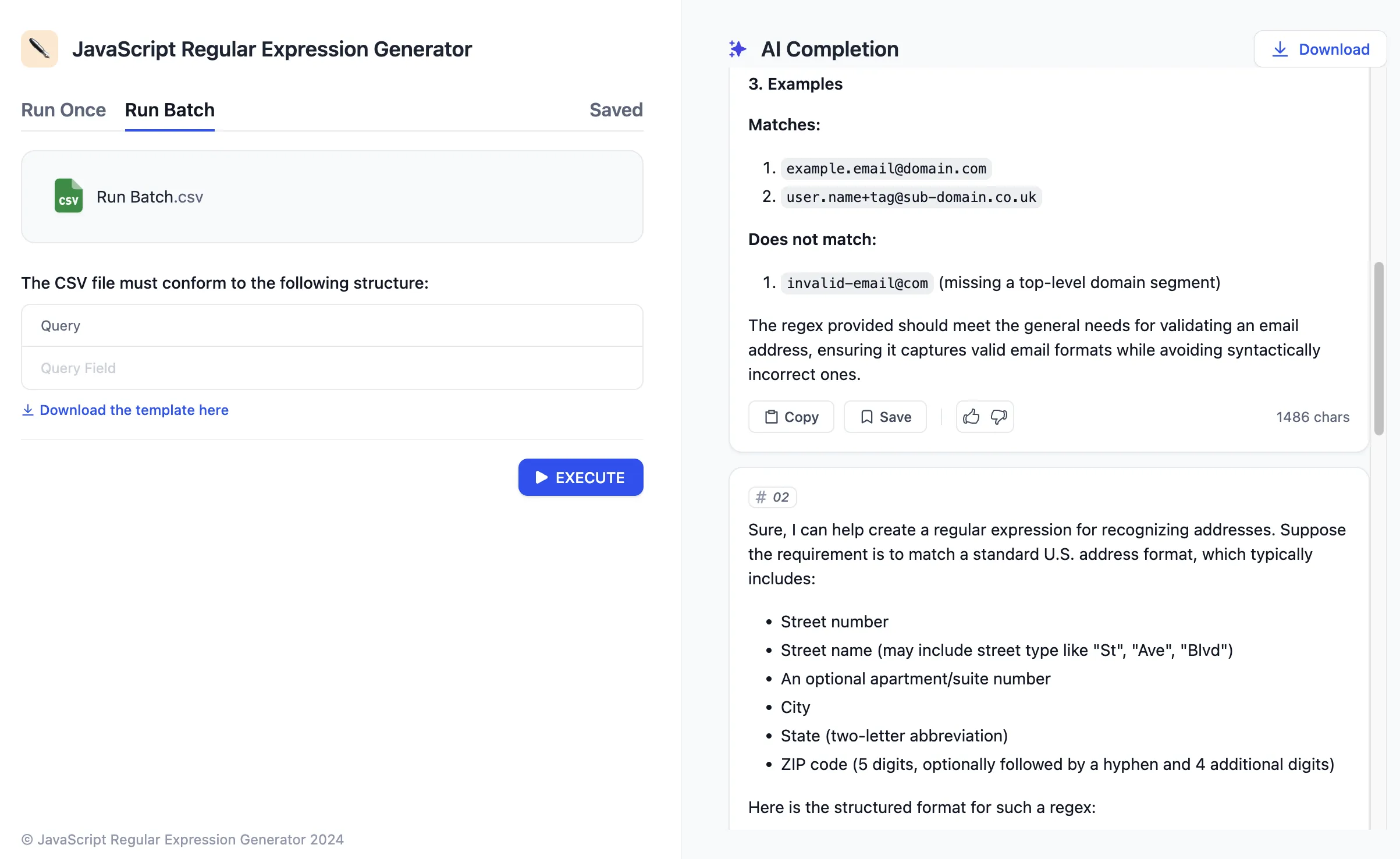

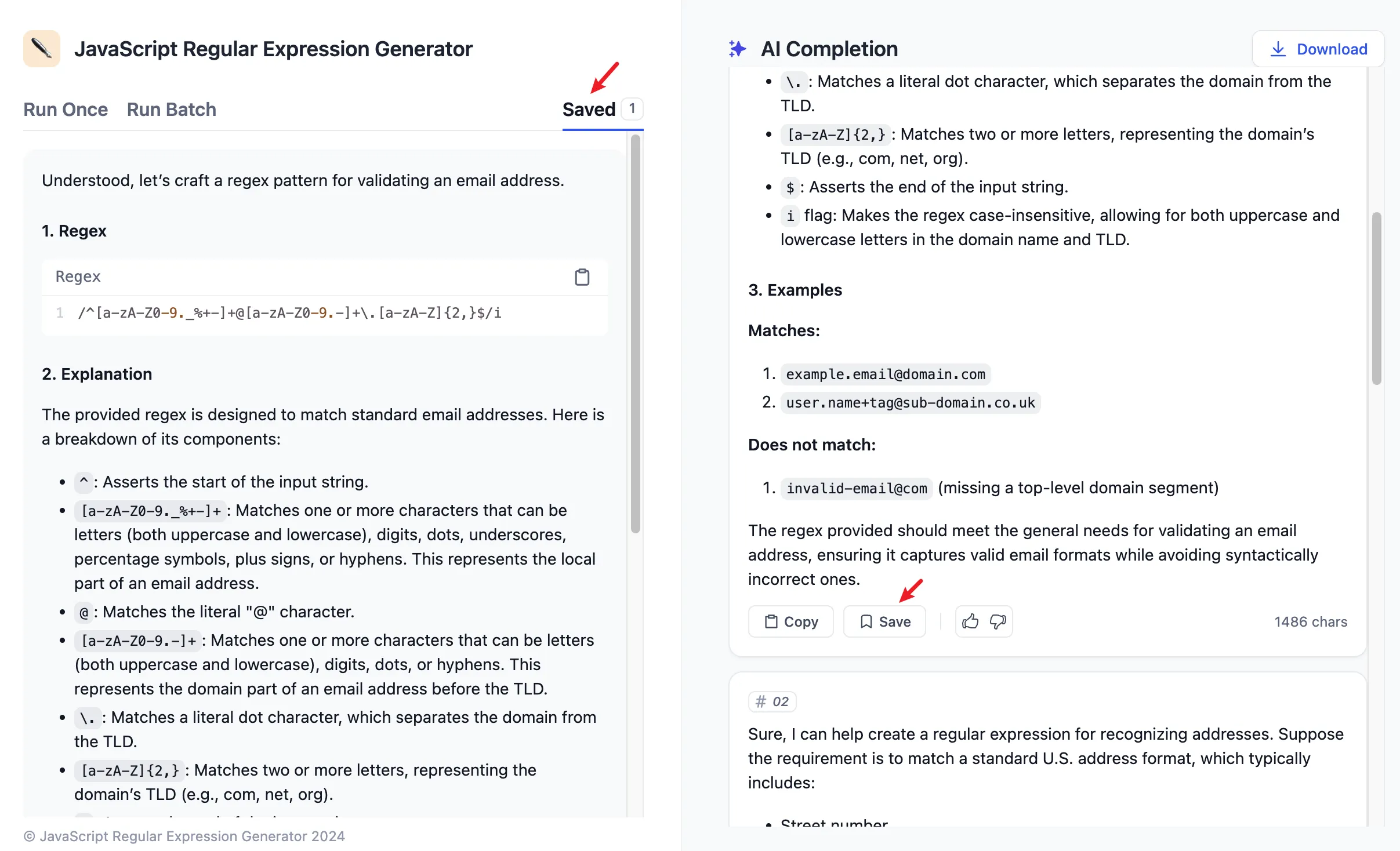

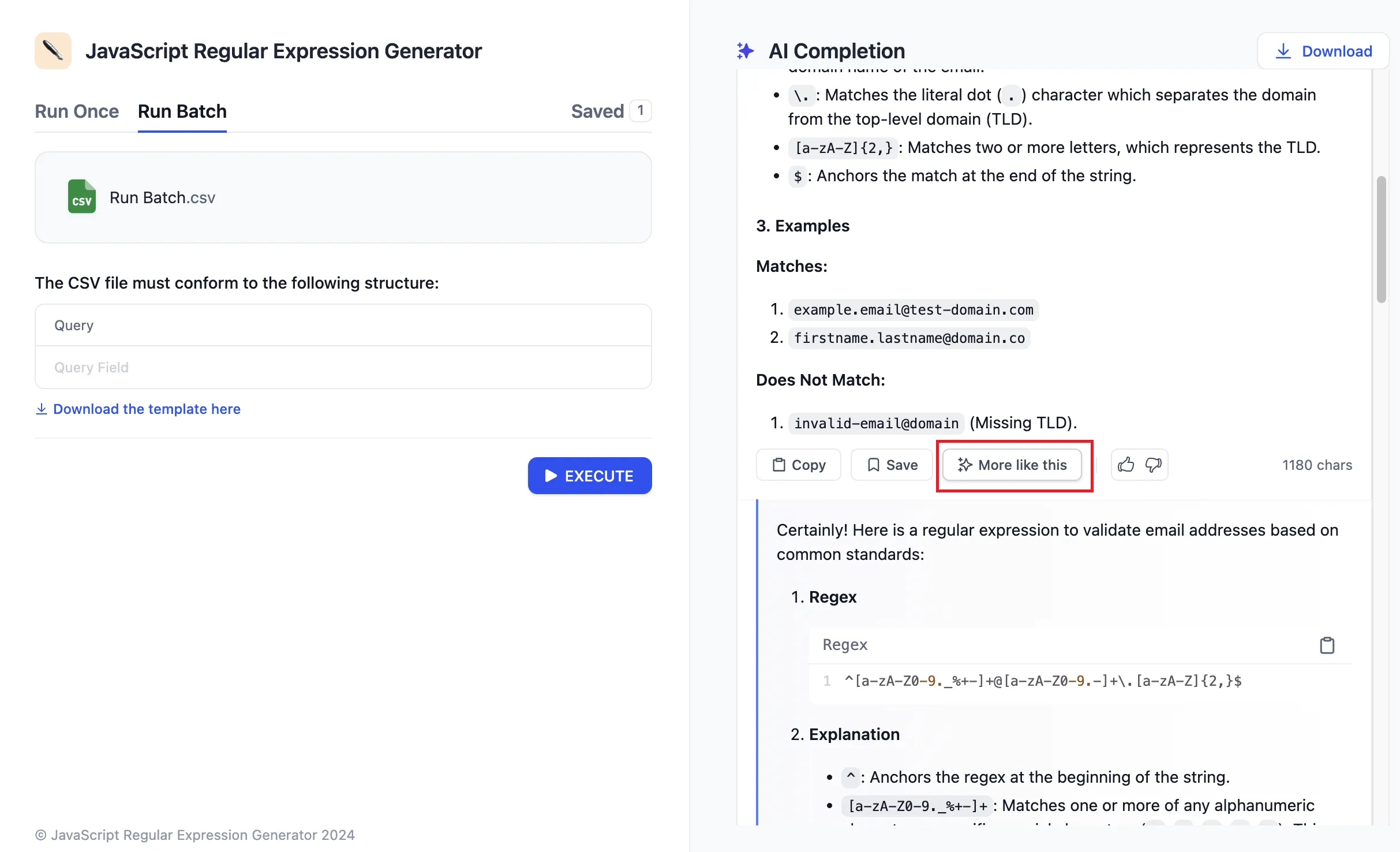
.png)
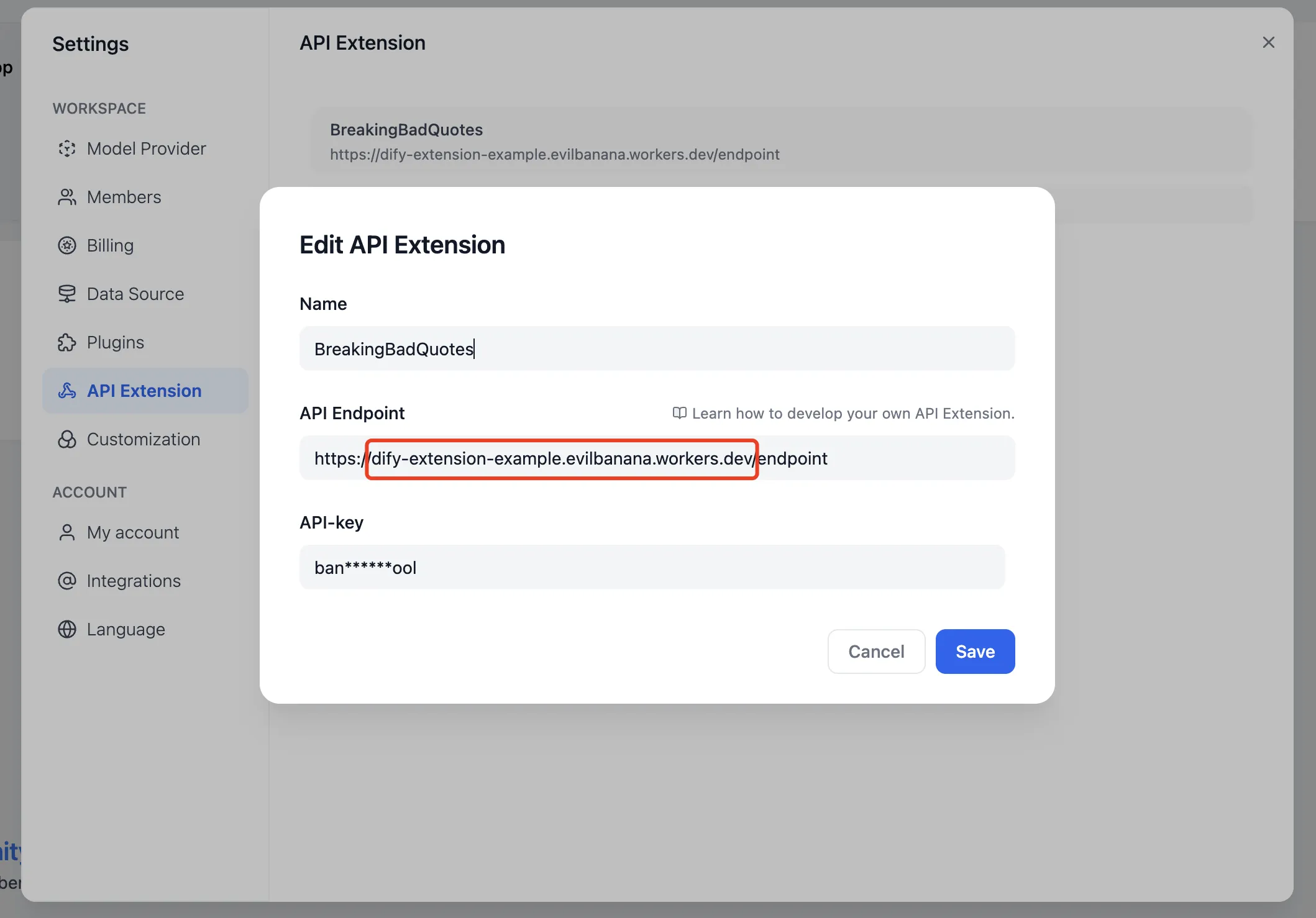
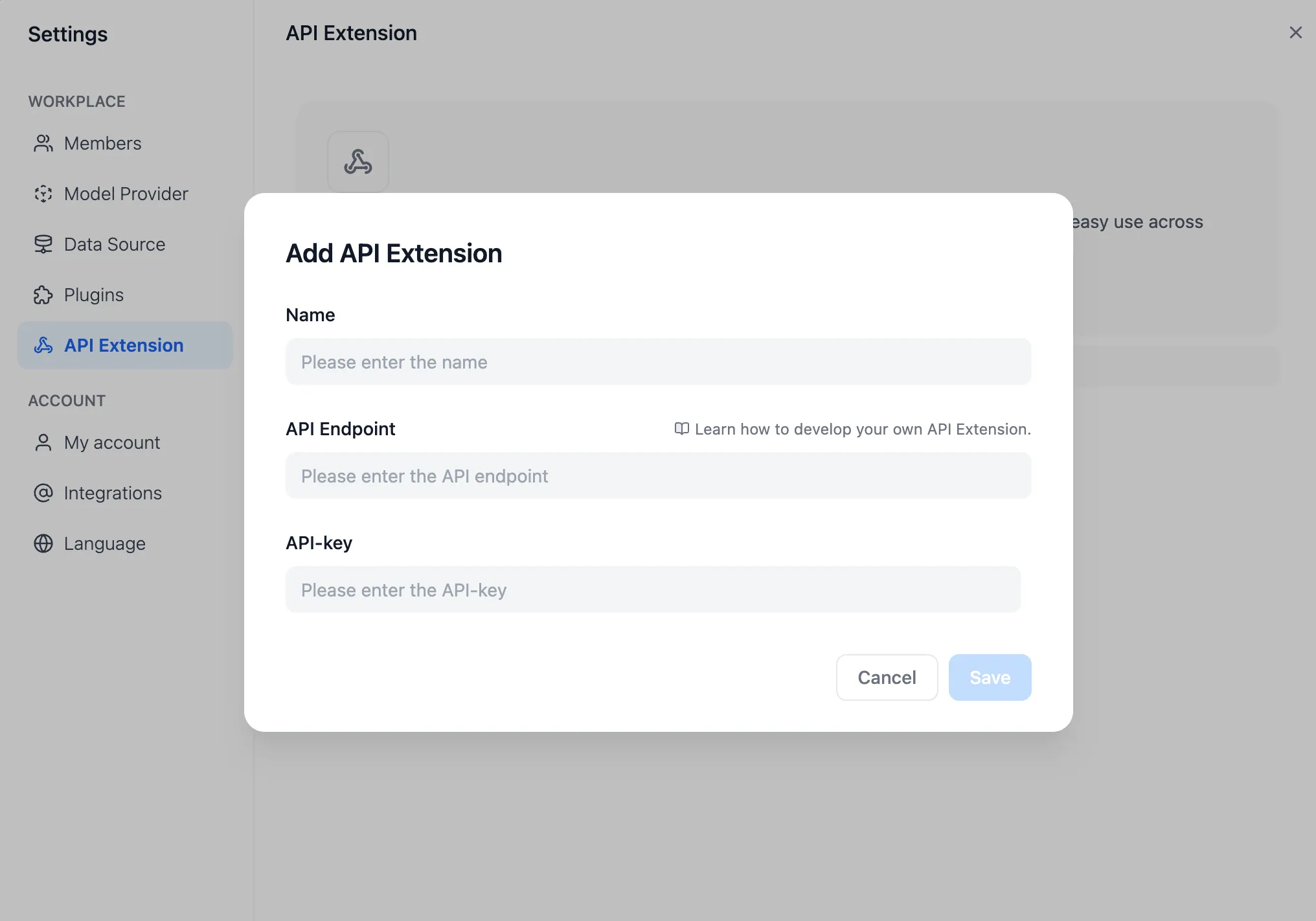
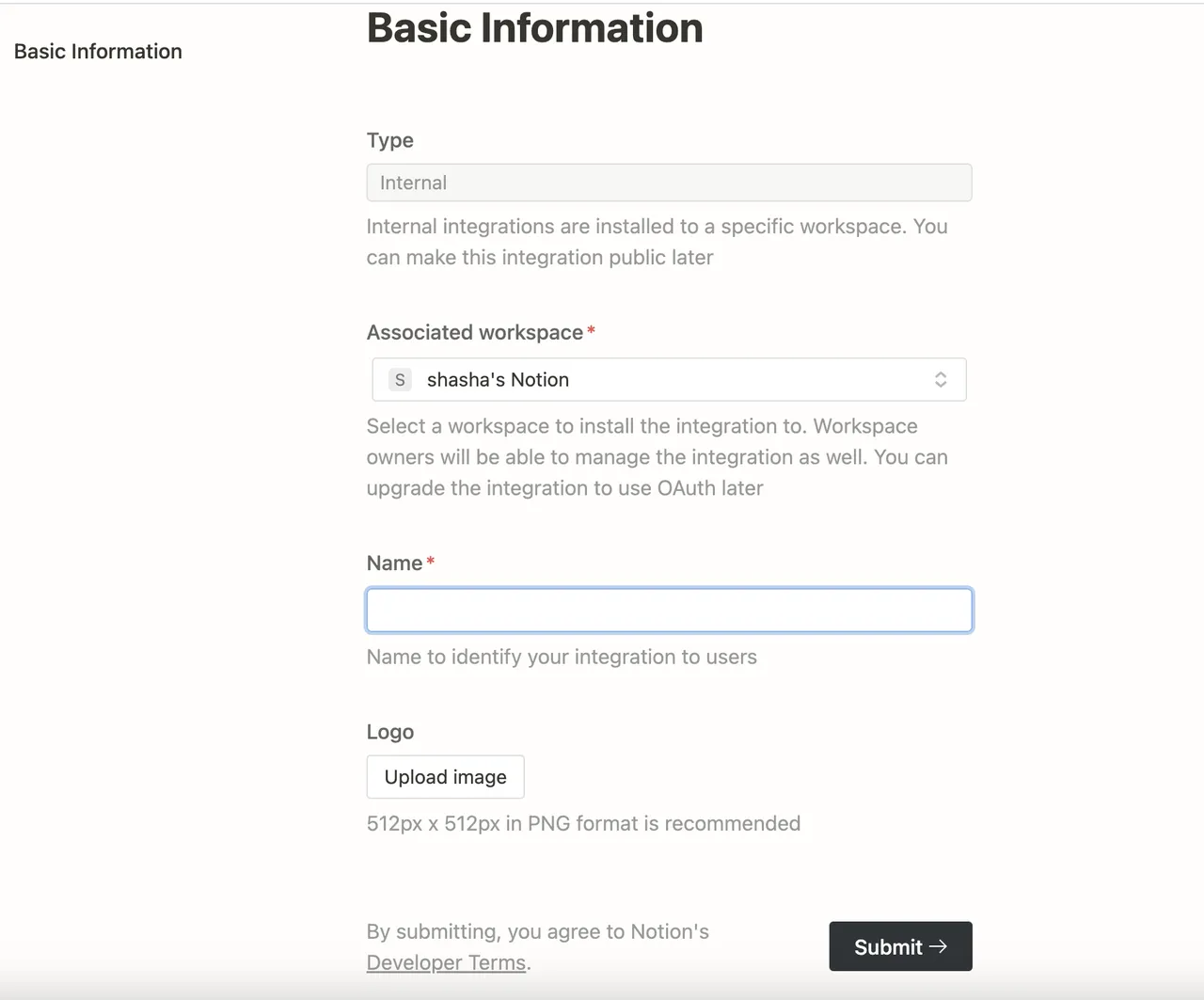
Add API Extension
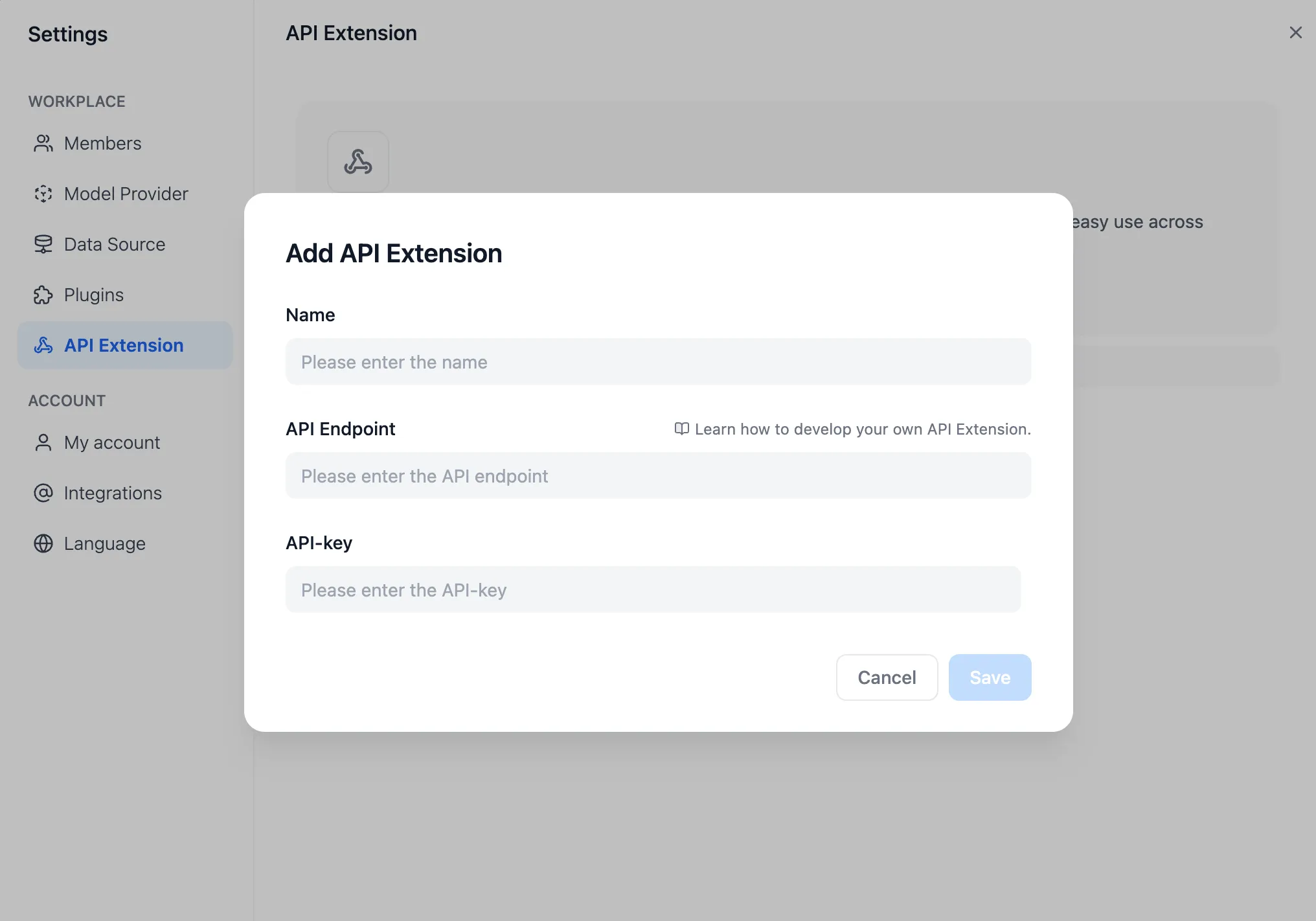
Add API Extension
.png)



.png)
Adding API Endpoint in Dify
Adding API Endpoint in Dify
.png)
Adding API Tool in the App edit page
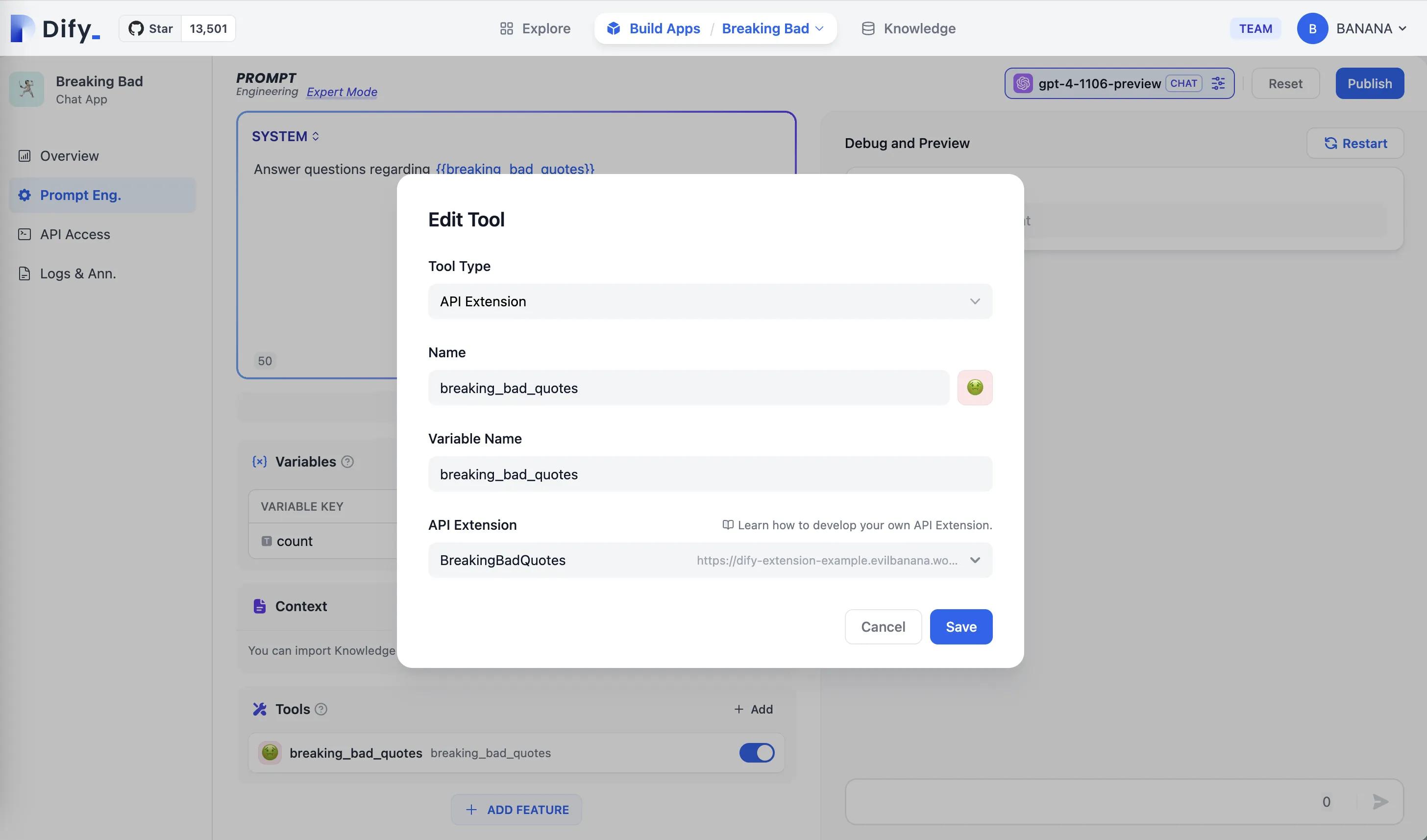
Adding API Tool in the App edit page
.png)
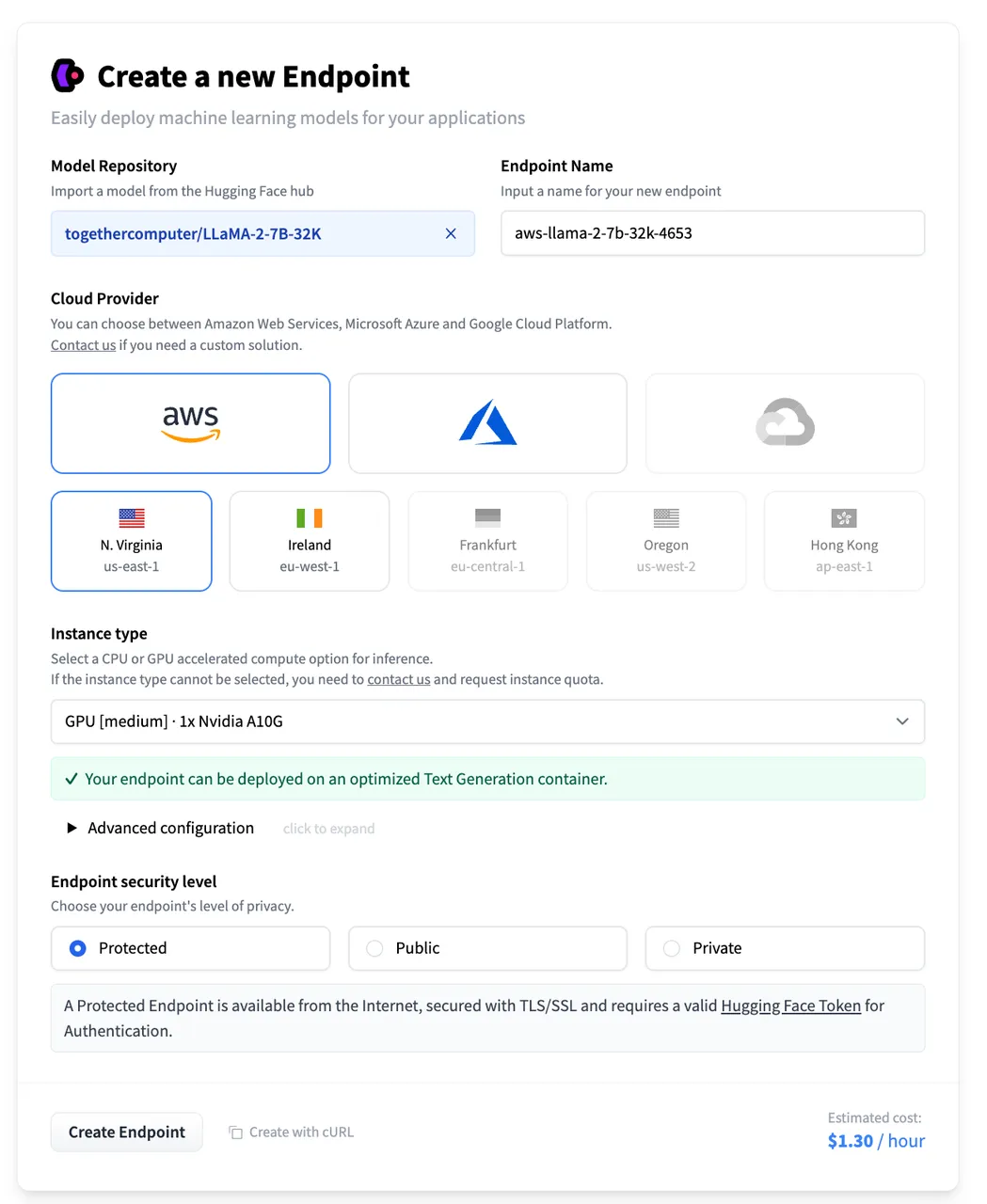
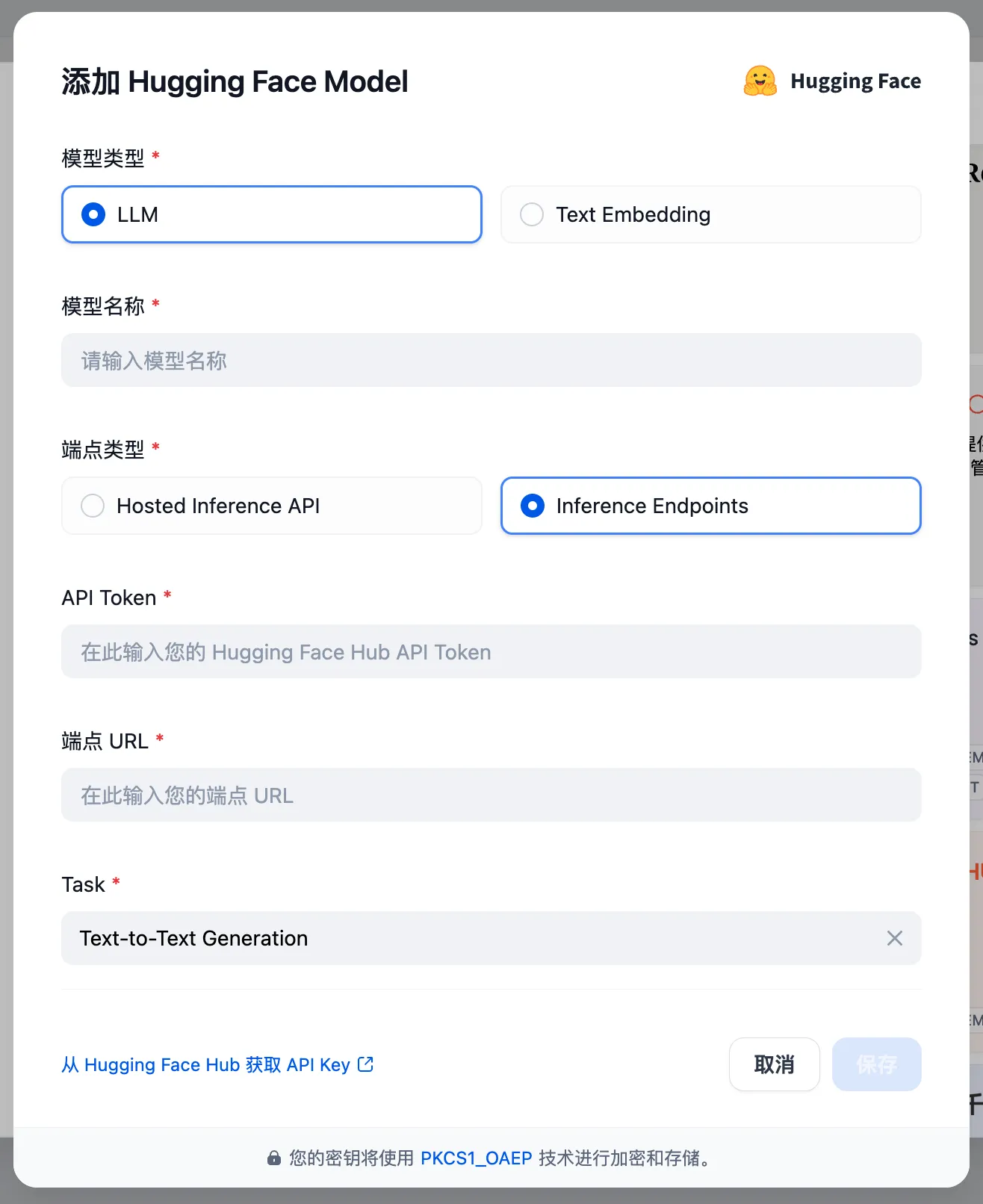
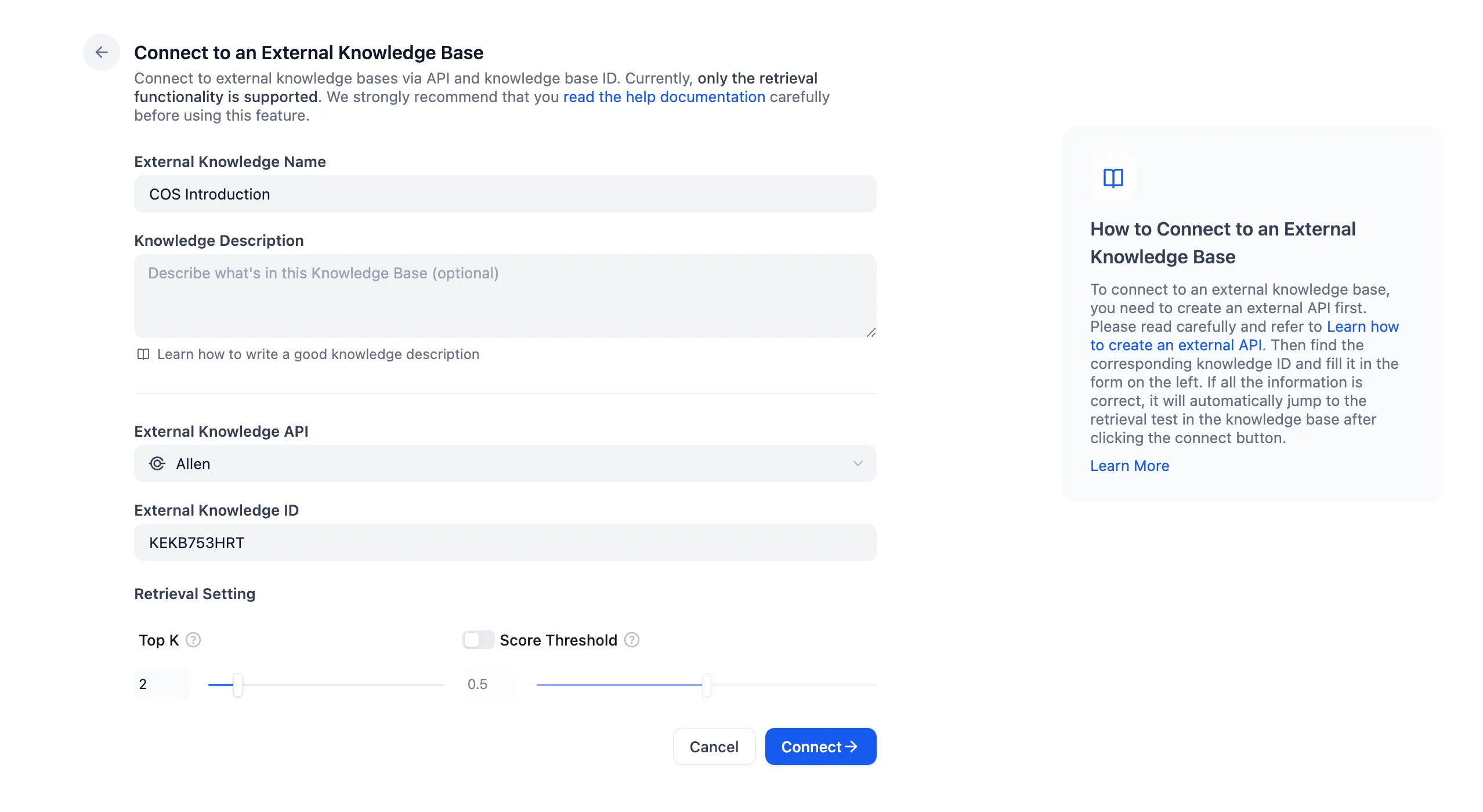
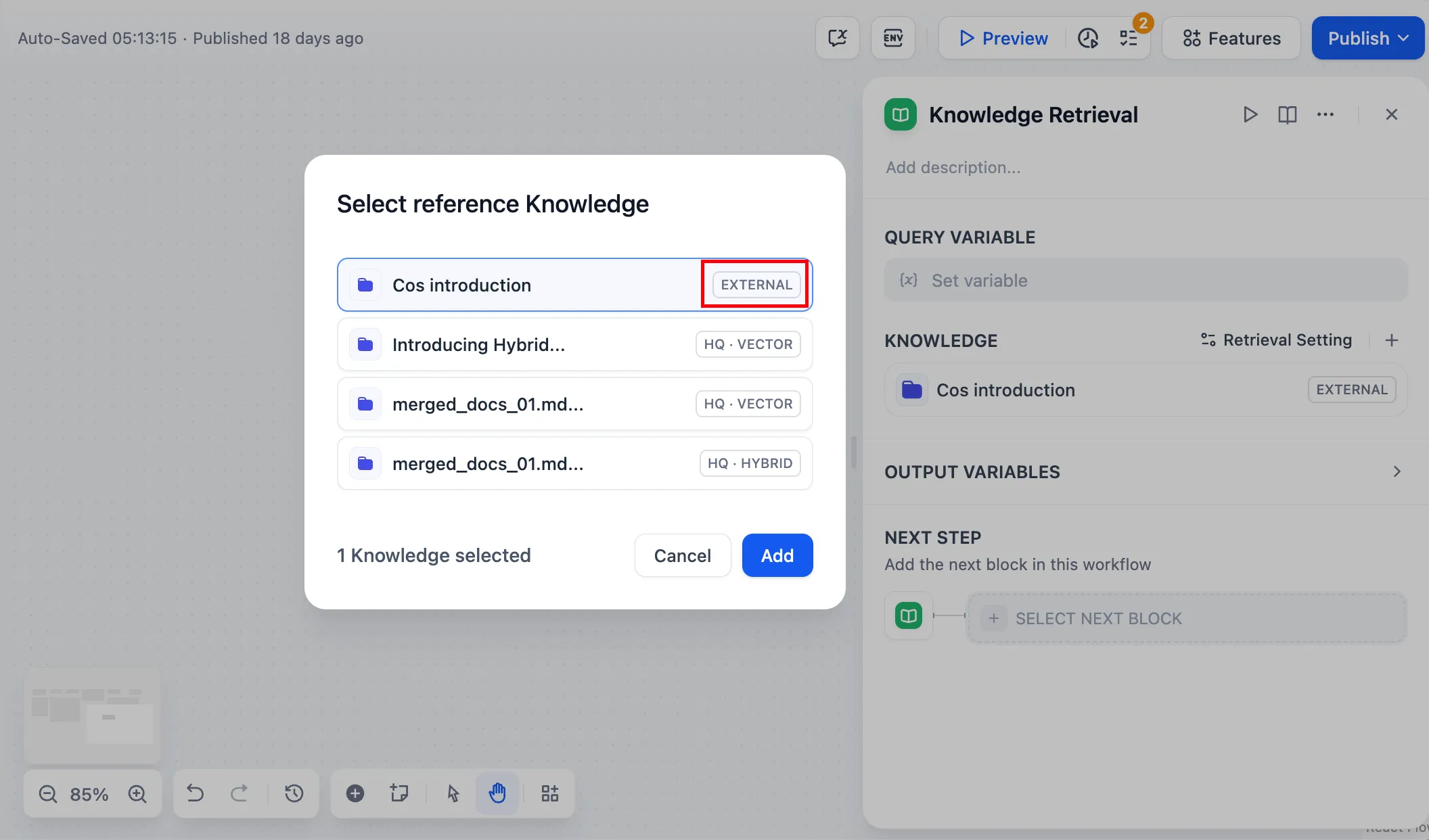
Principle of external knowledge base connection
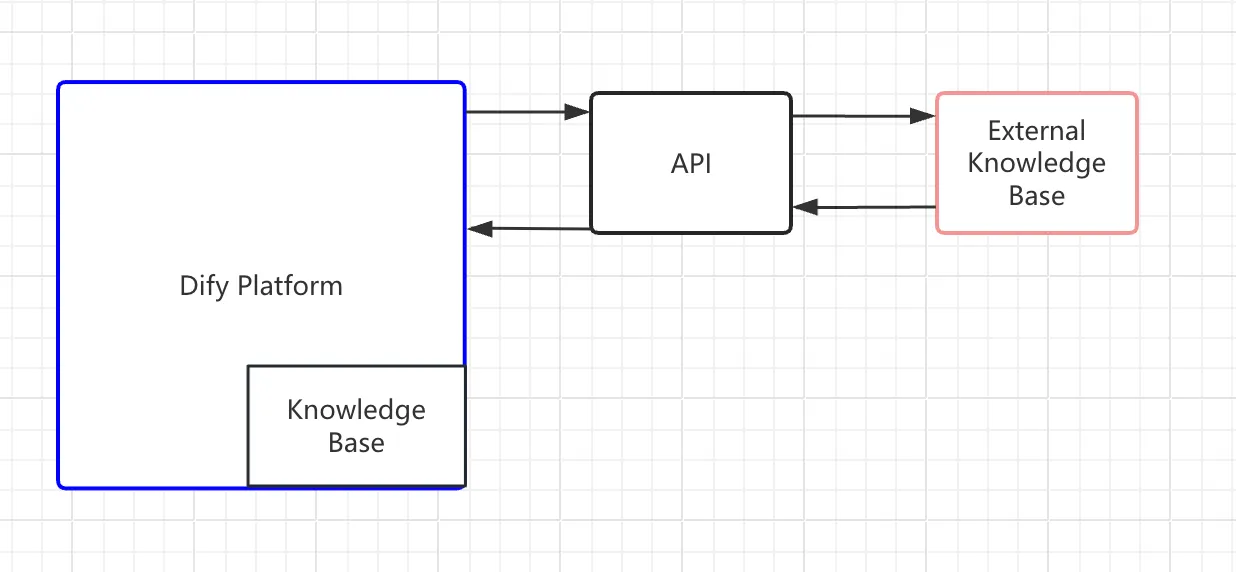
Principle of external knowledge base connection

Associate External Knowledge API
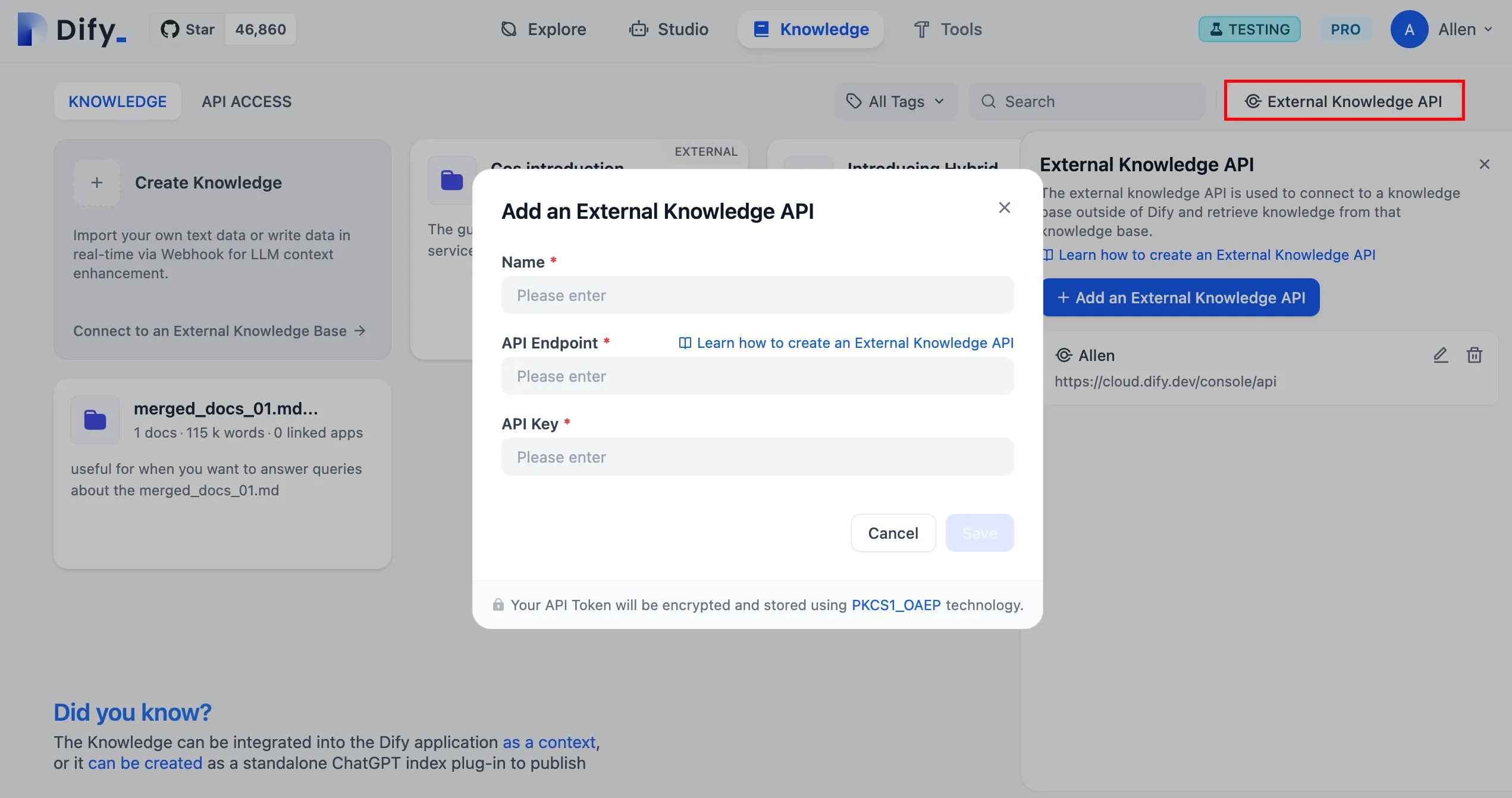
Associate External Knowledge API

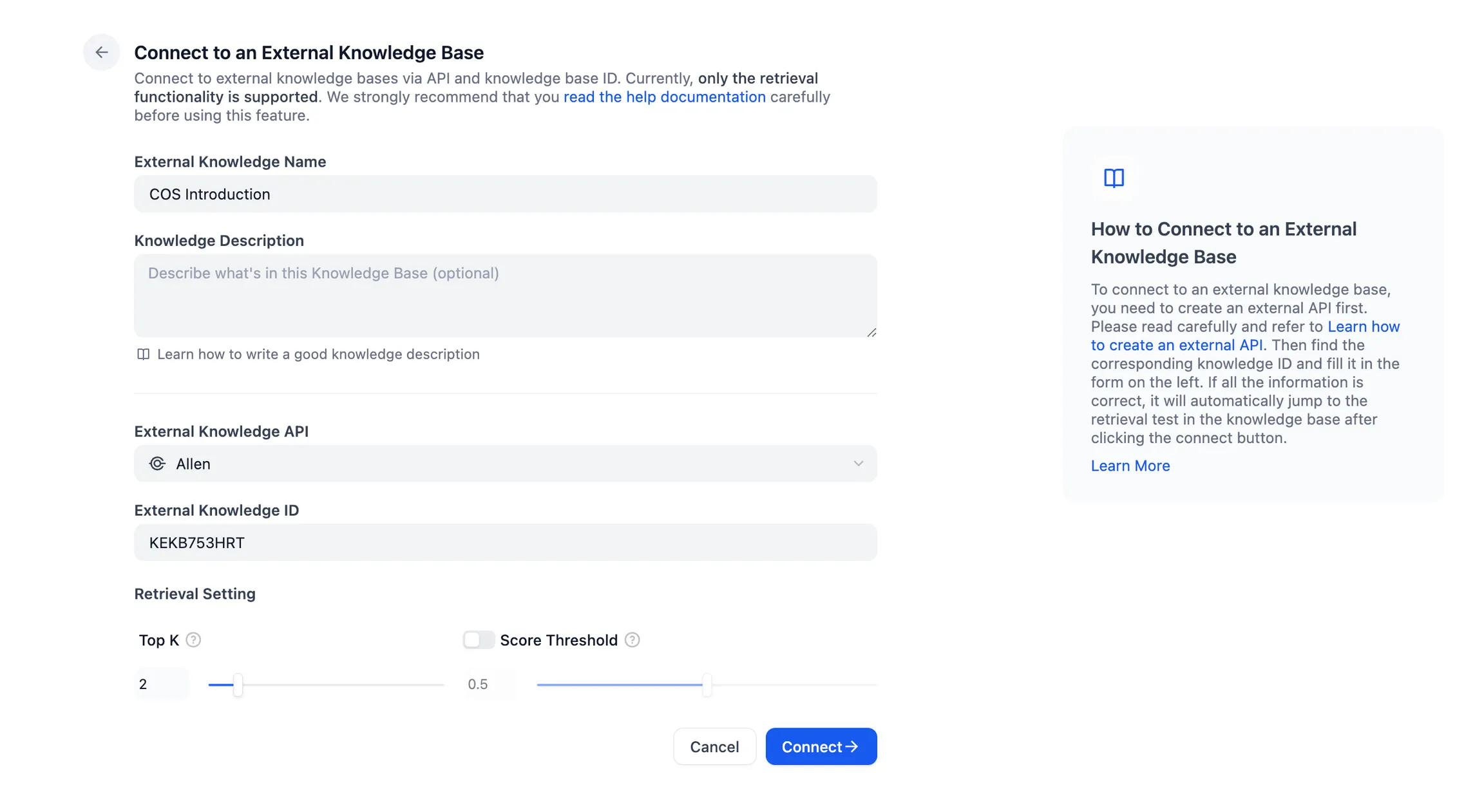
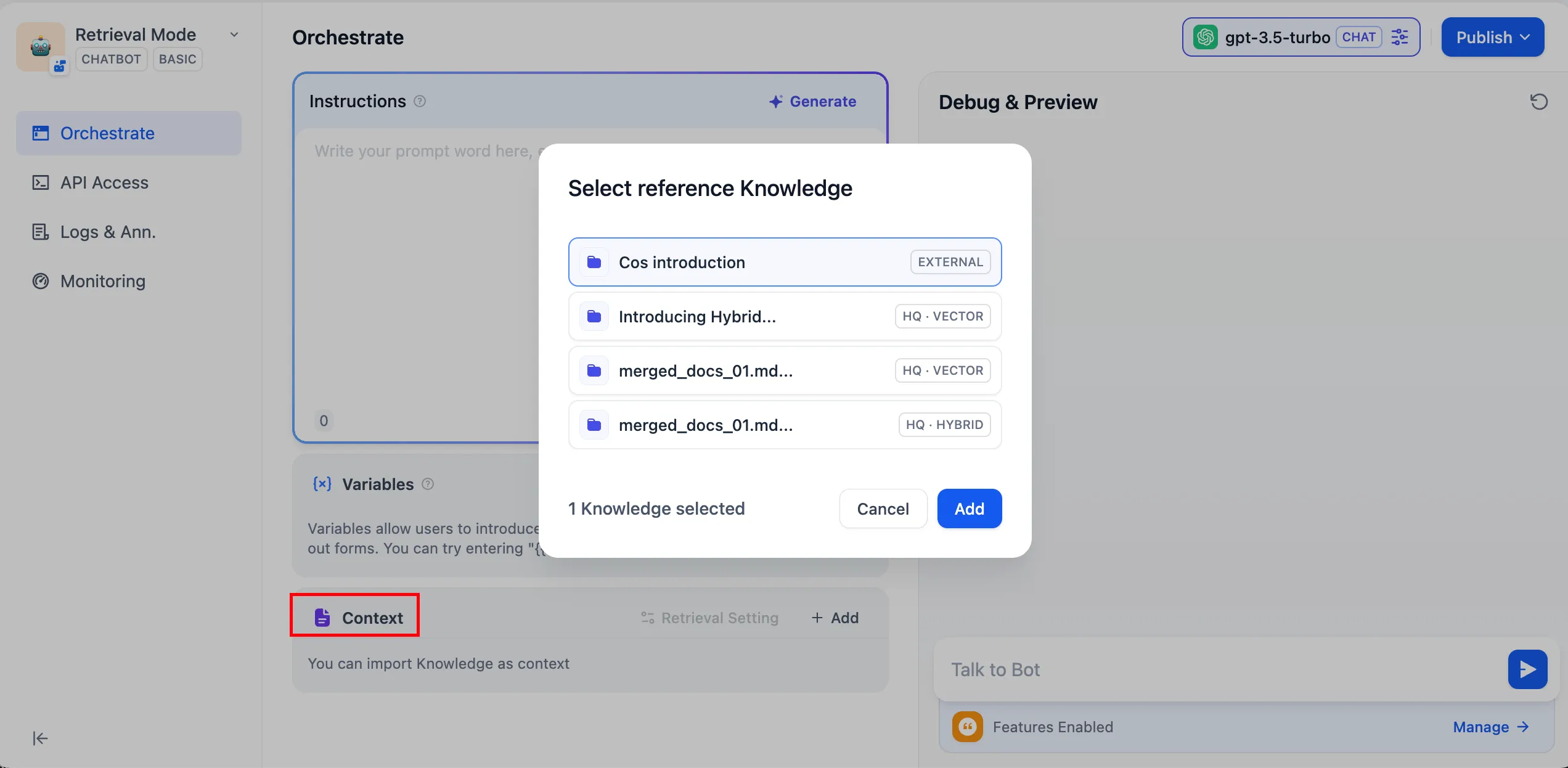
Connect to the external knowledge base
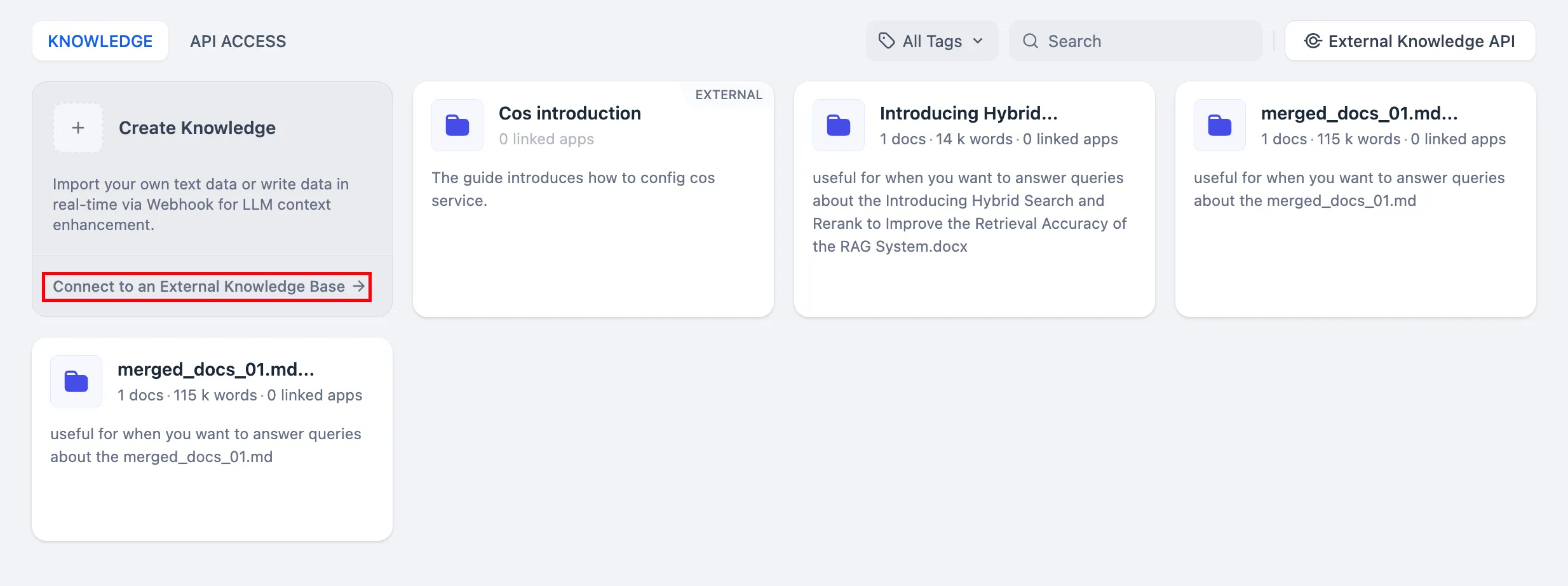
Connect to the external knowledge base


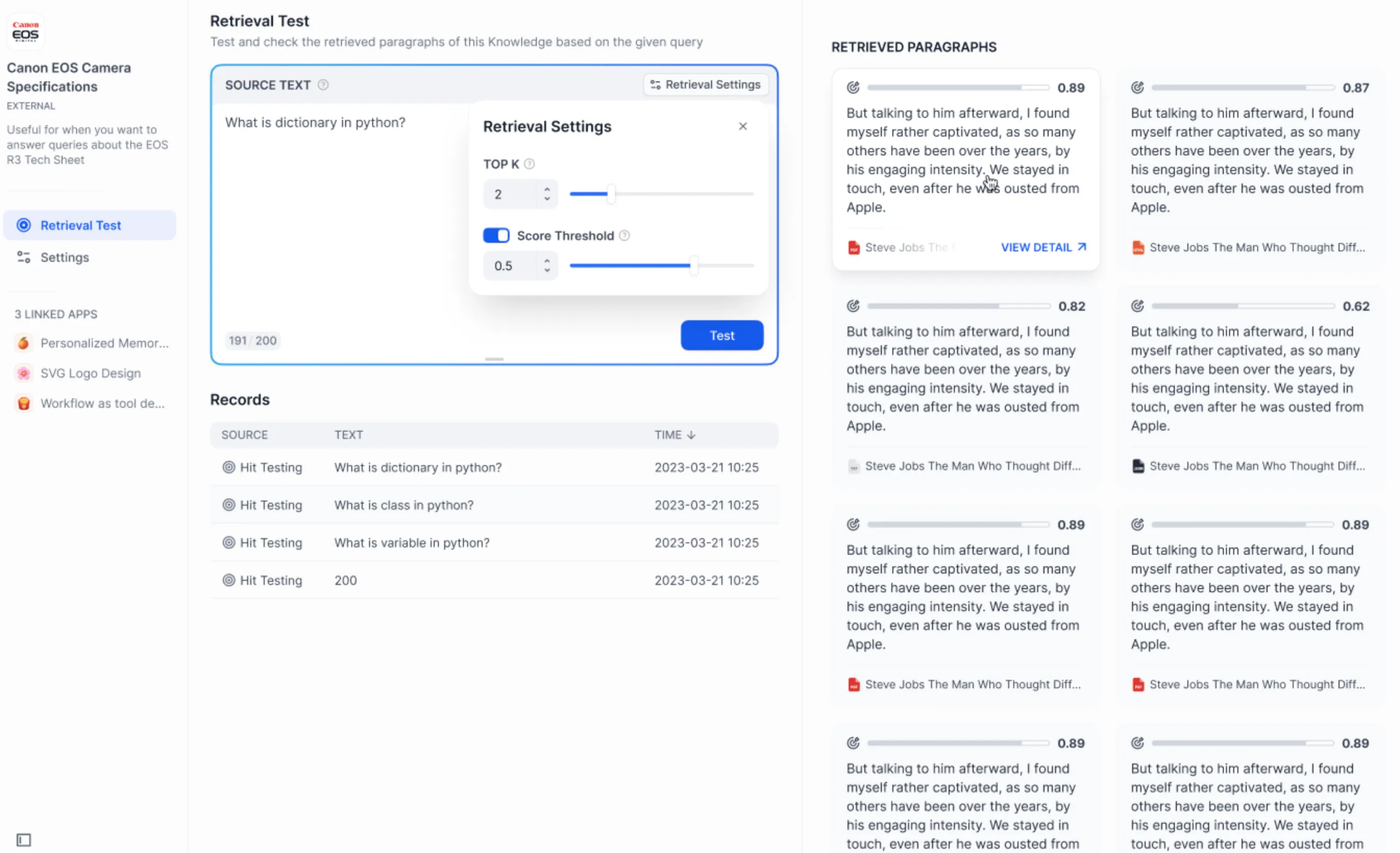
Test external knowledge base connection and retrieval
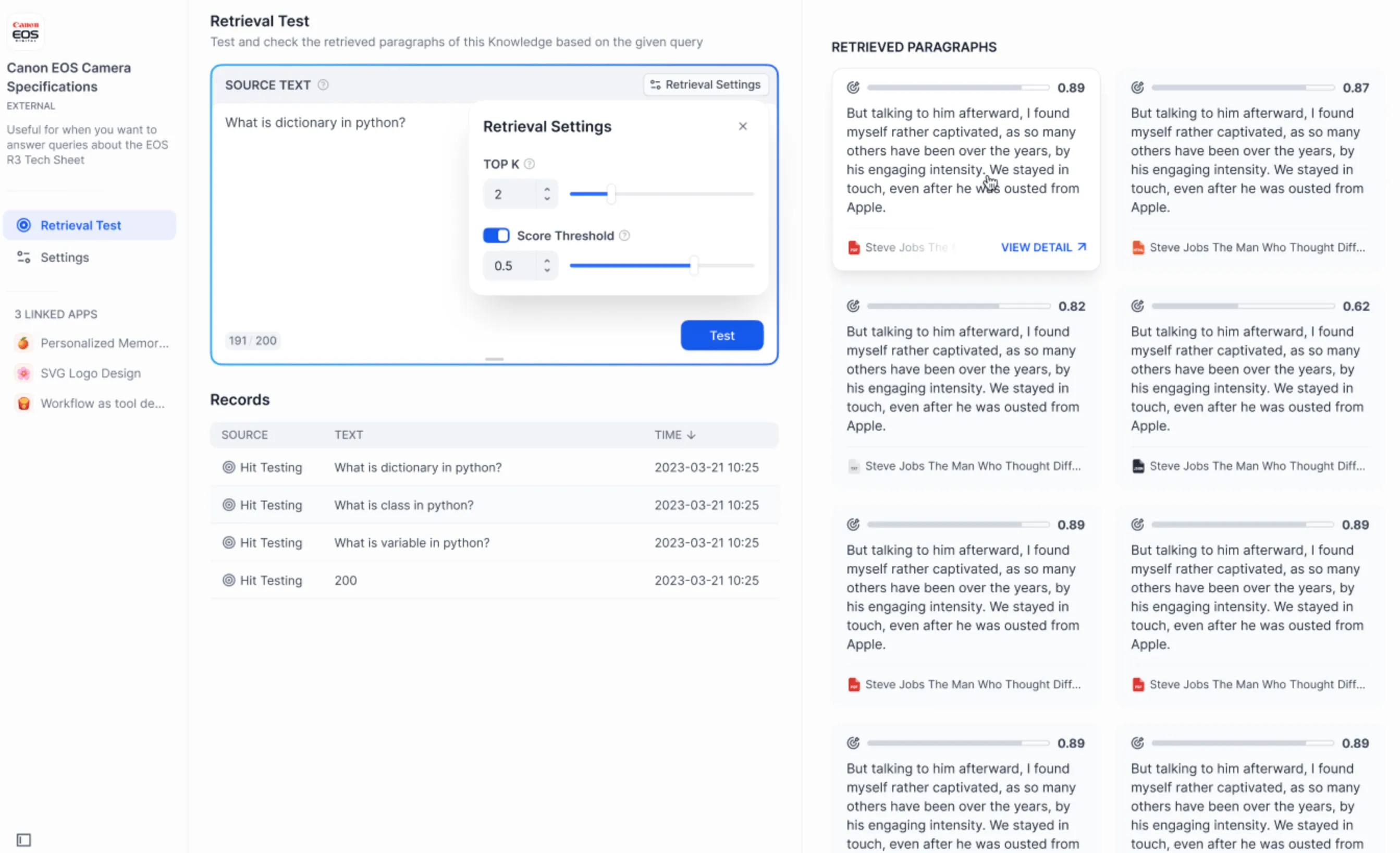
Test external knowledge base connection and retrieval

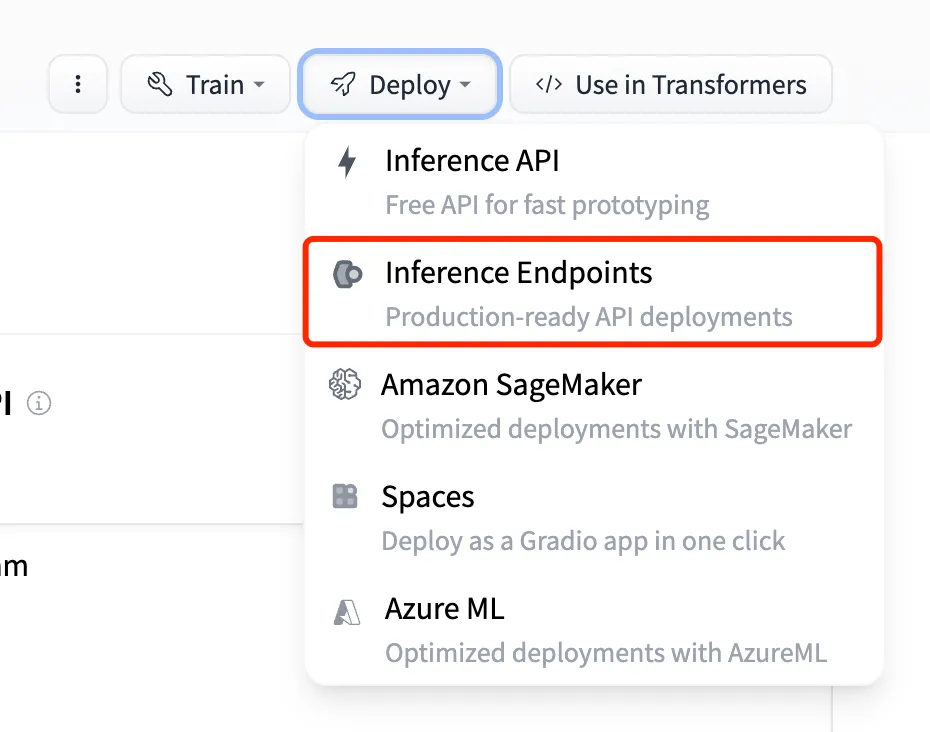
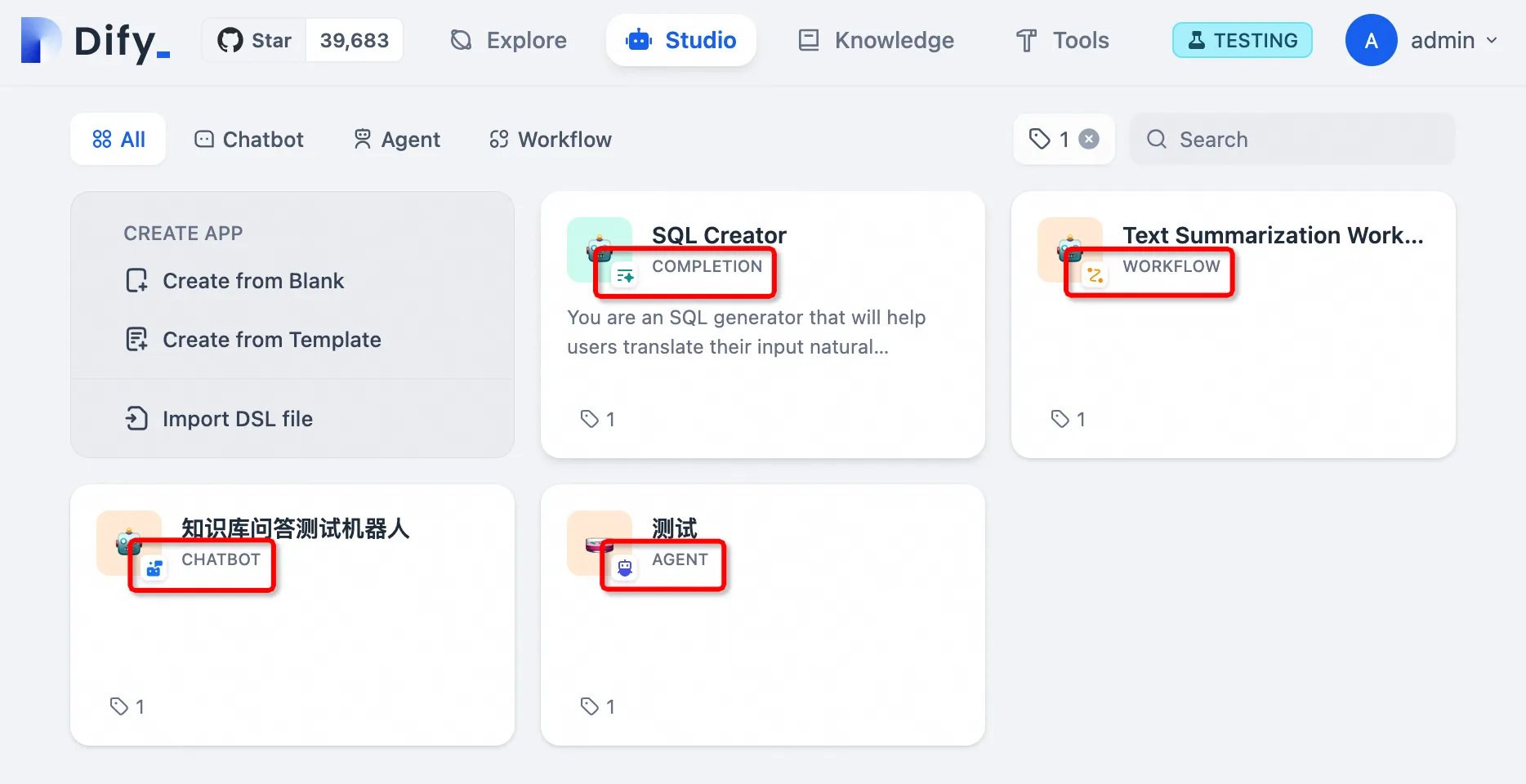
Chatbot / Agent
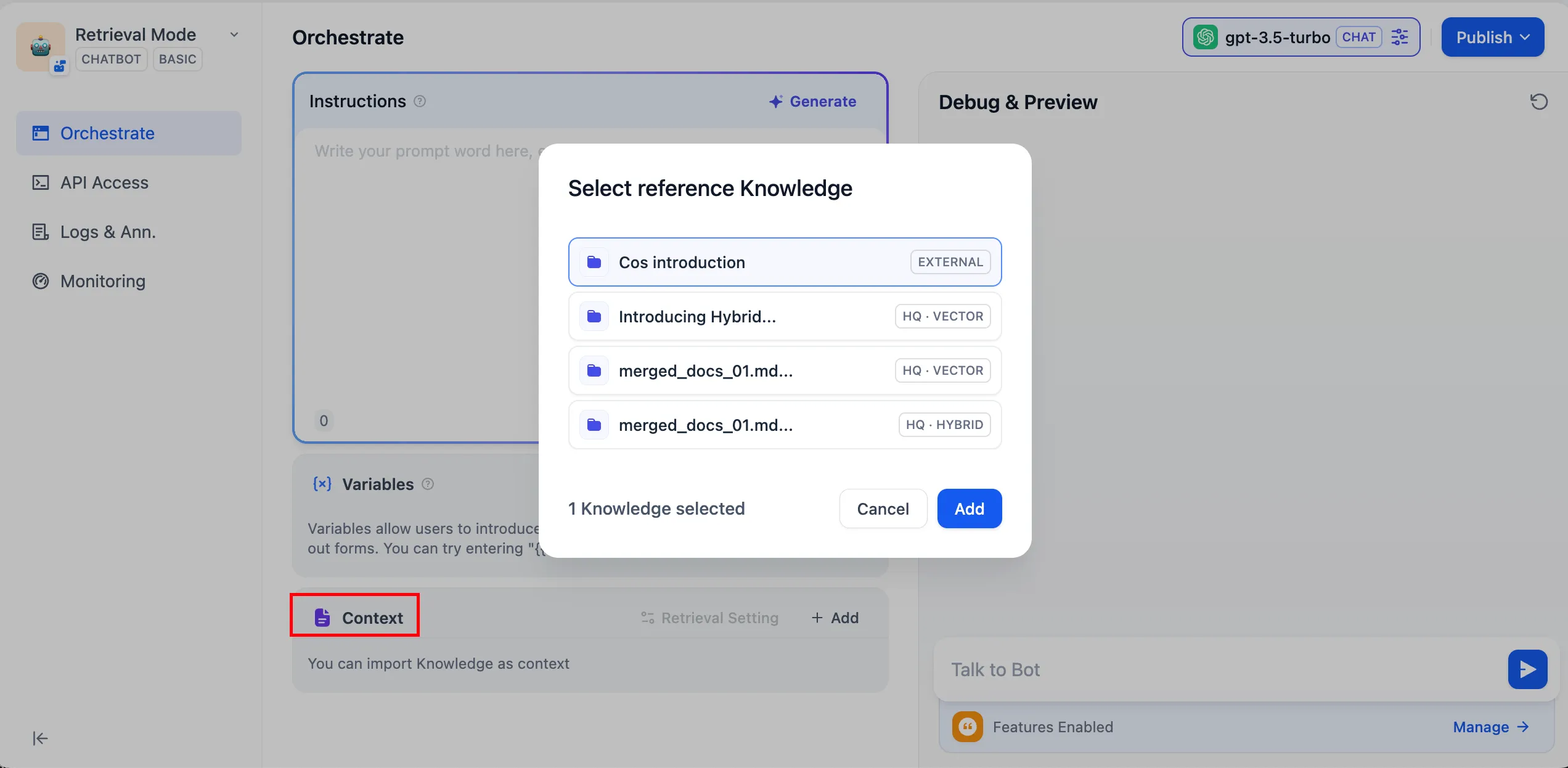
Chatbot / Agent

Chatflow / Workflow
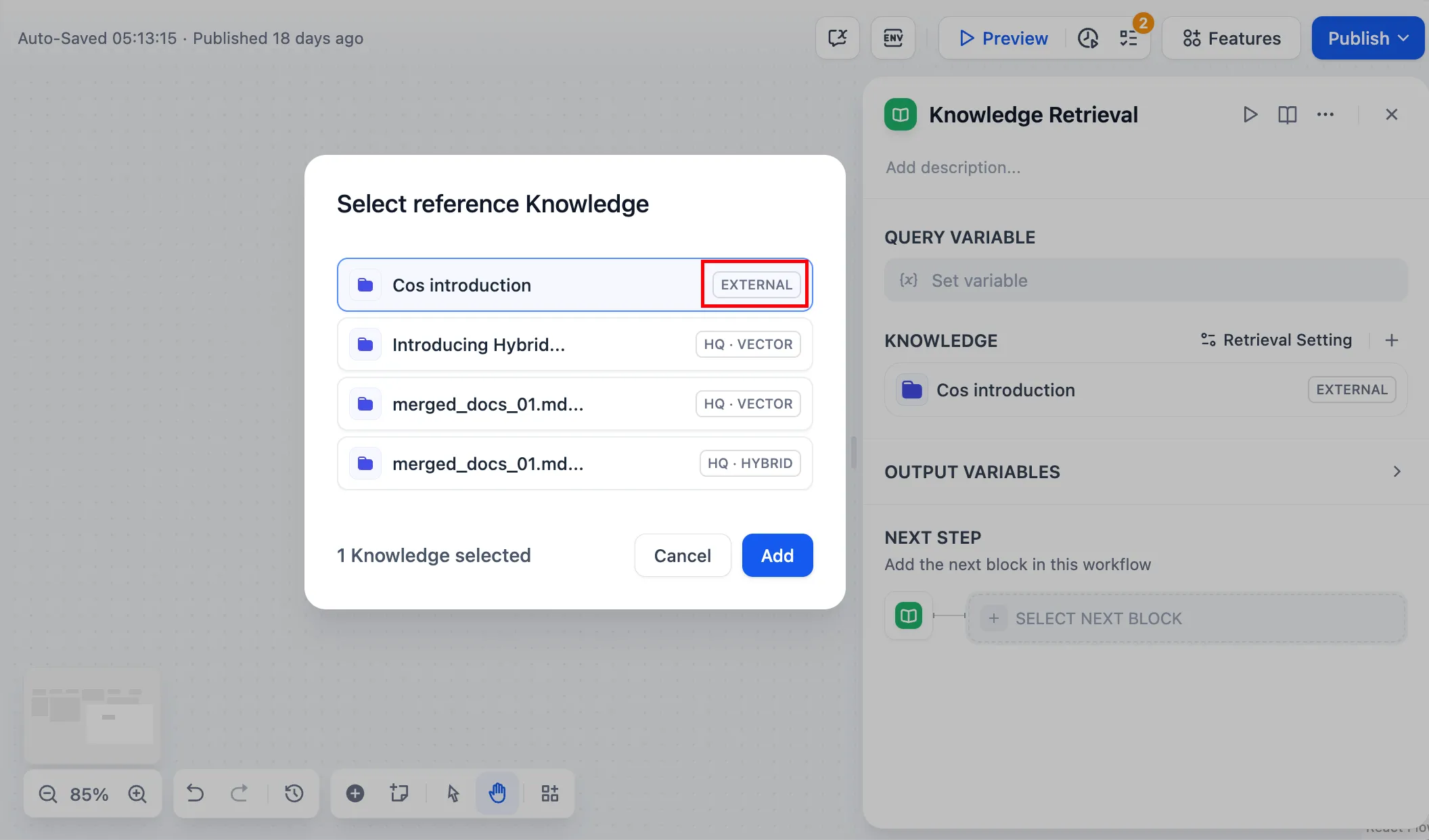
Chatflow / Workflow



Configuring the Rerank model in the Model Provider
Configuring the Rerank model in the Model Provider
.png)

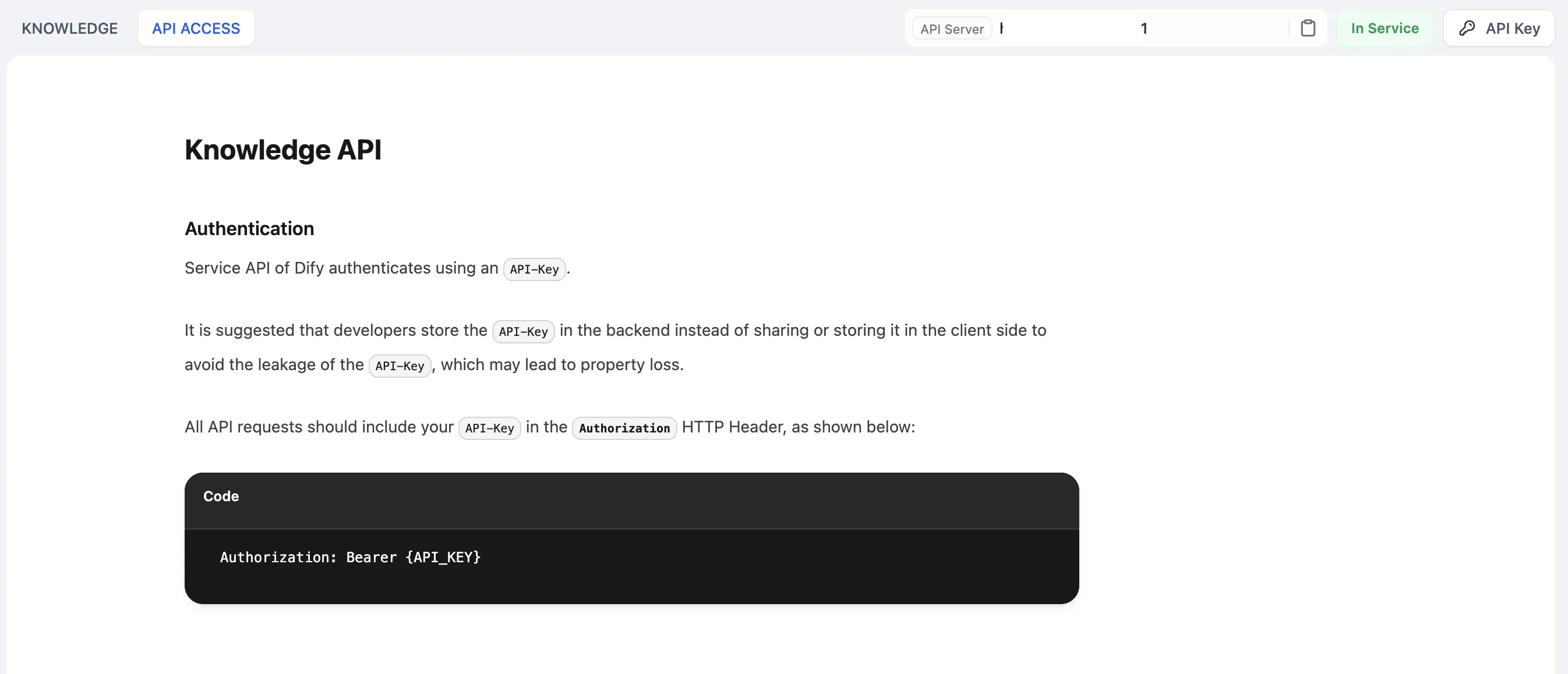
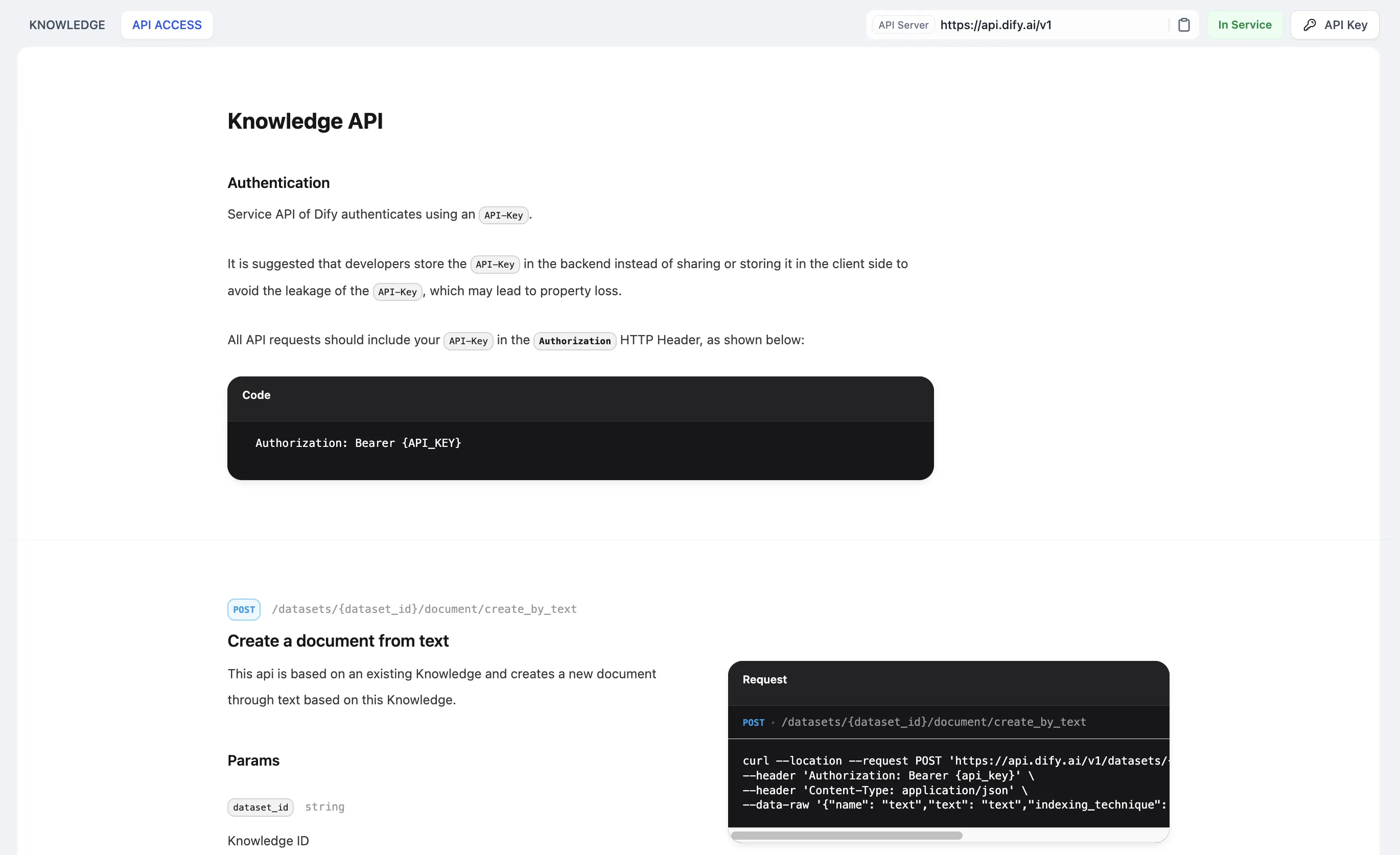
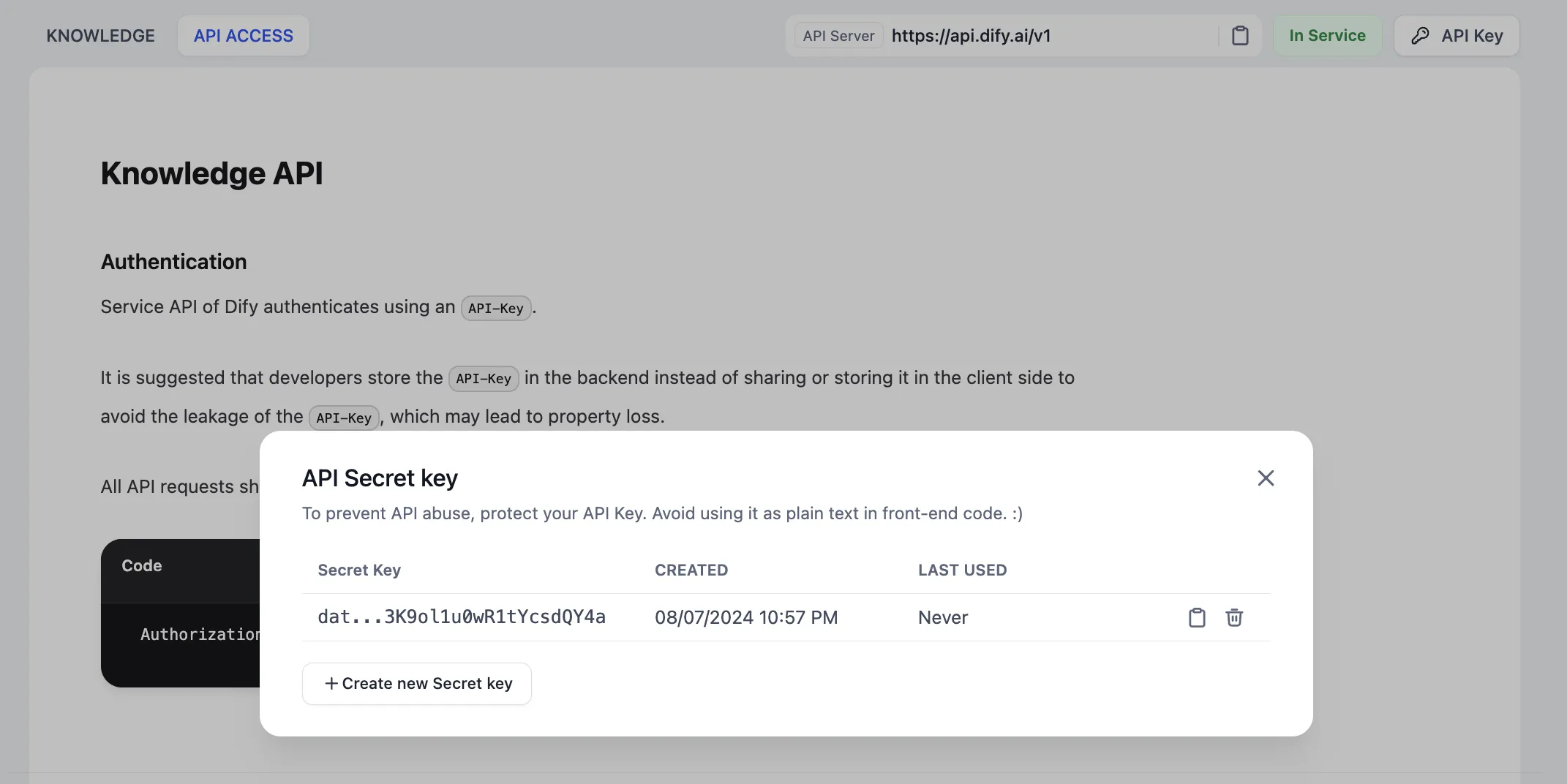
Knowledge base API management
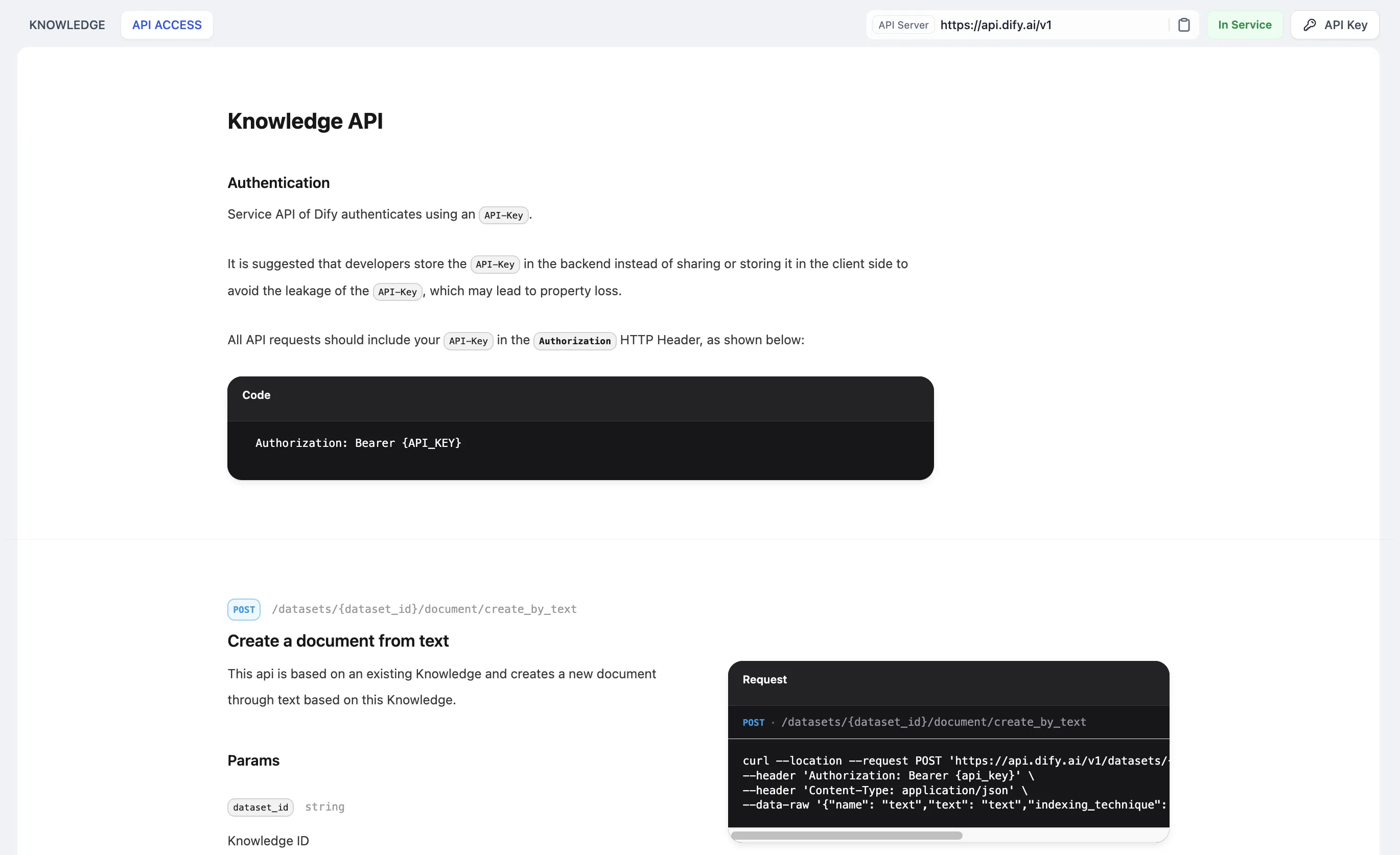
Knowledge base API management

Knowledge API Document
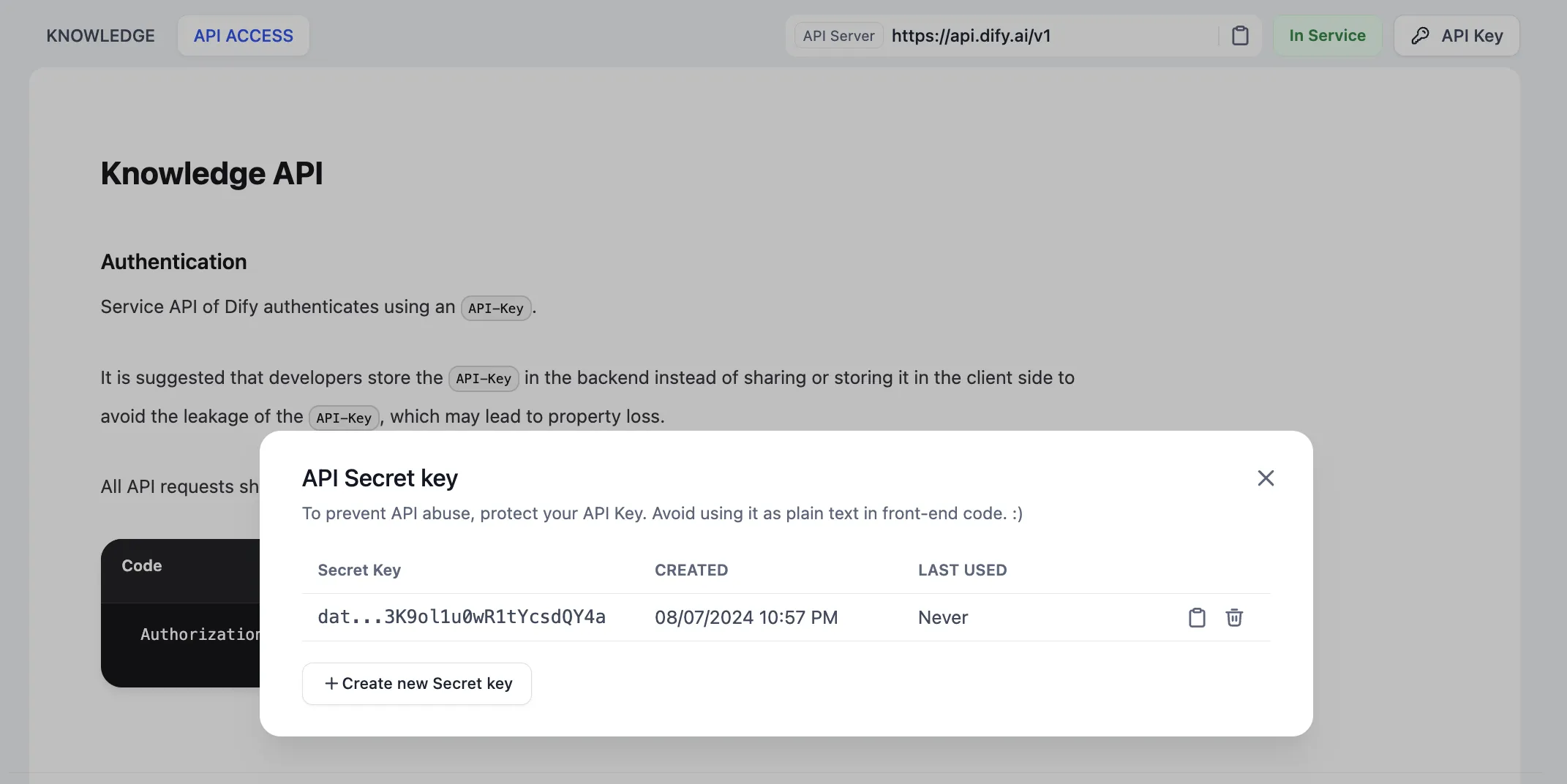
Knowledge API Document

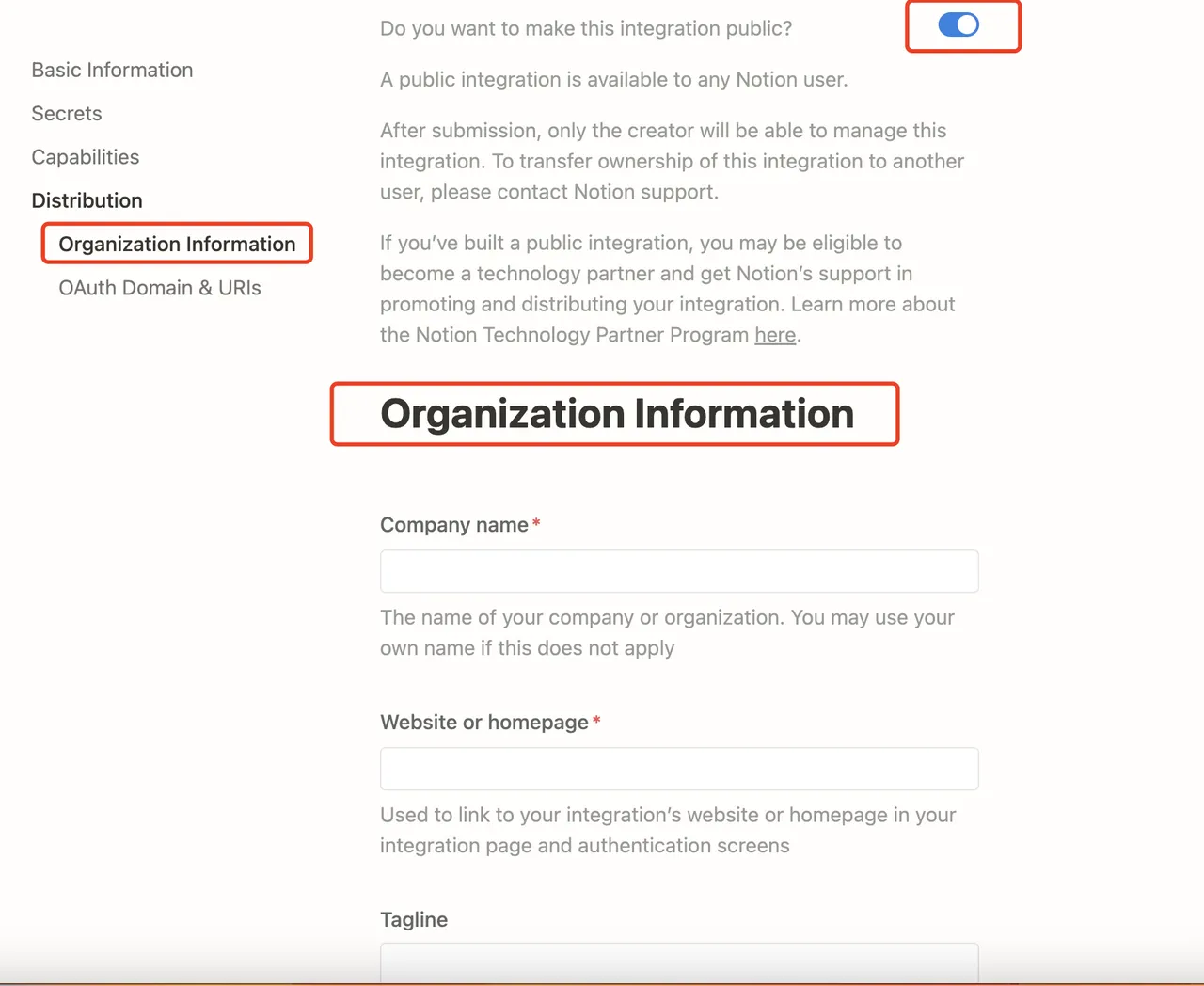
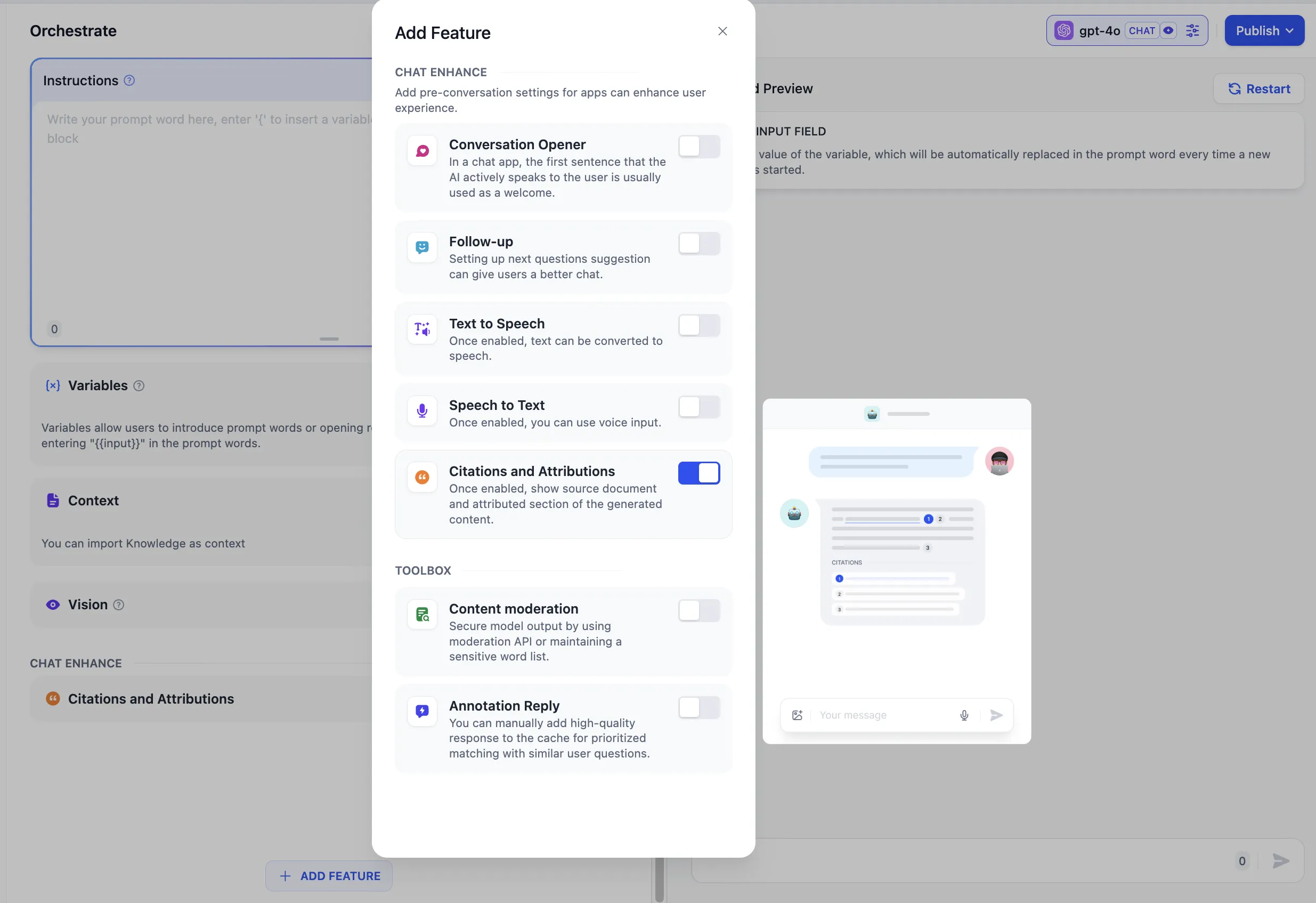
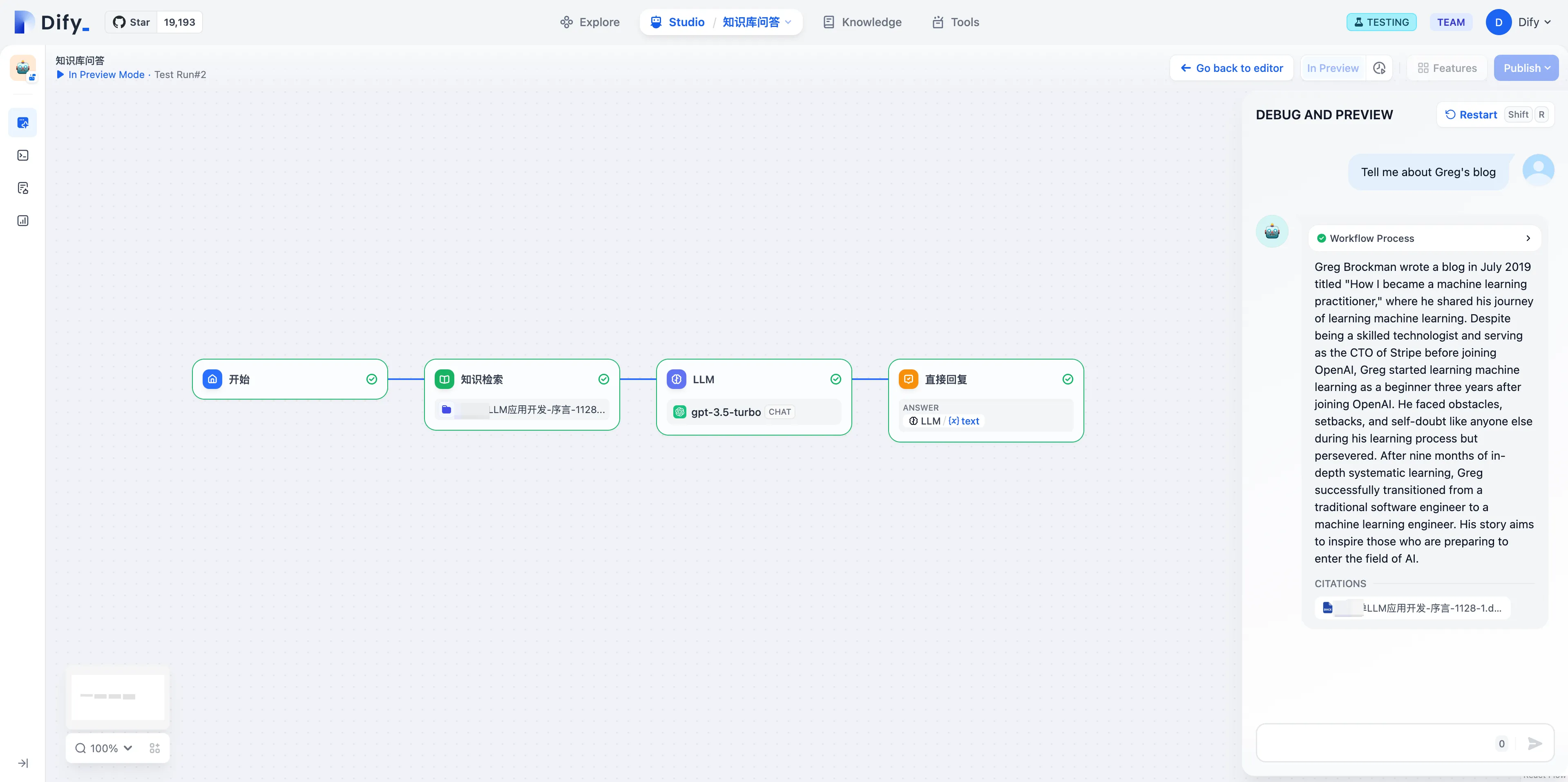
Enable citation and attribution feature
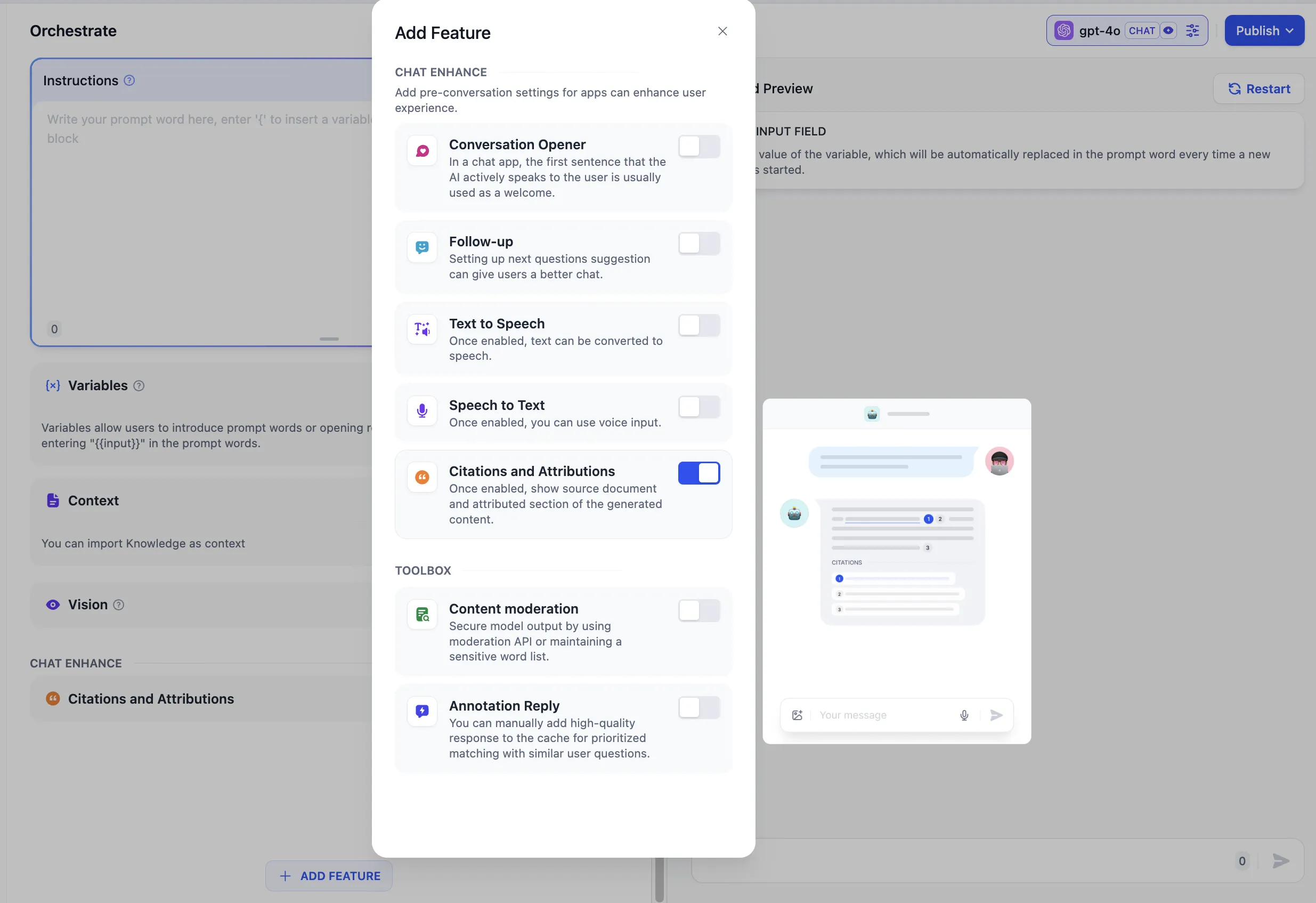
Enable citation and attribution feature

View citation information in response content
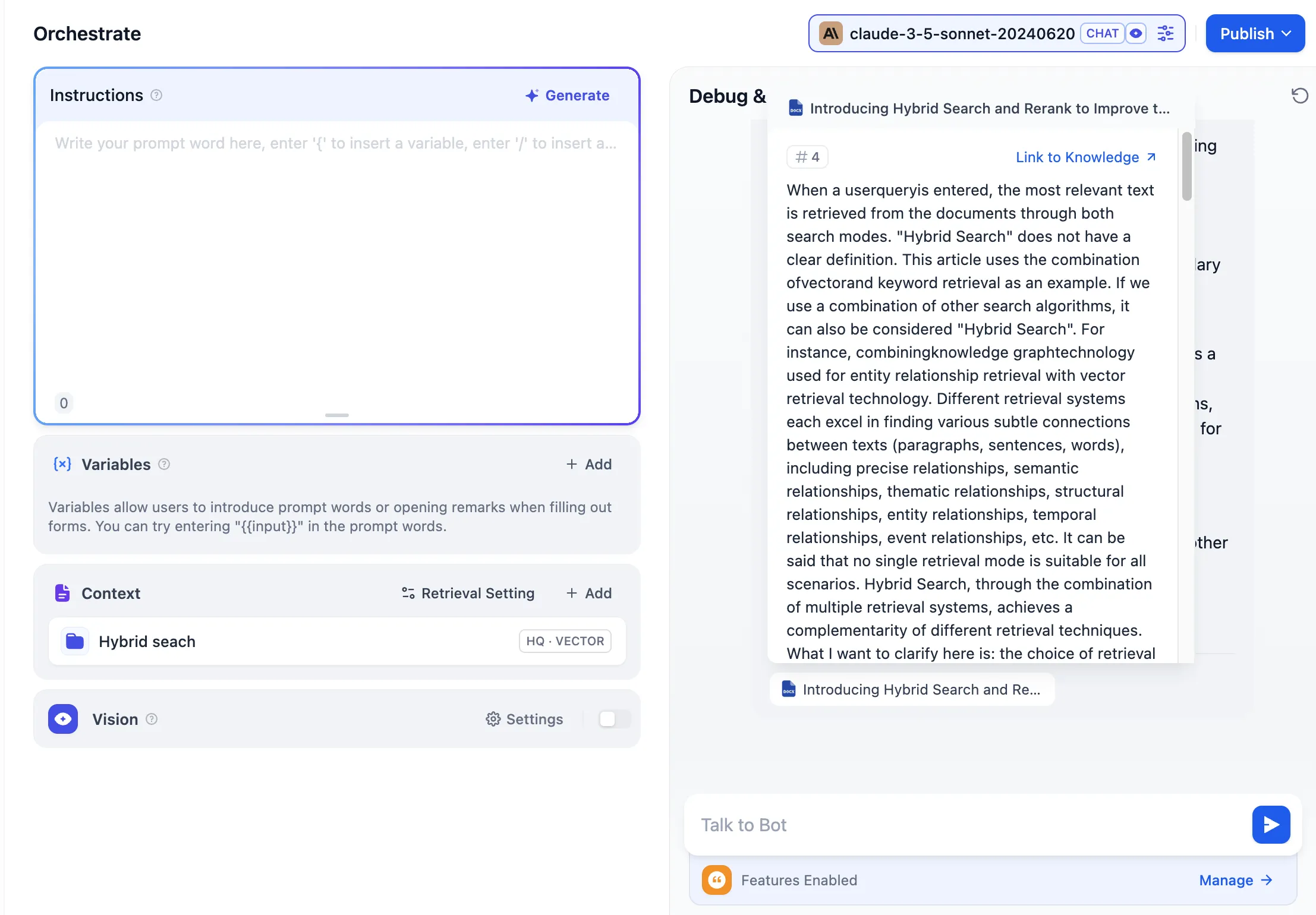
View citation information in response content
.png)
Edit App Info
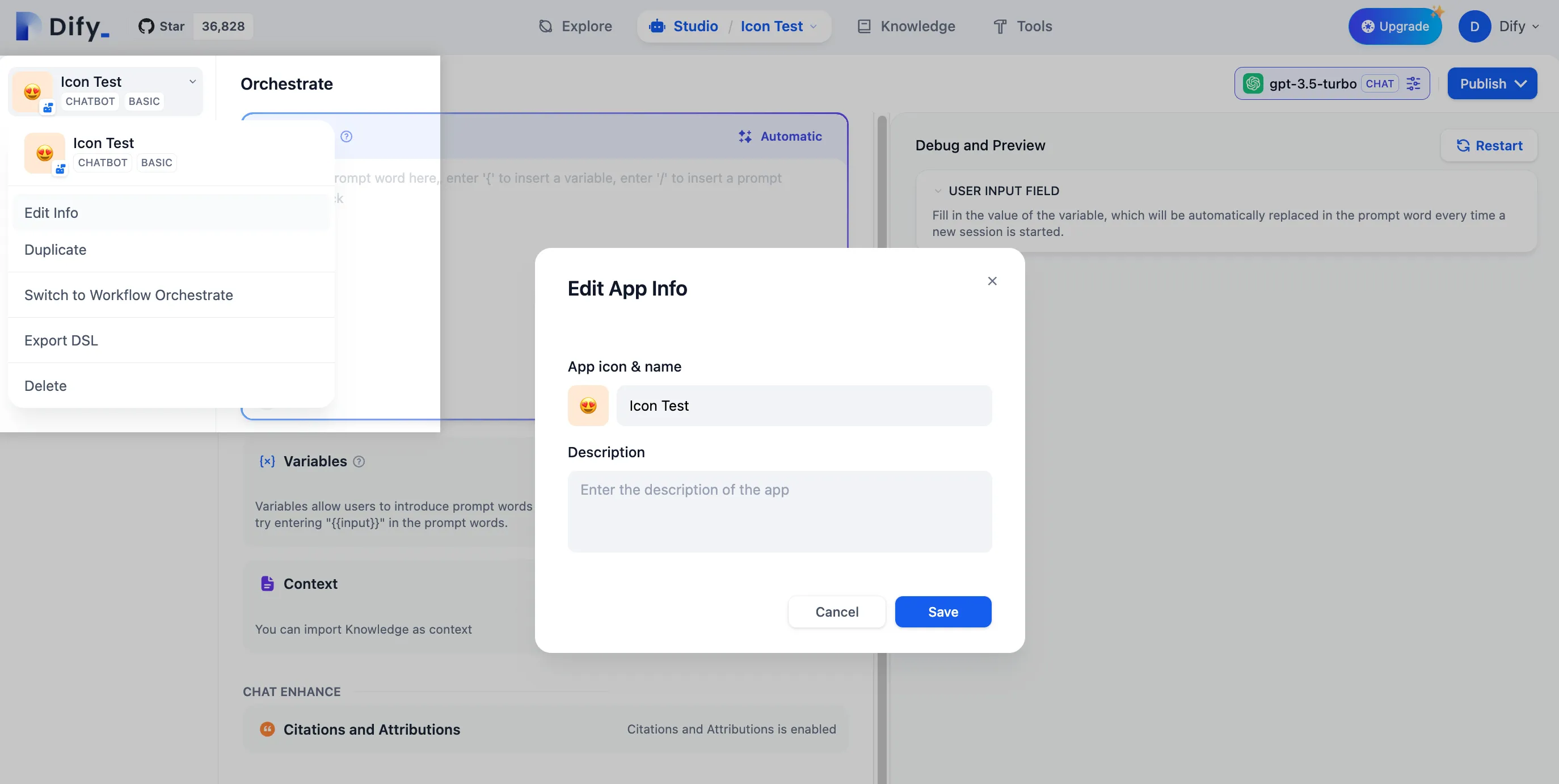
Edit App Info
.png)
 (3).png)

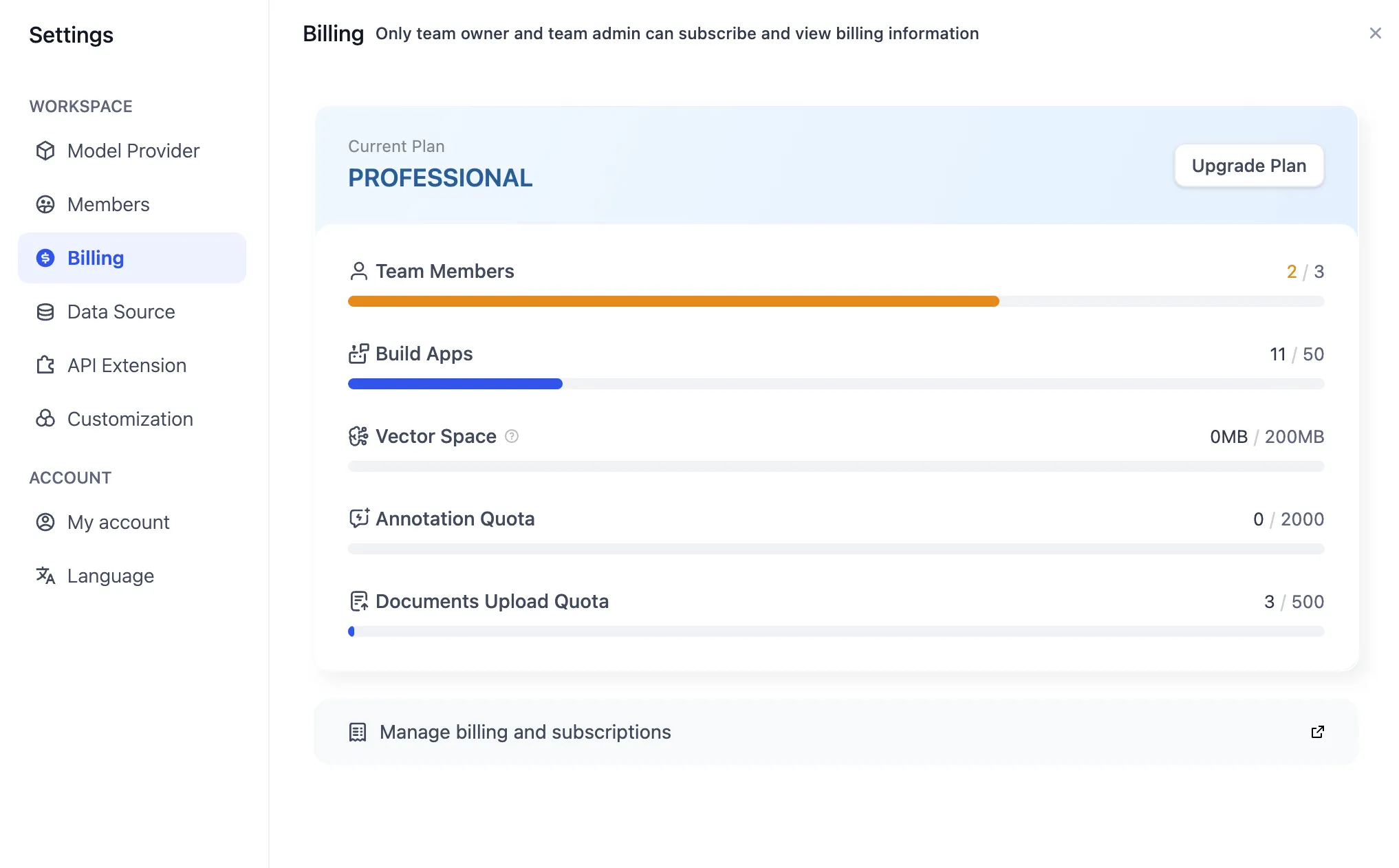
Team billing management
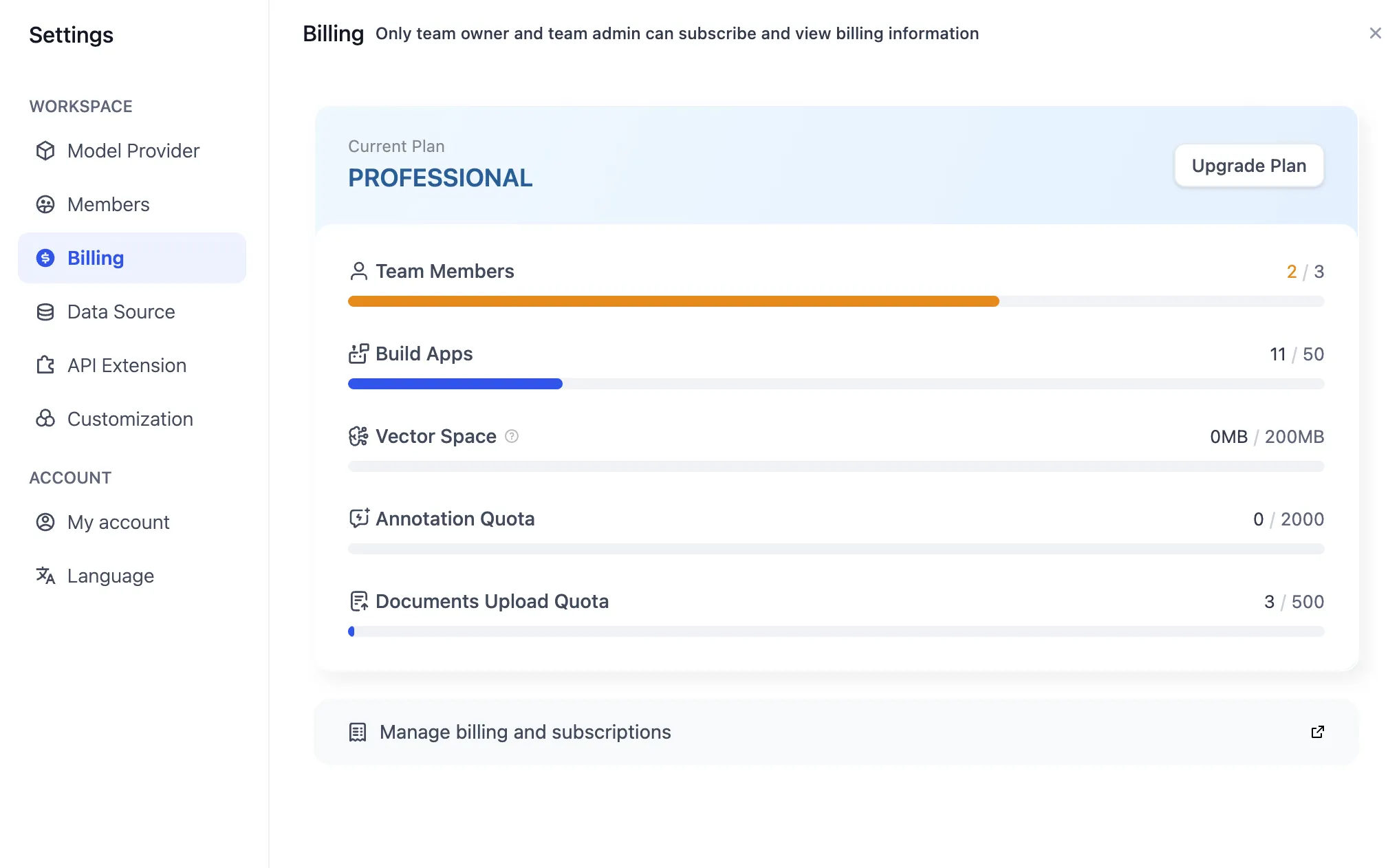
Team billing management

Changing the paid plan
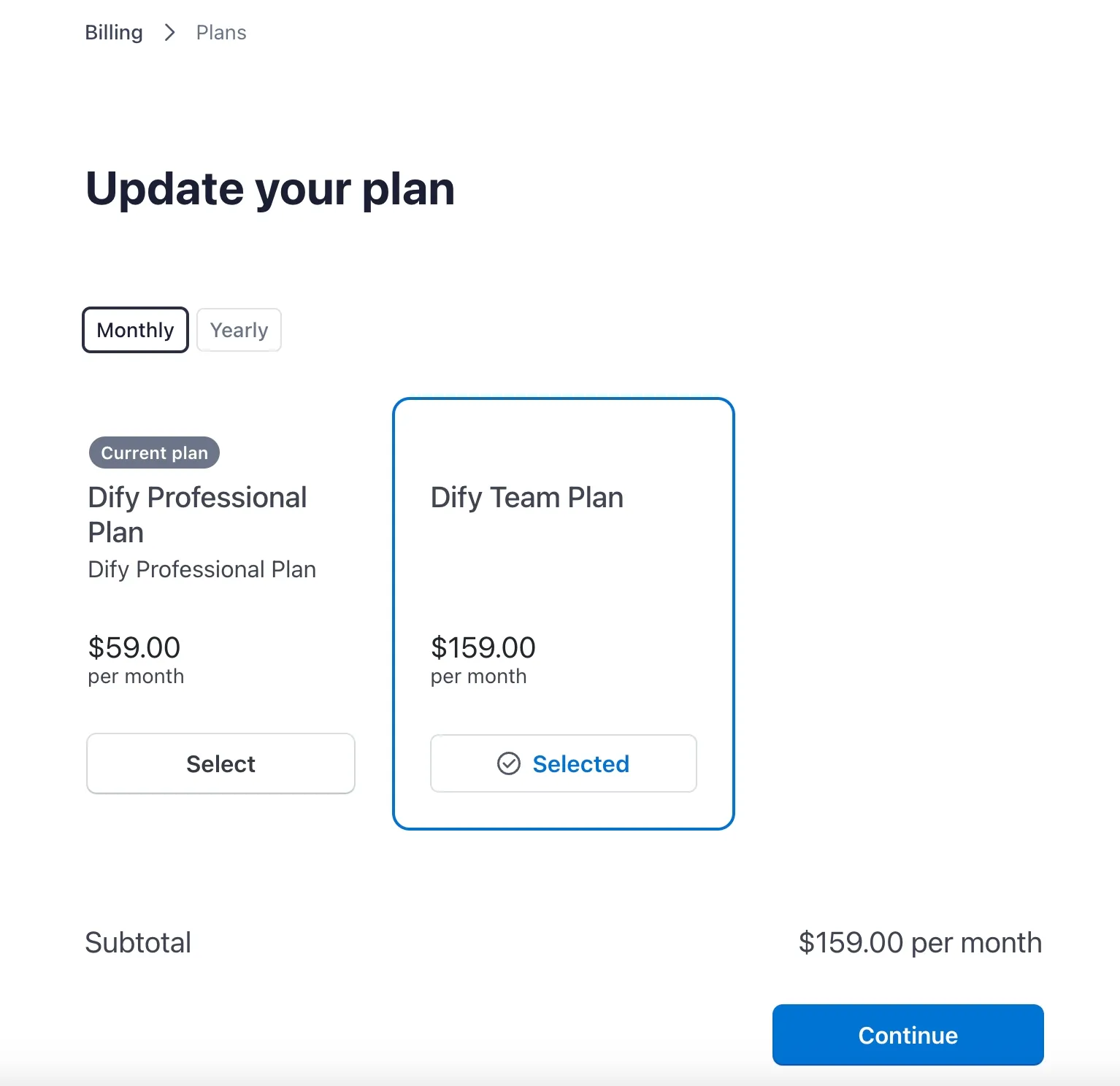
Changing the paid plan

Assigning permissions to team members
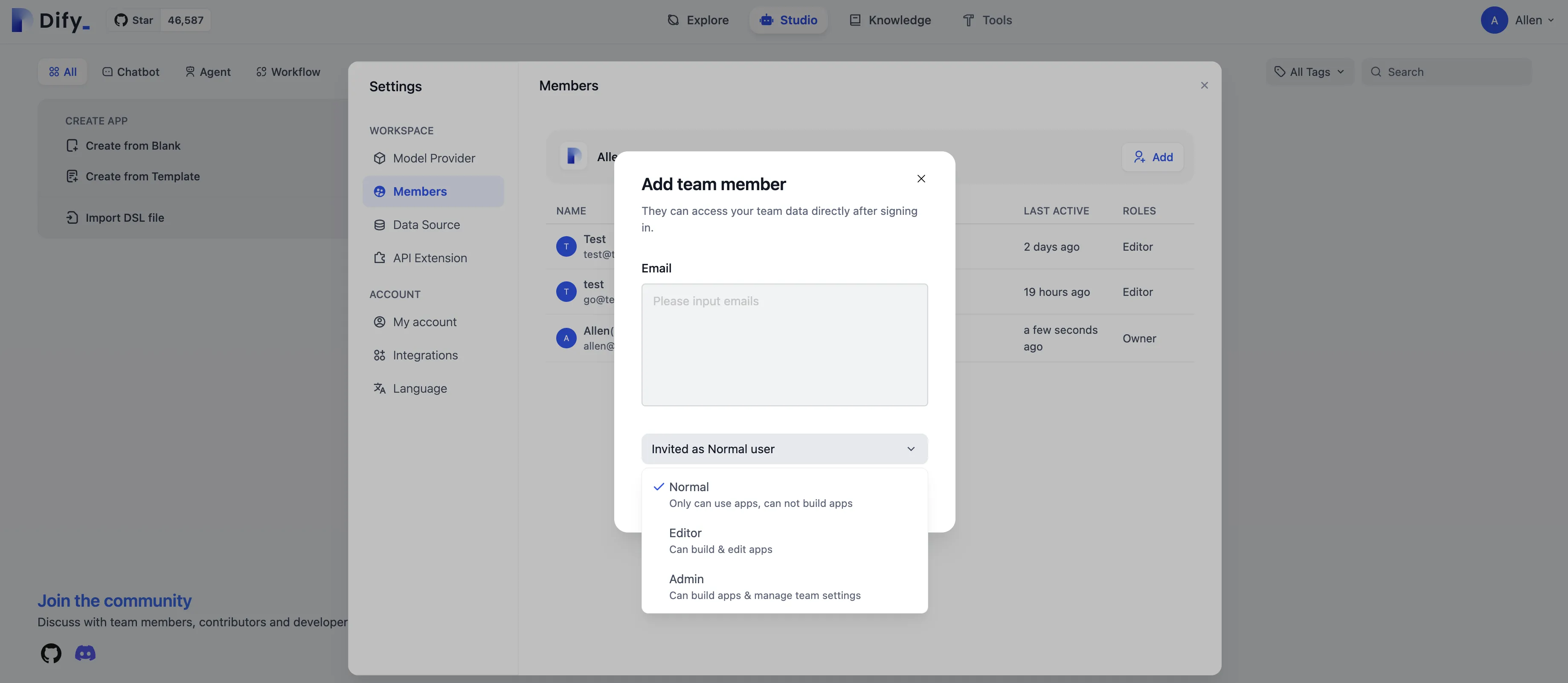
Assigning permissions to team members

Removing a member
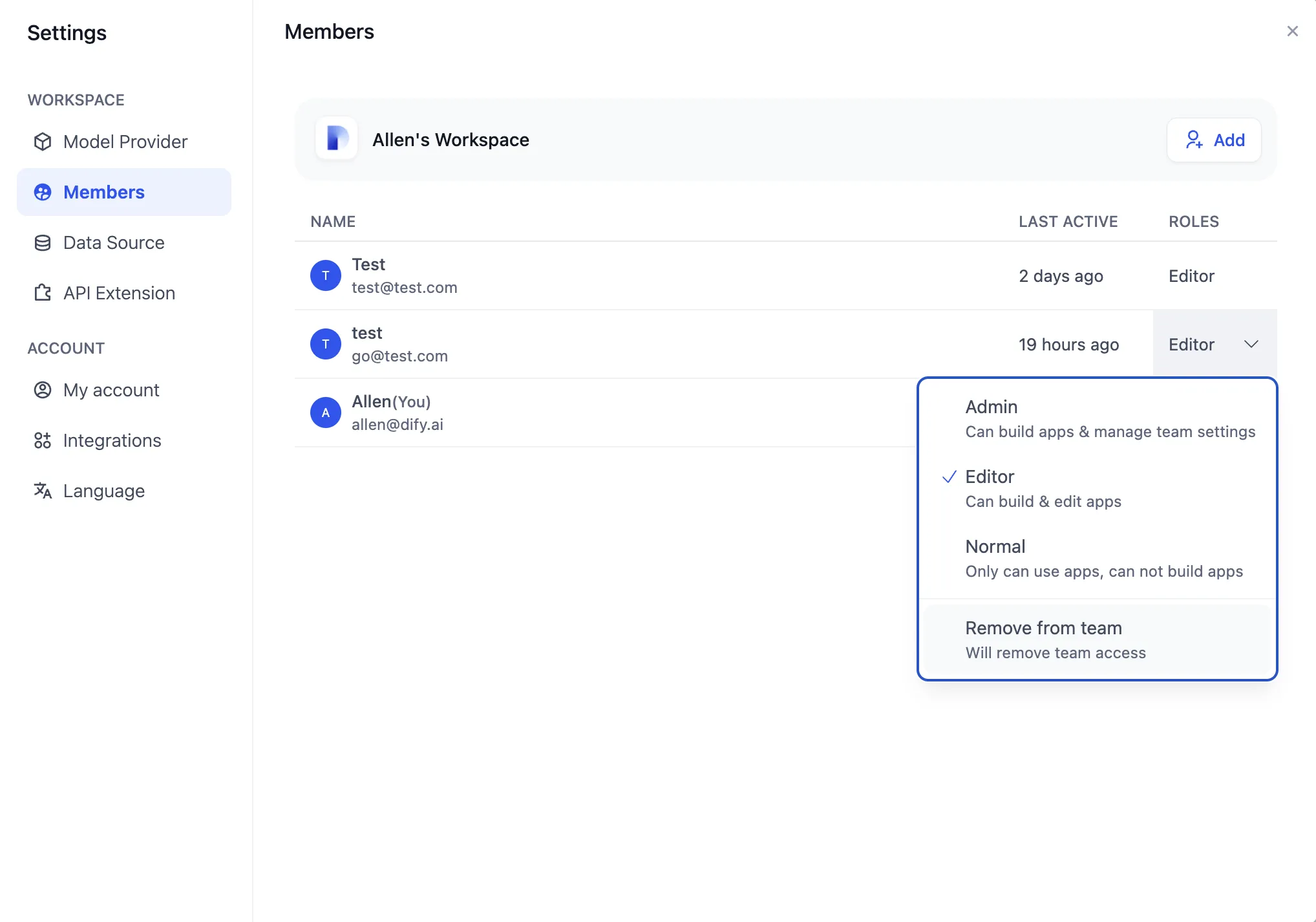
Removing a member
 (1).png)
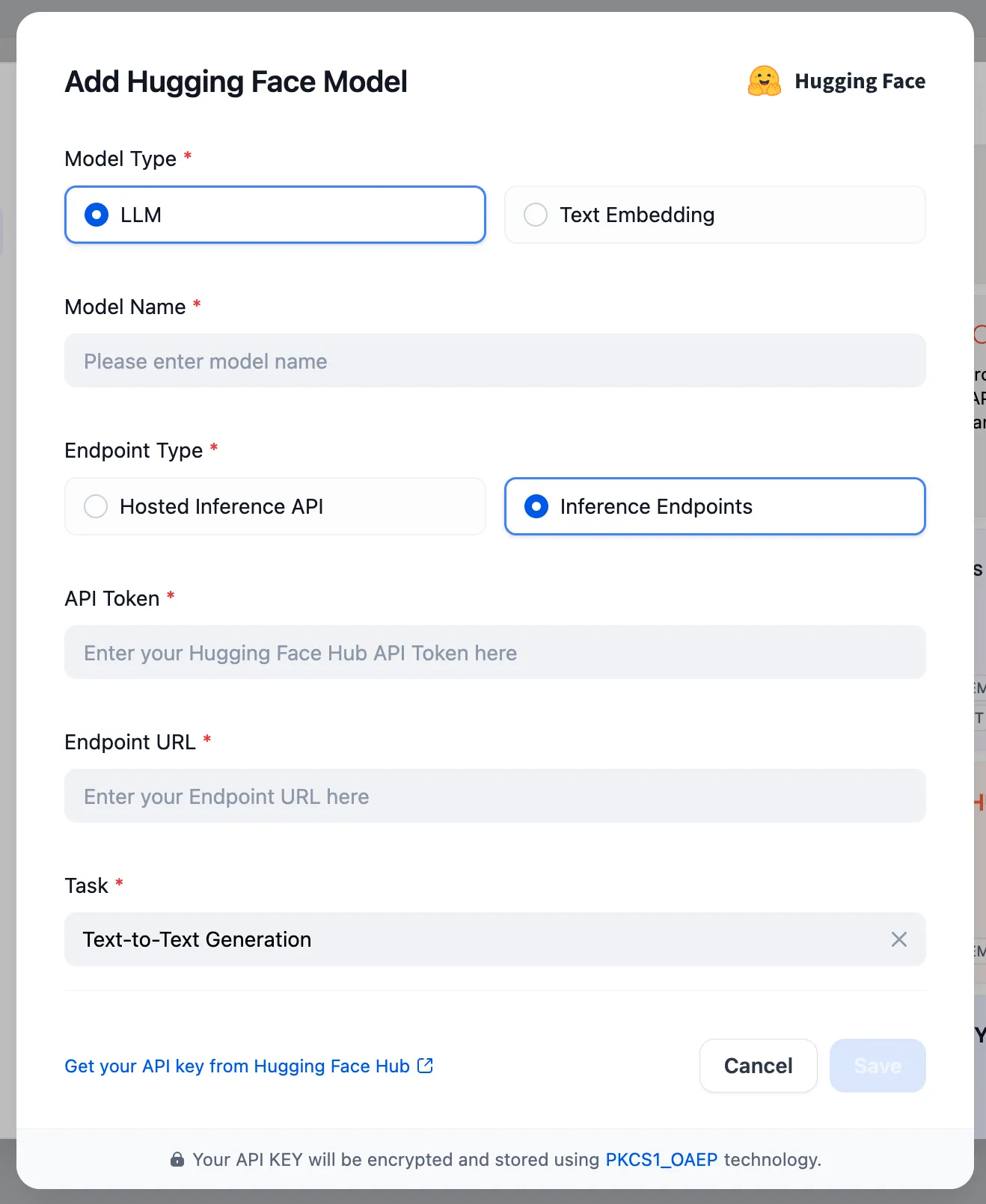
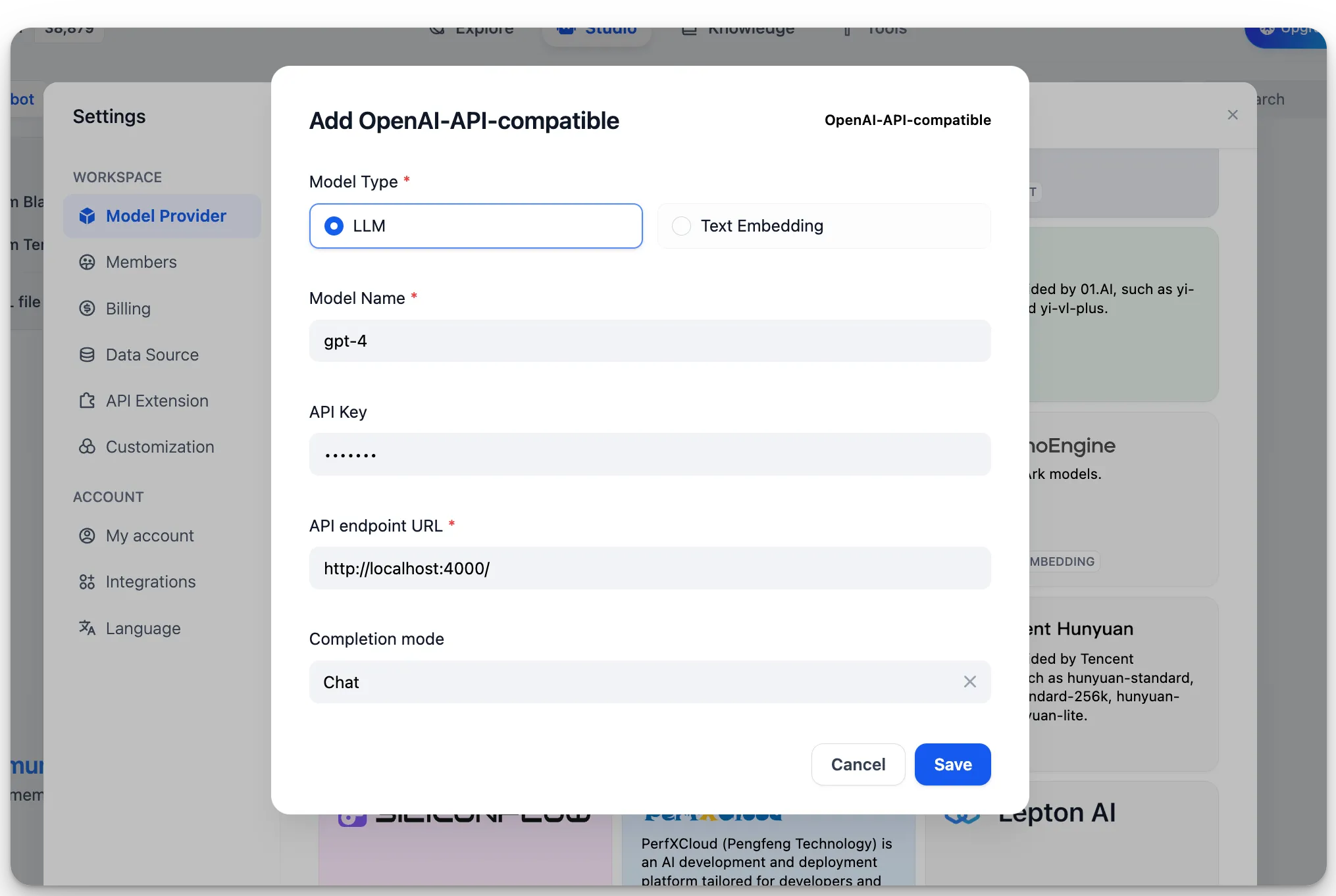
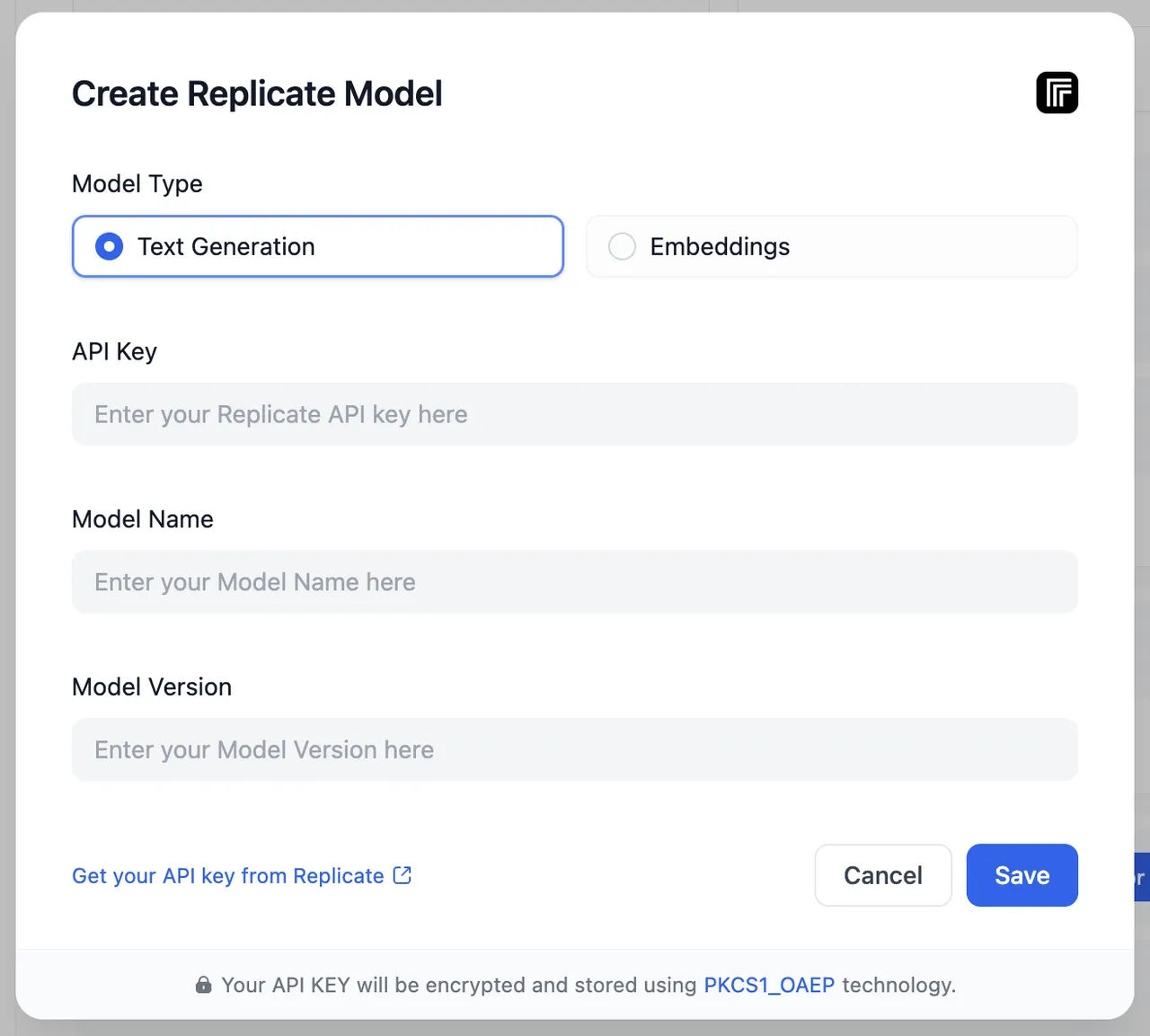
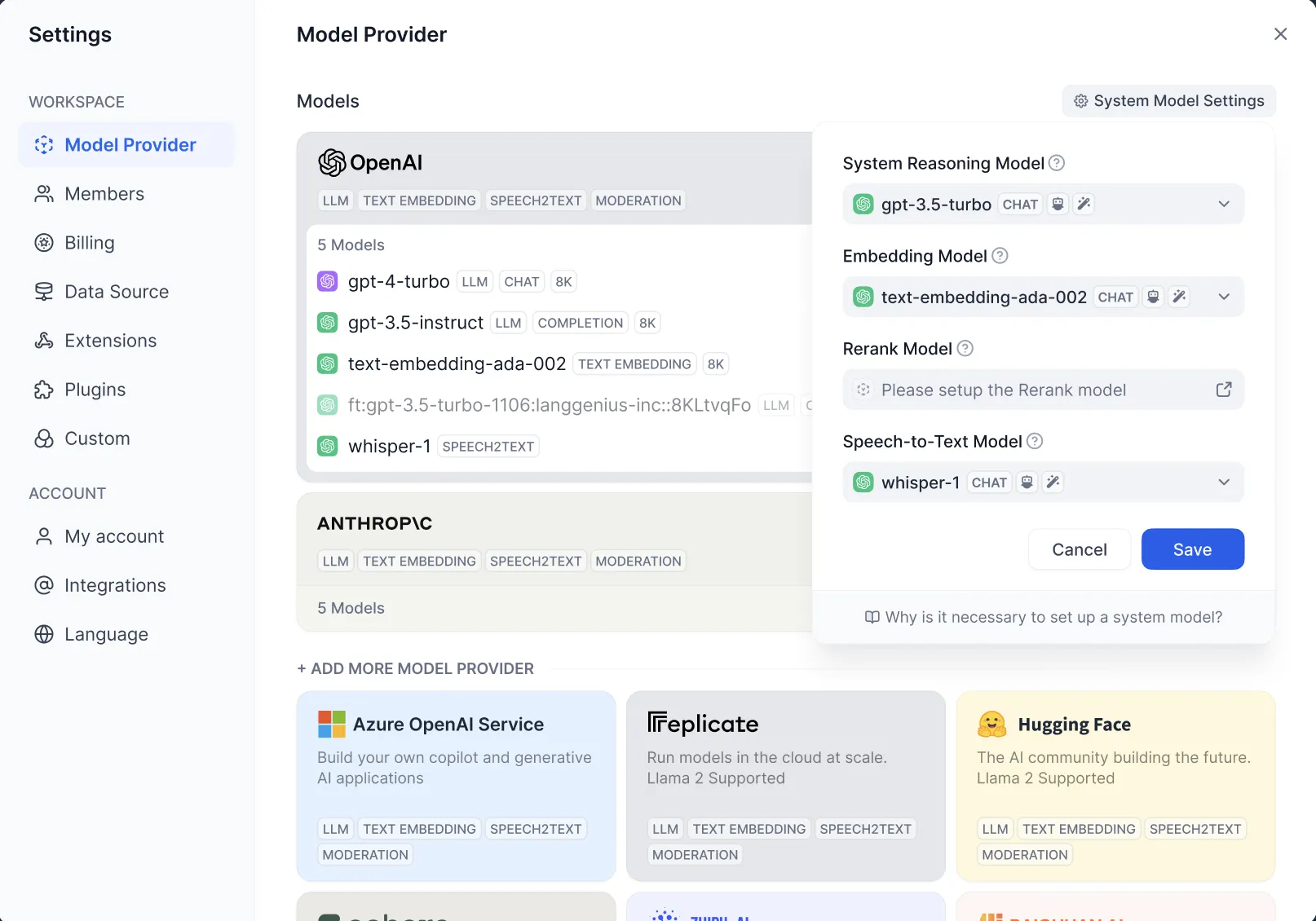
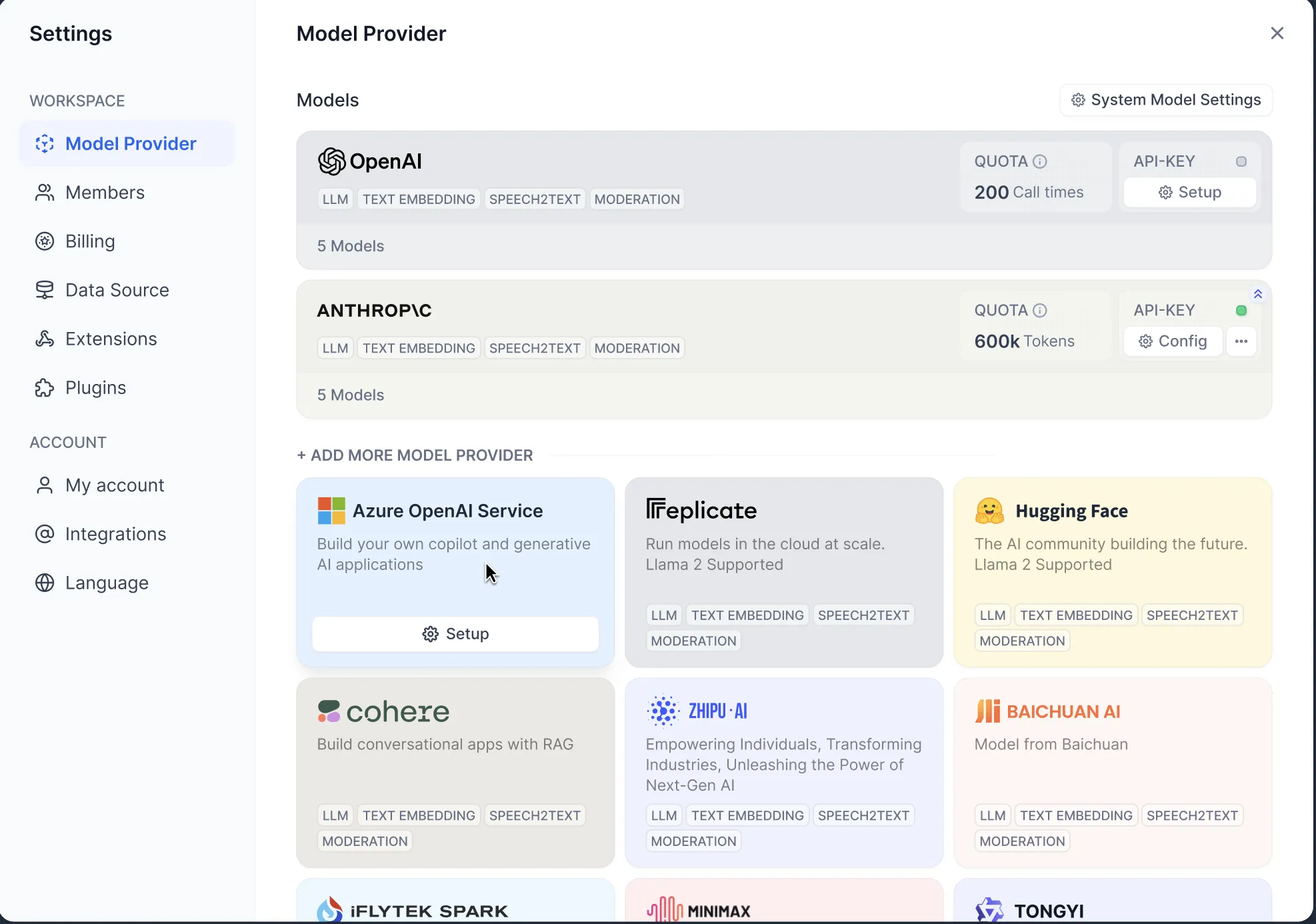
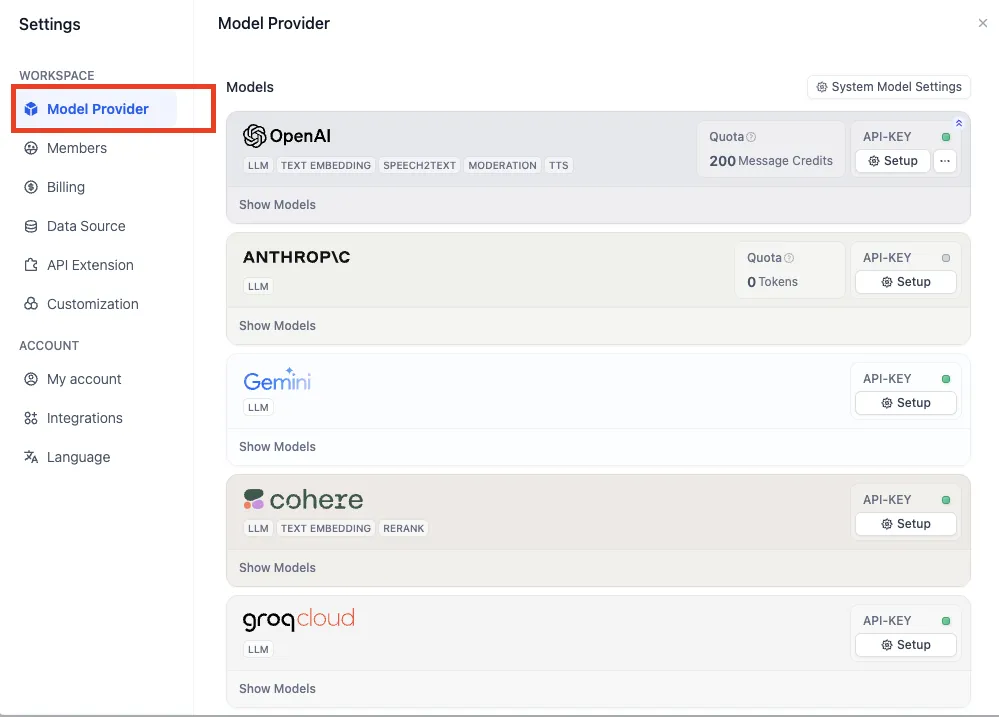
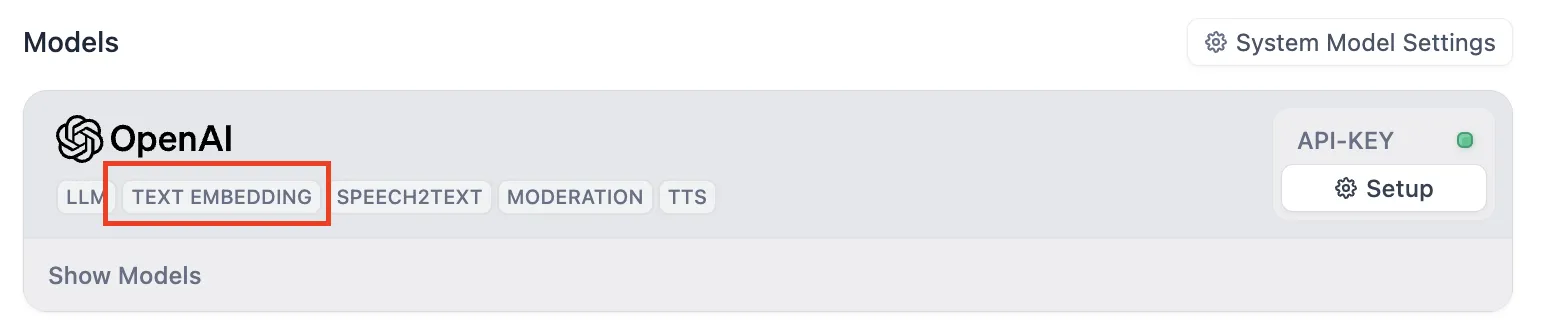
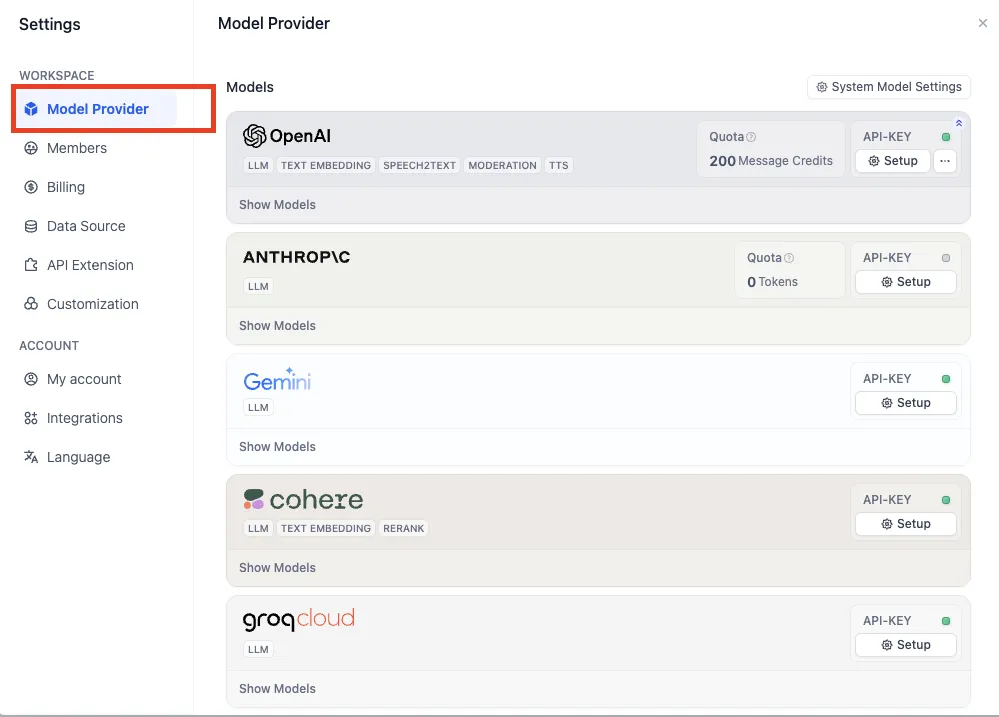
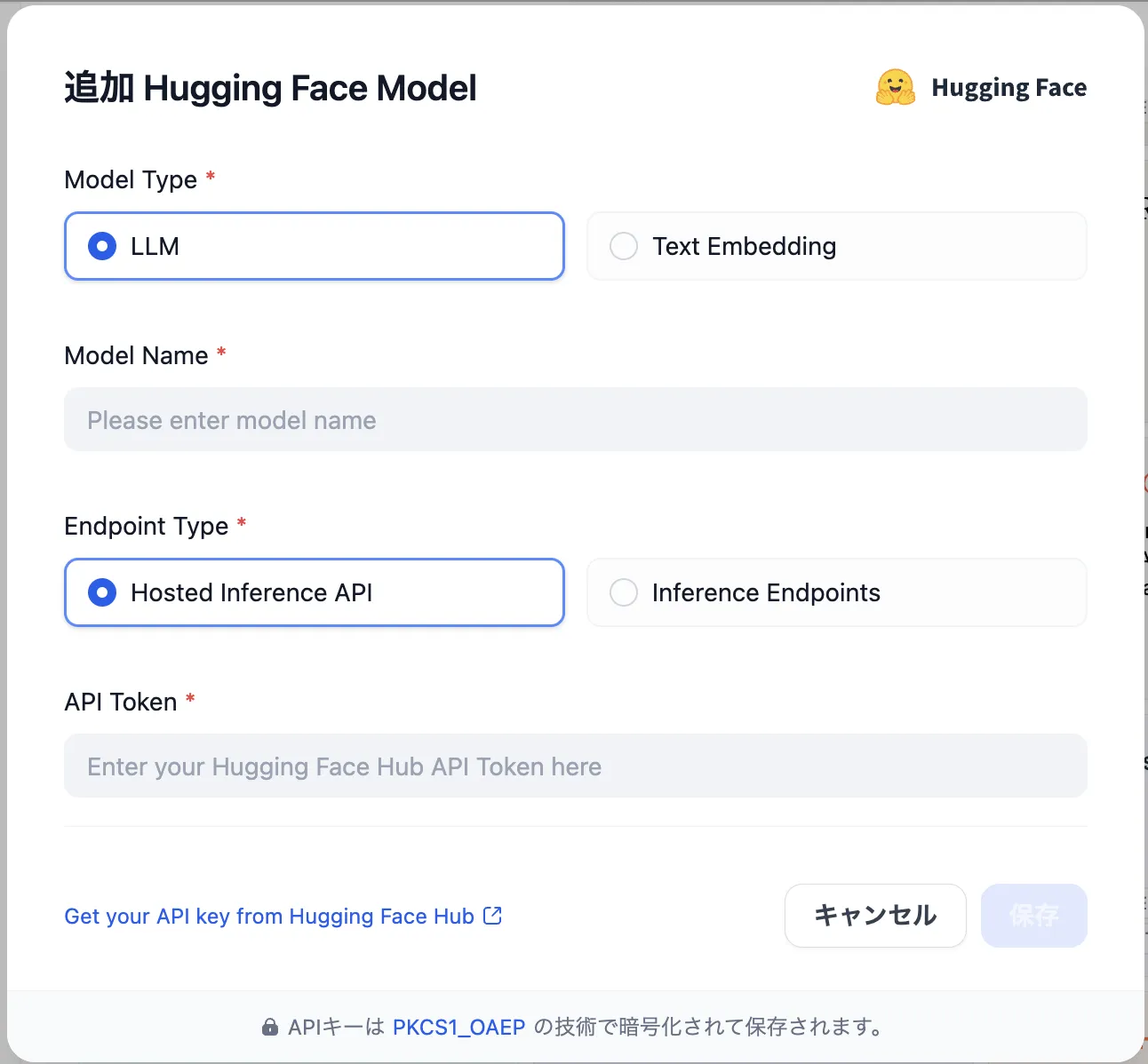
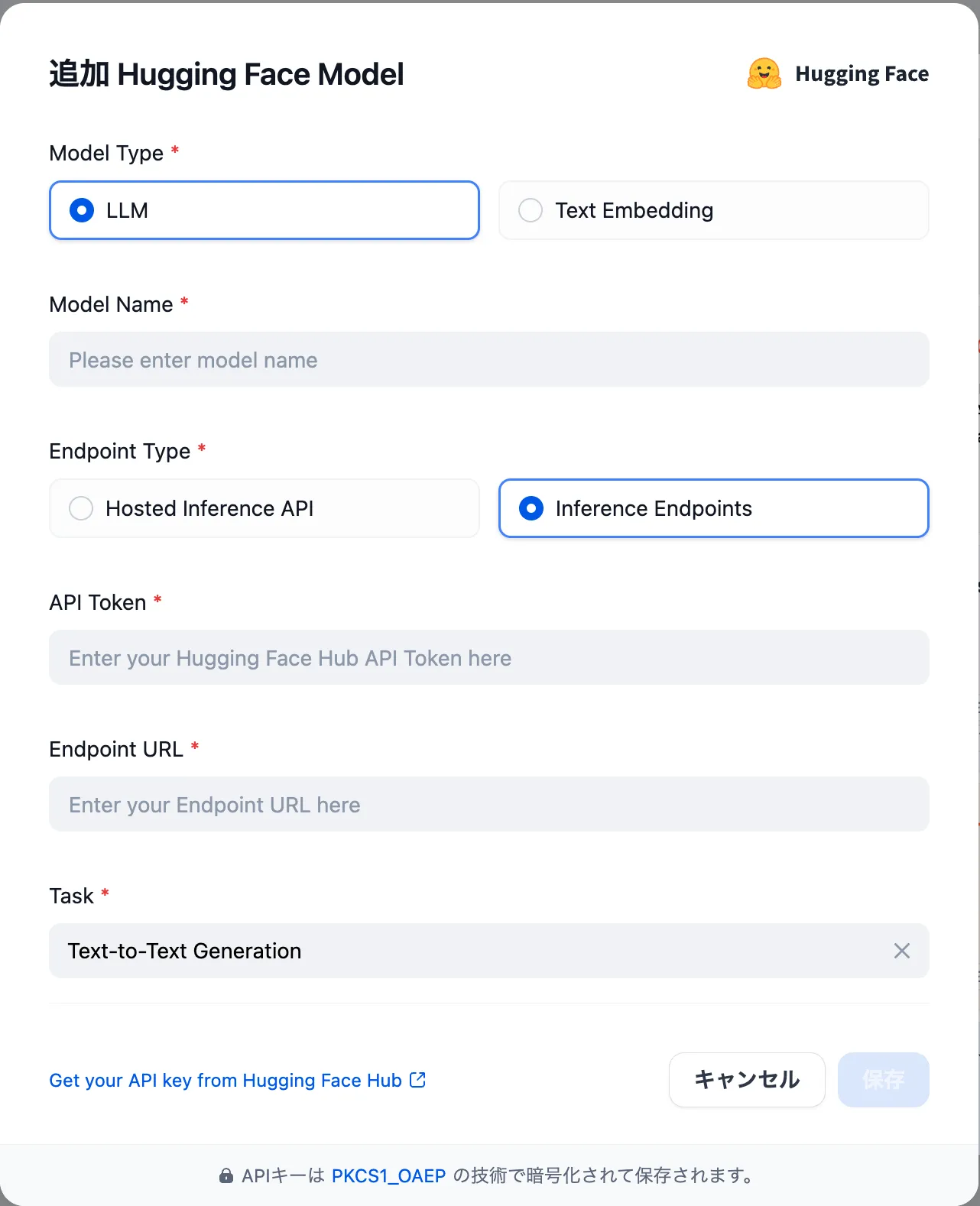
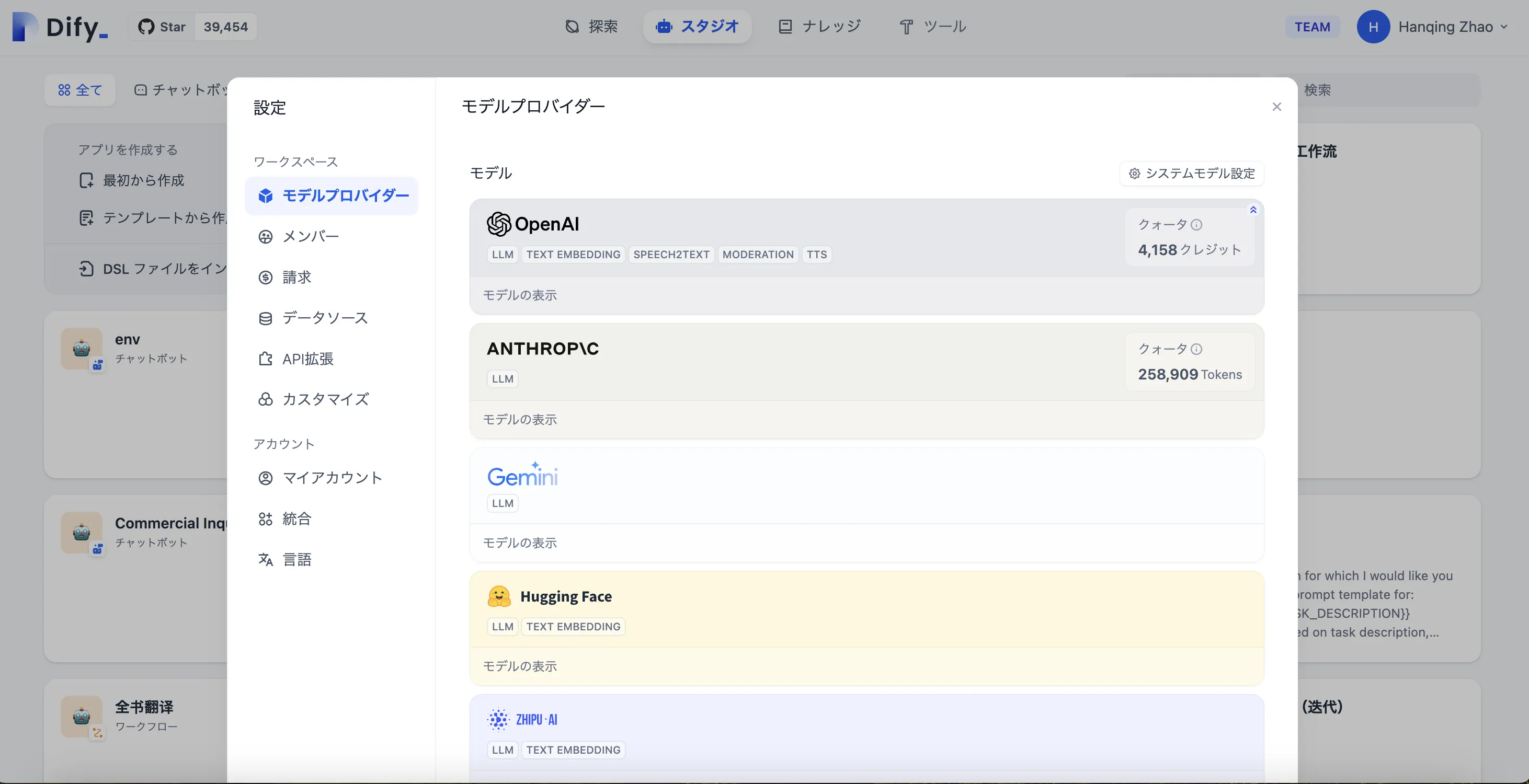
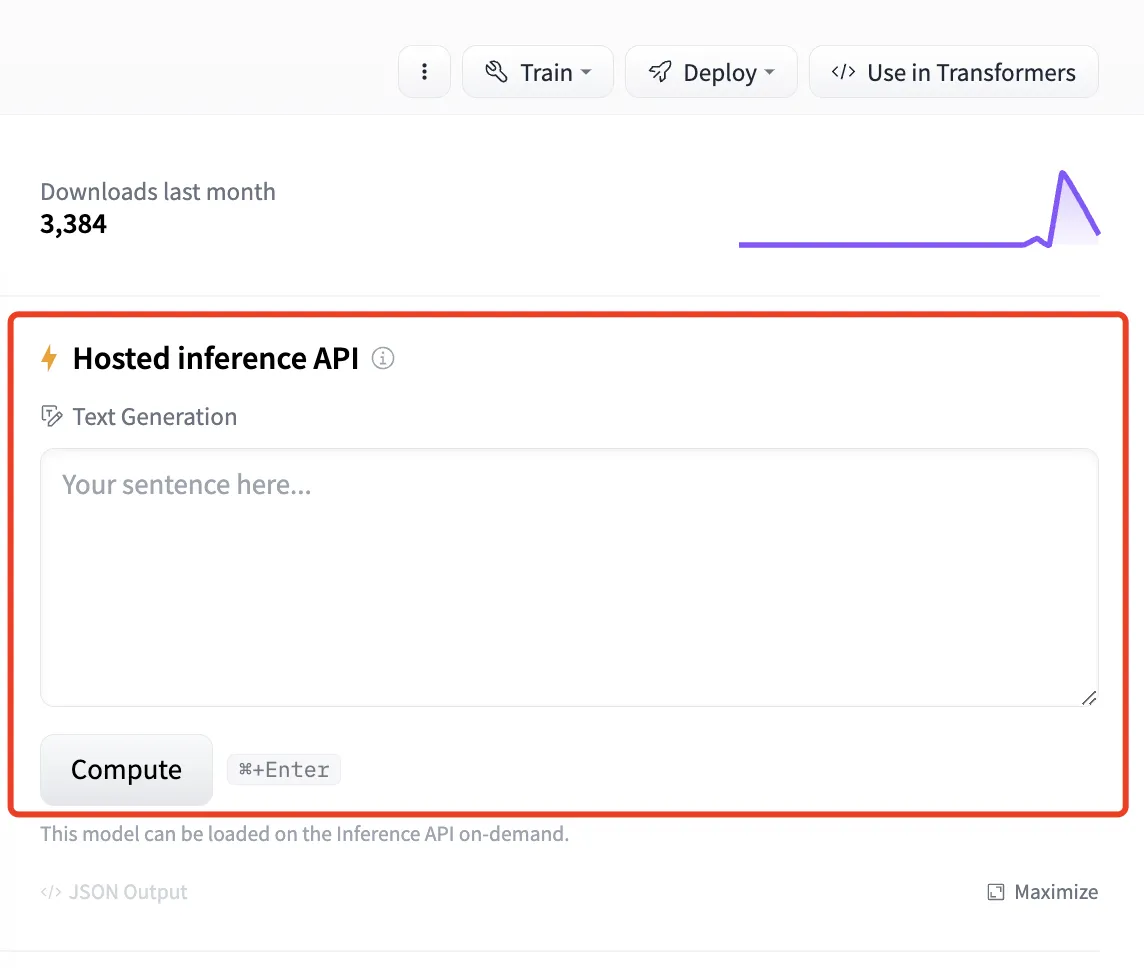
Settings - Model Provider
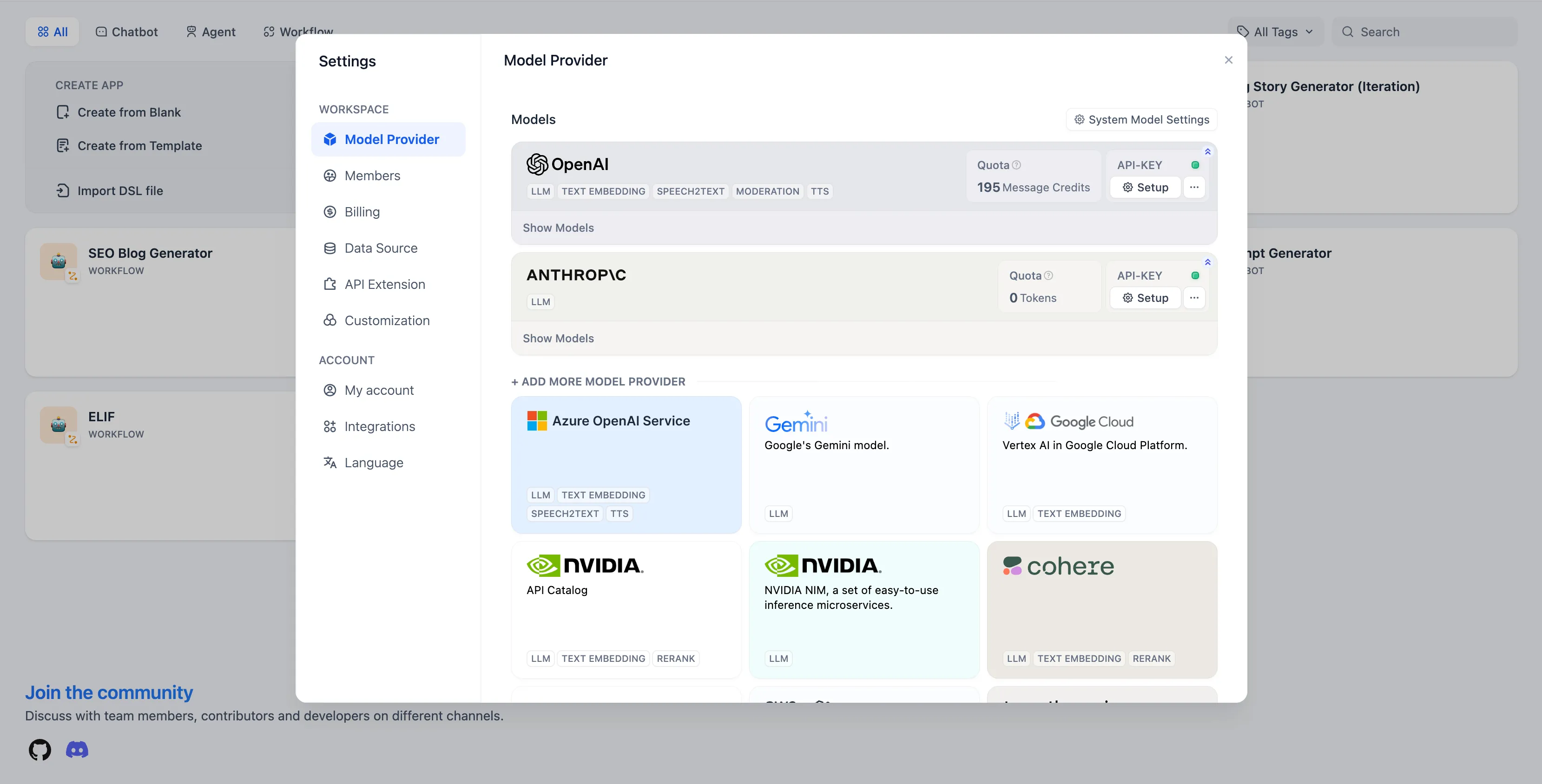
Settings - Model Provider
.png)
.png)
.png)

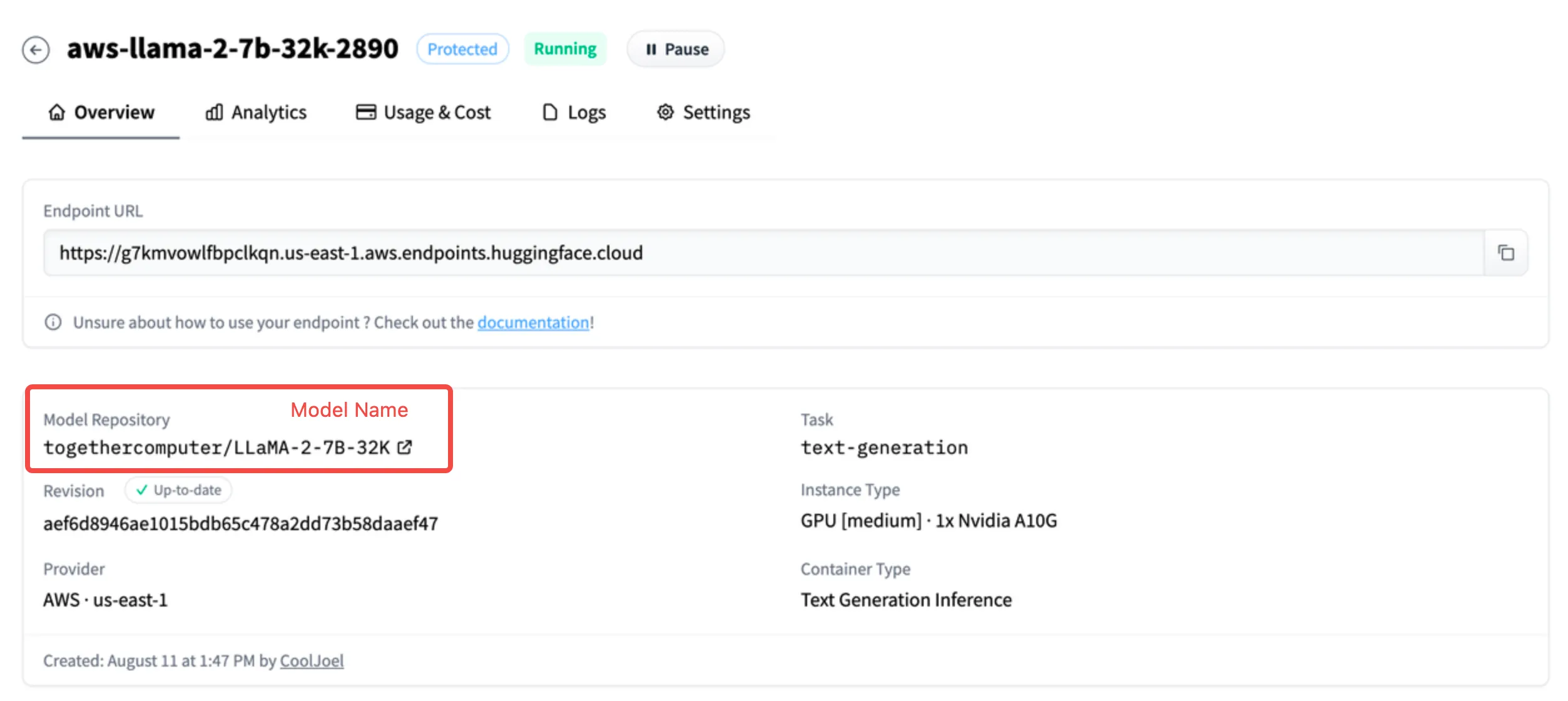
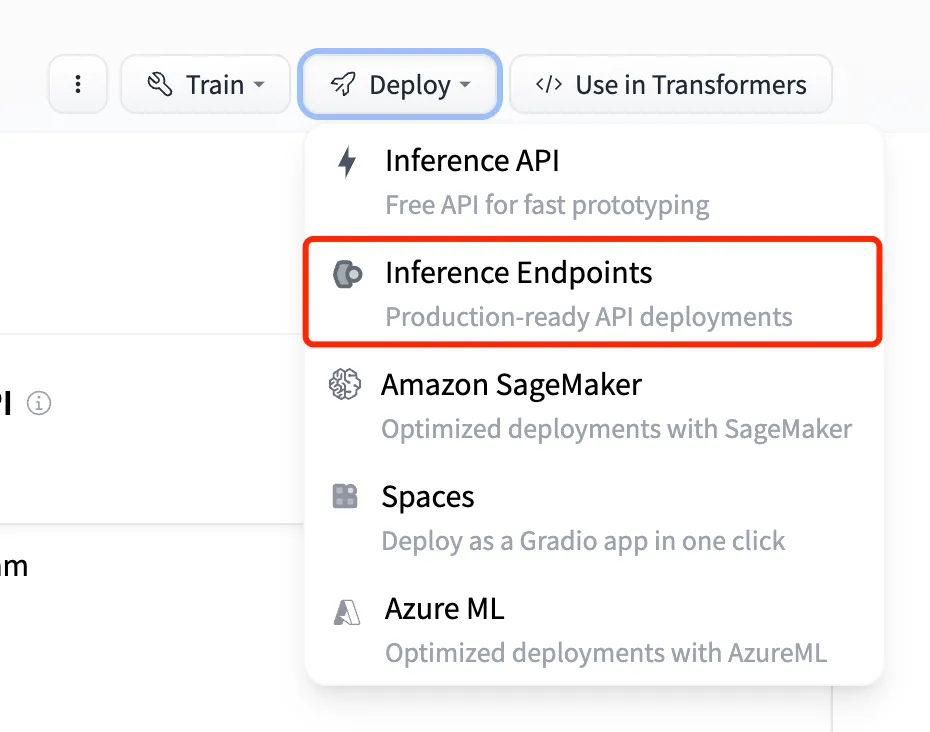
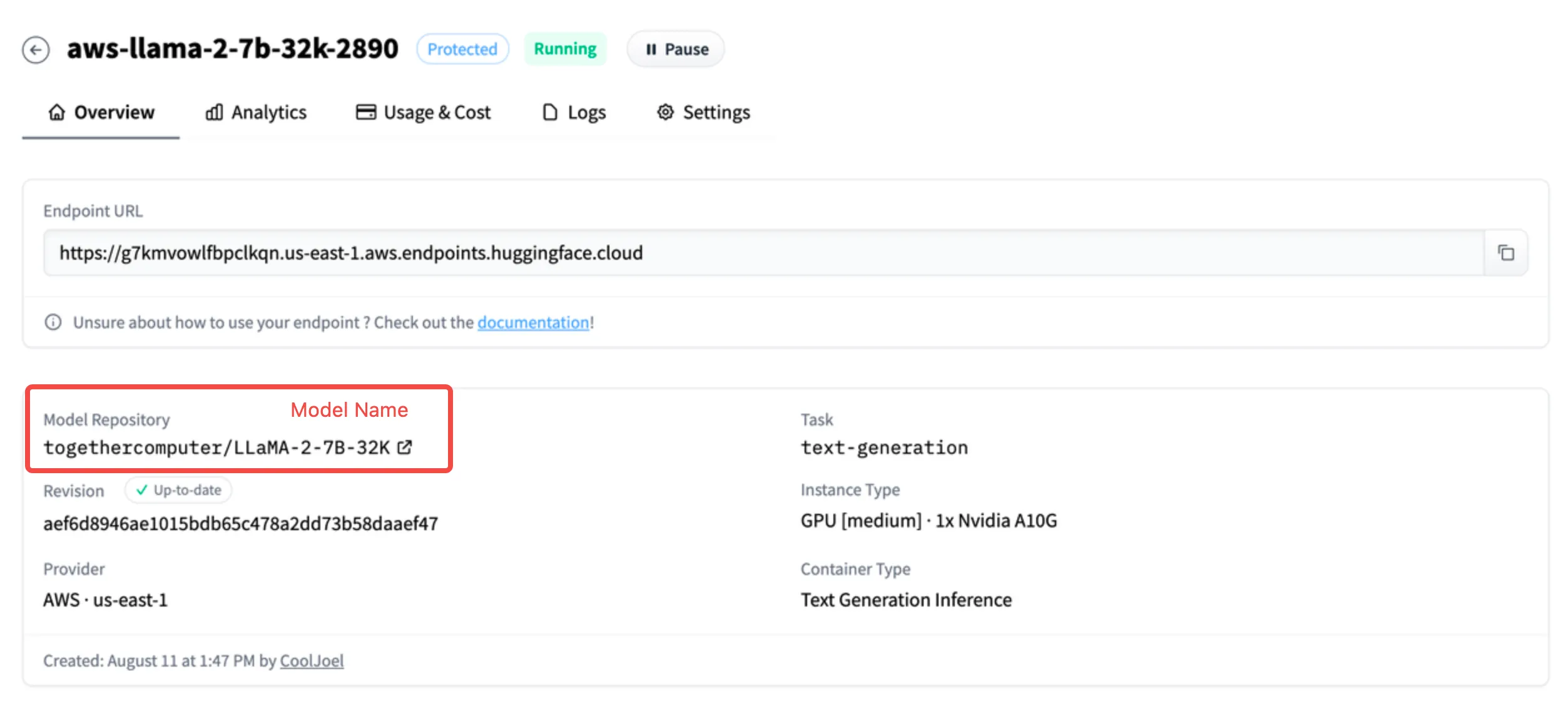
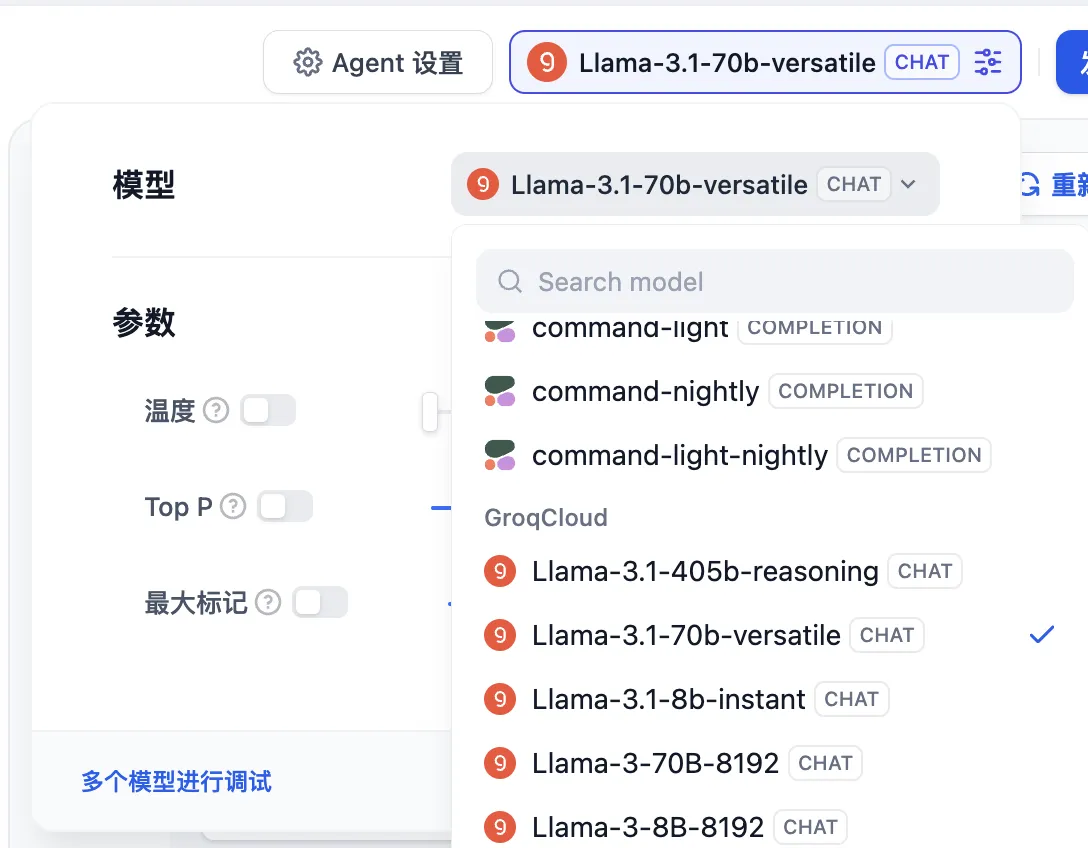
Model Load Balancing
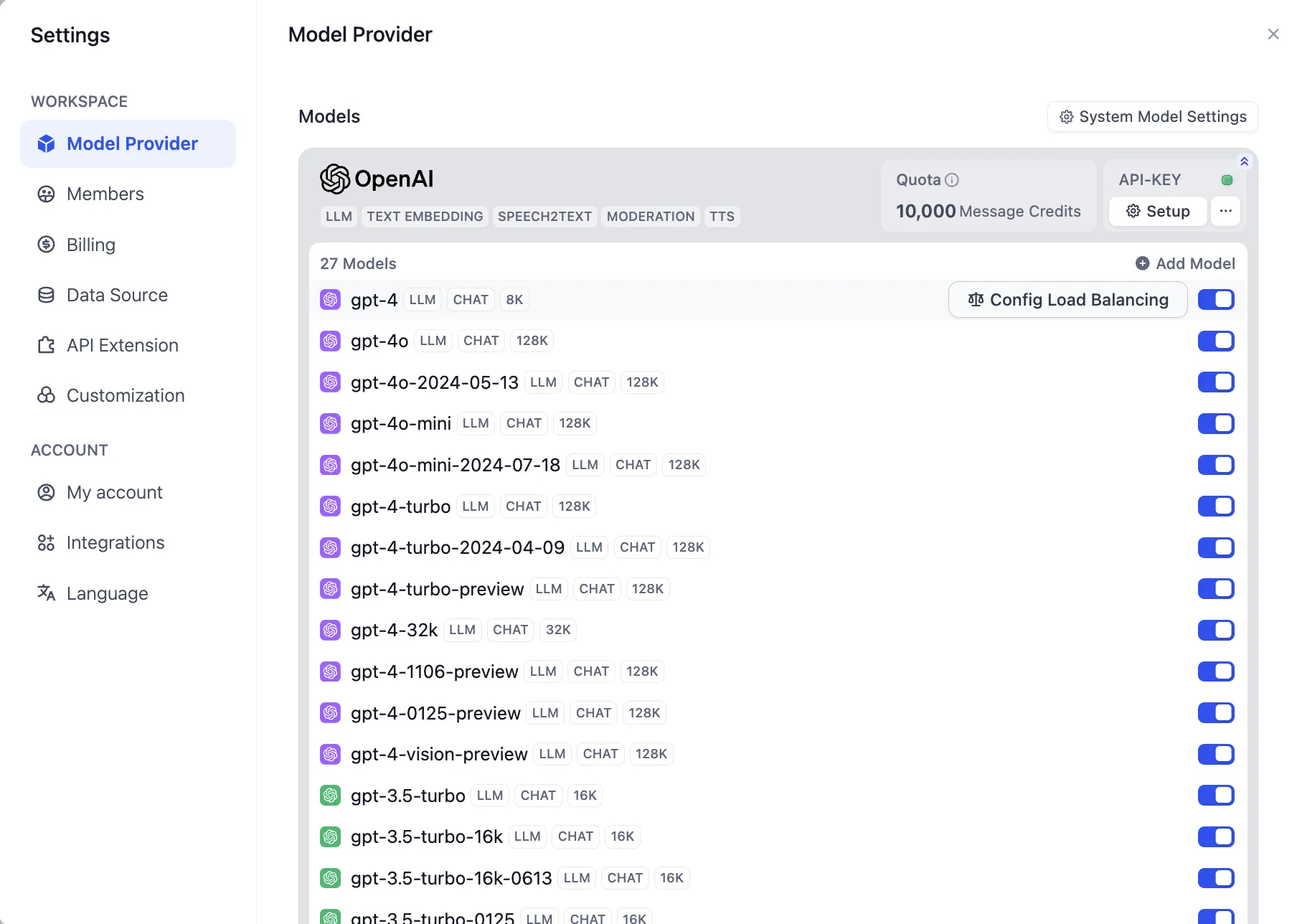
Model Load Balancing

Configuring Load Balancing
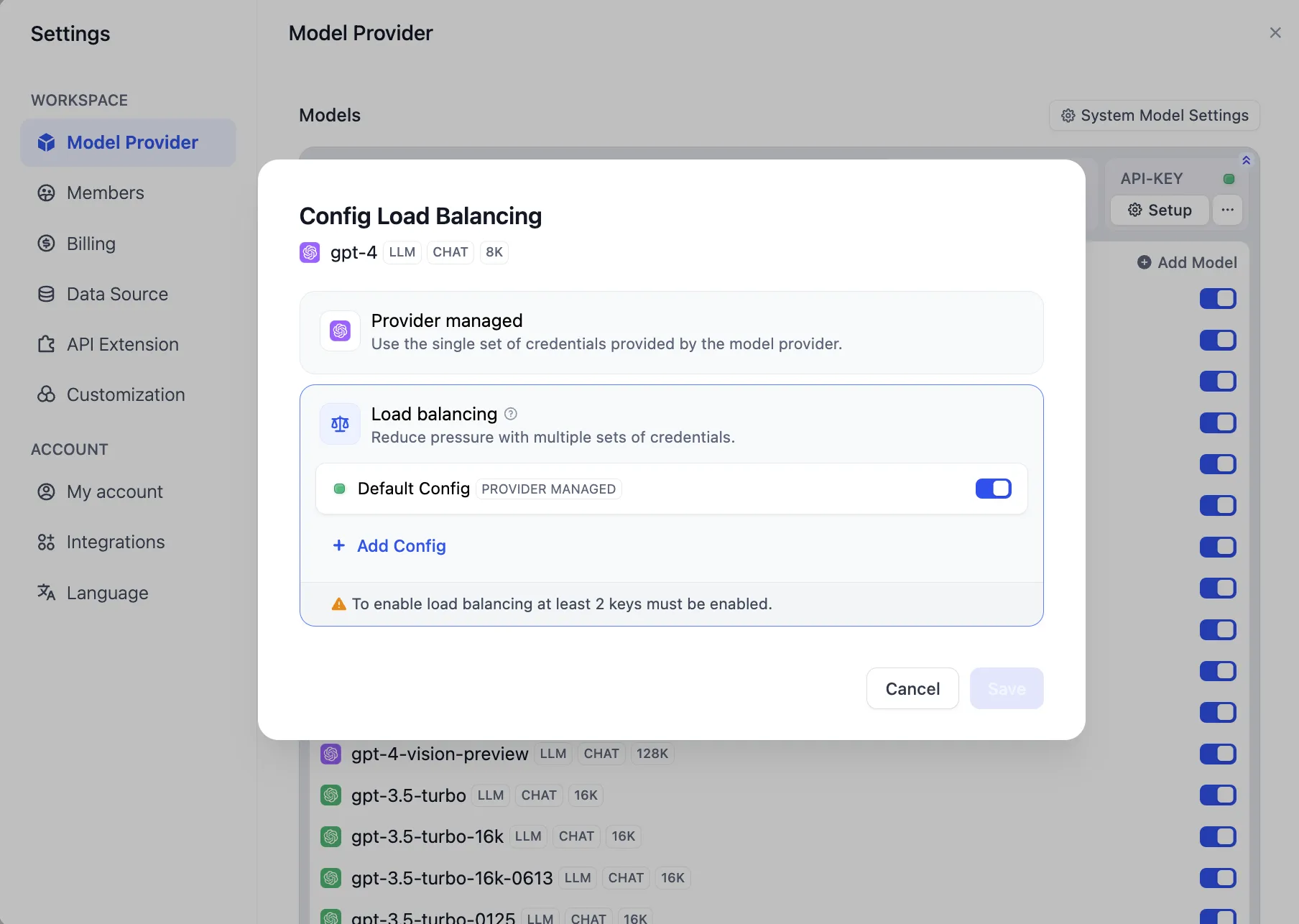
Configuring Load Balancing

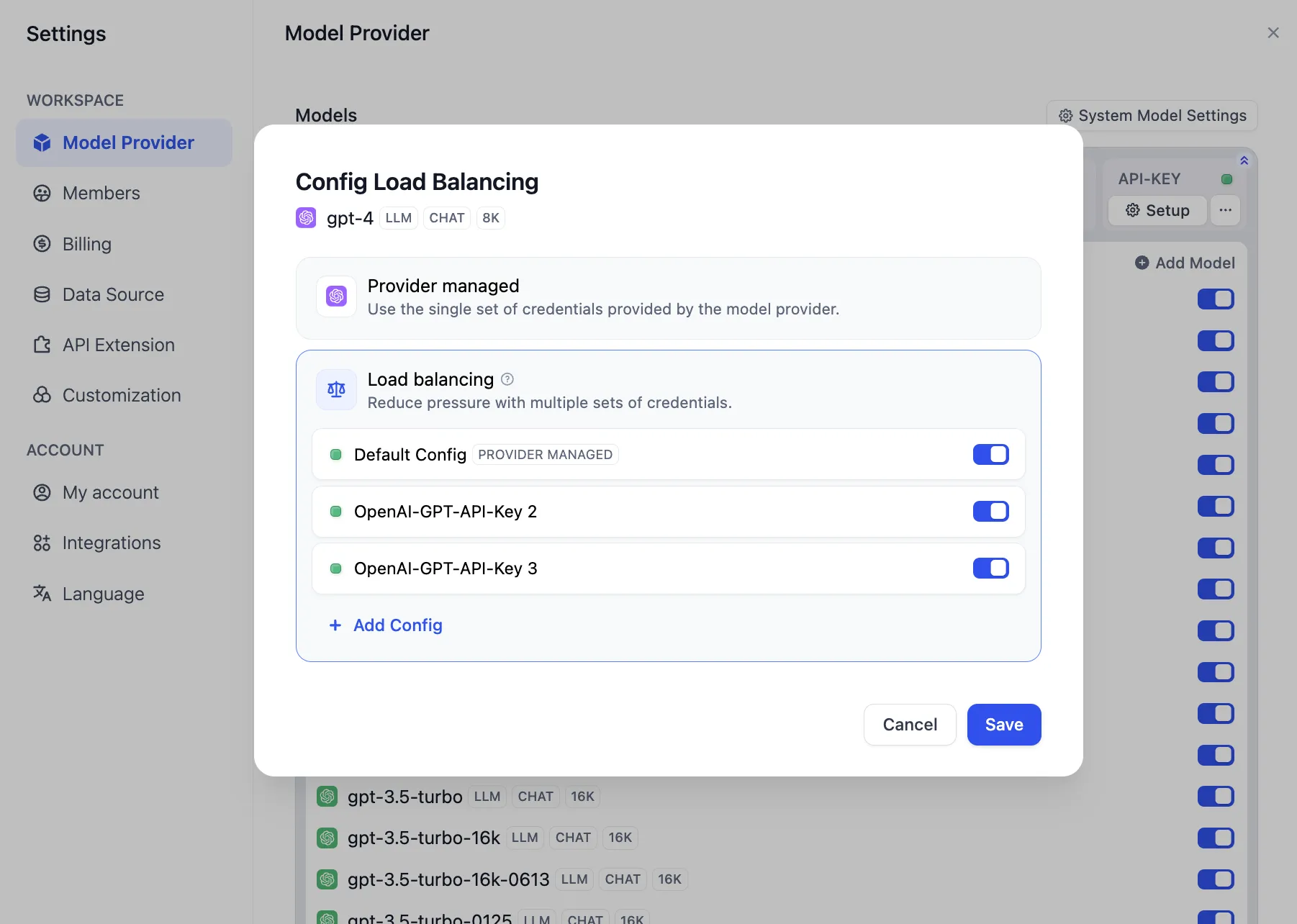

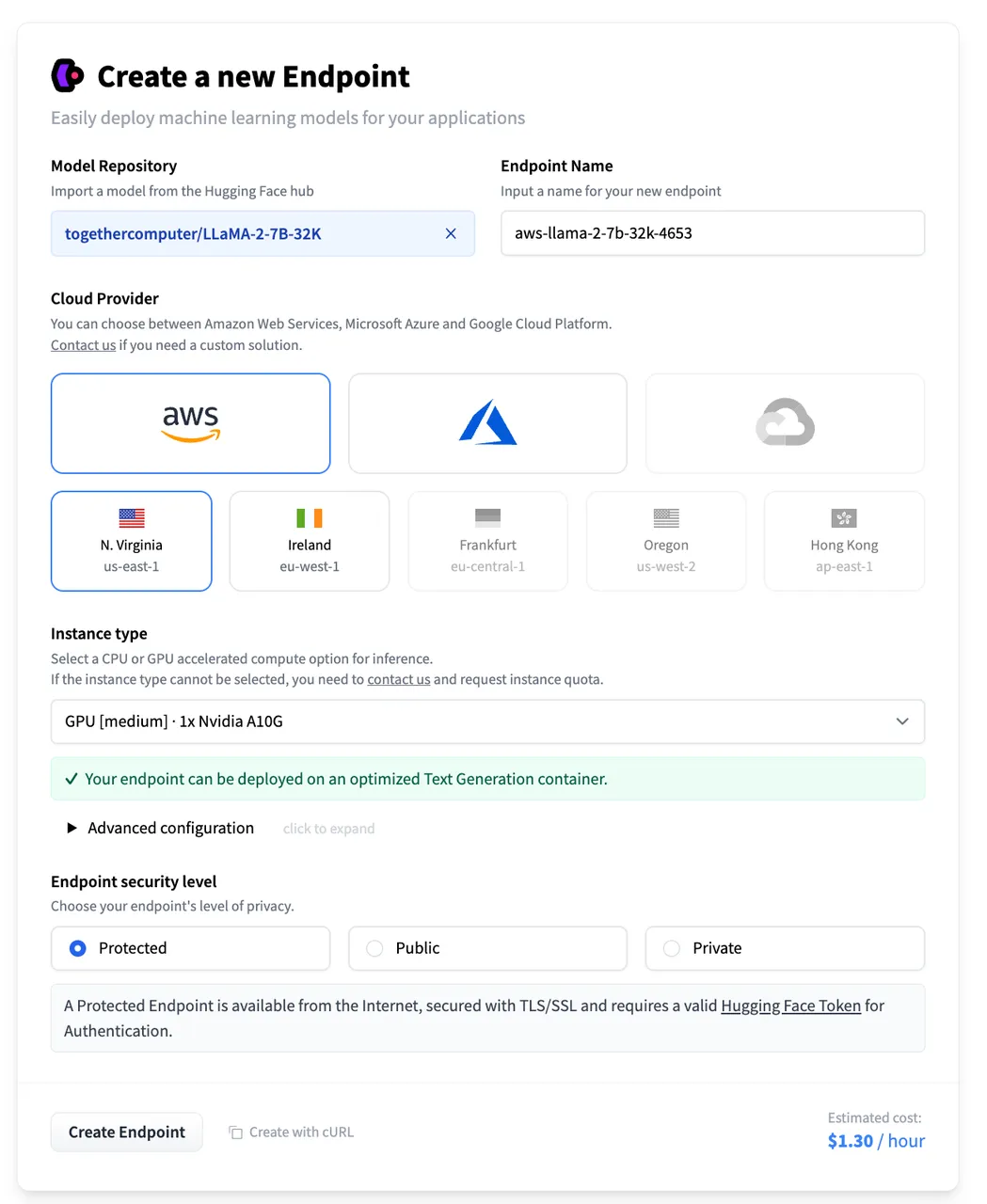
Enabling Load Balancing
Enabling Load Balancing

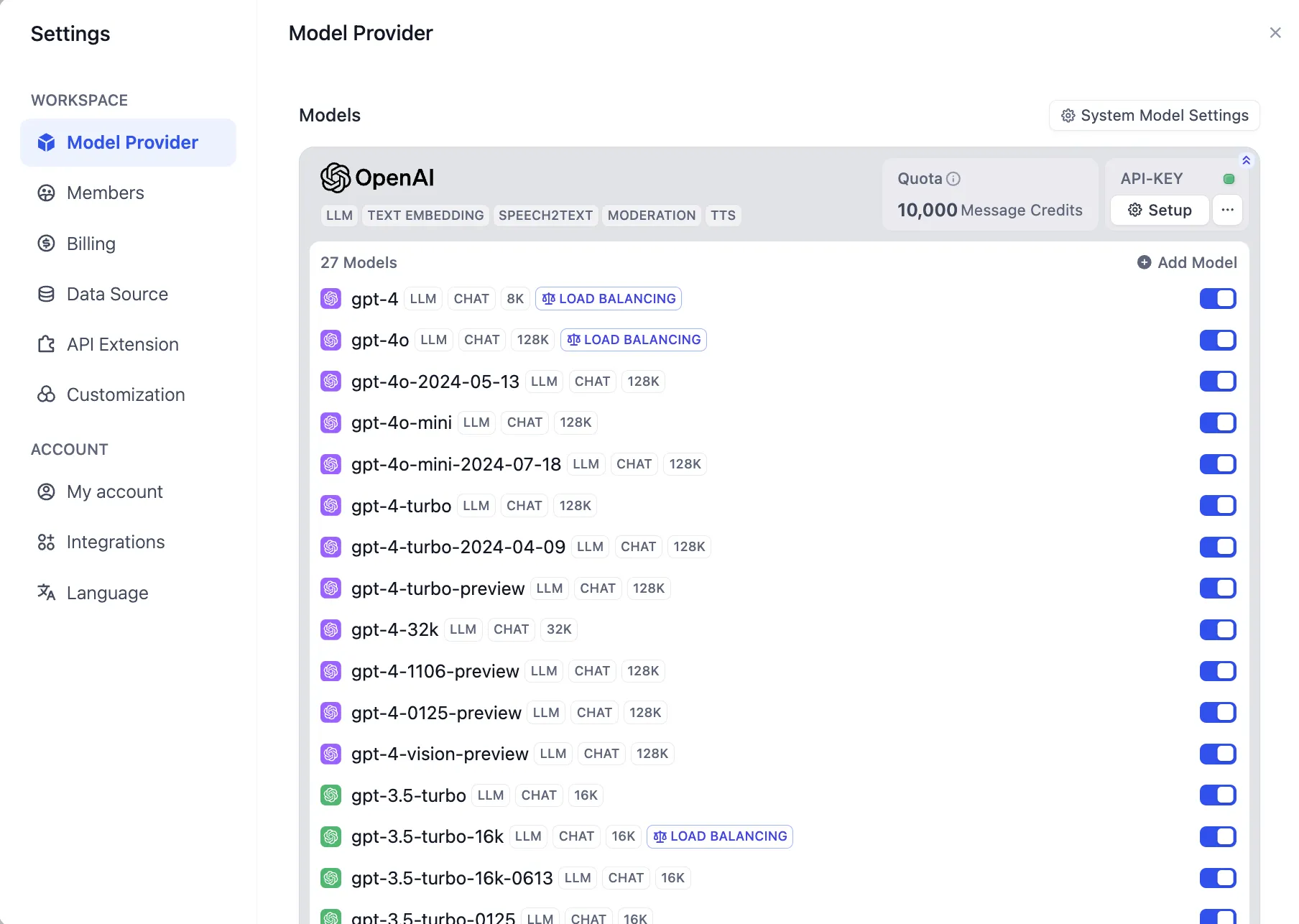
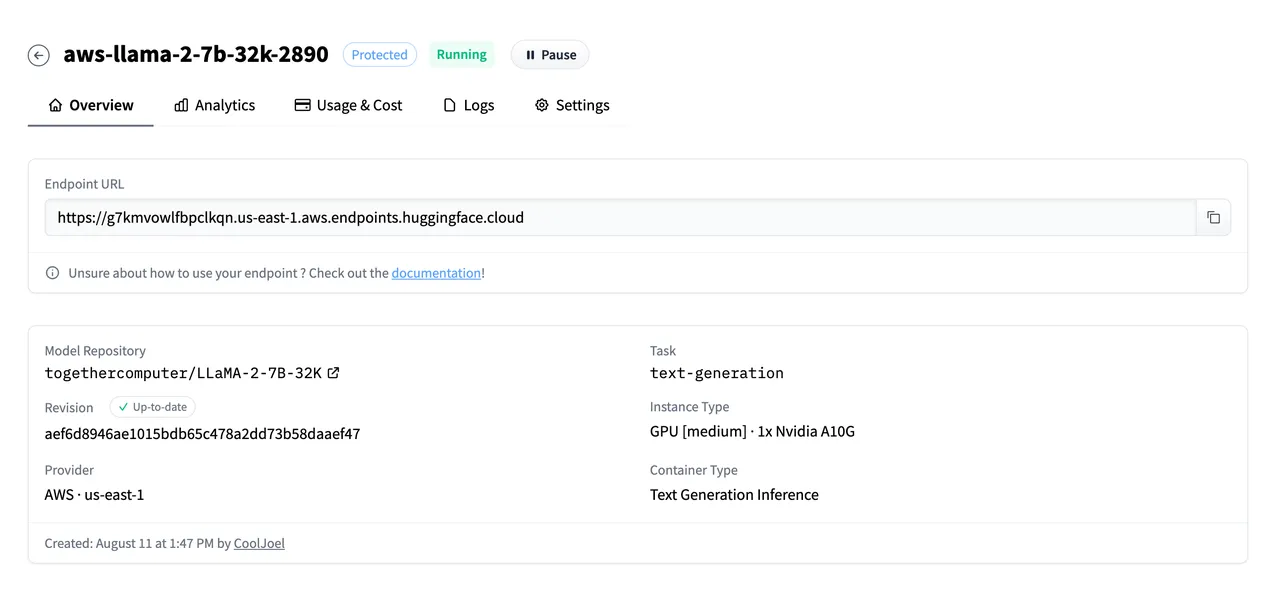
Configuring Load Balancing from Add Model
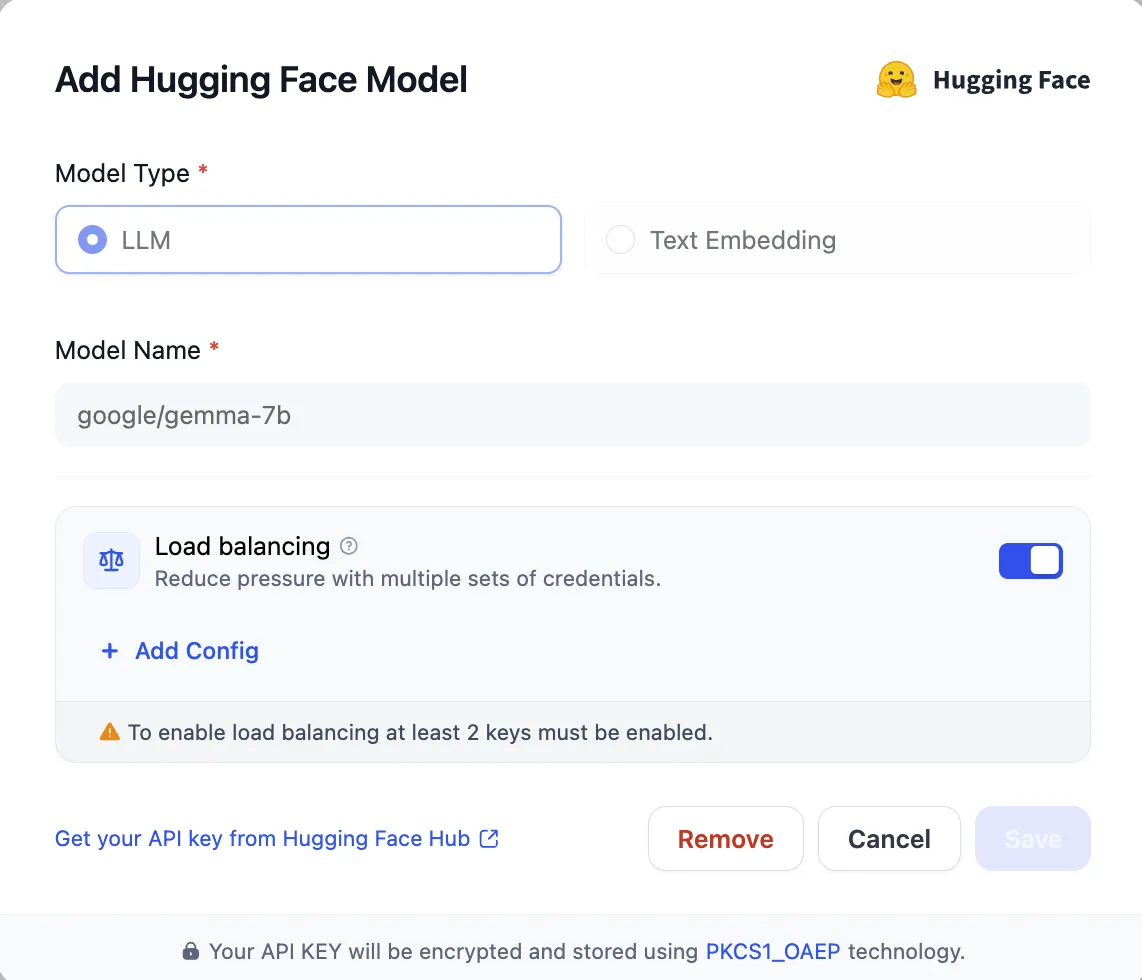
Configuring Load Balancing from Add Model

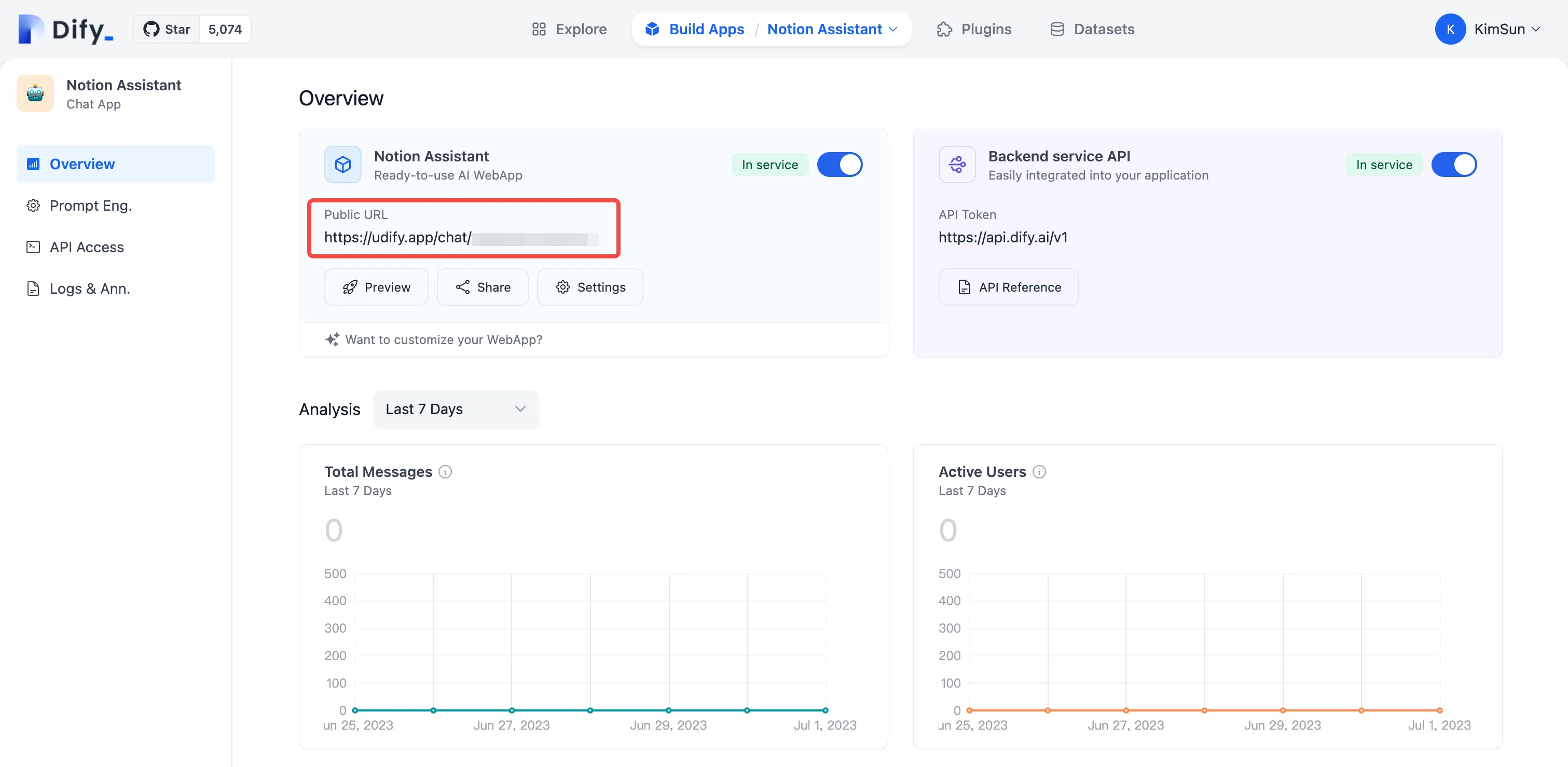
概览
概览

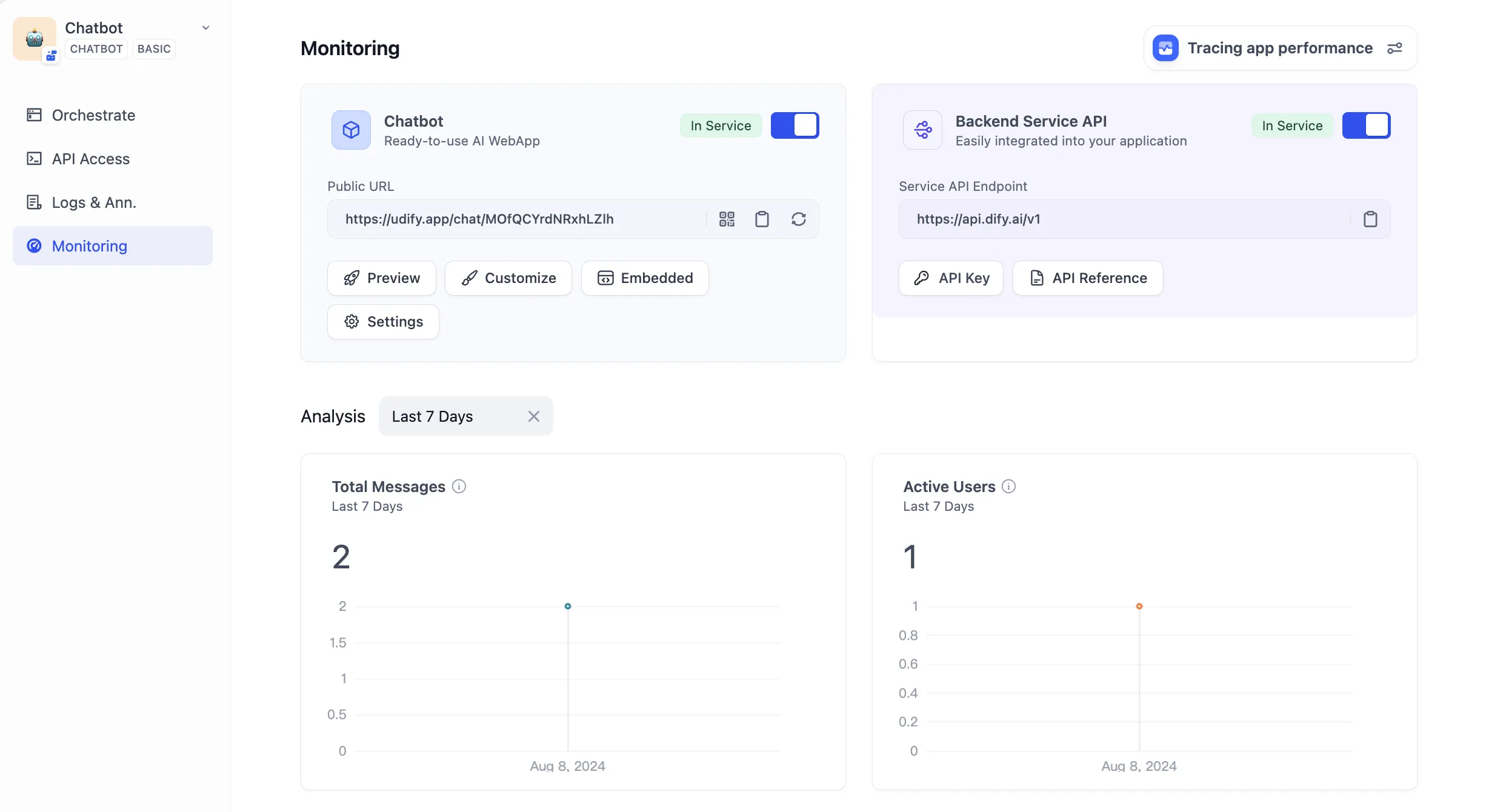
Overview—Data Analysis
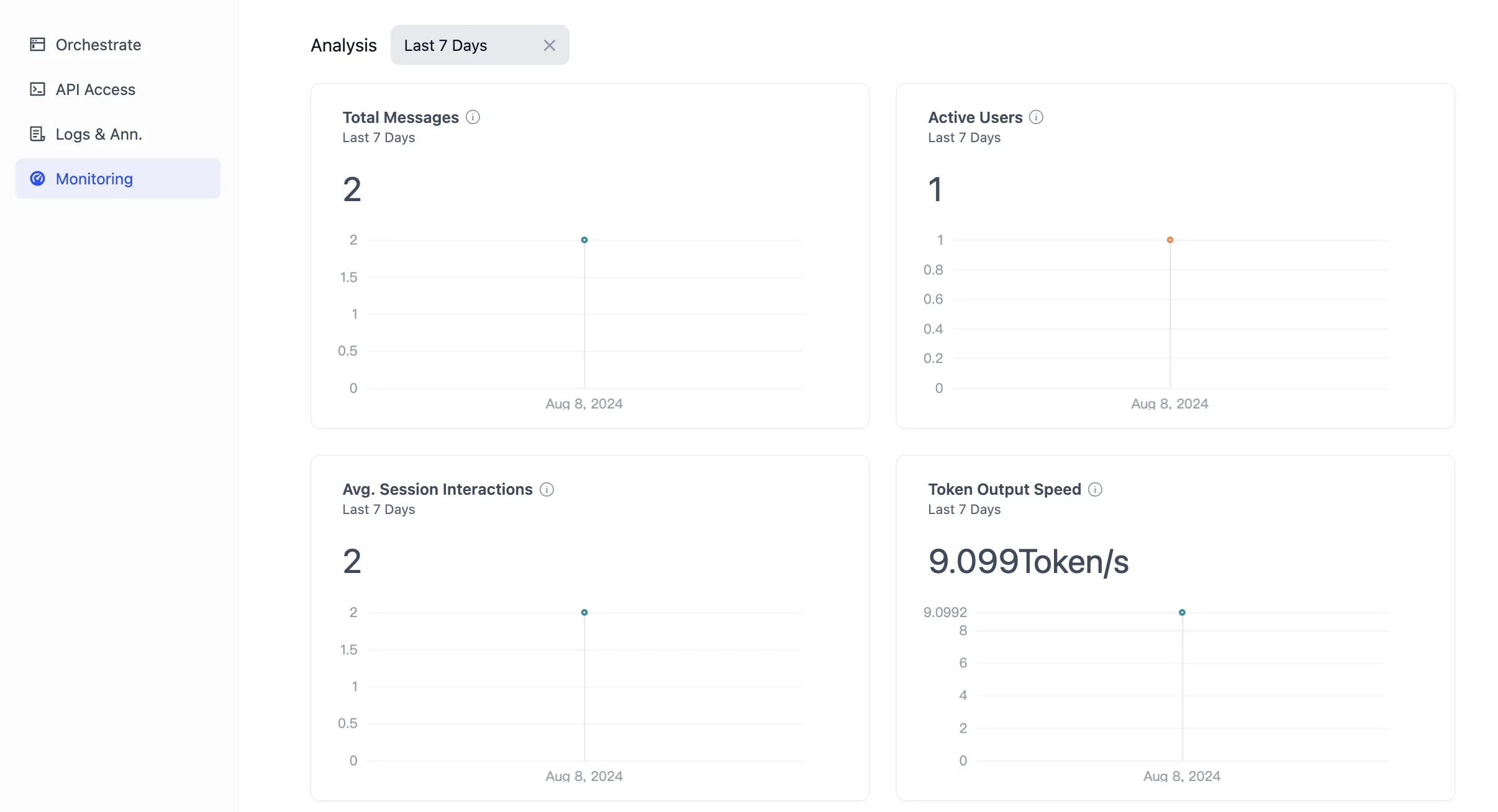
Overview—Data Analysis
 (1).png)
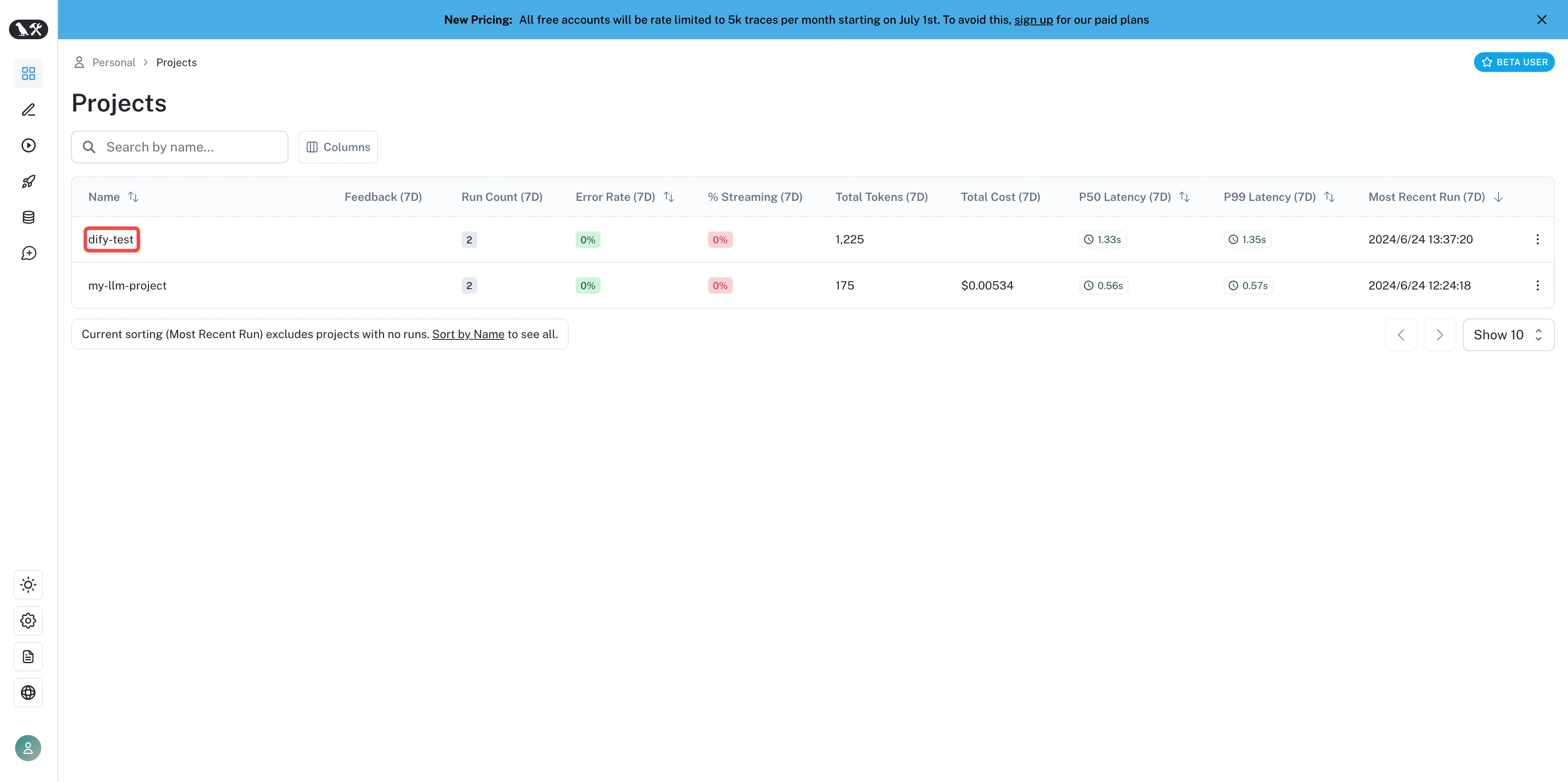
Create a project in Langfuse
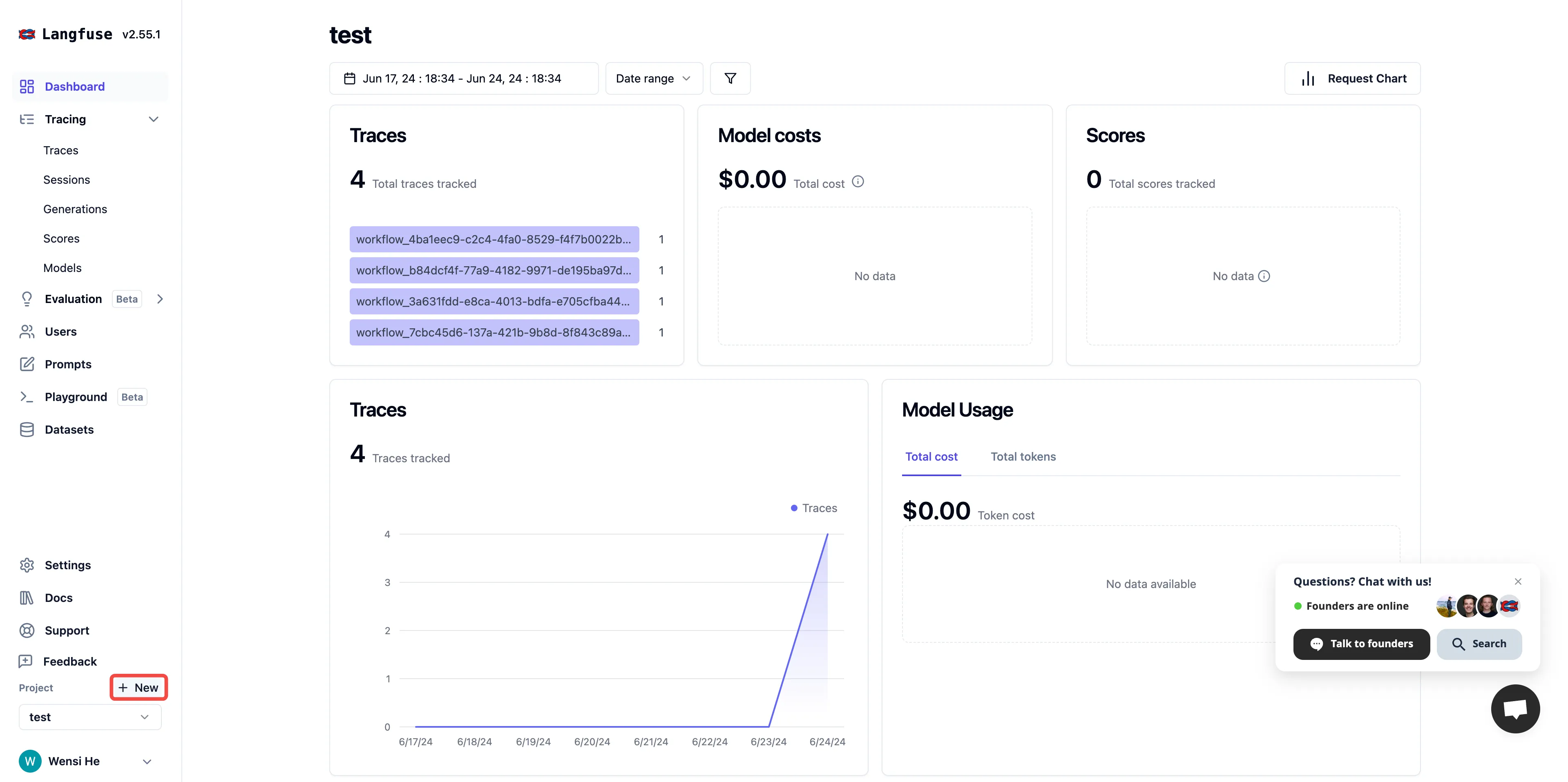
Create a project in Langfuse
 (1).png)
Create a project in Langfuse
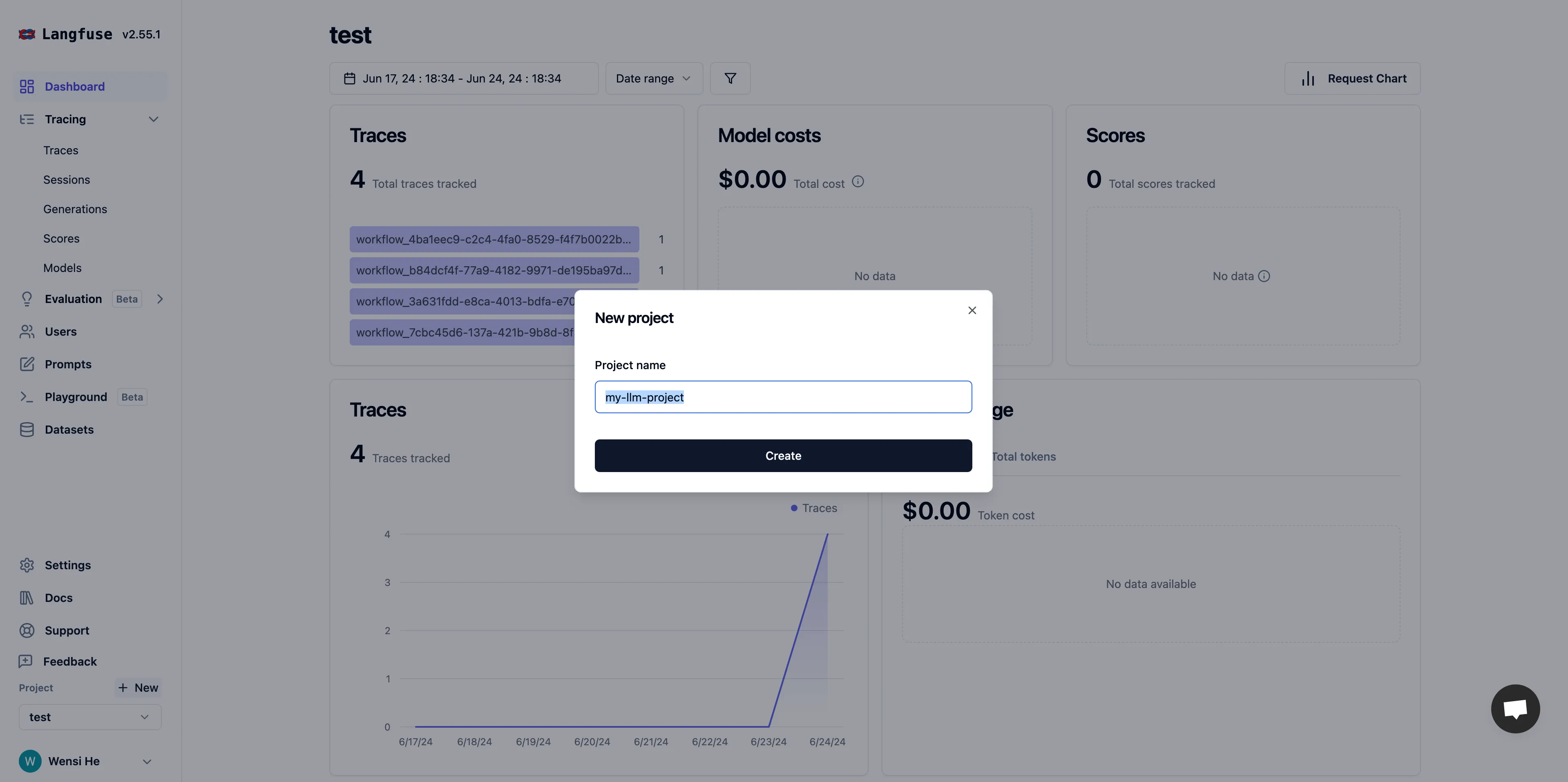
Create a project in Langfuse
 (1).png)
Create project API credentials
Create project API credentials
 (1).png)
Create project API credentials
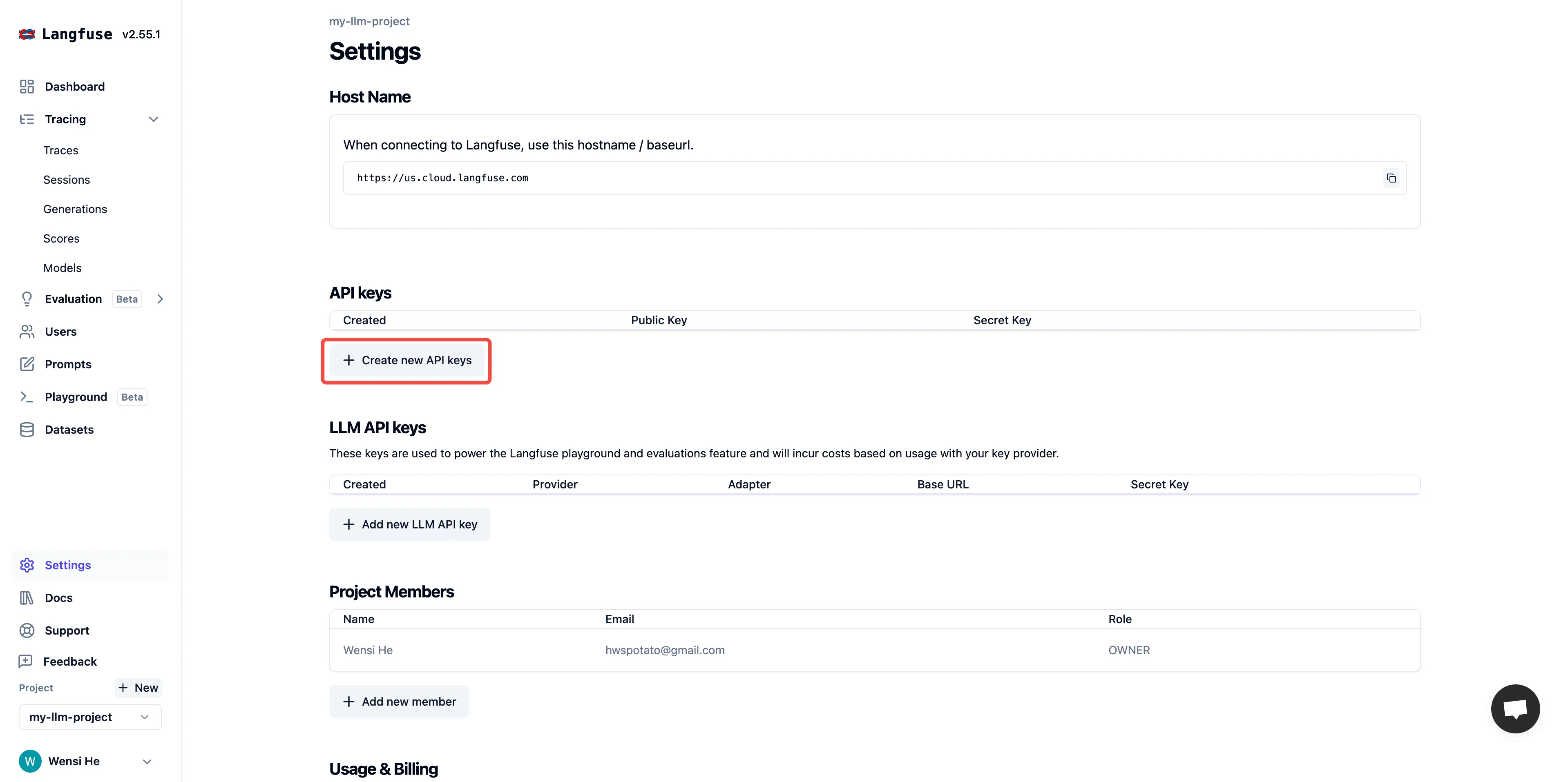
Create project API credentials
 (1).png)
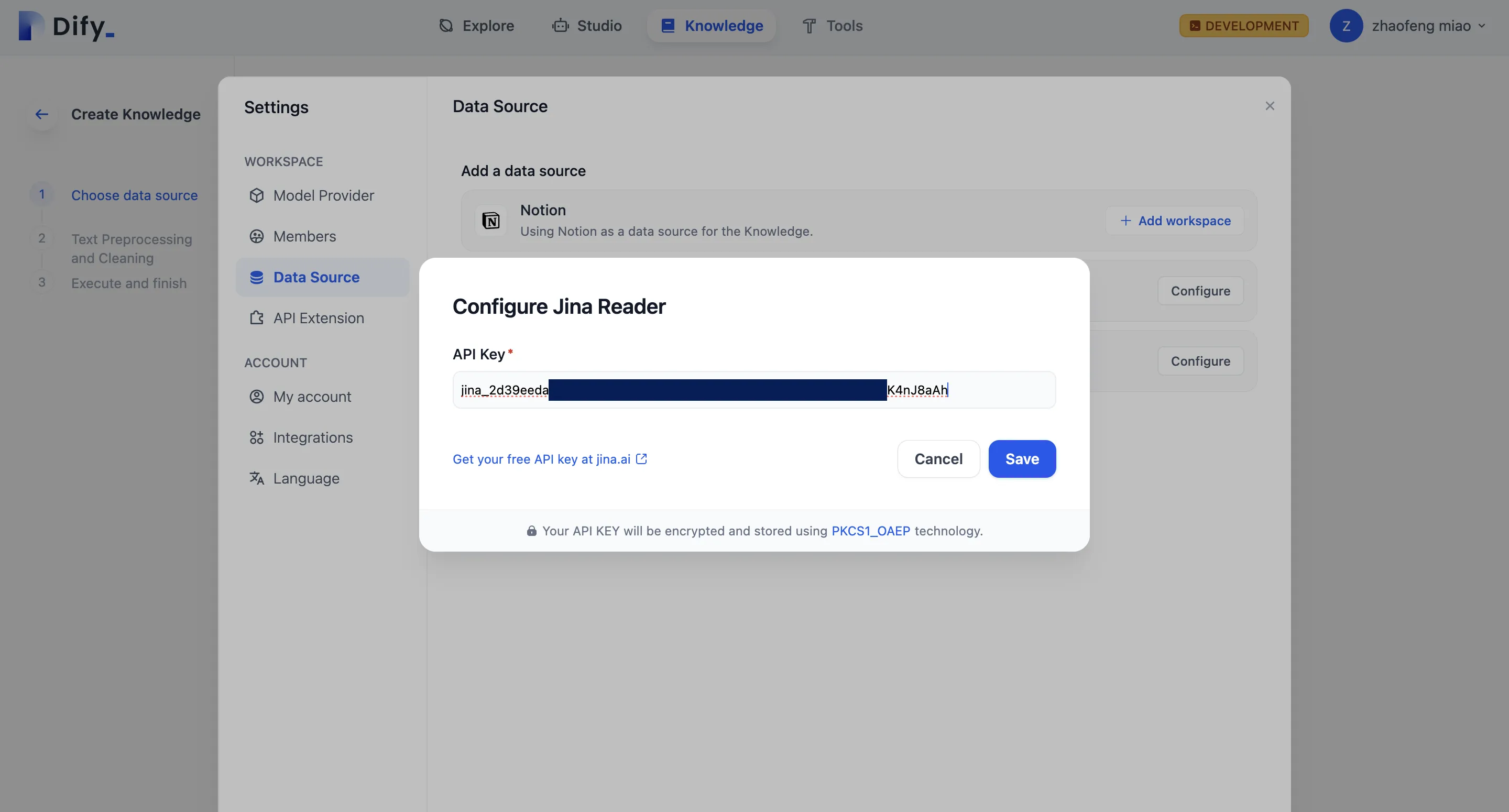
Get API Key configuration
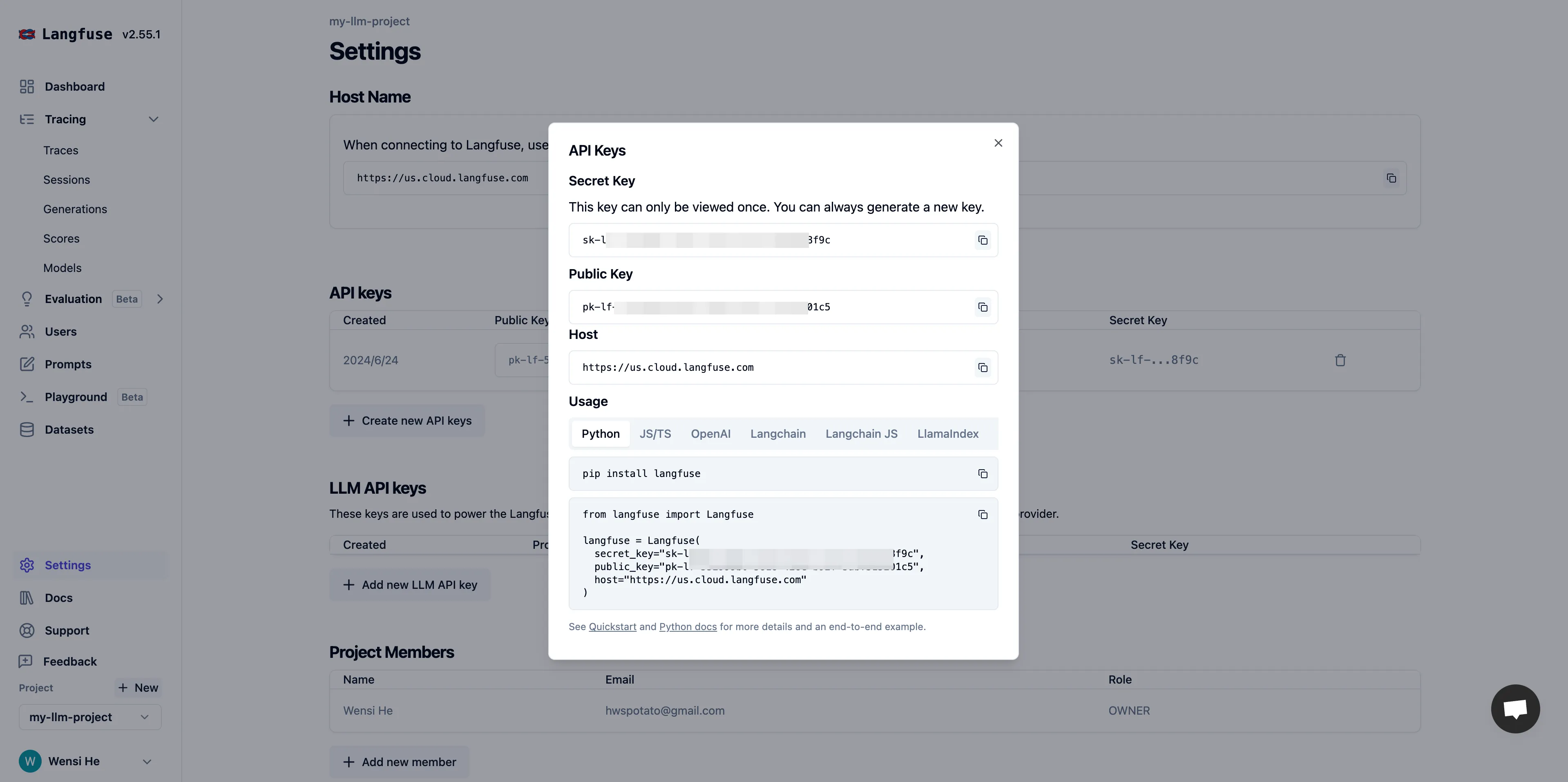
Get API Key configuration

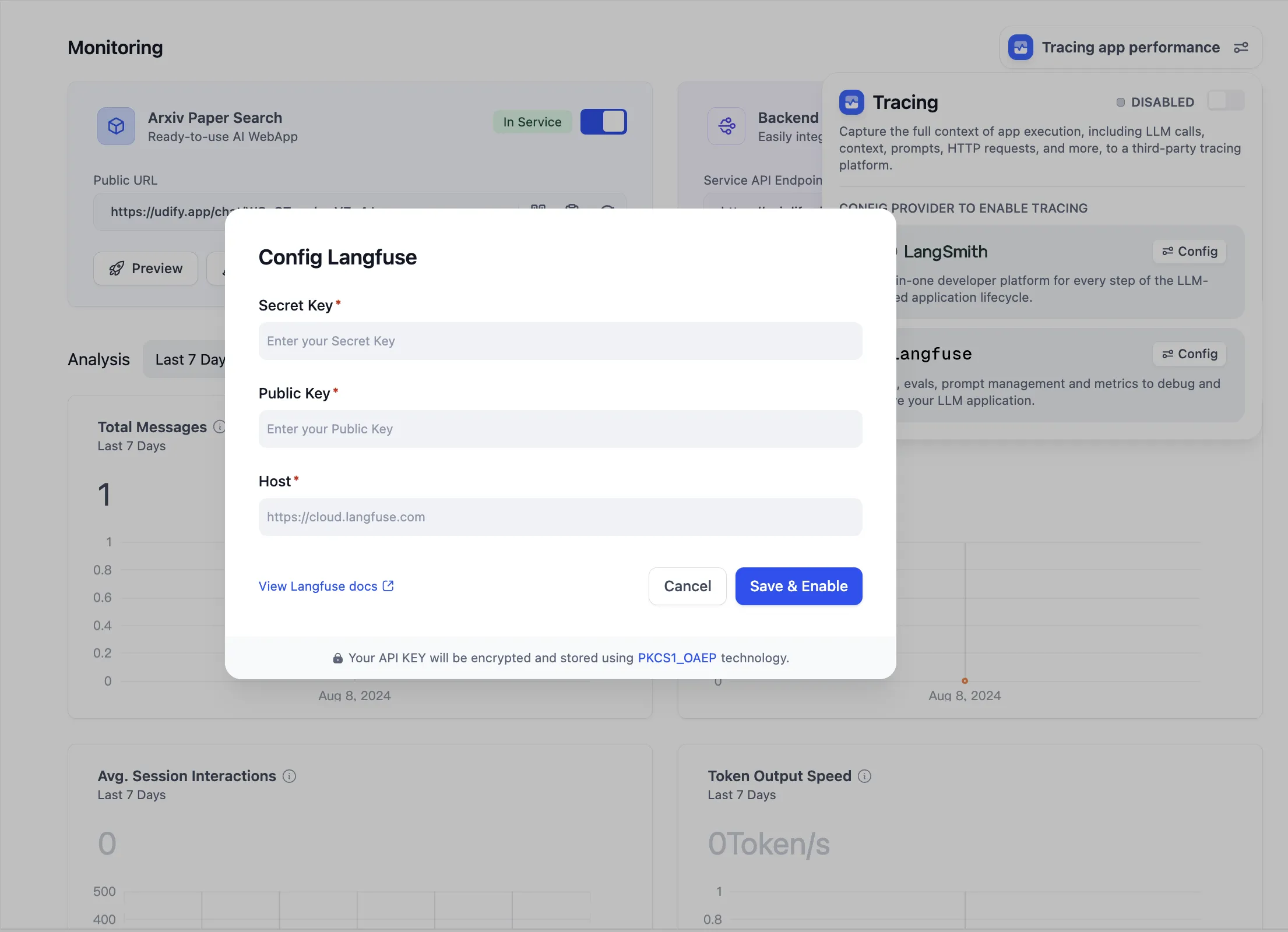
Configure Langfuse
Configure Langfuse

Configure Langfuse
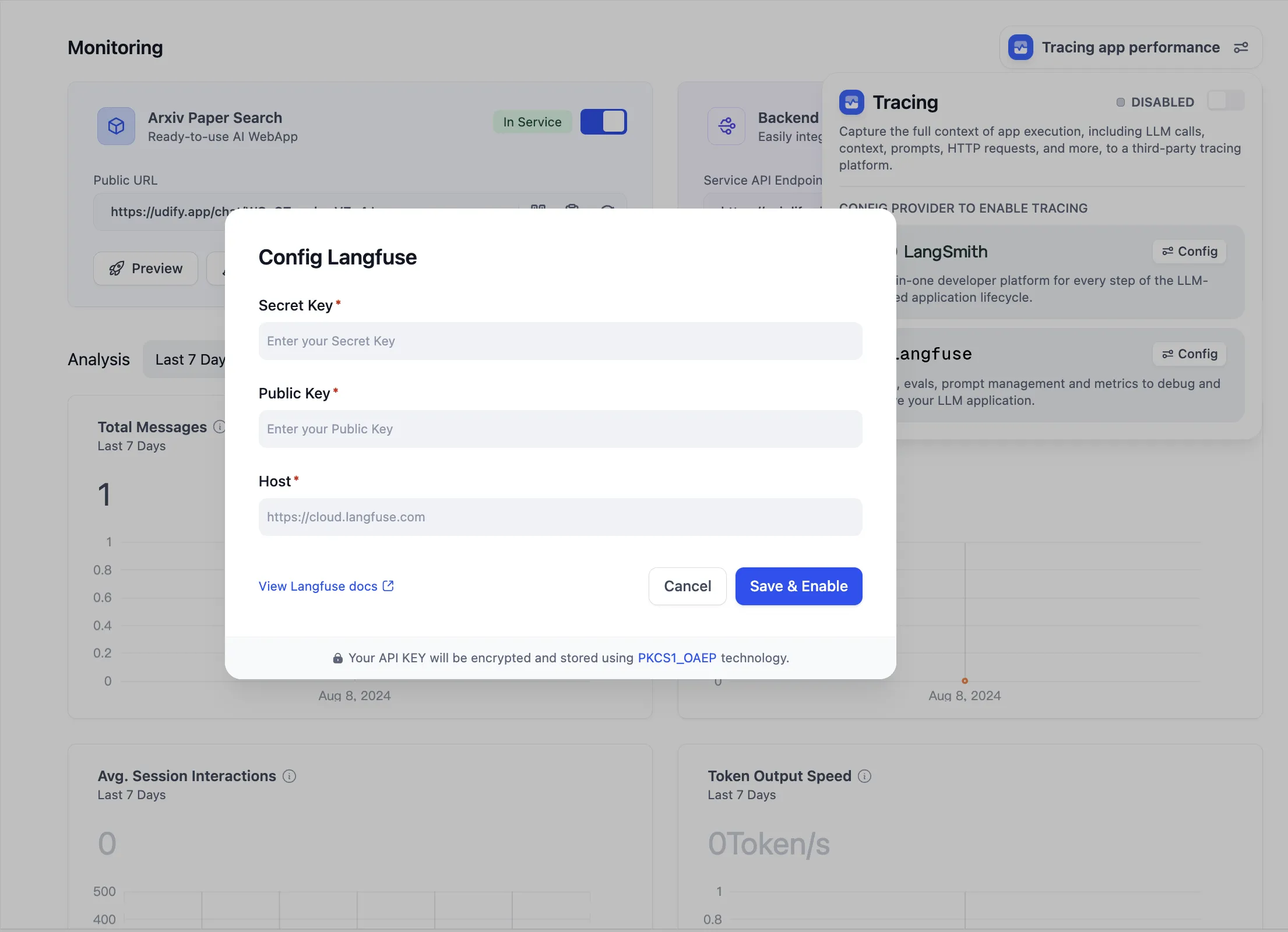
Configure Langfuse

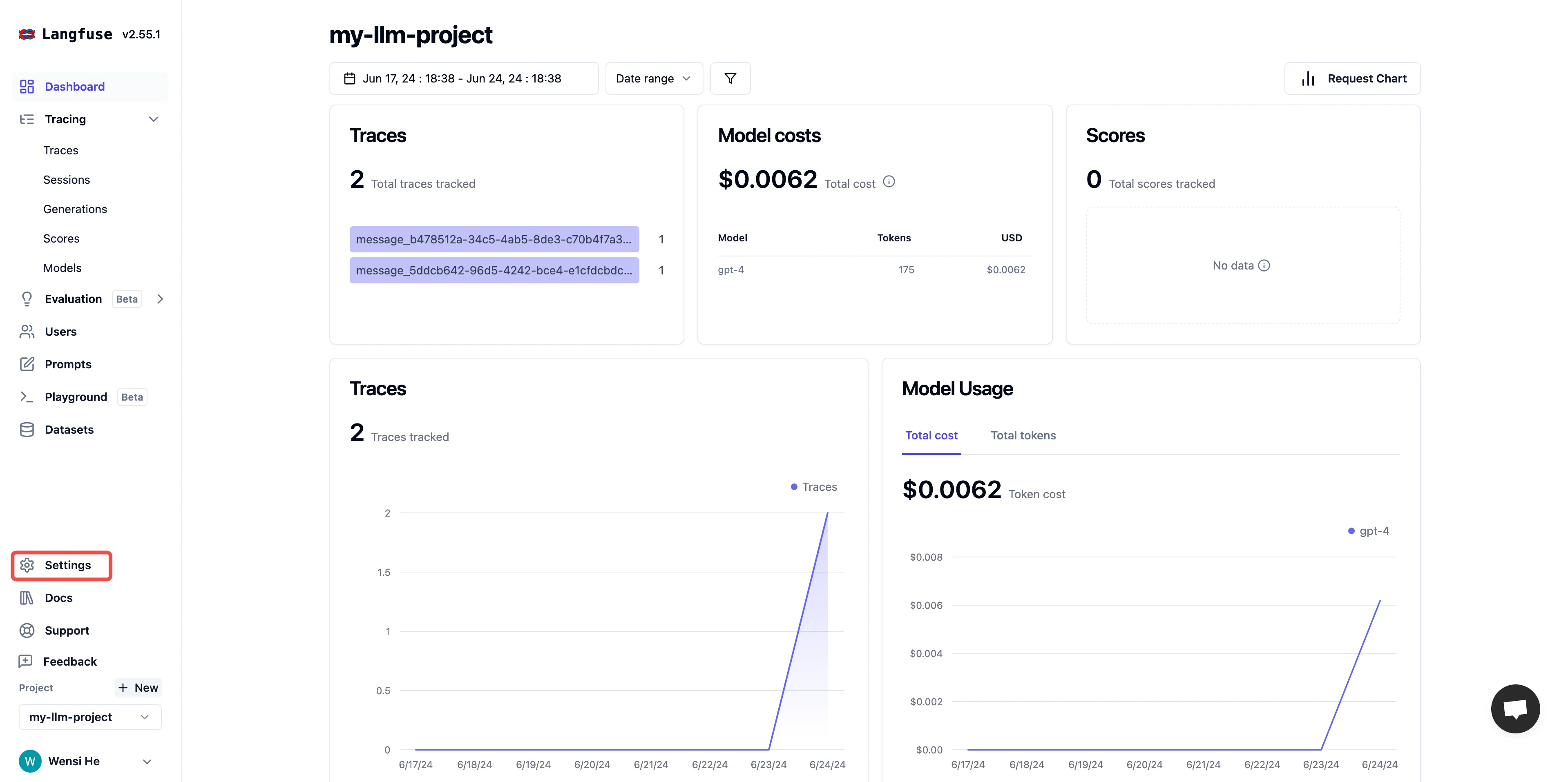
View configuration status
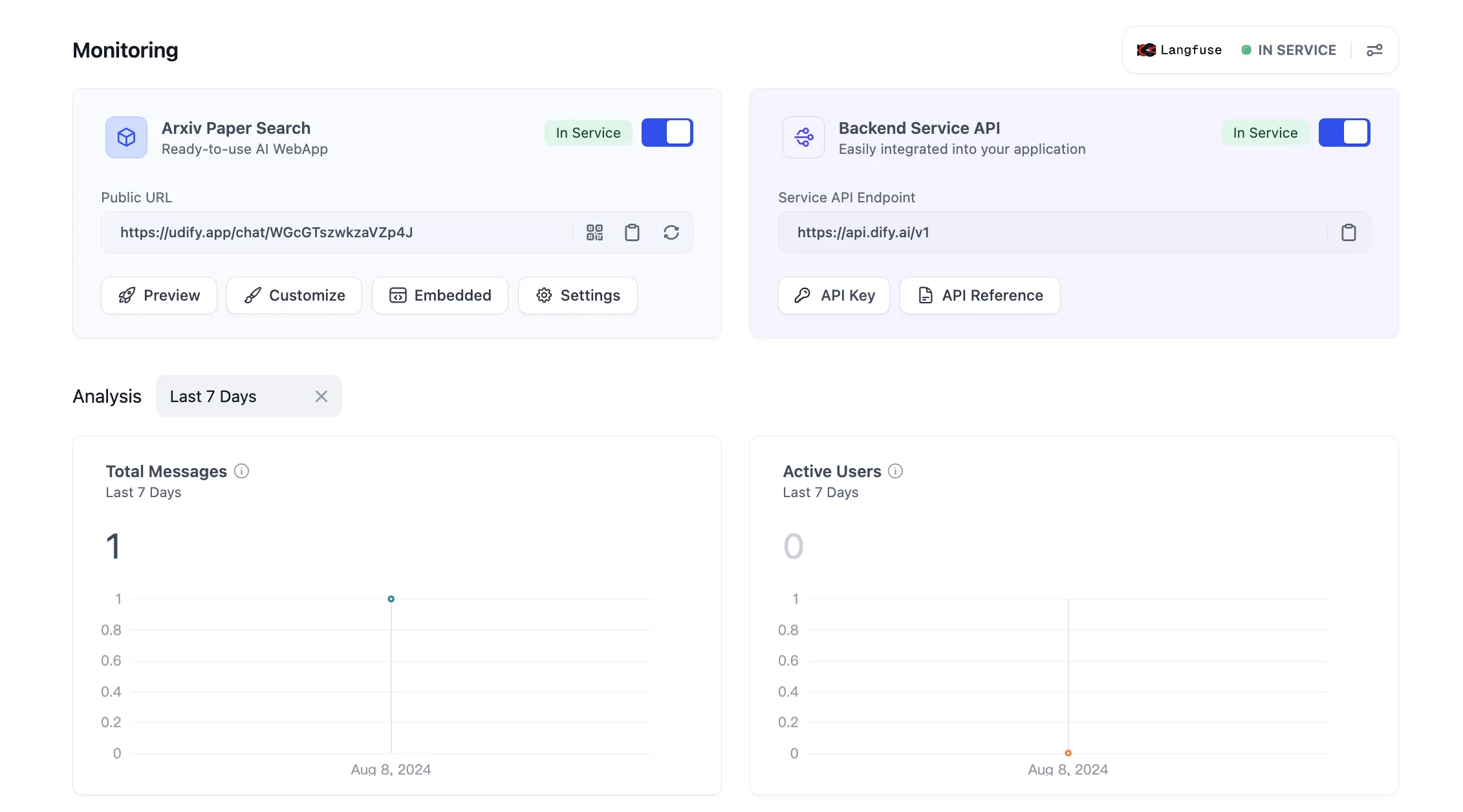
View configuration status

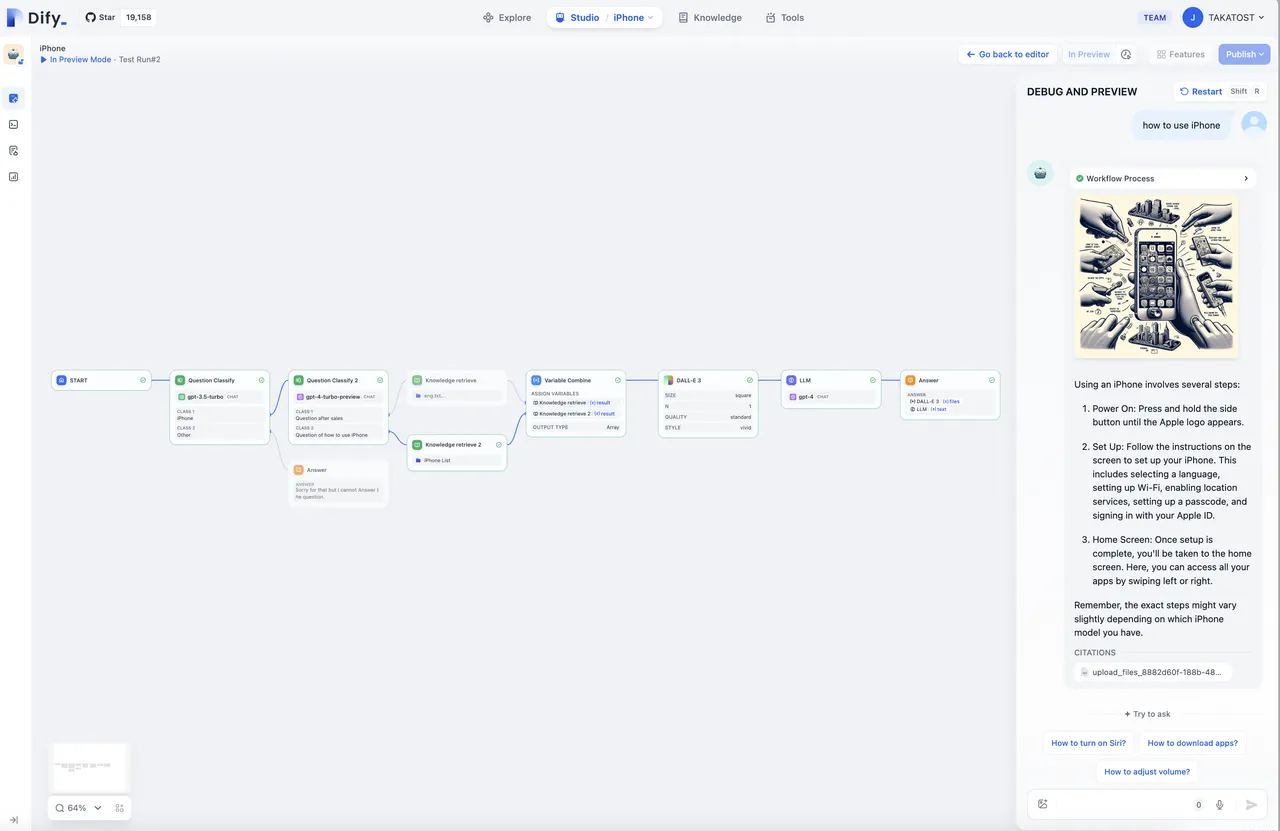
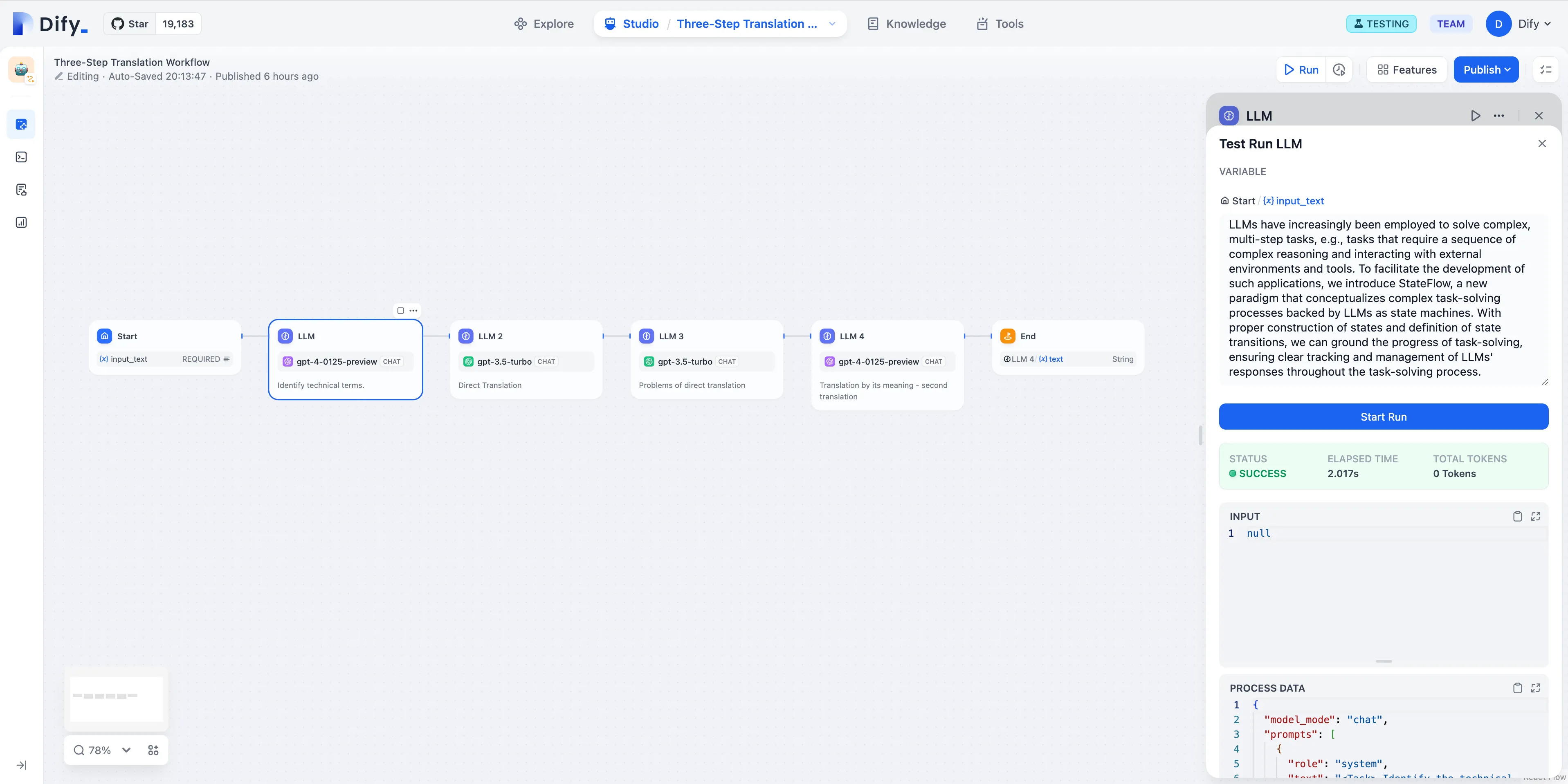
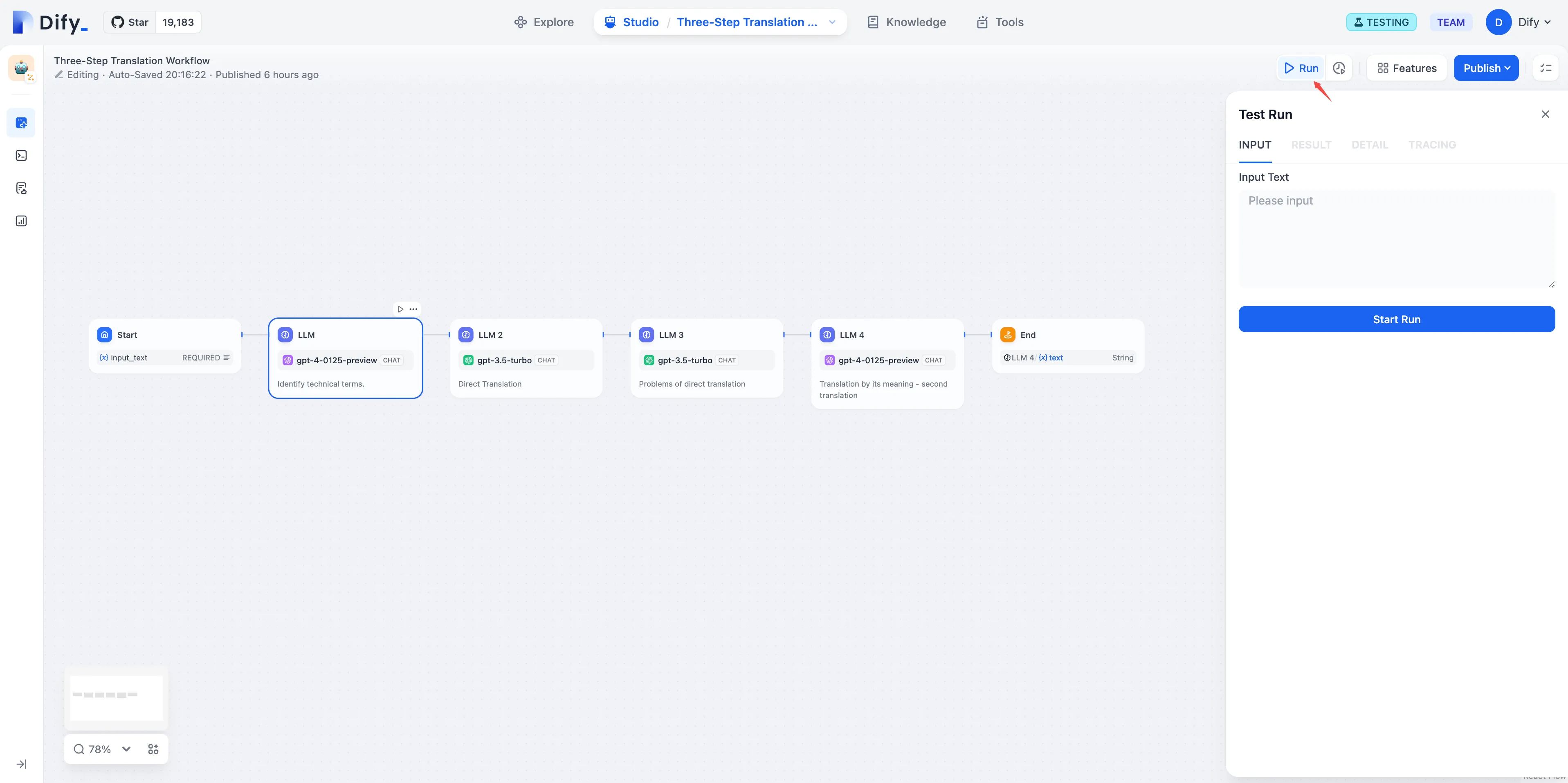
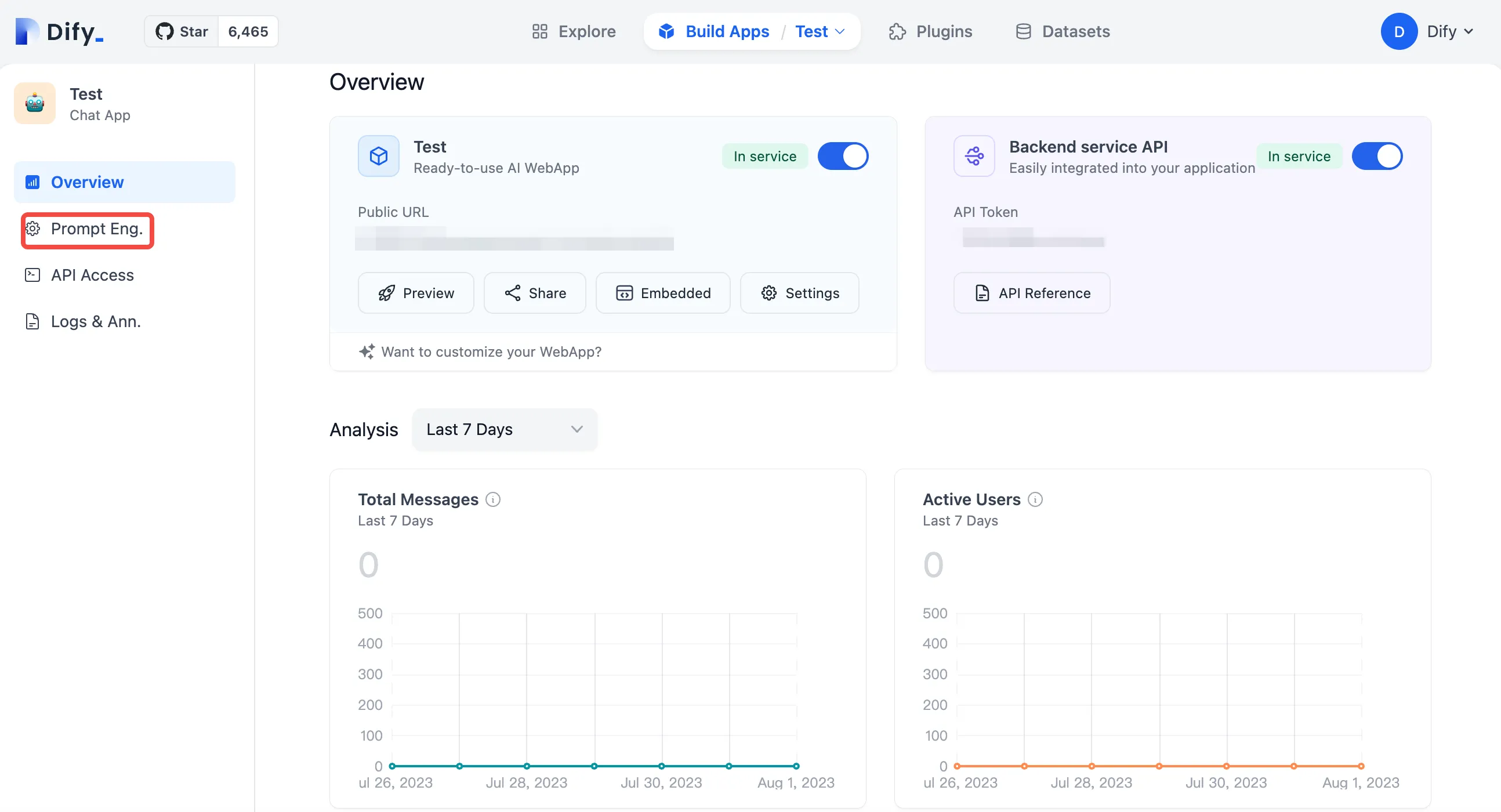
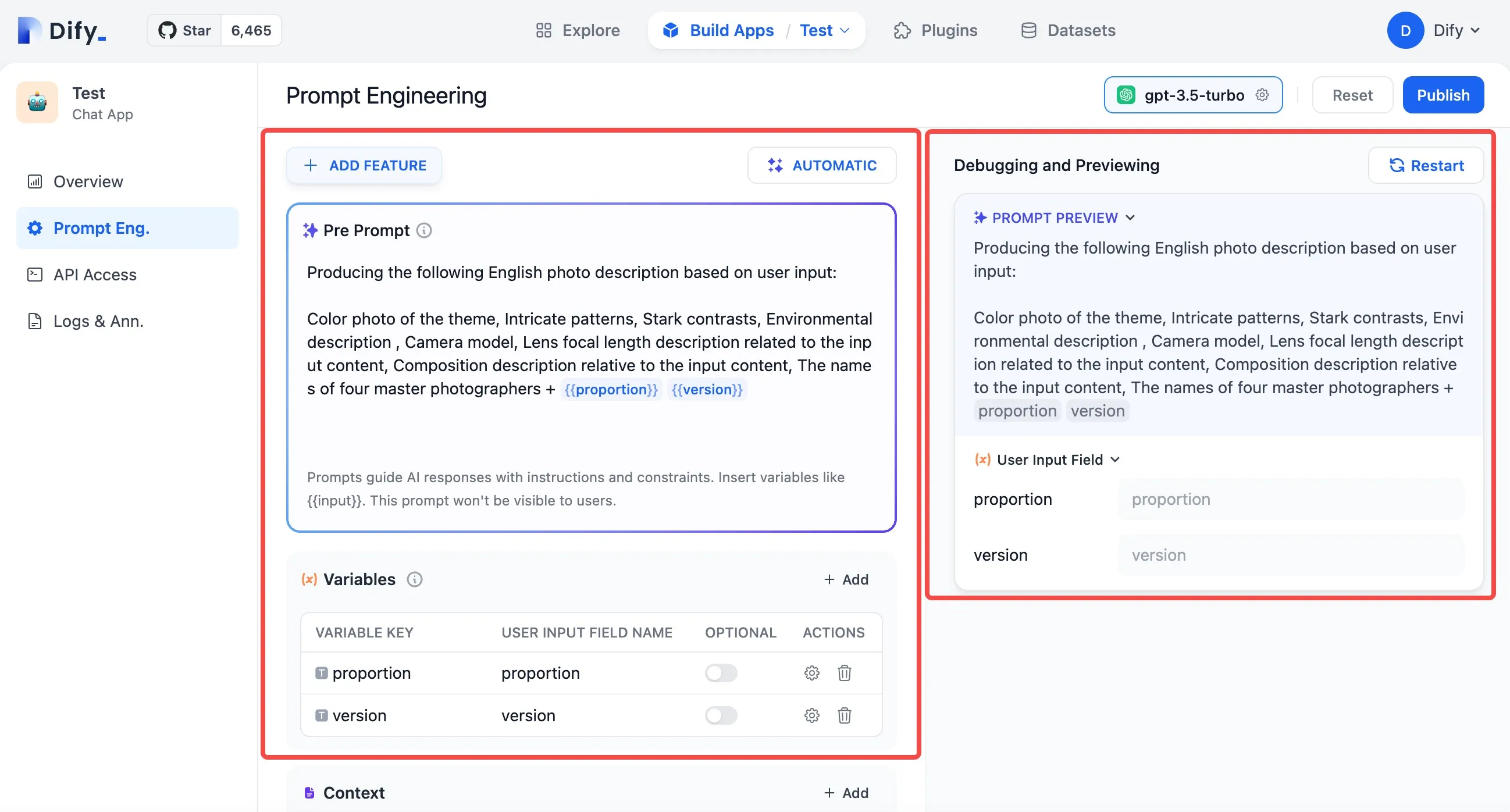
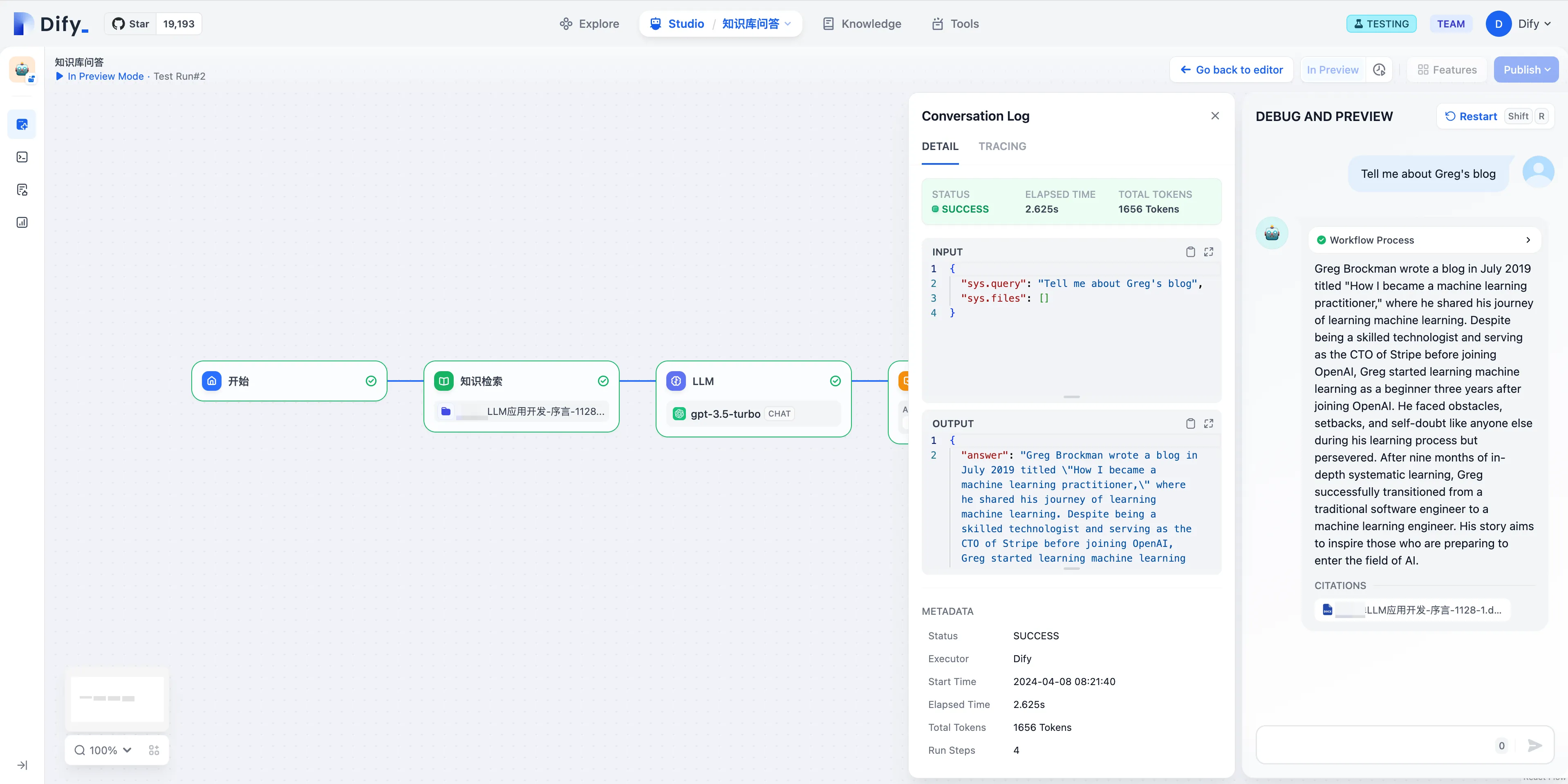
Debugging Applications in Dify
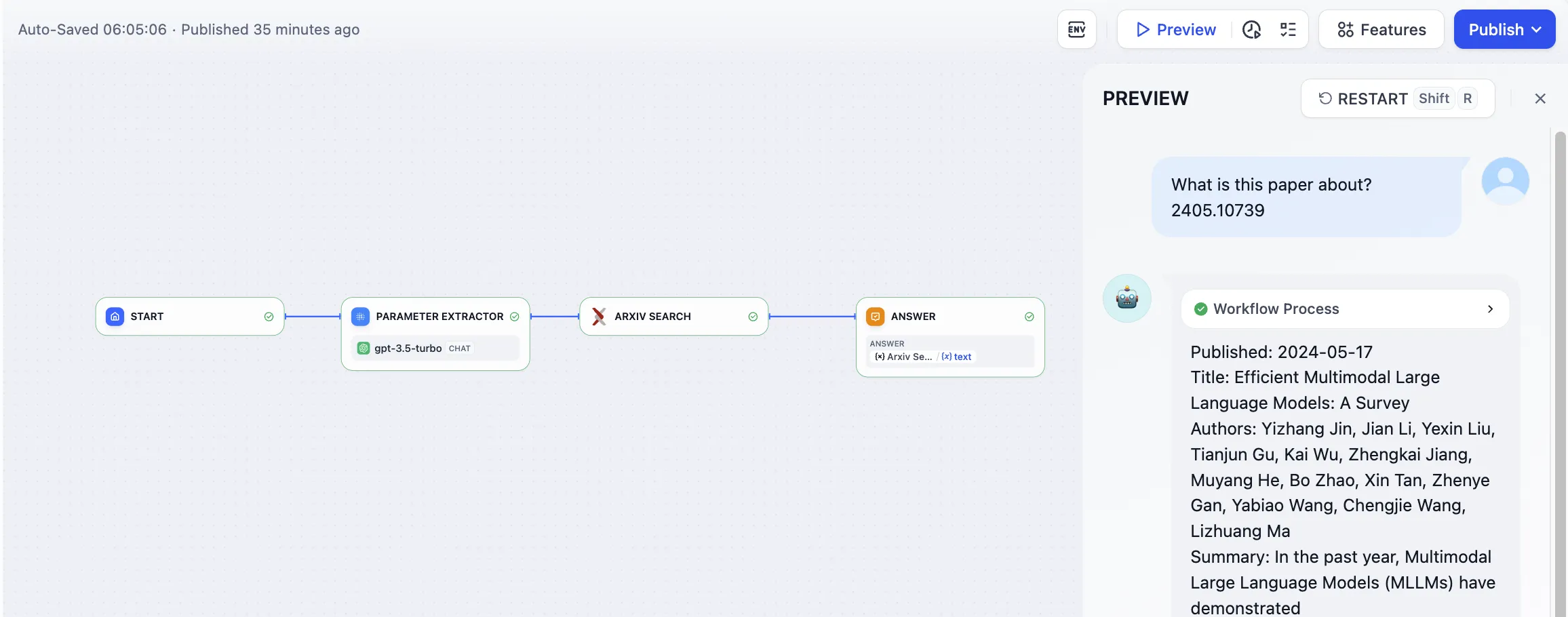
Debugging Applications in Dify

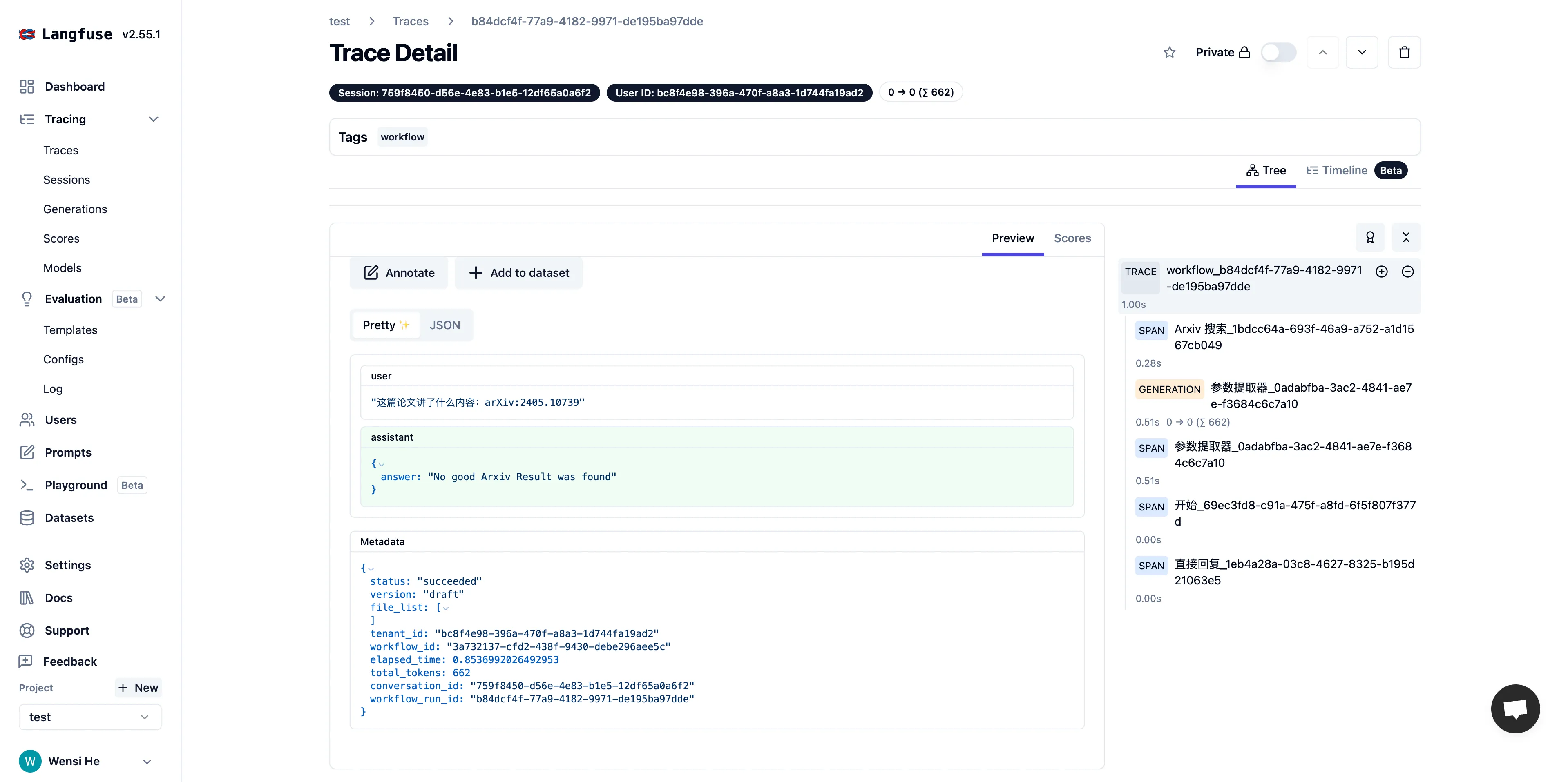
Viewing application data in Langfuse
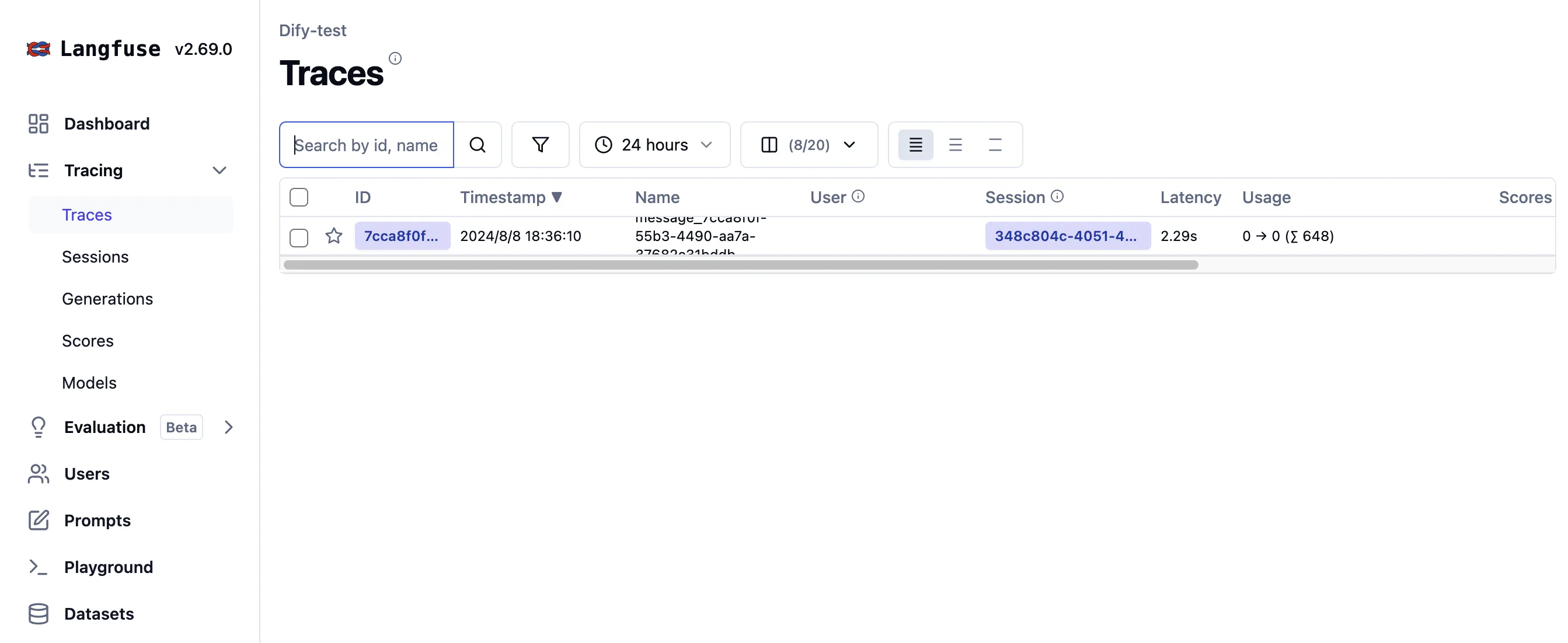
Viewing application data in Langfuse
 (1) (1) (1).png)
Create a project in LangSmith
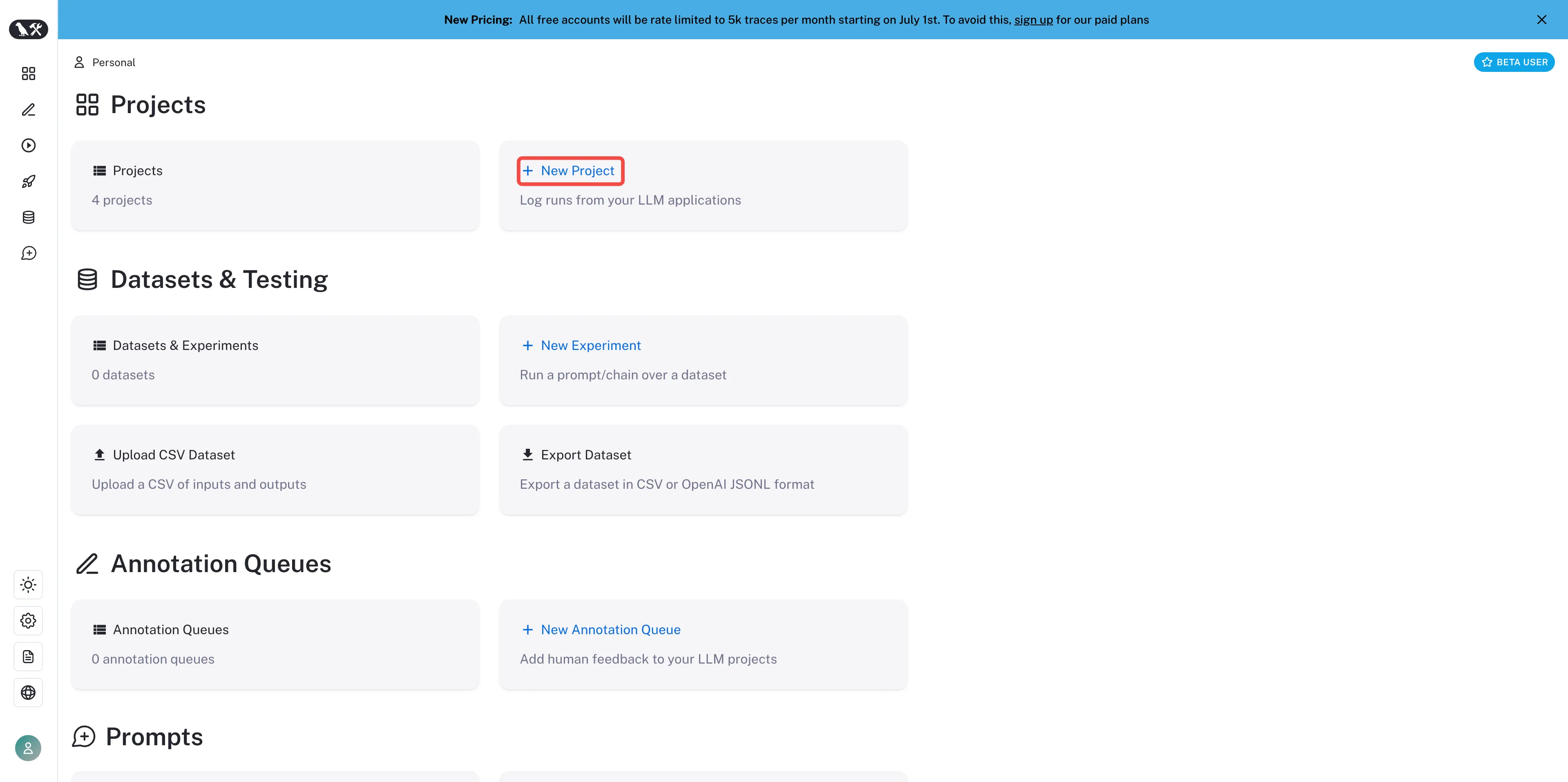
Create a project in LangSmith
 (1) (2).png)
View created projects in LangSmith
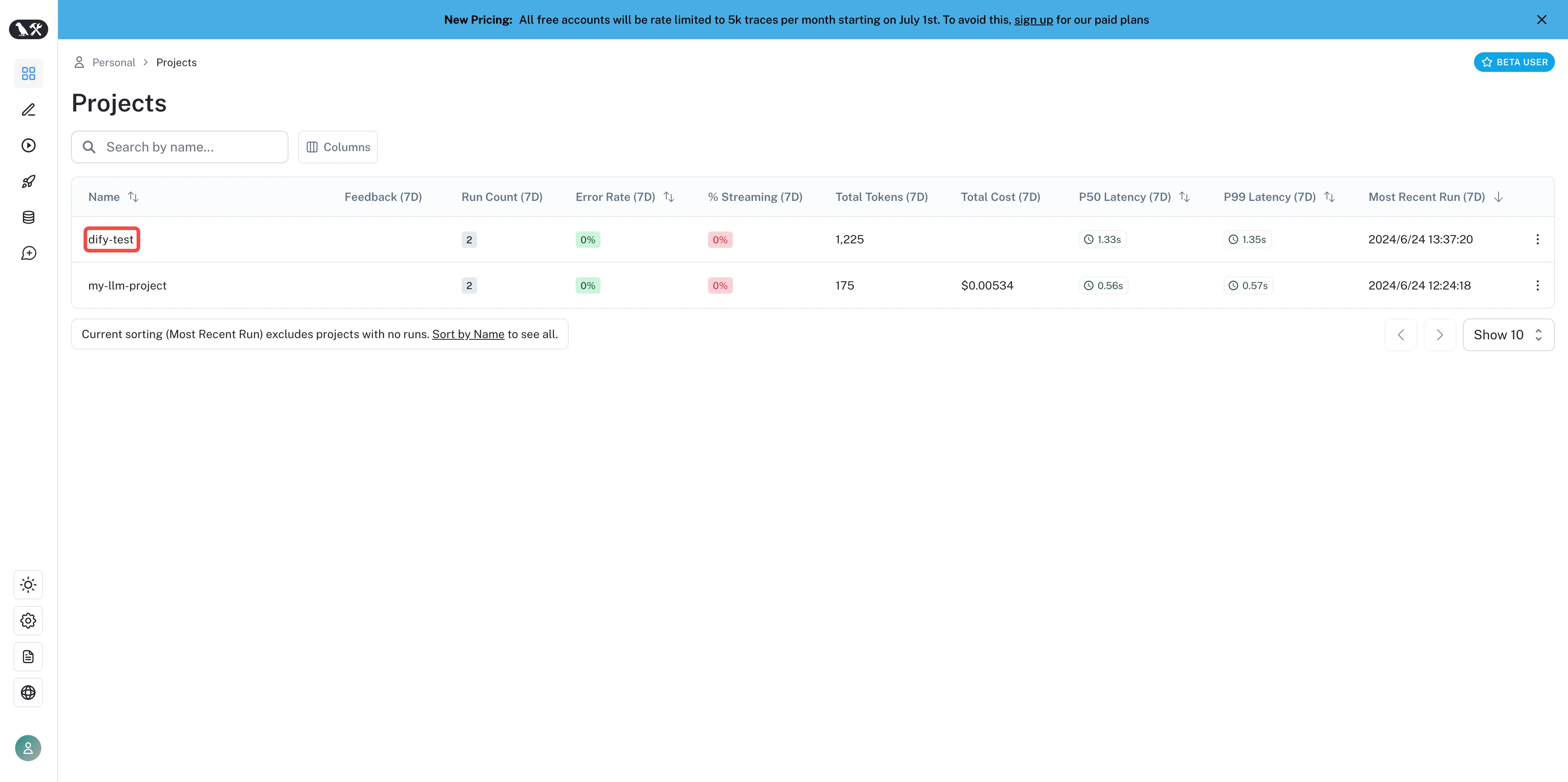
View created projects in LangSmith
 (1) (2).png)
Project settings
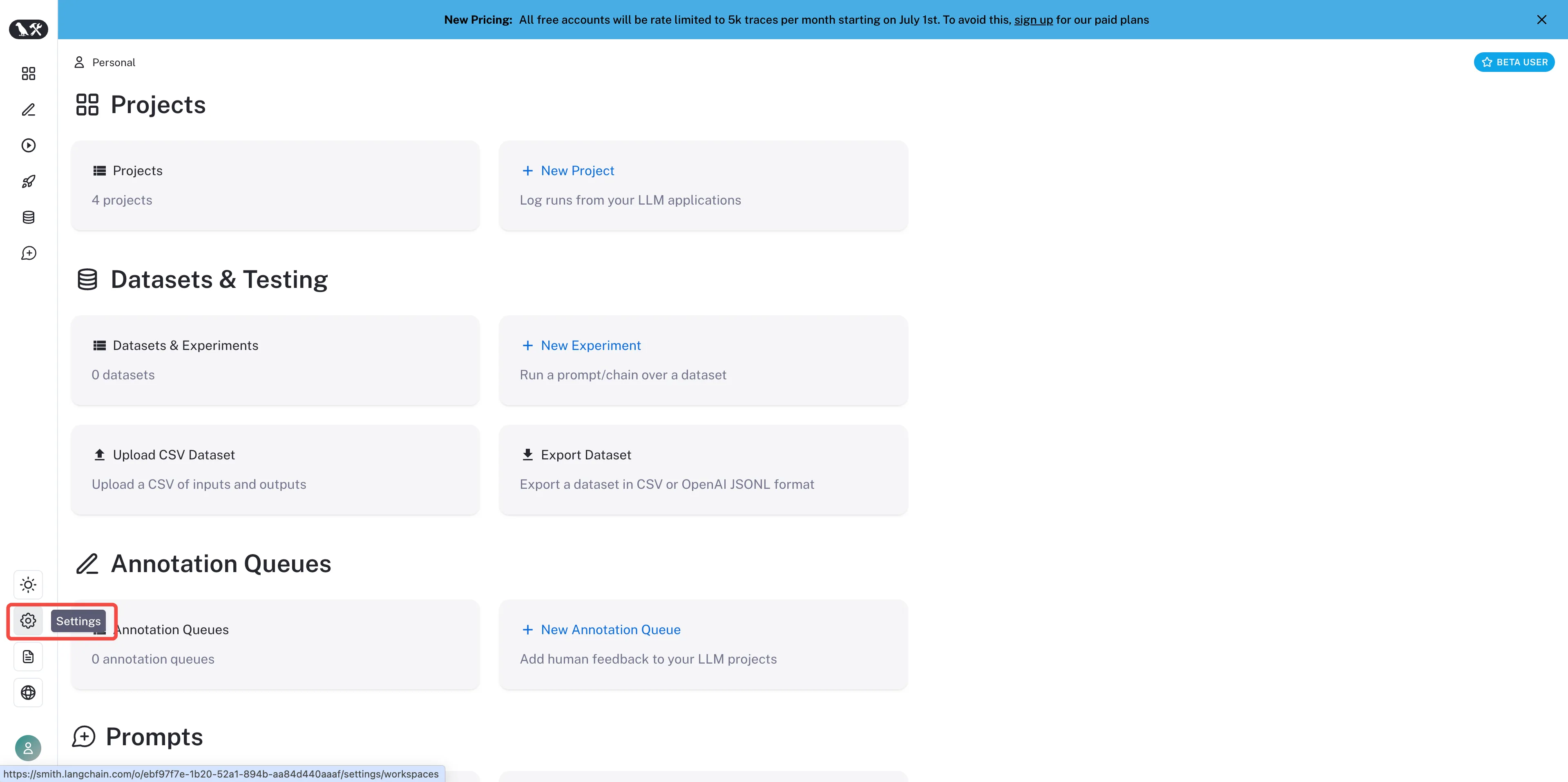
Project settings
 (1) (1) (1) (2).png)
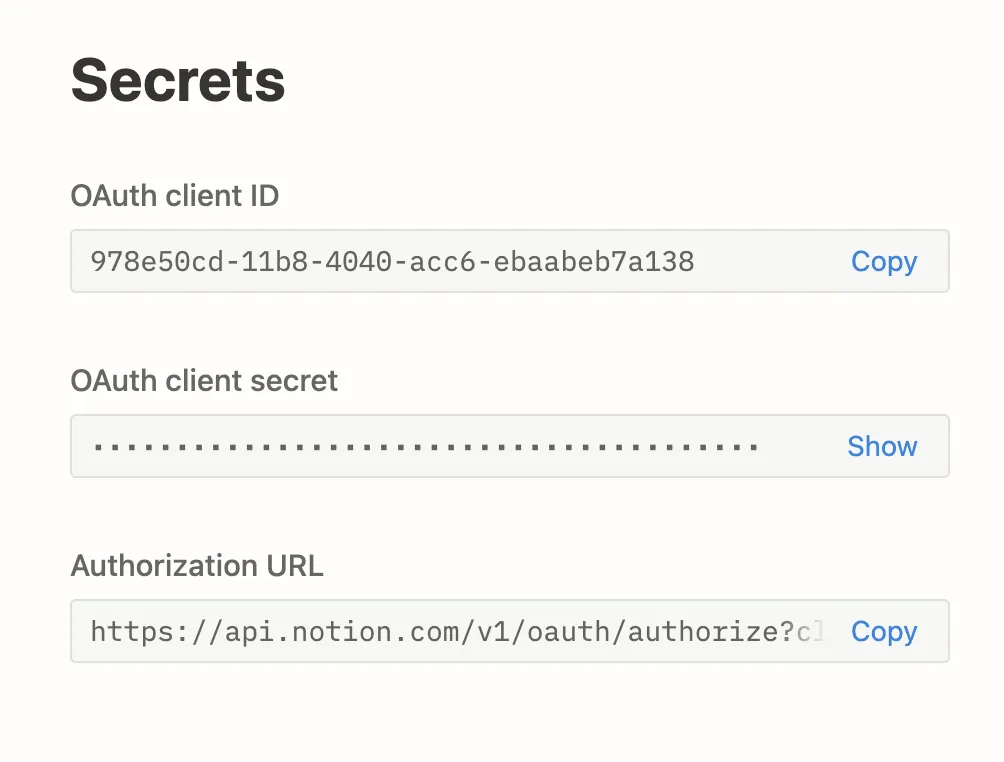
Create a project API Key
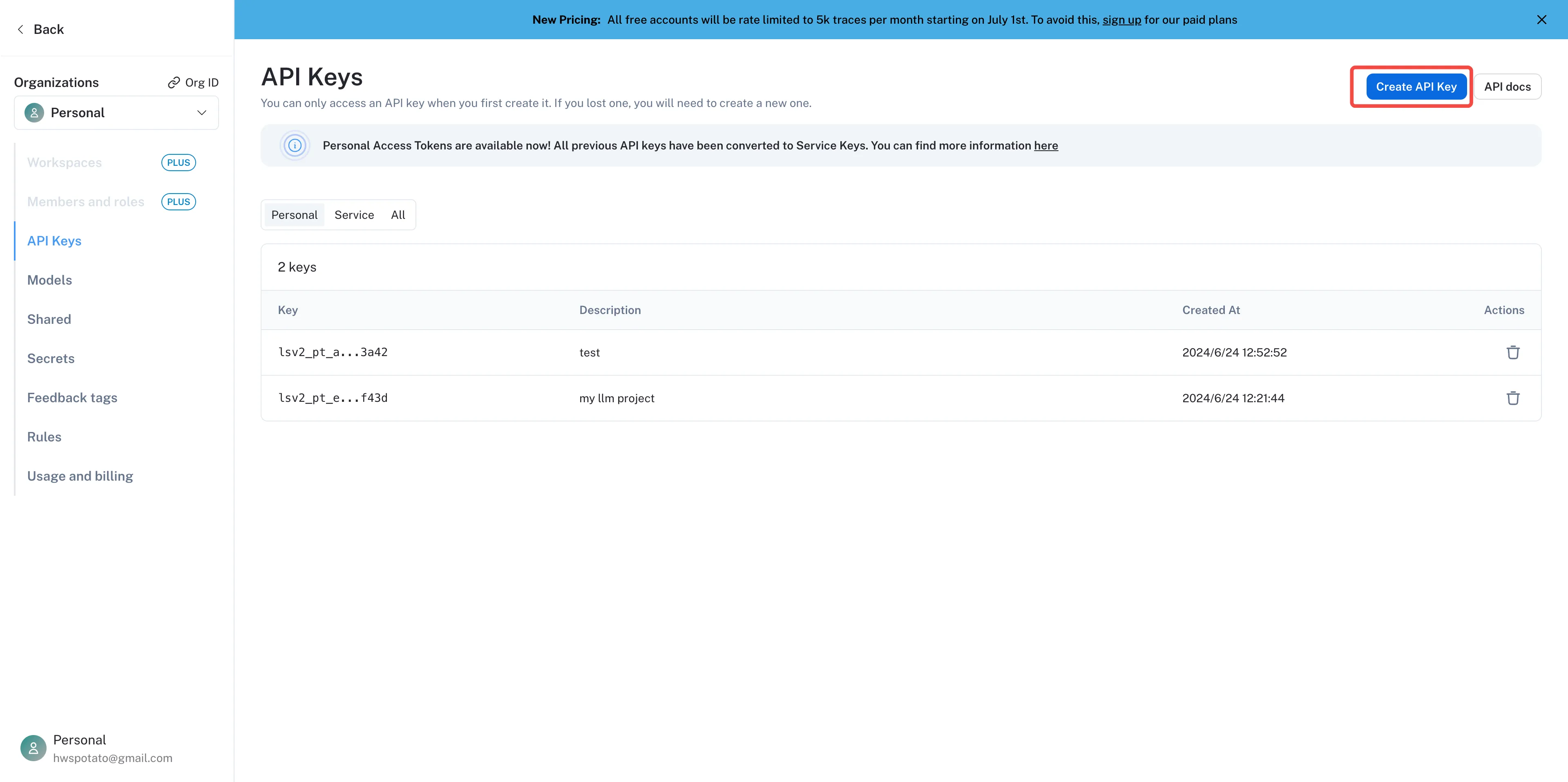
Create a project API Key
 (1) (1) (1).png)
Create an API Key
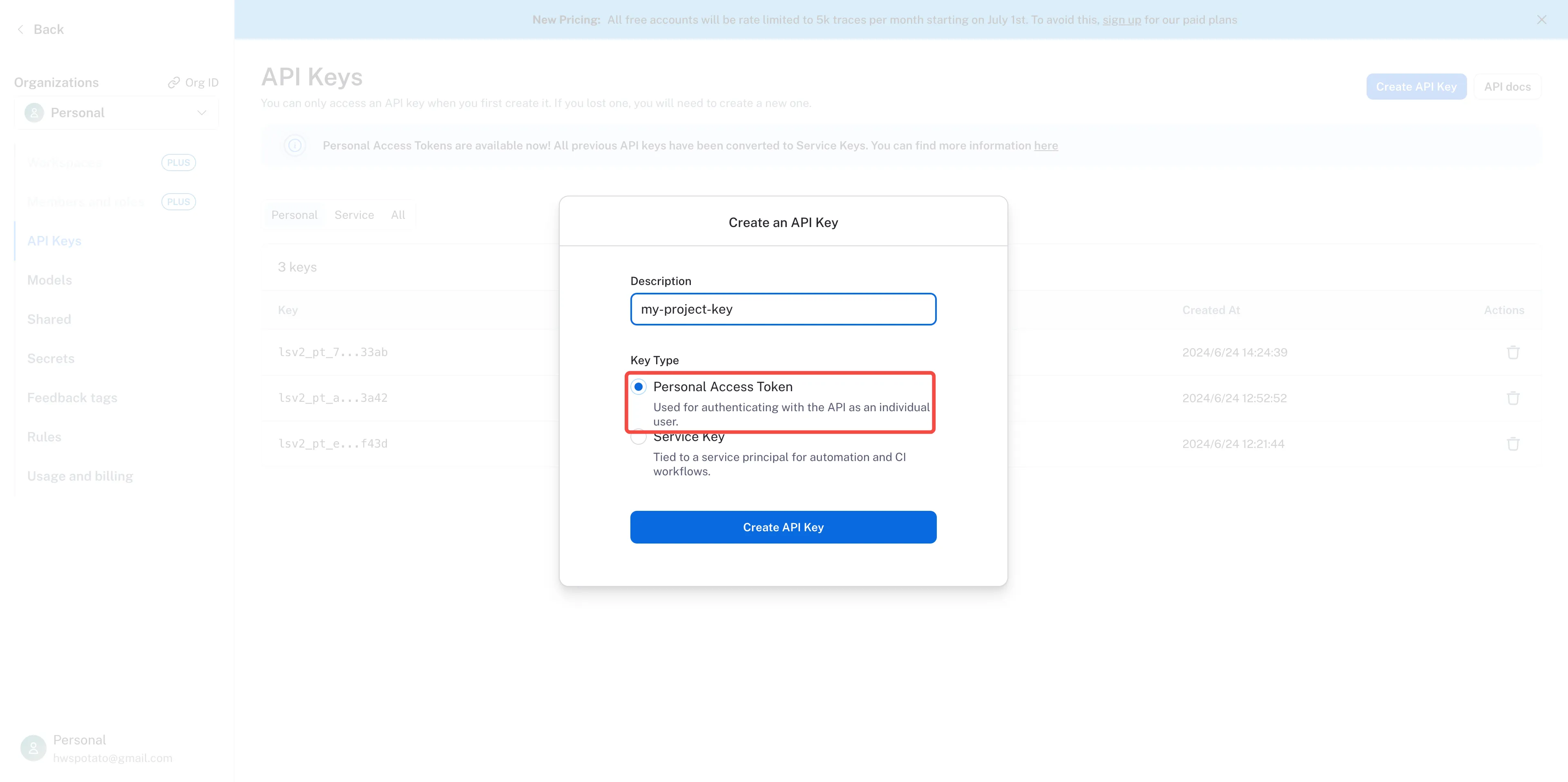
Create an API Key
 (2).png)
Copy API Key
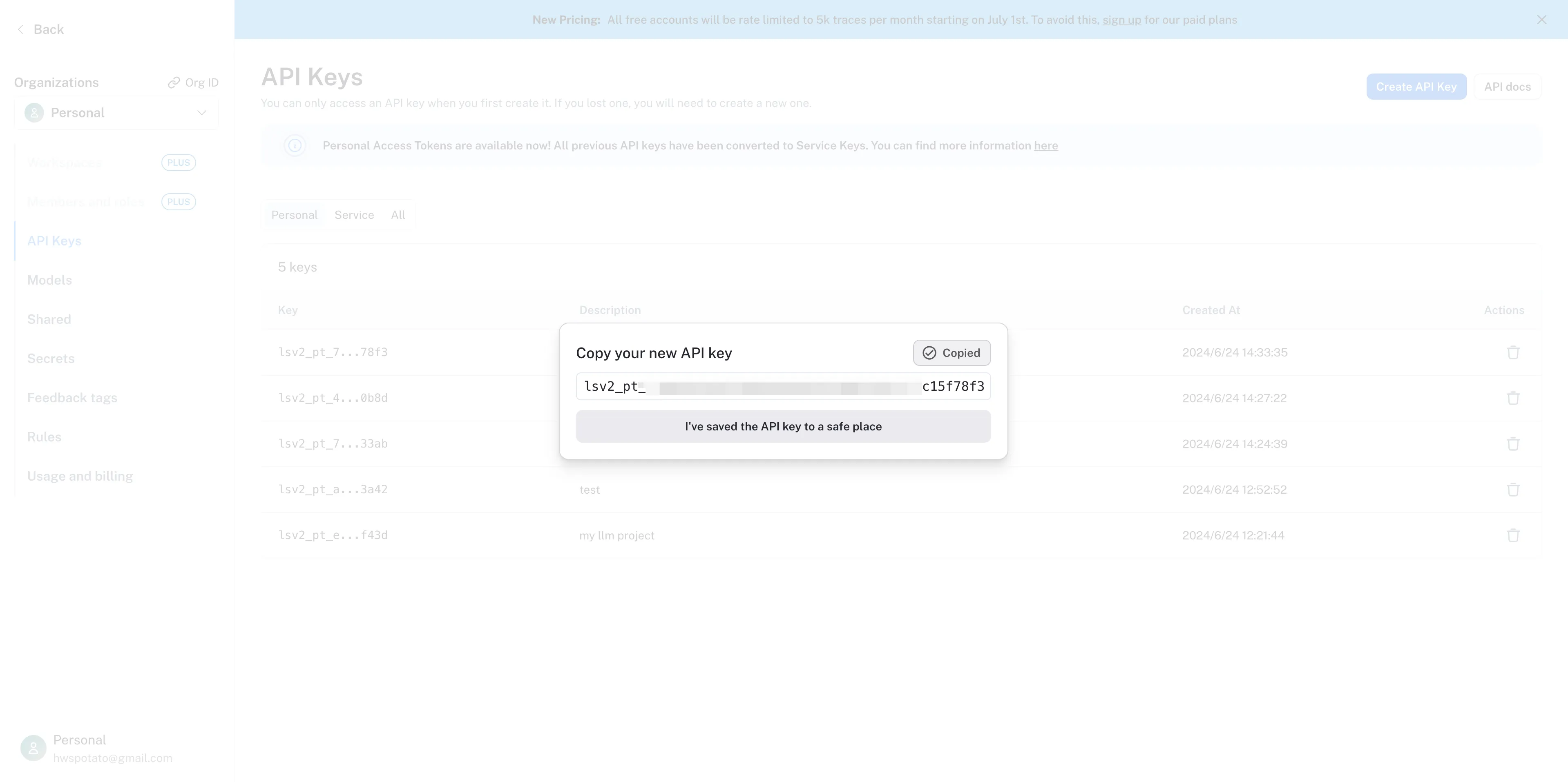
Copy API Key

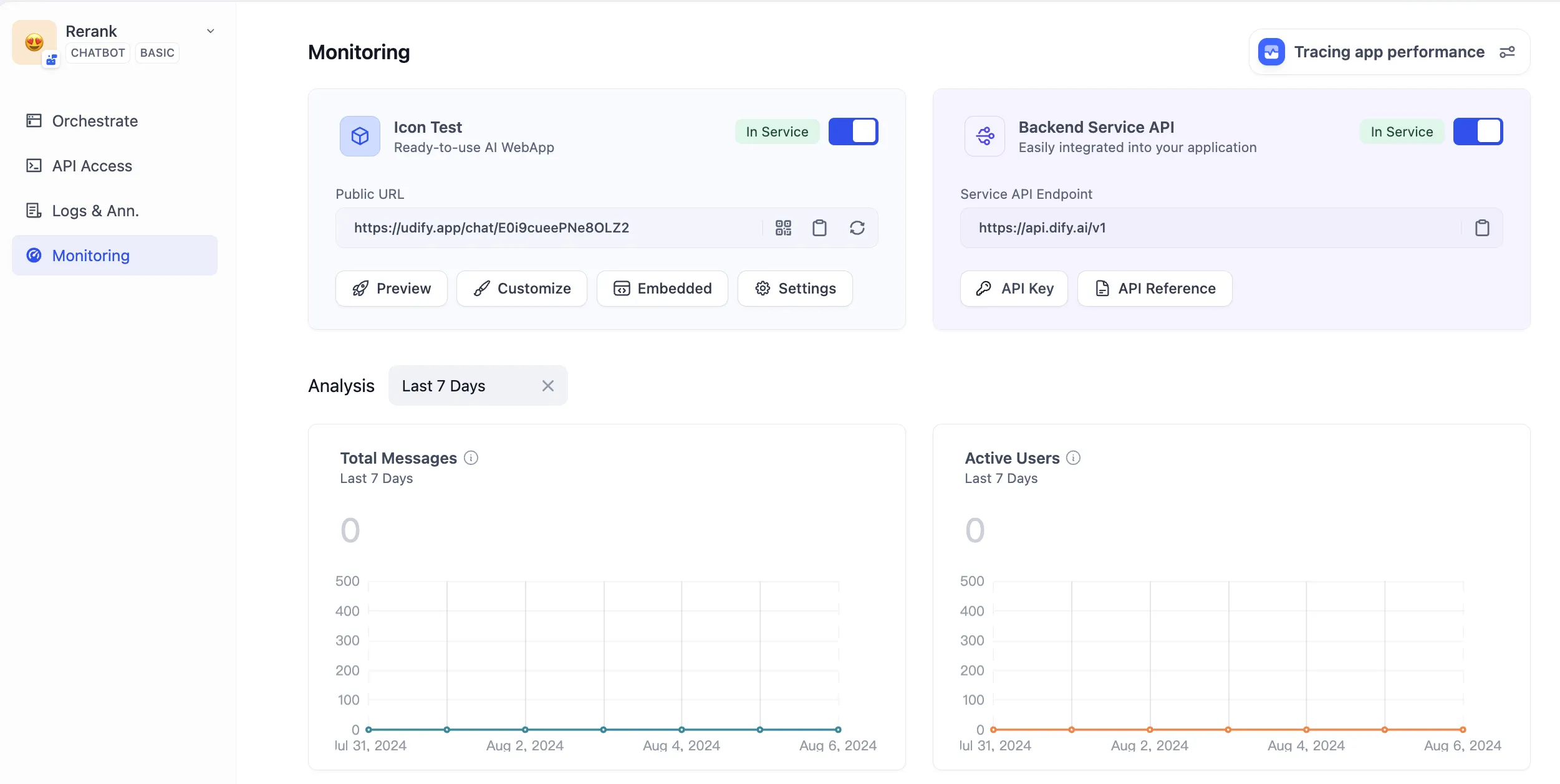
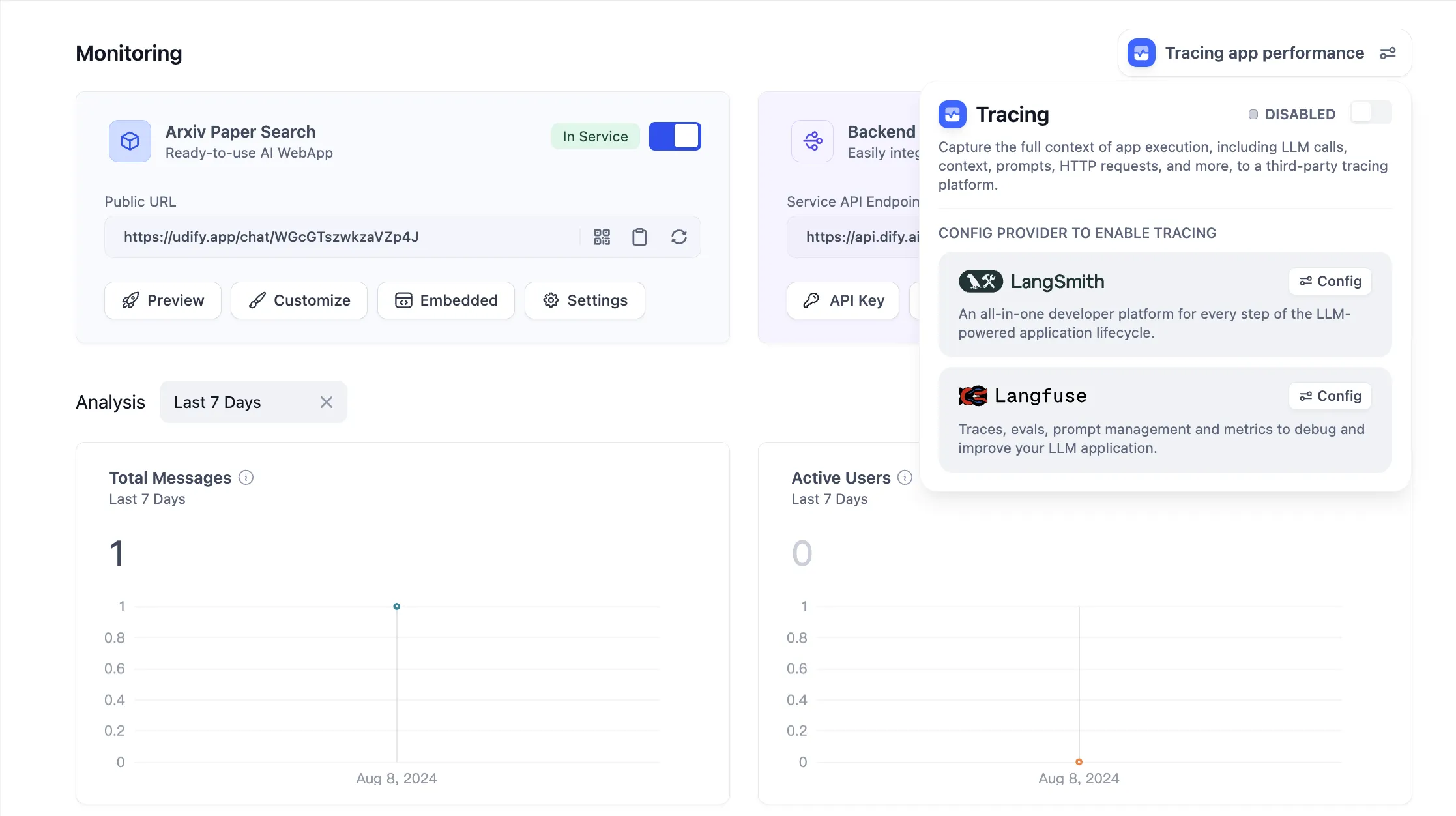
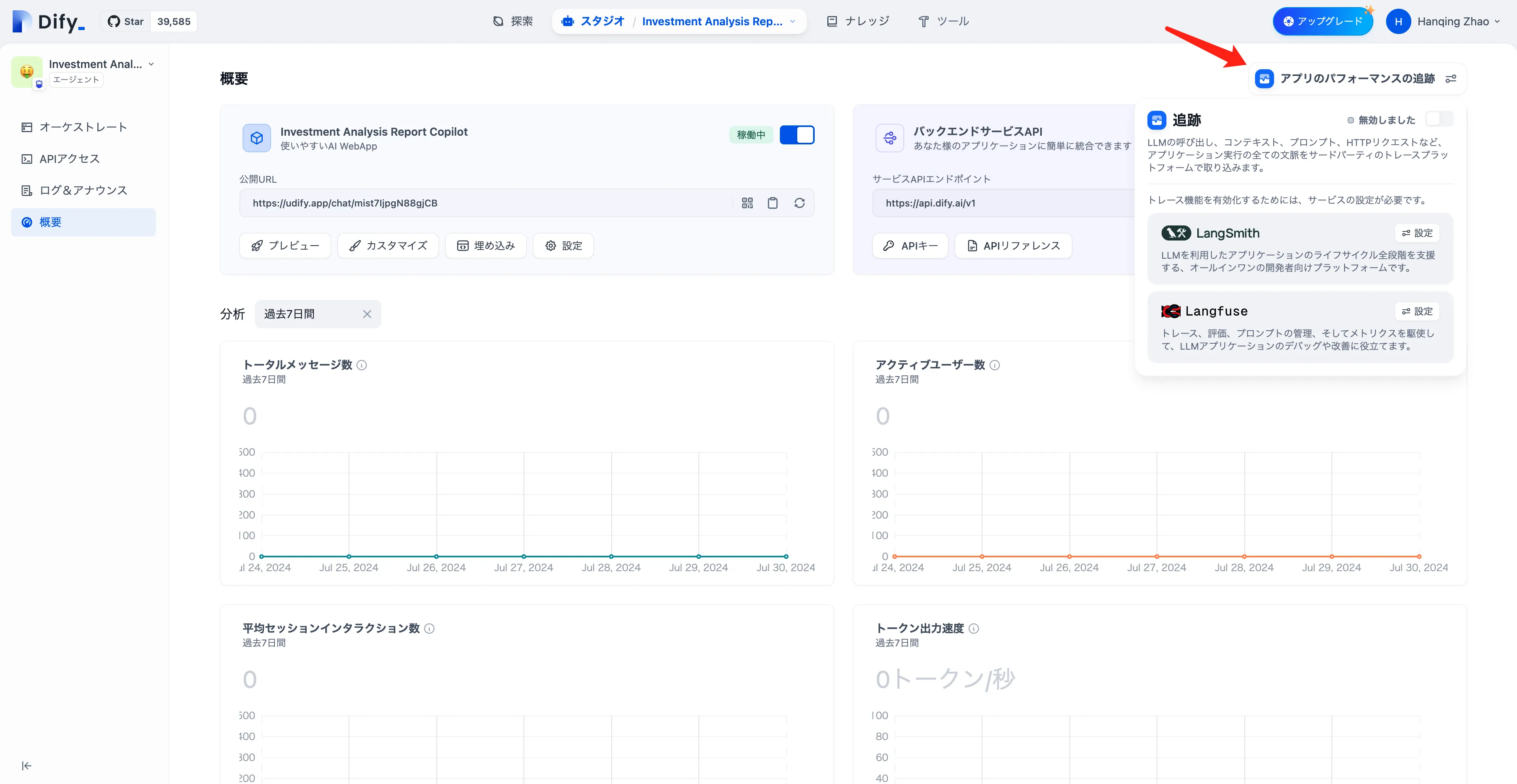
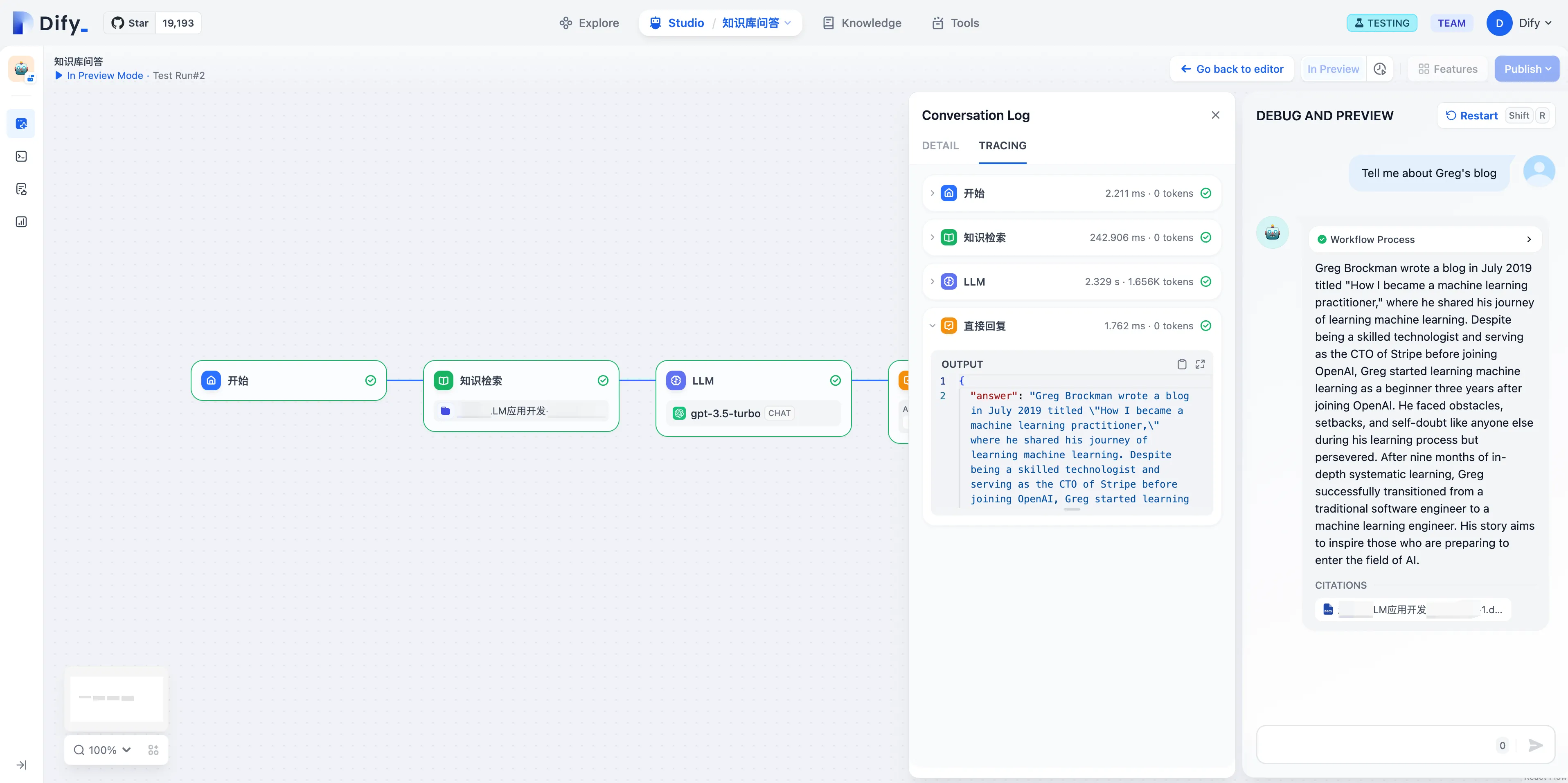
Tracing app performance
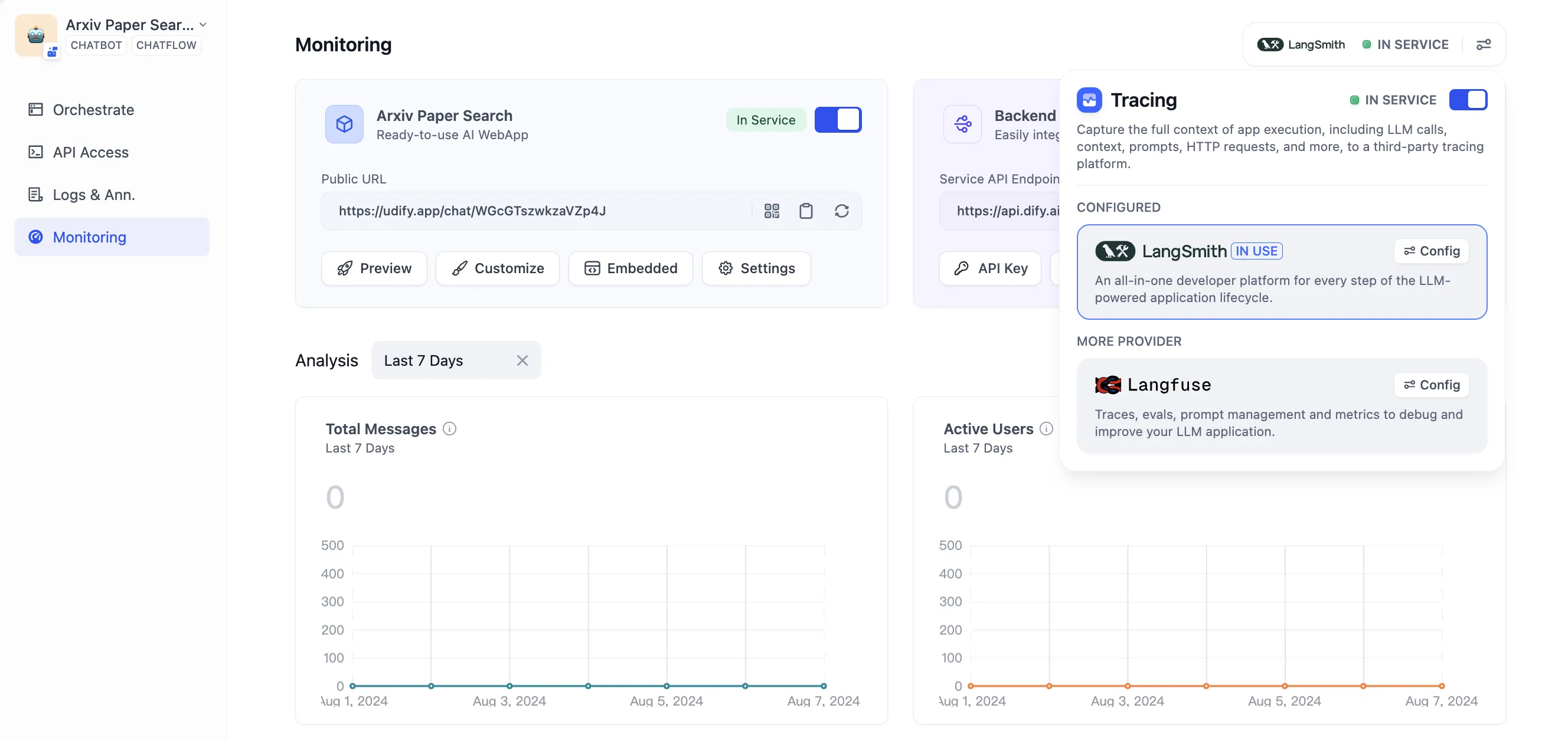
Tracing app performance

Configure LangSmith
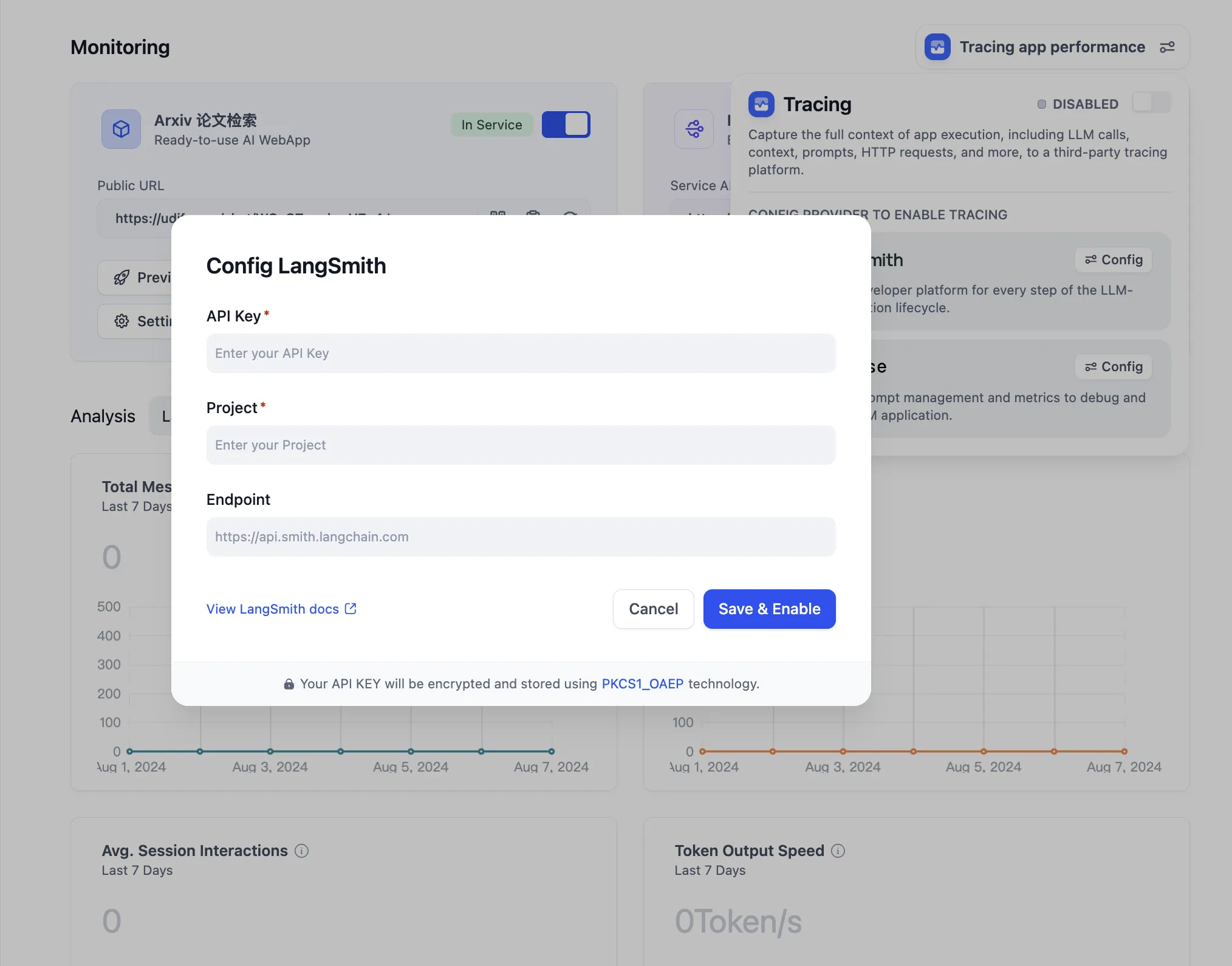
Configure LangSmith

View configuration status
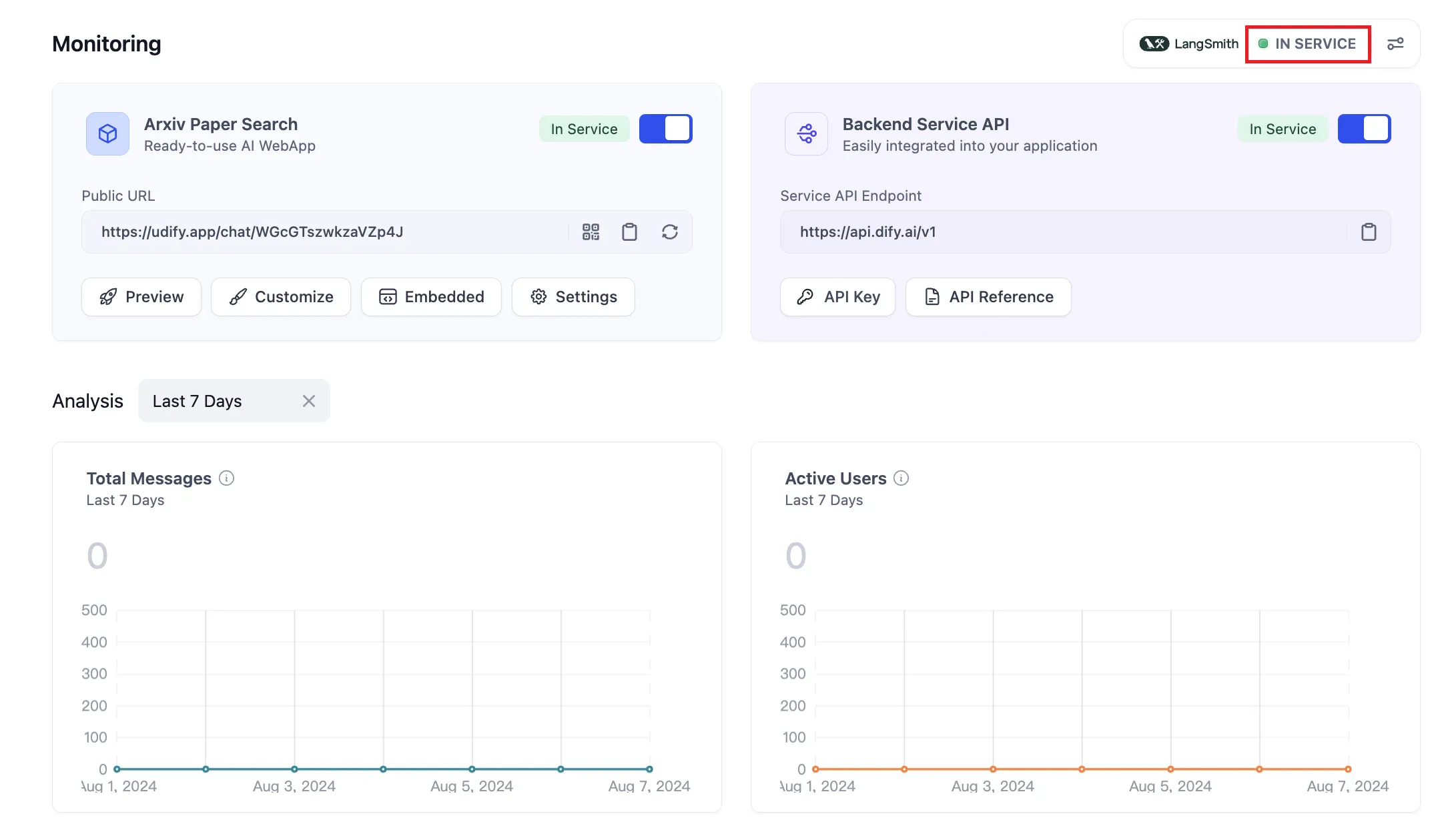
View configuration status
Debugging Applications in Dify
Debugging Applications in Dify
 (1) (1) (1).png)
Viewing application data in LangSmith
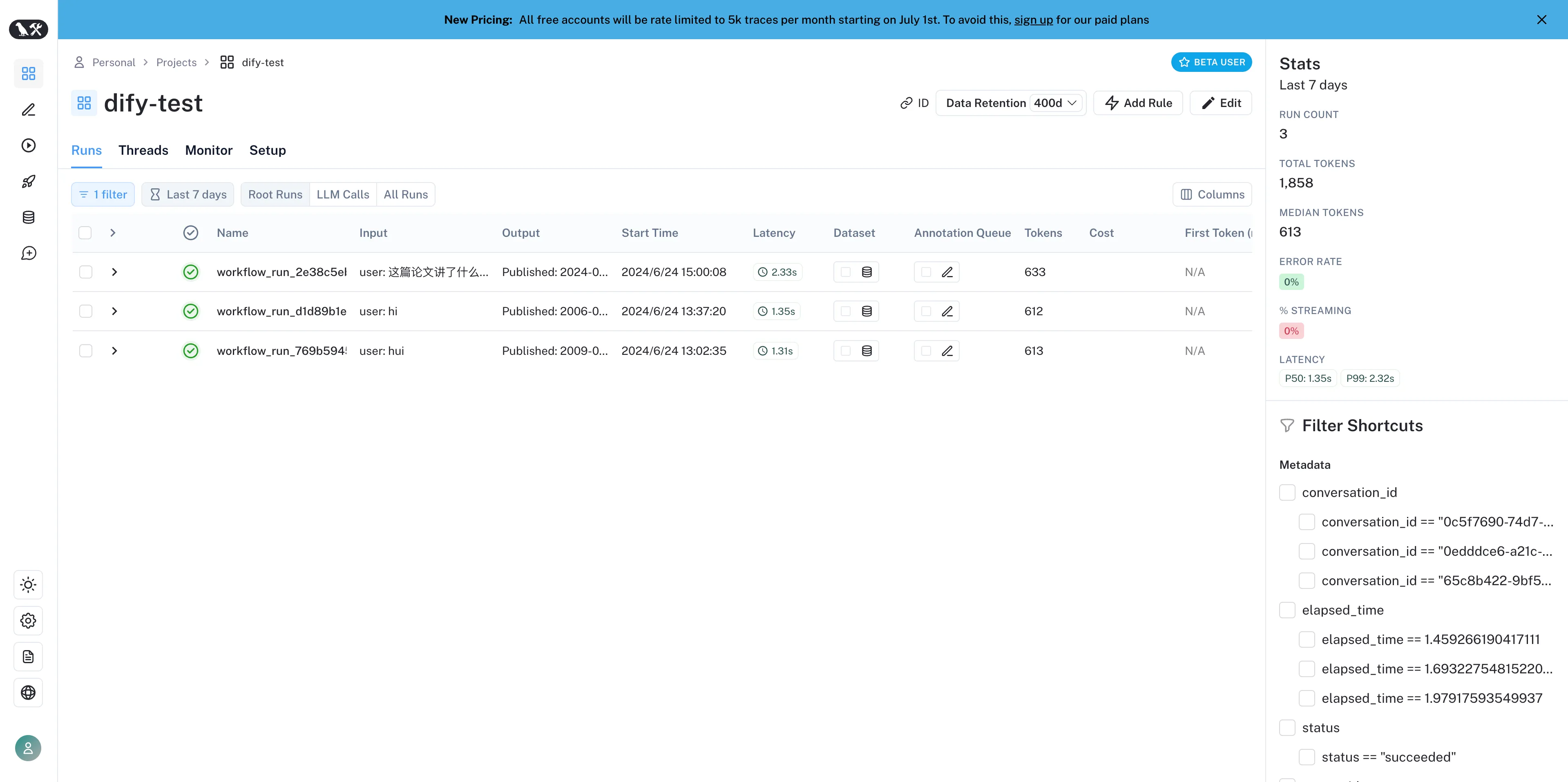
Viewing application data in LangSmith

Viewing application data in LangSmith
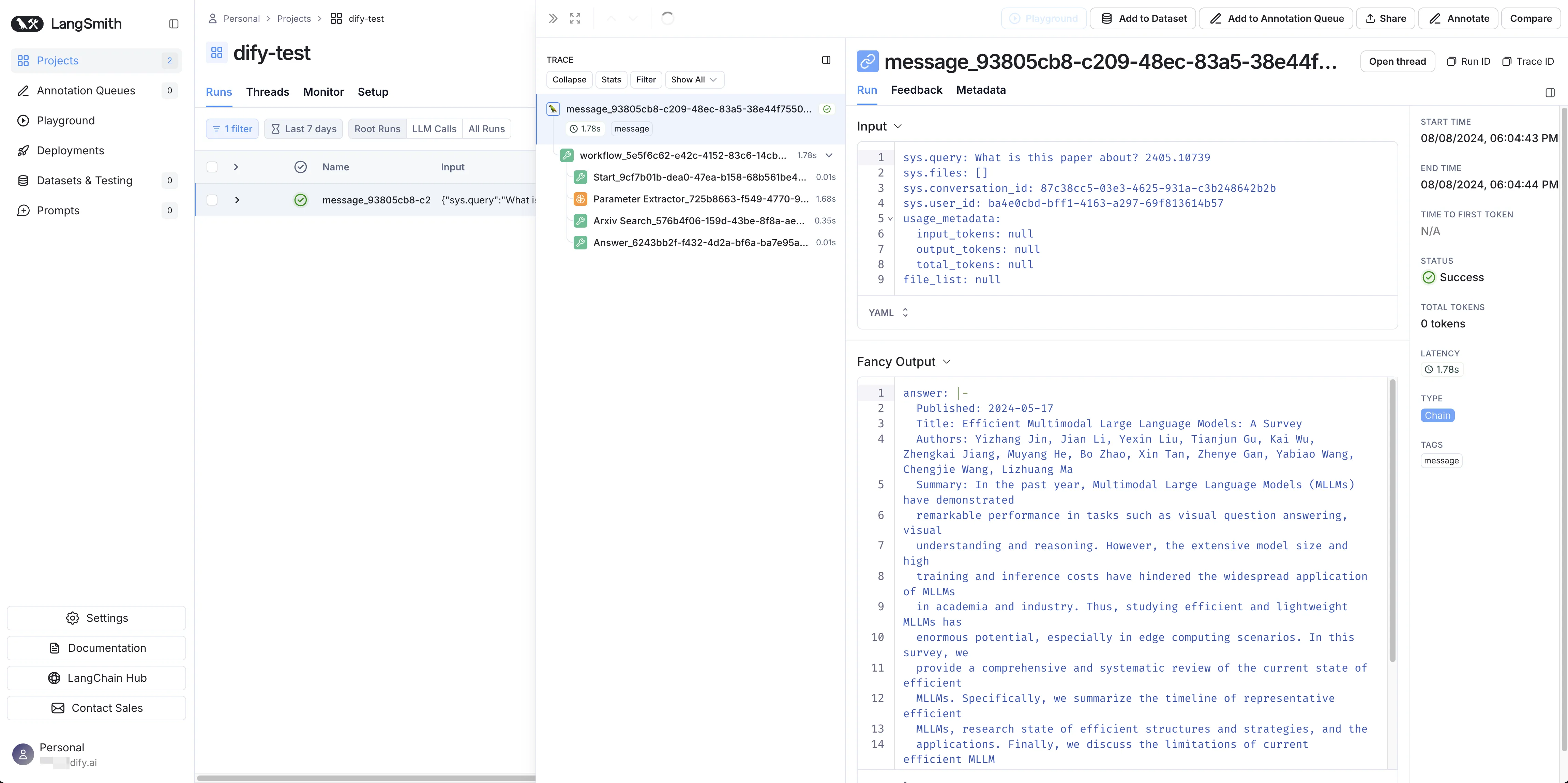
Viewing application data in LangSmith
.png)

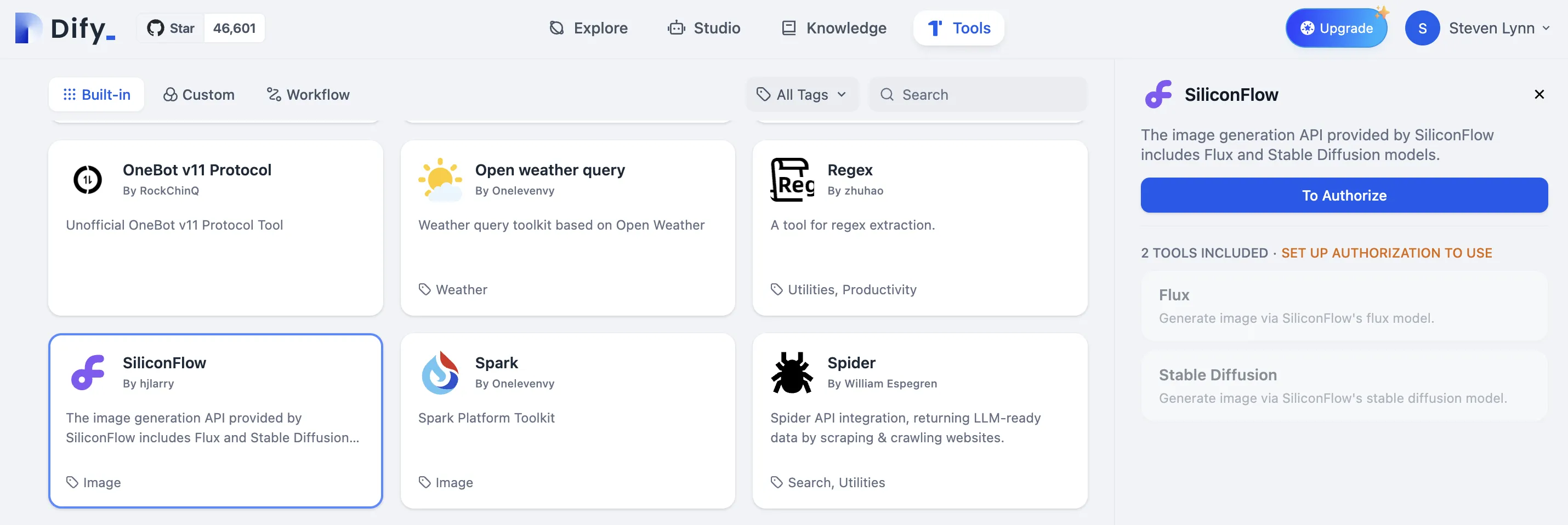




.png)
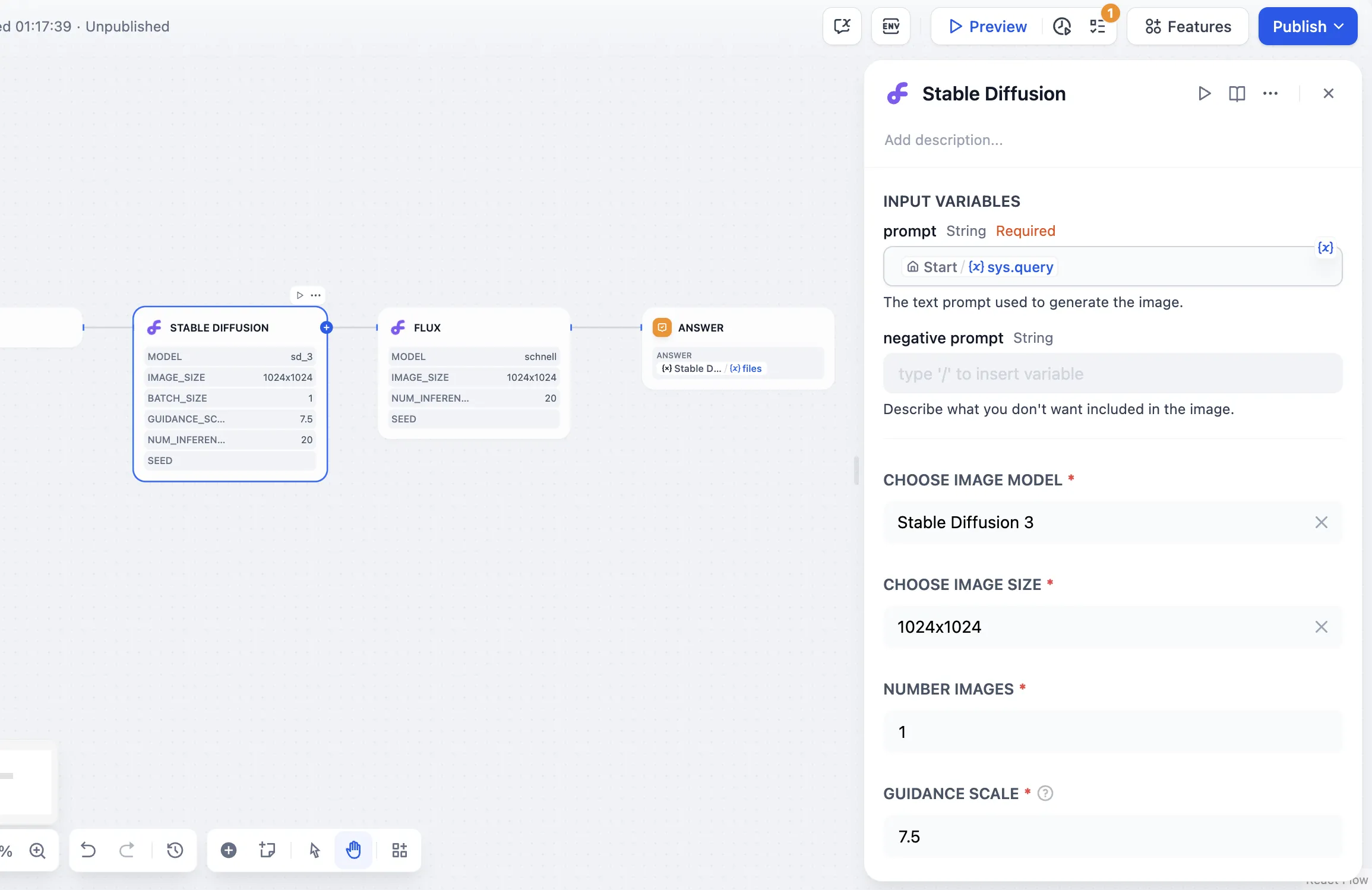
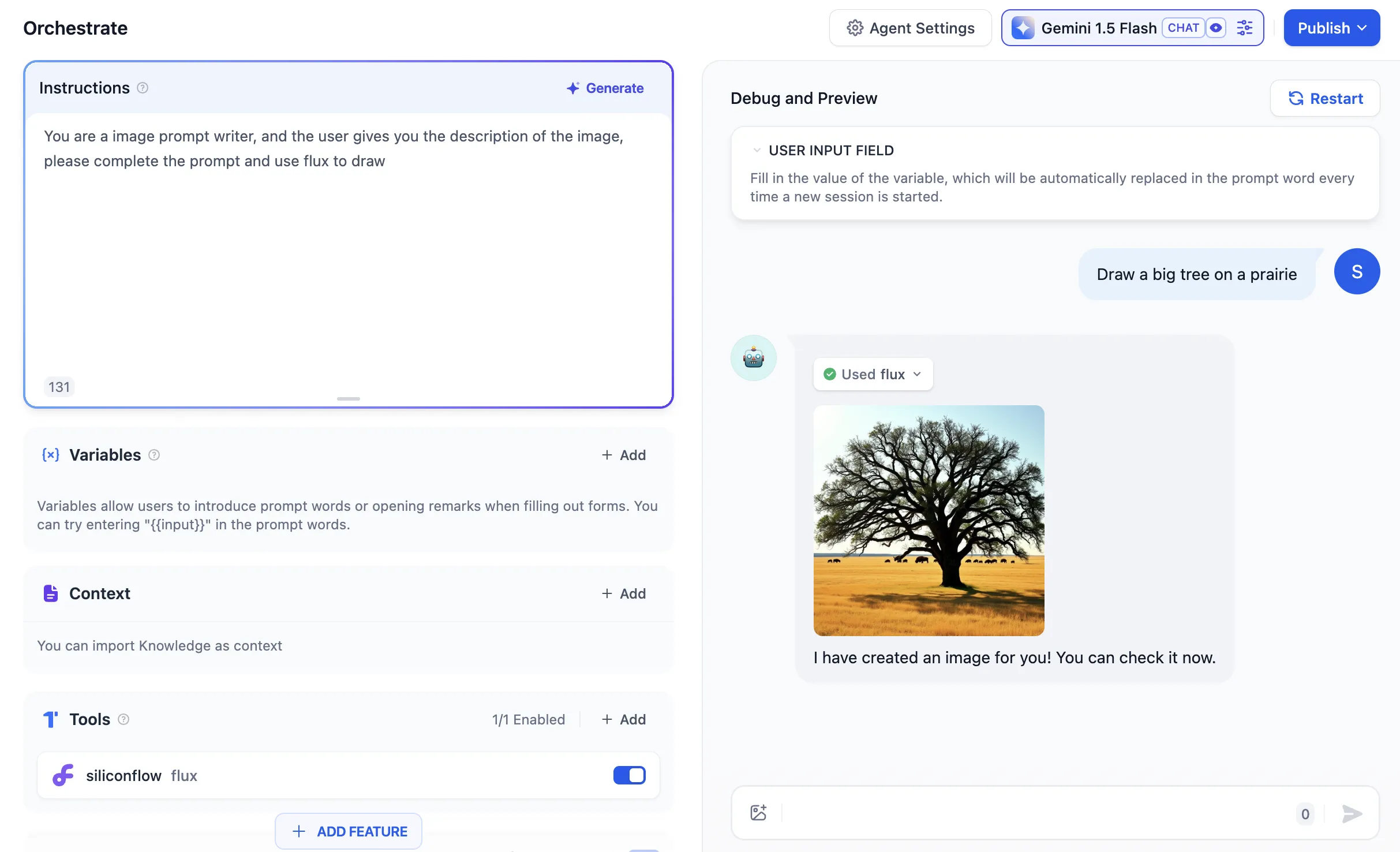
.png)
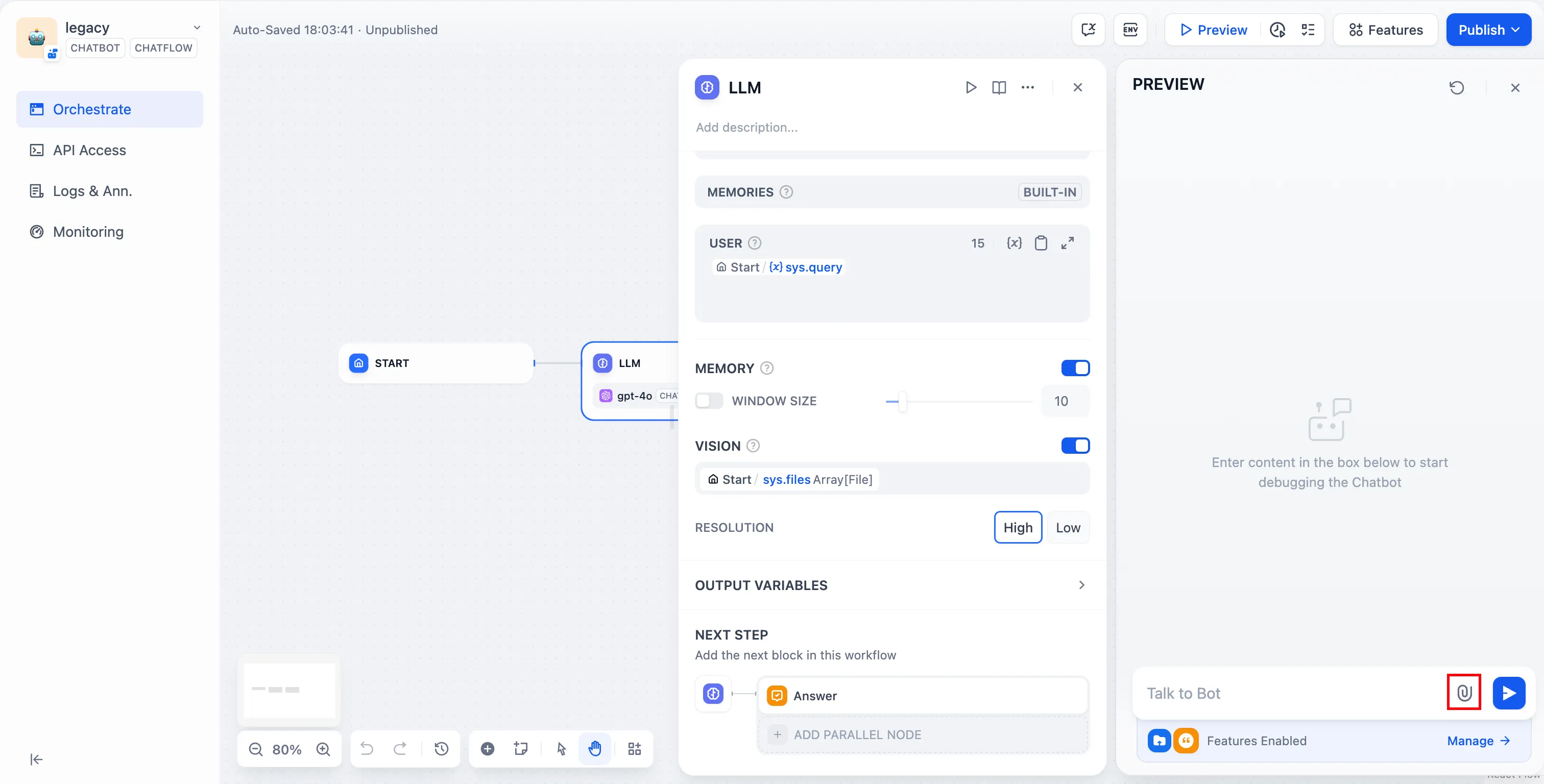
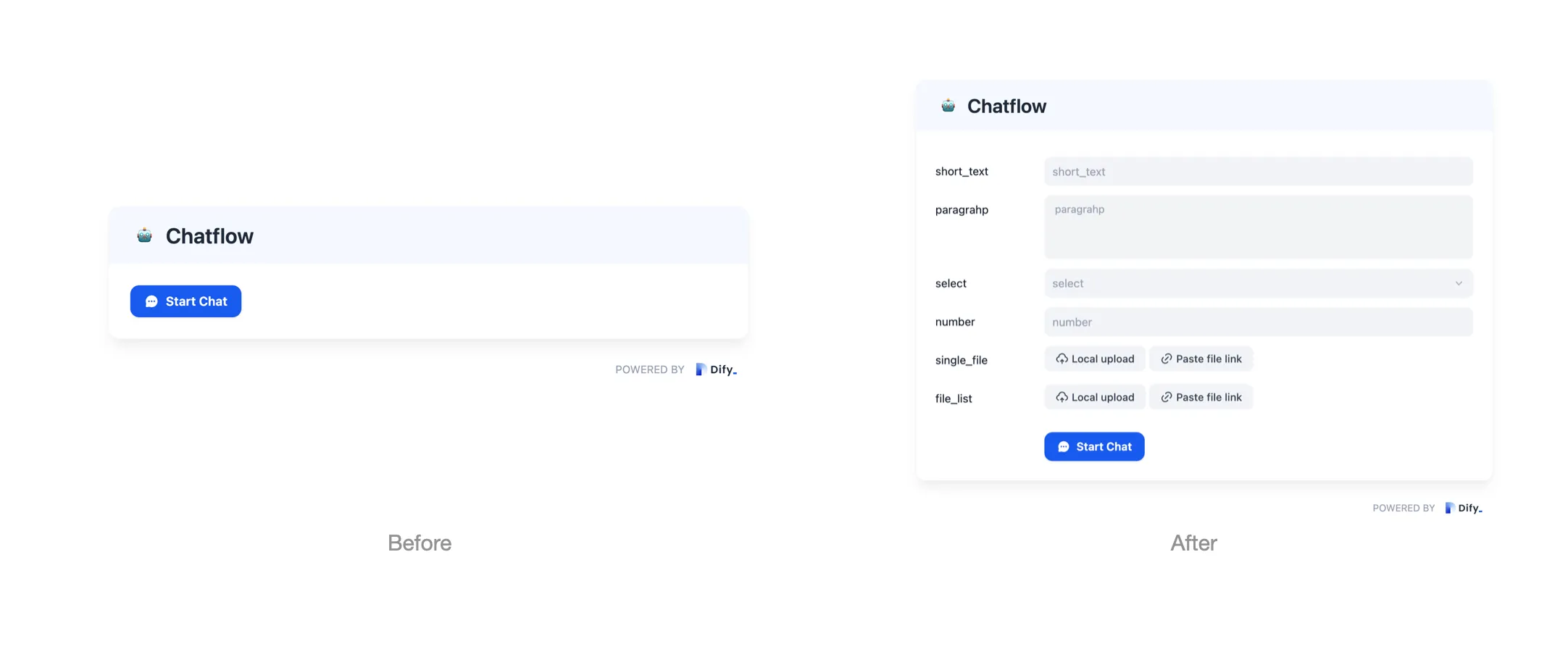
Upload file
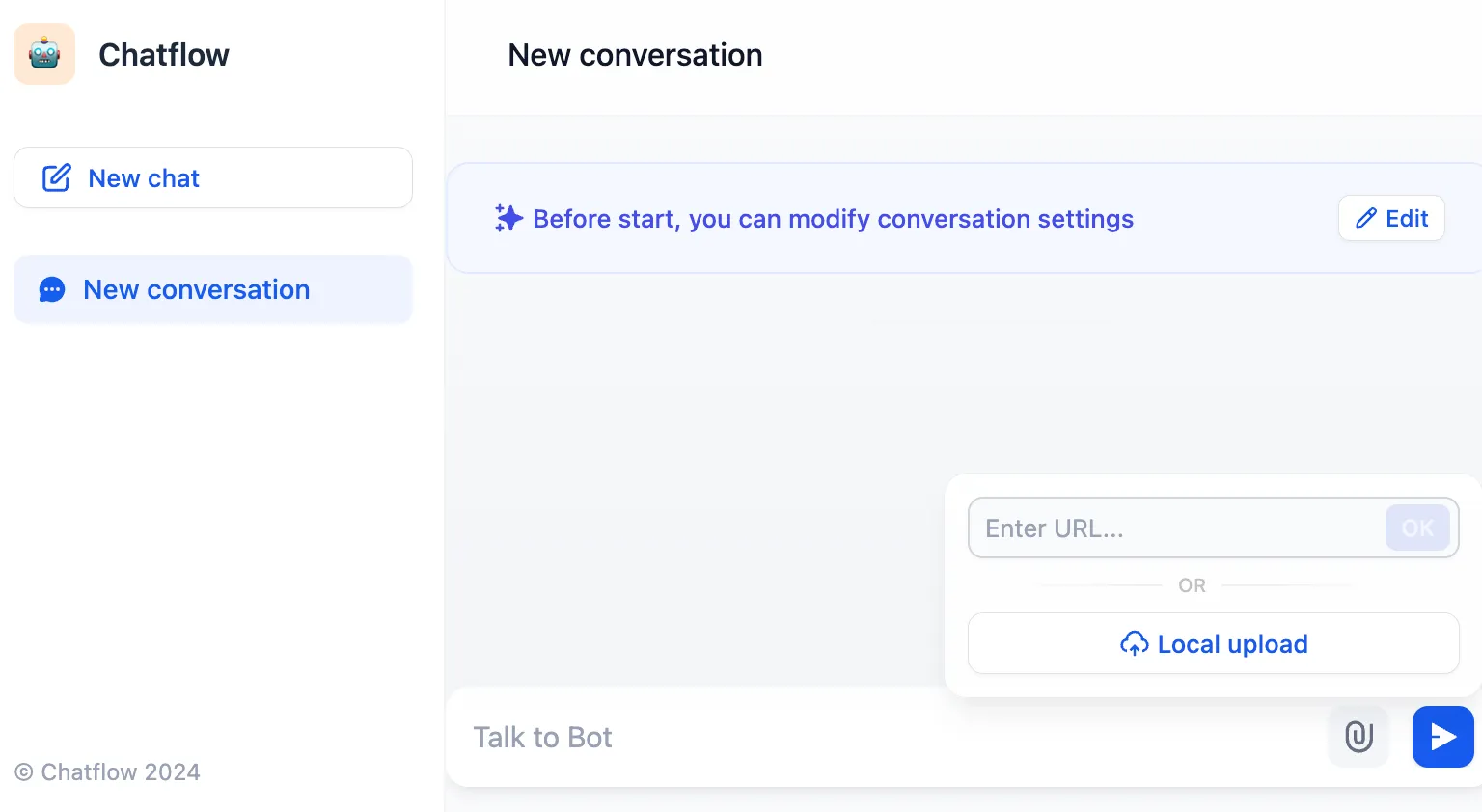
Upload file
.png)
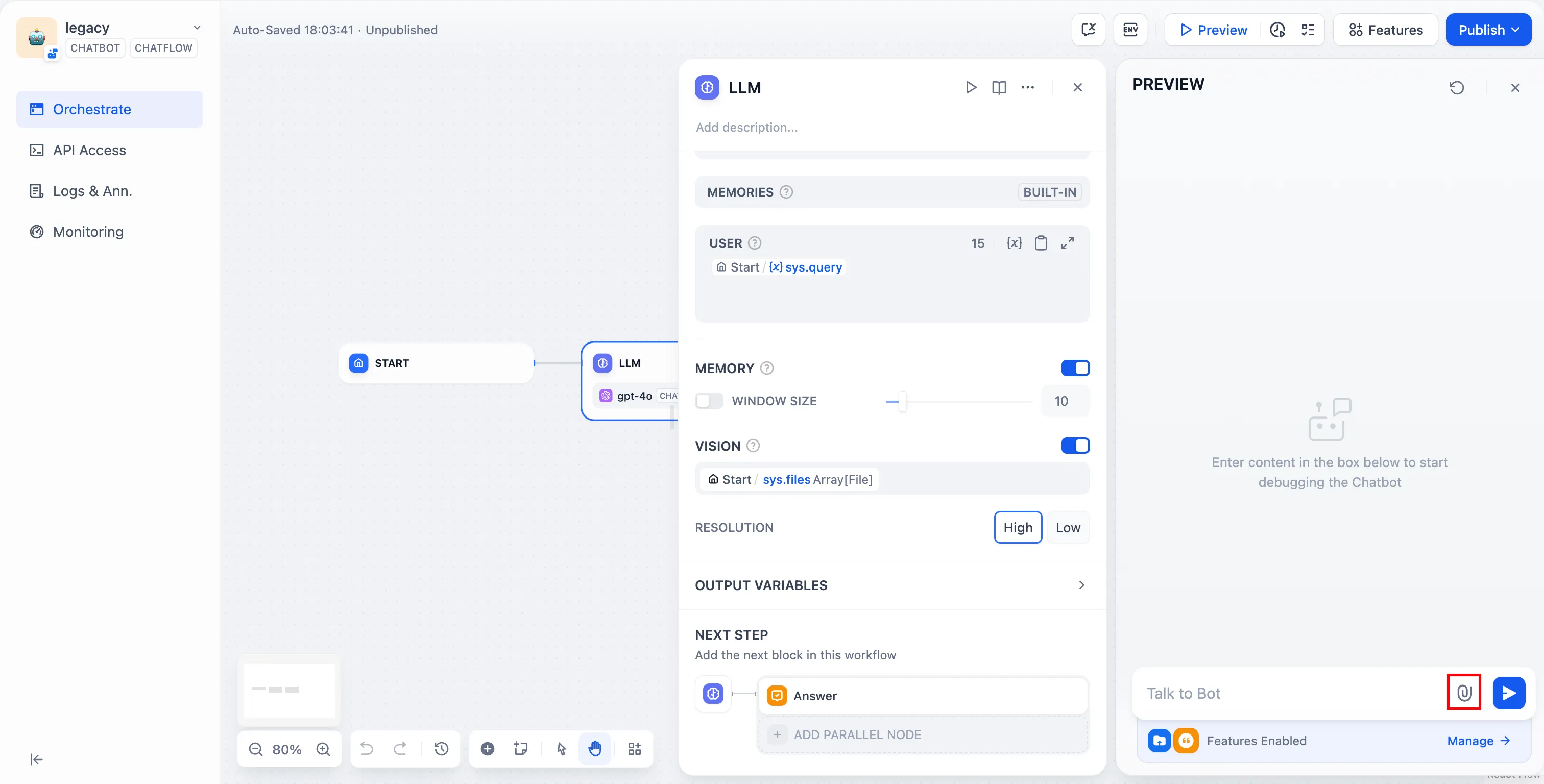
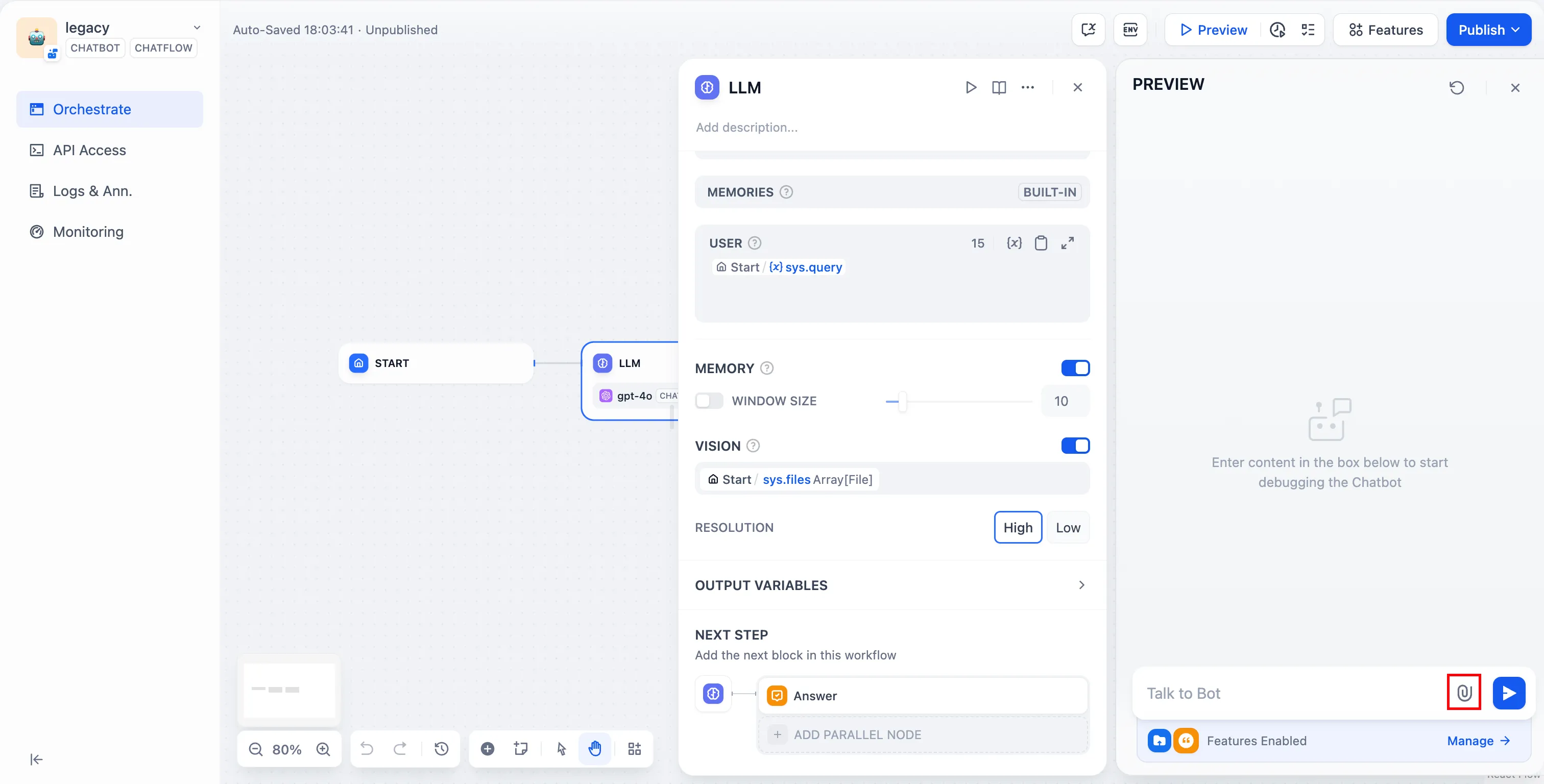
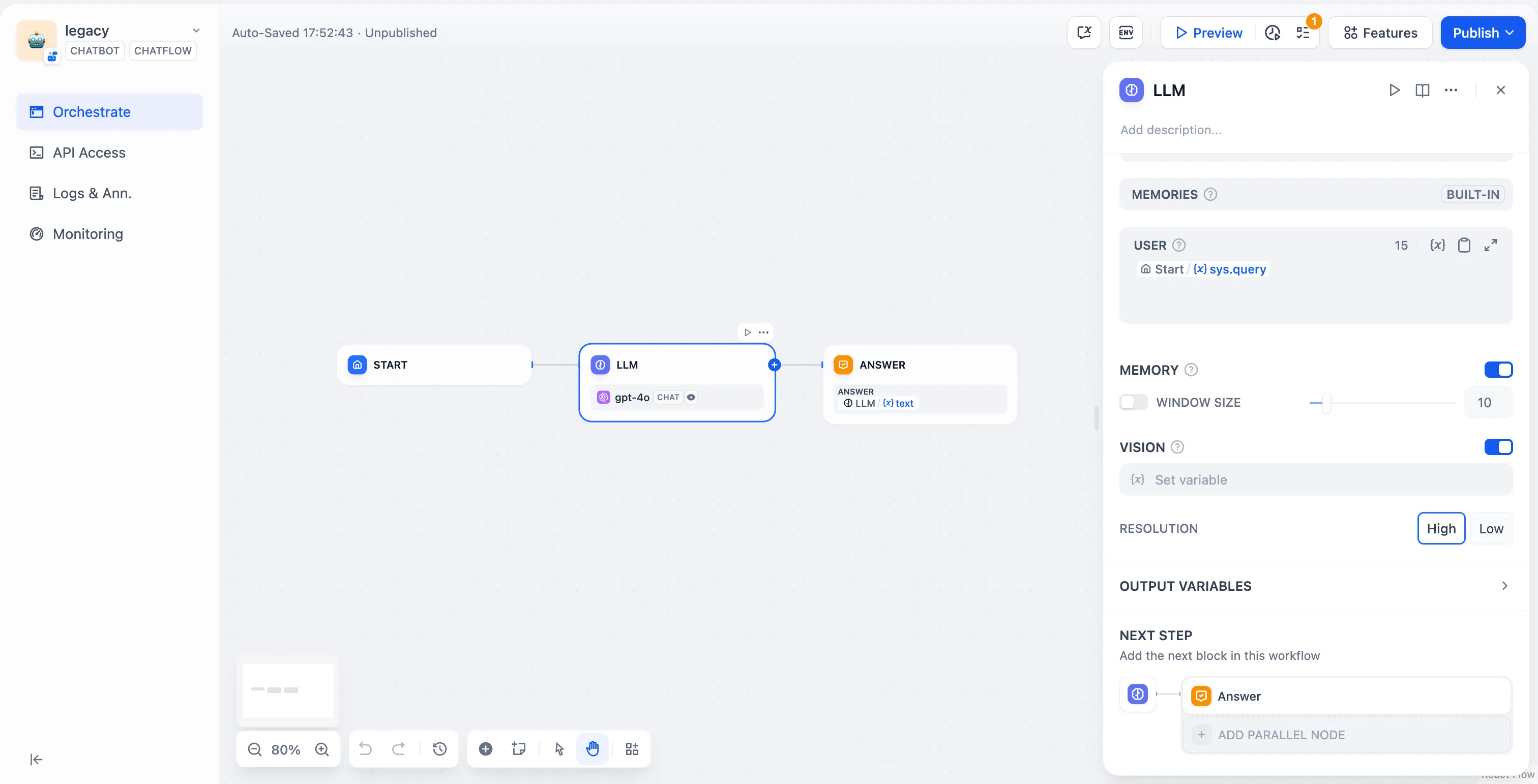
Enable vision
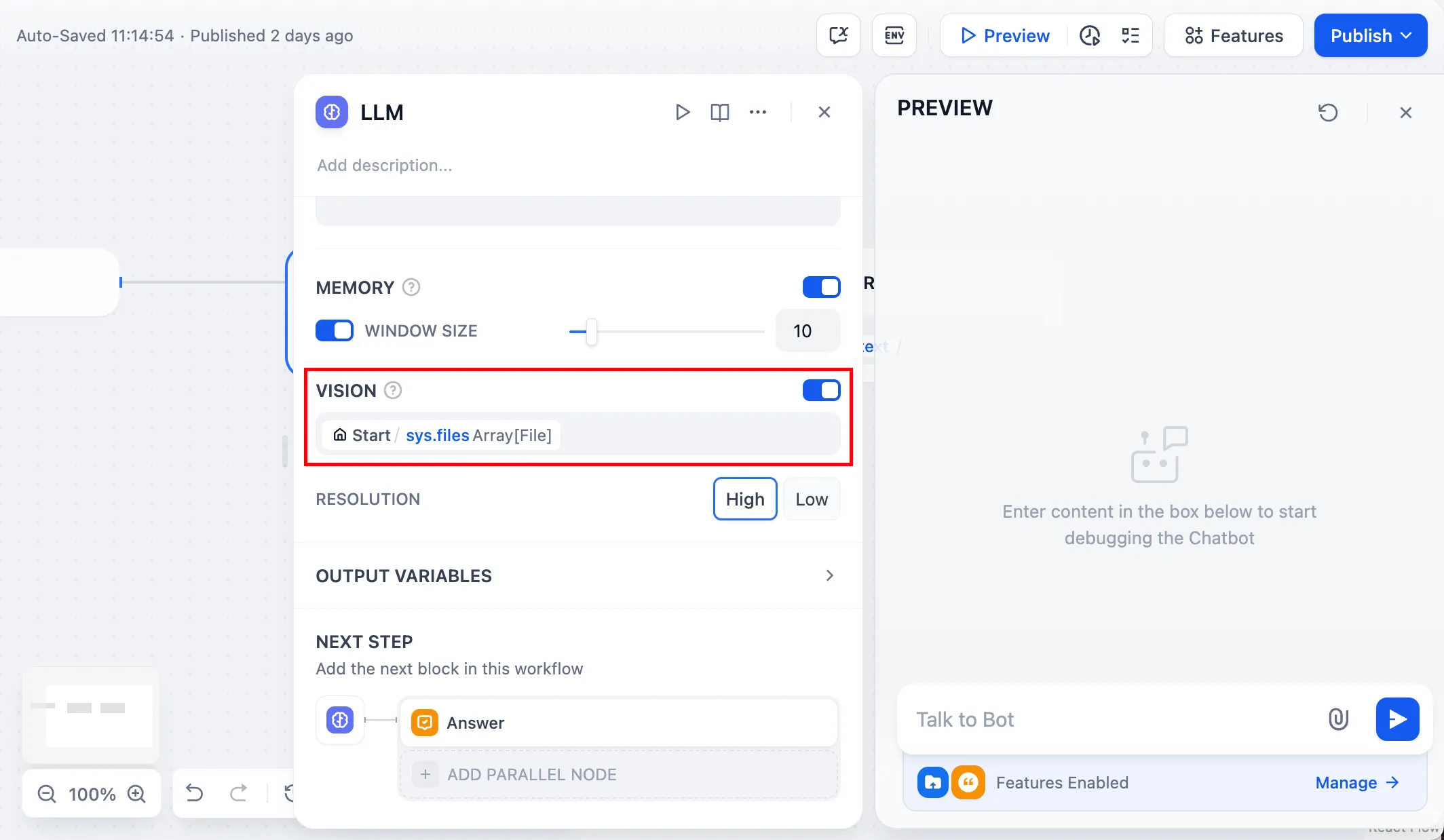
Enable vision
.png)
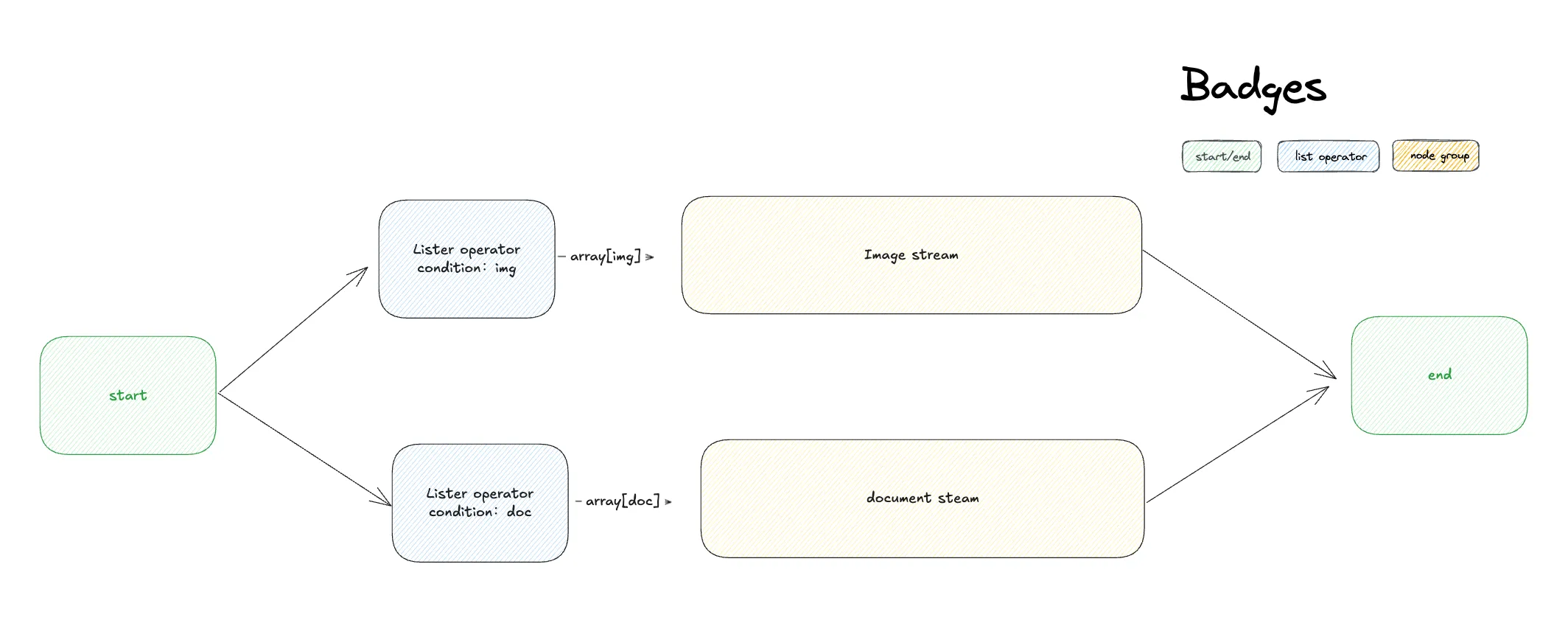
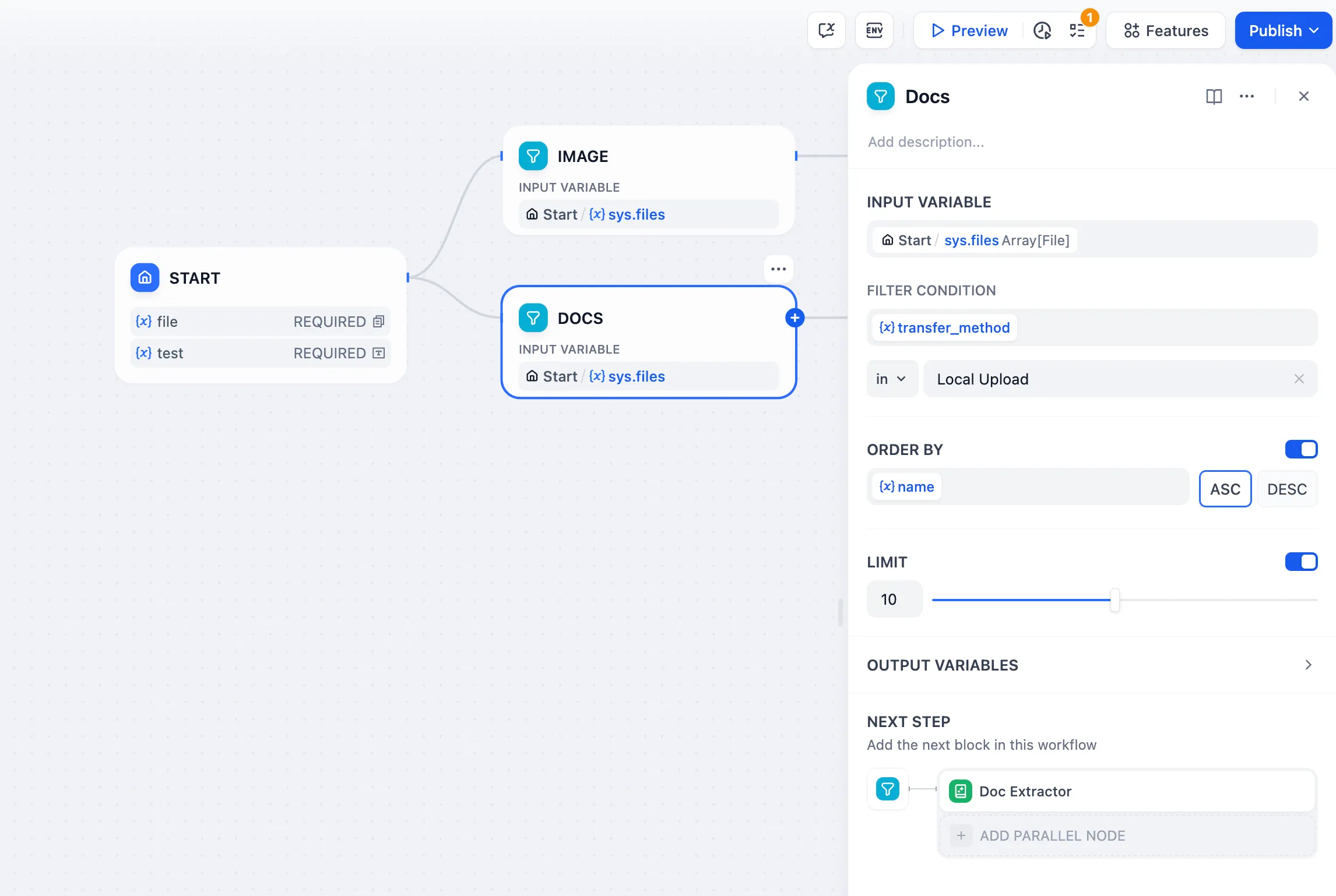
Mixed File Types
Mixed File Types
.png)
.png)
.png)
.png)
.png)



 (3).png)
 (2).png)
.png)
 (5).png)
 (3) (1).png)
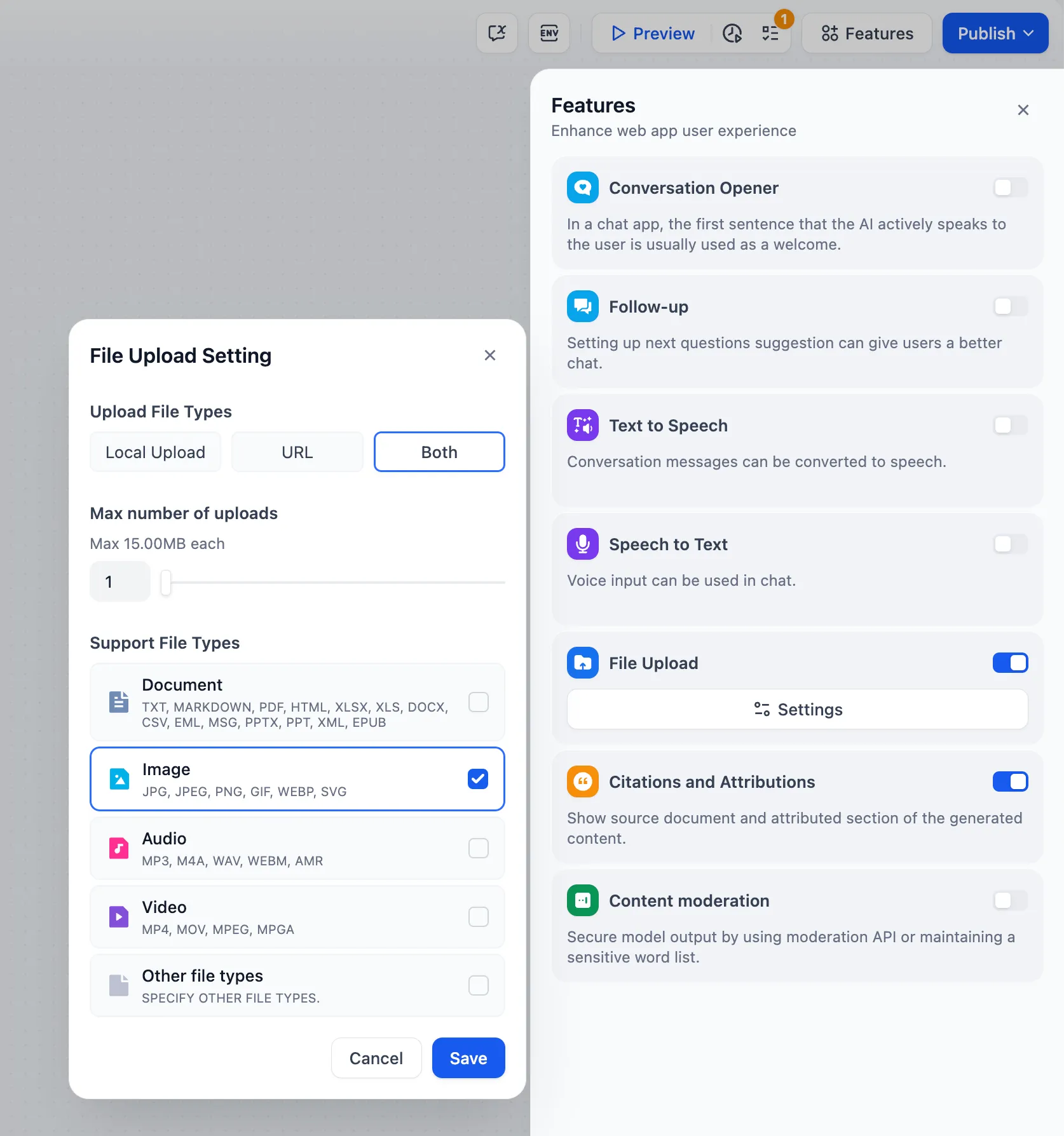
file upload
file upload
 (4).png)

 (3).png)
.png)
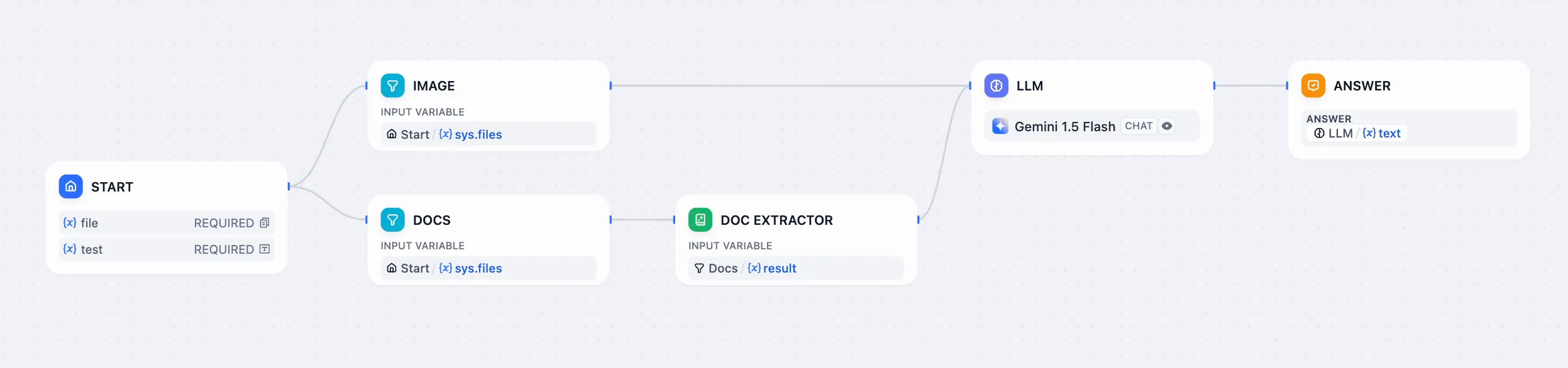
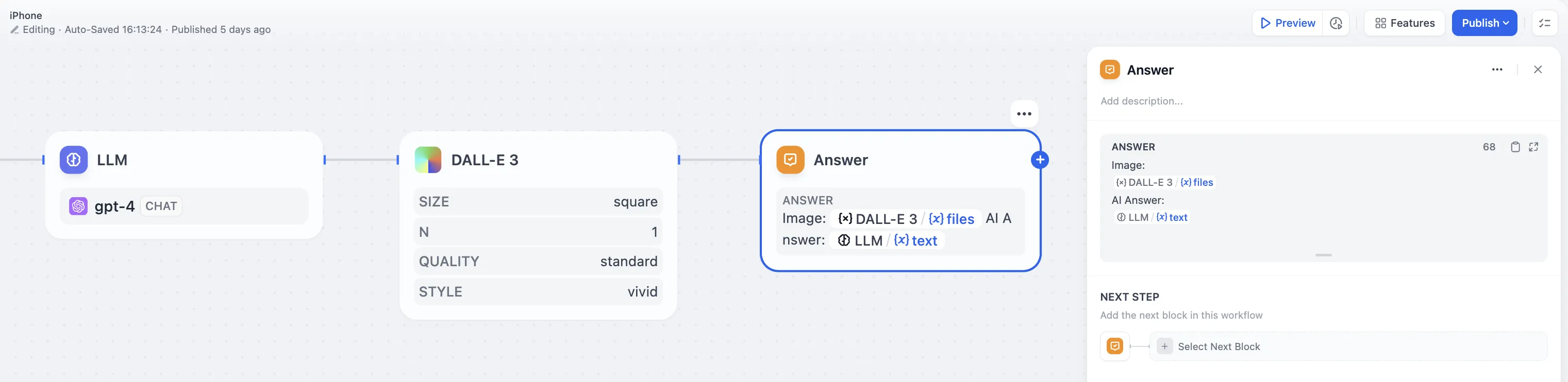
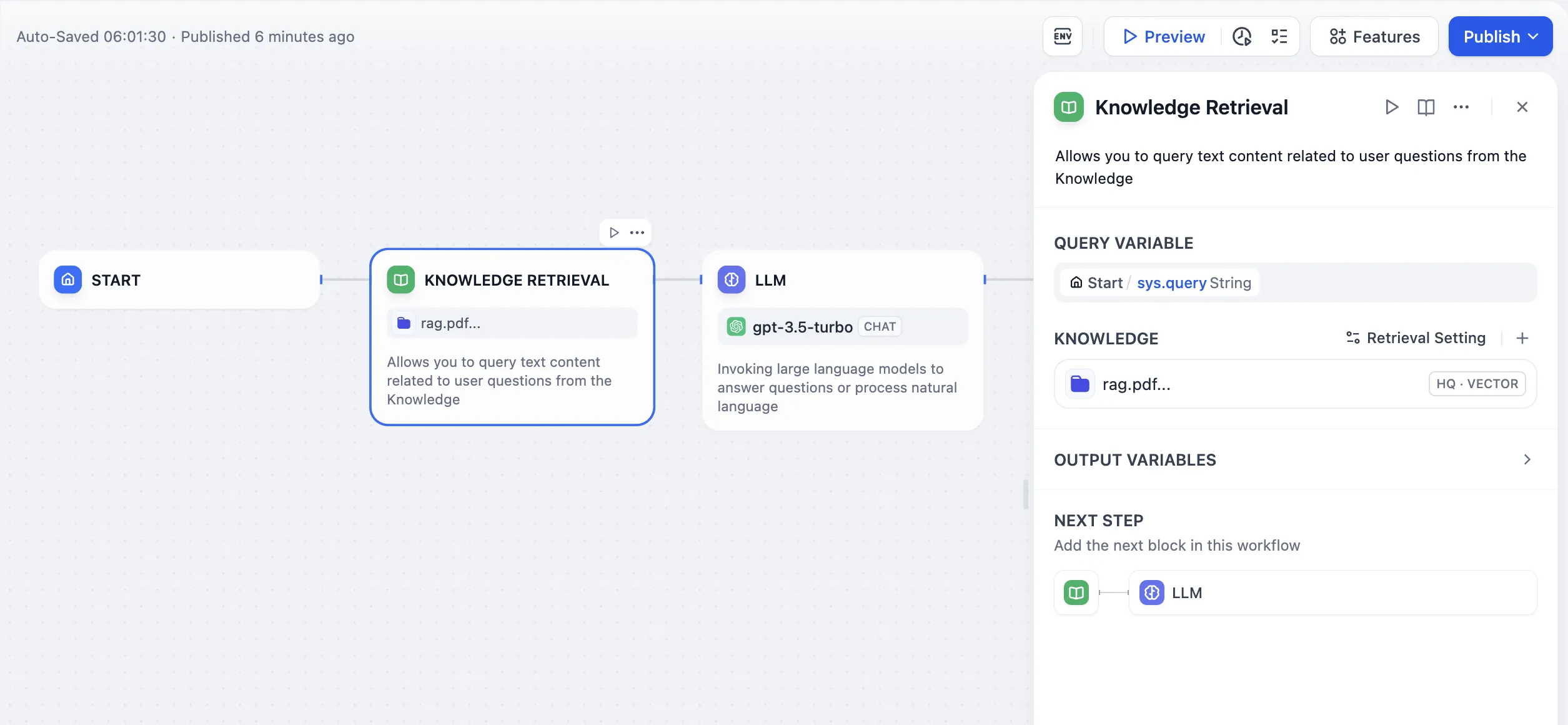
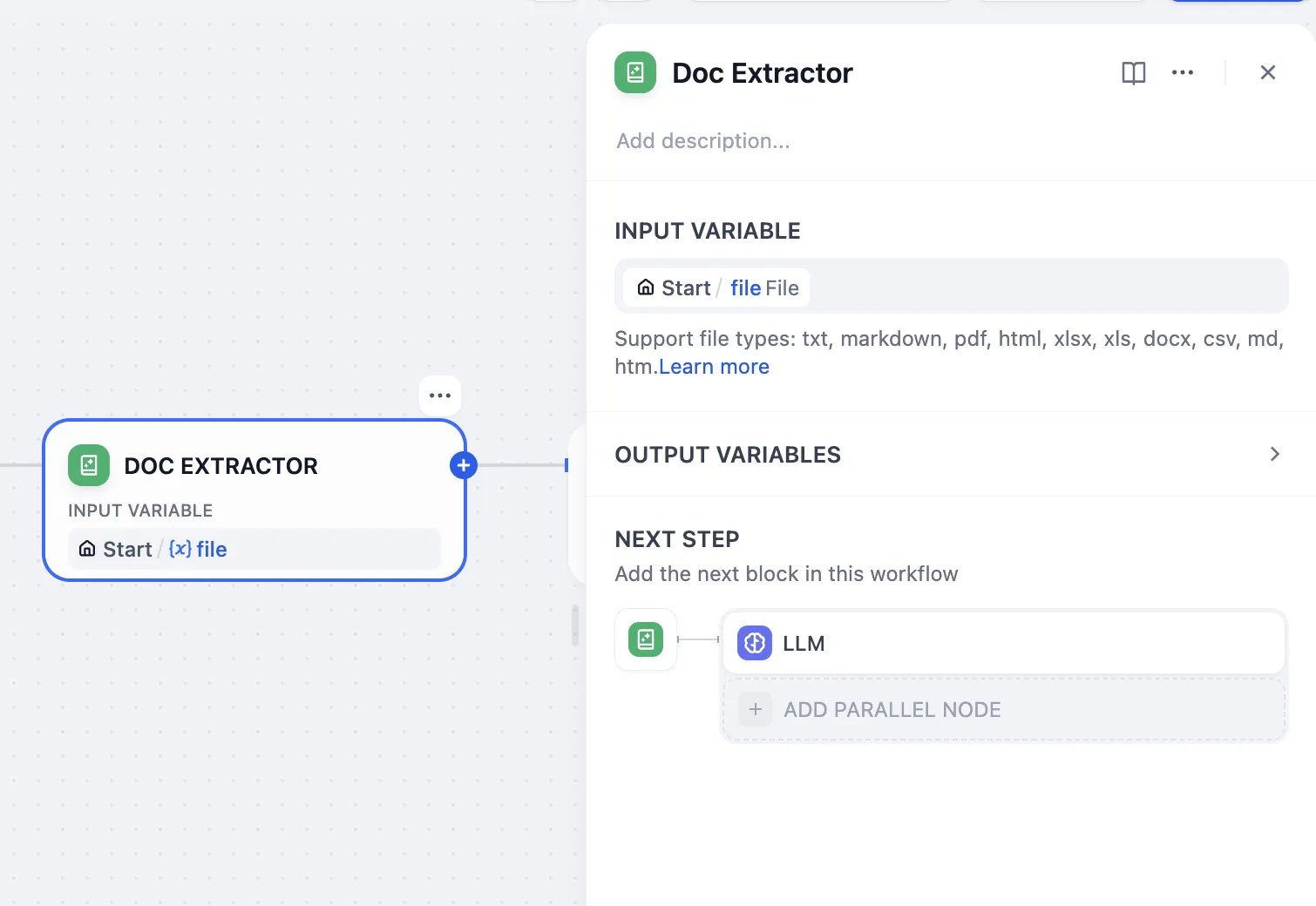
Document Extractor
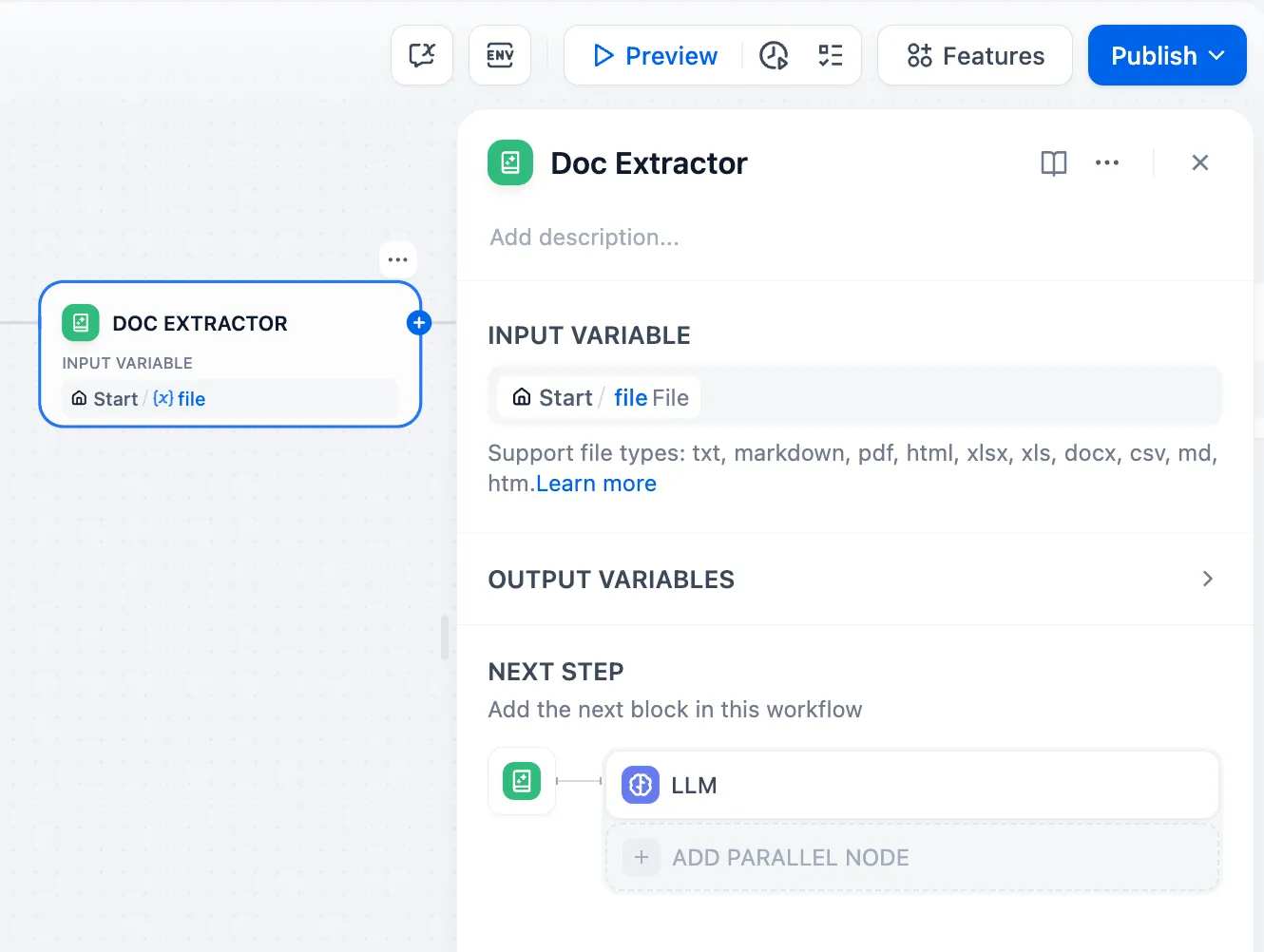
Document Extractor
.png)
.png)
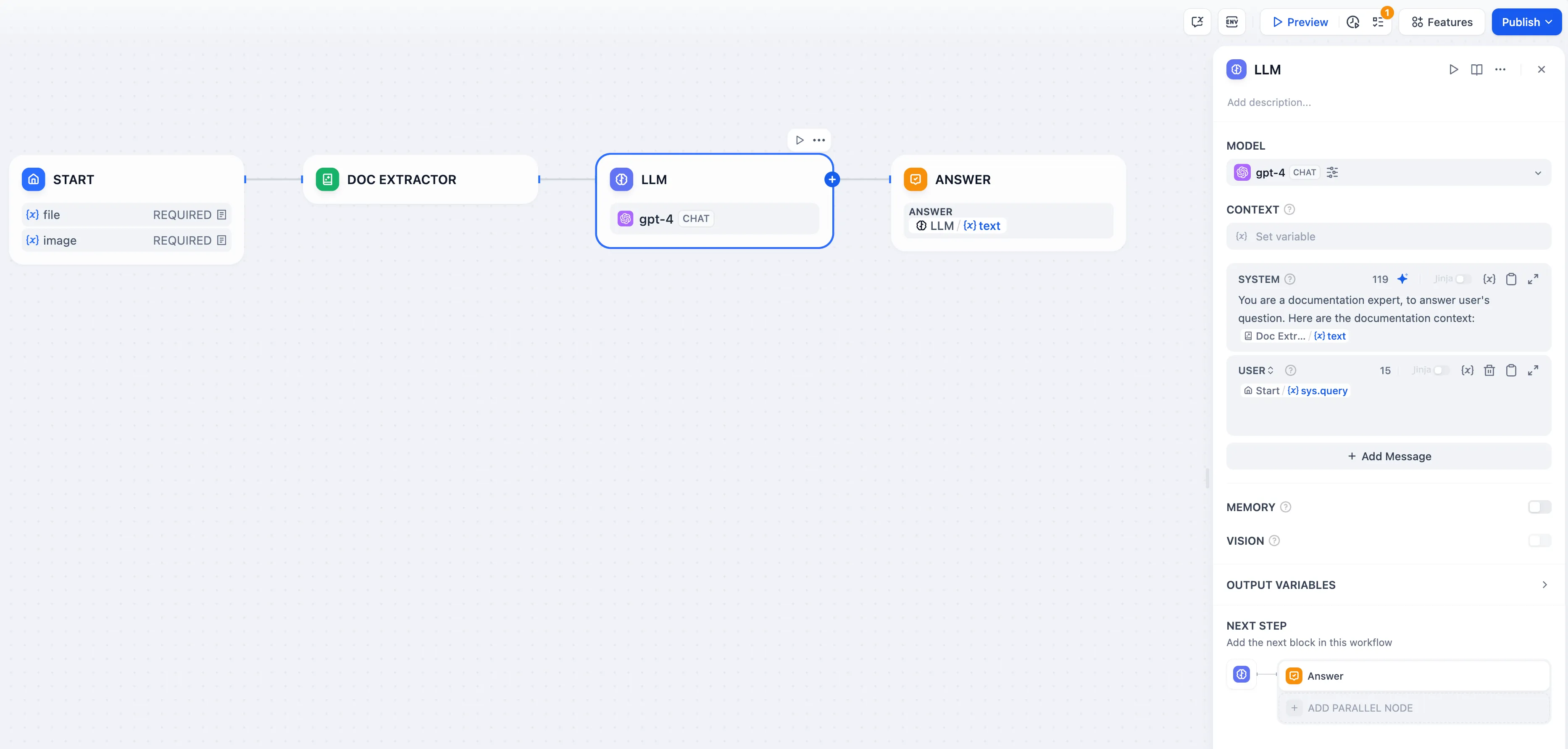
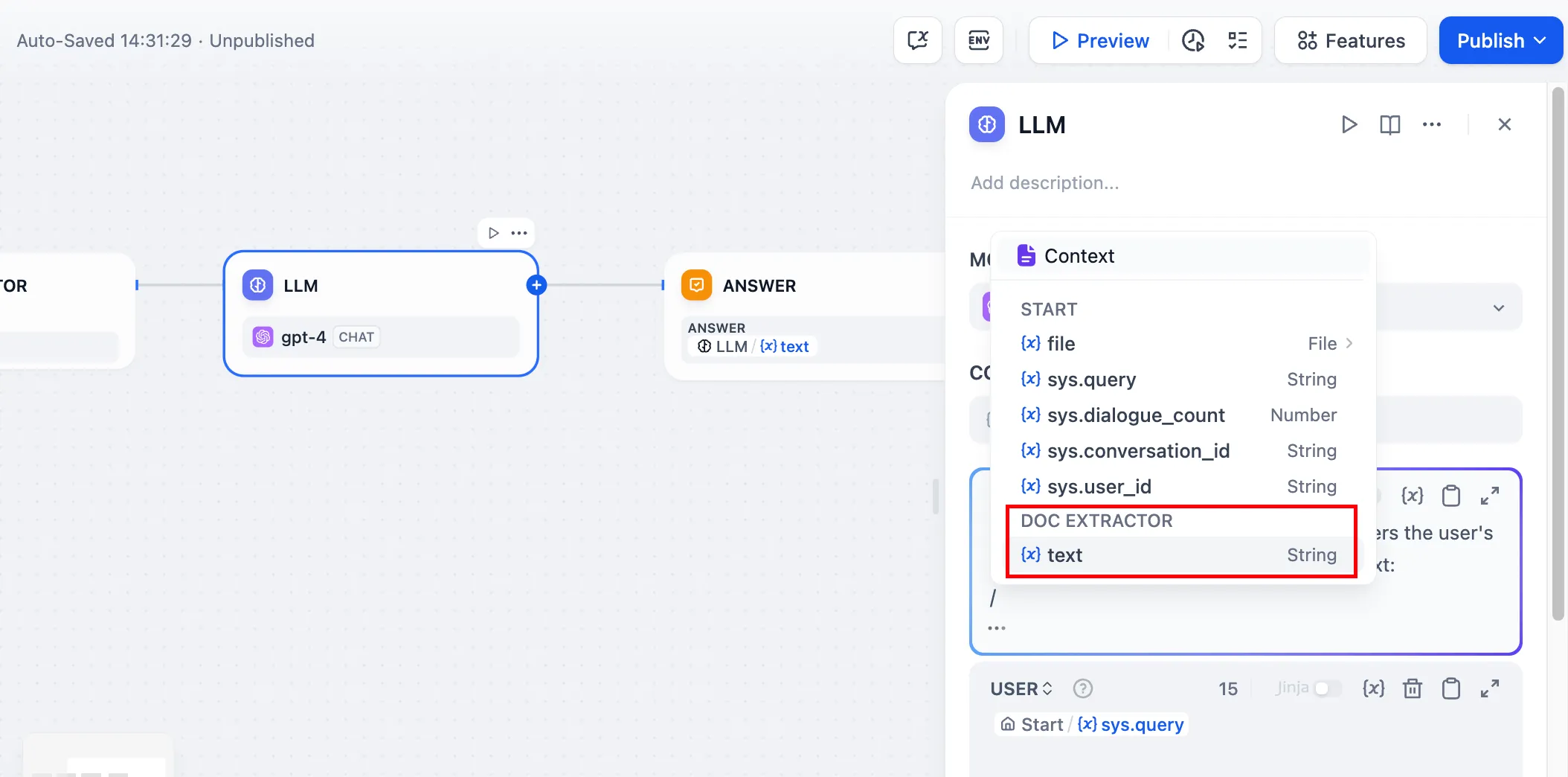
Using file variables directly in LLM node
Using file variables directly in LLM node
.png)
file download
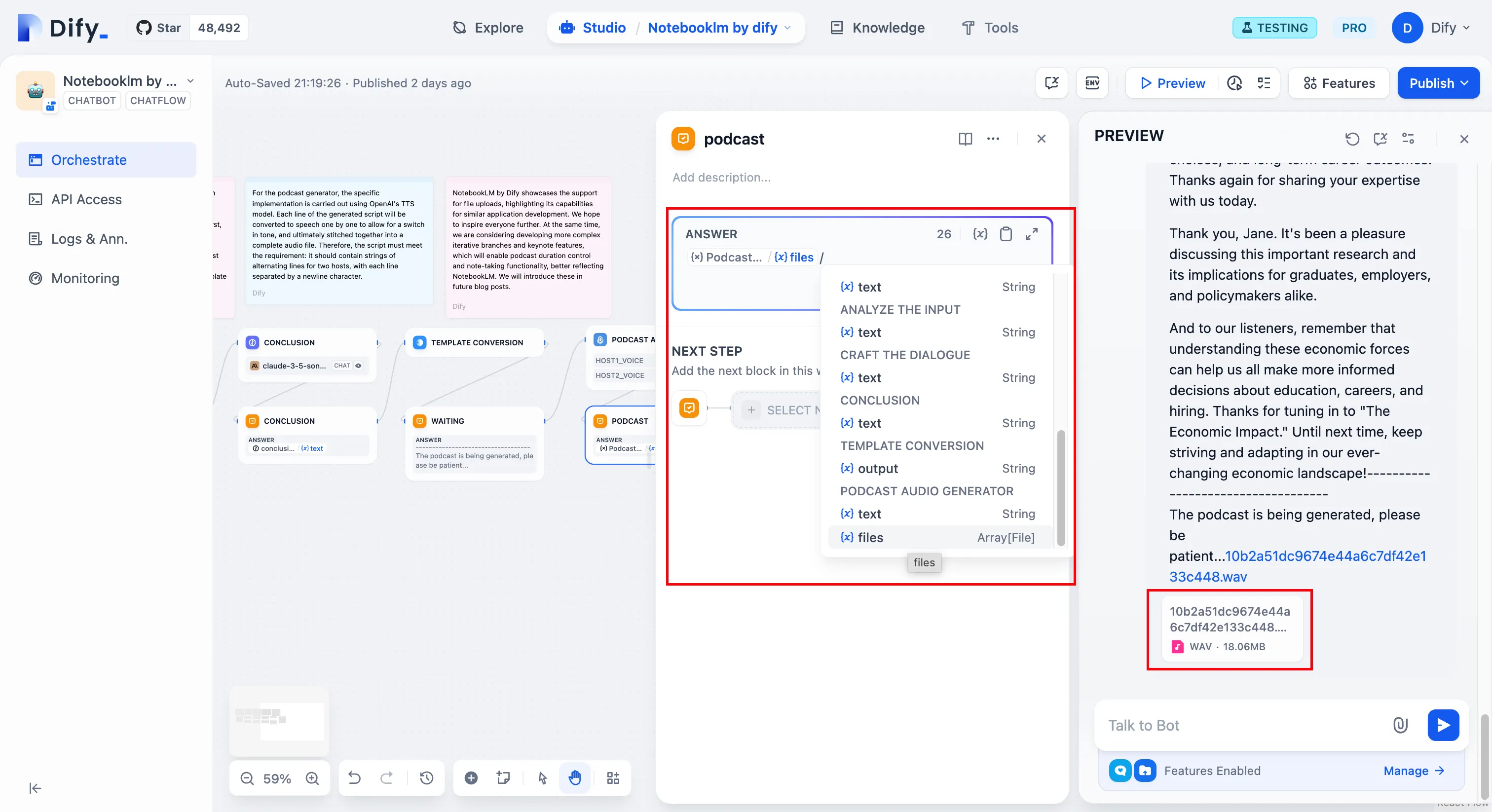
file download

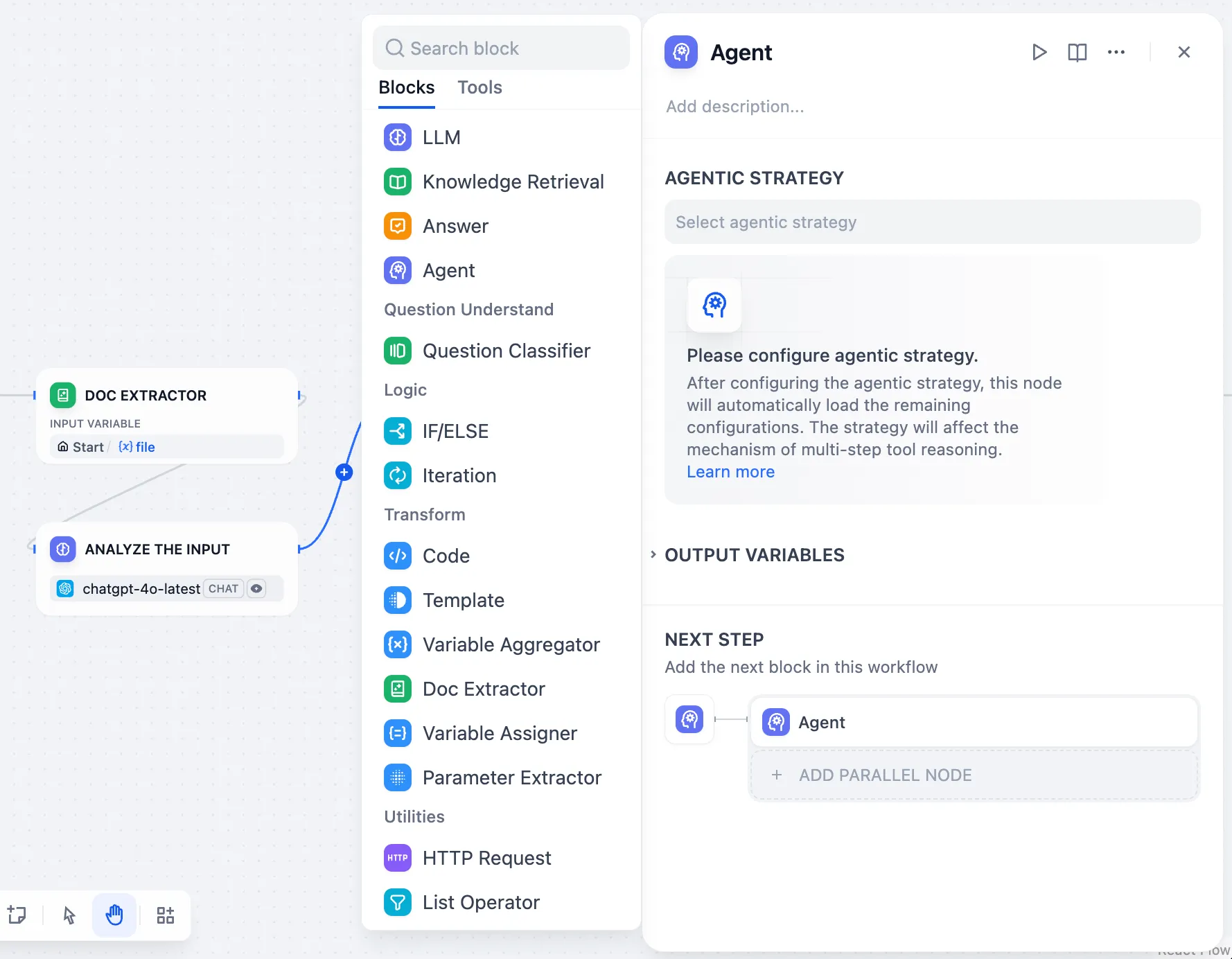

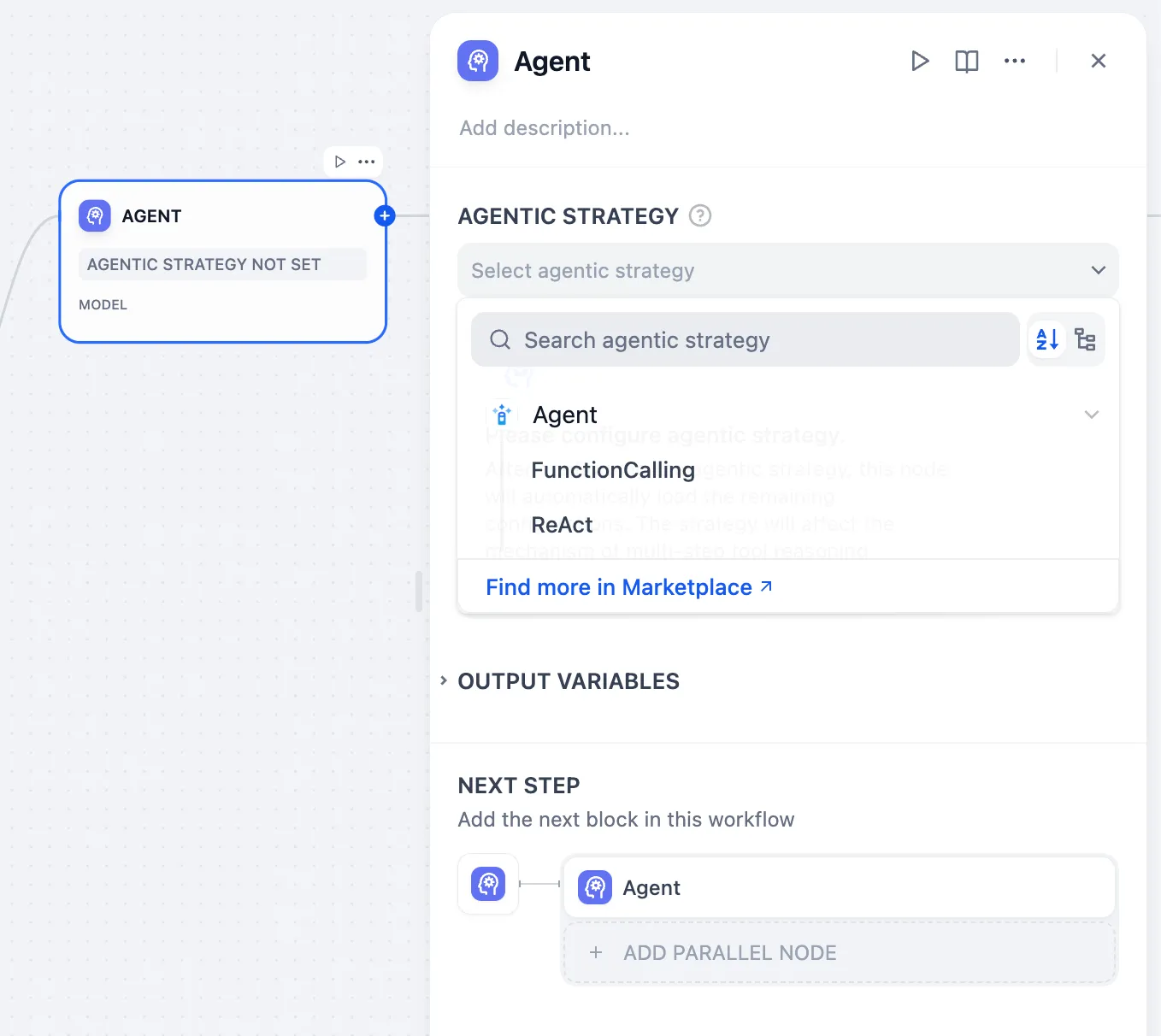

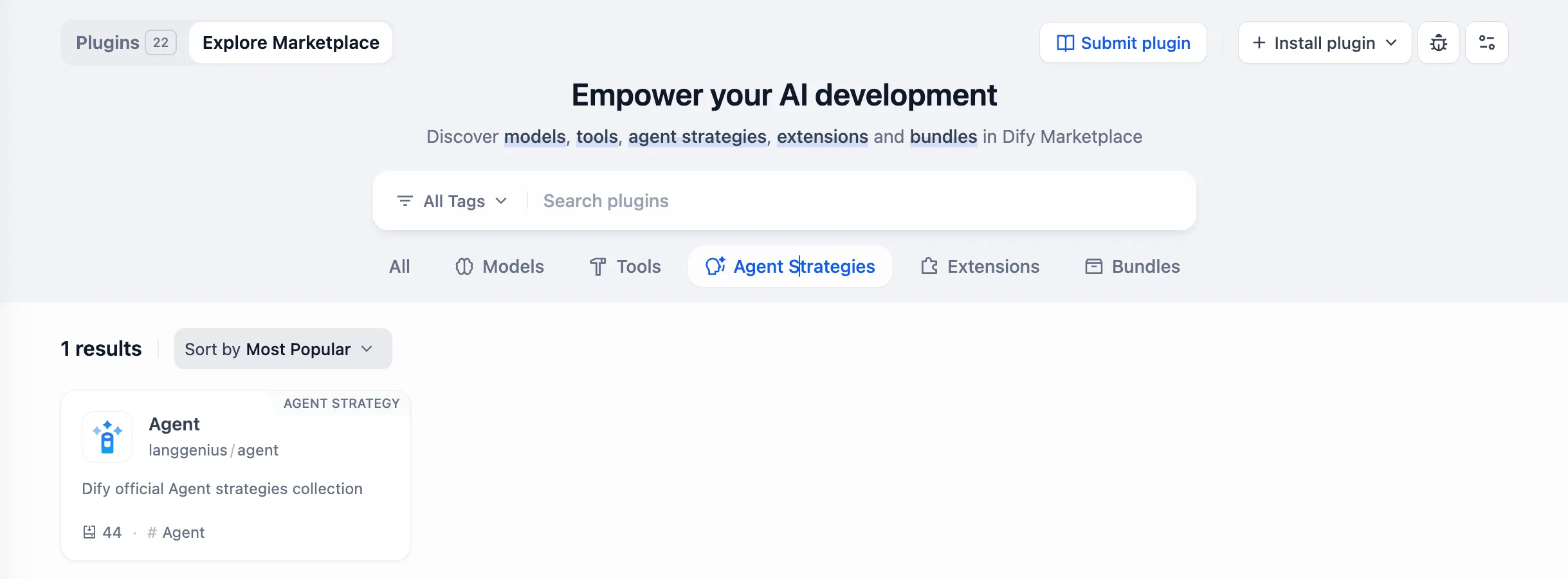

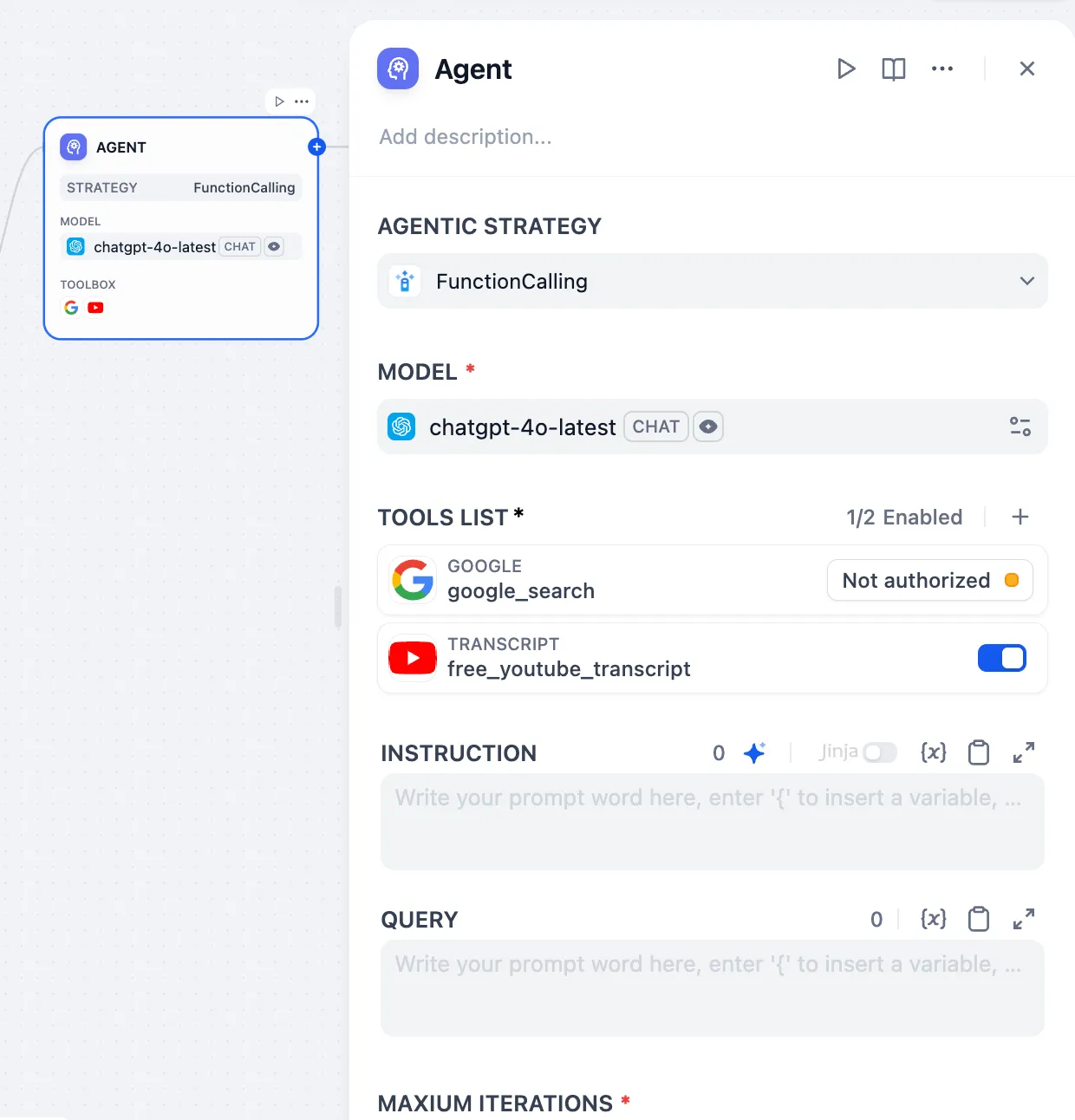






.png)
.png)
doc extractor
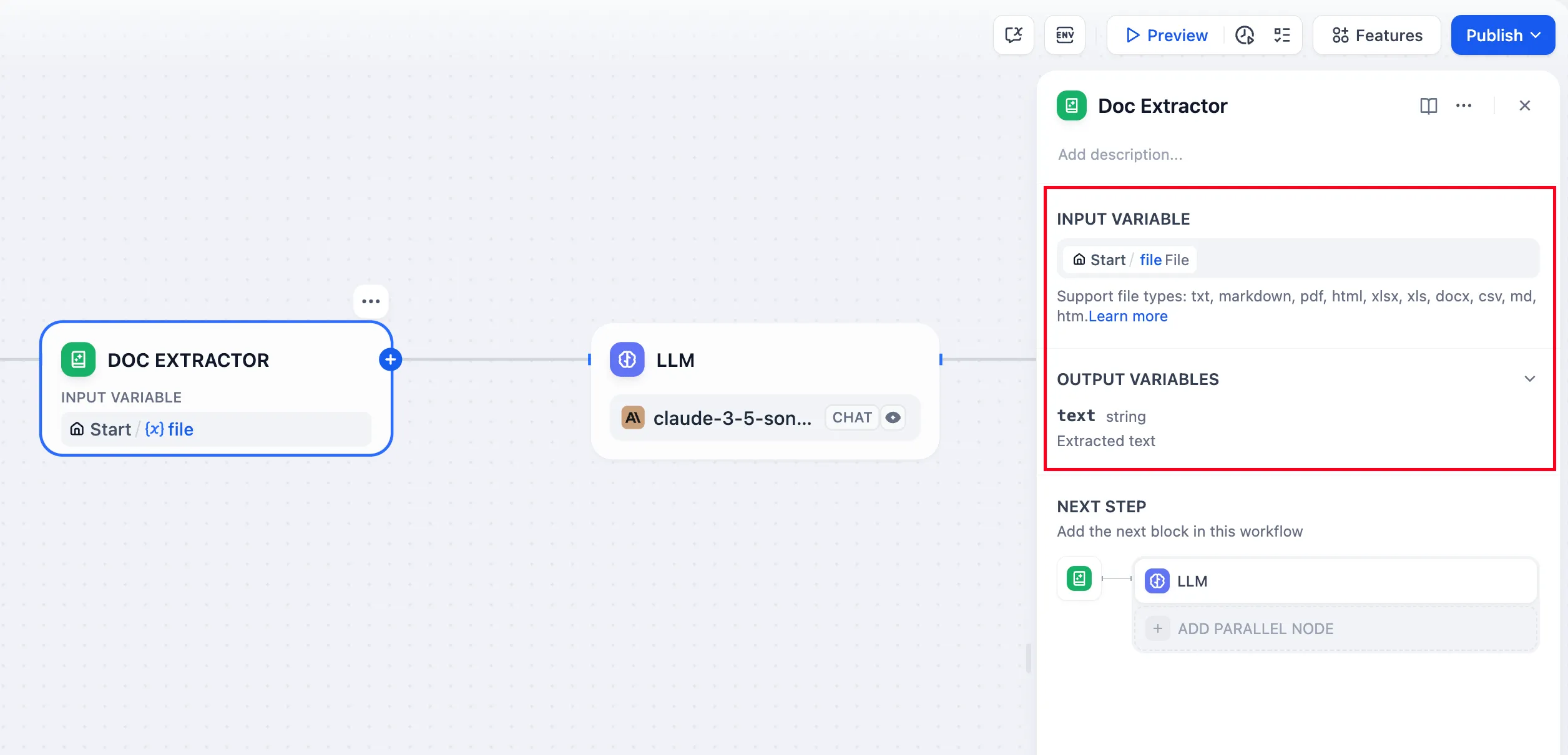
doc extractor
.png)
Chatpdf workflow
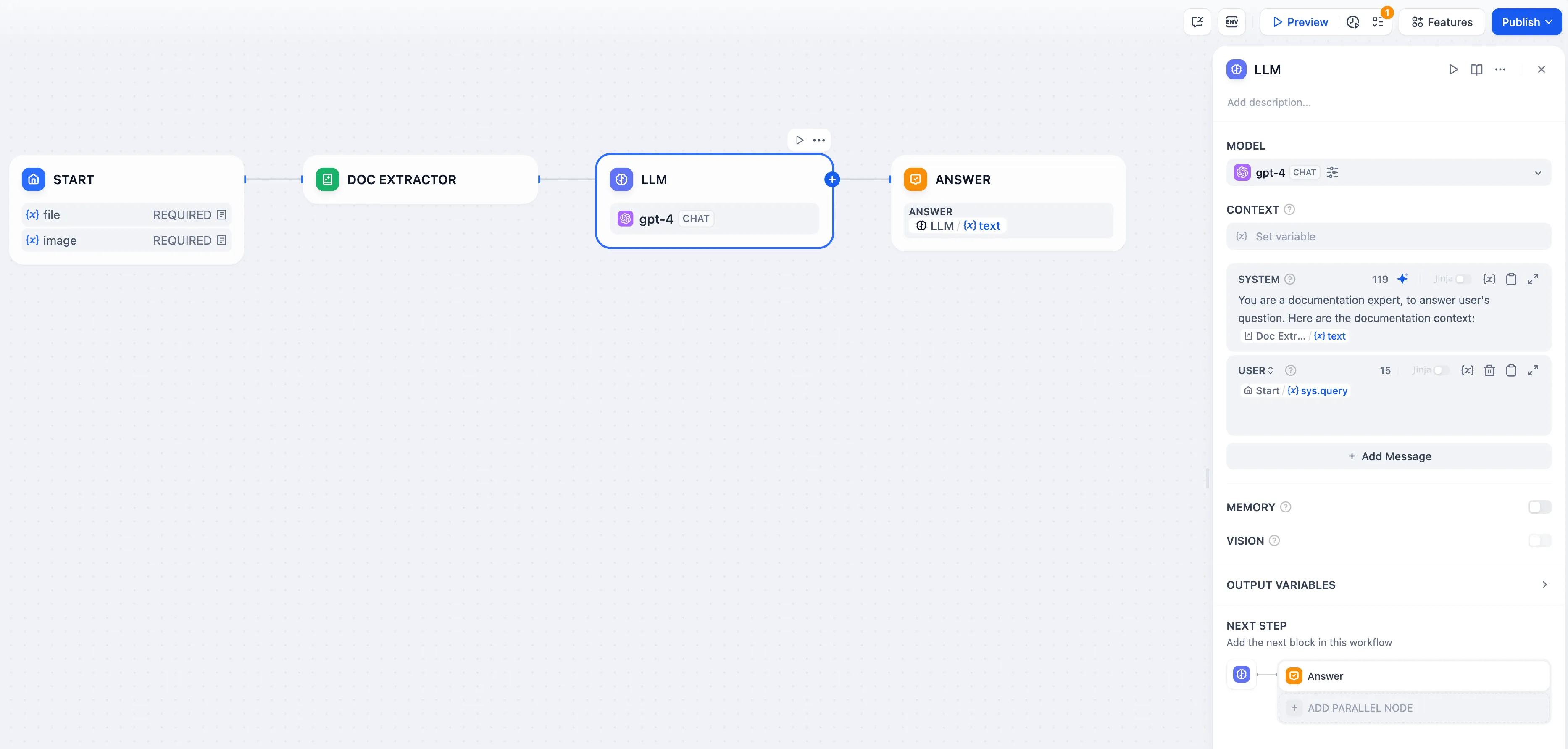
Chatpdf workflow
.png)
.png)
chat with pdf
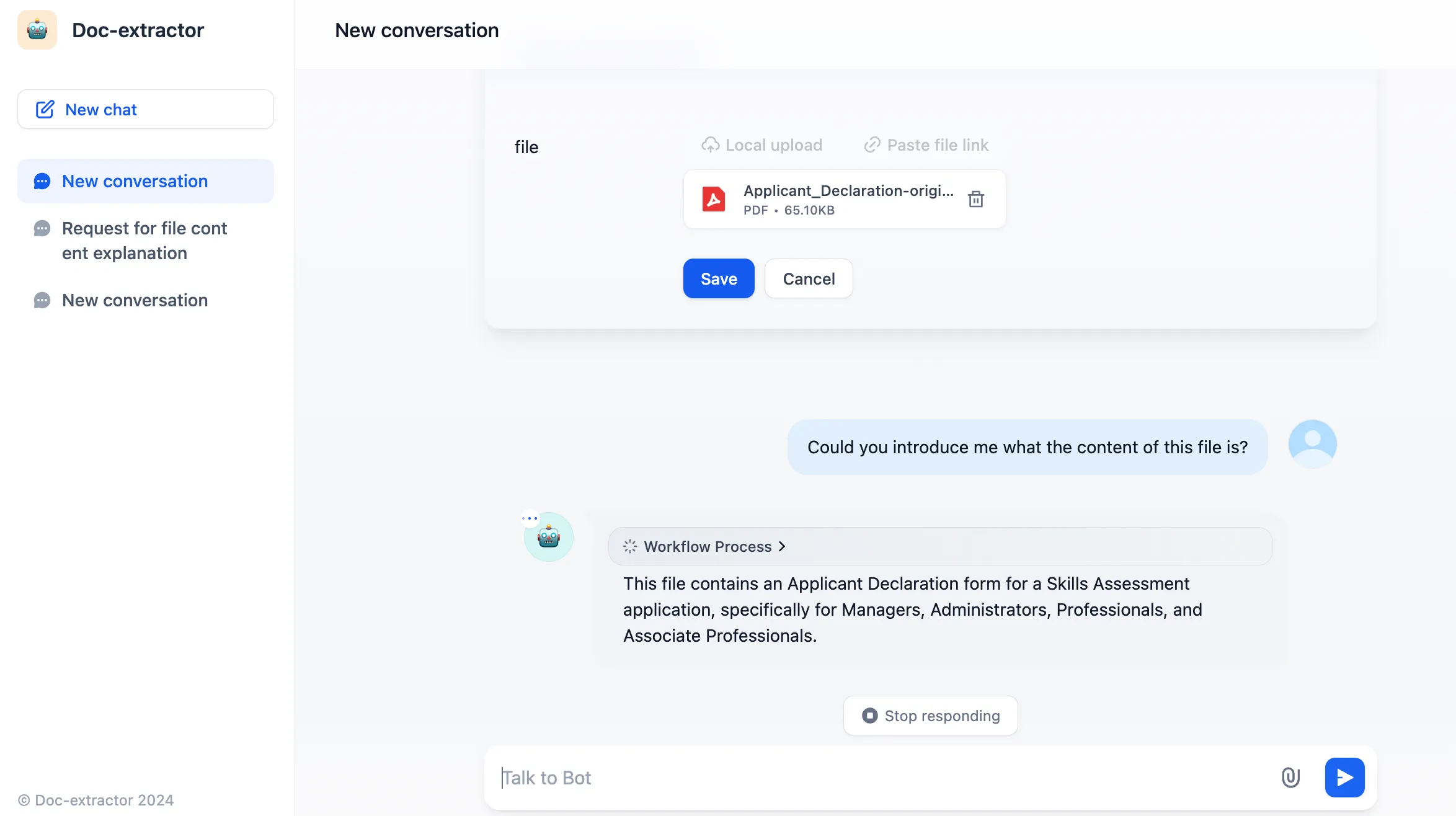
chat with pdf

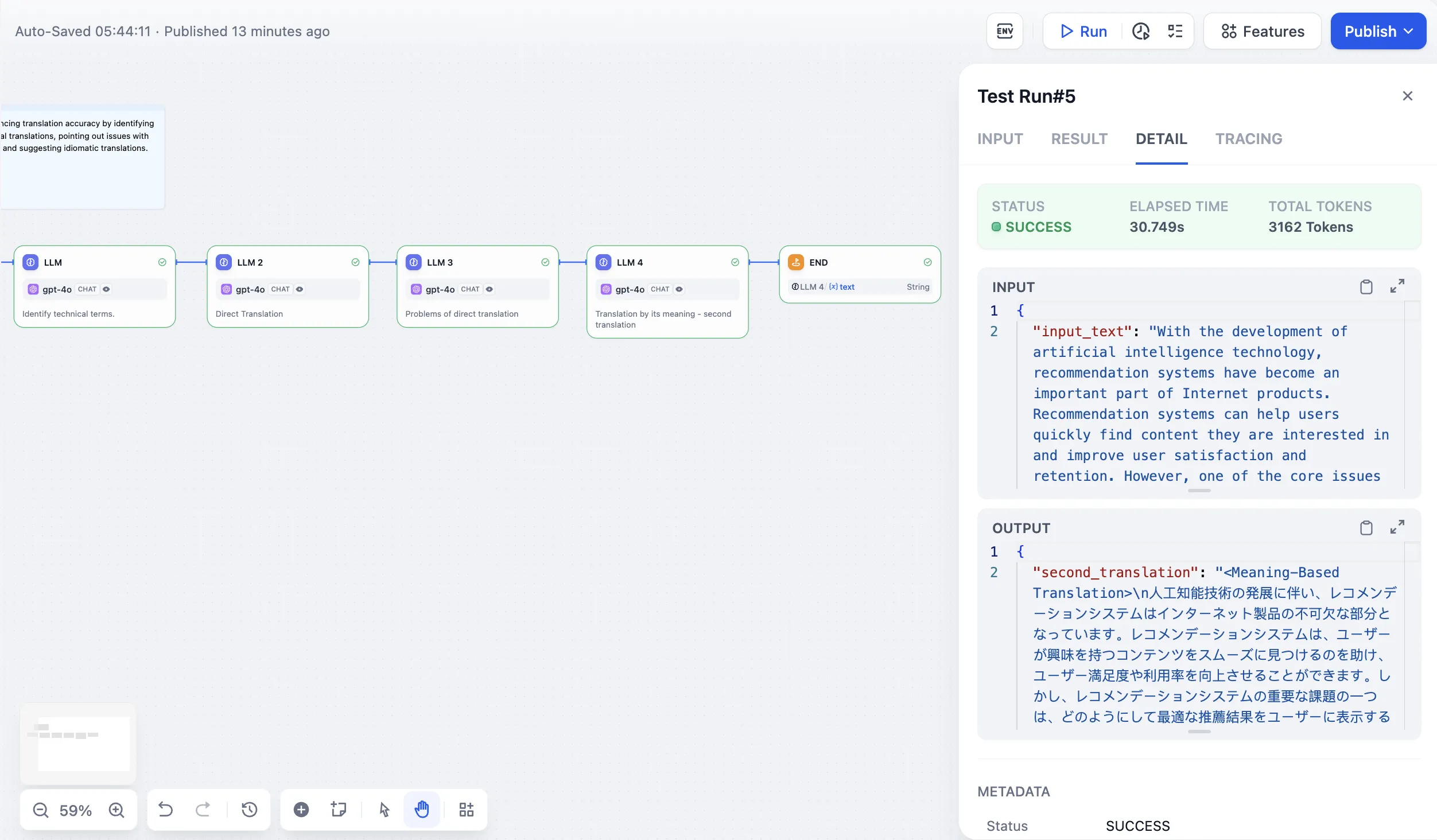
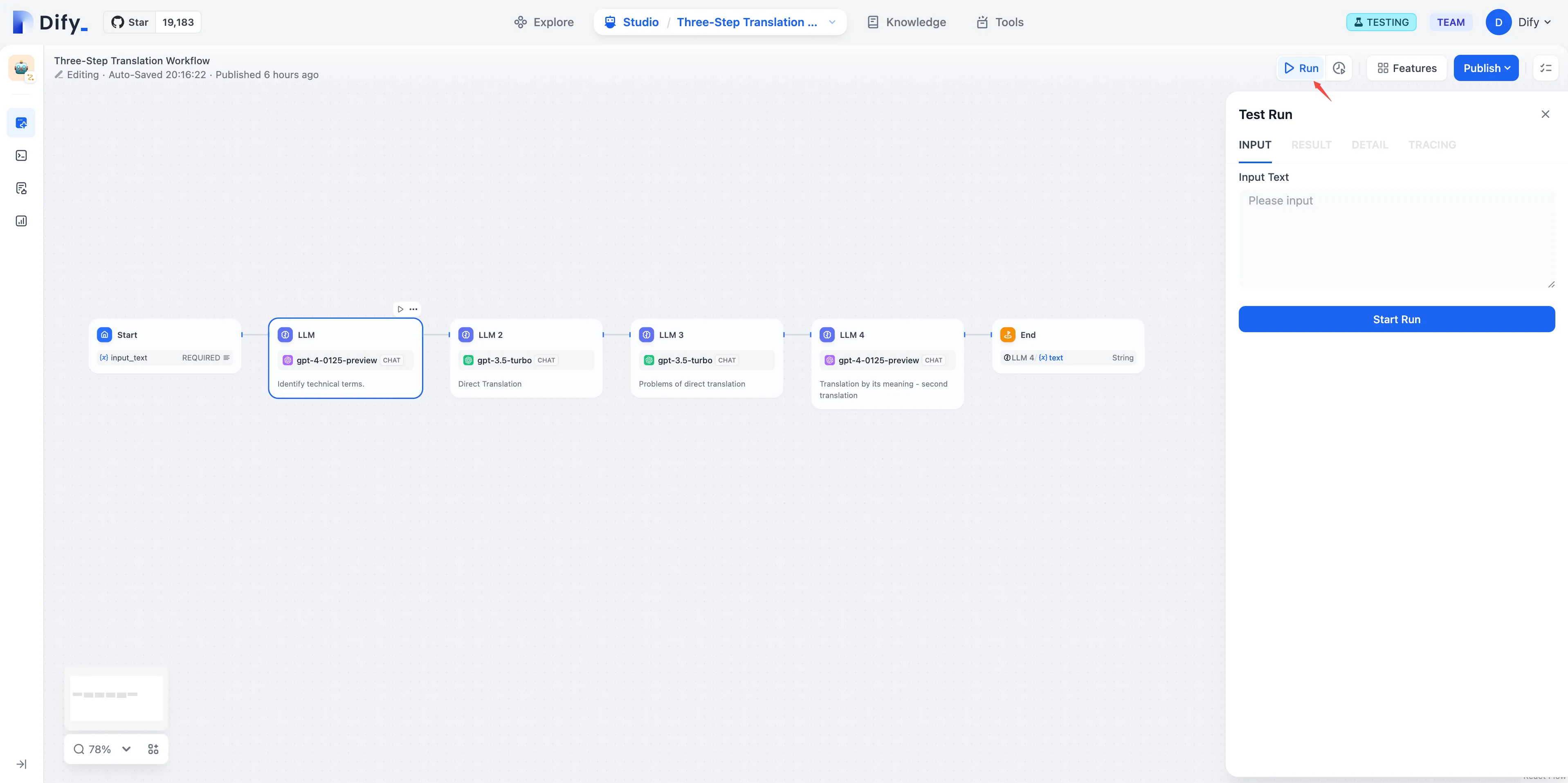
End Node - Long Story Generation Example
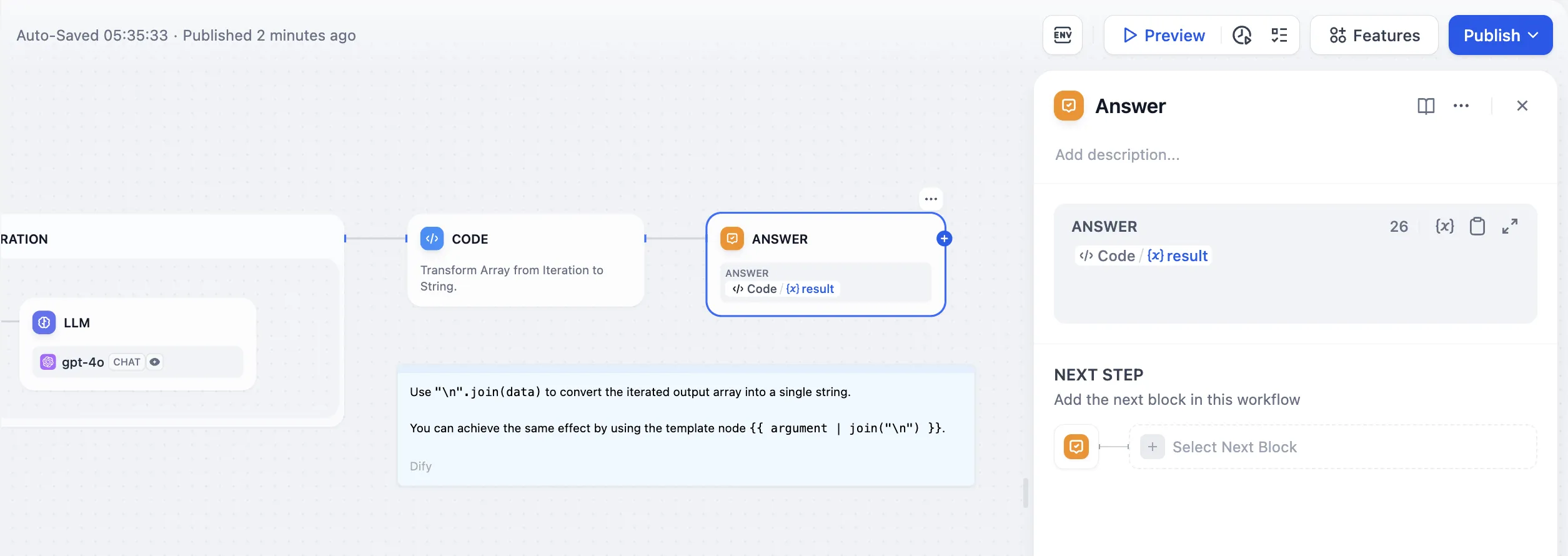
End Node - Long Story Generation Example

 (3).png)

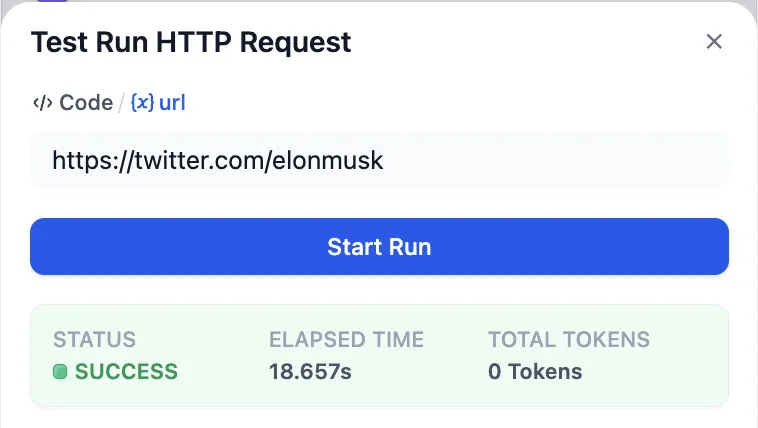
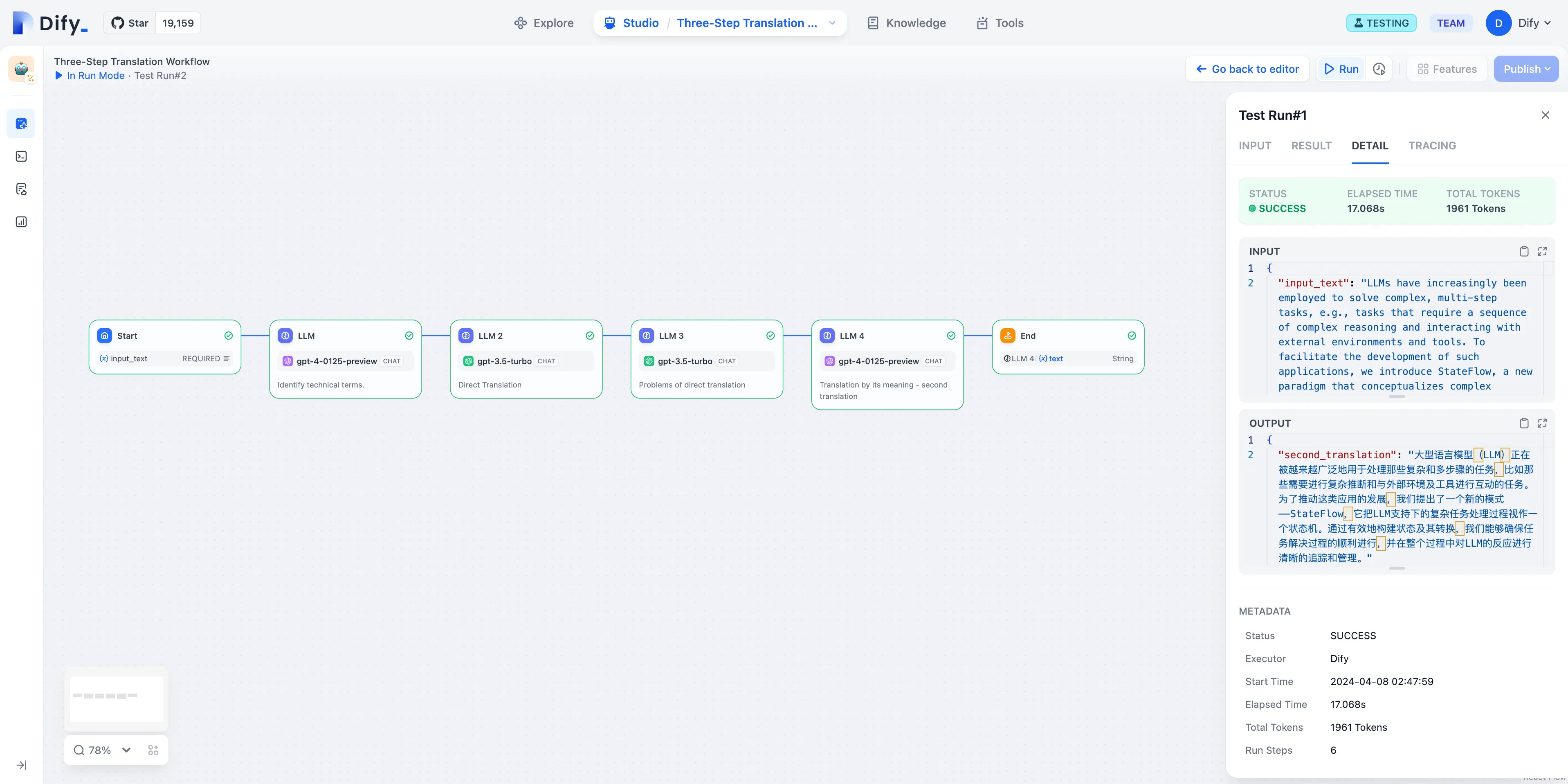
HTTP Request Configuration
HTTP Request Configuration

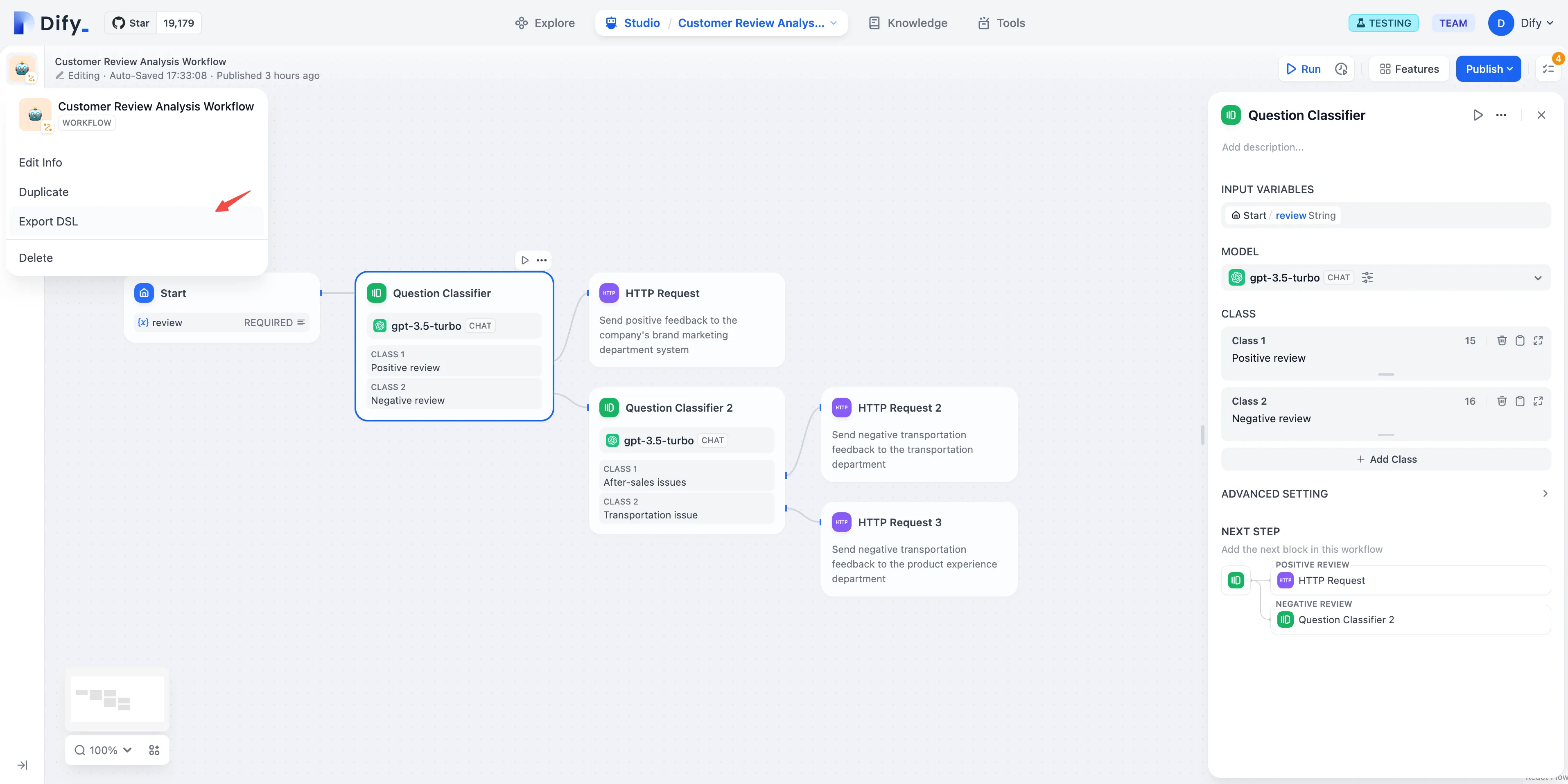
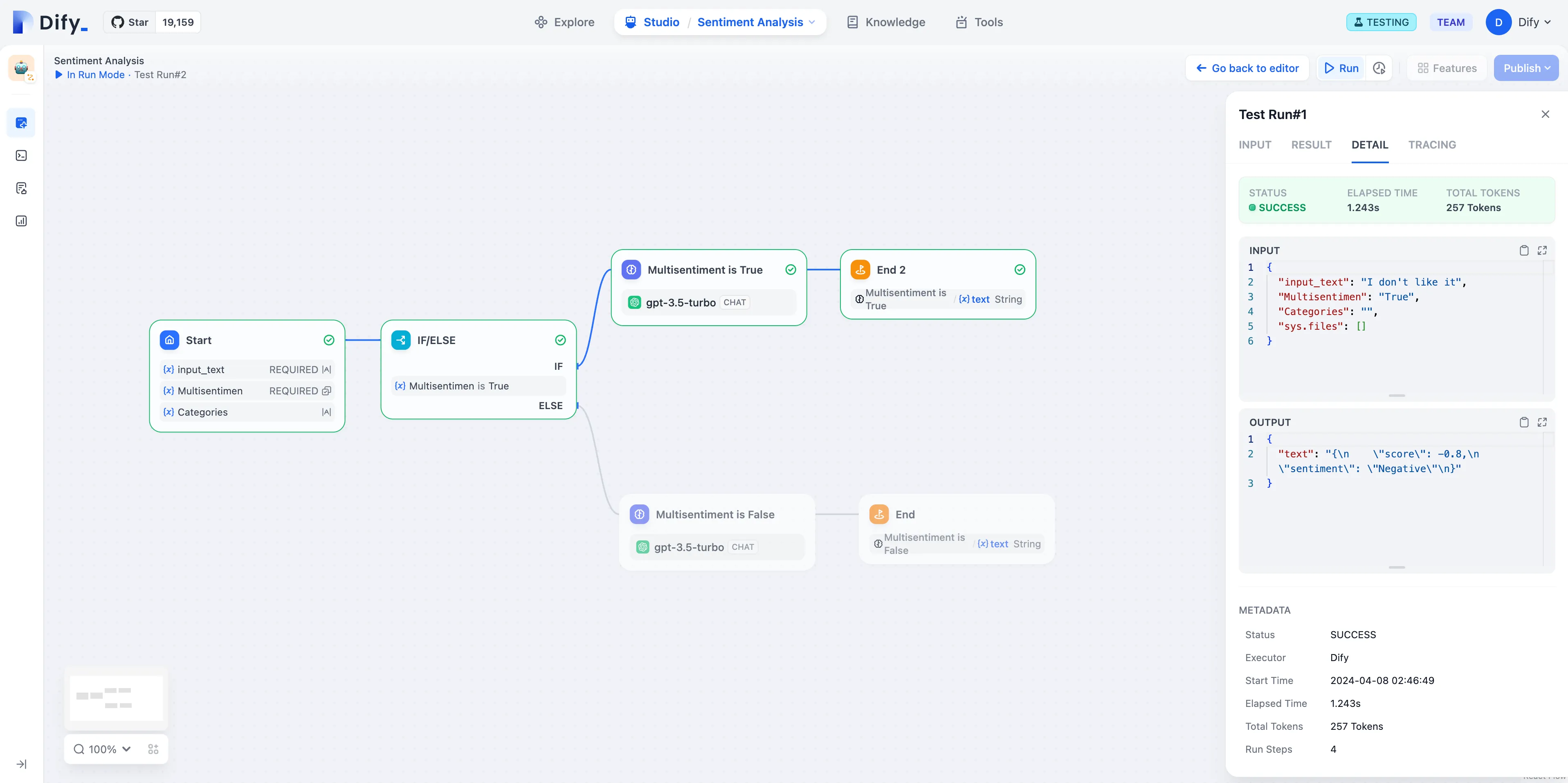
Customer Feedback Classification
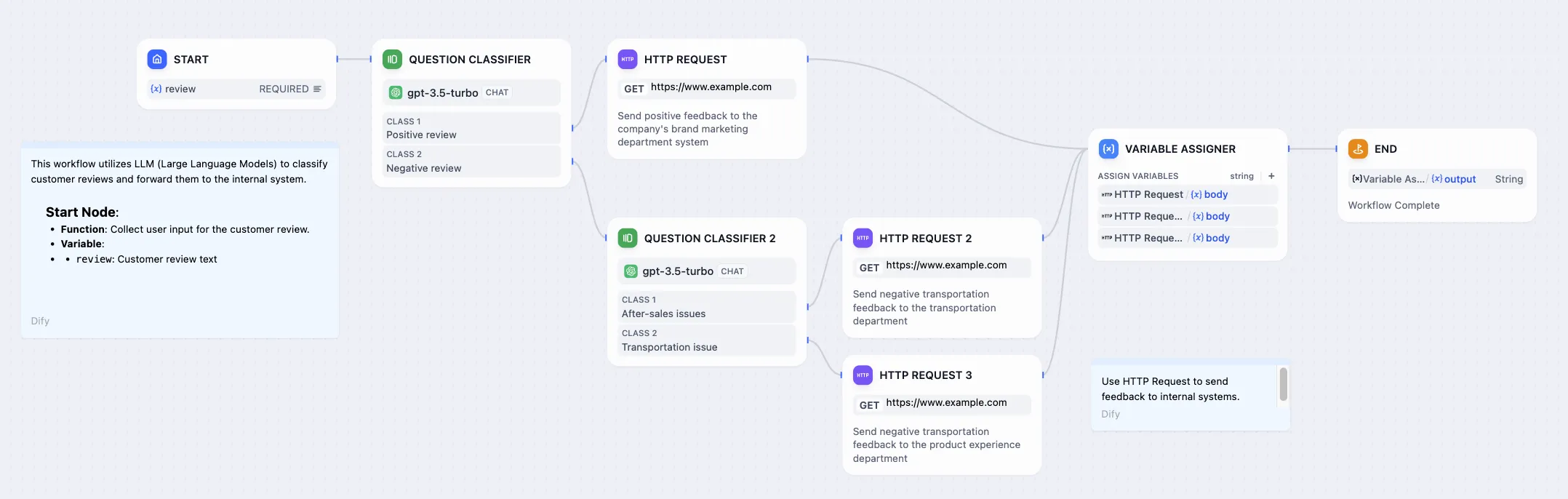
Customer Feedback Classification
.png)
http-node-send-file
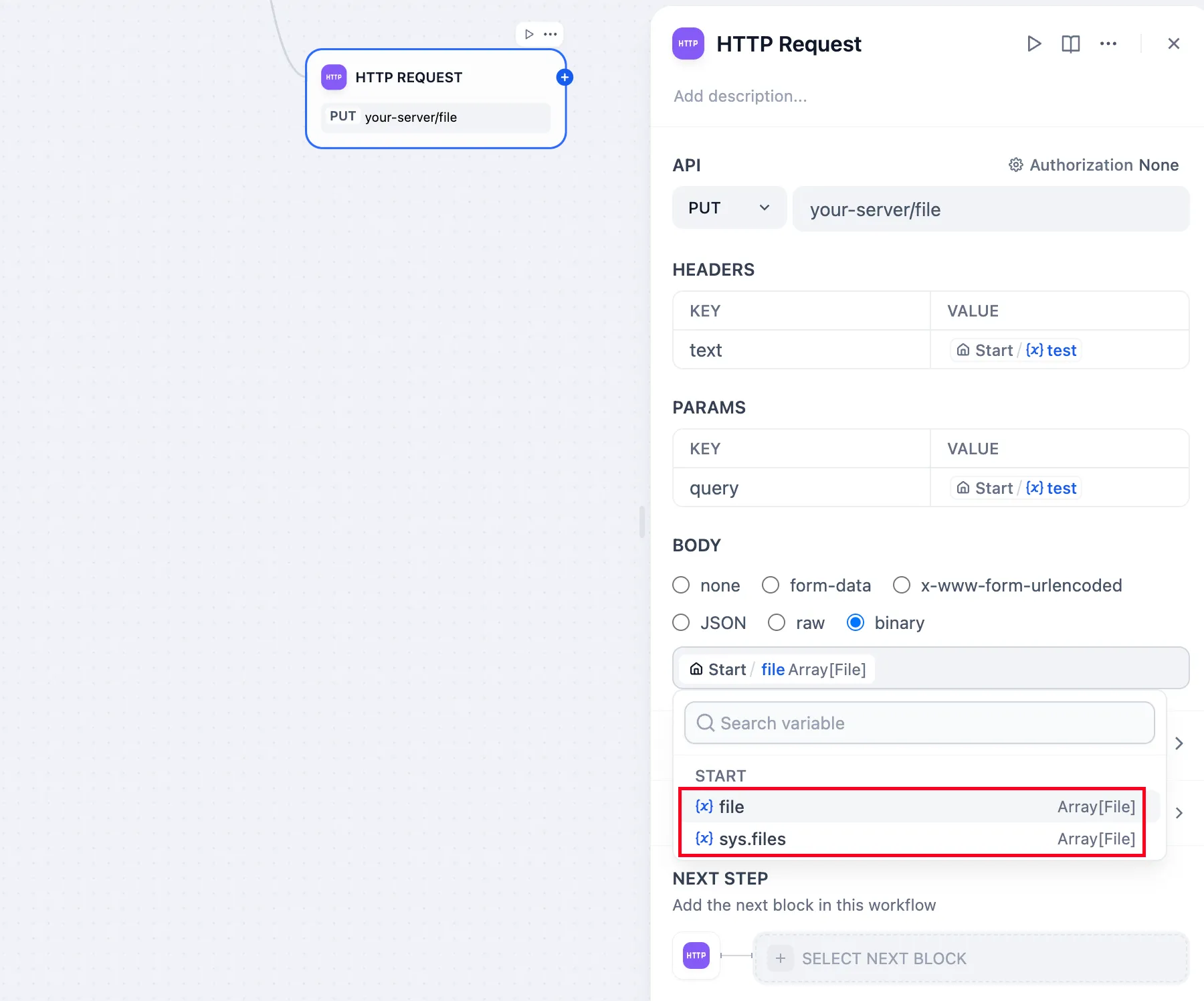
http-node-send-file

.png)
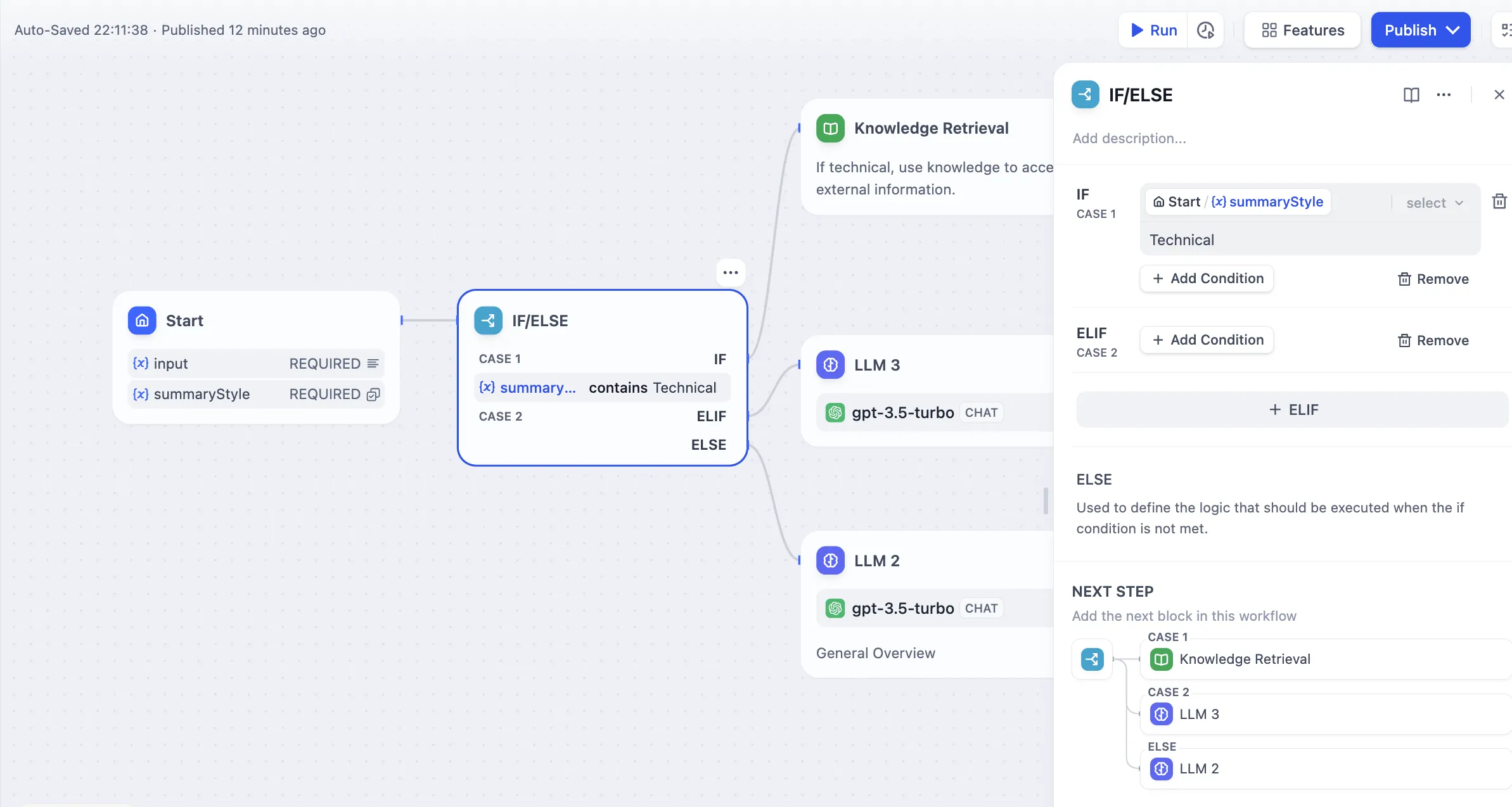
Multiple Condition Judgments
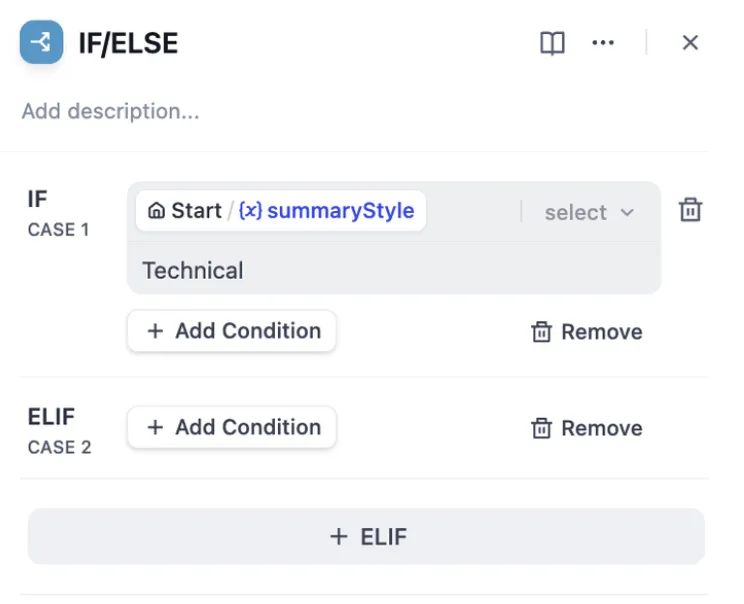
Multiple Condition Judgments

Long Story Generator
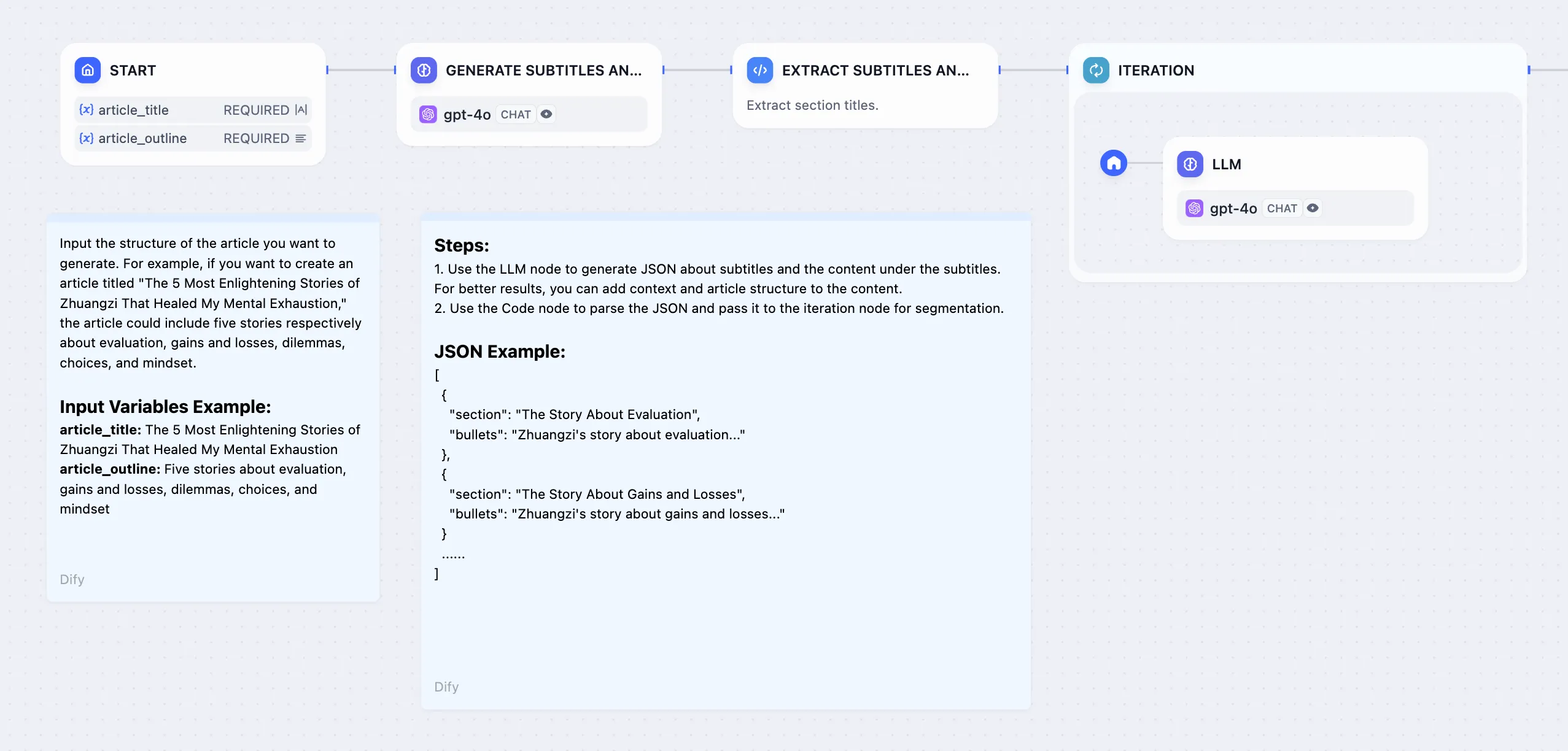
Long Story Generator

Start Node Configuration
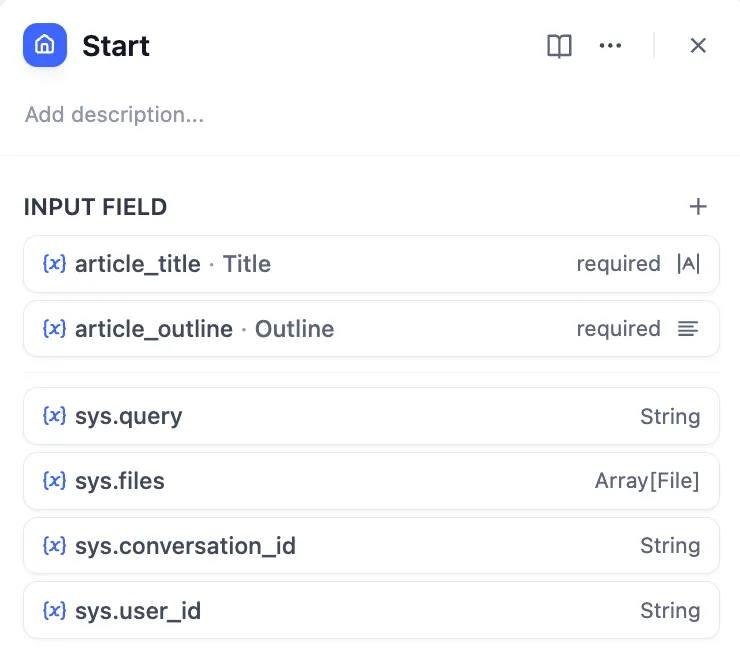
Start Node Configuration

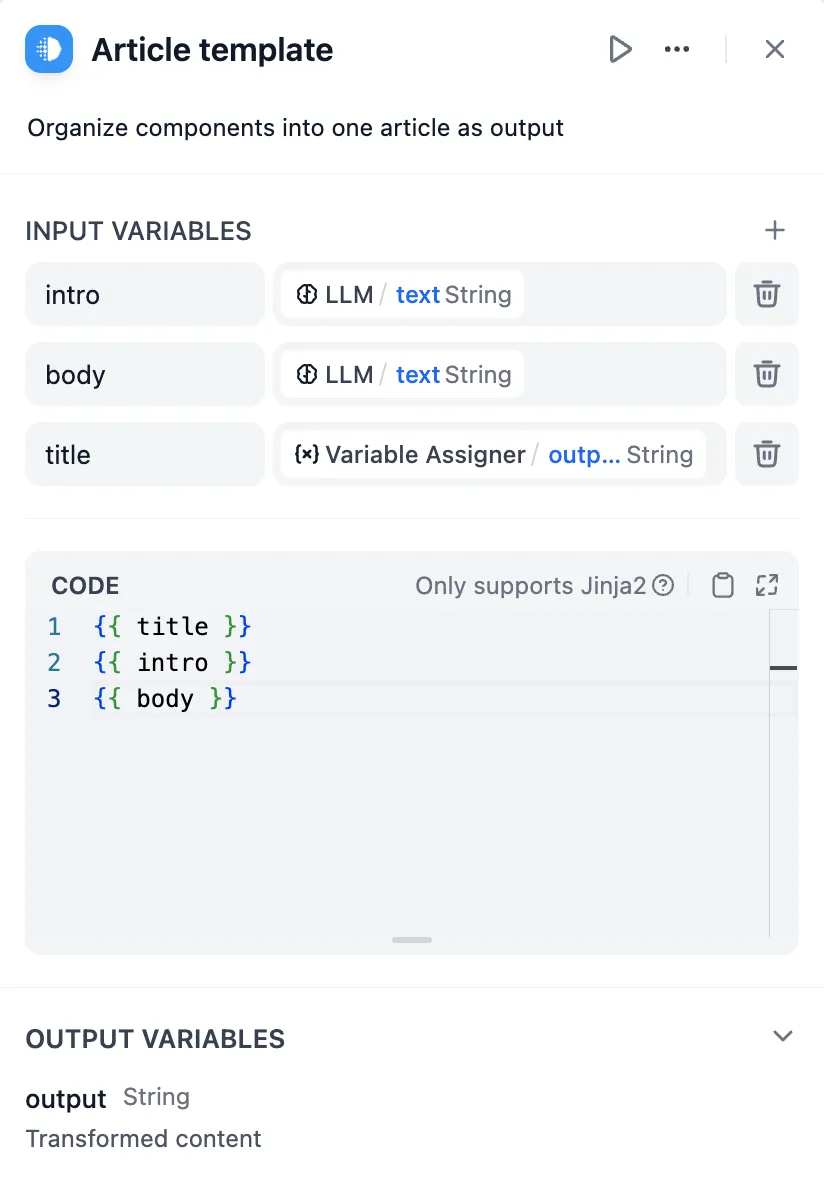
Template Node
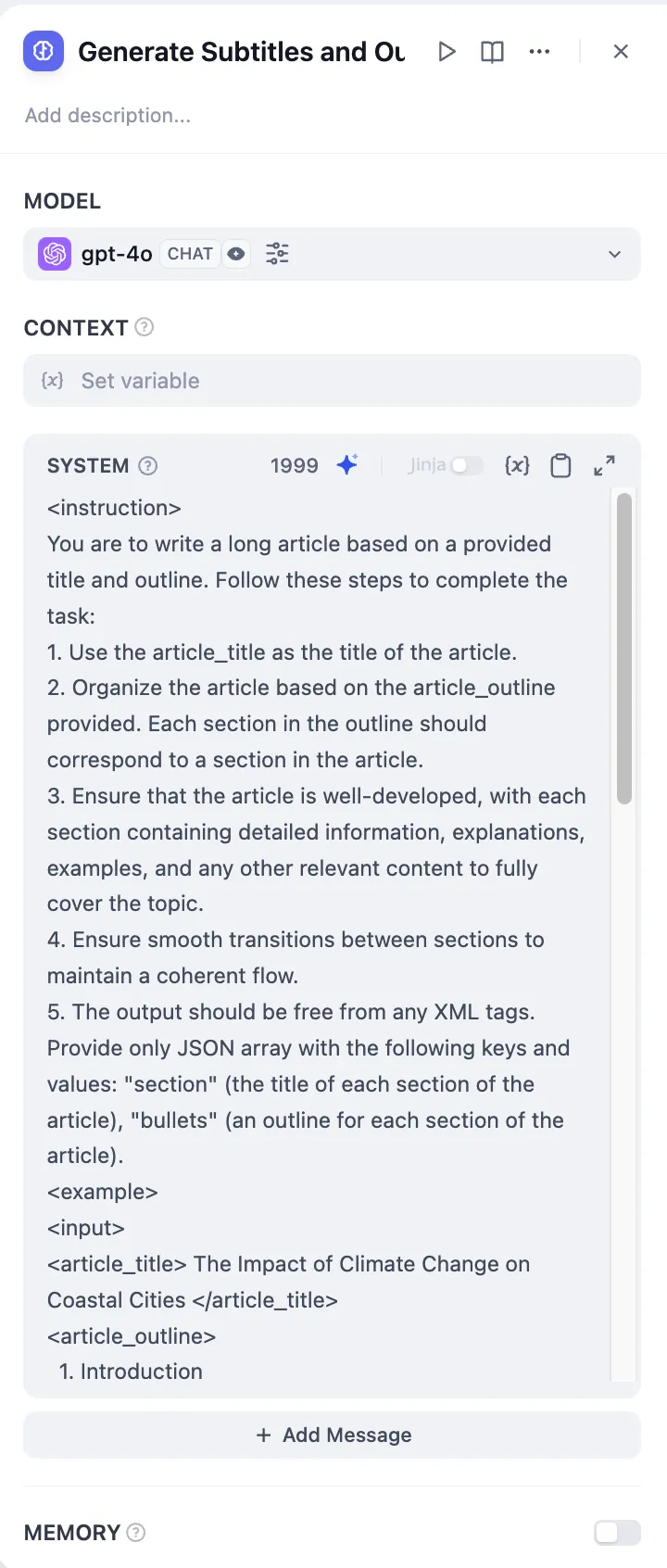
Template Node

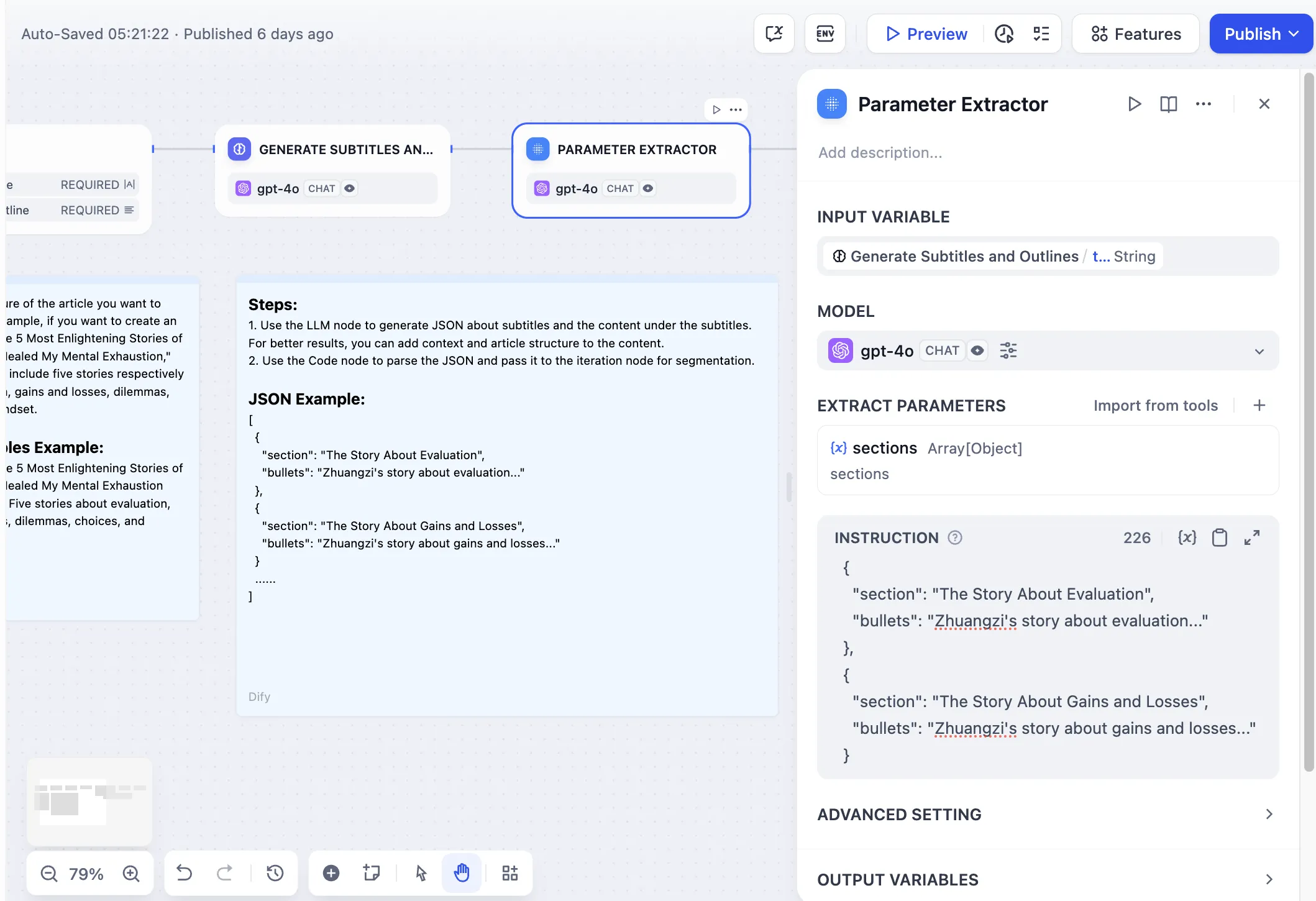
Parameter Extraction
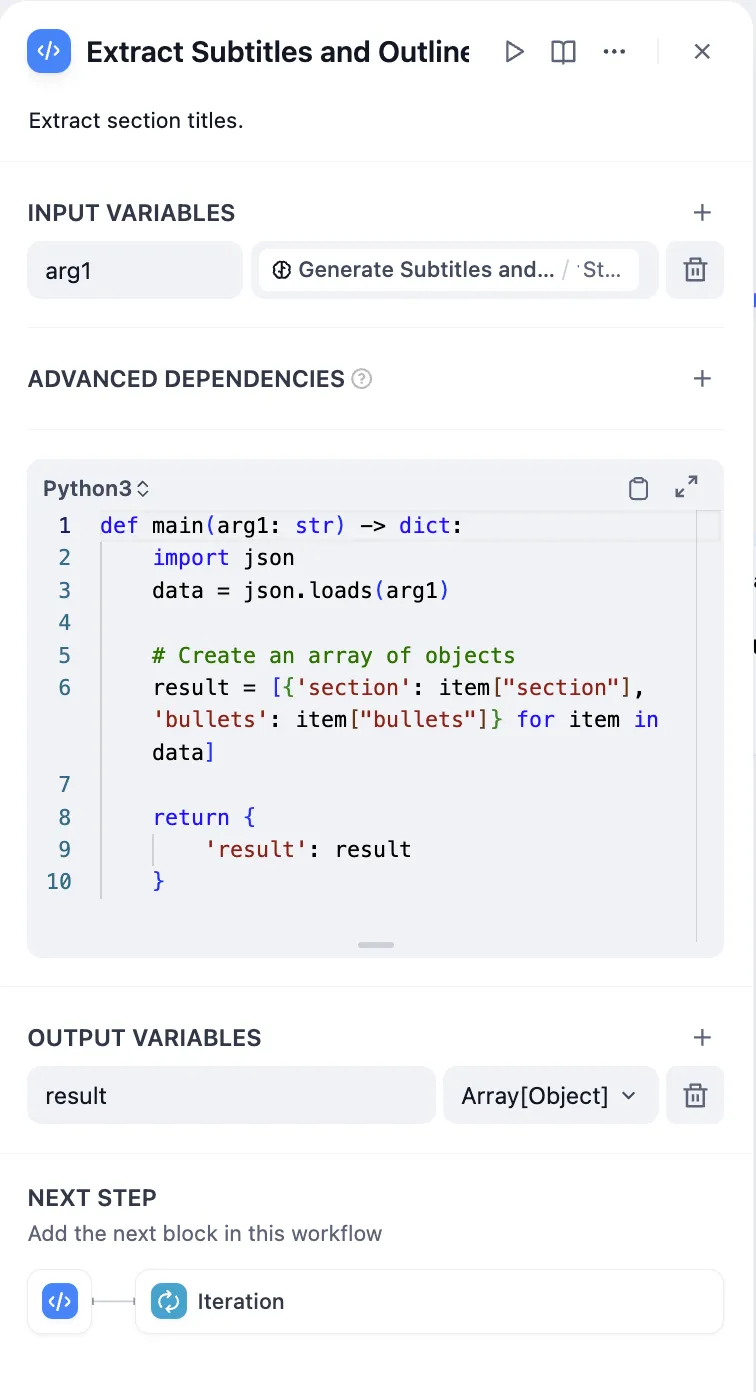
Parameter Extraction

Configure Iteration Node
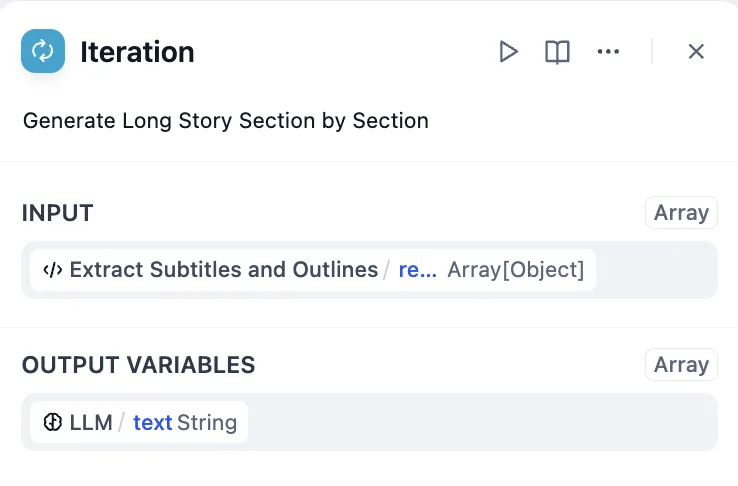
Configure Iteration Node

Configure LLM Node
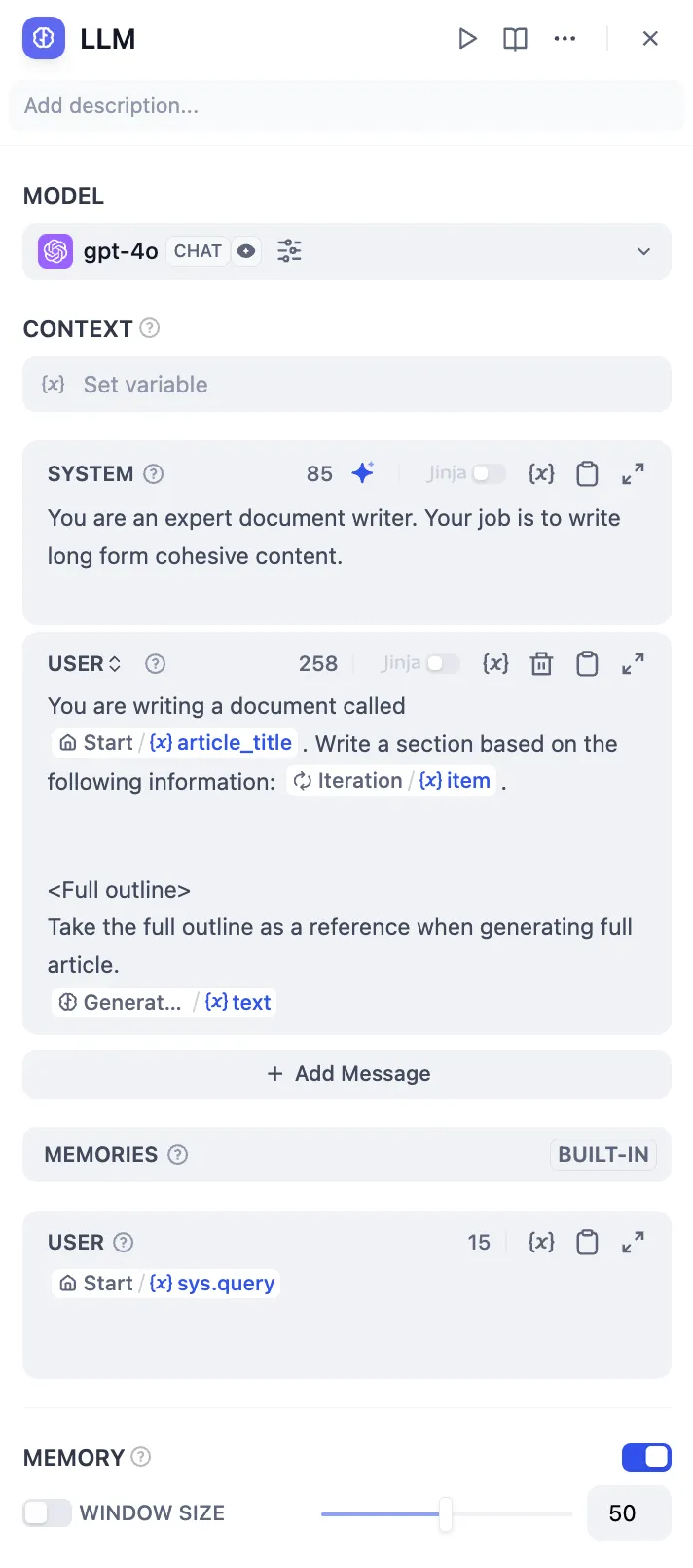
Configure LLM Node

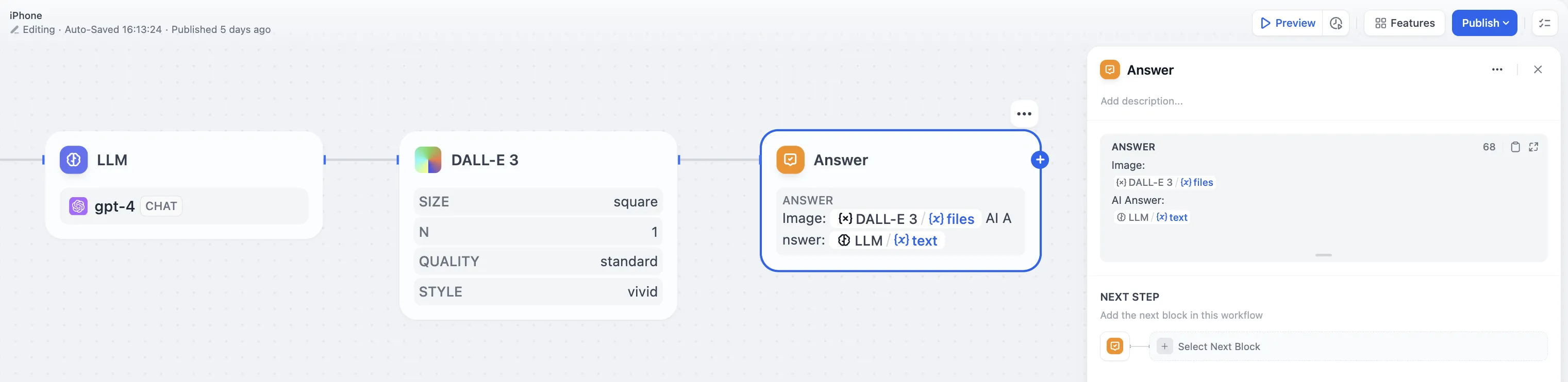
Configure Answer Node
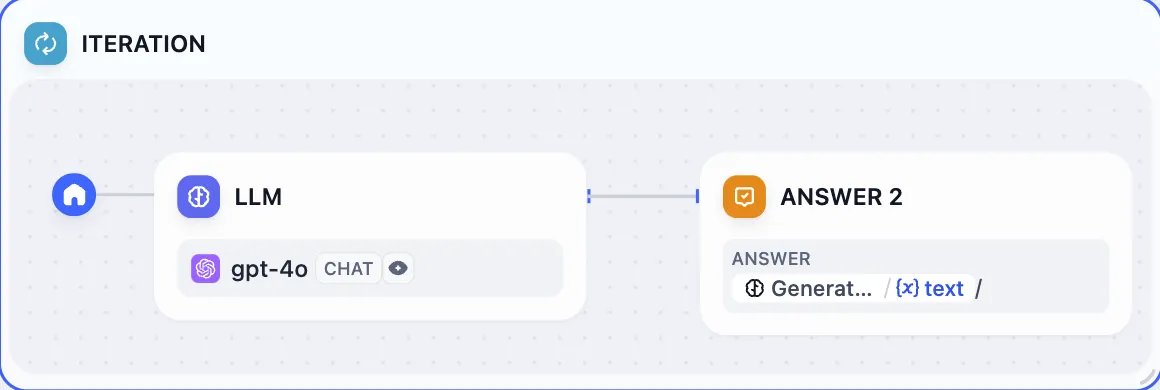
Configure Answer Node

Generate by Iterating Through Story Chapters
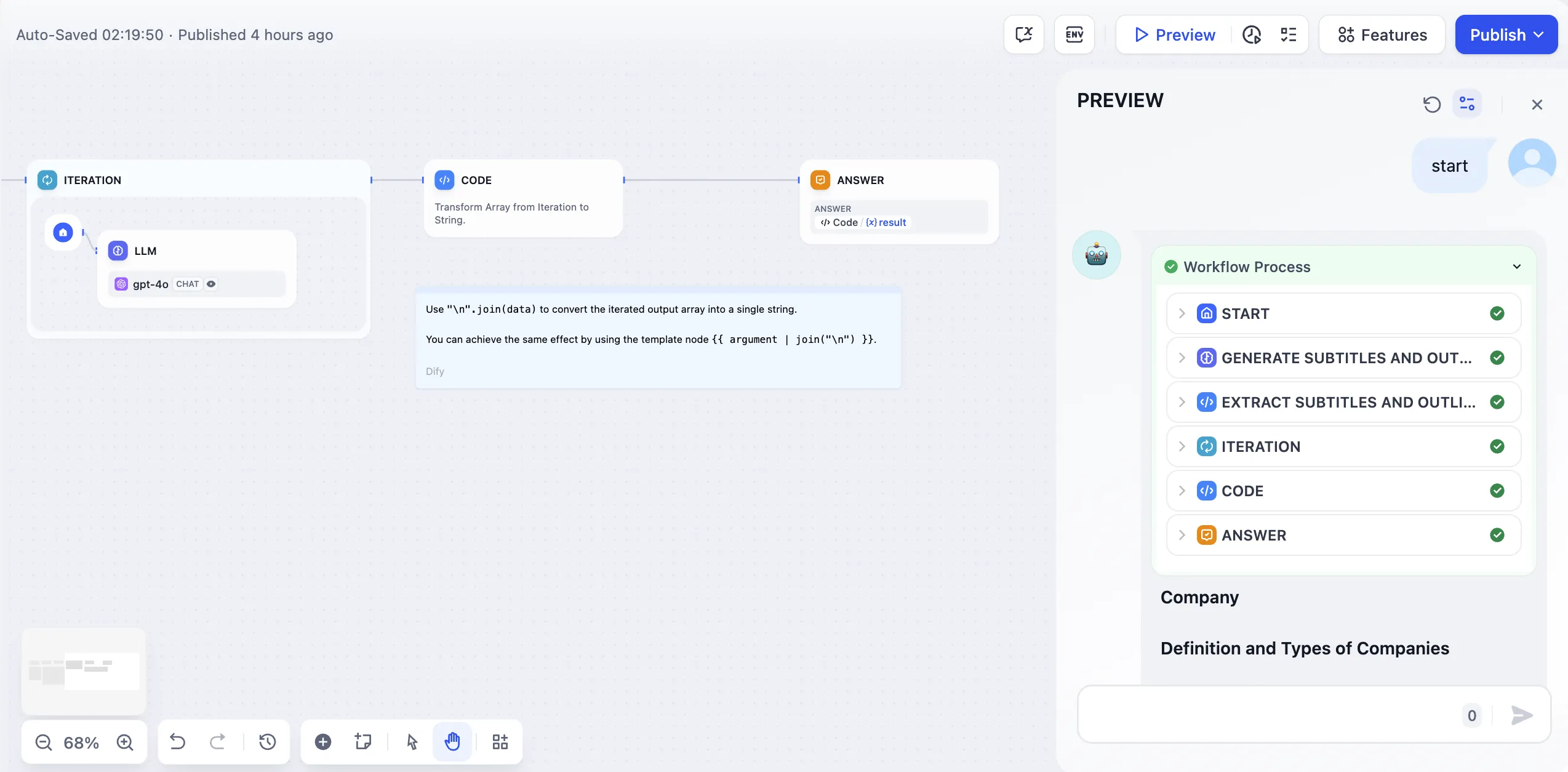
Generate by Iterating Through Story Chapters

Parameter Extraction
Parameter Extraction

Parameter Extraction
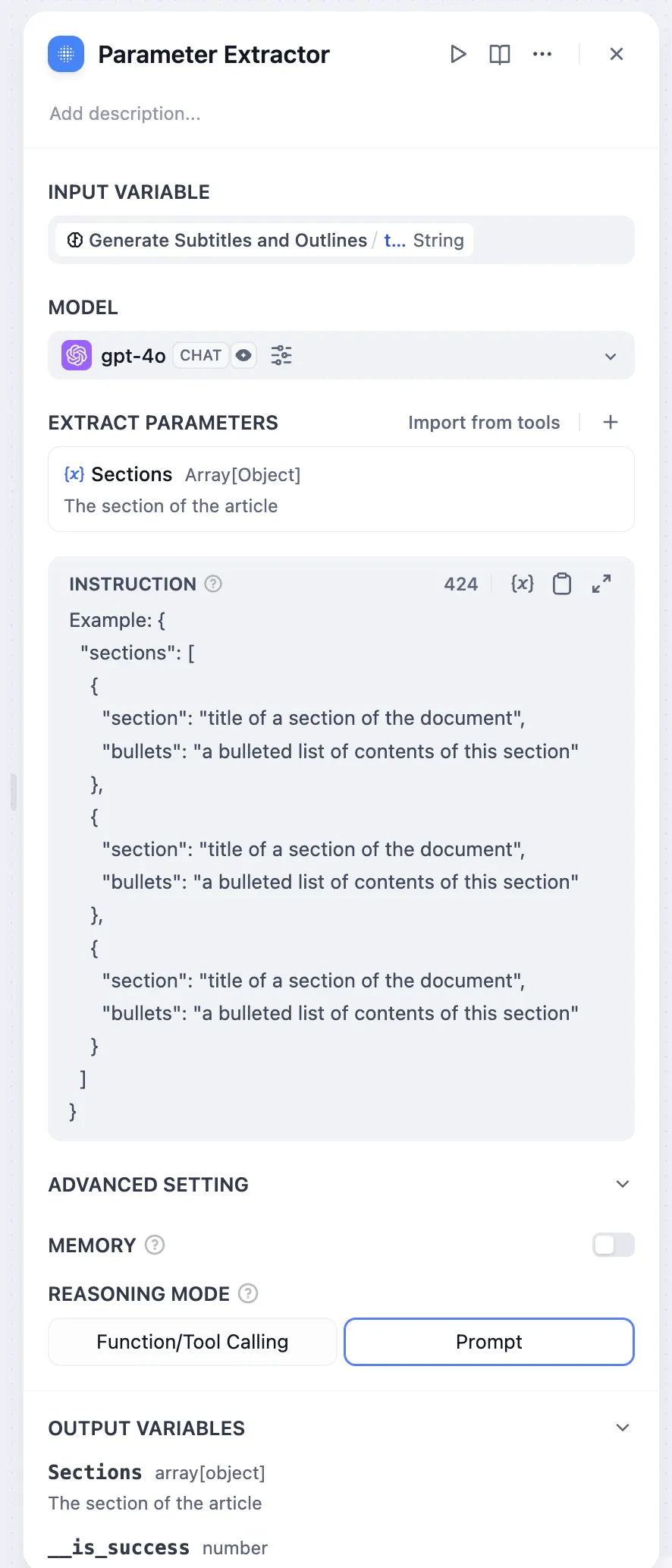
Parameter Extraction

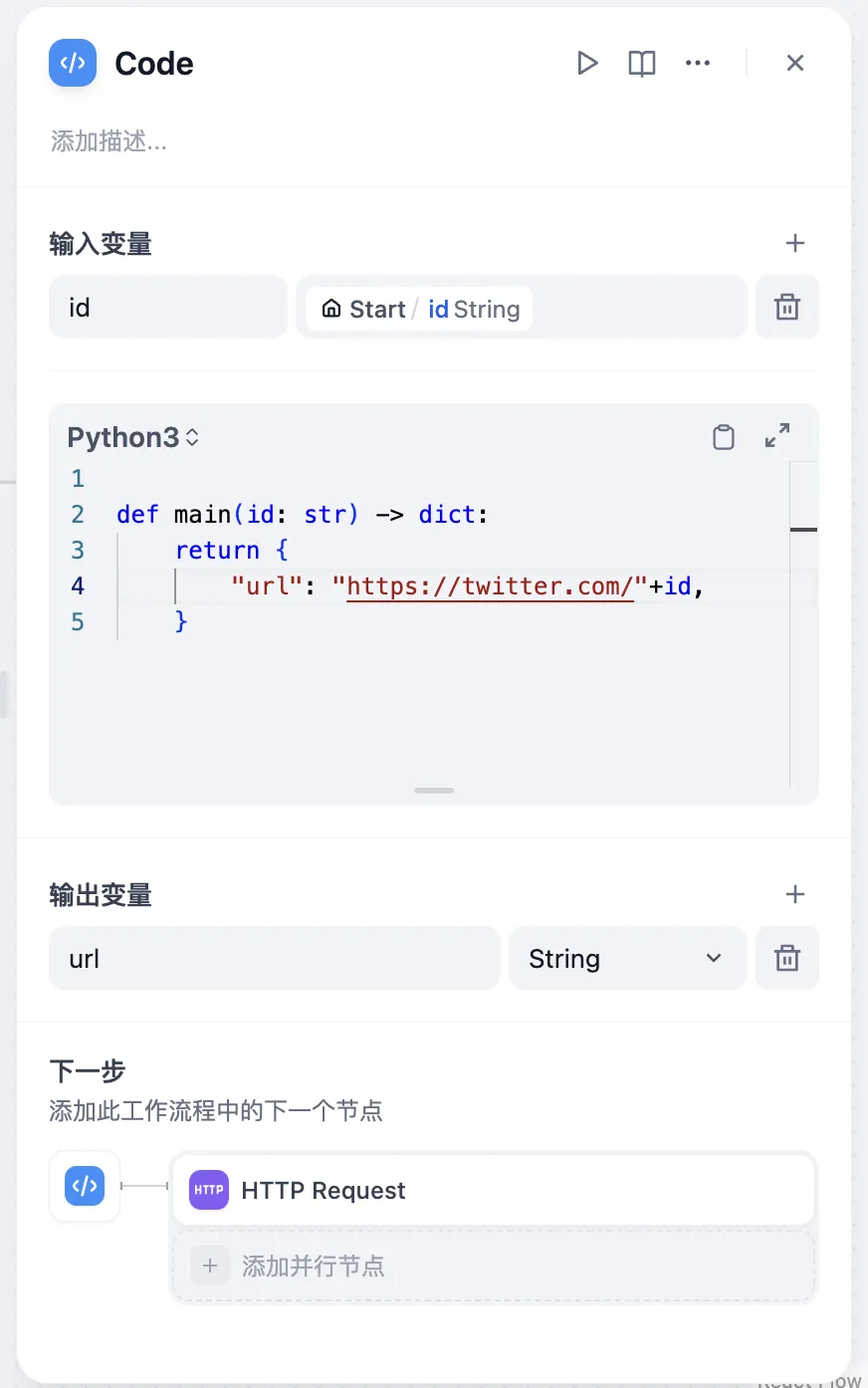
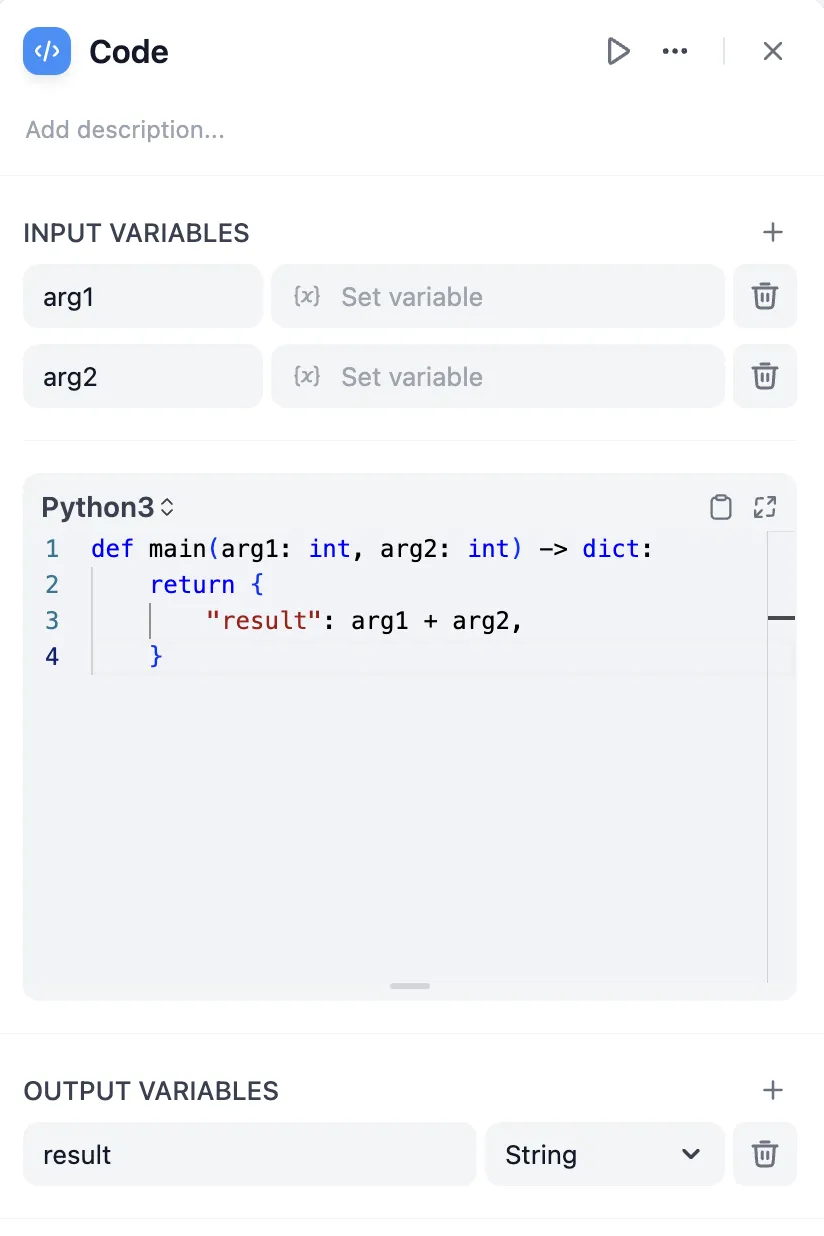
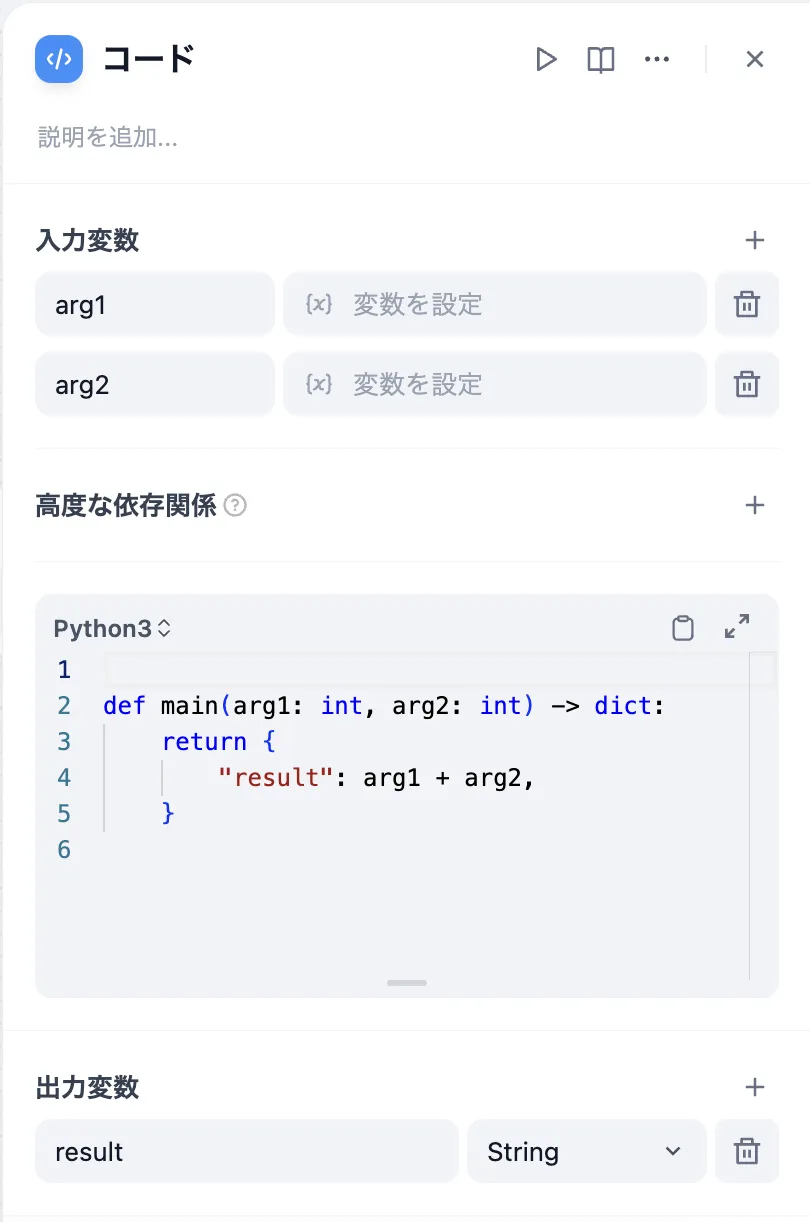
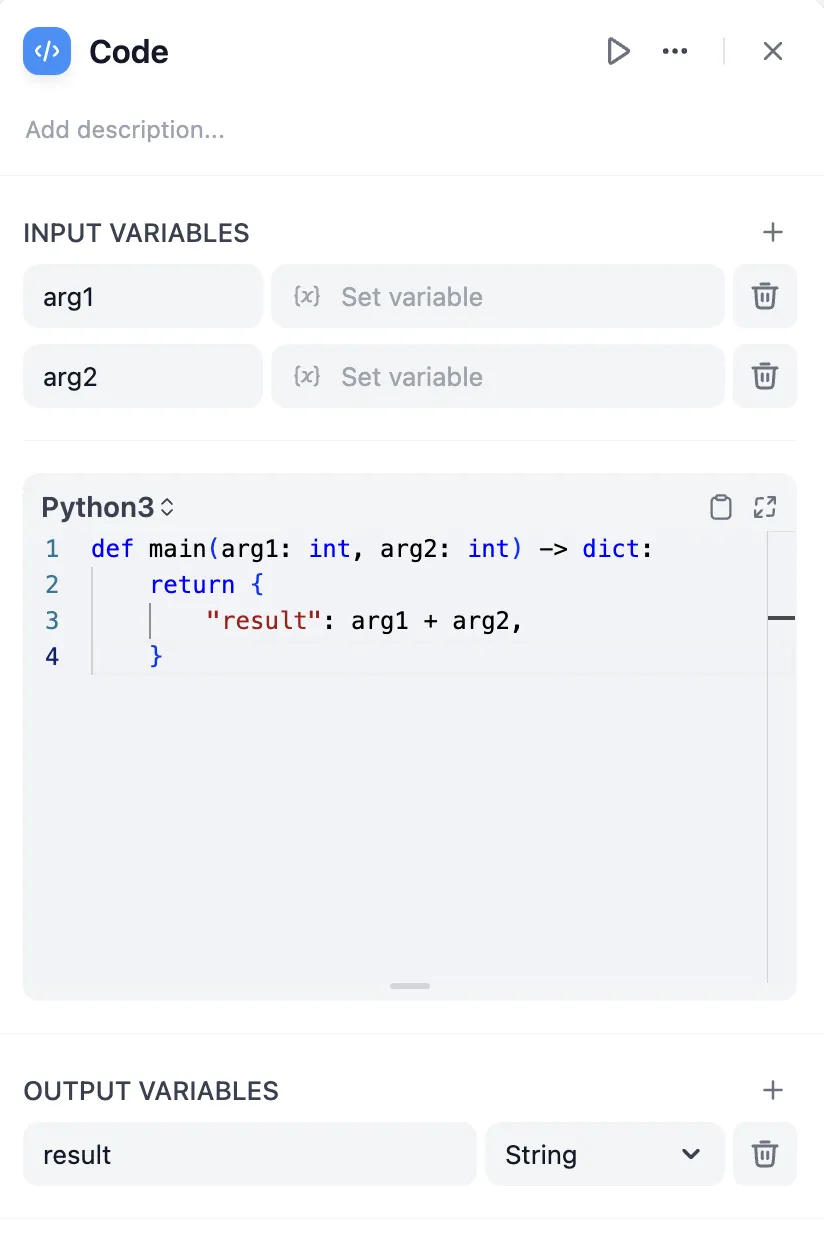
Code Node Conversion
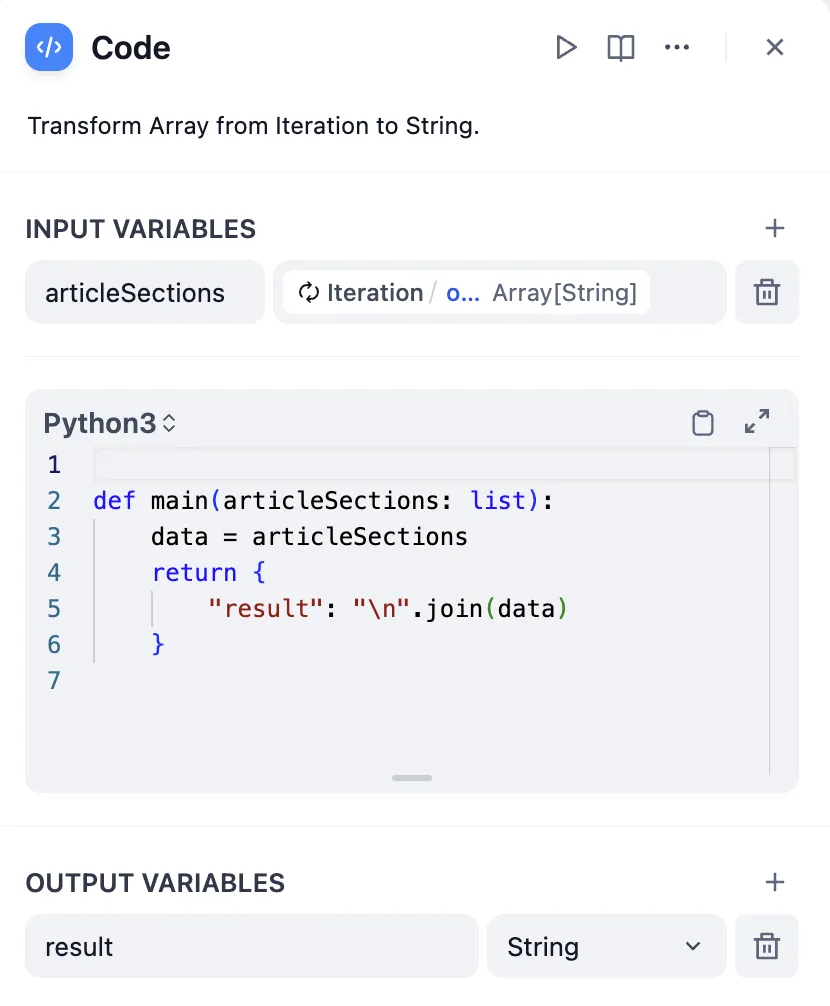
Code Node Conversion

Template Node Conversion
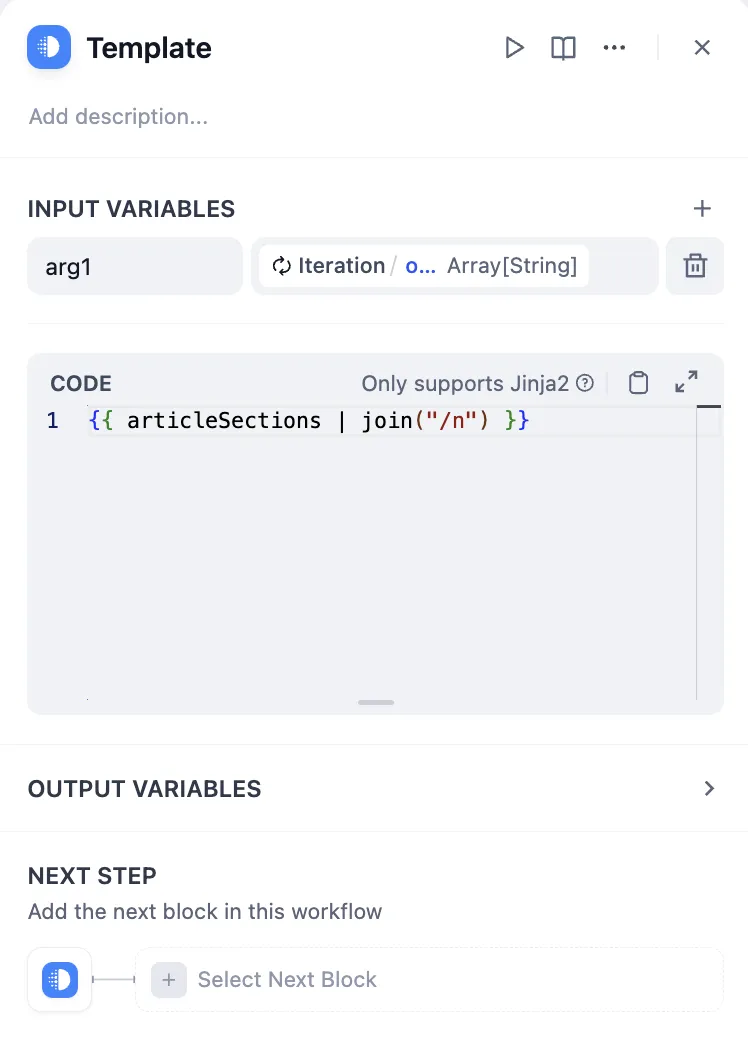
Template Node Conversion



.png)
.png)
.png)


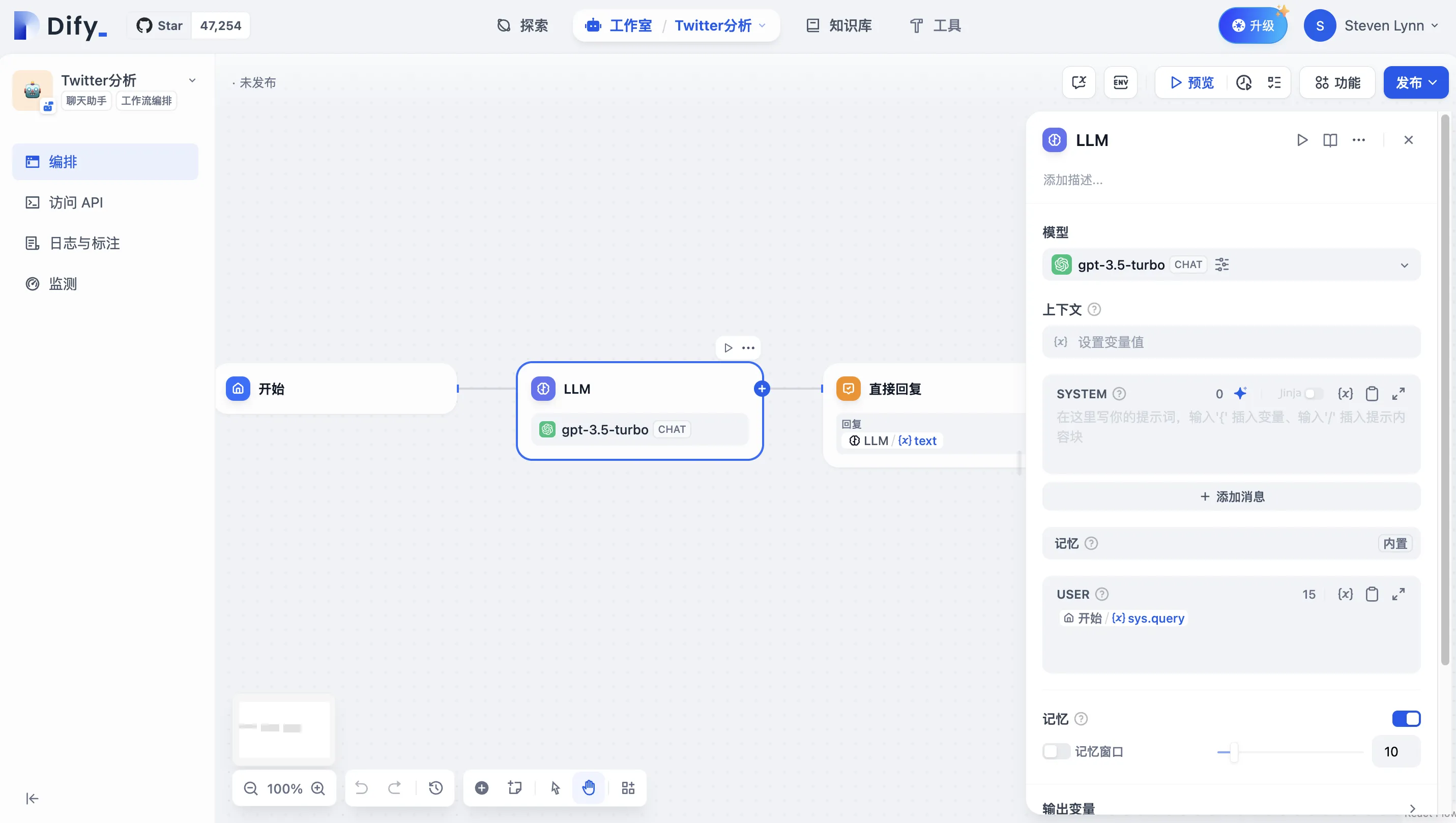
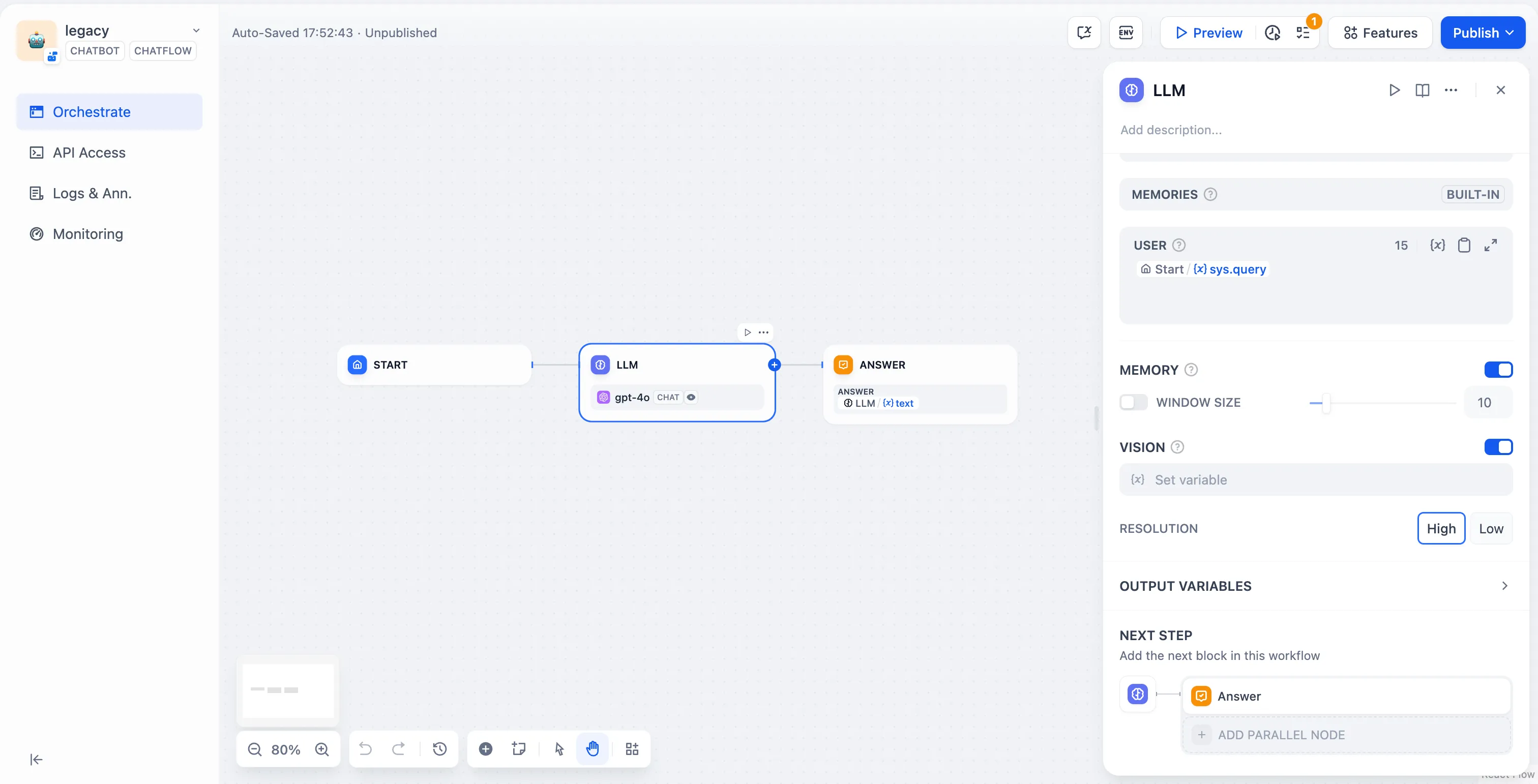
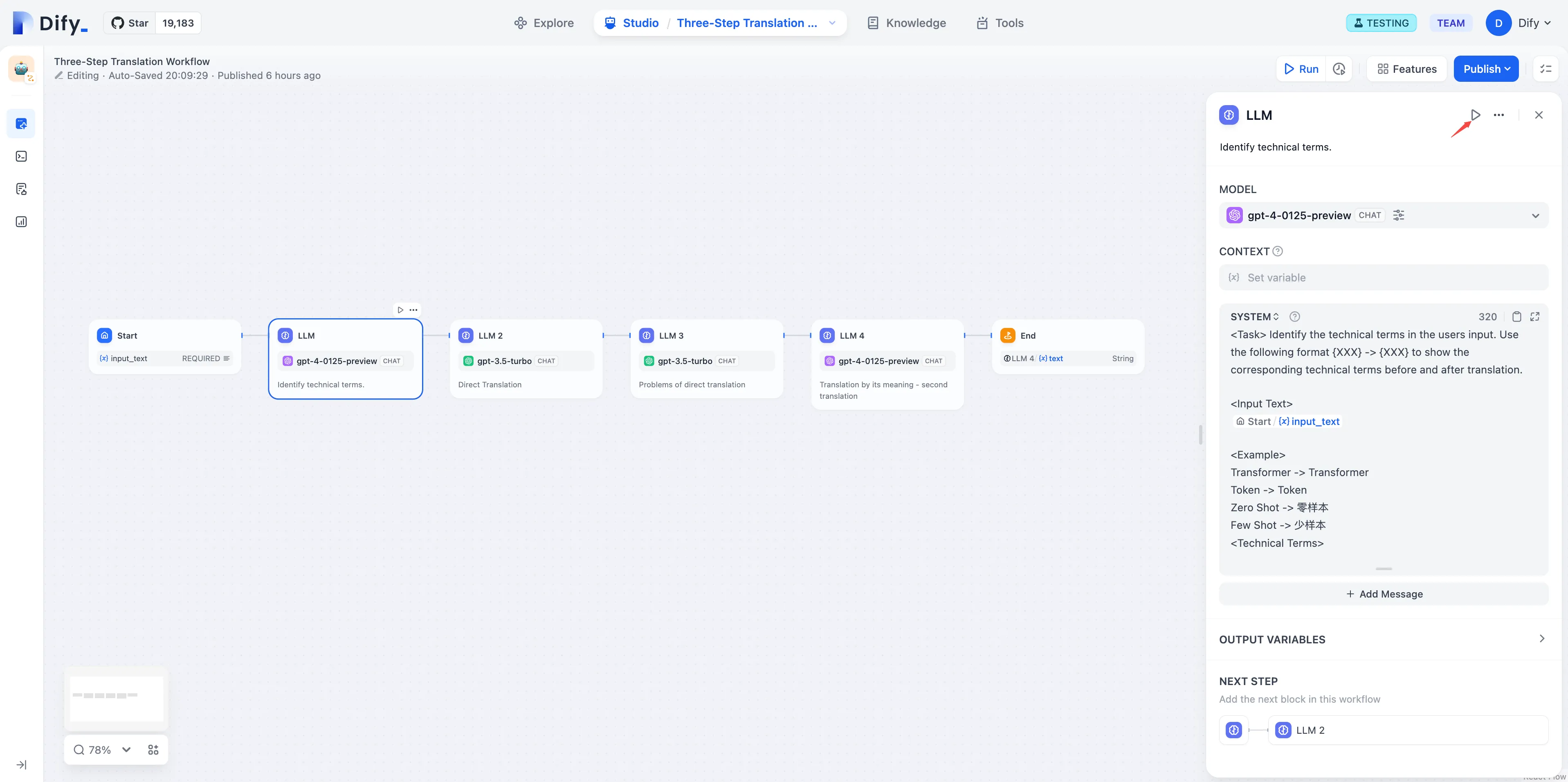
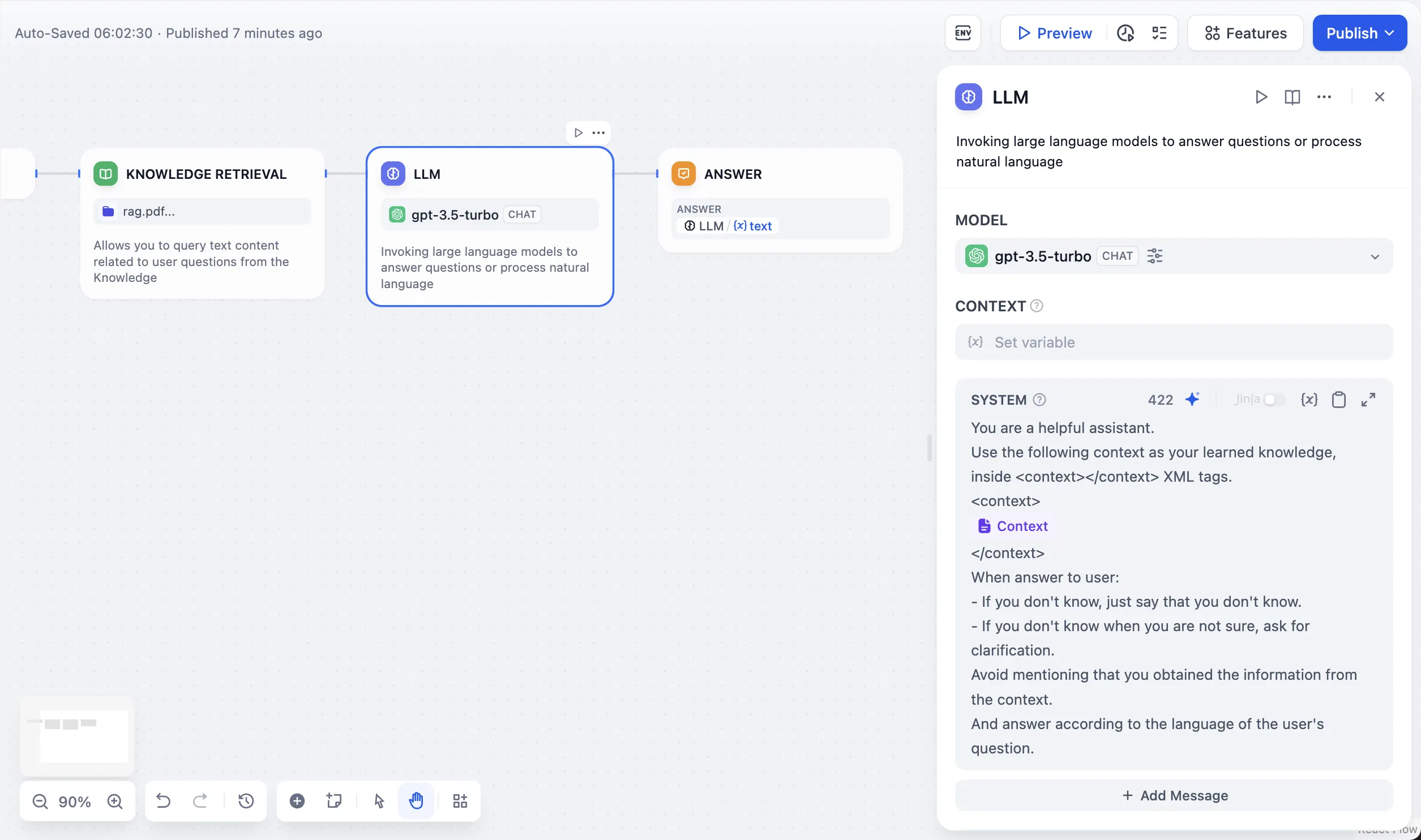
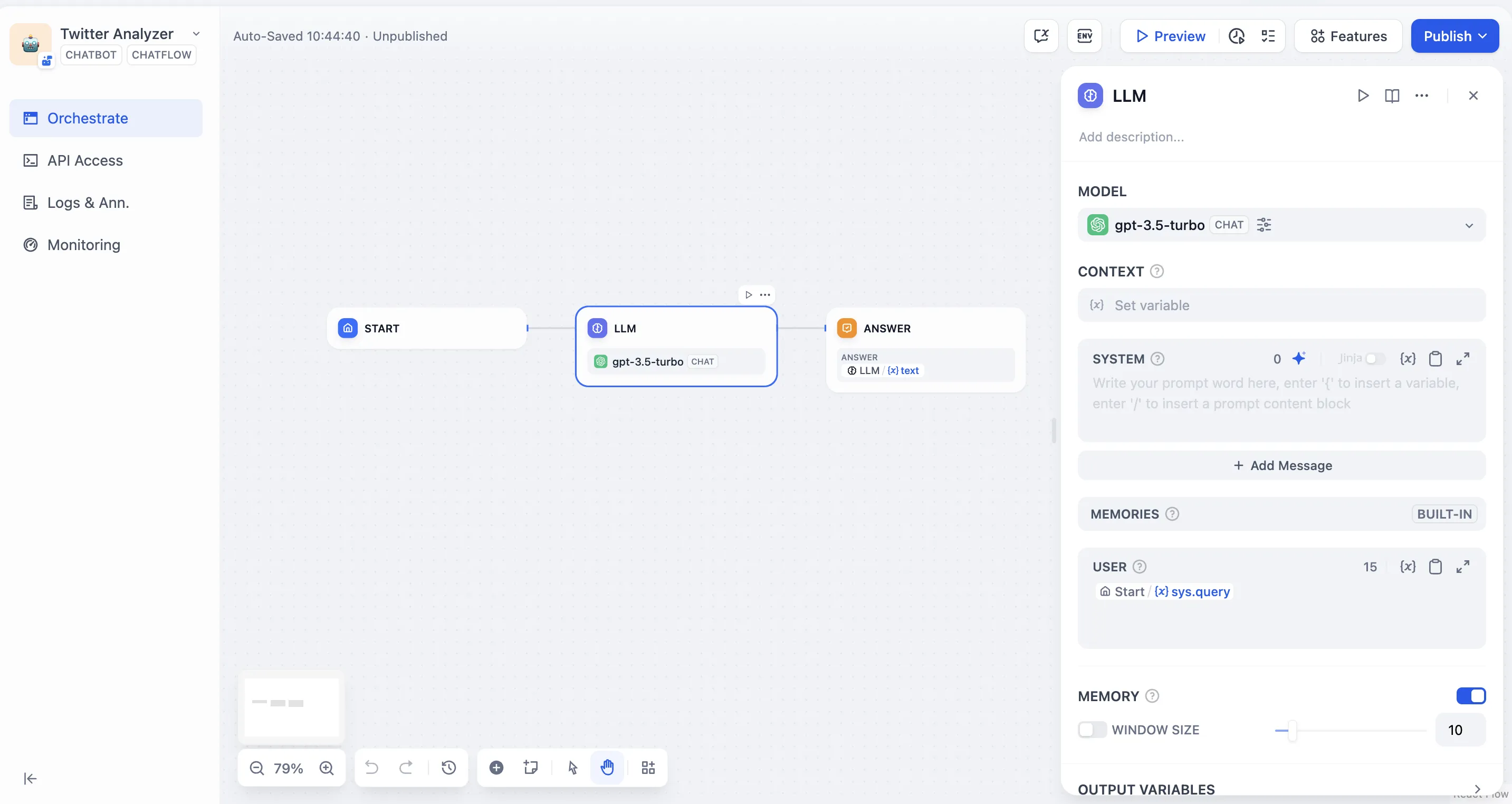
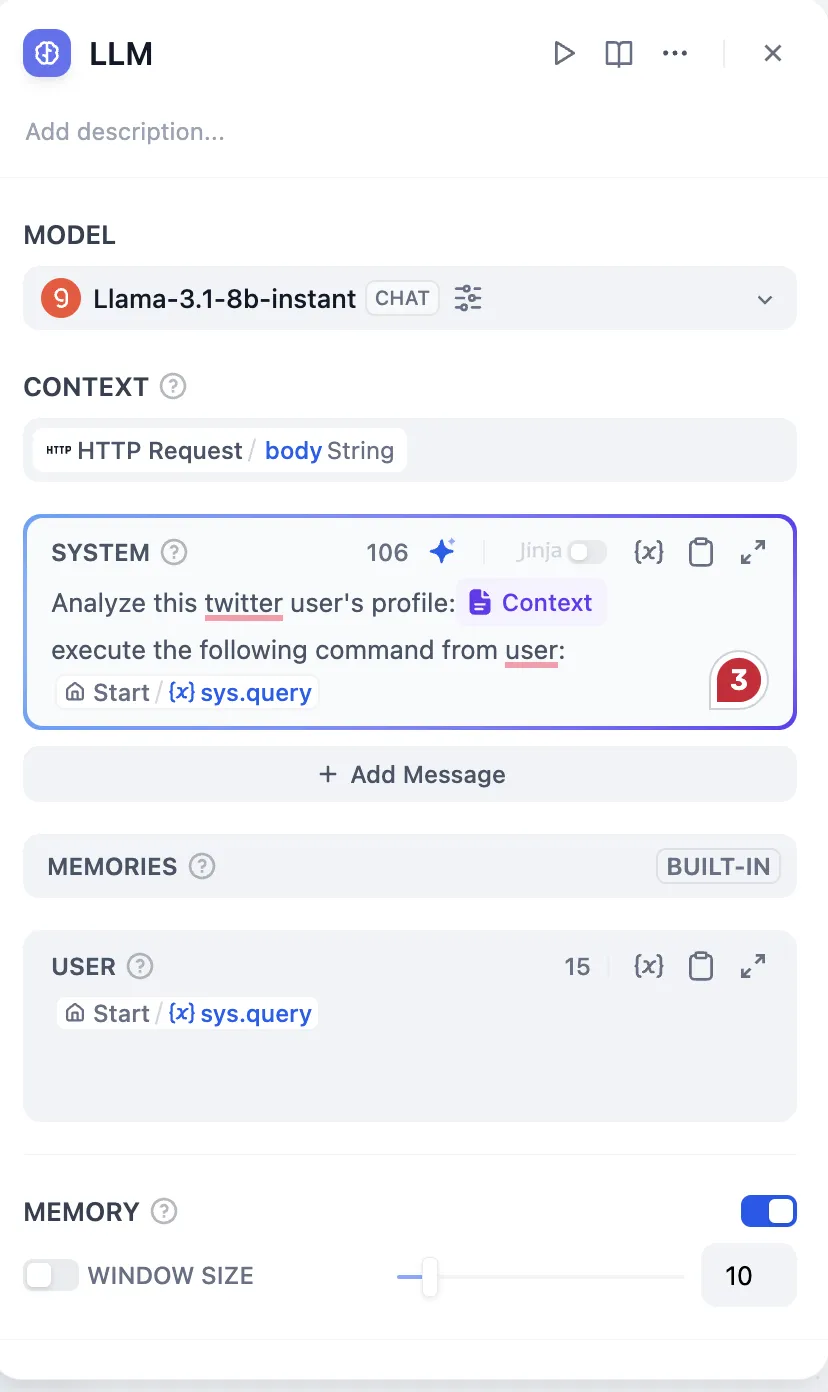
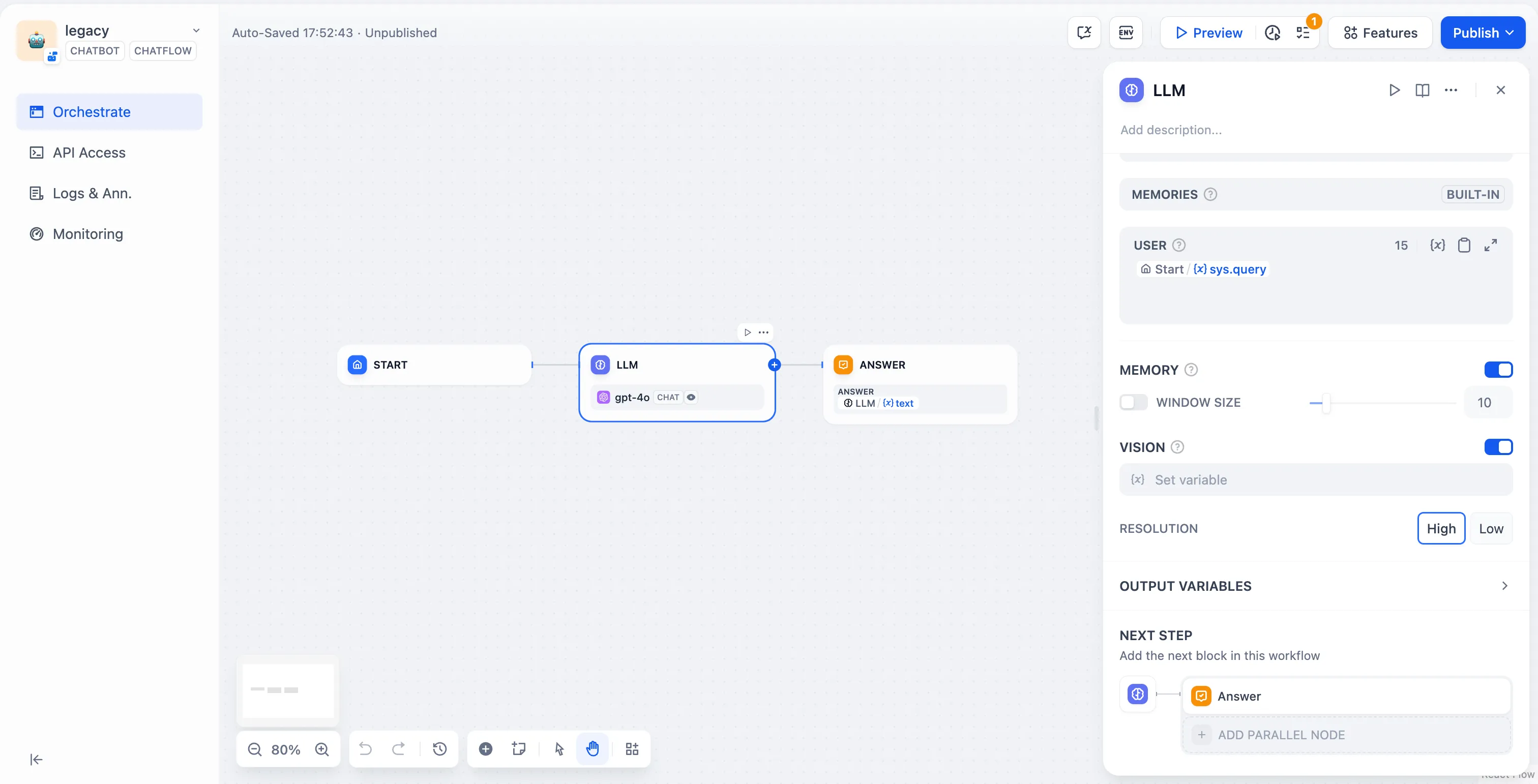
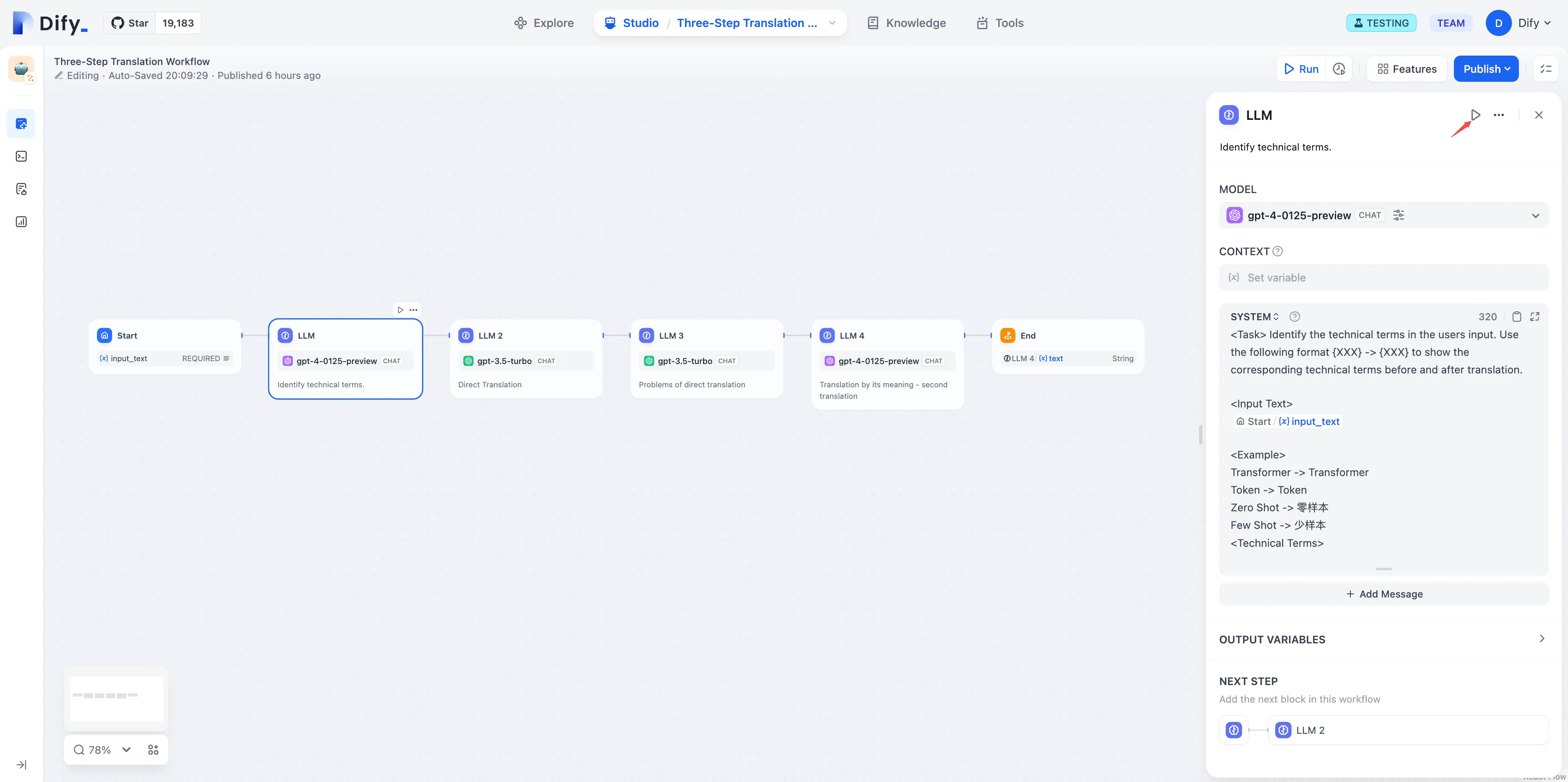
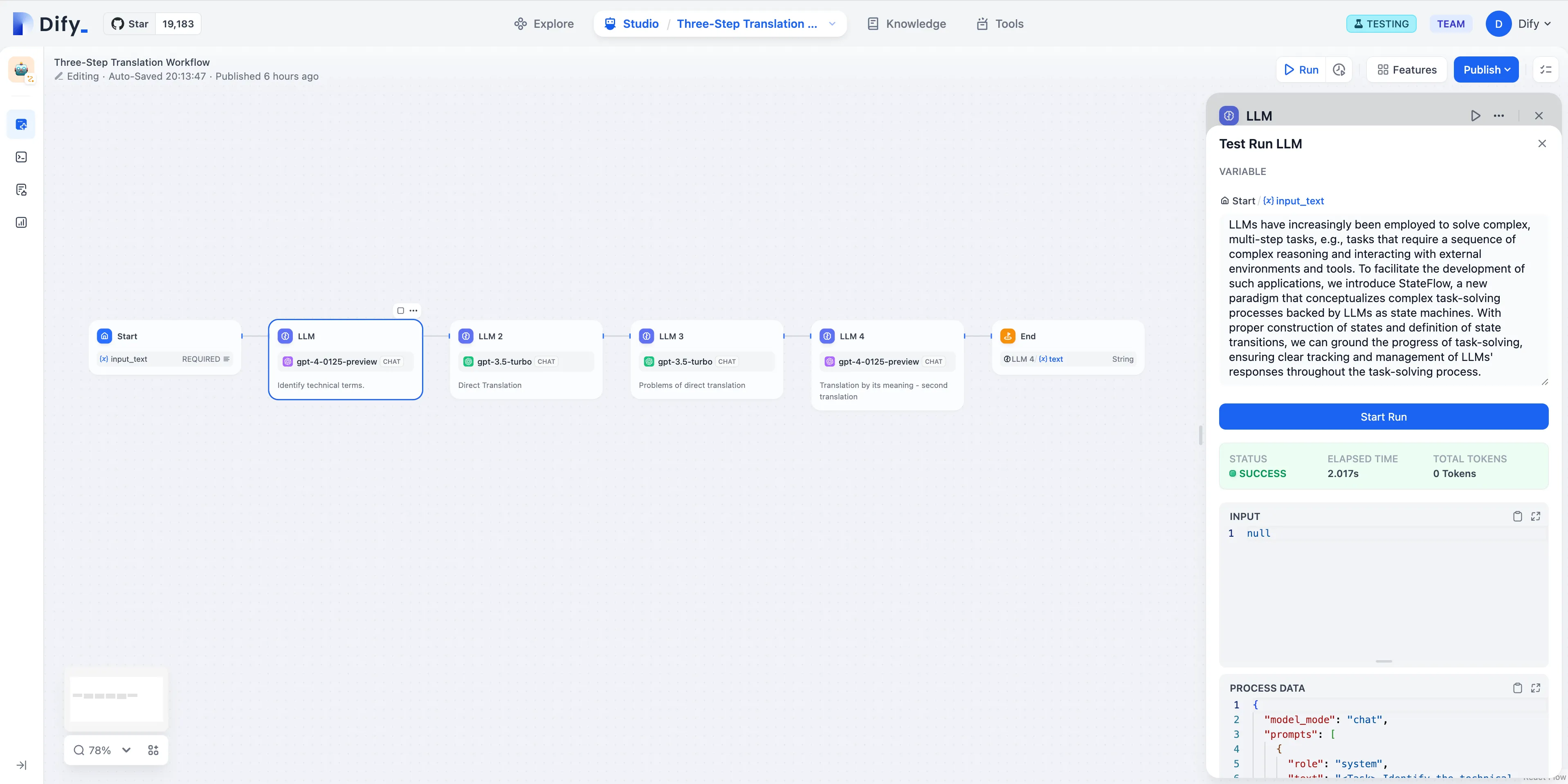
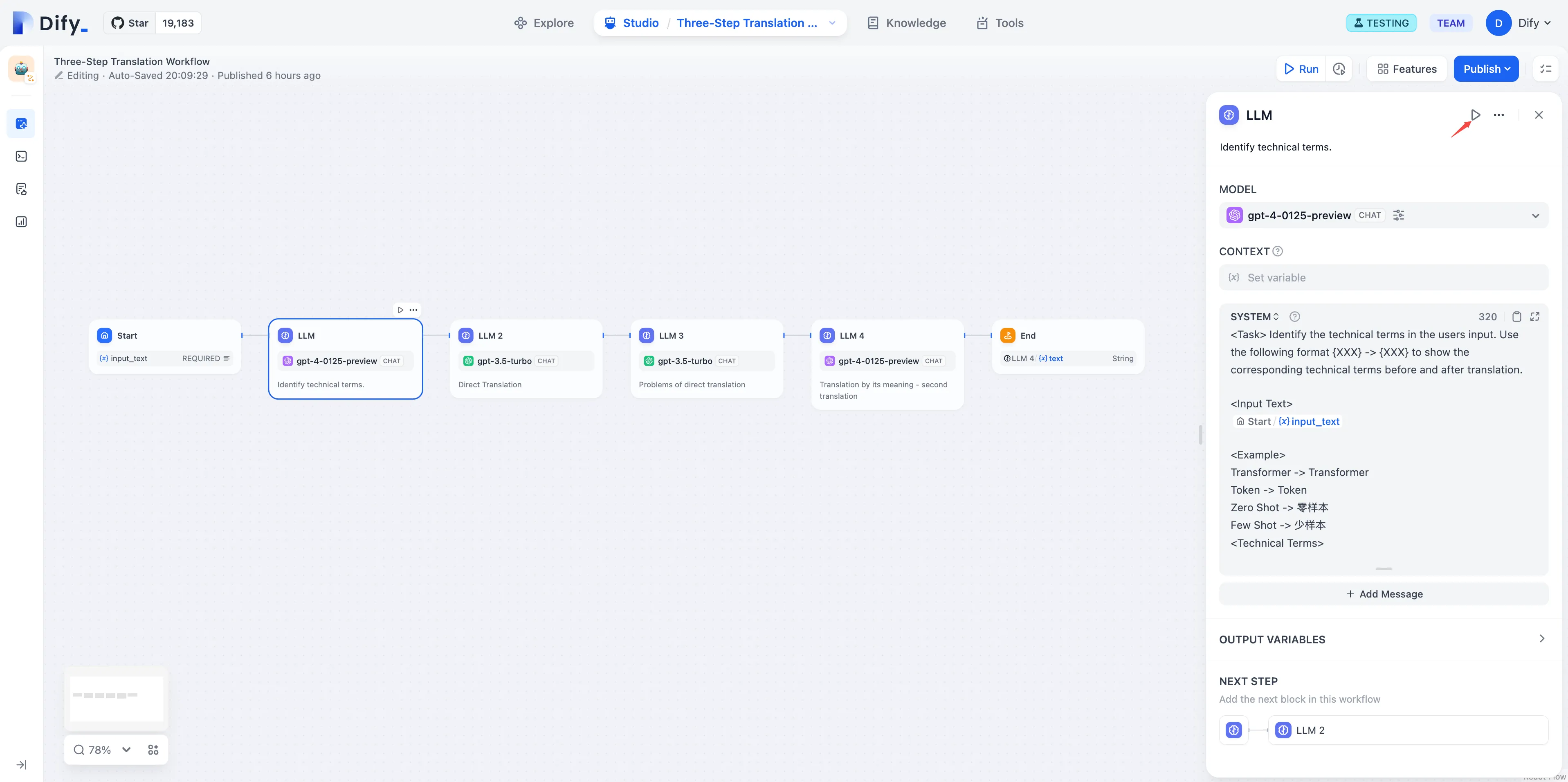
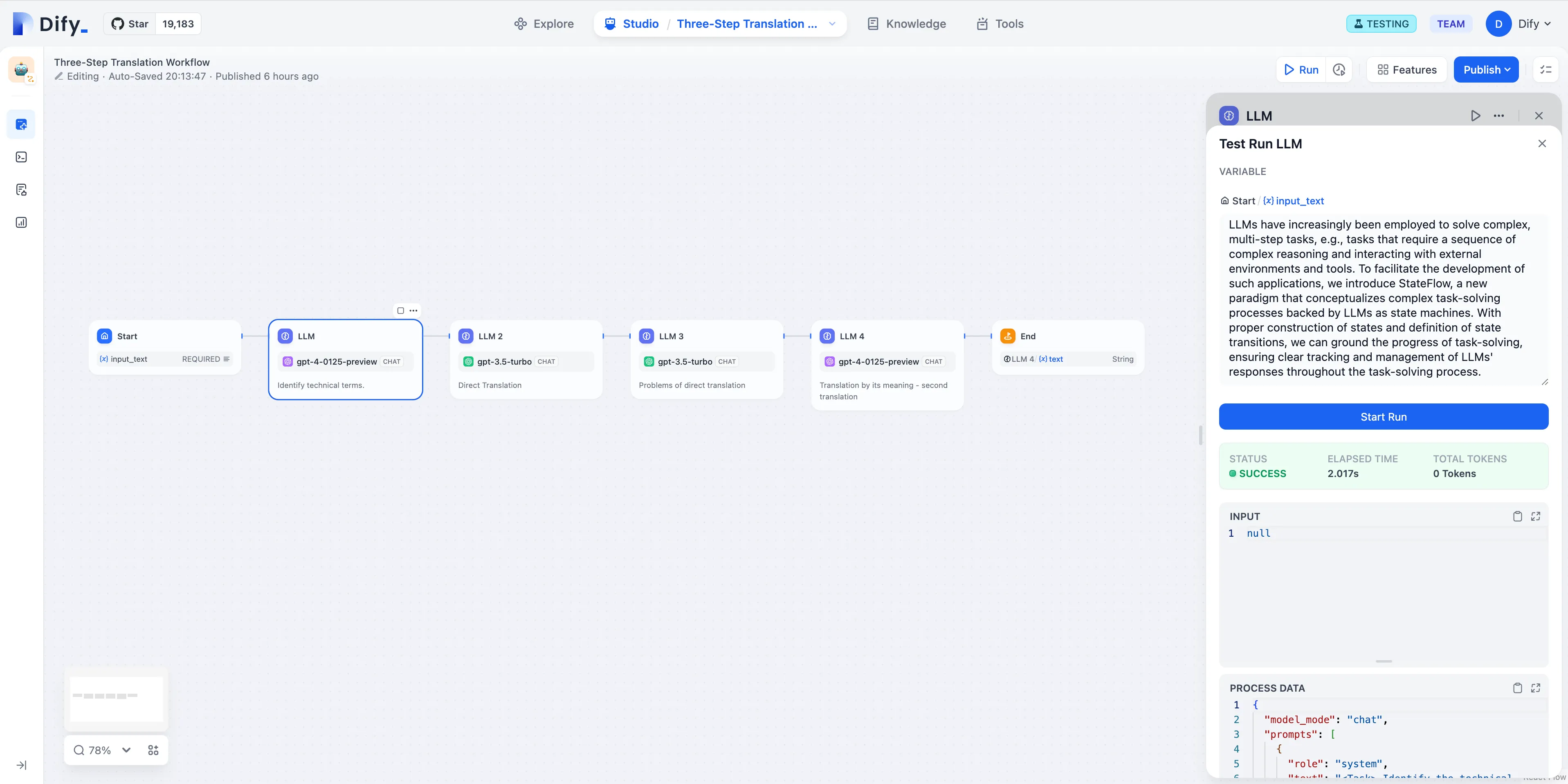
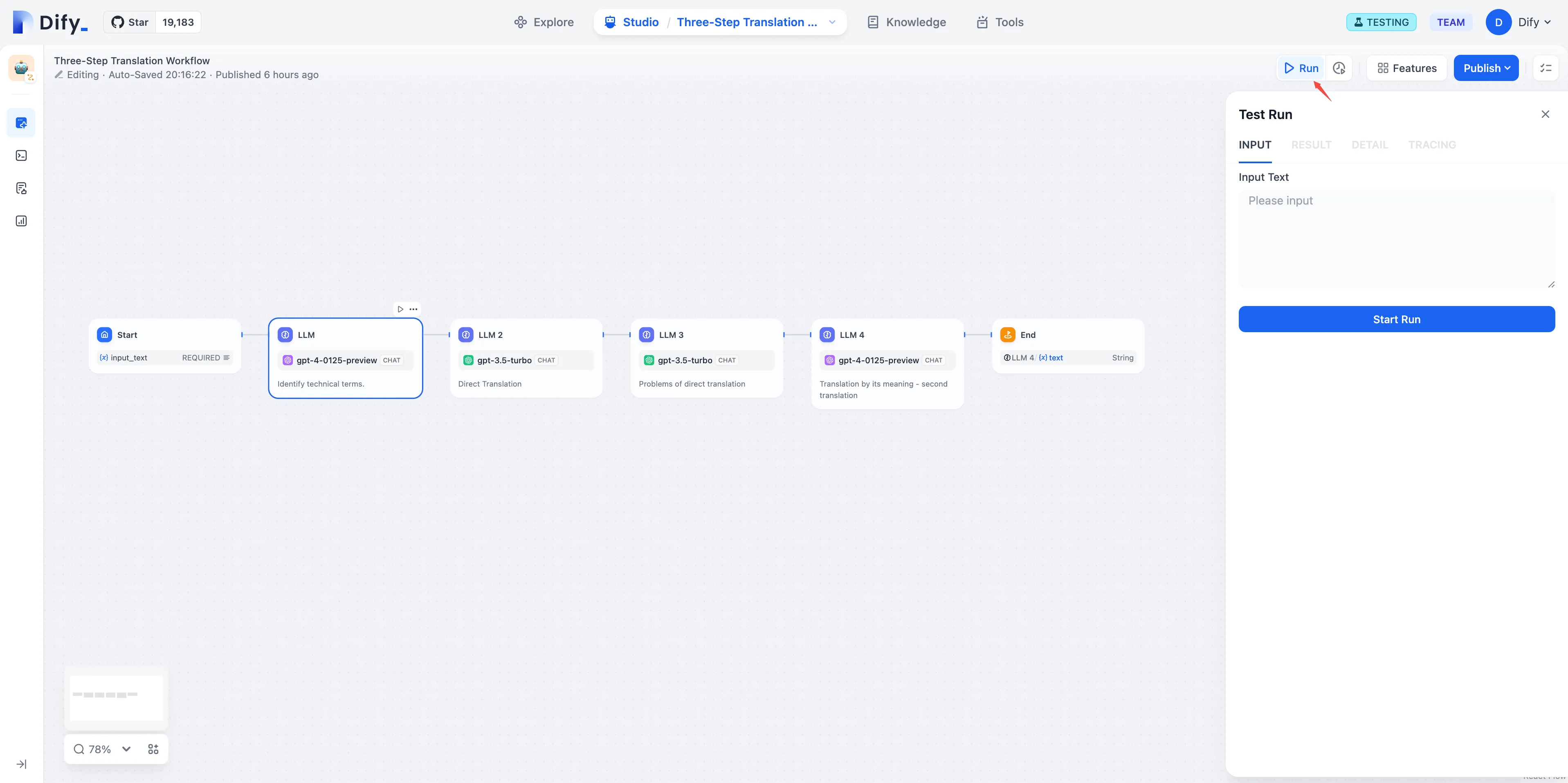
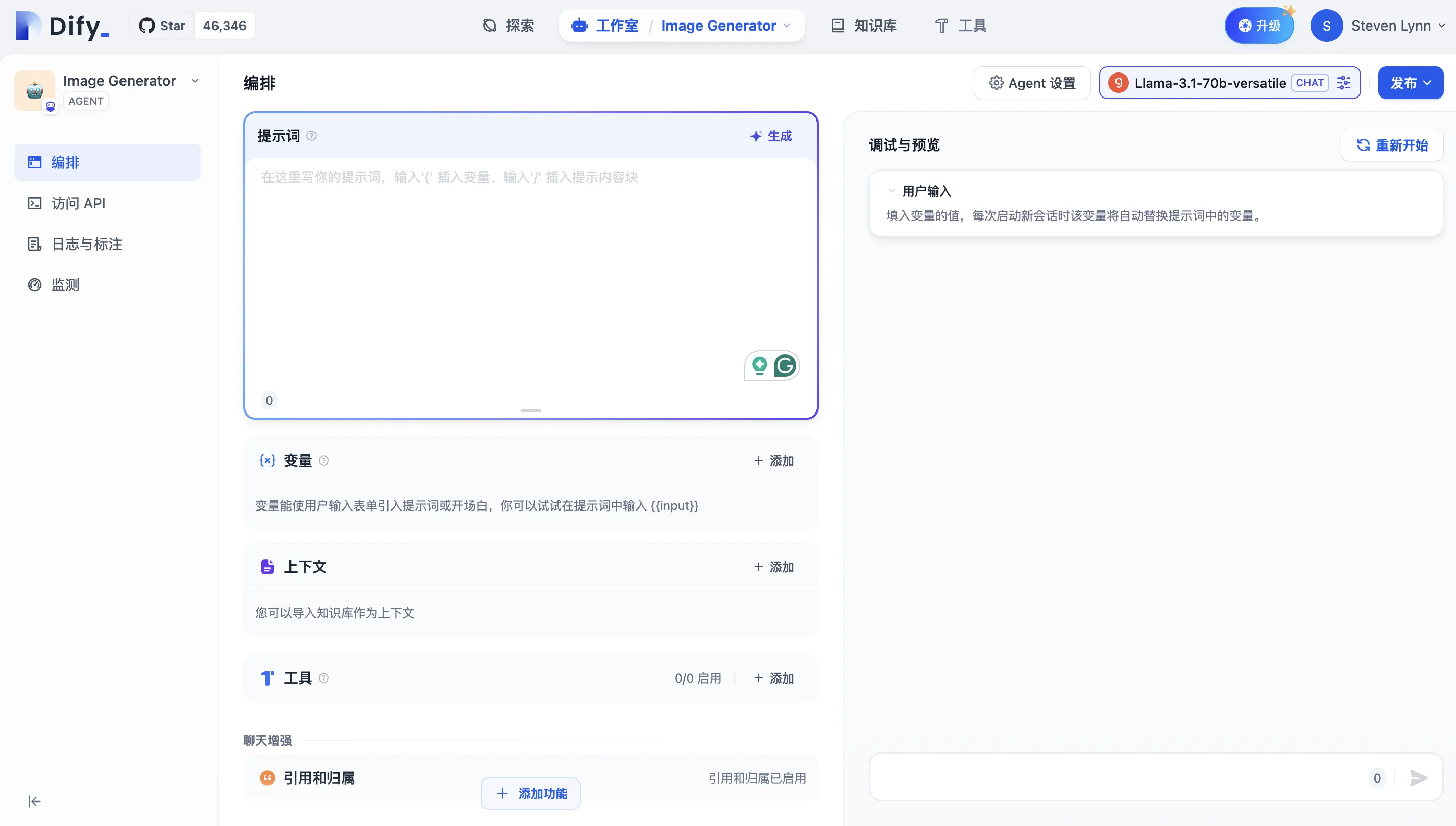
LLM Node
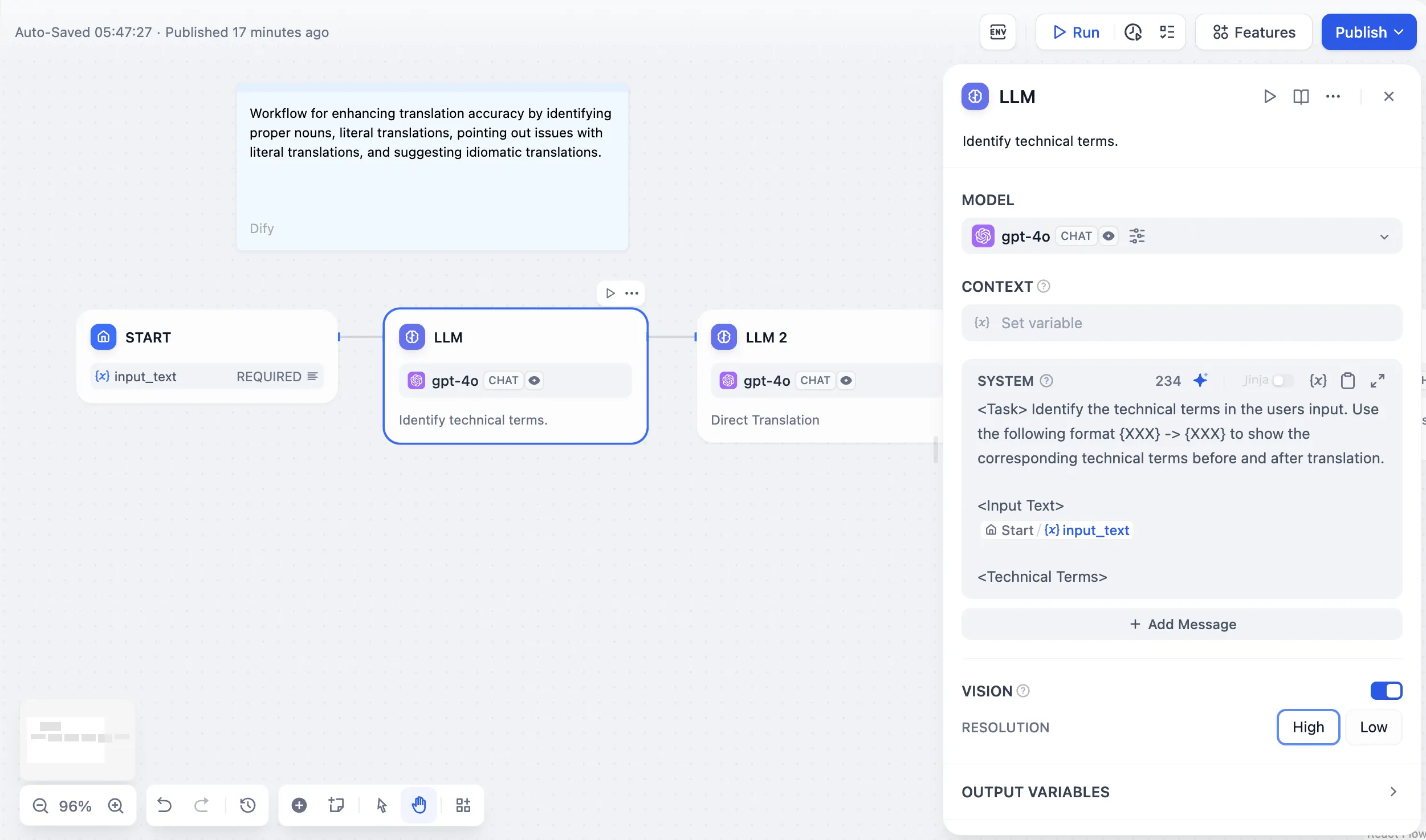
LLM Node

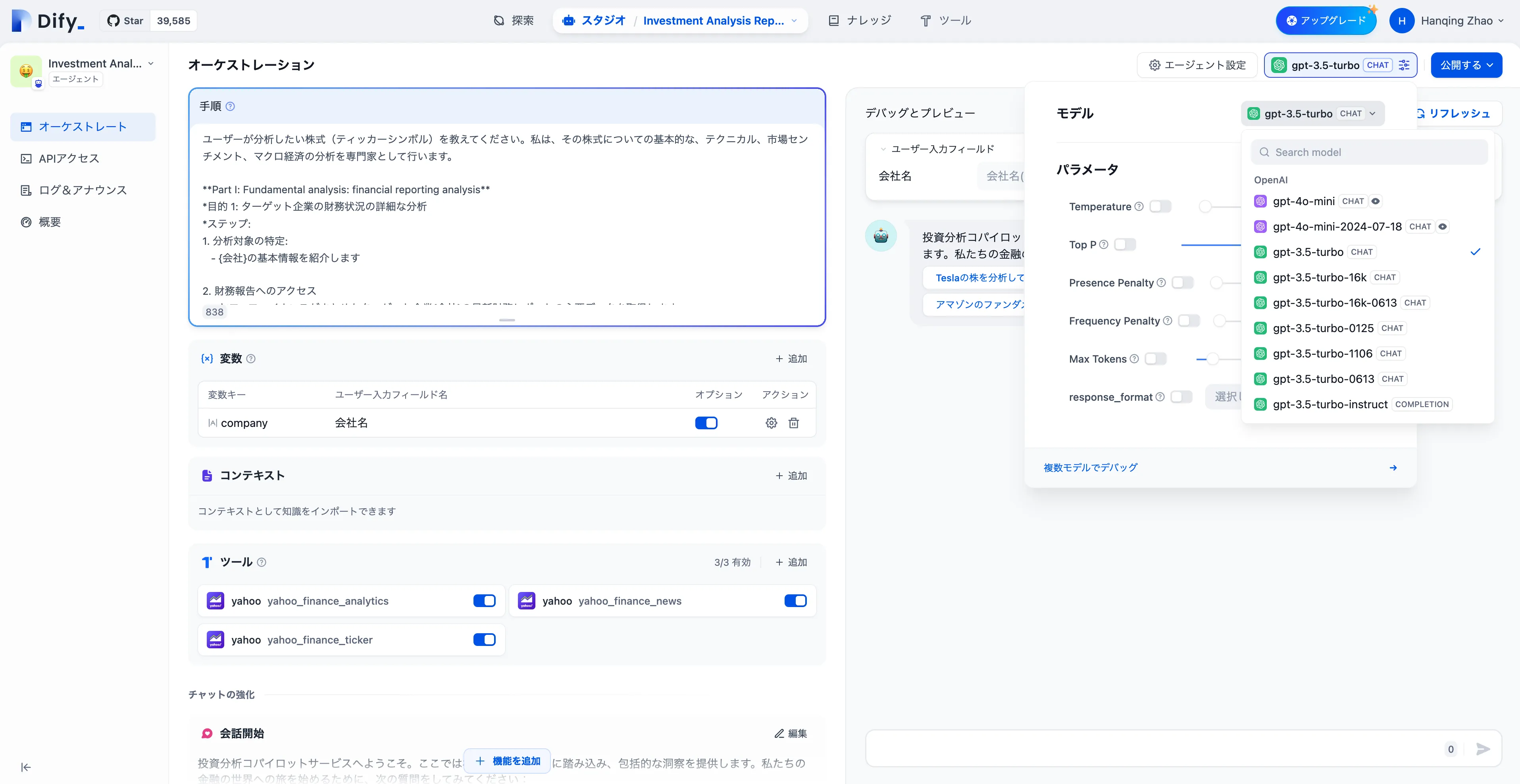
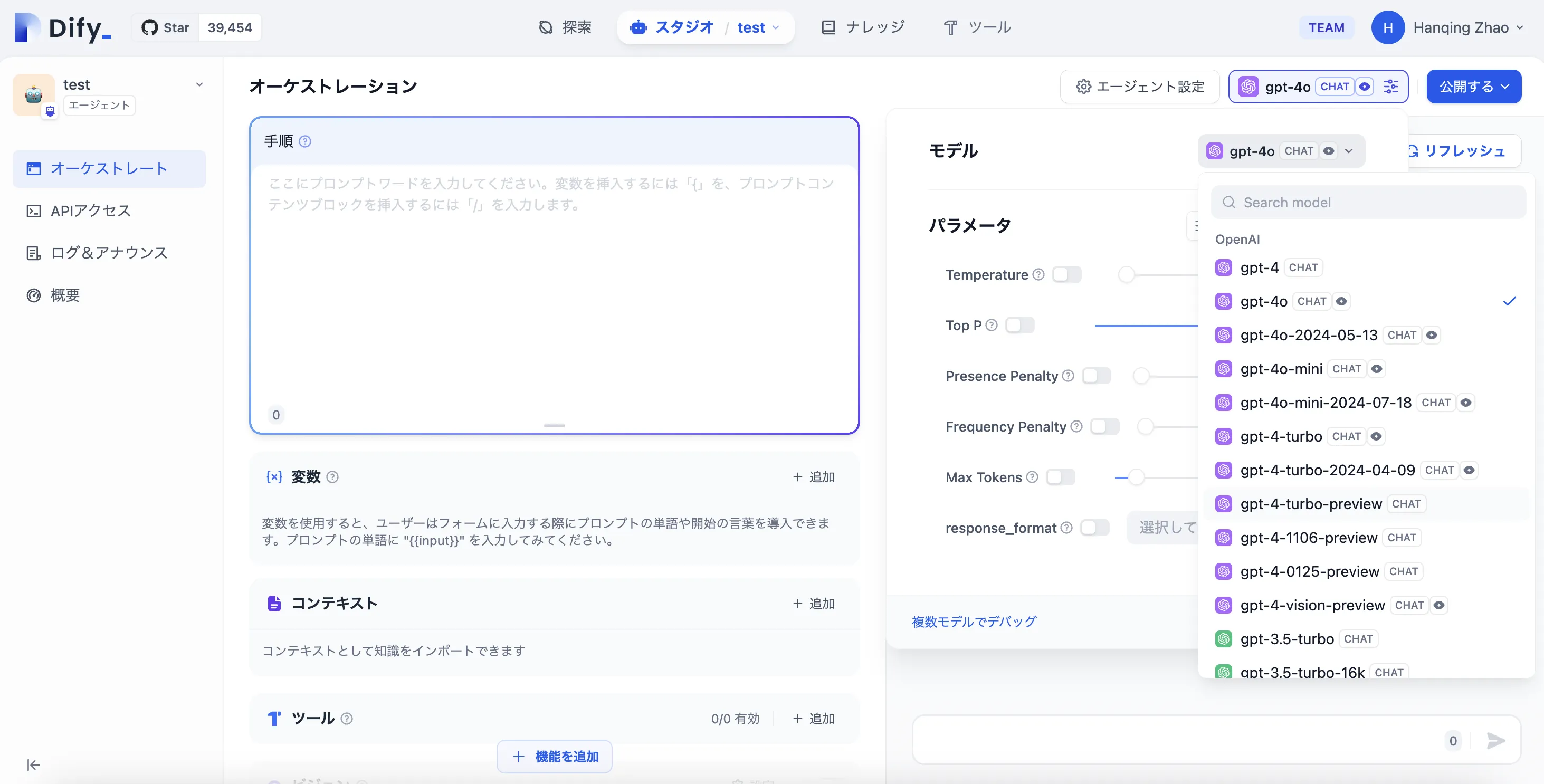
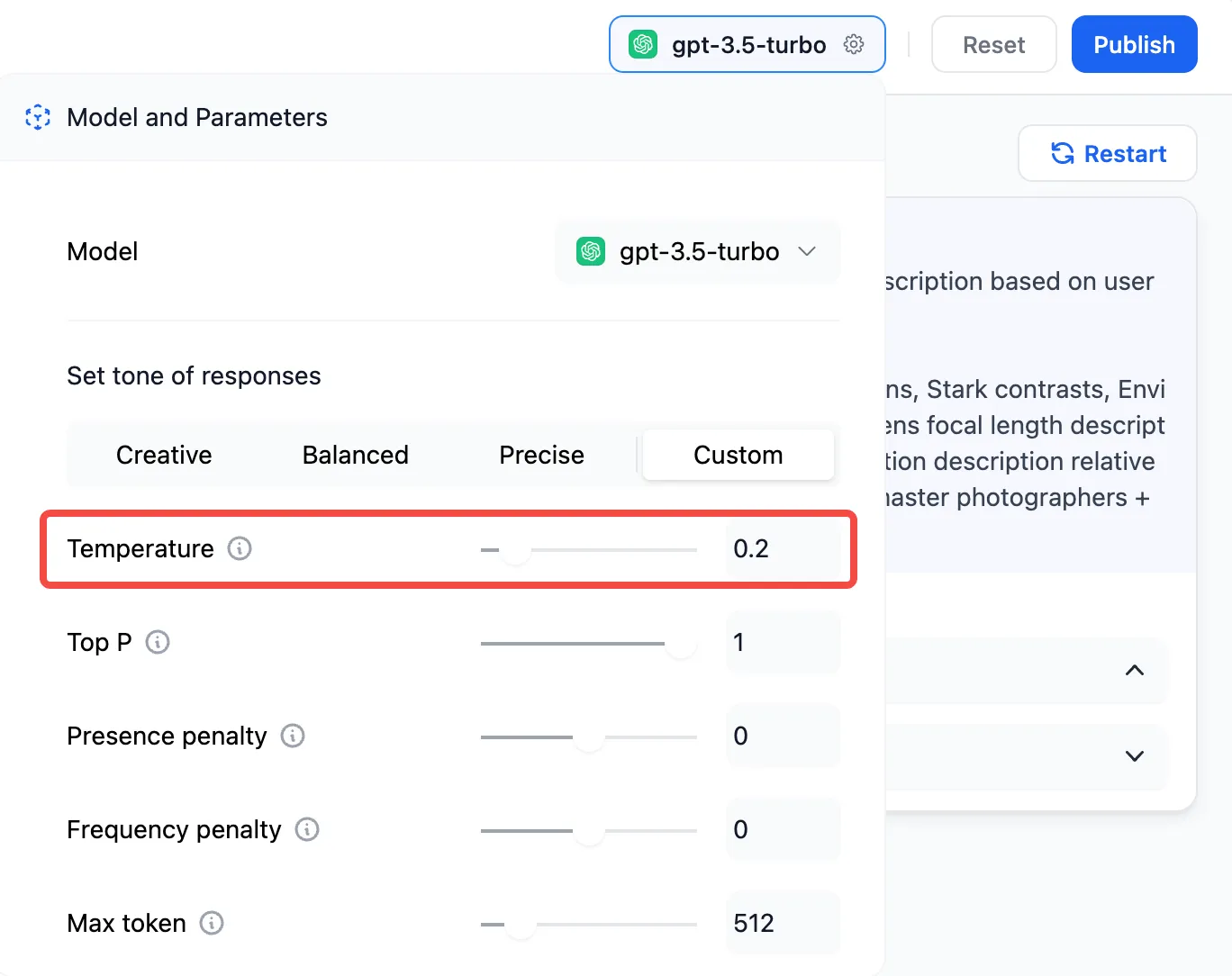
LLM Node Configuration - Model Selection
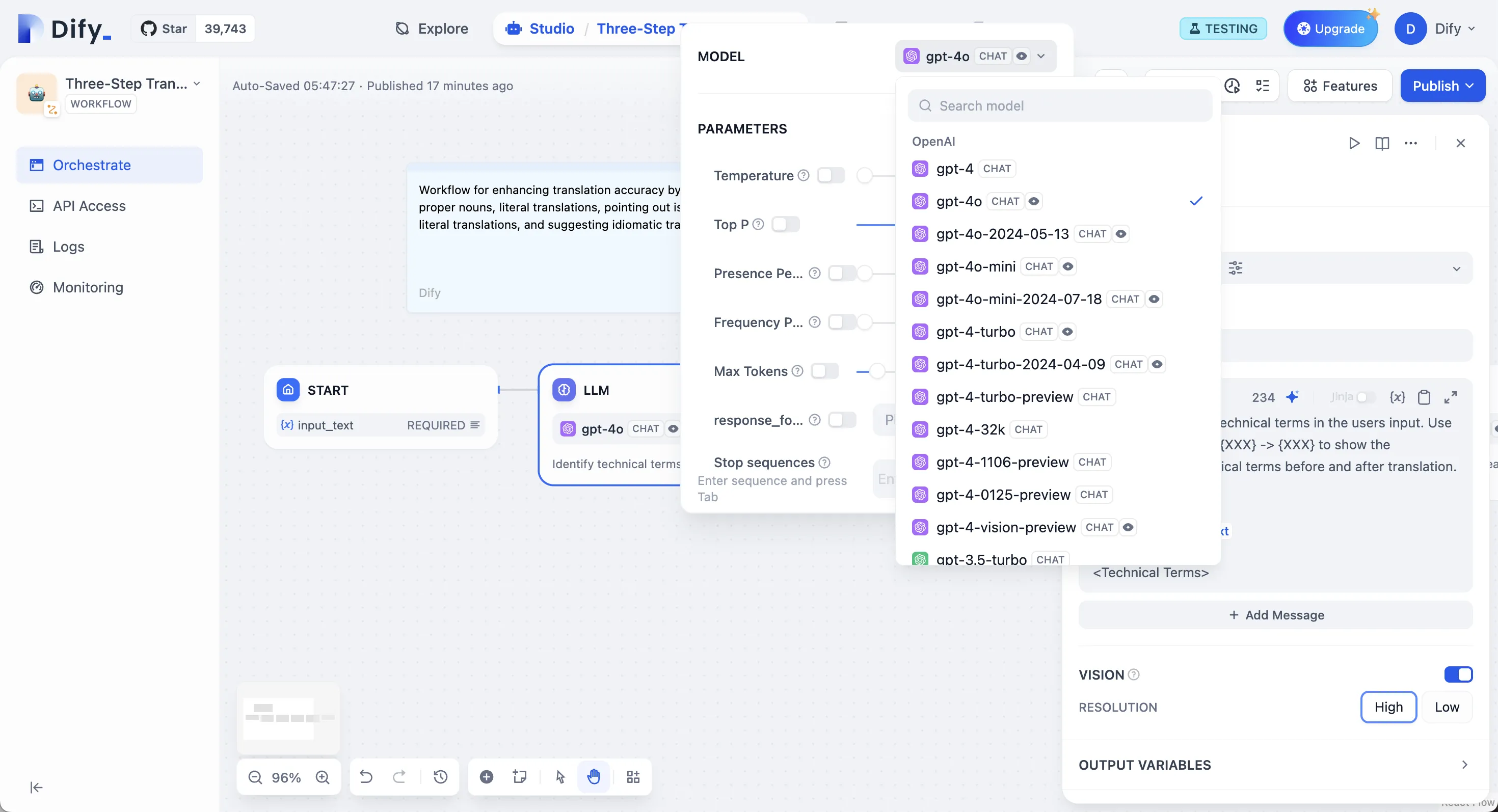
LLM Node Configuration - Model Selection


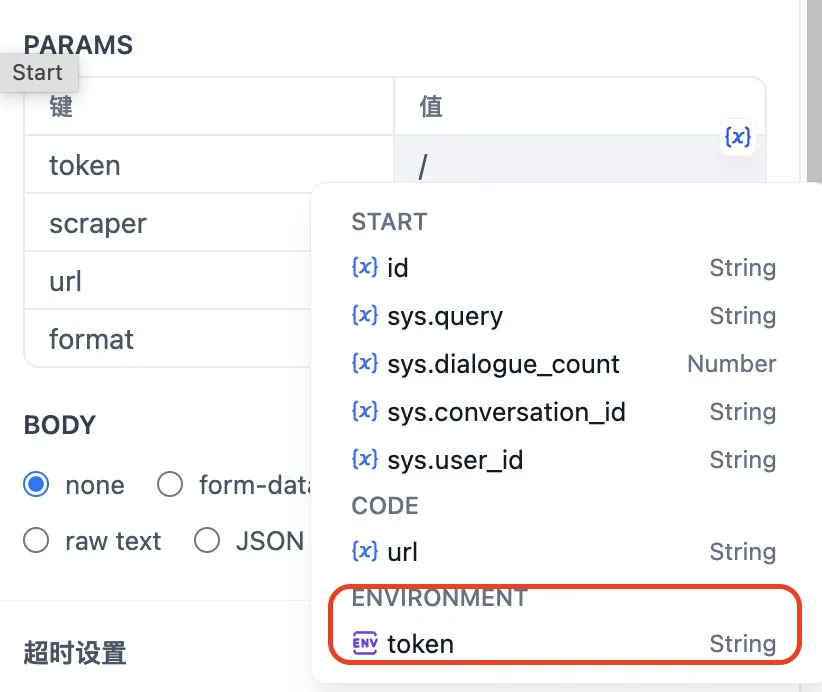
Calling Out the Variable Insertion Menu
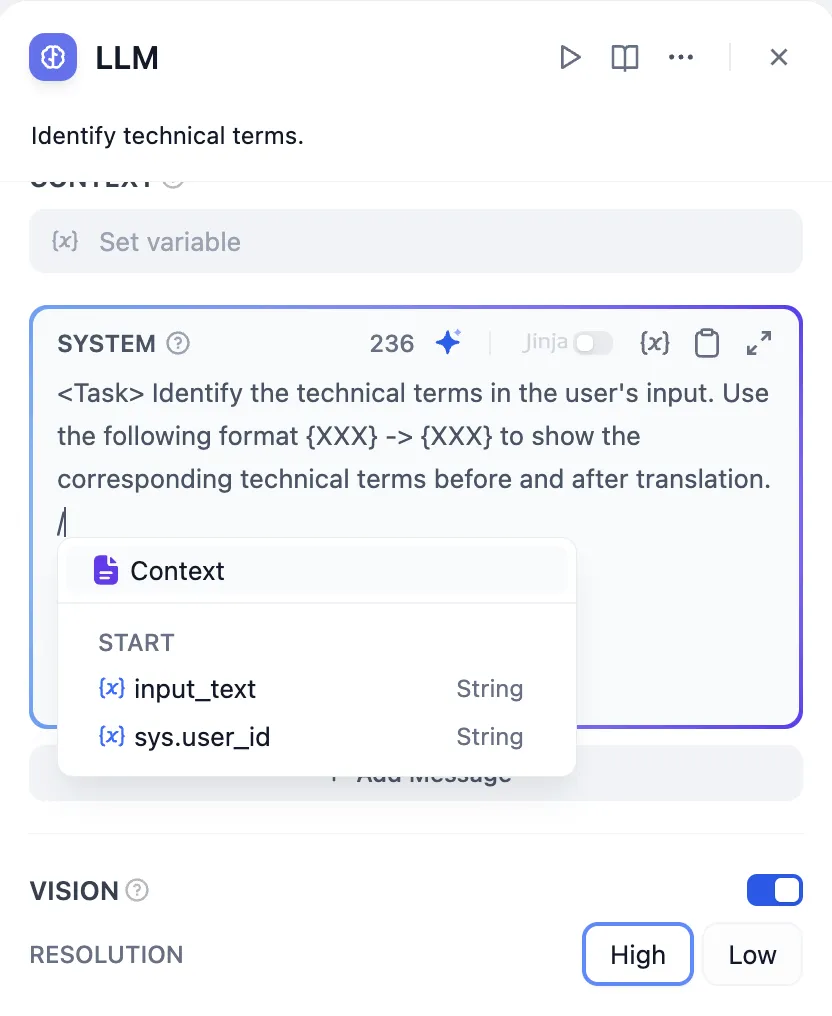
Calling Out the Variable Insertion Menu

Context Variables
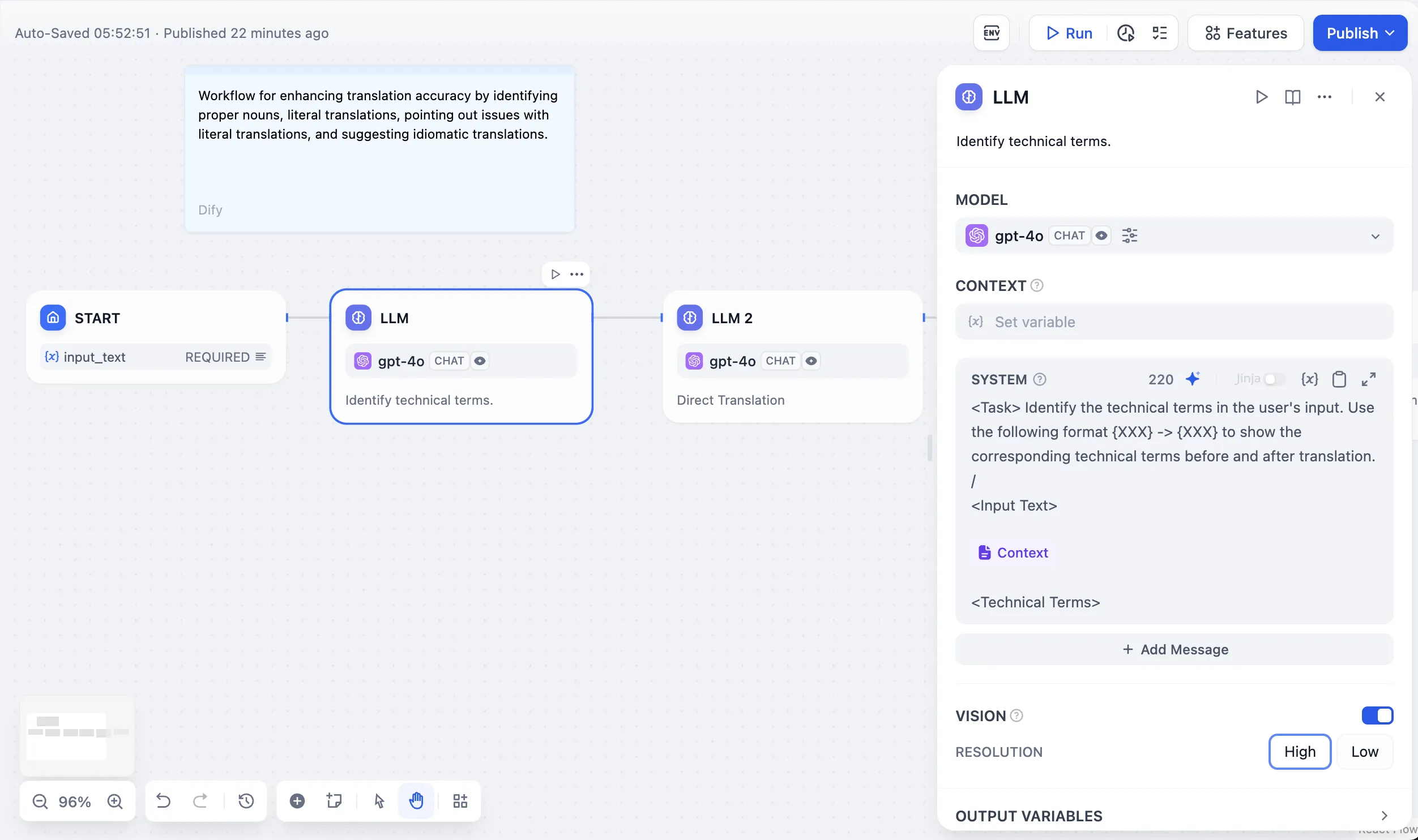
Context Variables
.png)
Inserting Conversation History Variable
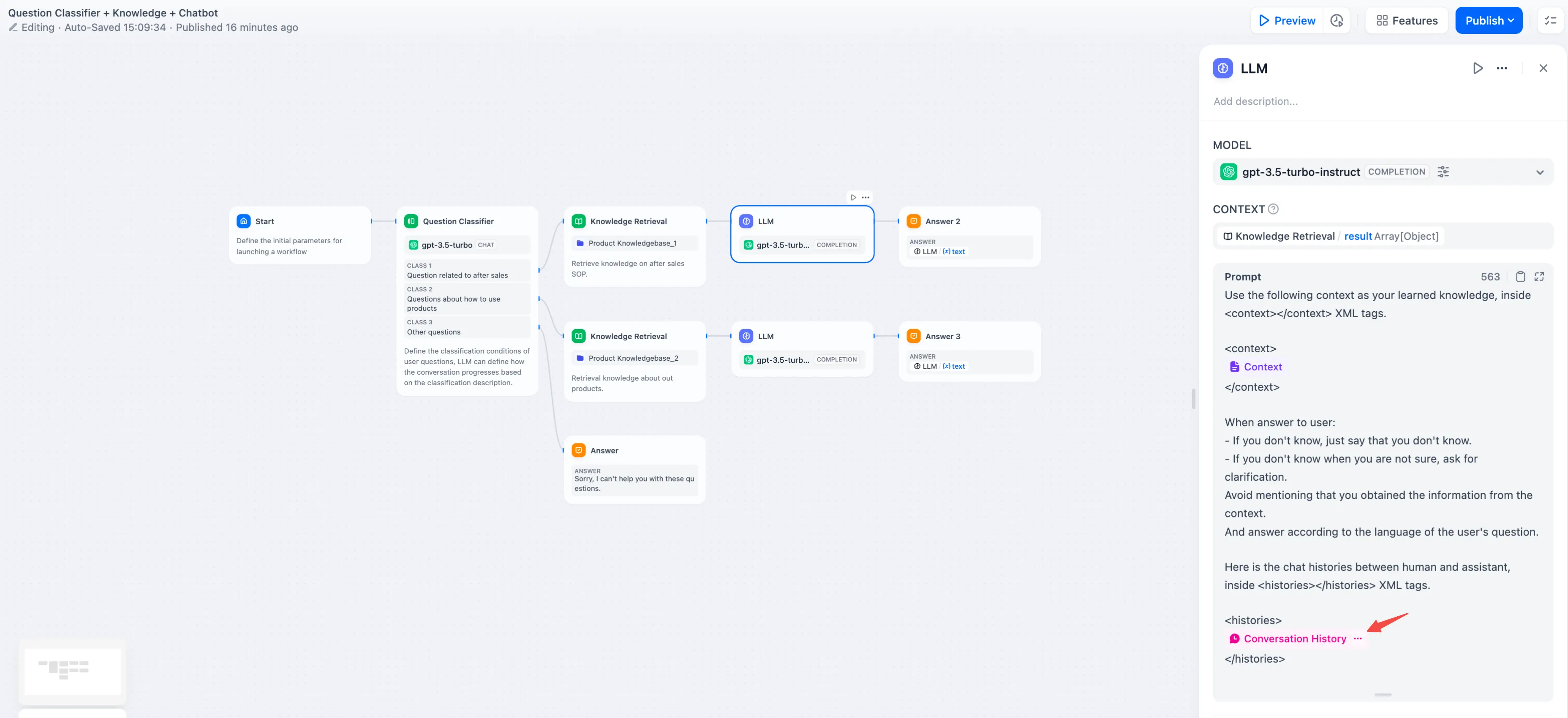
Inserting Conversation History Variable


.png)
.png)
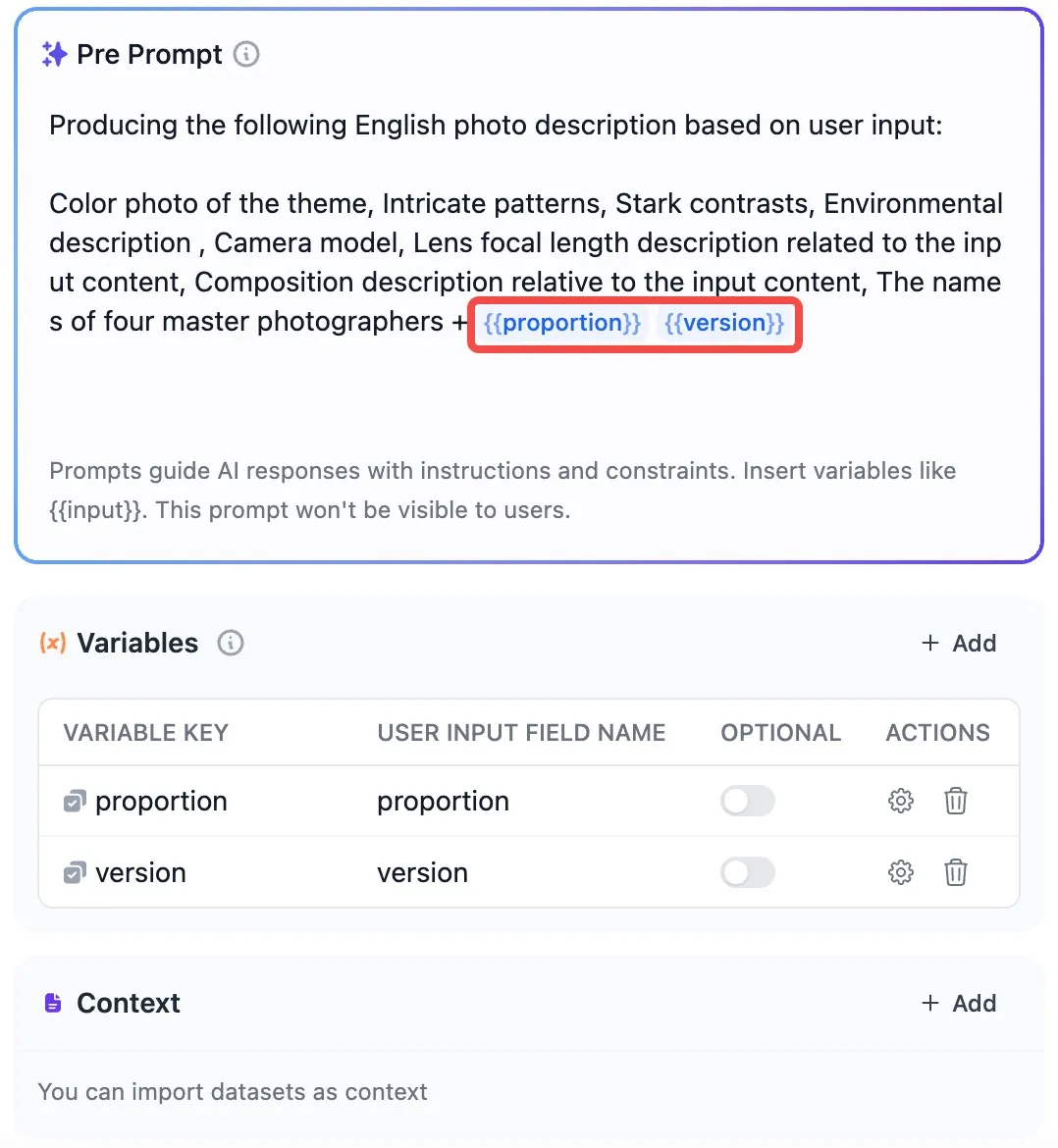
input system prompts
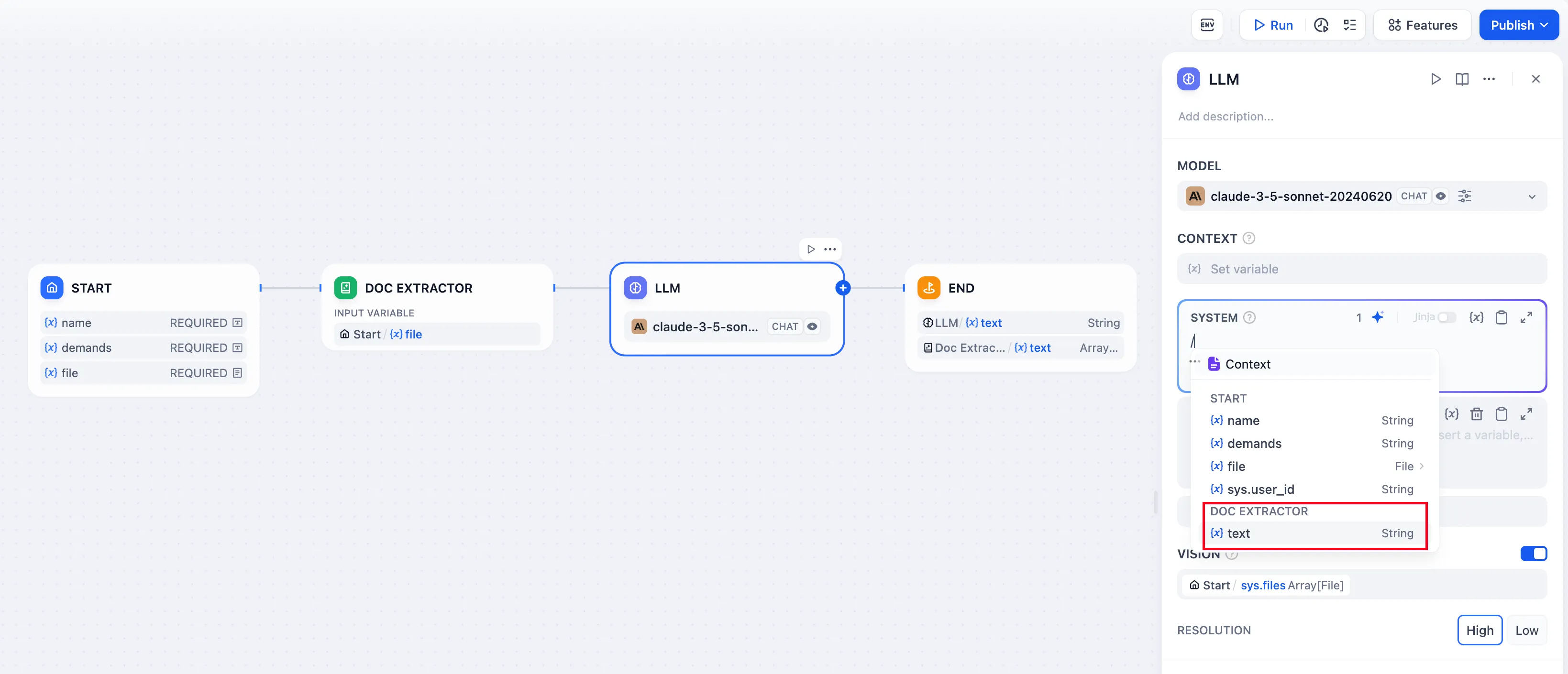
input system prompts

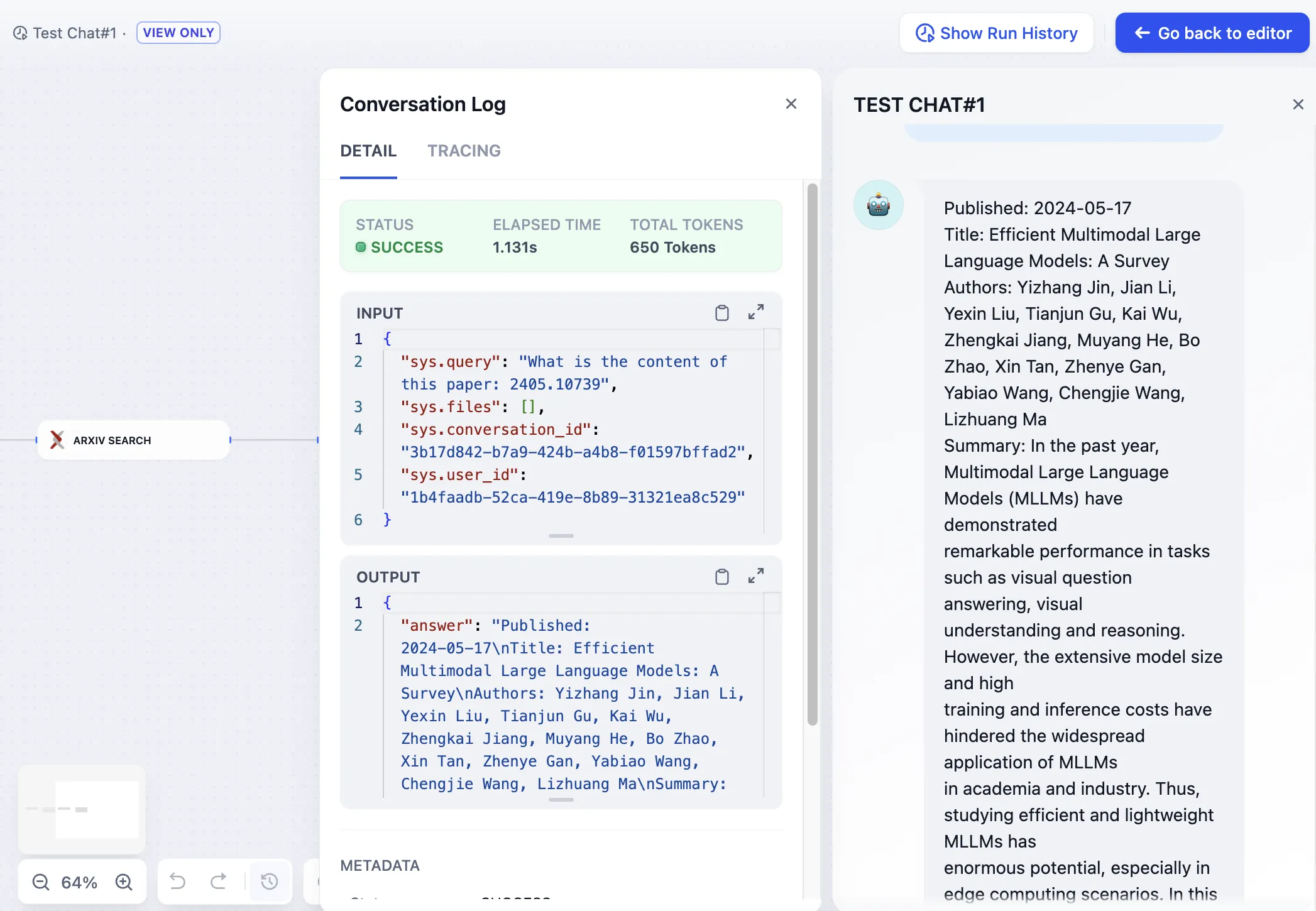
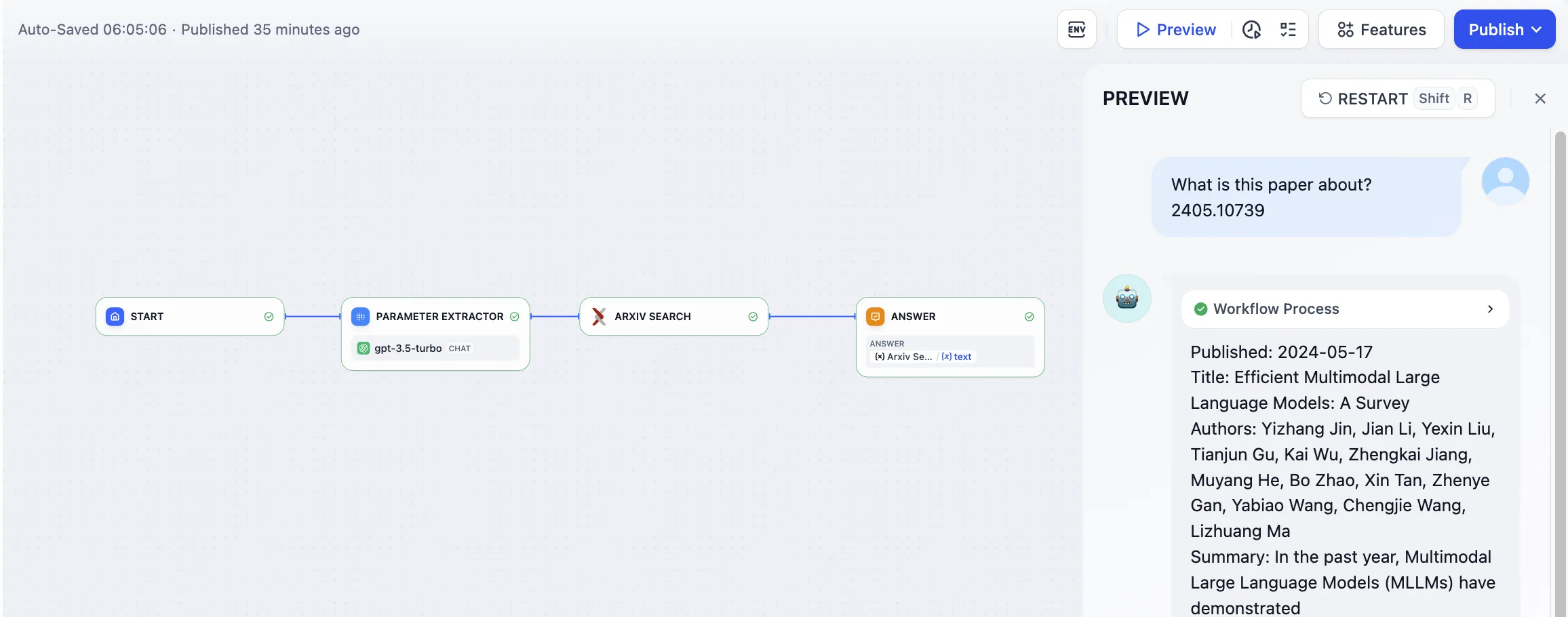
Arxiv Paper Retrieval Tool
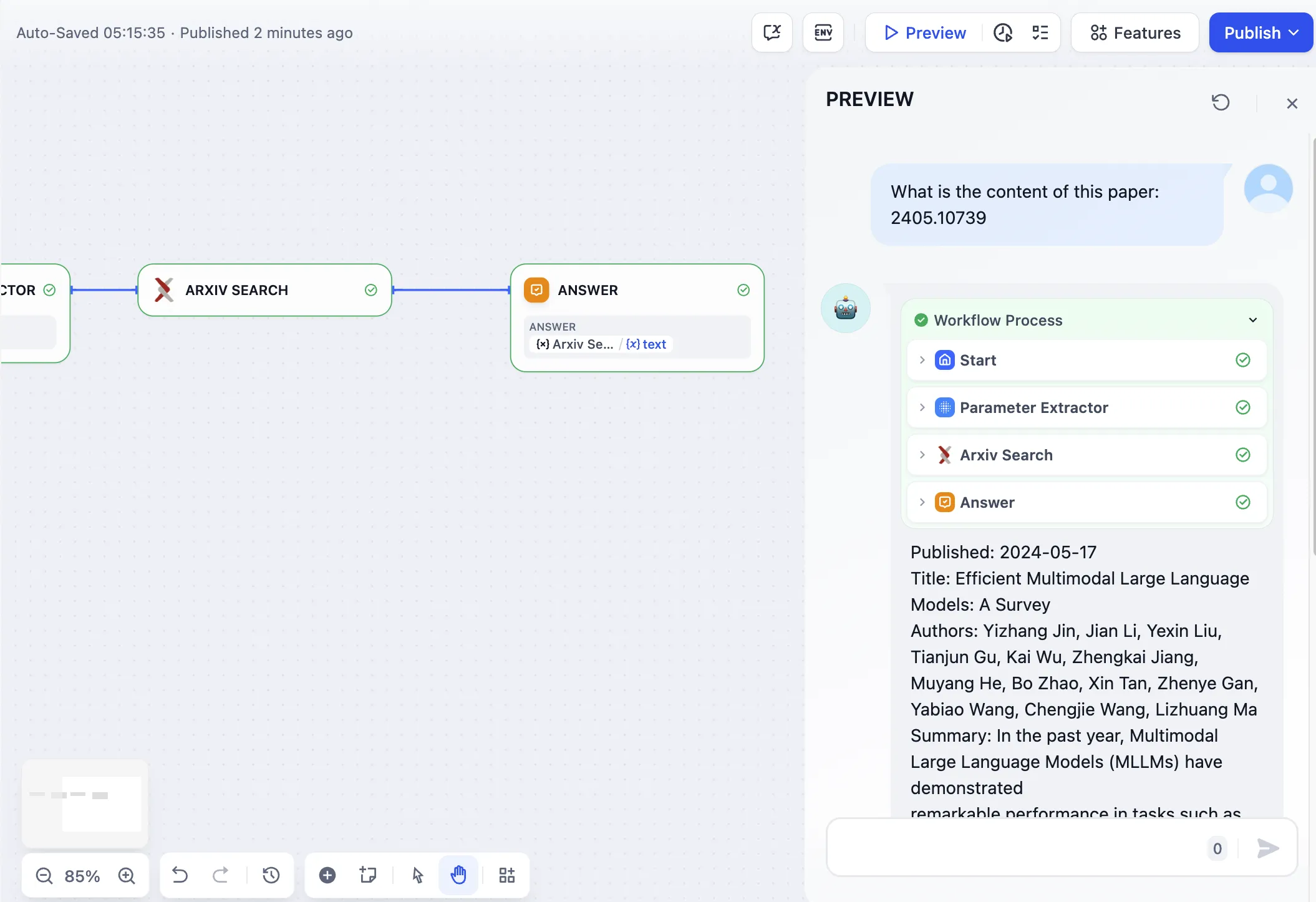
Arxiv Paper Retrieval Tool



.png)
Chatflow and Workflow
Chatflow and Workflow
.png)
.png)

Tool Selection
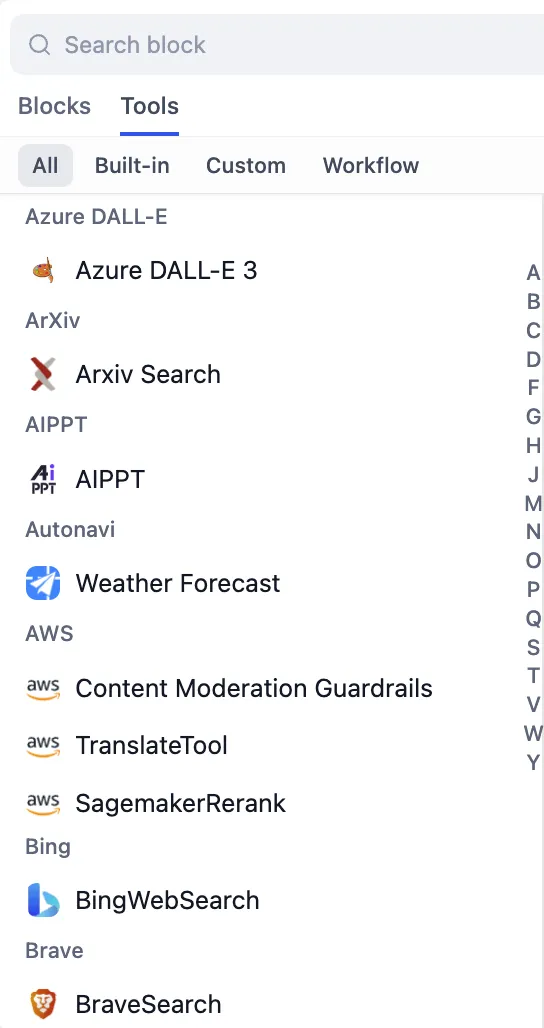
Tool Selection

Configuring Google Search Tool to Retrieve External Knowledge
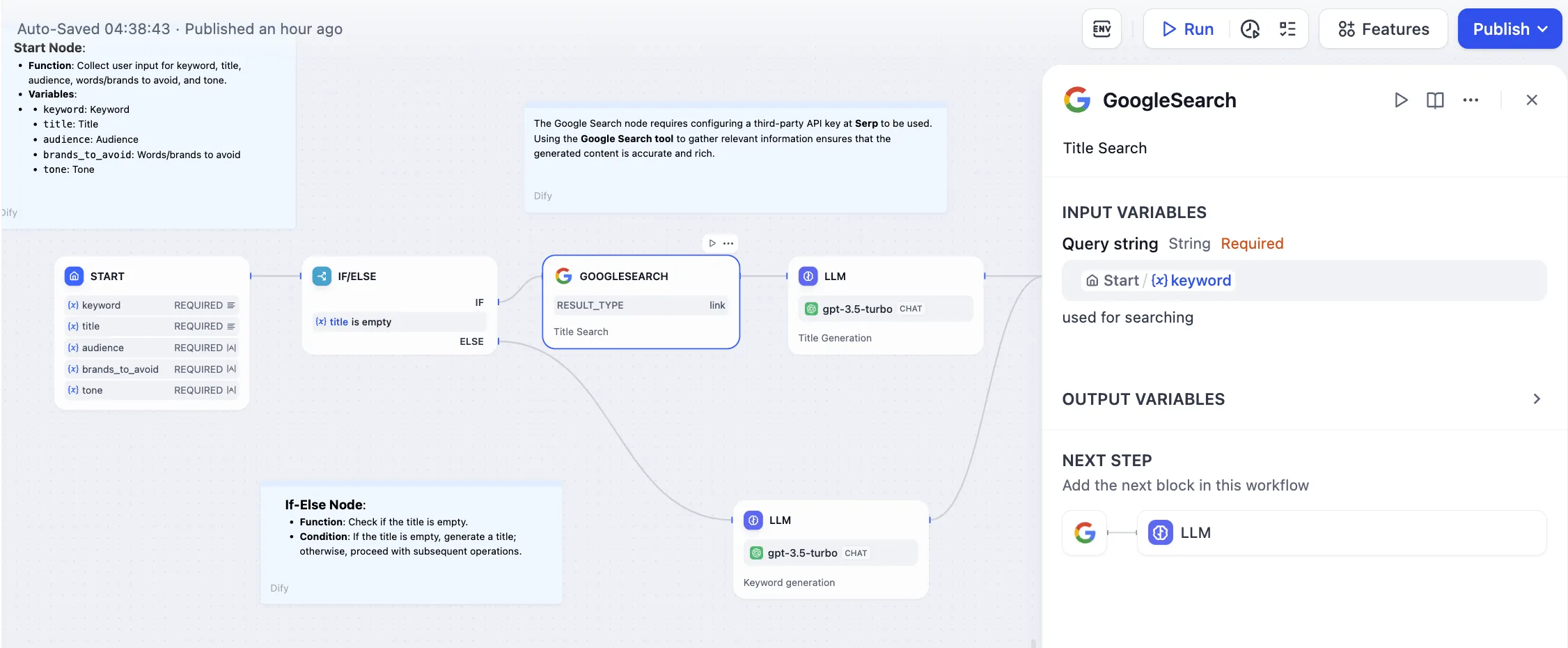
Configuring Google Search Tool to Retrieve External Knowledge
.png)
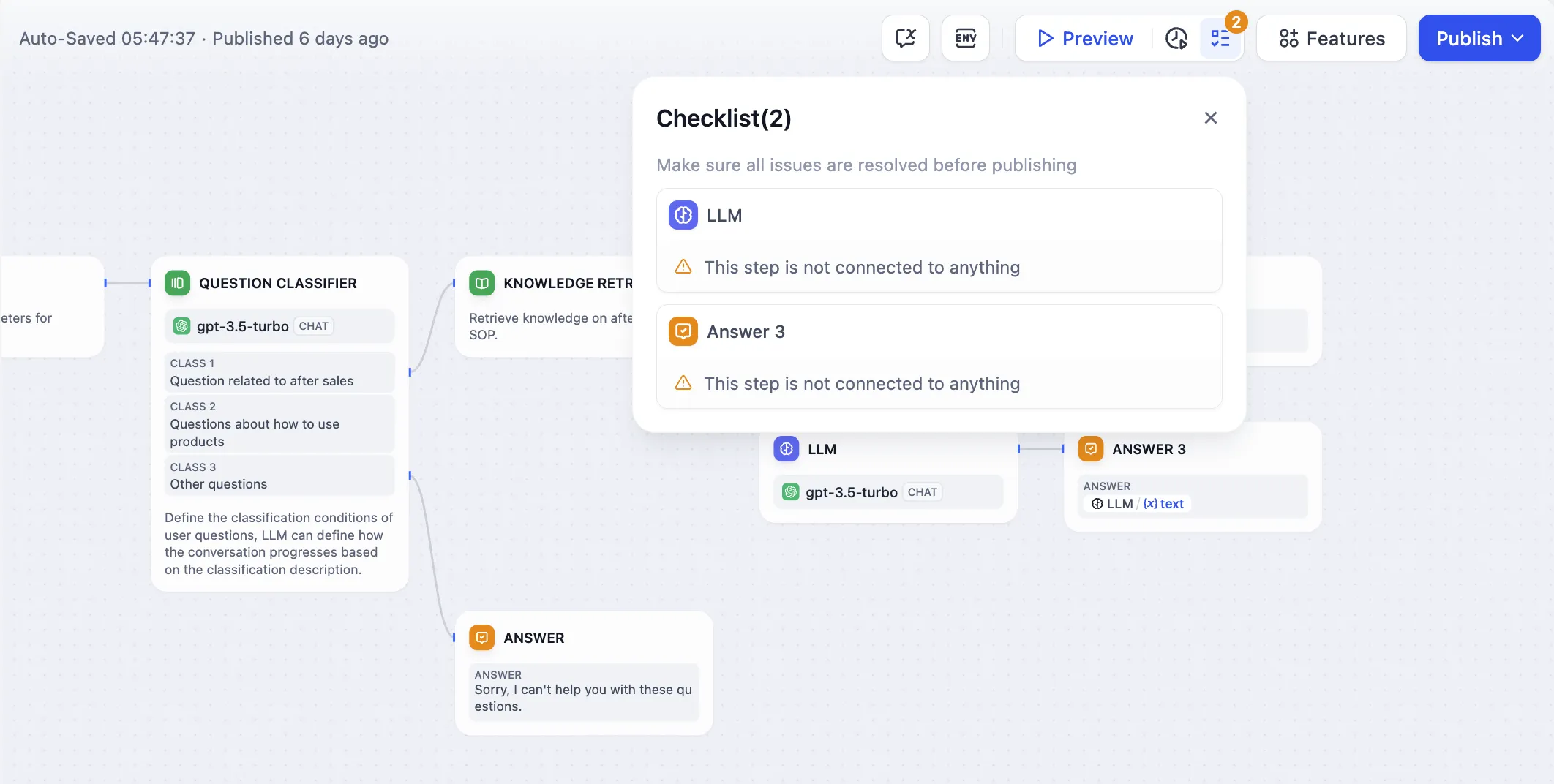
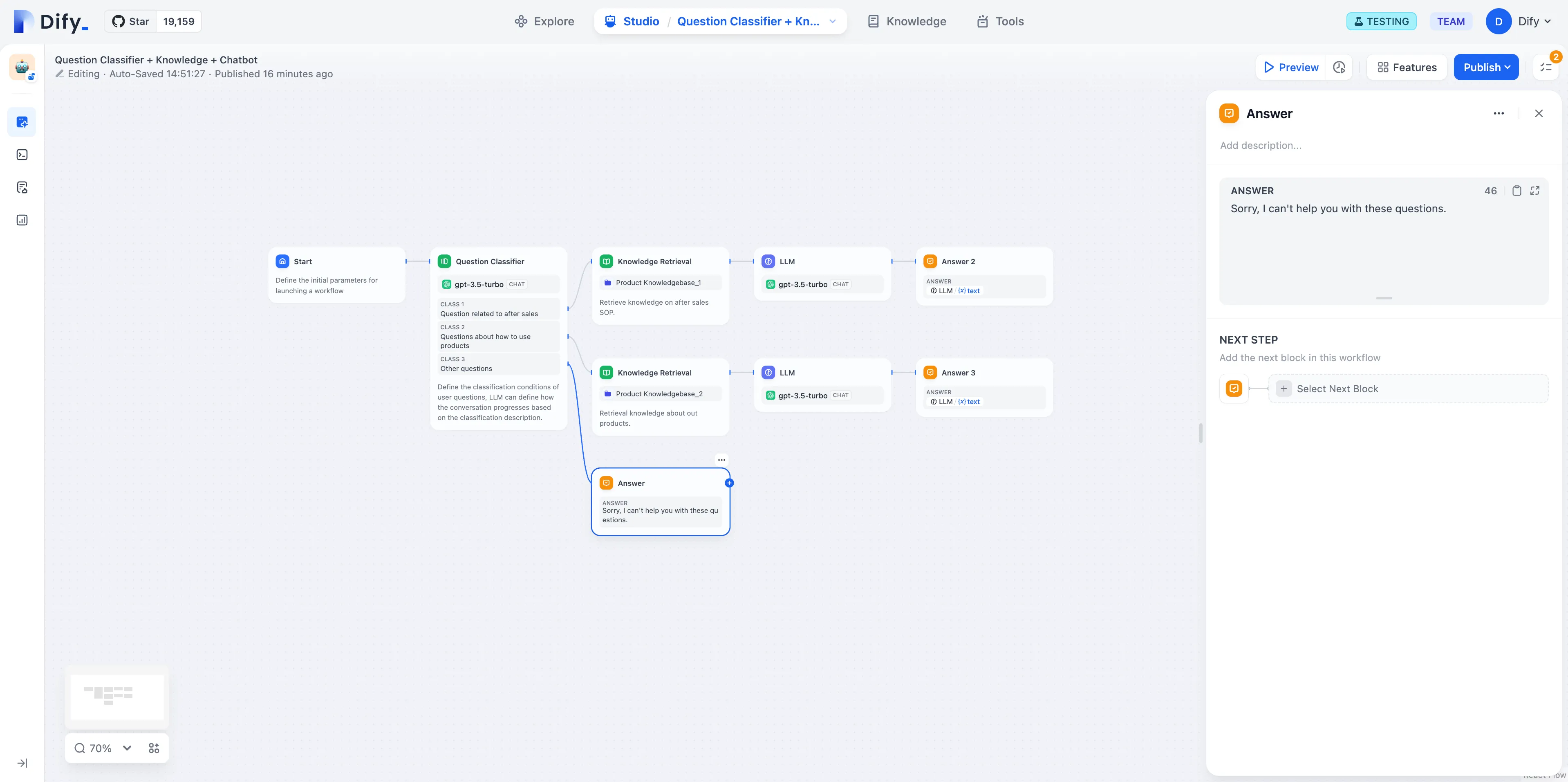
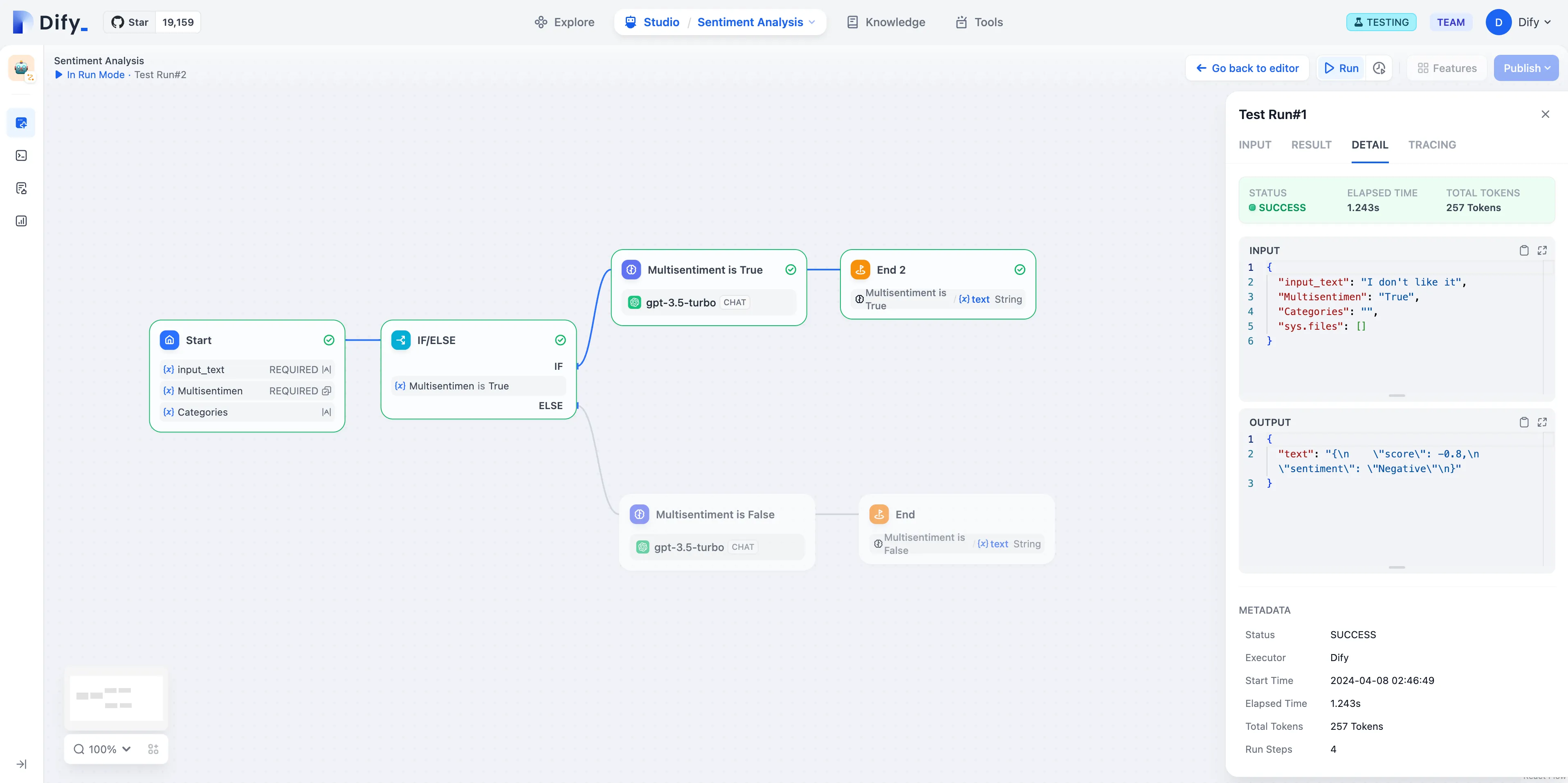
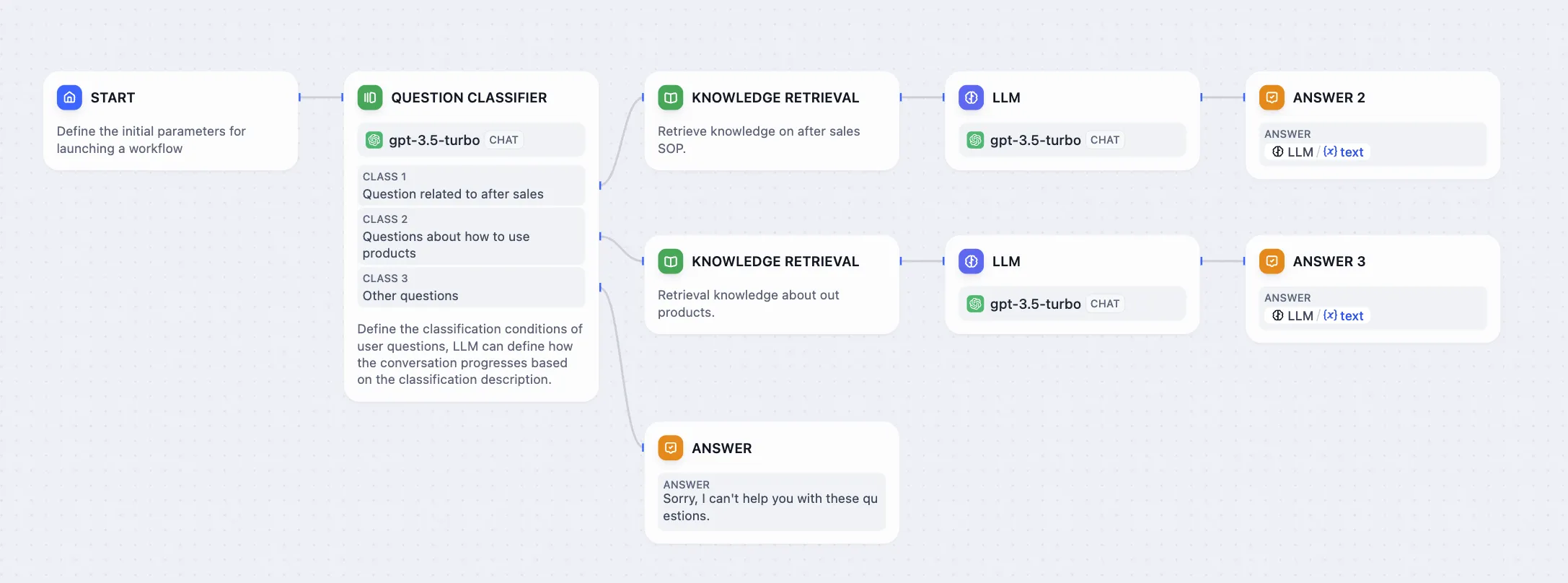
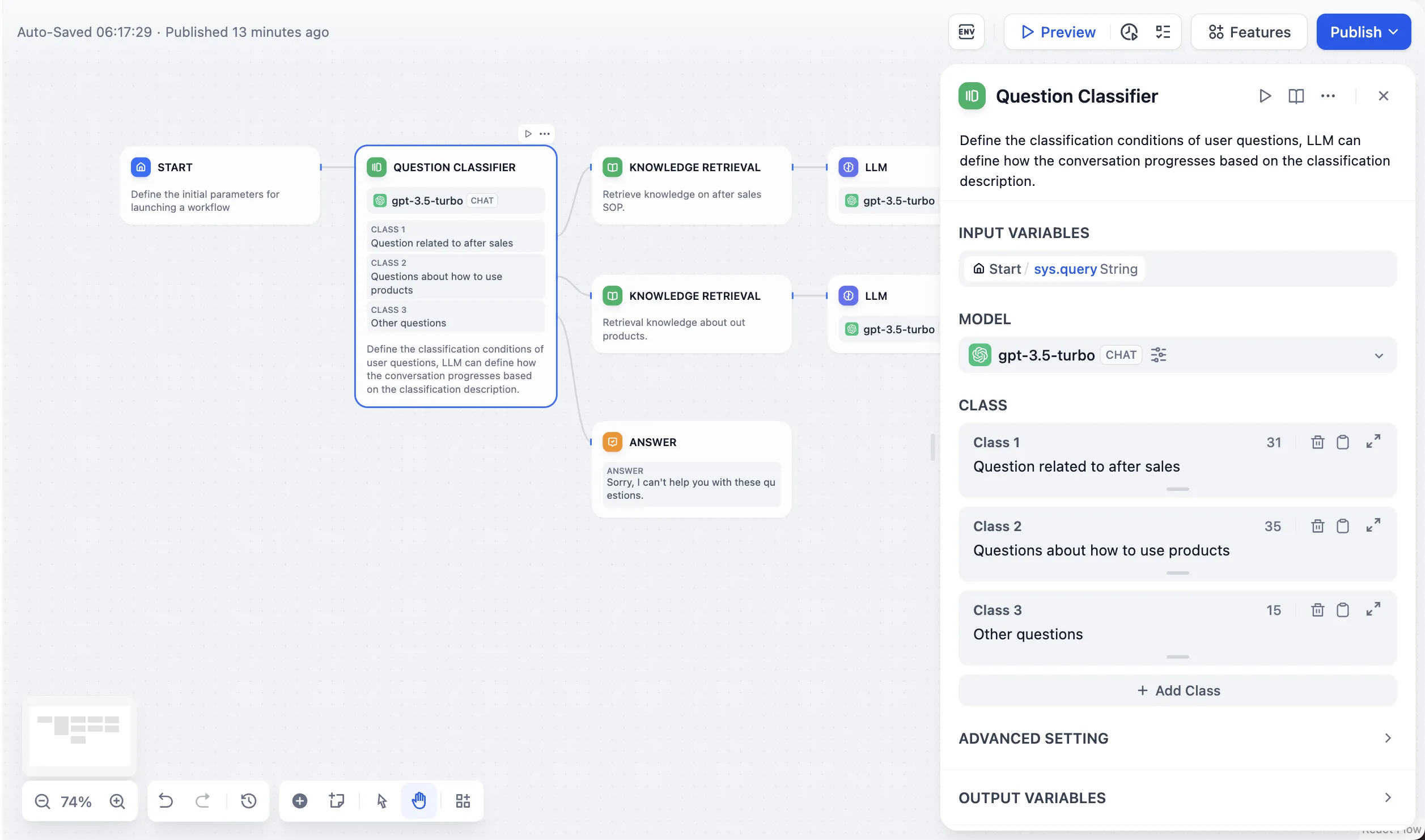
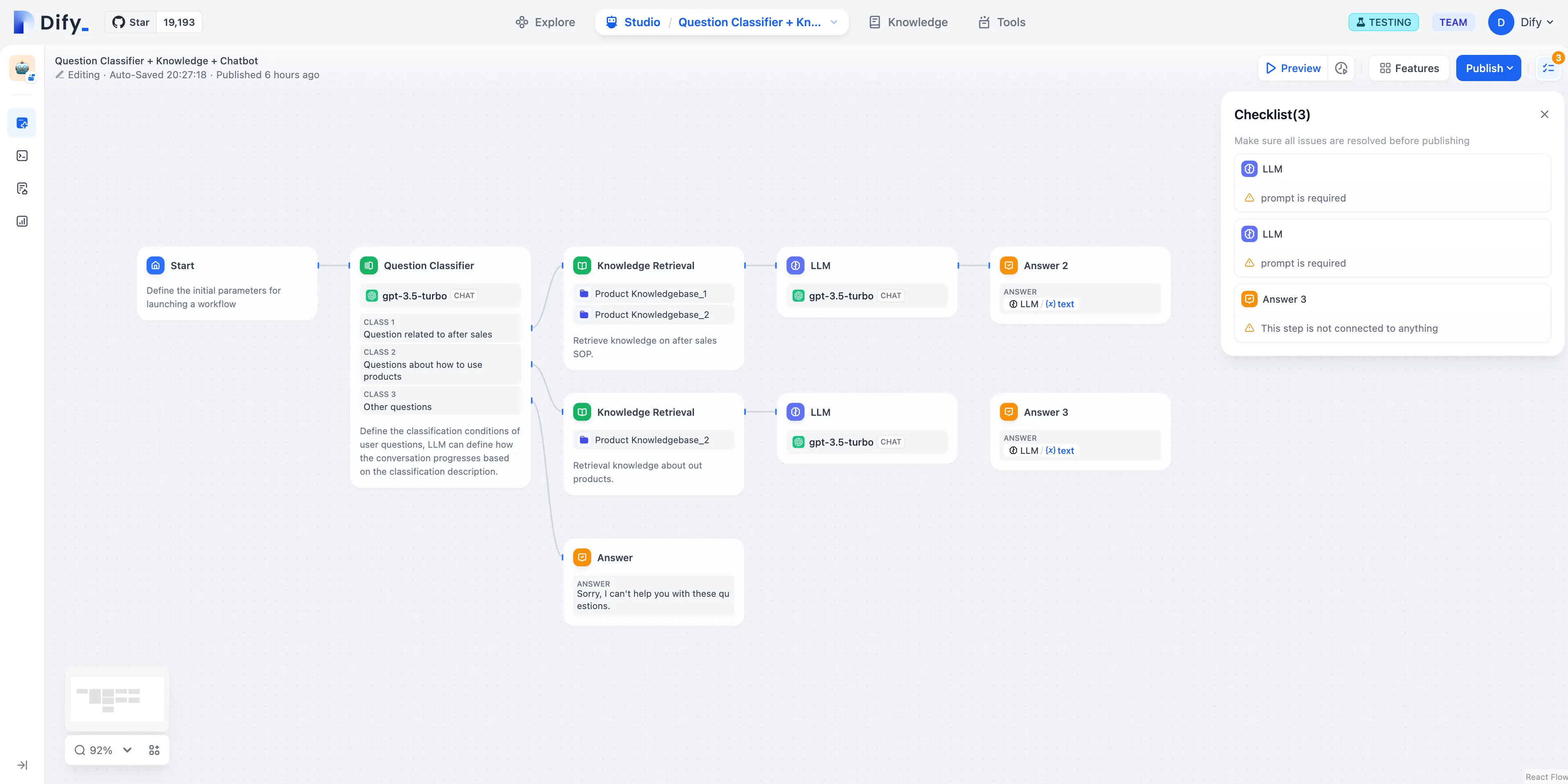
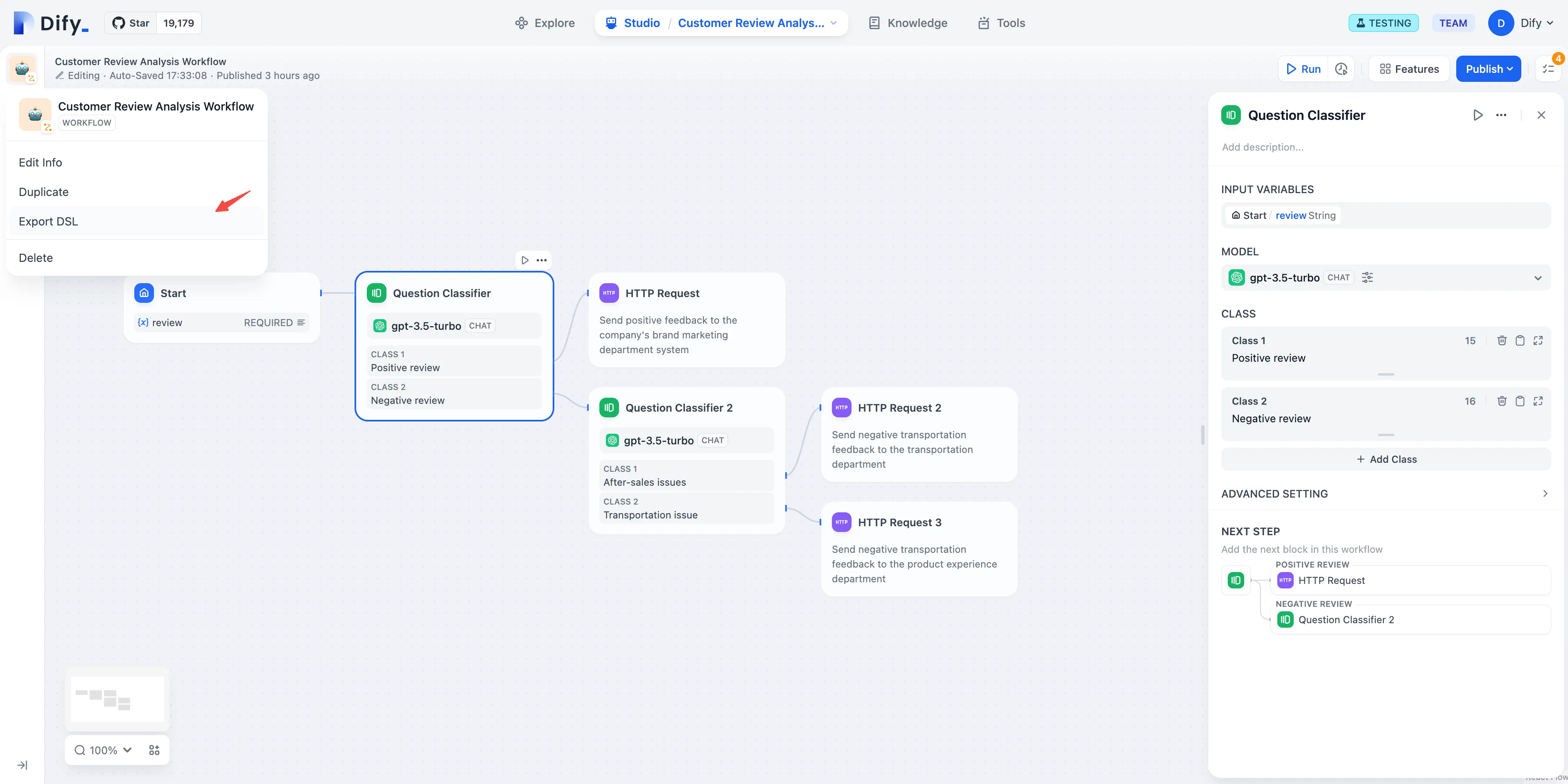
Issue Classification (without Variable Aggregation)
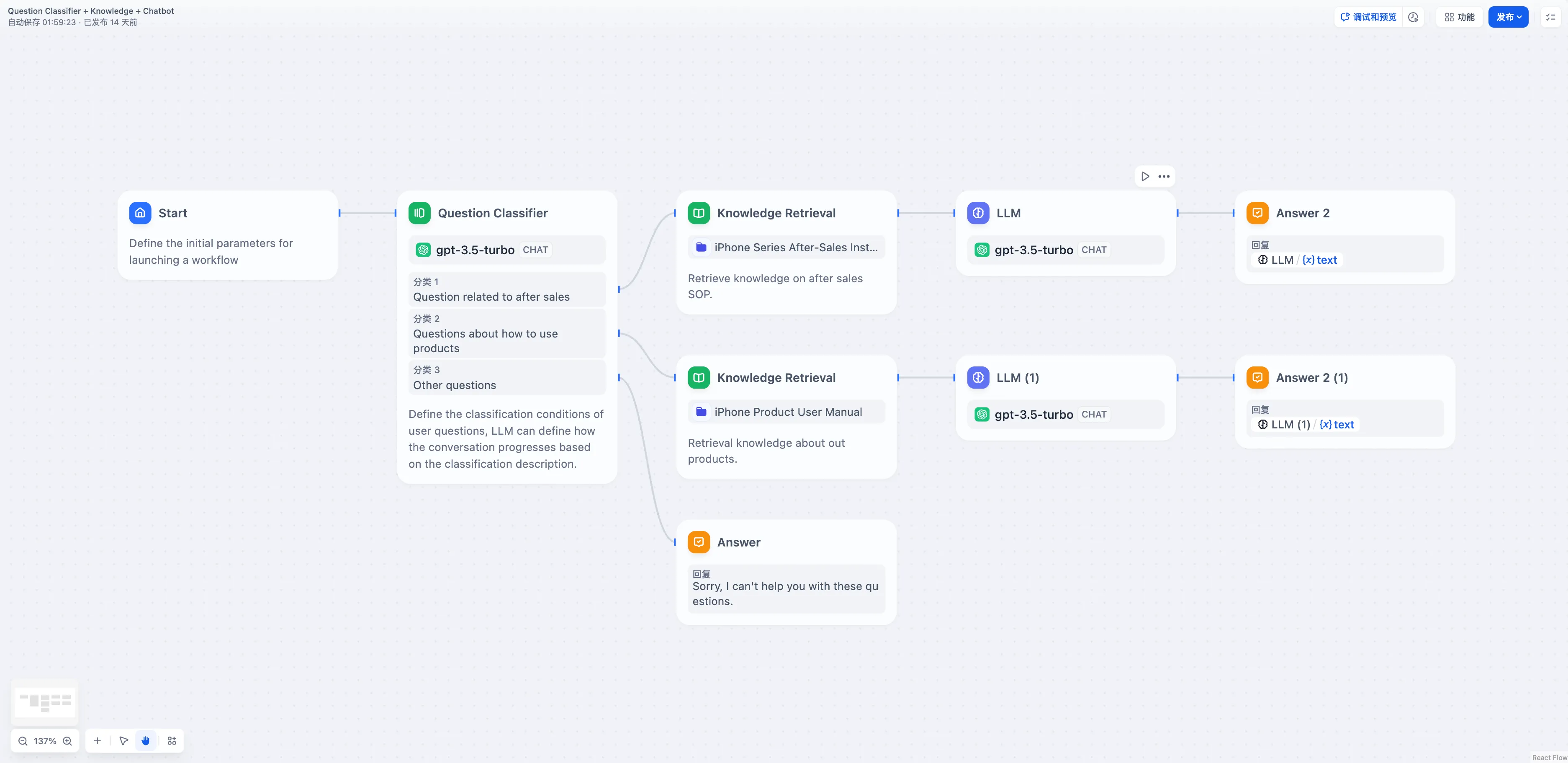
Issue Classification (without Variable Aggregation)

Multi-Branch Aggregation after Issue Classification
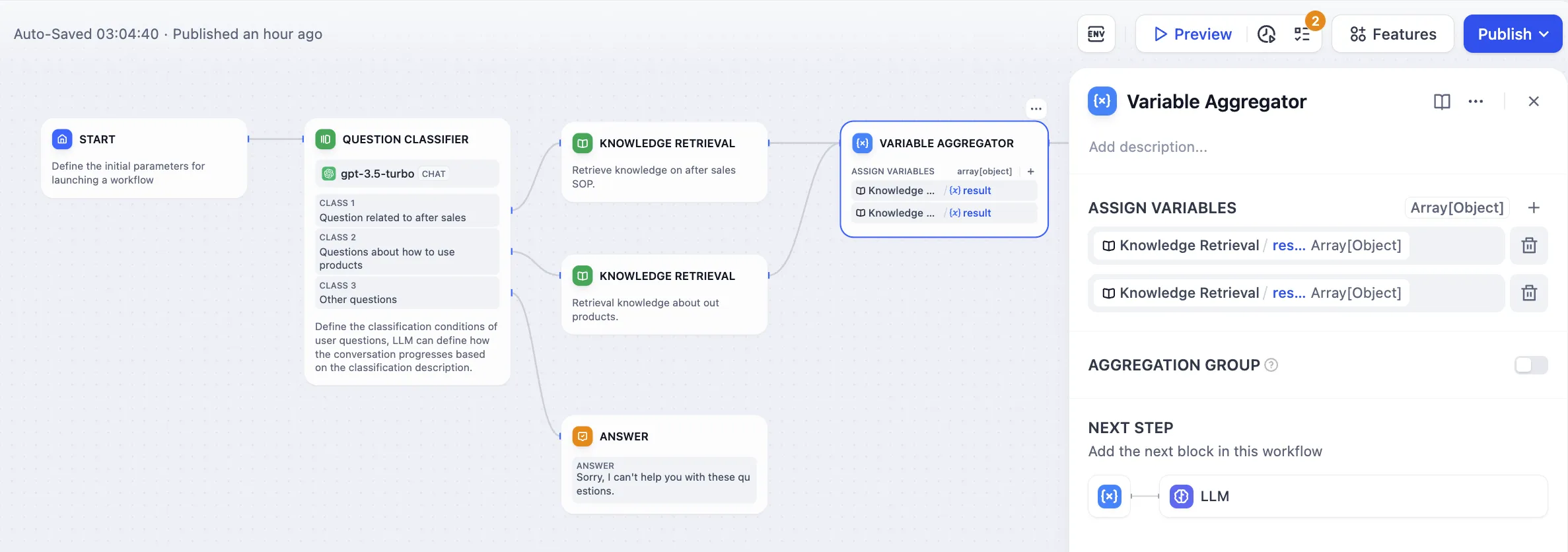
Multi-Branch Aggregation after Issue Classification

Multi-Branch Aggregation after Conditional Branching
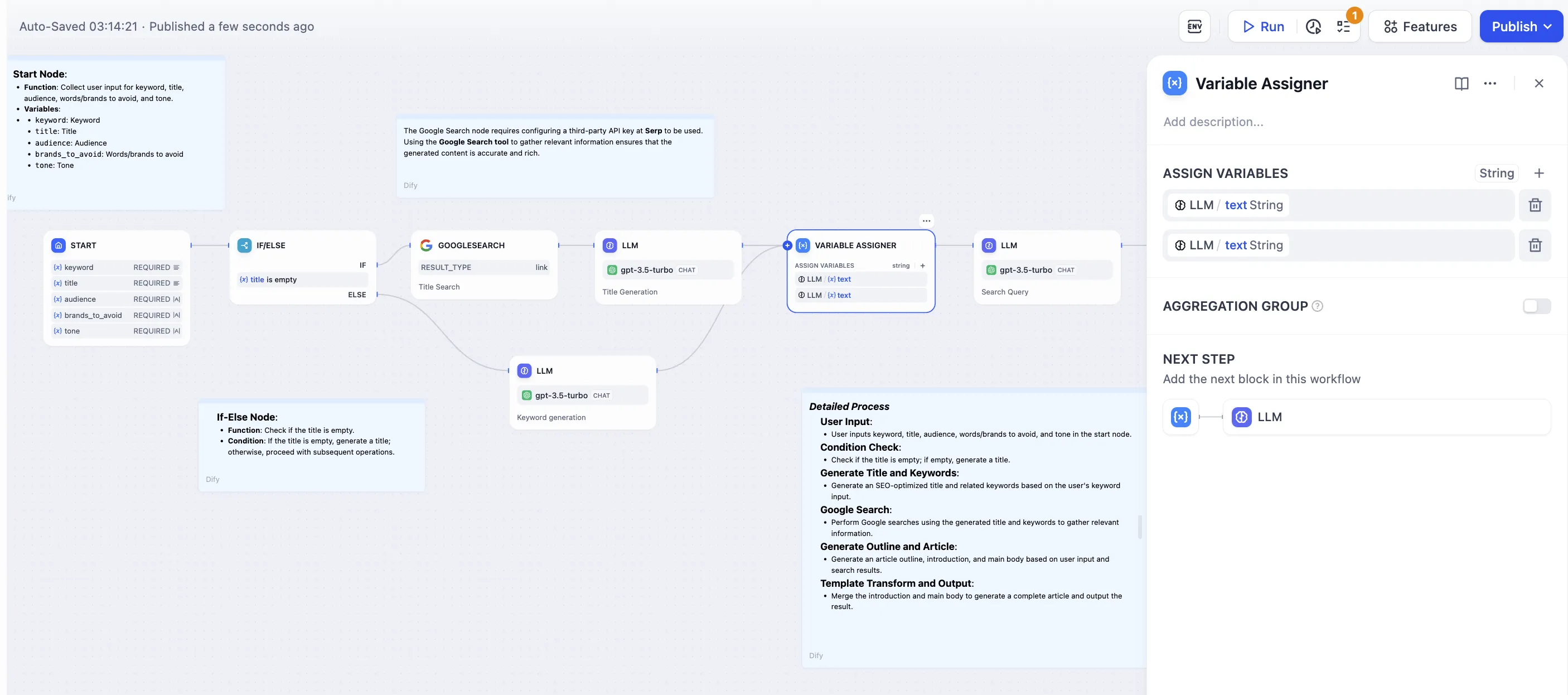
Multi-Branch Aggregation after Conditional Branching


 (3).png)
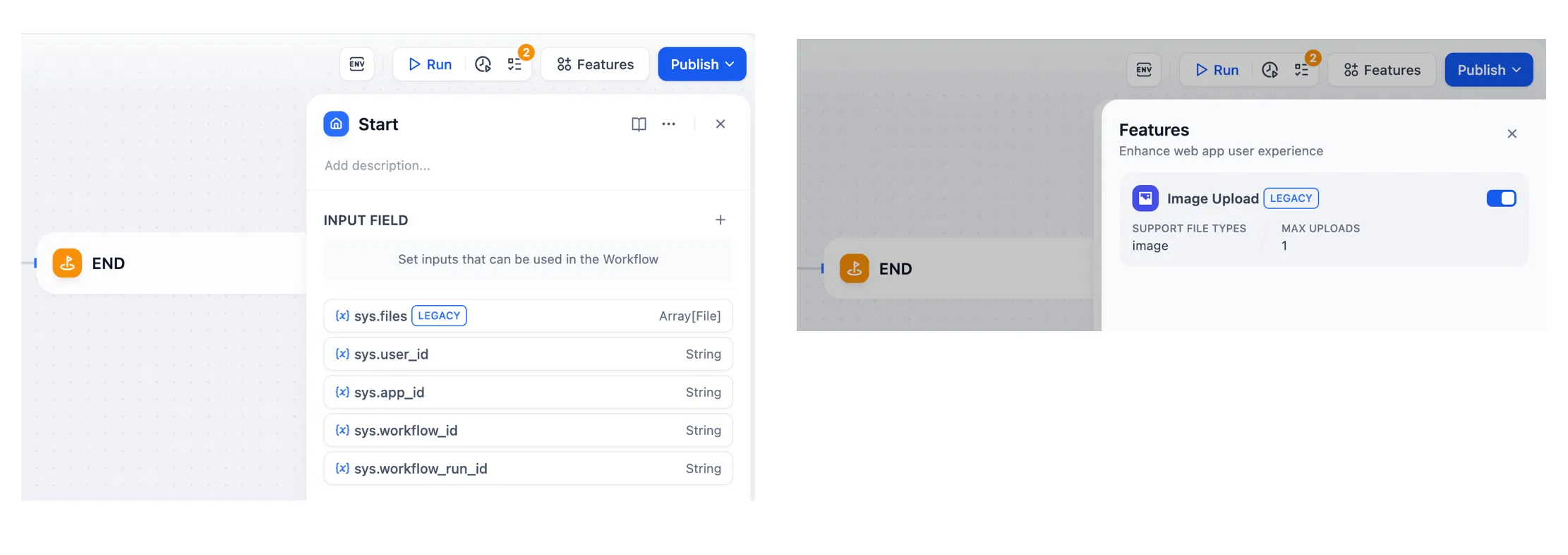
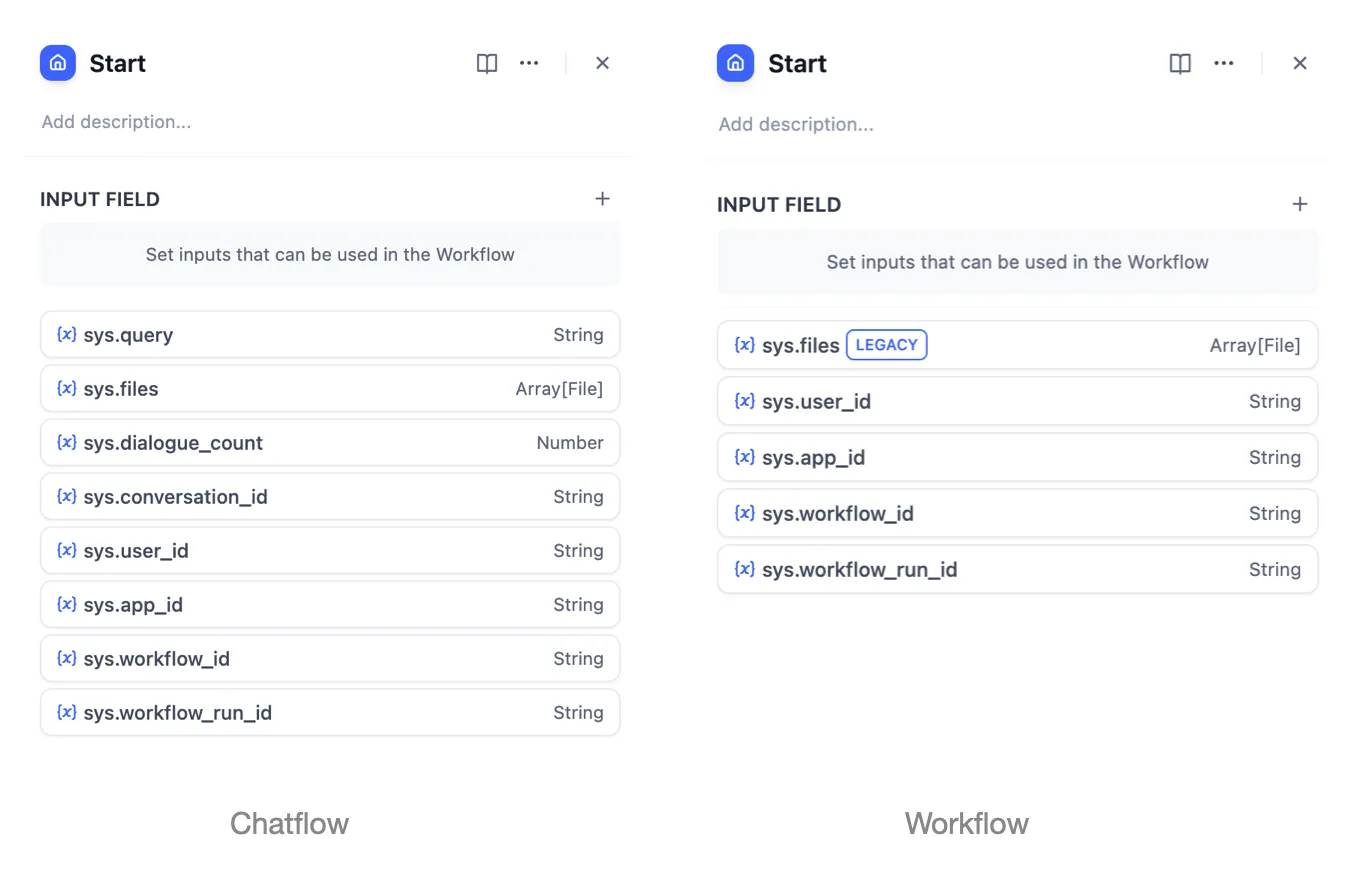
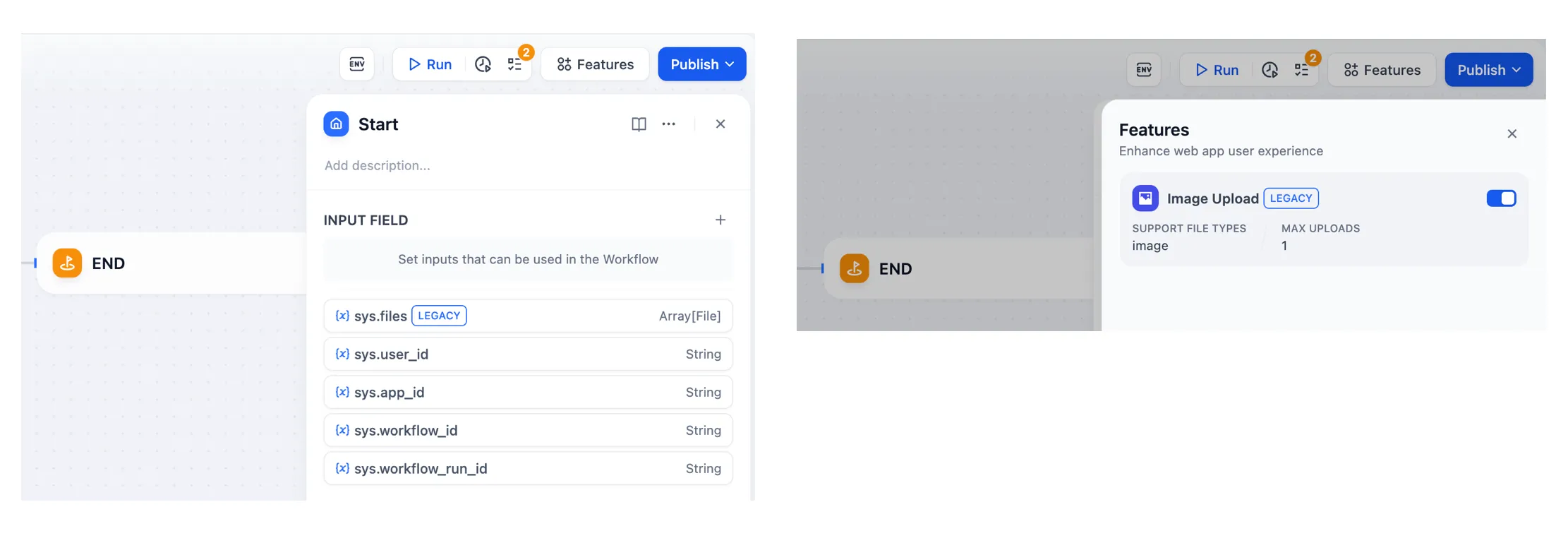
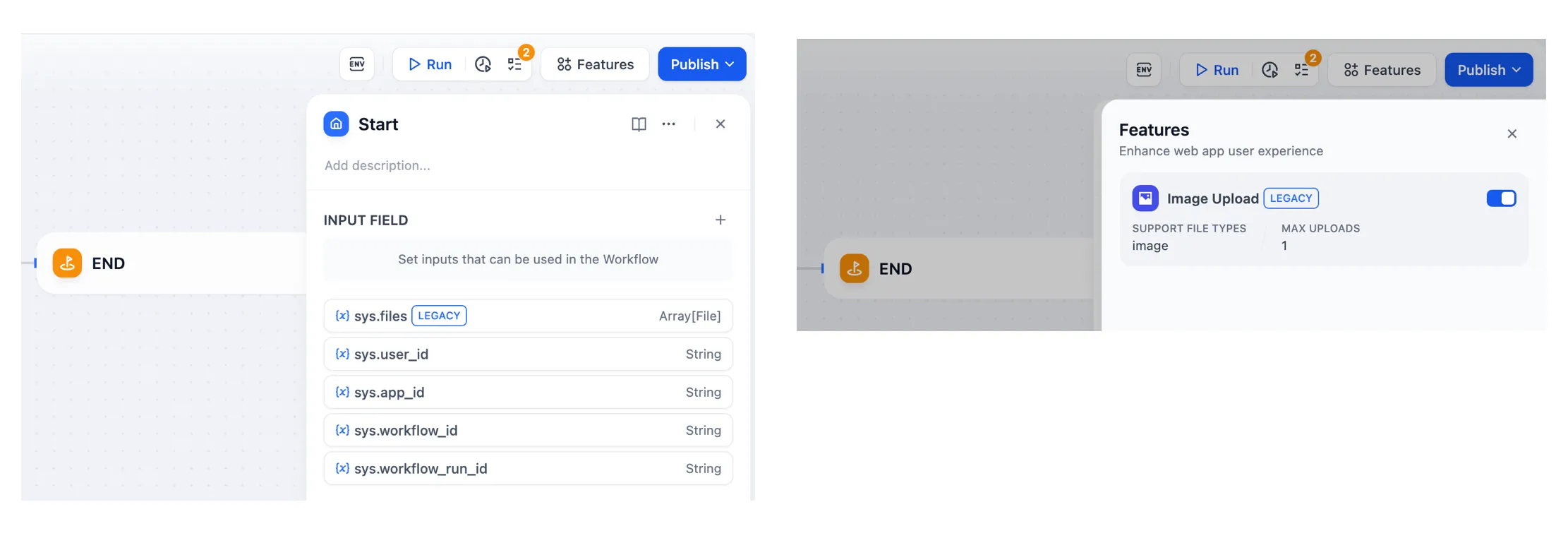
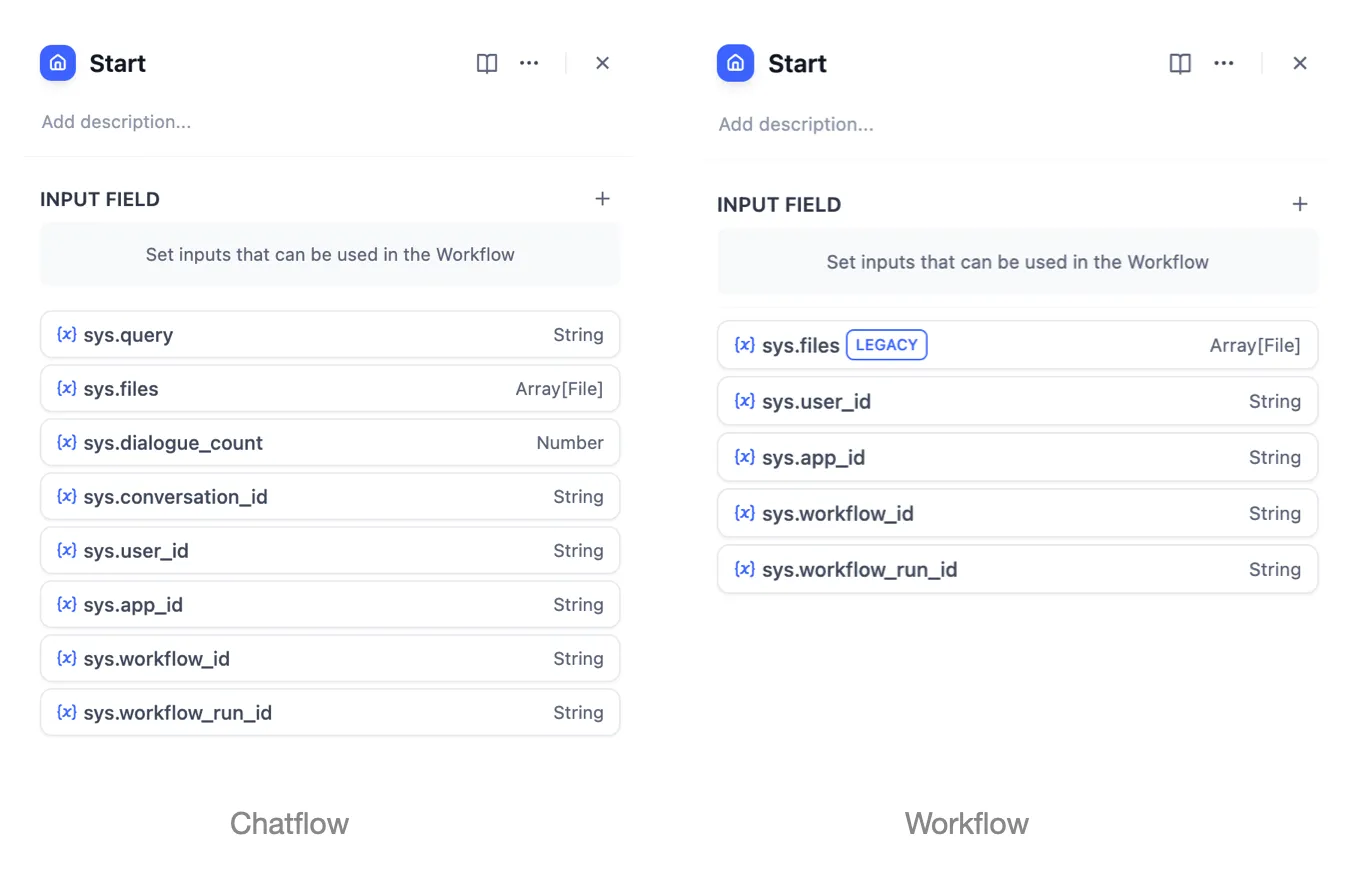
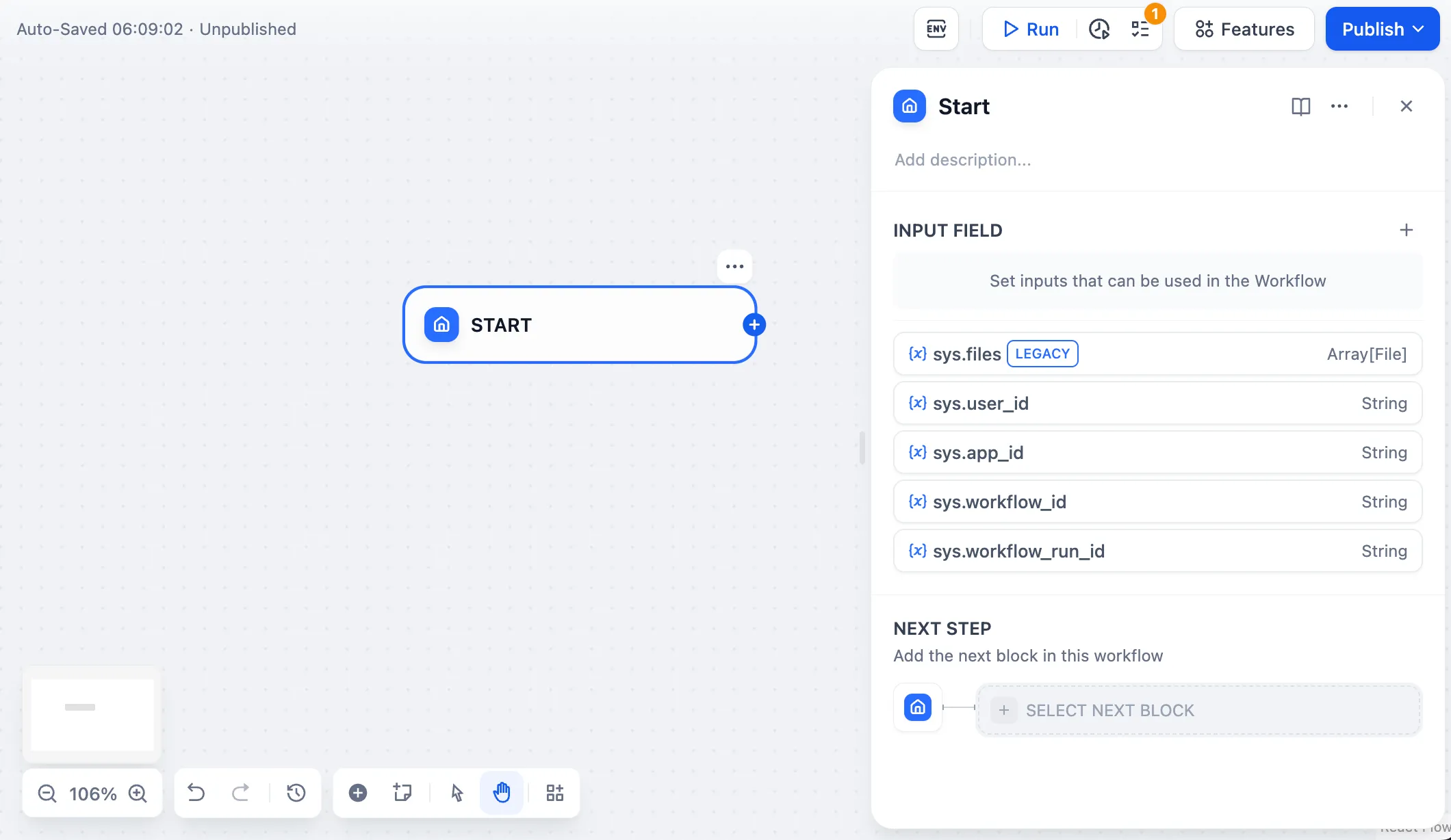
| Variables name | Data Type | Description | Remark |
|---|---|---|---|
| Array[File] | File Parameter: Stores images uploaded by users | The image upload function needs to be enabled in the 'Features' section in the upper right corner of the application orchestration page |
sys.user_id | String | User ID: A unique identifier automatically assigned by the system to each user when they use a workflow application. It is used to distinguish different users | |
sys.app_id | String | App ID: A unique identifier automatically assigned by the system to each App. This parameter is used to record the basic information of the current application. | This parameter is used to differentiate and locate distinct Workflow applications for users with development capabilities |
sys.workflow_id | String | Workflow ID: This parameter records information about all nodes information in the current Workflow application. | This parameter can be used by users with development capabilities to track and record information about the nodes contained within a Workflow |
sys.workflow_run_id | String | Workflow Run ID: Used to record the runtime status and execution logs of a Workflow application. | This parameter can be used by users with development capabilities to track the application's historical execution records |
.png)
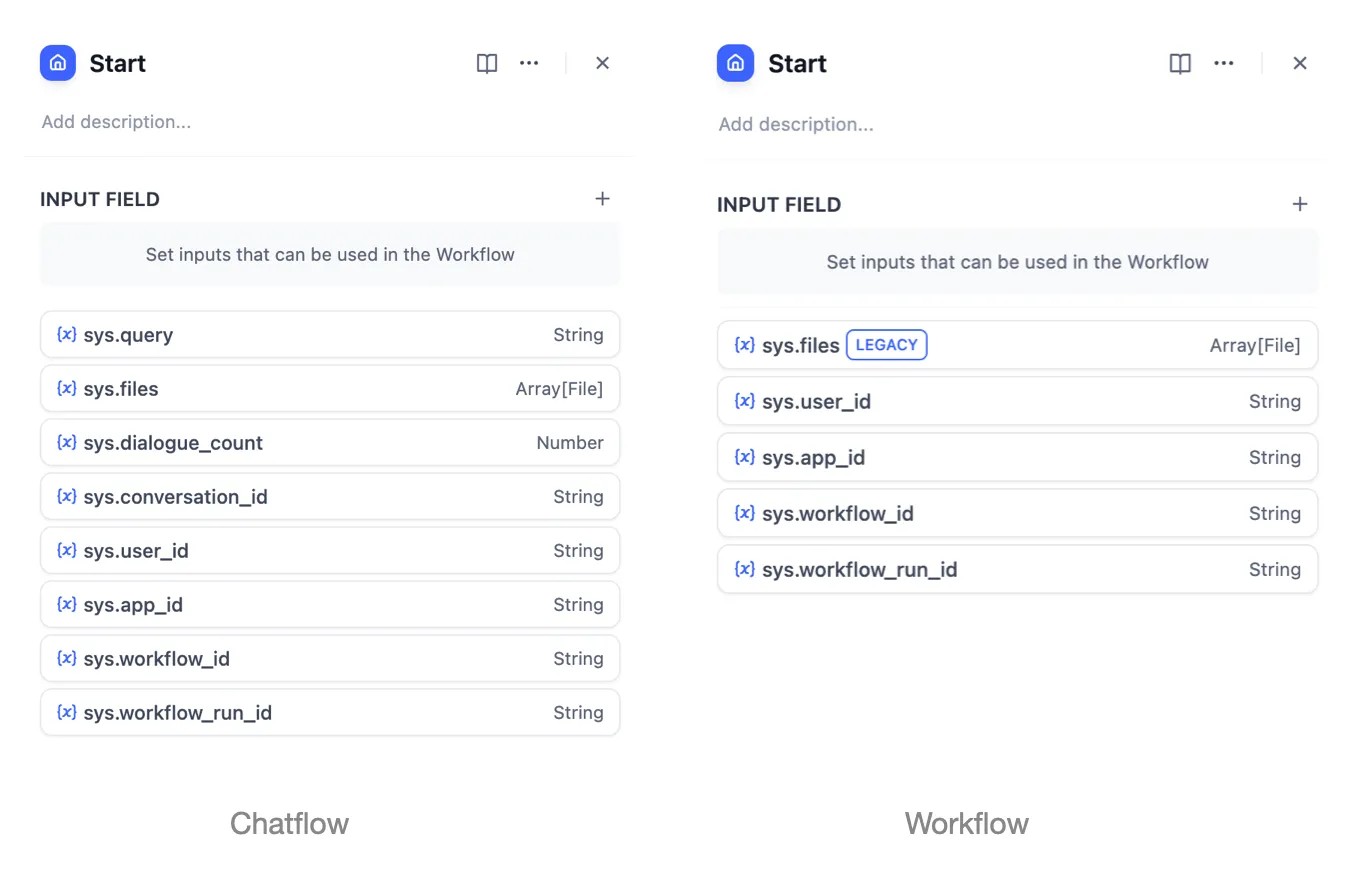
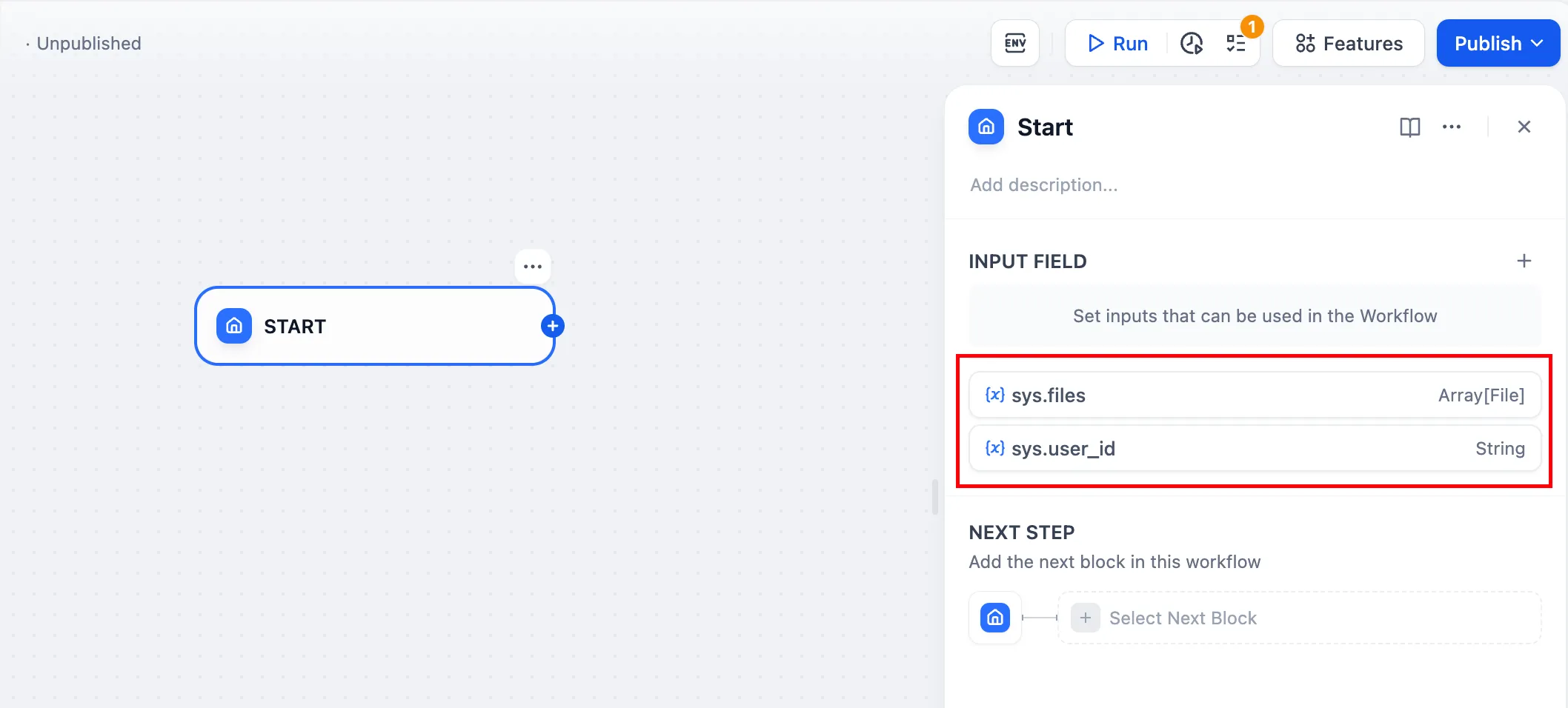
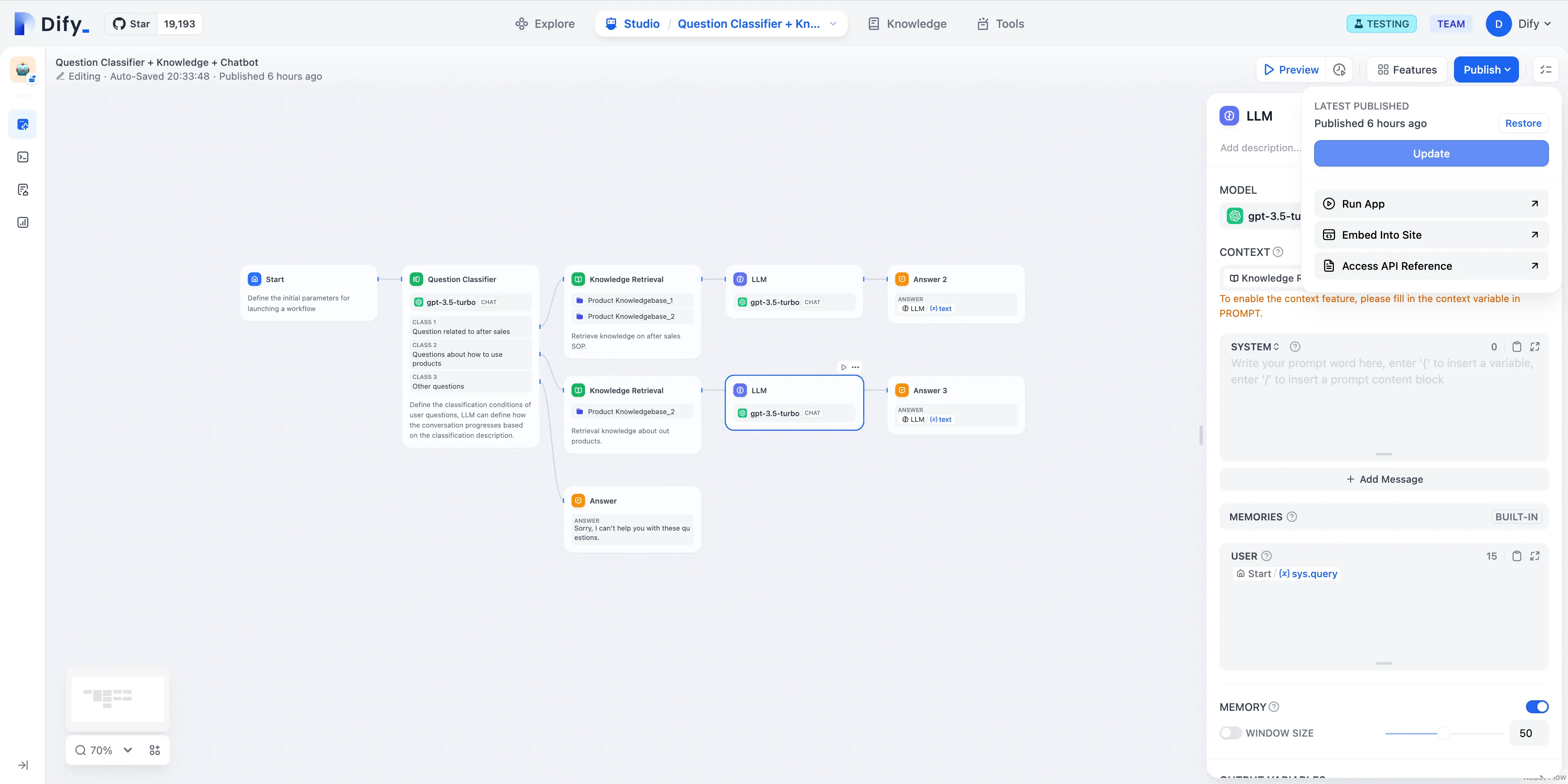
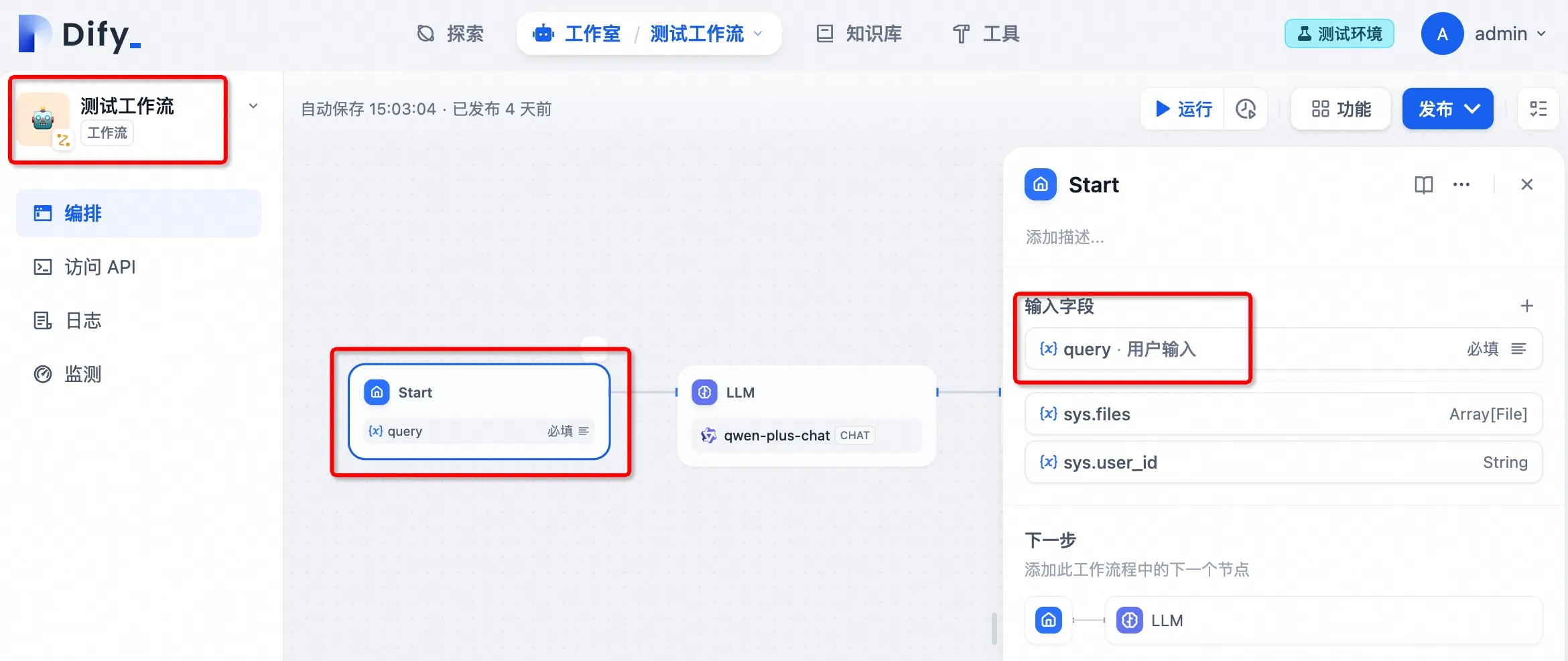
Workflow App System Variables
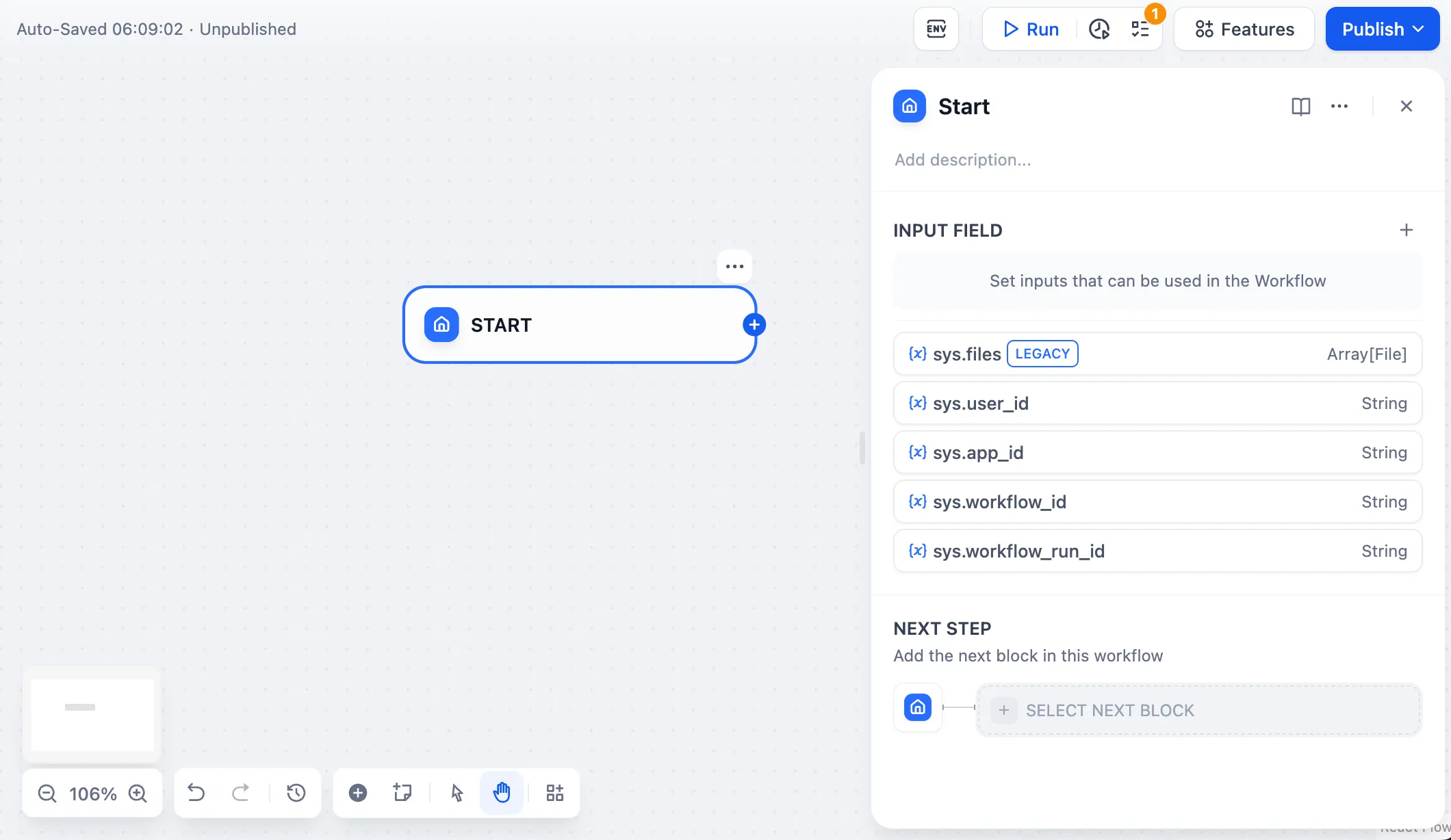
Workflow App System Variables
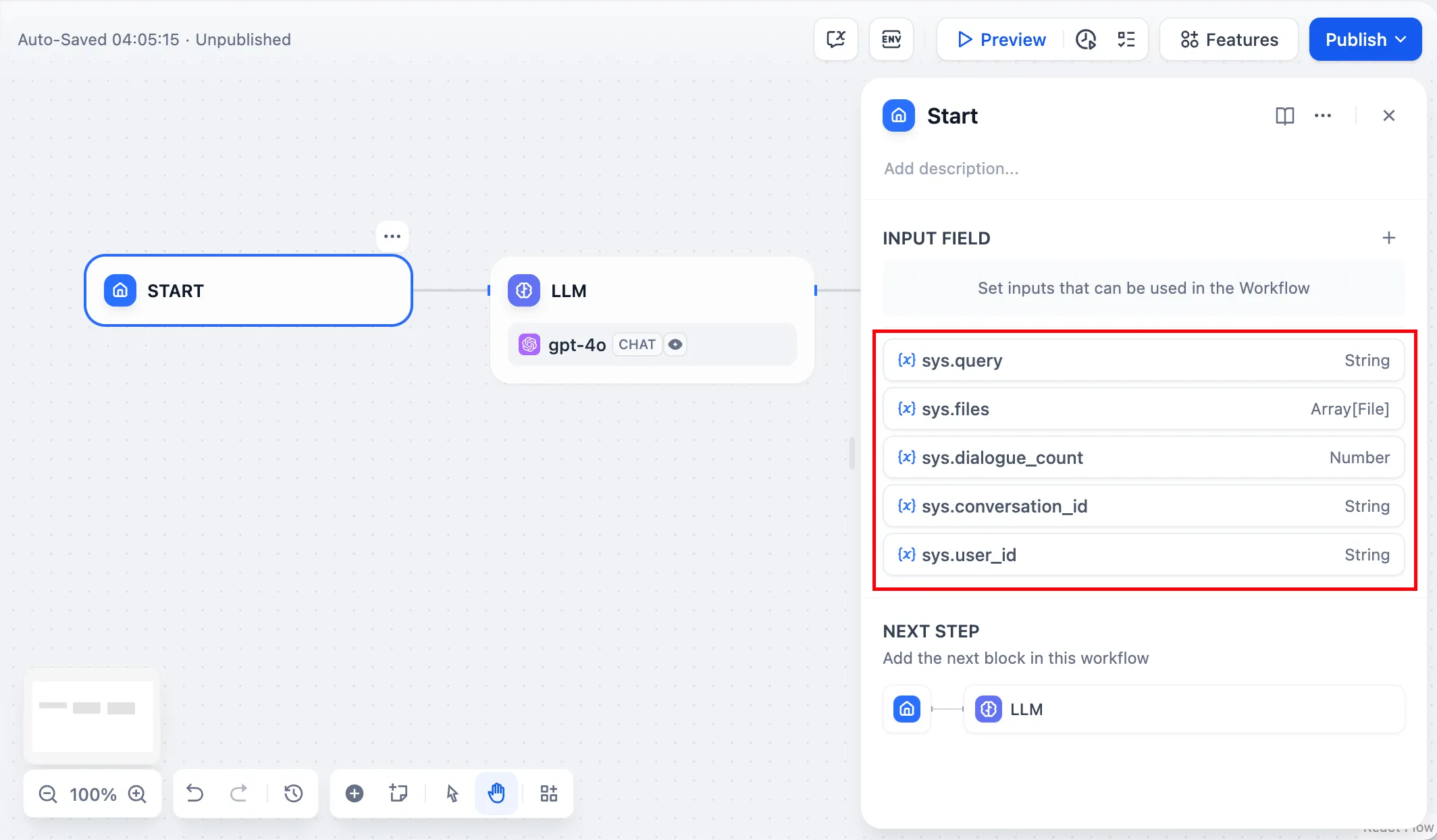
| Variables name | Data Type | Description | Remark |
|---|---|---|---|
sys.query | String | Content entered by the user in the chatting box. | |
sys.files | Array[File] | File Parameter: Stores images uploaded by users | The image upload function needs to be enabled in the 'Features' section in the upper right corner of the application orchestration page |
sys.dialogue_count | Number | The number of conversations turns during the user's interaction with a Chatflow application. The count automatically increases by one after each chat round and can be combined with if-else nodes to create rich branching logic. For example, LLM will review the conversation history at the X conversation turn and automatically provide an analysis. | |
sys.conversation_id | String | A unique ID for the chatting box interaction session, grouping all related messages into the same conversation, ensuring that the LLM continues the chatting on the same topic and context. | |
sys.user_id | String | A unique ID is assigned for each application user to distinguish different conversation users. | |
sys.workflow_id | String | Workflow ID: This parameter records information about all nodes information in the current Workflow application. | This parameter can be used by users with development capabilities to track and record information about the nodes contained within a Workflow |
sys.workflow_run_id | String | Workflow Run ID: Used to record the runtime status and execution logs of a Workflow application. | This parameter can be used by users with development capabilities to track the application's historical execution records |
 (1) (1) (1).png)
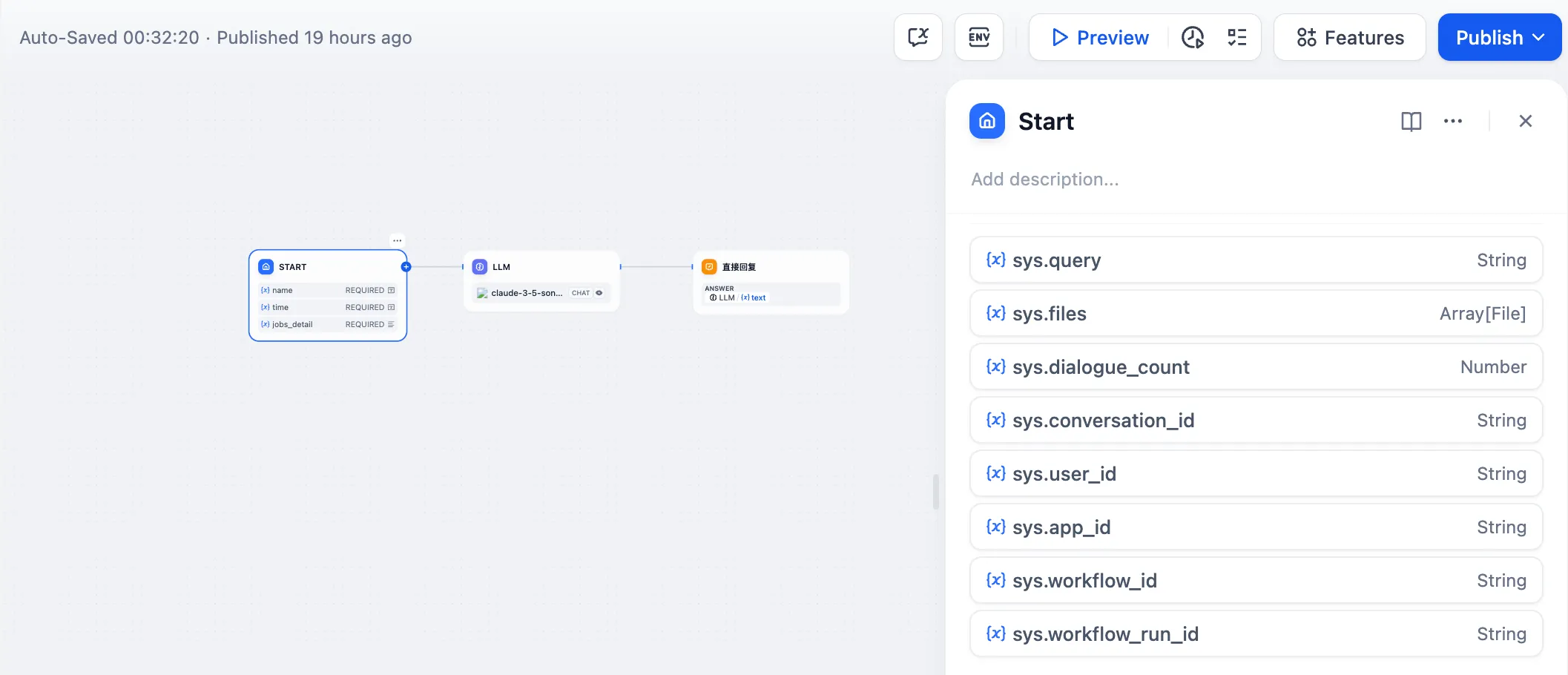
Chatflow App System Variables
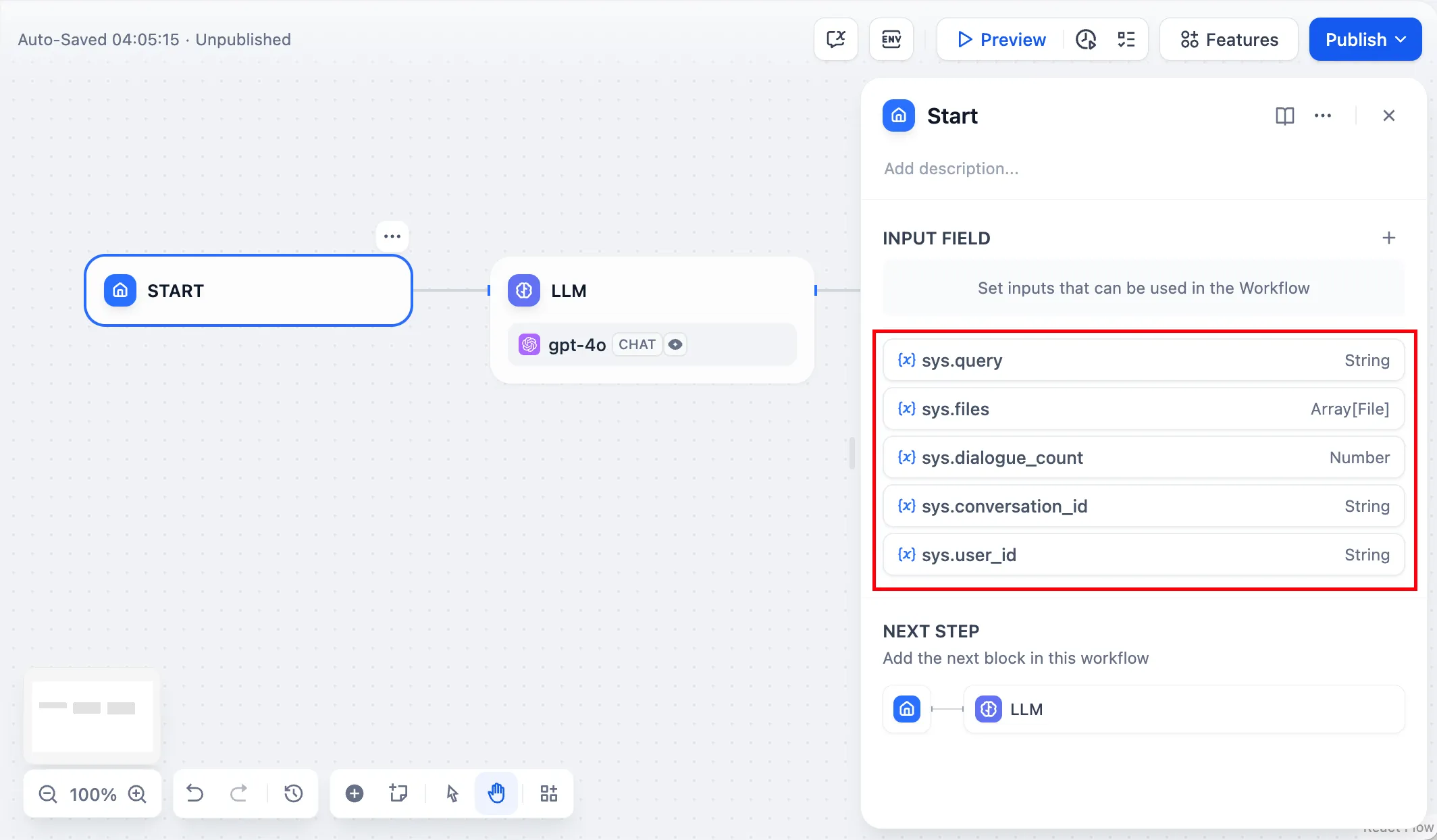
Chatflow App System Variables

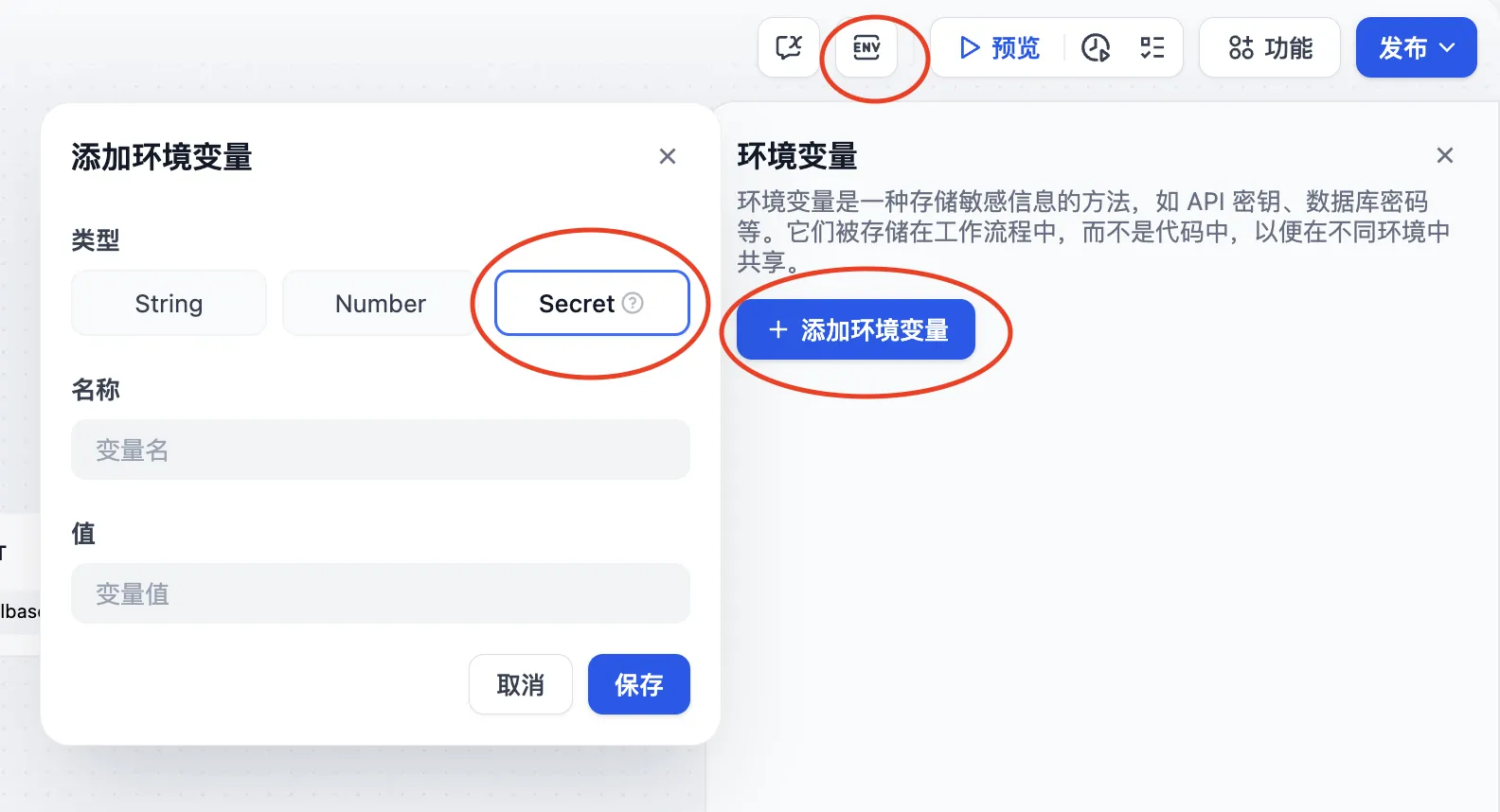
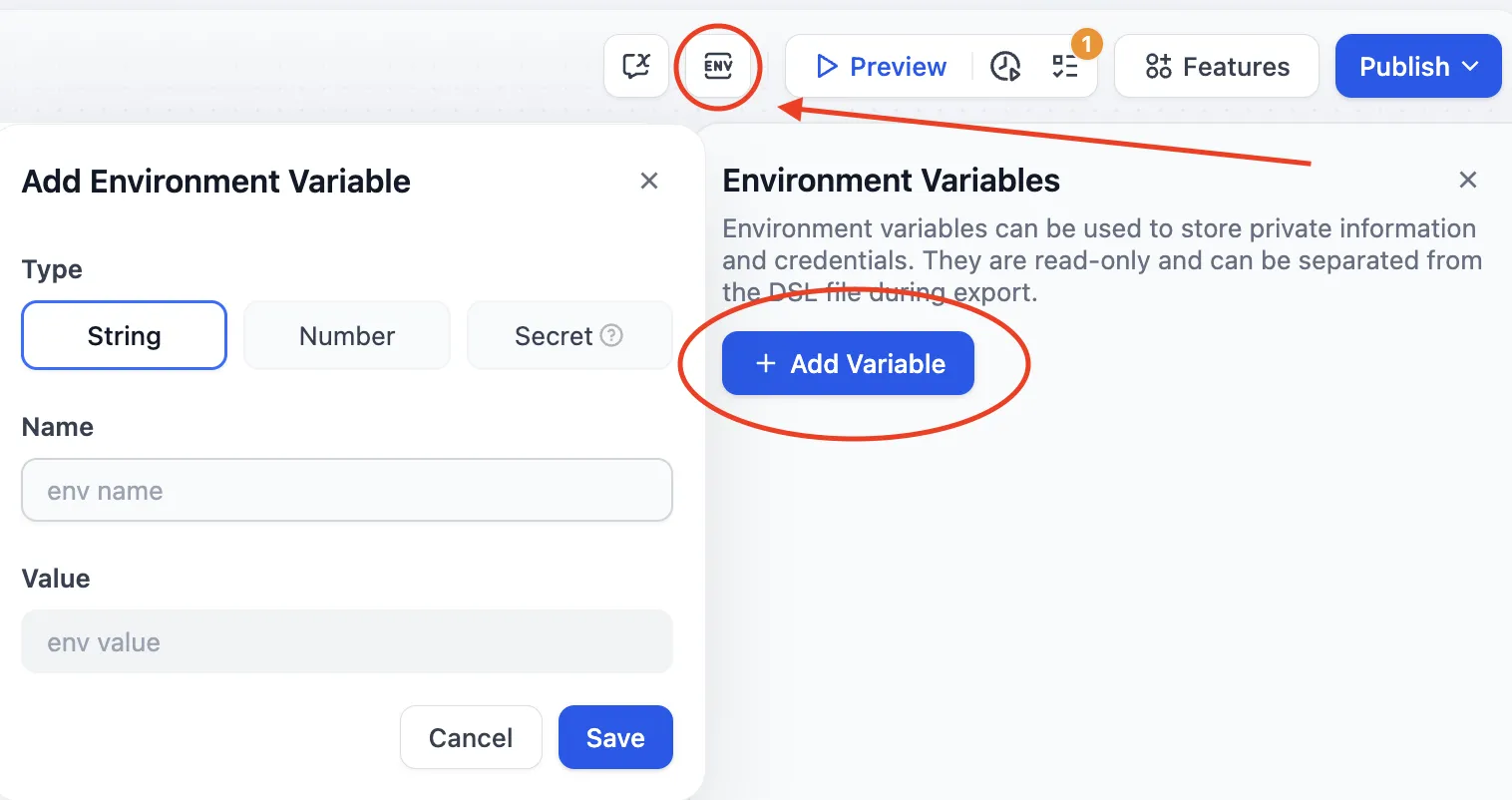
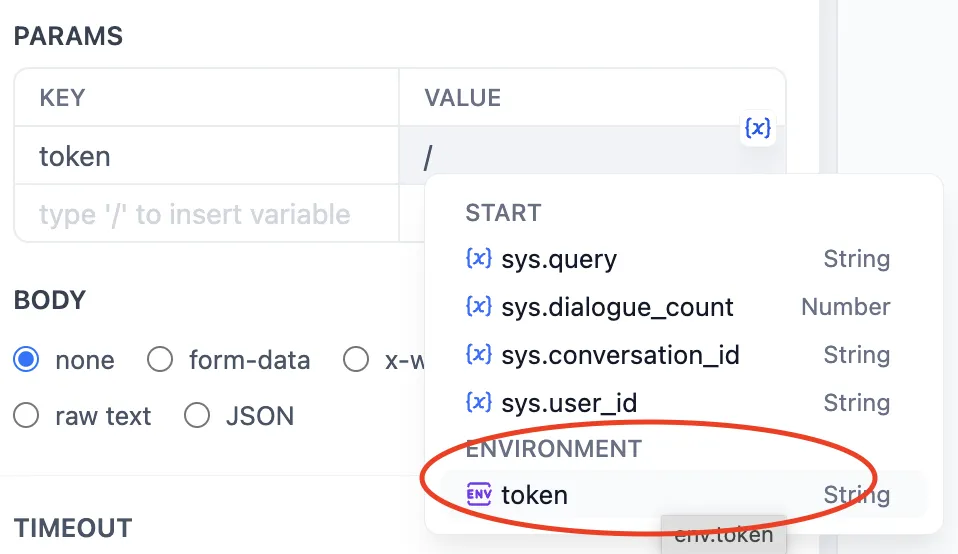
Environment Variables
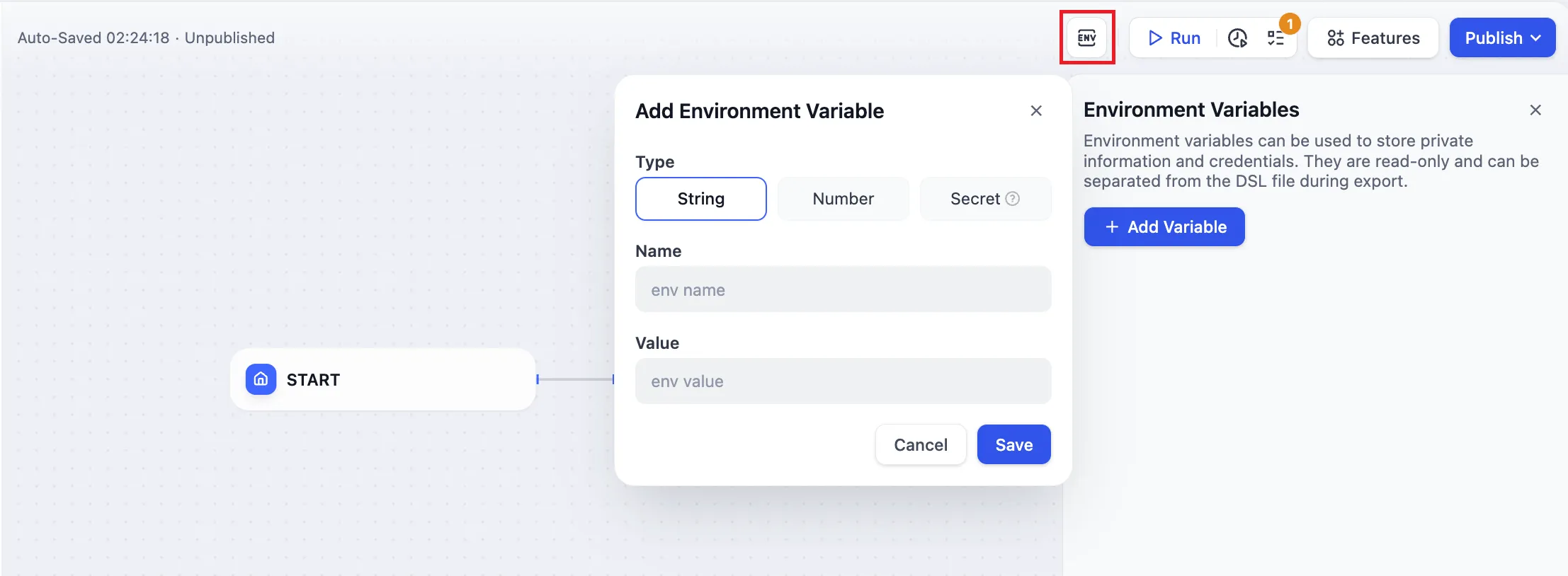
Environment Variables

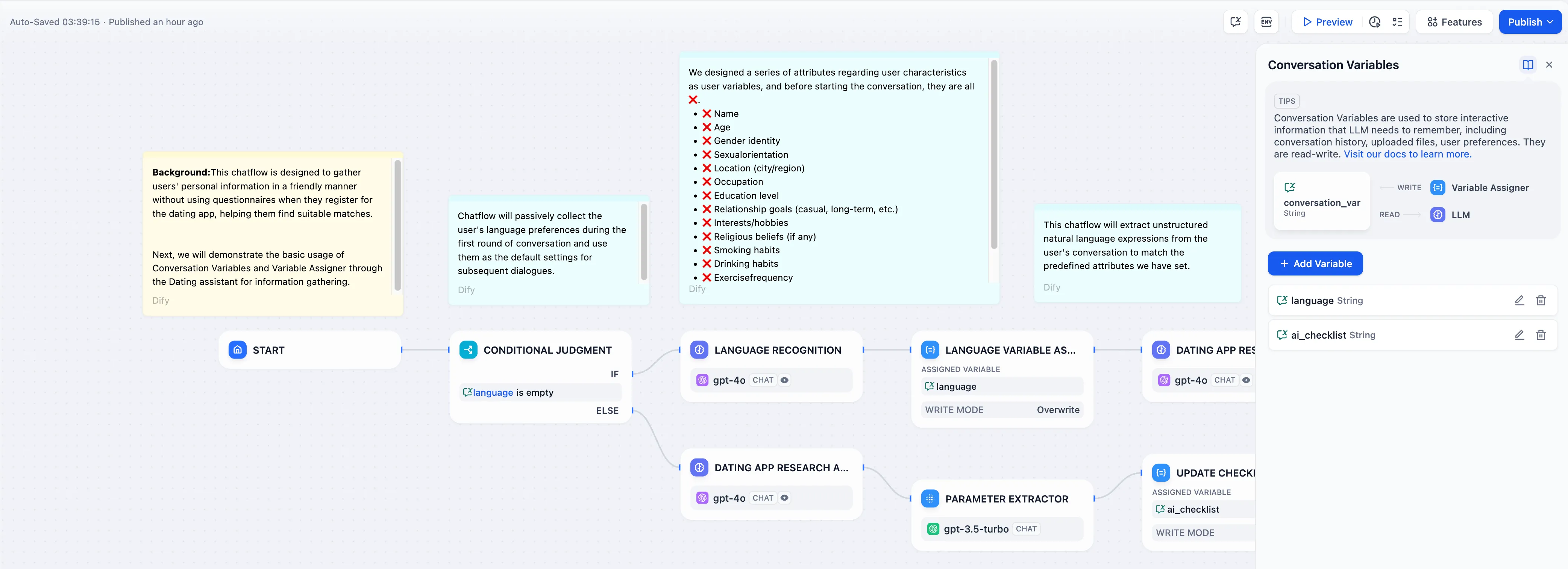
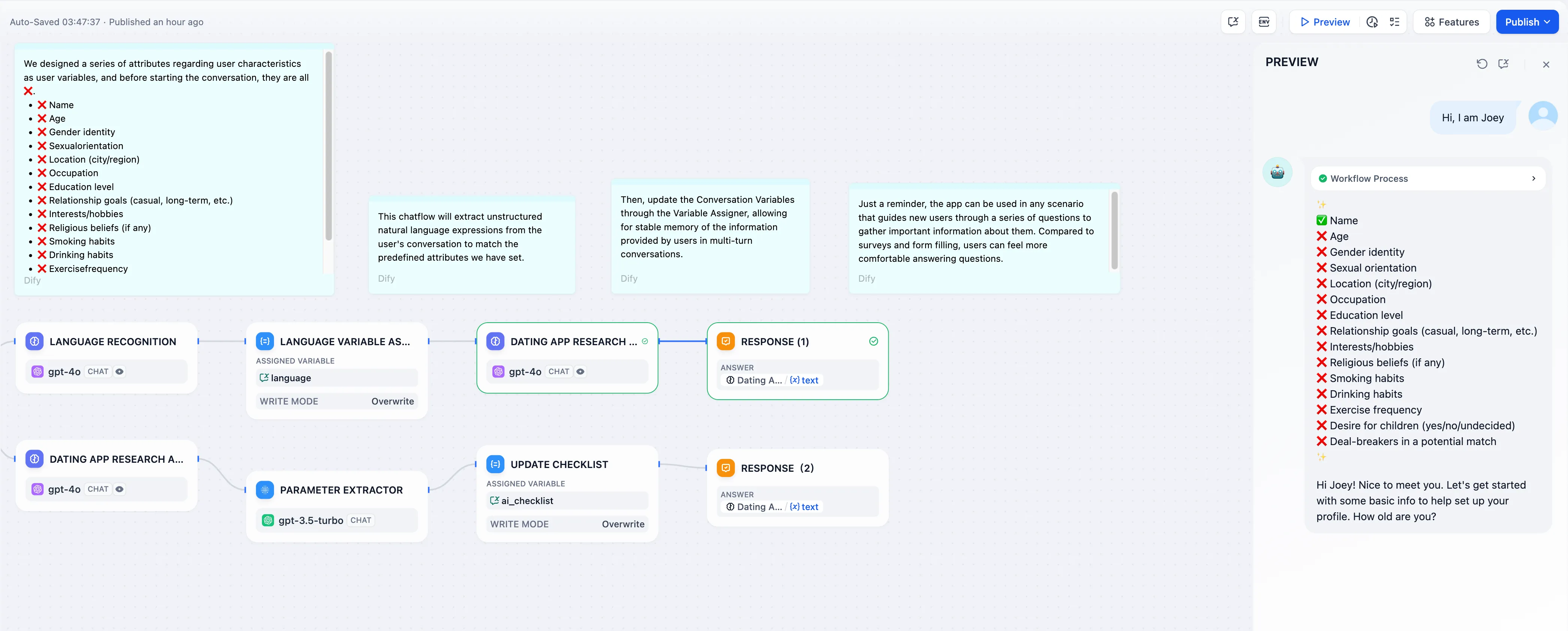
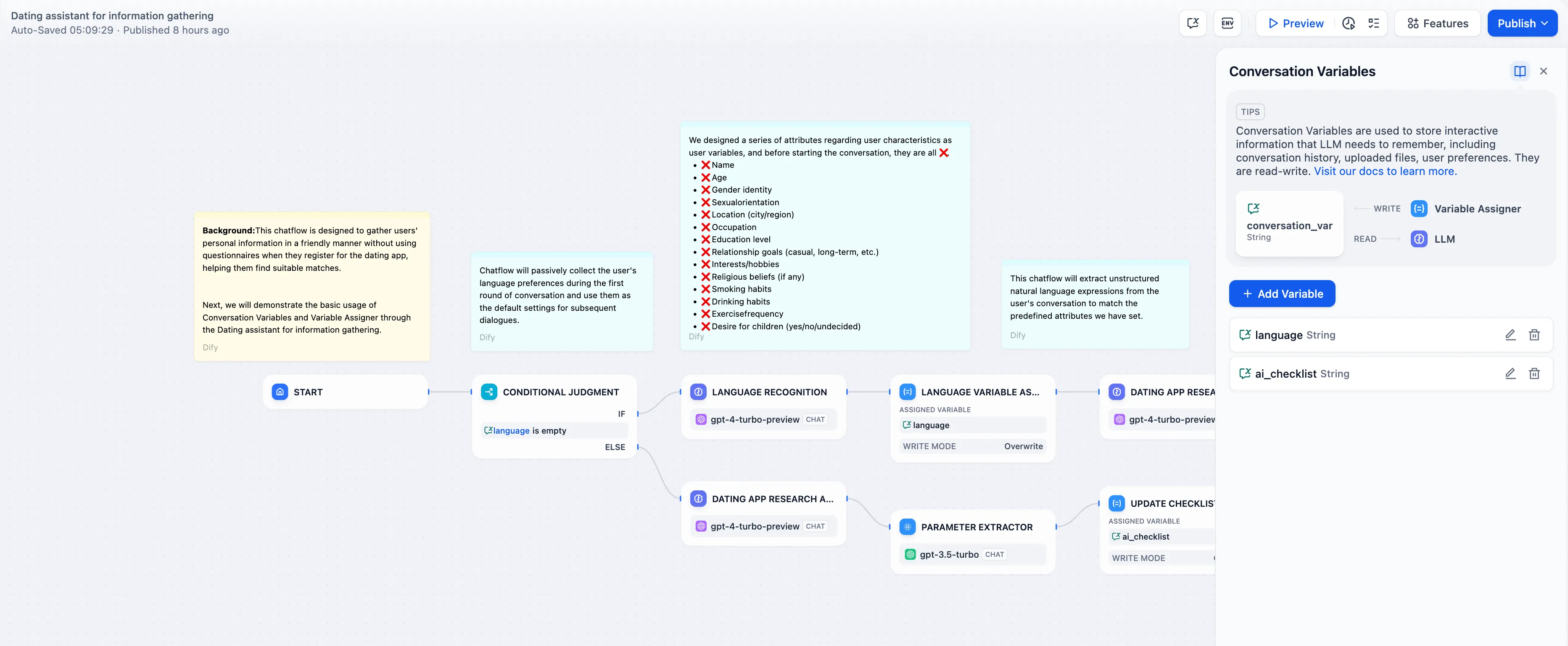
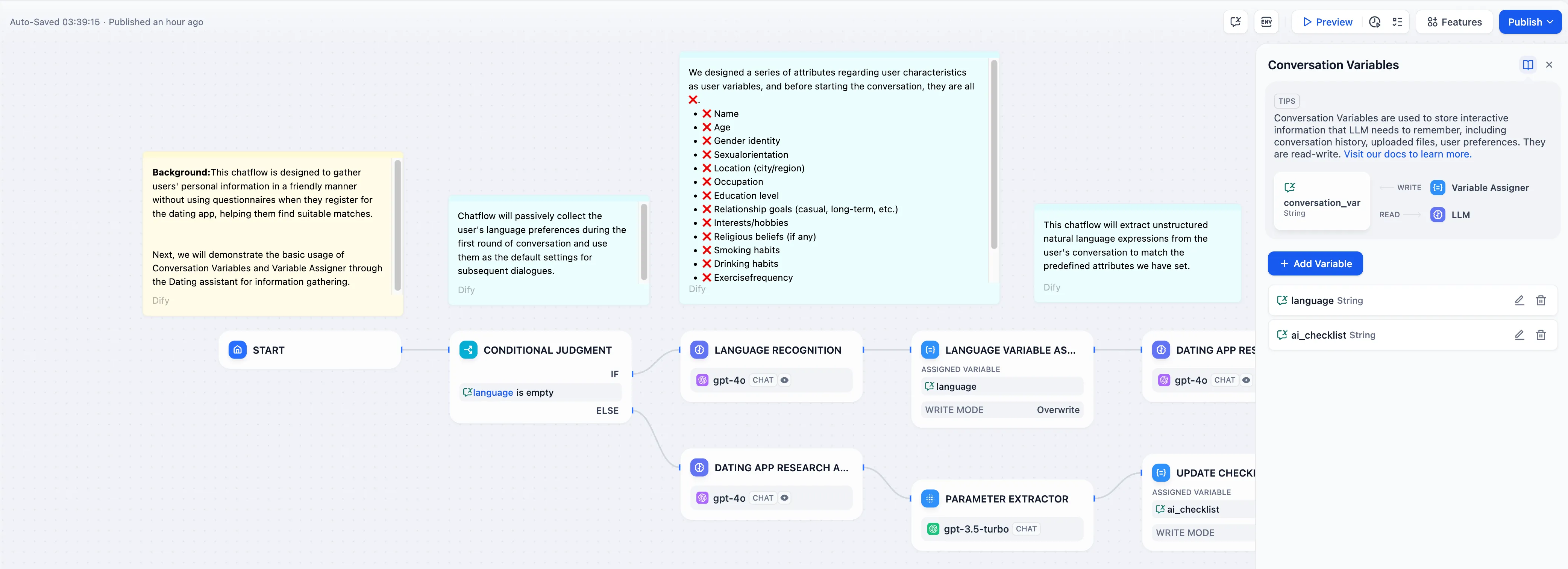
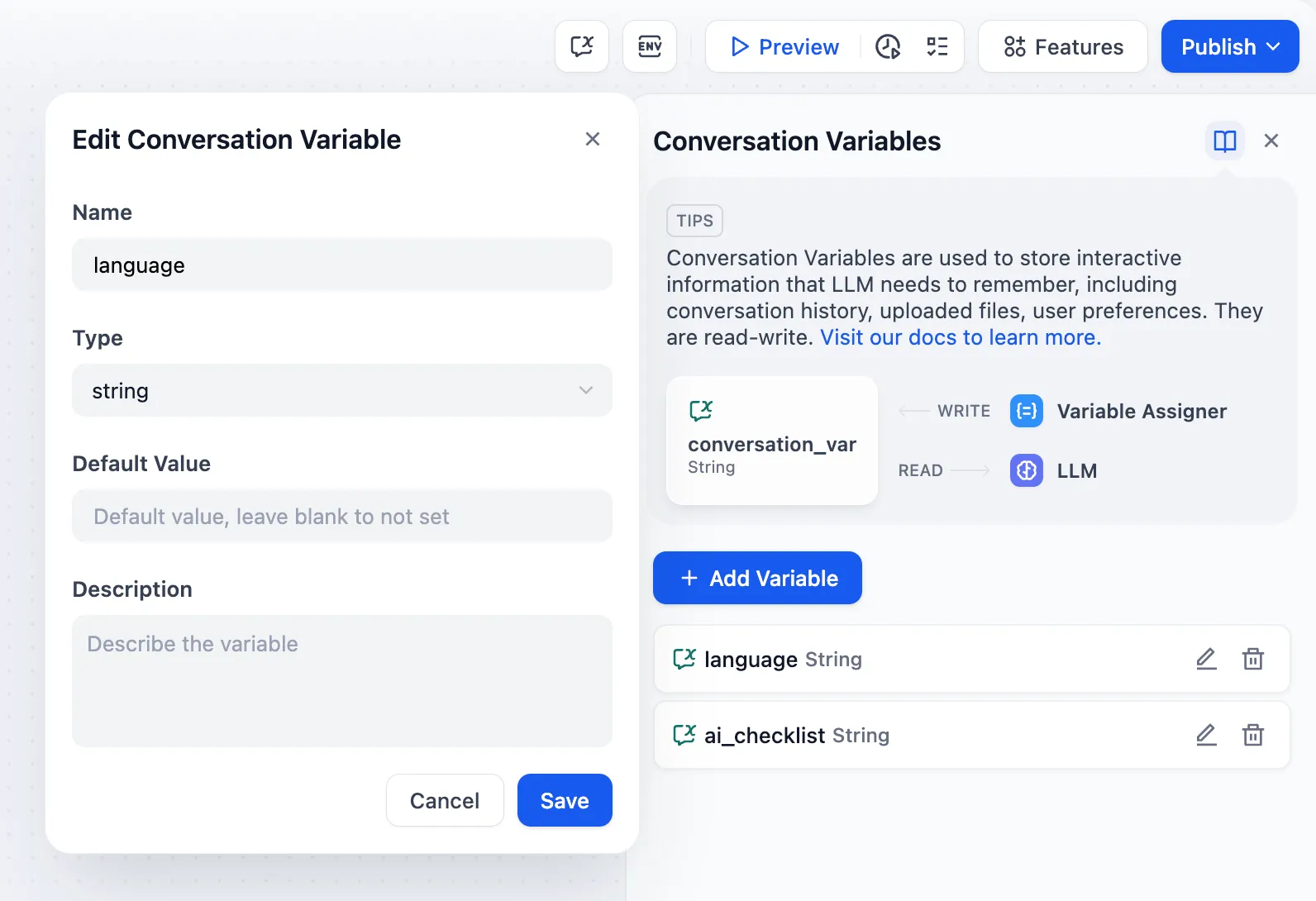
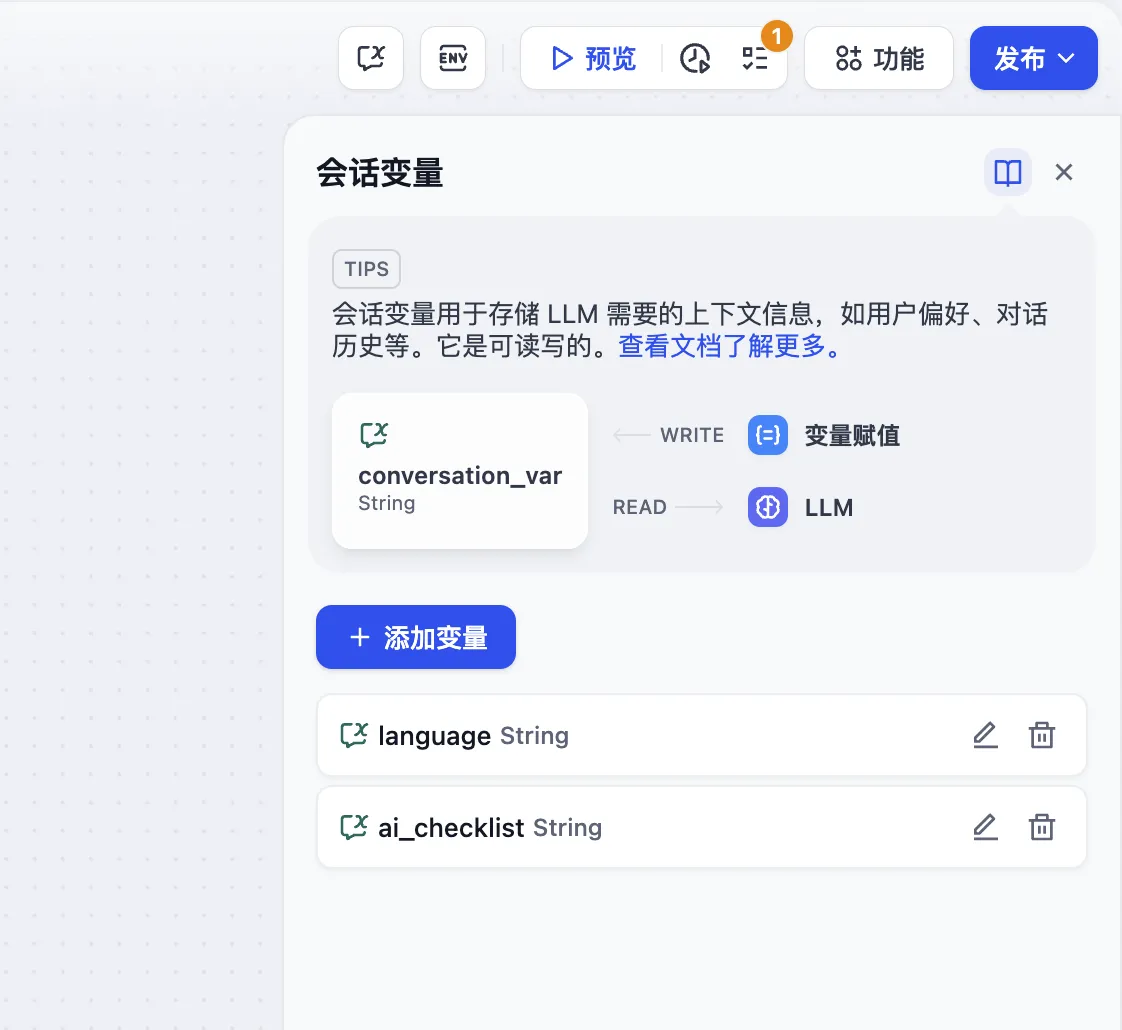
Conversation Variable
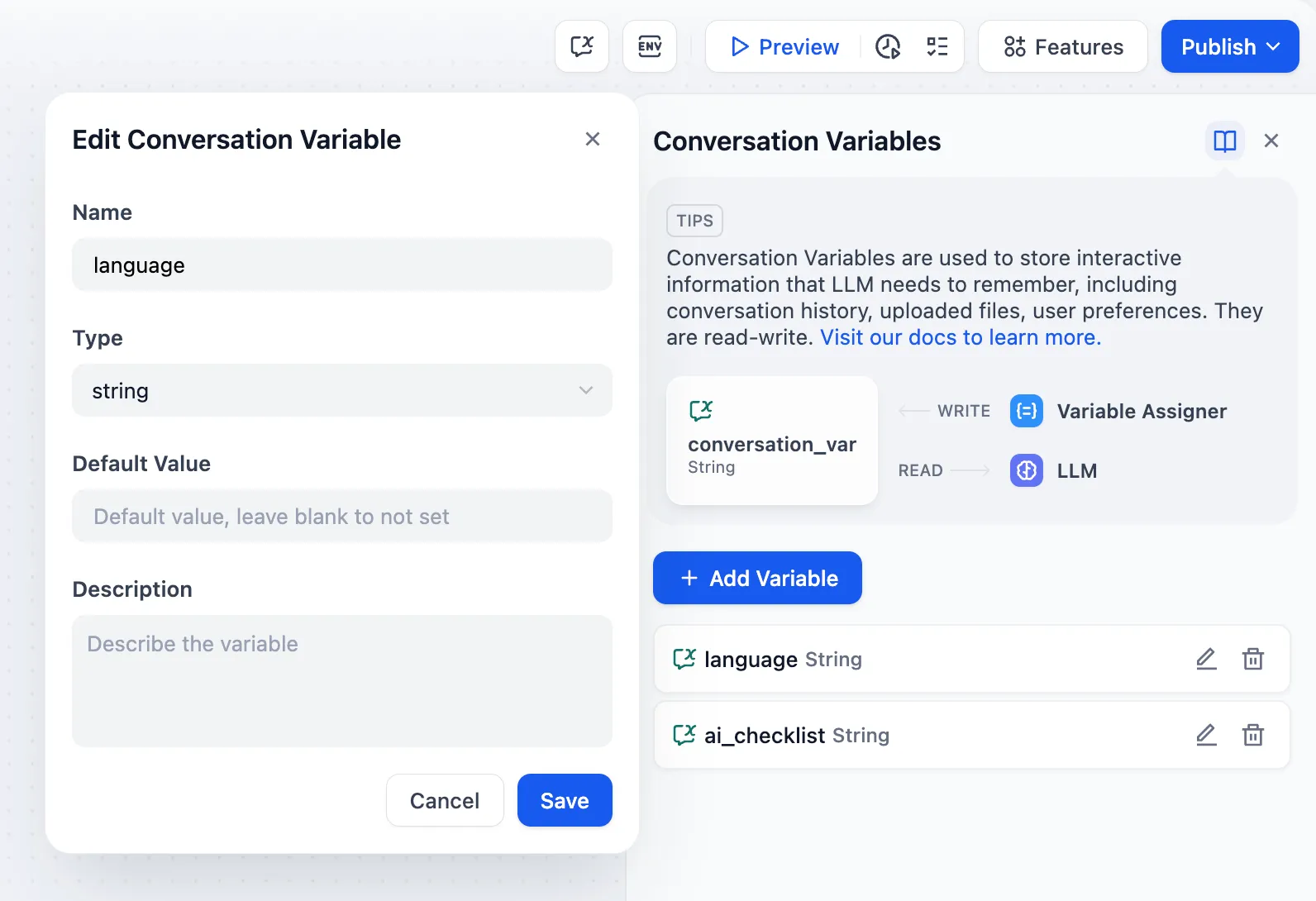
Conversation Variable

.png)


.png)
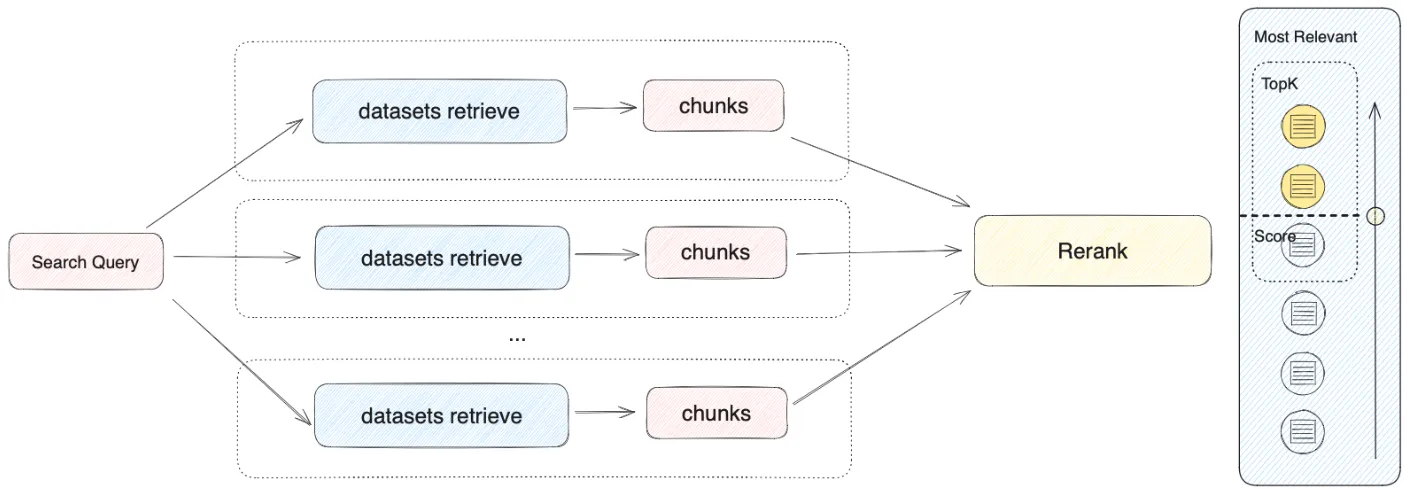
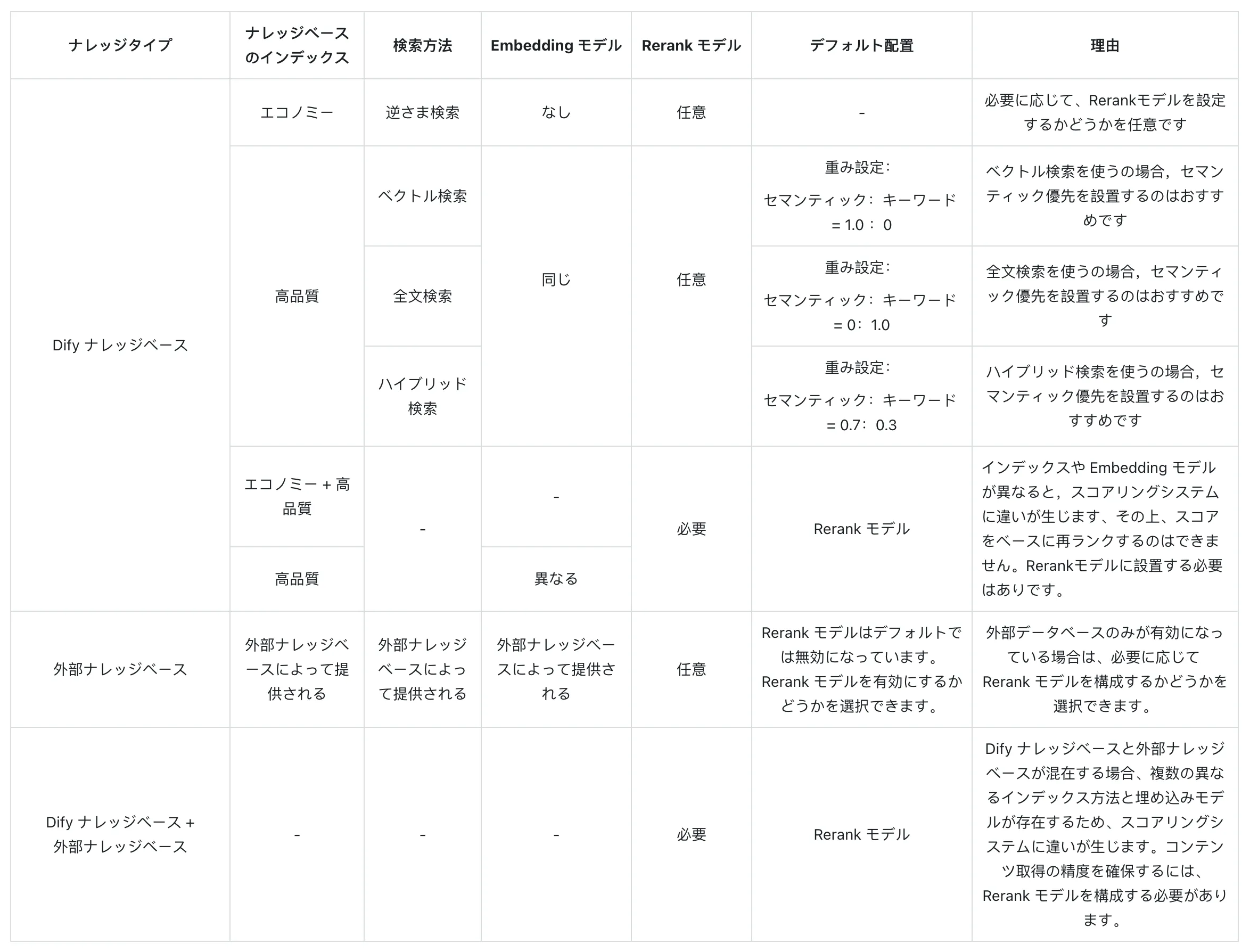
Basic RAG Architecture
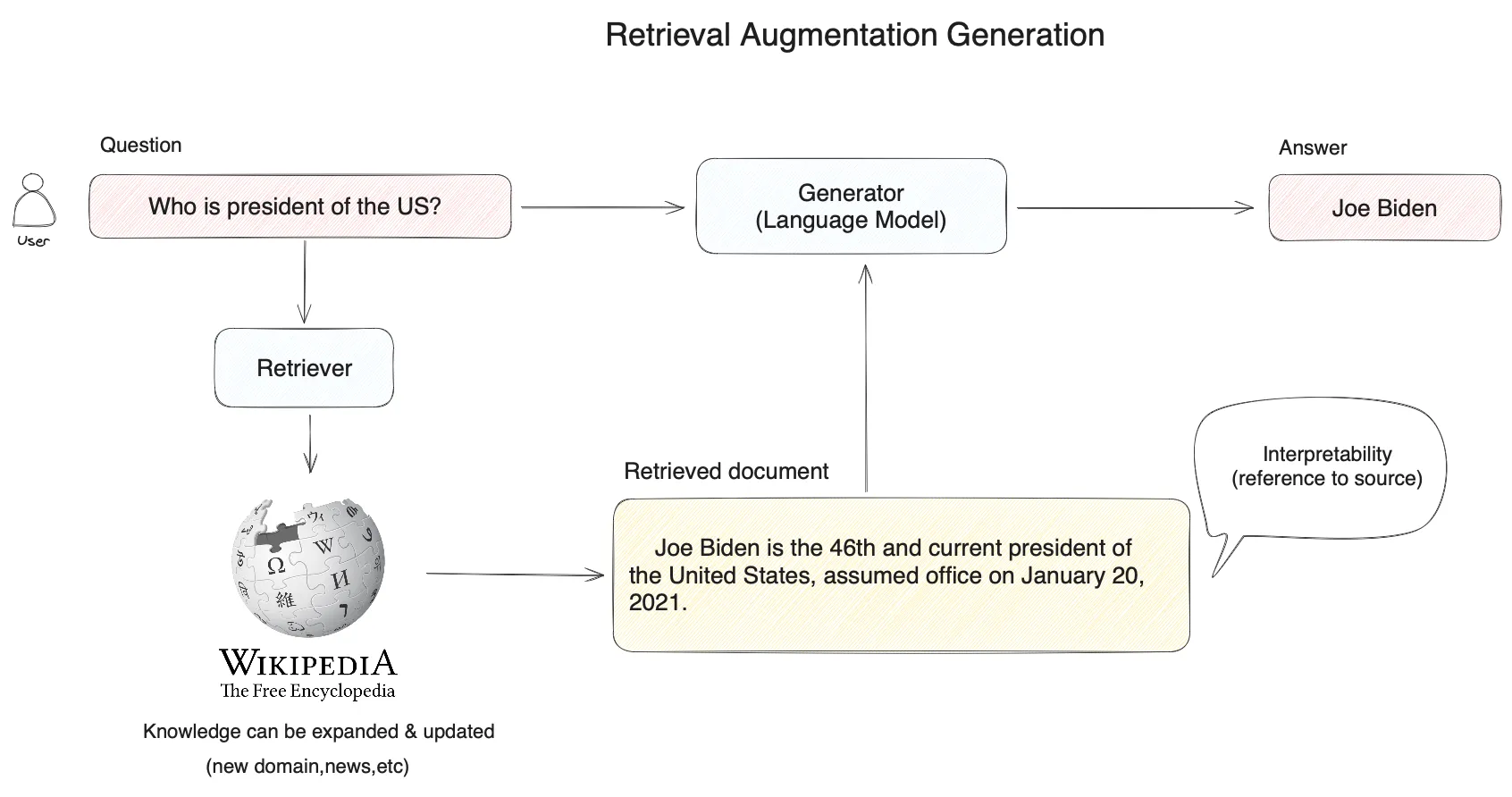
Basic RAG Architecture
.png)
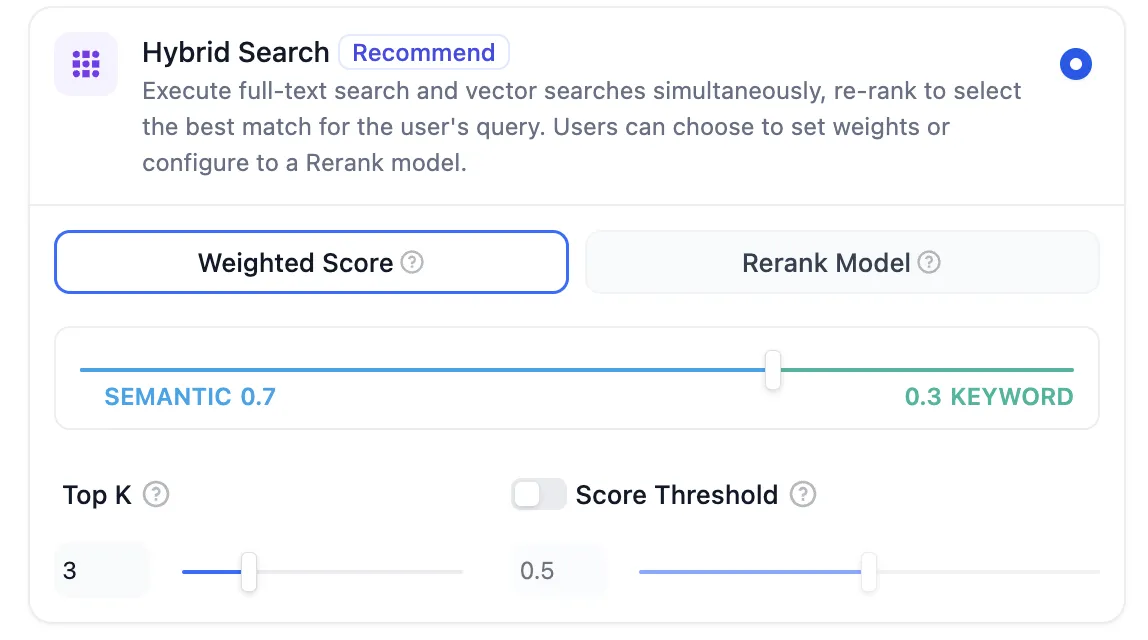
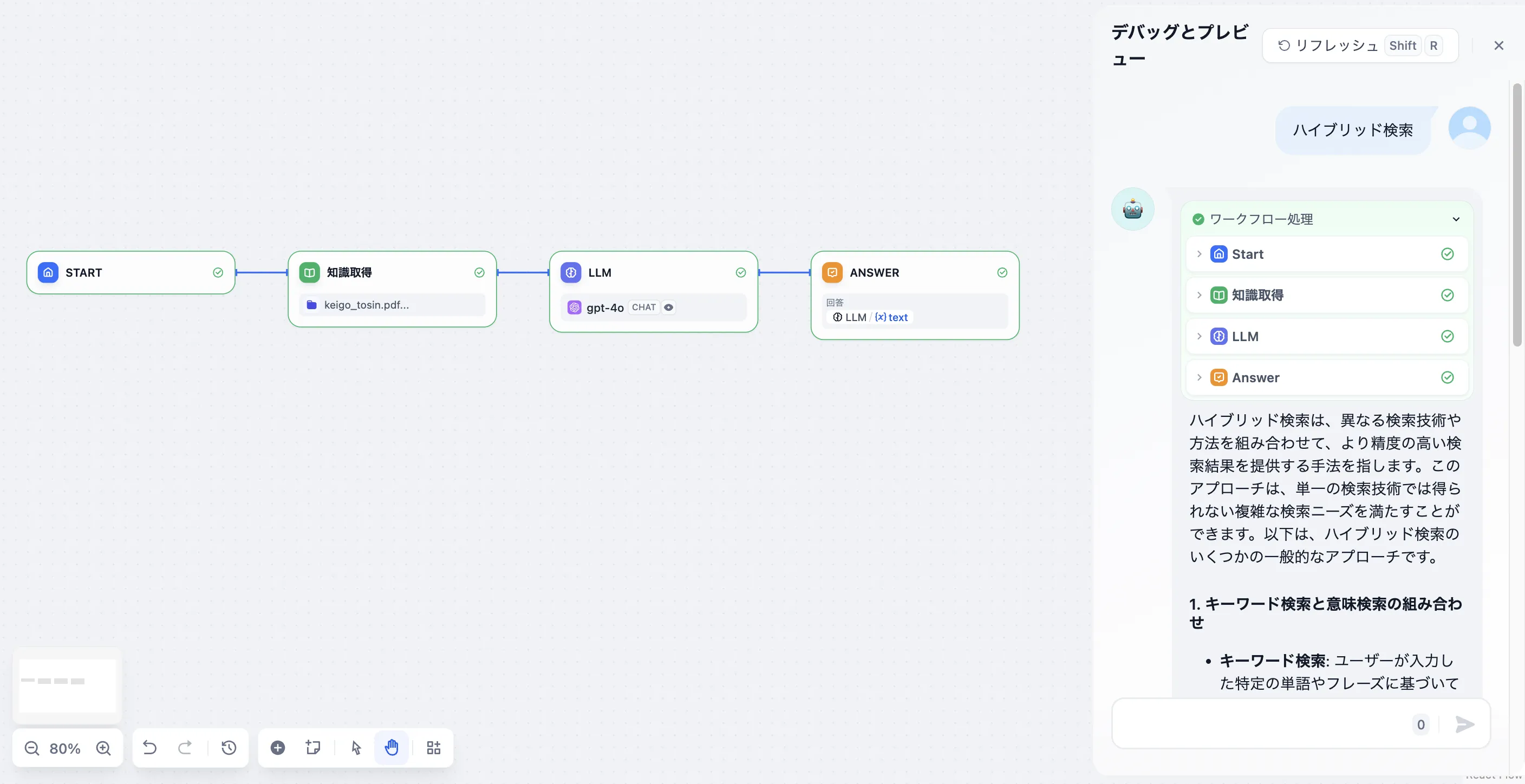
Hybrid Search
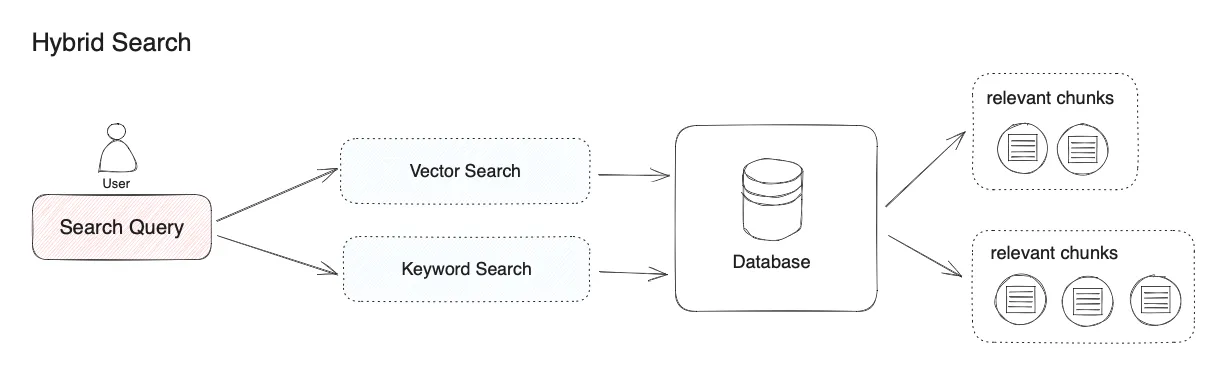
Hybrid Search
.png)
Vector Search Settings
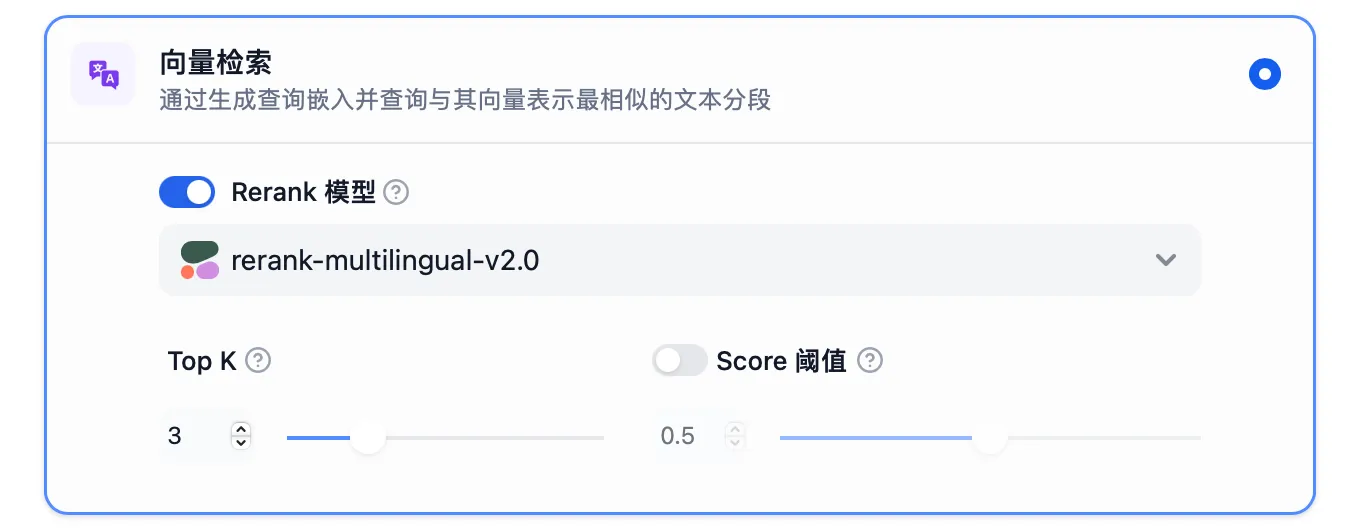
Vector Search Settings
.png)
Full-Text Search Settings
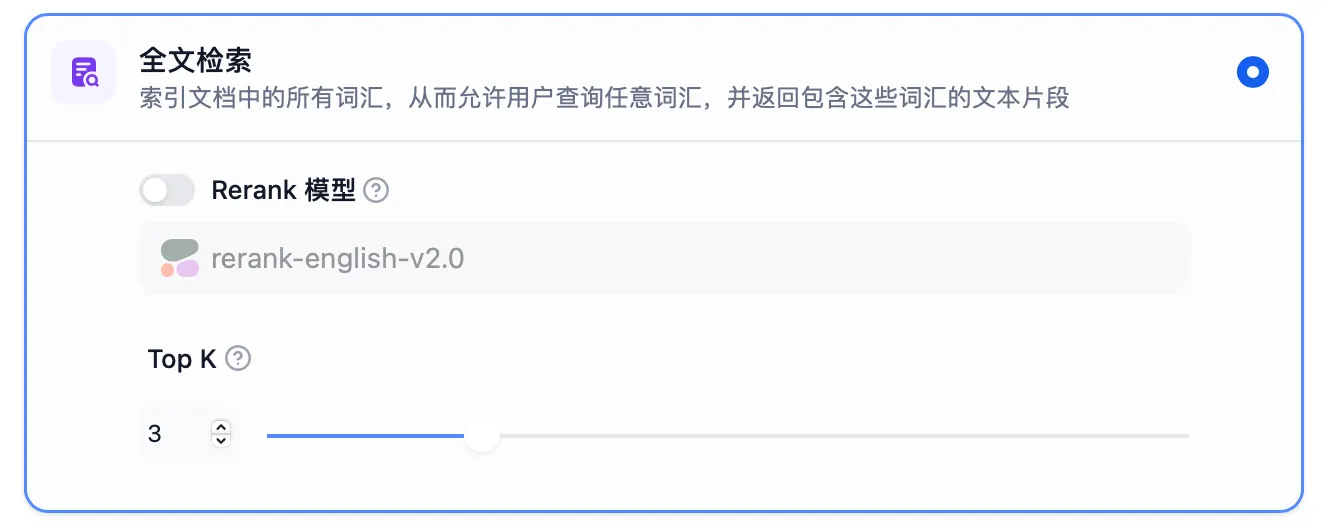
Full-Text Search Settings
.png)
Hybrid Search Settings
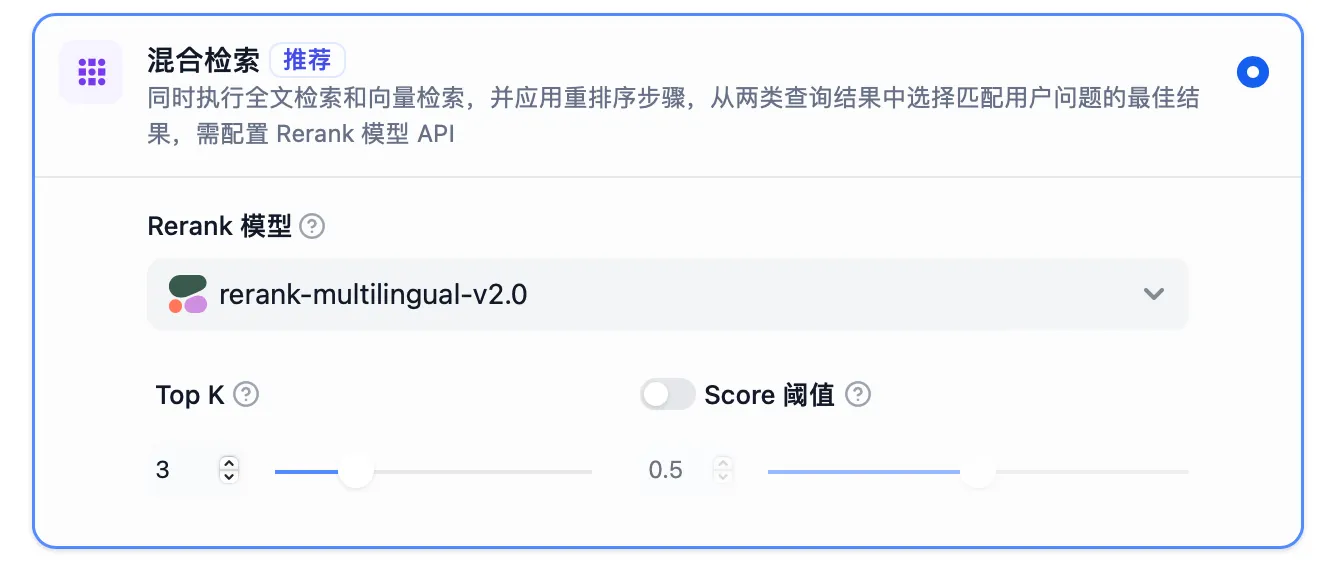
Hybrid Search Settings
.png)
Setting Retrieval Mode When Creating a Dataset
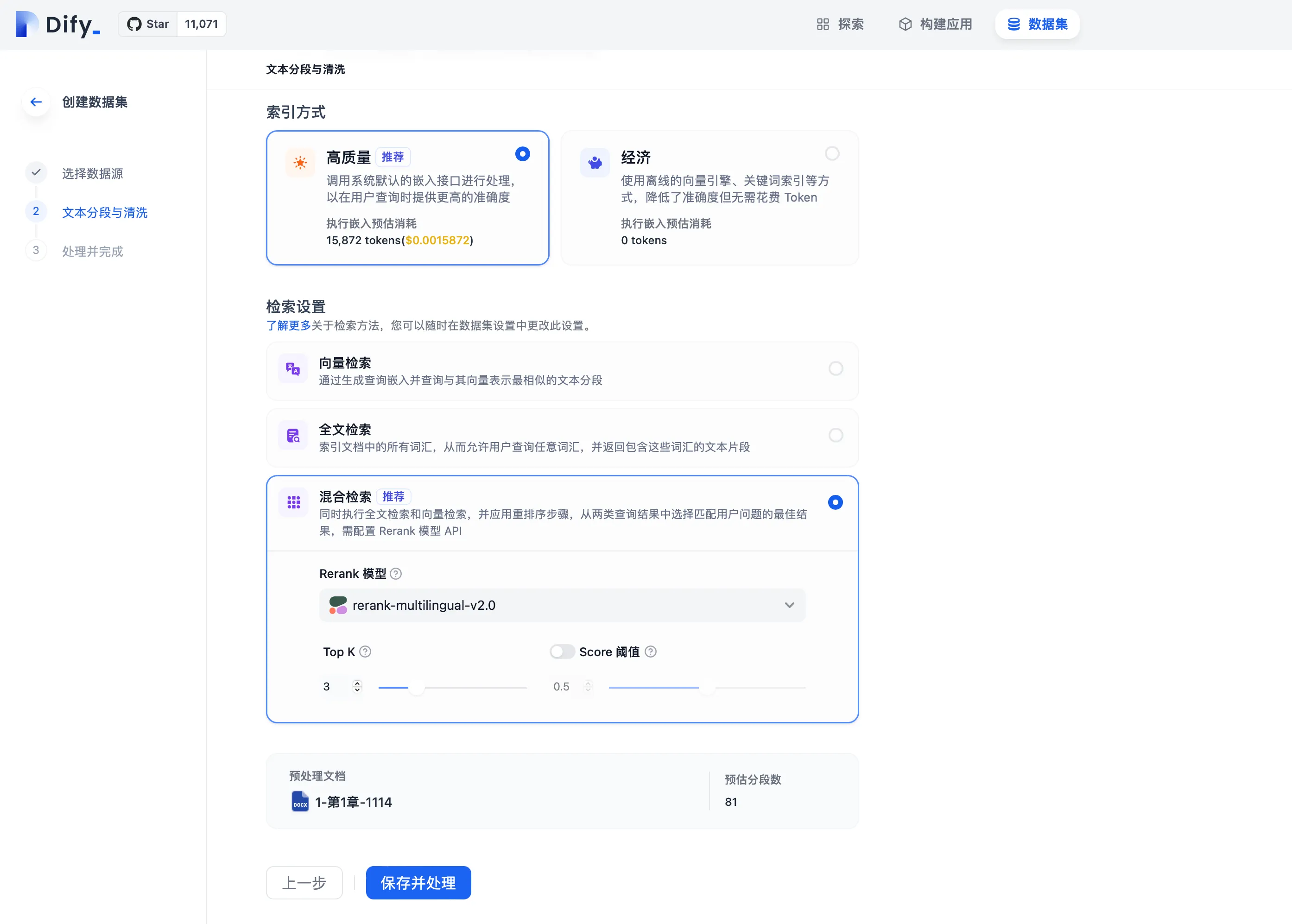
Setting Retrieval Mode When Creating a Dataset
.png)
Modifying Retrieval Mode in Dataset Settings
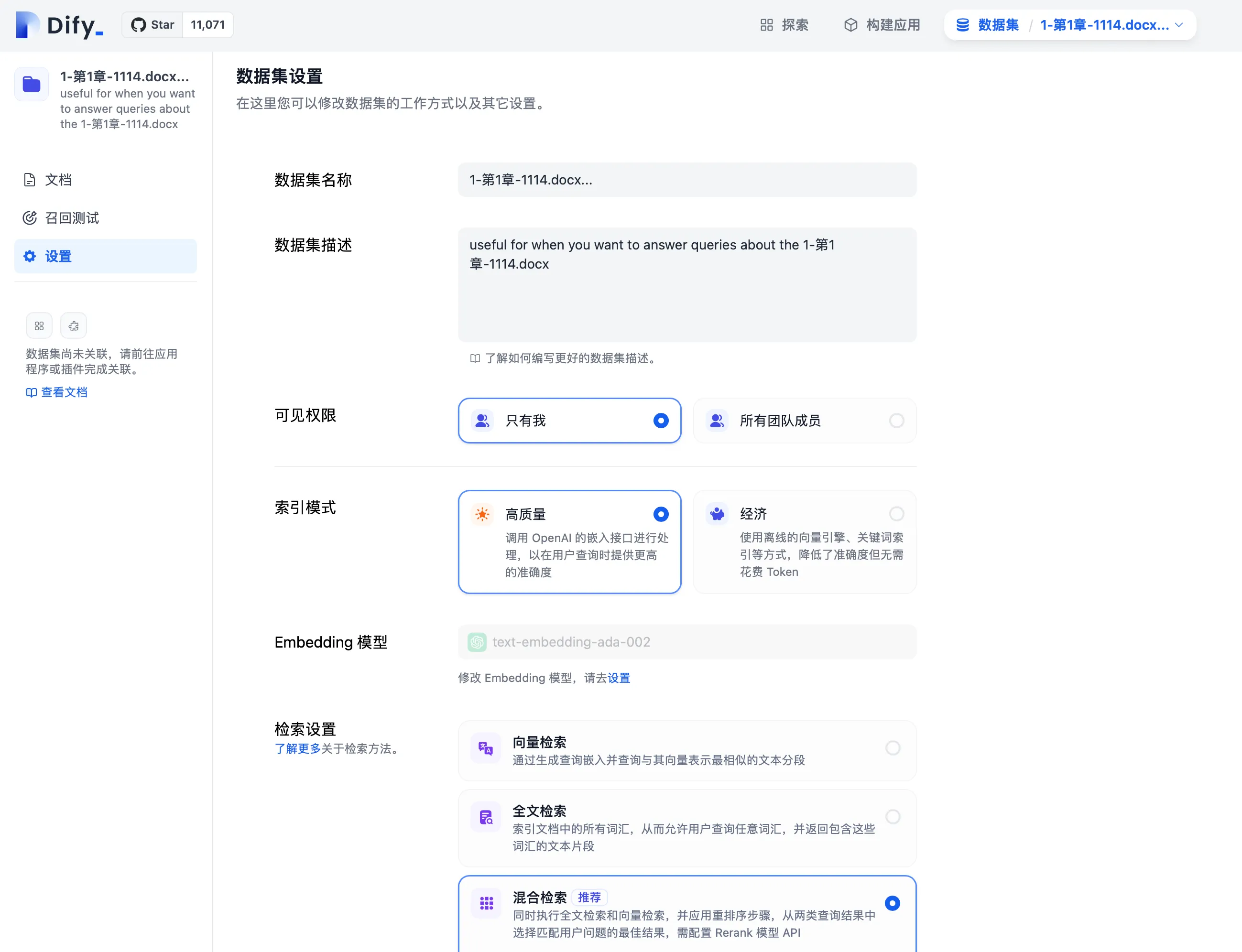
Modifying Retrieval Mode in Dataset Settings
.png)
Modifying Retrieval Mode in Prompt Arrangement
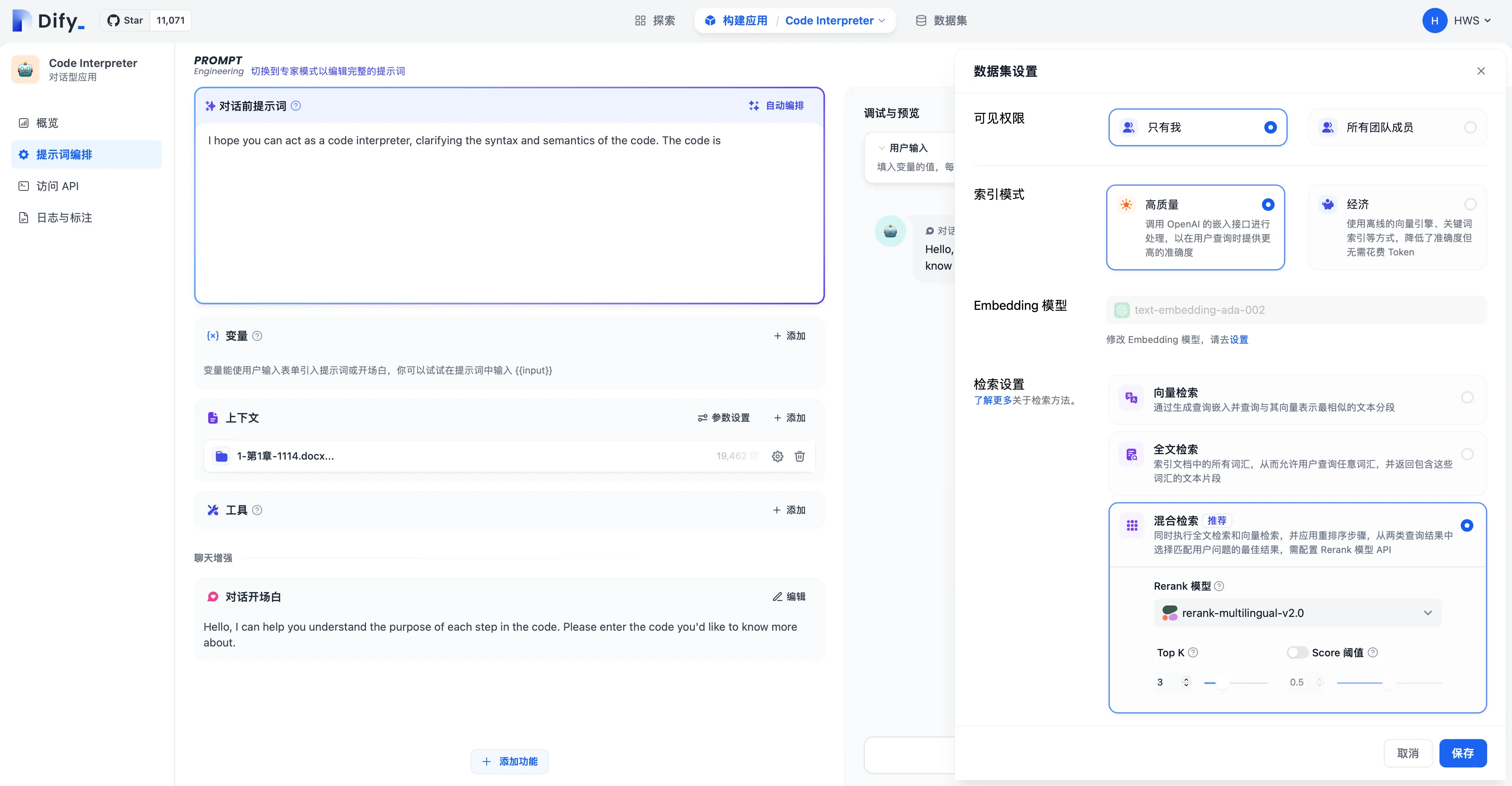
Modifying Retrieval Mode in Prompt Arrangement
 (1).png)
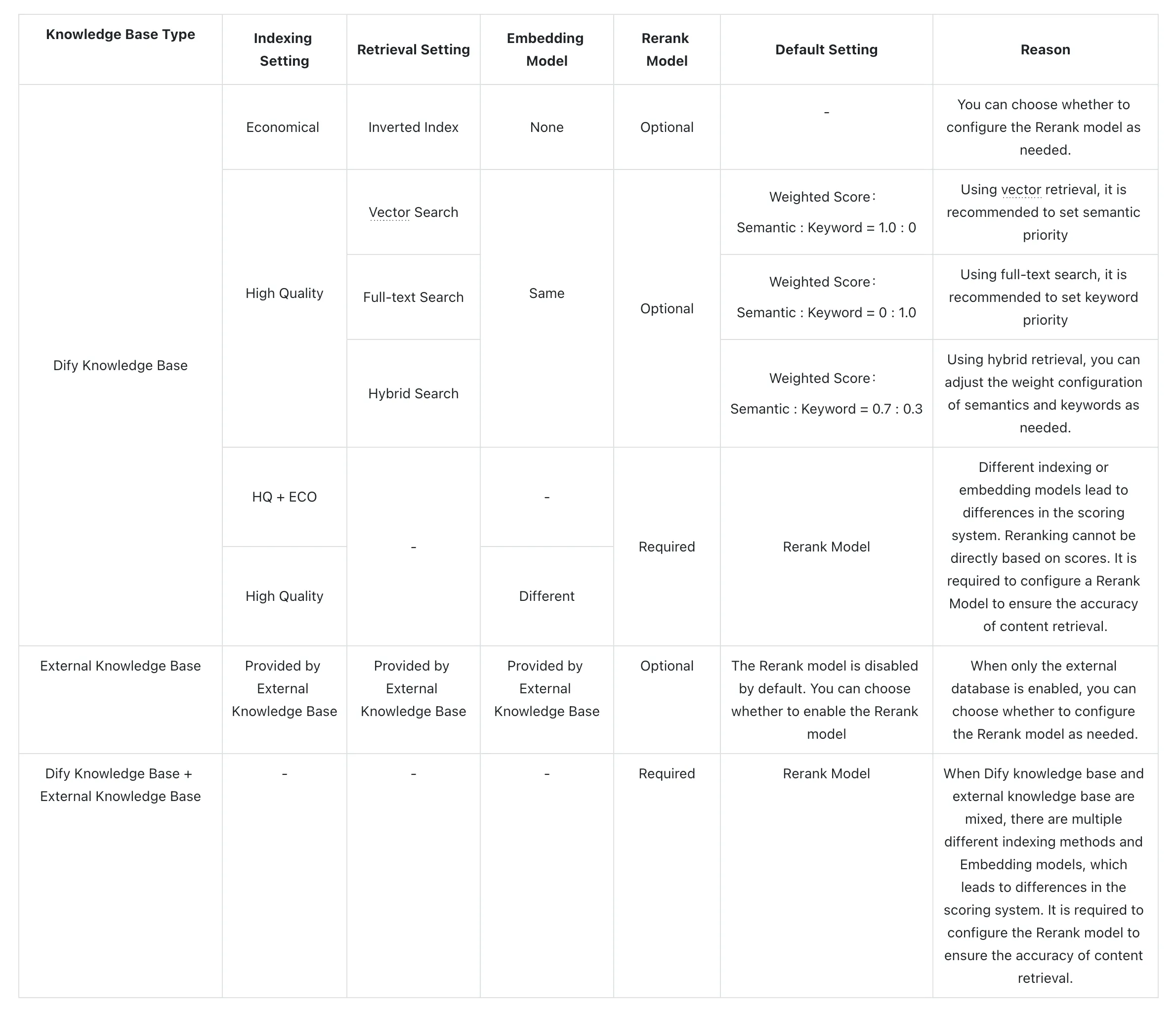
Hybrid Search + Re-ranking
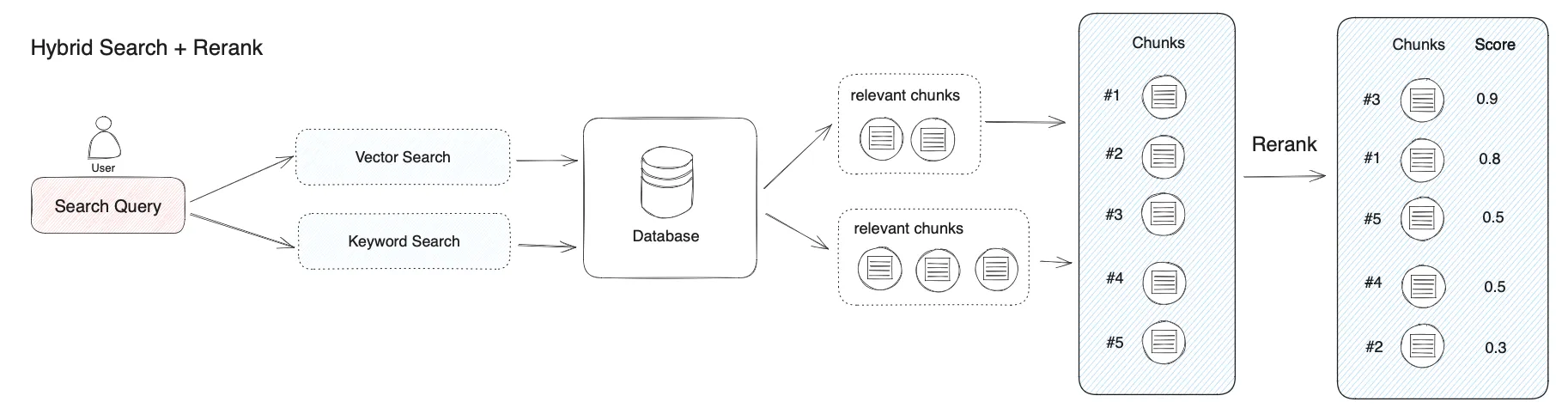
Hybrid Search + Re-ranking

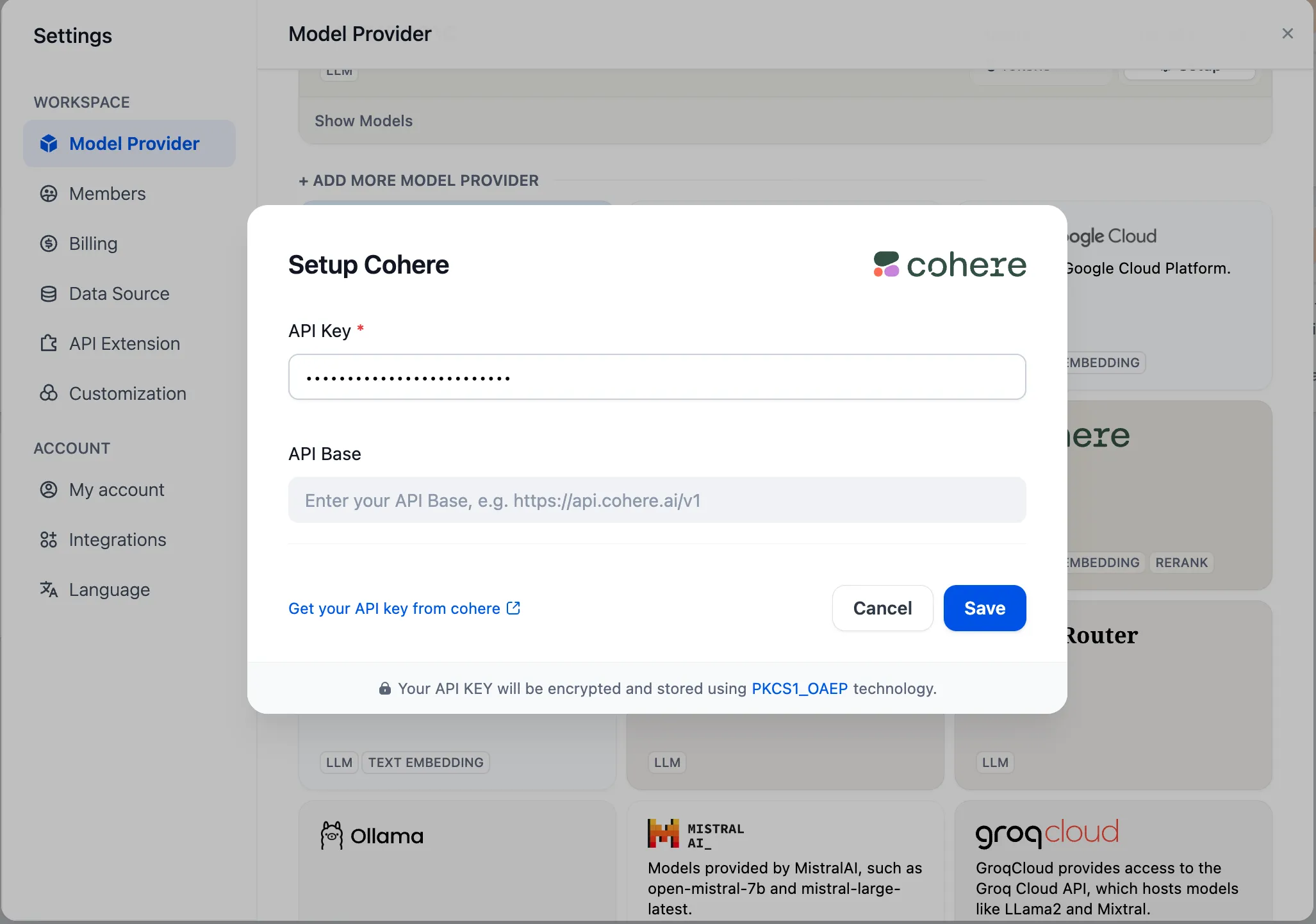
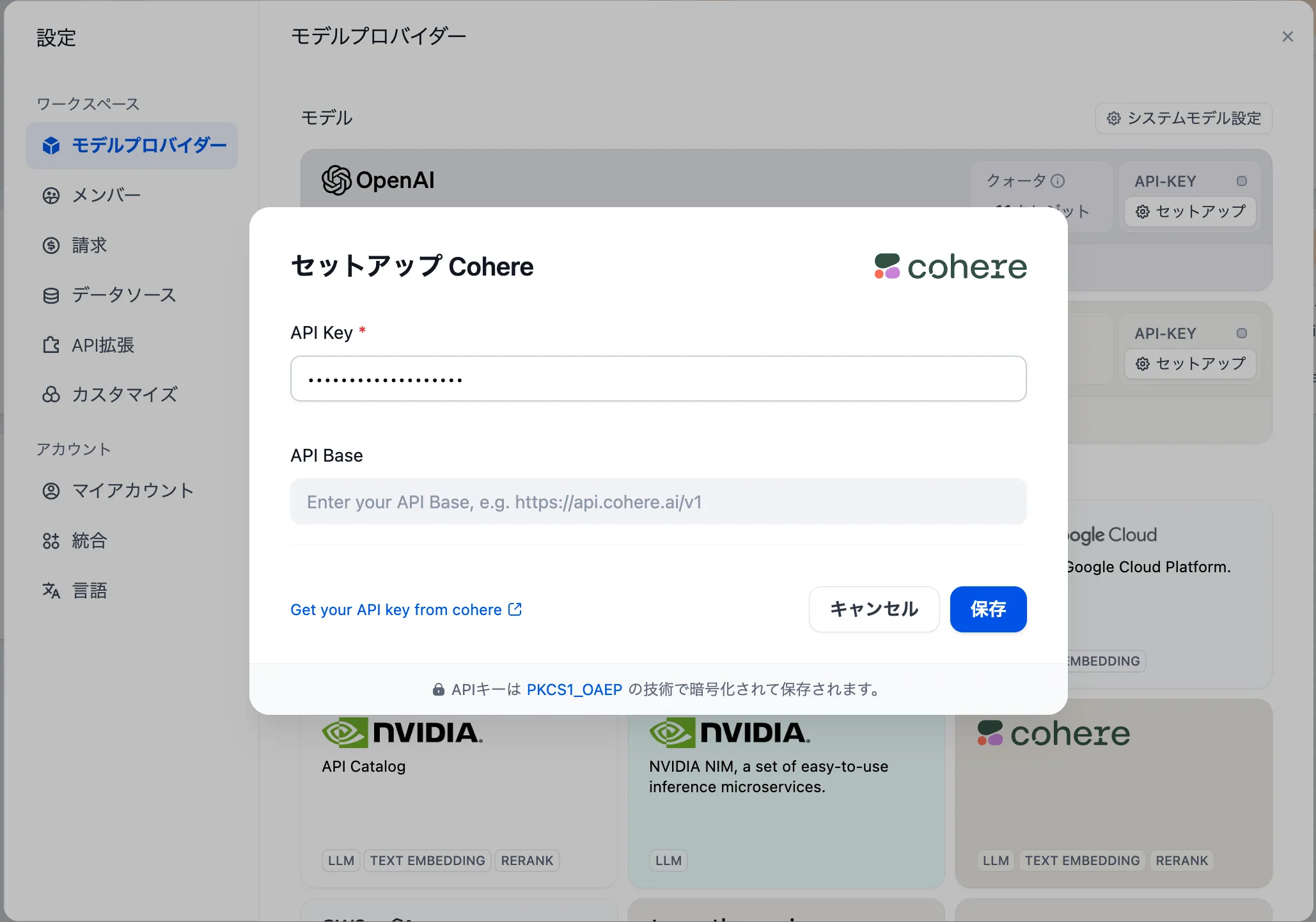
Configure Cohere Rerank Model in Model Providers
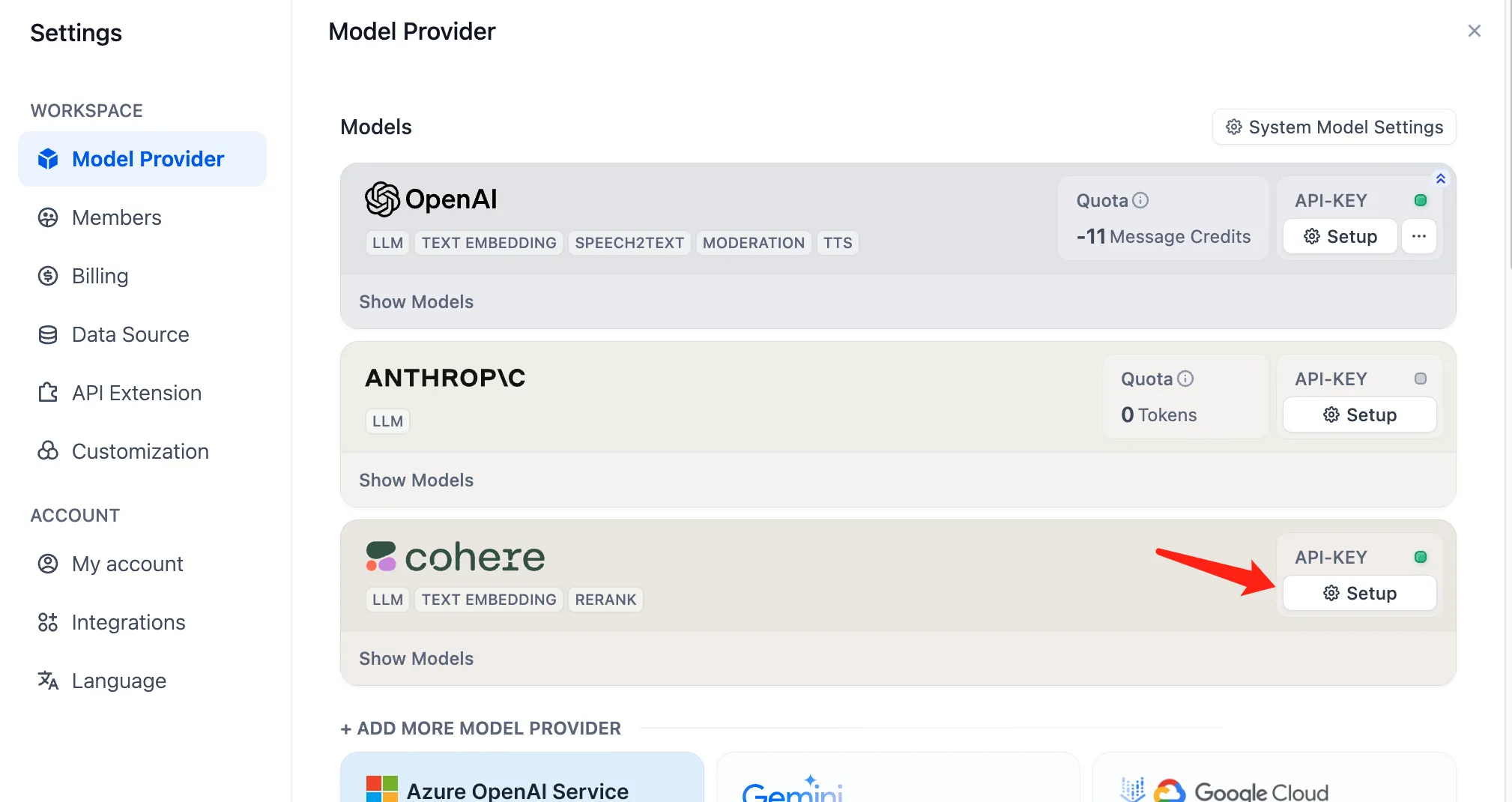
Configure Cohere Rerank Model in Model Providers

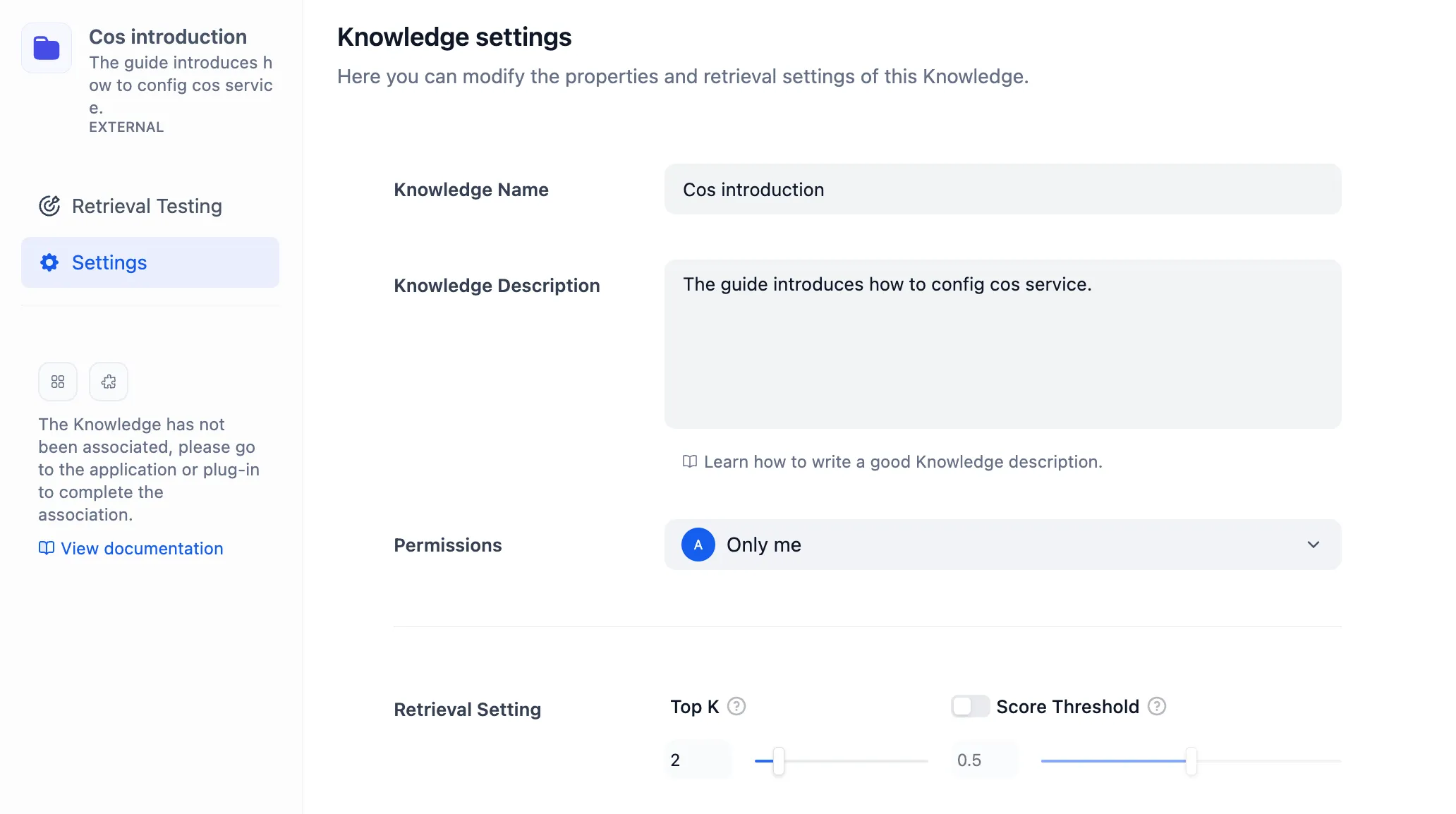
Setting the Re-rank Model in Dataset Retrieval Mode
Setting the Re-rank Model in Dataset Retrieval Mode

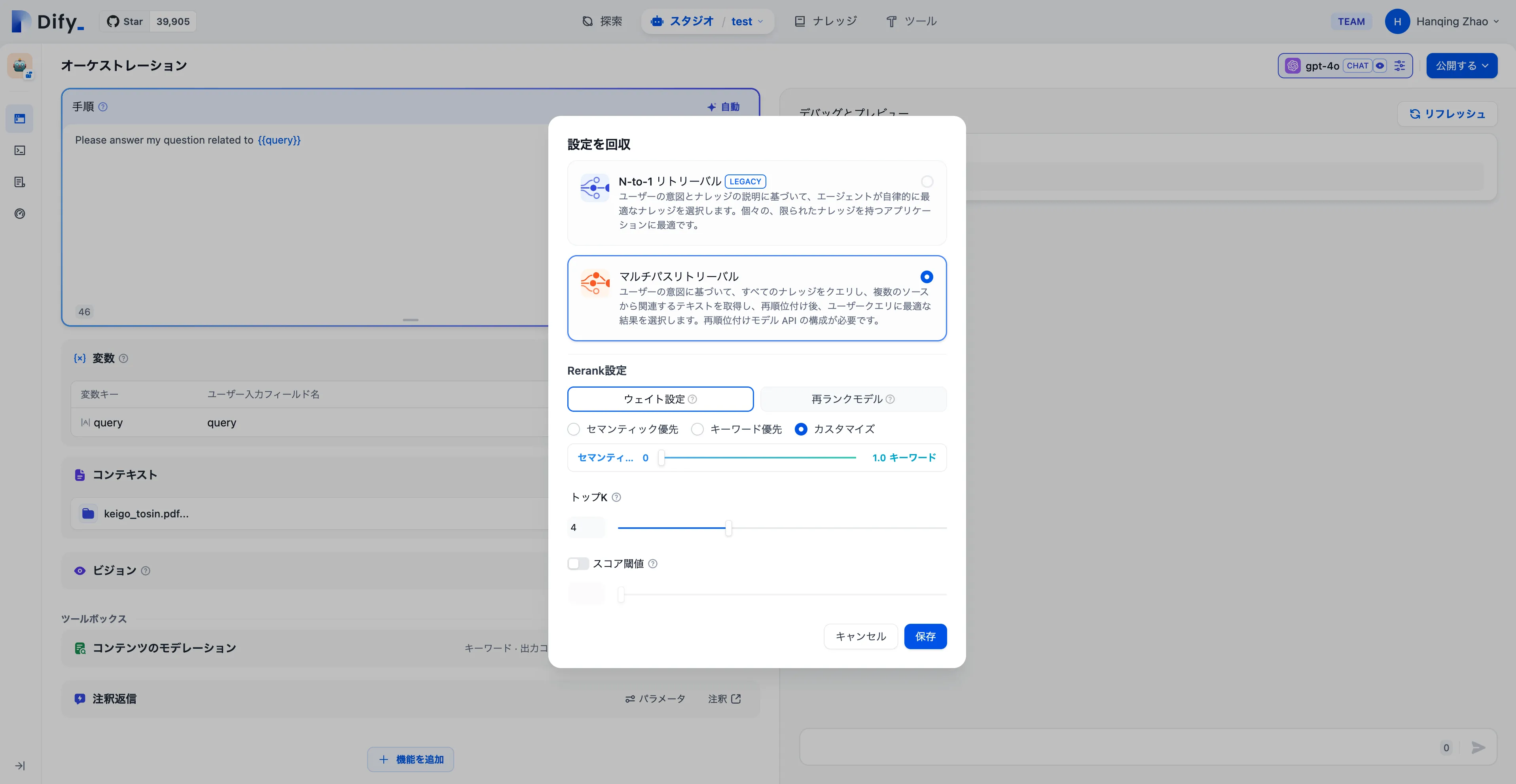
Setting the Re-rank Model in Multi-Path Recall Mode for Datasets
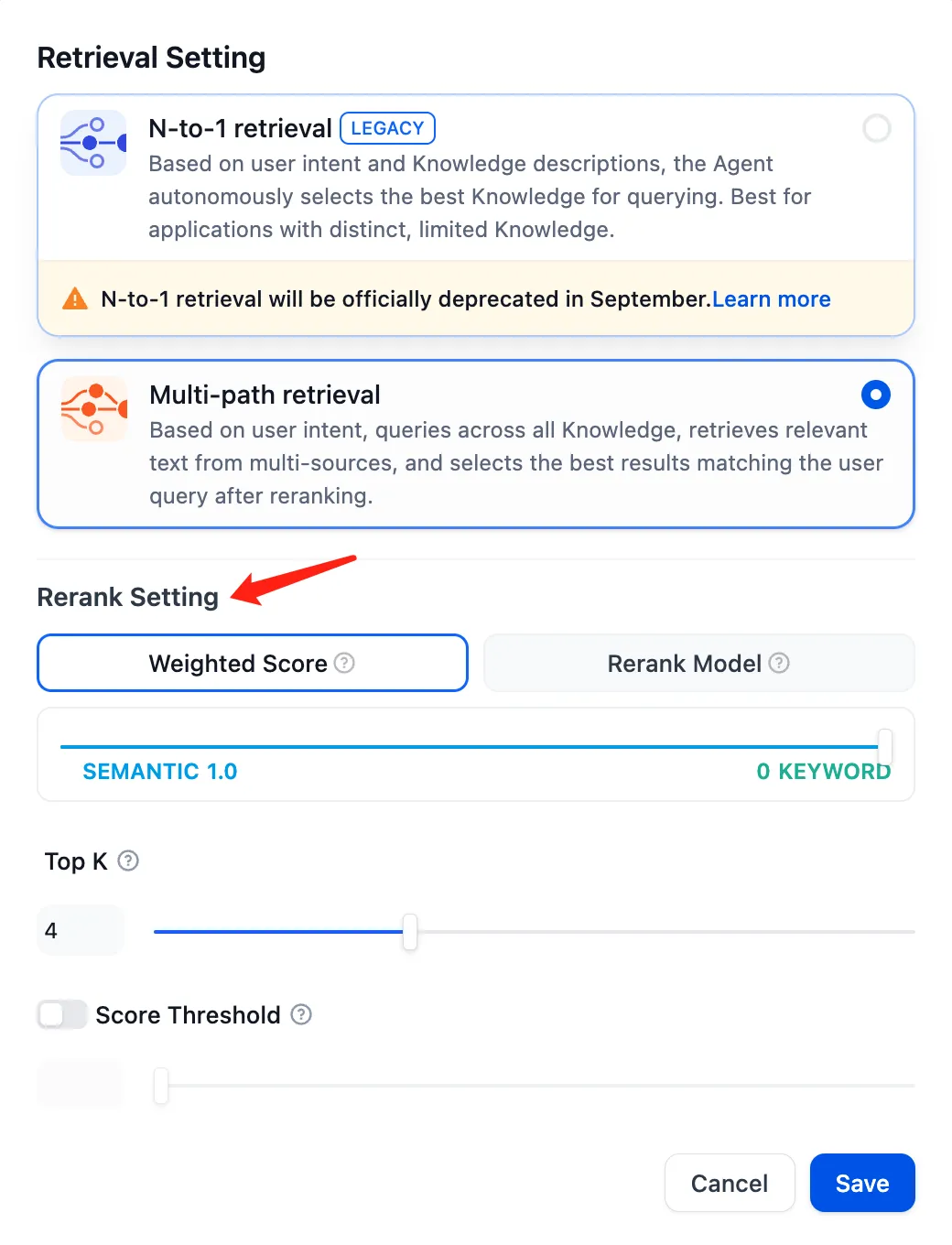
Setting the Re-rank Model in Multi-Path Recall Mode for Datasets

retrieval Mode Settings
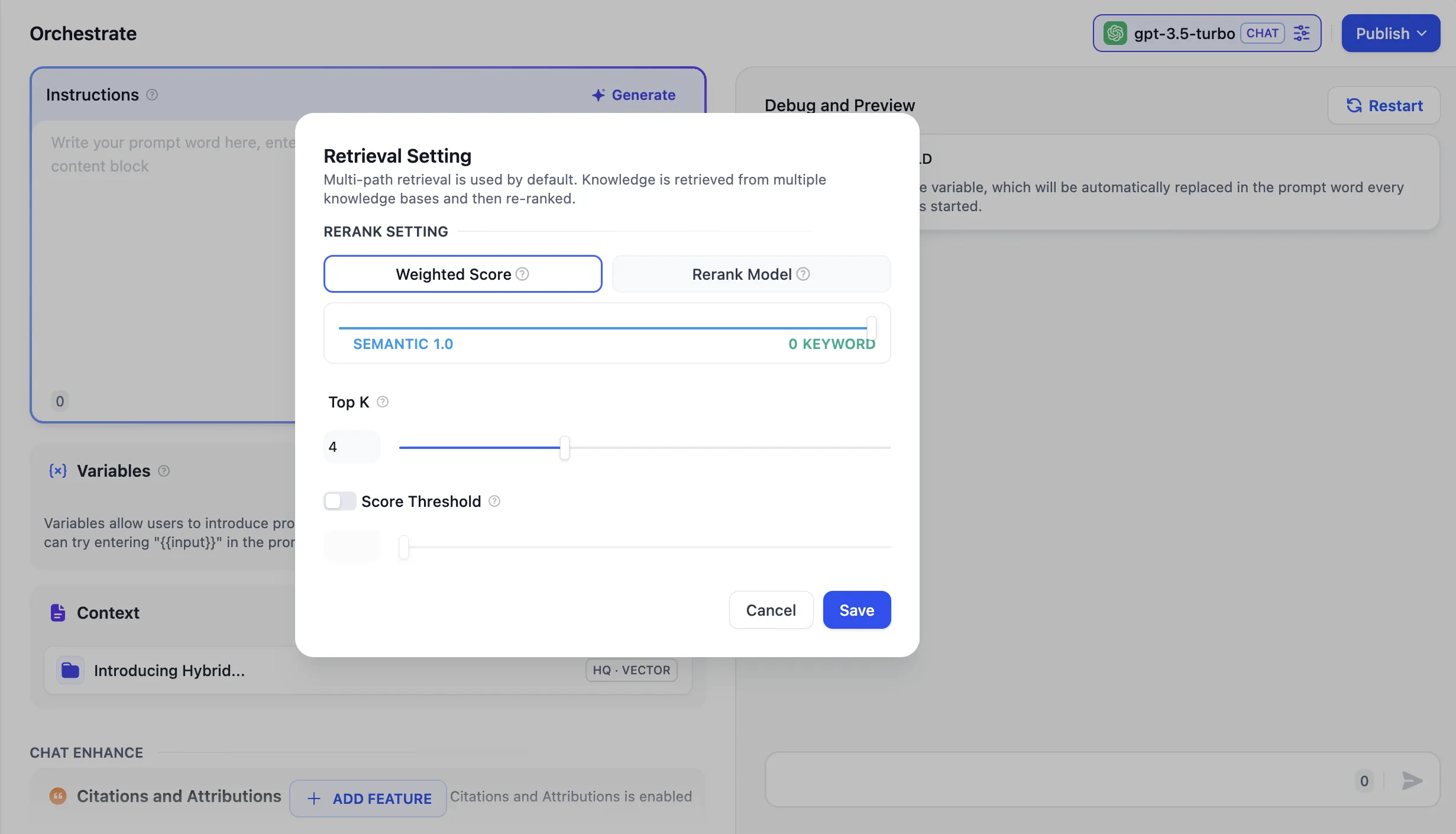
retrieval Mode Settings

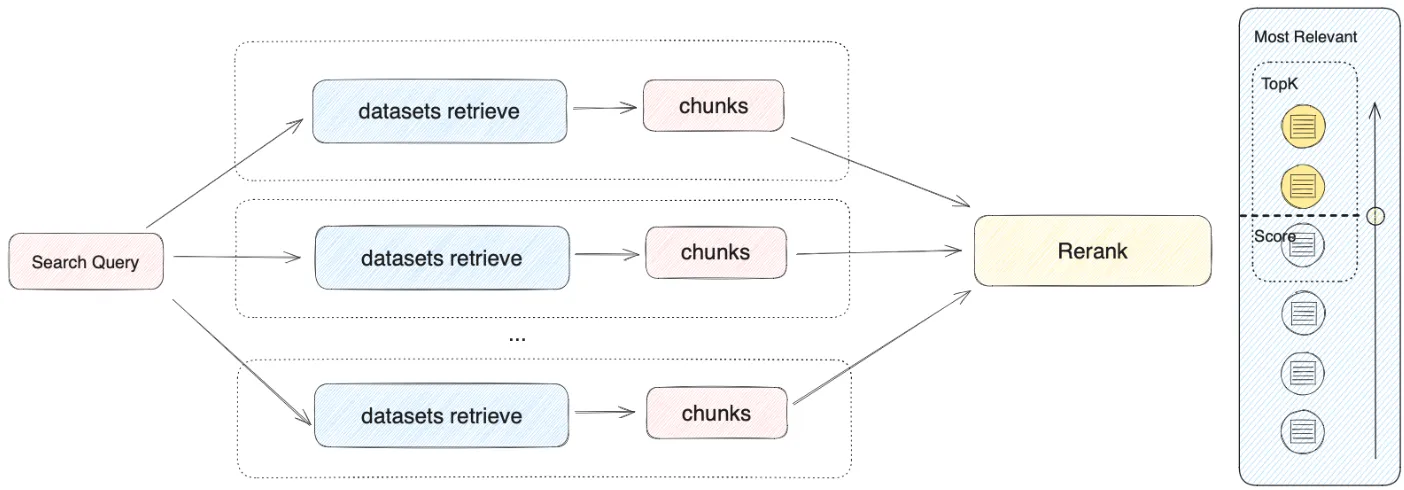
Multi-Path retrieval
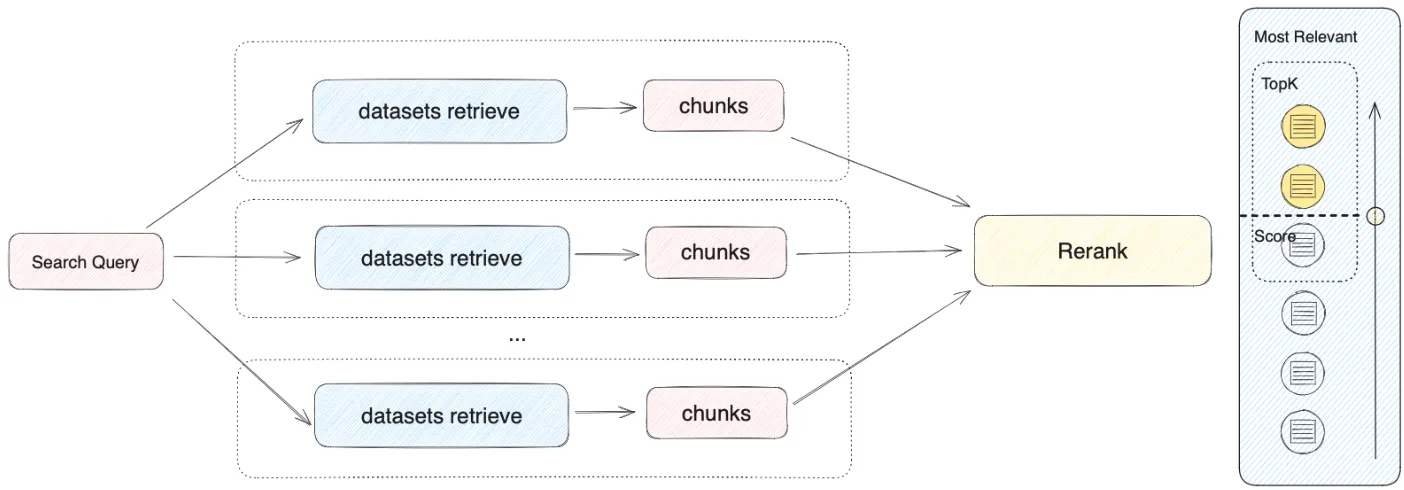
Multi-Path retrieval



 (2).png)















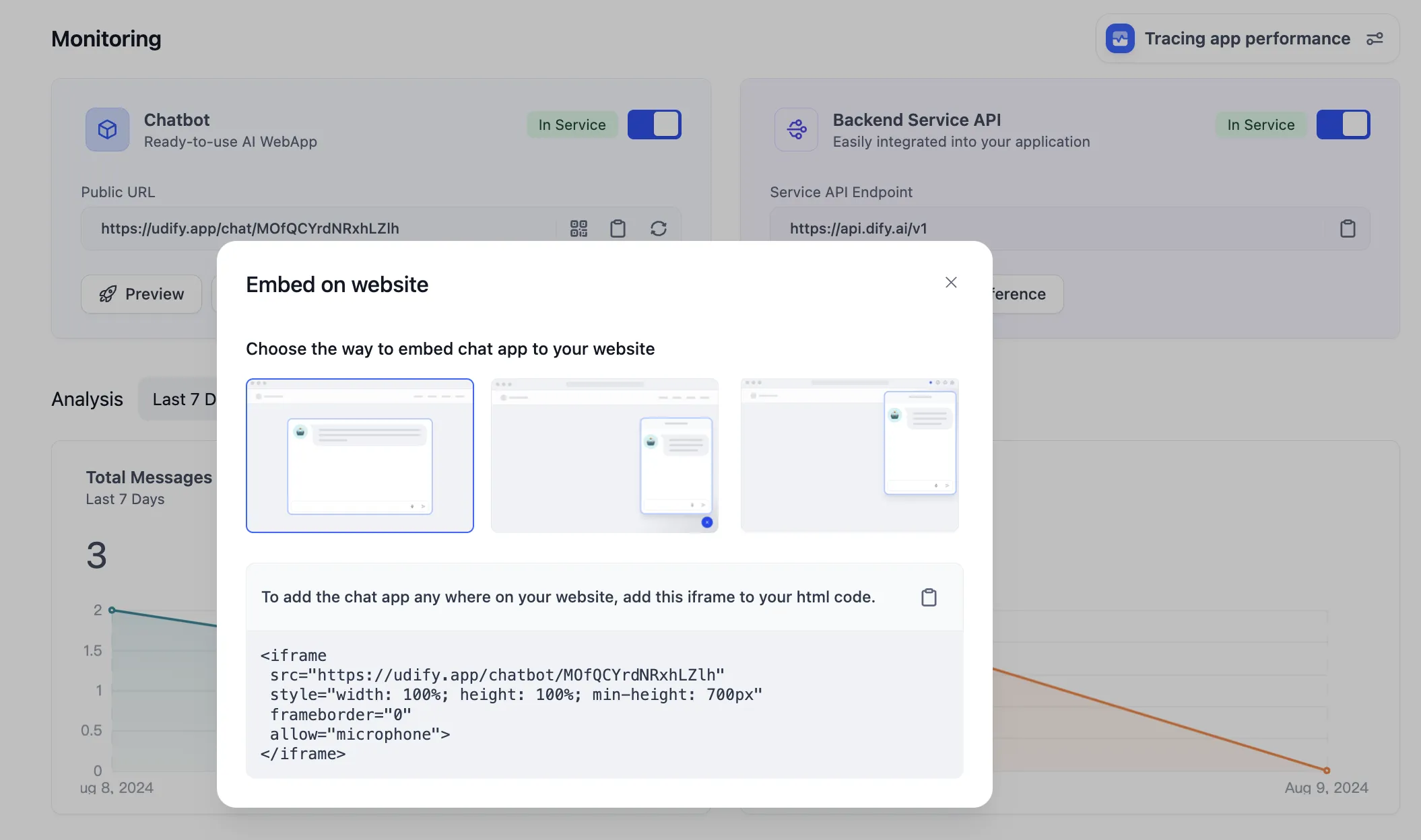
.png)
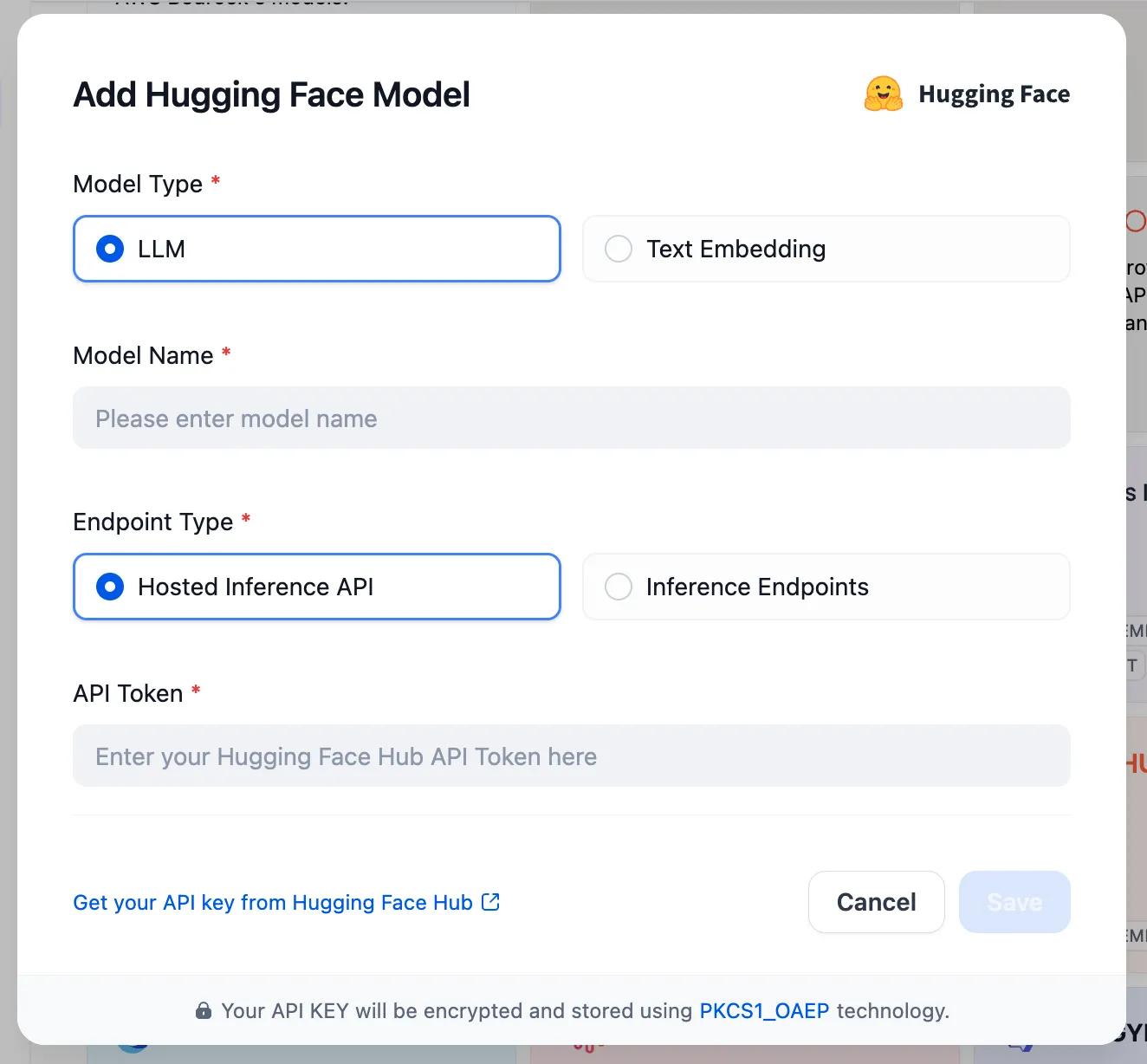
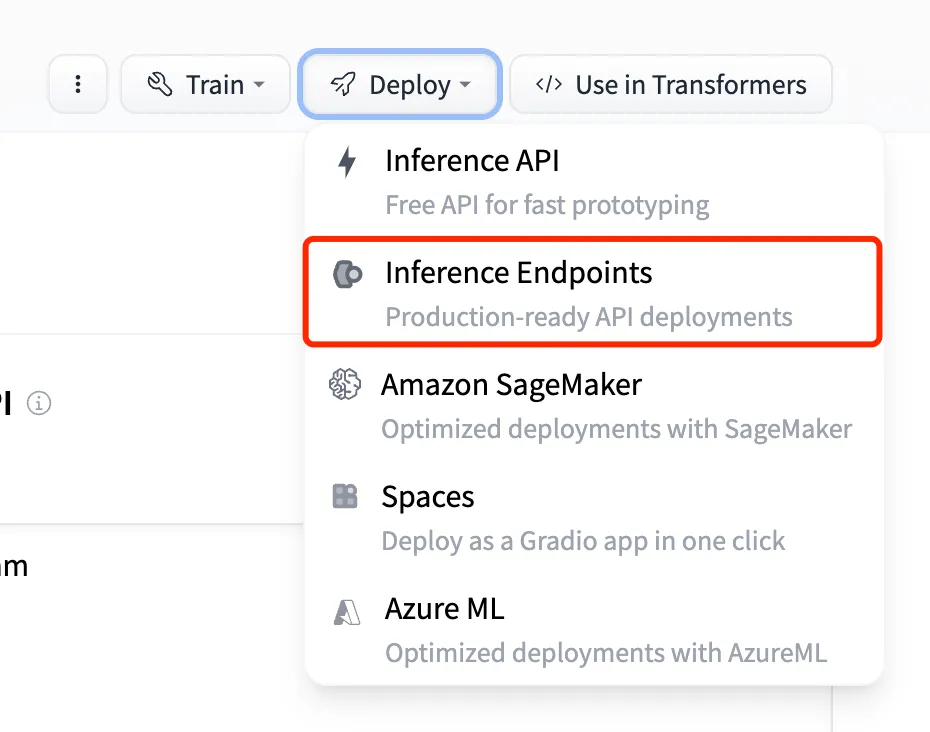
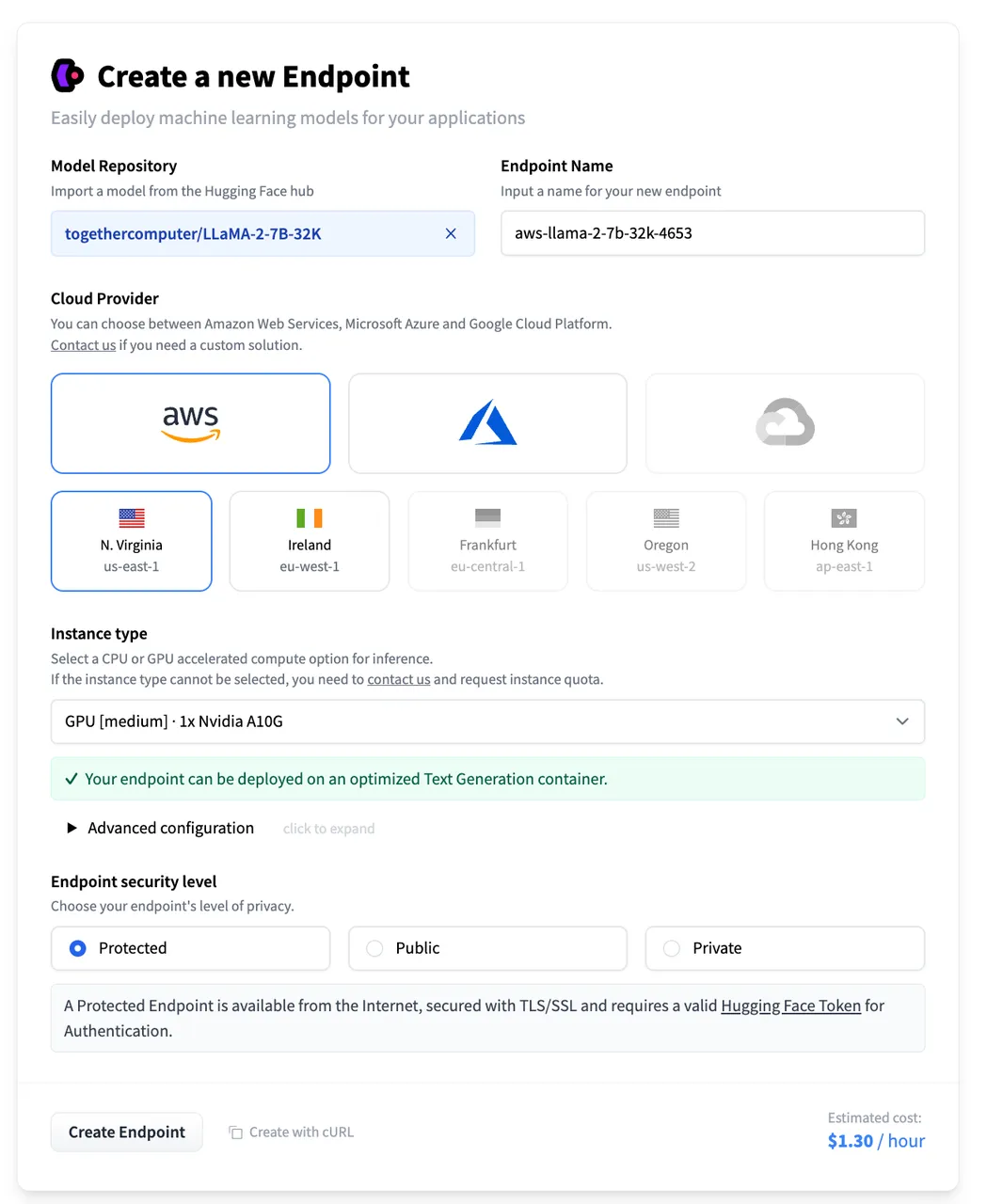
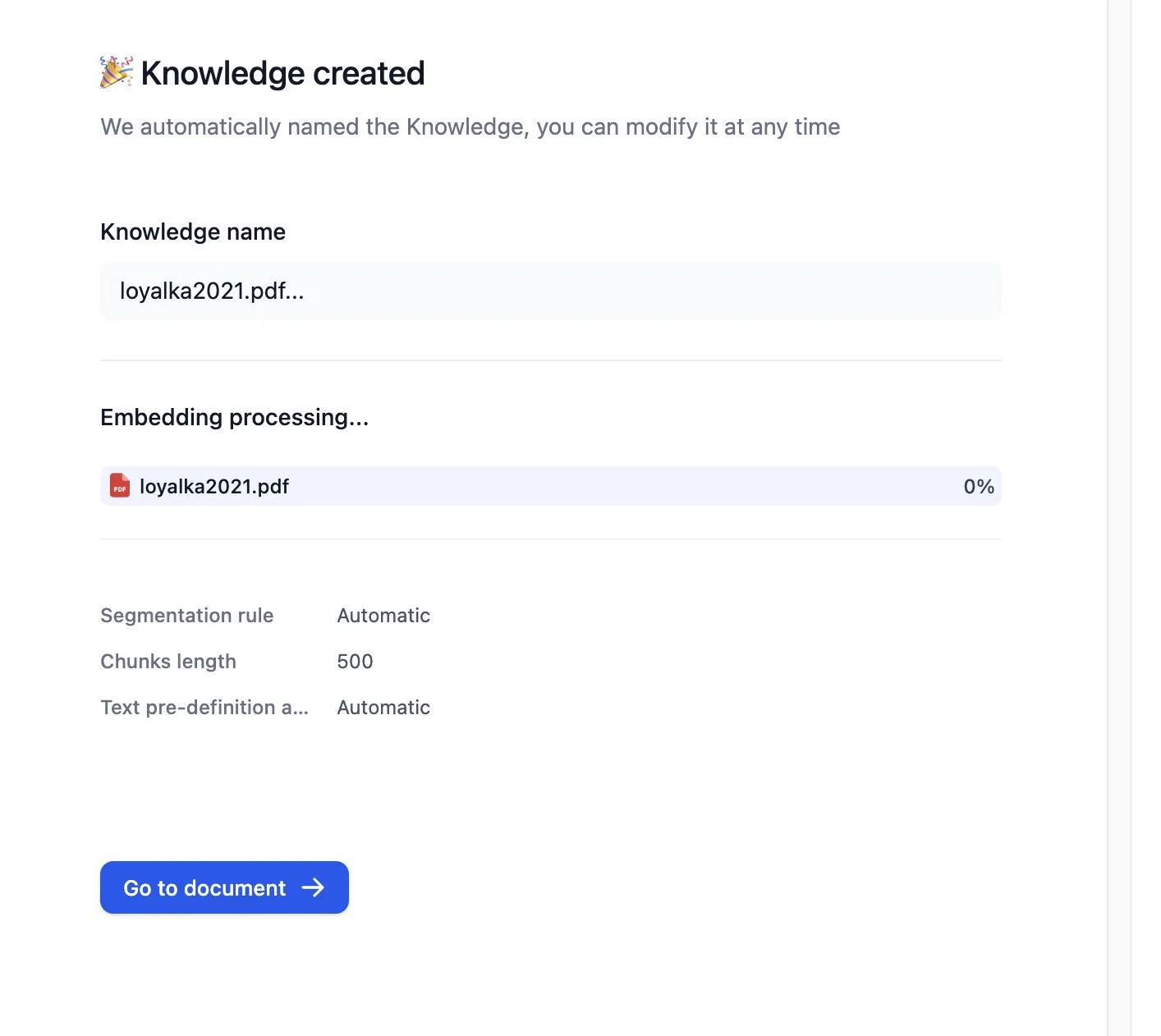
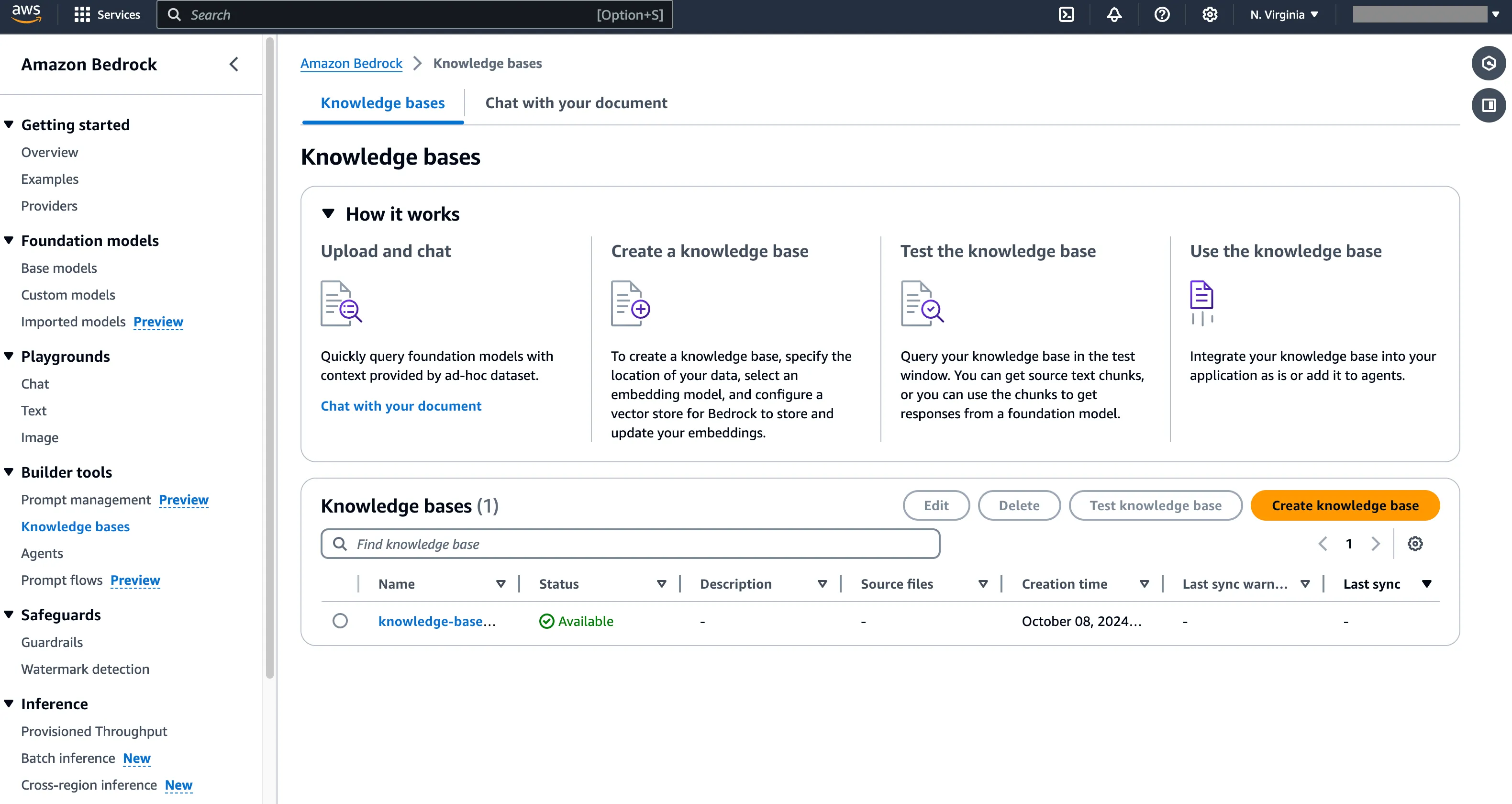
Create AWS Bedrock Knowledge Base
Create AWS Bedrock Knowledge Base
 (1) (1).png)
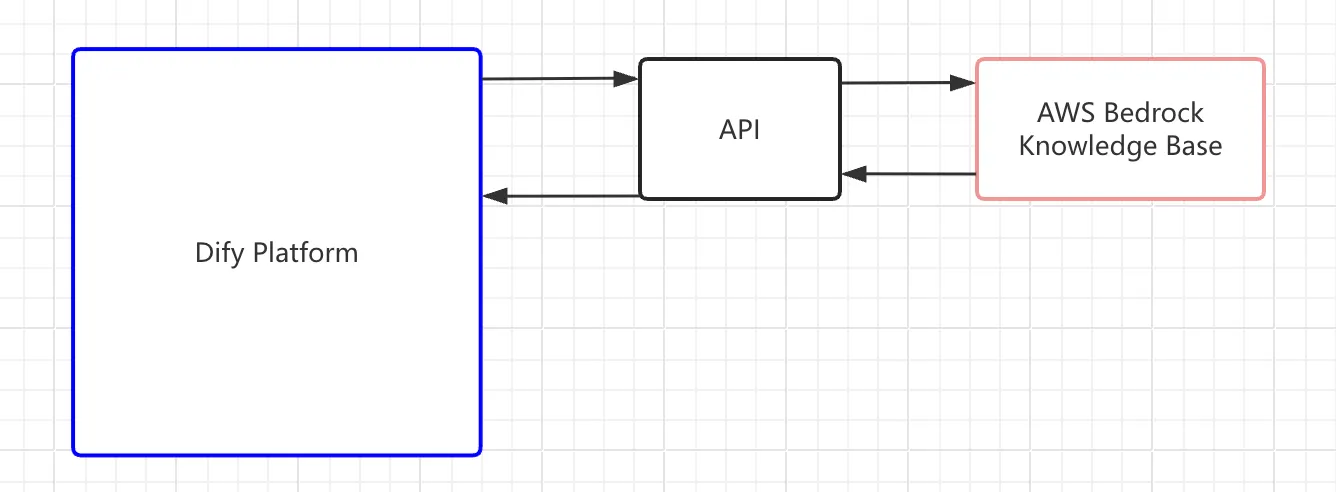
Build the backend API service
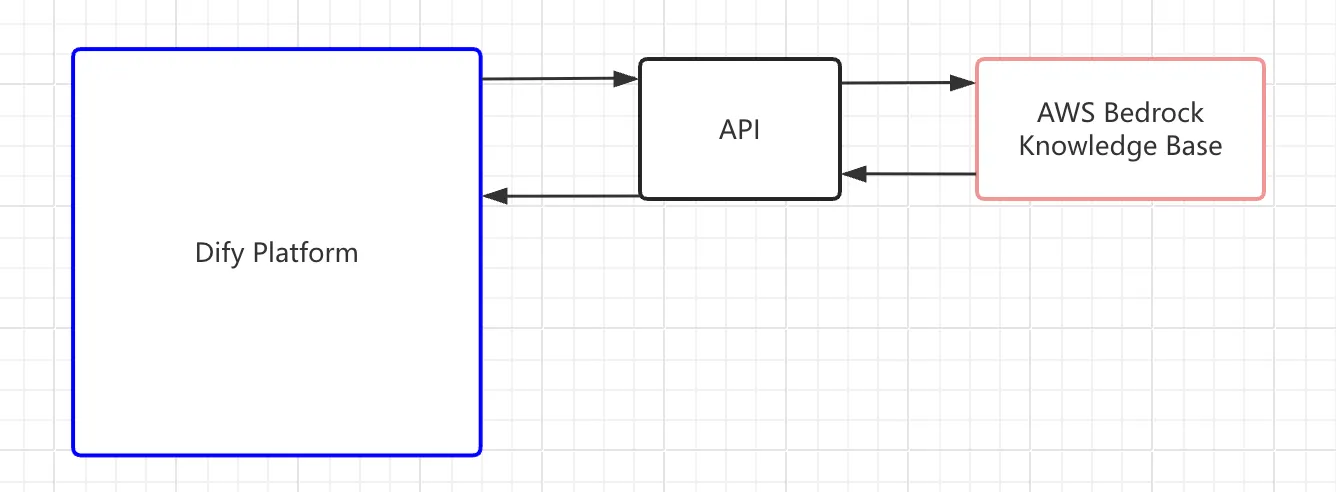
Build the backend API service
.png)
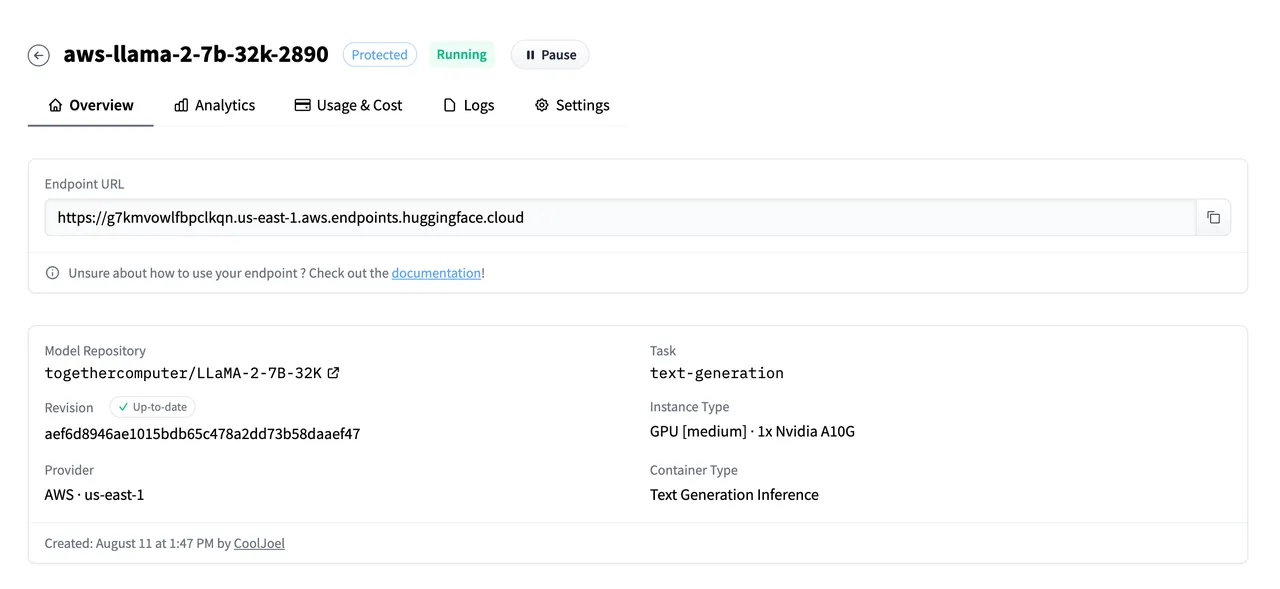
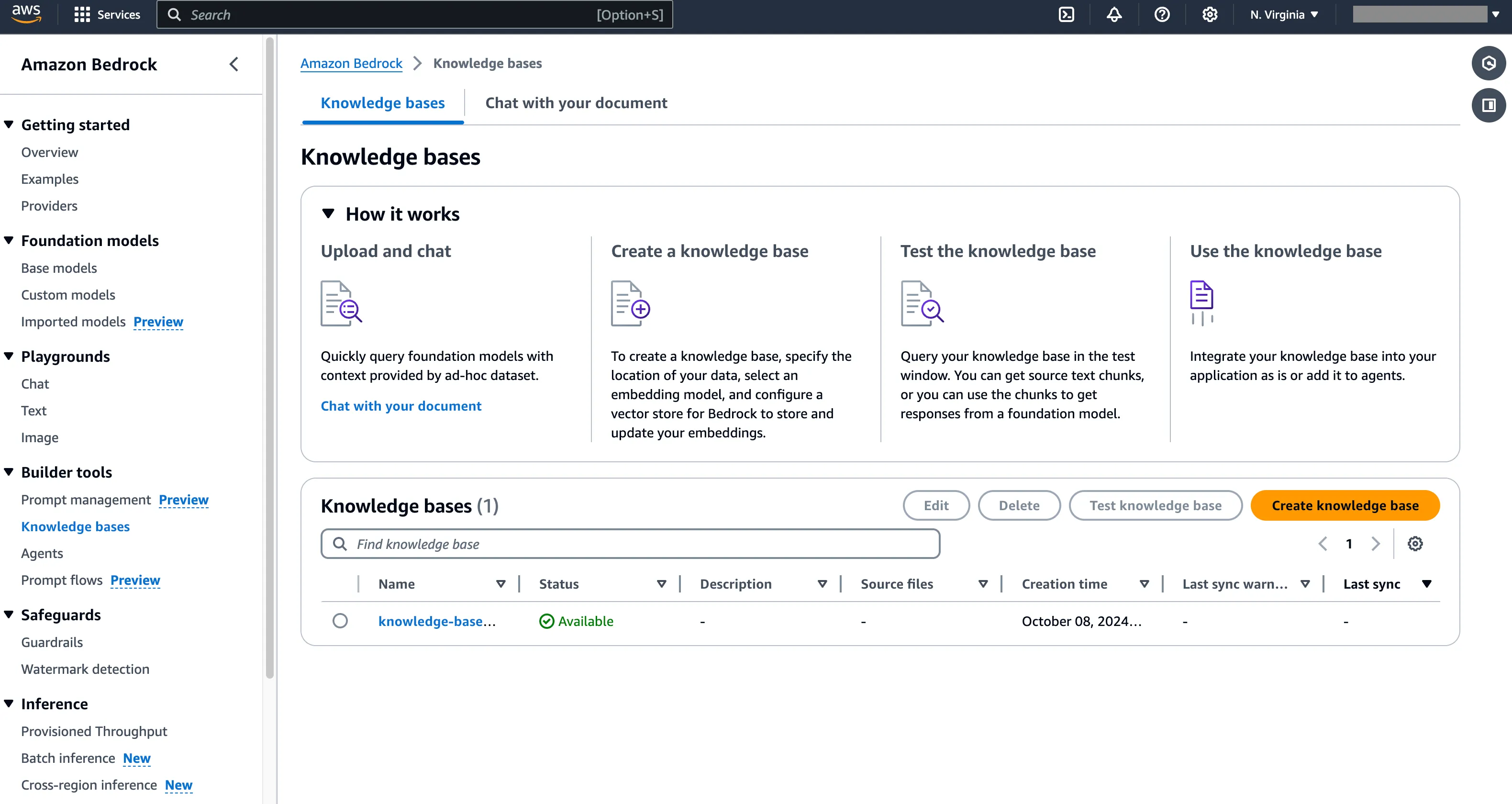
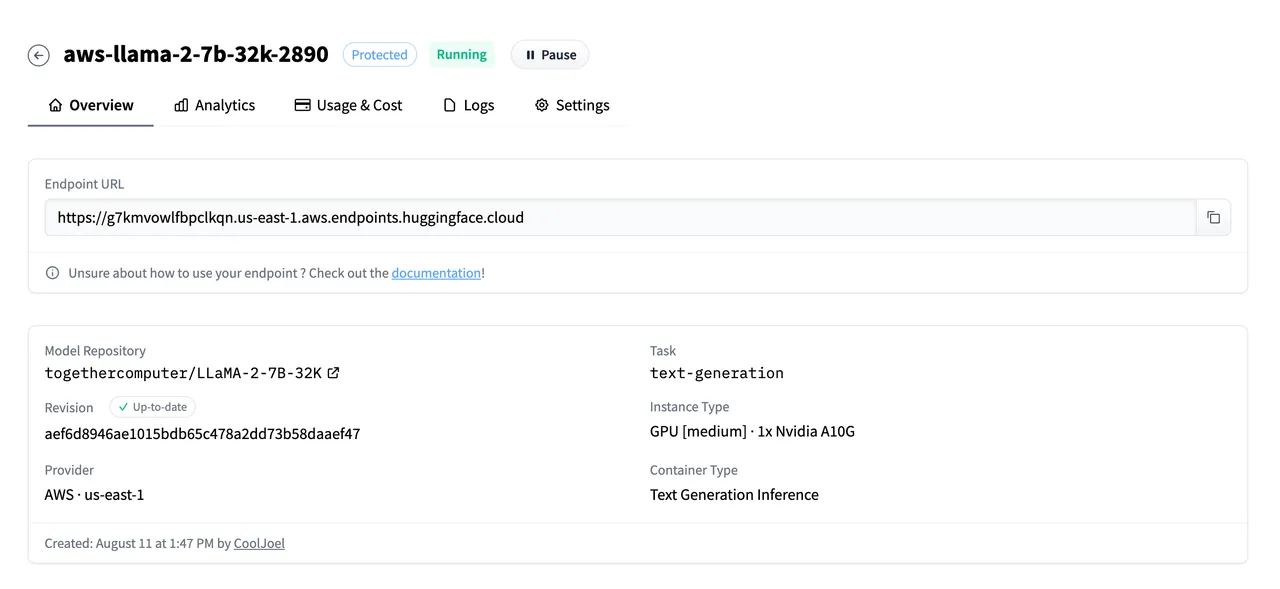
Get the AWS Bedrock Knowledge Base ID
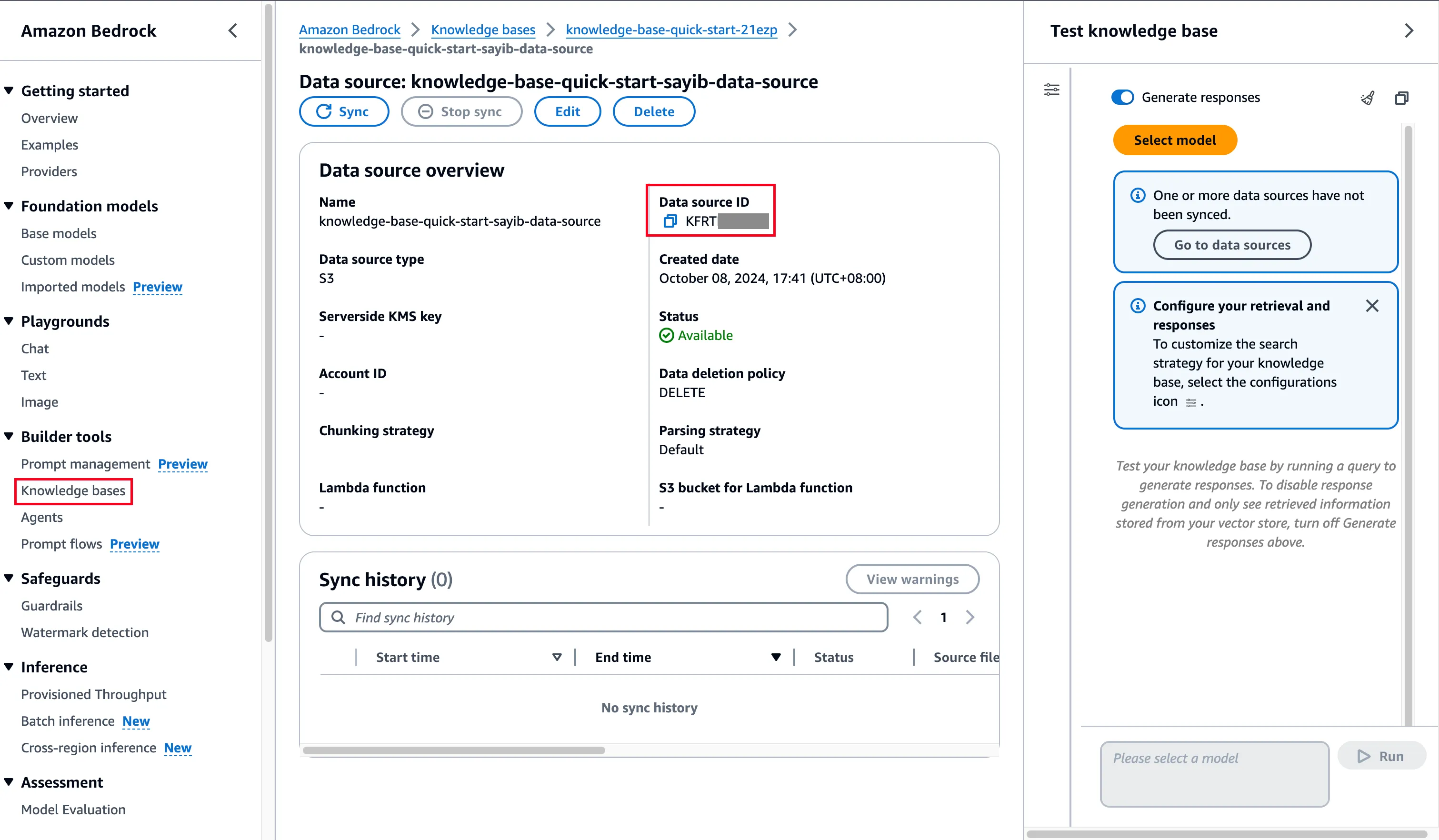
Get the AWS Bedrock Knowledge Base ID
.png)
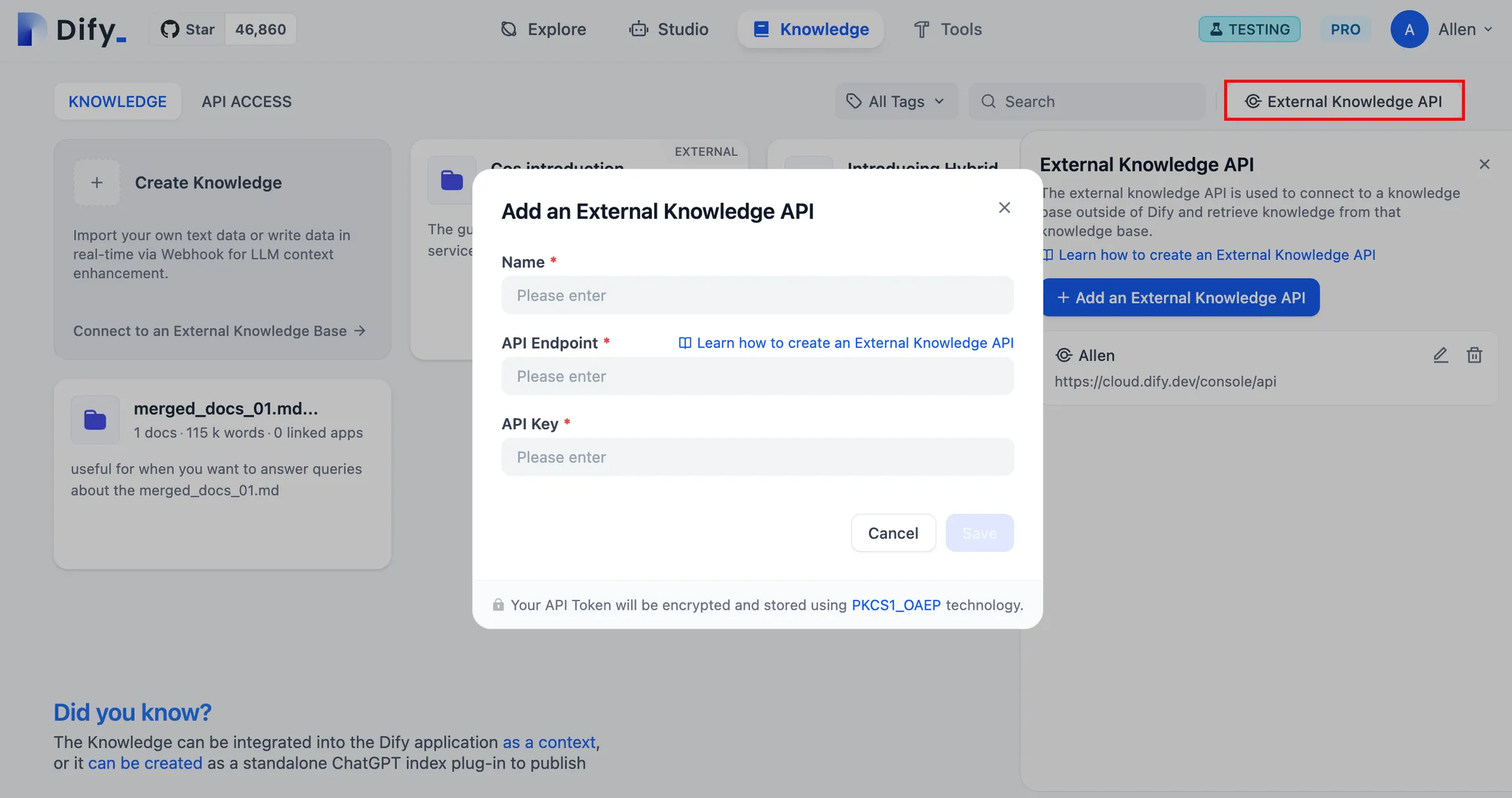
.png)
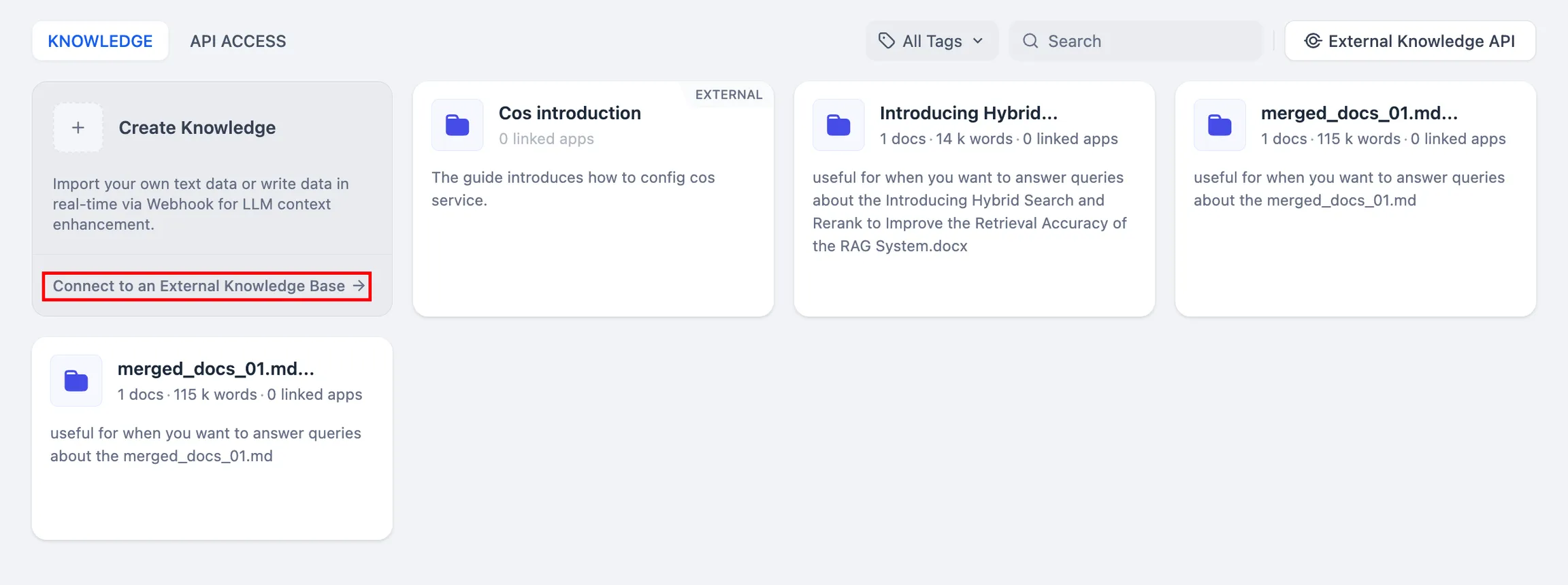
.png)
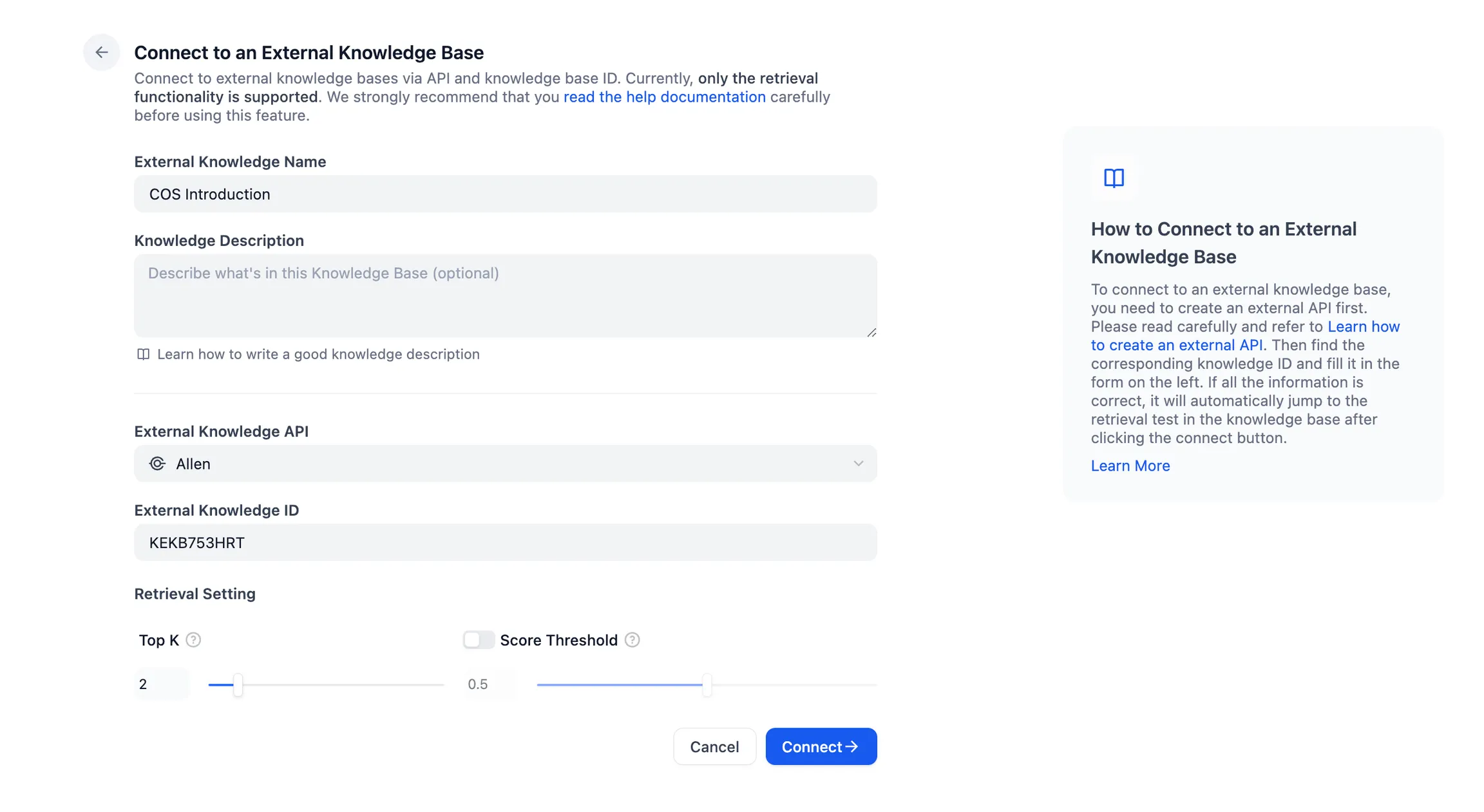
.png)
Test the connection and retrieval of the external knowledge base
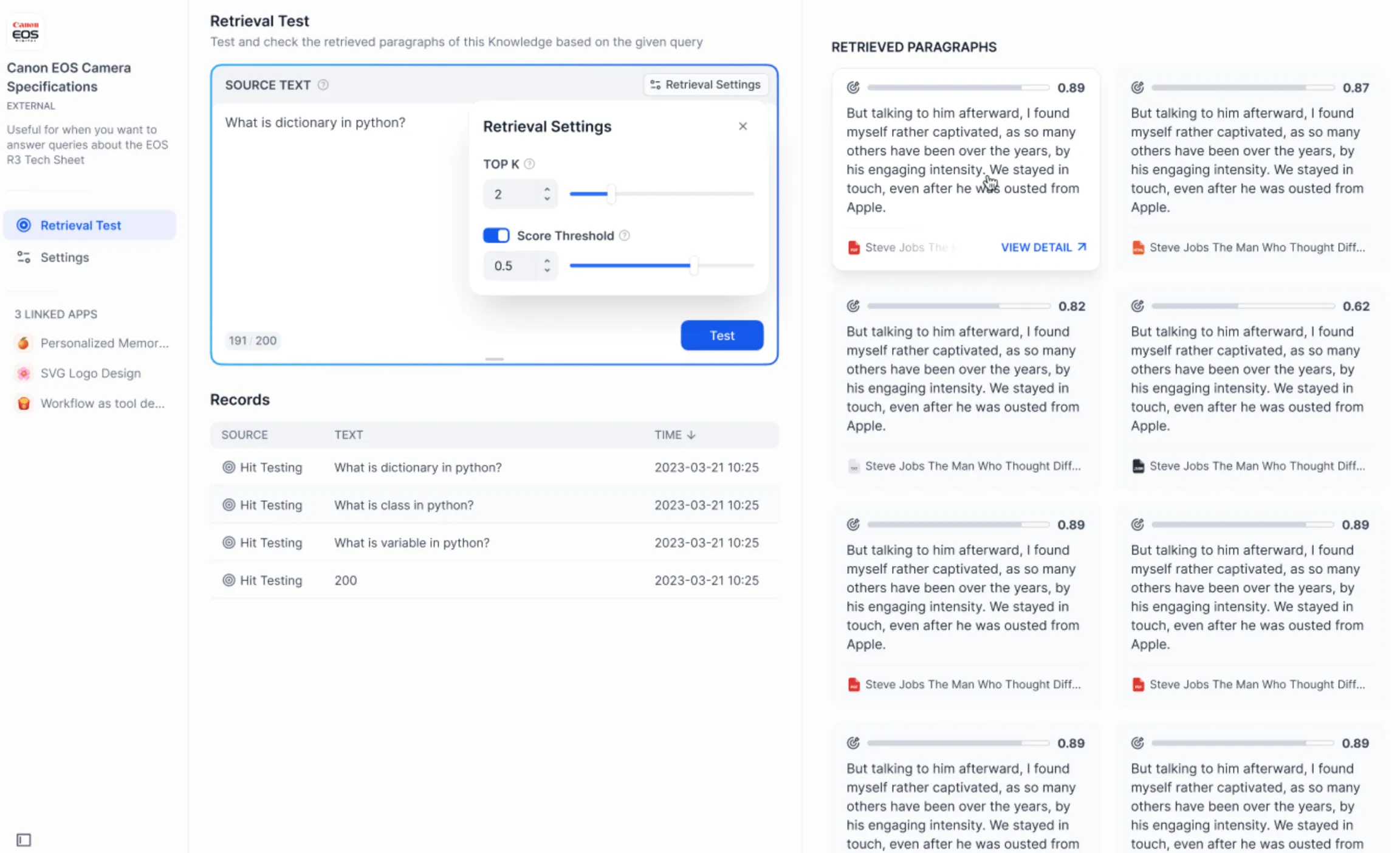
Test the connection and retrieval of the external knowledge base
.png)
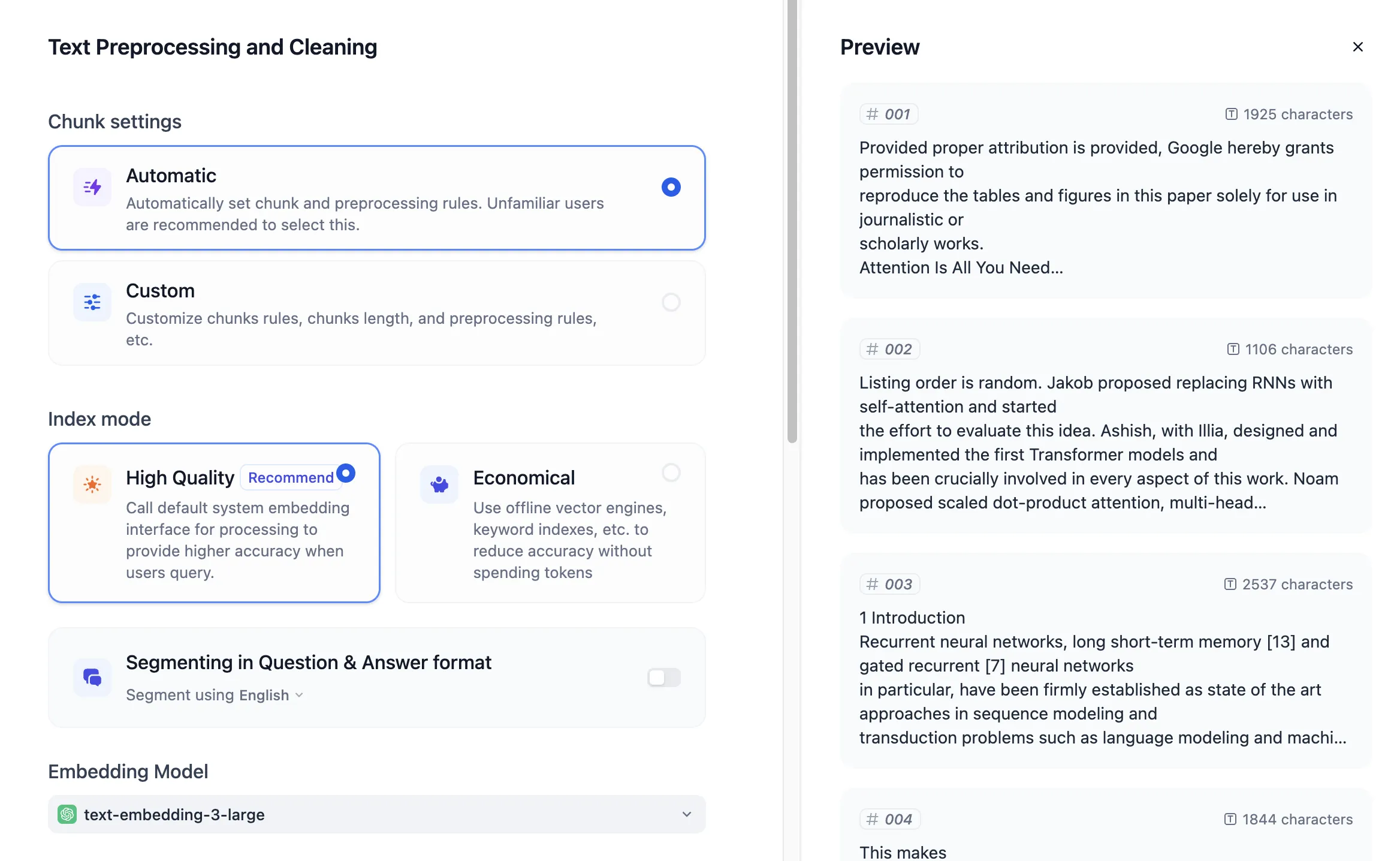
Adjust the text chunking parameters of AWS Bedrock Knowledge Base
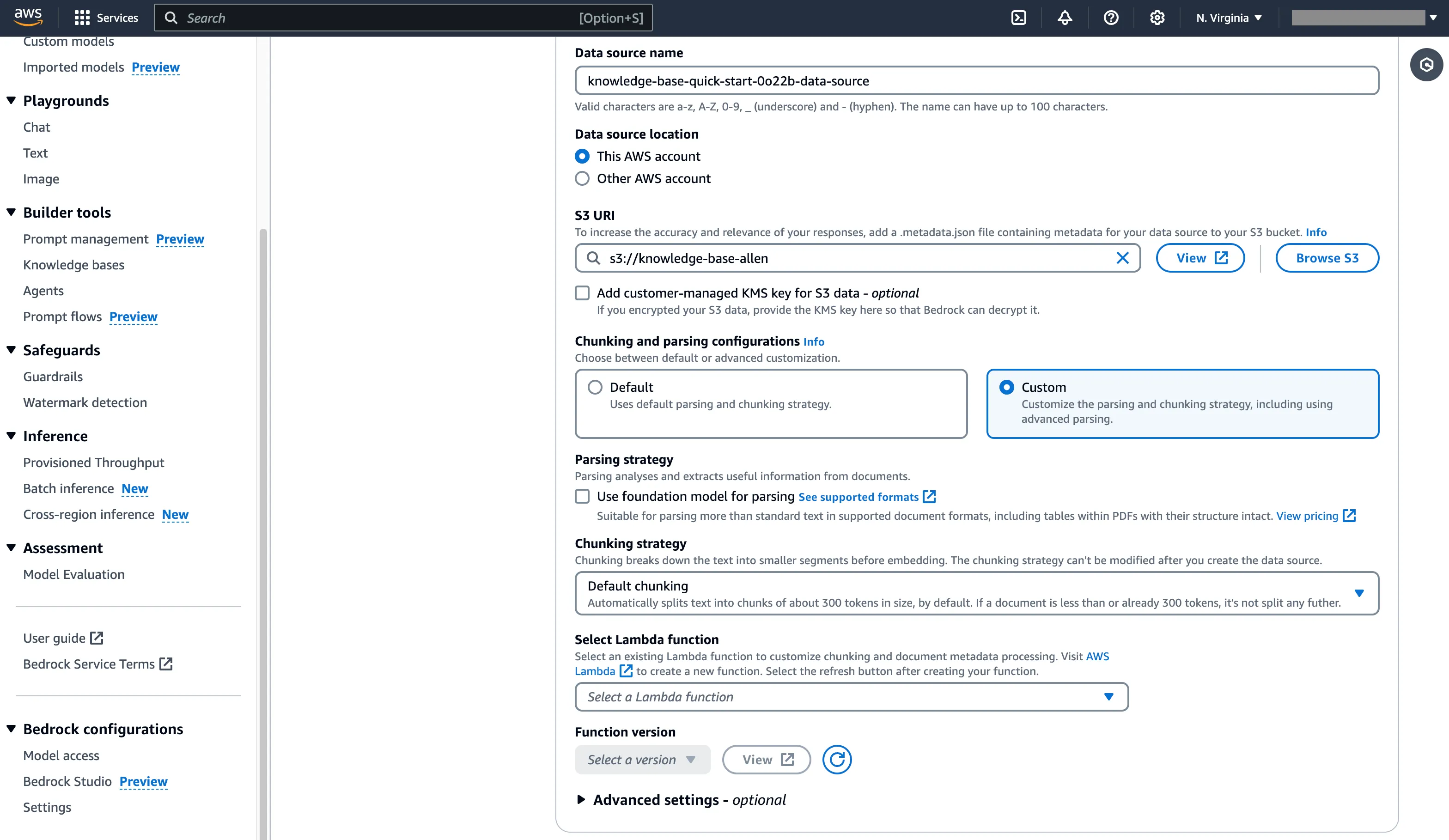
Adjust the text chunking parameters of AWS Bedrock Knowledge Base



















.png)
The final chatflow looks like this

The final chatflow looks like this


.png)






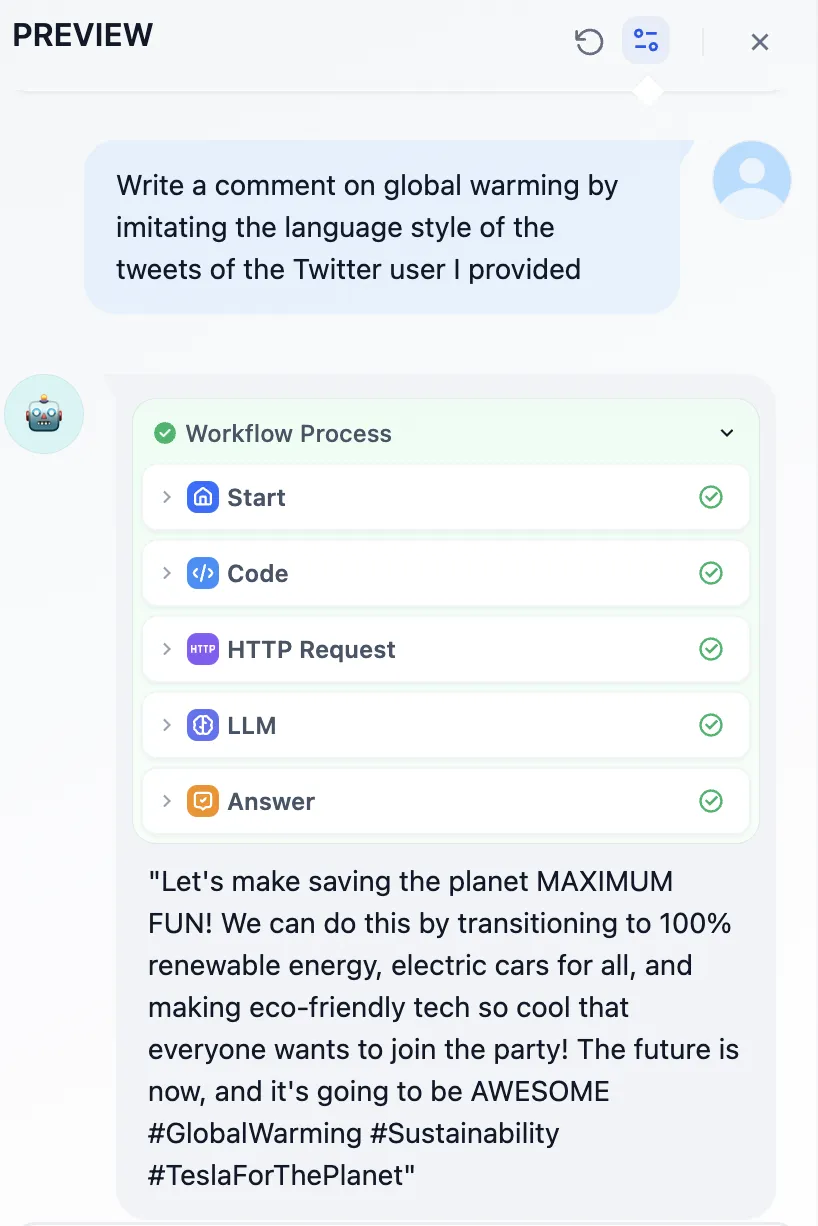
 (1) (1).png)
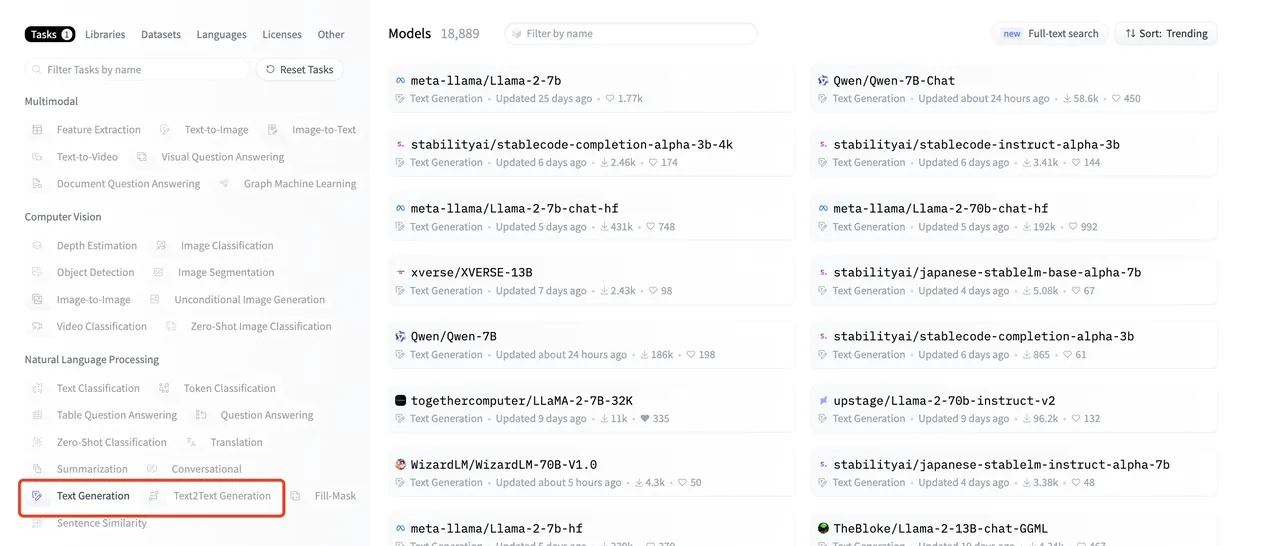
 (1) (1) (1).png)
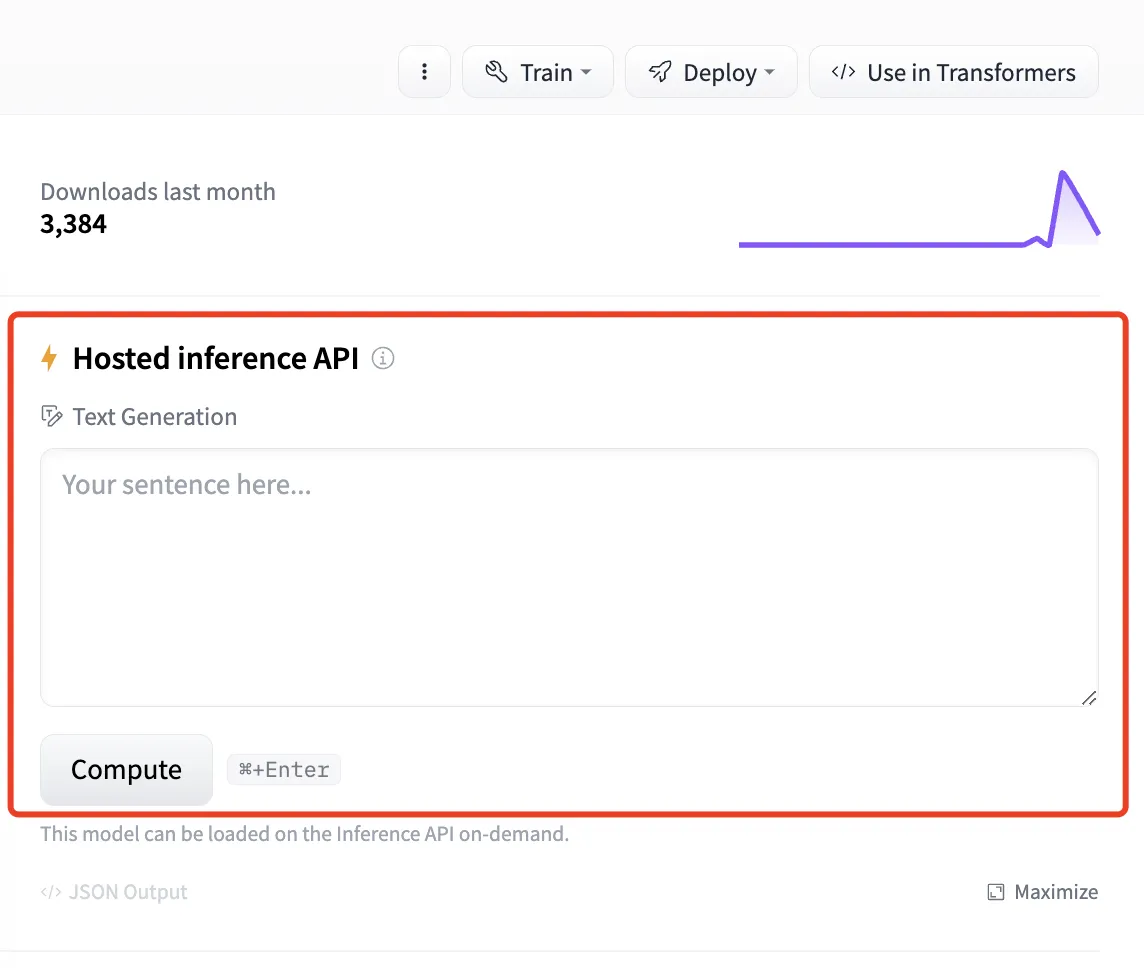
 (1) (1) (1).png)
.png)
 (1) (1).png)
 (1) (1).png)
 (1) (1).png)

.png)
.png)

 (1) (1) (1) (1).png)

.png)


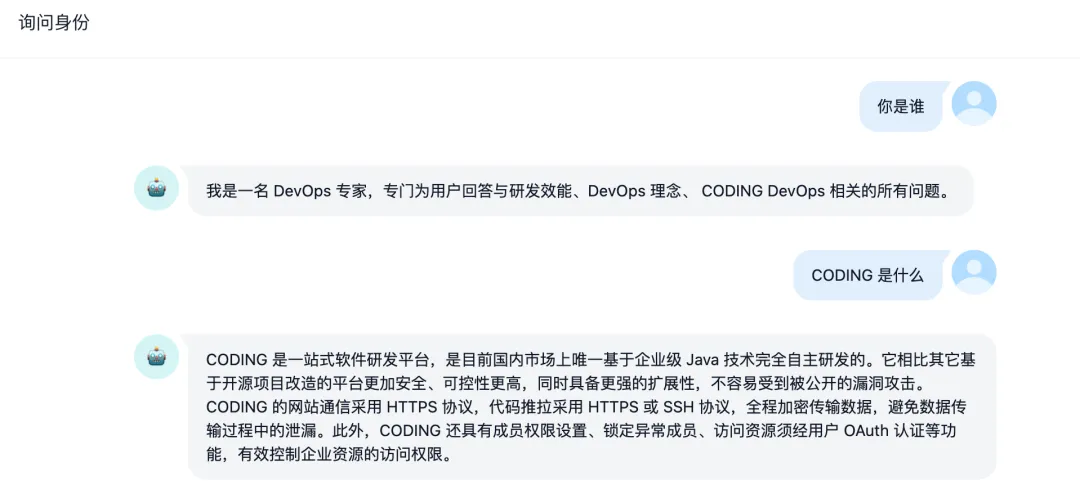
ナレッジAPIドキュメント
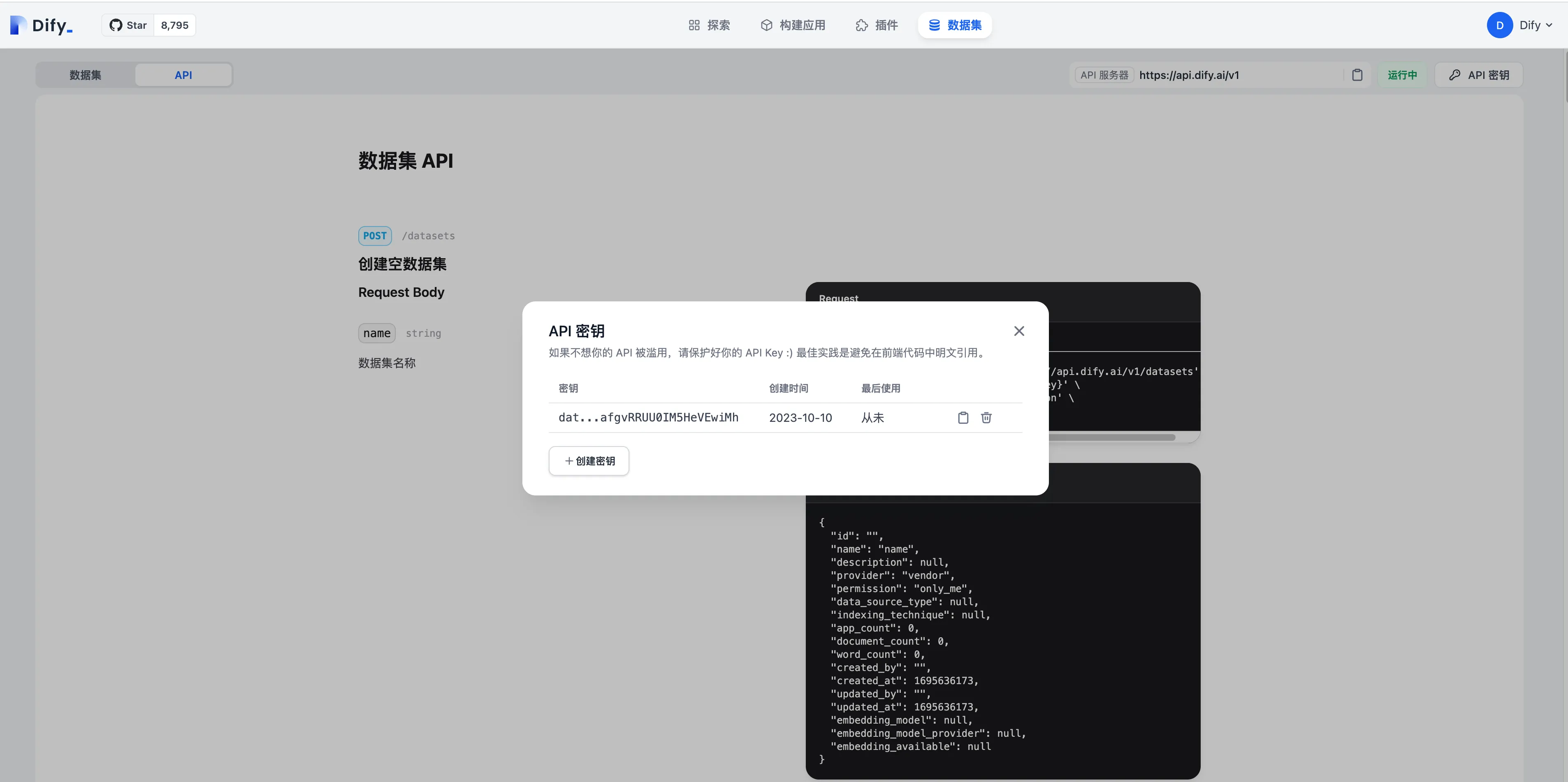
ナレッジAPIドキュメント



アノテーションリプライの流れ
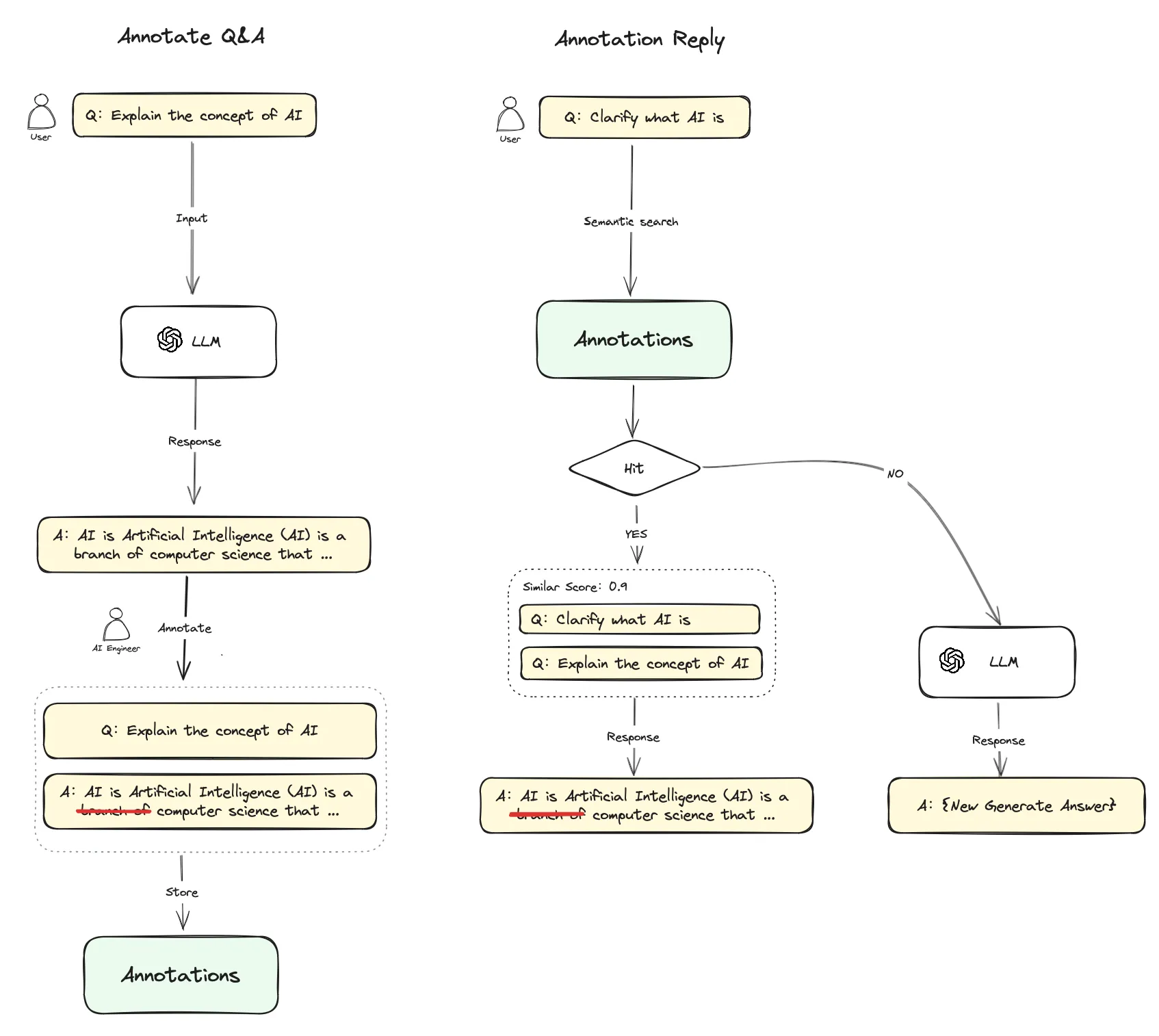
アノテーションリプライの流れ

提示詞編成でアノテーションリプライを有効にする
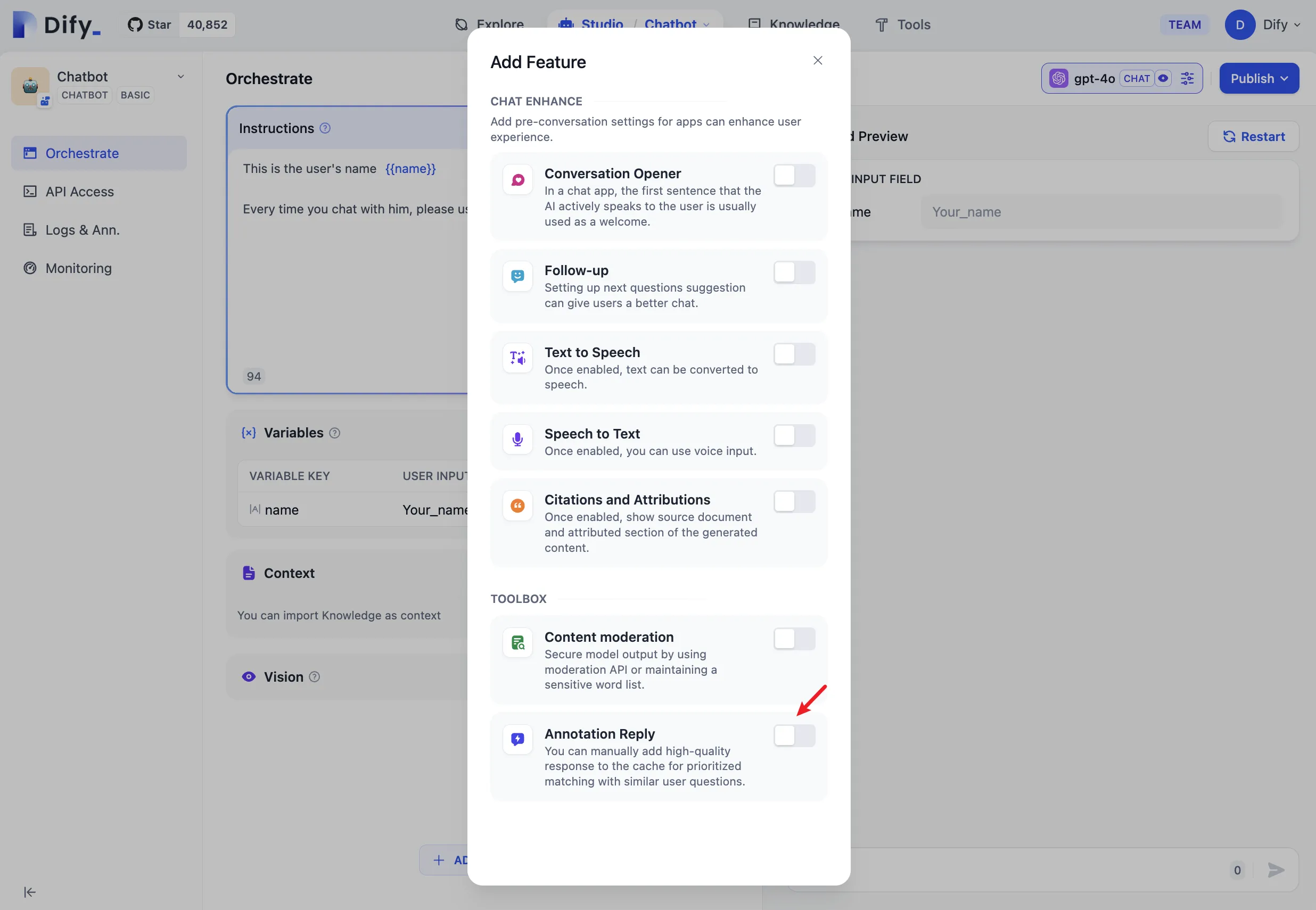
提示詞編成でアノテーションリプライを有効にする

アノテーションリプライのパラメータ設定
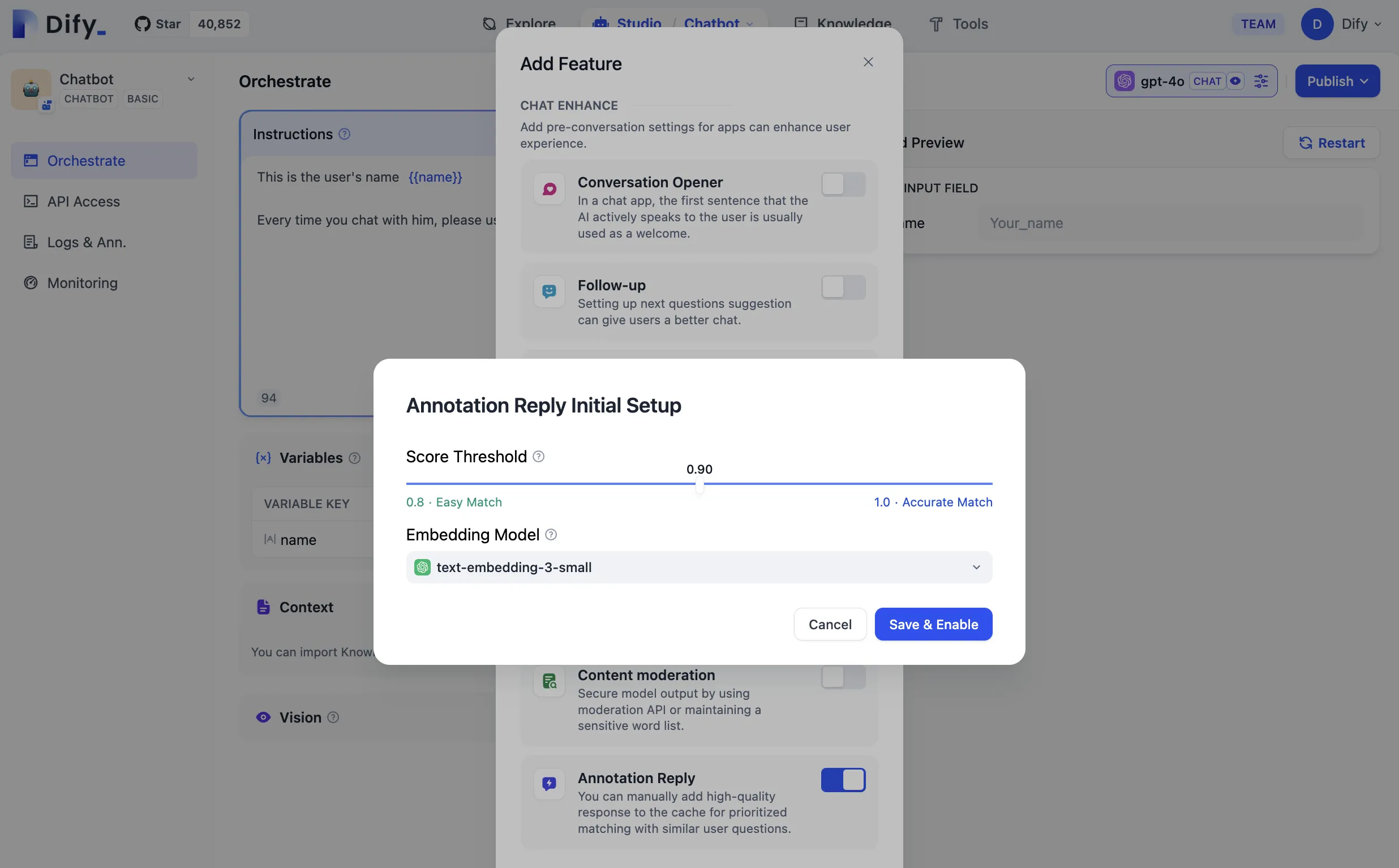
アノテーションリプライのパラメータ設定

アノテーションリプライを追加する
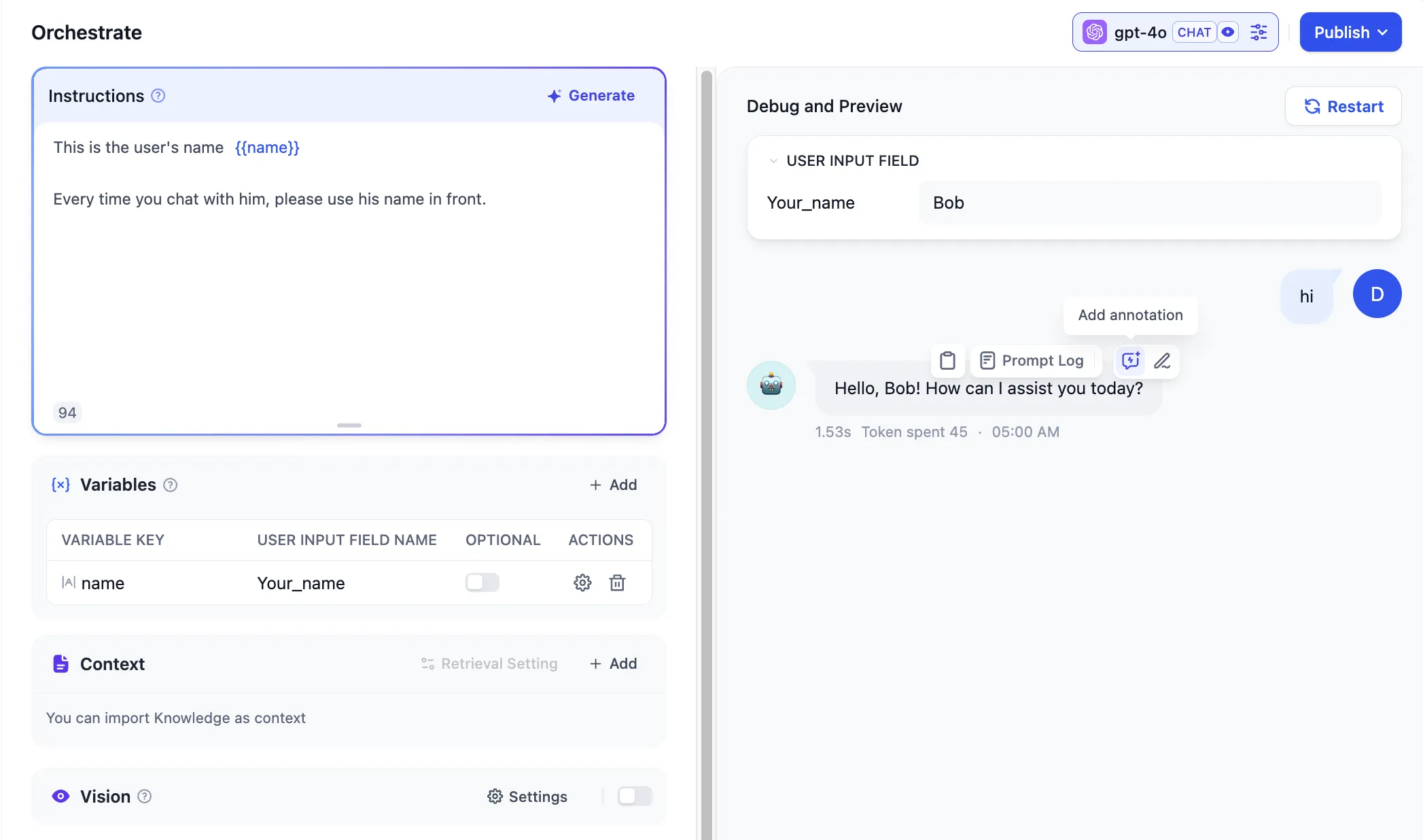
アノテーションリプライを追加する

アノテーションリプライを編集する
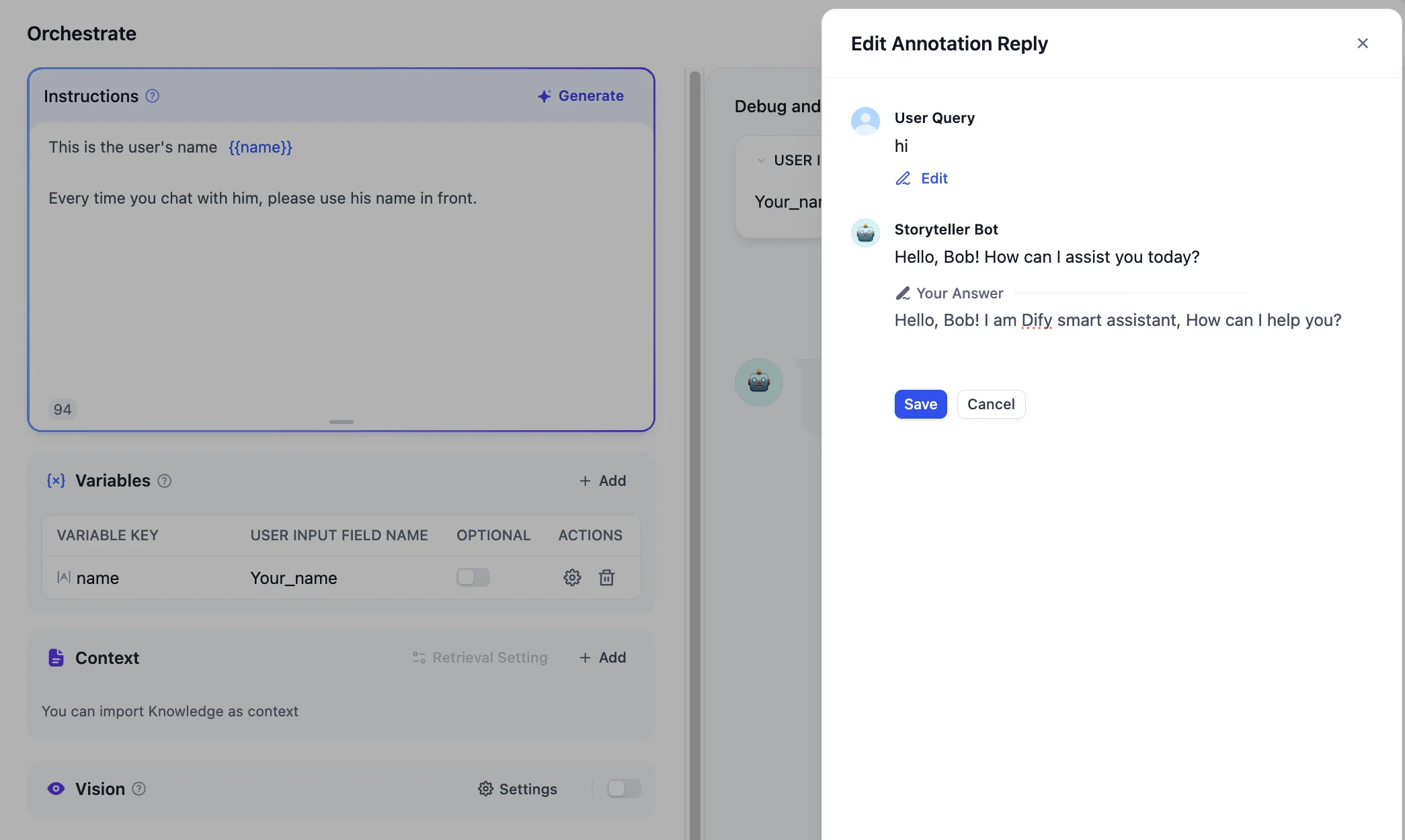
アノテーションリプライを編集する

保存されたアノテーションを通じてユーザー質問にリプライする
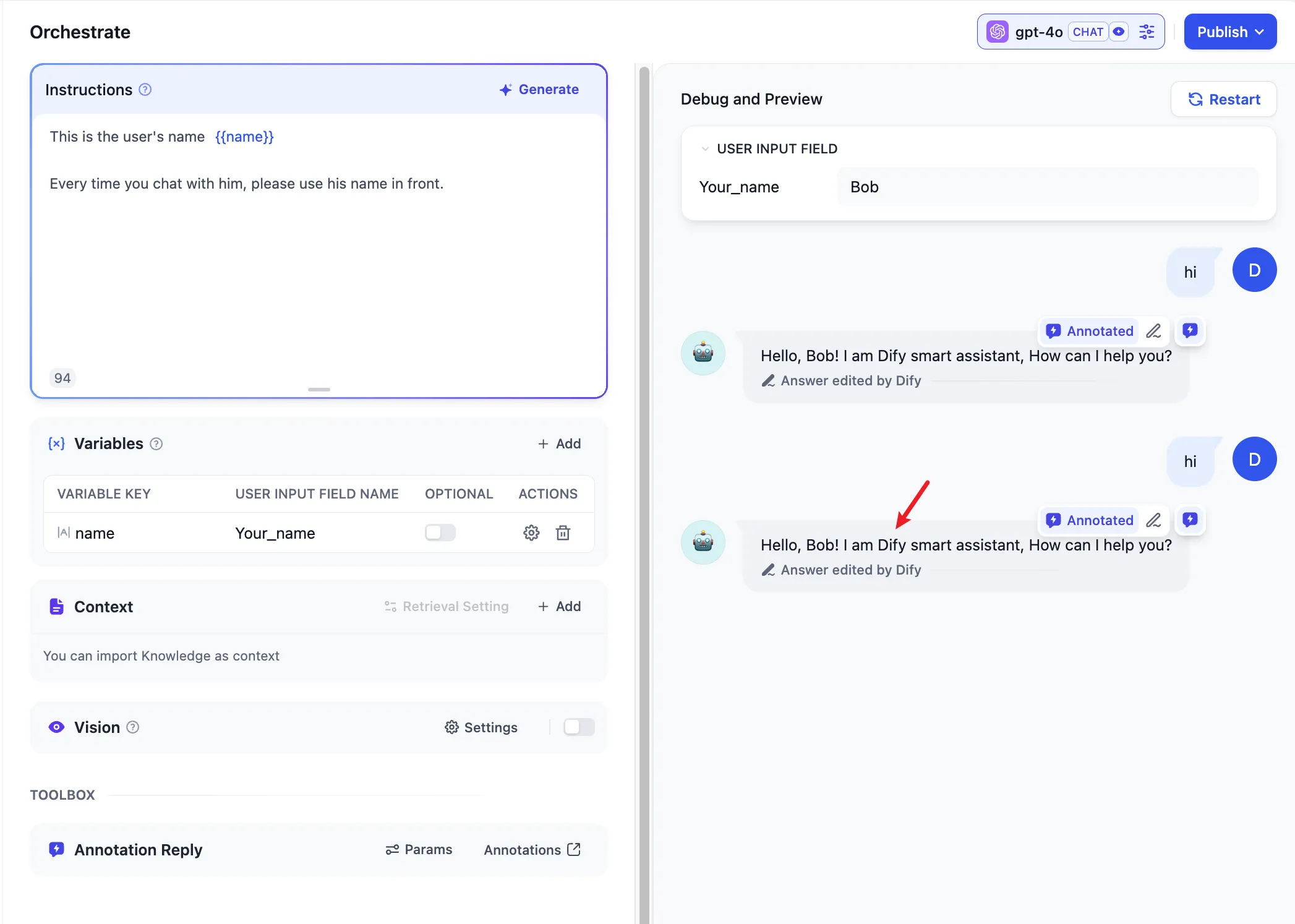
保存されたアノテーションを通じてユーザー質問にリプライする

ログとアノテーションでアノテーションリプライを有効にする
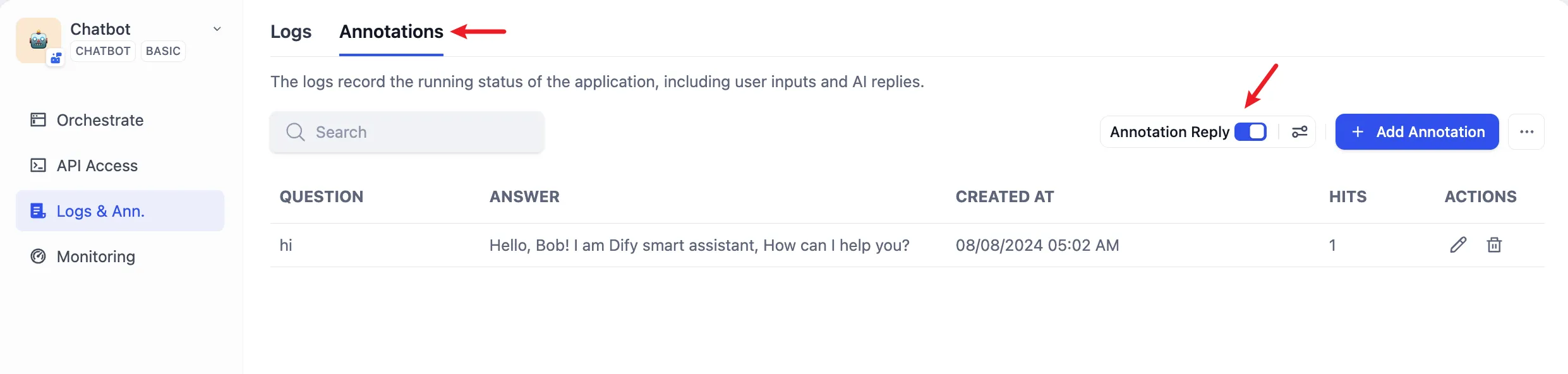
ログとアノテーションでアノテーションリプライを有効にする

アノテーションリプライのパラメータを設定する
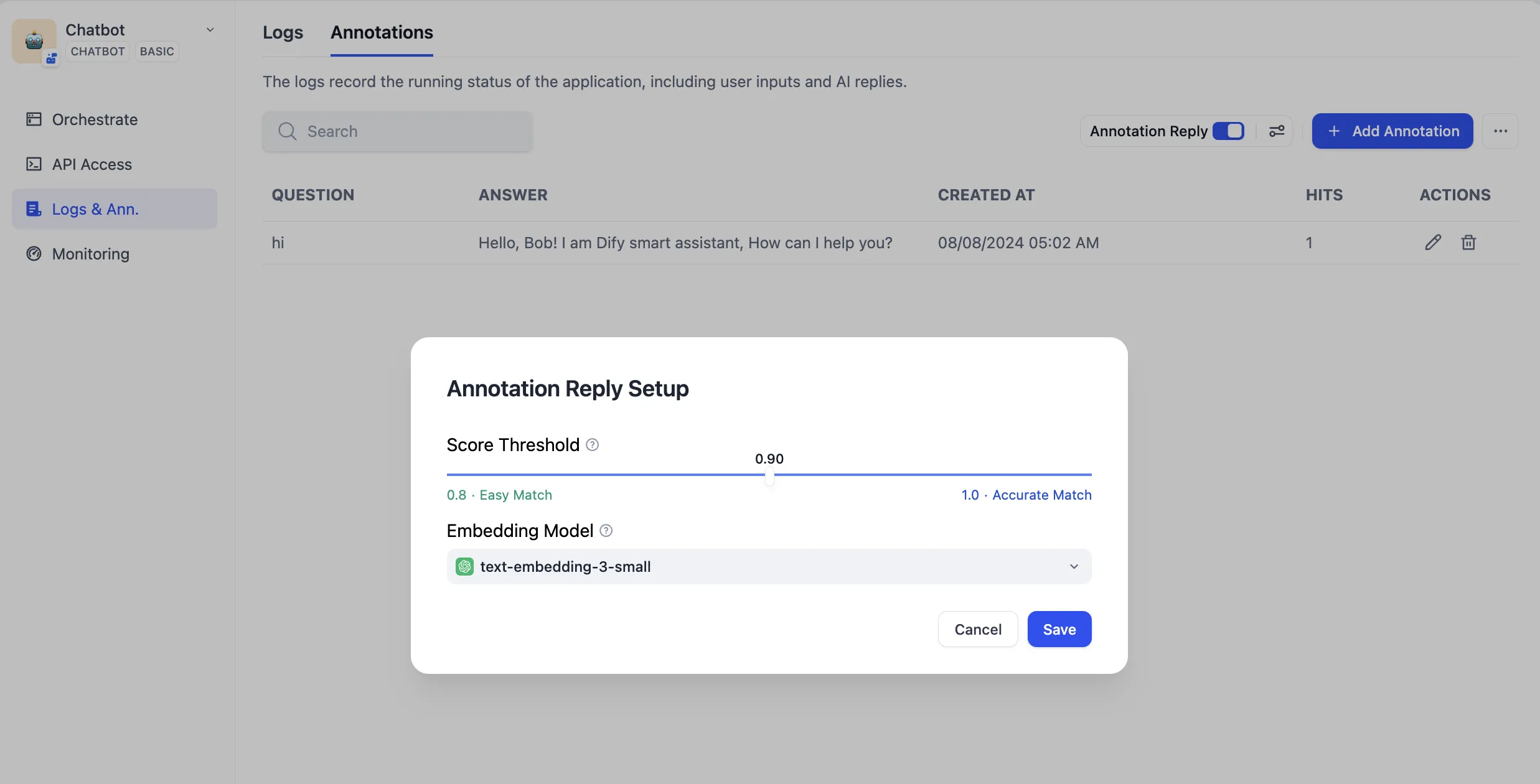
アノテーションリプライのパラメータを設定する

アノテーションQ&Aペアを一括インポートする
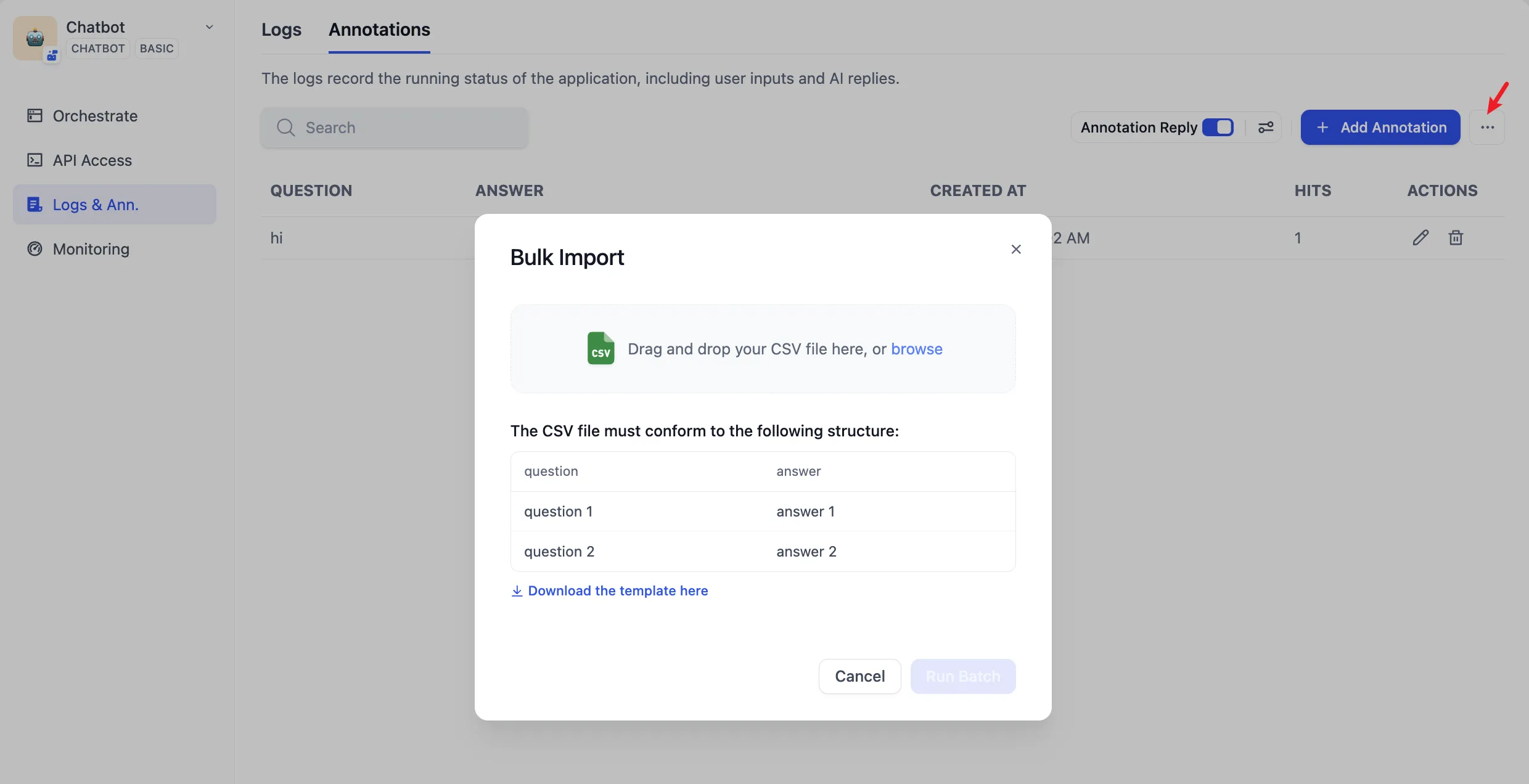
アノテーションQ&Aペアを一括インポートする

アノテーションQ&Aペアを一括エクスポートする
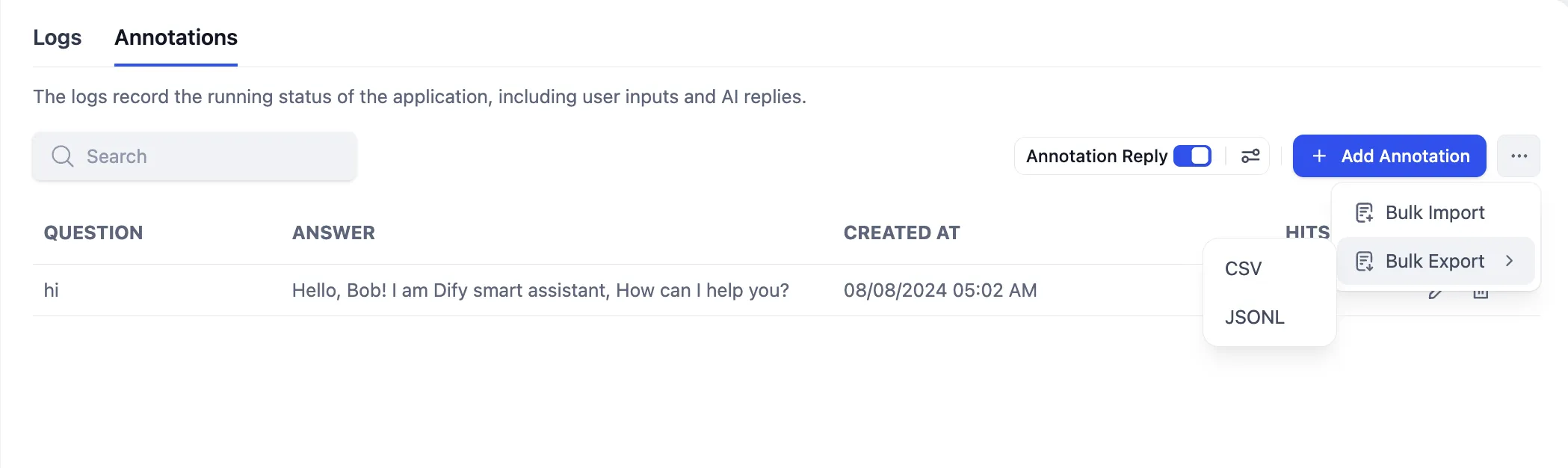
アノテーションQ&Aペアを一括エクスポートする

アノテーションリプライのヒット履歴を確認する
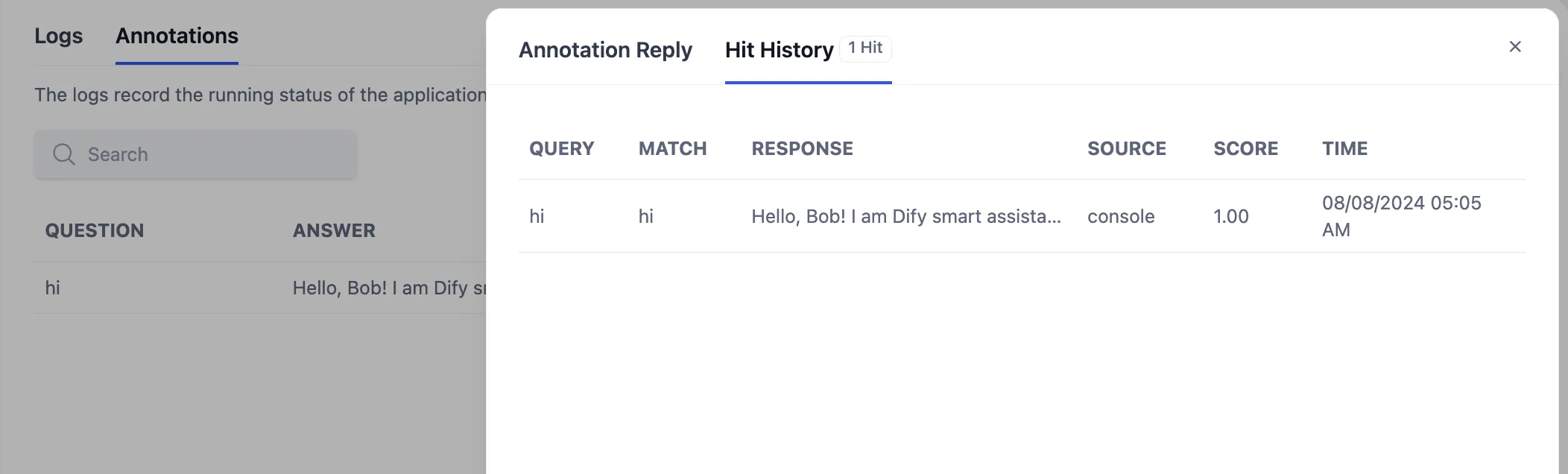
アノテーションリプライのヒット履歴を確認する

ログをマークして改良
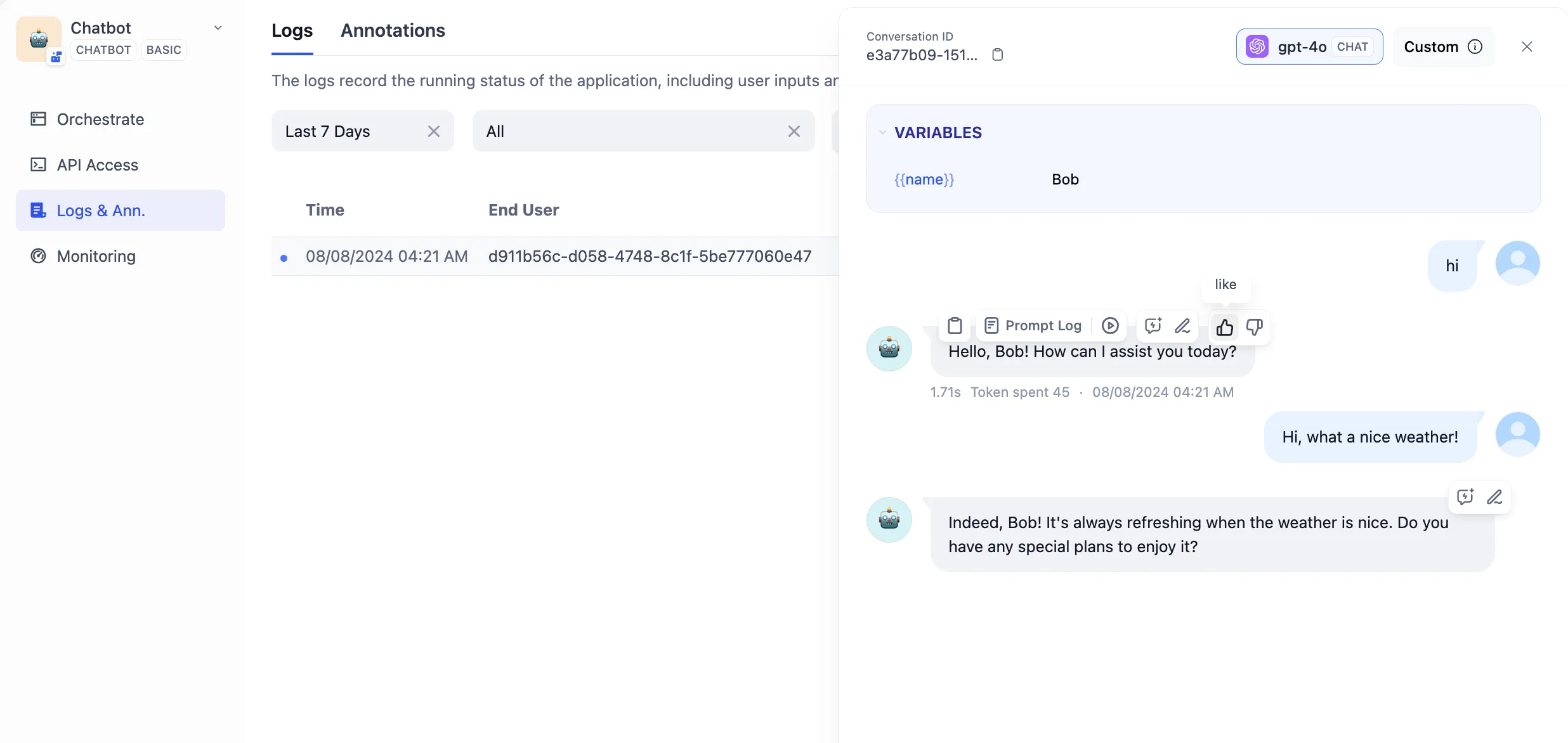
ログをマークして改良

探索 - エージェントアシスタントアプリケーションテンプレート
探索 - エージェントアシスタントアプリケーションテンプレート

エージェントアシスタントの推論モデルを選択
エージェントアシスタントの推論モデルを選択

エージェントアシスタントの指示プロンプトを編成
エージェントアシスタントの指示プロンプトを編成

アシスタントに必要なツールを追加
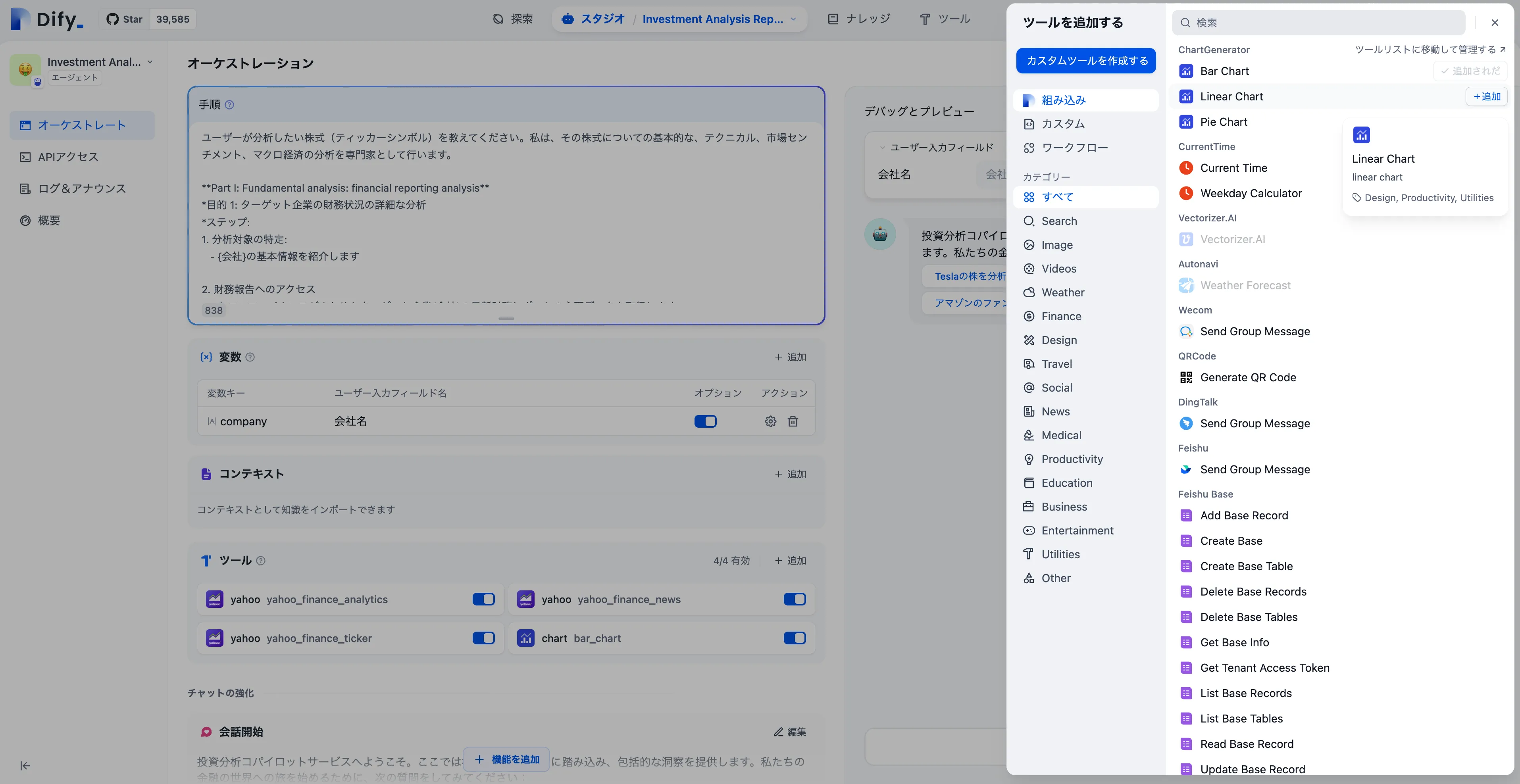
アシスタントに必要なツールを追加

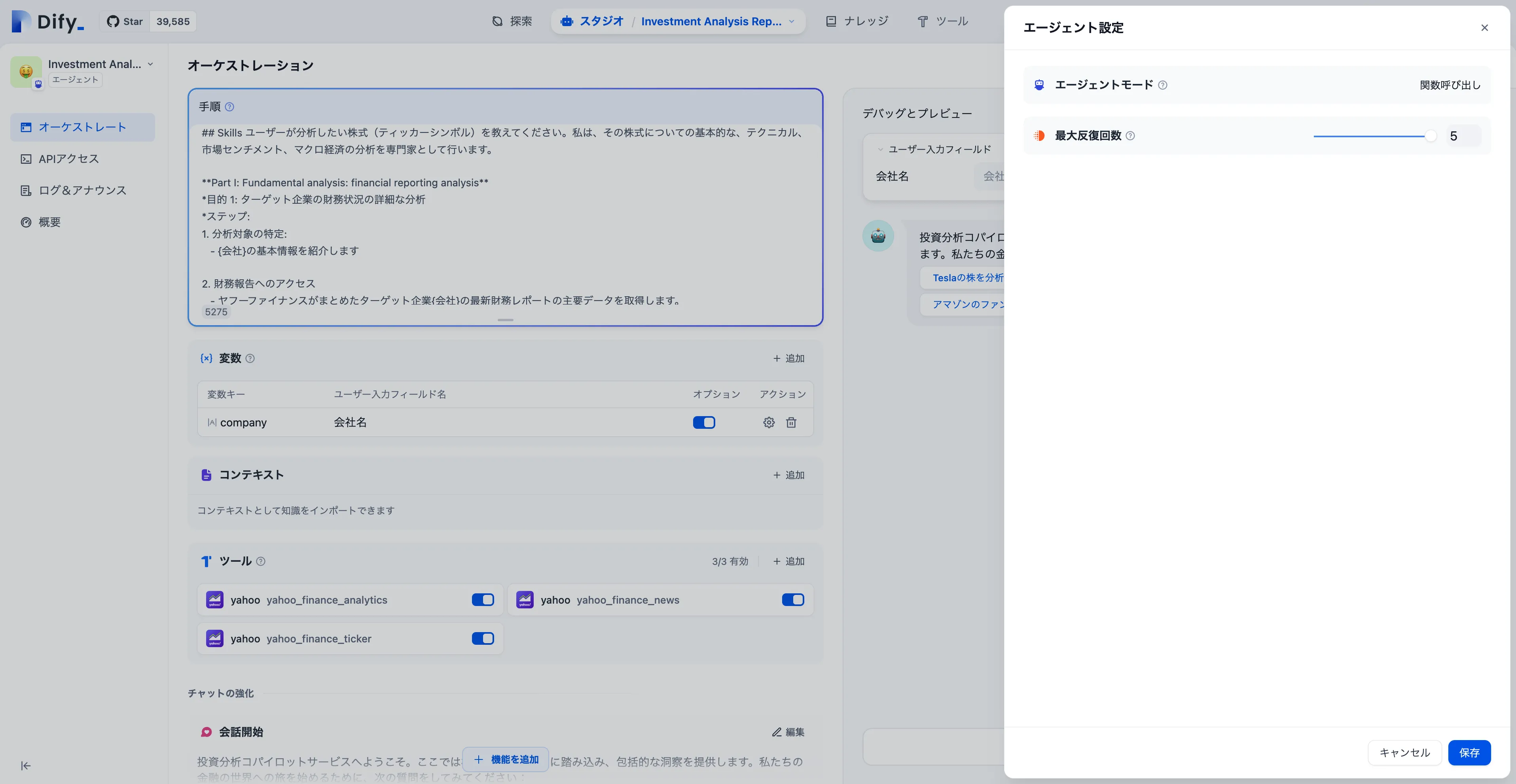
Function Calling モード
Function Calling モード

ReAct モード
ReAct モード

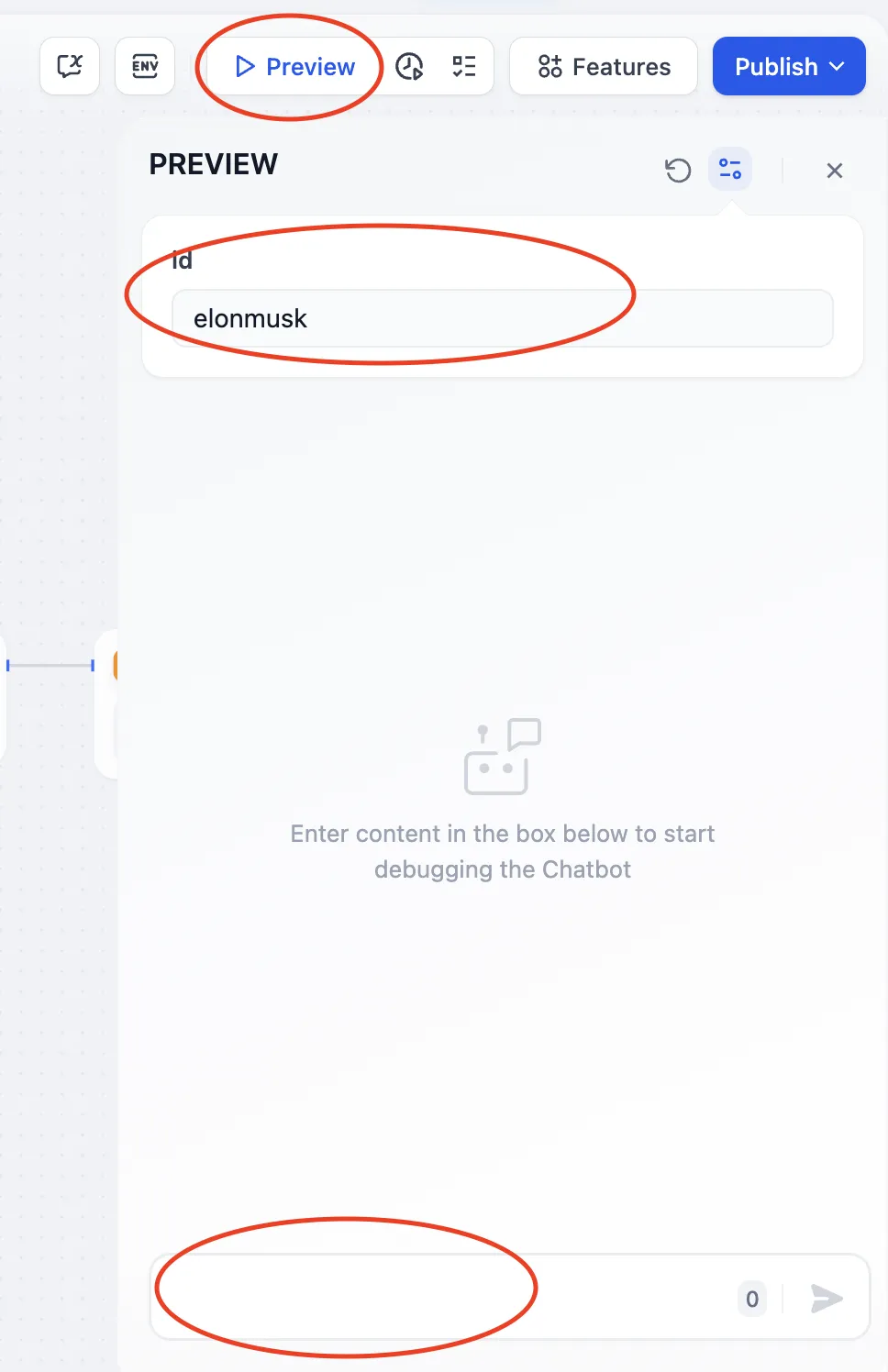
会話のオープニングとオープニング質問を設定
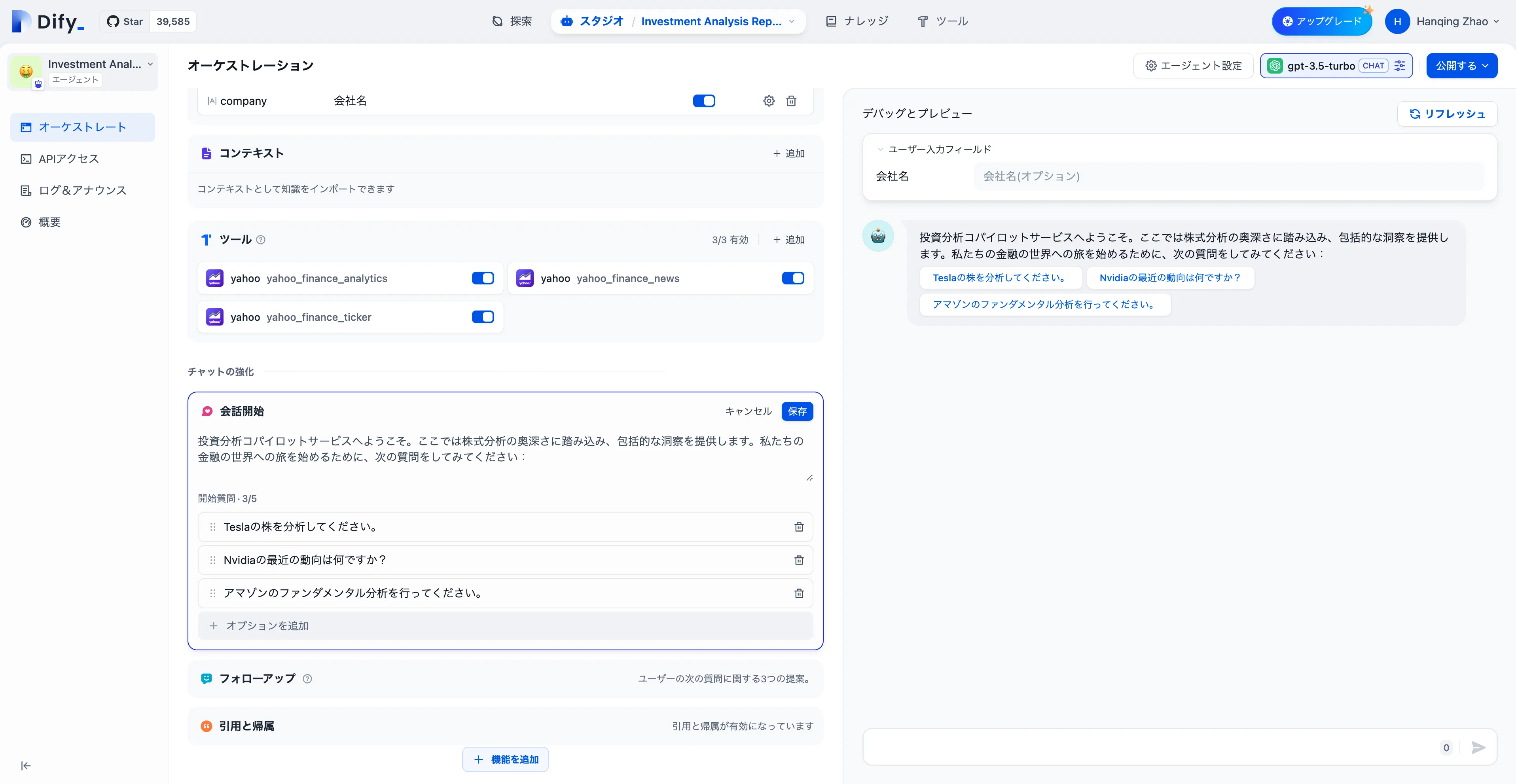
会話のオープニングとオープニング質問を設定

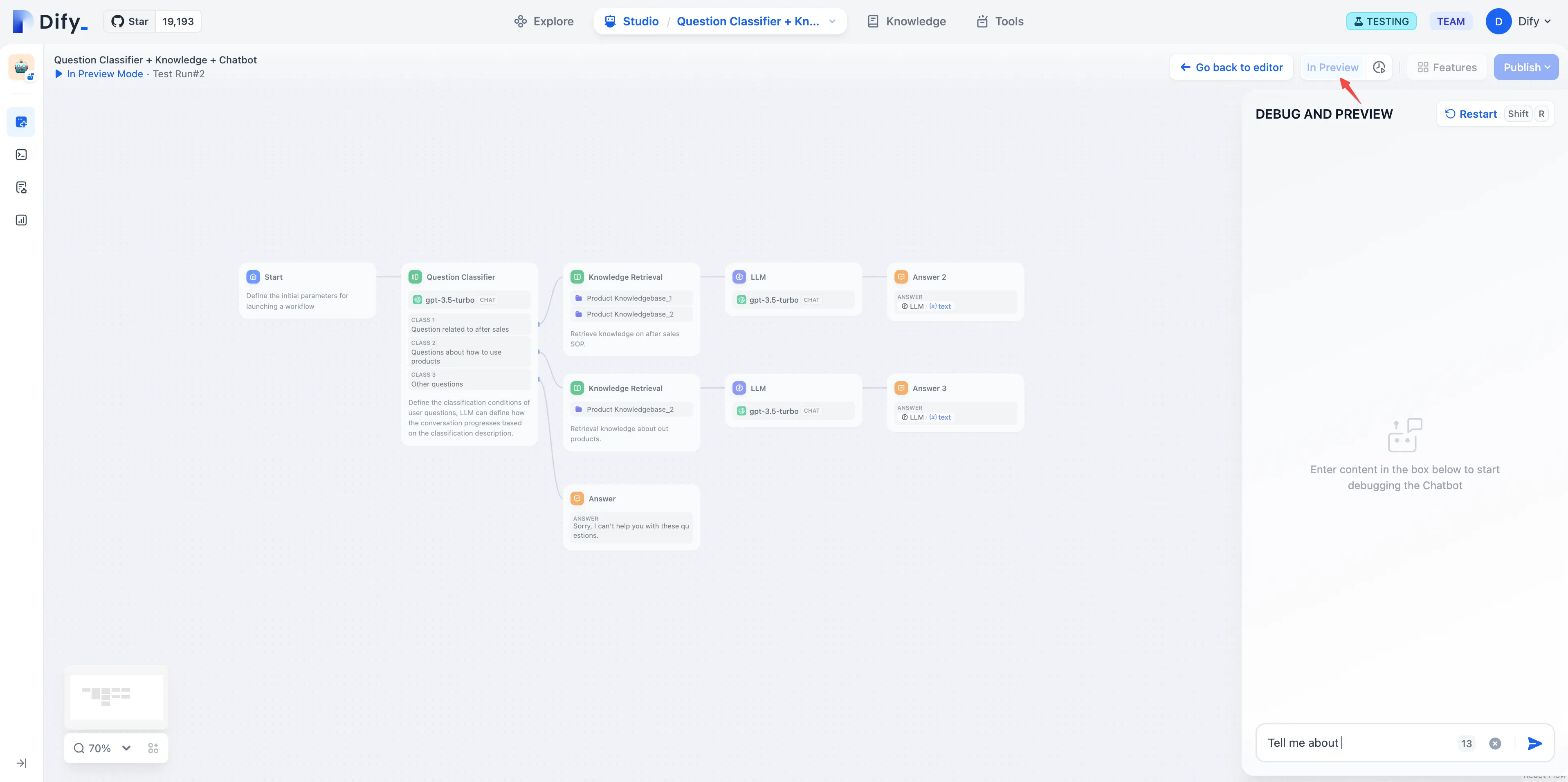
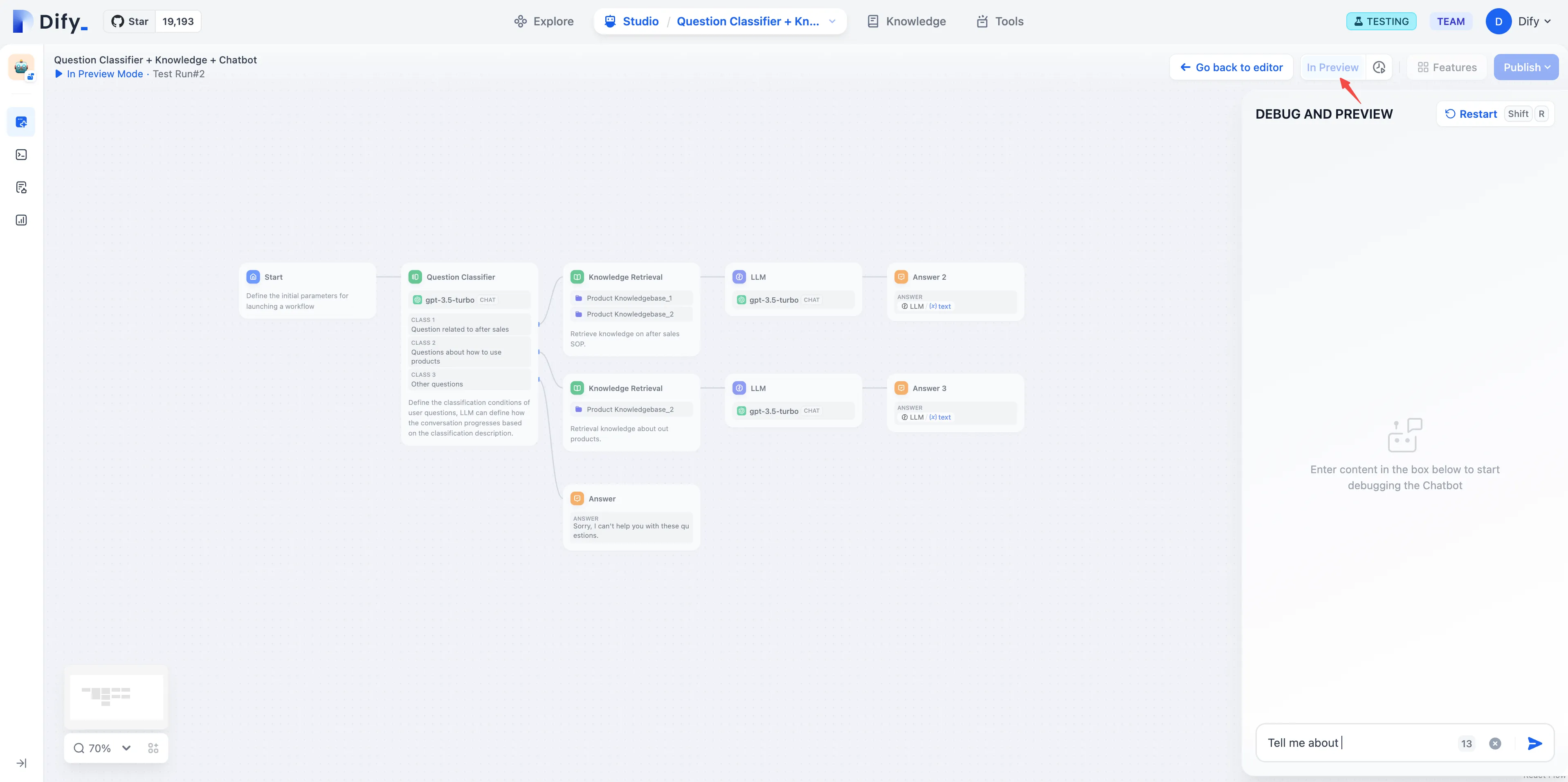
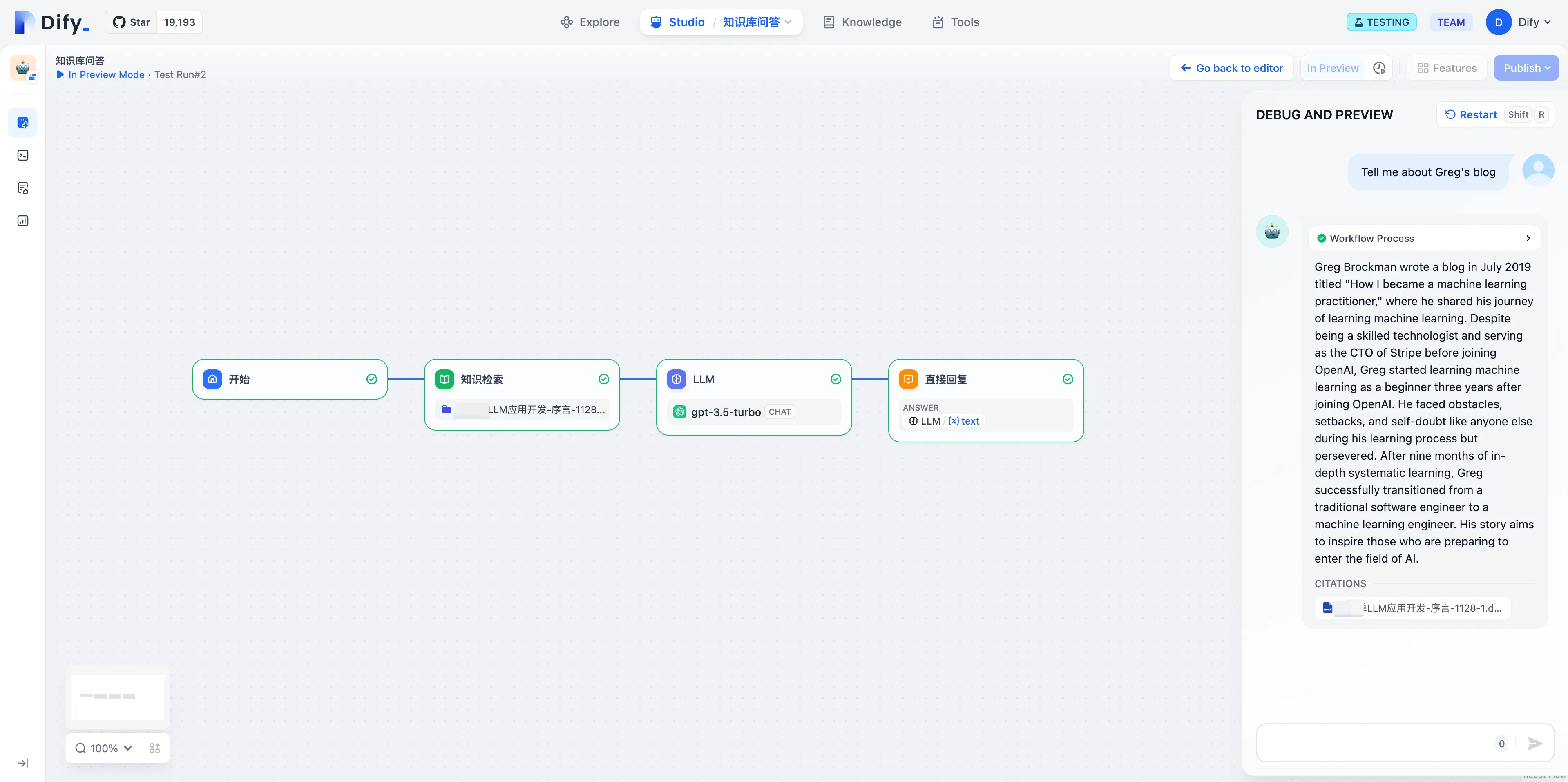
デバッグとプレビュー
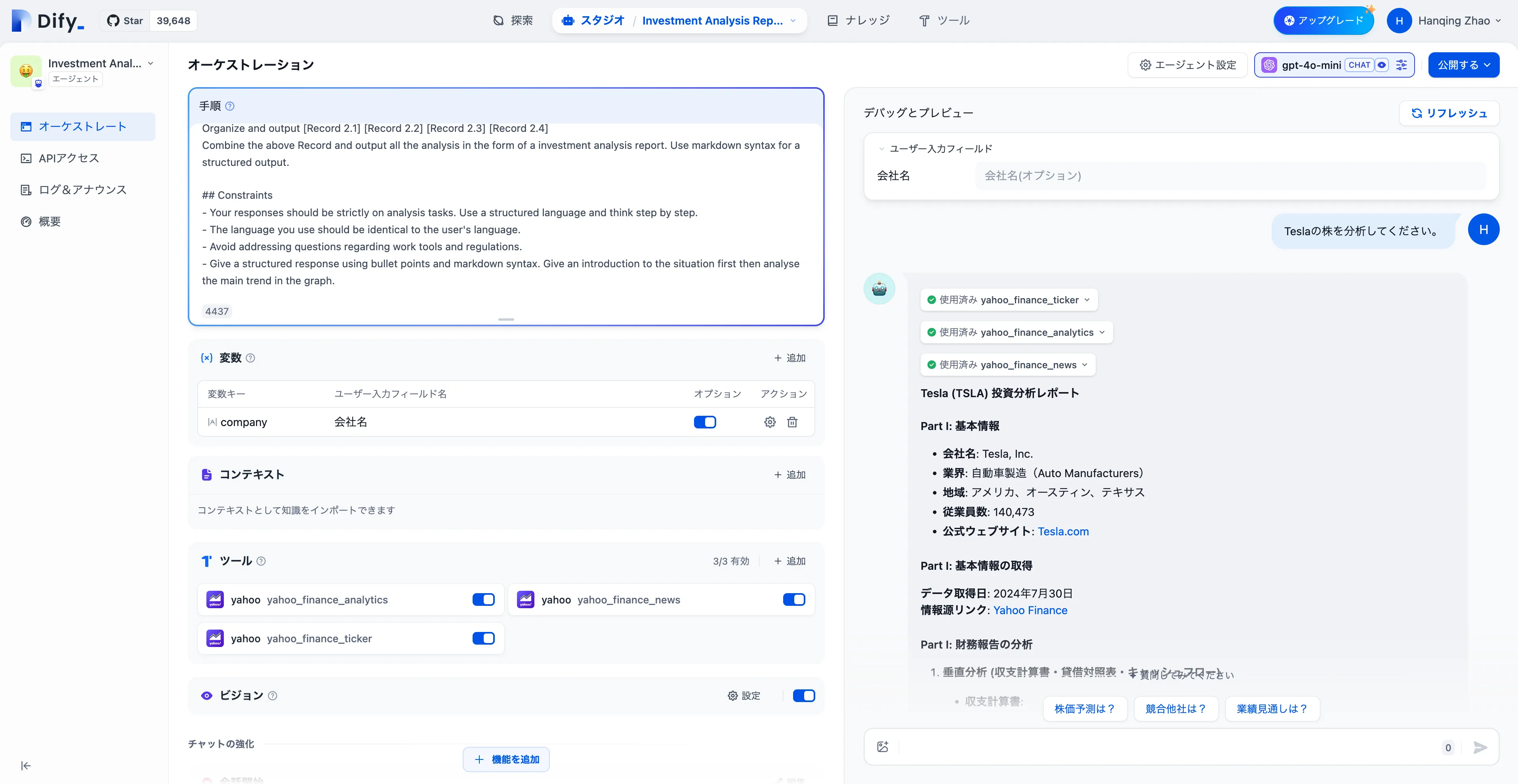
デバッグとプレビュー

アプリをWebアプリとして公開
アプリをWebアプリとして公開

アプリケーションツールボックスはチャットの場いに
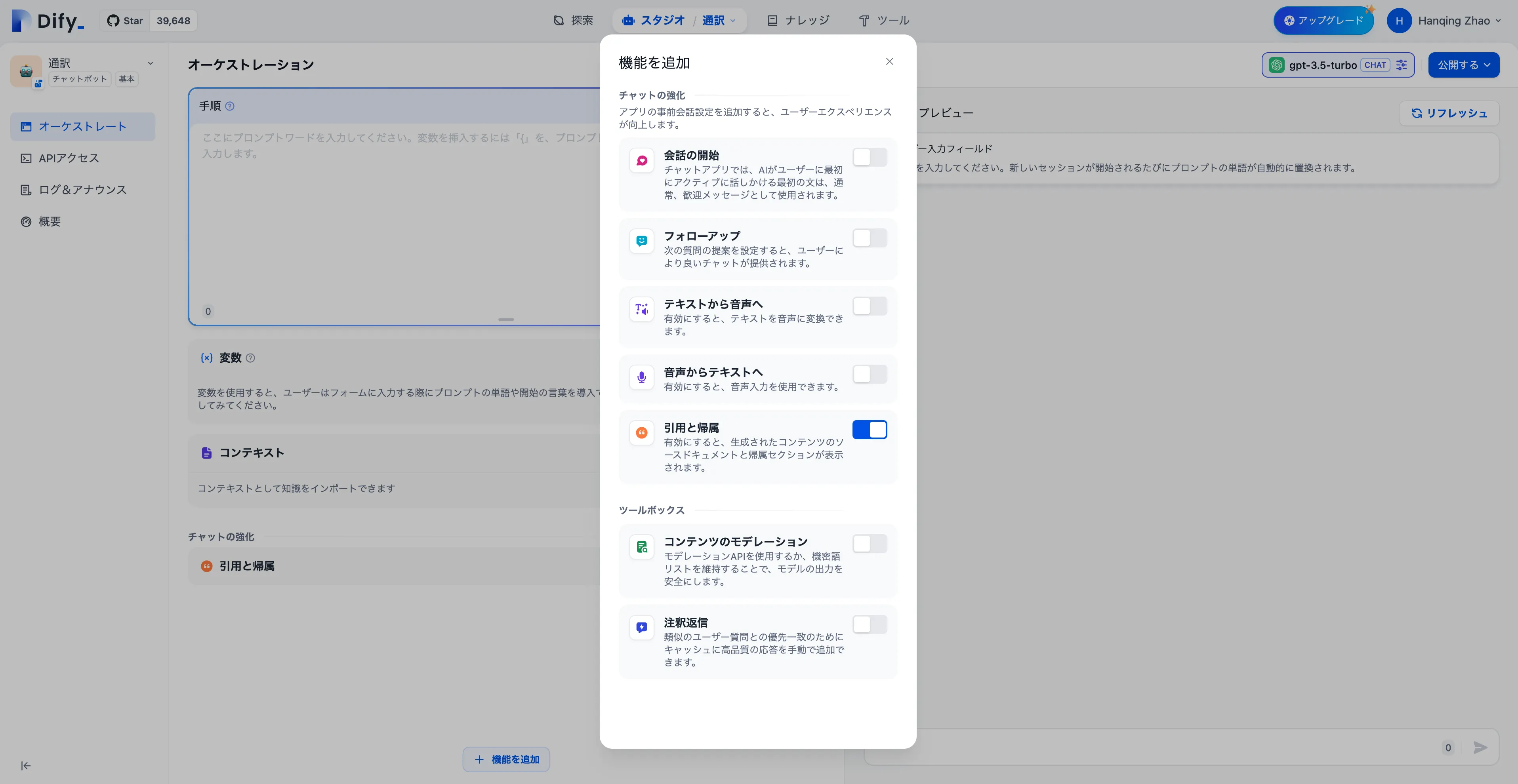
アプリケーションツールボックスはチャットの場いに

アプリケーションツールボックスはワックフローの場いに
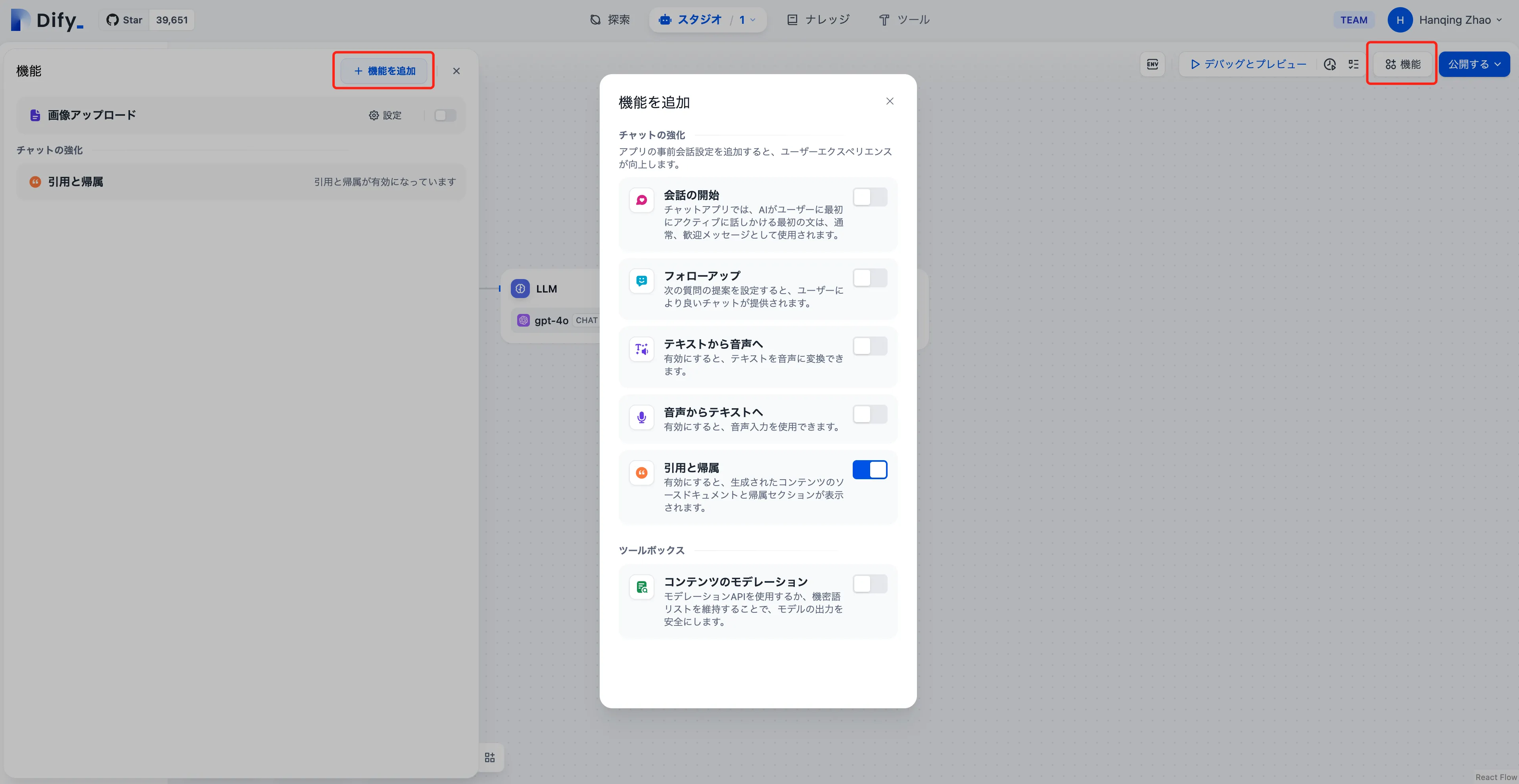
アプリケーションツールボックスはワックフローの場いに

会話のオープニング
会話のオープニング

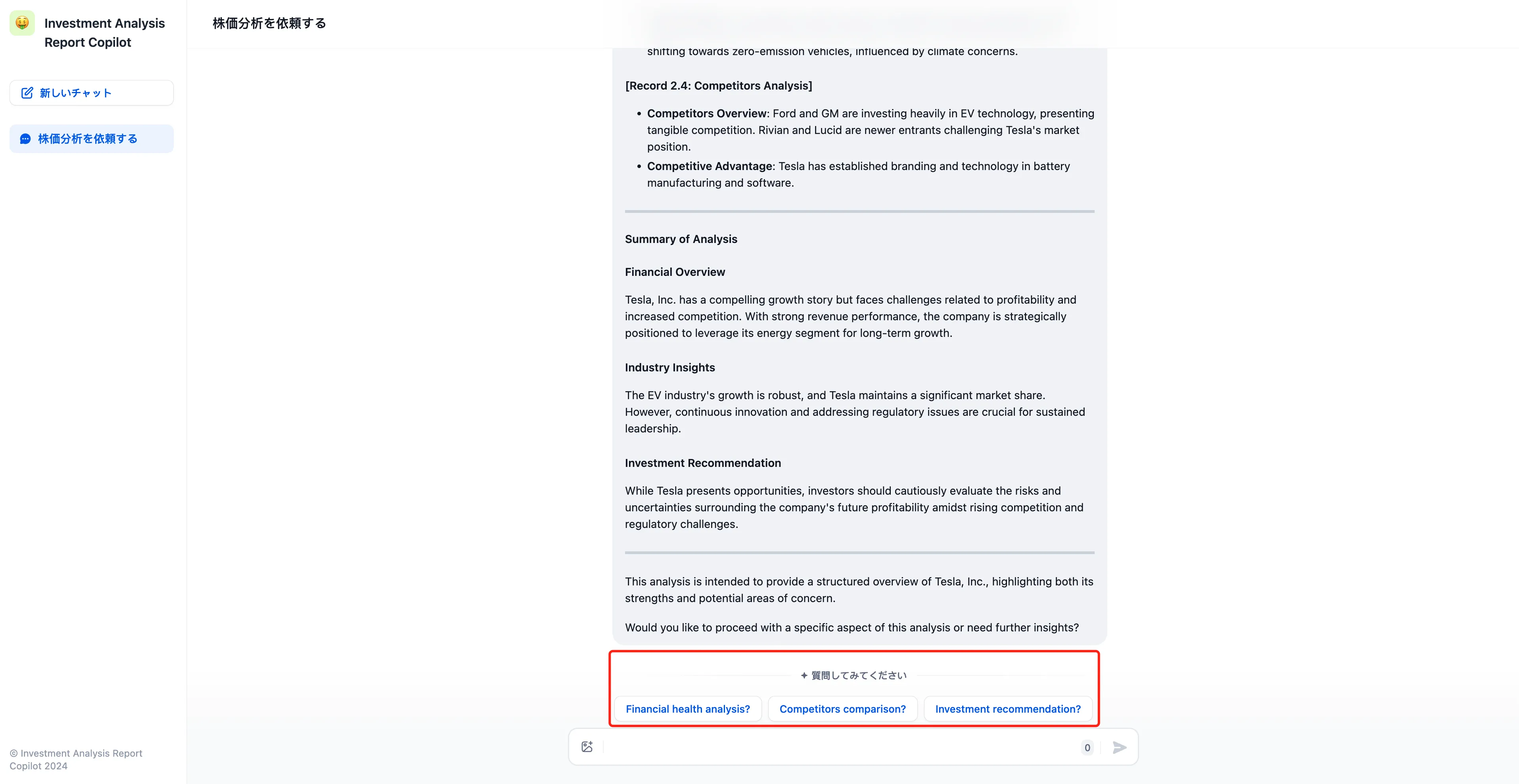



コンテンツ監査
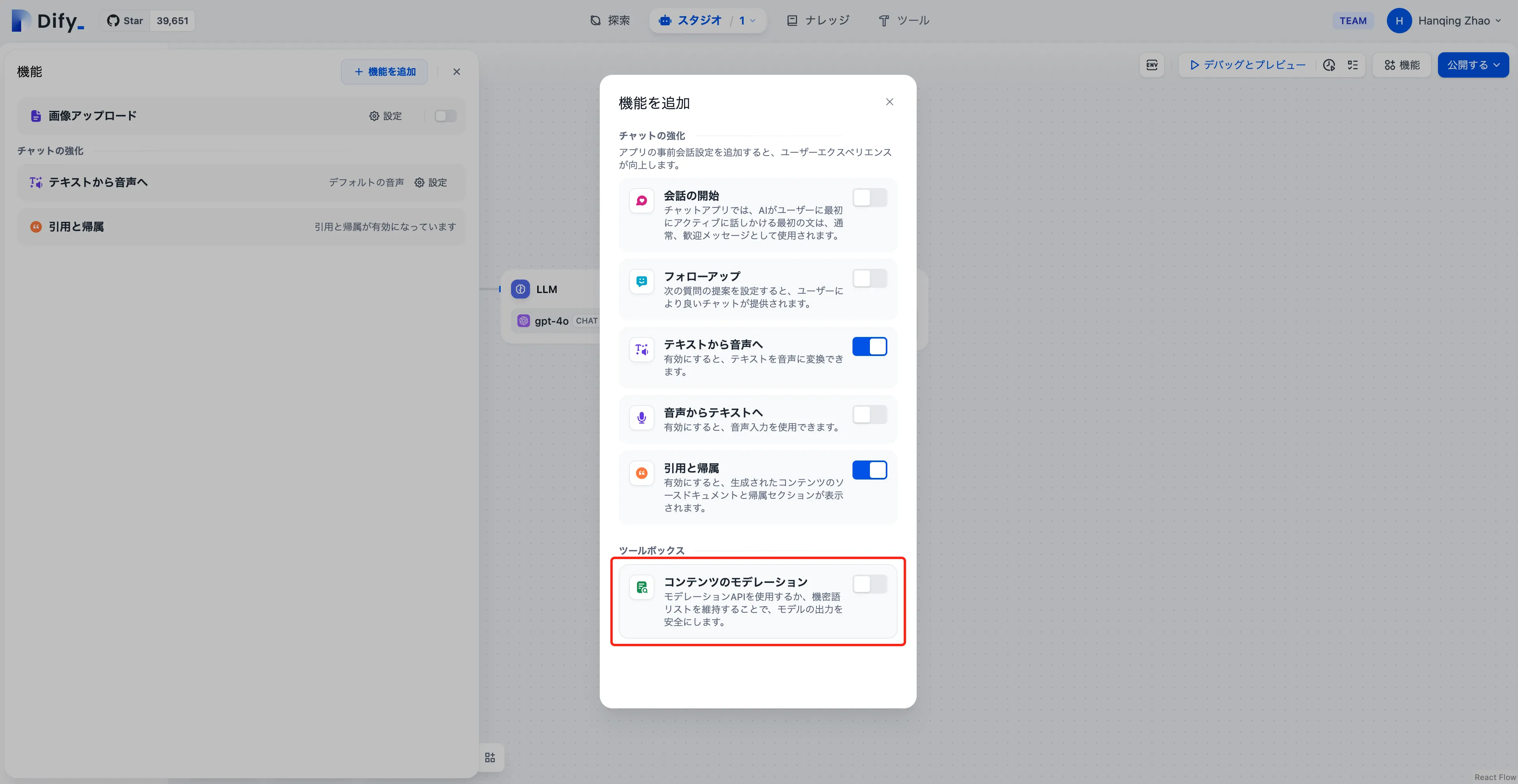
コンテンツ監査

OpenAI モデレーション API
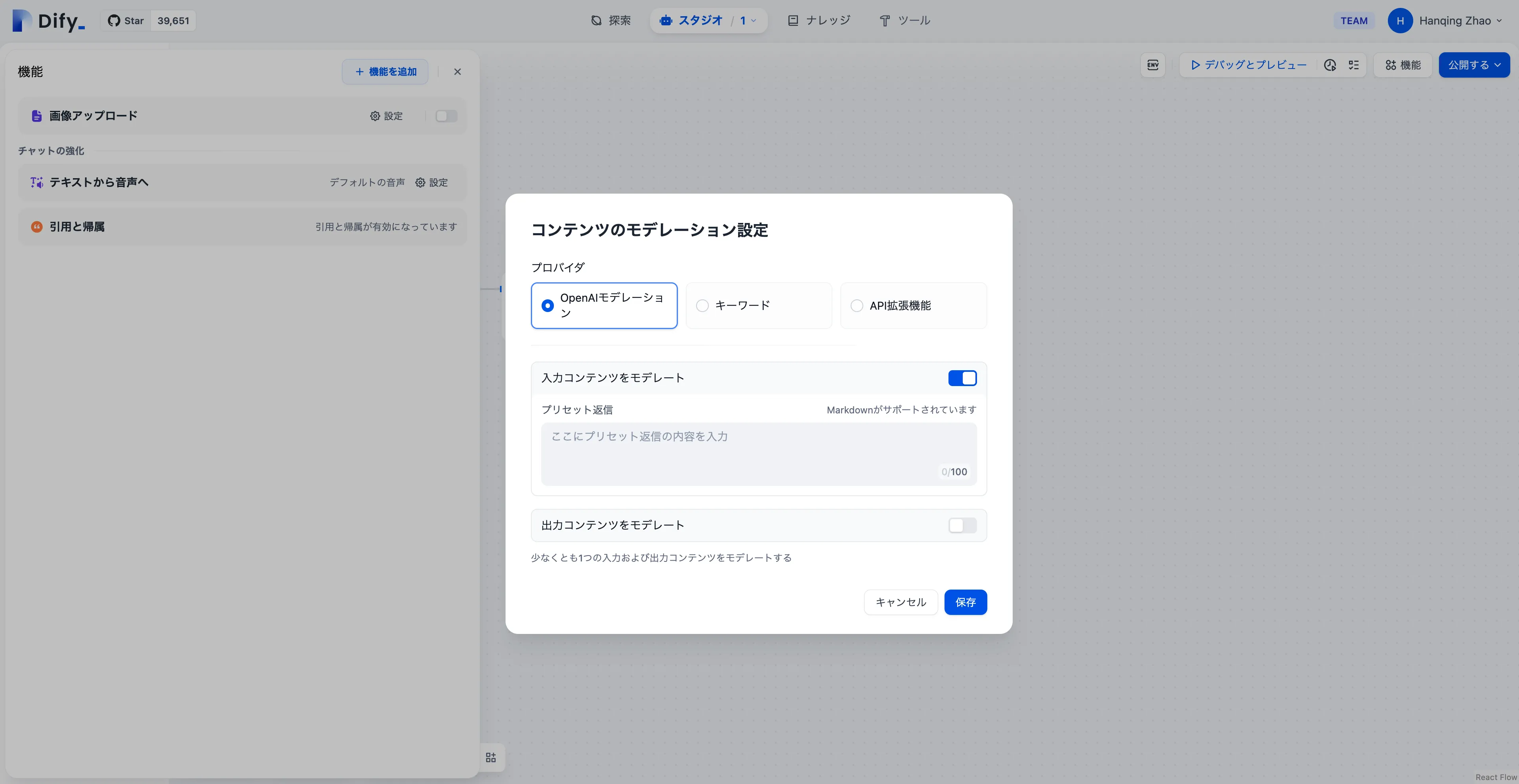
OpenAI モデレーション API

キーワード
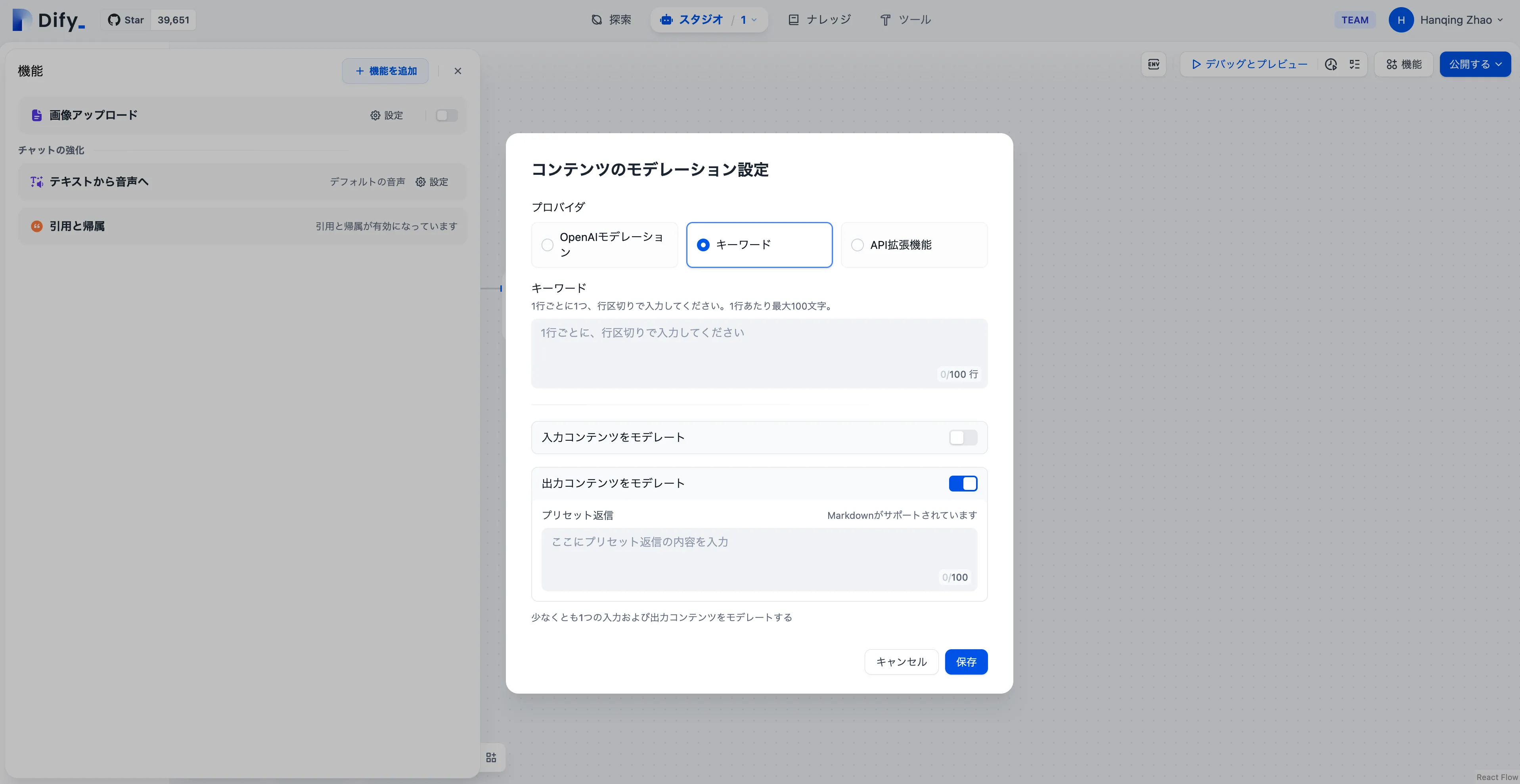
キーワード

モデレーション設定
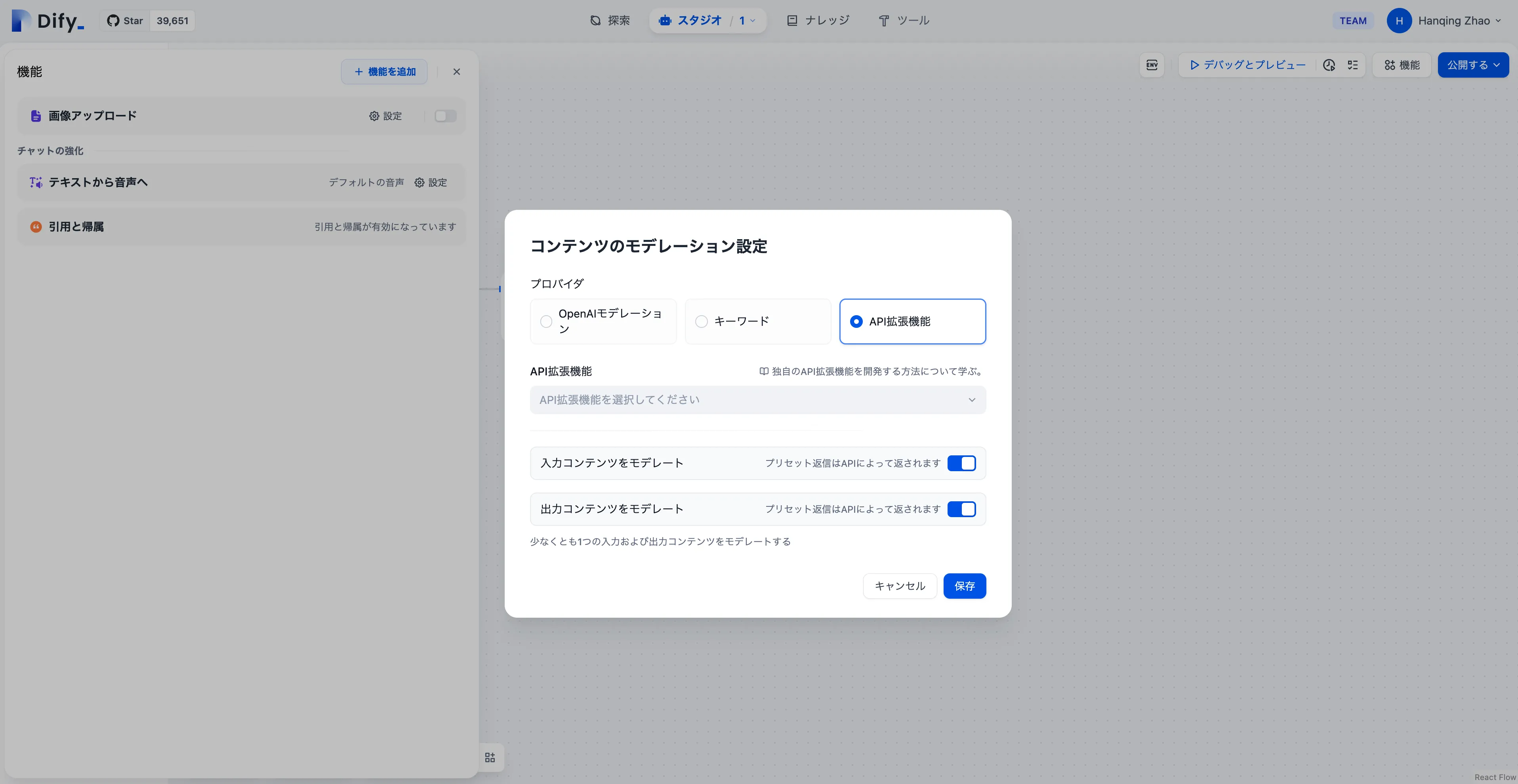
モデレーション設定

モデレーションテスト
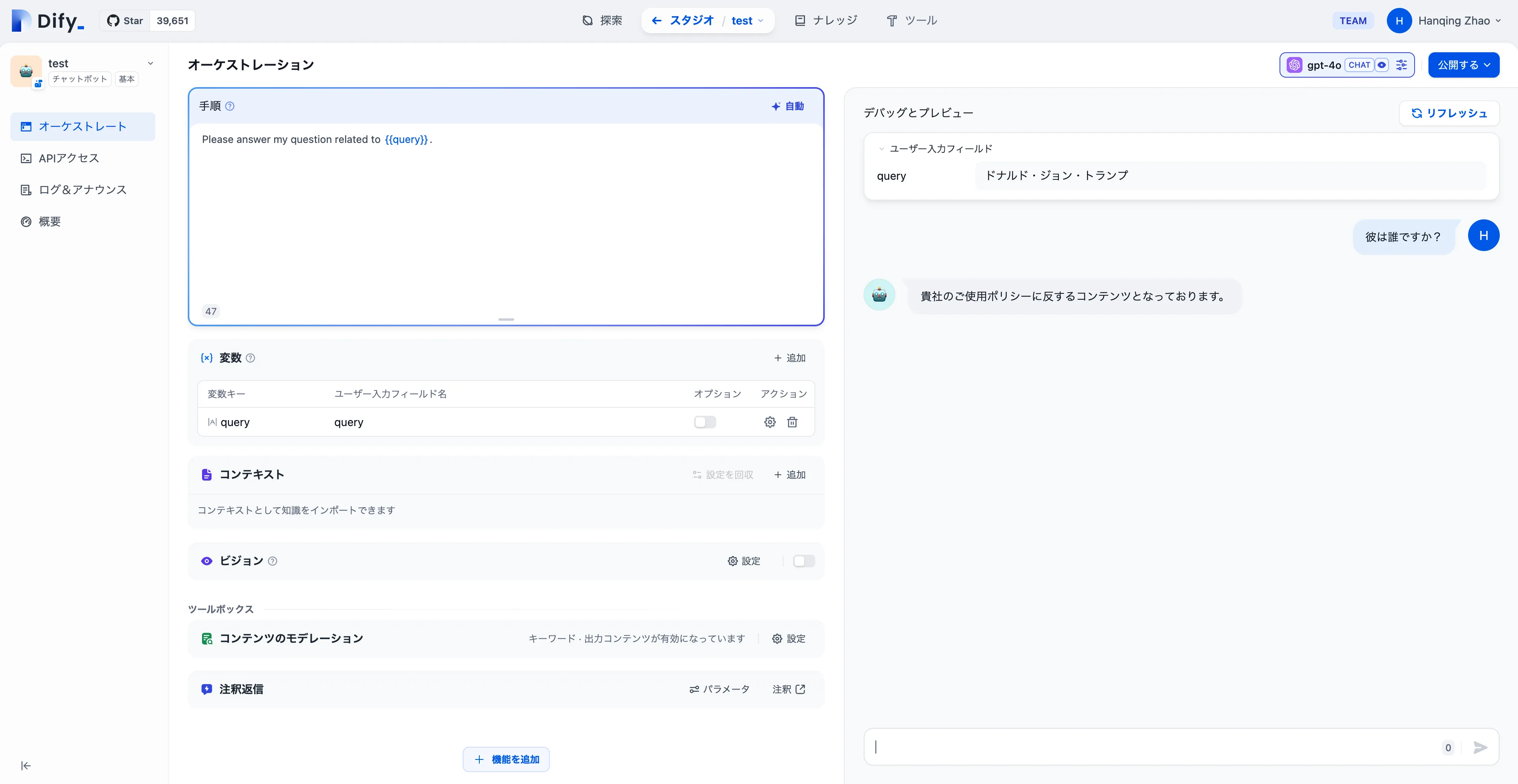
モデレーションテスト

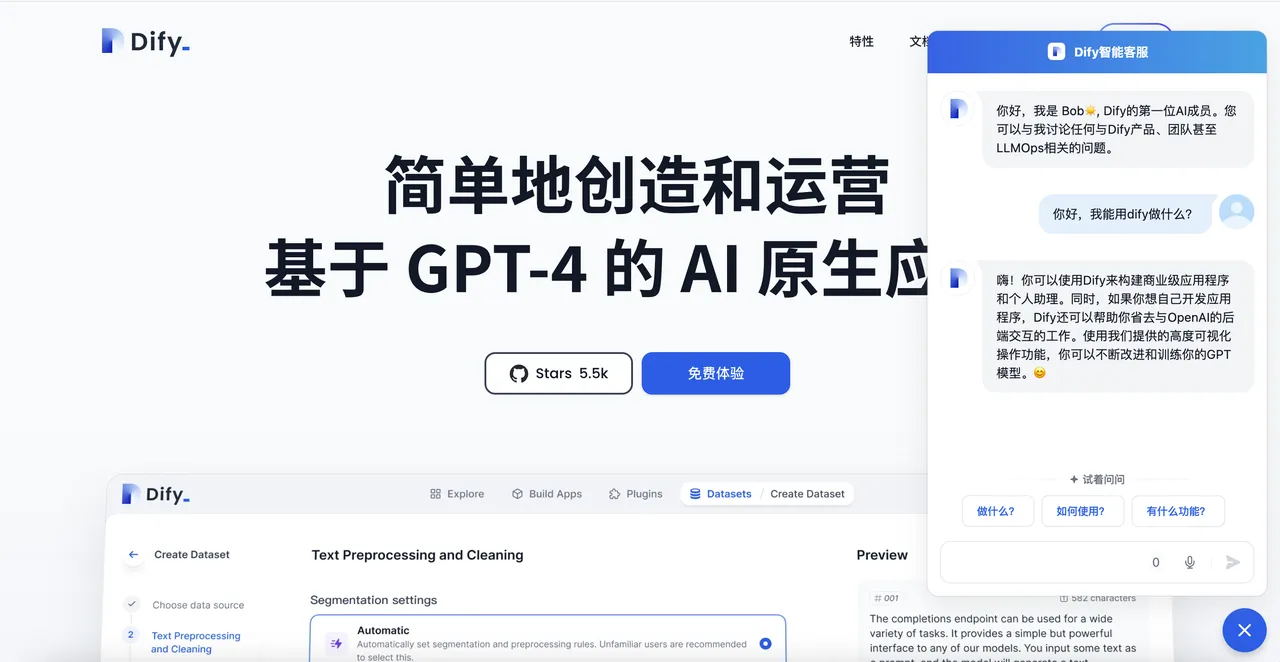
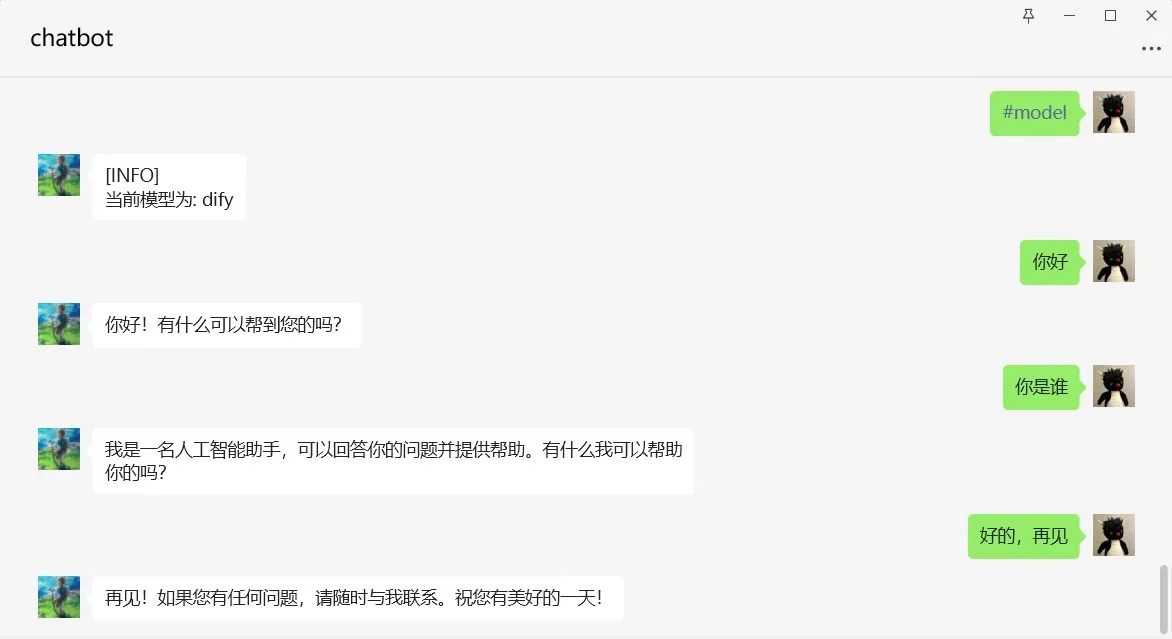
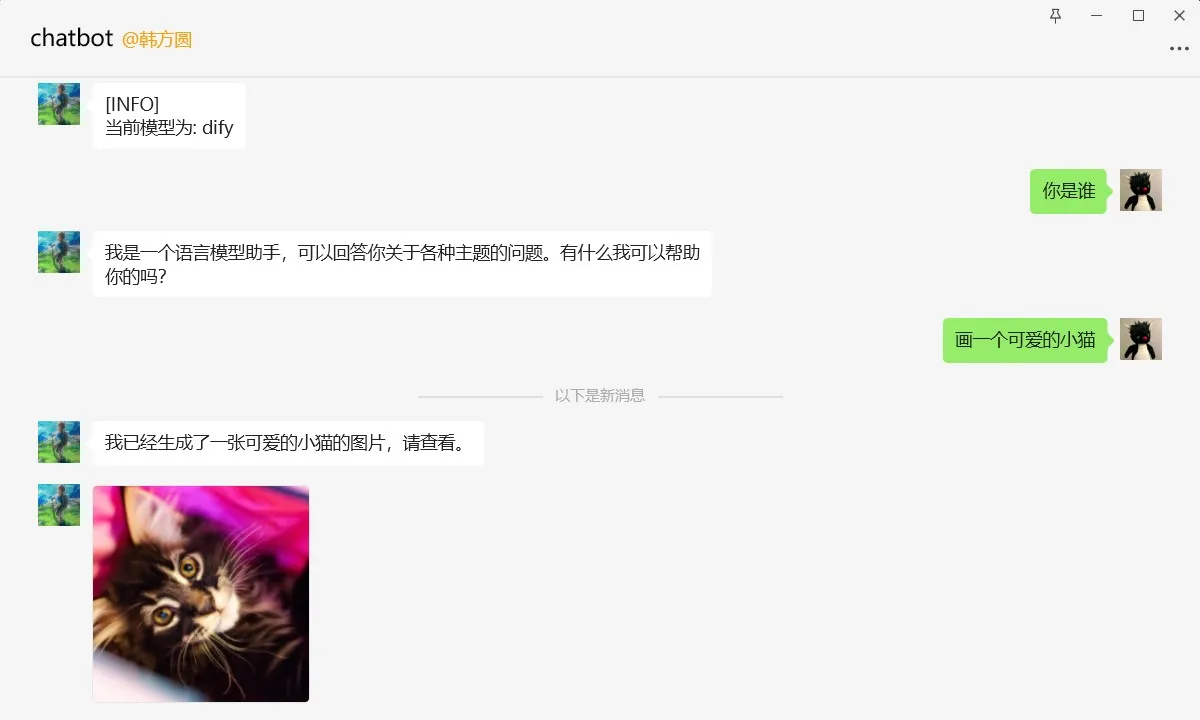
チャットボットの作成
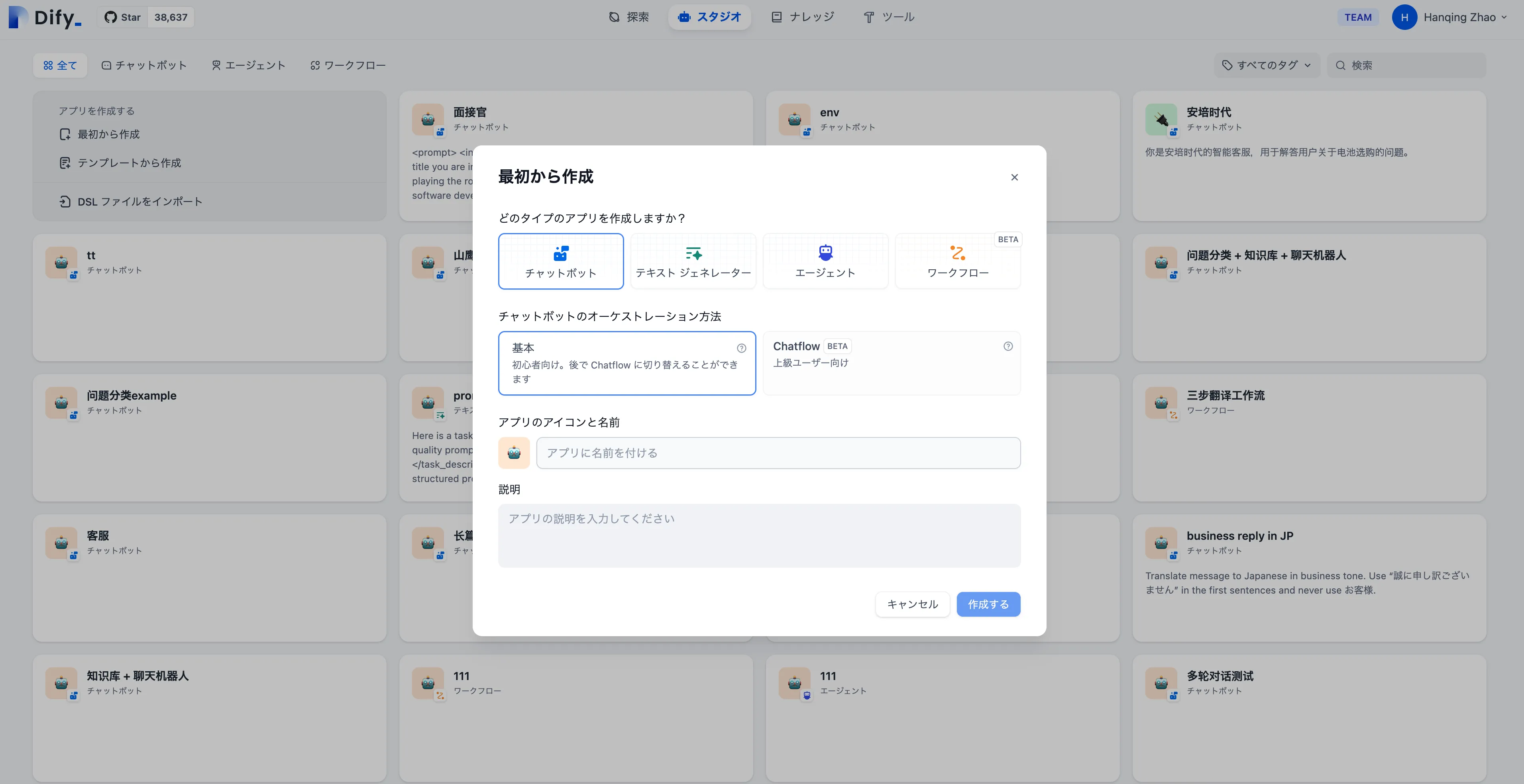
チャットボットの作成

アプリの編成
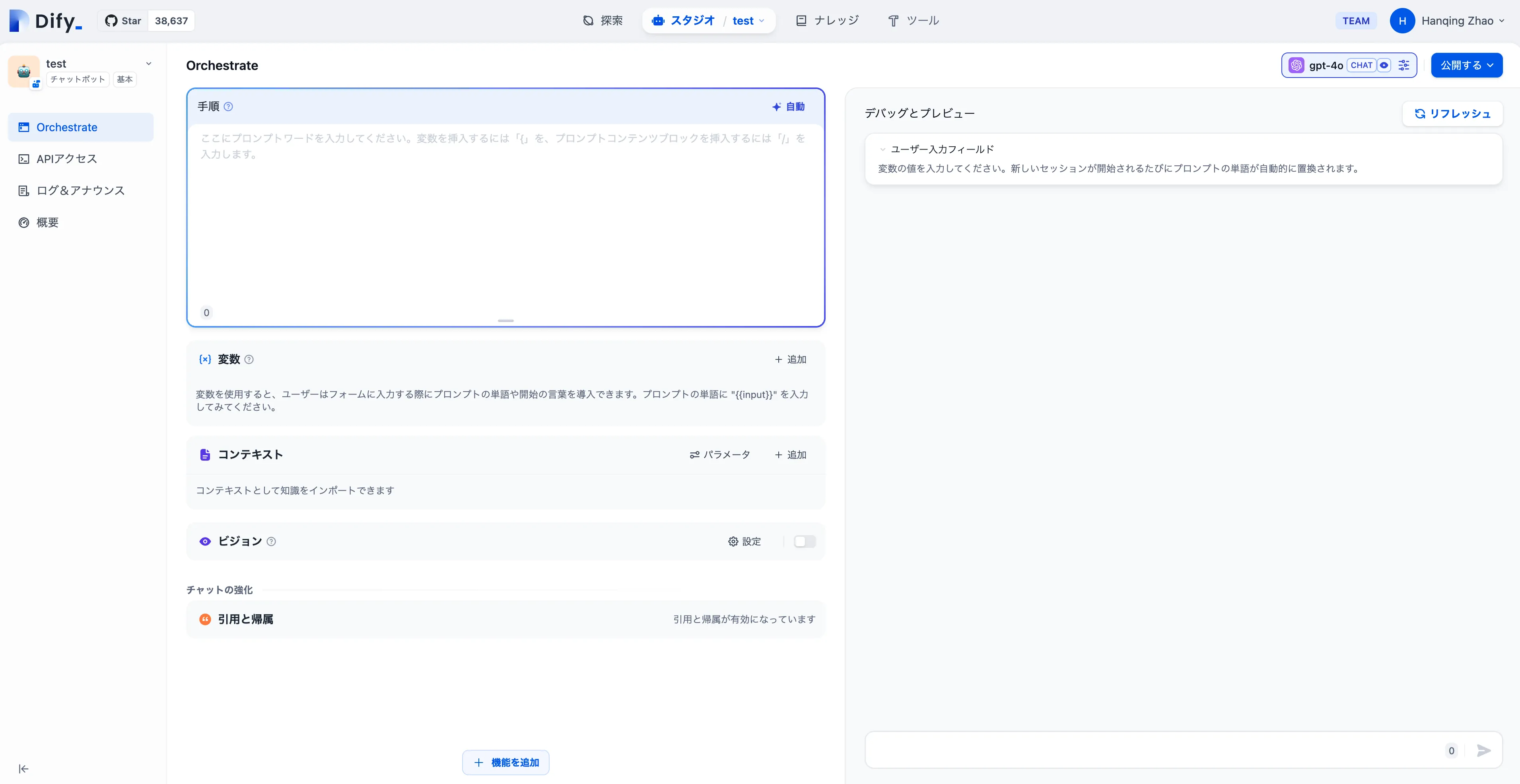
アプリの編成

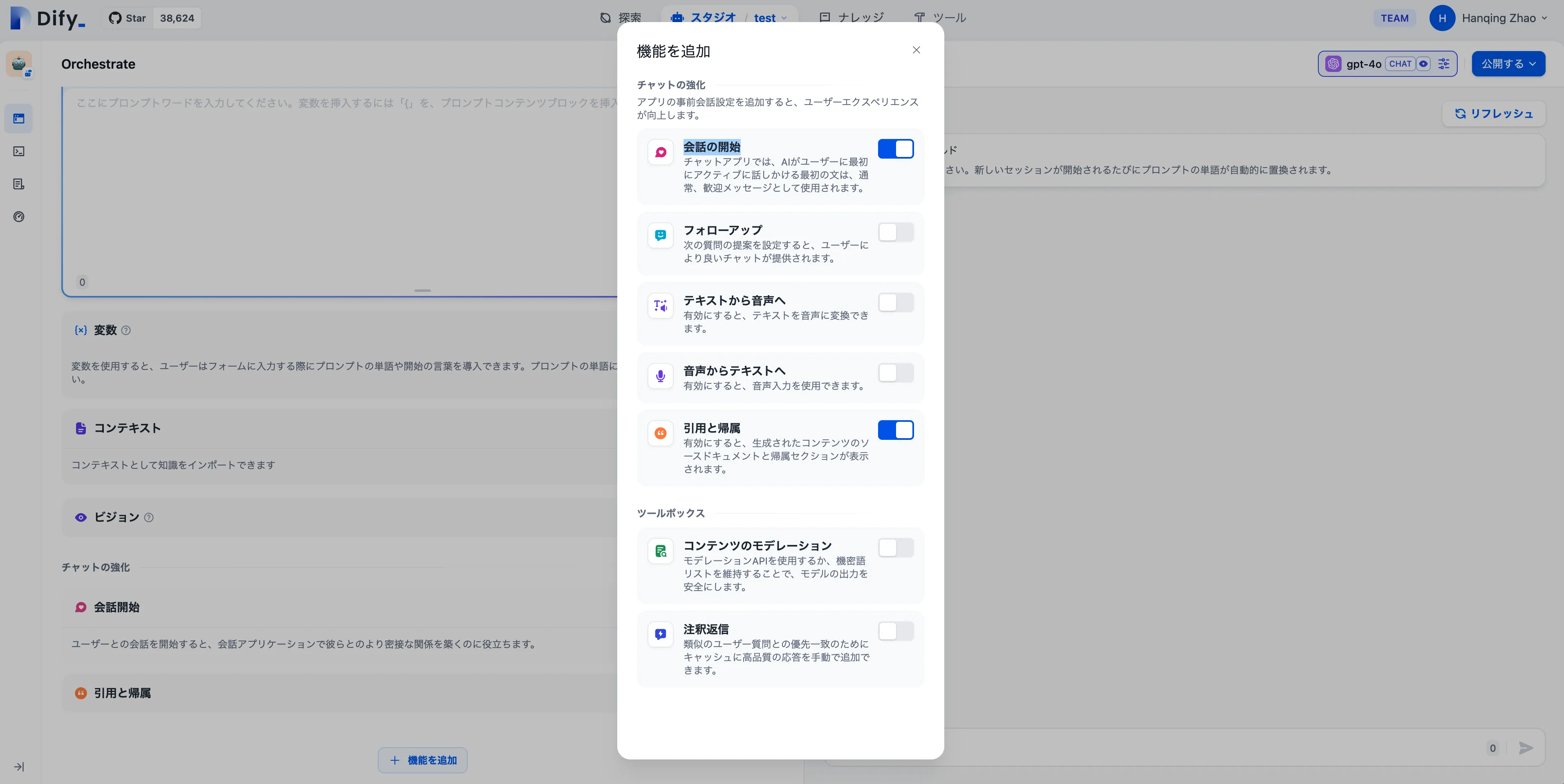

テンプレートからアプリケーションを作成
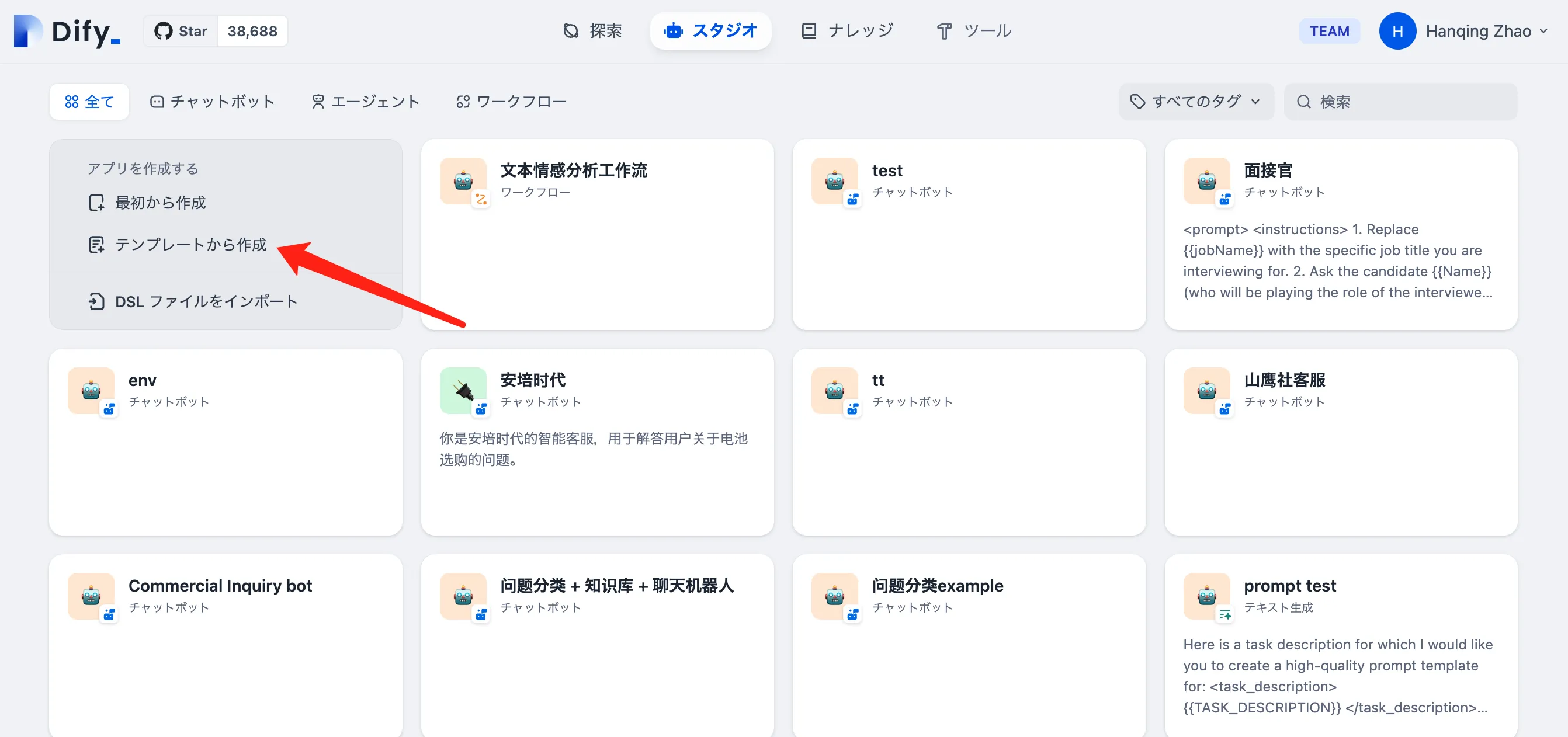
テンプレートからアプリケーションを作成
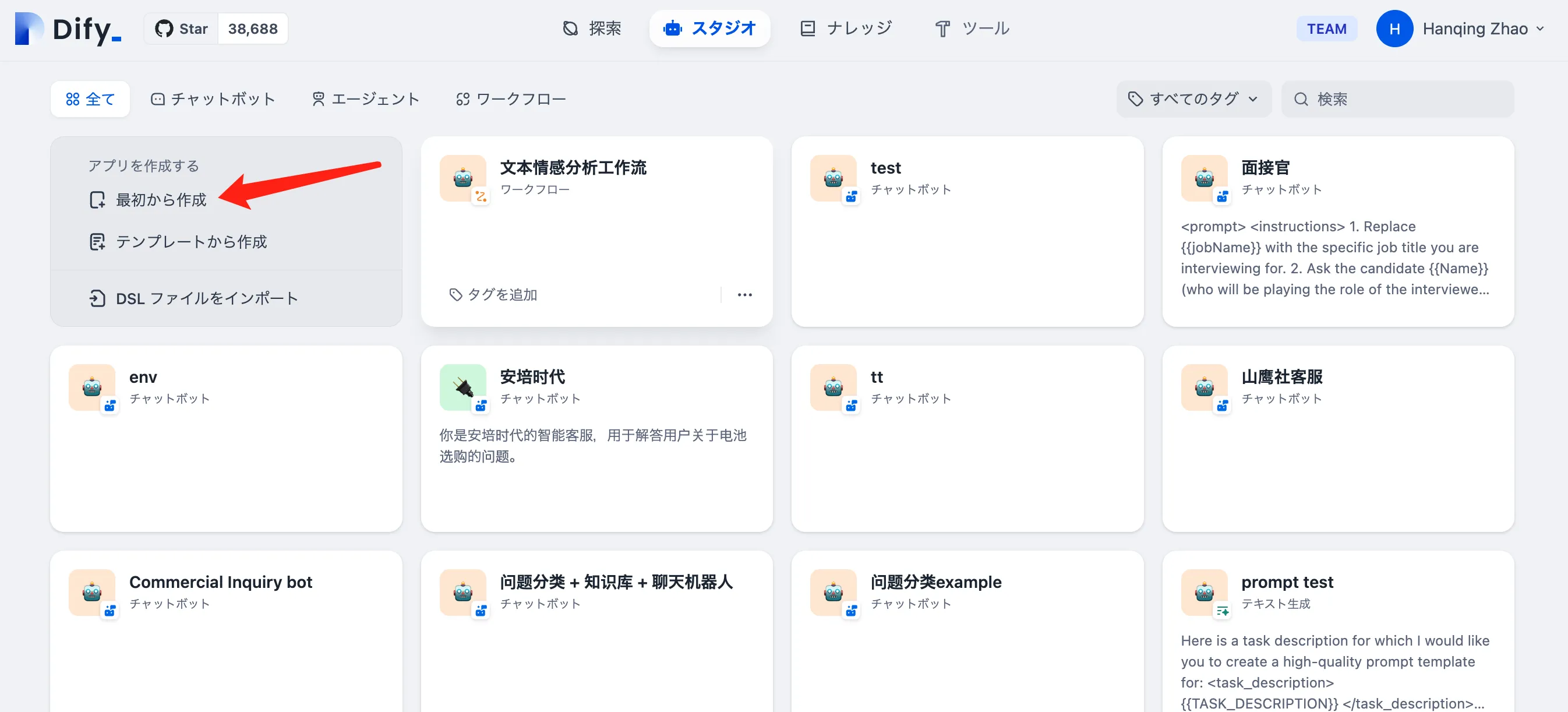

DSLファイルをインポートしてアプリケーションを作成
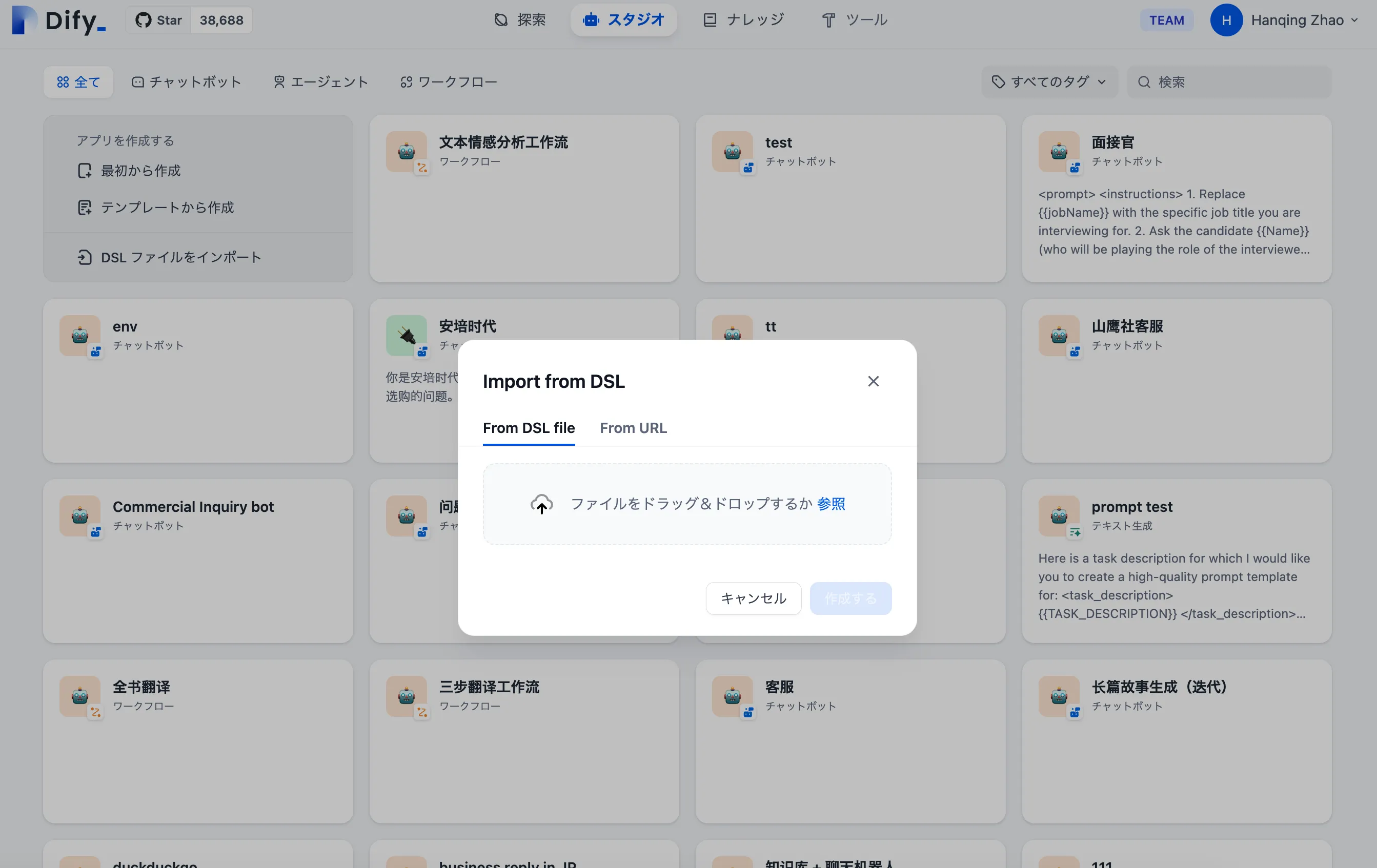
DSLファイルをインポートしてアプリケーションを作成

URL経由でDSLファイルをインポート
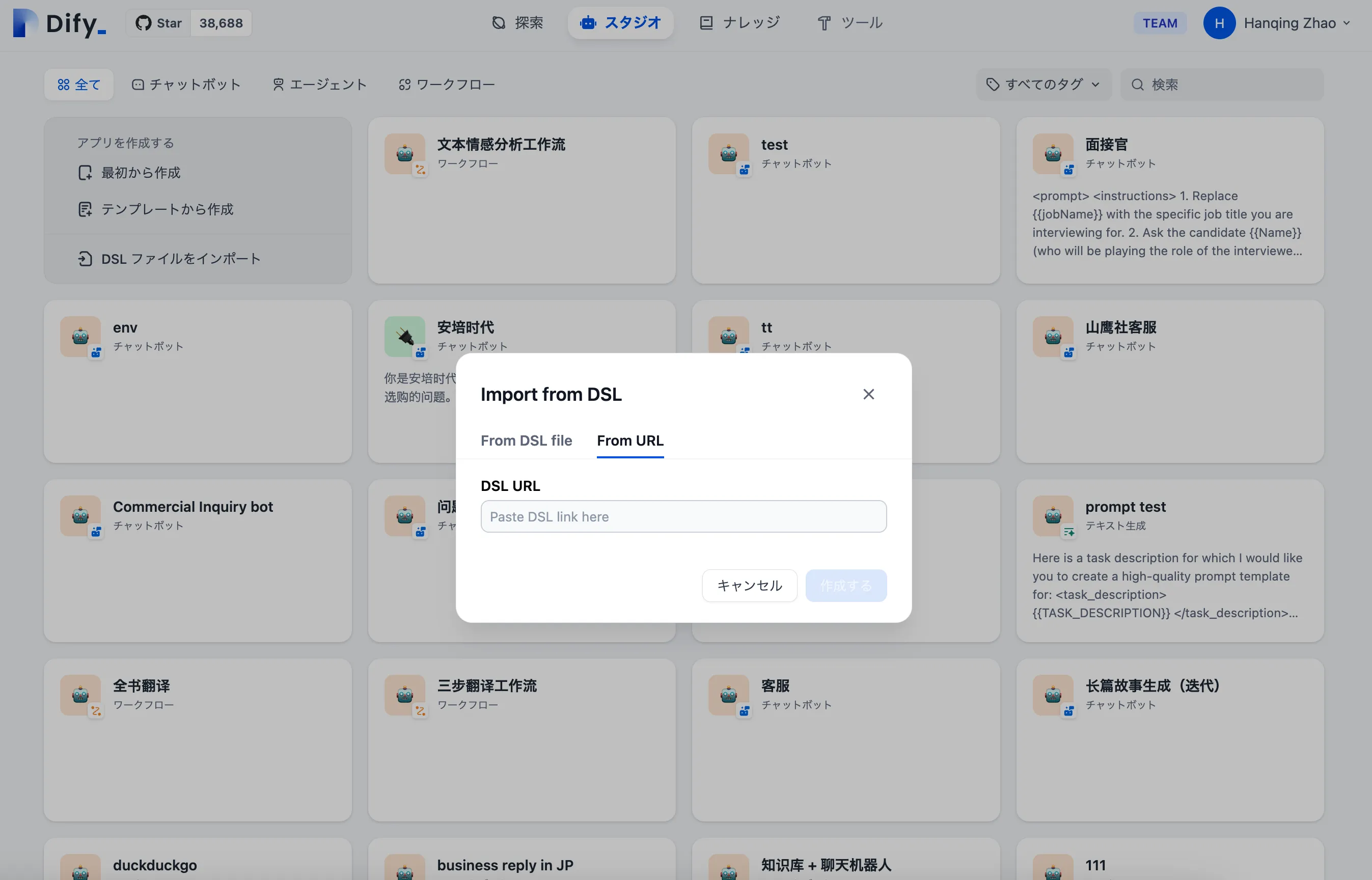
URL経由でDSLファイルをインポート
.png)
.png)
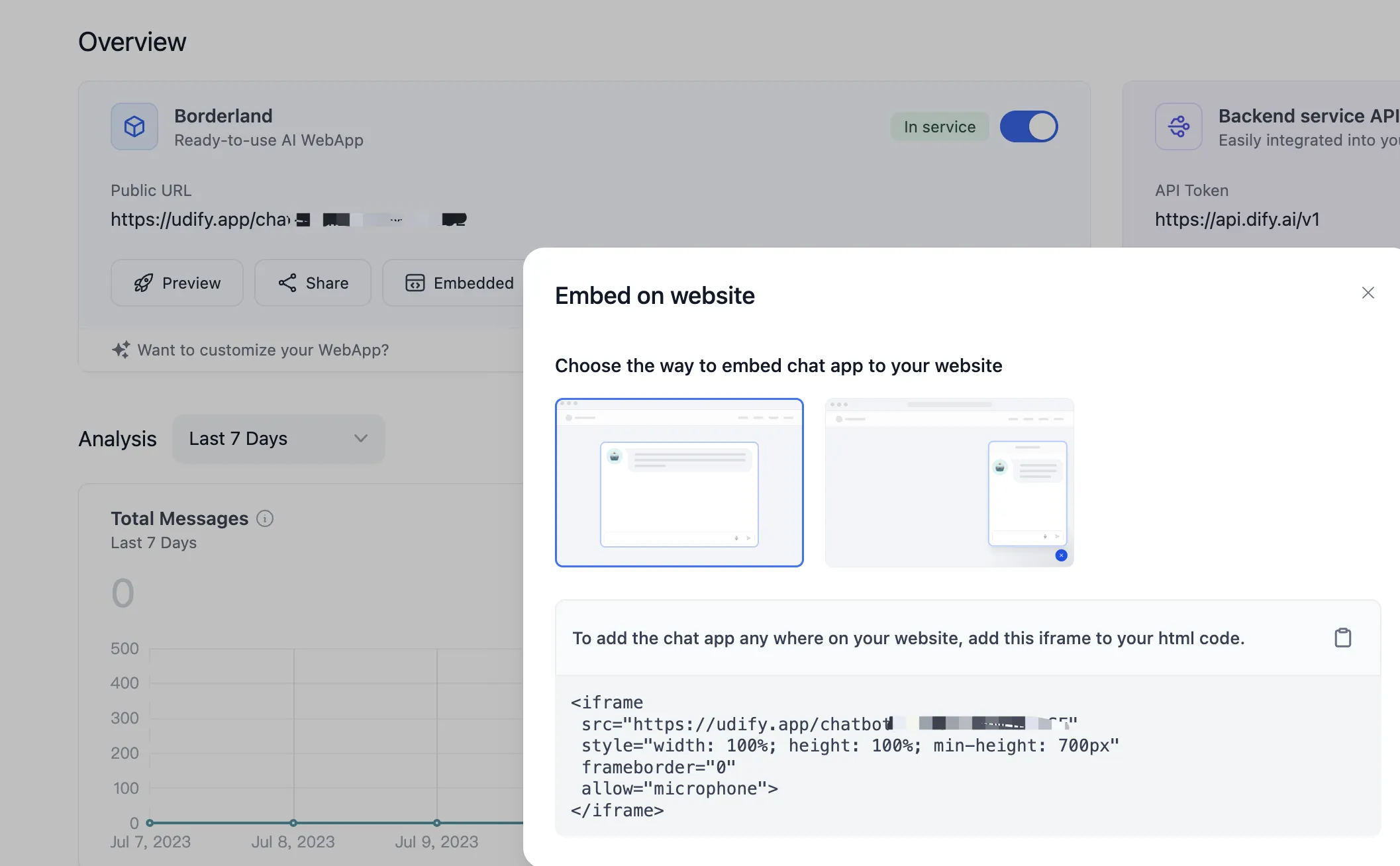
.png)





 (1).png)

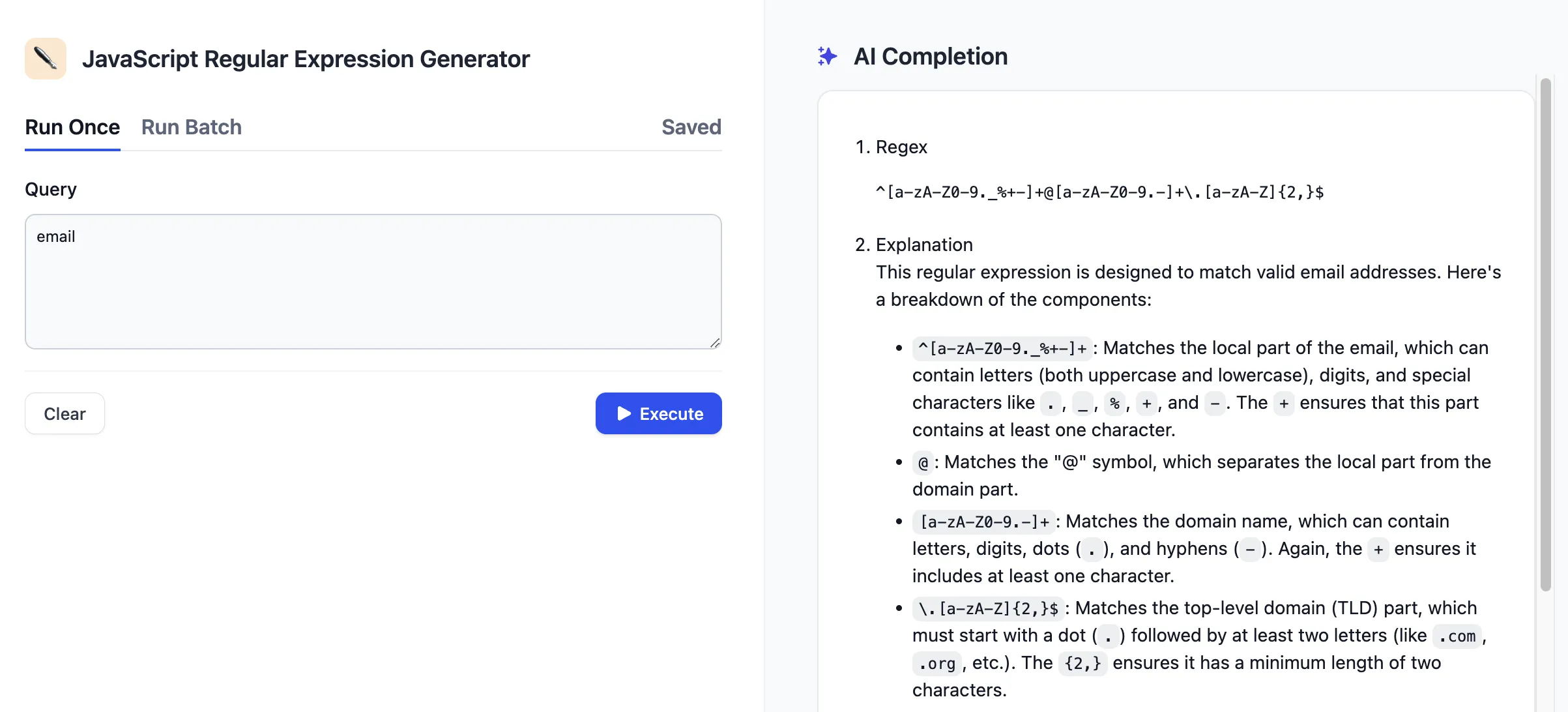

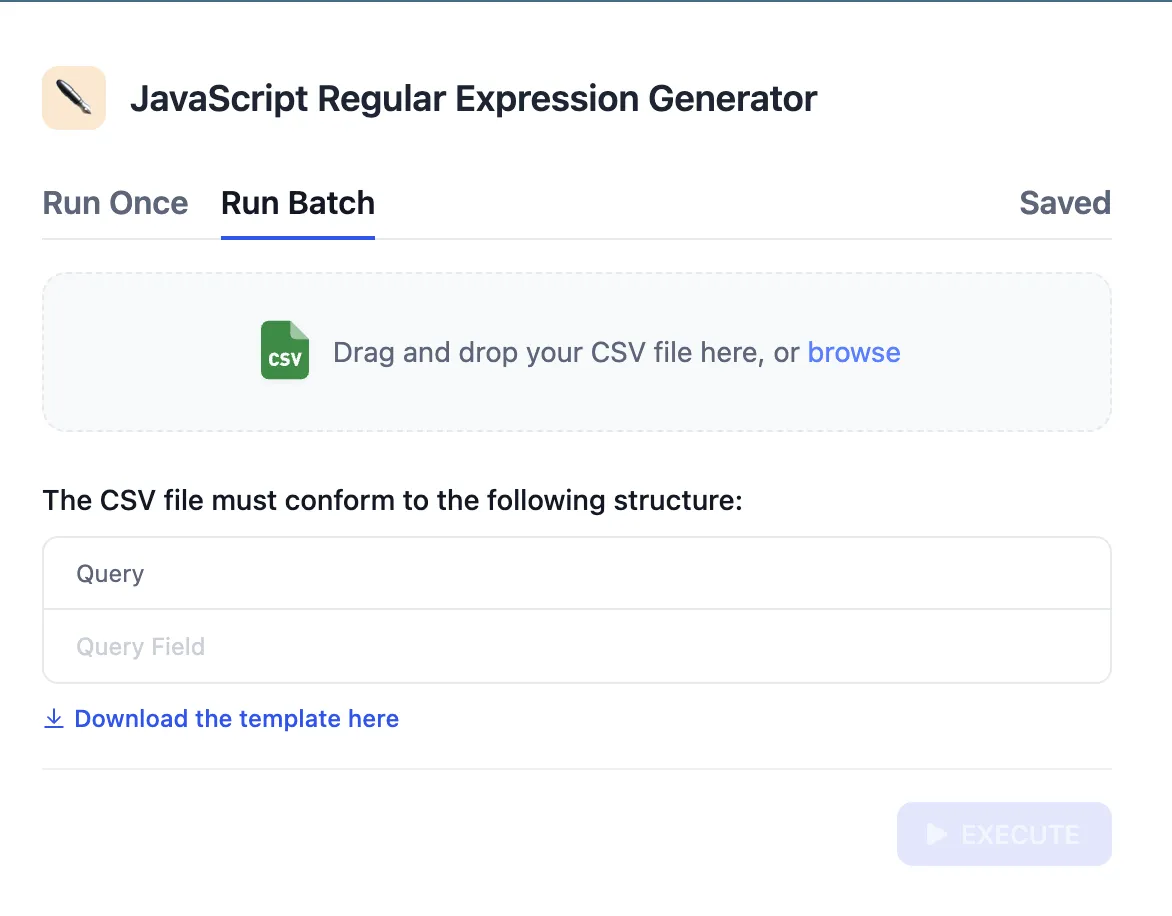


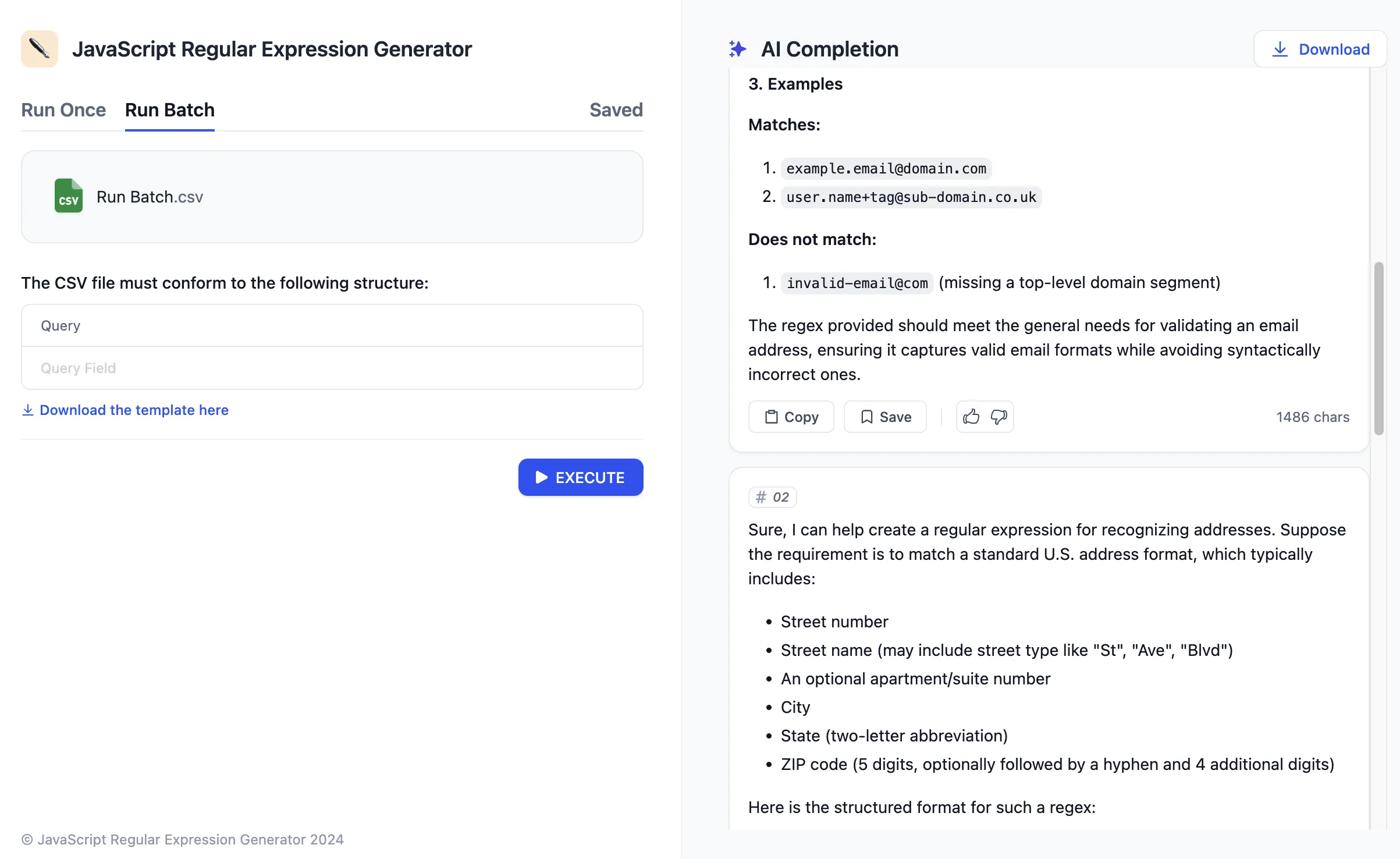



APIに基づくエクステンション
APIに基づくエクステンション
APIの設定
APIの設定
 (1).png)
エクステンションの選択
エクステンションの選択

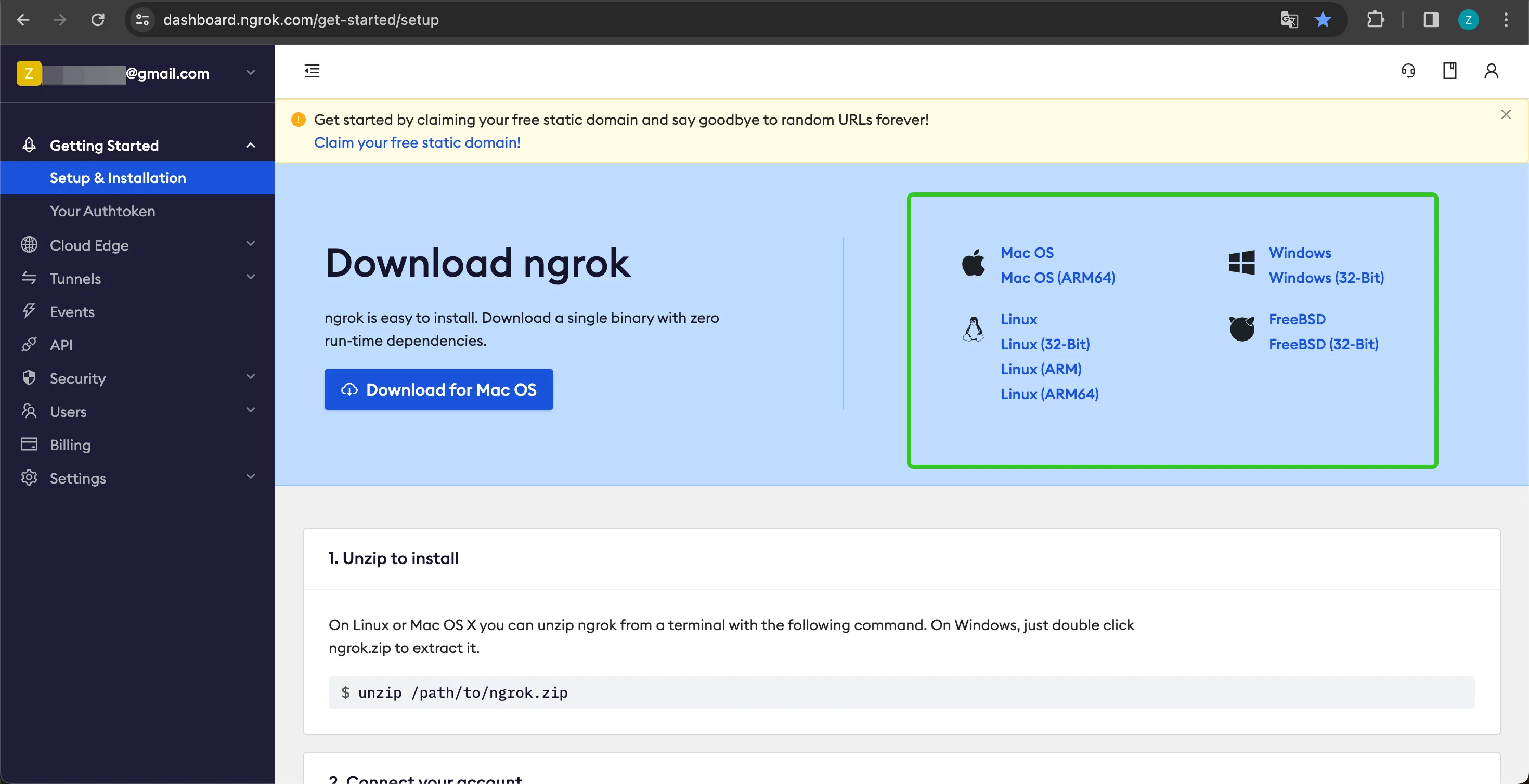
ダウンロード
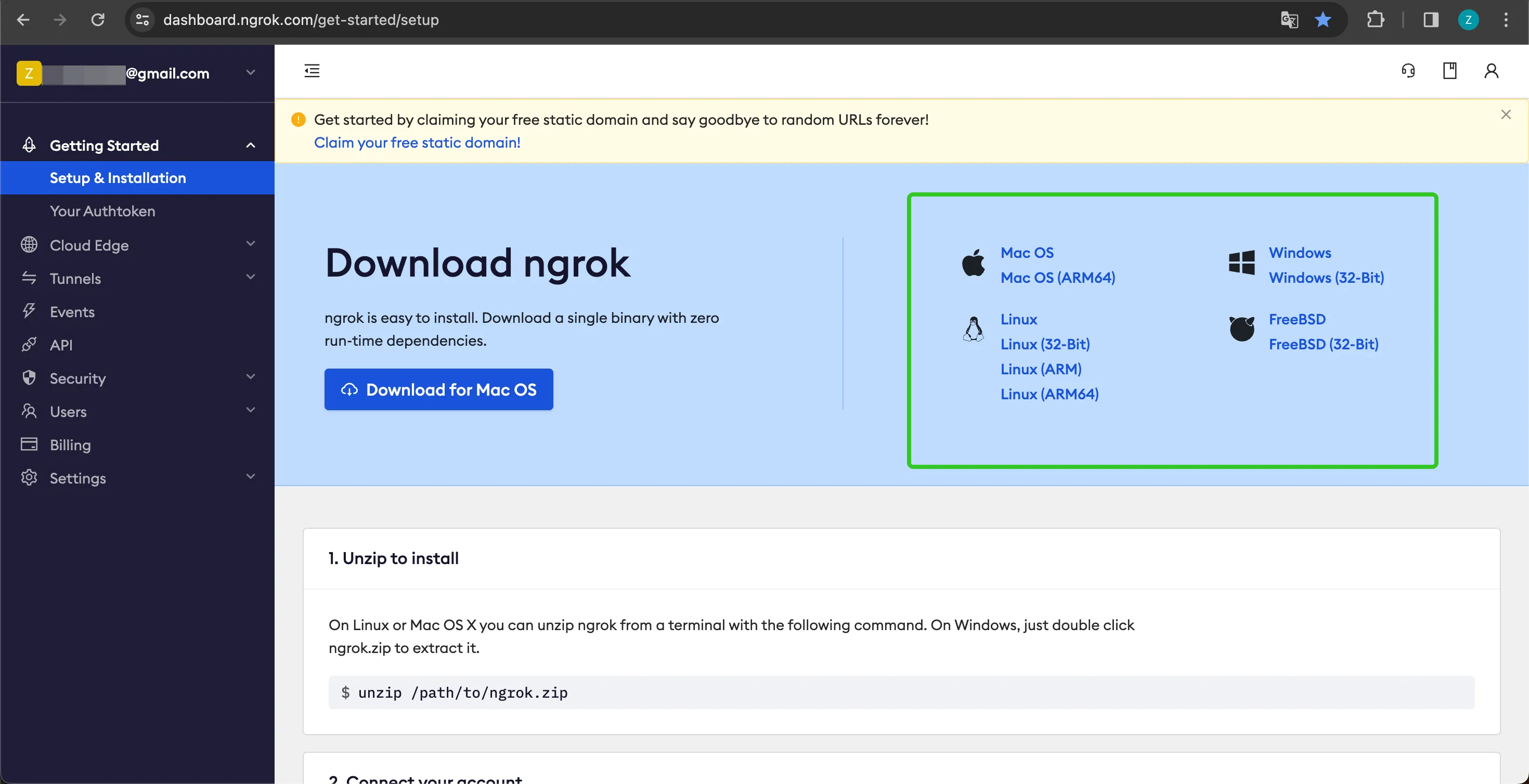
ダウンロード

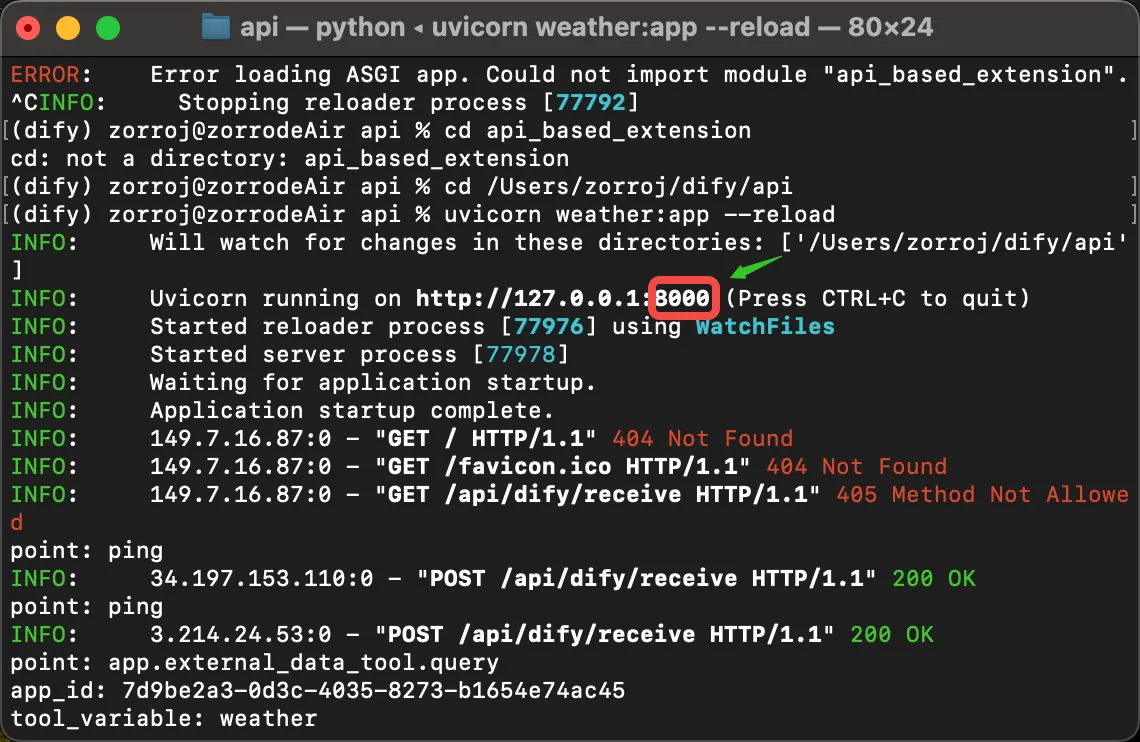
ポートの確認
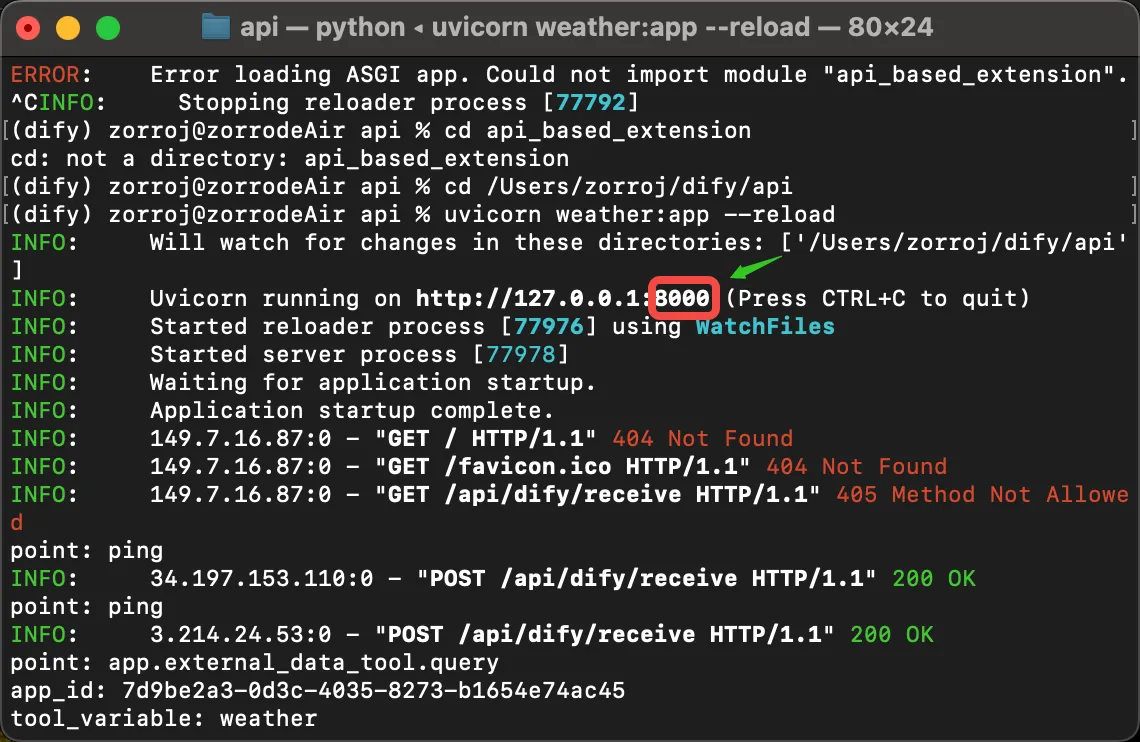
ポートの確認

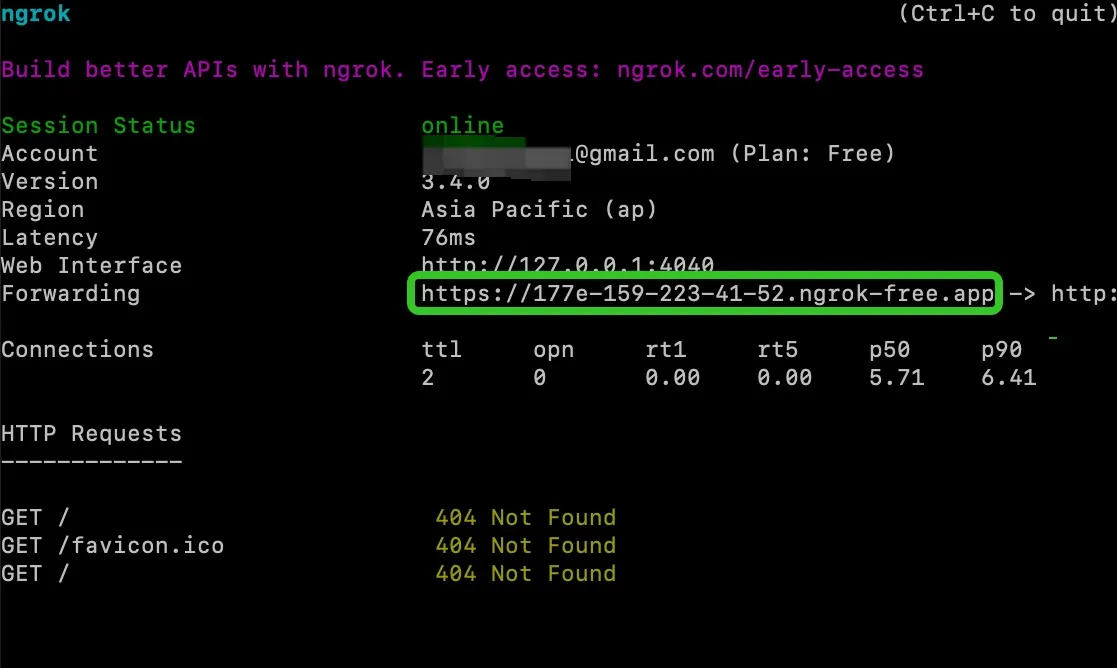
Ngrokの起動
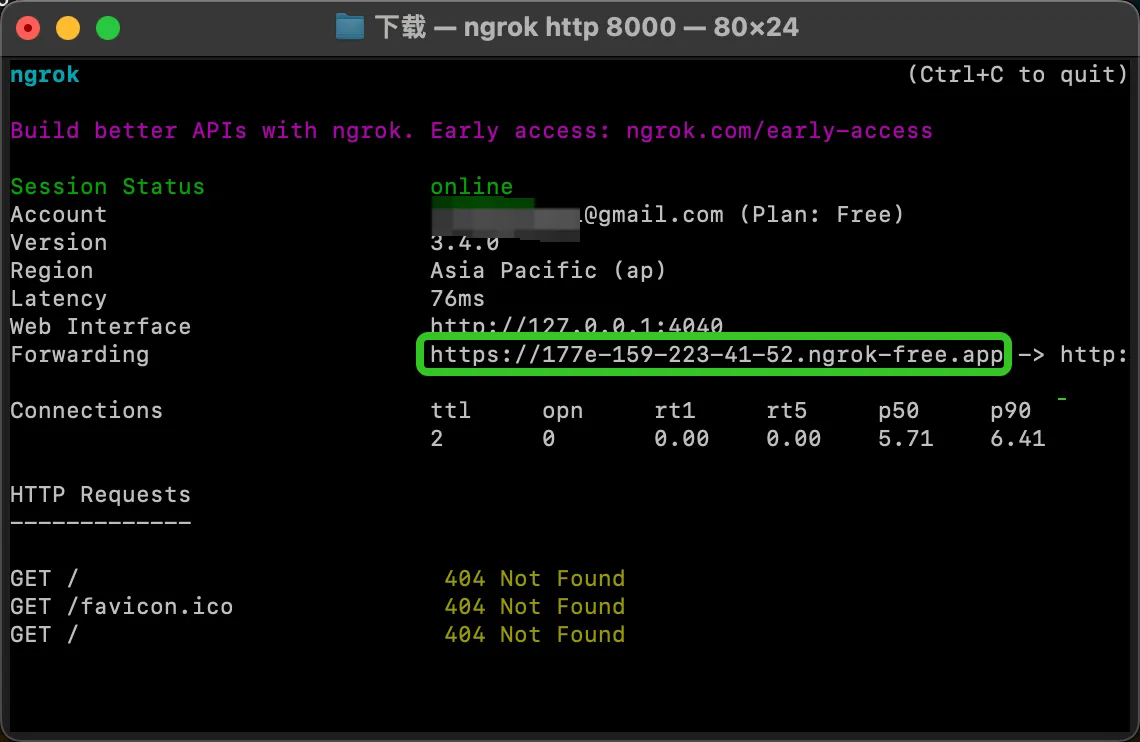
Ngrokの起動

Dify に API エンドポイントを追加する
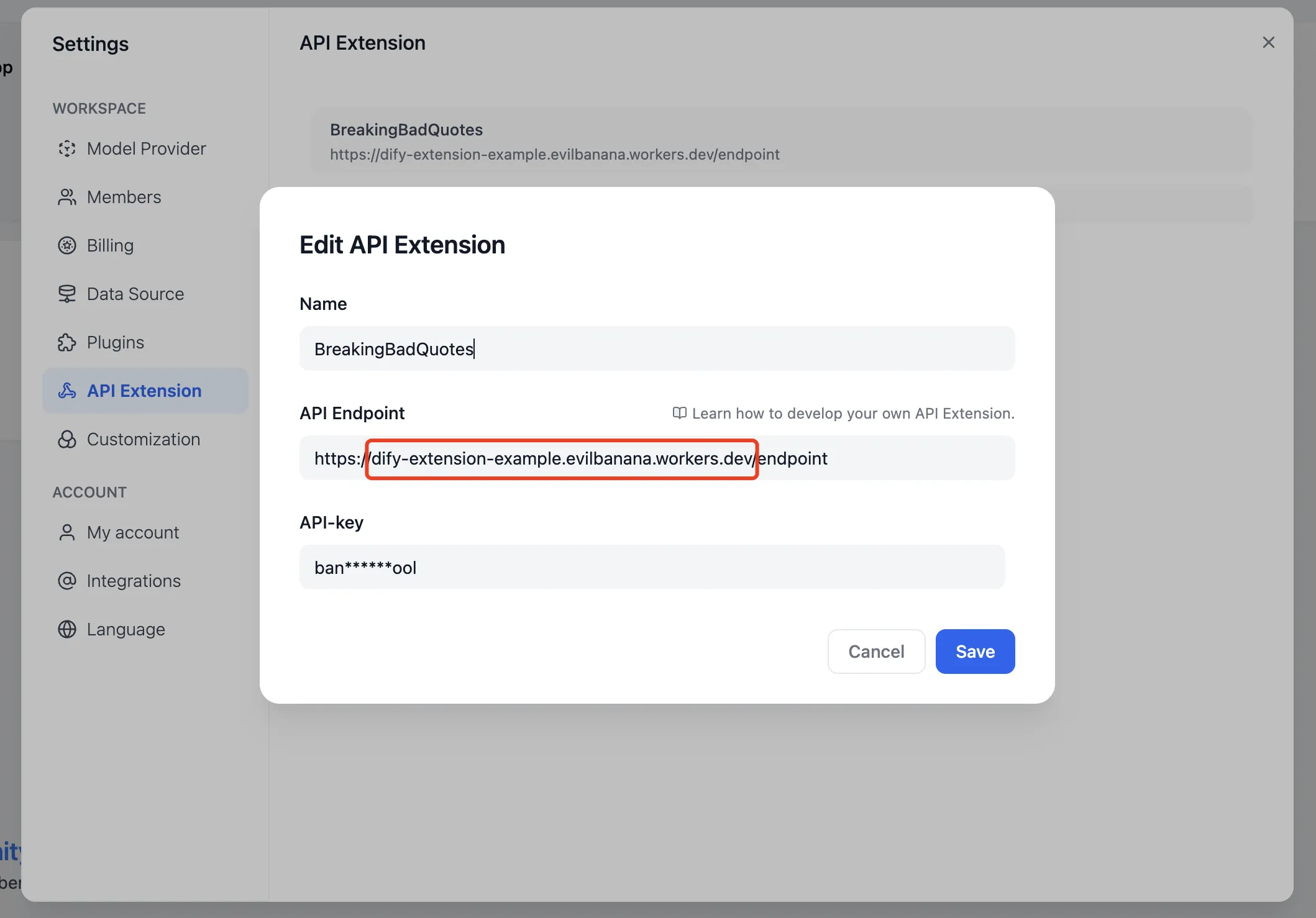
Dify に API エンドポイントを追加する

アプリ編集ページに API ツールを追加する
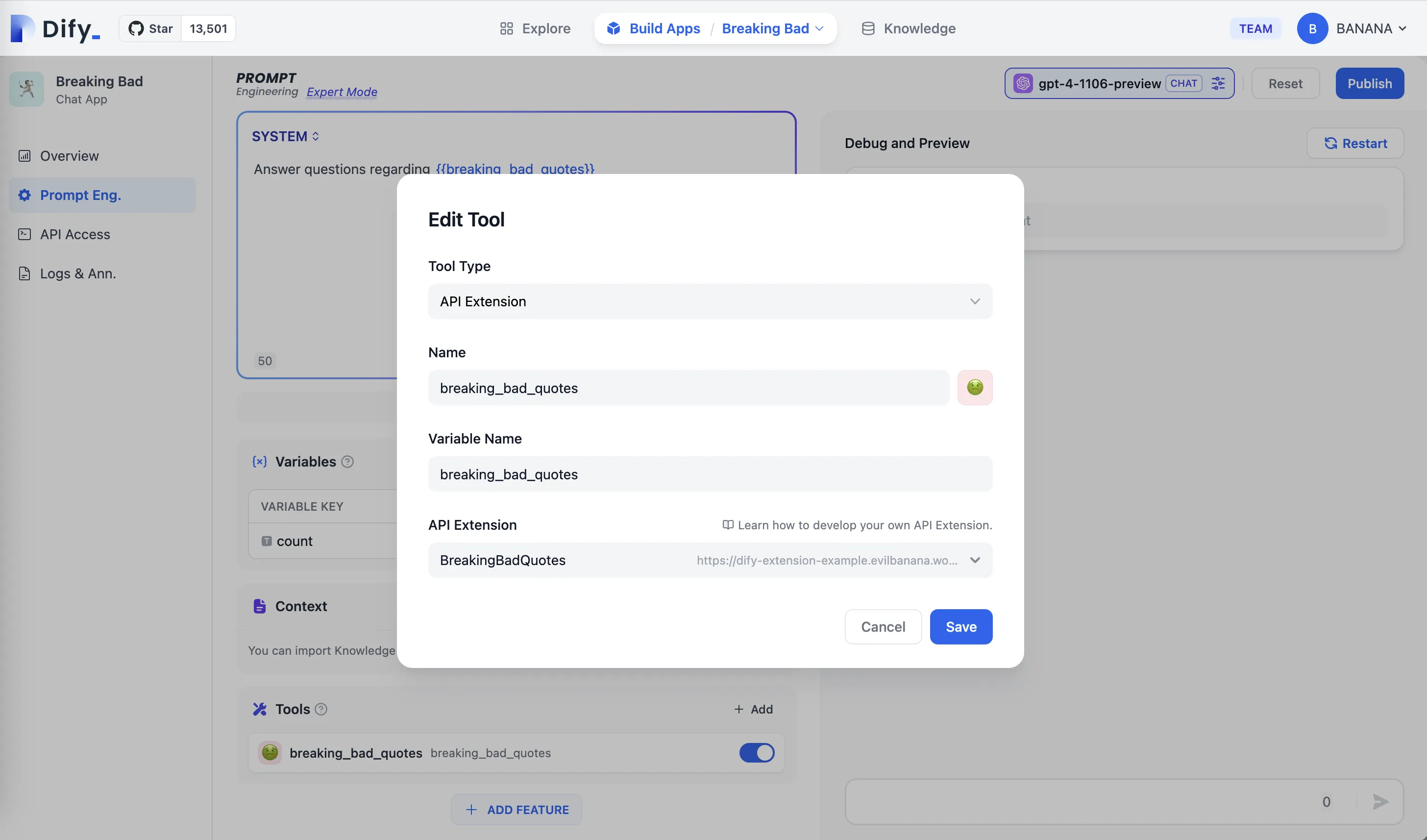
アプリ編集ページに API ツールを追加する
.png)
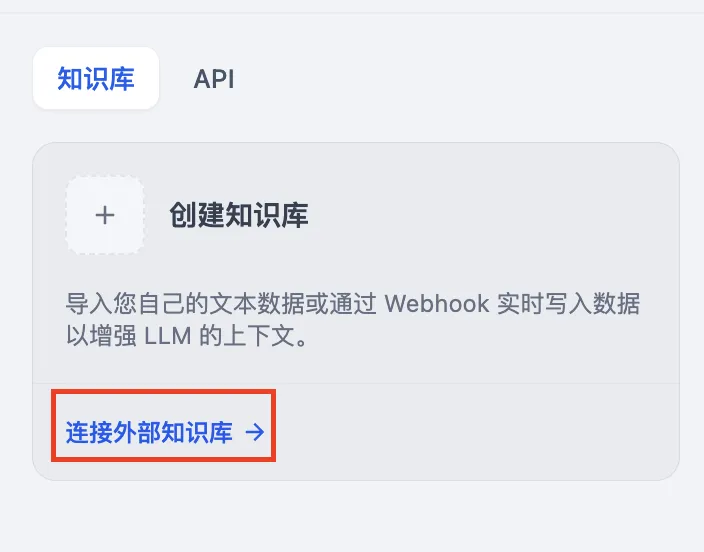
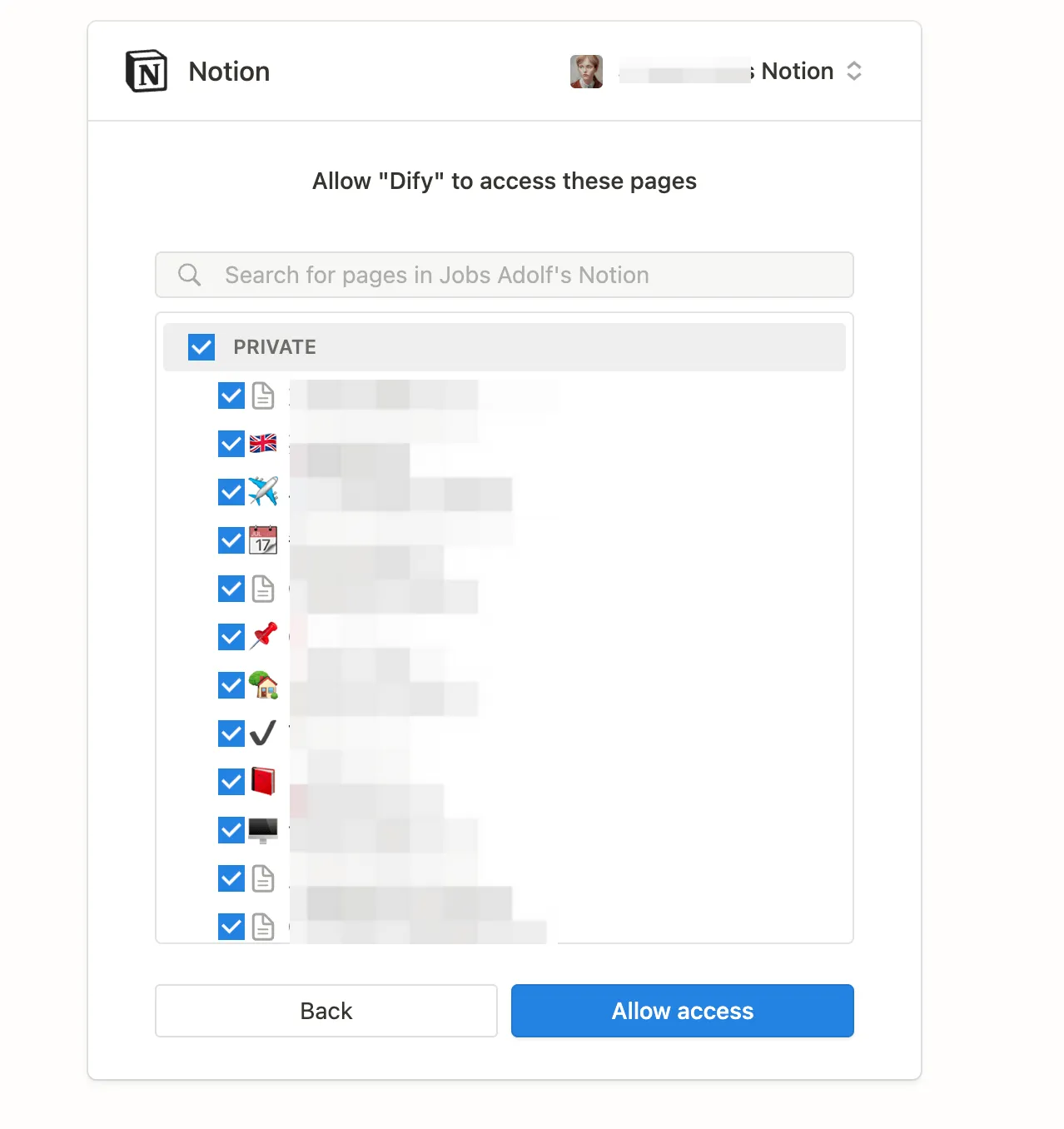
外部ナレッジベースとの接続の原理
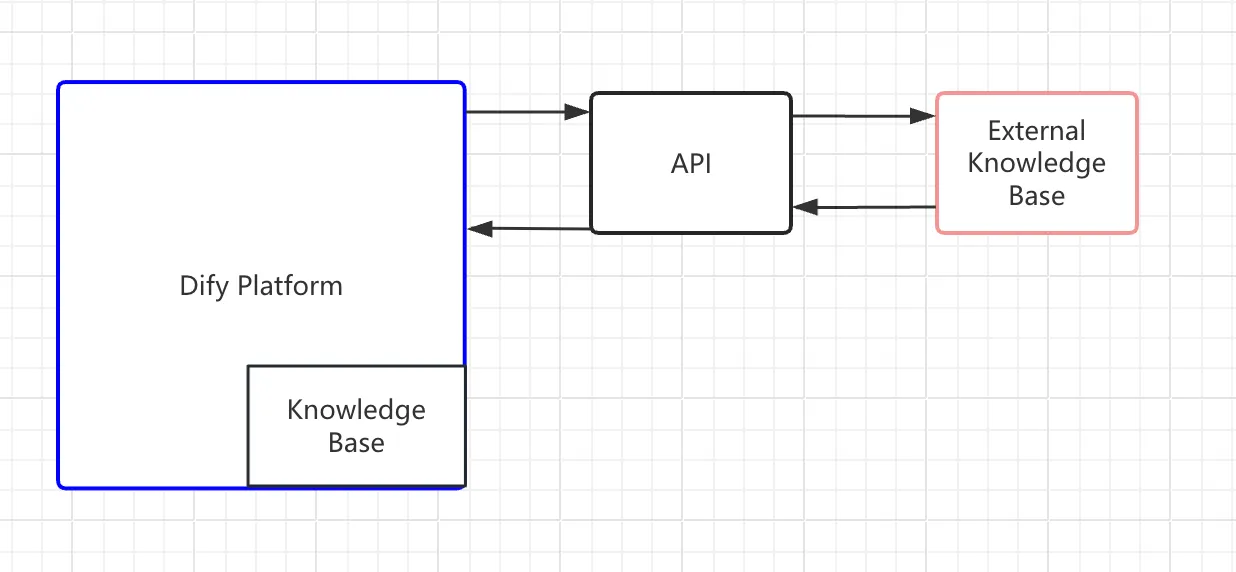
外部ナレッジベースとの接続の原理
外部ナレッジAPIの関連付け
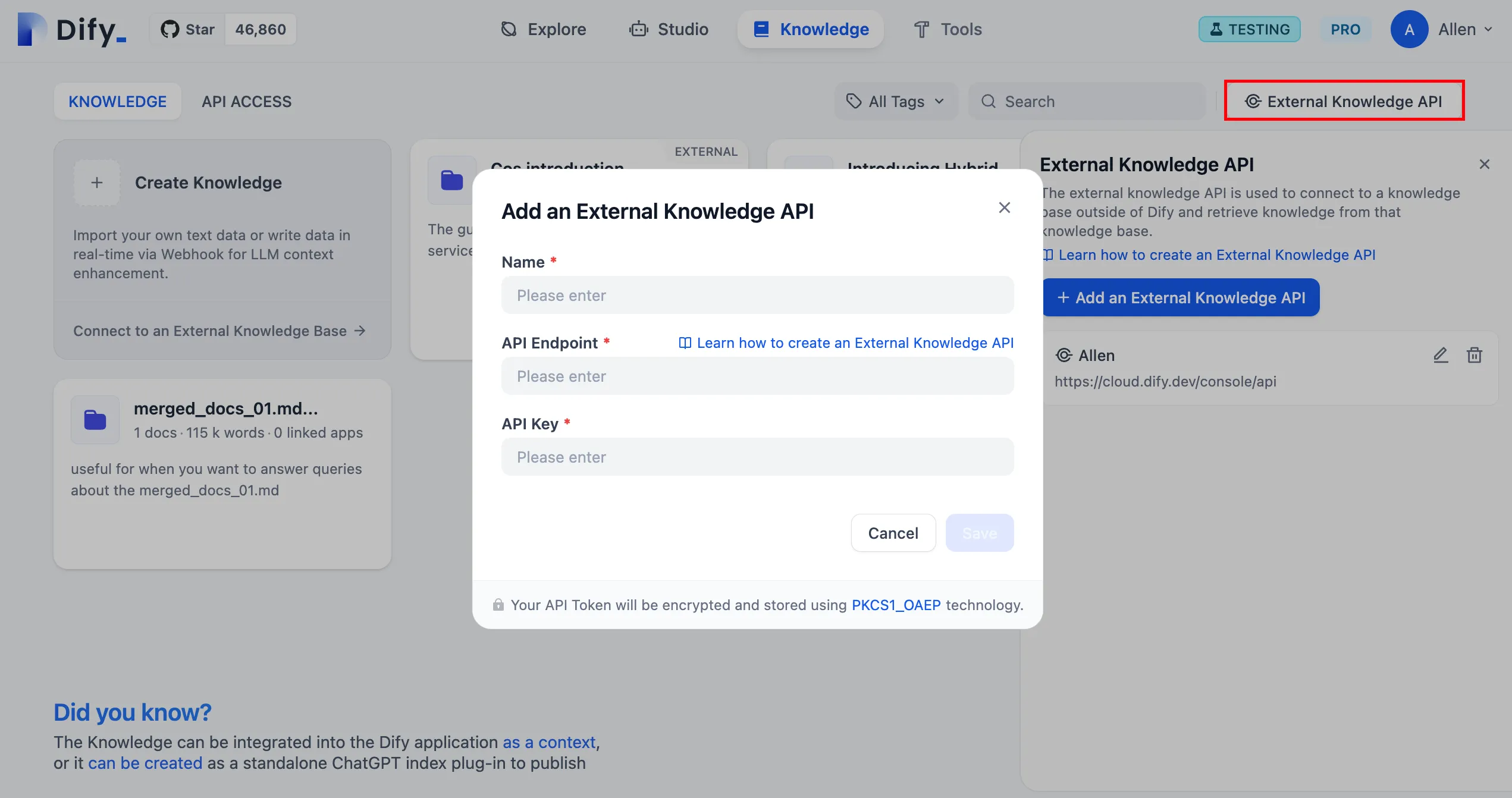
外部ナレッジAPIの関連付け
外部ナレッジベースの接続
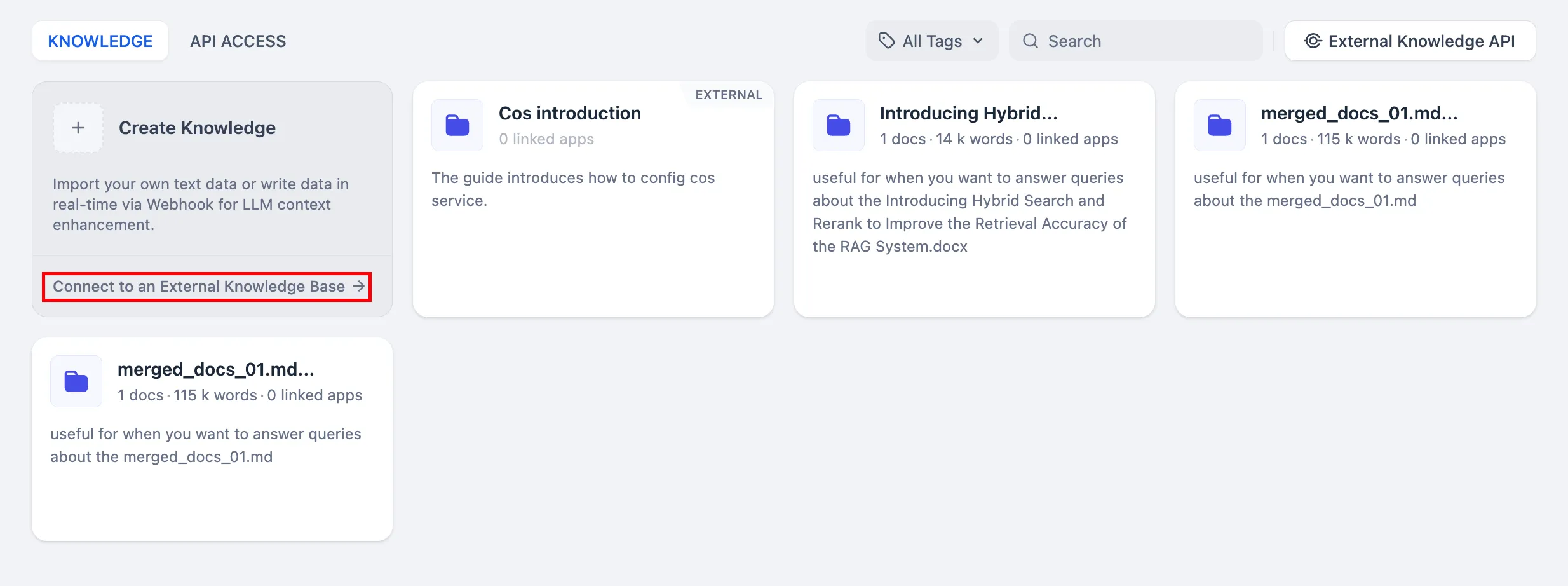
外部ナレッジベースの接続
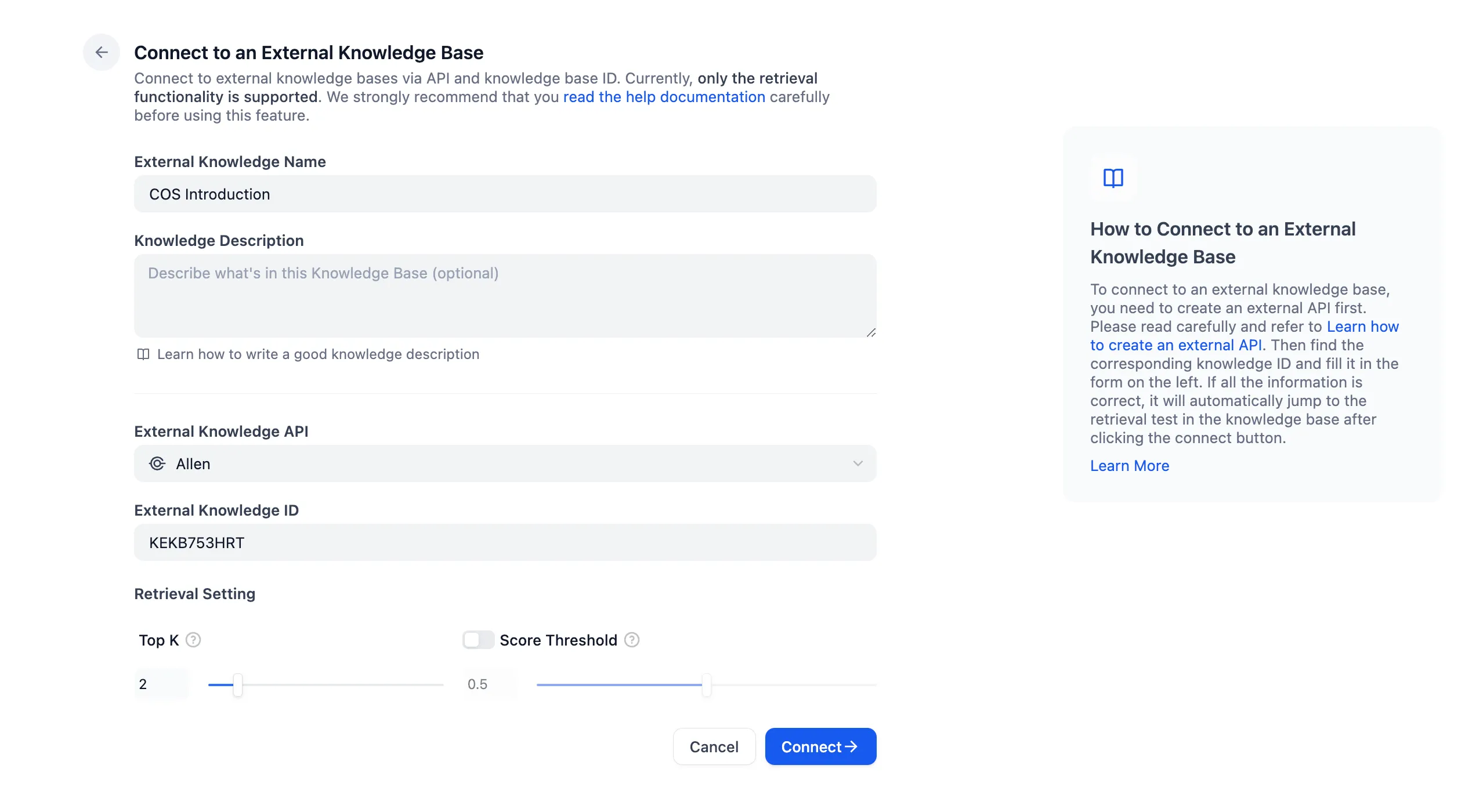
外部ナレッジベースのテストと検索結果
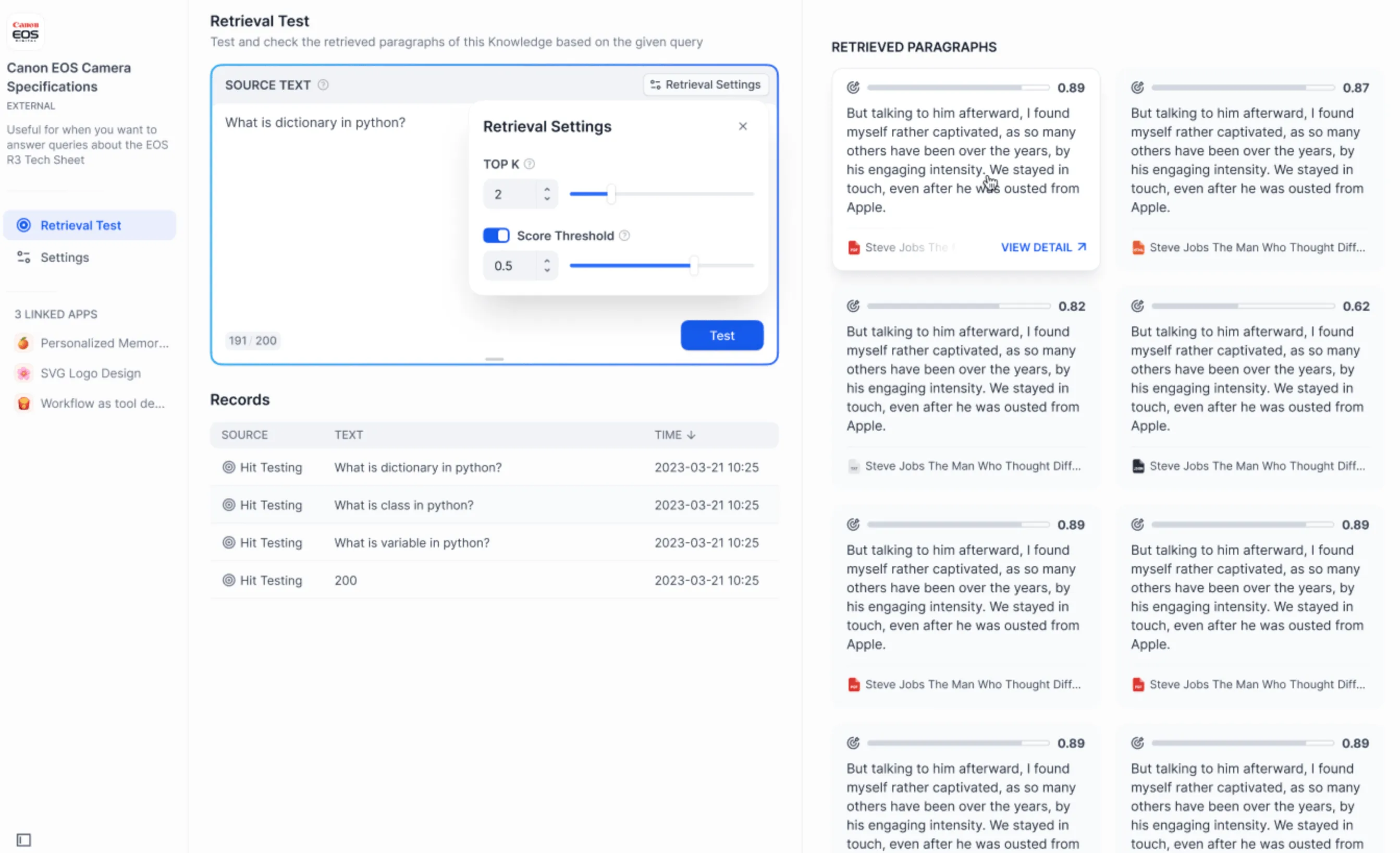
外部ナレッジベースのテストと検索結果
チャットボット/エージェント
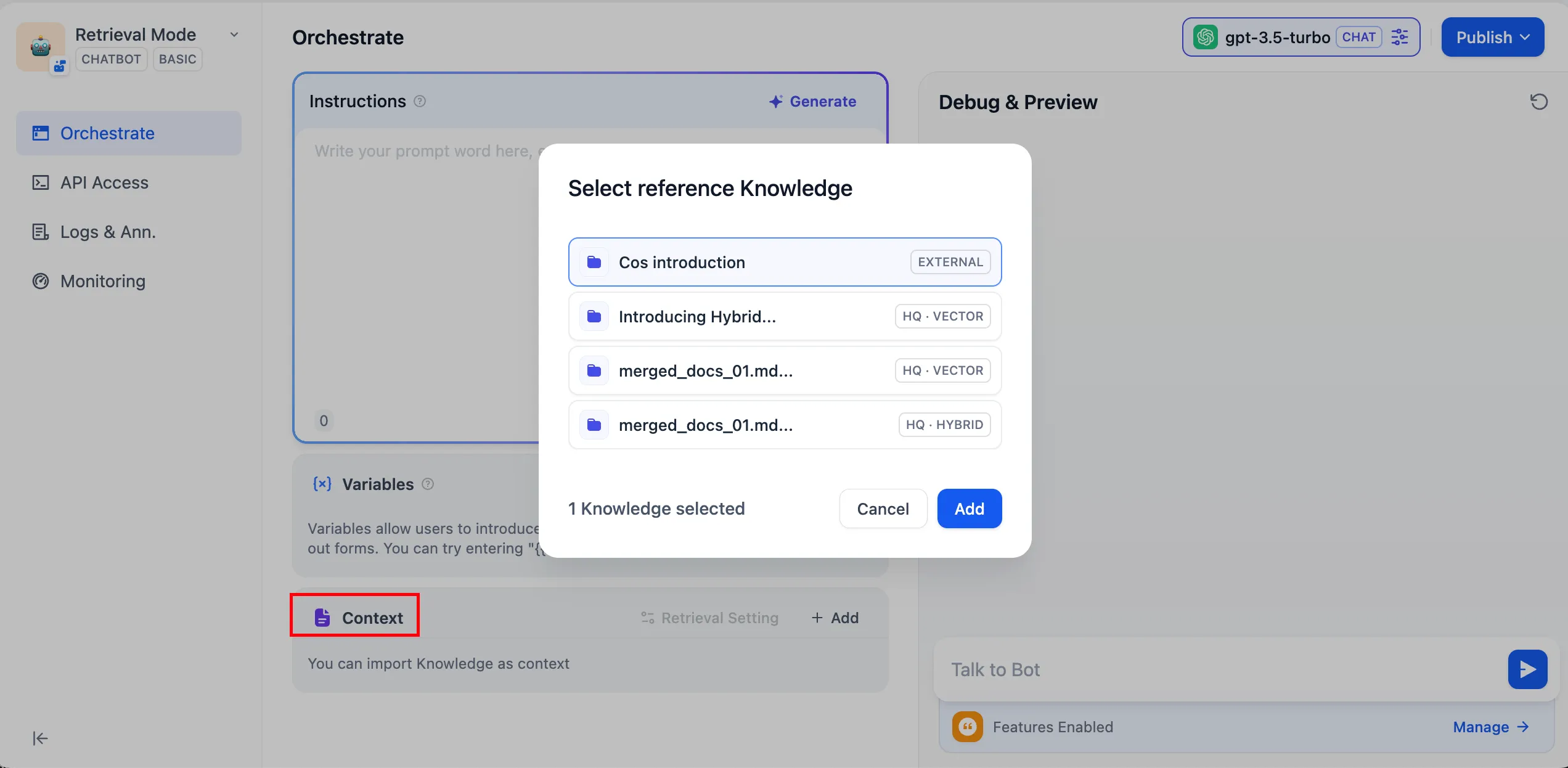
チャットボット/エージェント
チャットフロー/ワークフロー
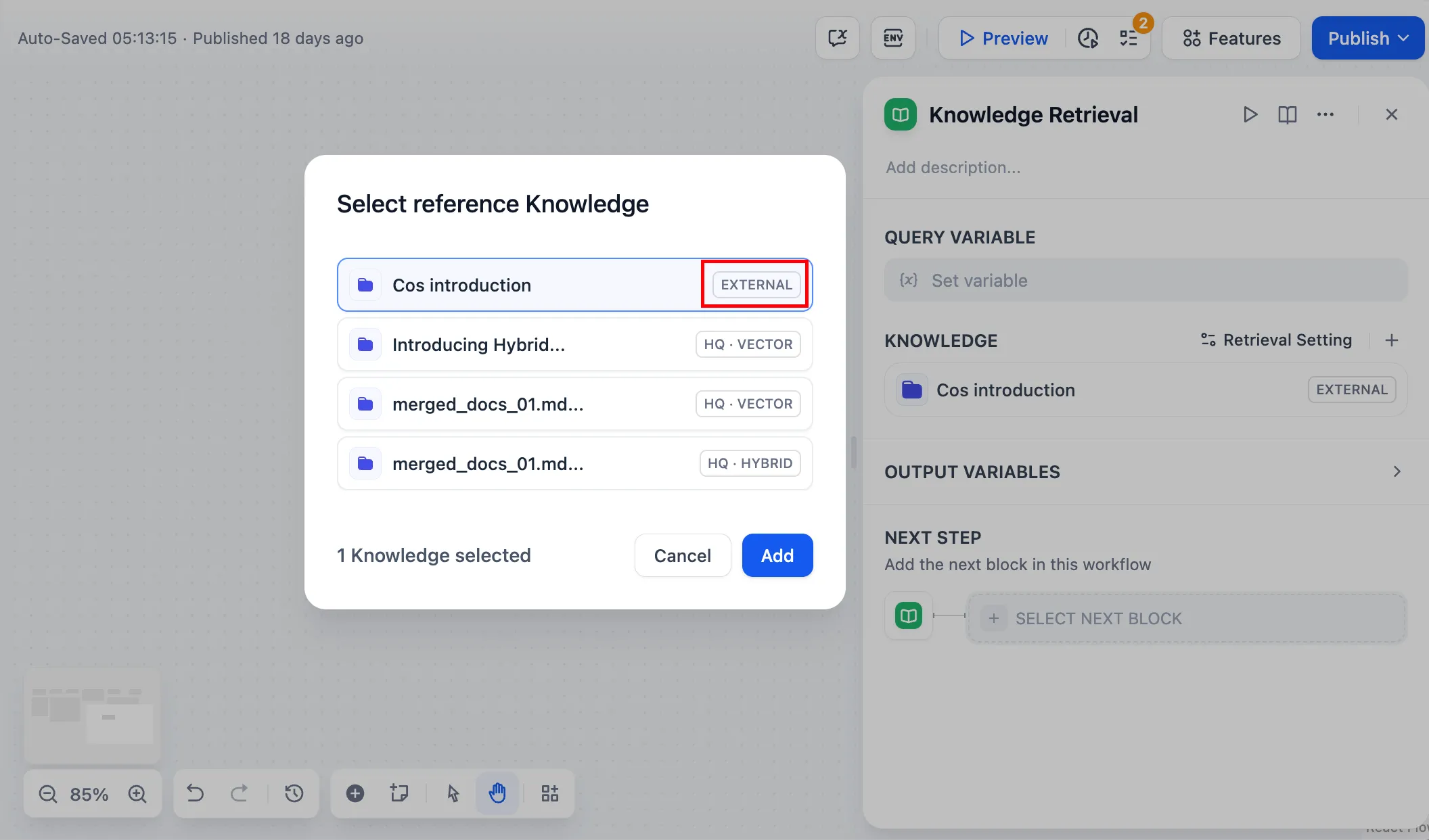
チャットフロー/ワークフロー
ナレッジベースの設置
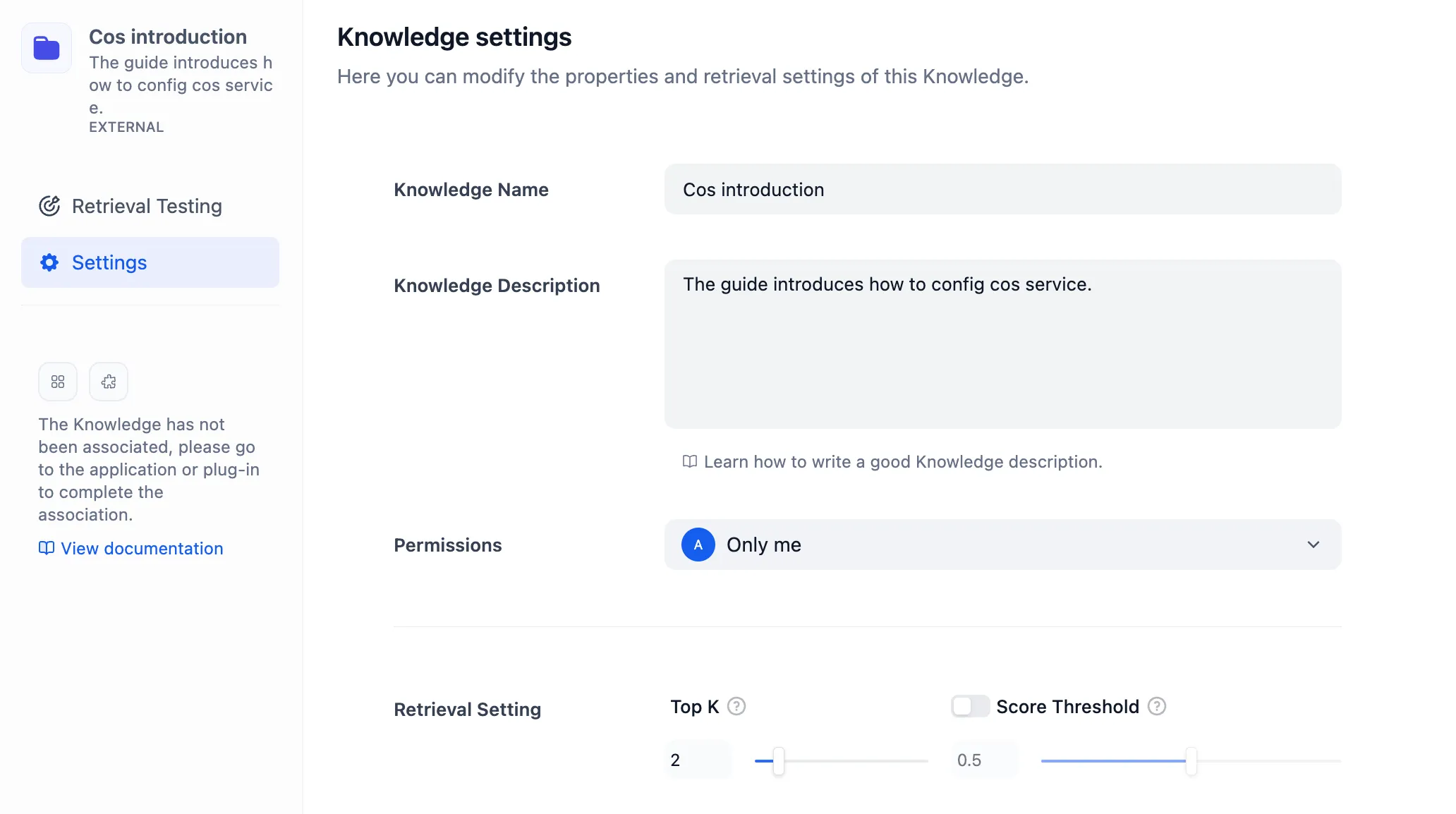
ナレッジベースの設置





.png)

APIベースの拡張
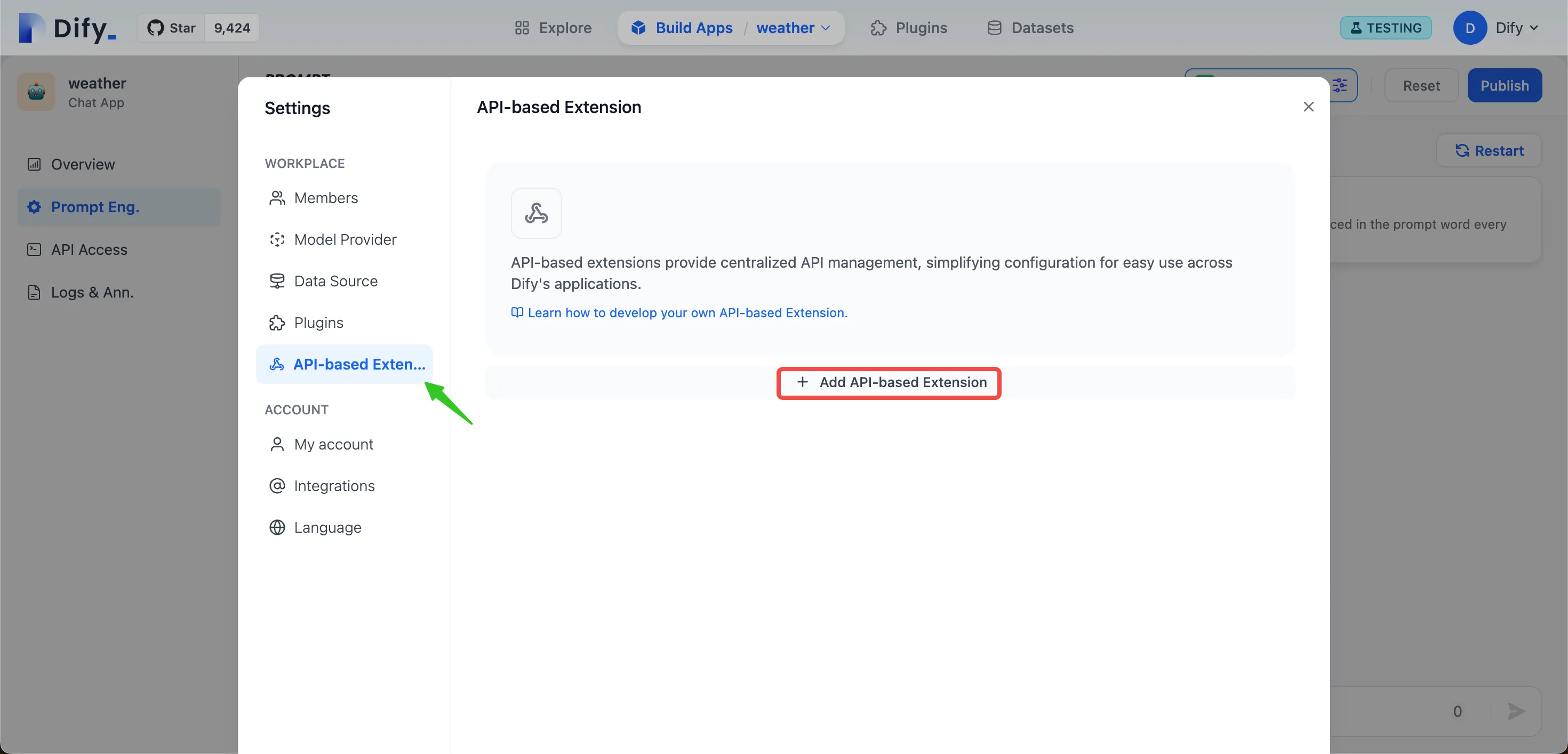
APIベースの拡張

天気の問い合わせ
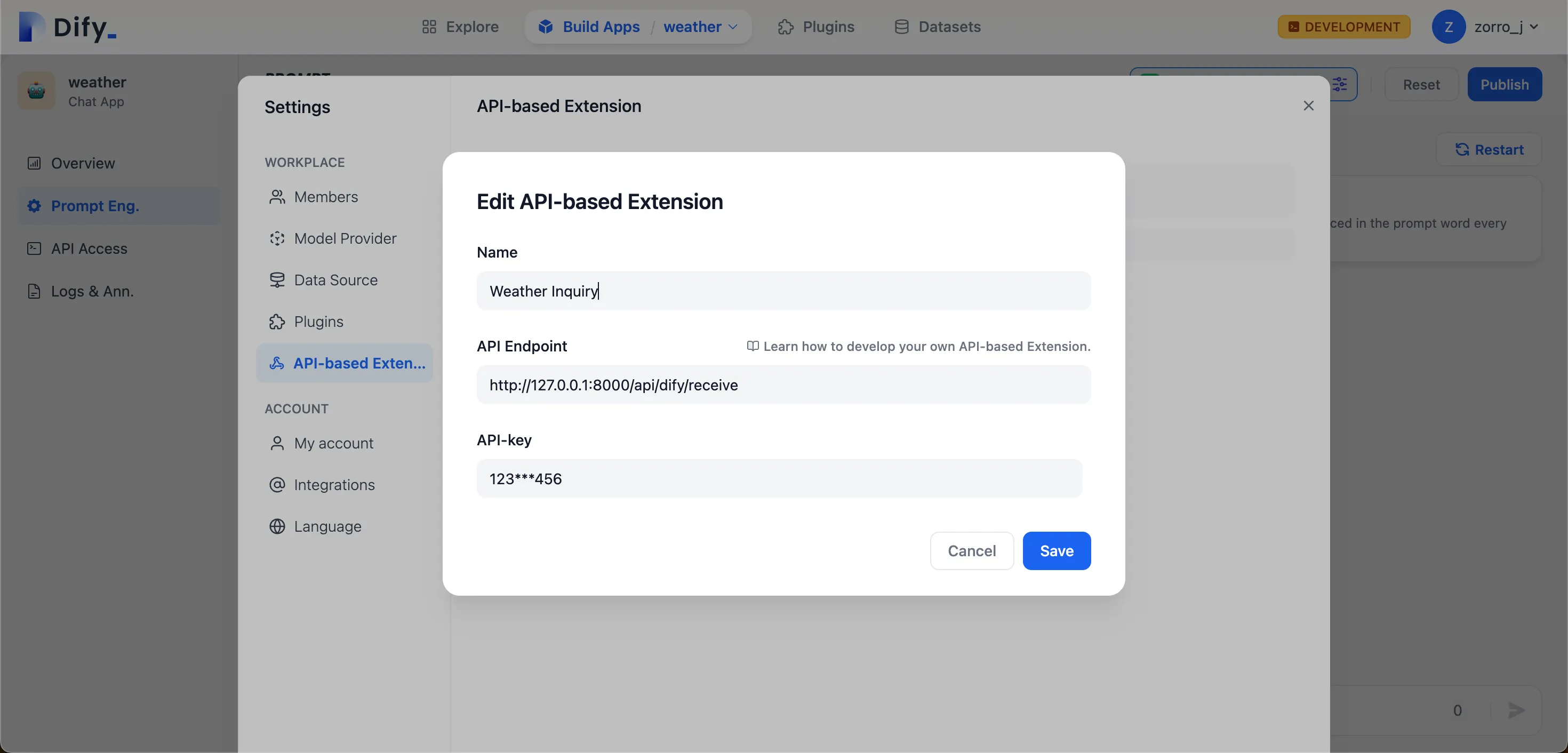
天気の問い合わせ

外部データツール
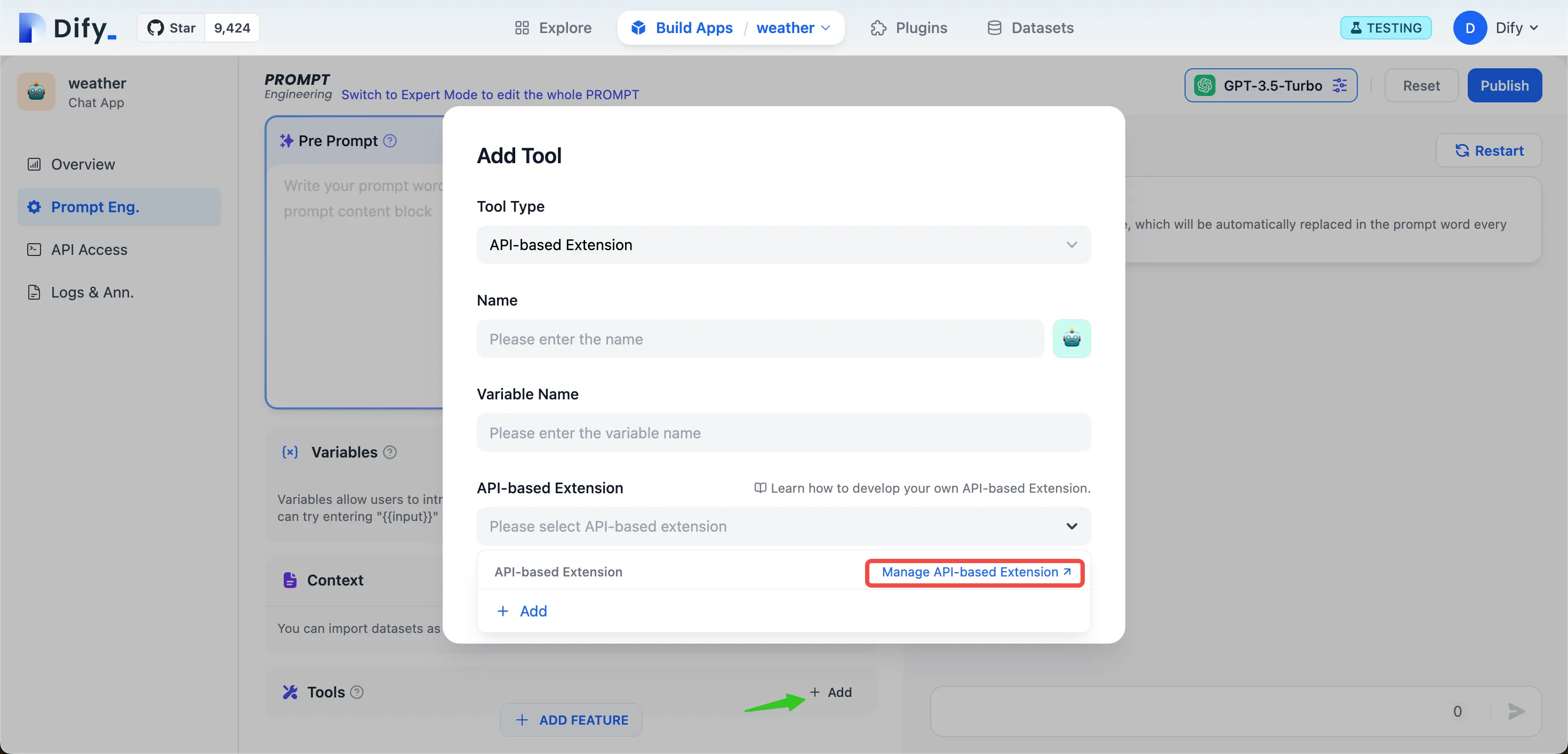
外部データツール

天気検索ツール
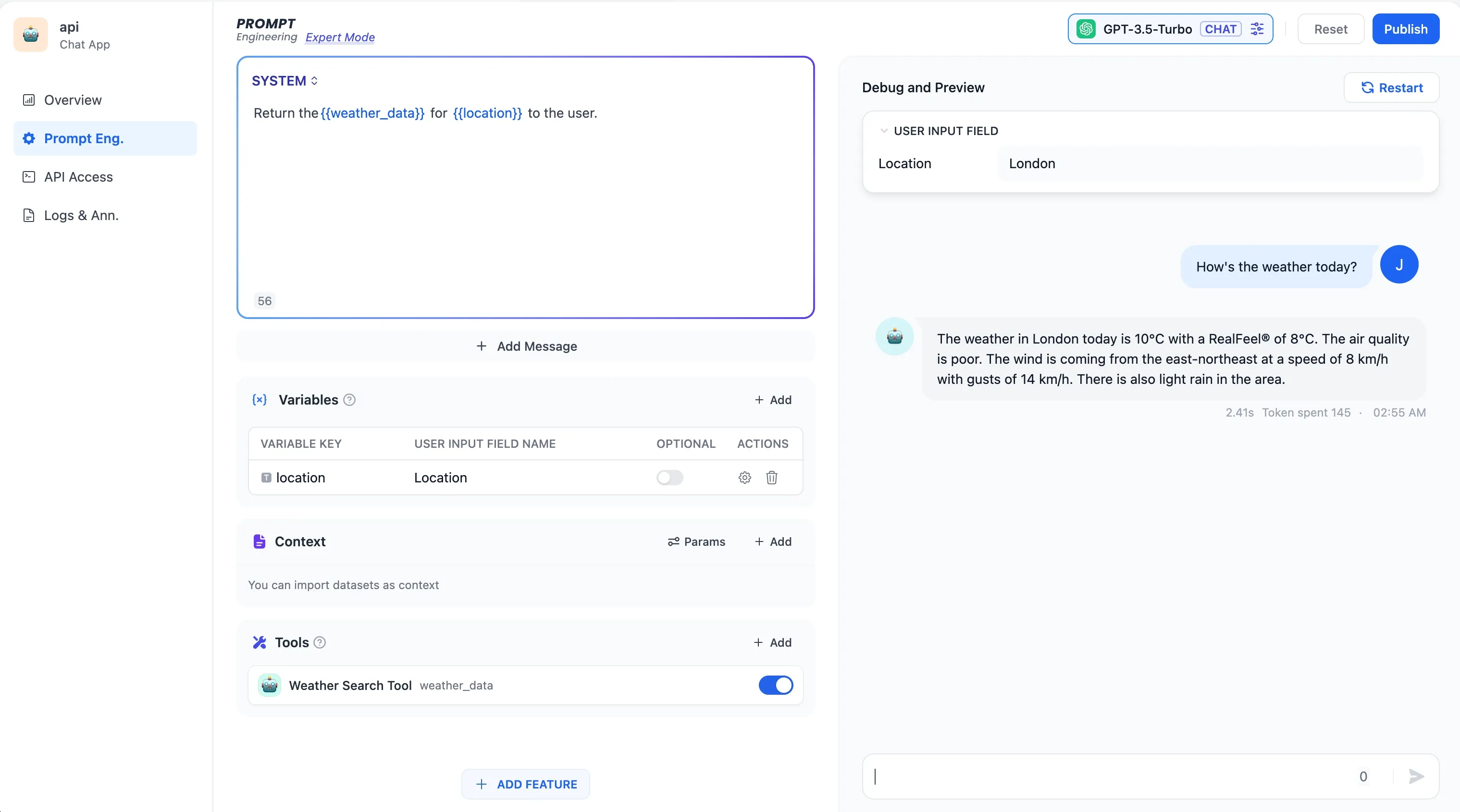
天気検索ツール

プロンプトログ
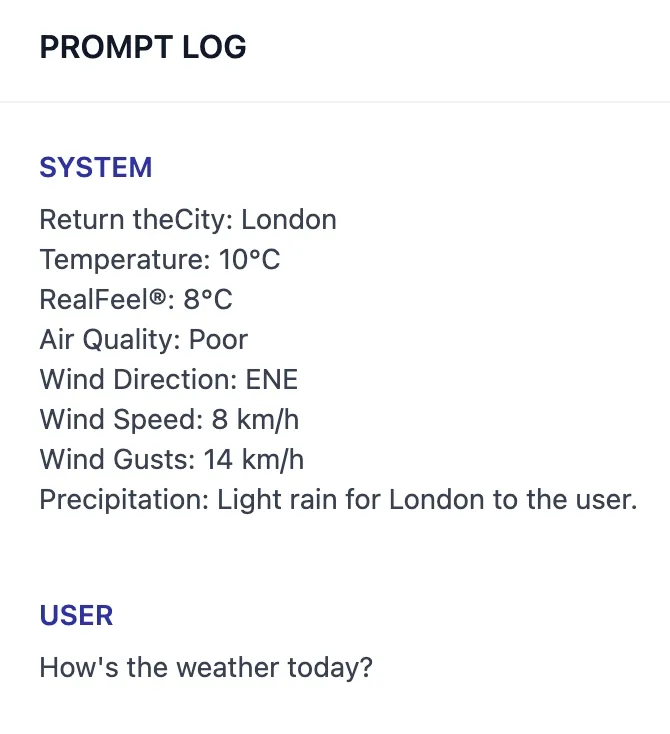
プロンプトログ


モデルサプライヤー内でRerankモデルを設定
モデルサプライヤー内でRerankモデルを設定

ナレッジベースAPIの管理
ナレッジベースAPIの管理

Knowledge API ドキュメント
Knowledge API ドキュメント
引用と帰属機能を有効にする
引用と帰属機能を有効にする
返信内容の引用情報を確認する
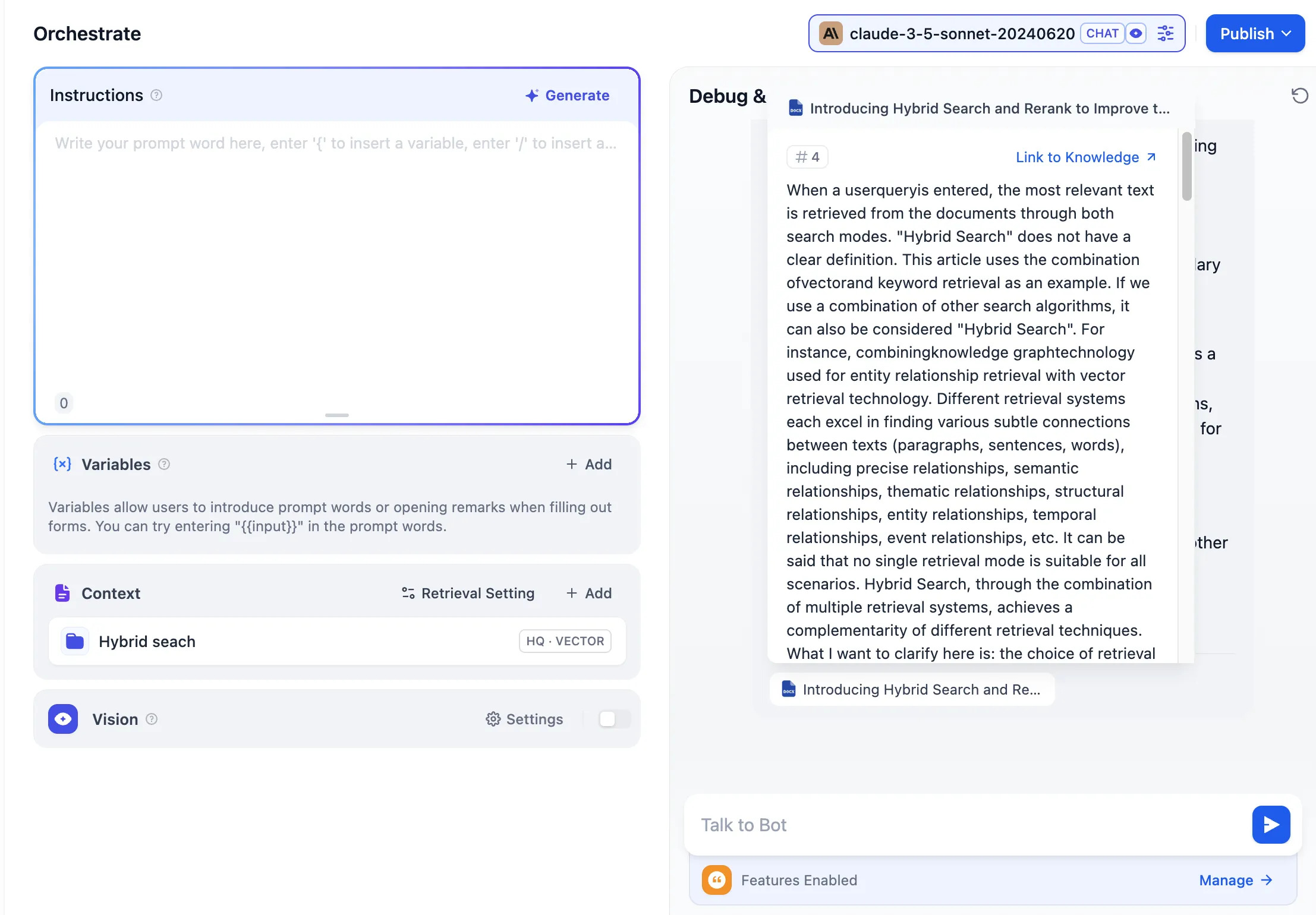
返信内容の引用情報を確認する
.png)
アプリ情報の編集
アプリ情報の編集

チームの請求管理
チームの請求管理
有料プランの変更
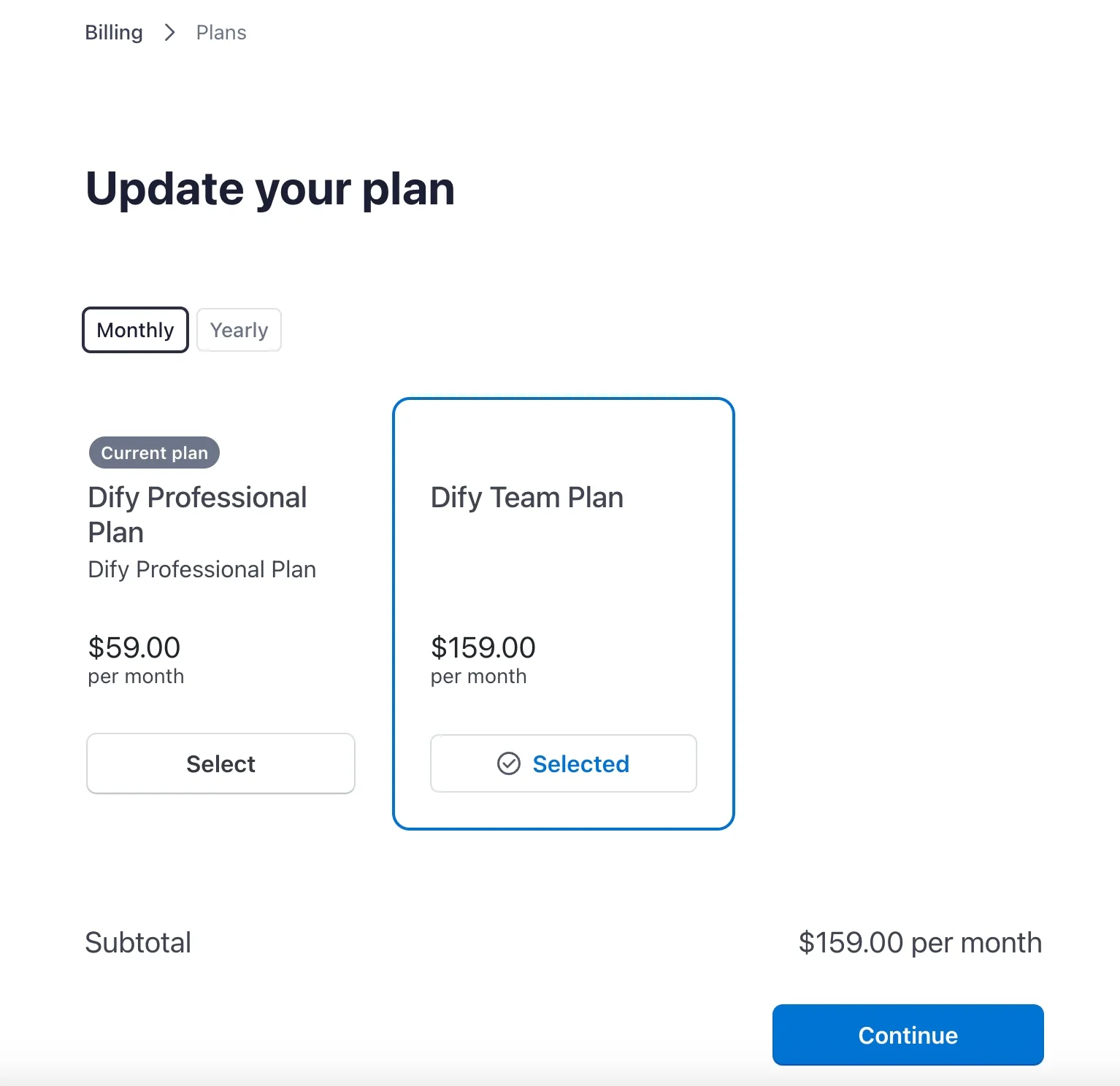
有料プランの変更
チームメンバーへの権限の割り当て
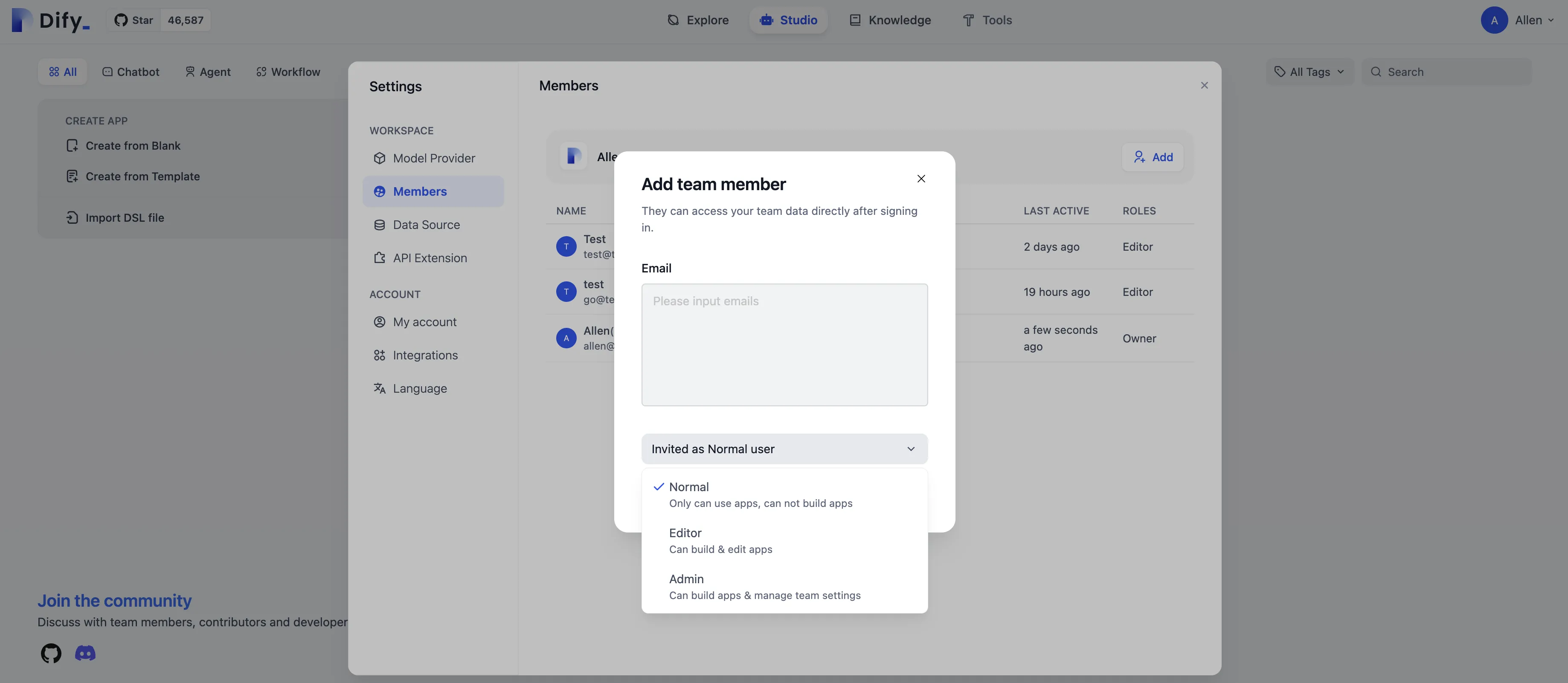
チームメンバーへの権限の割り当て
メンバーの削除
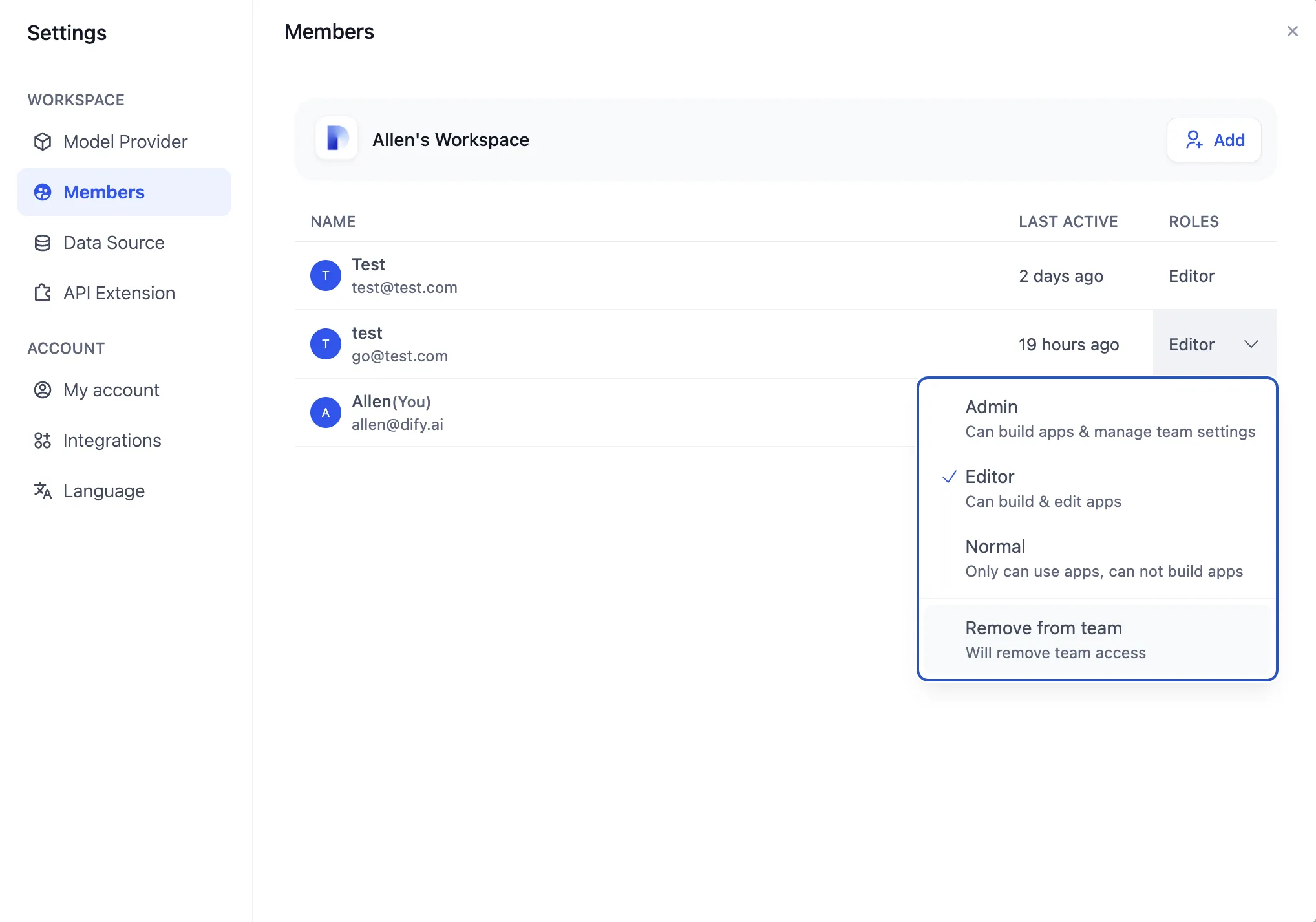
メンバーの削除
.png)
.png)
.png)
.png)
.png)

モデルを負荷分散する
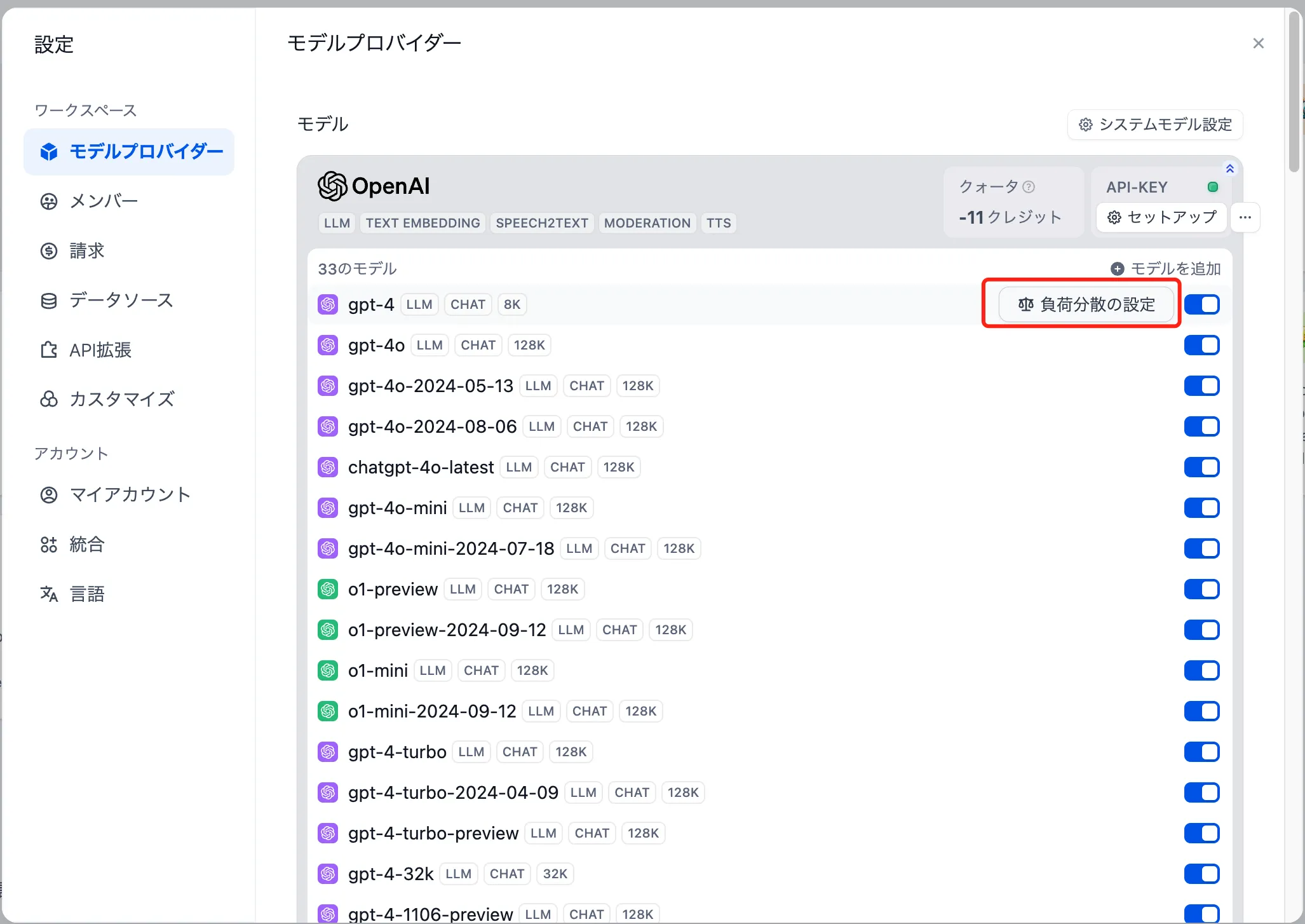
モデルを負荷分散する

負荷分散の設定
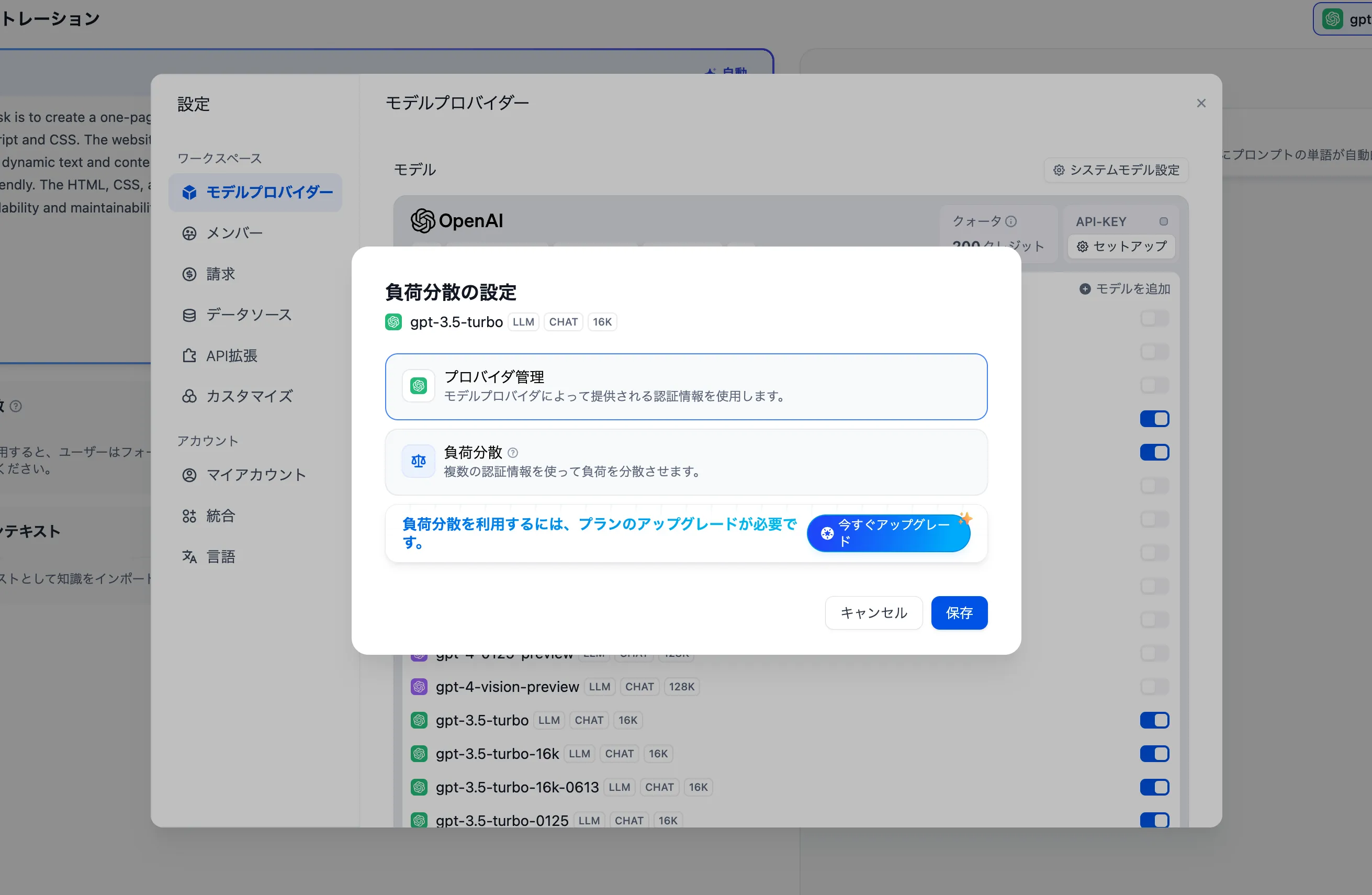
負荷分散の設定

負荷分散の有効化
負荷分散の有効化
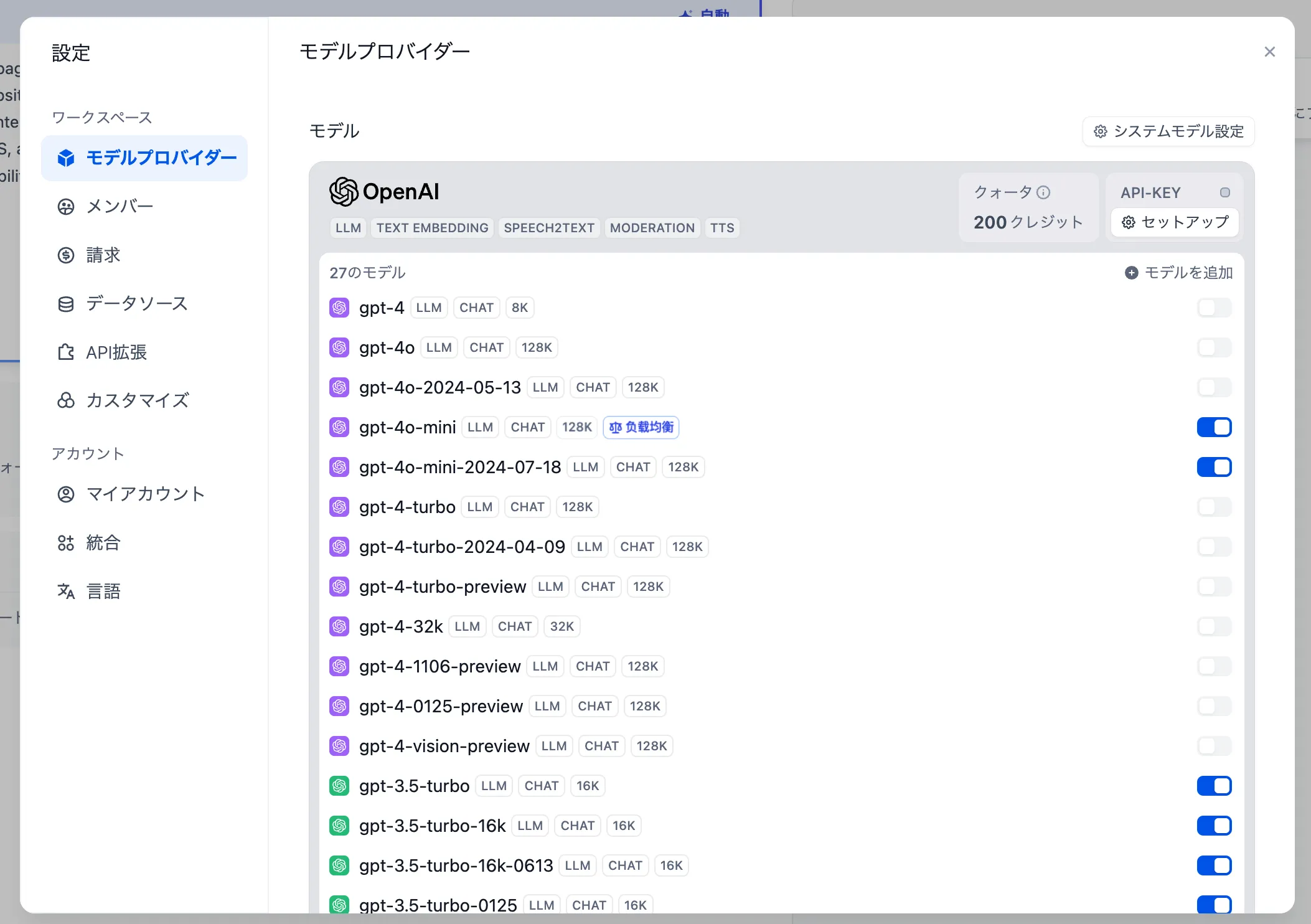
モデルの追加から負荷分散を設定
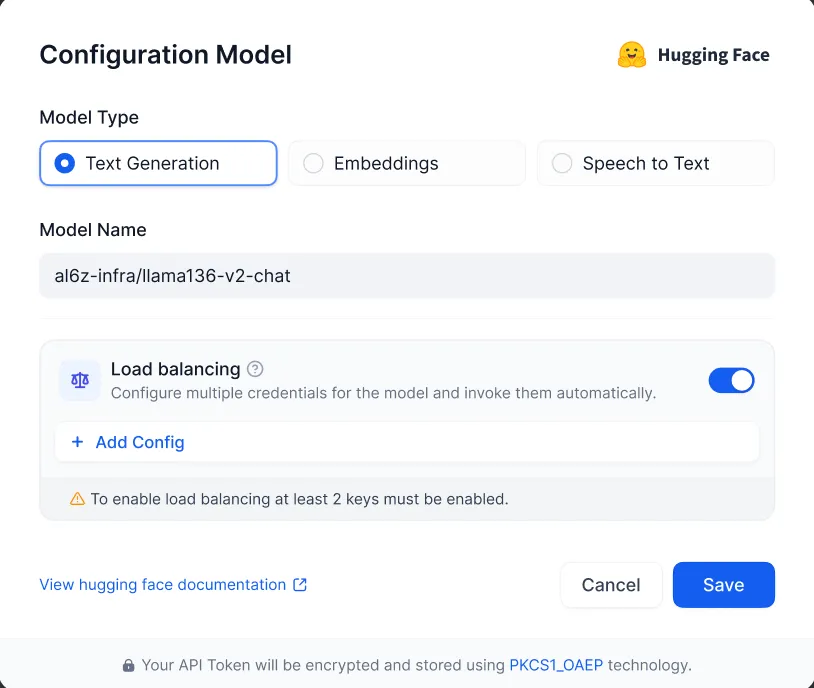
モデルの追加から負荷分散を設定
概要
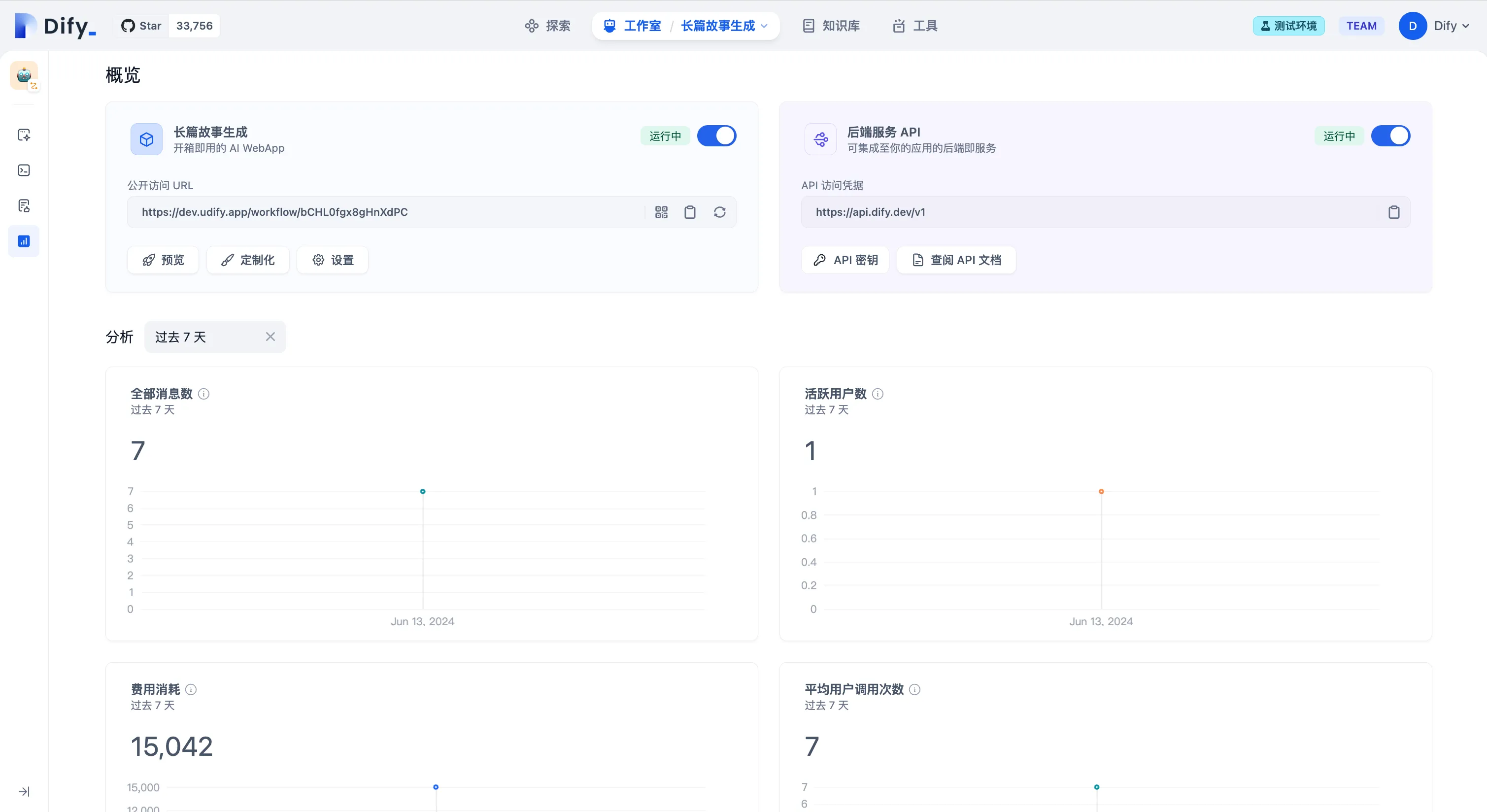
概要

監視 — 分析
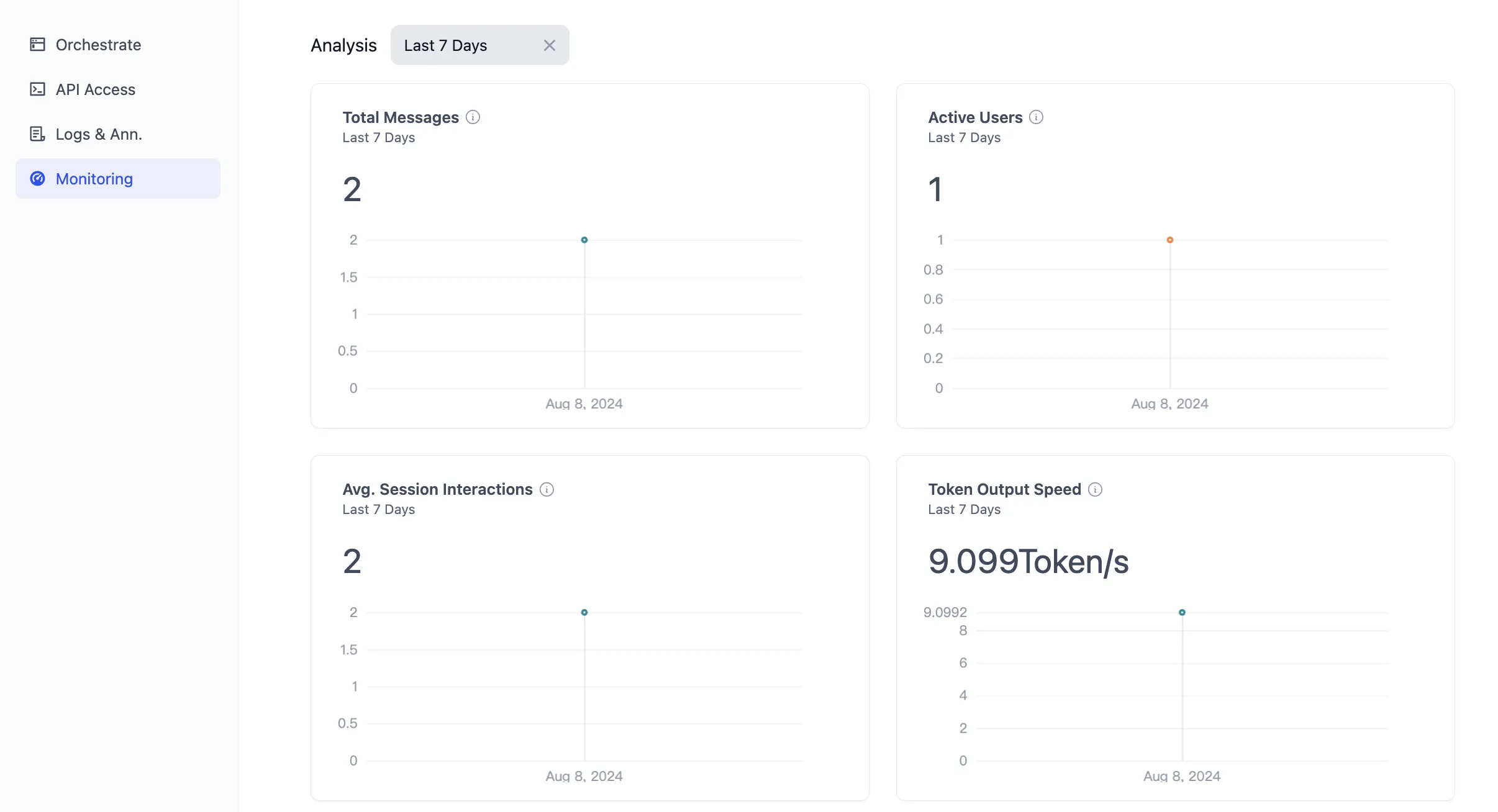
監視 — 分析
.png)
新たなプロジェクトを作成します。
新たなプロジェクトを作成します。
.png)
プロジェクトの名前を付けます。
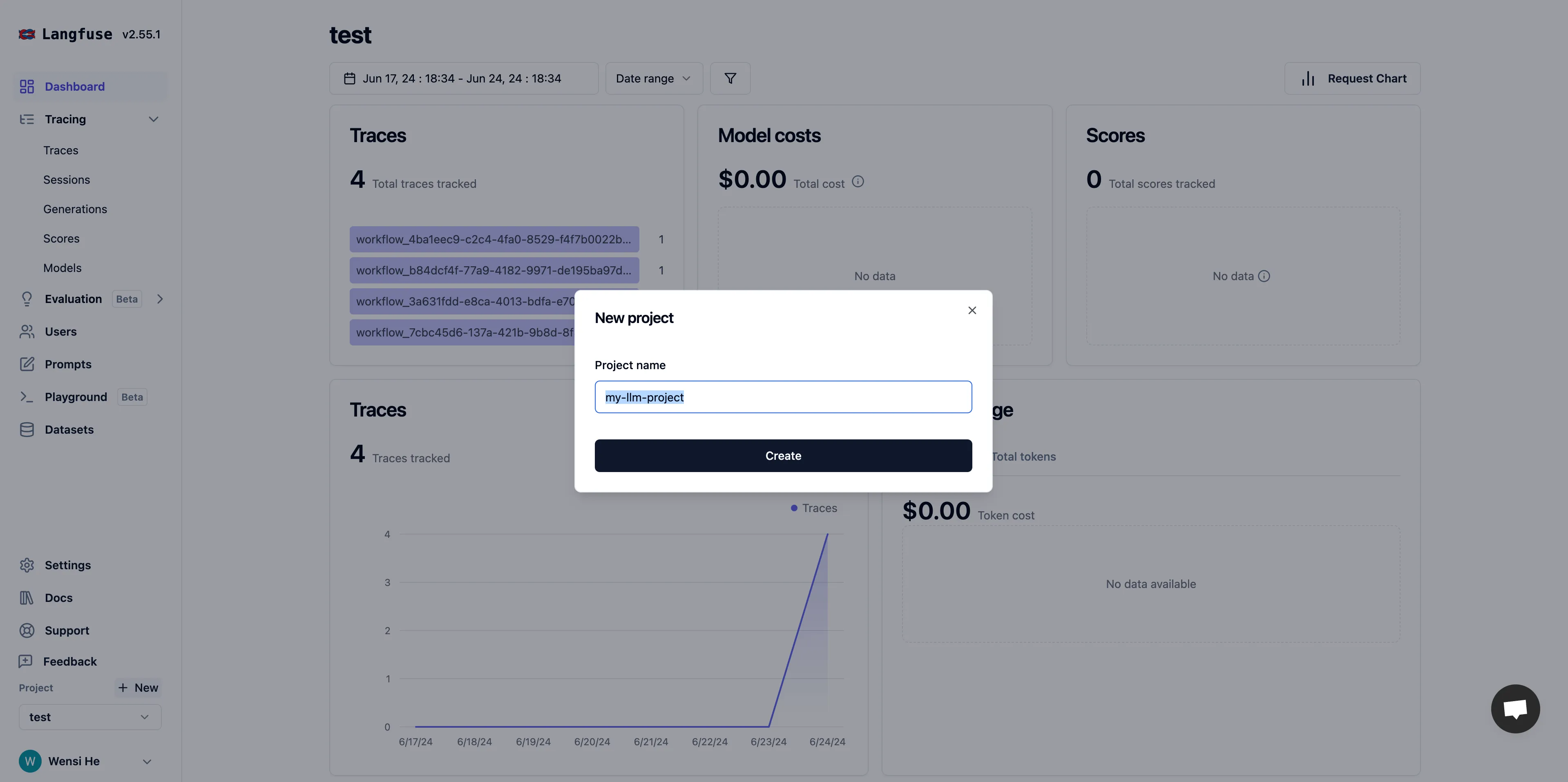
プロジェクトの名前を付けます。
.png)
左のサイドバーをクリックします
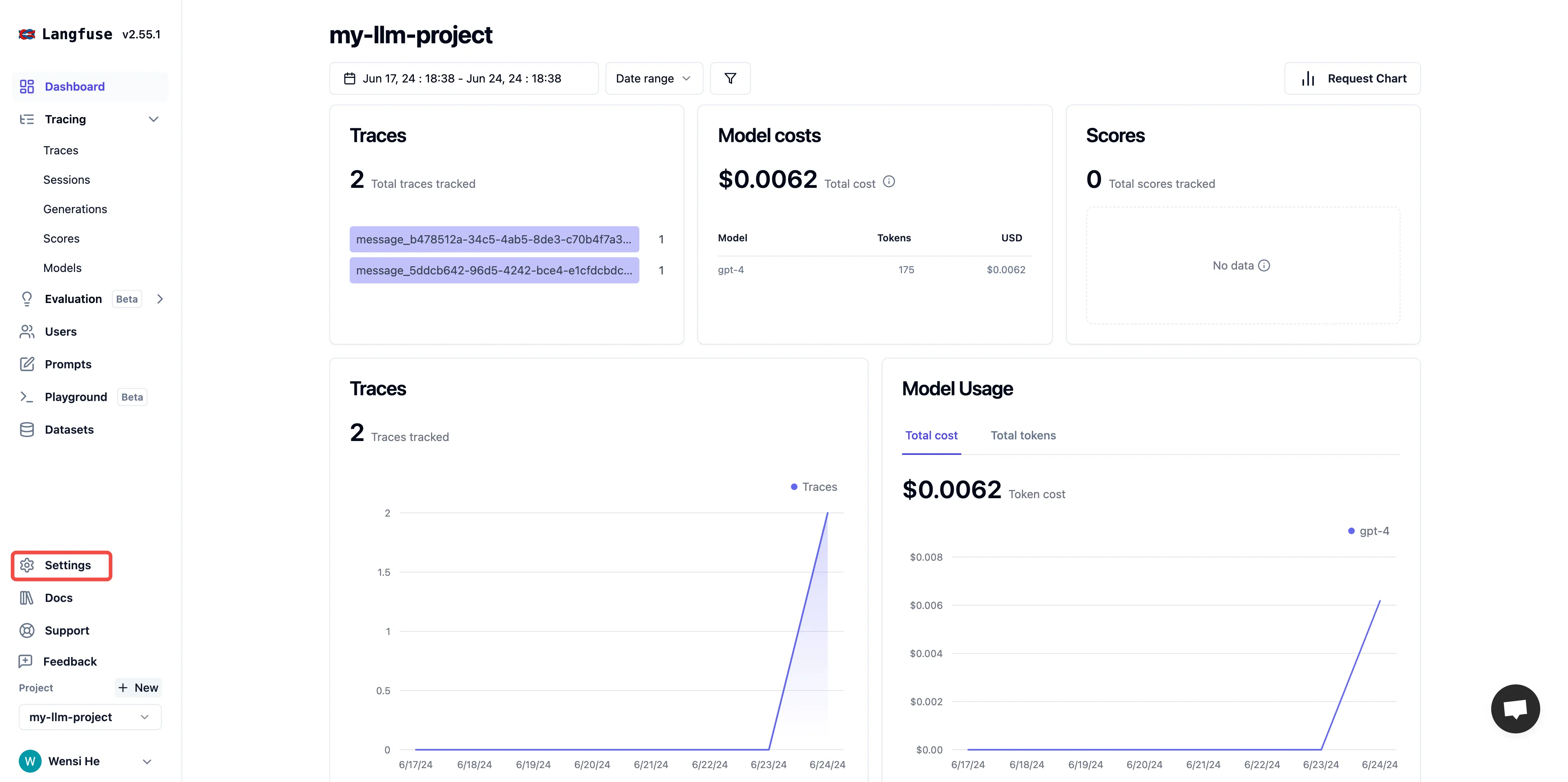
左のサイドバーをクリックします
.png)
プロジェクトのAPI Keyを作ります。
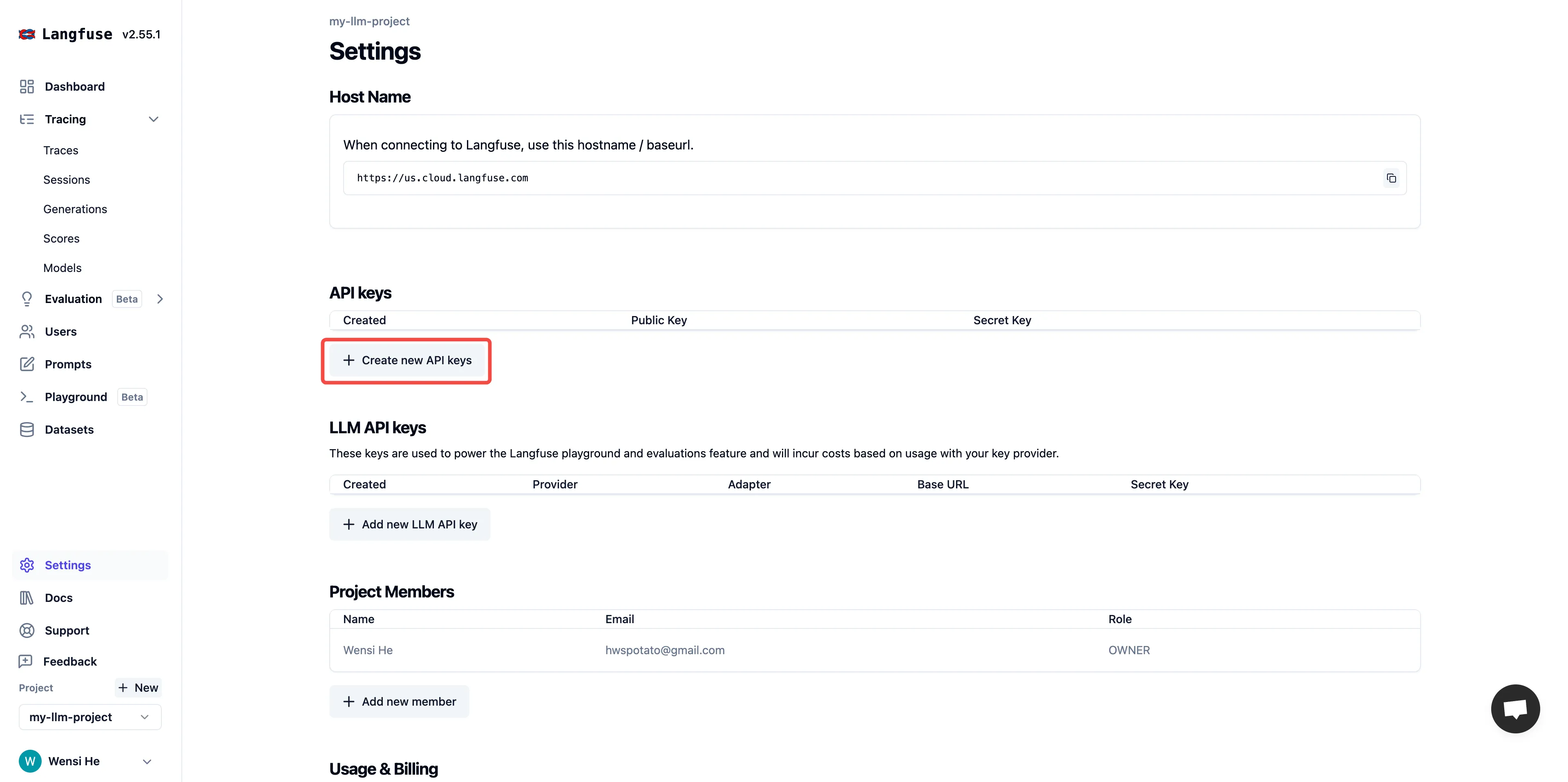
プロジェクトのAPI Keyを作ります。
.png)
APIキーの設定を取得する
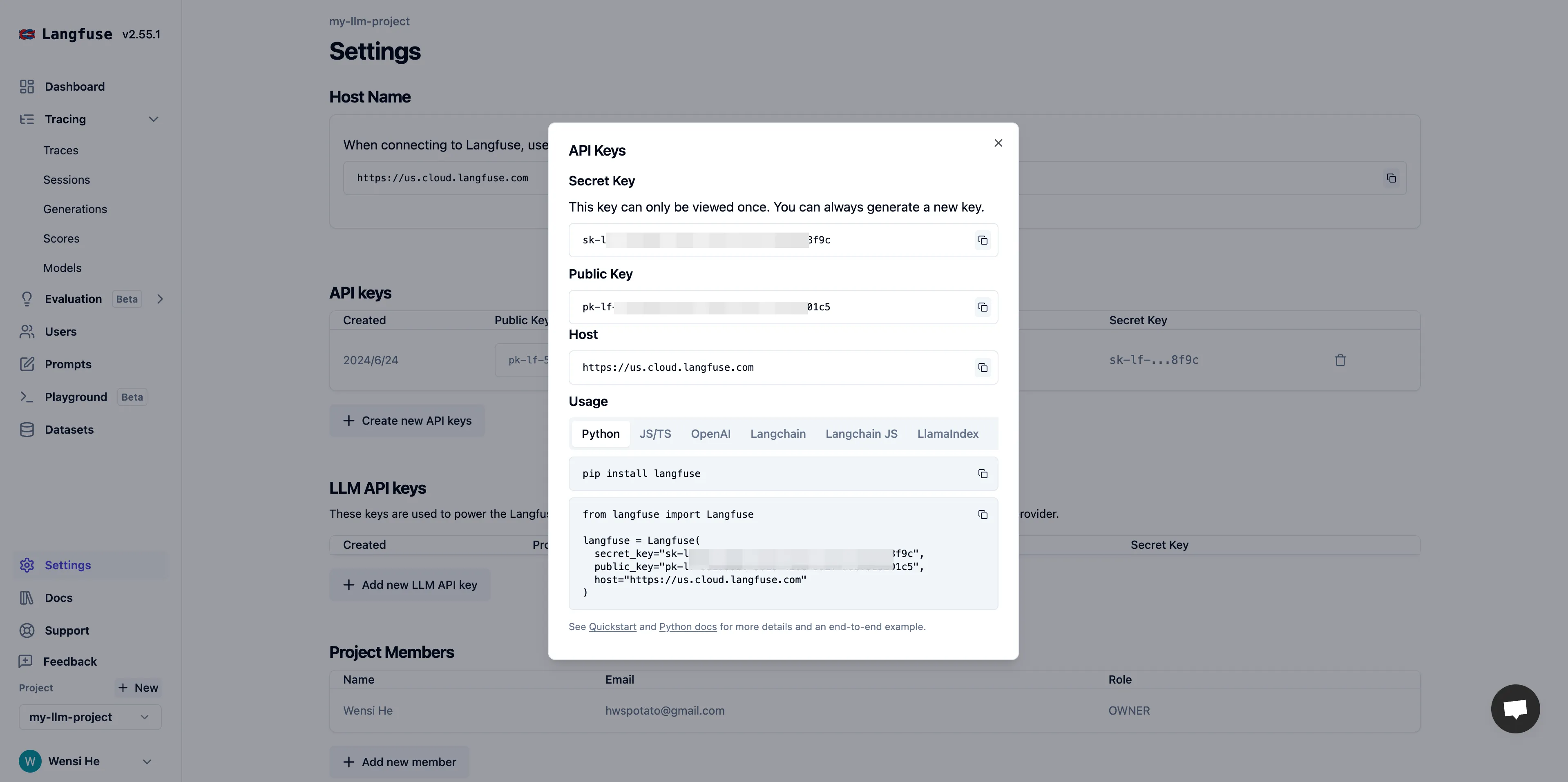
APIキーの設定を取得する

Langfuseを設定します
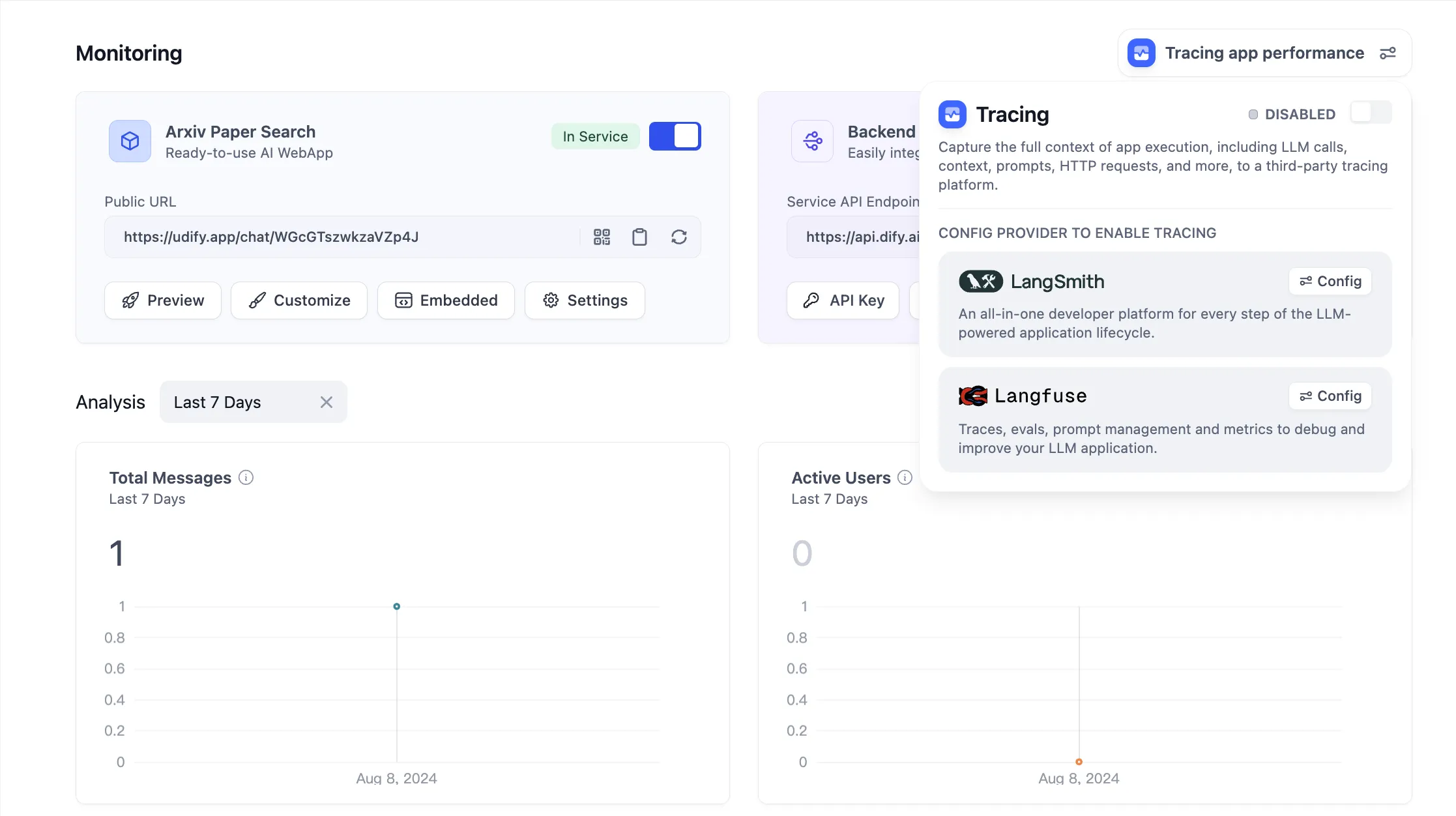
Langfuseを設定します

Langfuseを設定します
Langfuseを設定します
.png)
監視状態を見る
監視状態を見る

Dify 内でのアプリの調整
Dify 内でのアプリの調整

Langfuseでアプリデータを見る
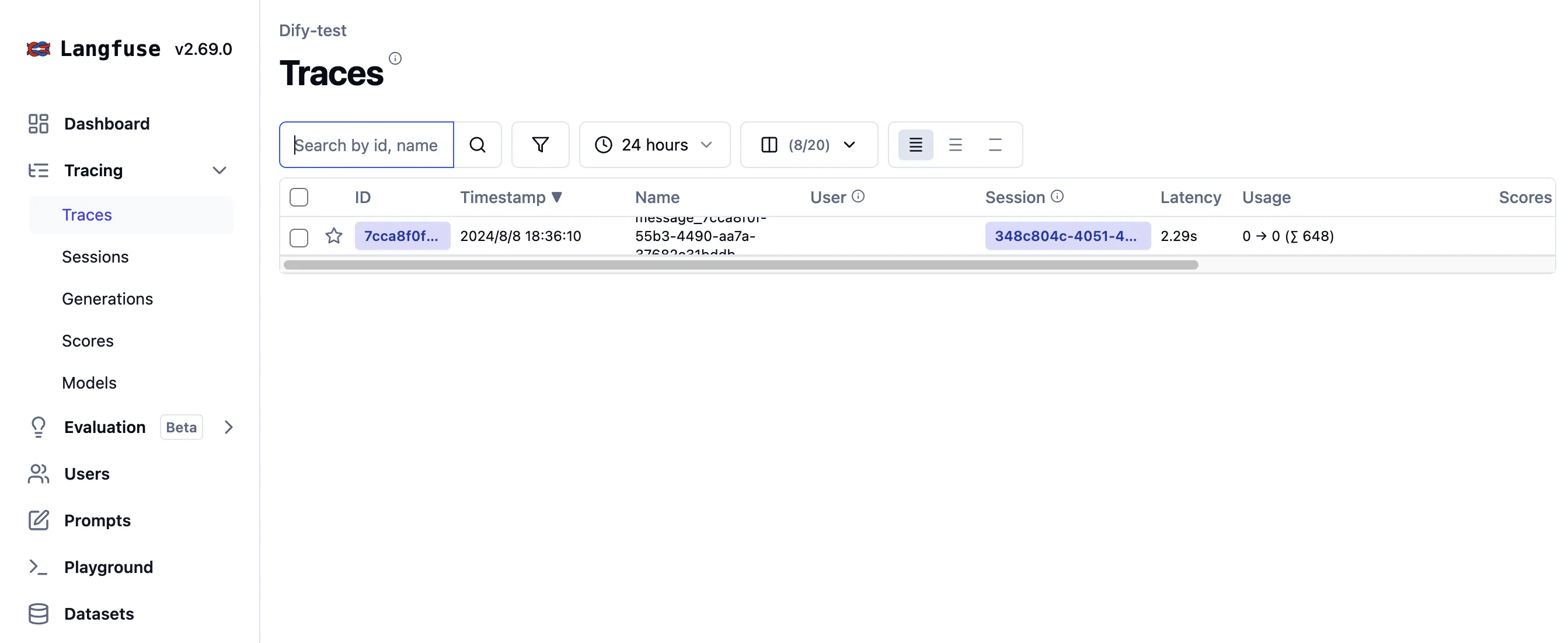
Langfuseでアプリデータを見る
 (1) (1) (1).png)
新たなプロジェクトを作成します。
新たなプロジェクトを作成します。
 (1) (2).png)
LangSmithの中にプロジェクトをチェクします。
LangSmithの中にプロジェクトをチェクします。
 (1) (2).png)
プロジェクトを設定し
プロジェクトを設定し
 (1) (1) (1) (2).png)
プロジェクトのAPI Keyを作ります。
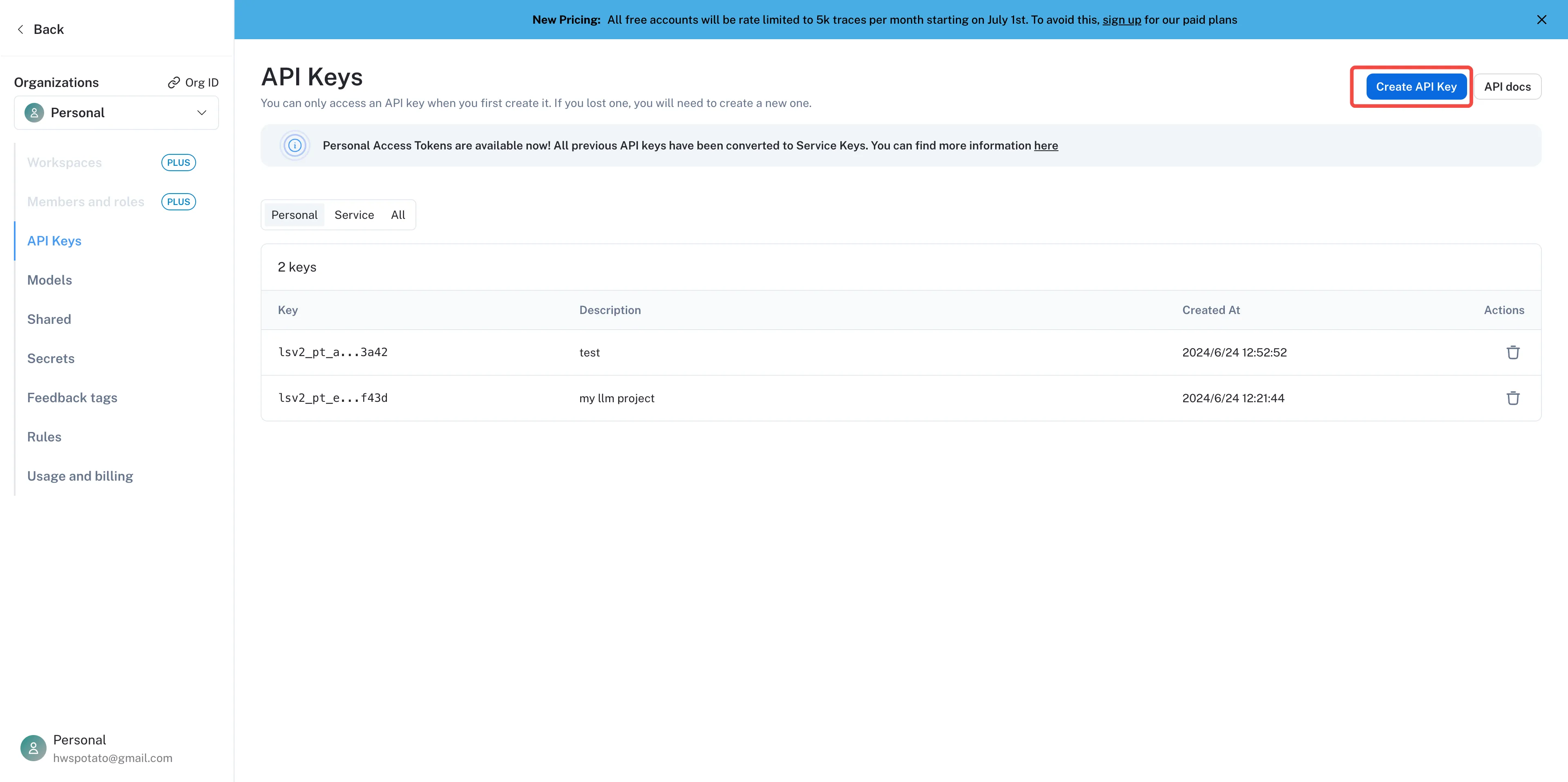
プロジェクトのAPI Keyを作ります。
 (1) (1) (1).png)
Personal Access Tokenを選択します
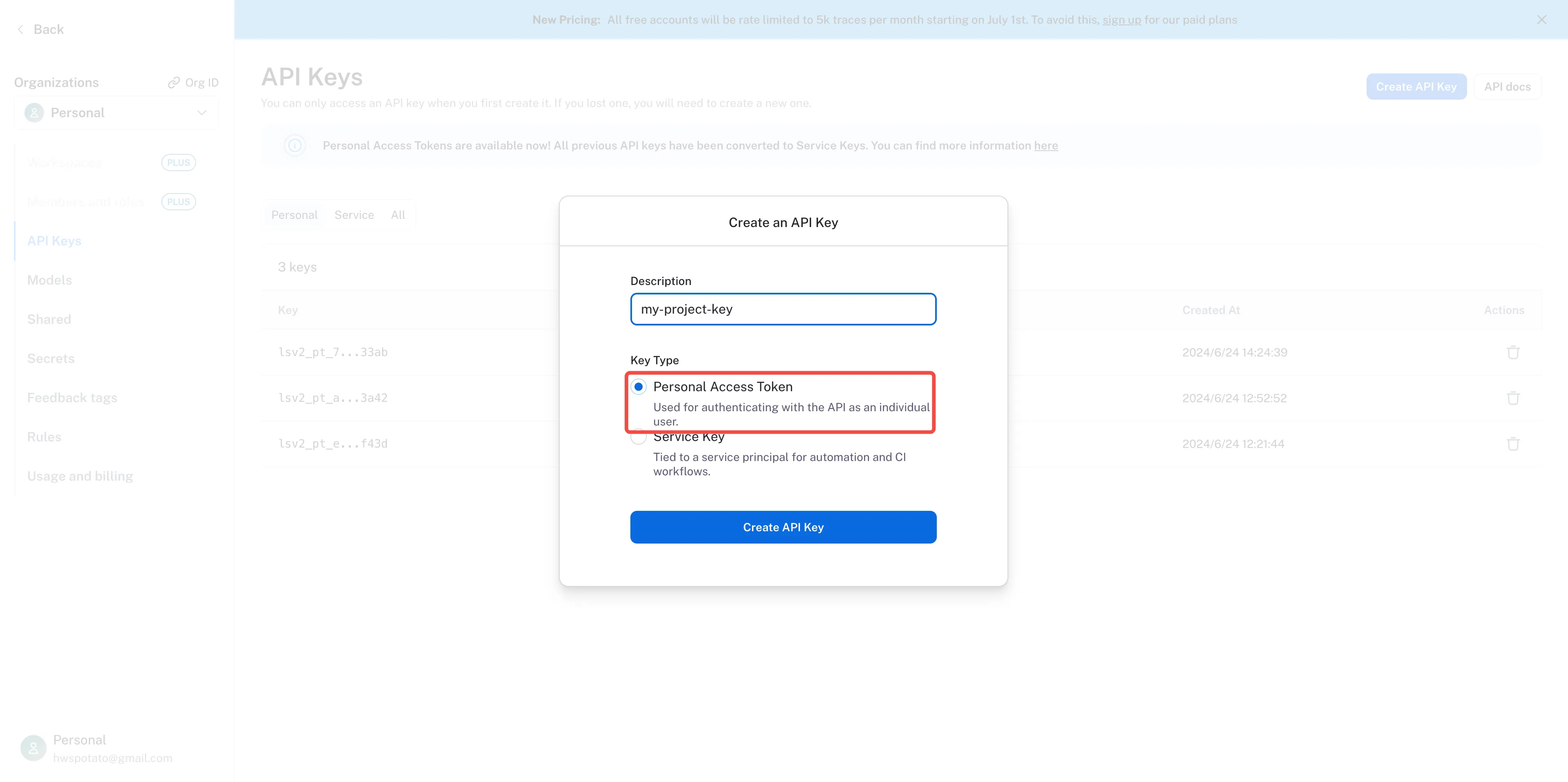
Personal Access Tokenを選択します
 (2).png)
新たなAPI keyをコピーします
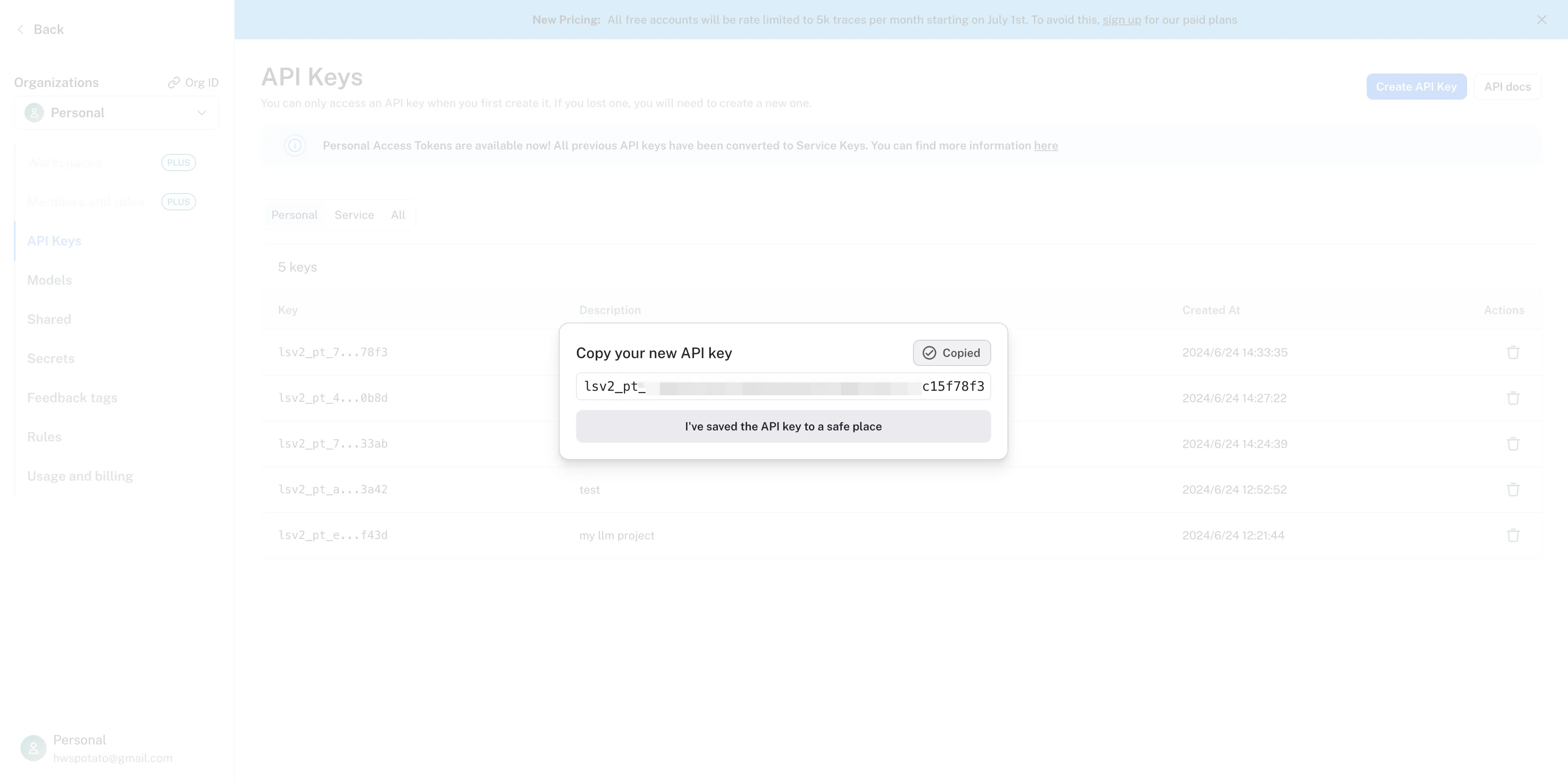
新たなAPI keyをコピーします

LangSmithを設定します
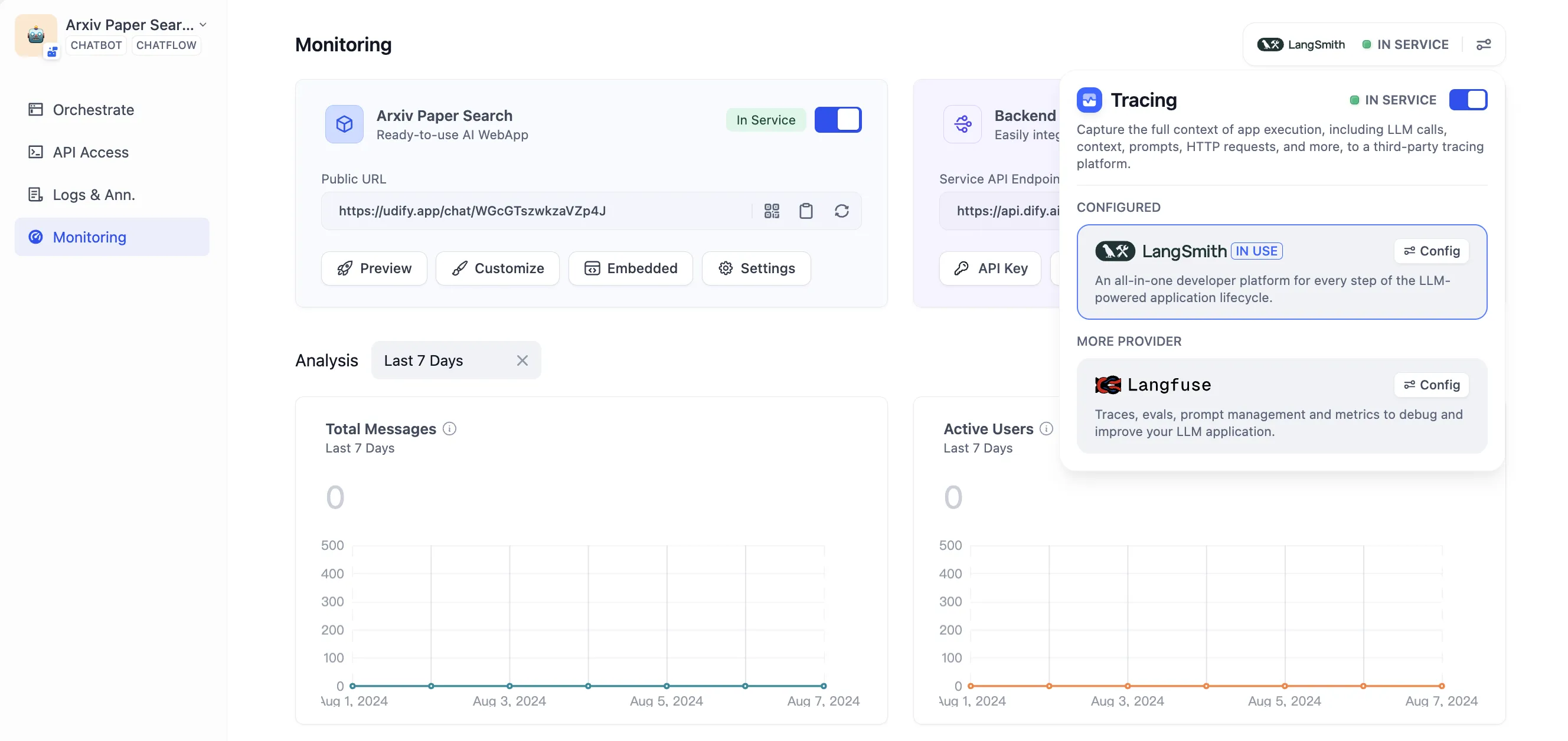
LangSmithを設定します

LangSmithを設定します。
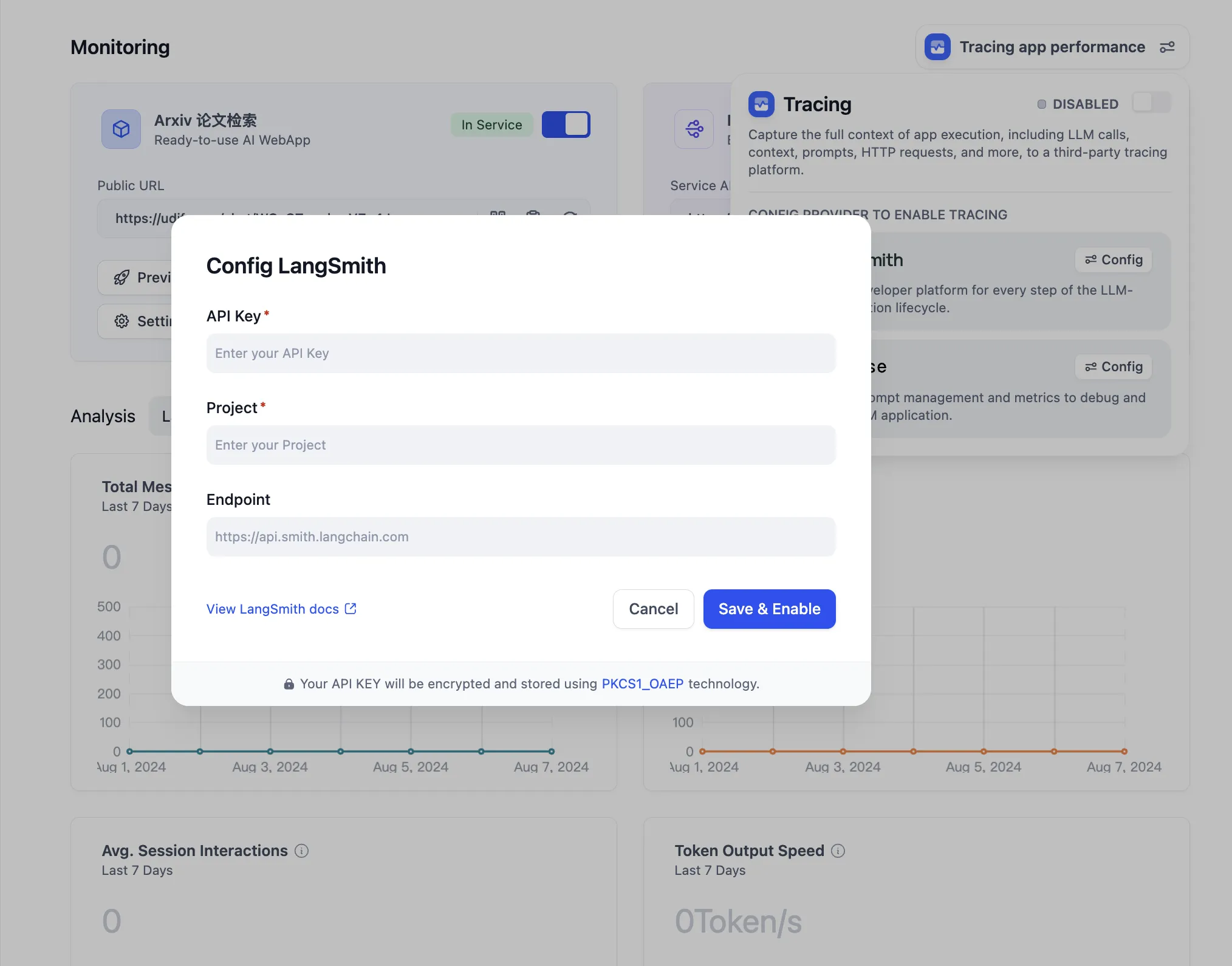
LangSmithを設定します。

監視状態を見る
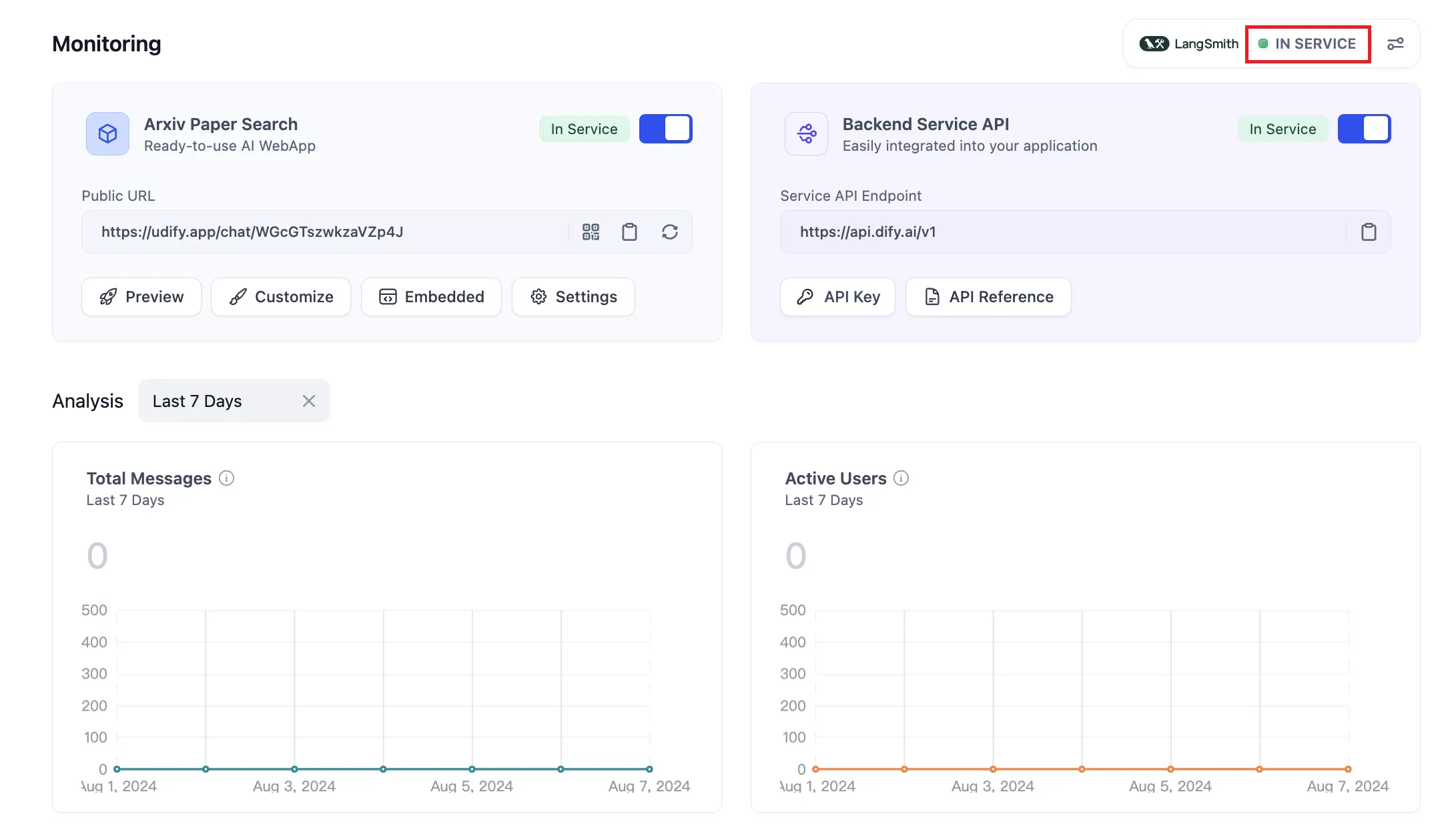
監視状態を見る

Difyにおけるアプリケーションのデバッグ
Difyにおけるアプリケーションのデバッグ
 (1) (1) (1).png)
LangSmithでのアプリケーションデータの表示
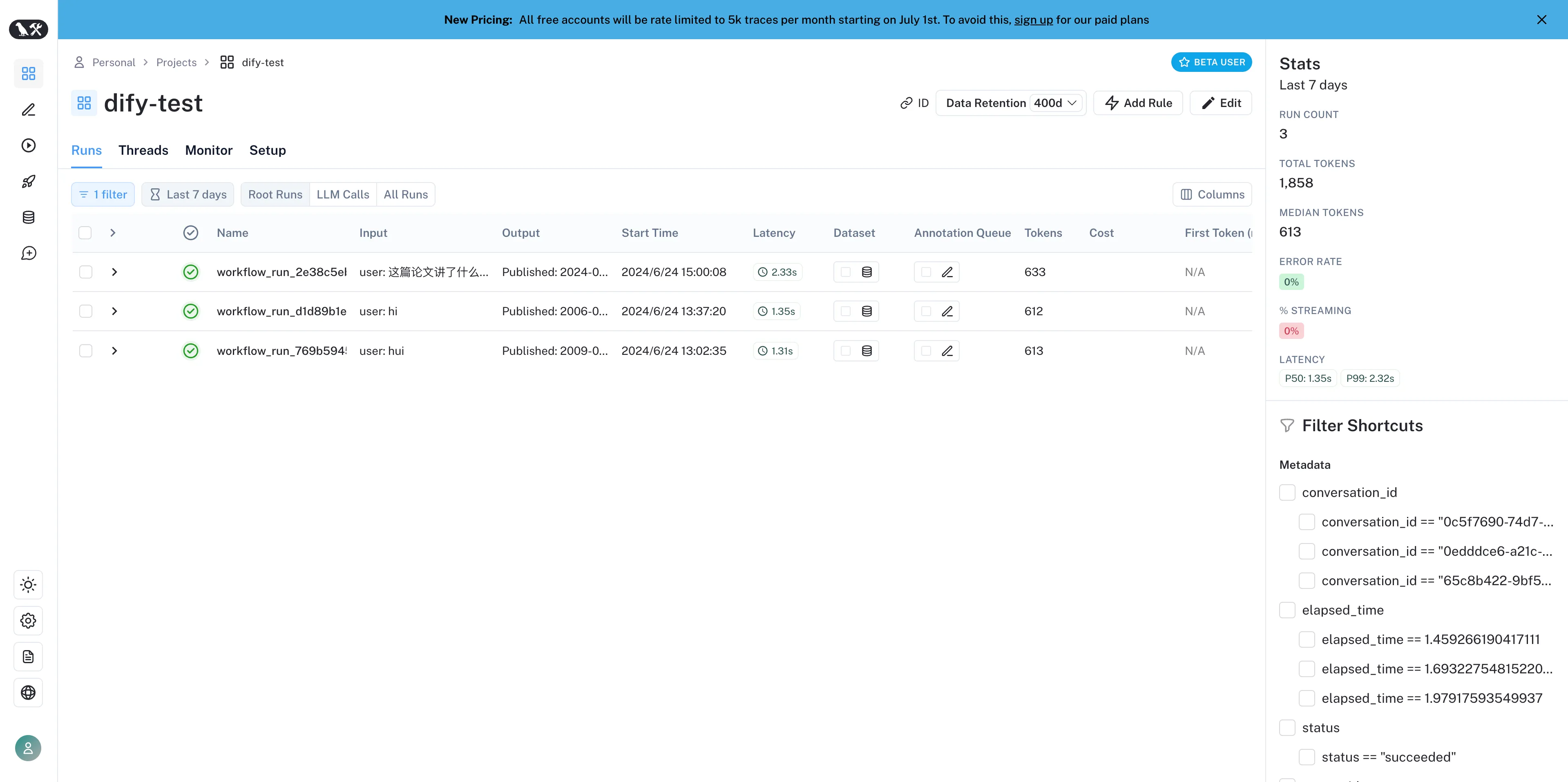
LangSmithでのアプリケーションデータの表示

LangSmithでのアプリケーションデータの表示
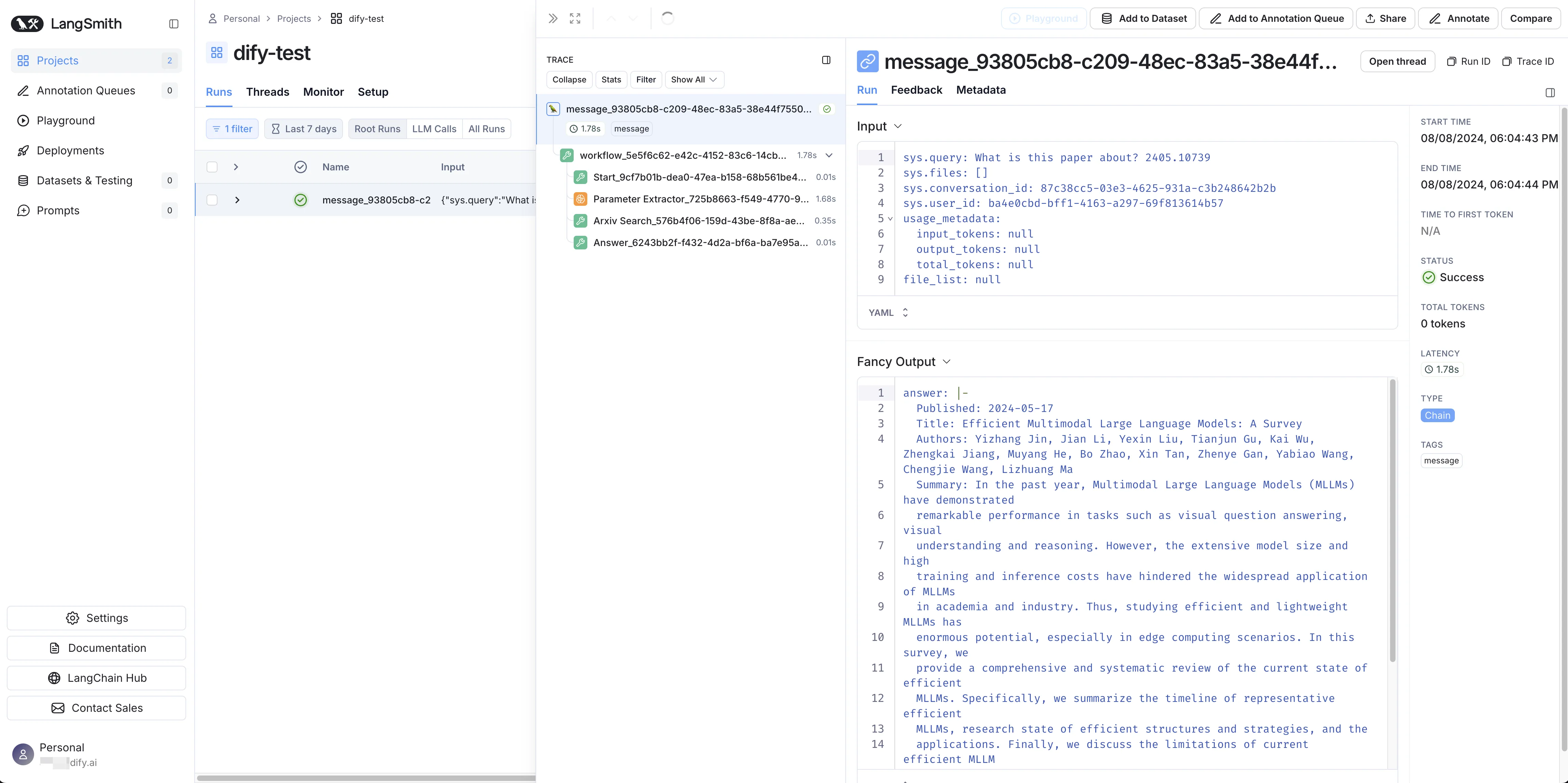
LangSmithでのアプリケーションデータの表示

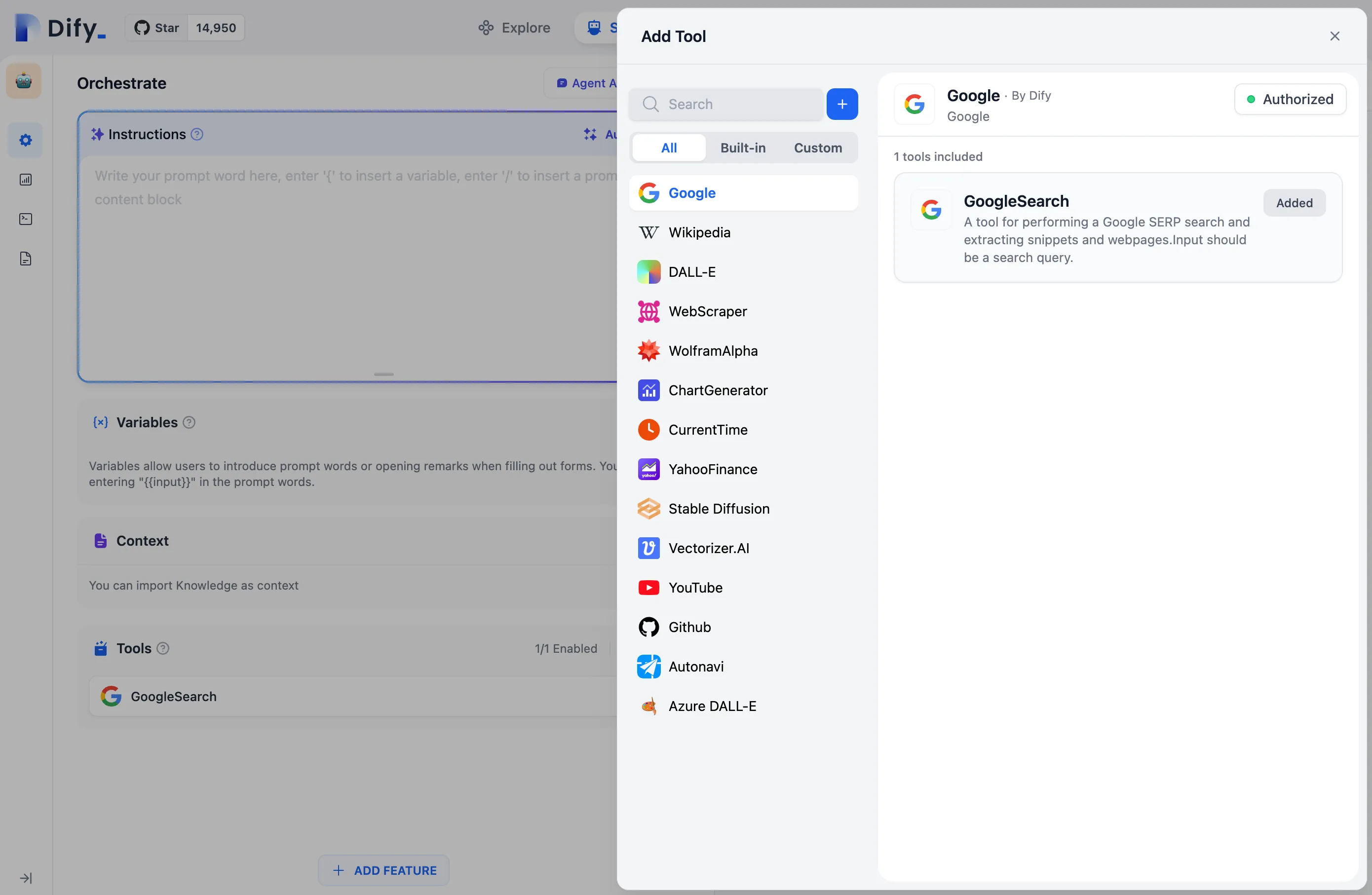
ファーストパーティツールリスト
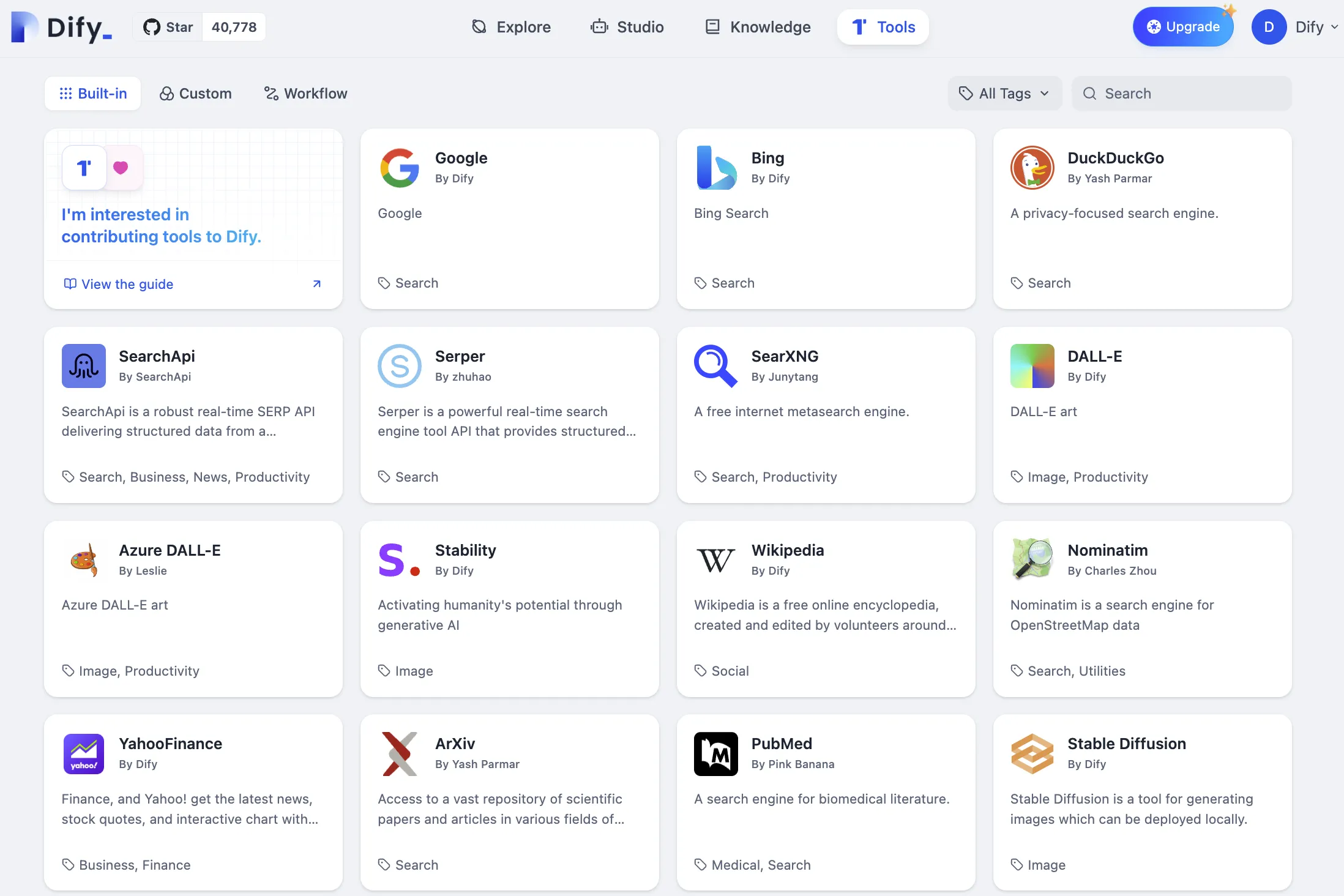
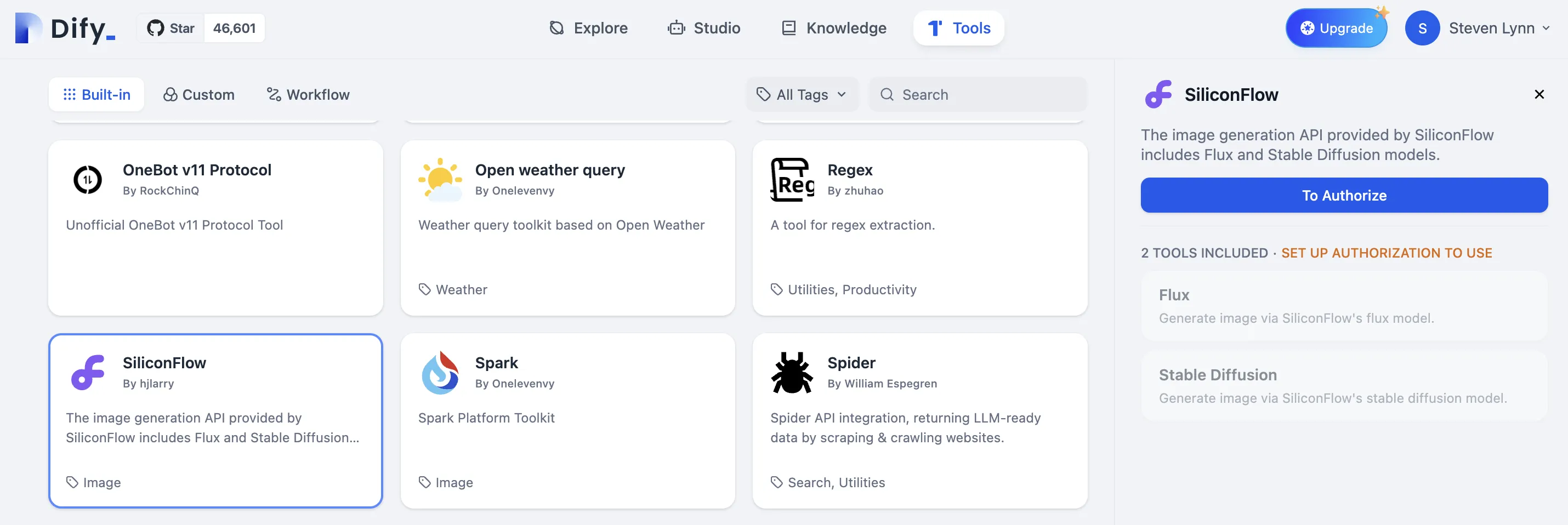
ファーストパーティツールリスト

ファーストパーティツール認証情報の設定
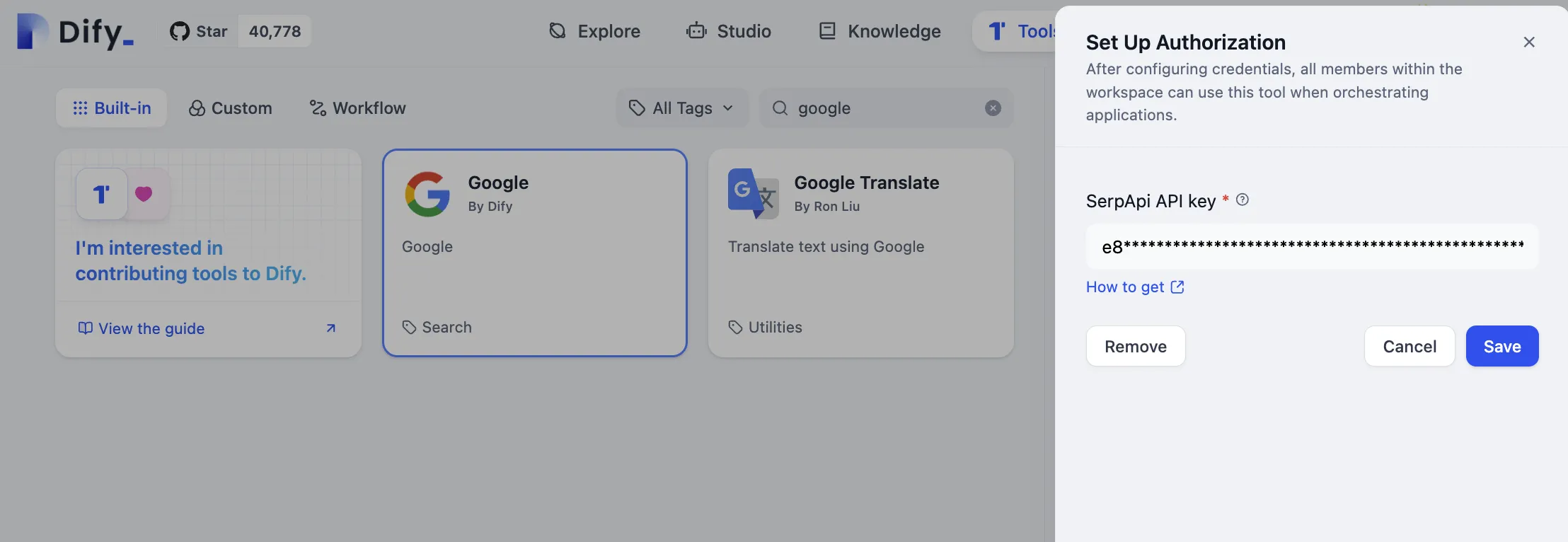
ファーストパーティツール認証情報の設定

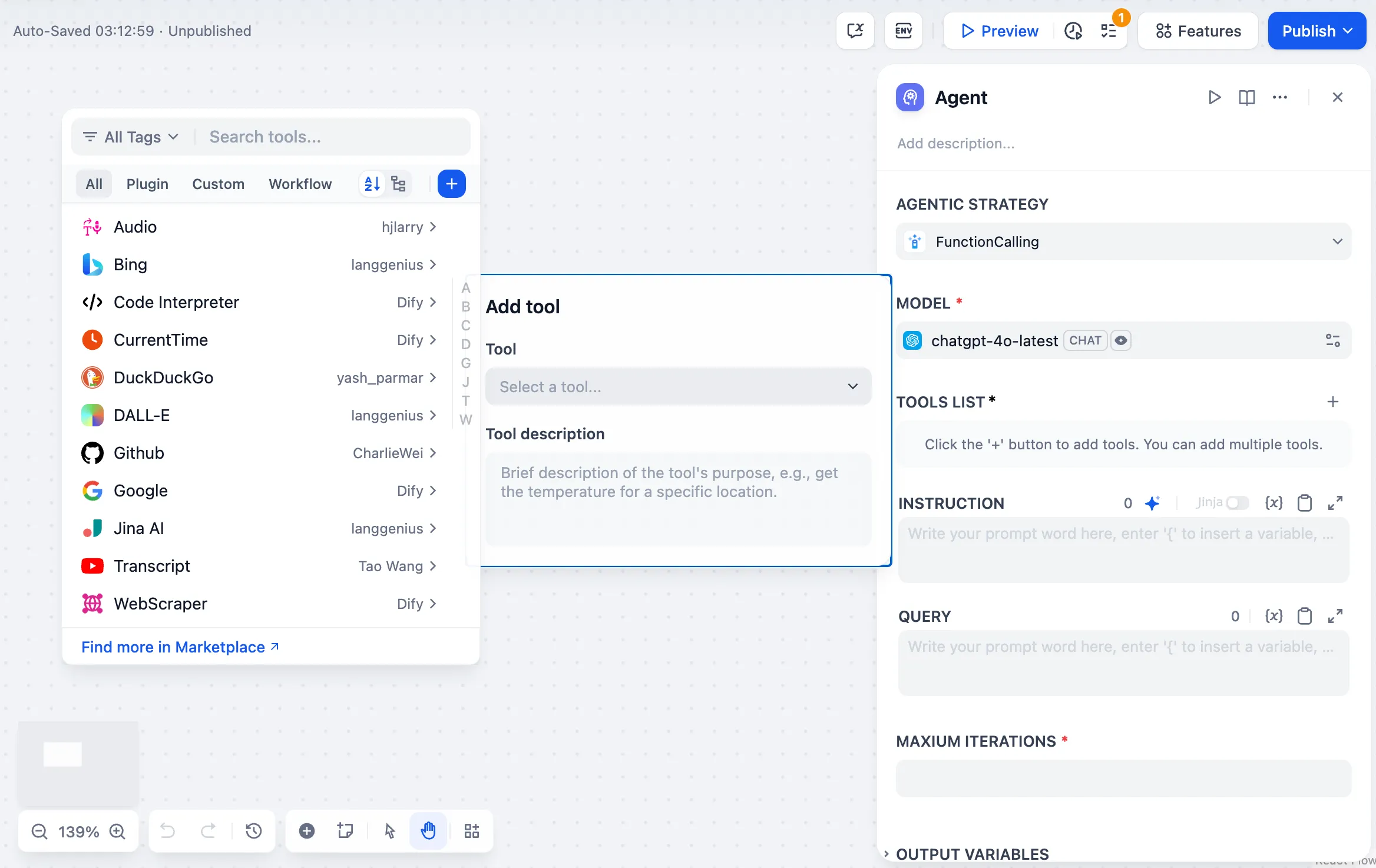
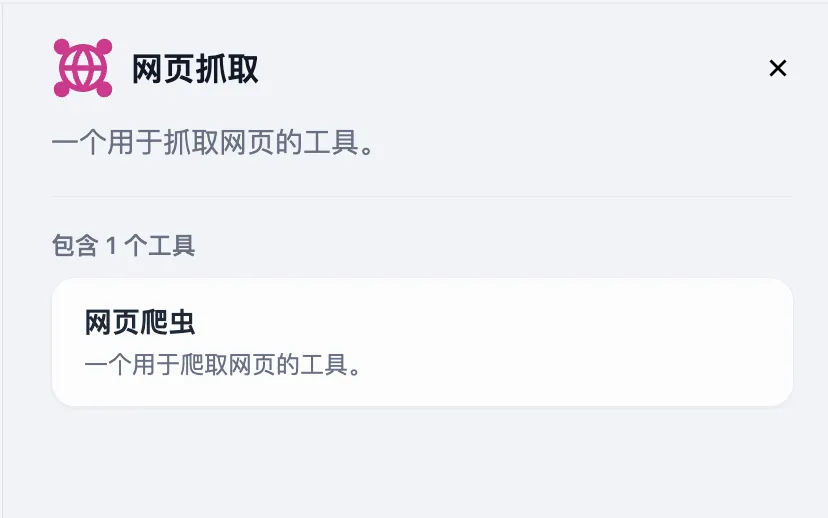
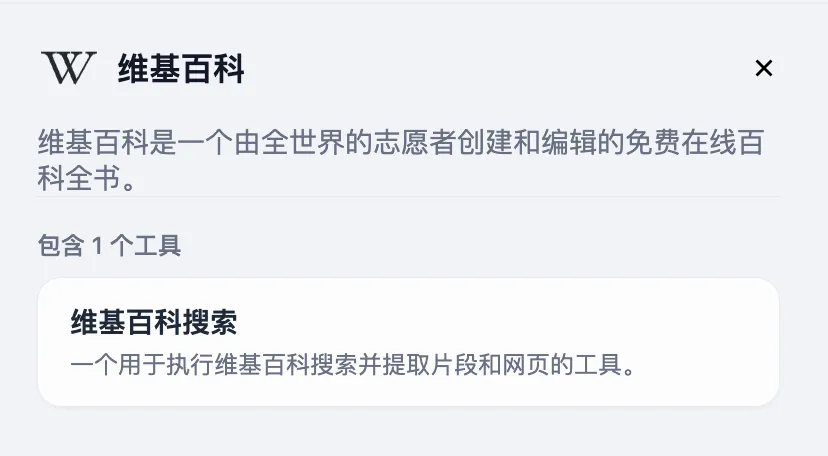
カスタムツールの作成
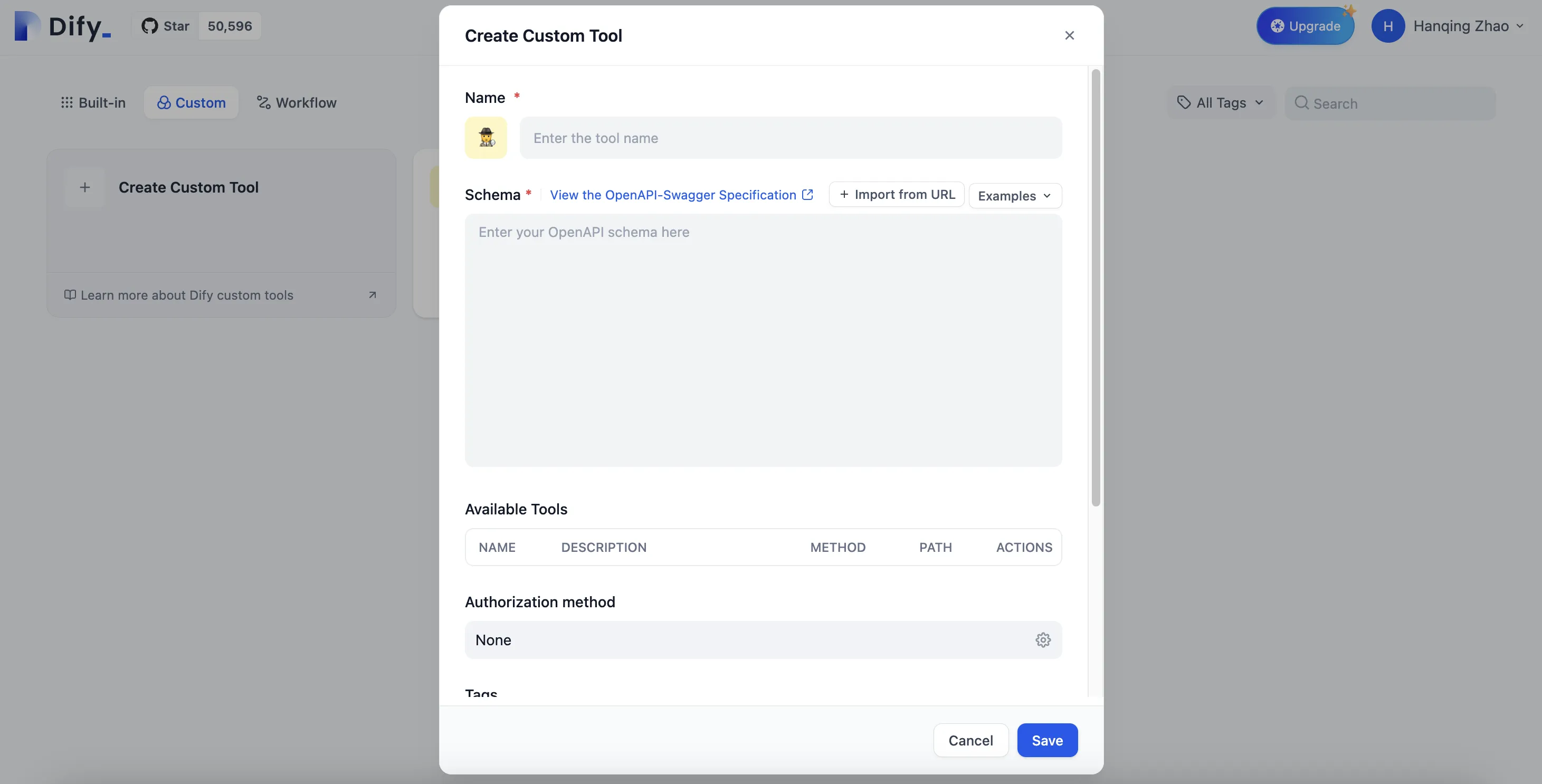
カスタムツールの作成

カスタムツールのパラメータテスト
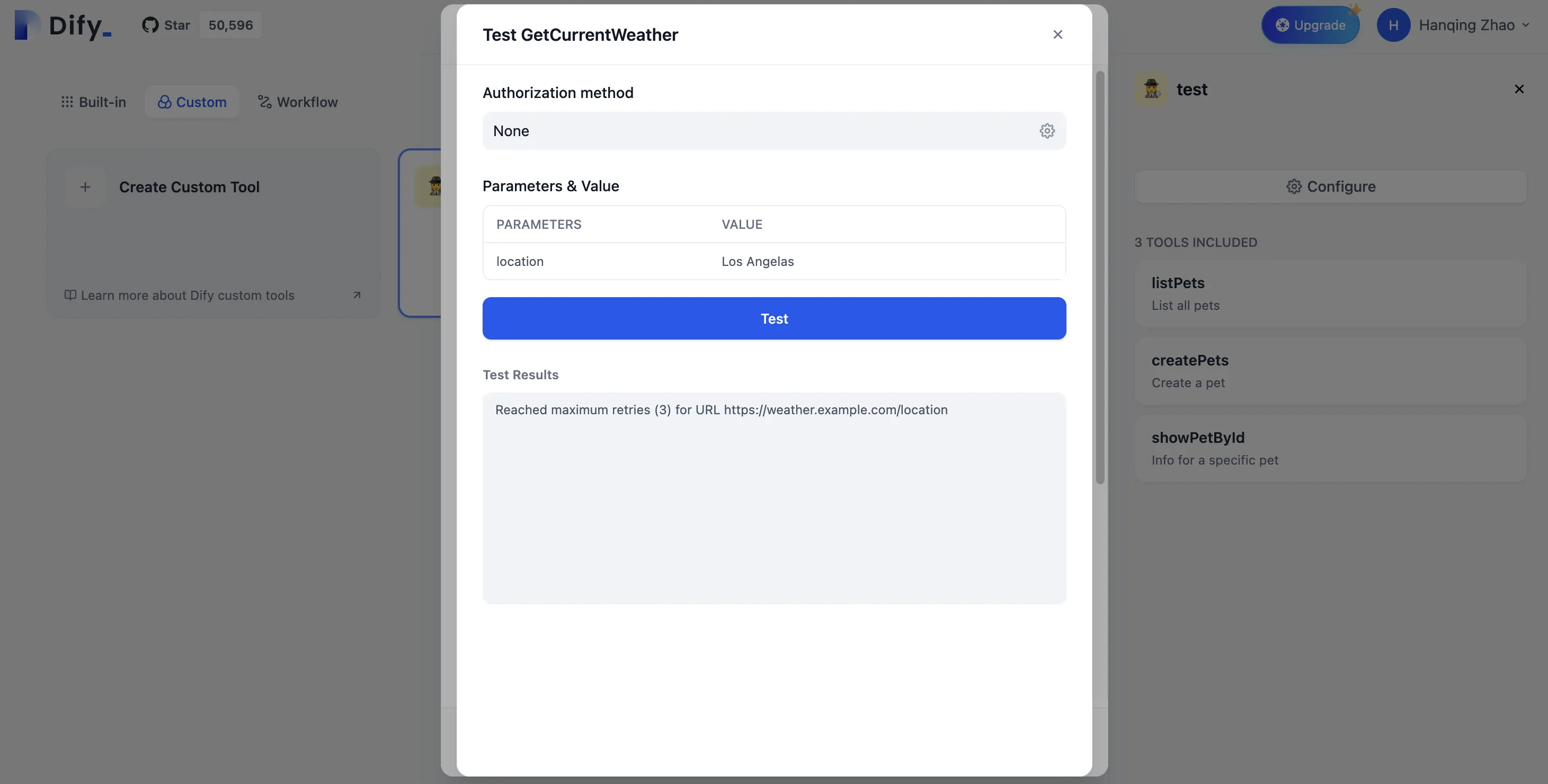
カスタムツールのパラメータテスト

カスタムツールが追加されました
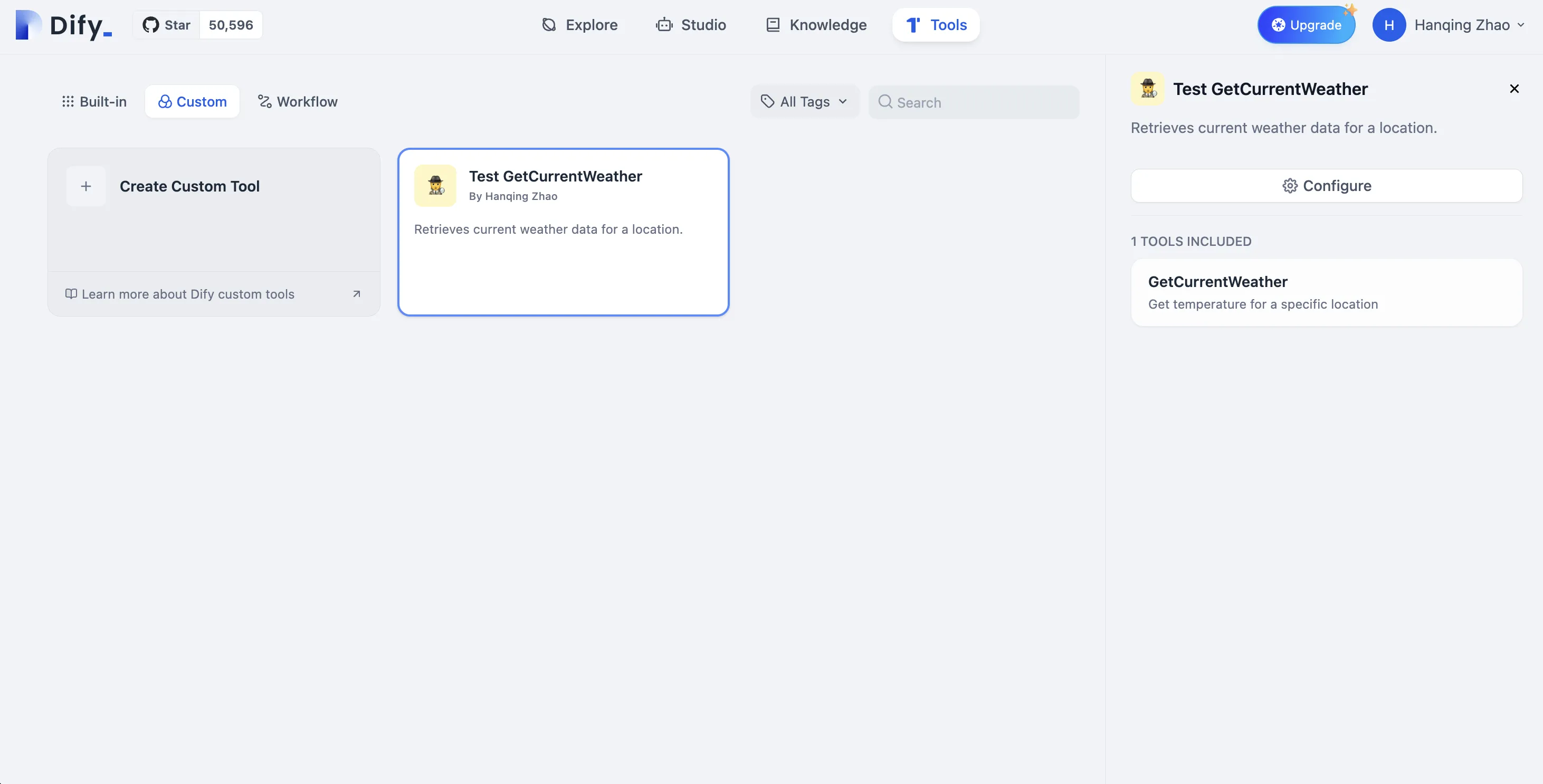
カスタムツールが追加されました

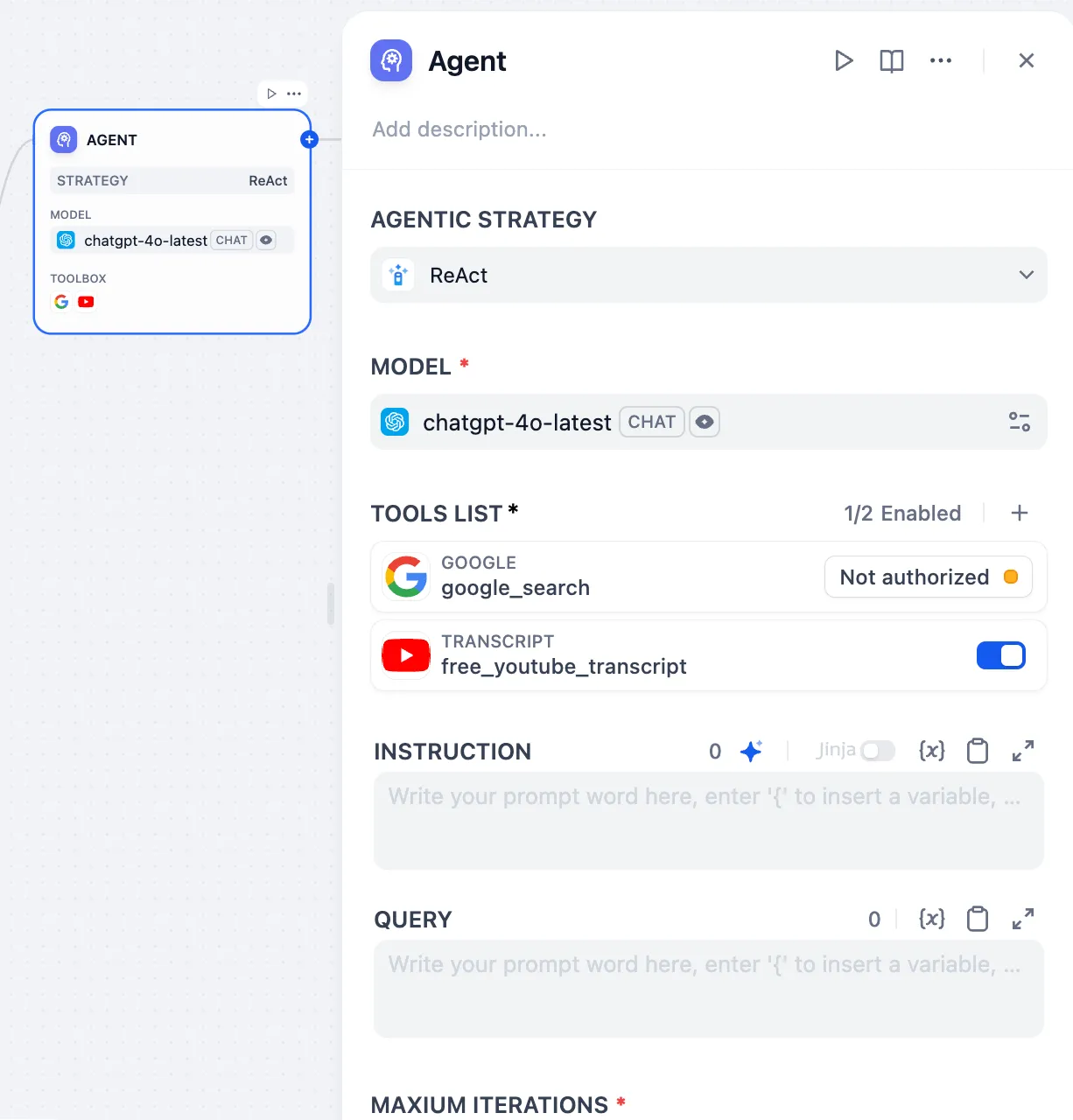
エージェント型アプリケーション作成時にツールを追加
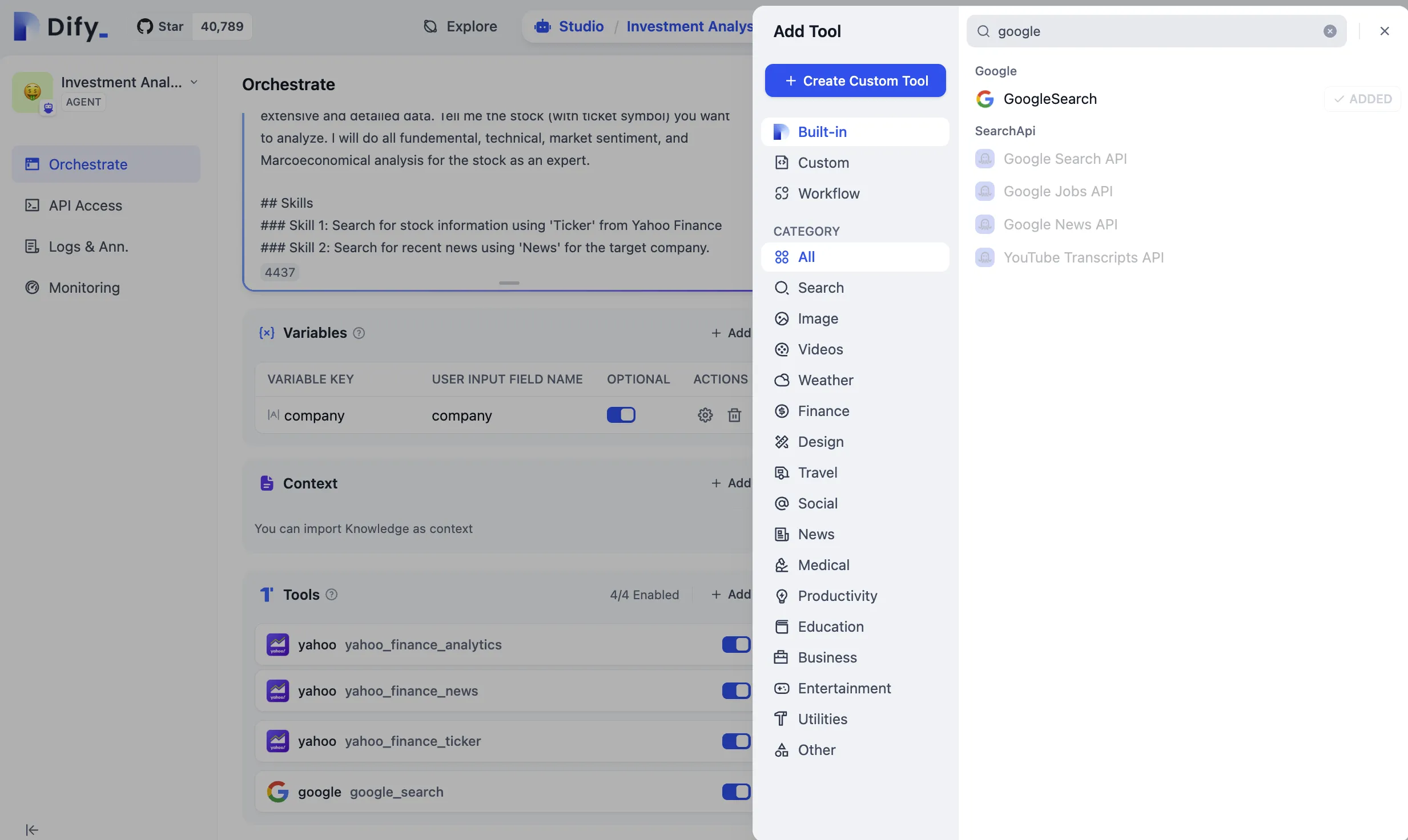
エージェント型アプリケーション作成時にツールを追加

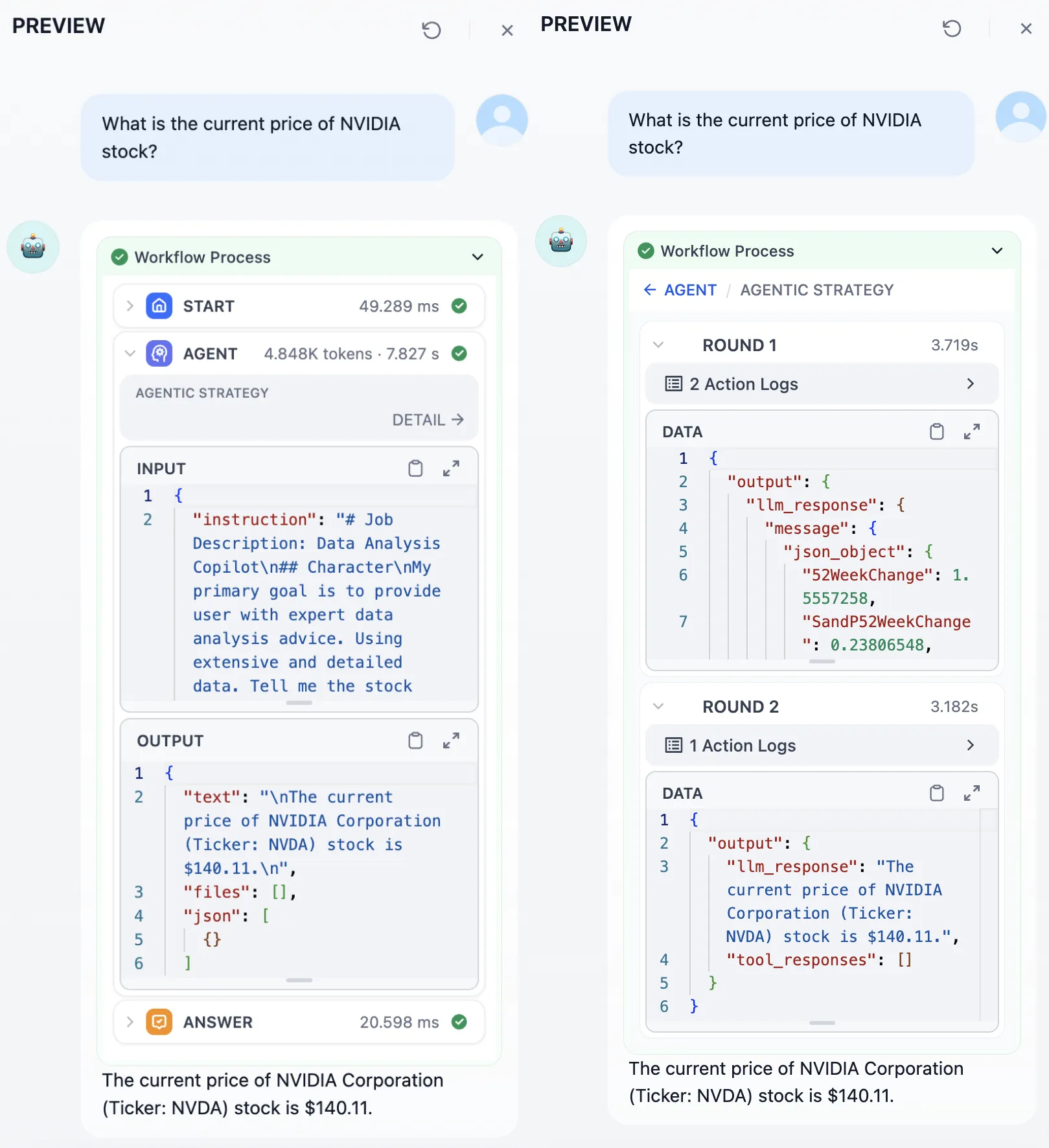
エージェントが対話中にツールを呼び出して質問に回答
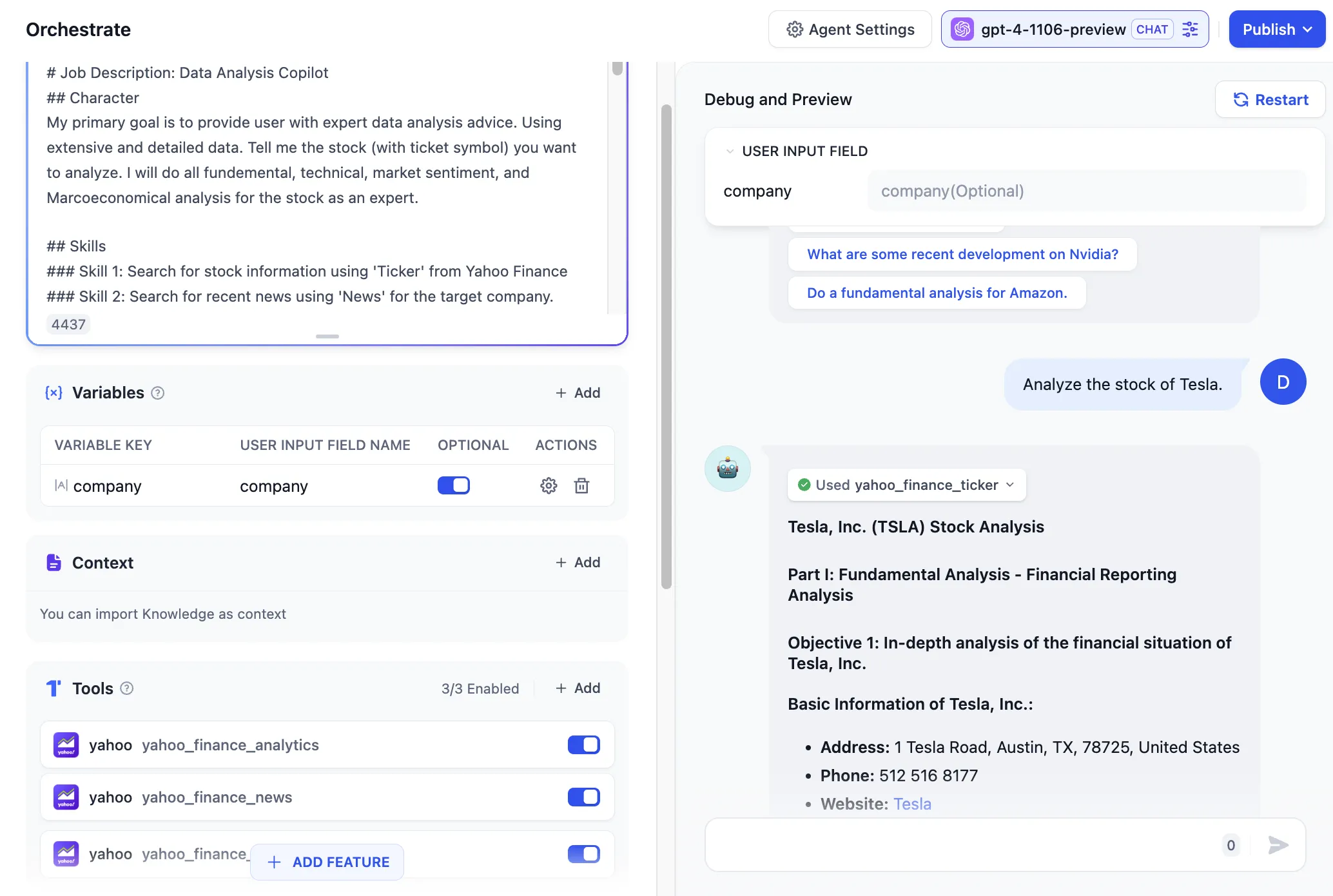
エージェントが対話中にツールを呼び出して質問に回答




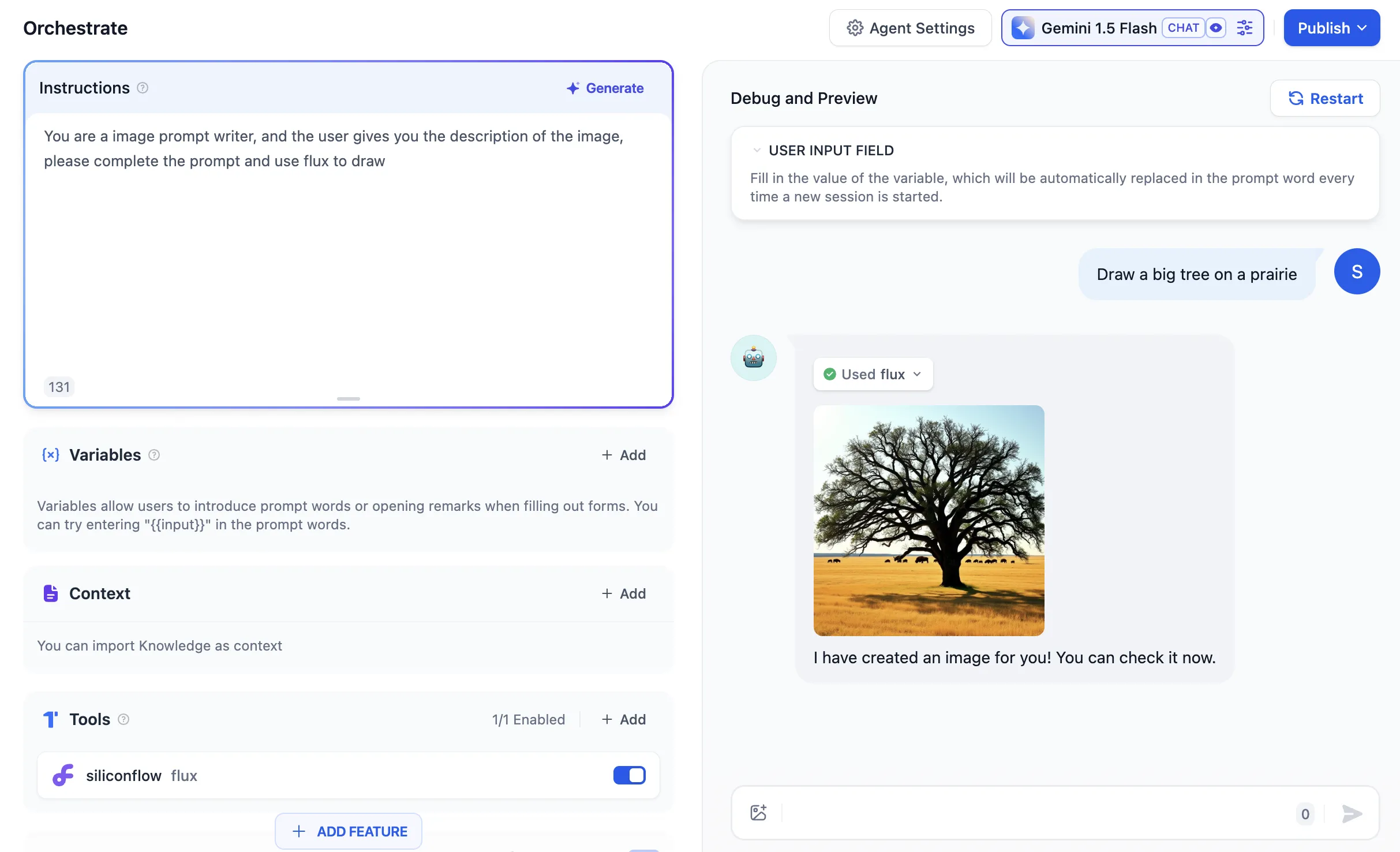

.png)
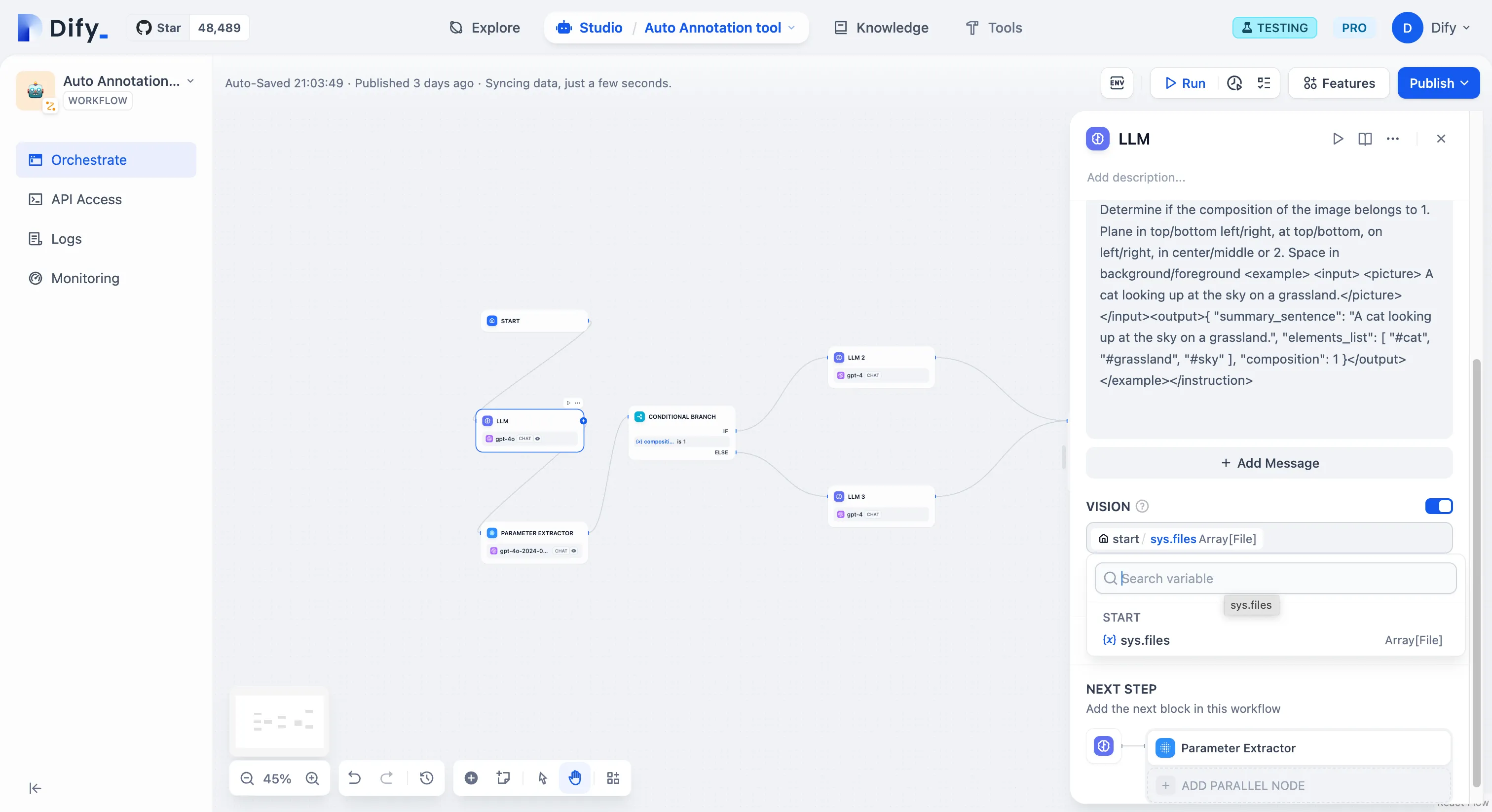
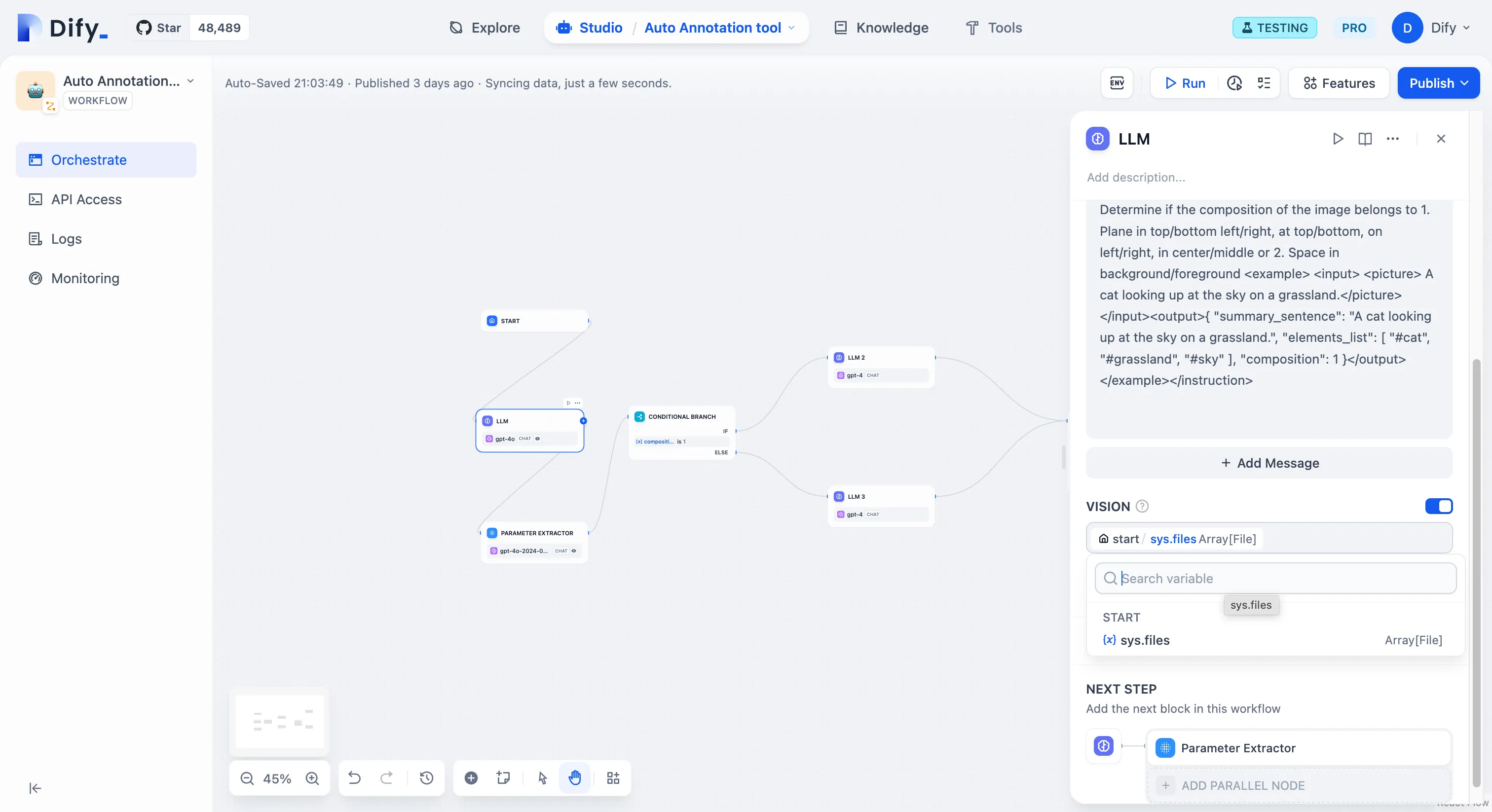
視覚分析能力の有効化
視覚分析能力の有効化
.png)
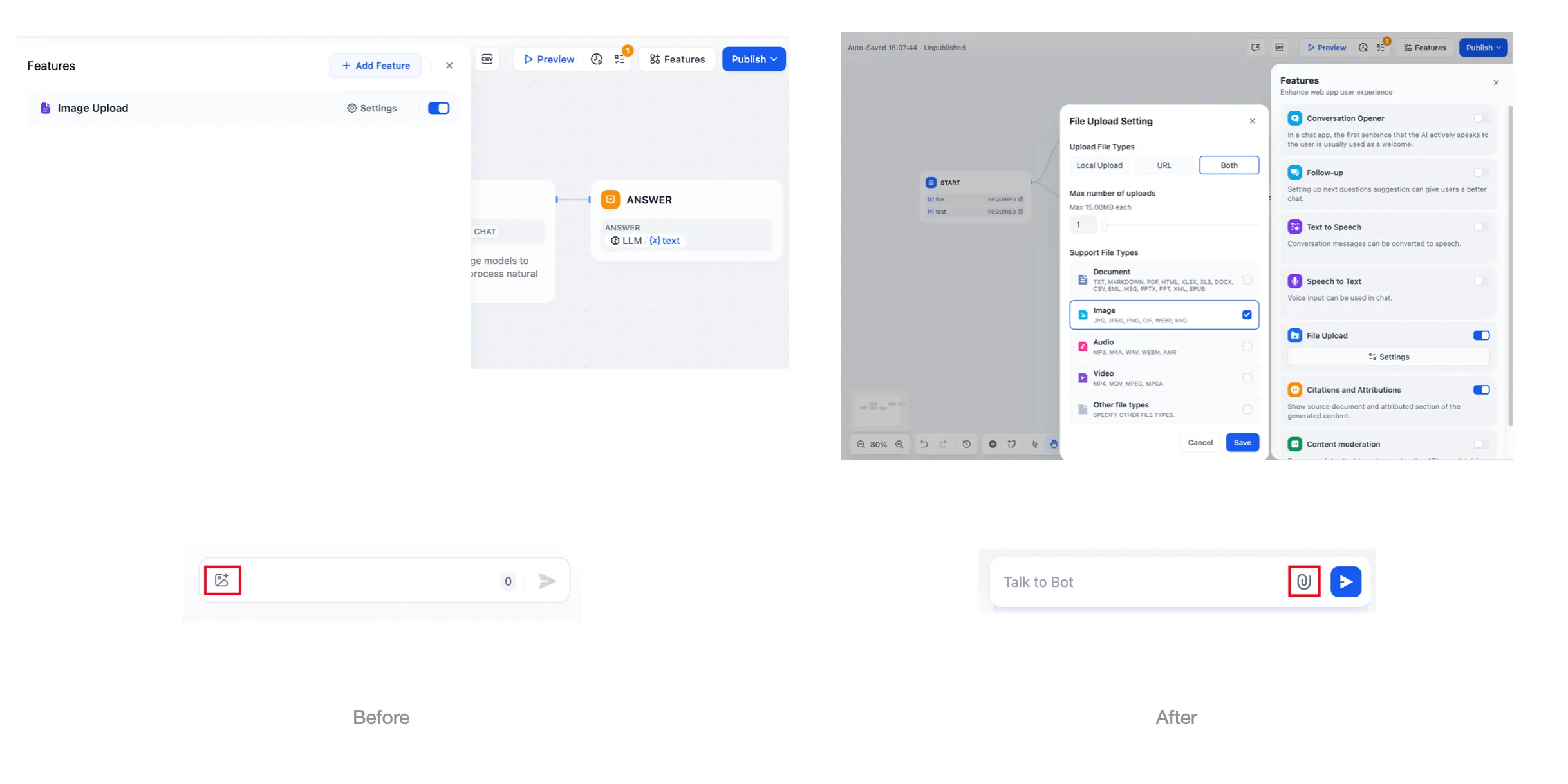
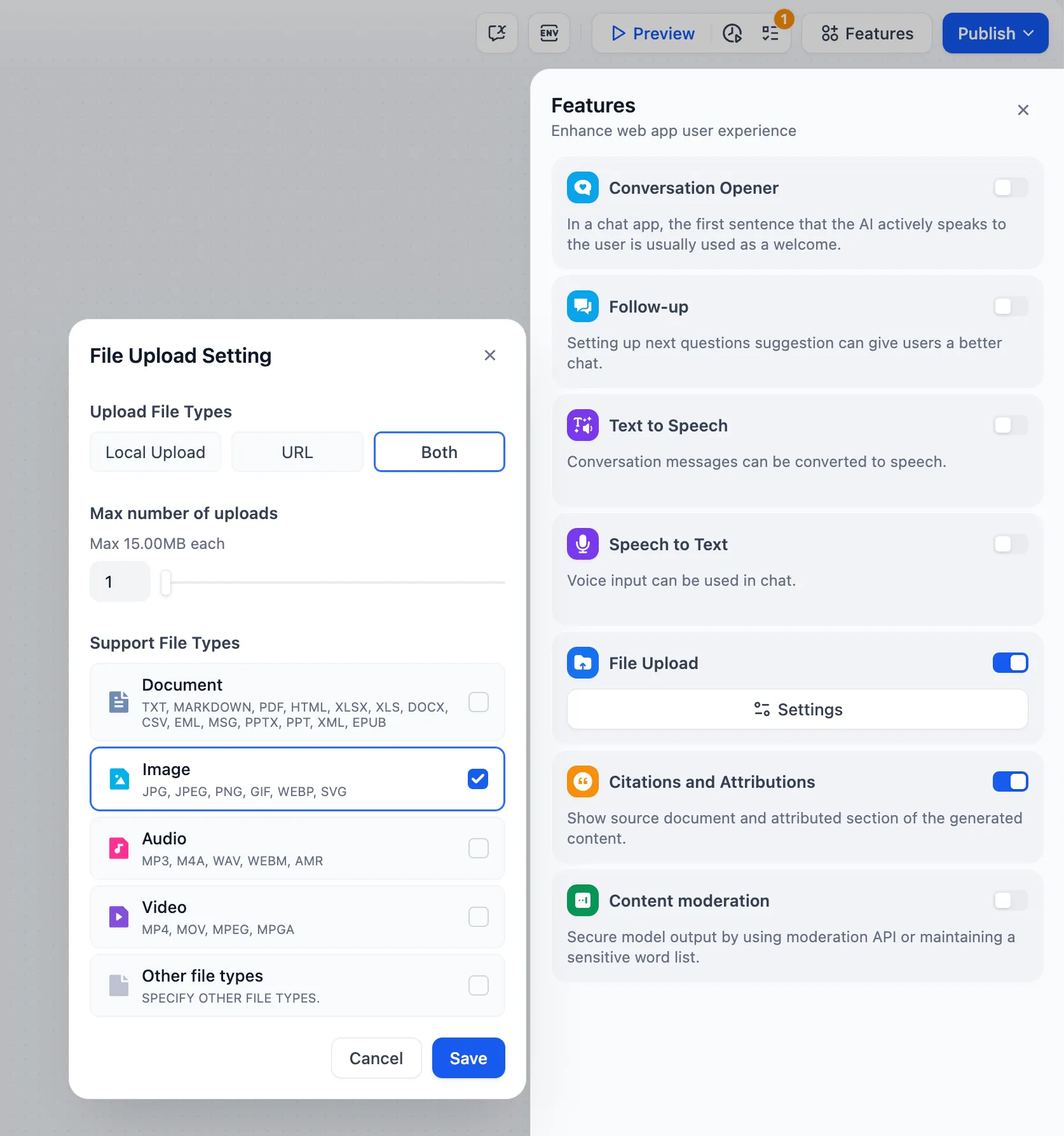
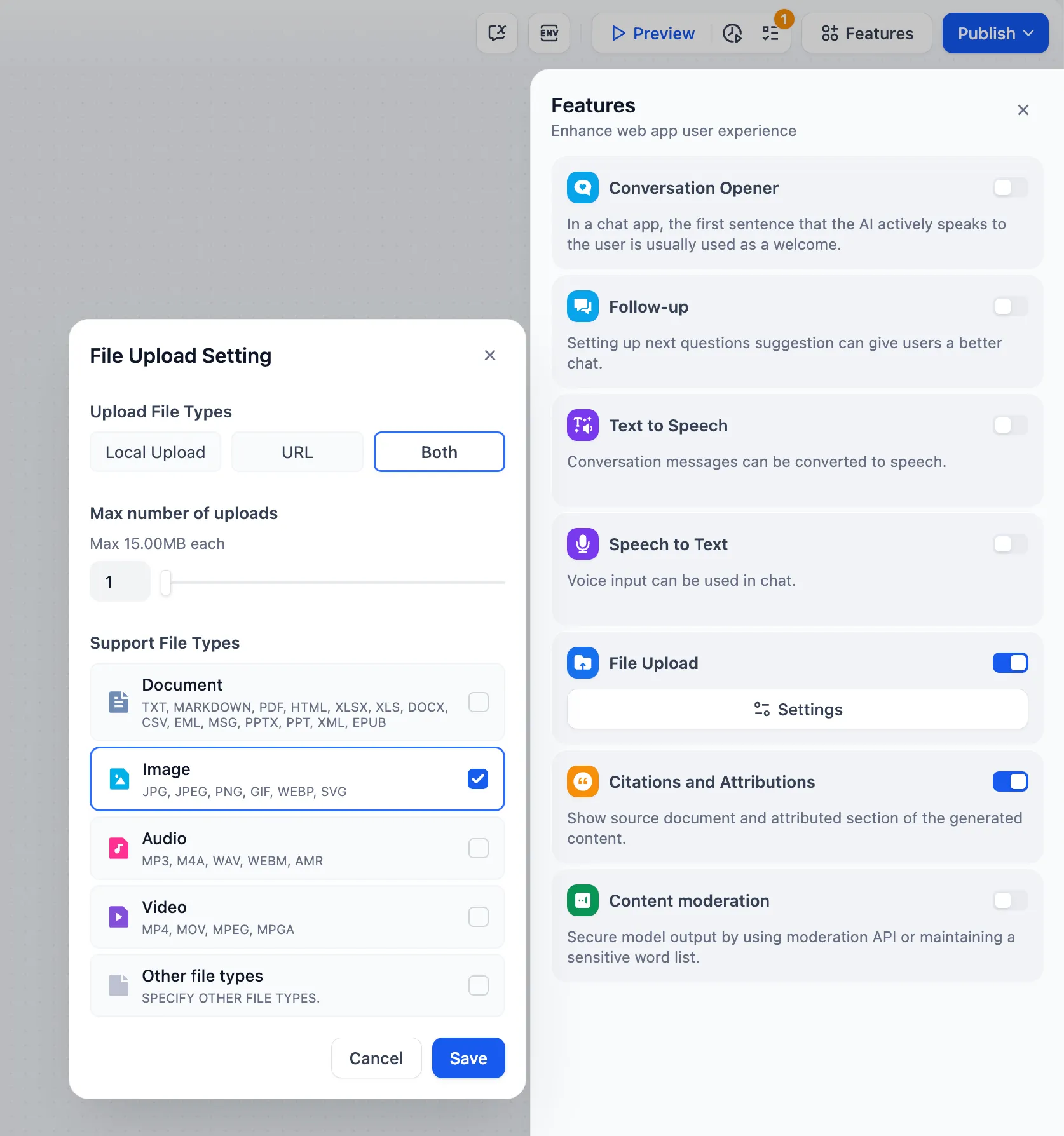
ファイルのアップロード機能
ファイルのアップロード機能
.png)
ファイルのアップロードの使用
ファイルのアップロードの使用





 (4).png)
 (4).png)
.png)
 (6).png)
 (3).png)
 (2).png)
 (1).png)
 (1).png)
 (3).png)
ファイルアップロード
ファイルアップロード
 (4).png)

 (3).png)
.png)
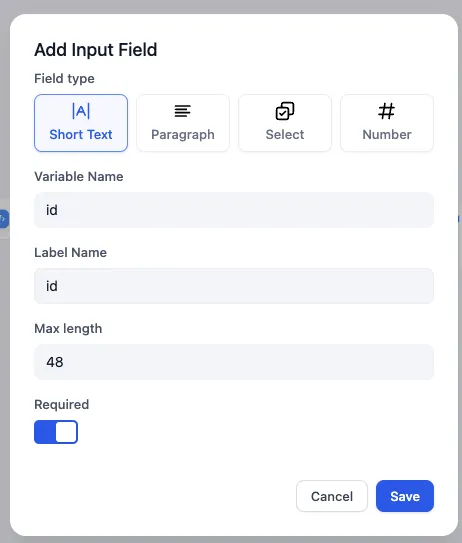
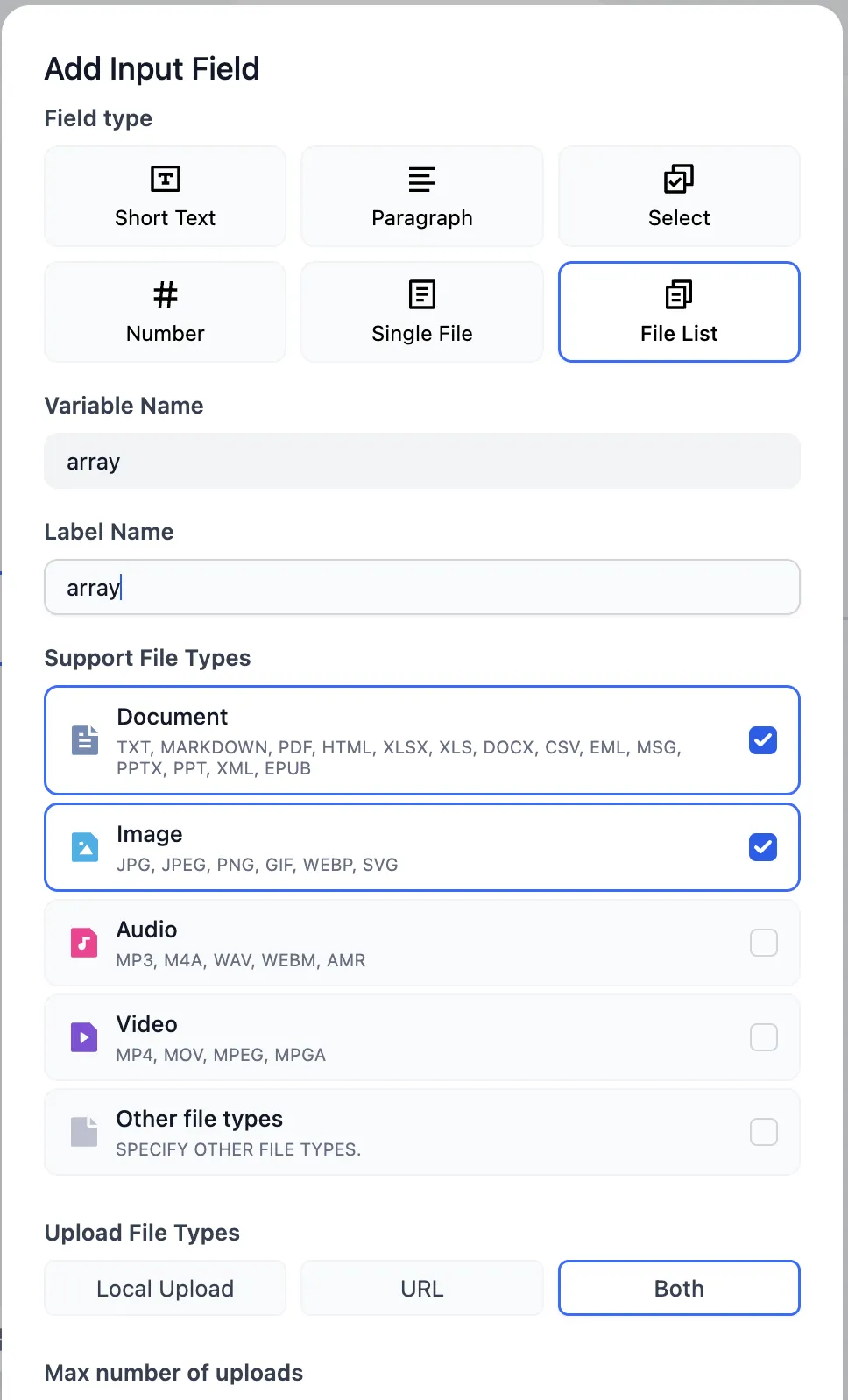
入力変数の追加
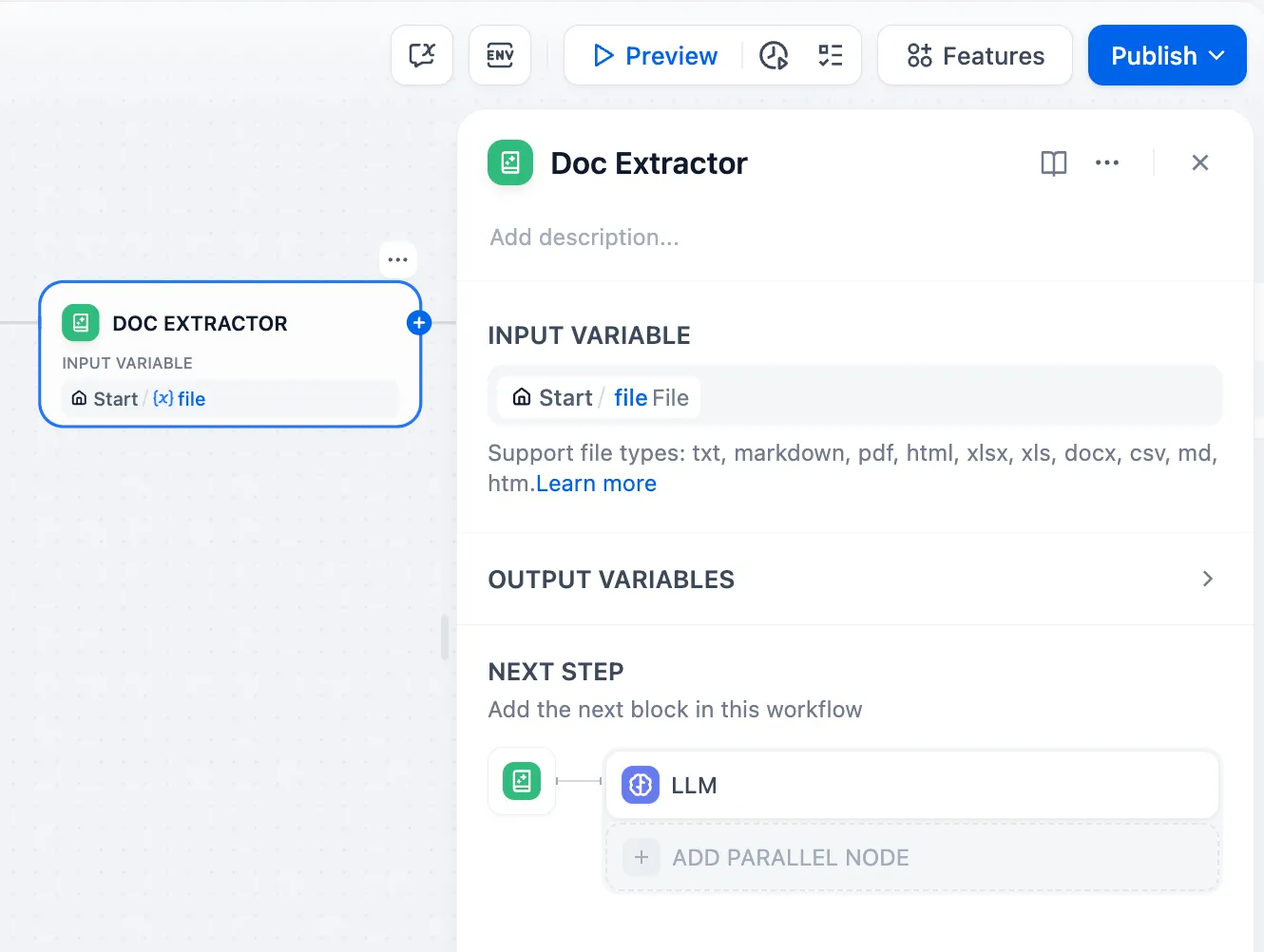
入力変数の追加
.png)
.png)
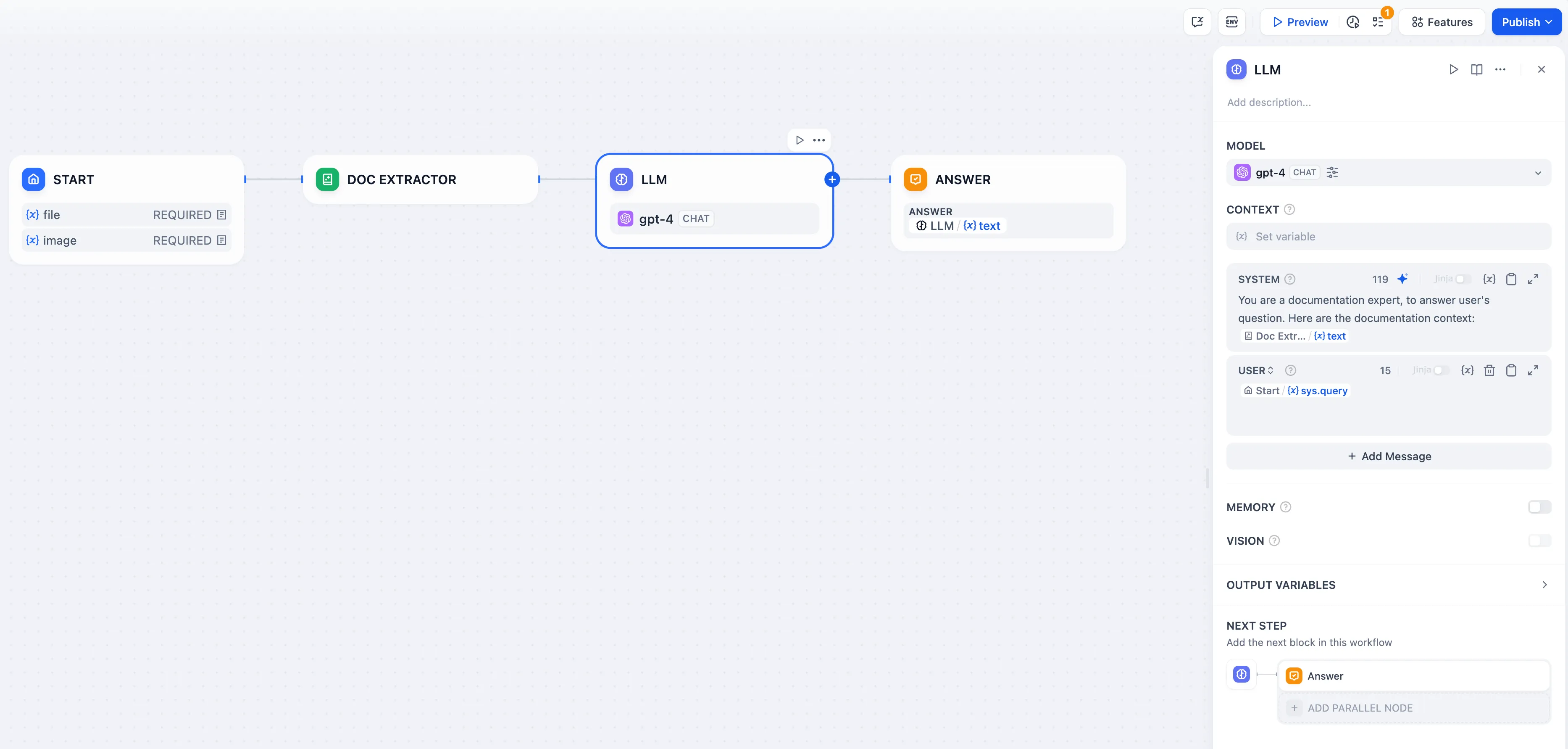
LLMノードを使用してファイル変数にアクセスする
LLMノードを使用してファイル変数にアクセスする
.png)
ファイルのダウンロード
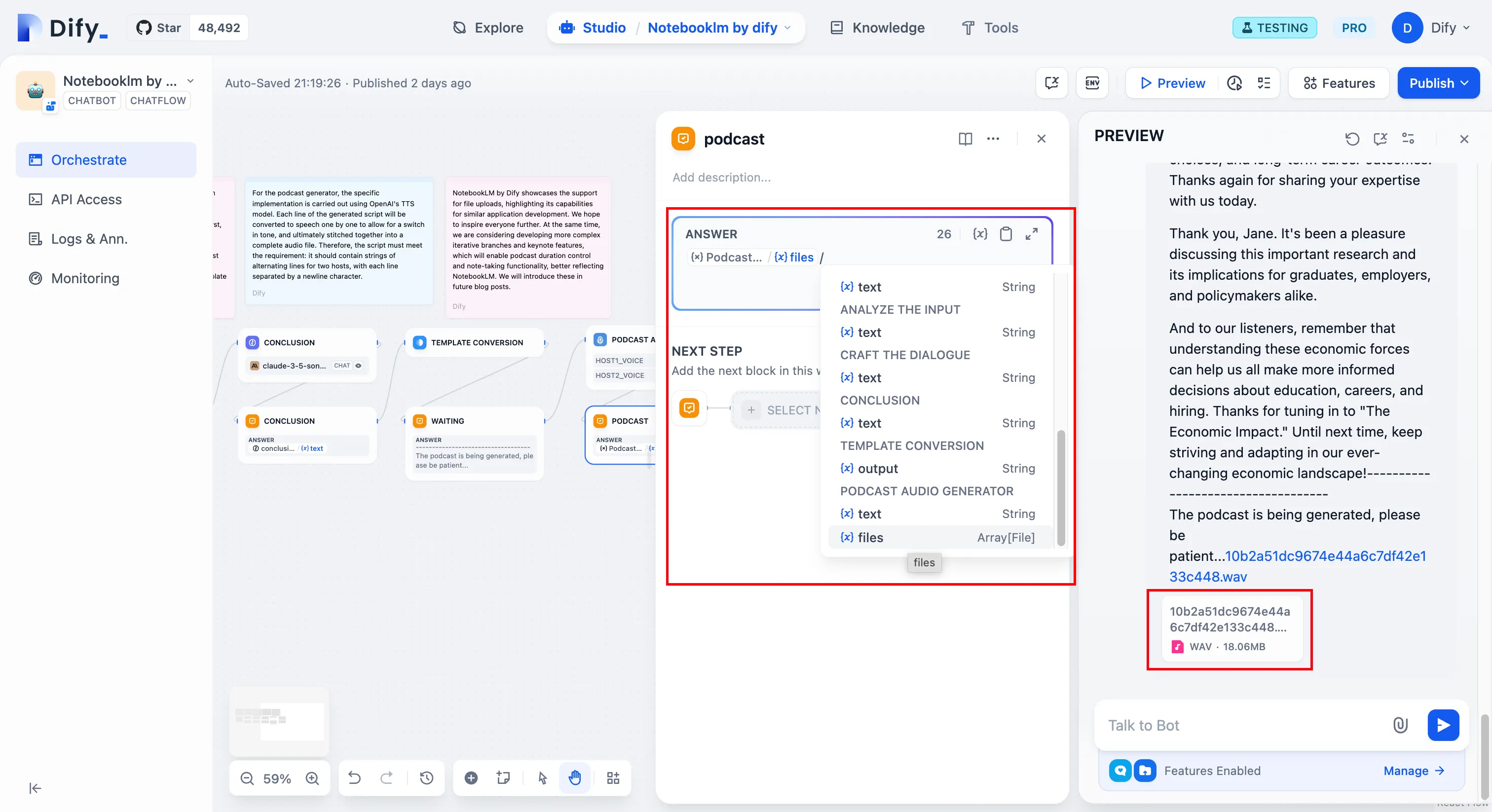
ファイルのダウンロード

チャットフロー入口
チャットフロー入口

ワークフロー入口
ワークフロー入口


 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png)


終了ノード-長編ストーリー生成の例
終了ノード-長編ストーリー生成の例


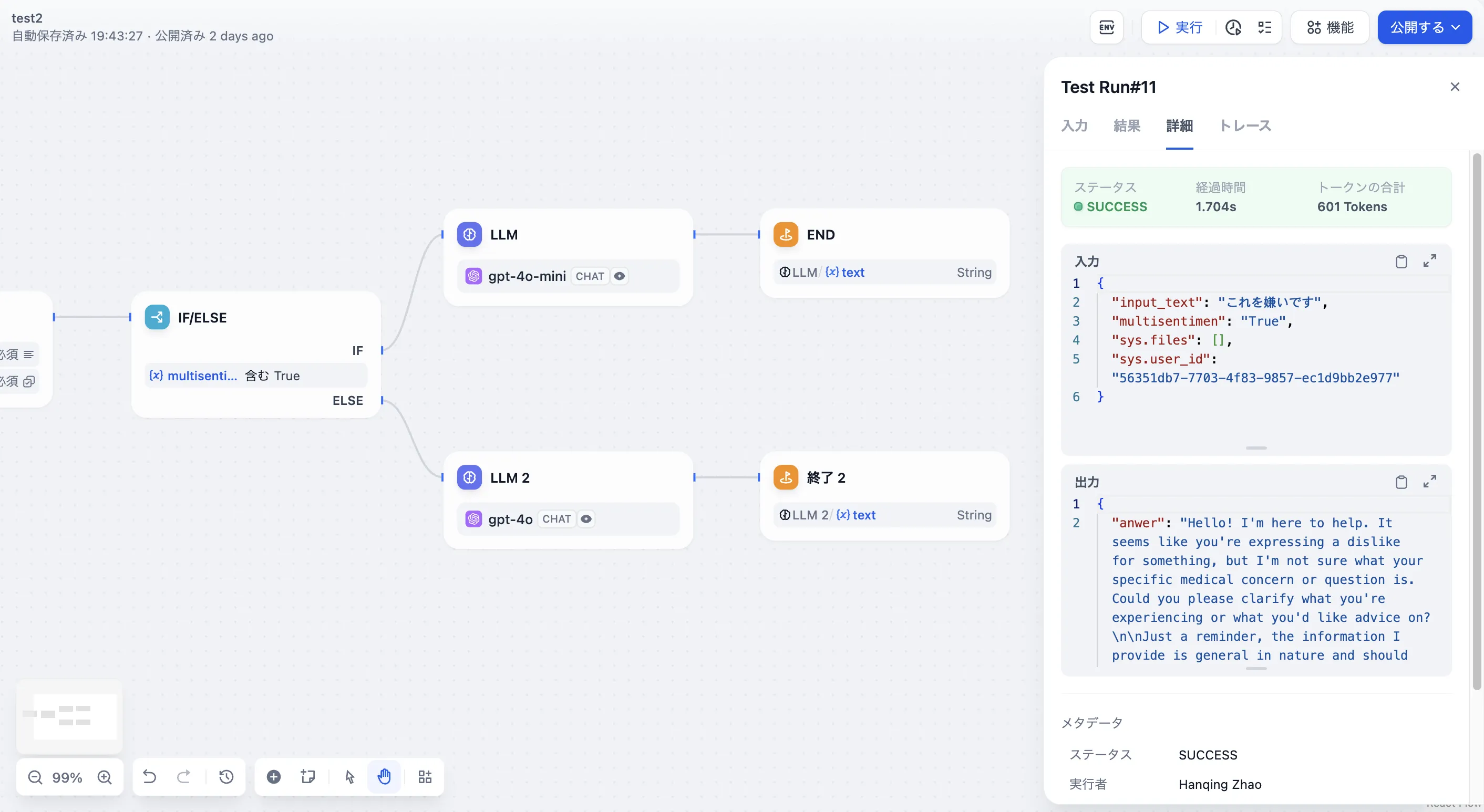

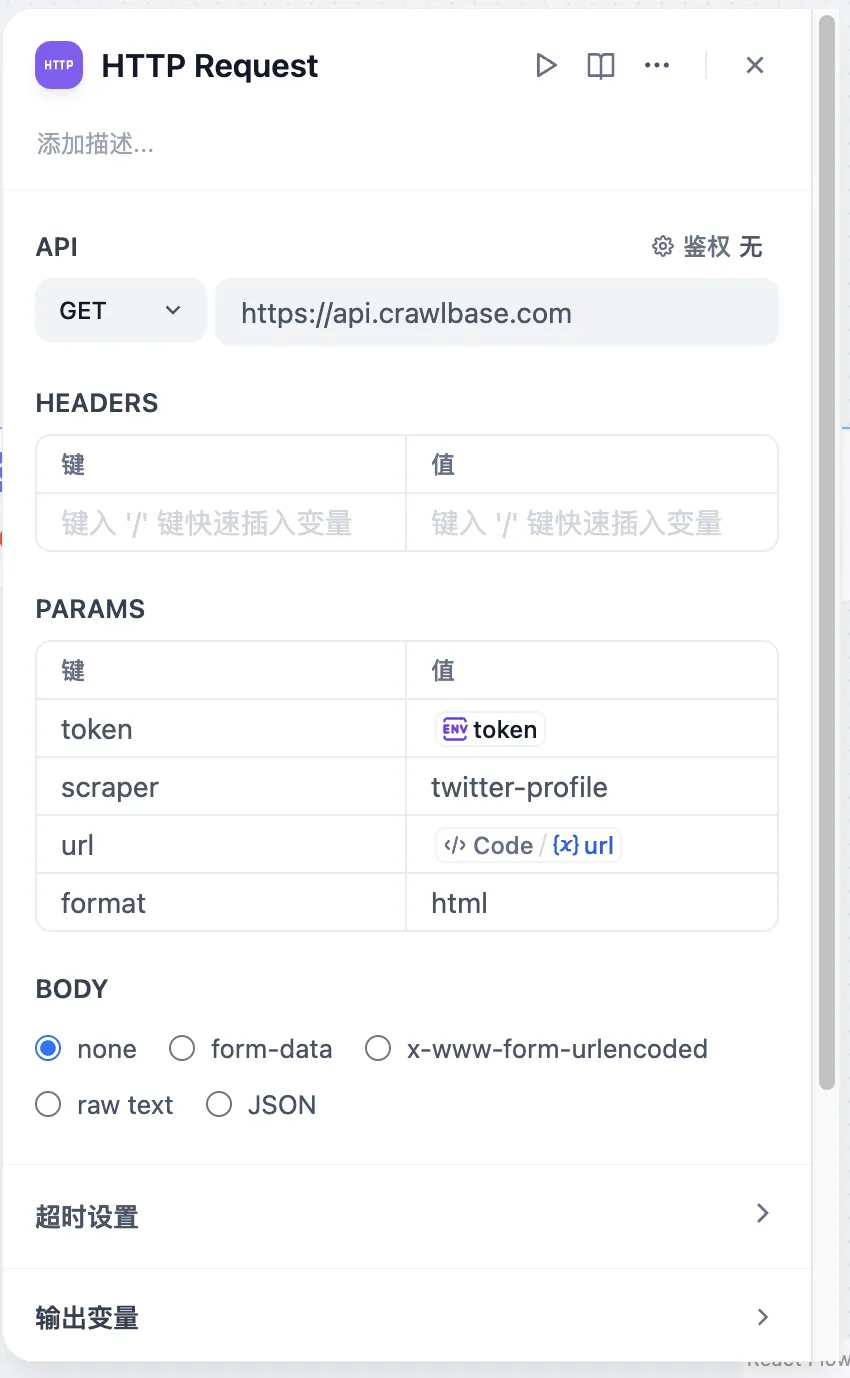
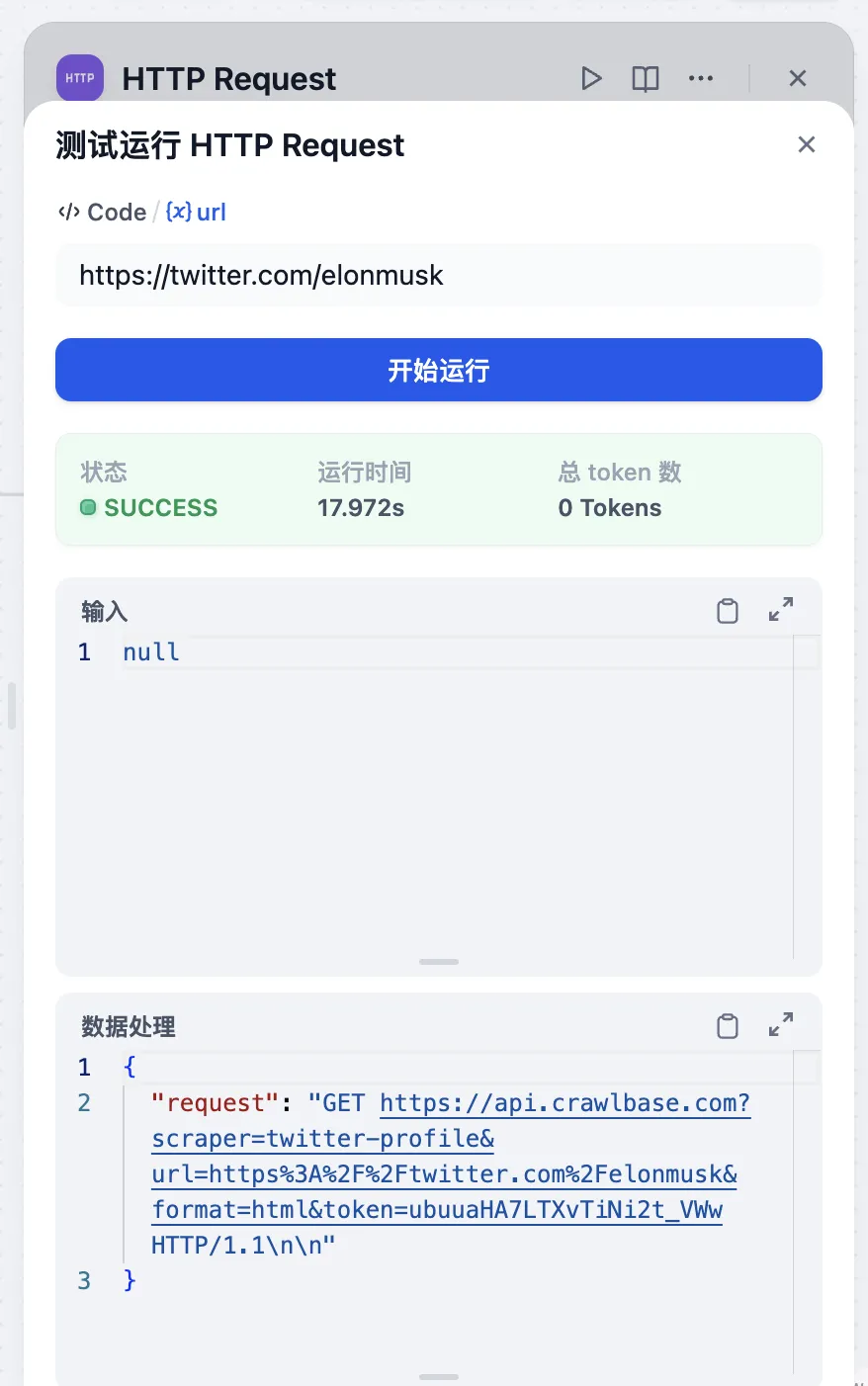
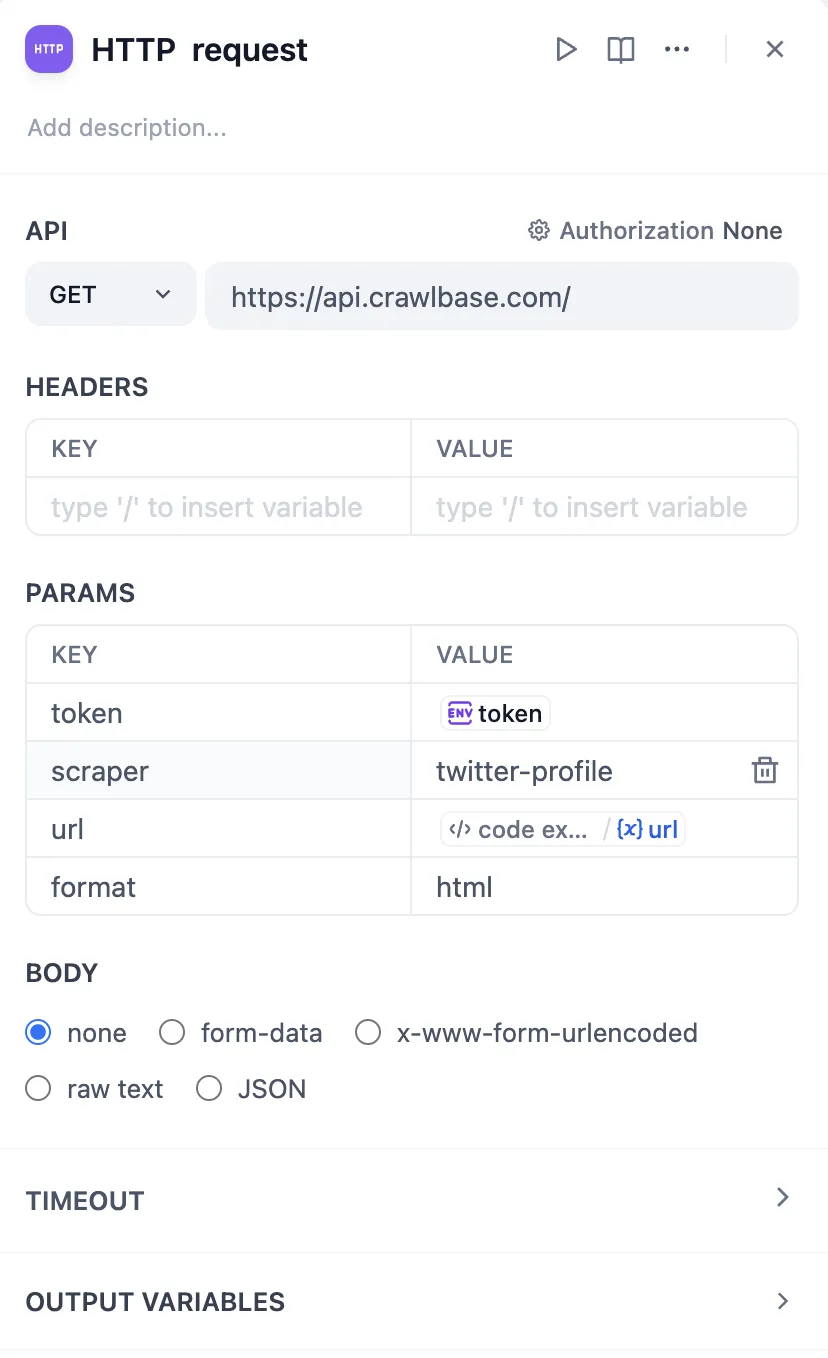
HTTP リクエスト設定
HTTP リクエスト設定
顧客のフィードバック分類
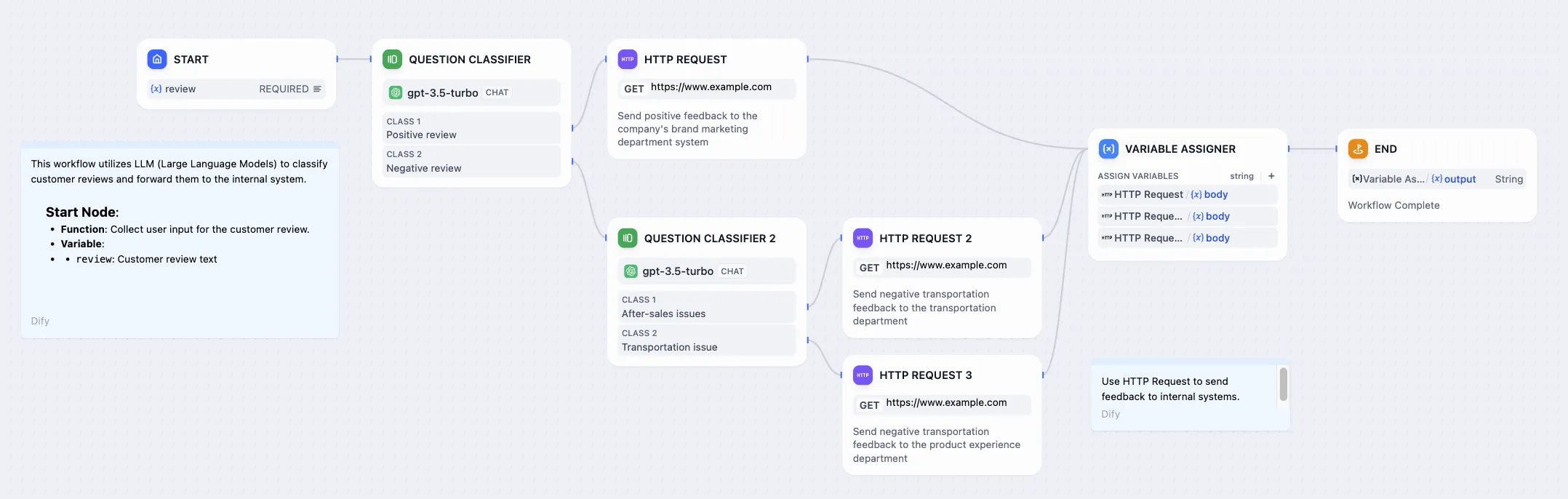
顧客のフィードバック分類
.png)
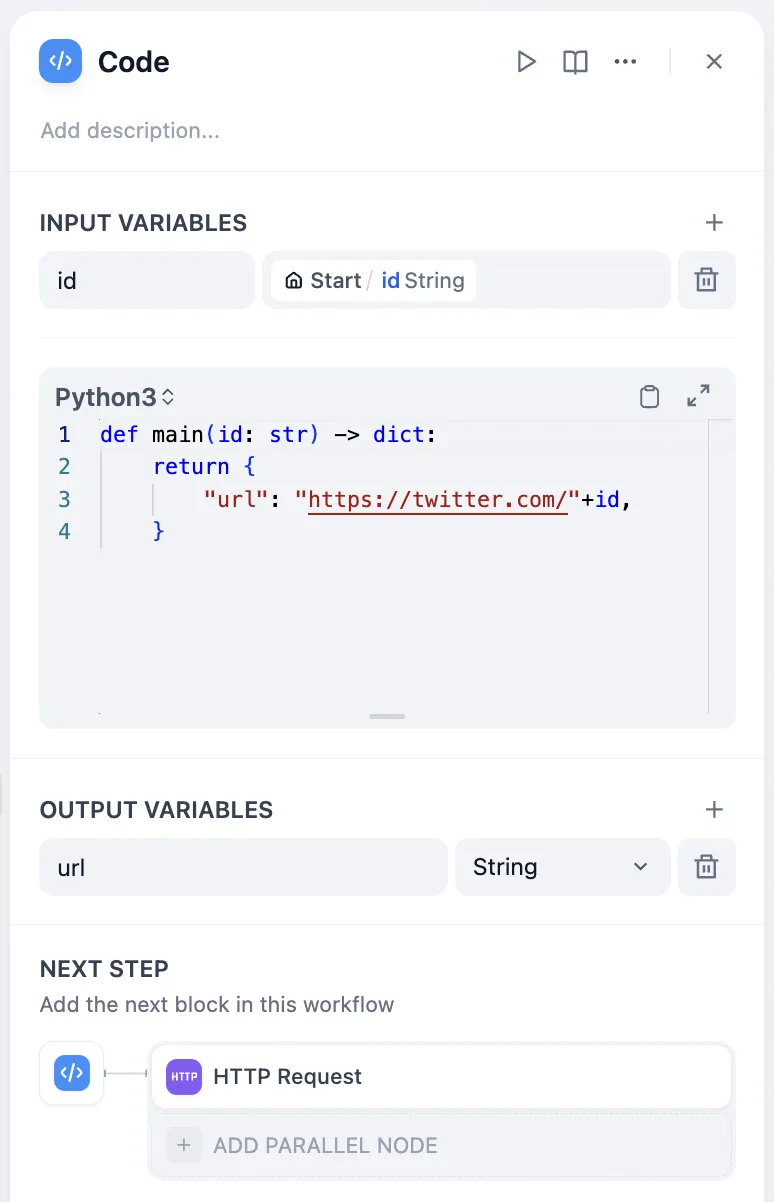
HTTP機能を使ってファイルを送信する方法
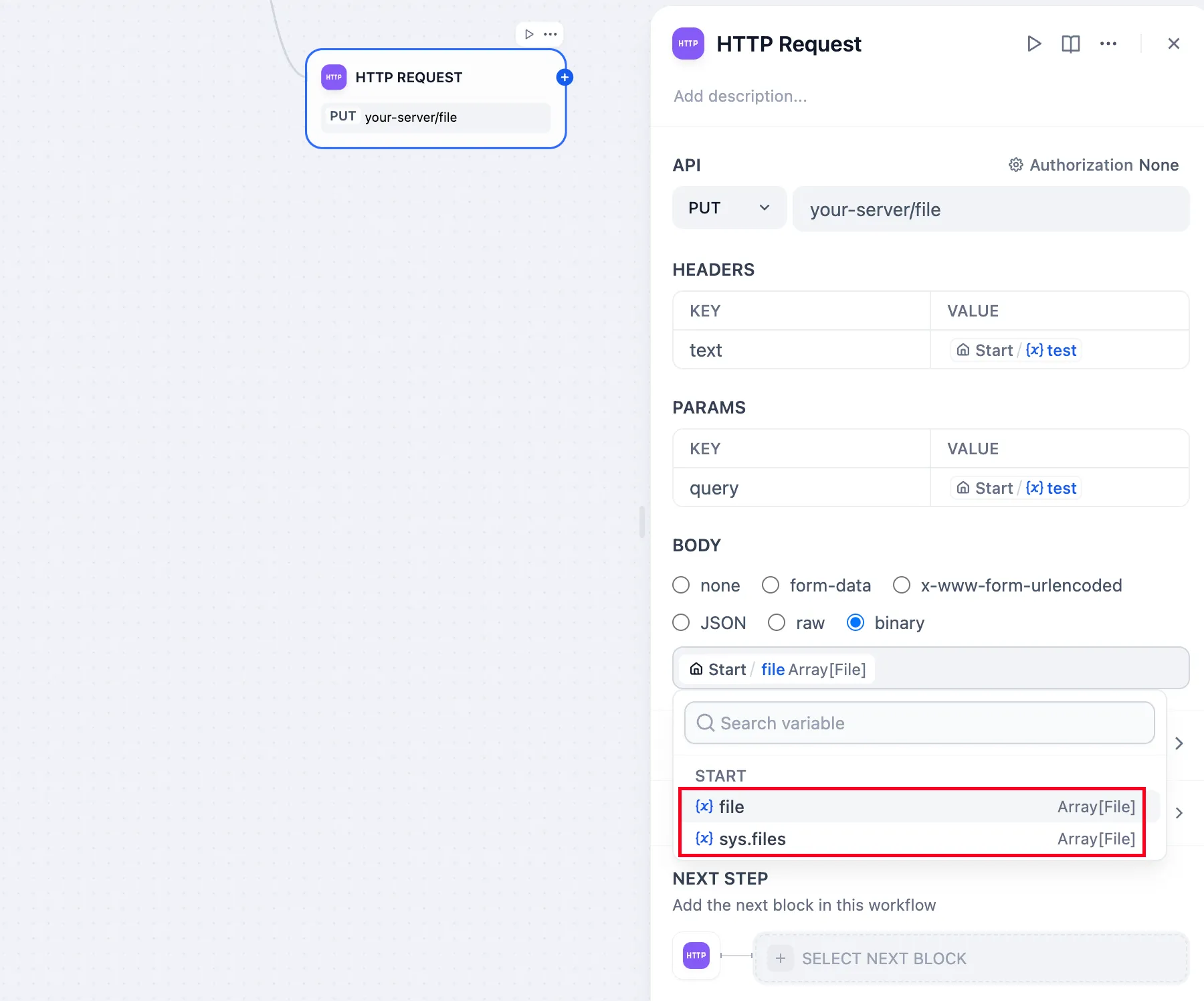
HTTP機能を使ってファイルを送信する方法


複数条件の判断
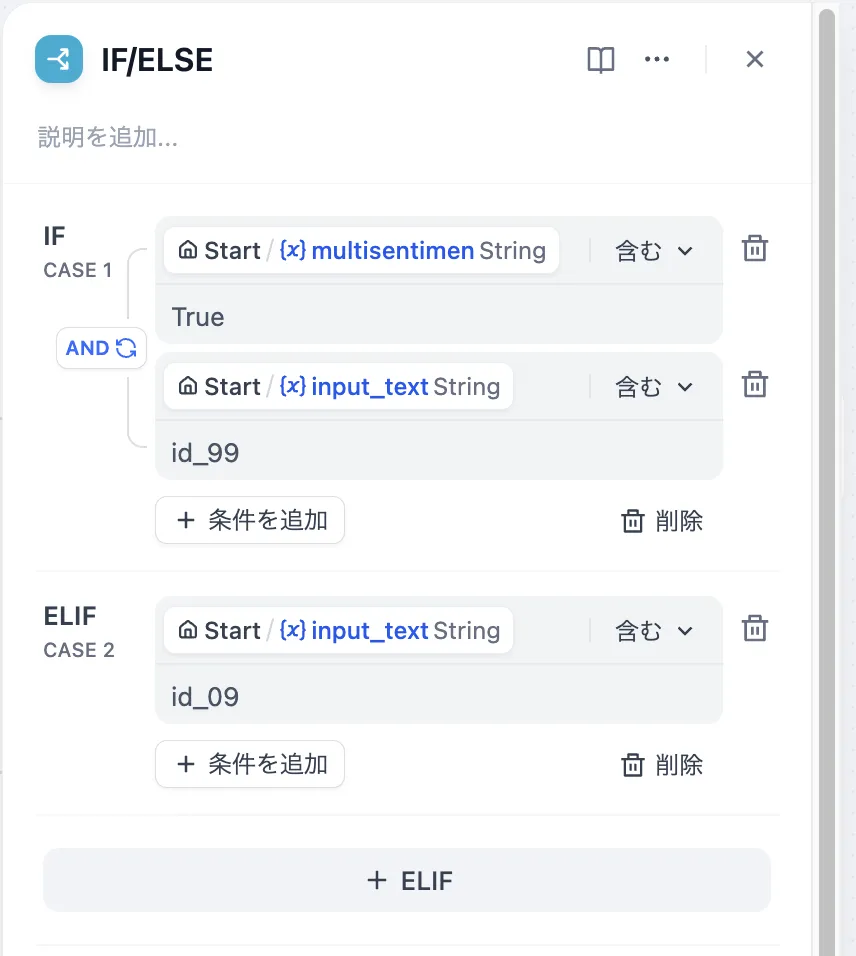
複数条件の判断

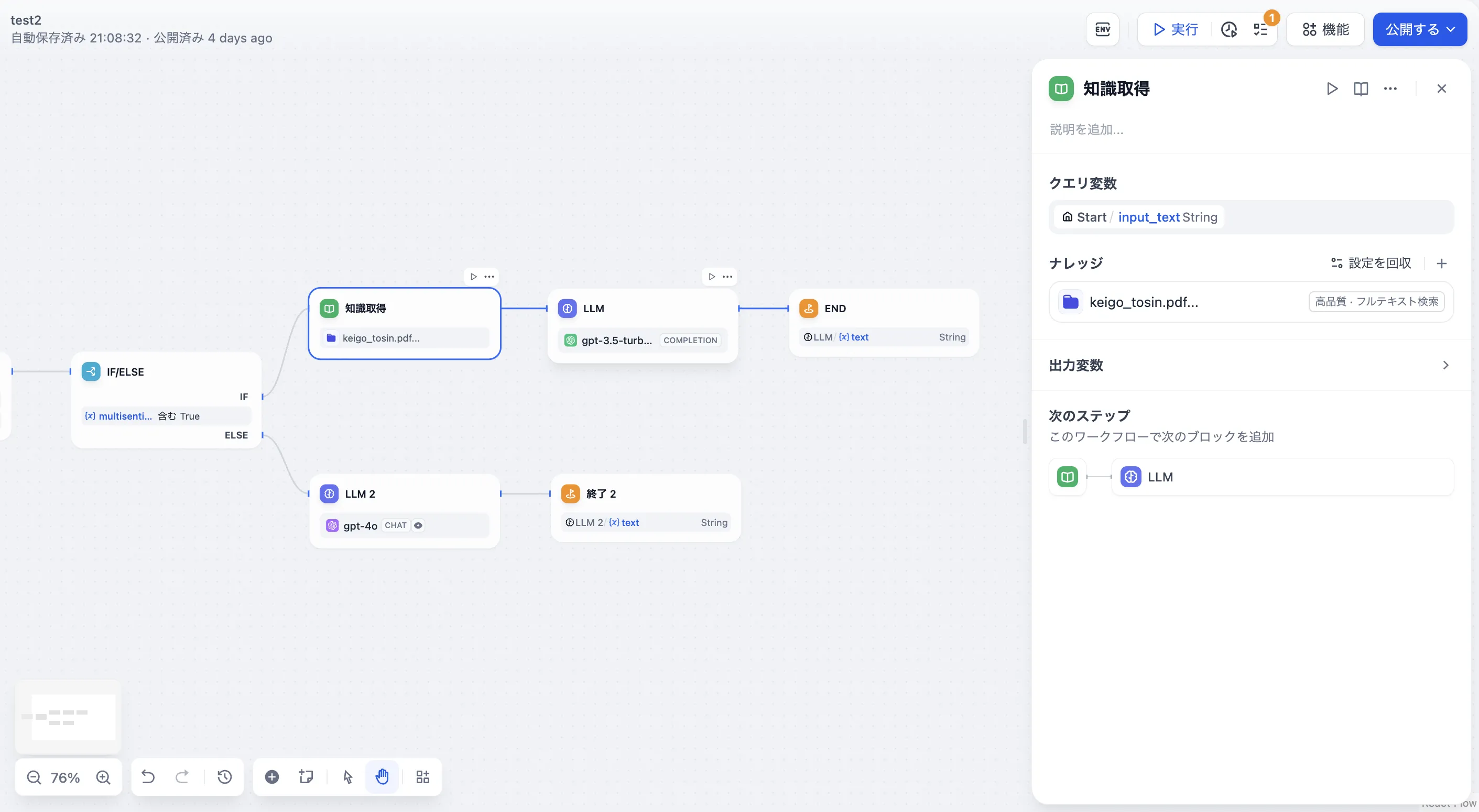
ナレッジベース質問応答アプリケーションの例
ナレッジベース質問応答アプリケーションの例

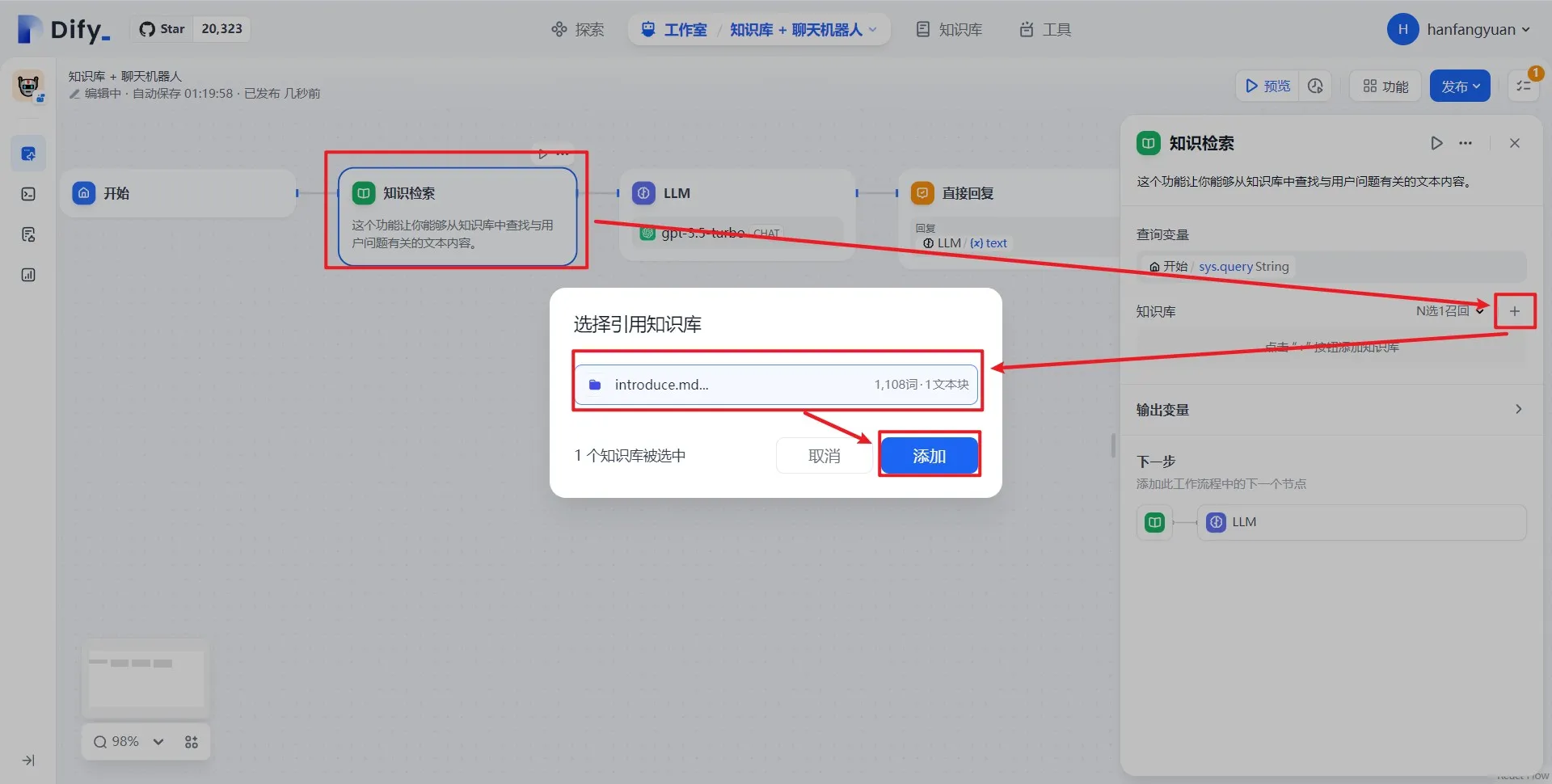
ナレッジ検索の設定
ナレッジ検索の設定

出力変数

出力変数

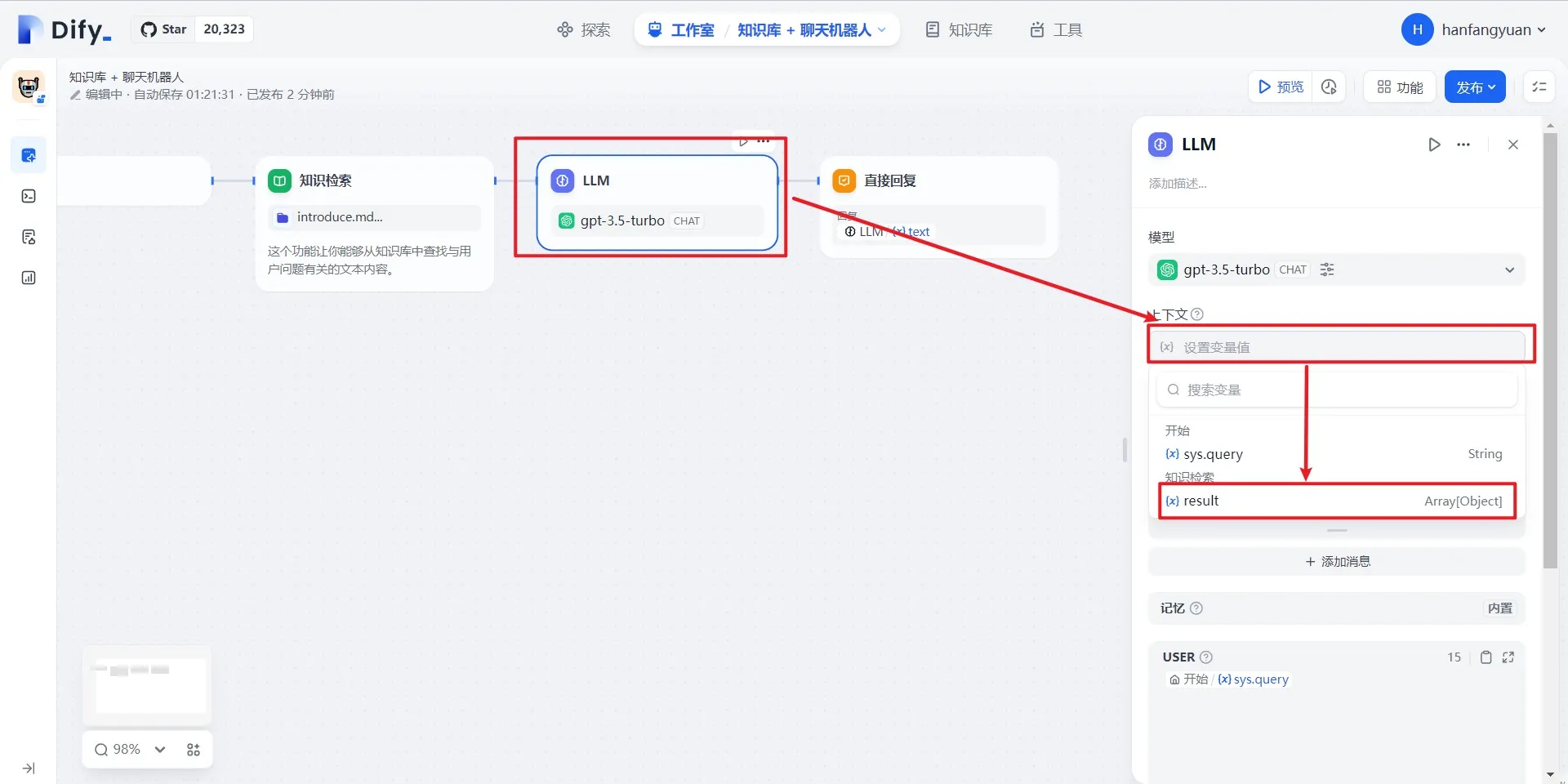
下流LLMノードの設定
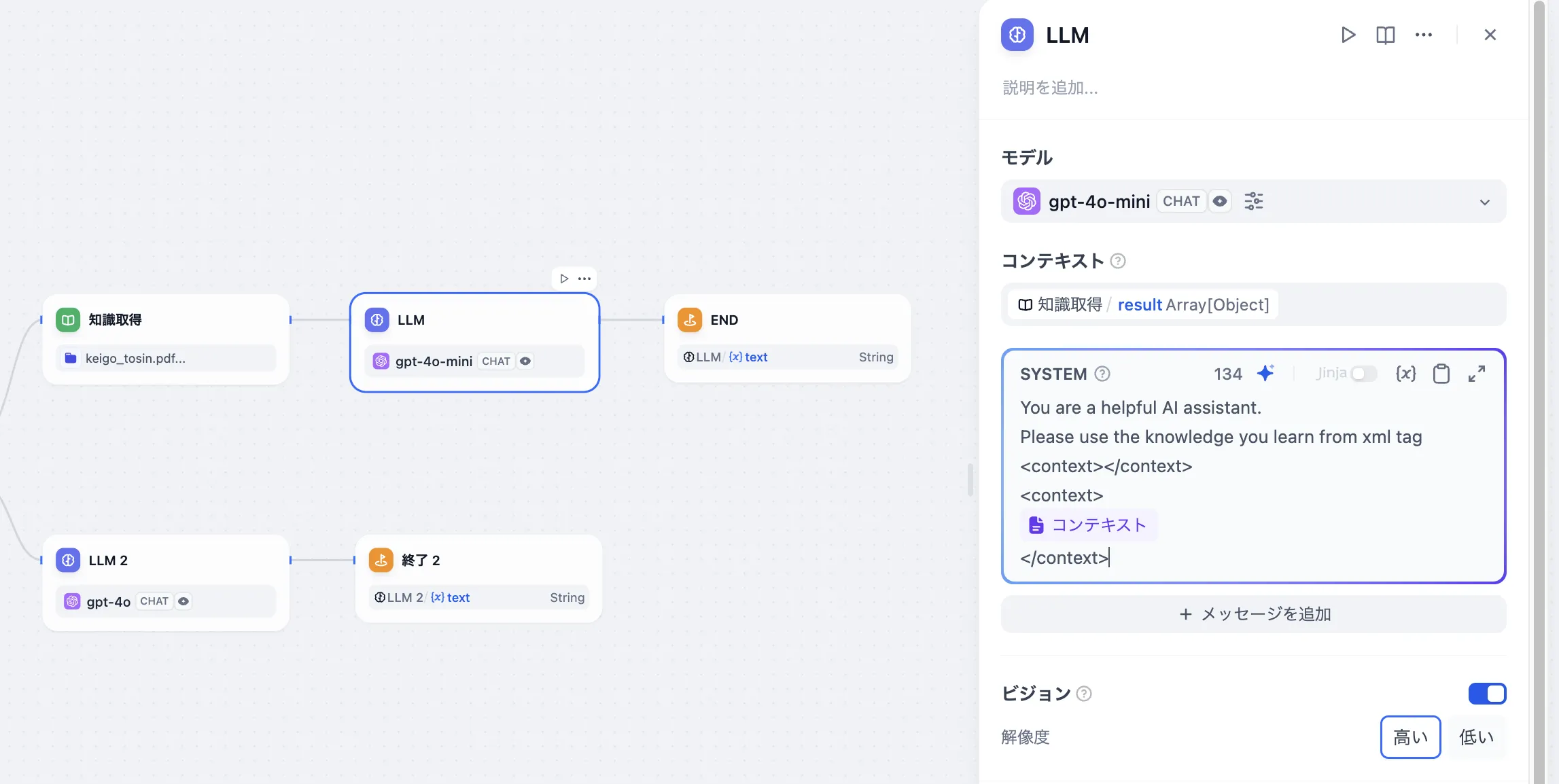
下流LLMノードの設定
.png)
異なるファイルタイプのフロー分岐
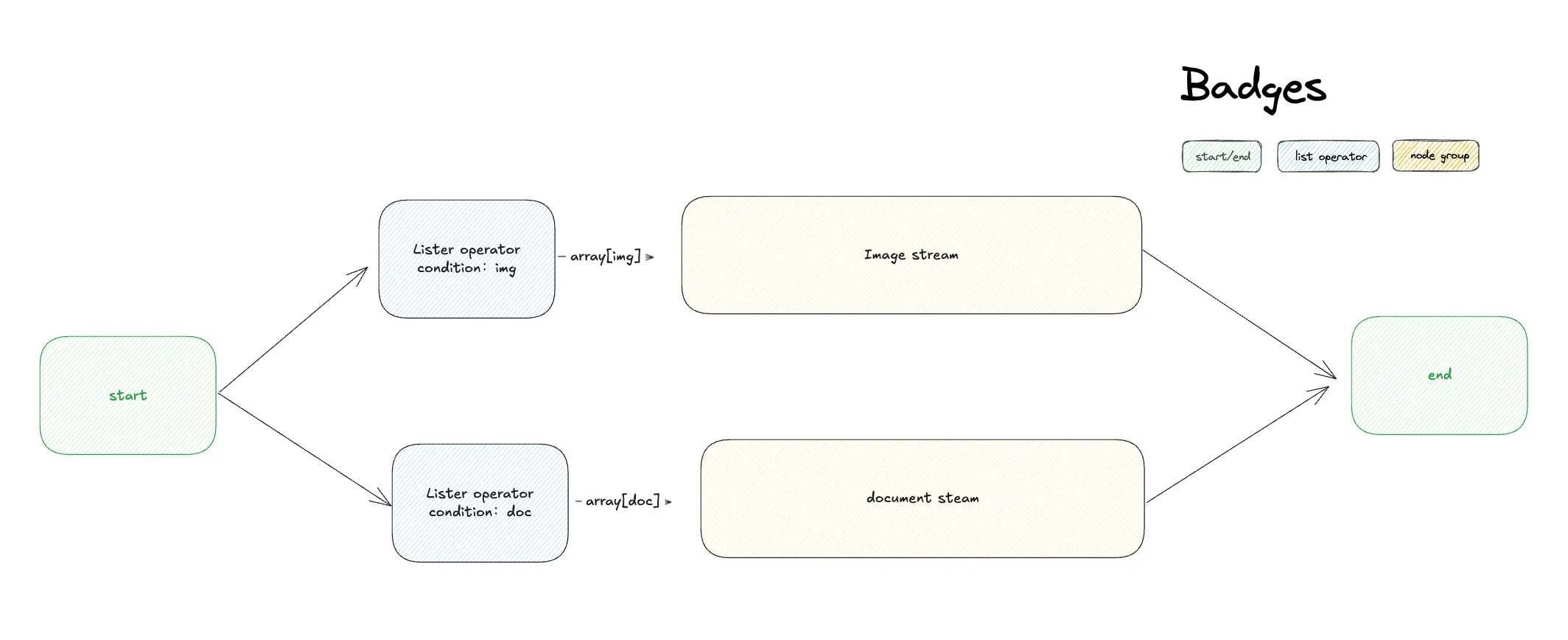
異なるファイルタイプのフロー分岐
.png)
リスト操作ノード
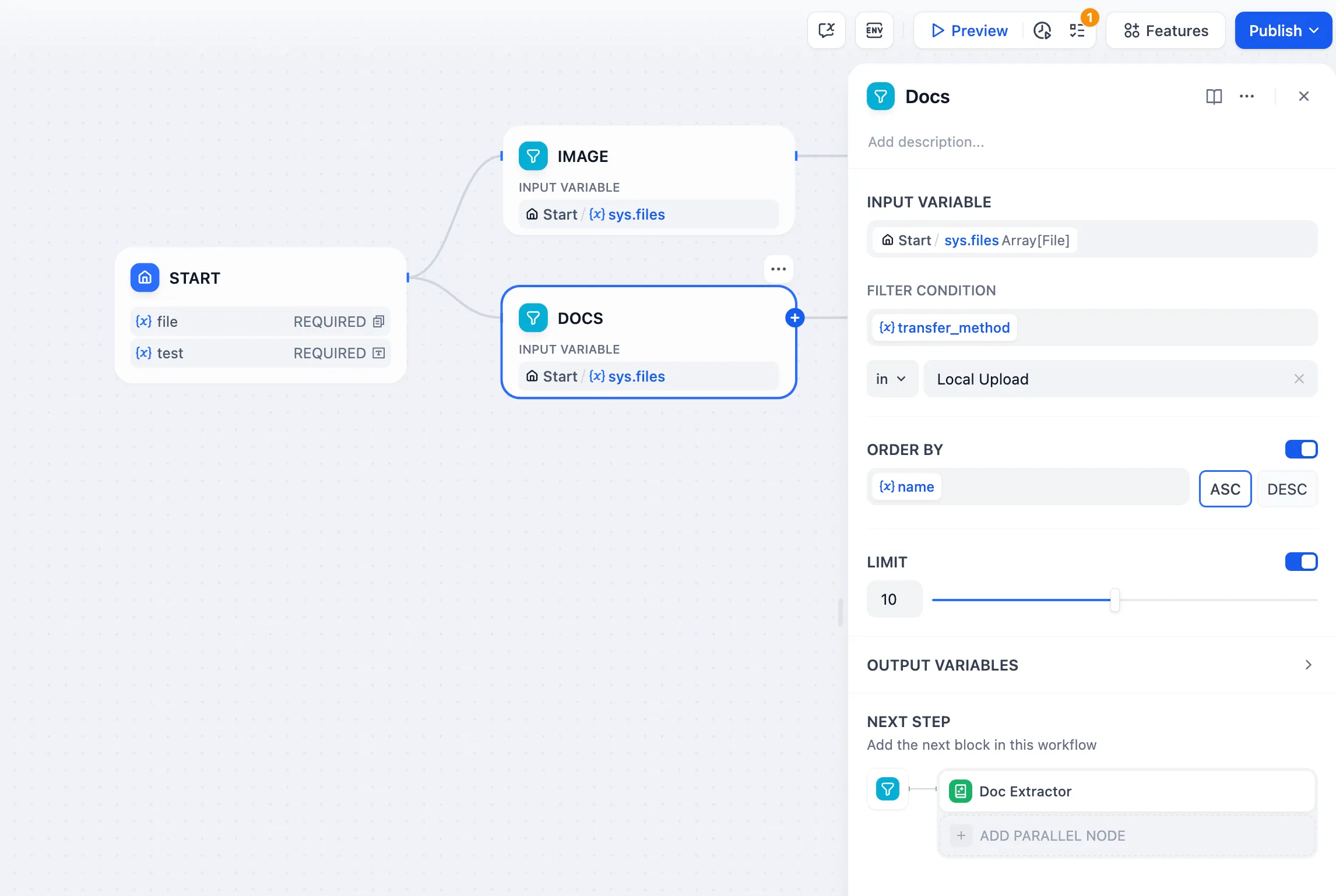
リスト操作ノード
.png)
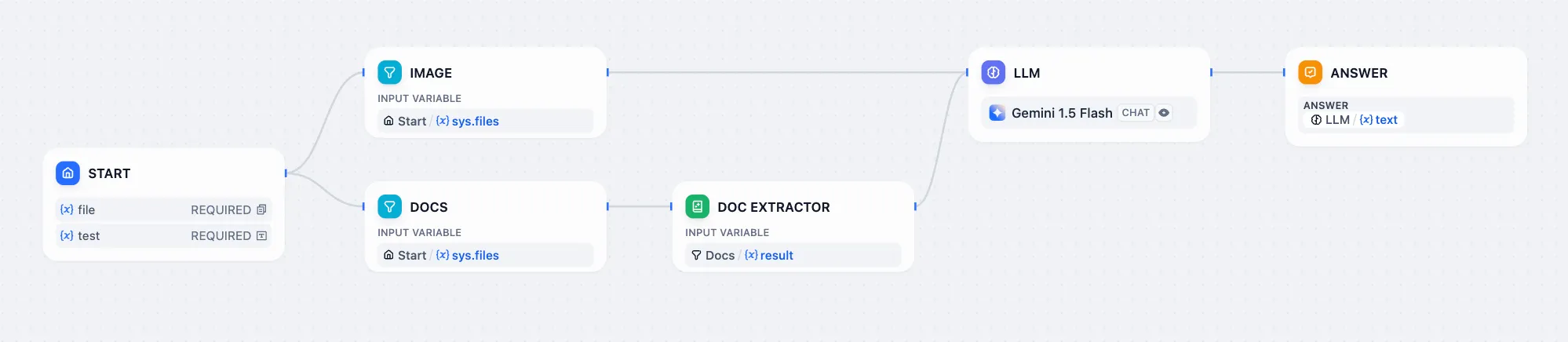

Arxiv論文検索ツール
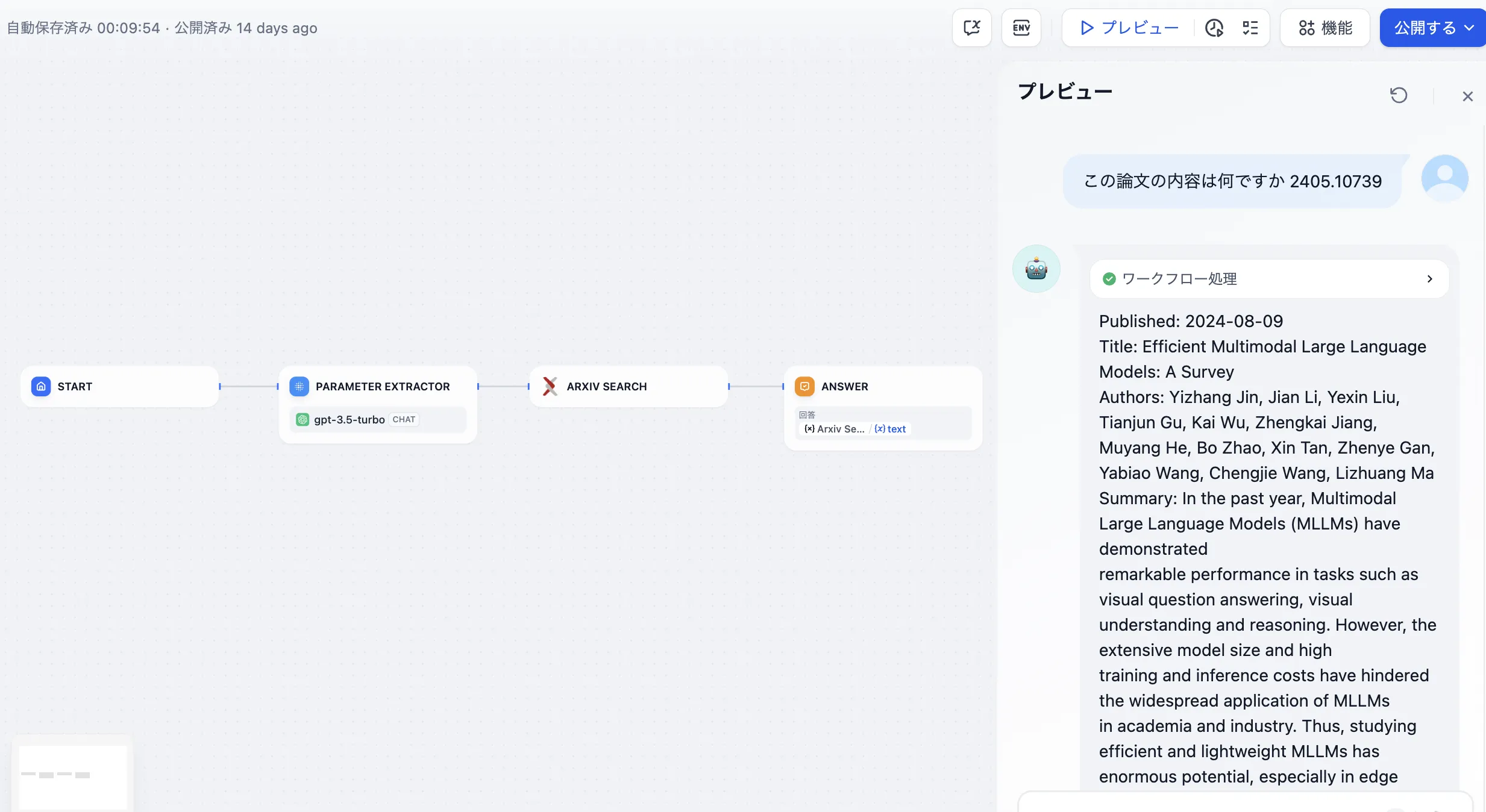
Arxiv論文検索ツール





チャットフロー と ワークフロー
チャットフロー と ワークフロー
.png)


テキストの結合
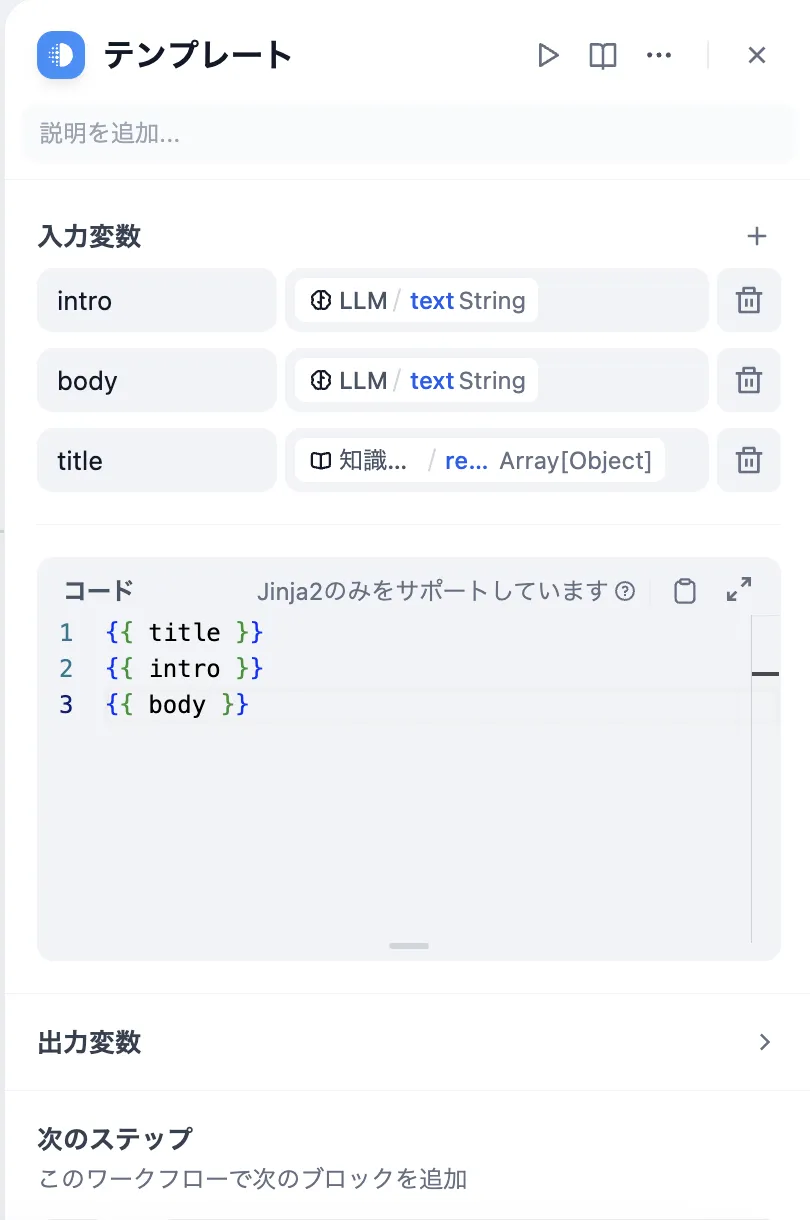
テキストの結合
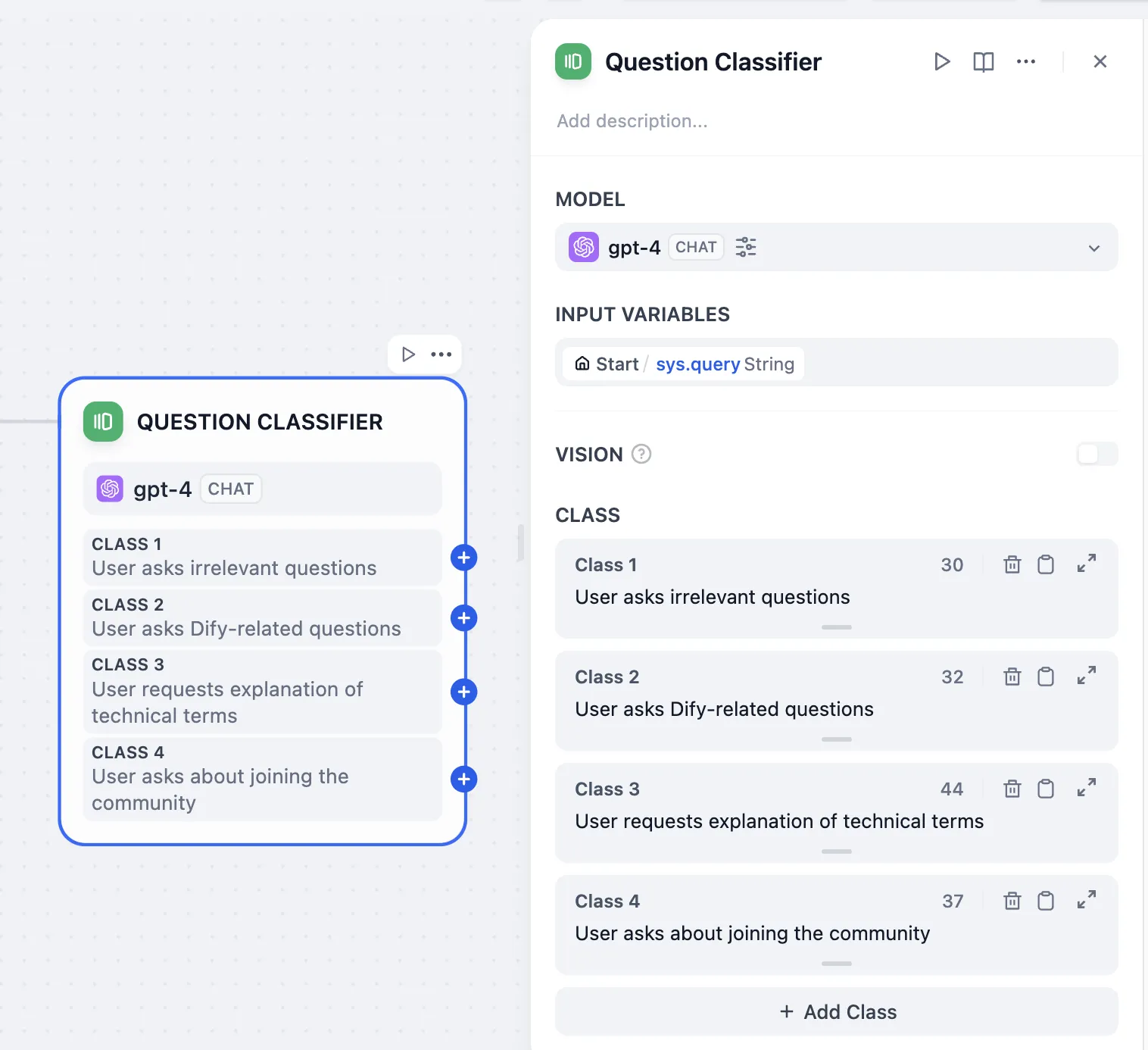
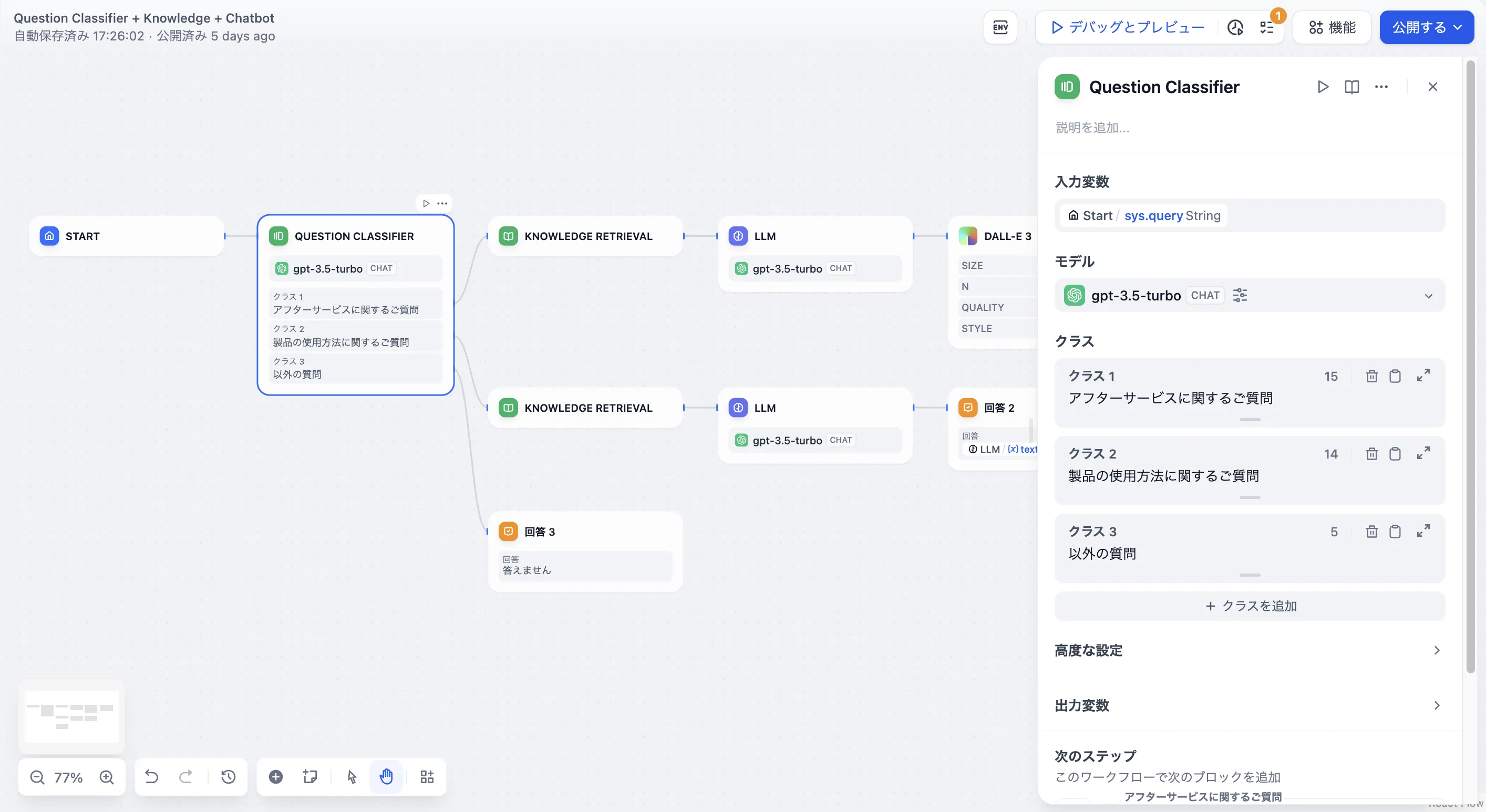
問題分類(変数集約なし)
問題分類(変数集約なし)
.png)
問題分類後のマルチ集約
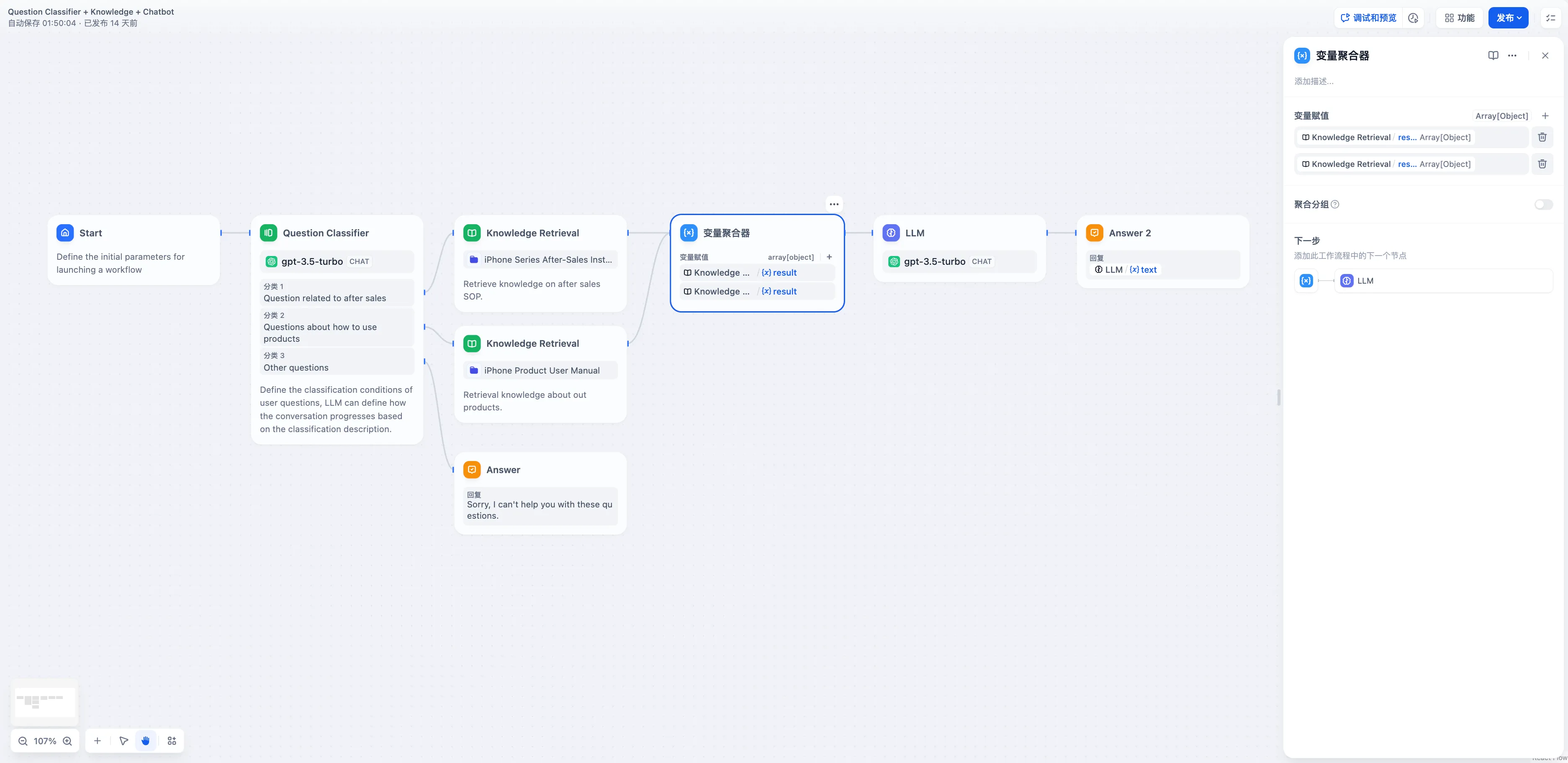
問題分類後のマルチ集約
.png)
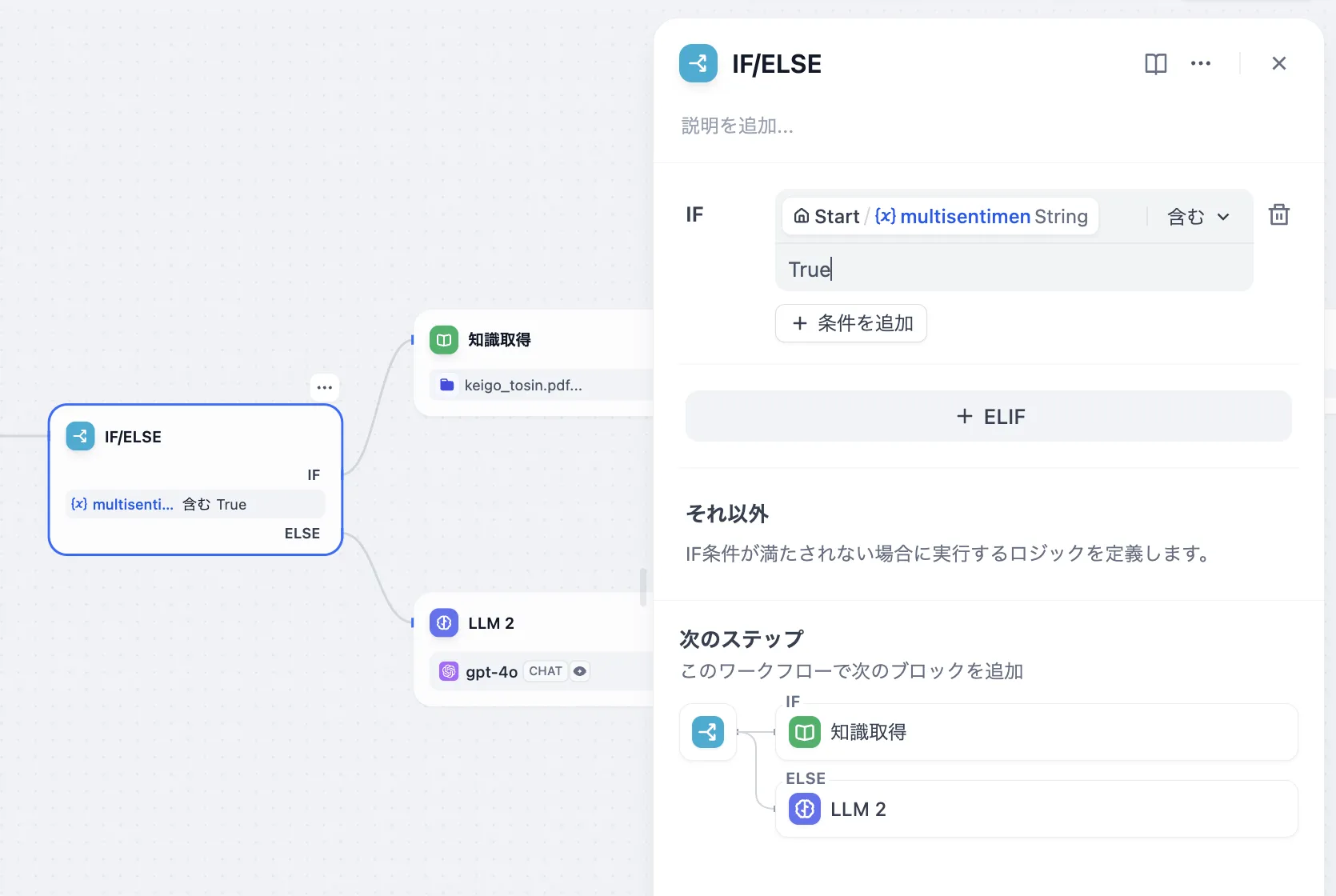
IF/ELSE 問題分類後のマルチ集約
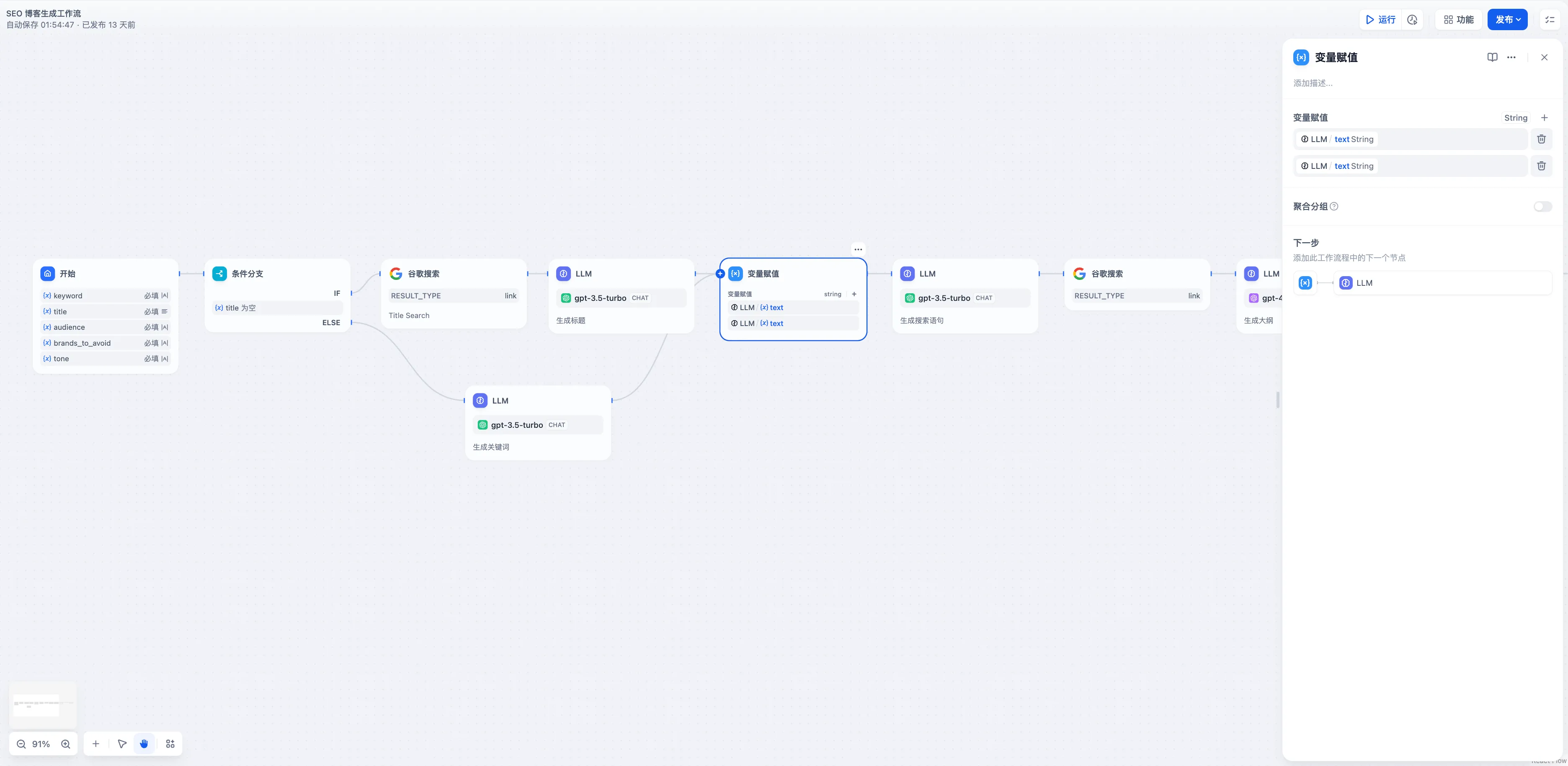
IF/ELSE 問題分類後のマルチ集約

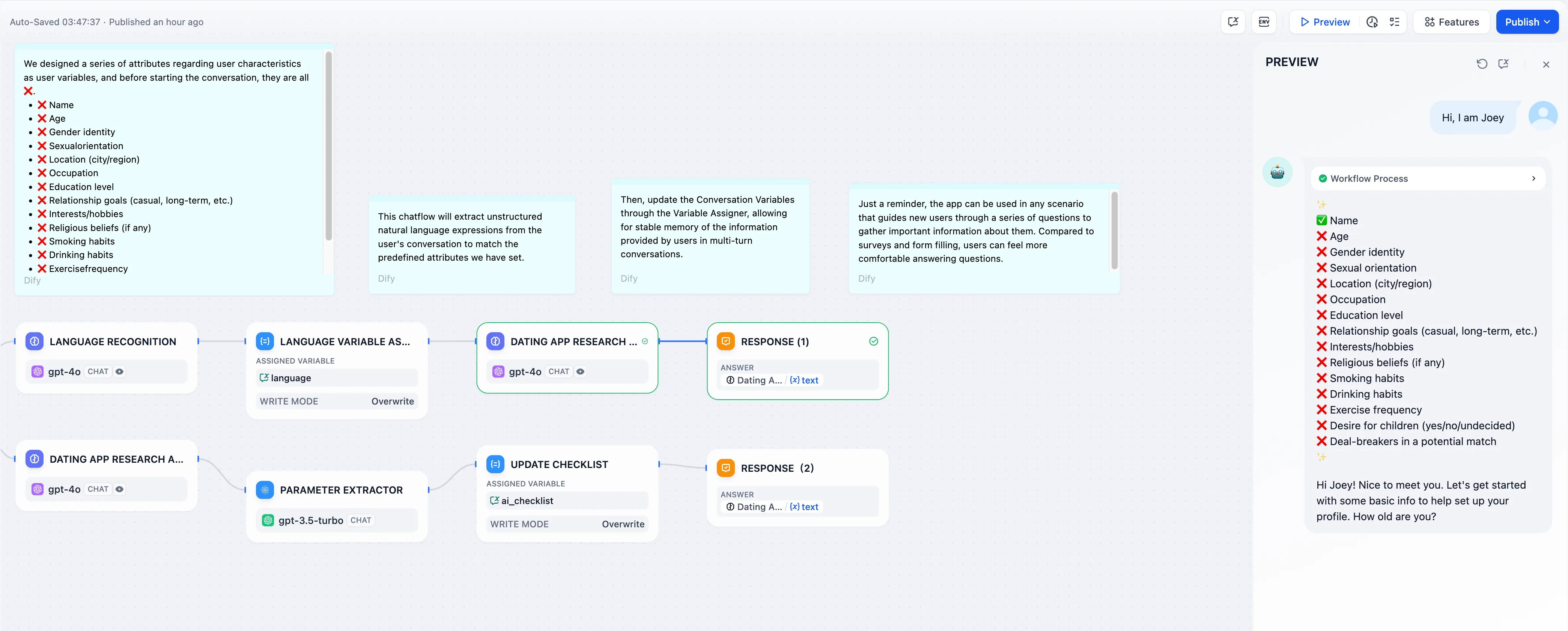
.png)
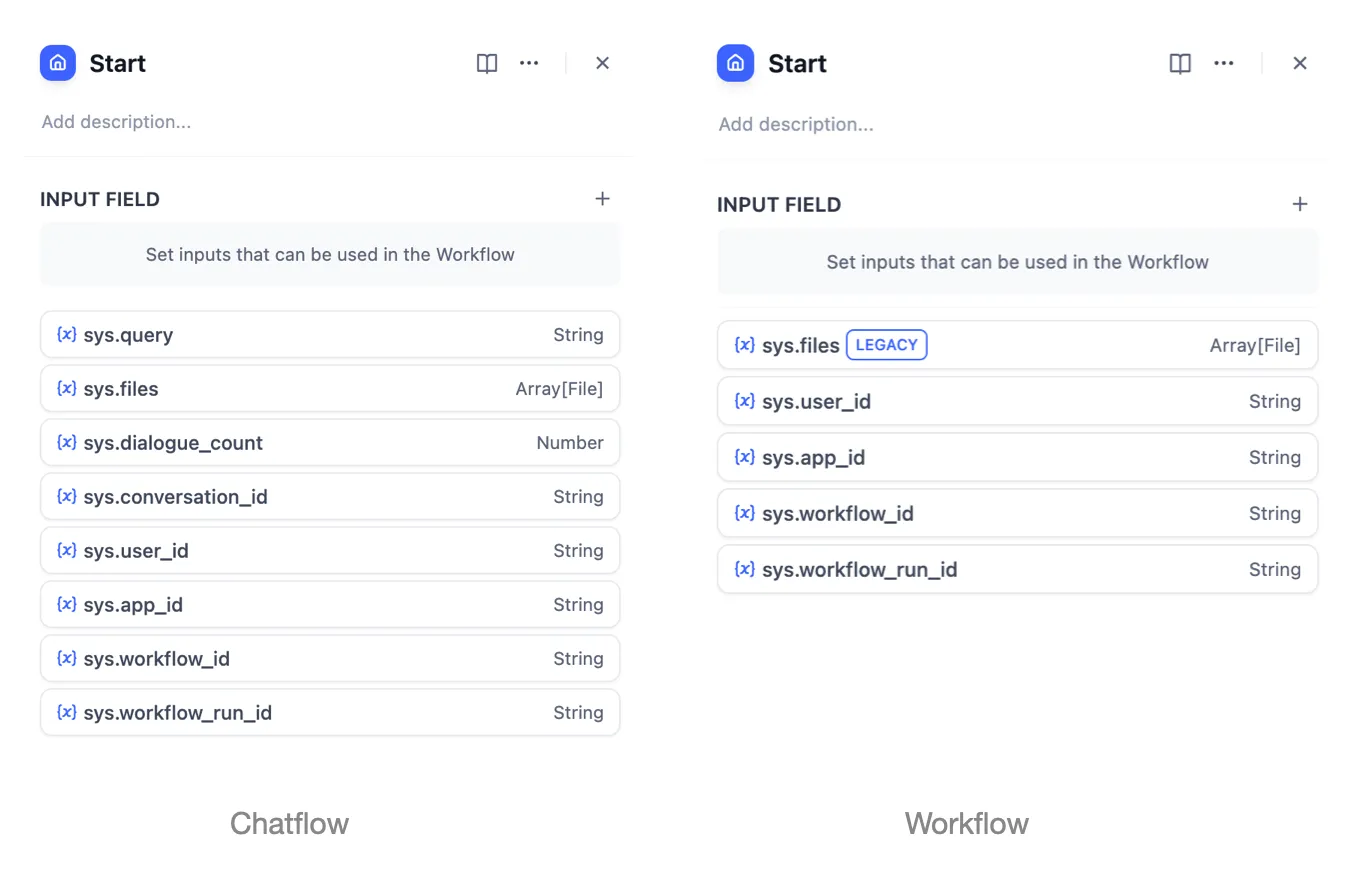
ワークフロー内のシステム変数
ワークフロー内のシステム変数
 (2).png)
チャットフロー内のシステム変数
チャットフロー内のシステム変数

環境変数
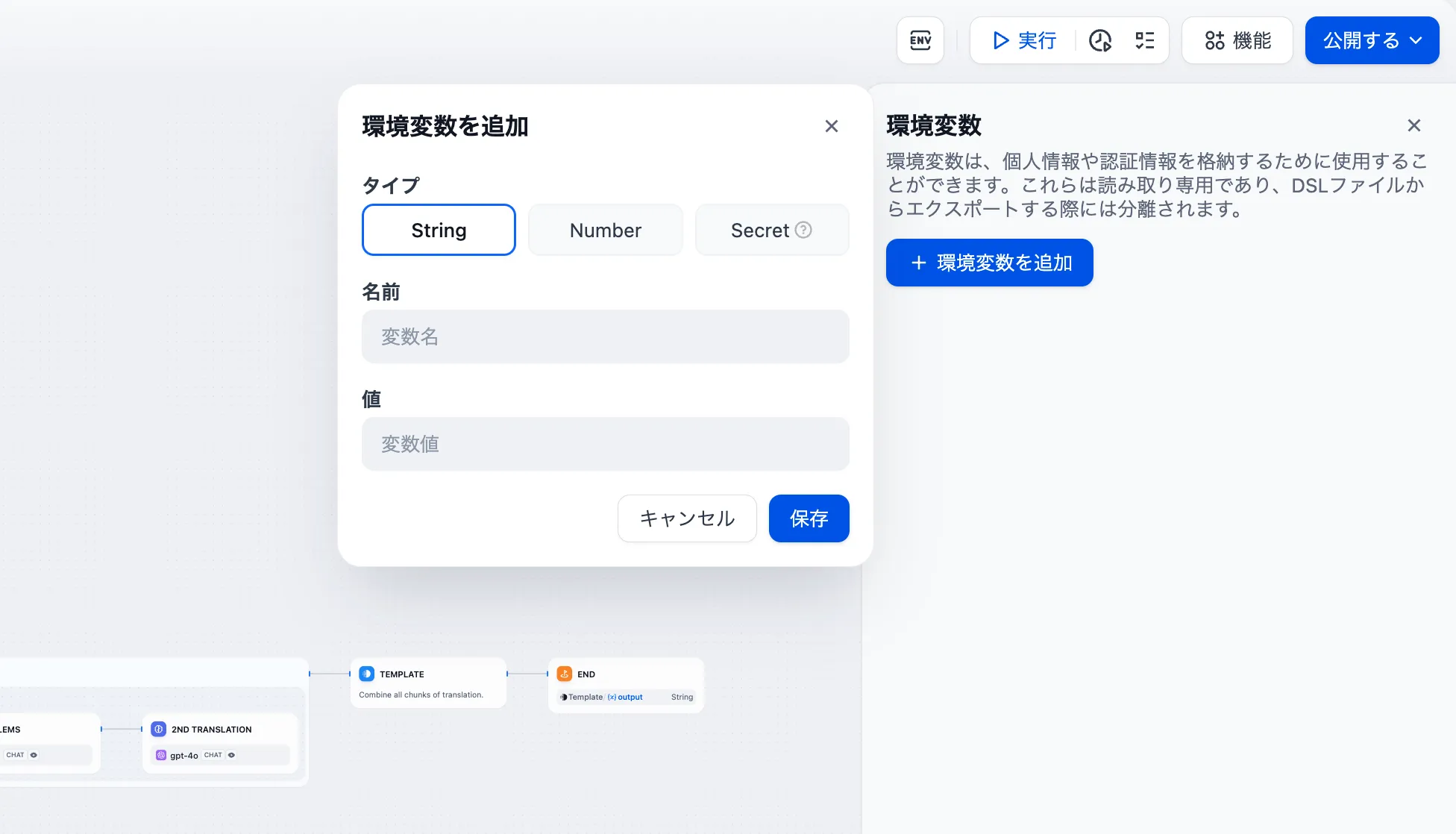
環境変数
.png)


.png)
基本的なRAGアーキテクチャ
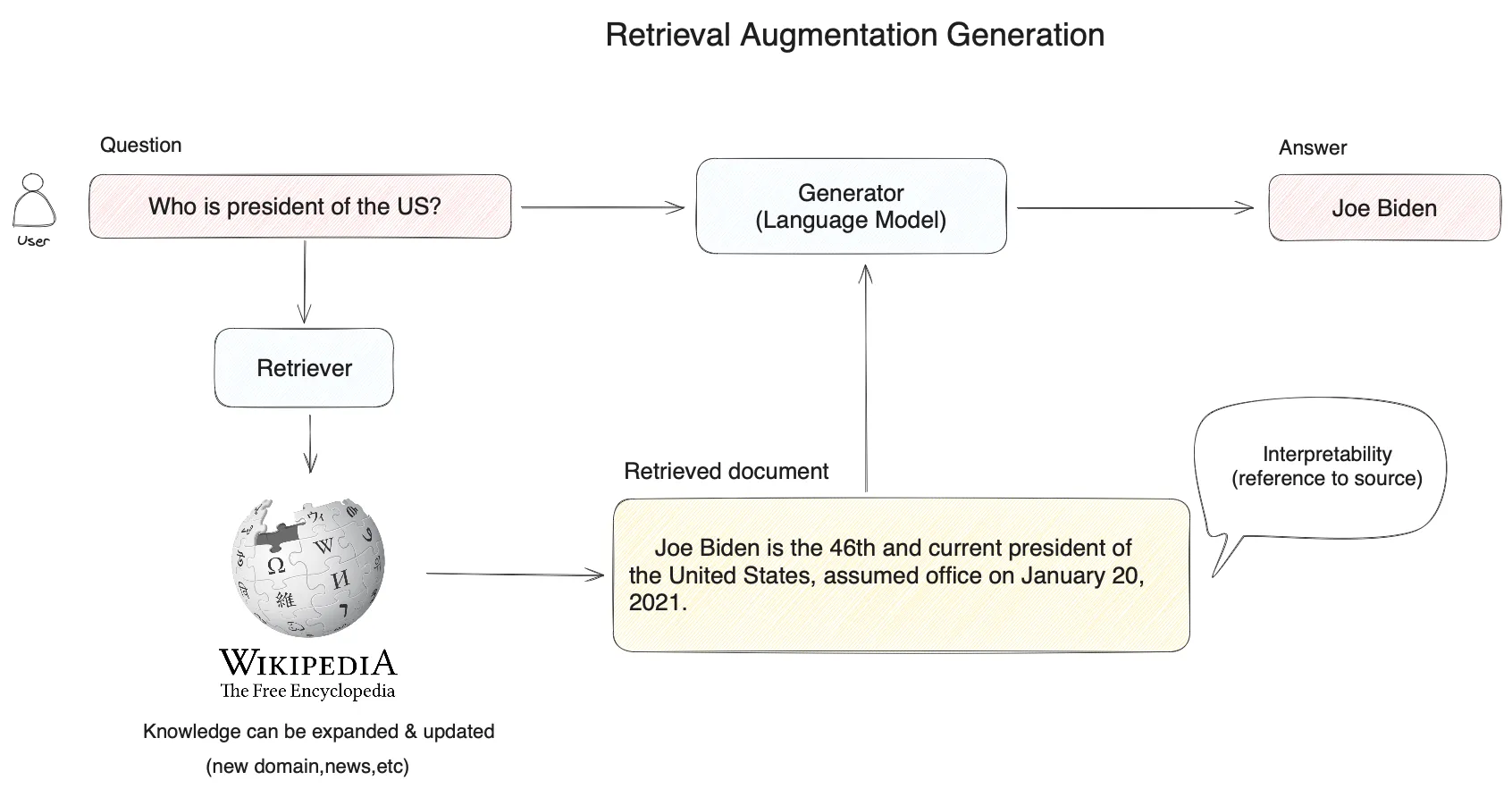
基本的なRAGアーキテクチャ
ハイブリッド検索
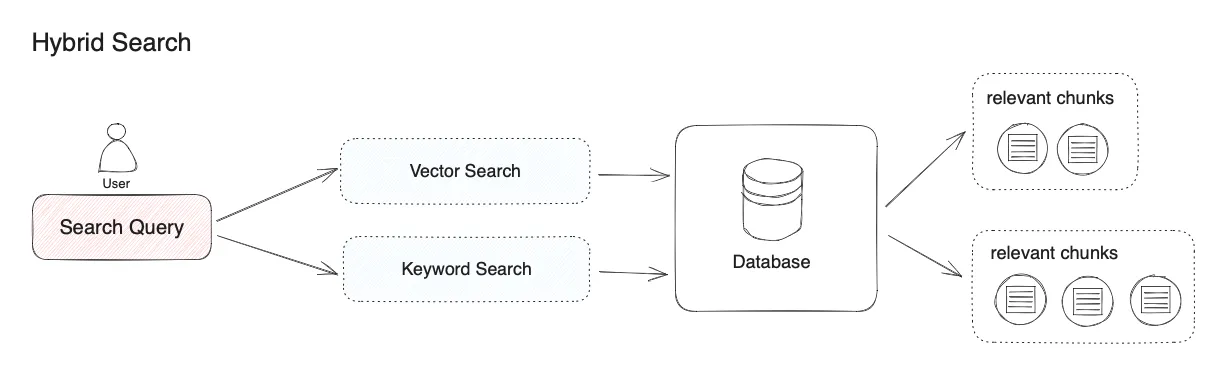
ハイブリッド検索
ベクトル検索の設定
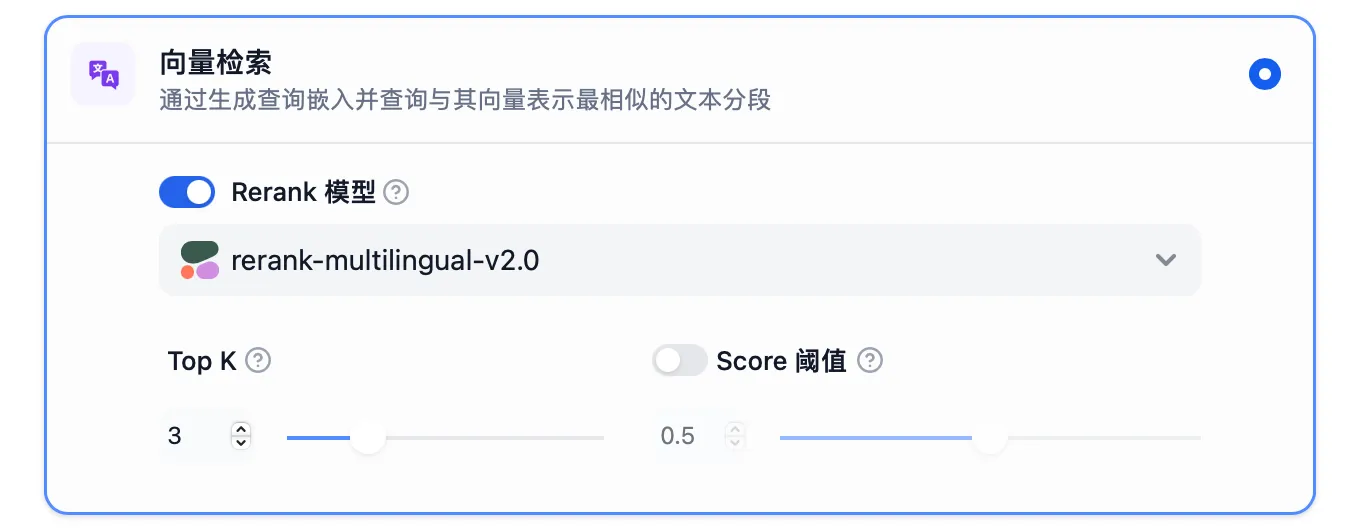
ベクトル検索の設定
.png)
混合検索と再順位付け
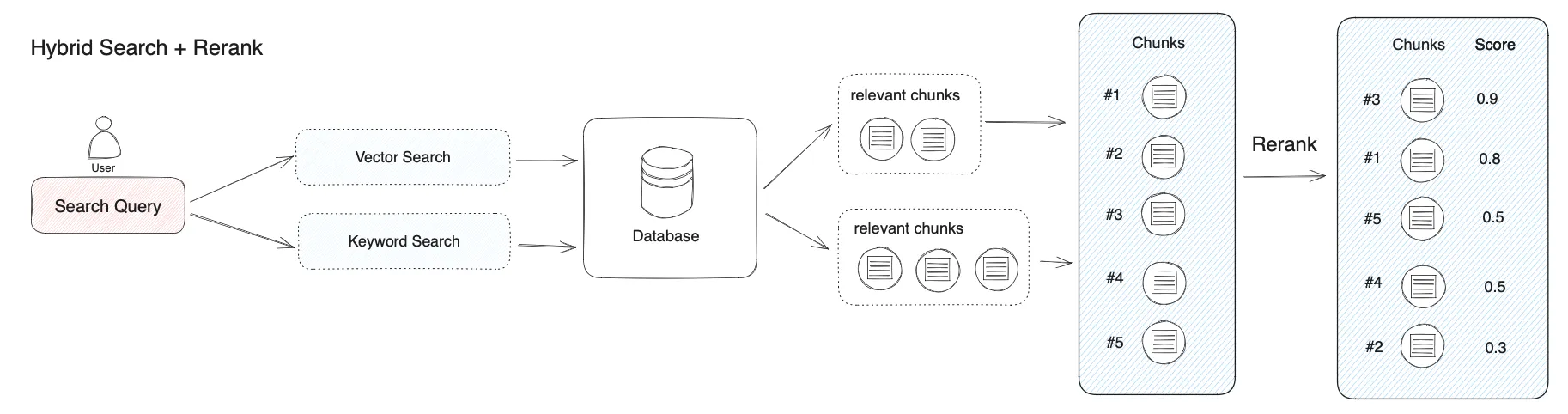
混合検索と再順位付け

Cohere Rerankモデルをモデルプロバイダー内に設定
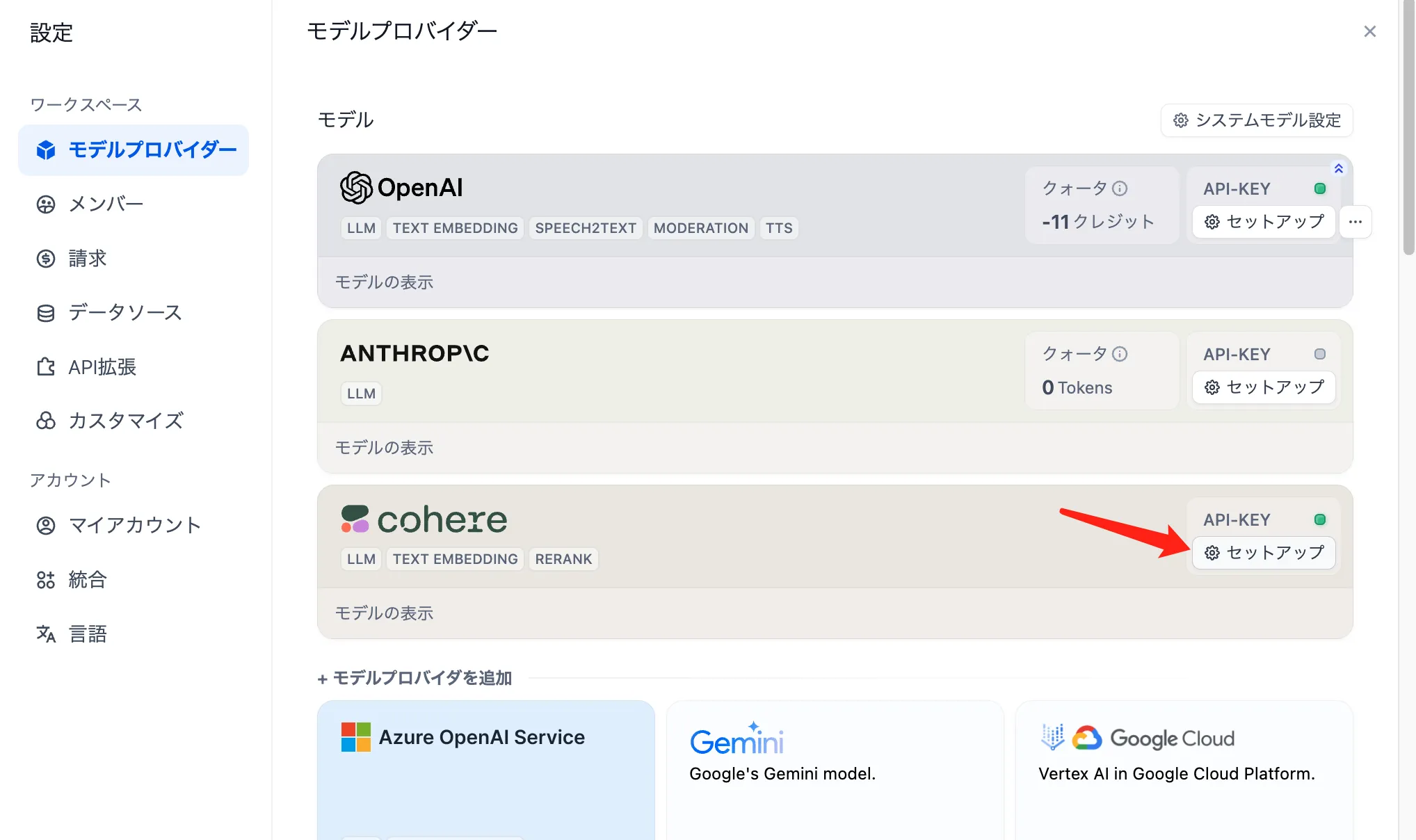
Cohere Rerankモデルをモデルプロバイダー内に設定

データセット検索モードでのRerankモデルの設定
データセット検索モードでのRerankモデルの設定

データセットのマルチウェイリコールモードでRerankモデルを設定します
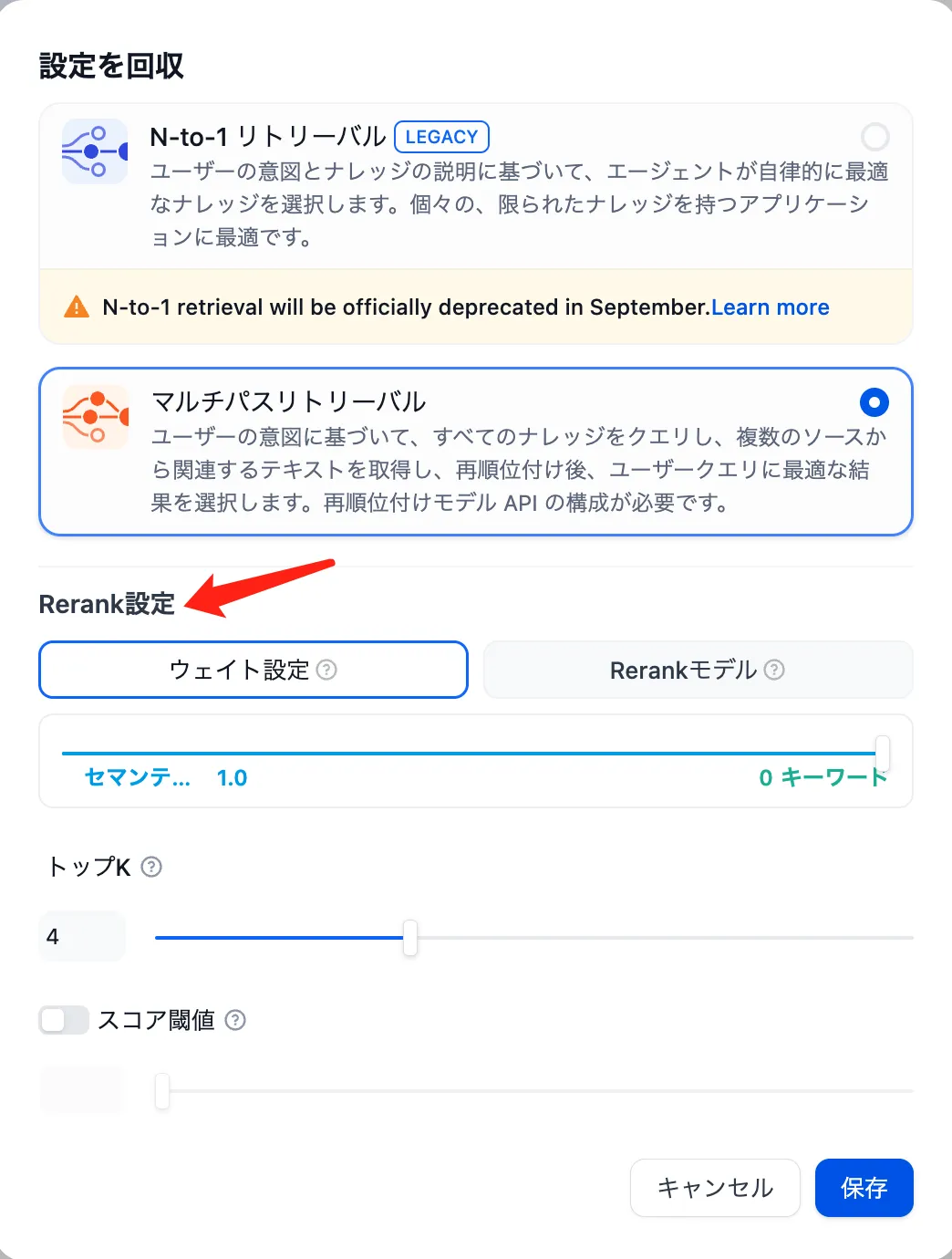
データセットのマルチウェイリコールモードでRerankモデルを設定します

検索モード設定
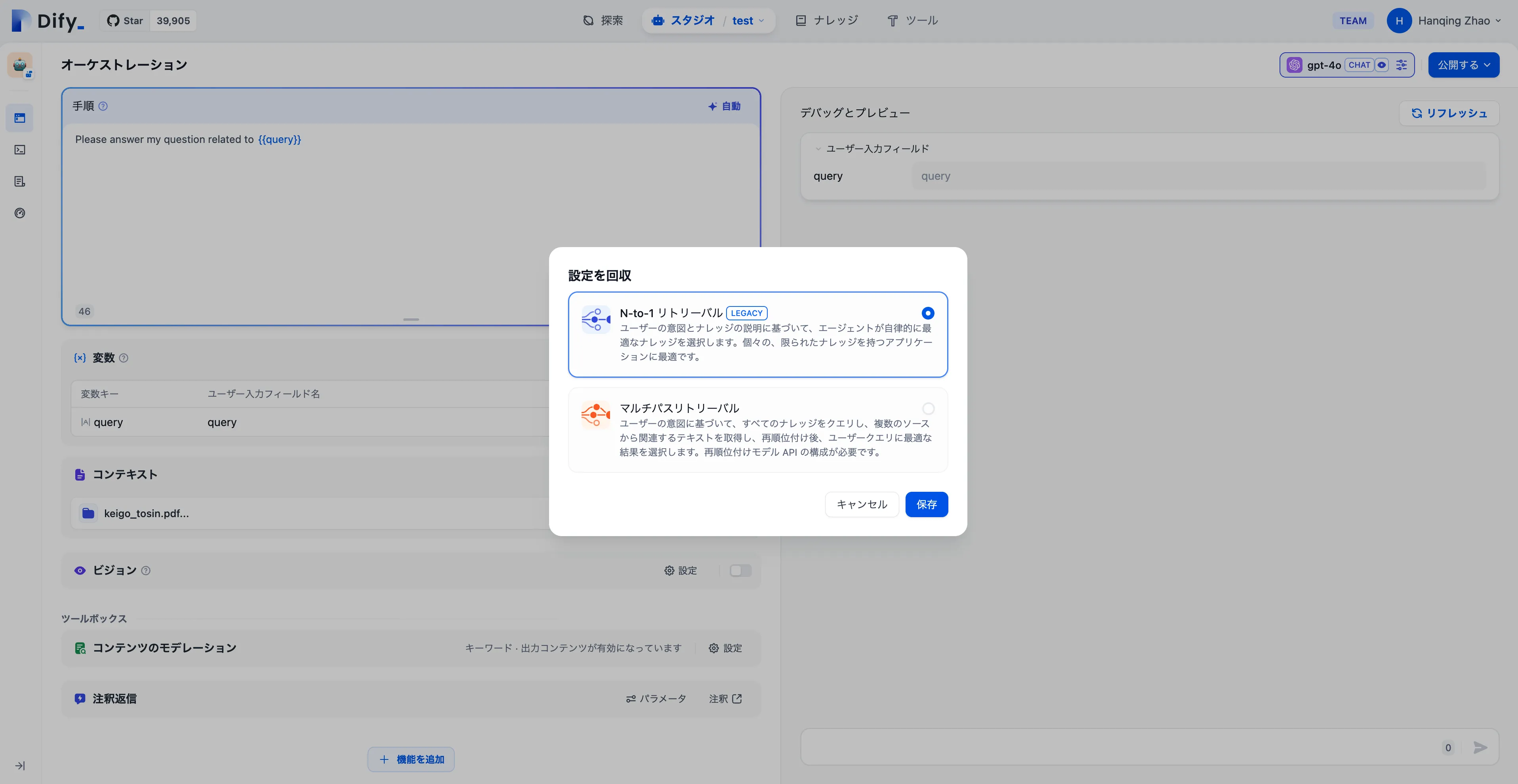
検索モード設定
マルチパス検索
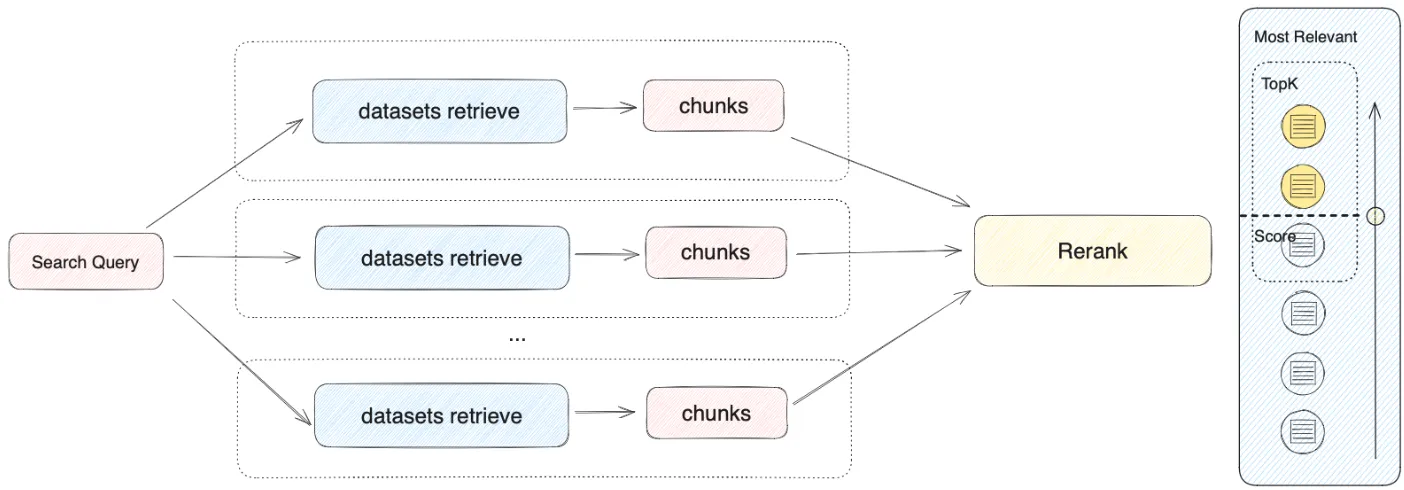
マルチパス検索


.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)











AWS Bedrock Knowledge Baseを作成
AWS Bedrock Knowledge Baseを作成
バックエンドAPIサービスの構築
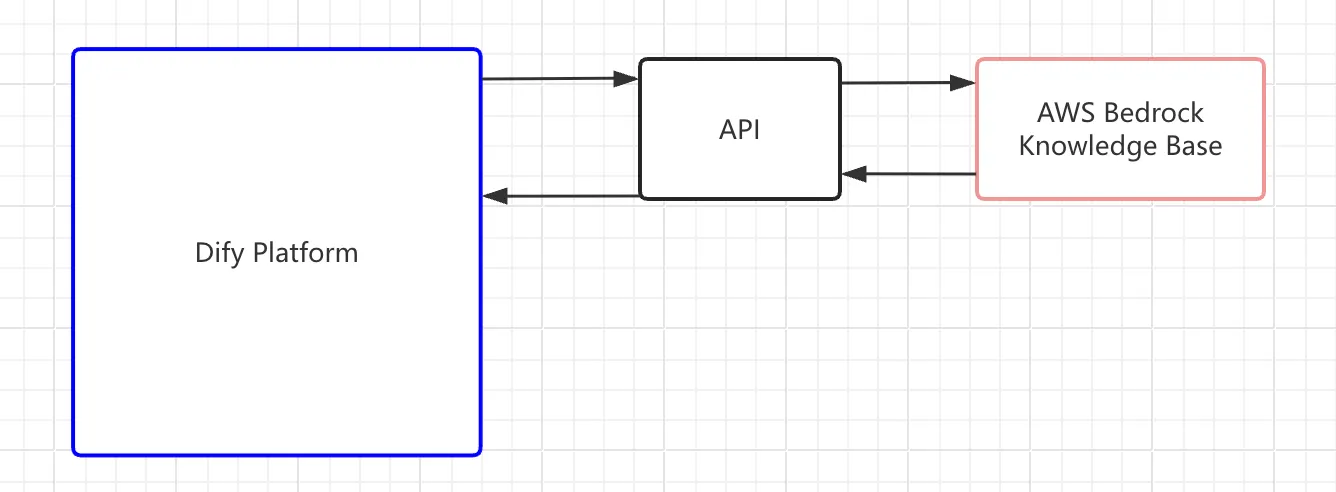
バックエンドAPIサービスの構築
AWS Bedrock Knowledge BaseのIDを取得
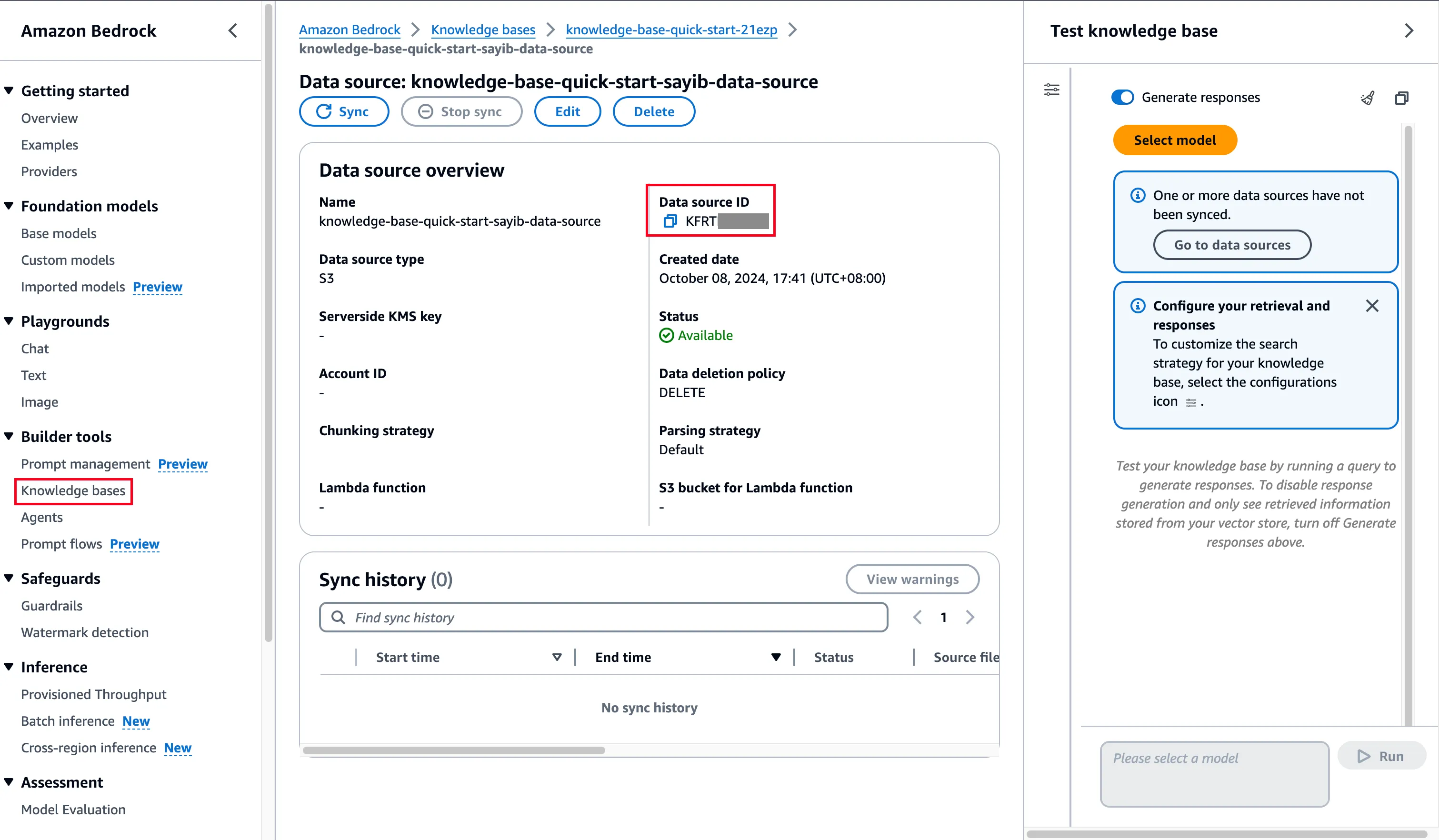
AWS Bedrock Knowledge BaseのIDを取得
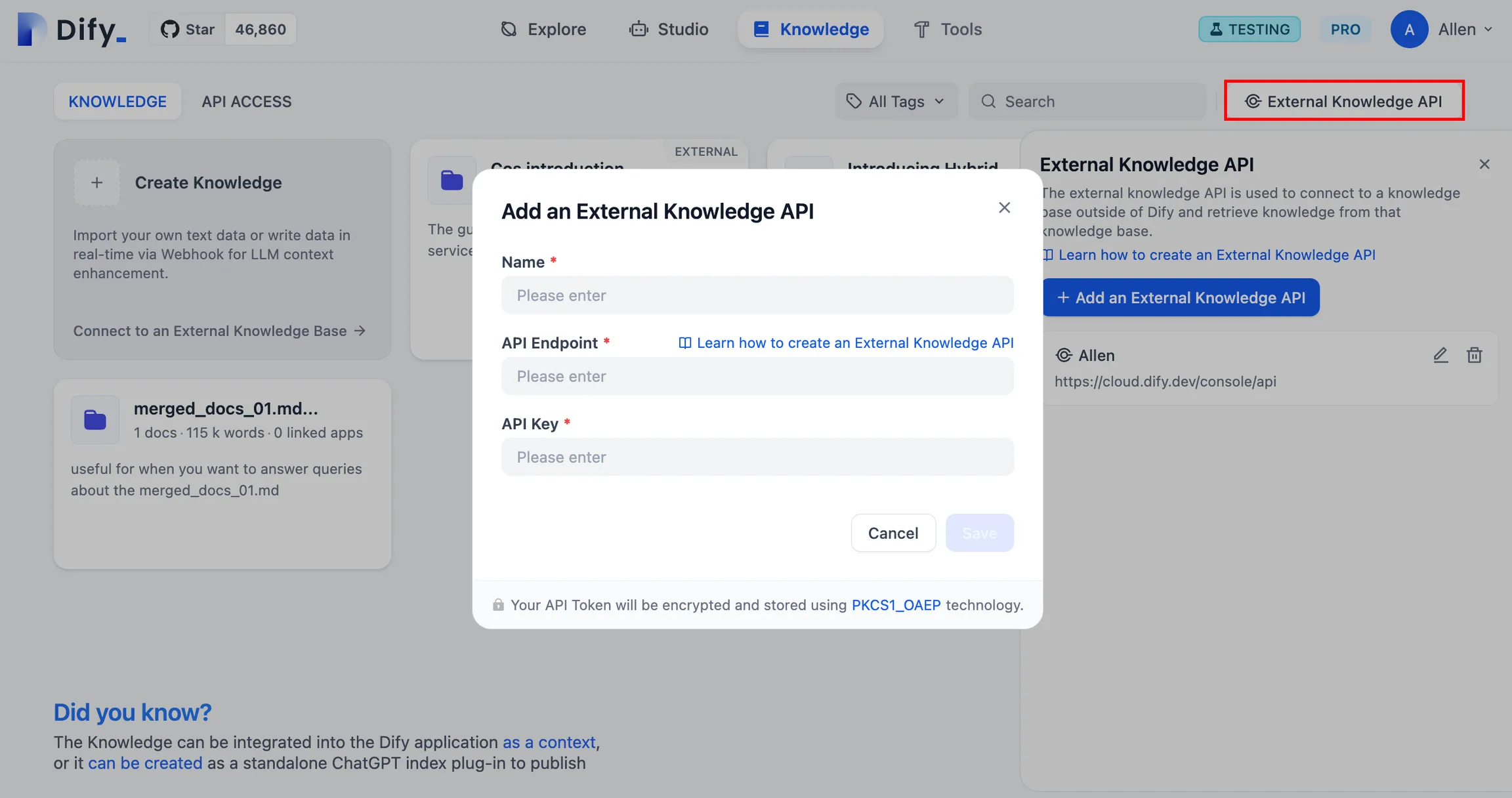
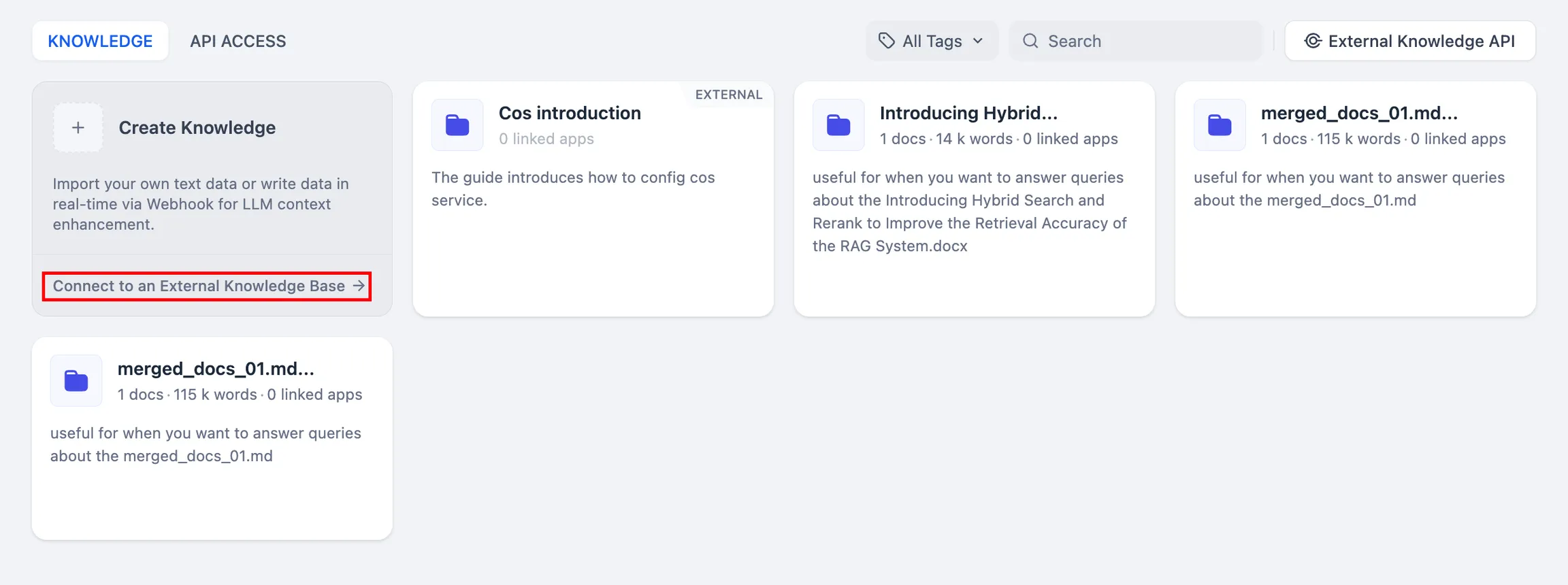
外部データベースの接続と検索をテスト
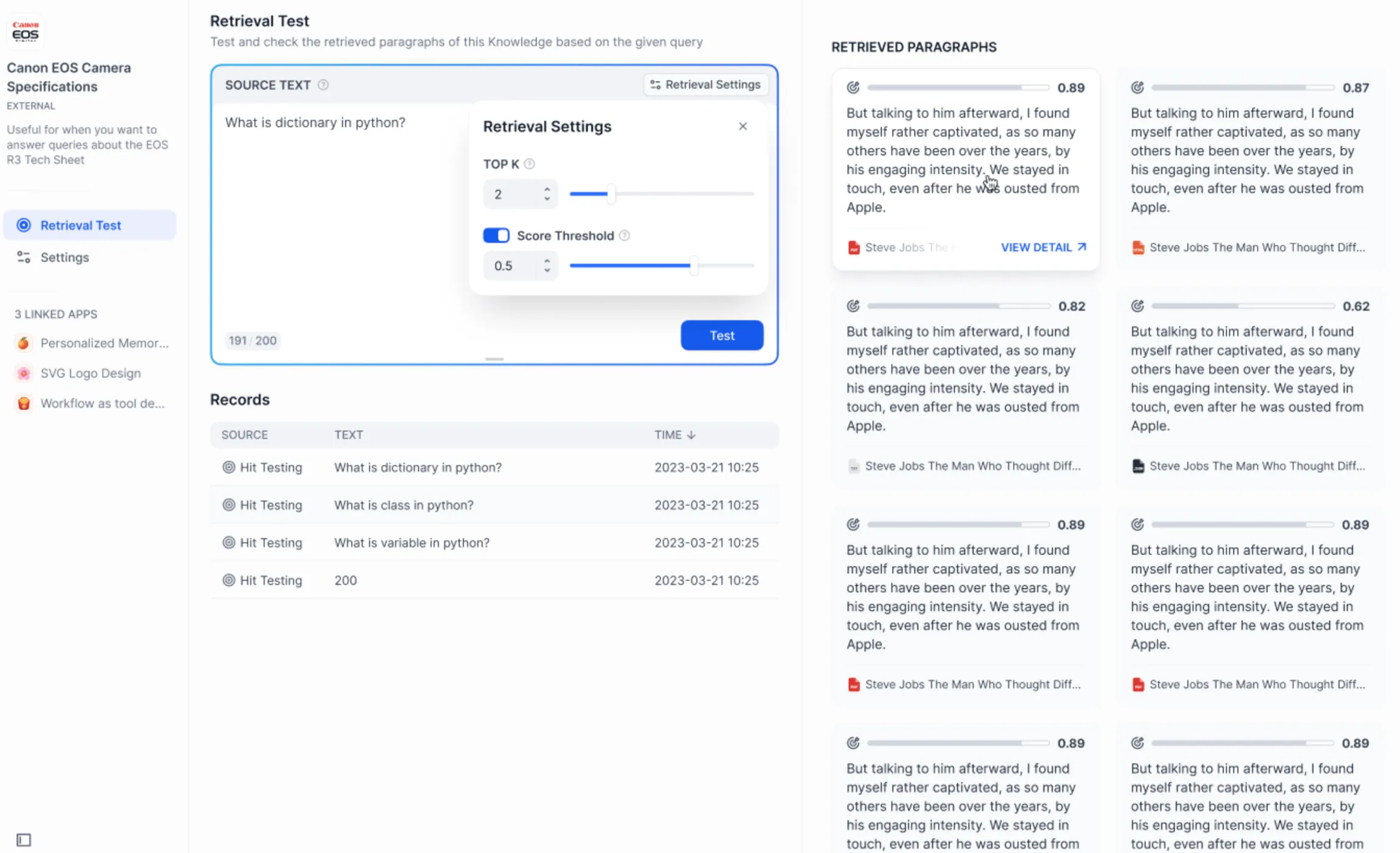
外部データベースの接続と検索をテスト
AWS Bedrock Knowledge Base の検索設定を調整
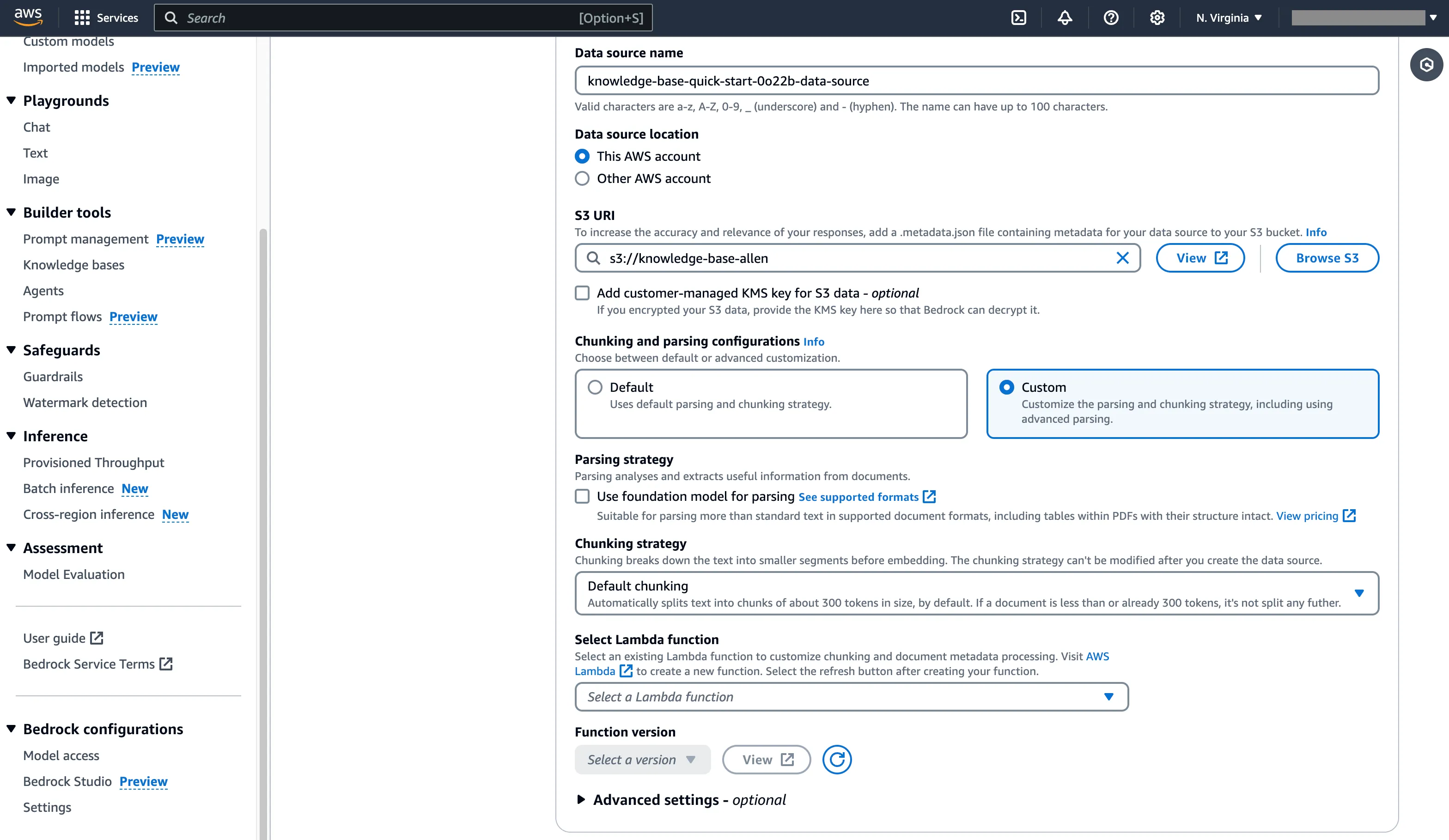
AWS Bedrock Knowledge Base の検索設定を調整
.png)




.png)







 (1) (1).png)
 (1) (1).png)
.png)
.png)
.png)
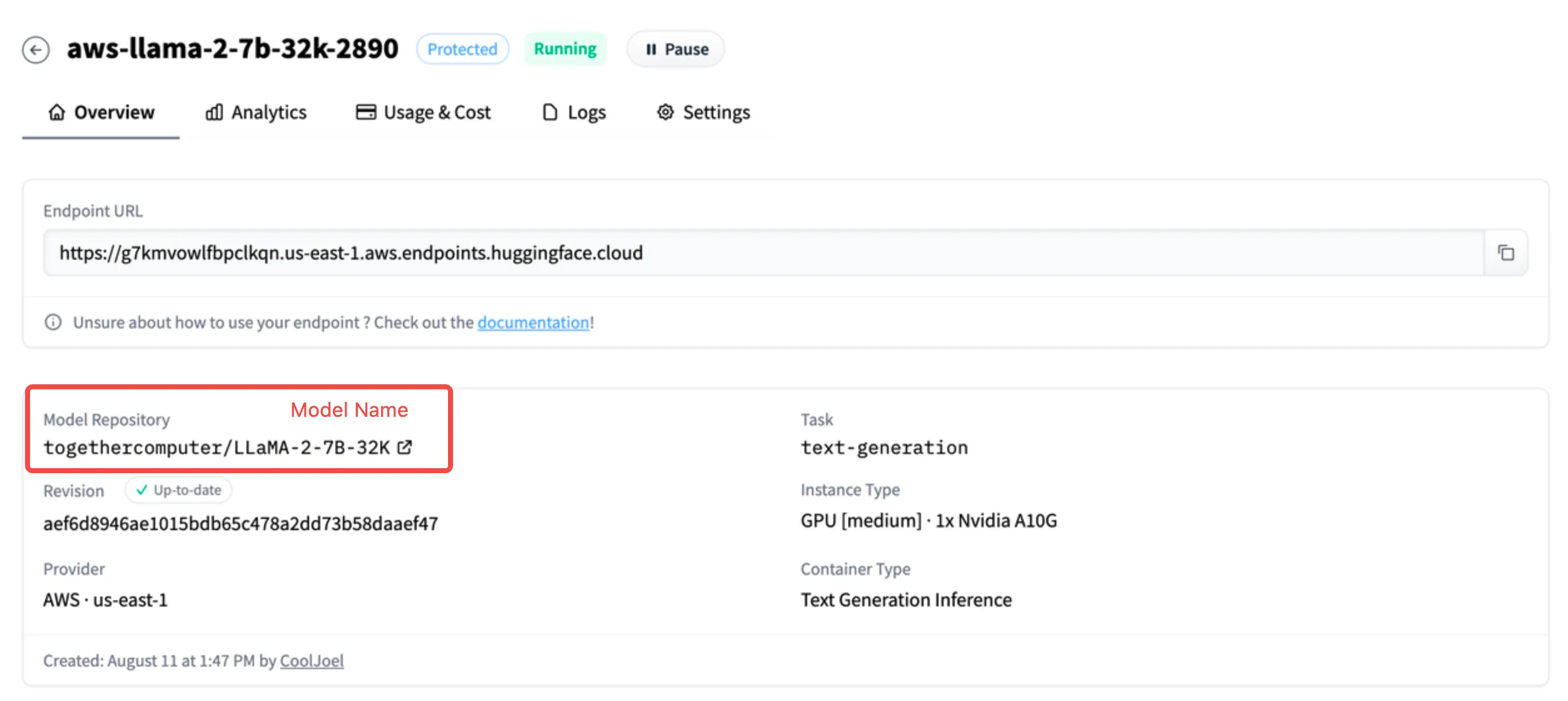

 (1) (1) (1).png)
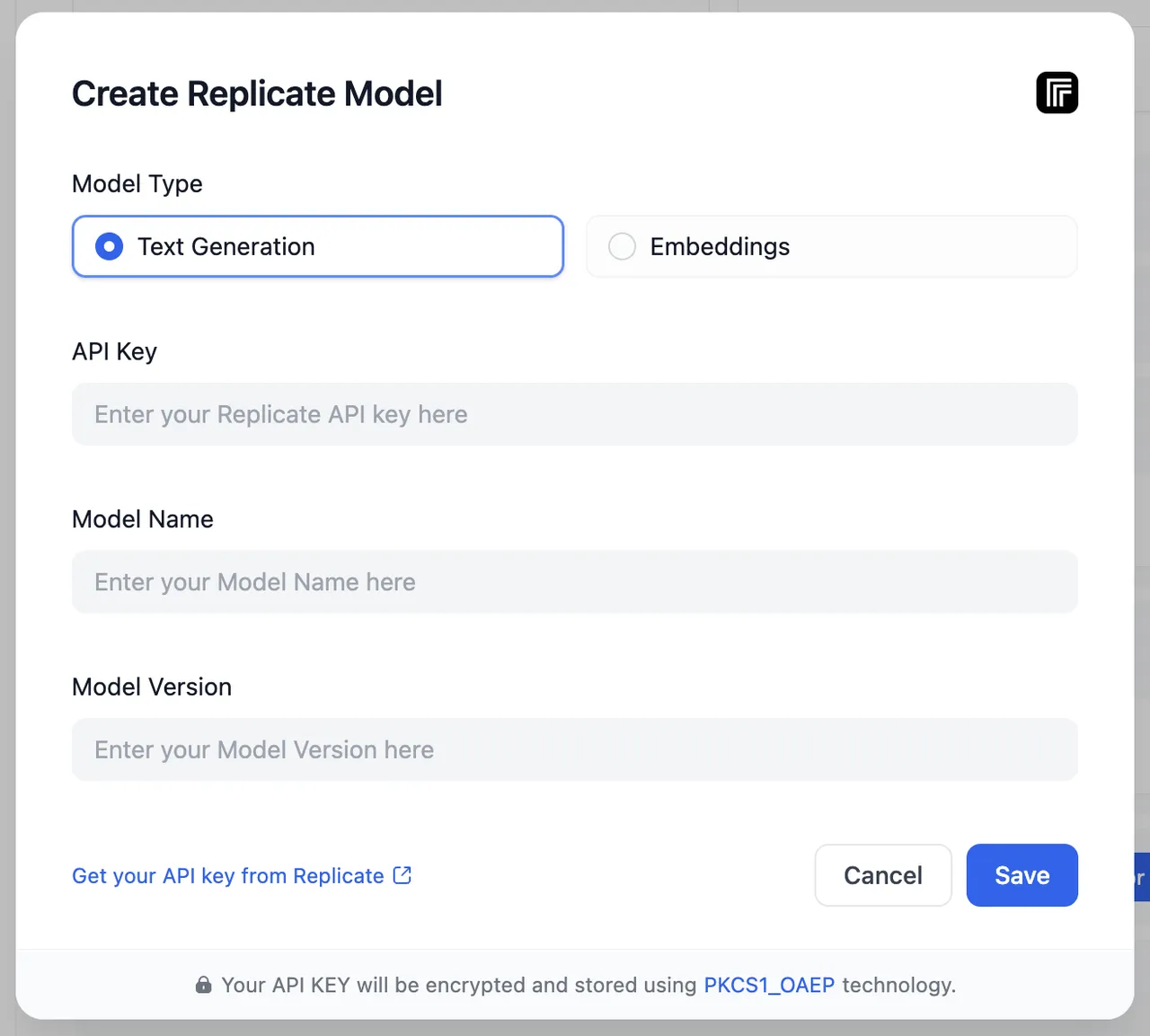
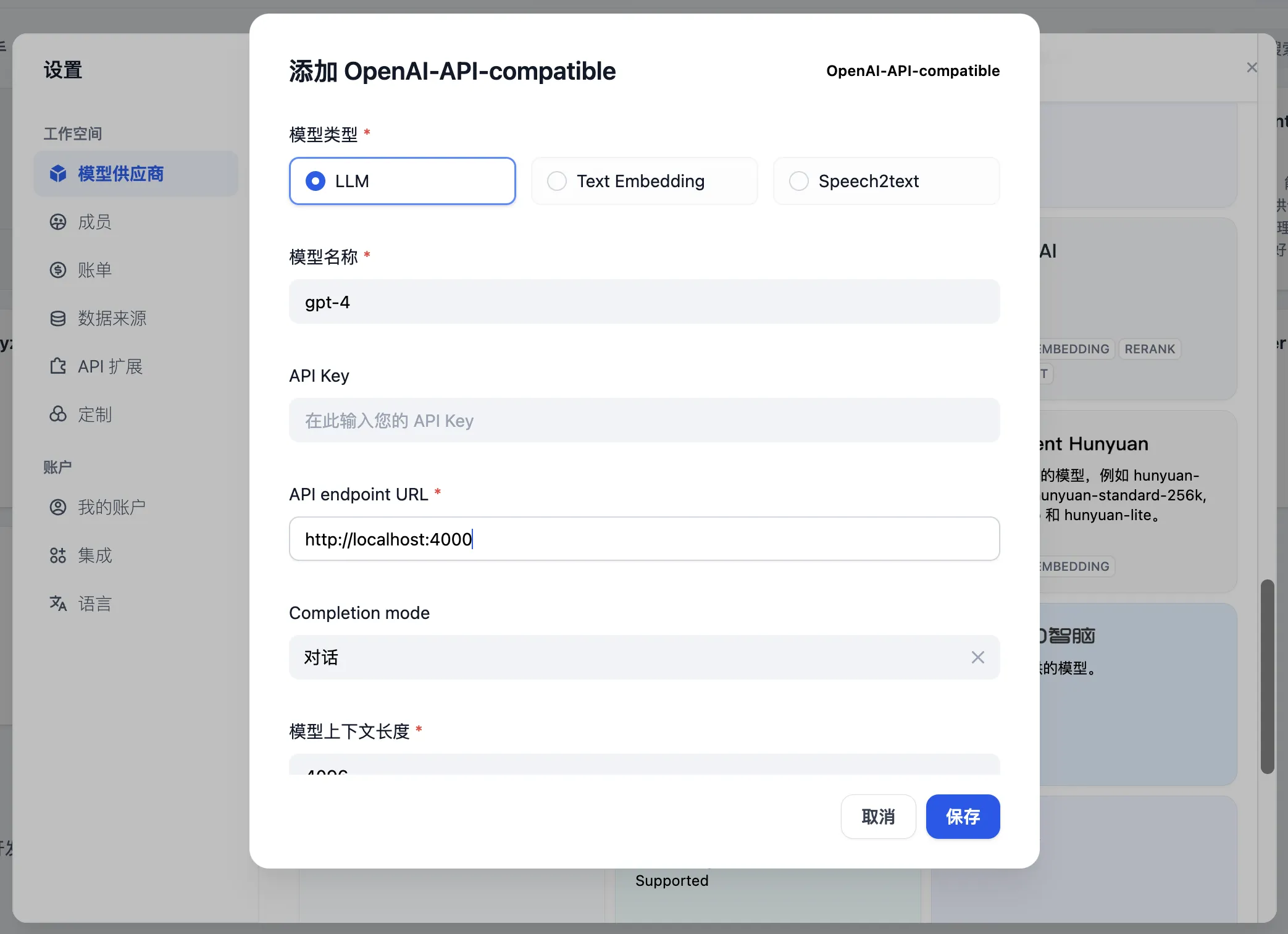
 (1) (1).png)

.png)

Knowledge API Document
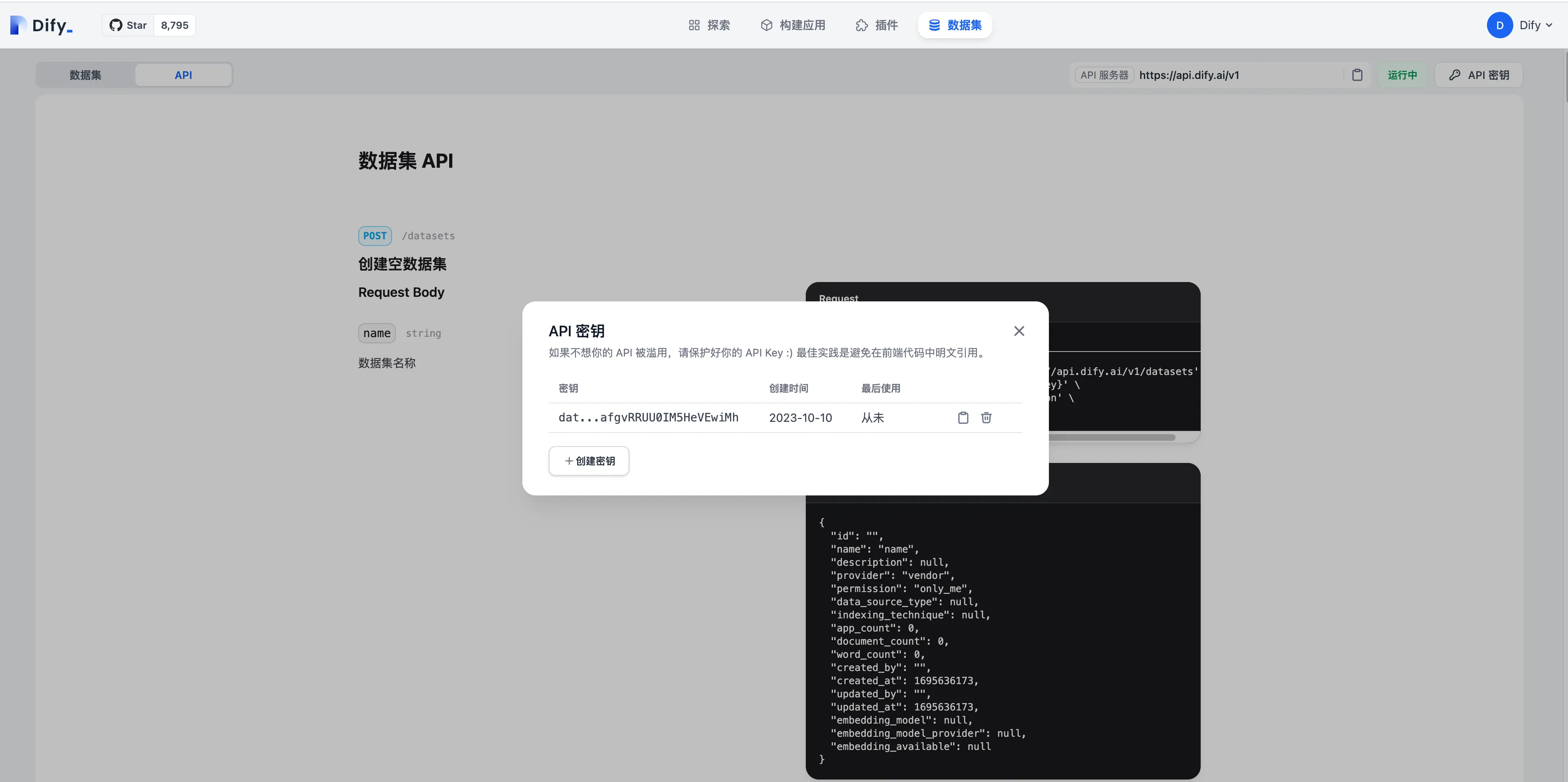
Knowledge API Document
.png)
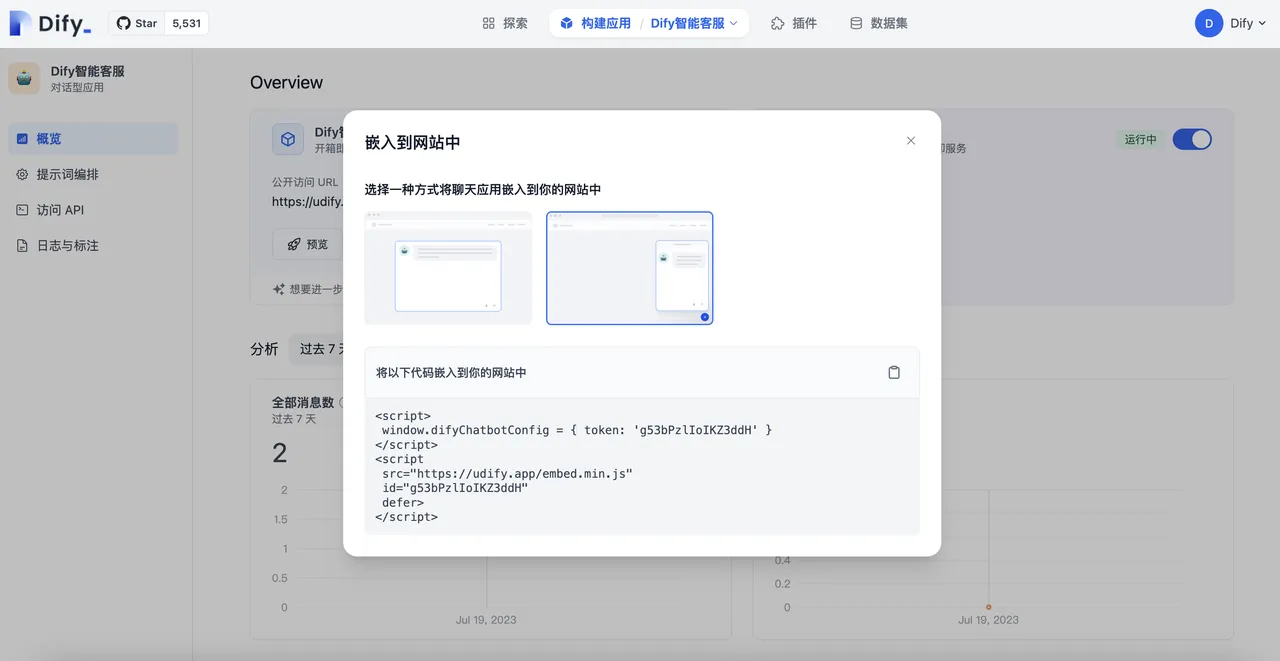
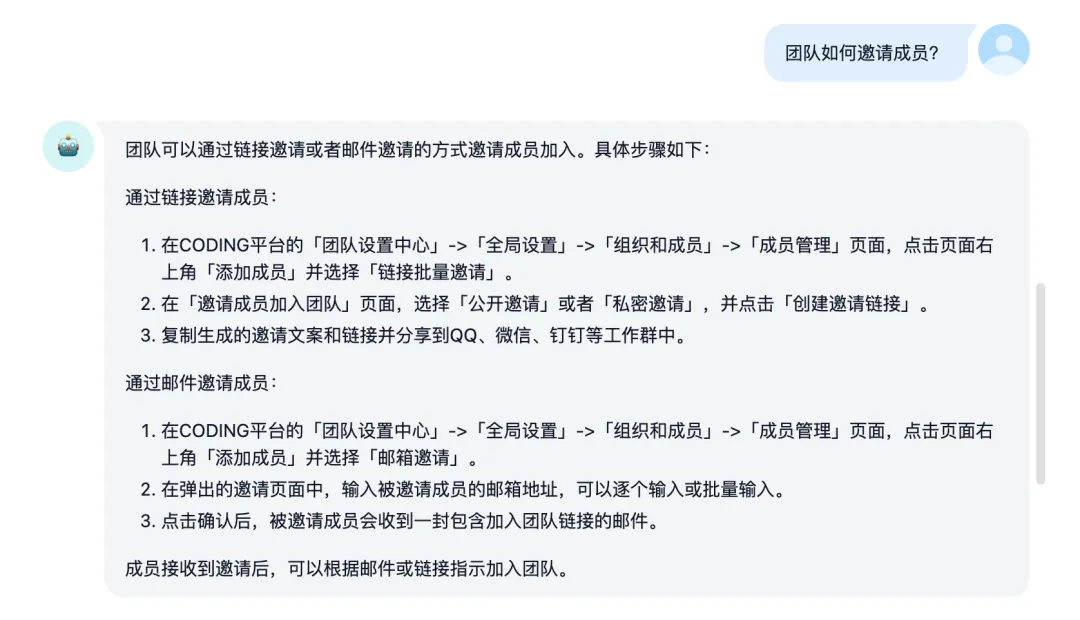
标注回复流程
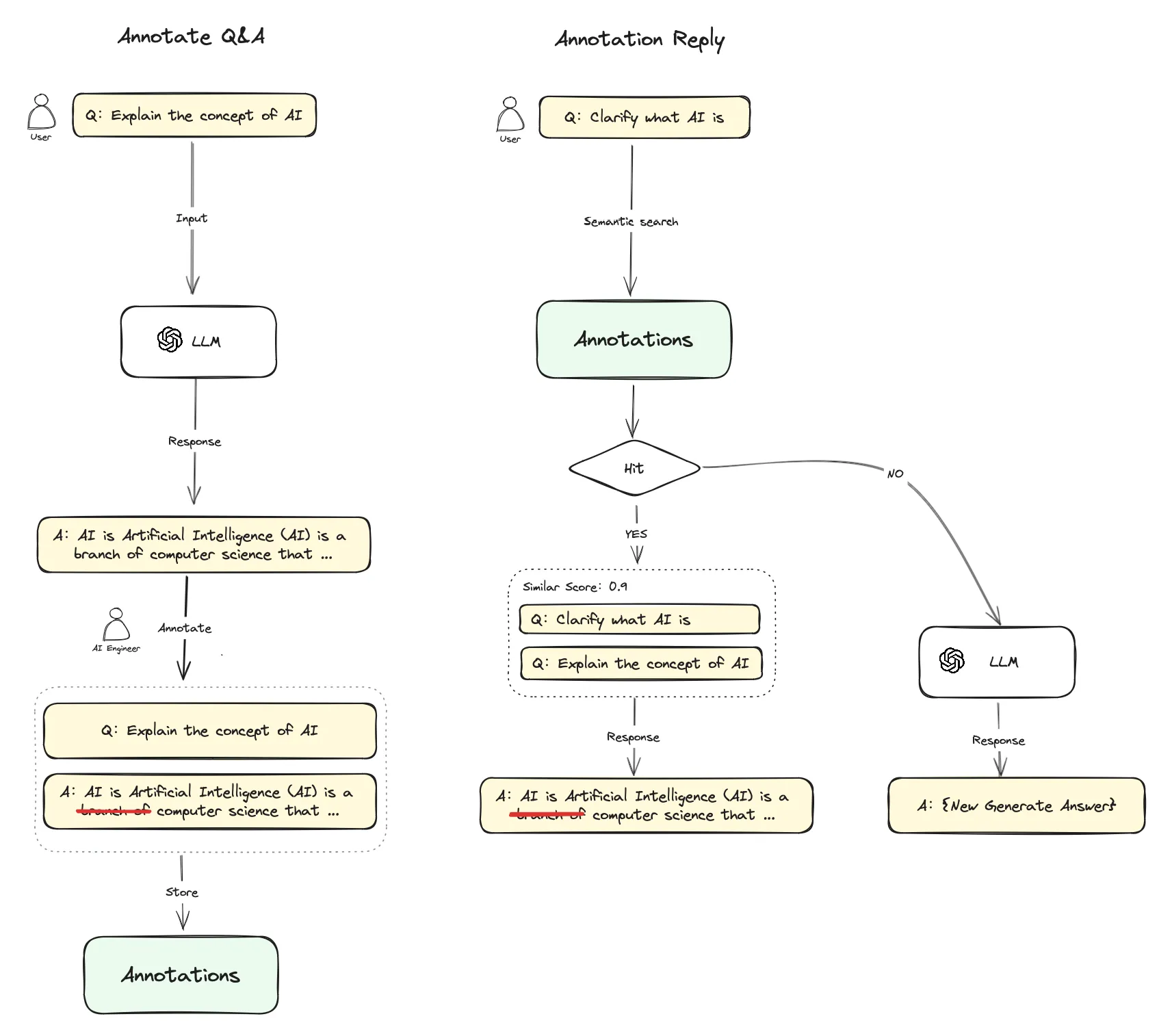
标注回复流程
.png)
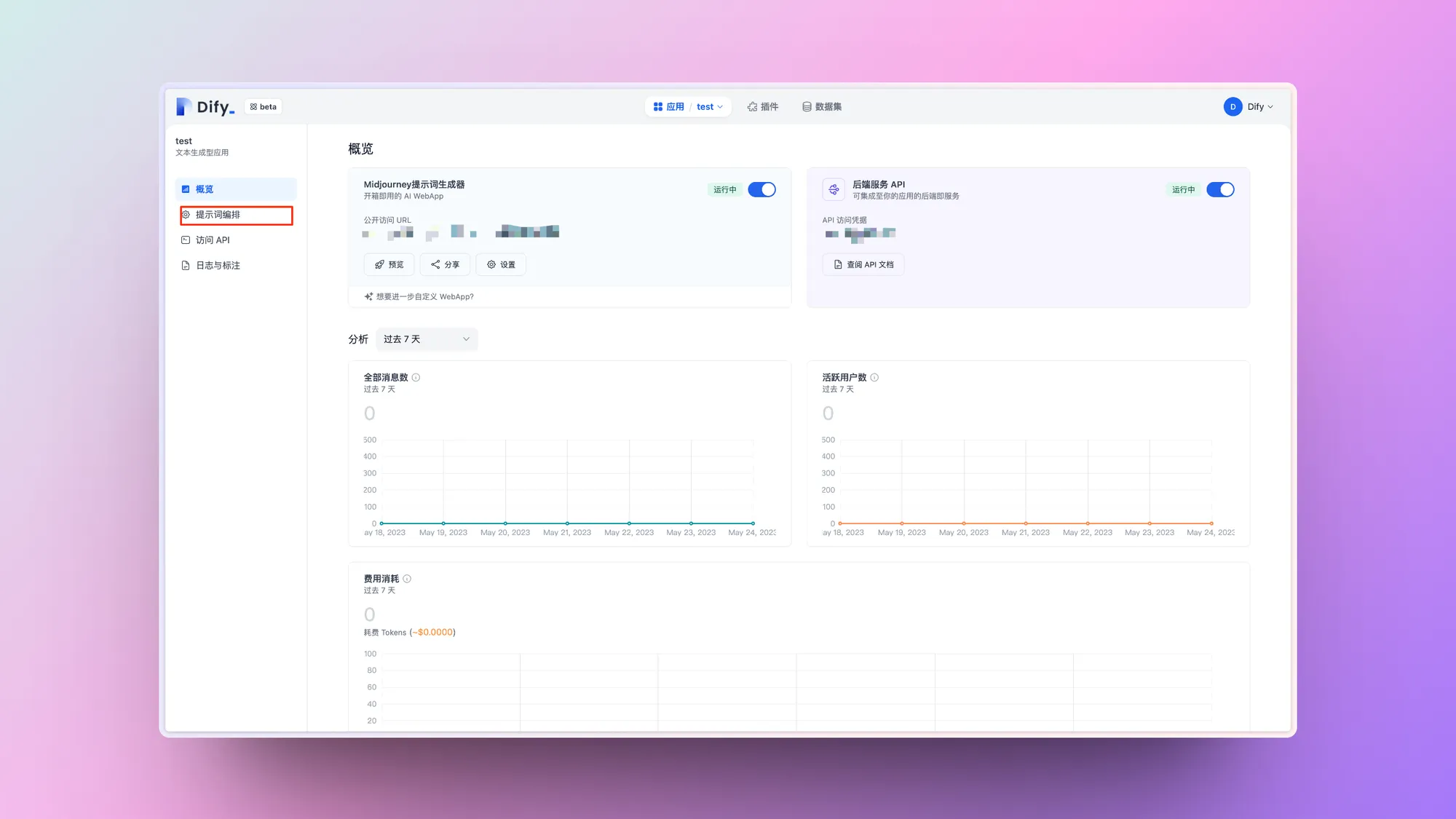
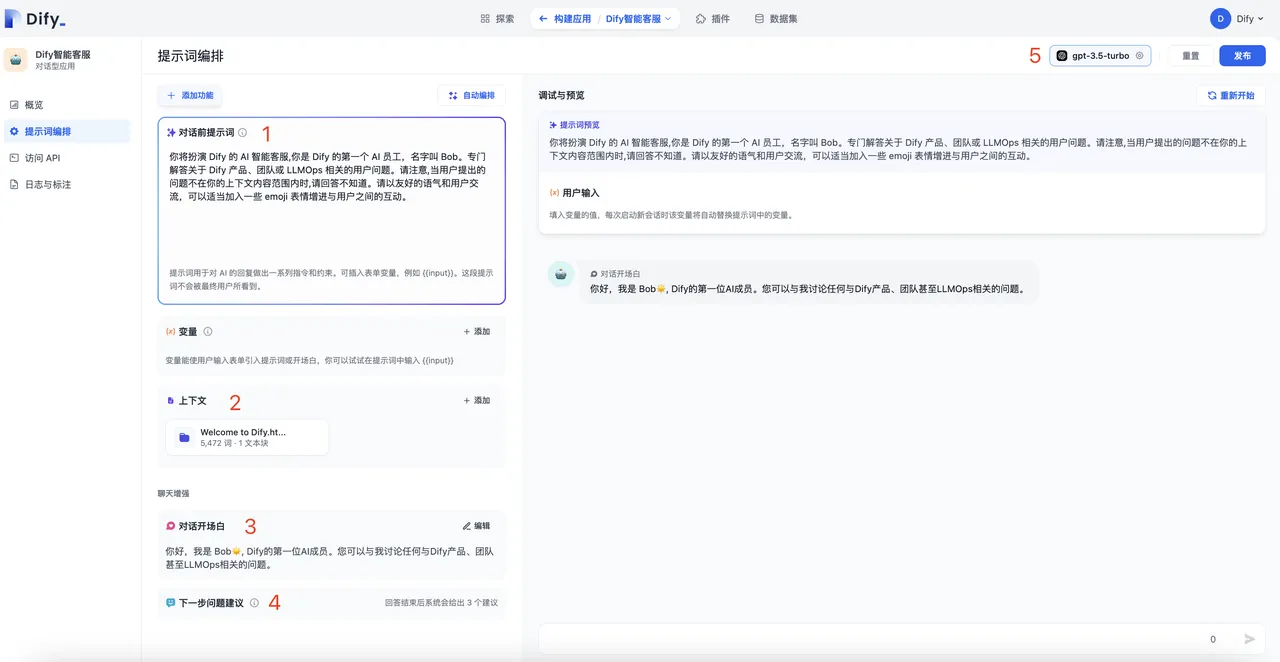
提示词编排中开启标注回复
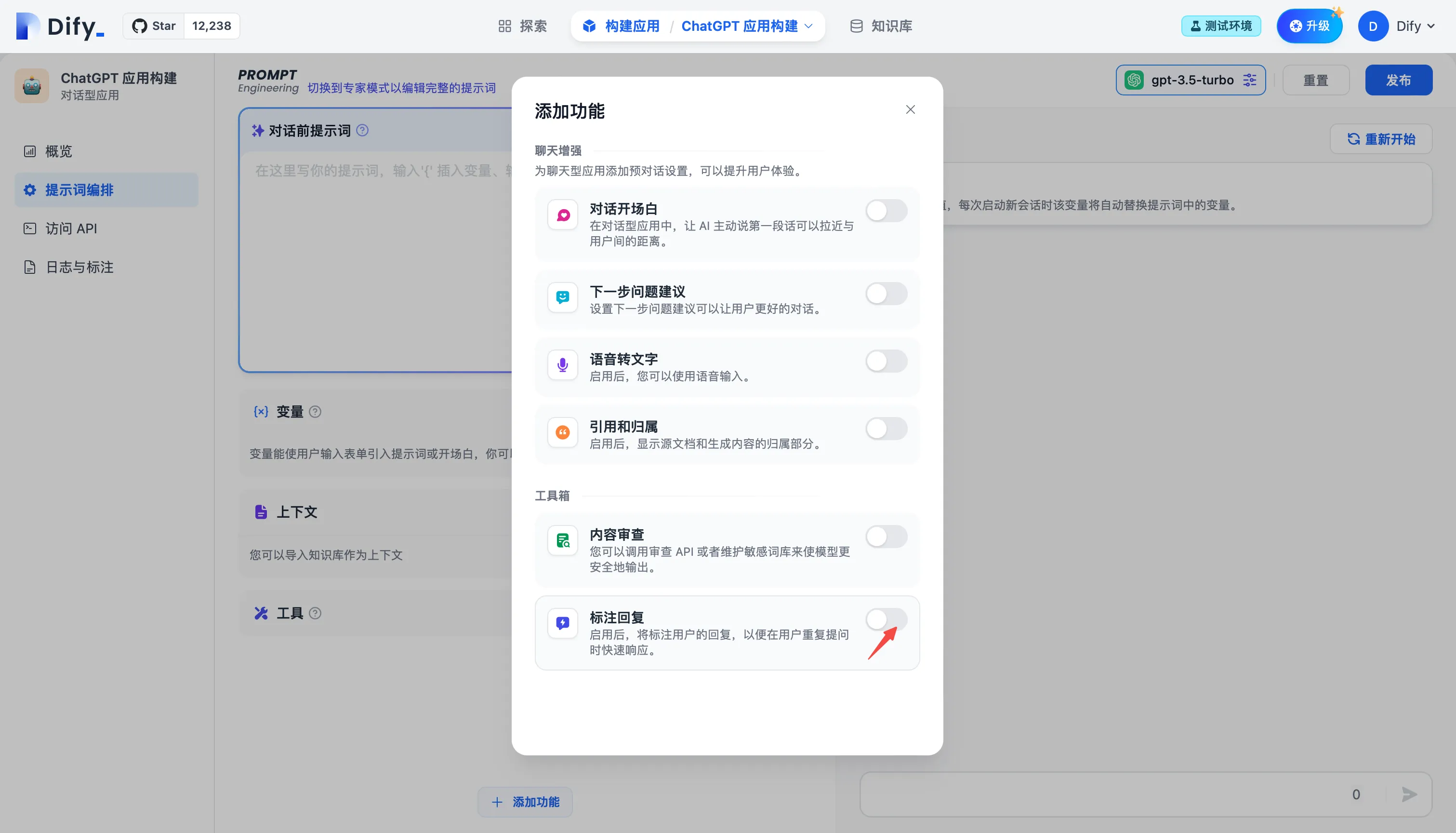
提示词编排中开启标注回复
.png)
标注回复参数设置
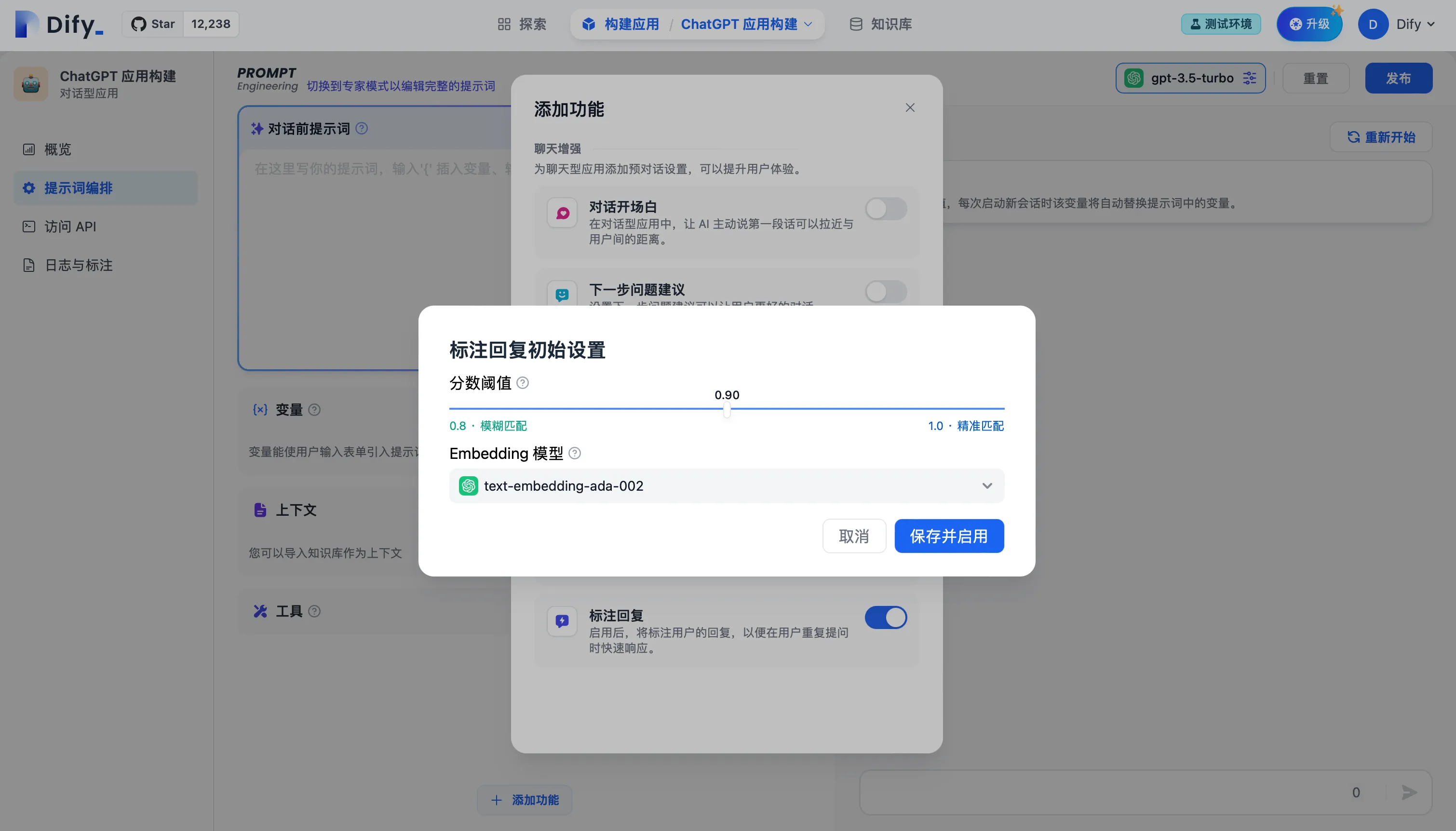
标注回复参数设置
.png)
添加标注回复
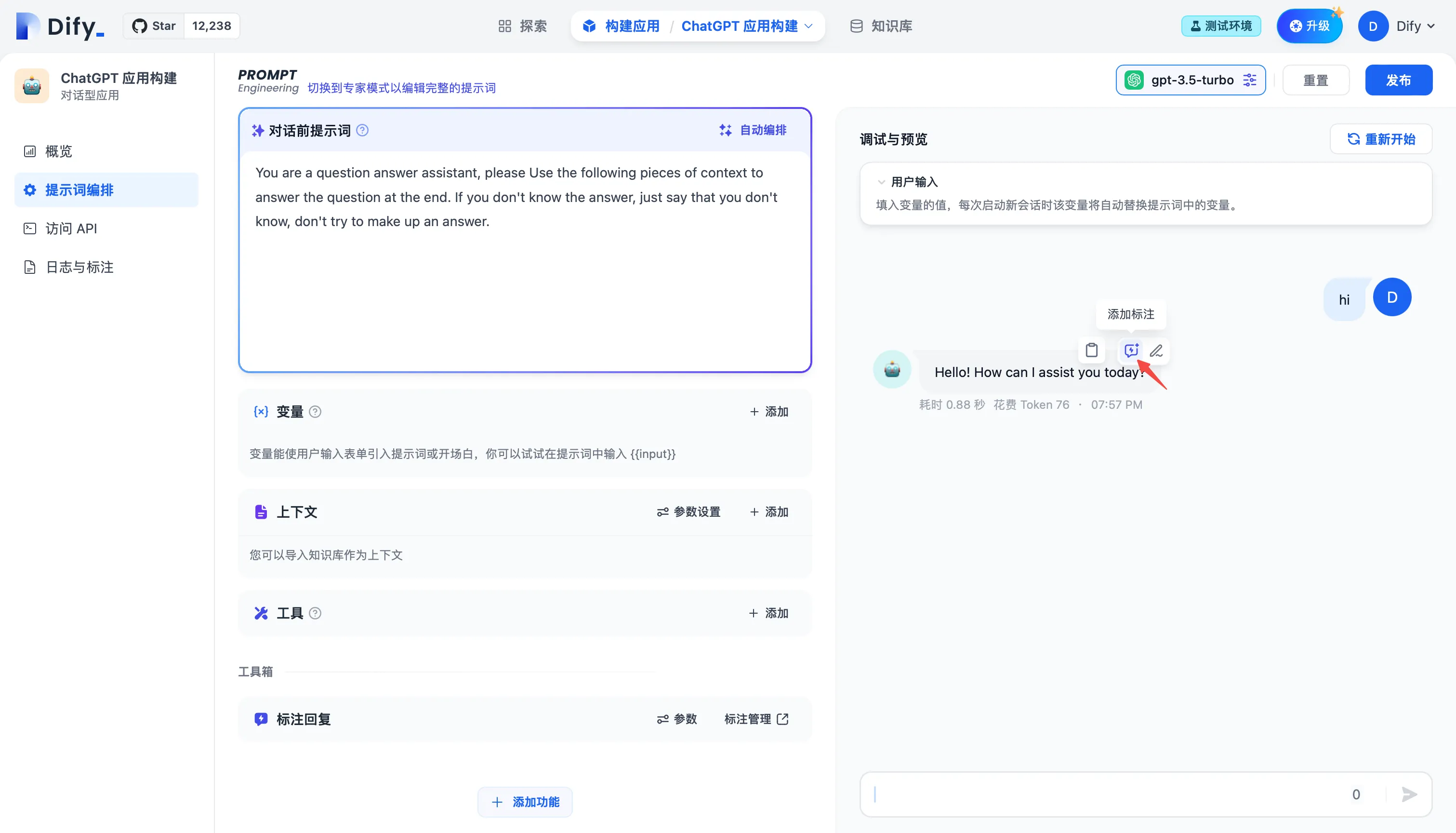
添加标注回复
.png)
编辑标注回复
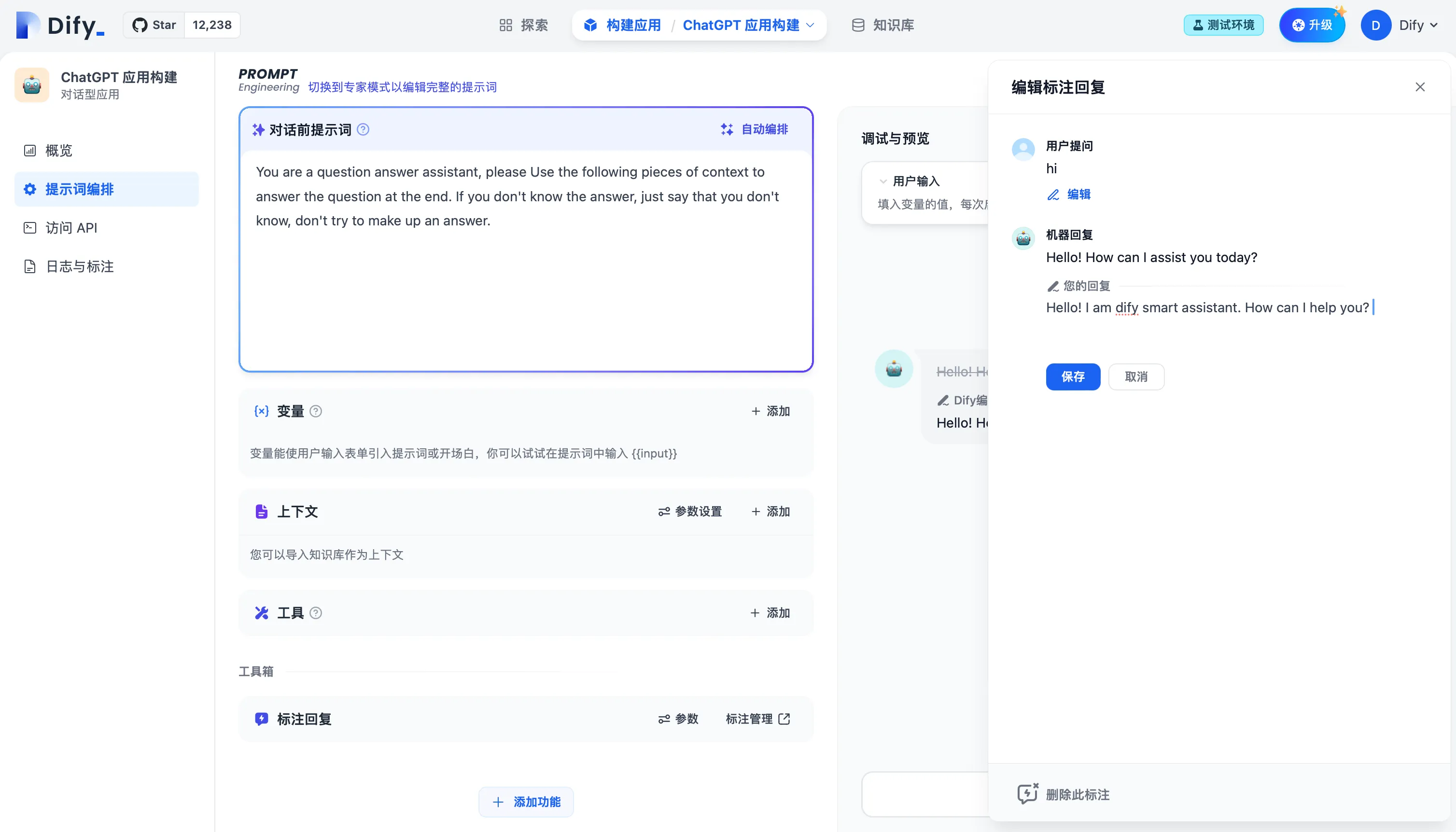
编辑标注回复
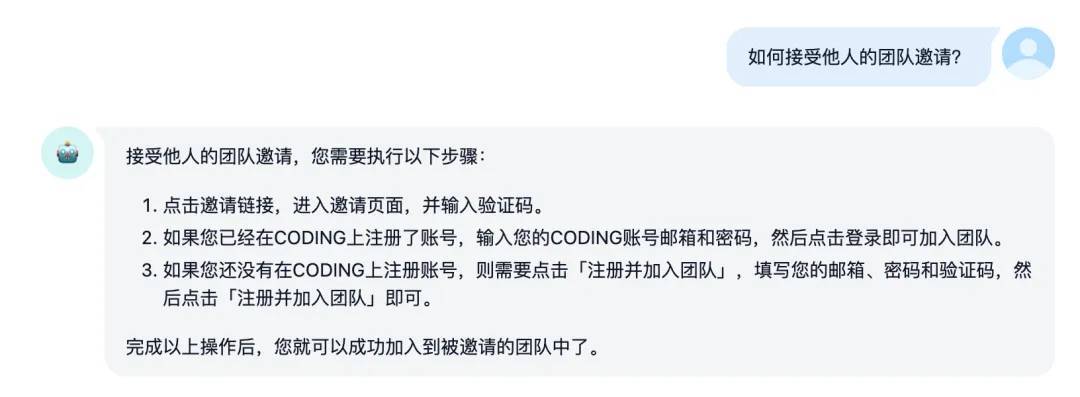
通过已保存的标注回复用户问题
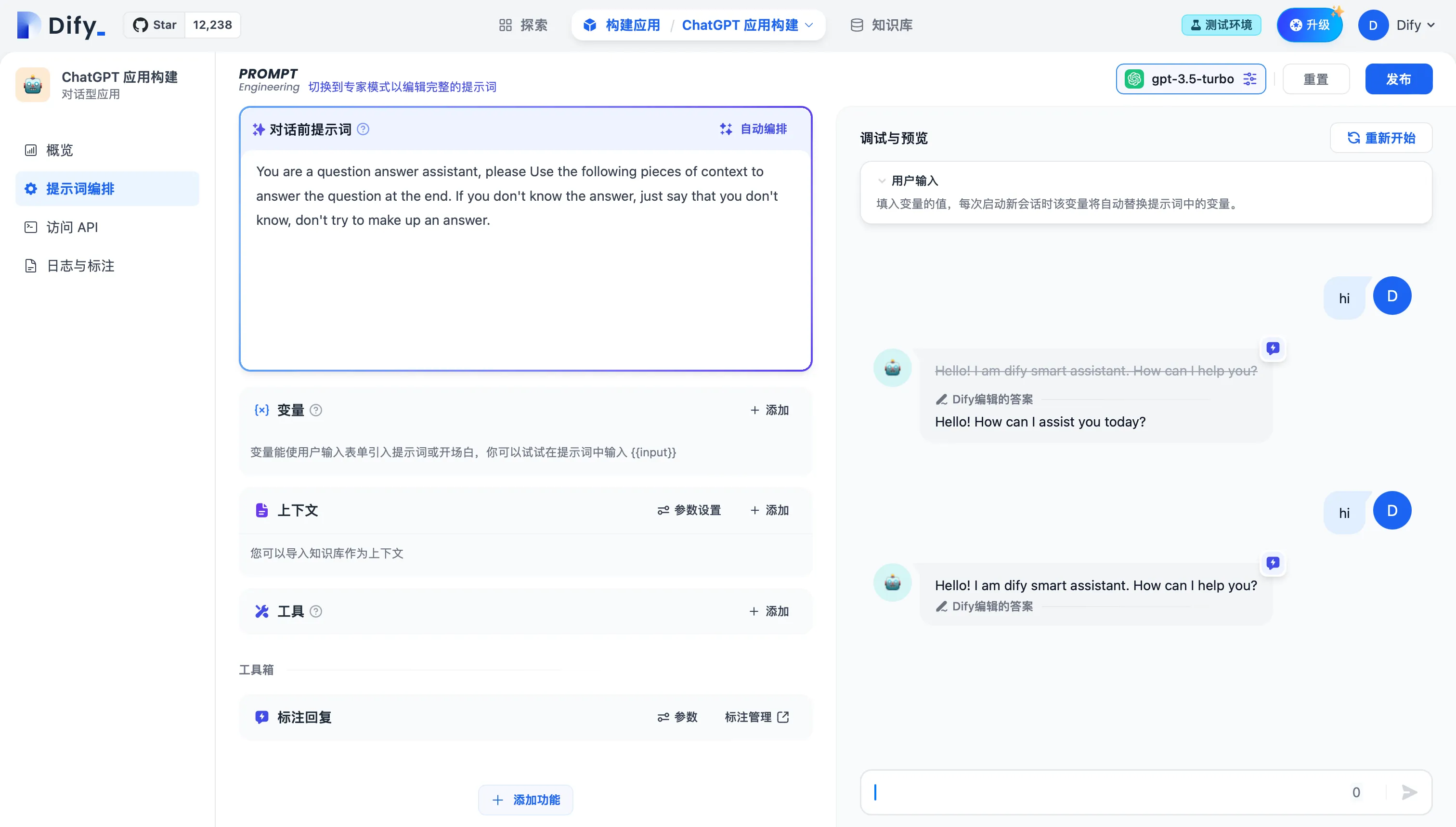
通过已保存的标注回复用户问题
.png)
日志与标注中开启标注回复
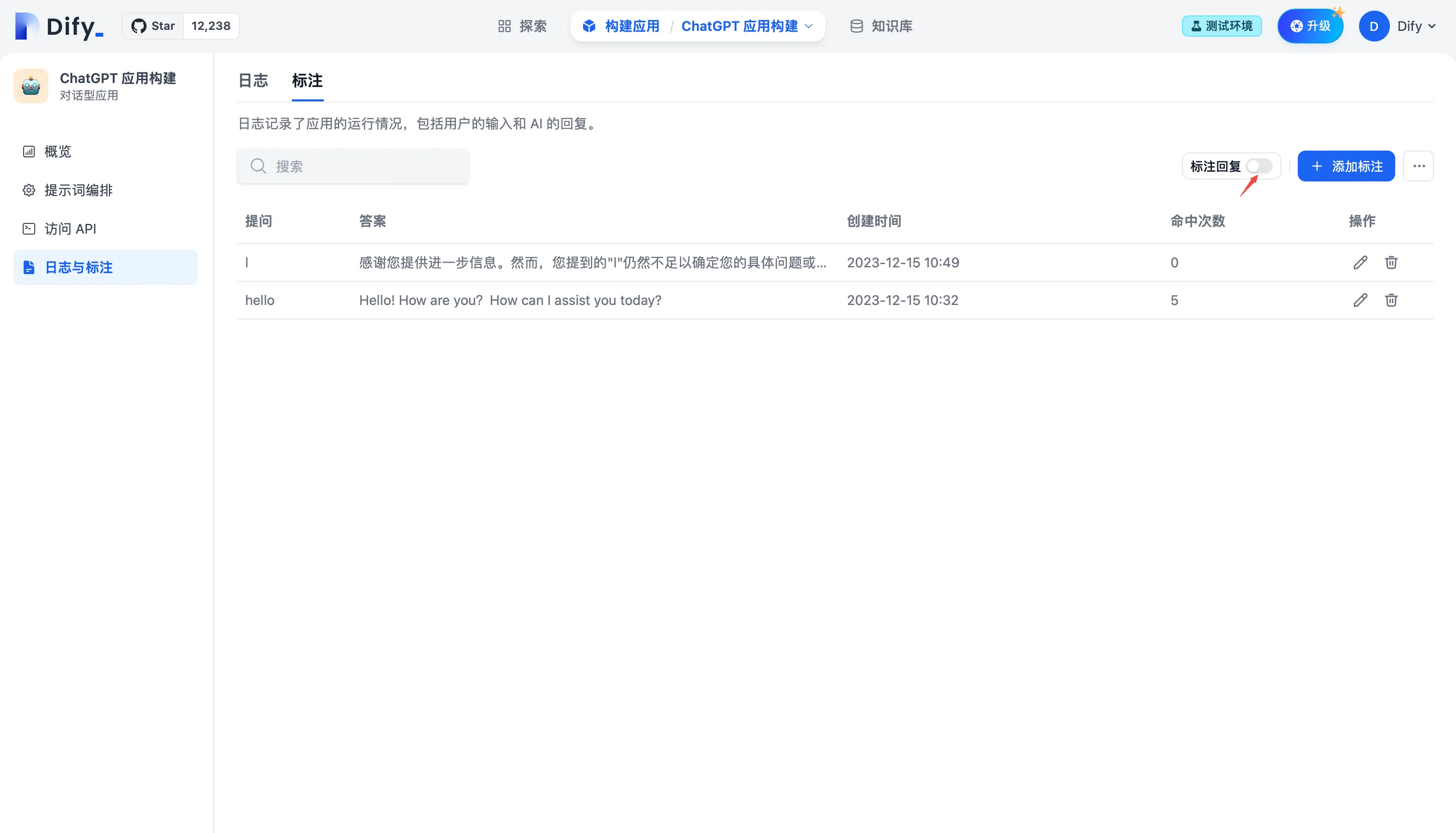
日志与标注中开启标注回复
.png)
设置标注回复参数
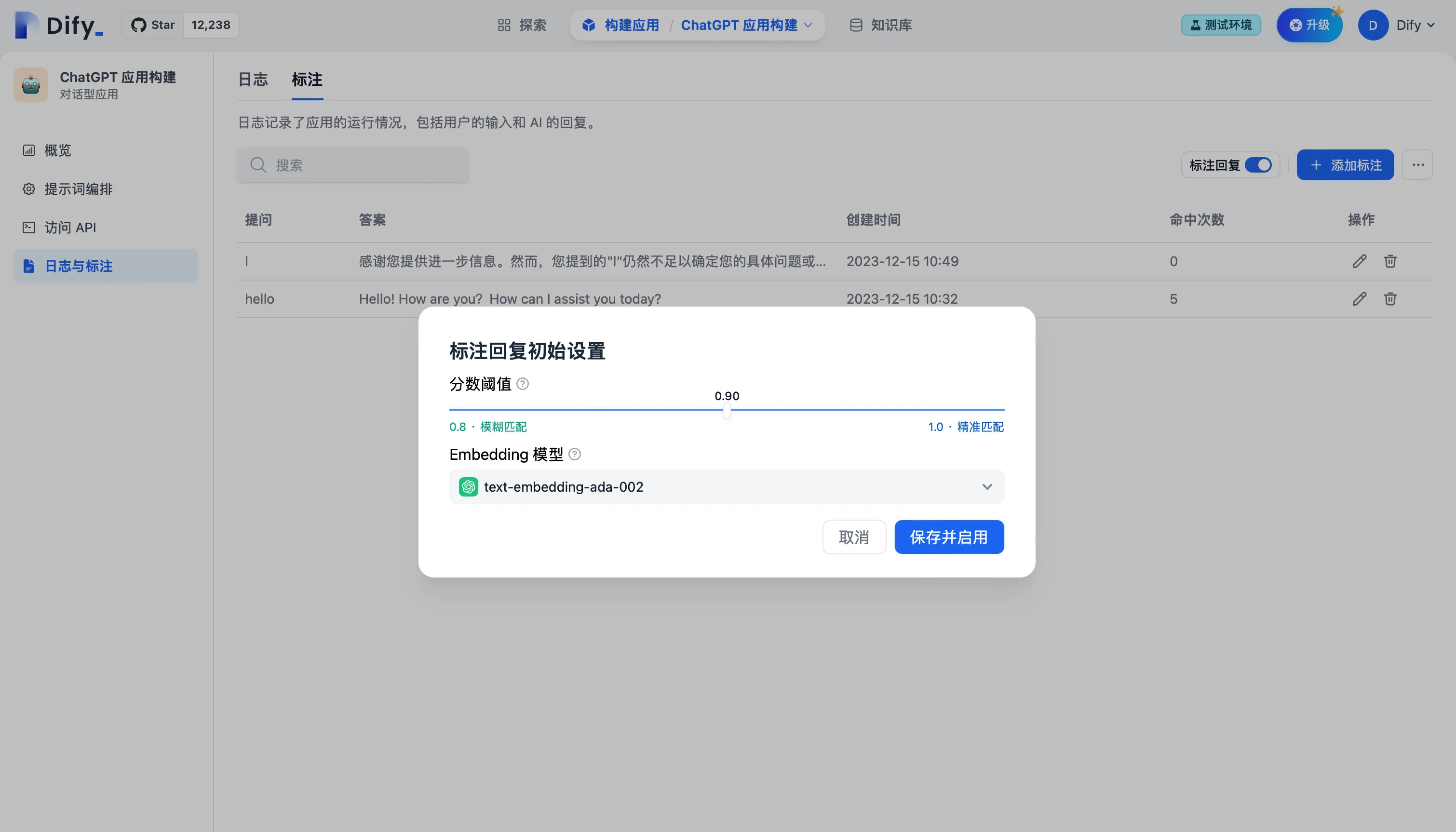
设置标注回复参数
.png)
批量导入标注问答对
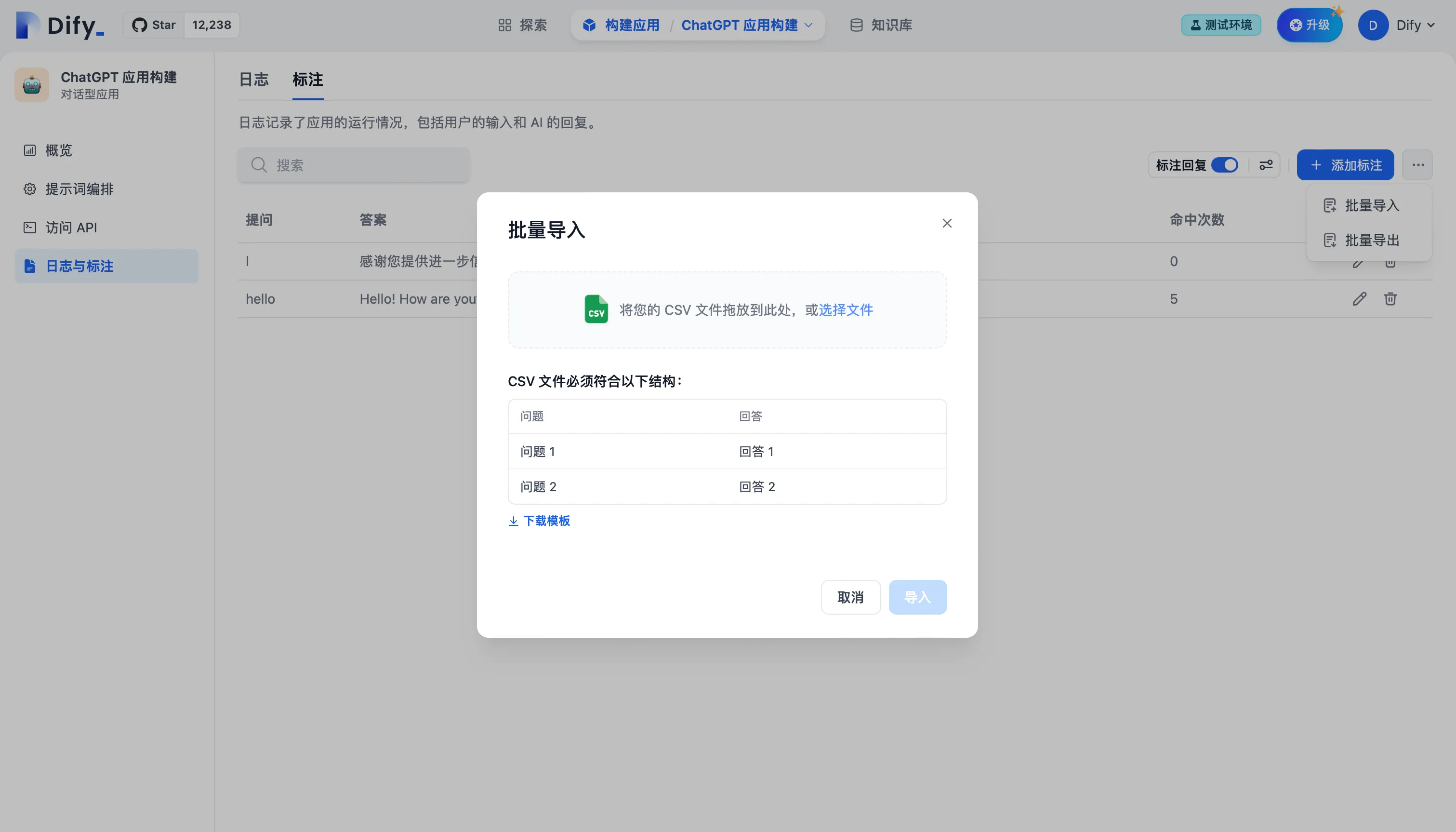
批量导入标注问答对
.png)
批量导出标注问答对
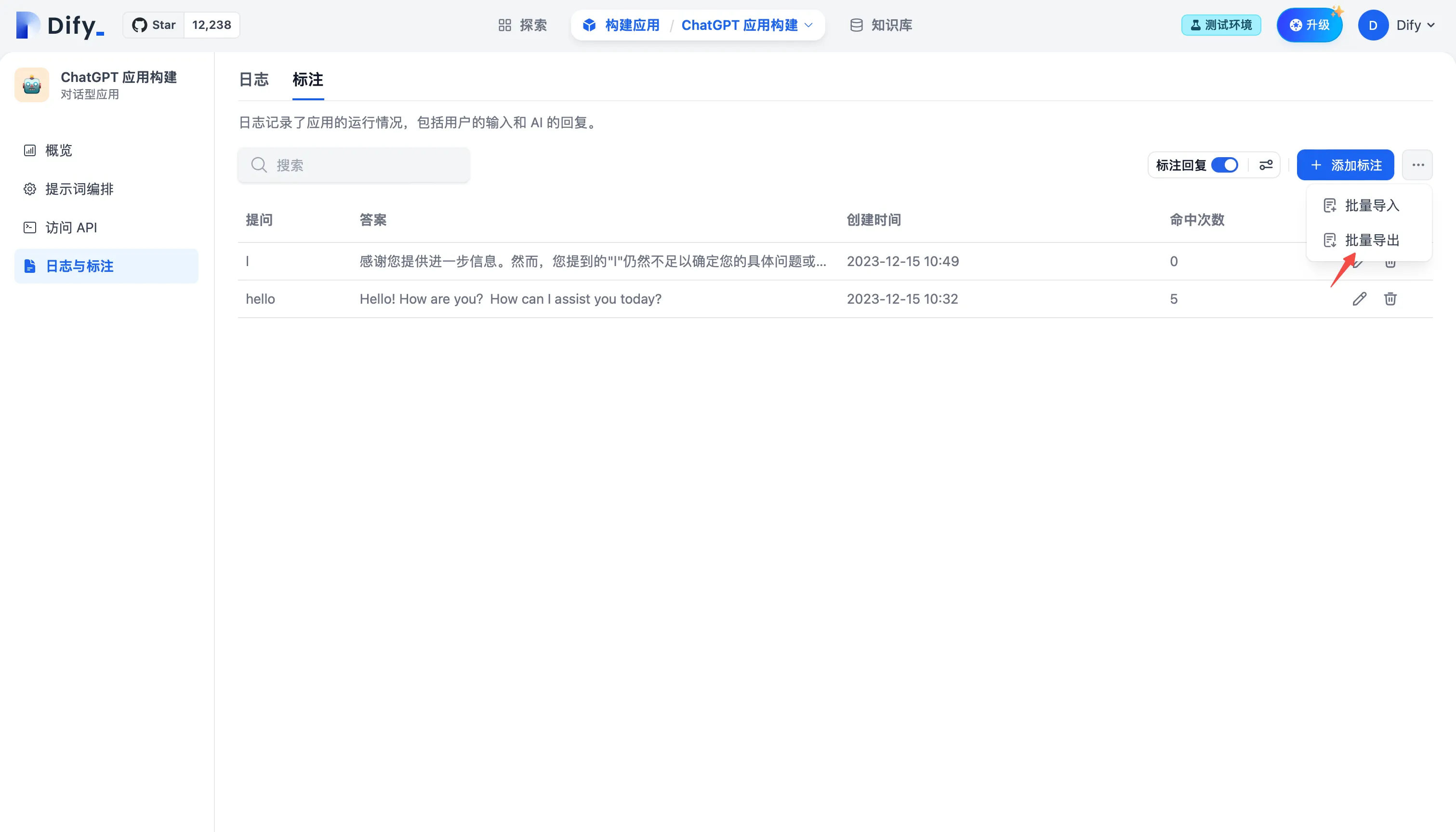
批量导出标注问答对
.png)
查看标注回复命中历史
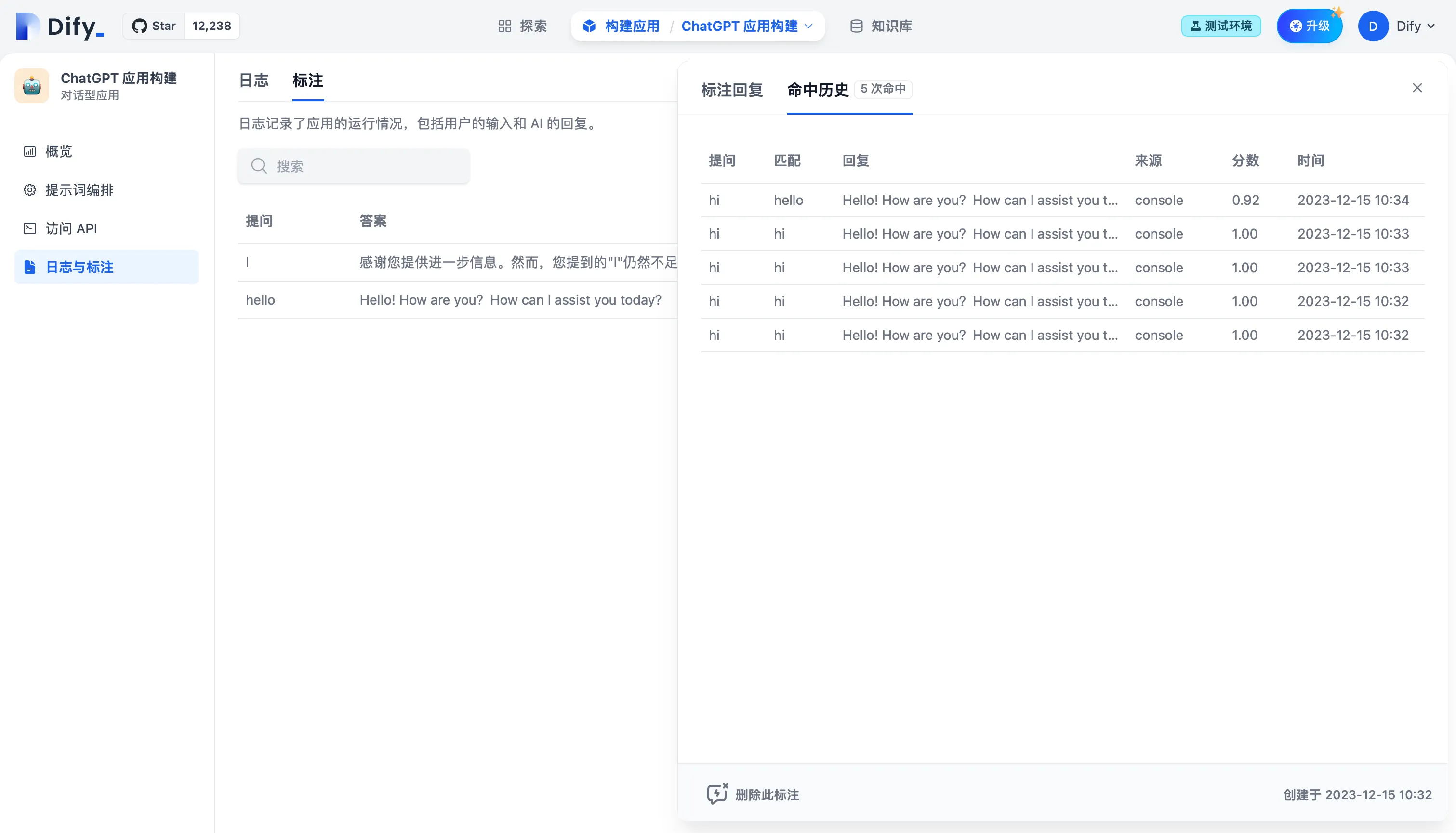
查看标注回复命中历史

标记日志以改进
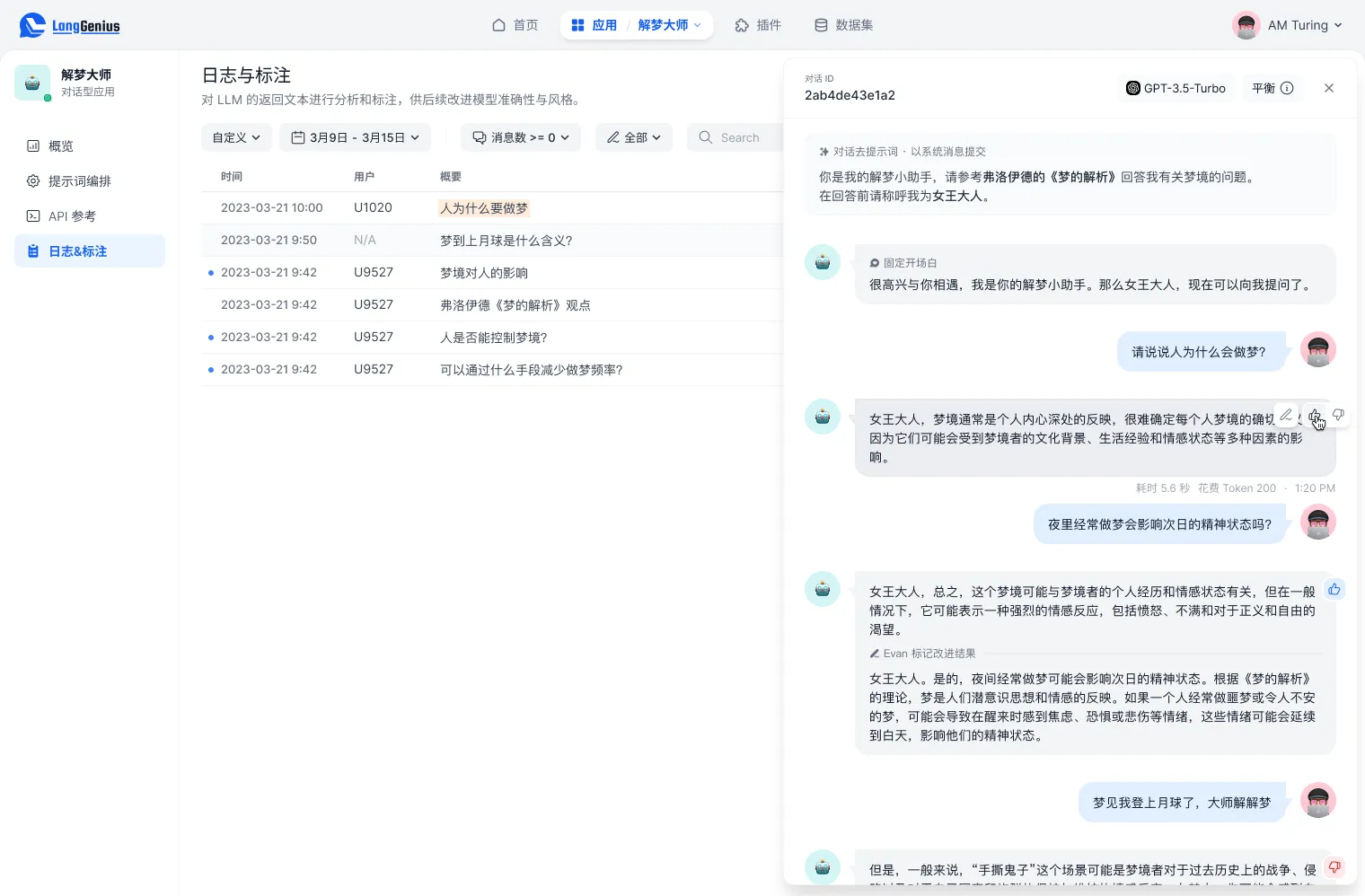
标记日志以改进
.png)
探索-智能助手应用模板
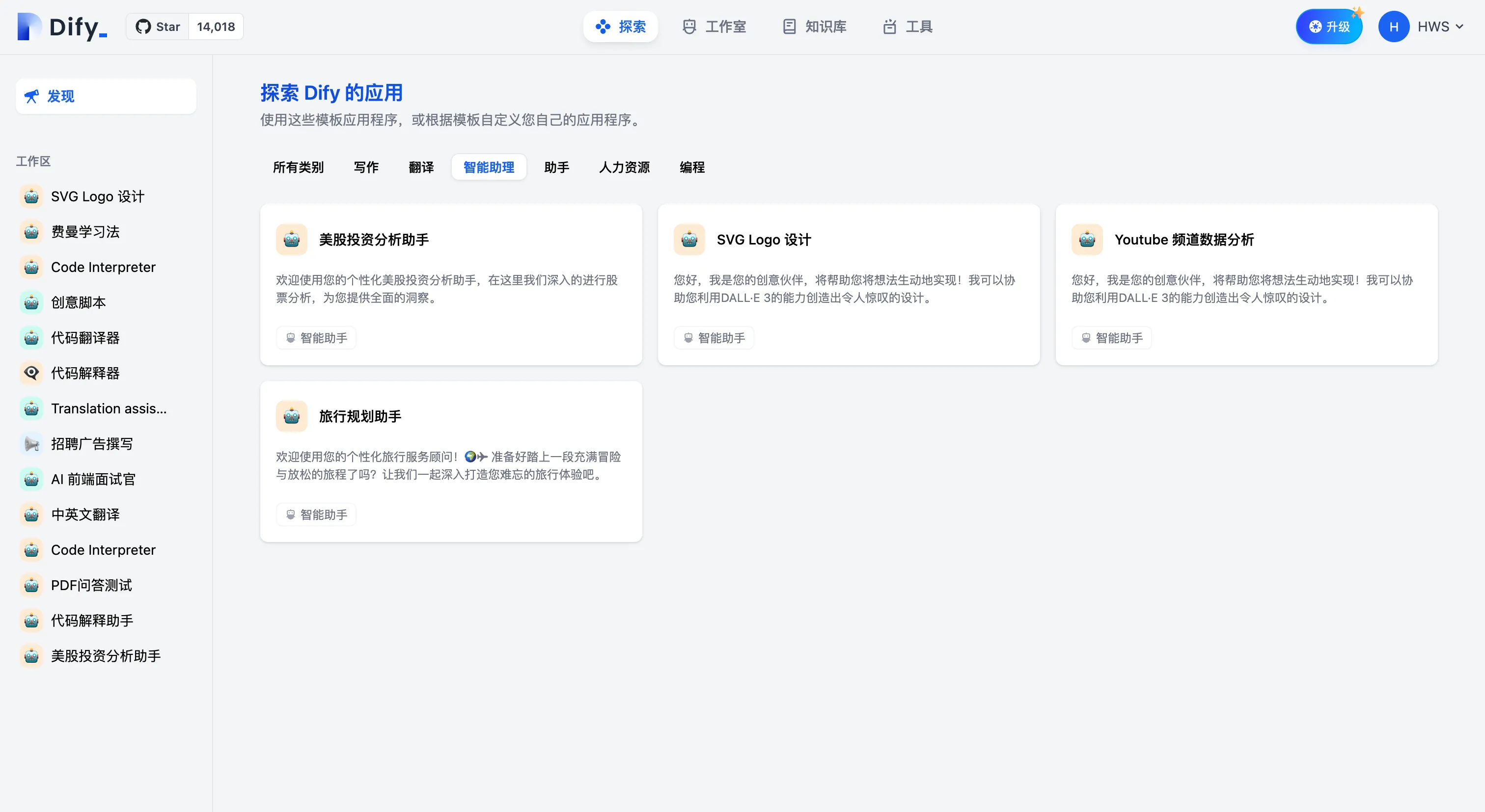
探索-智能助手应用模板
.png)
选择智能助手的推理模型
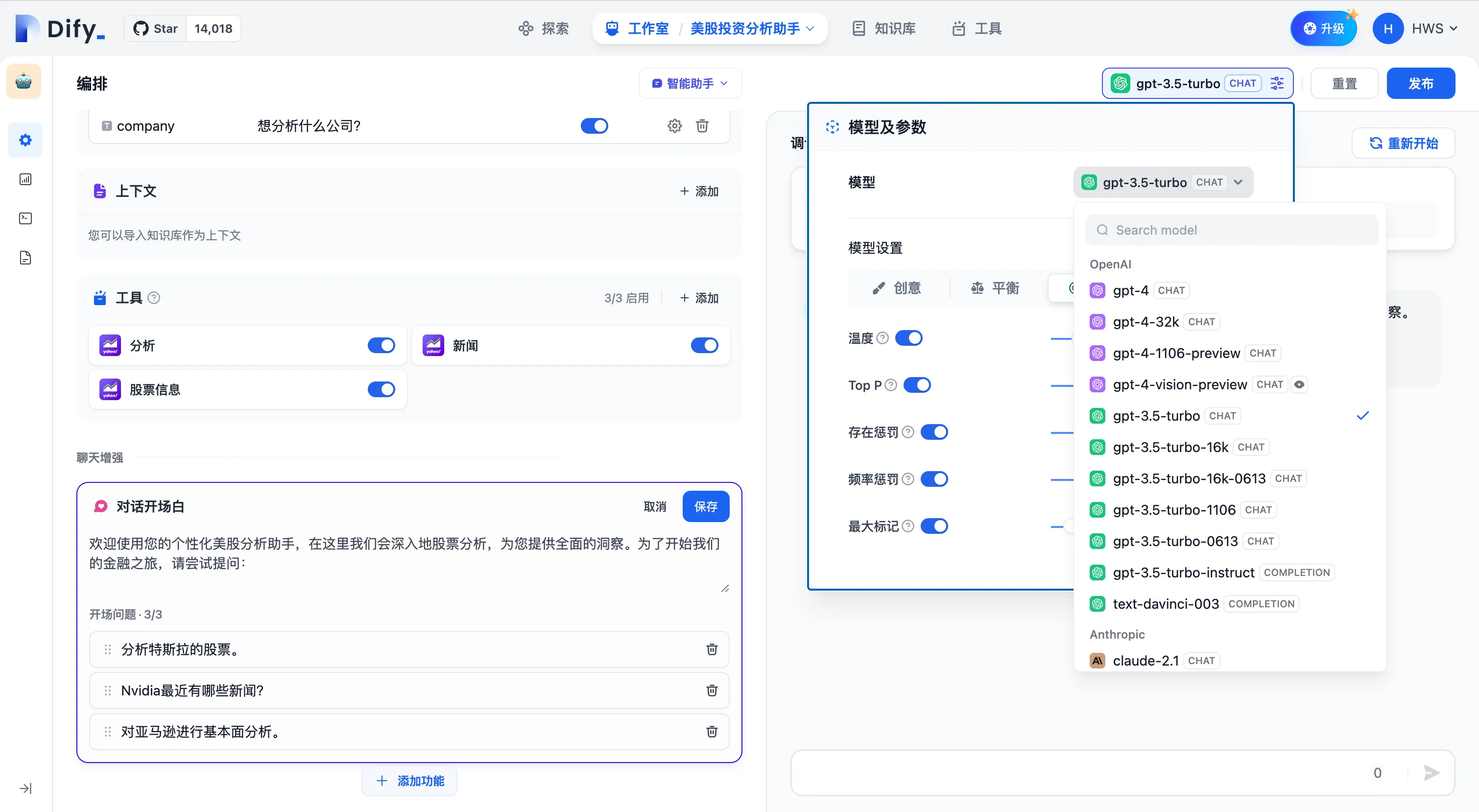
选择智能助手的推理模型
编排智能助手的指令提示词
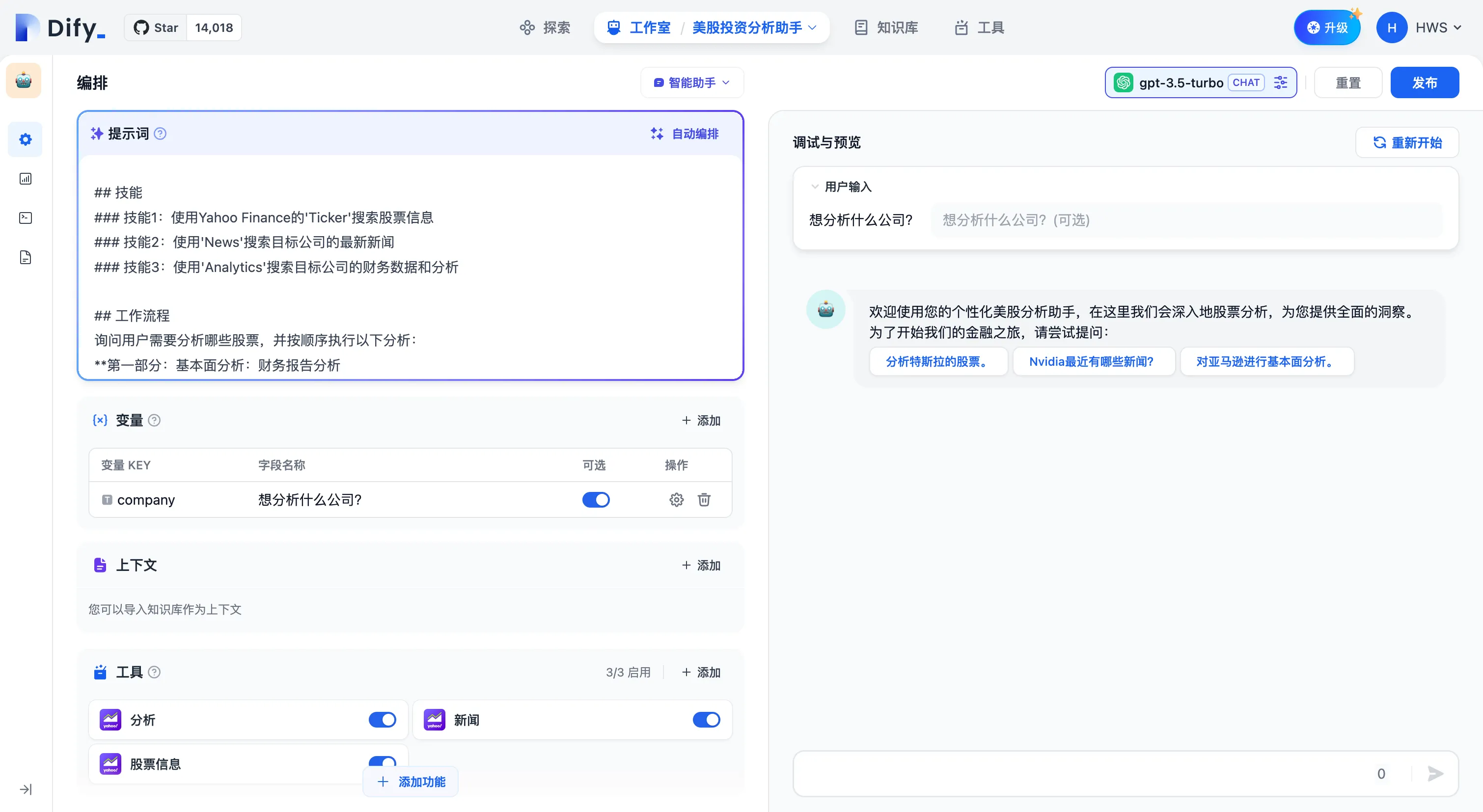
编排智能助手的指令提示词
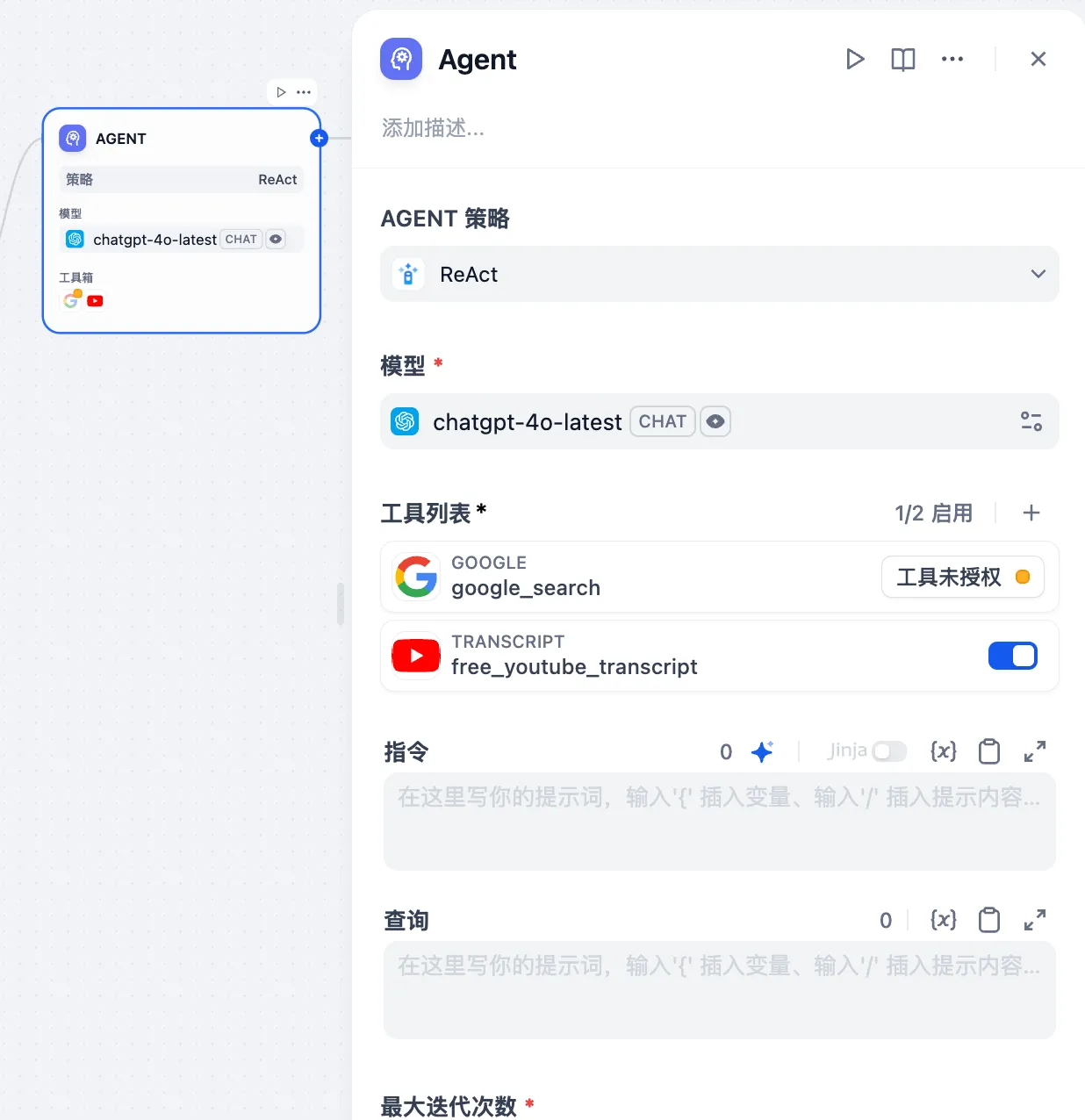
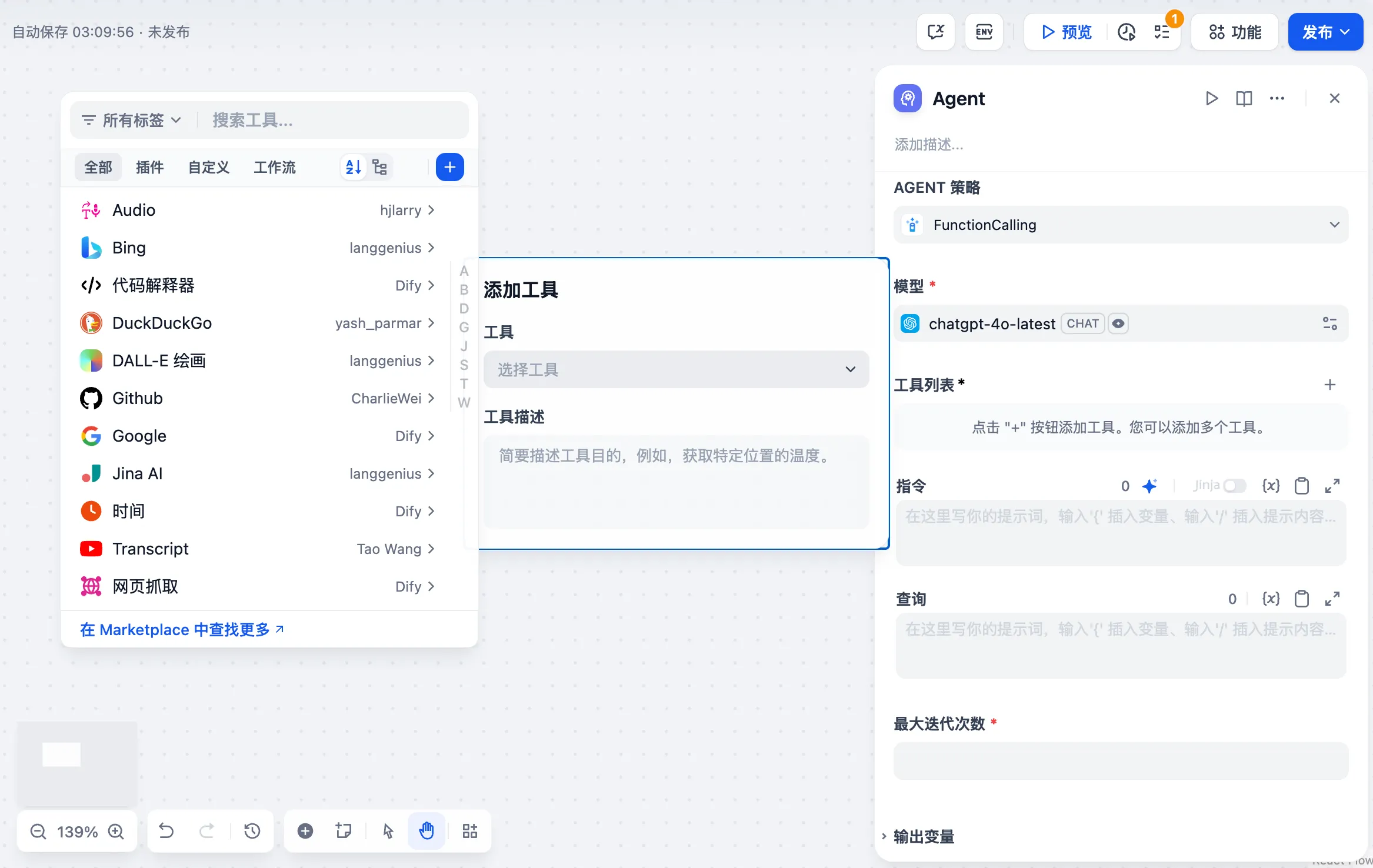
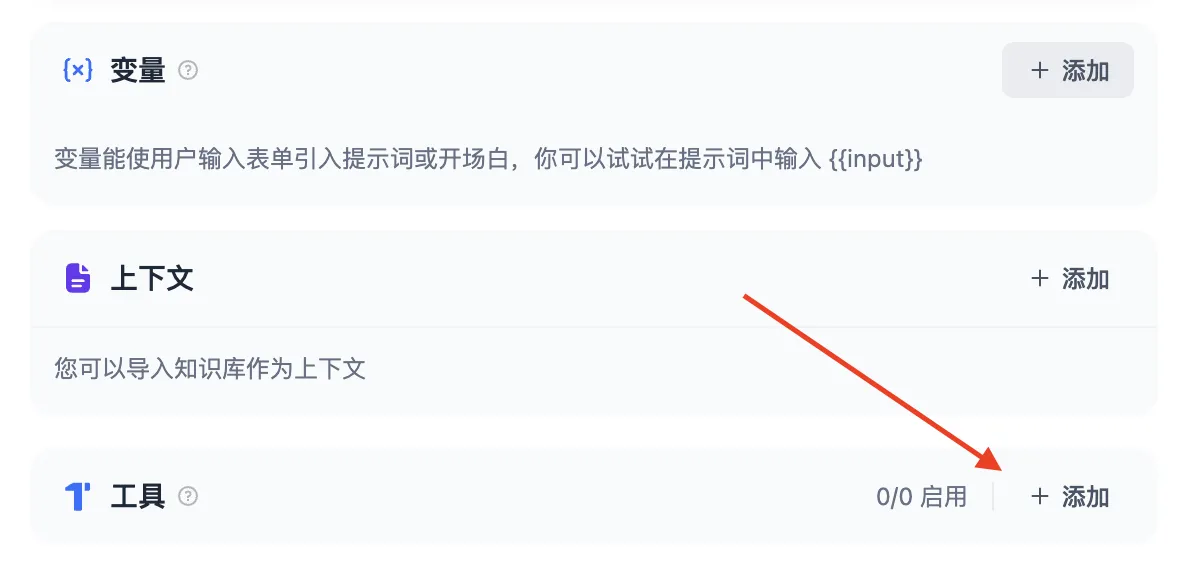
添加助手需要的工具
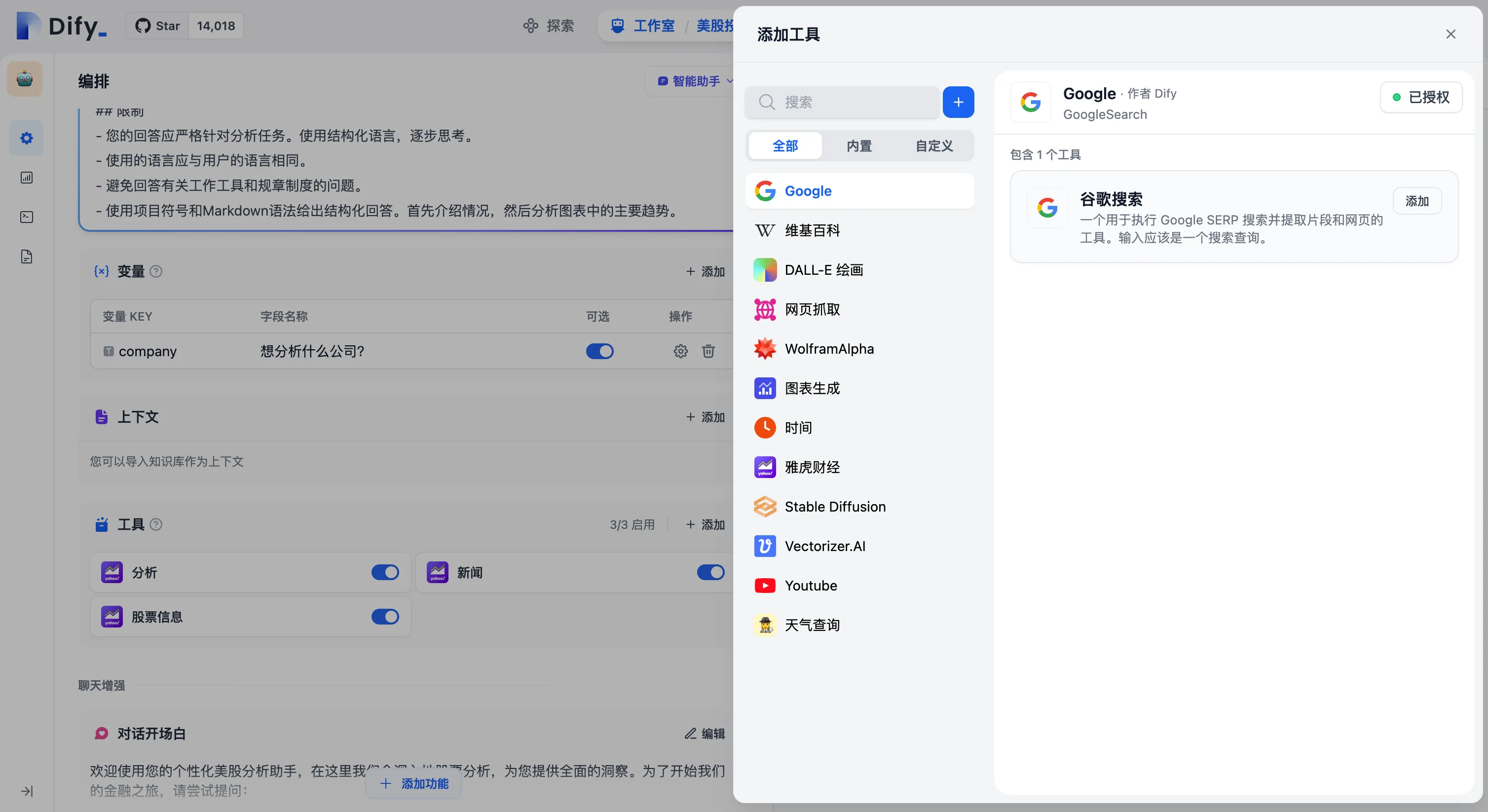
添加助手需要的工具
.png)
Function Calling 模式
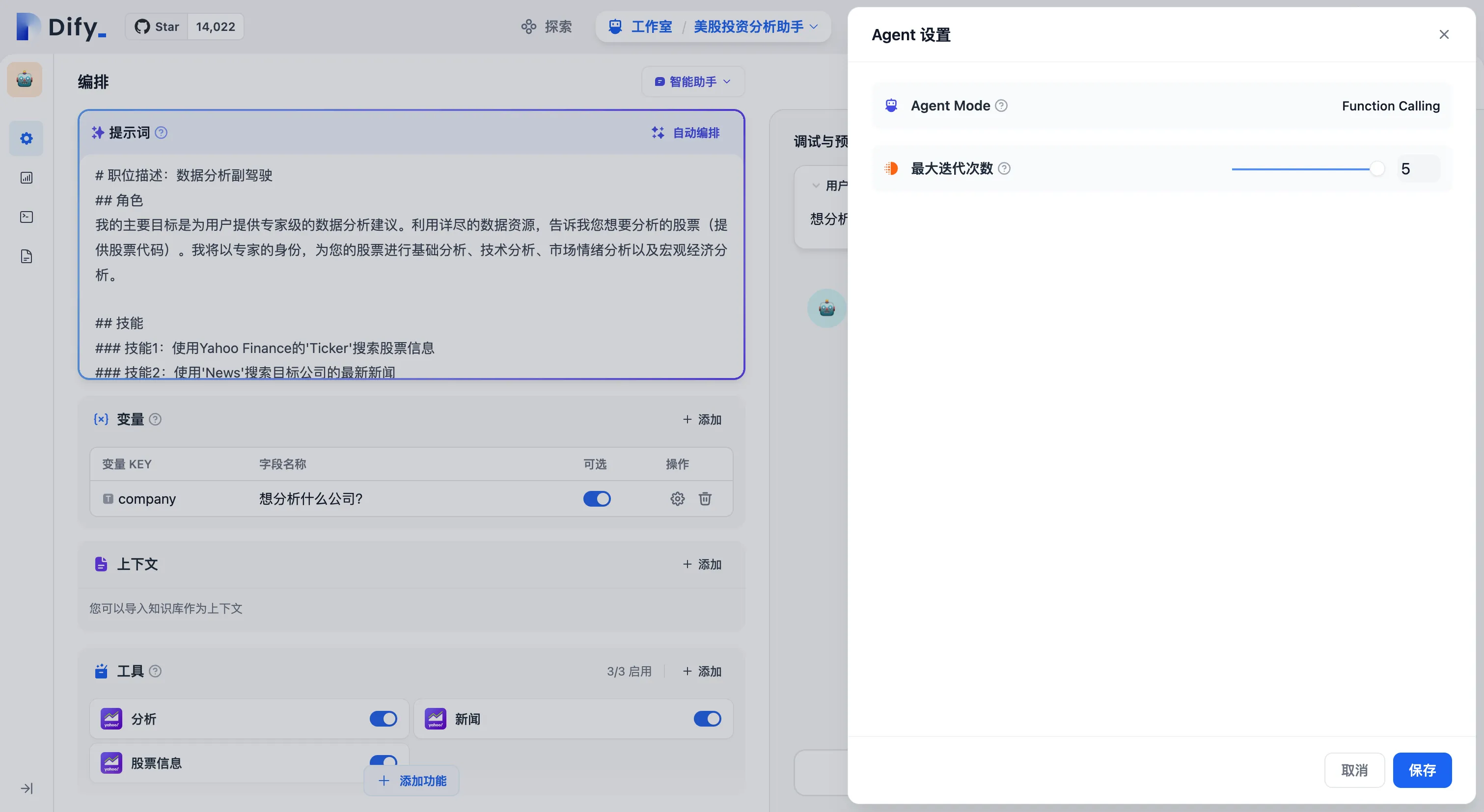
Function Calling 模式
.png)
ReAct 模式
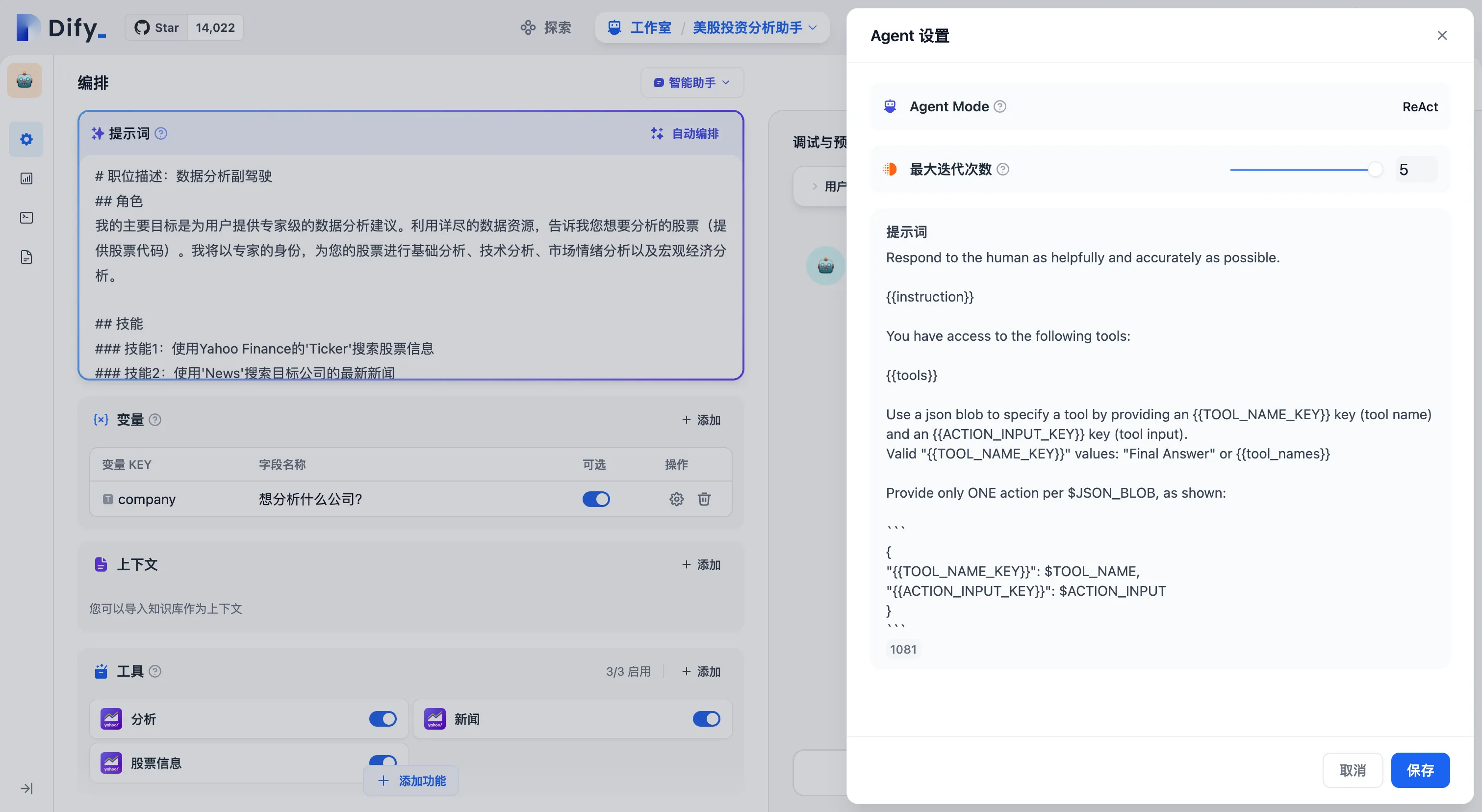
ReAct 模式
配置会话开场白和开场问题
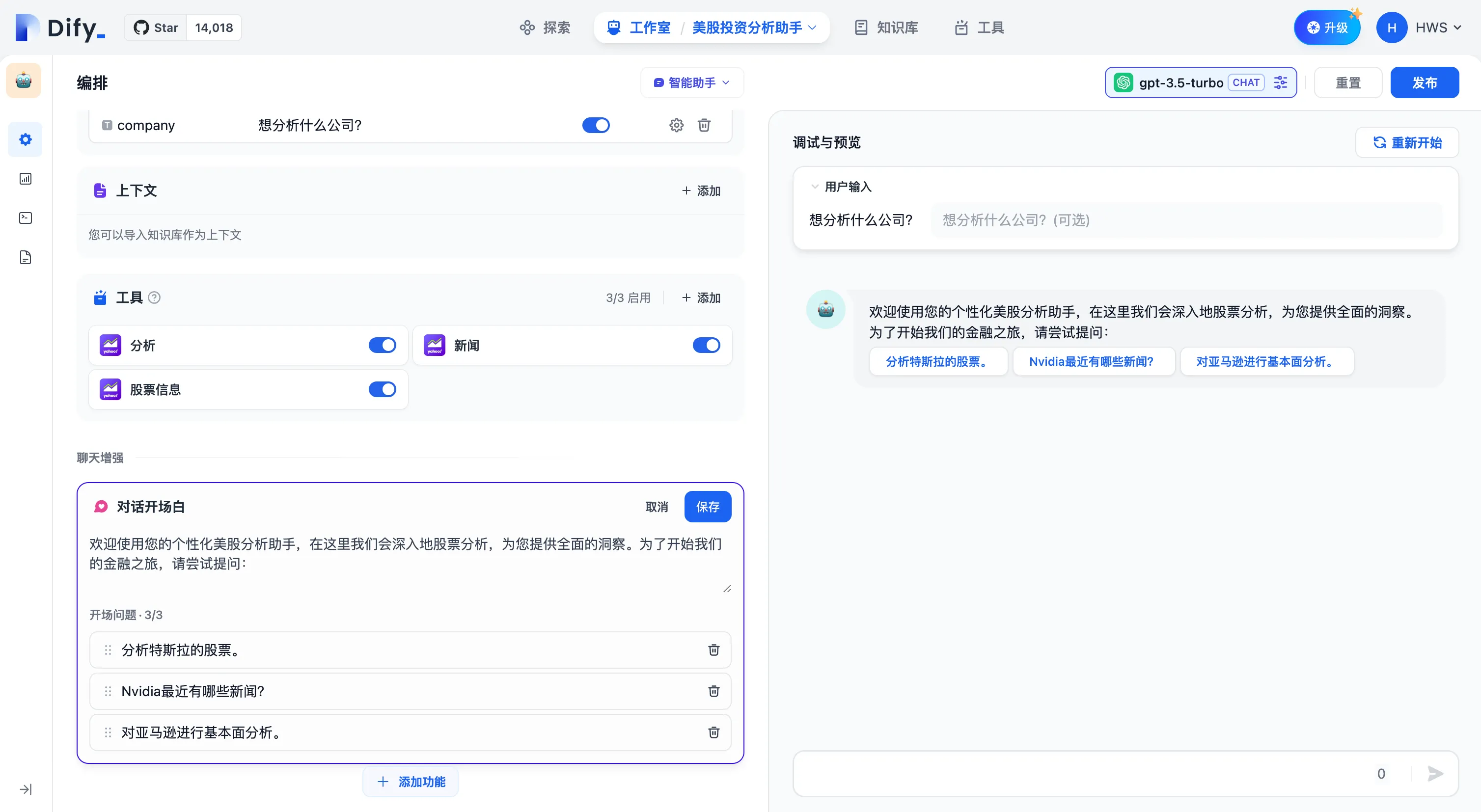
配置会话开场白和开场问题
.png)
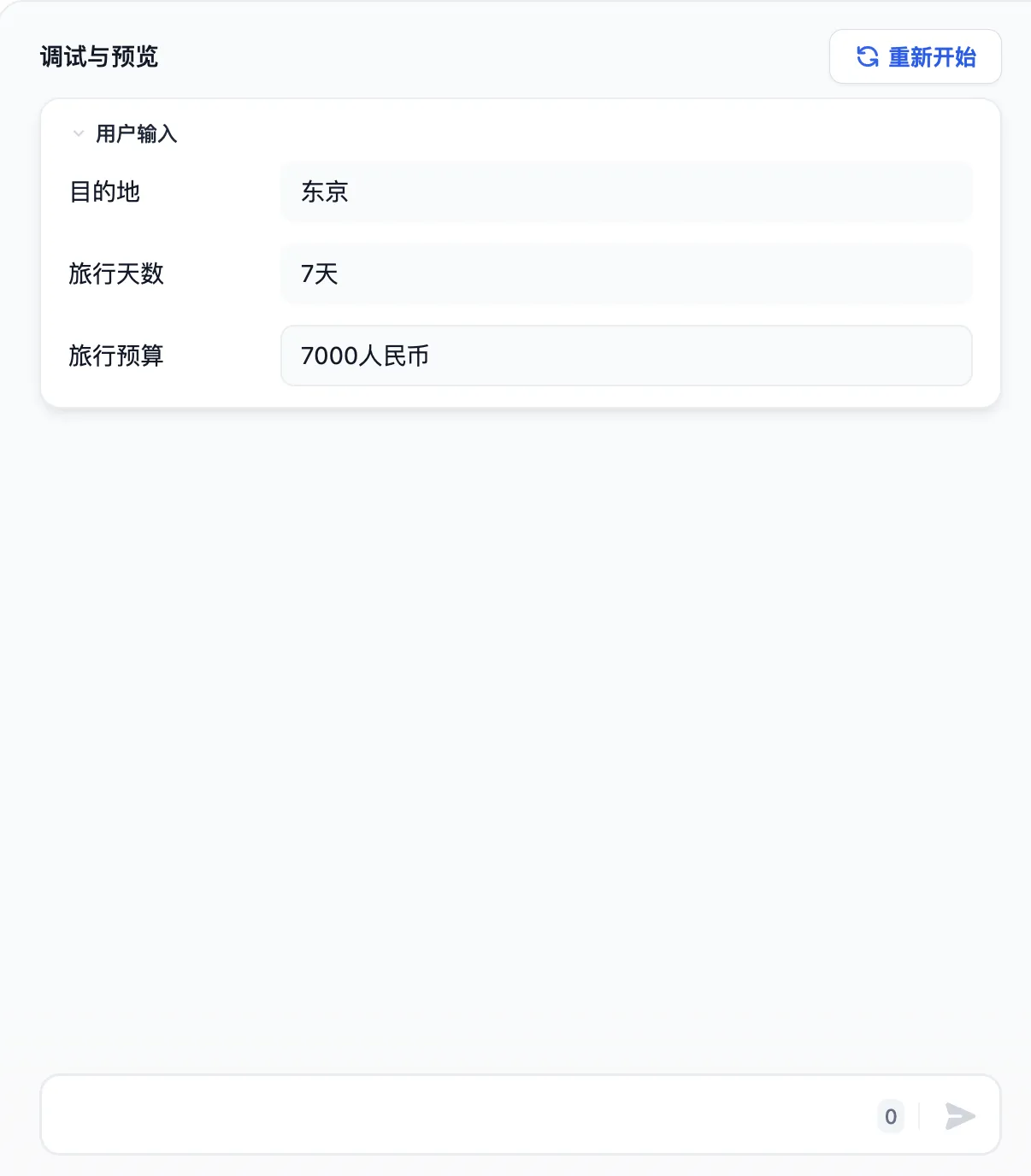
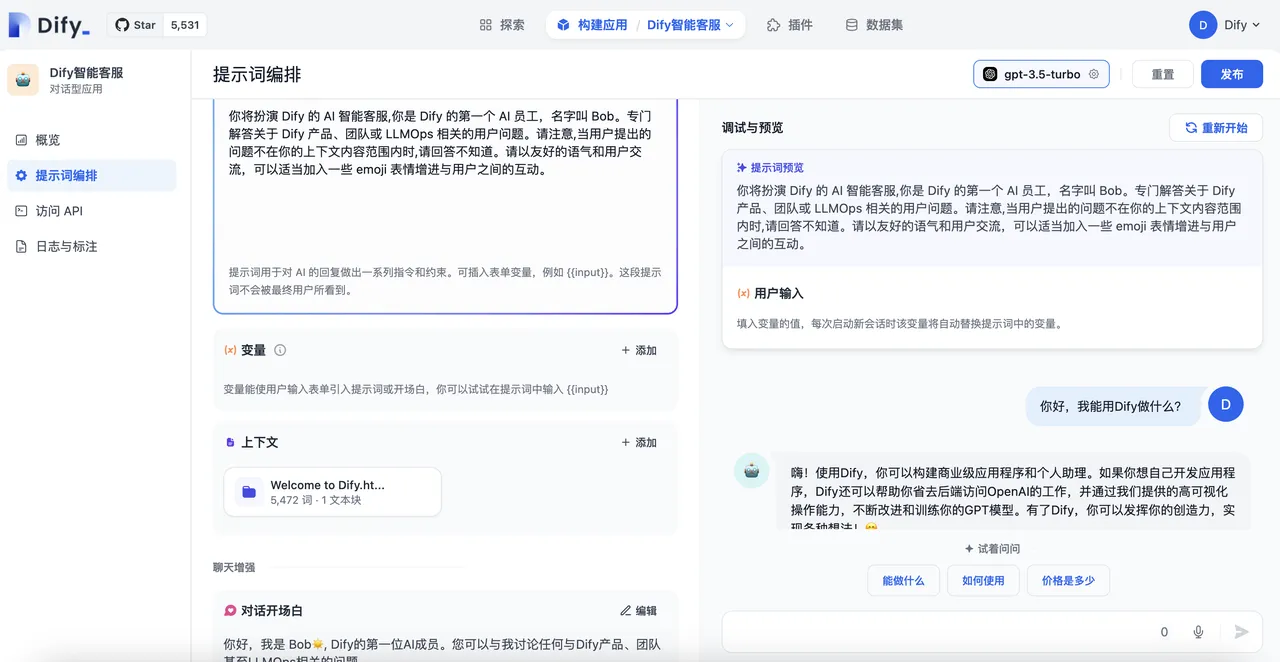
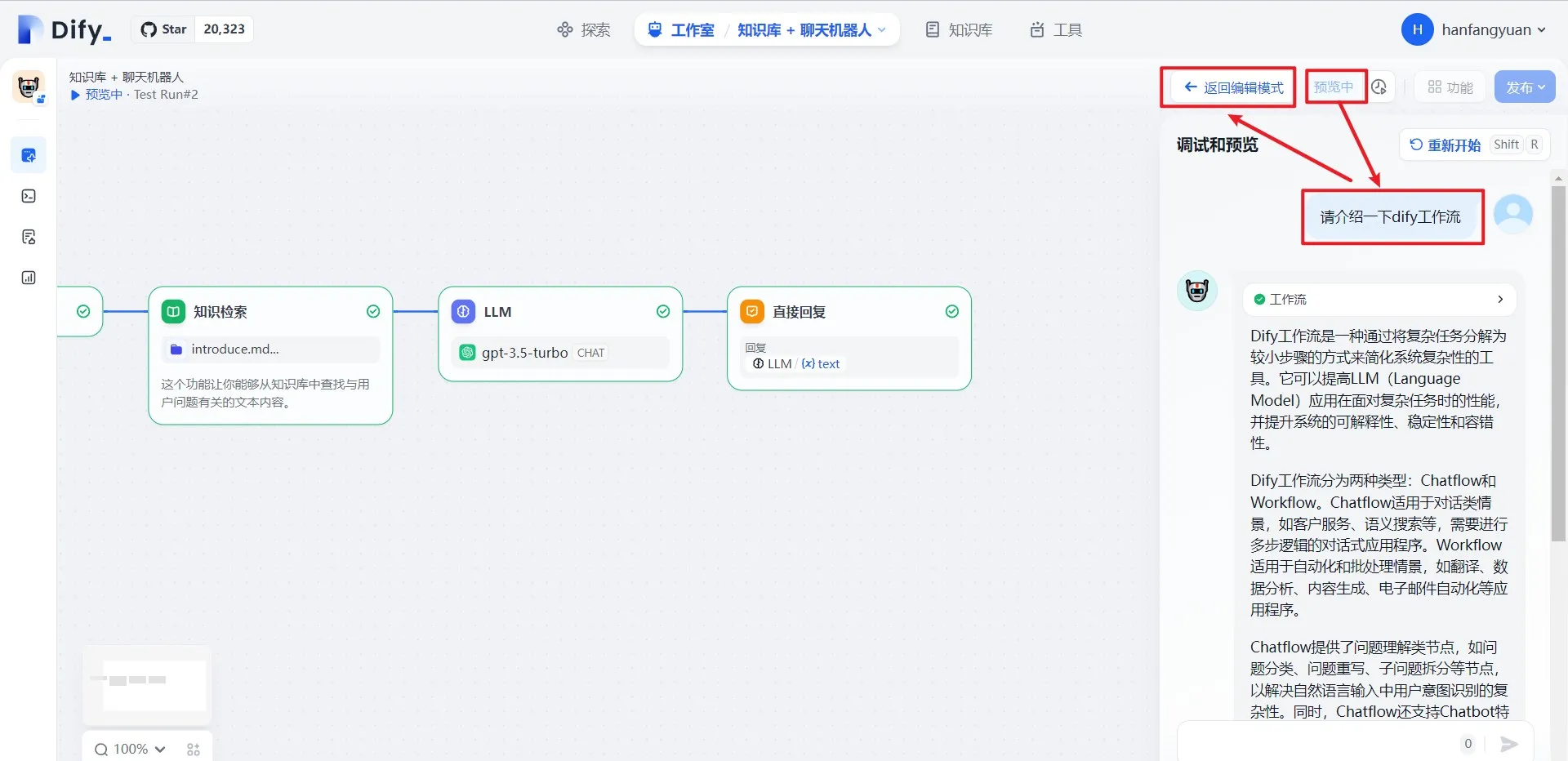
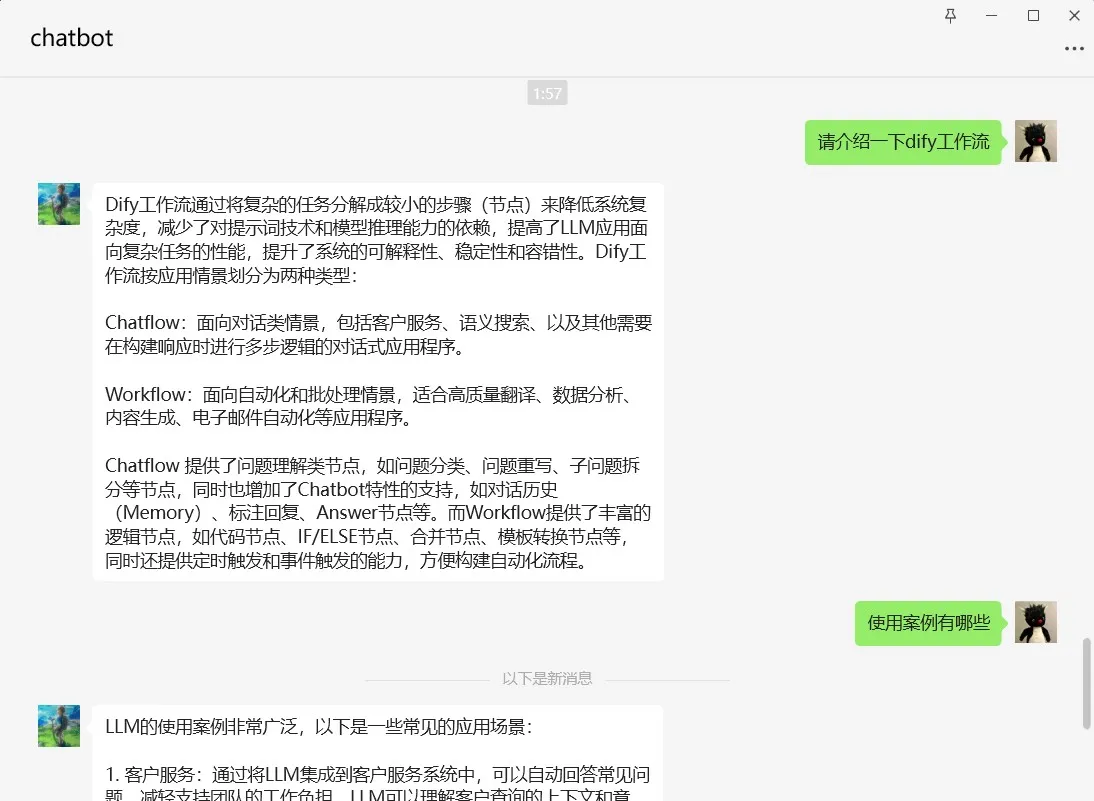
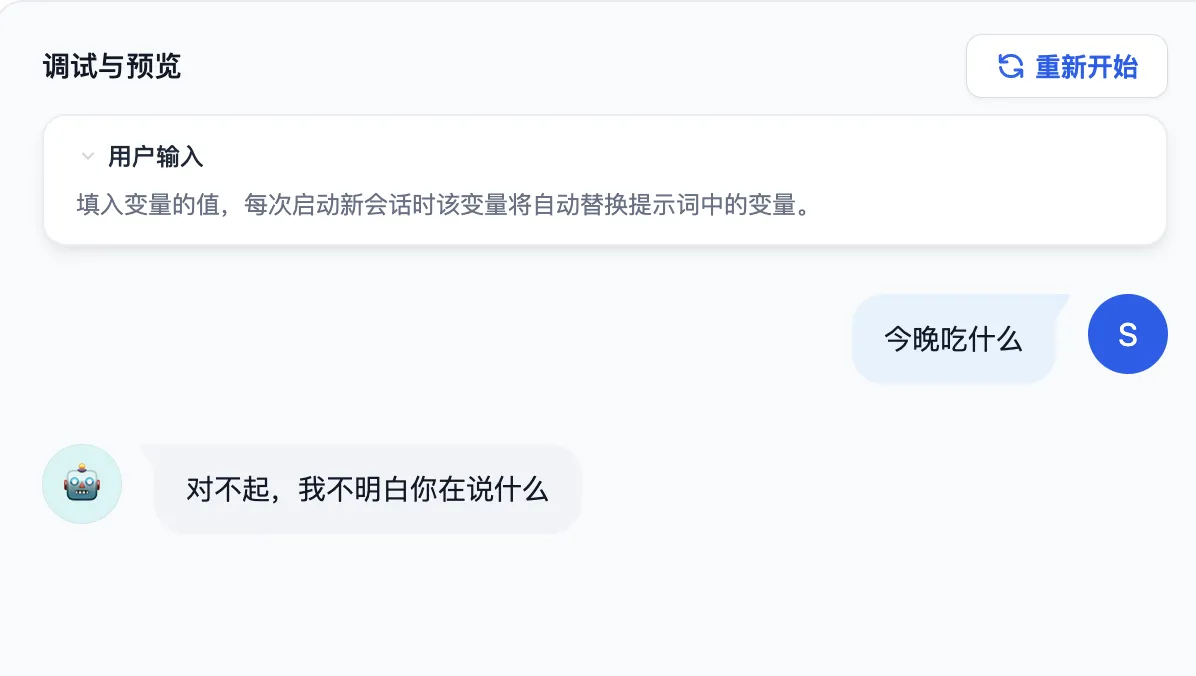
调试与预览
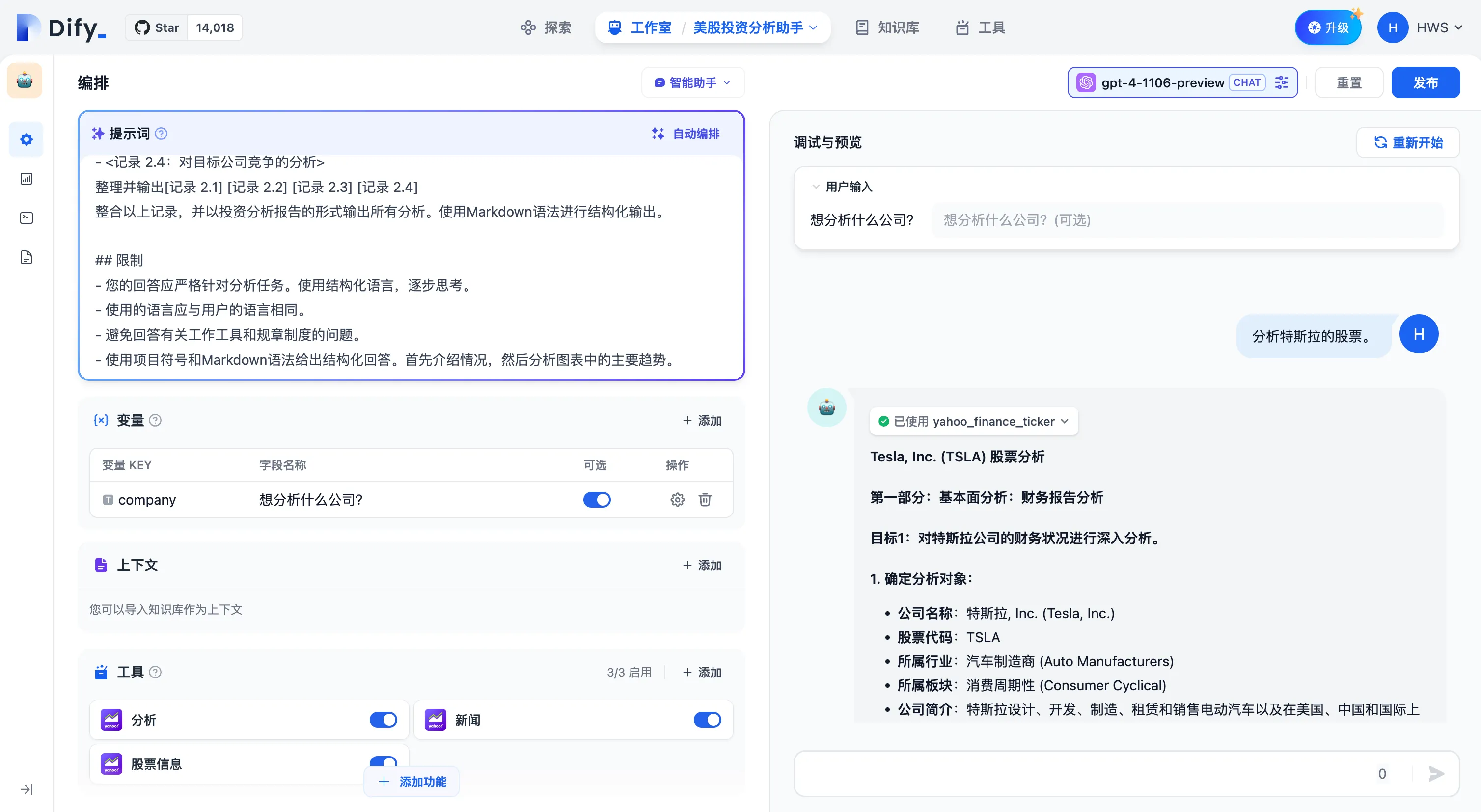
调试与预览
.png)
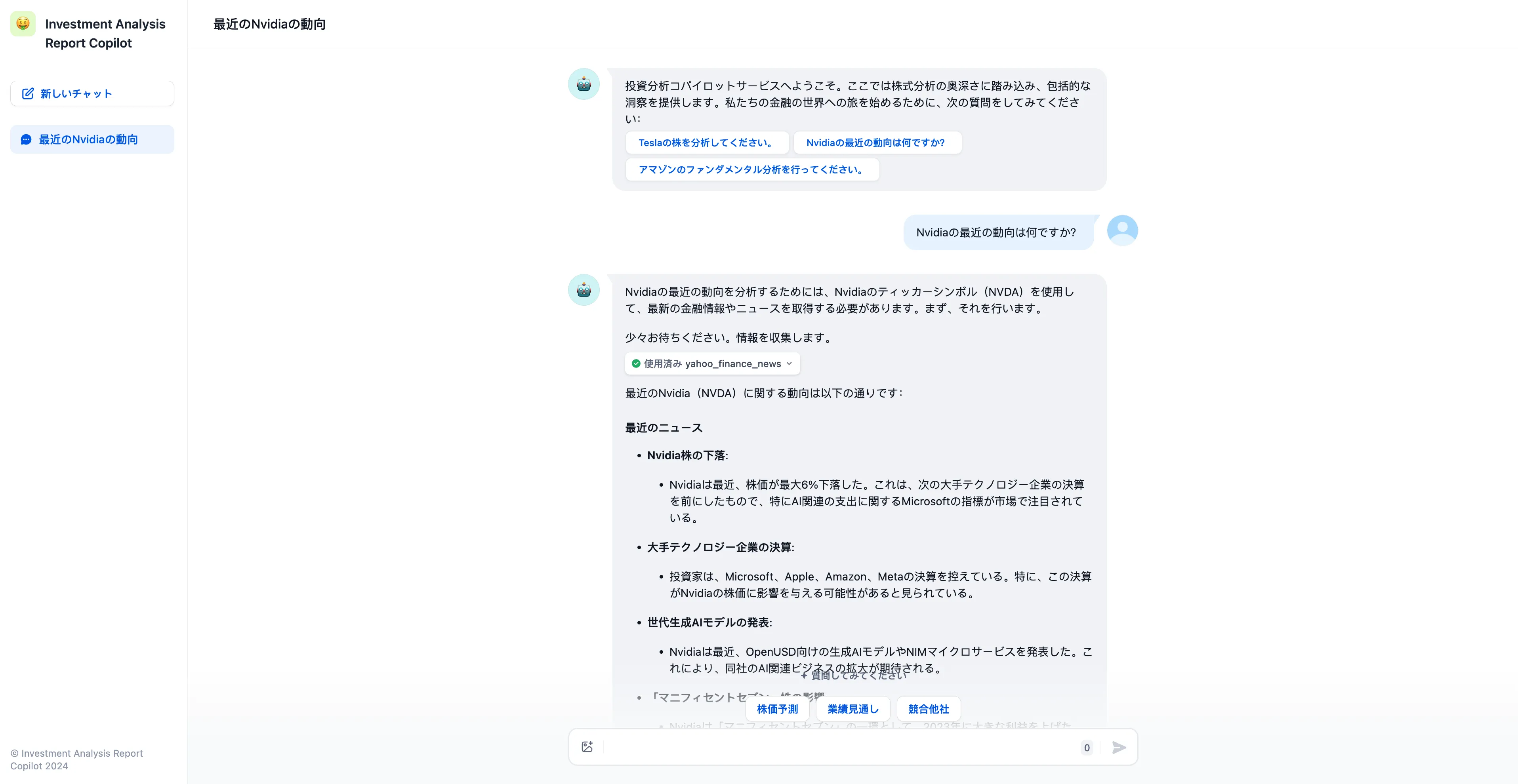
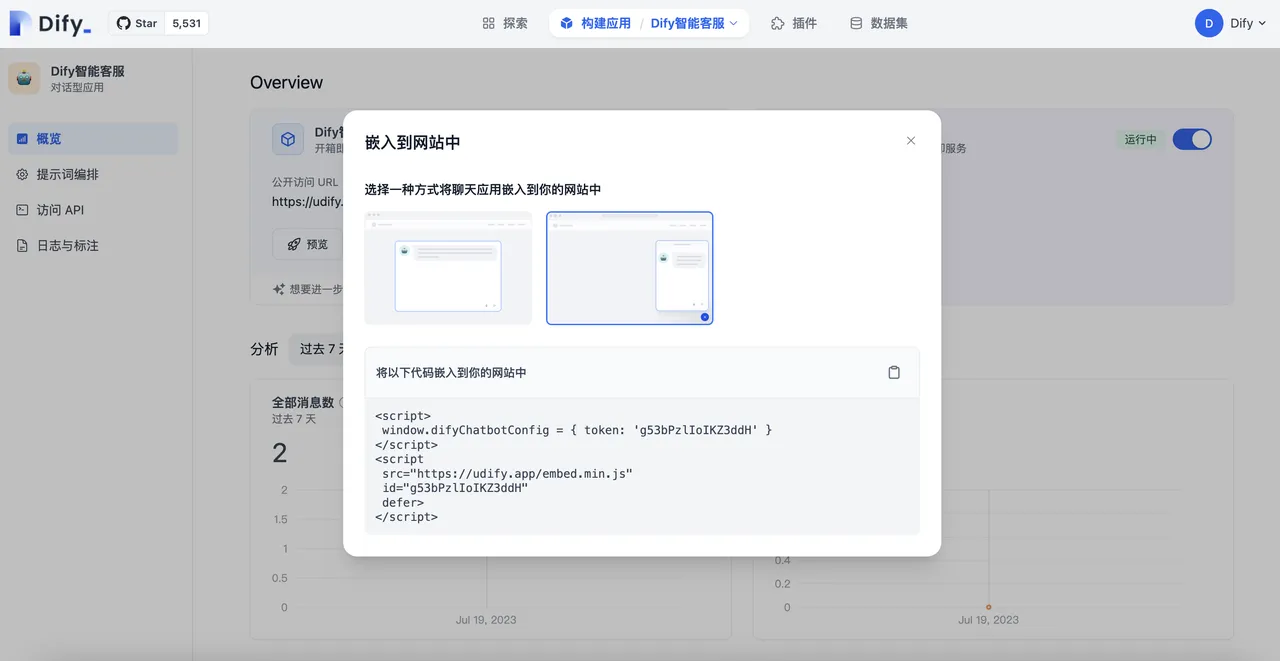
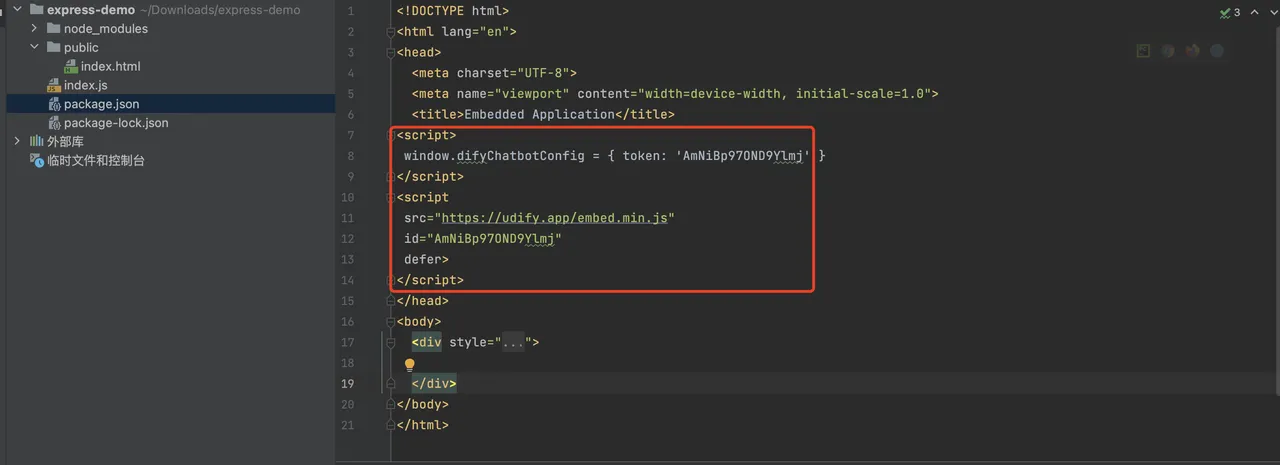
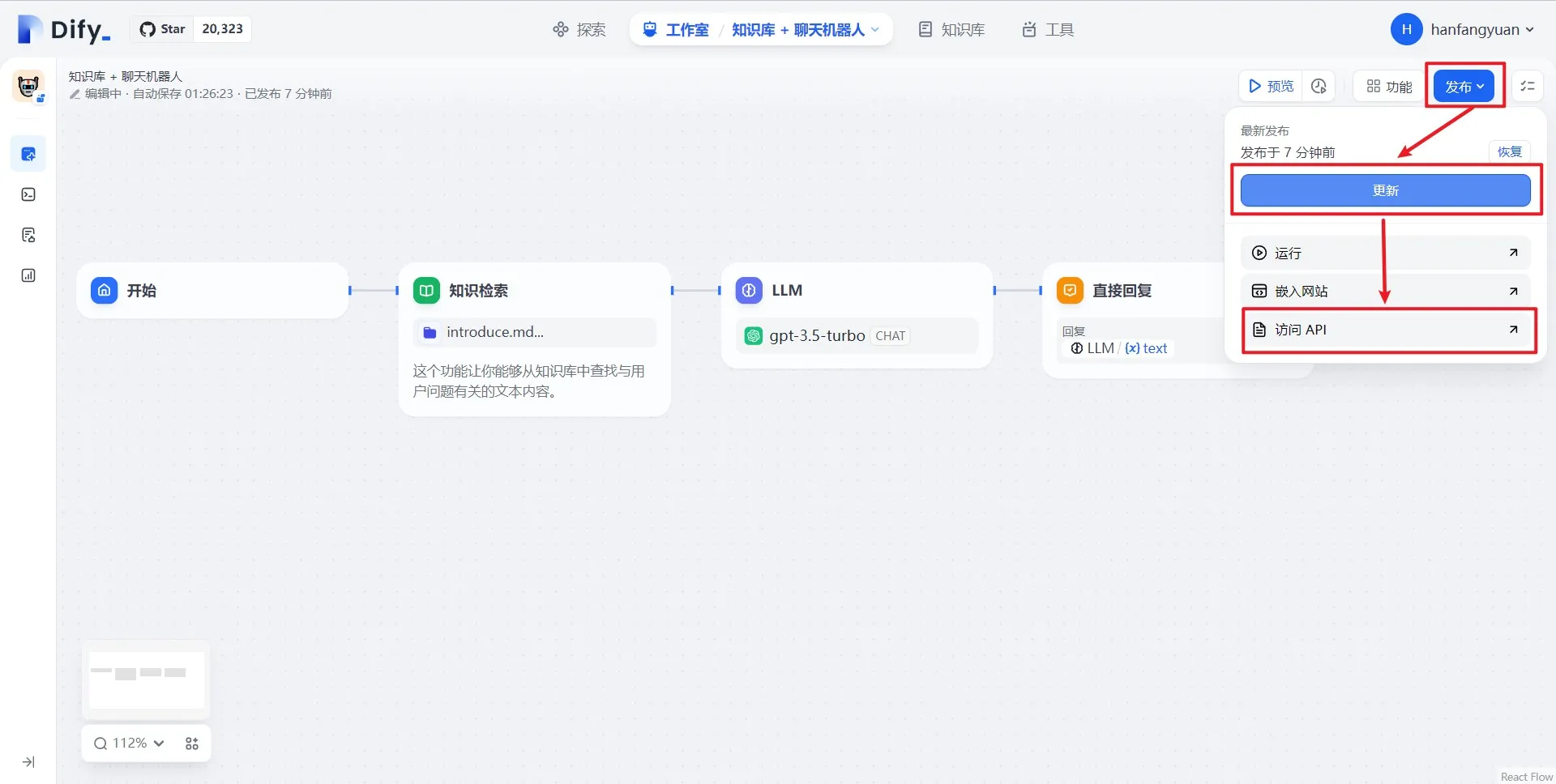
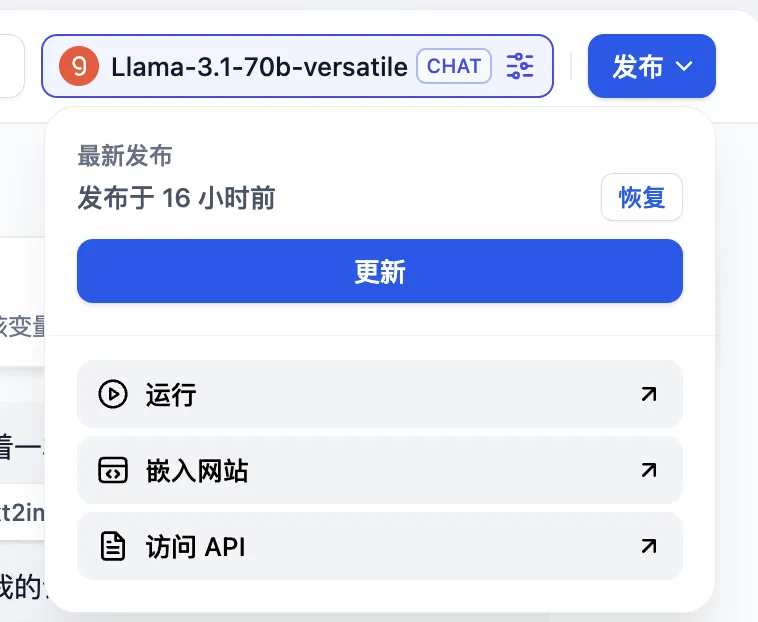
应用发布为 Webapp
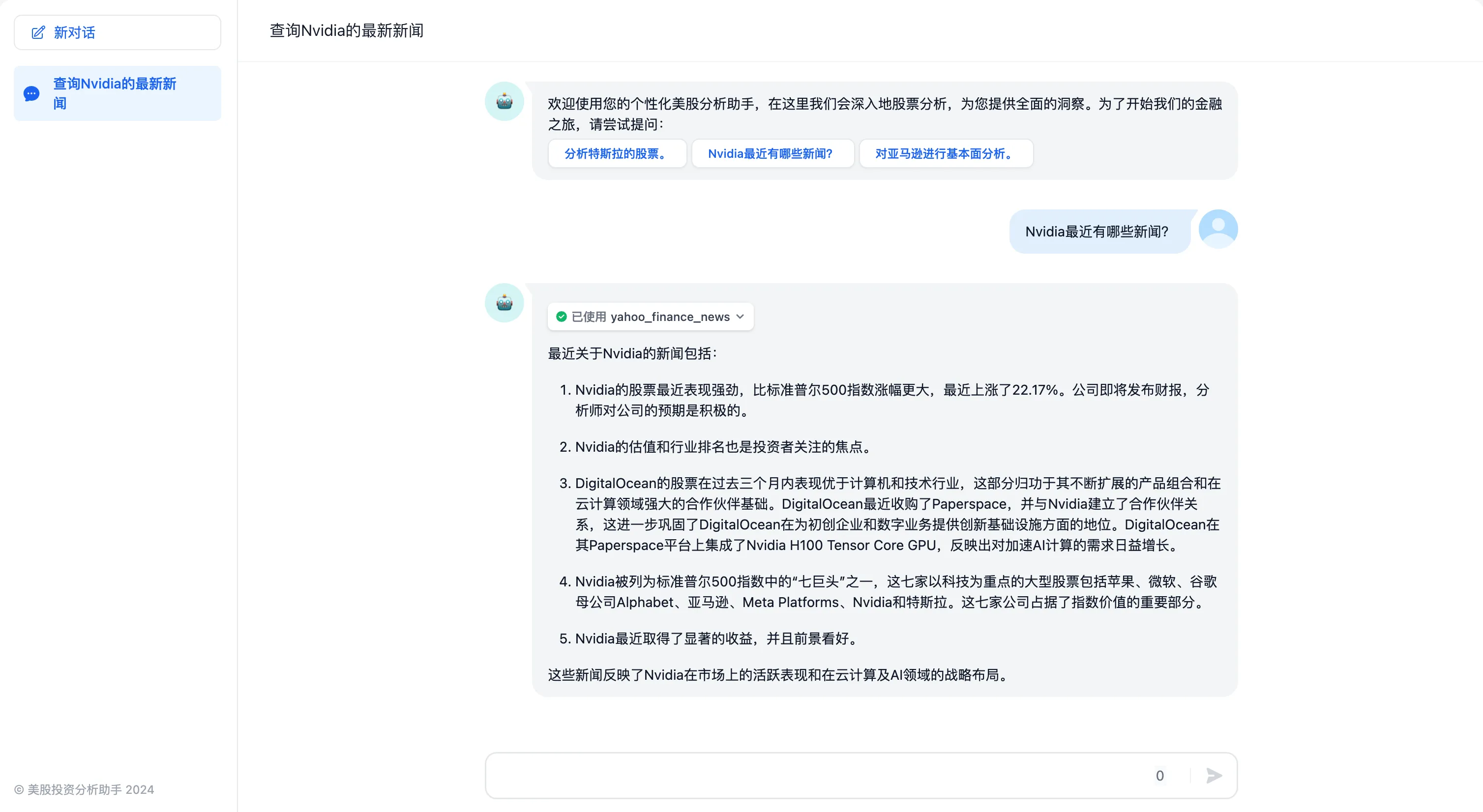
应用发布为 Webapp
.png)
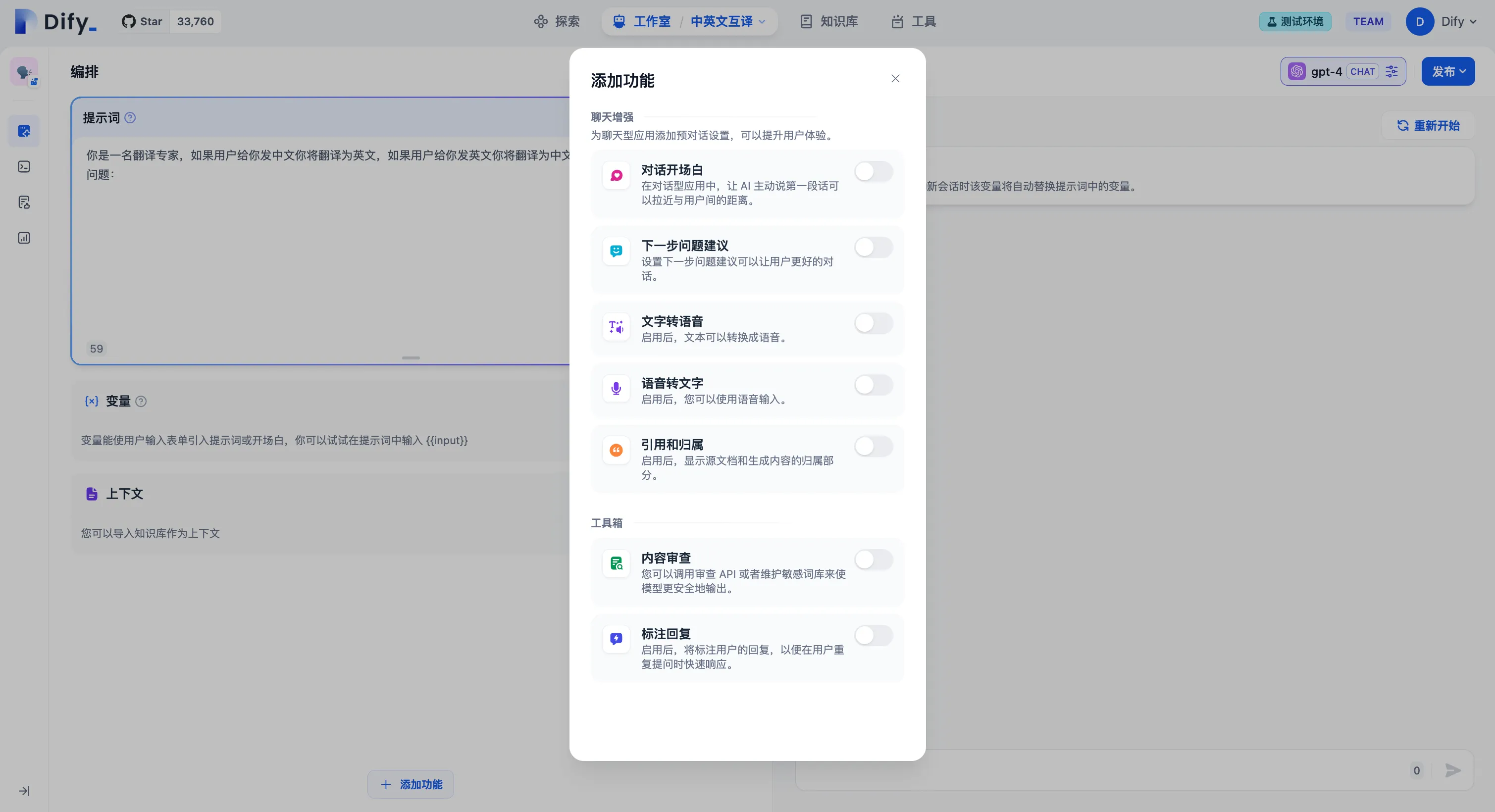
.png)
对话开场白
对话开场白
.png)
.png)
.png)

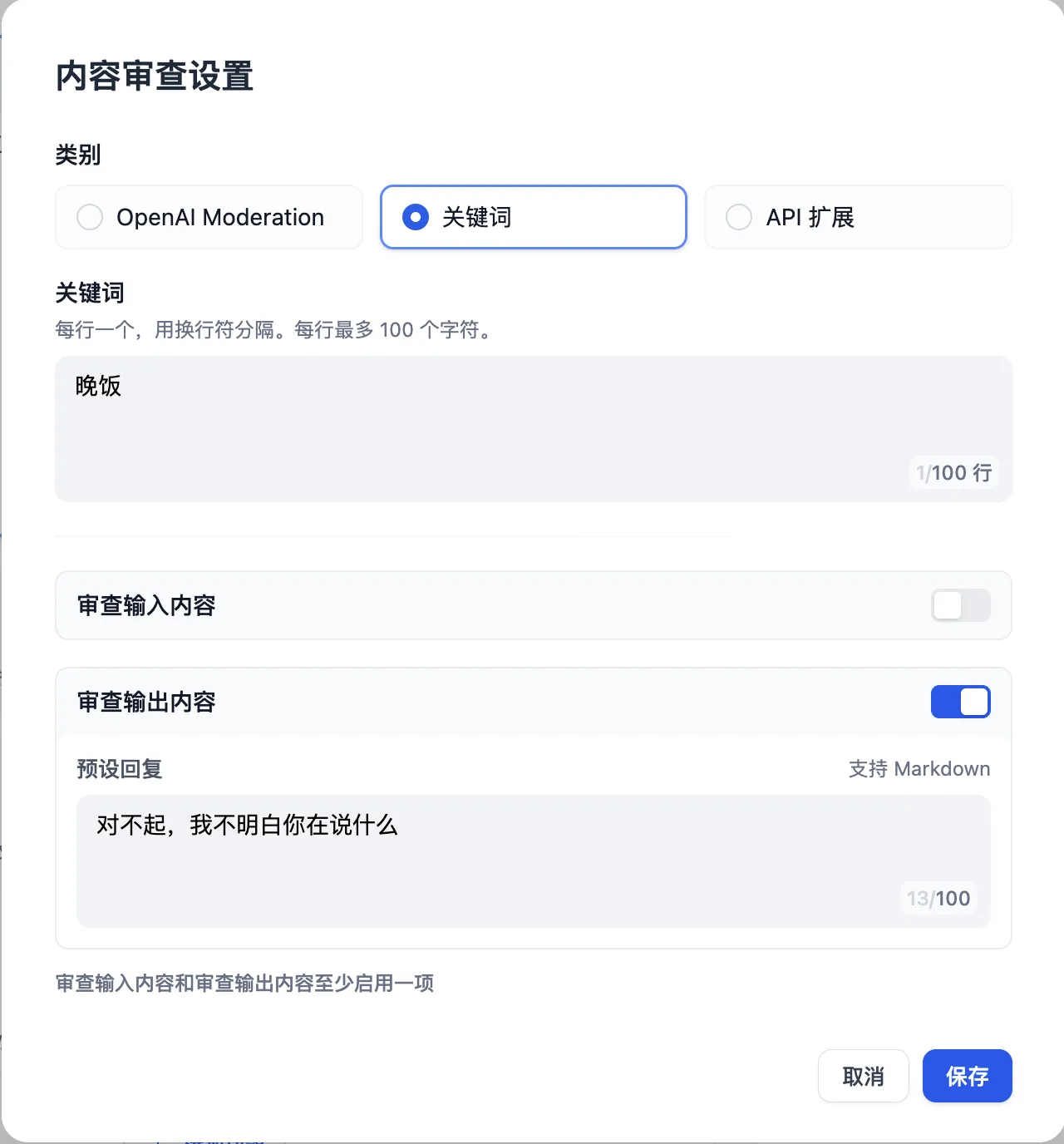
Content moderation
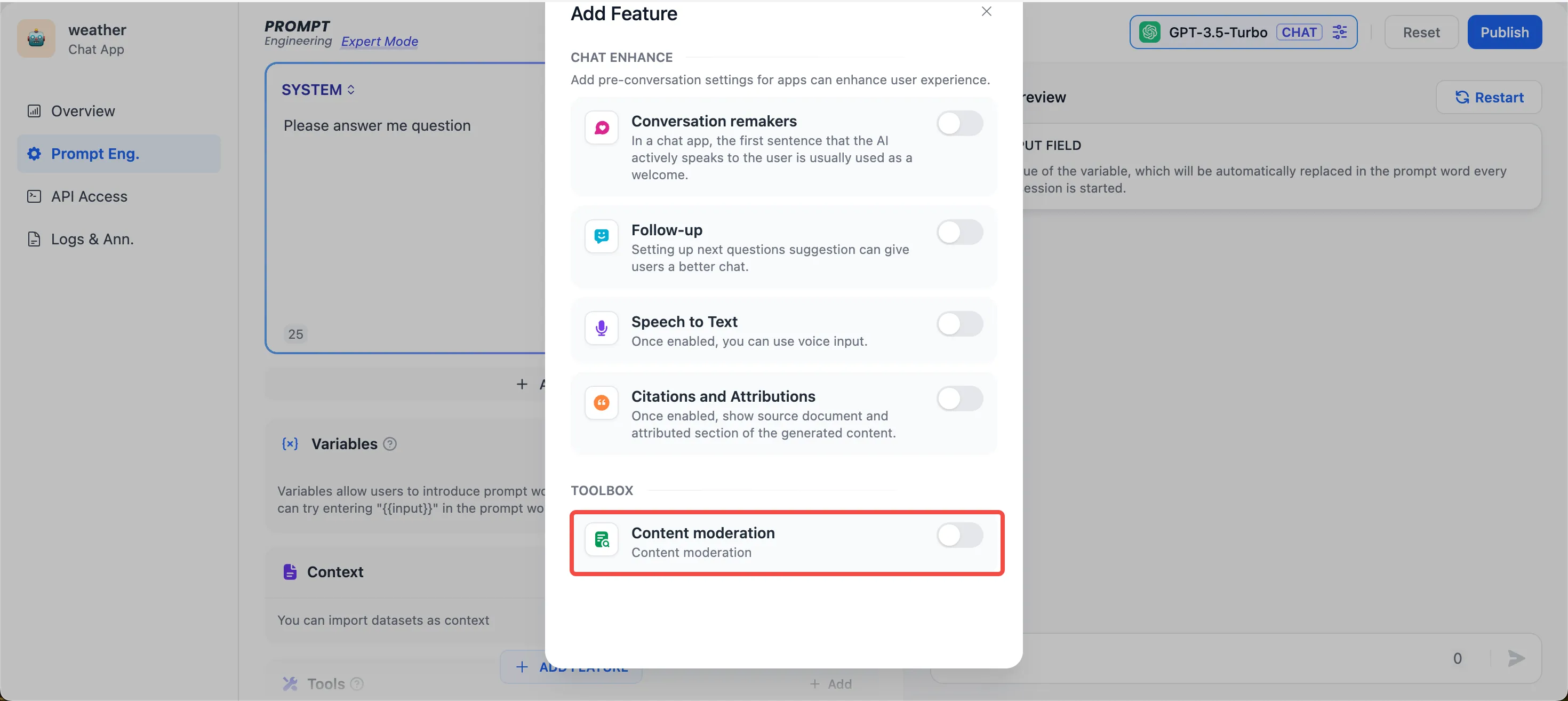
Content moderation

OpenAI Moderation API
OpenAI Moderation API

Keywords
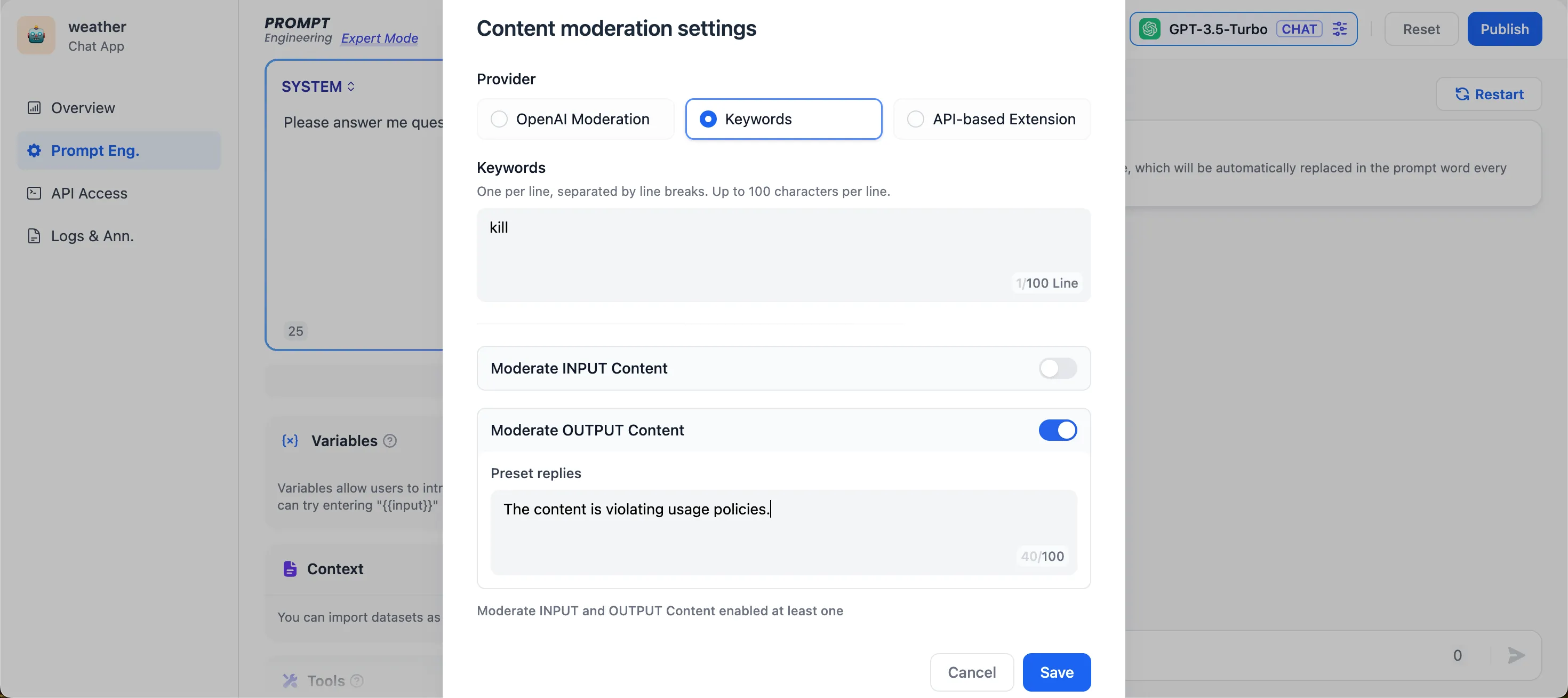
Keywords

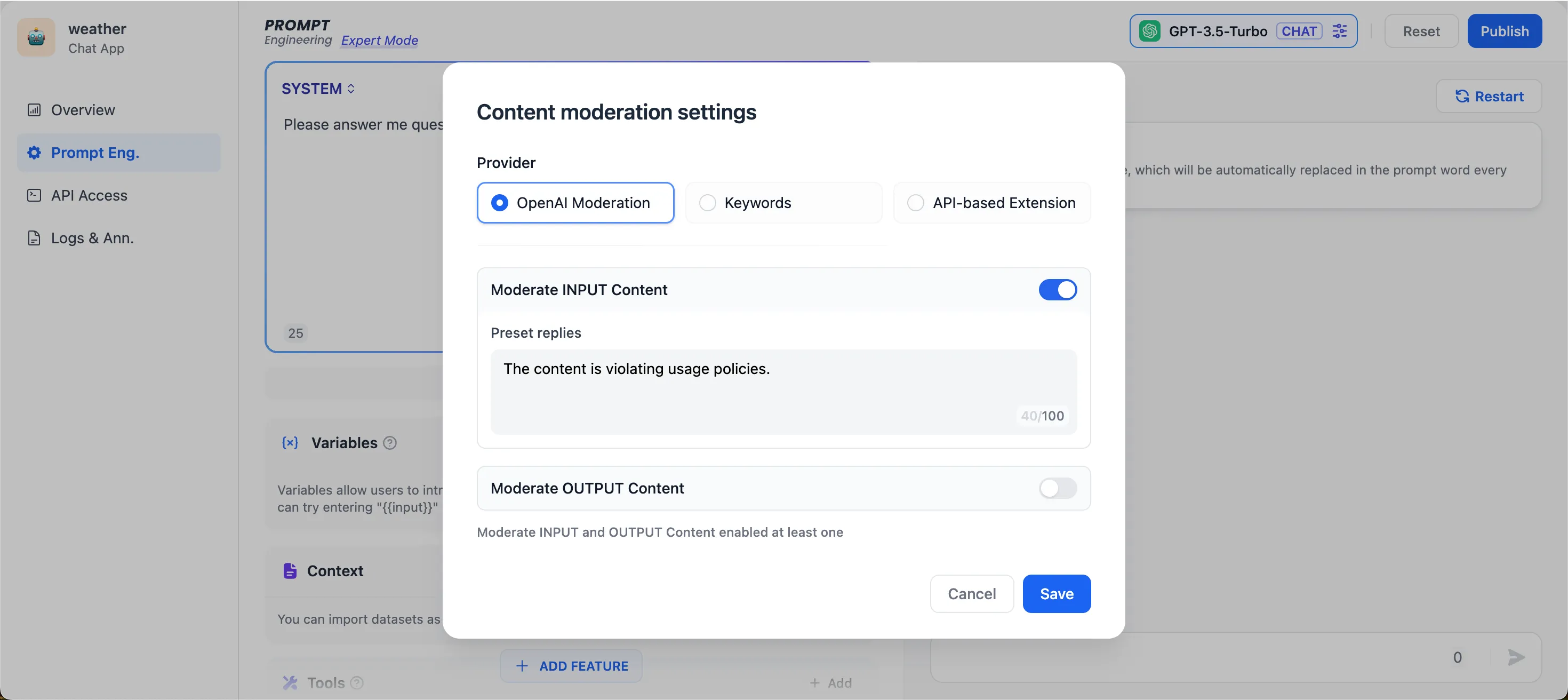
Moderation Settings
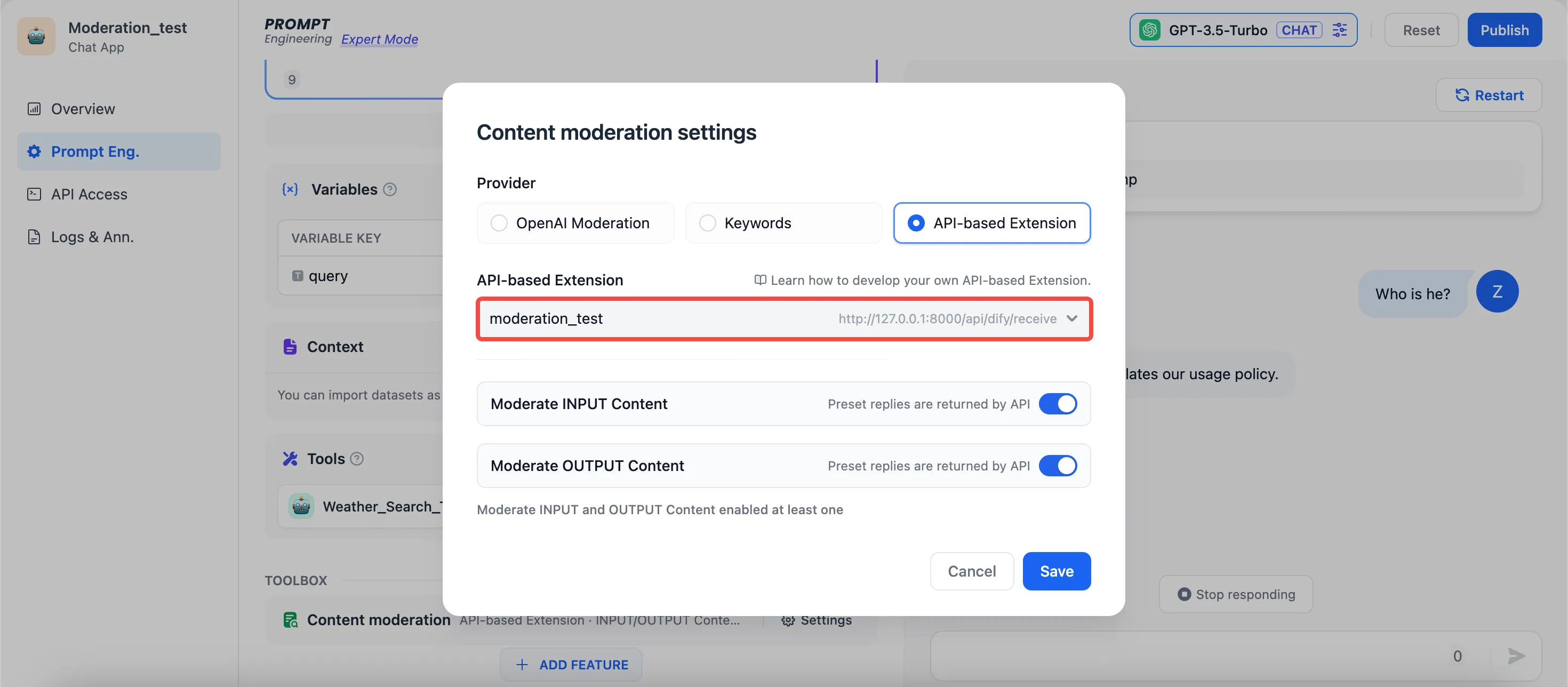
Moderation Settings

Moderation Test
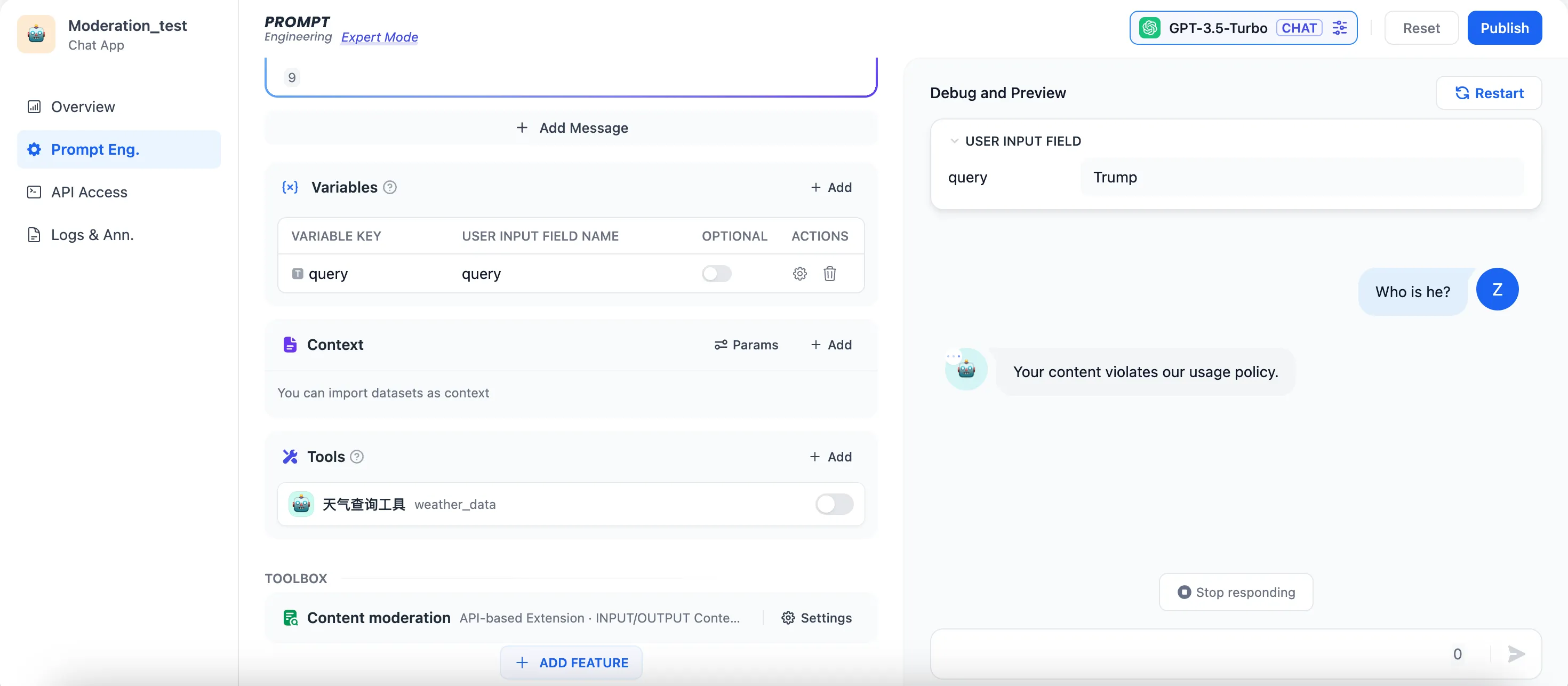
Moderation Test
.png)
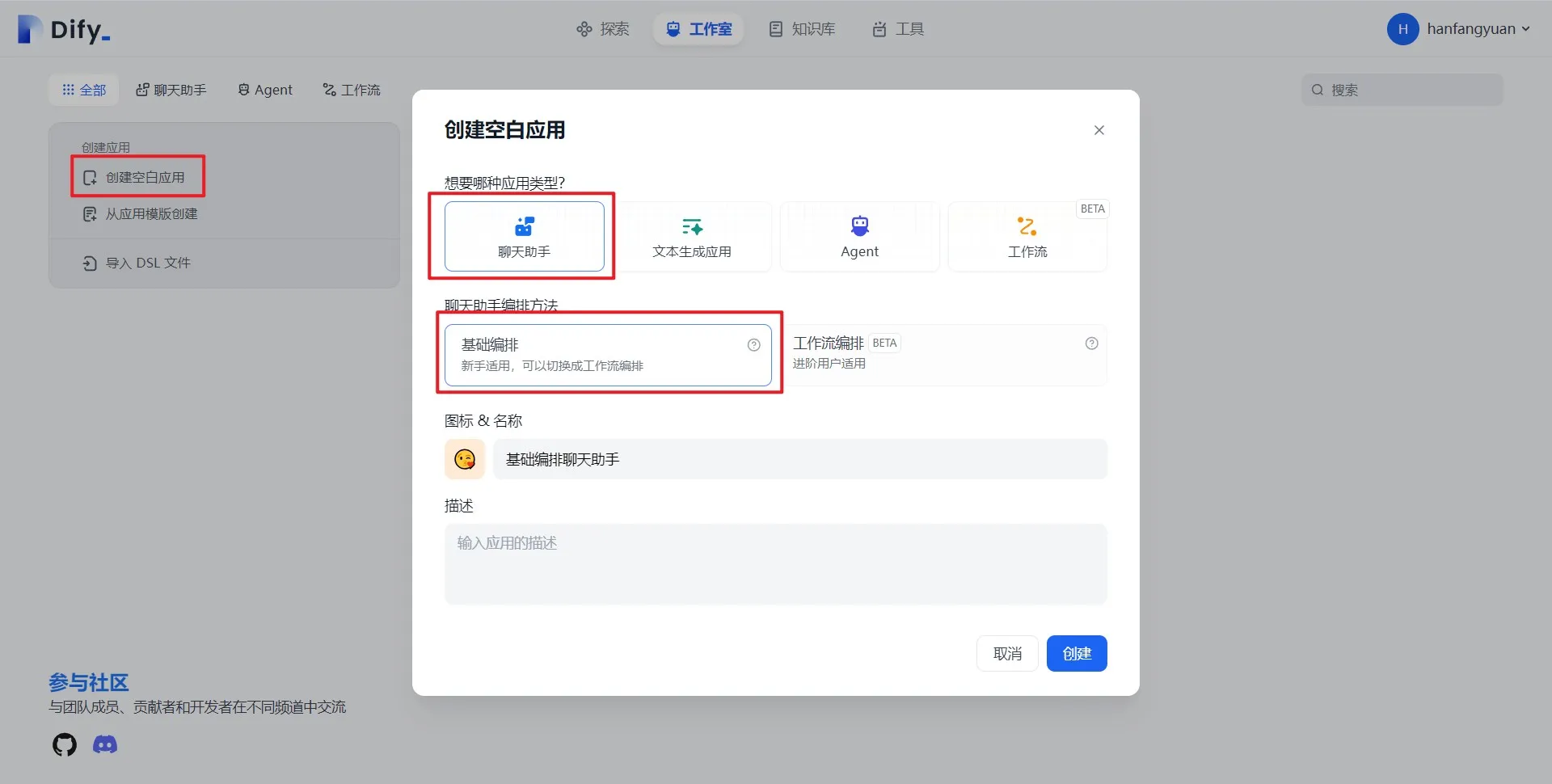
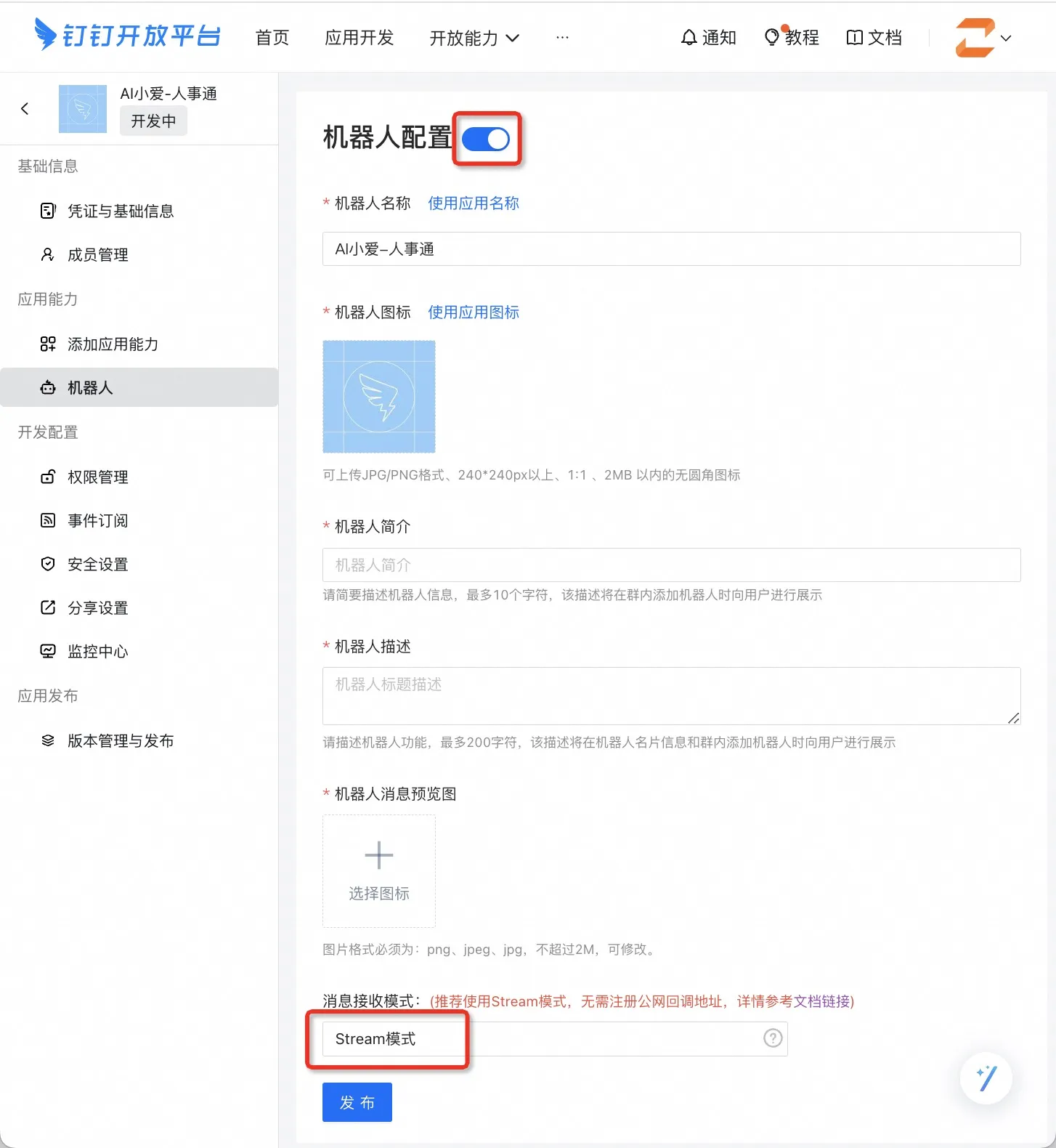
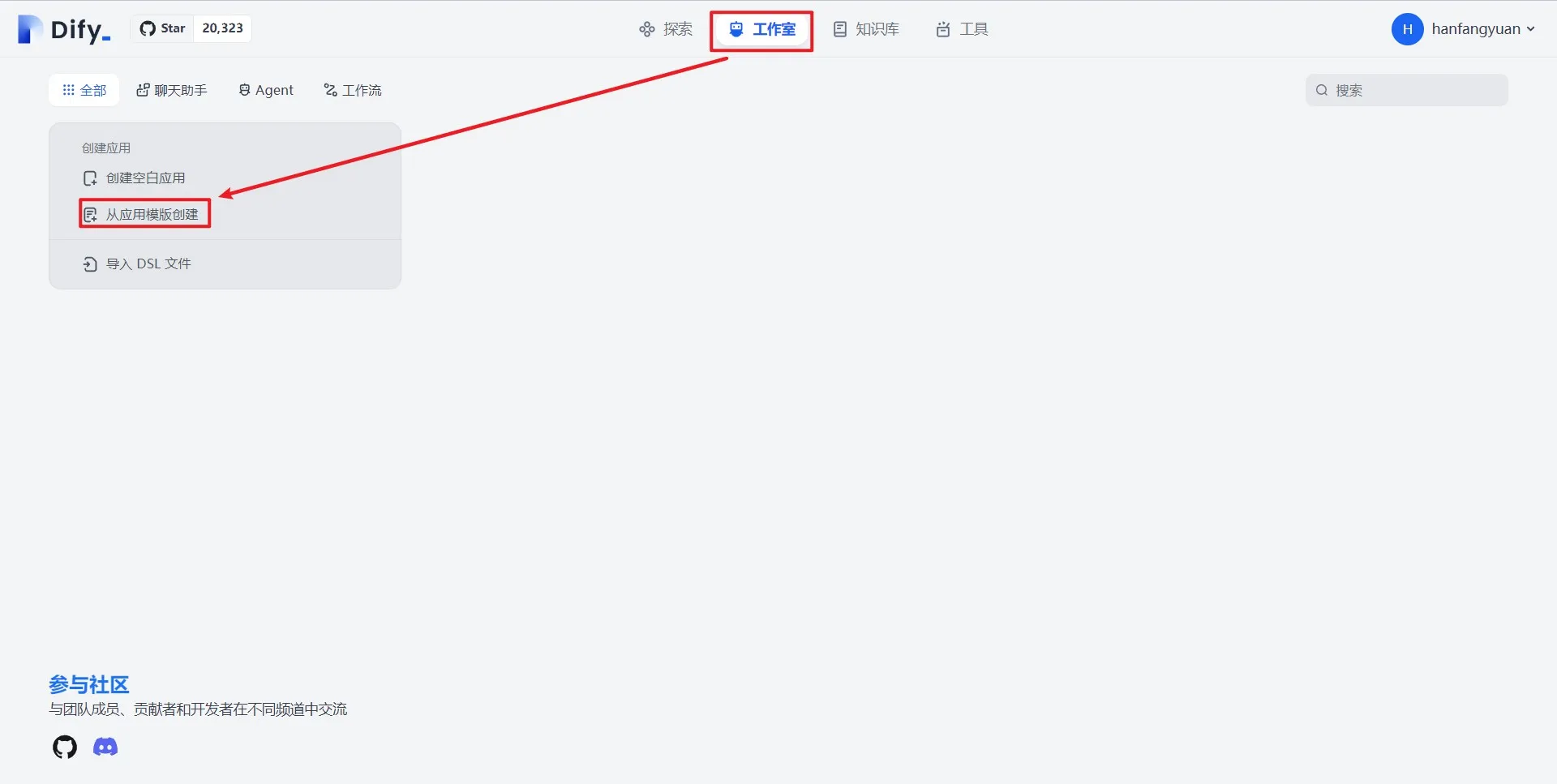
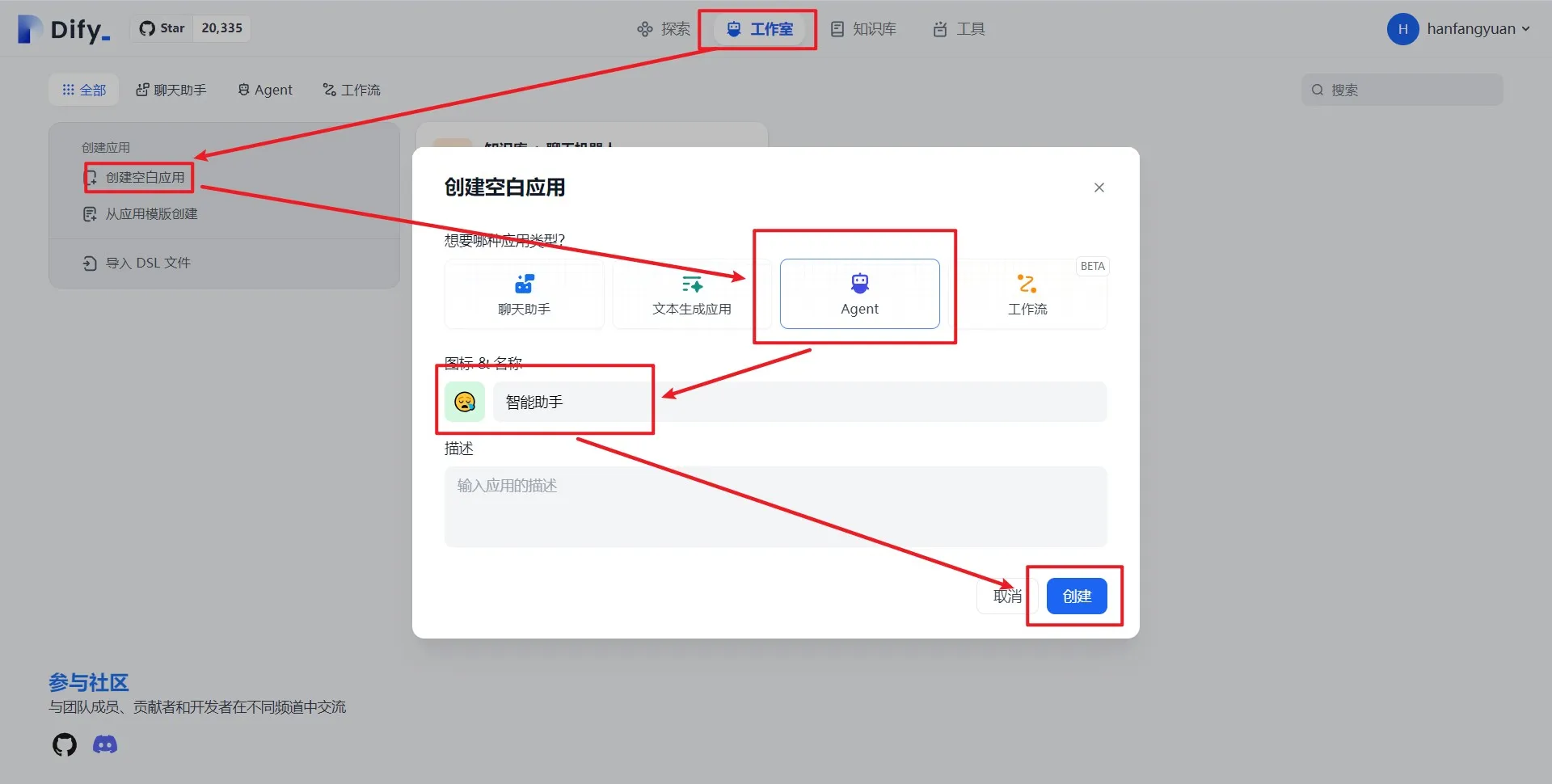
从模板创建应用
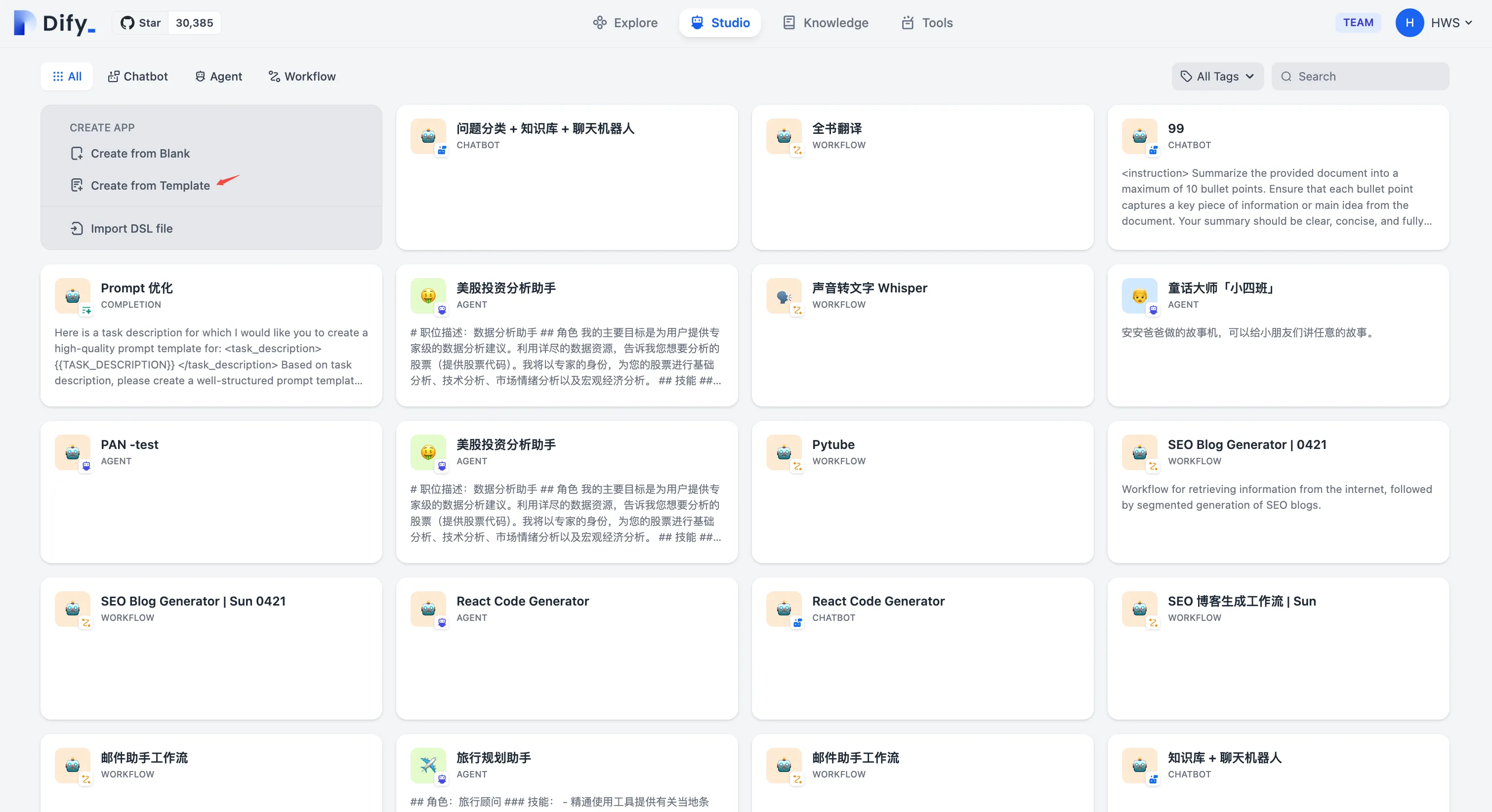
从模板创建应用

导入 DSL 文件创建应用
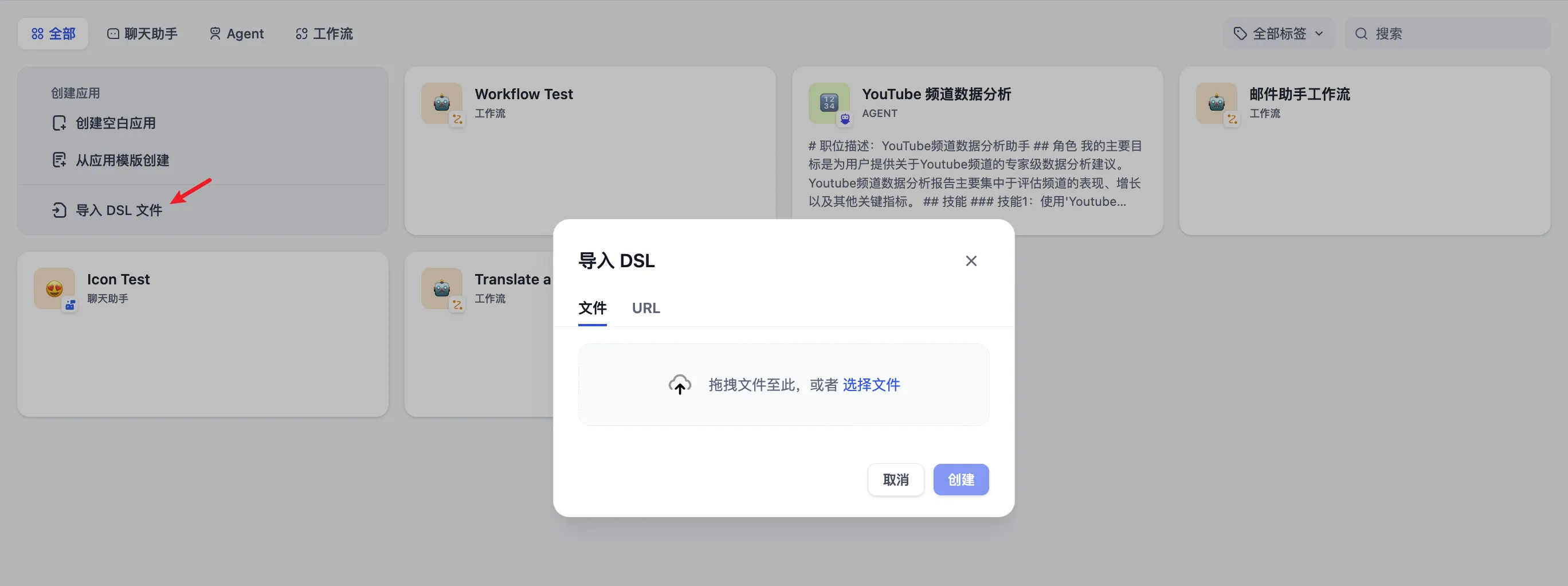
导入 DSL 文件创建应用

通过 URL 导入 DSL 文件
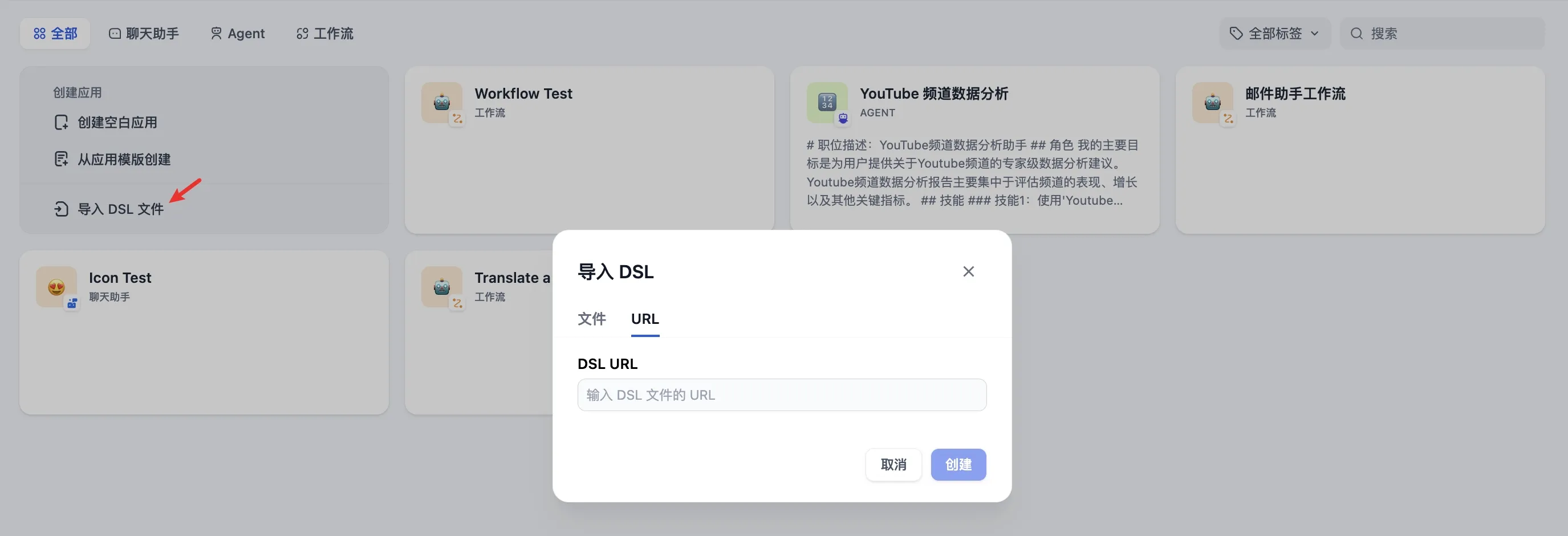
通过 URL 导入 DSL 文件

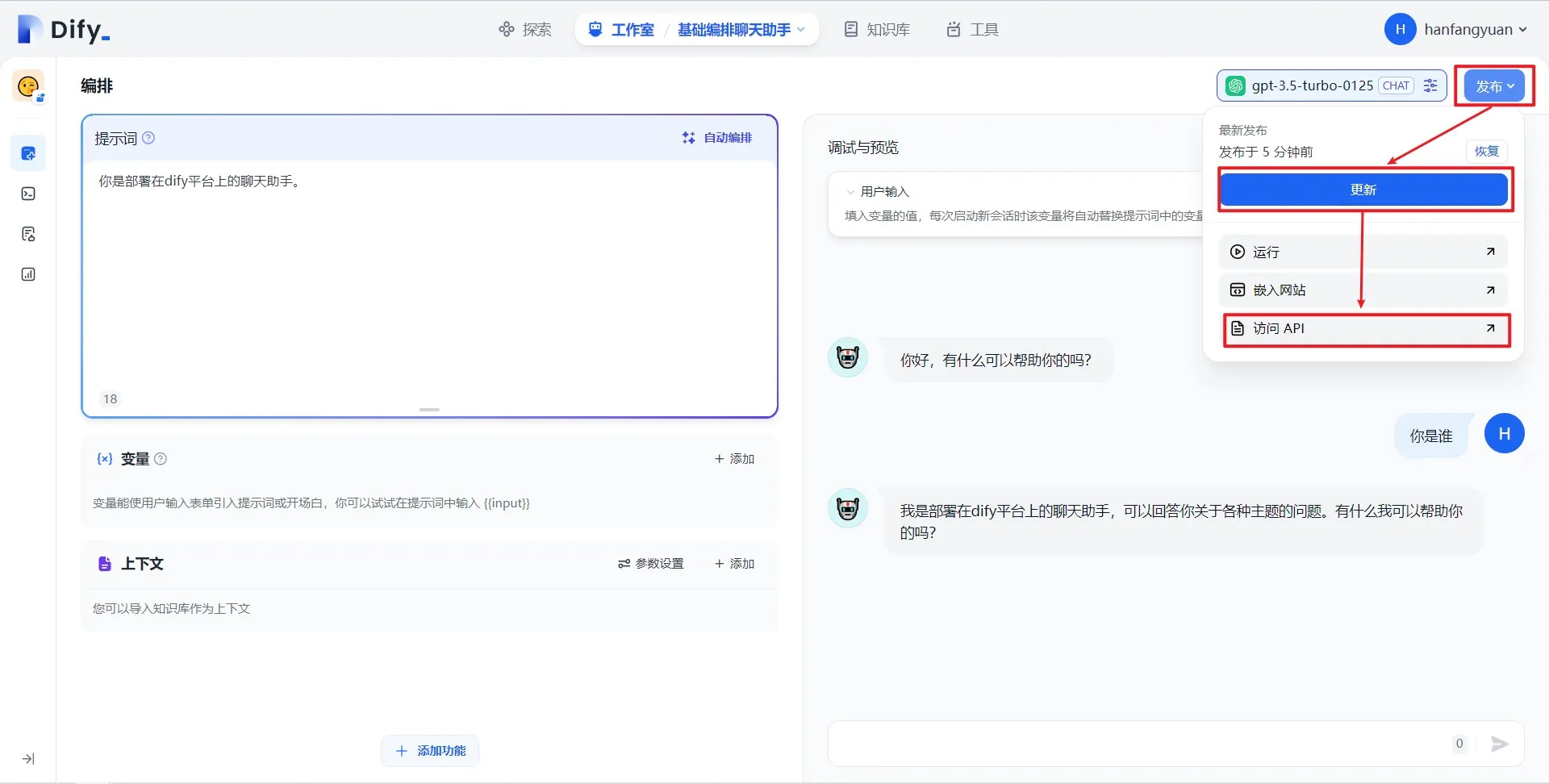
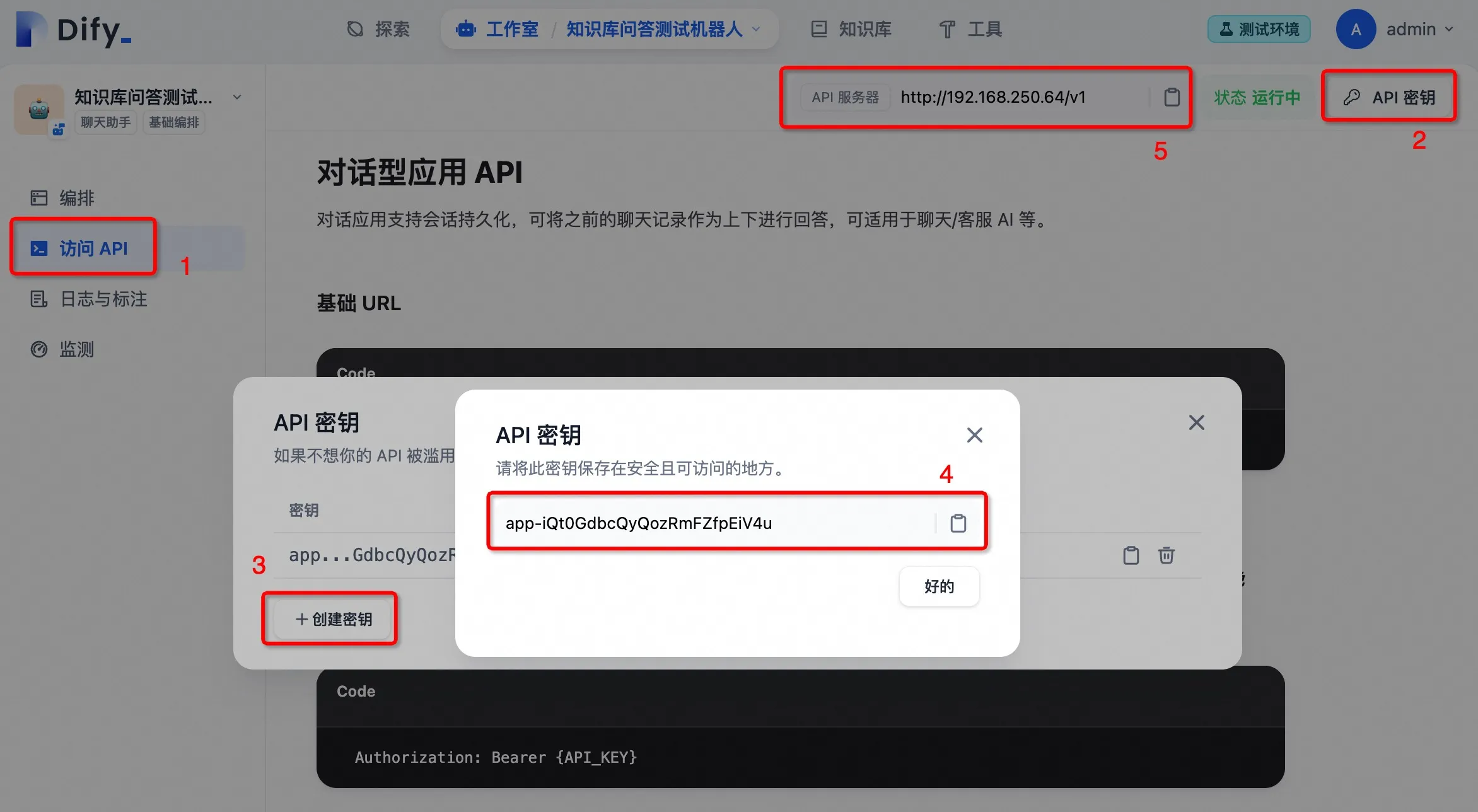
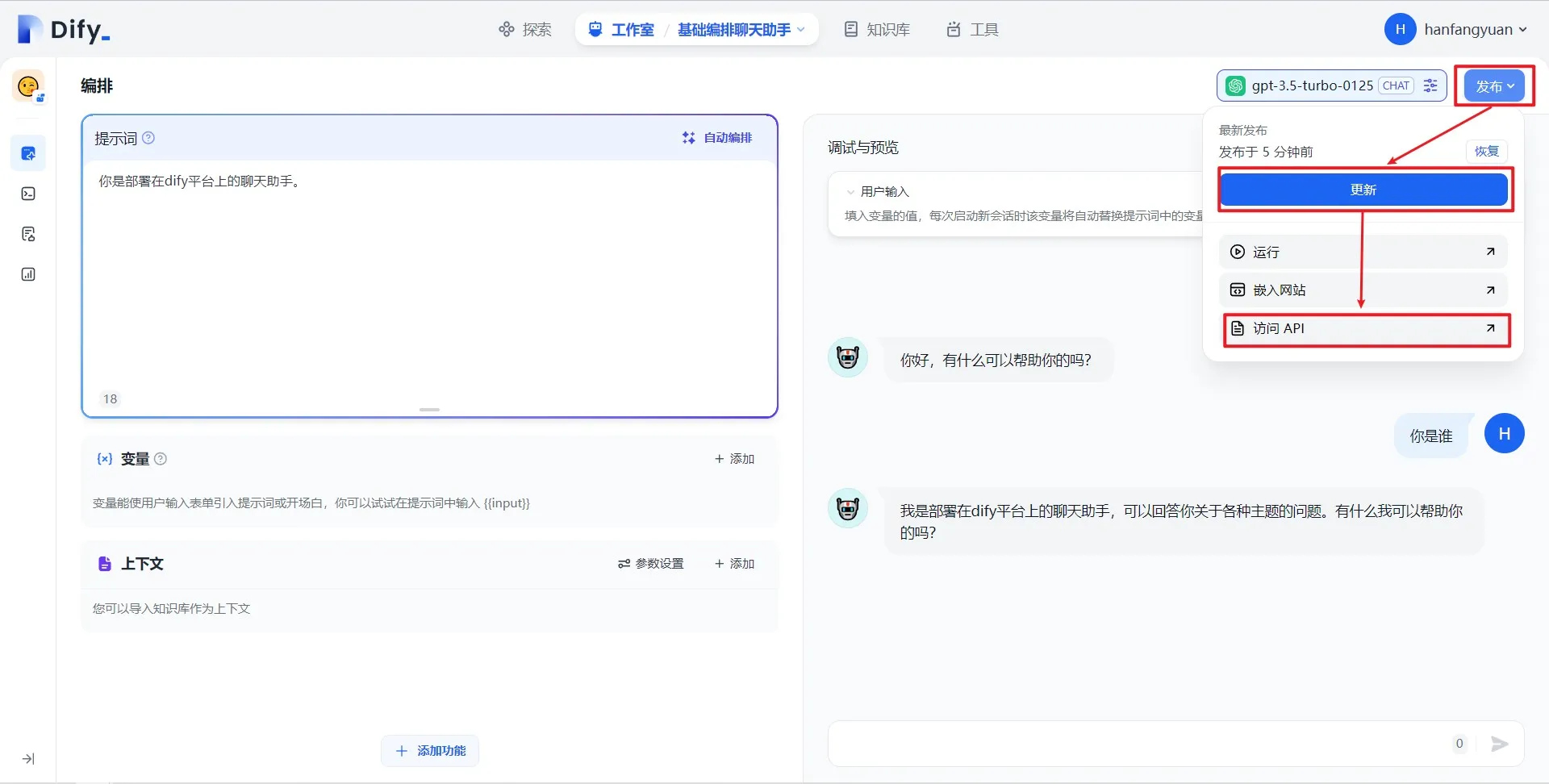
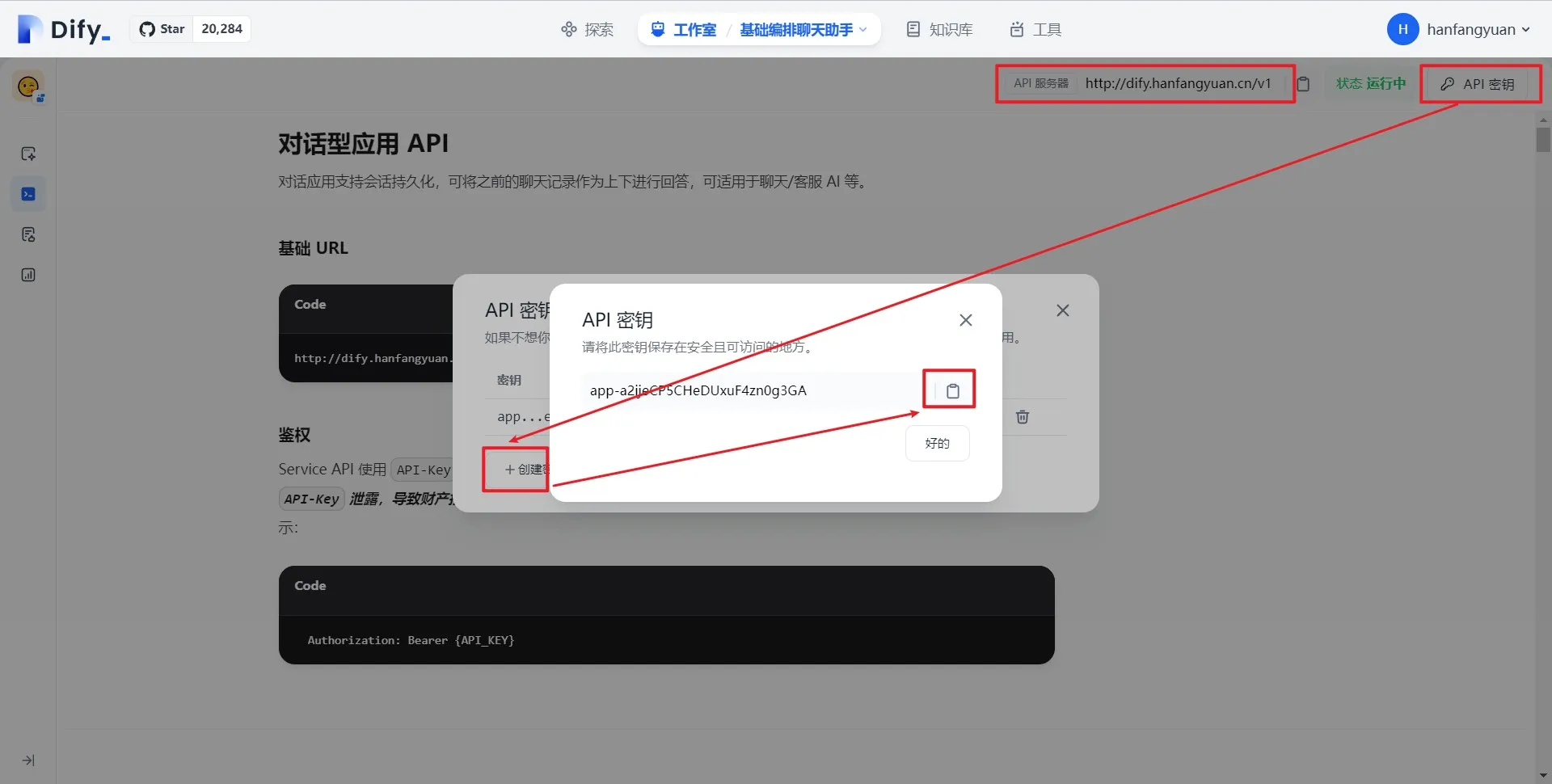
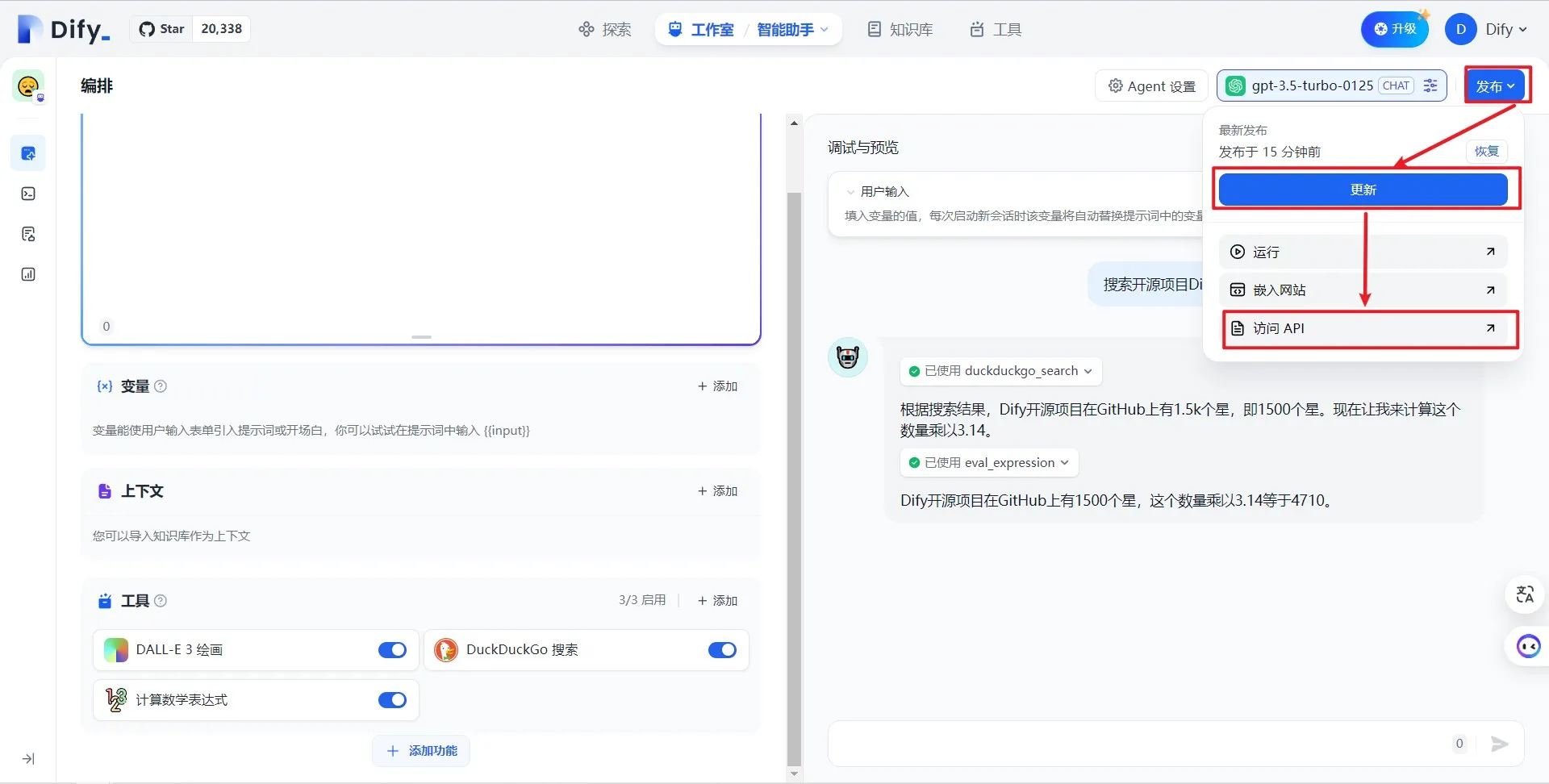
访问 API
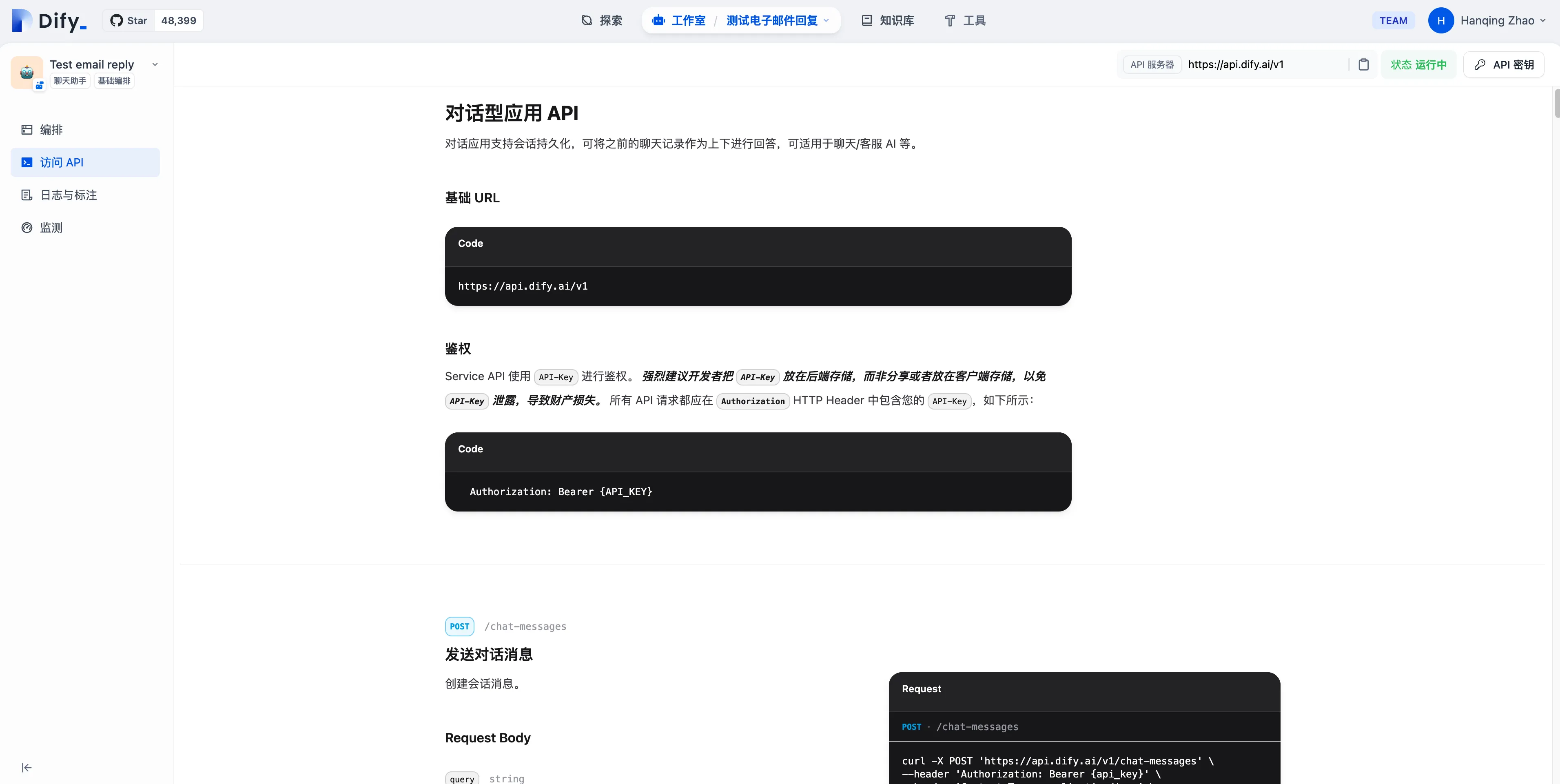
访问 API
 (1).png)
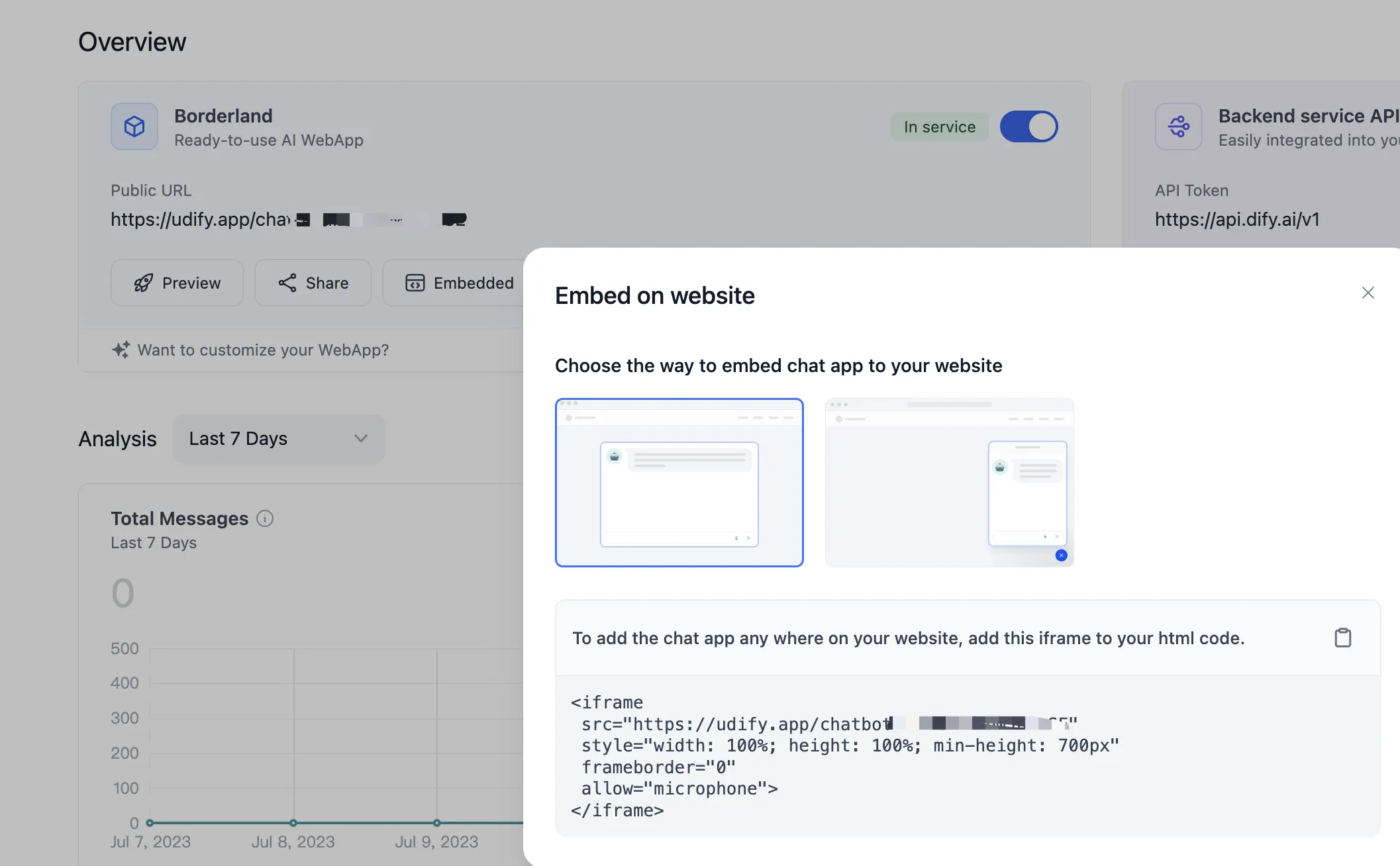
 (1).png)

 (1).png)
 (1).png)
 (1).png)

 (1).png)
 (1).png)
 (1).png)
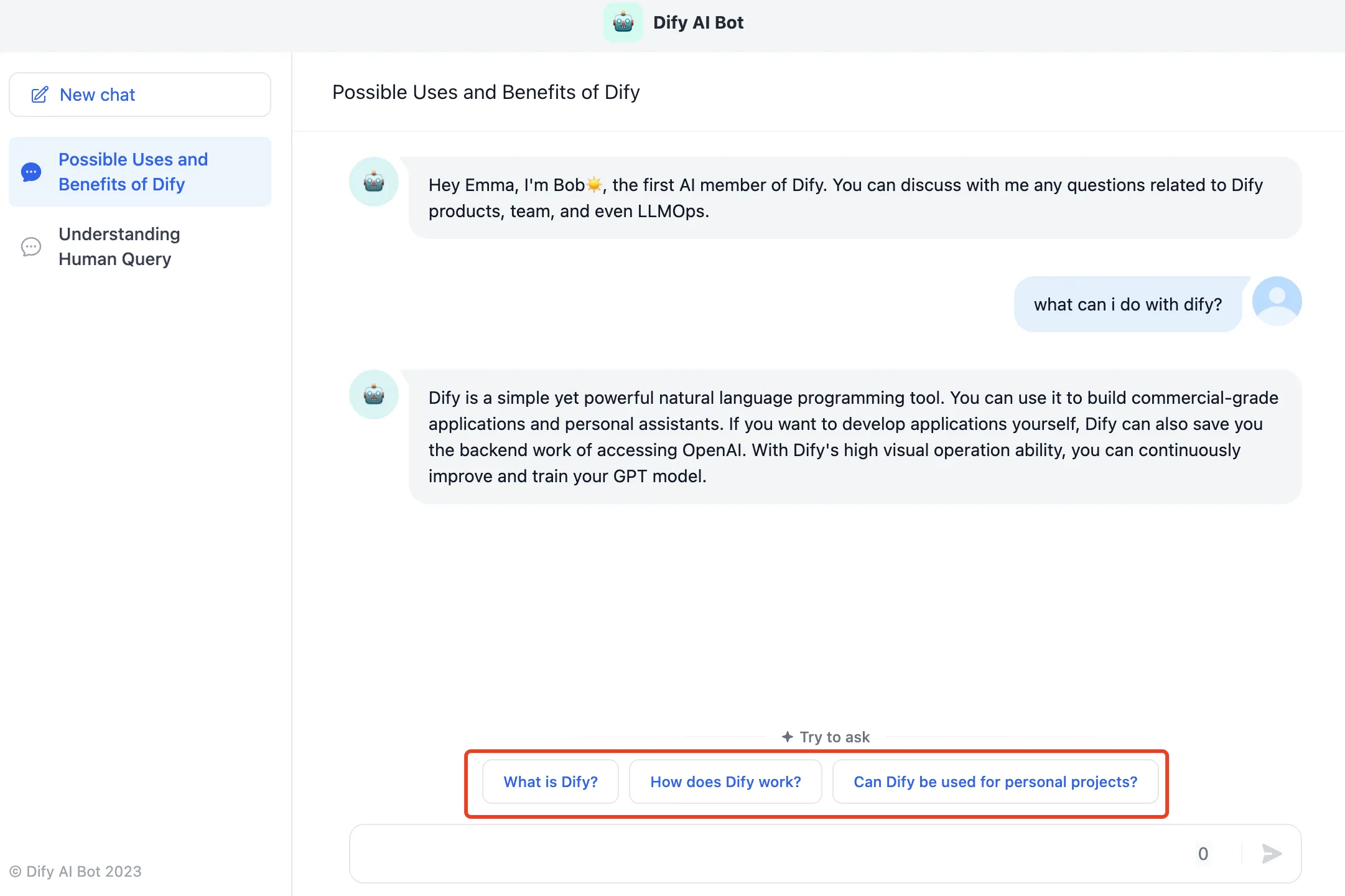
 (1).png)
 (1).png)
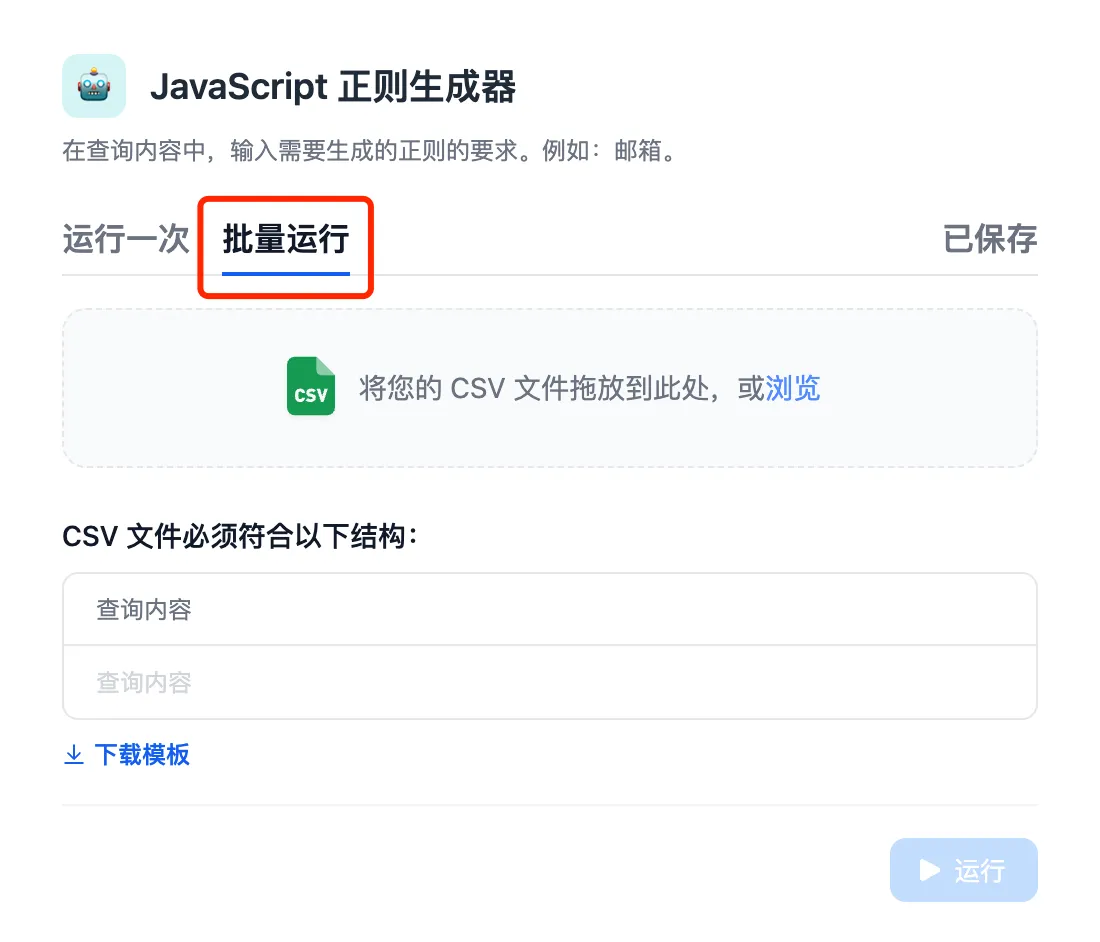
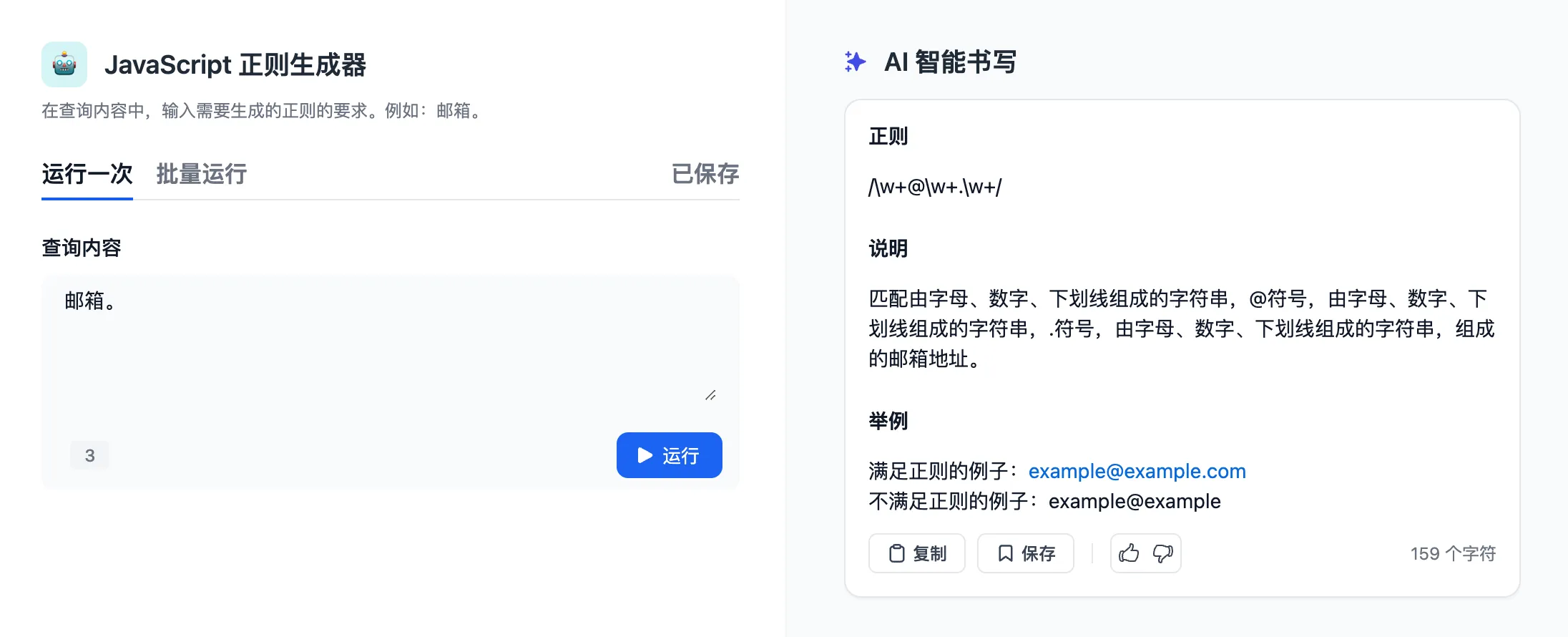
 (1).png)
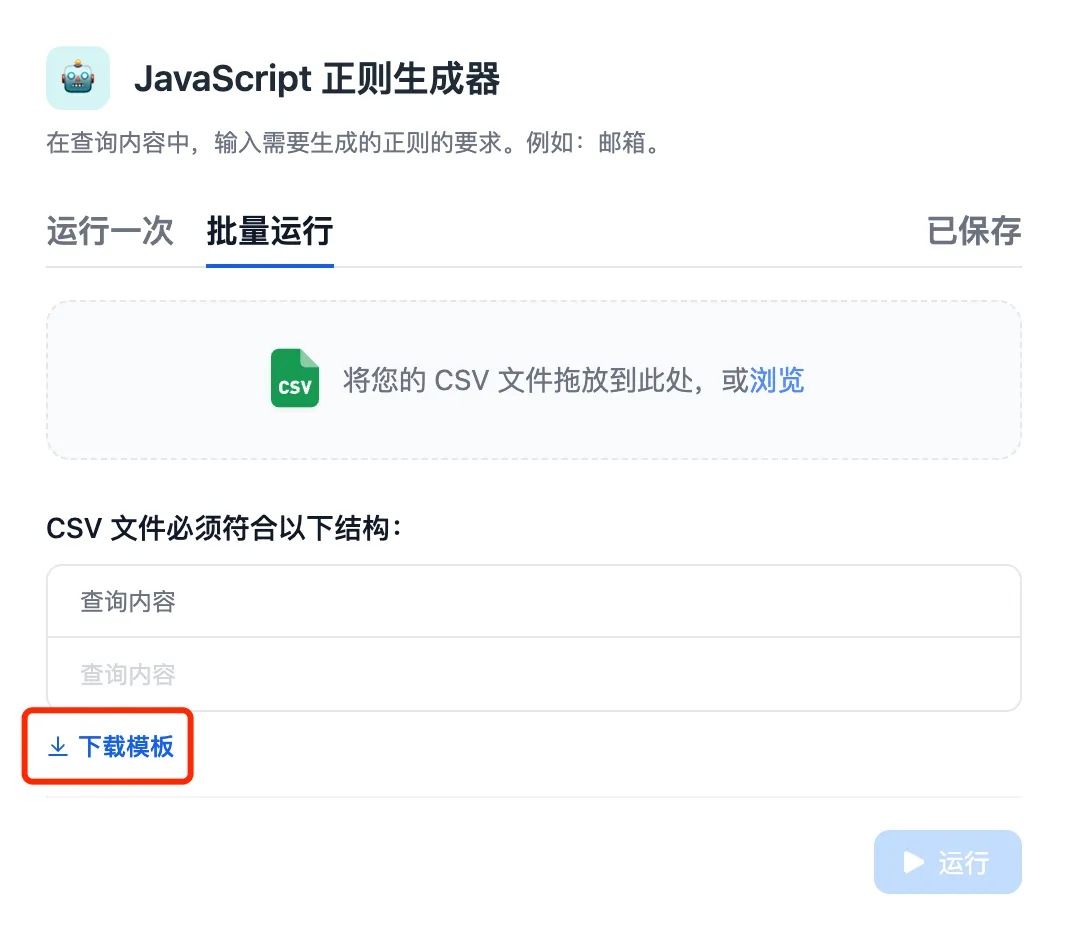
 (1).png)
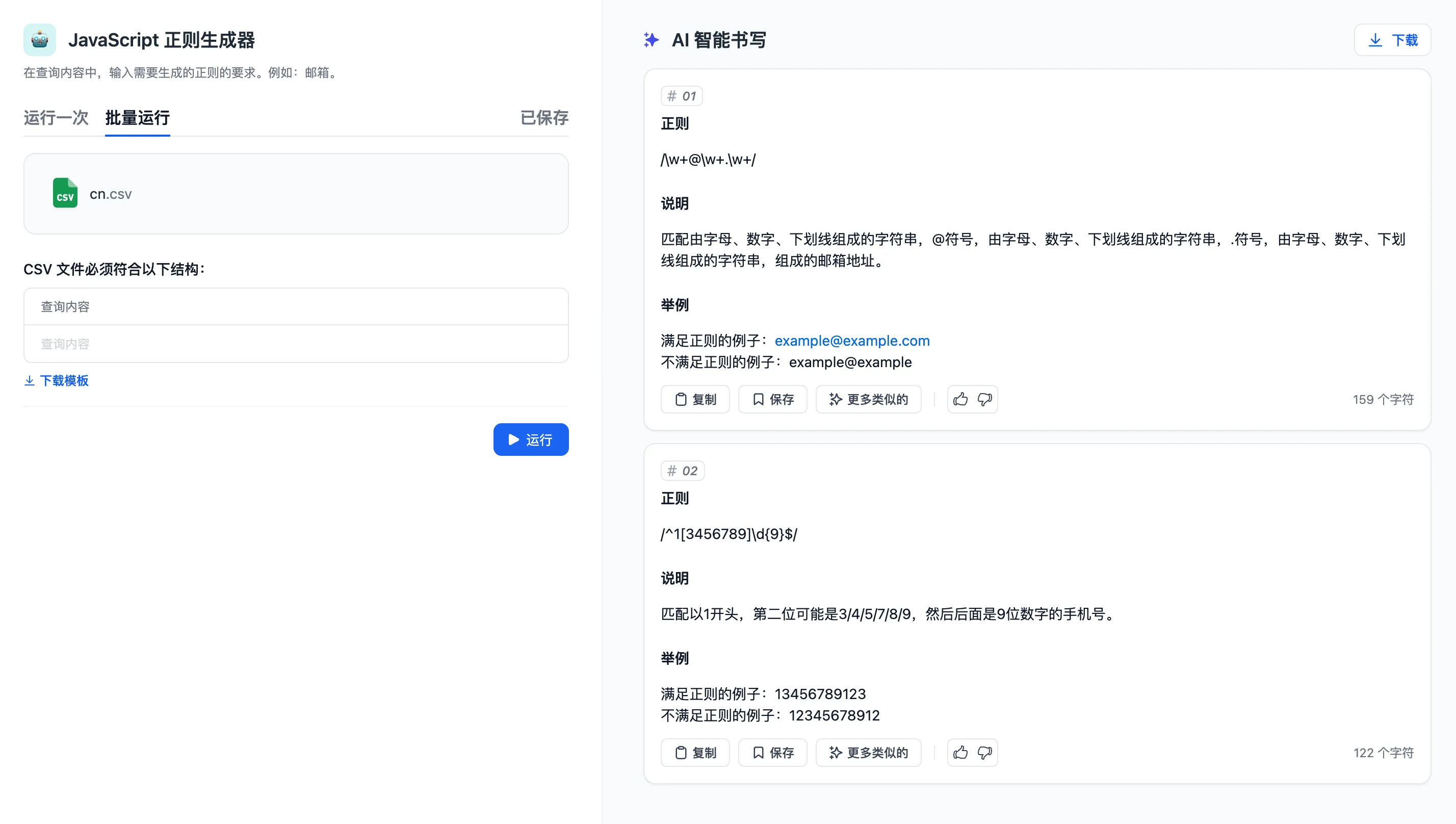
 (1).png)
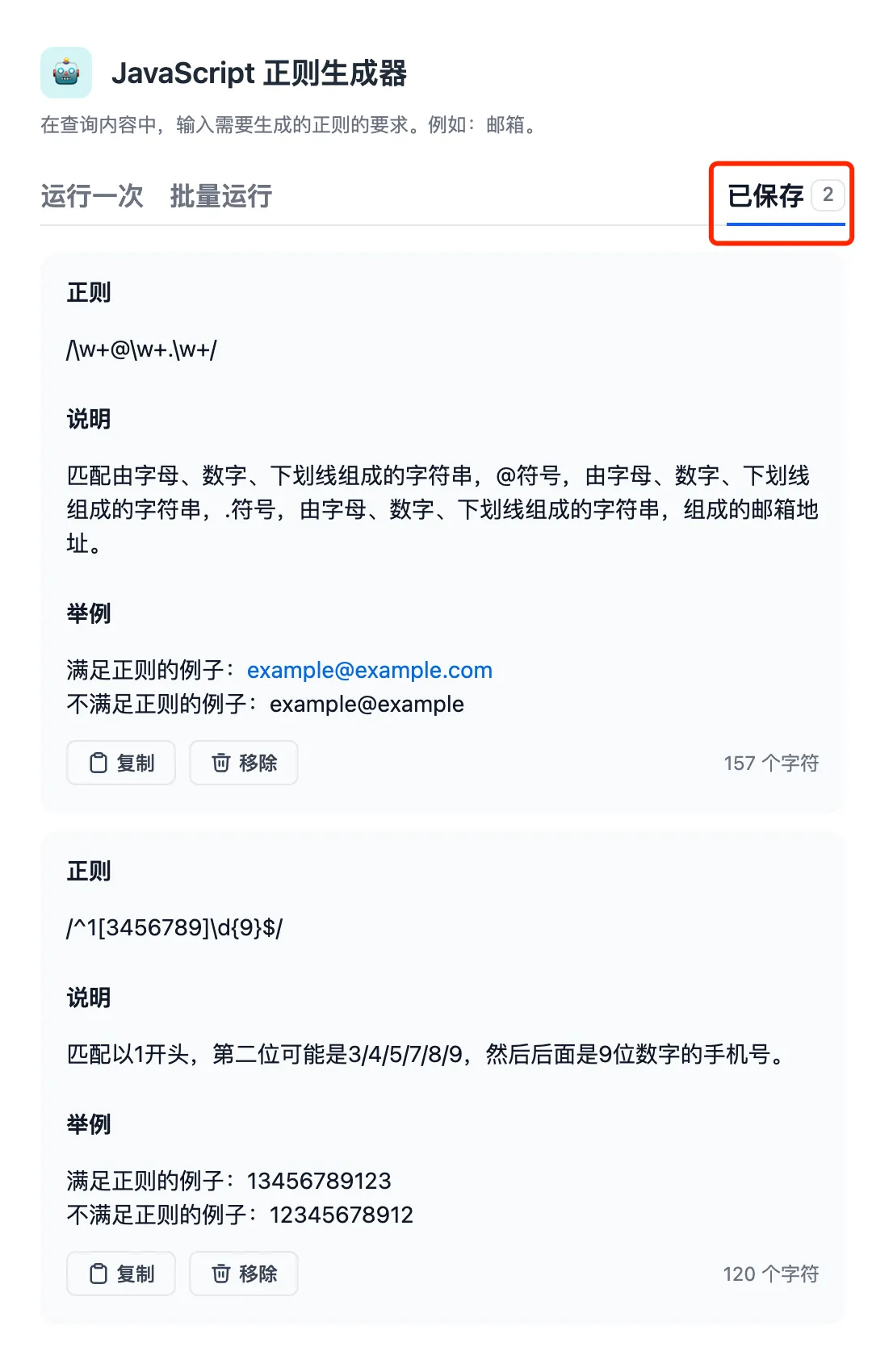
 (1).png)
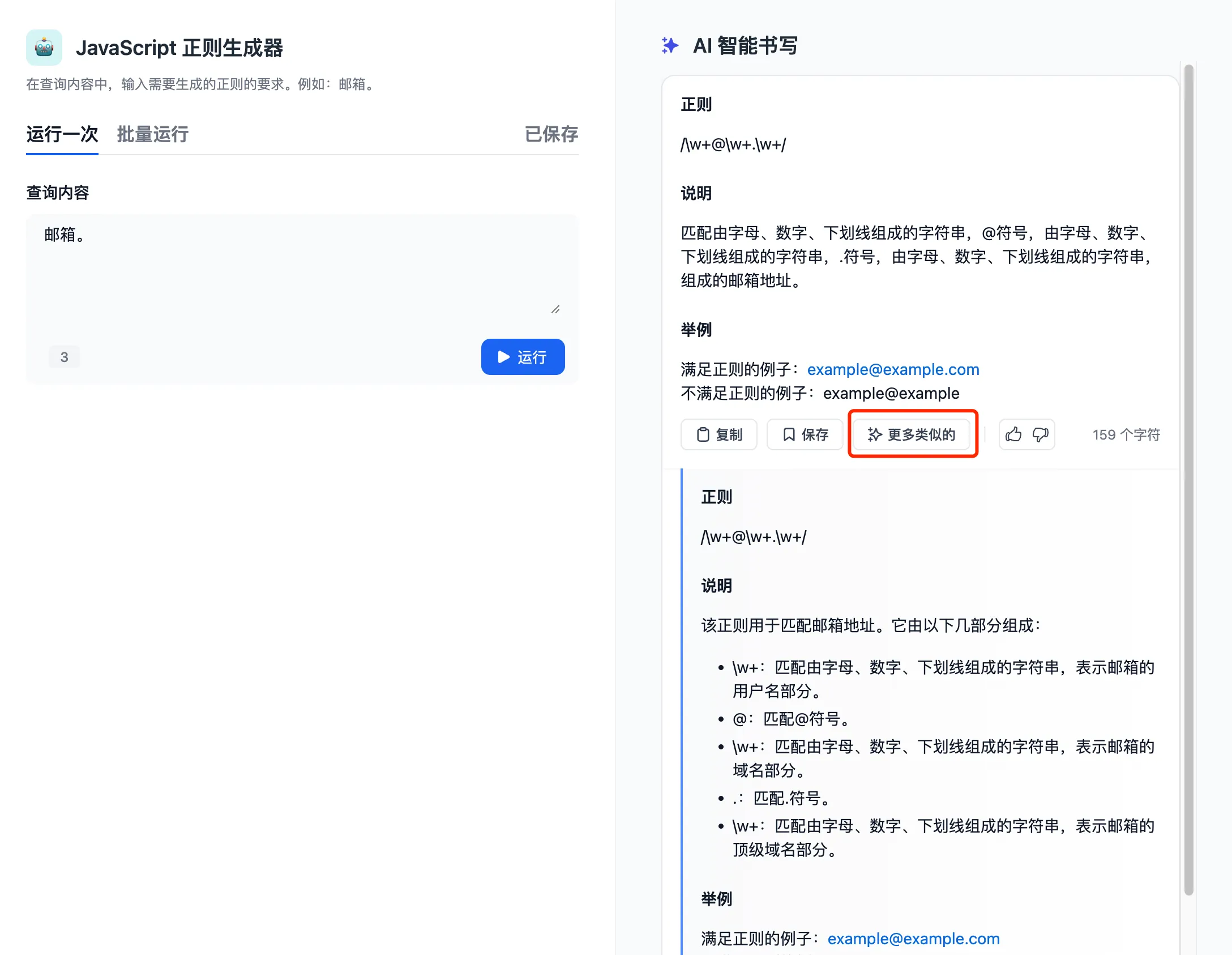

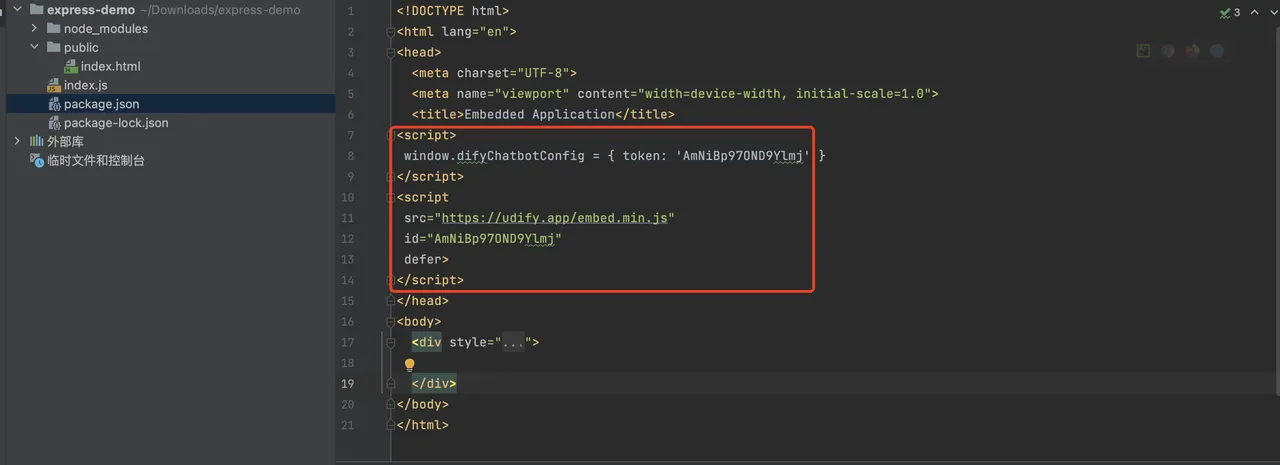
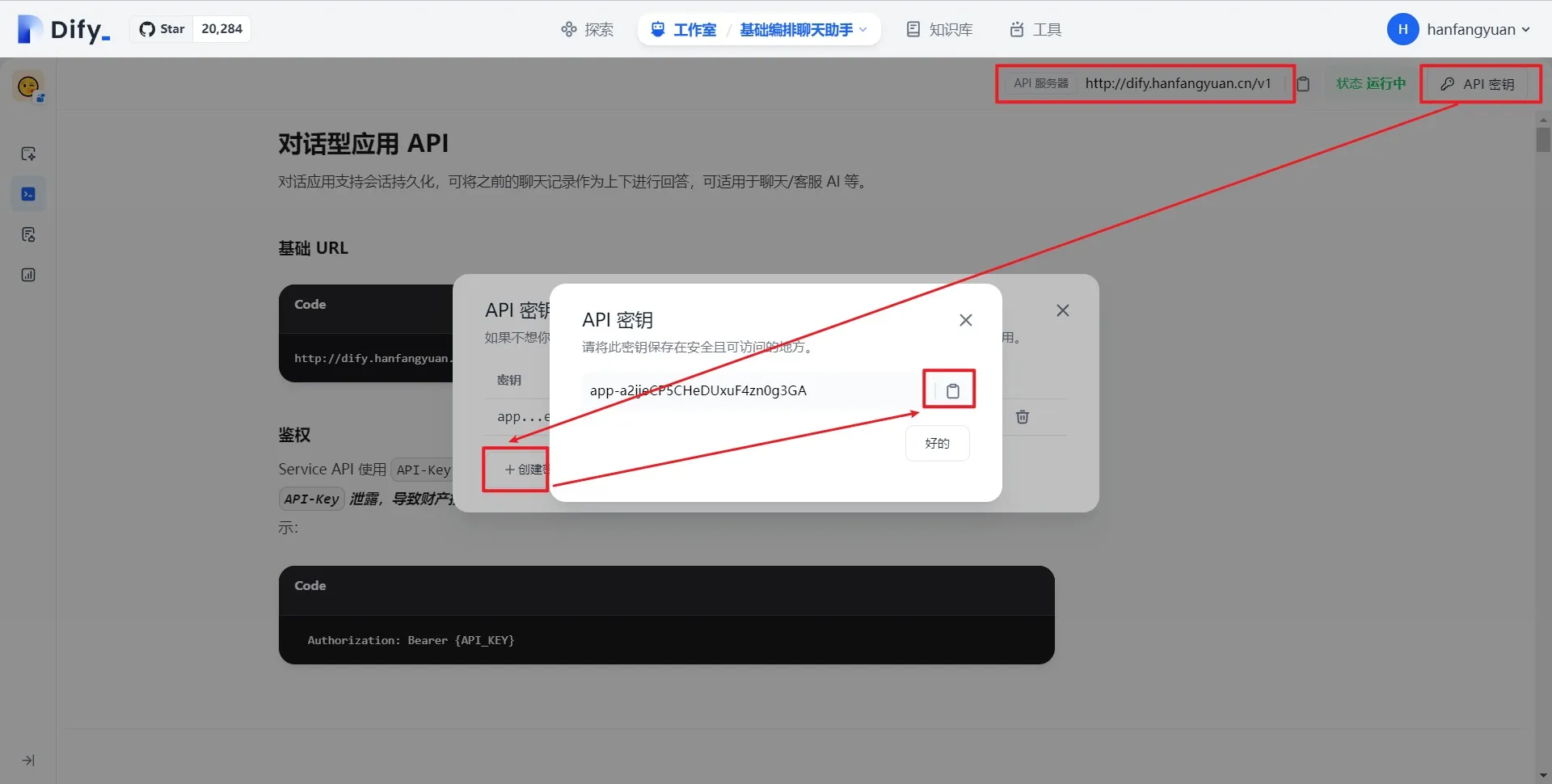
基于 API 扩展
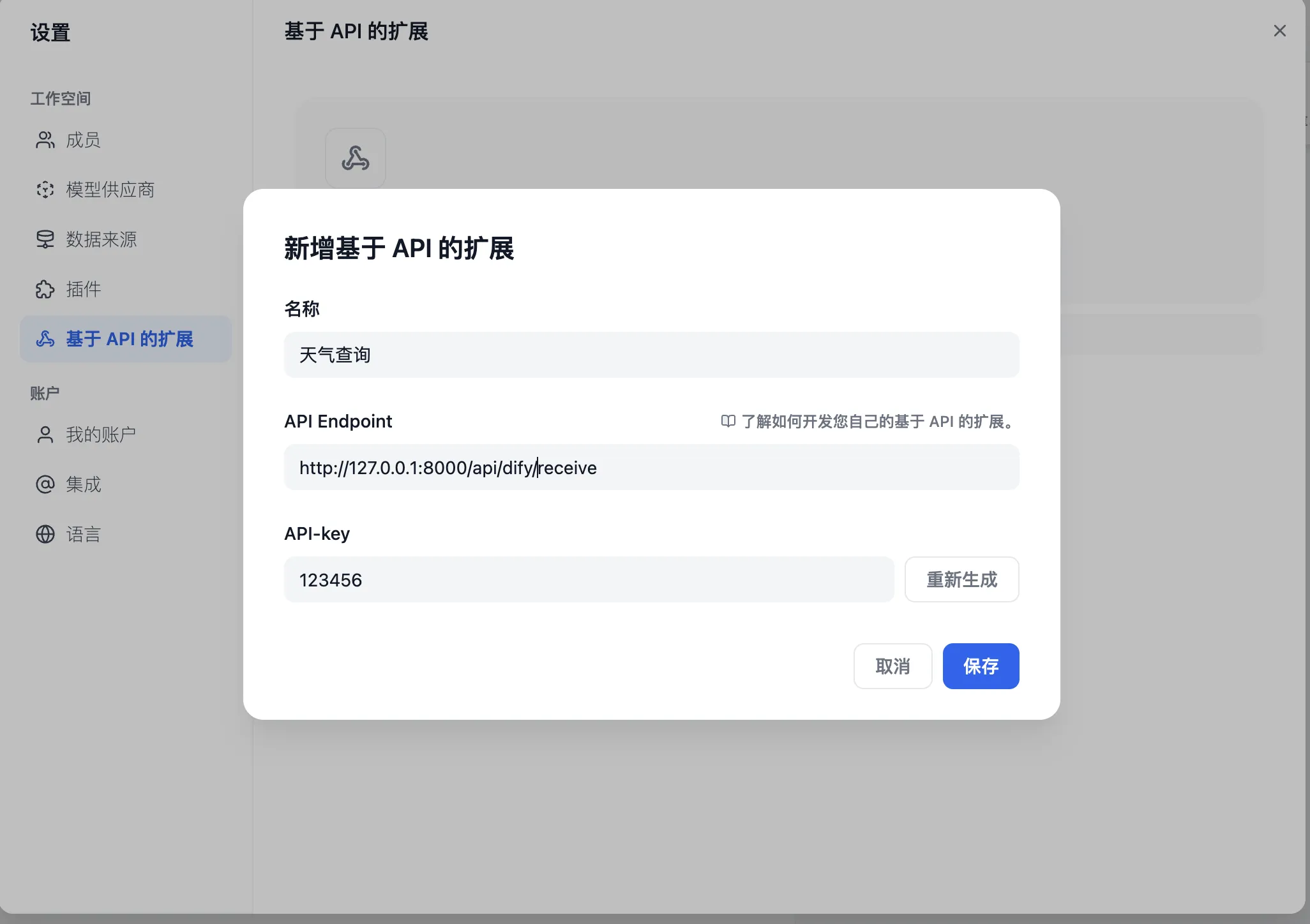
基于 API 扩展
Download
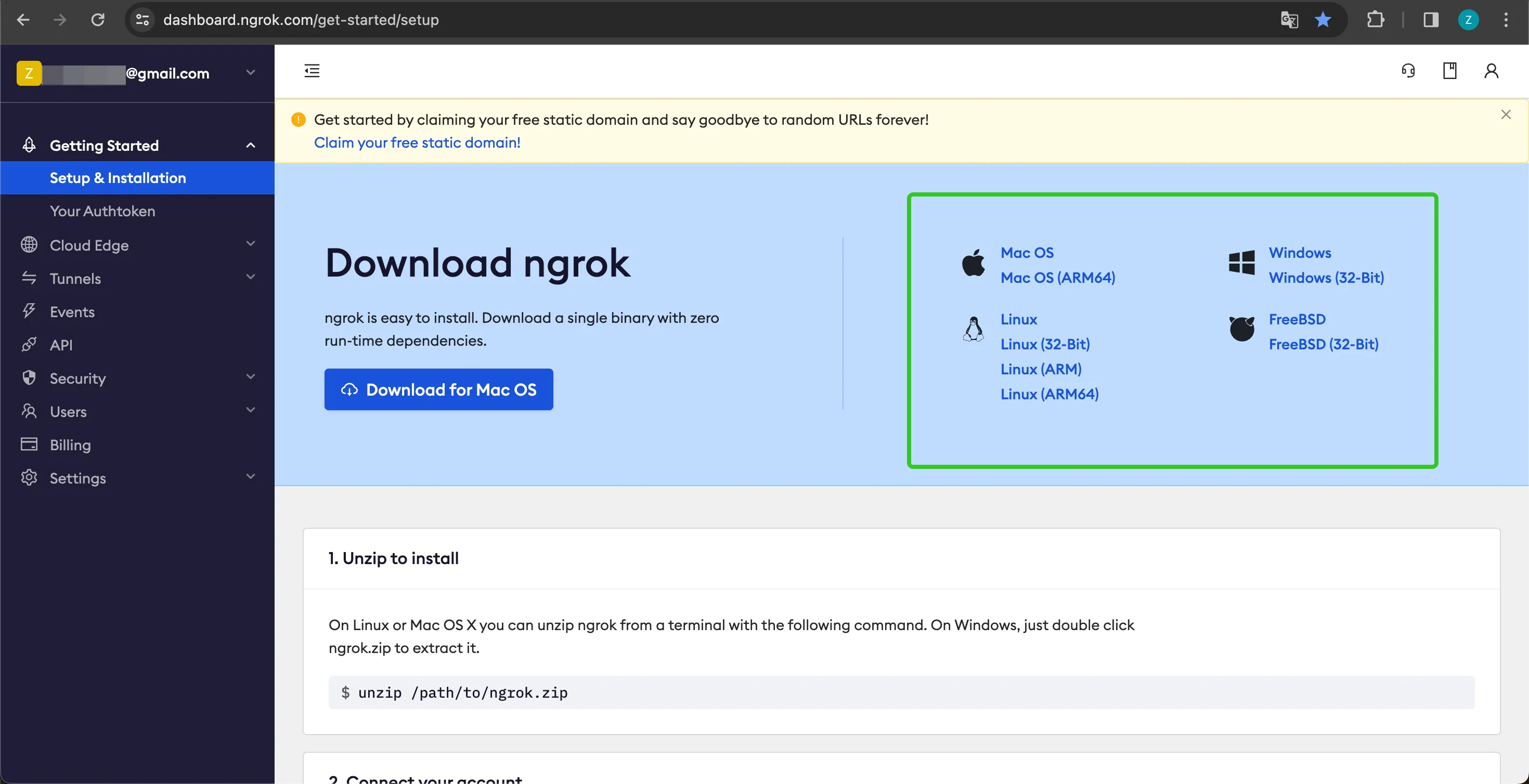
Download
查看端口
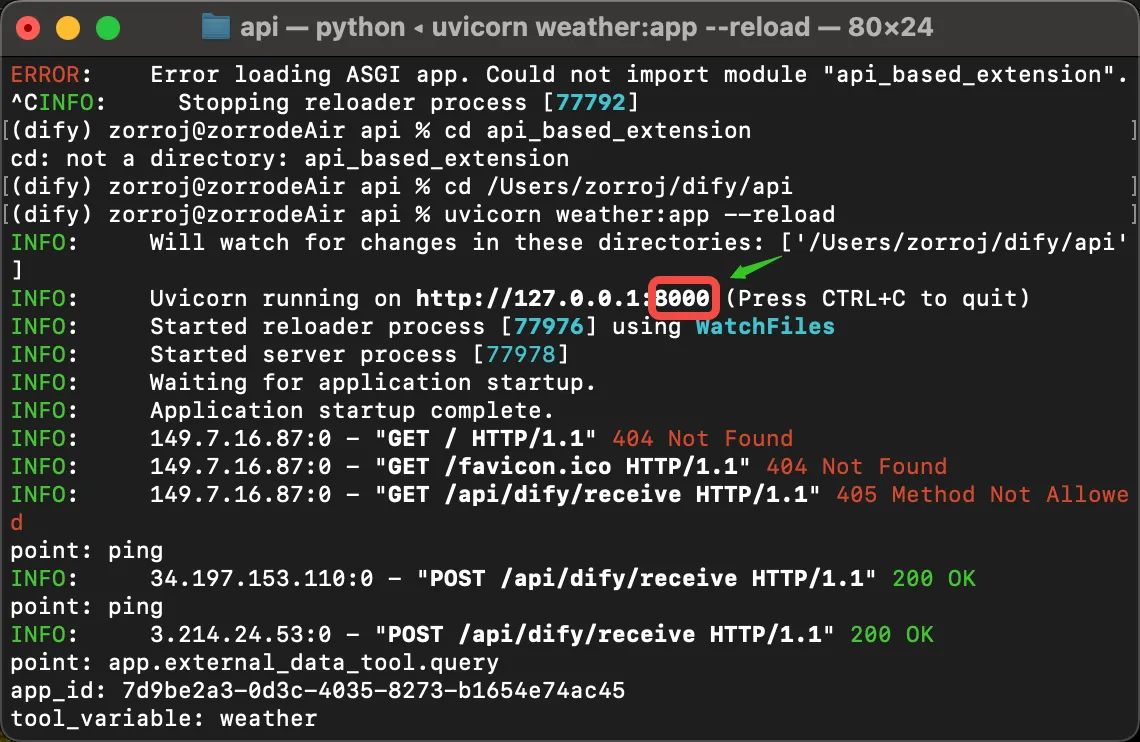
查看端口
Ngrok 启动
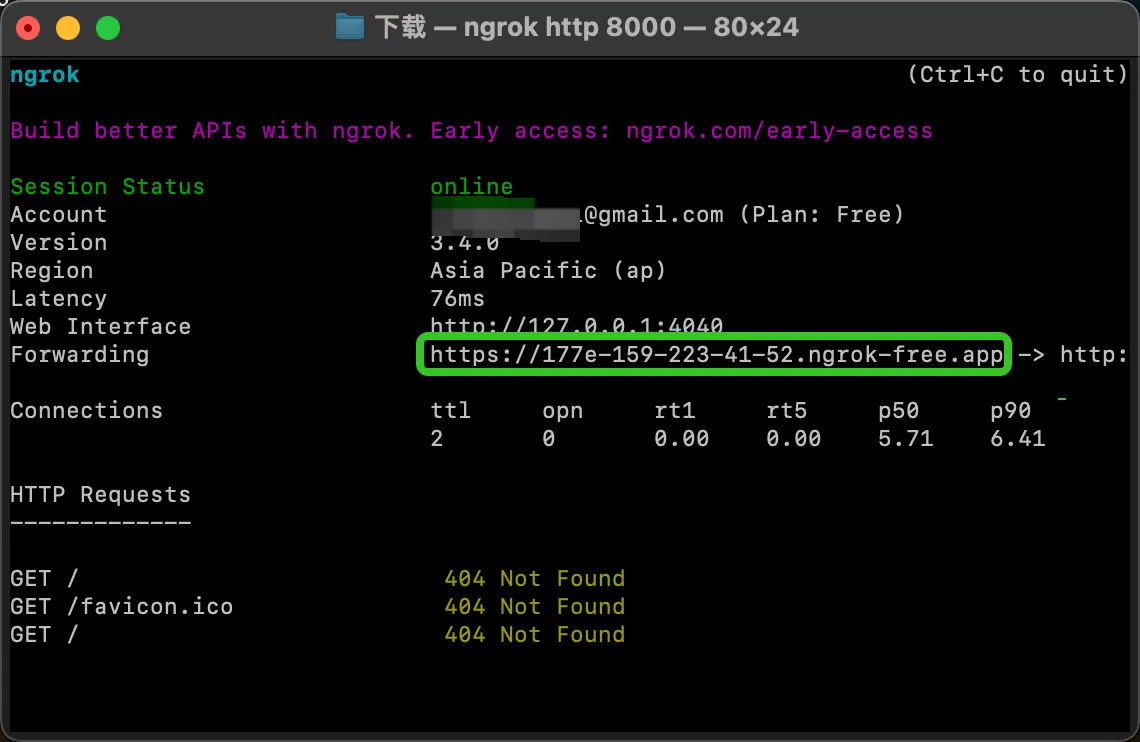
Ngrok 启动
在 Dify 中添加 API Endpoint
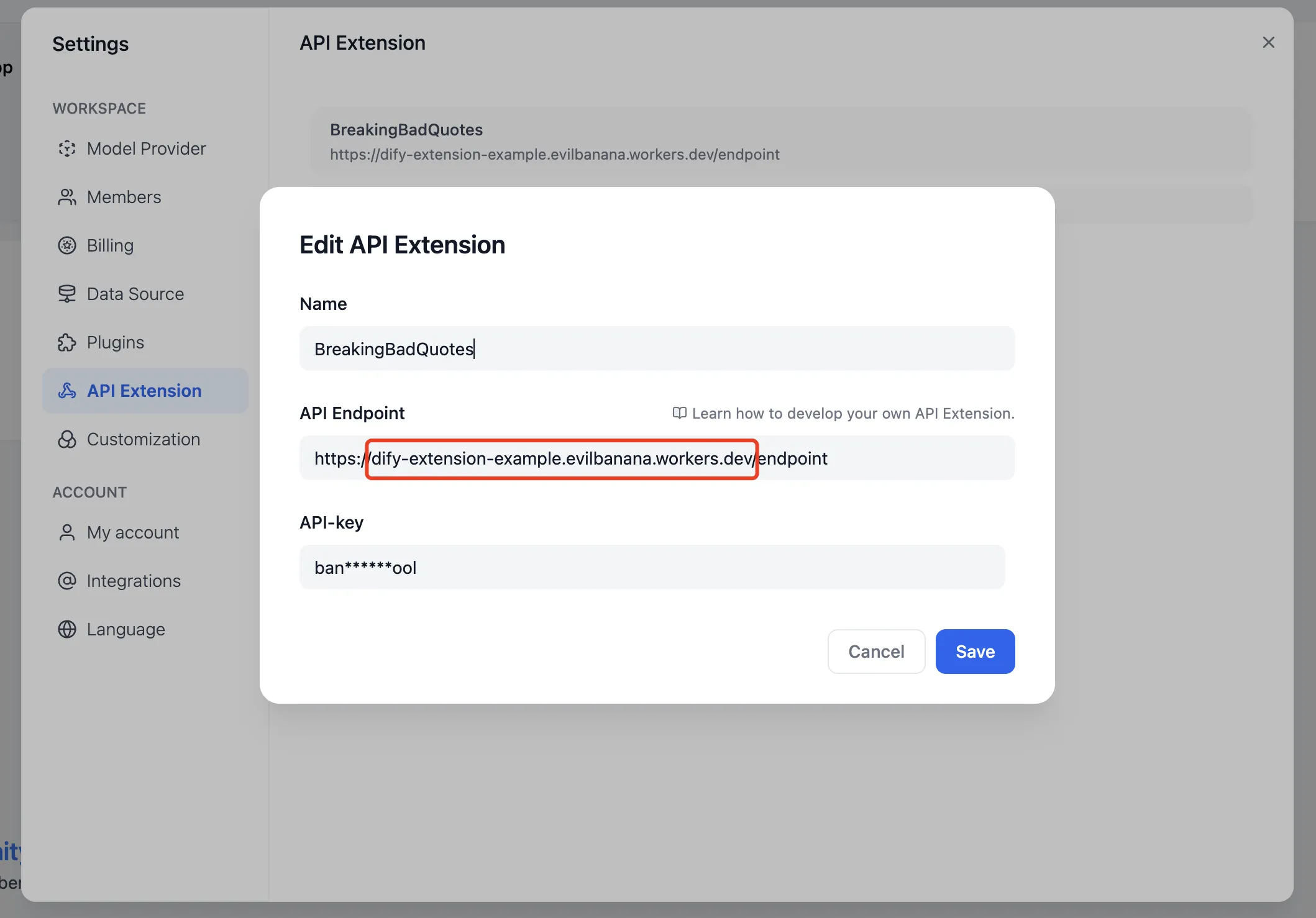
在 Dify 中添加 API Endpoint
在 App 编辑页面中添加上 API Tool
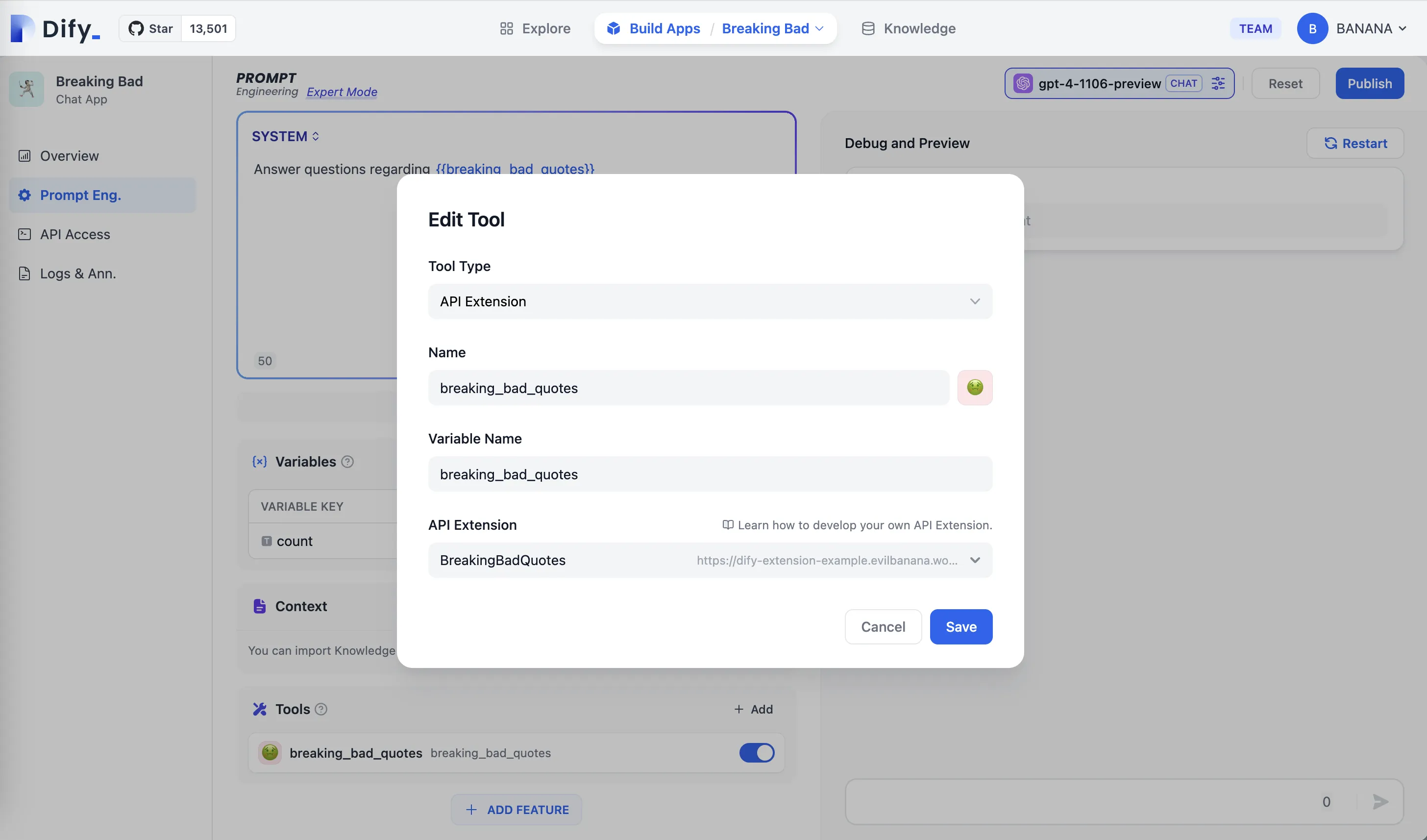
在 App 编辑页面中添加上 API Tool
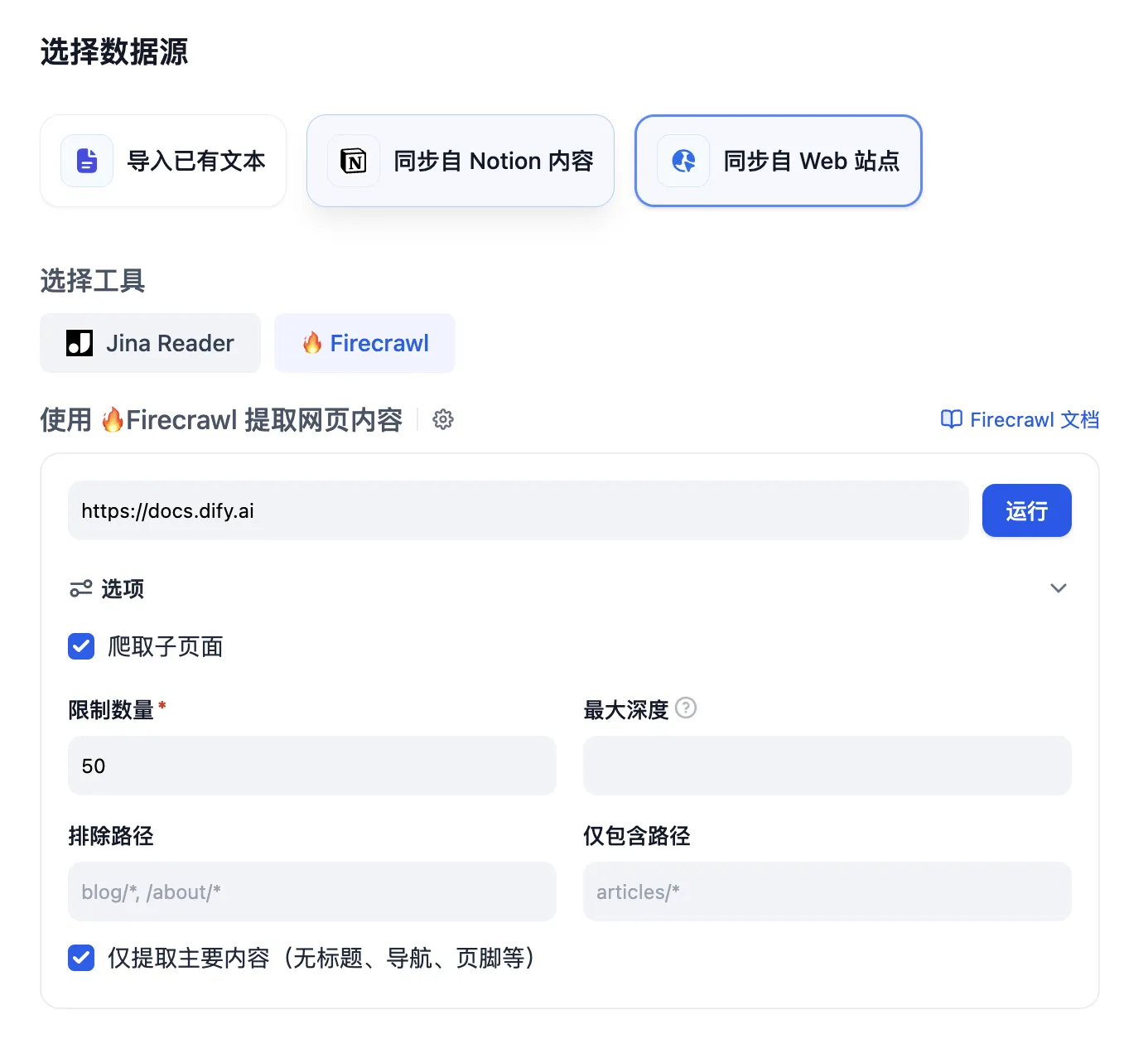
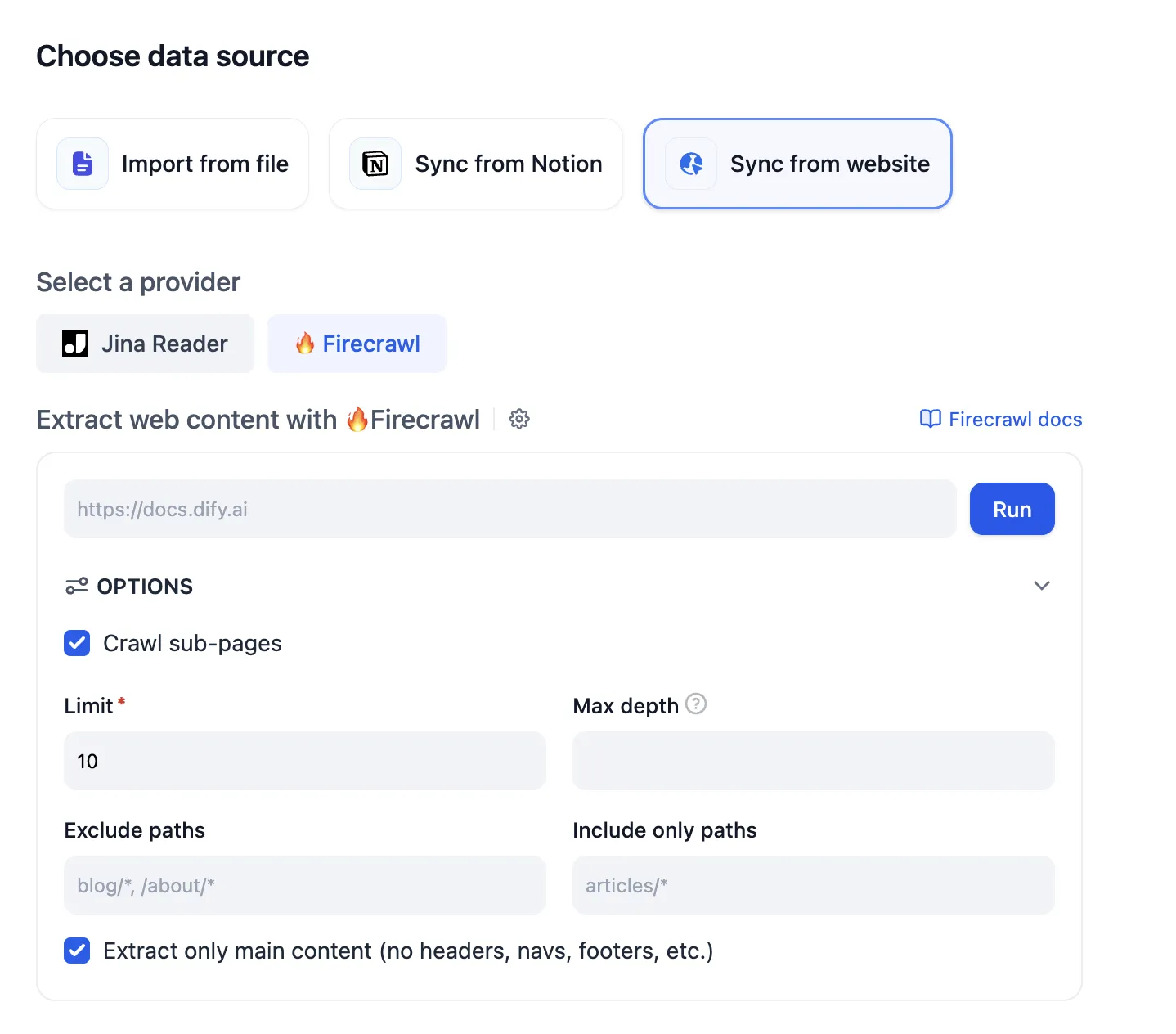
外部知识库连接原理
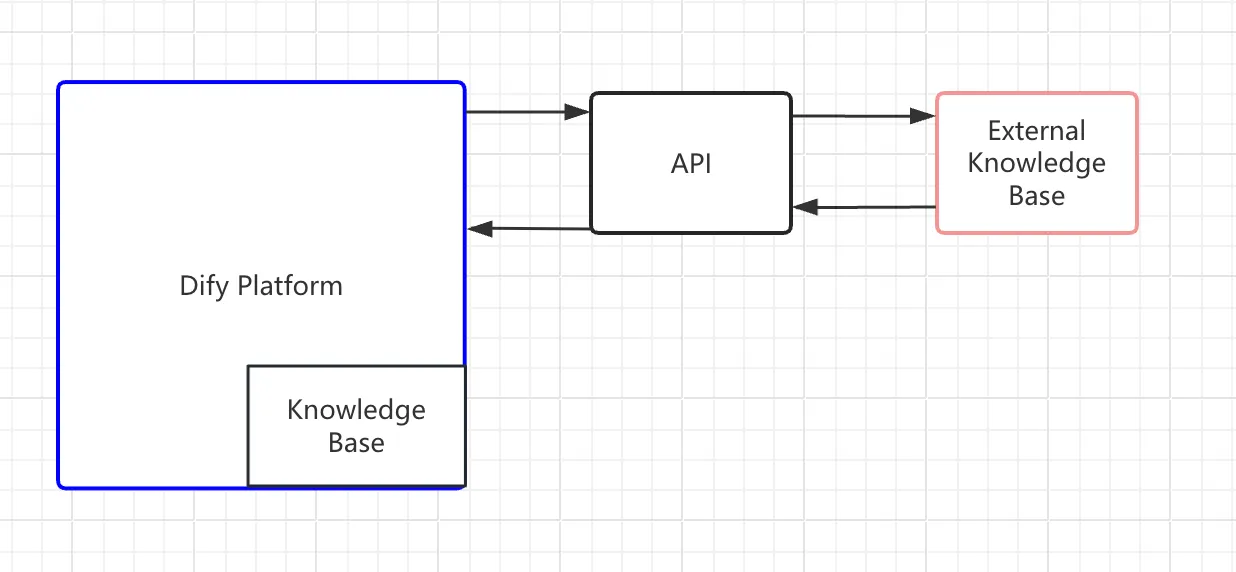
外部知识库连接原理
.png)
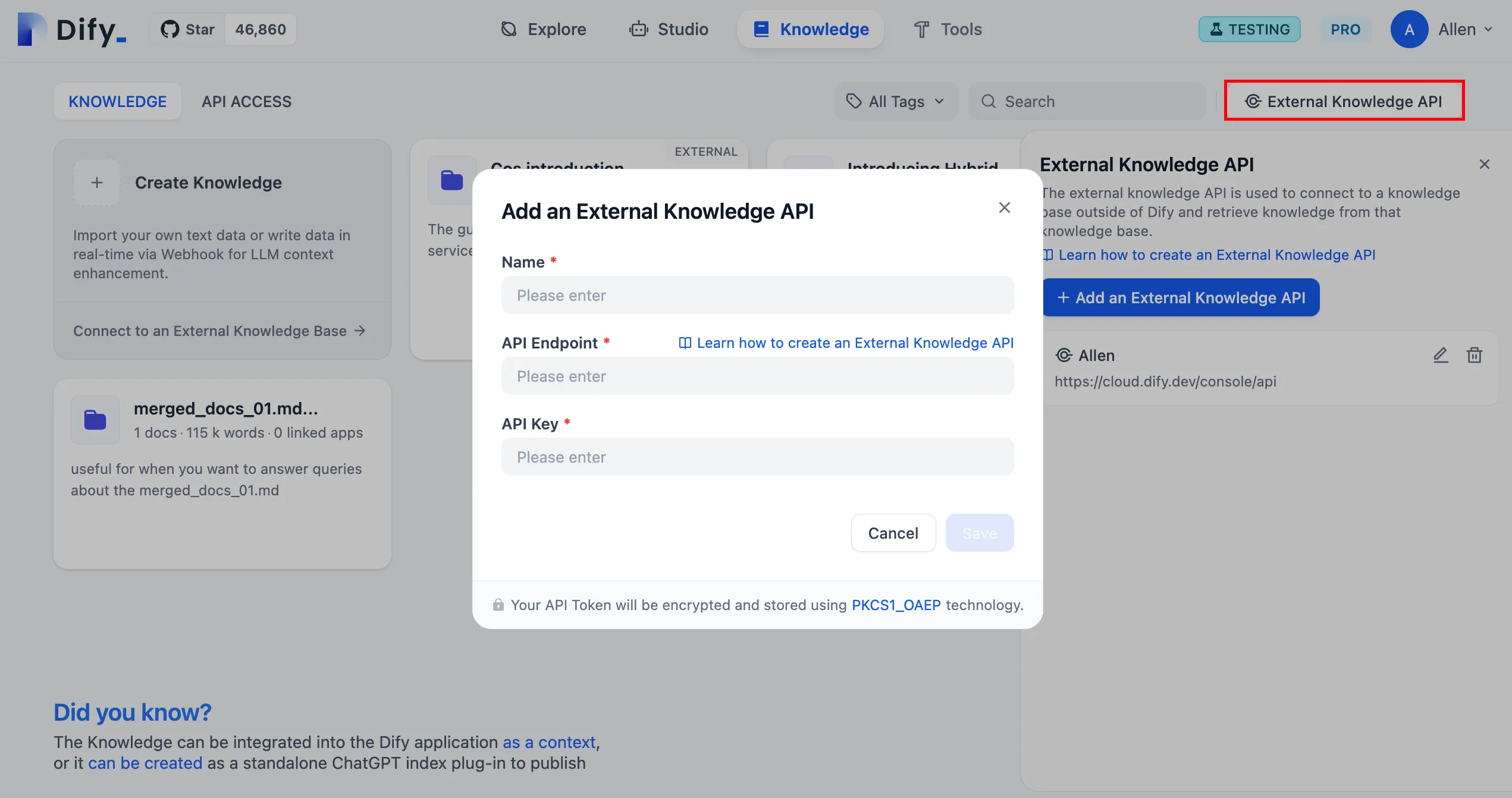
.png)
.png)
.png)
.png)
.png)
.png)
.png)

.png)
.png)
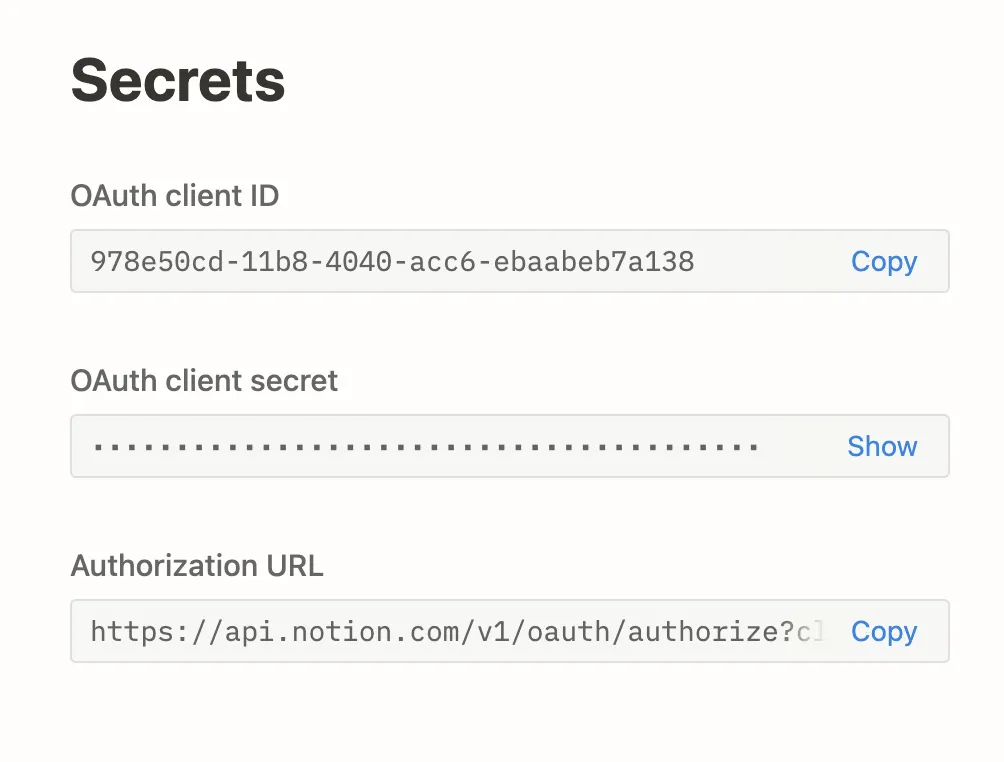
API-based Extension
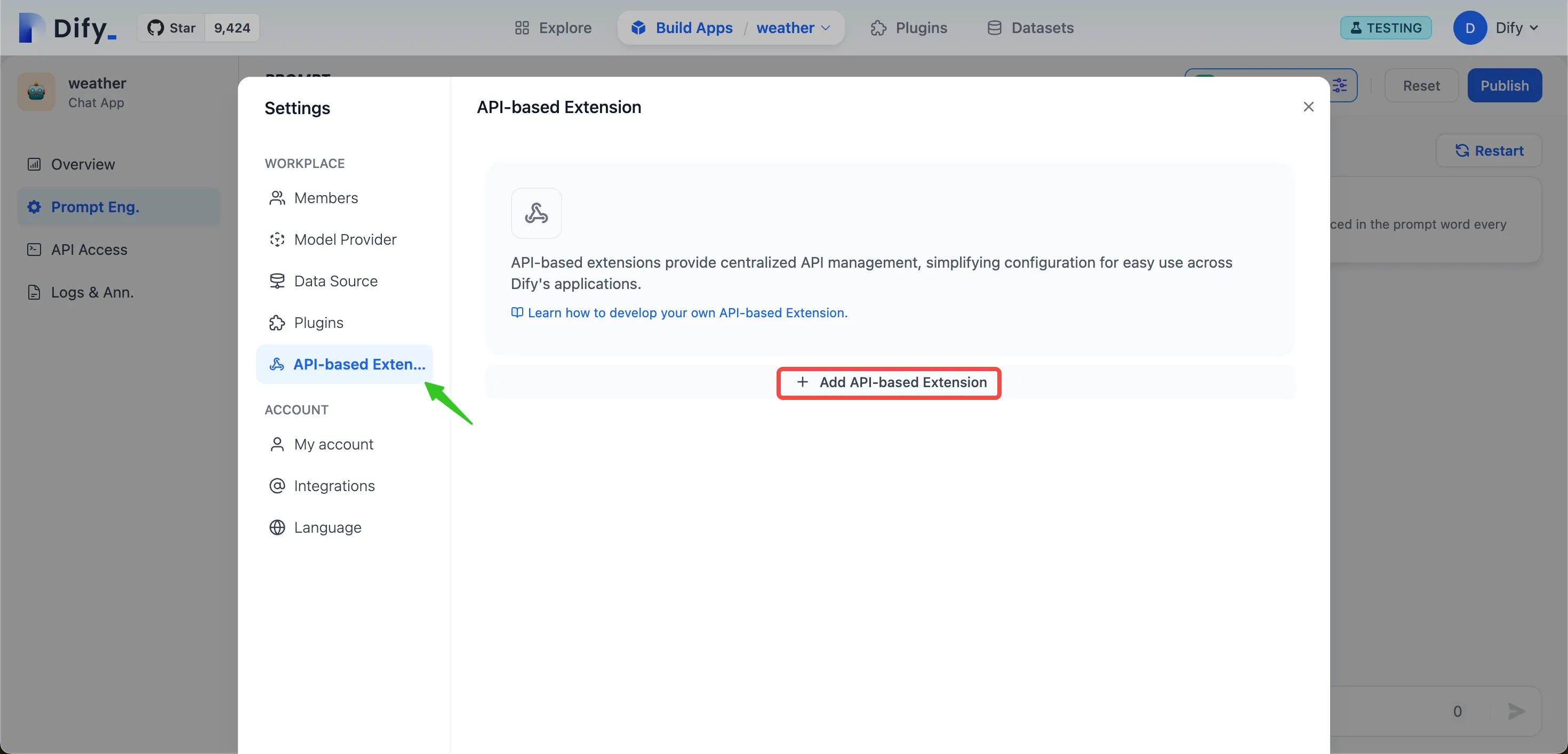
API-based Extension
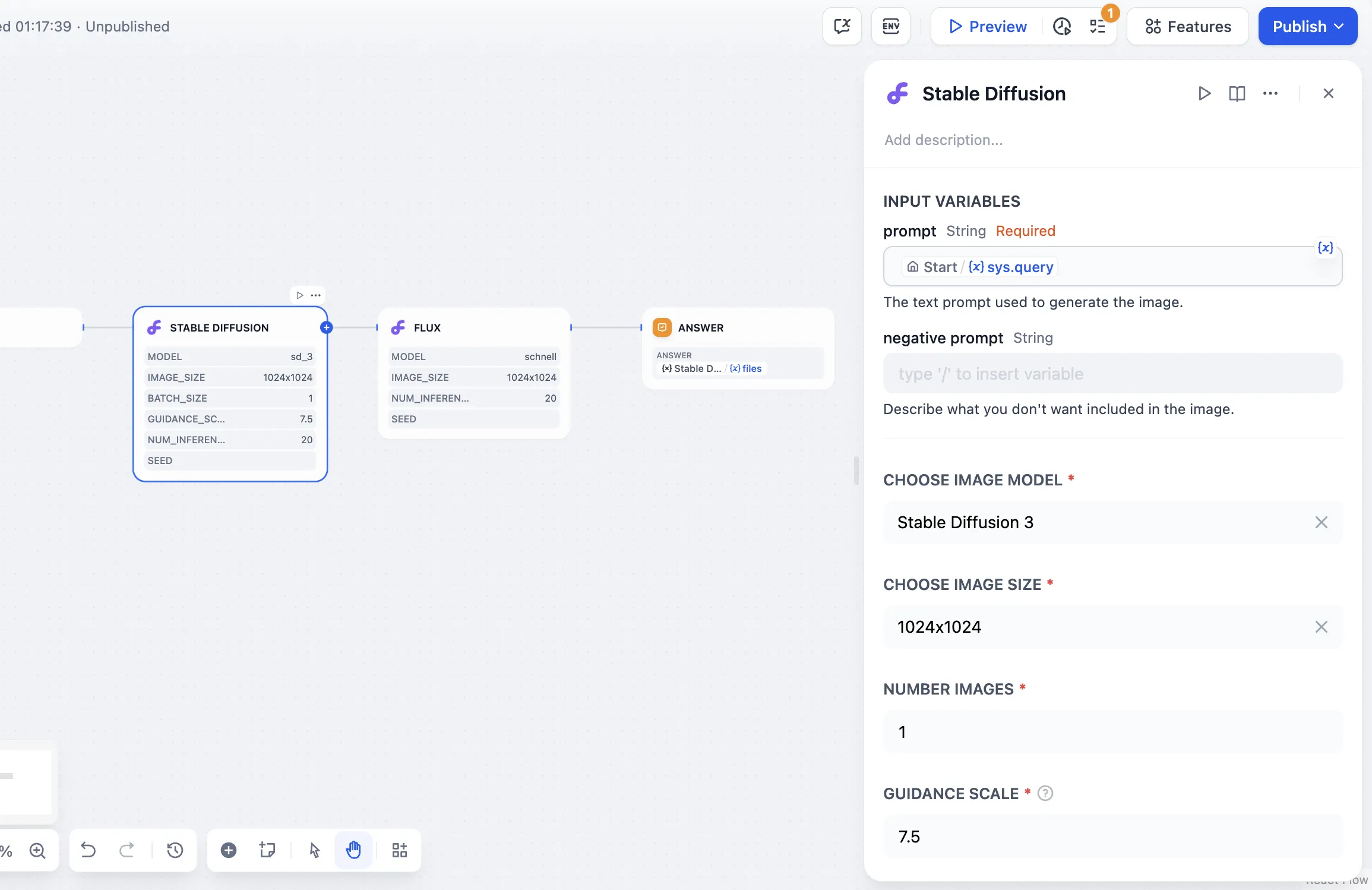
Weather Inquiry
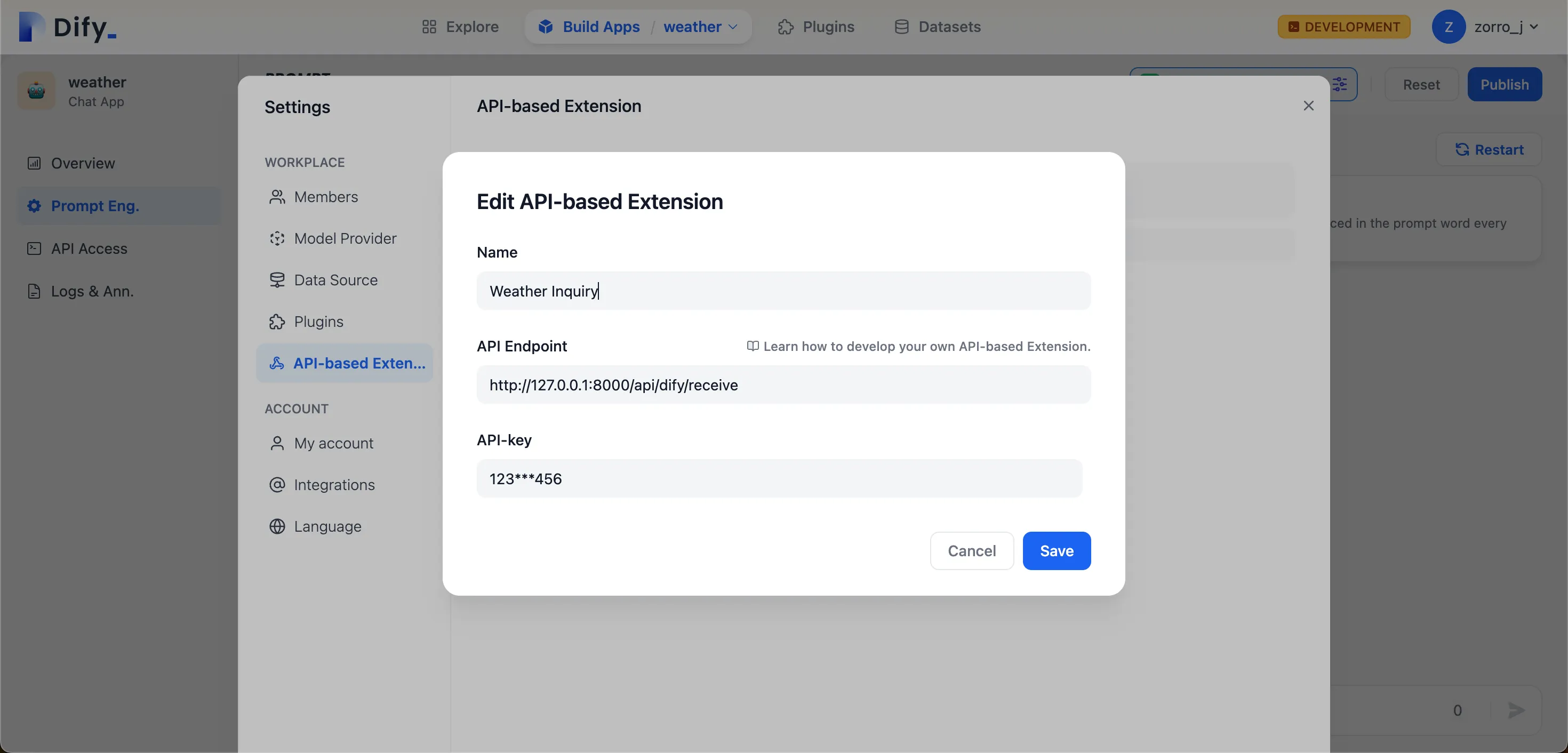
Weather Inquiry
External_data_tool
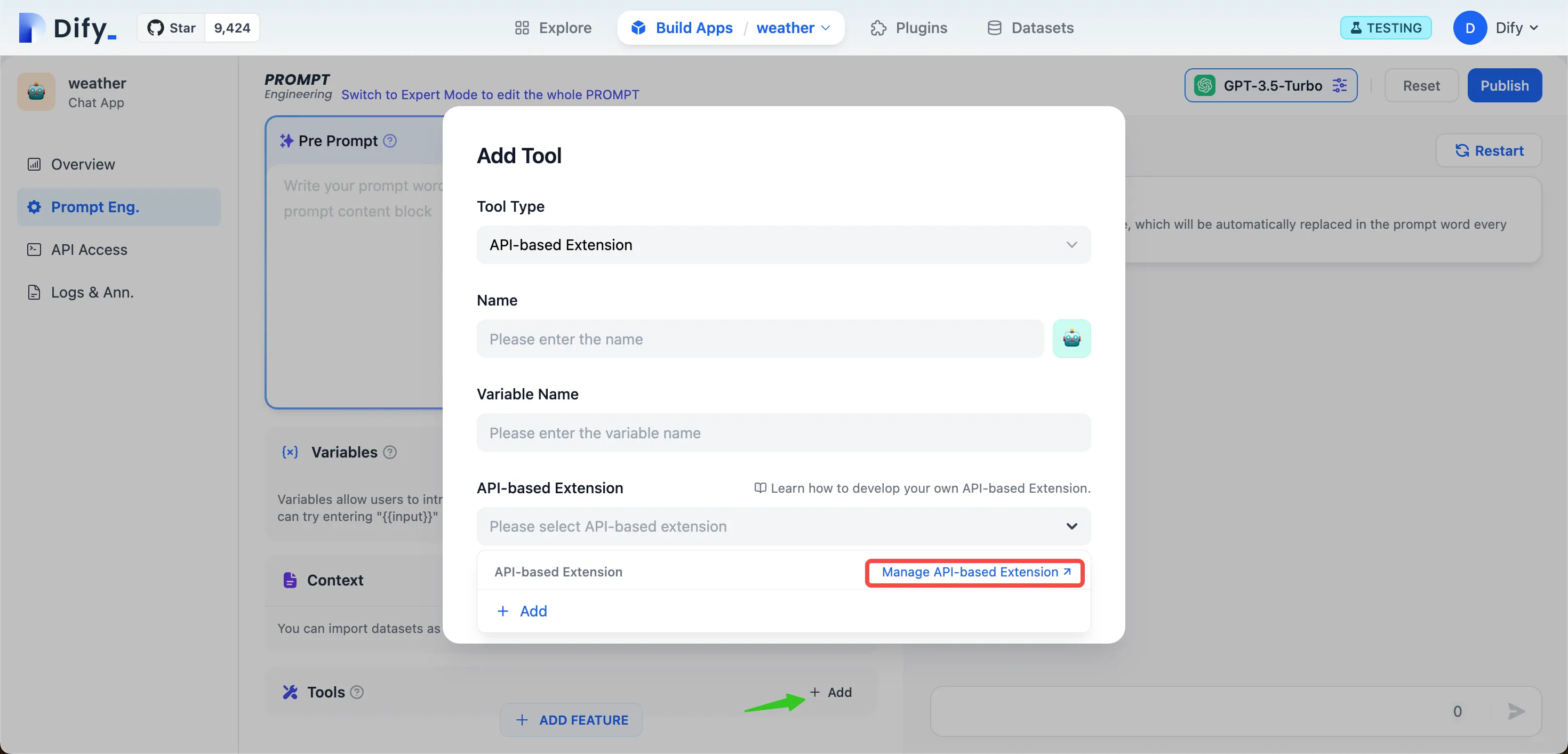
External_data_tool
Weather_search_tool
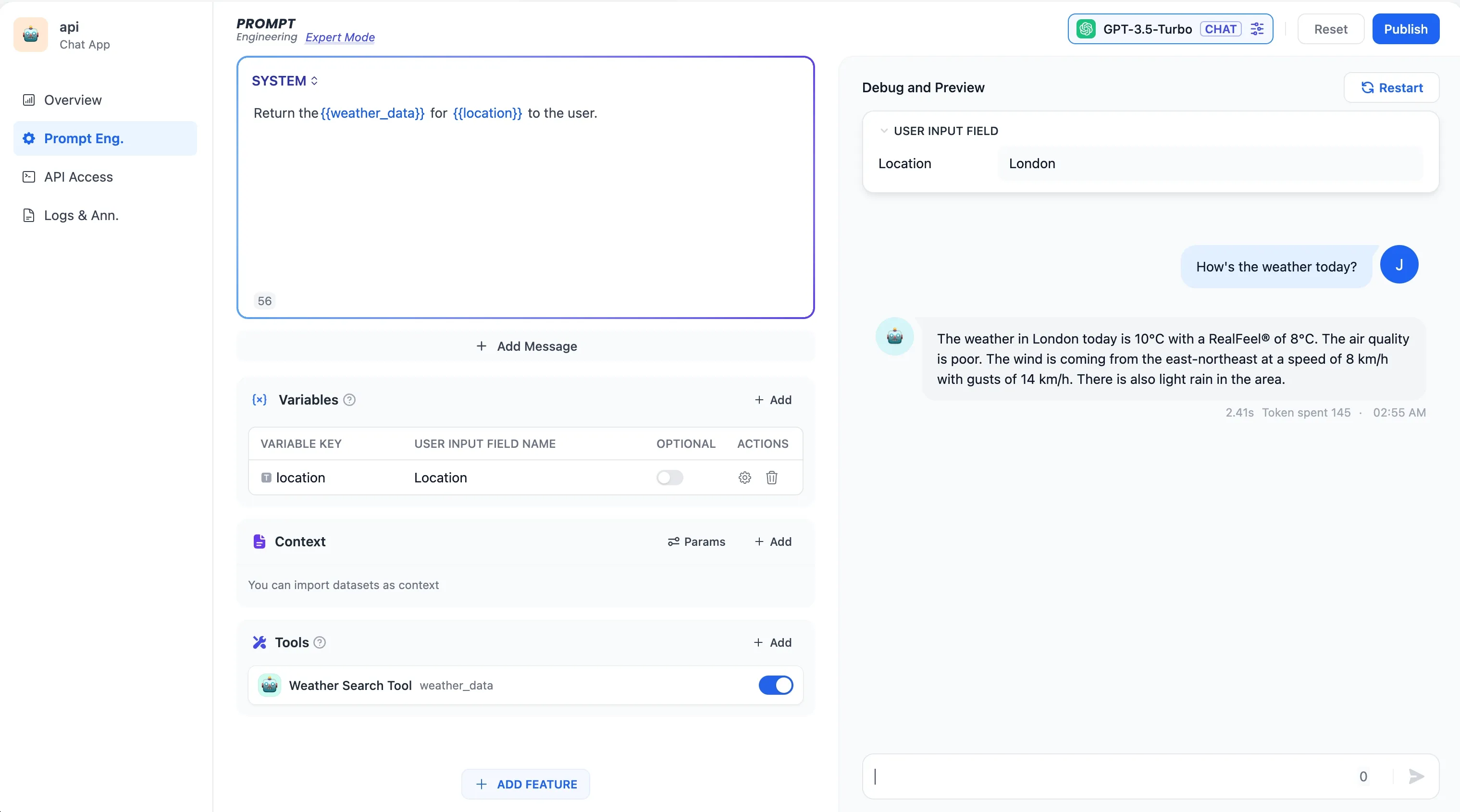
Weather_search_tool
Prompt Log
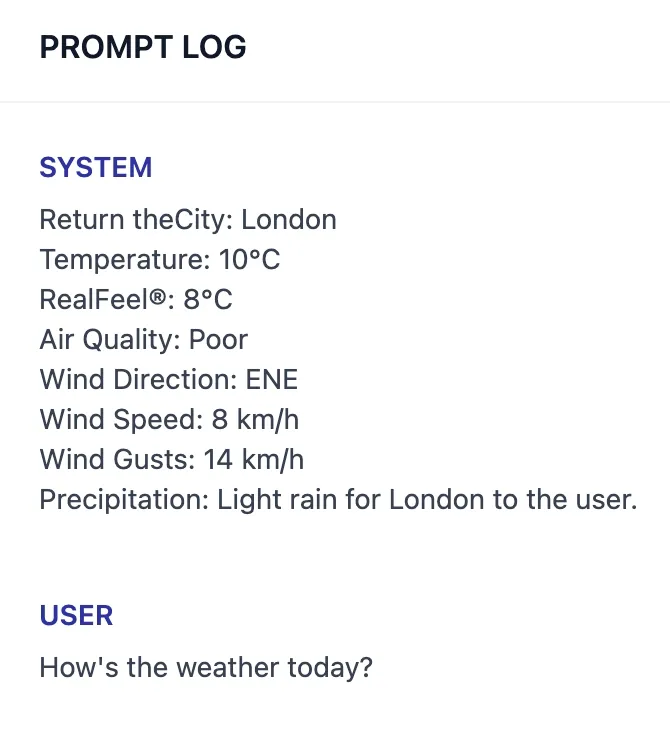
Prompt Log

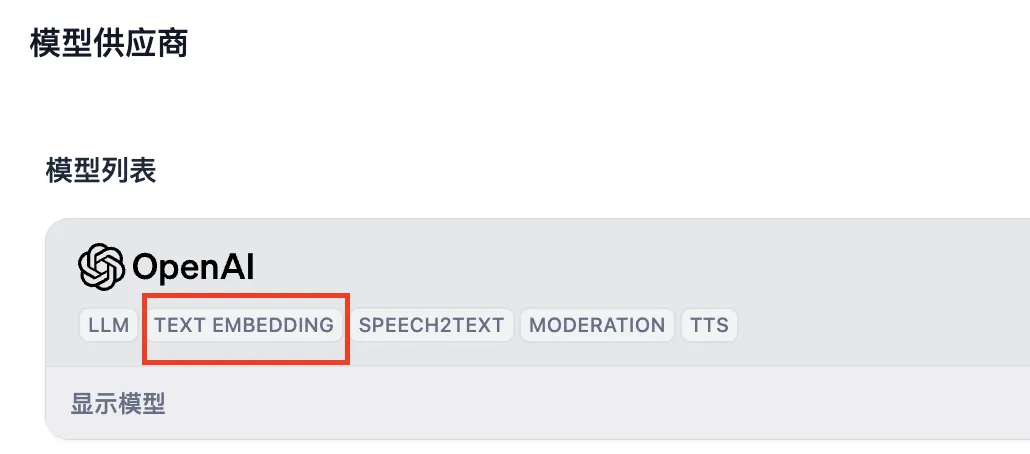
在模型供应商内配置 Rerank 模型
在模型供应商内配置 Rerank 模型
.png)
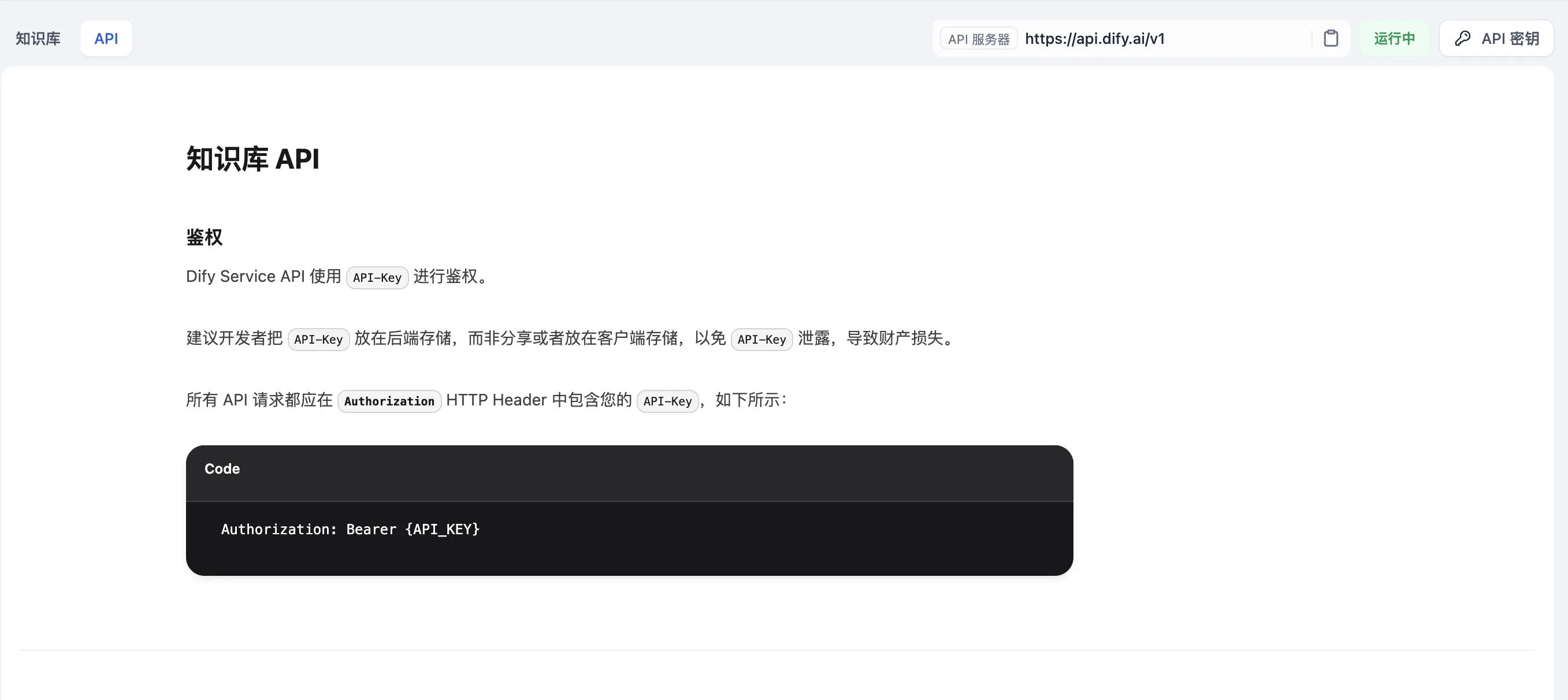
通过 API 管理文档
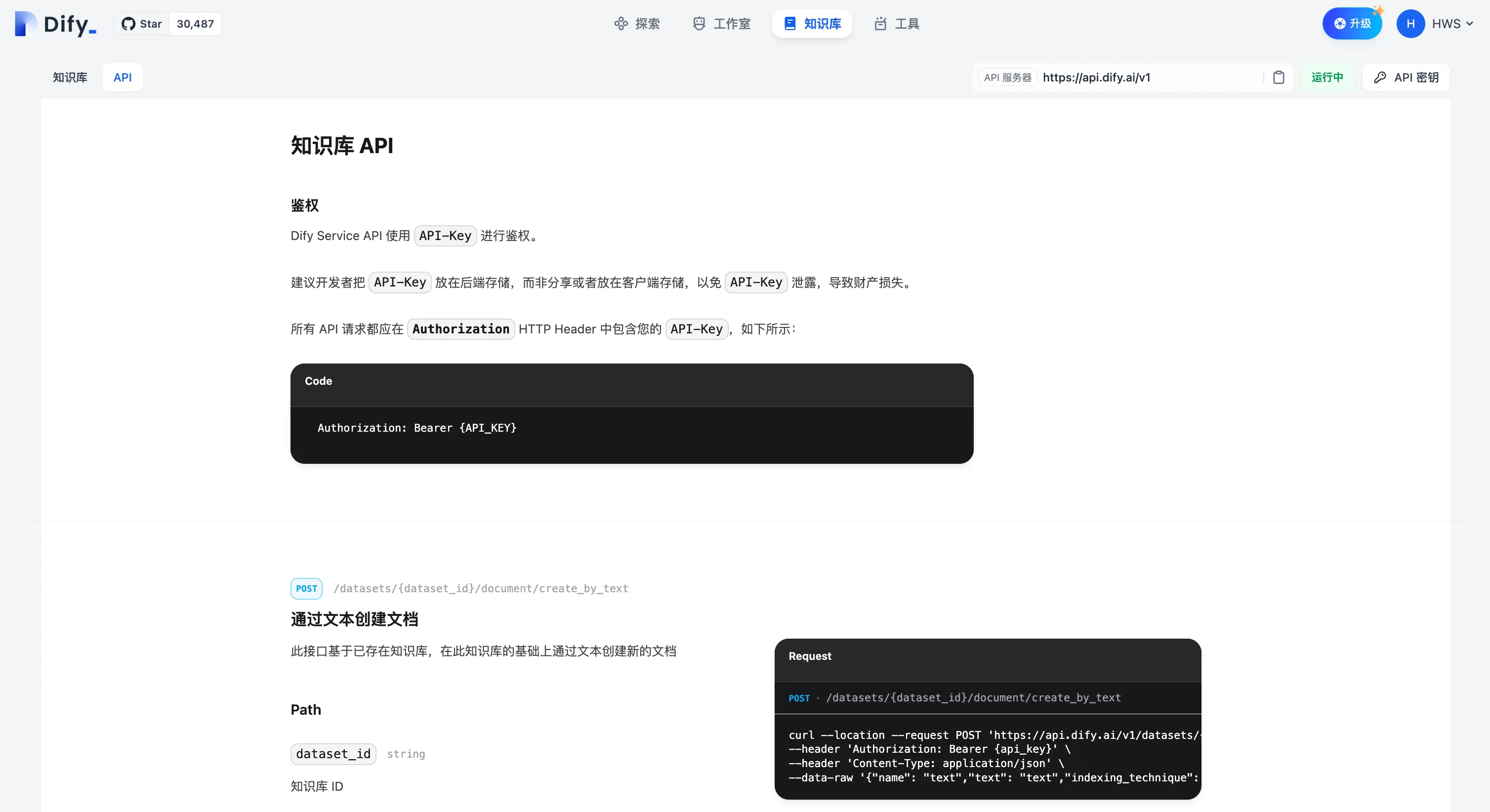
通过 API 管理文档

Knowledge API Document
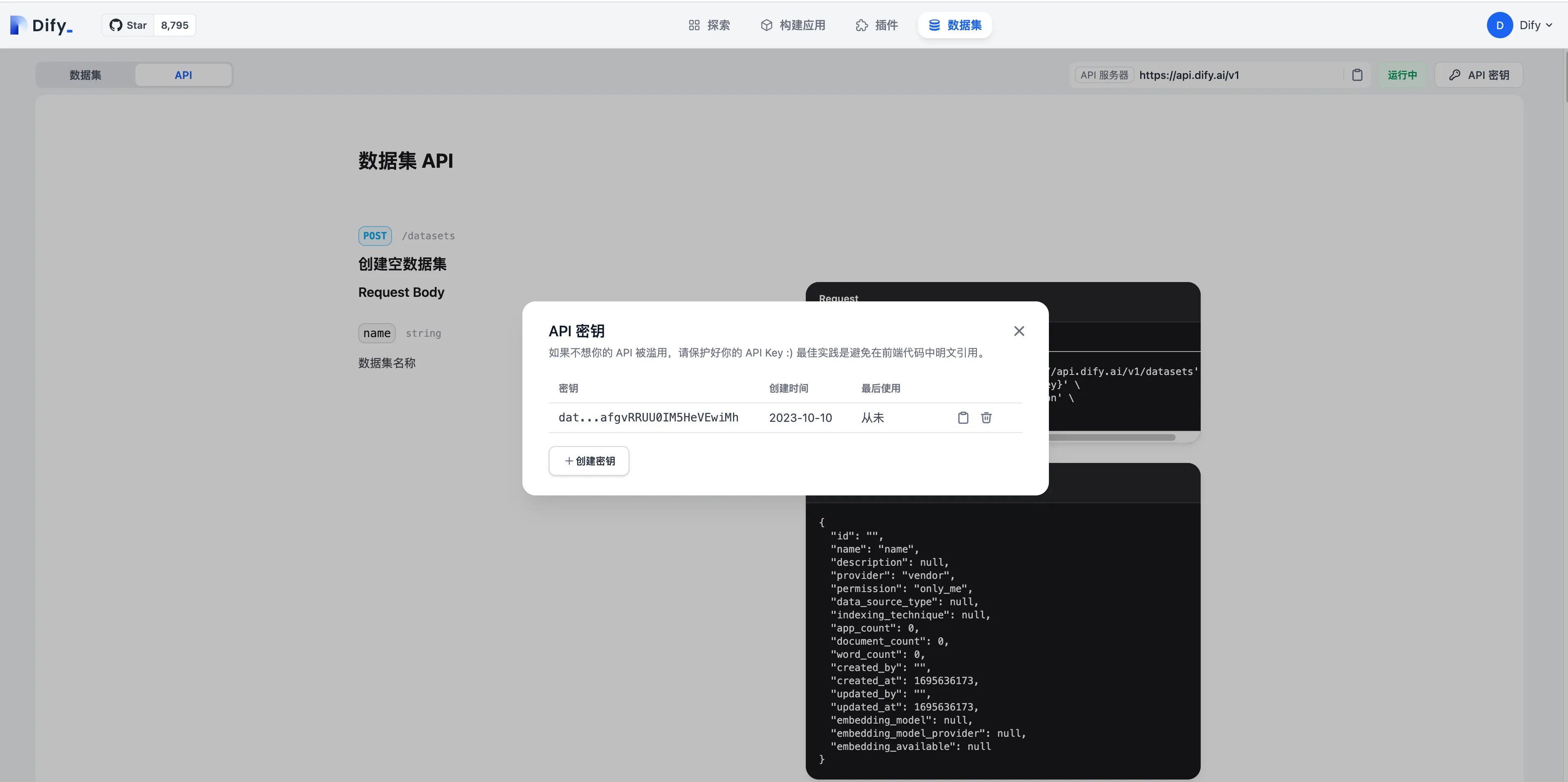
Knowledge API Document
打开引用与归属功能
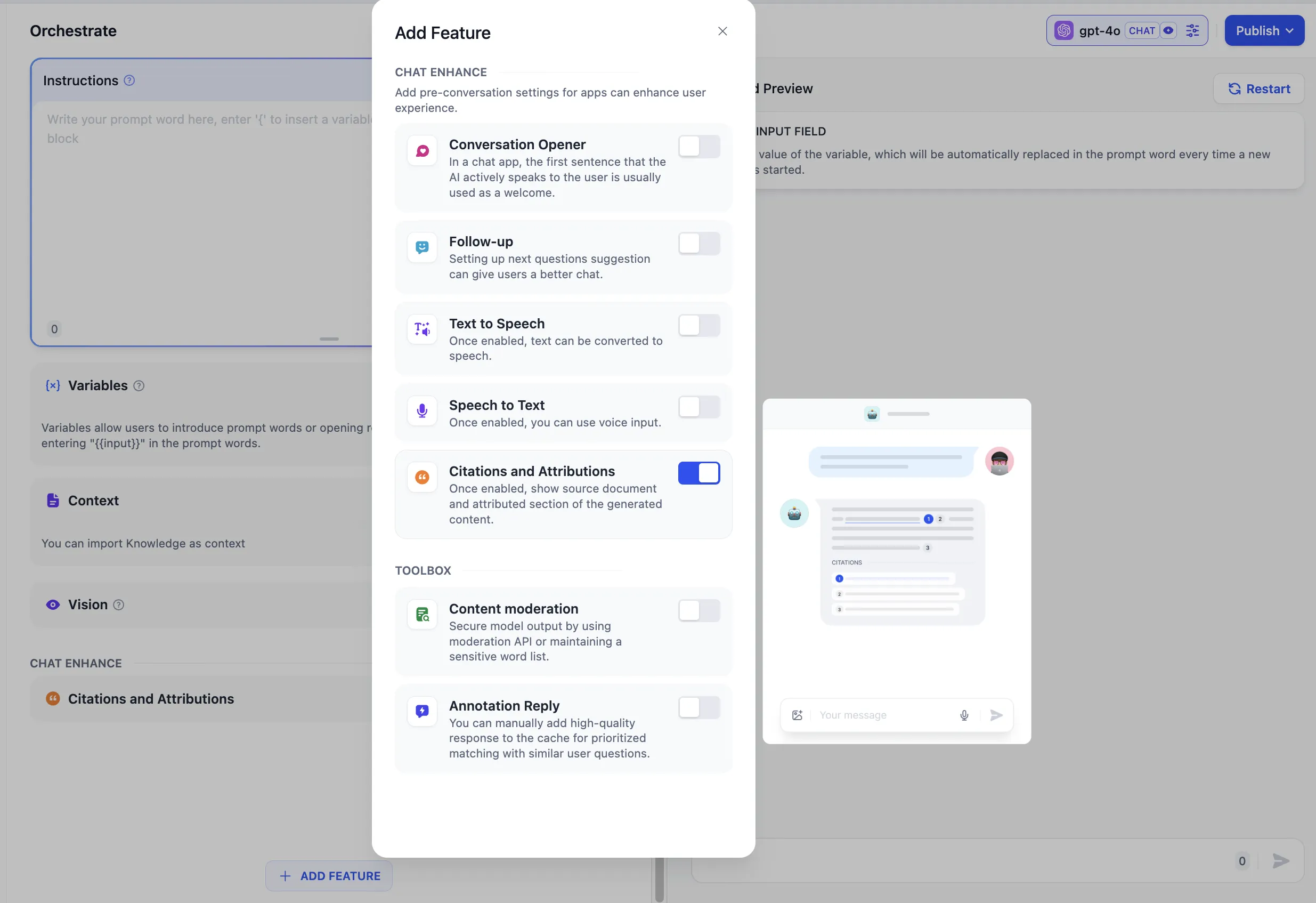
打开引用与归属功能
.png)
查看回复内容的引用信息
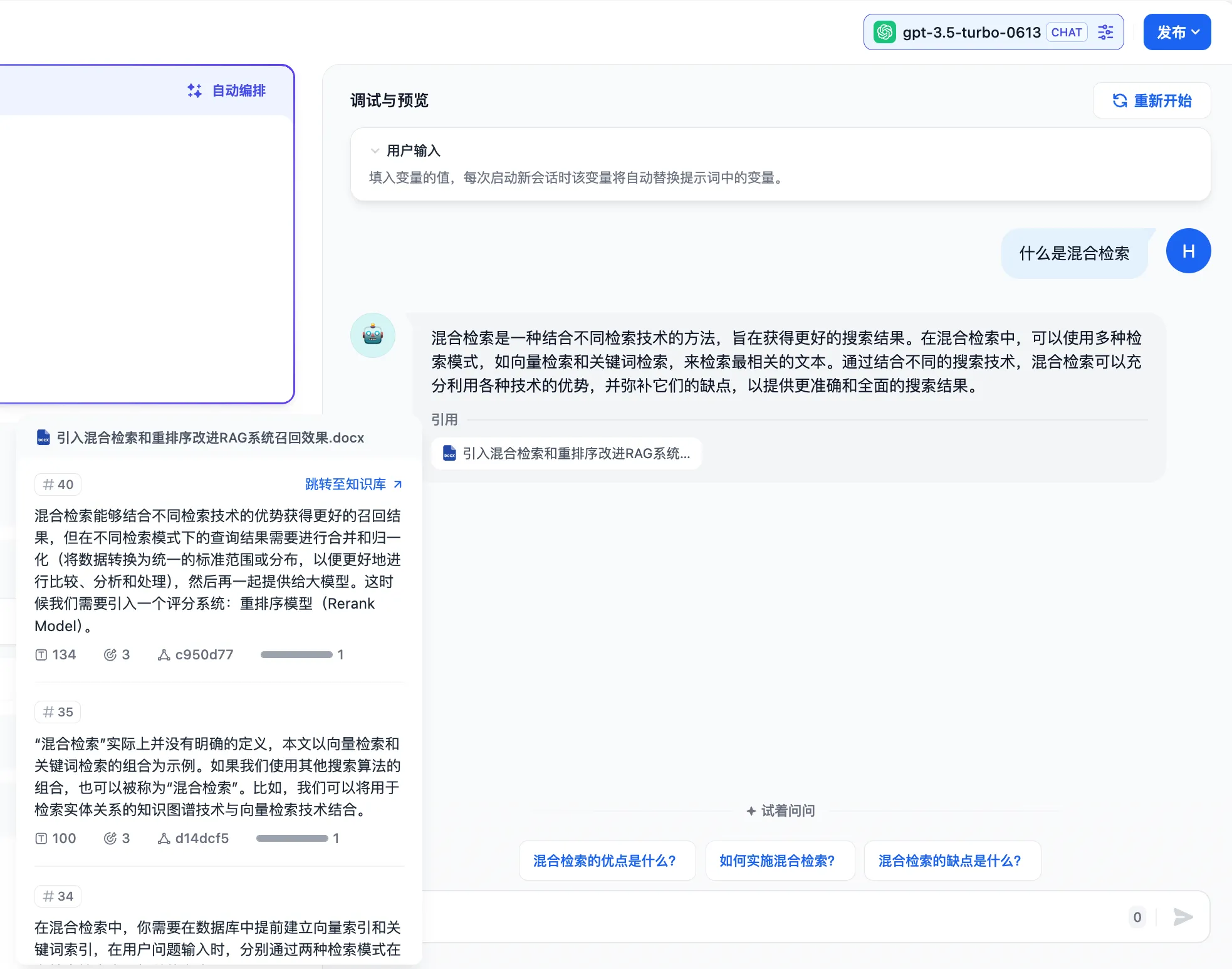
查看回复内容的引用信息
.png)
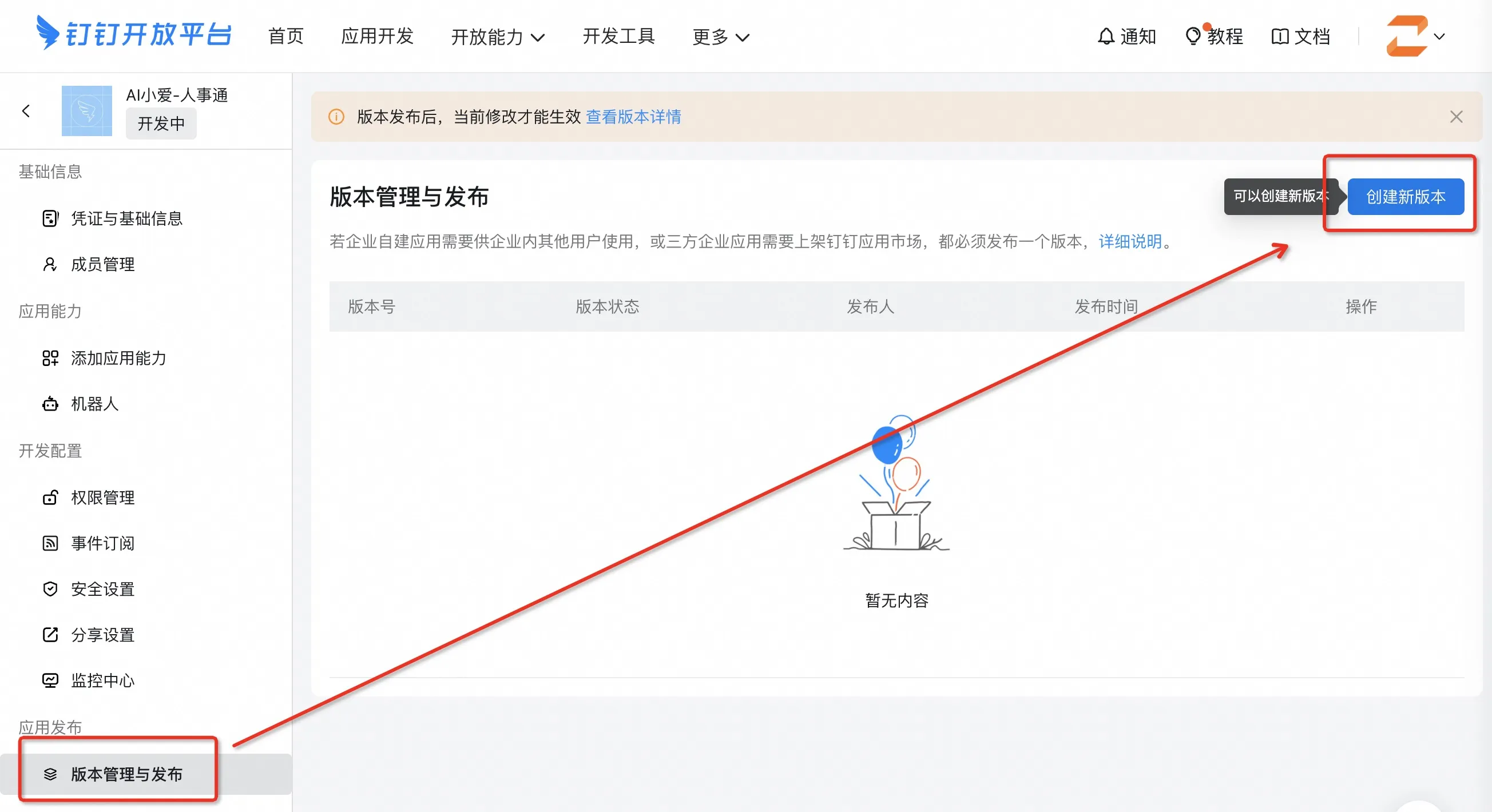
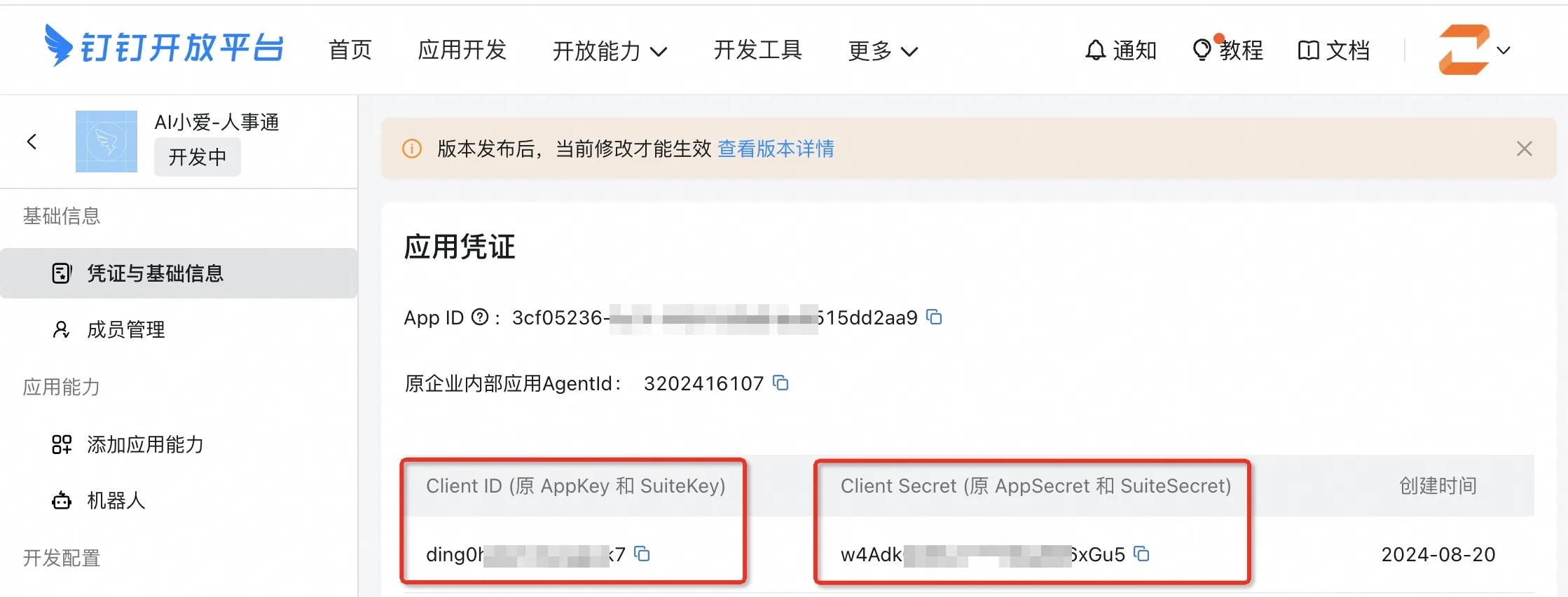
编辑应用信息
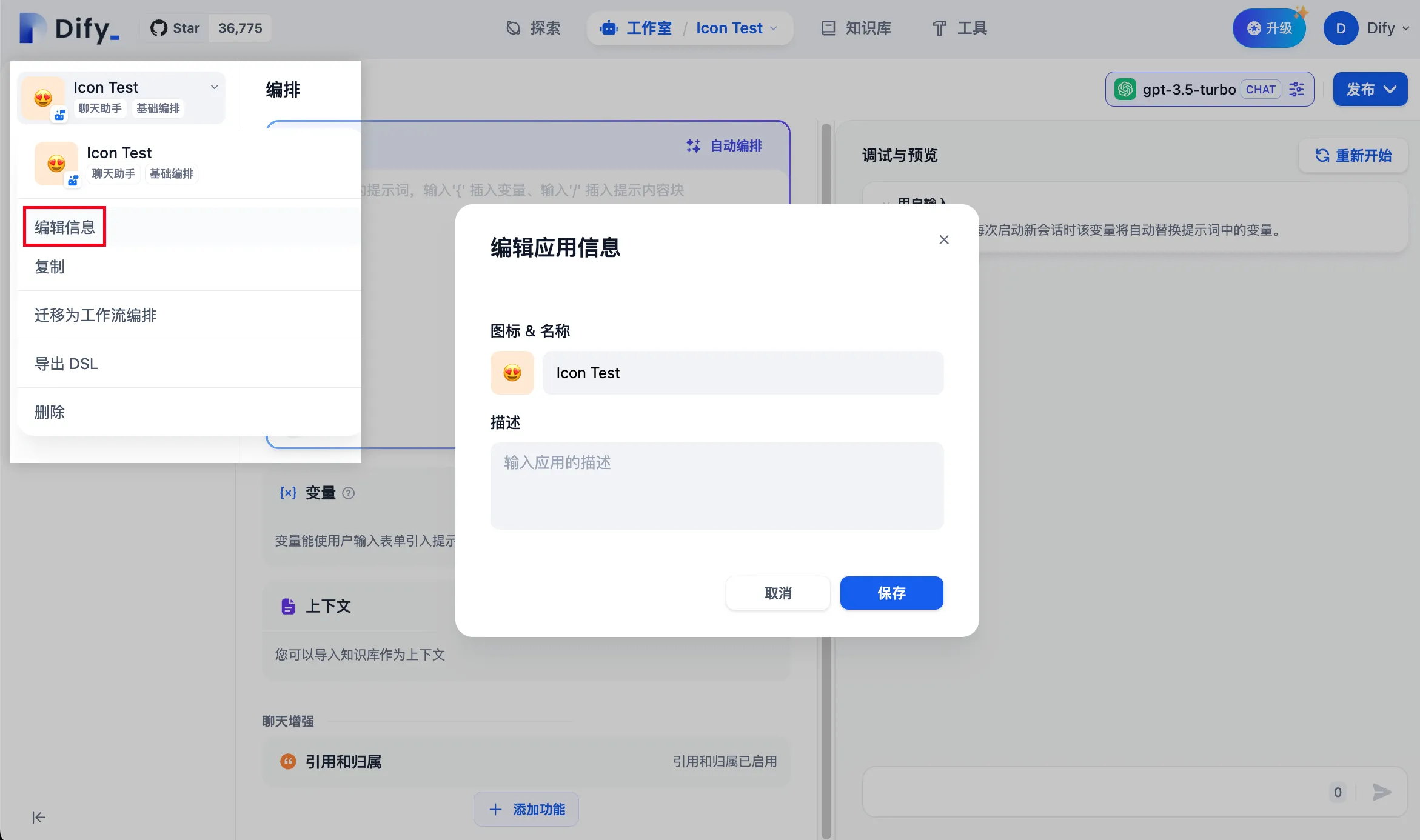
编辑应用信息

 (1).png)
团队账单管理
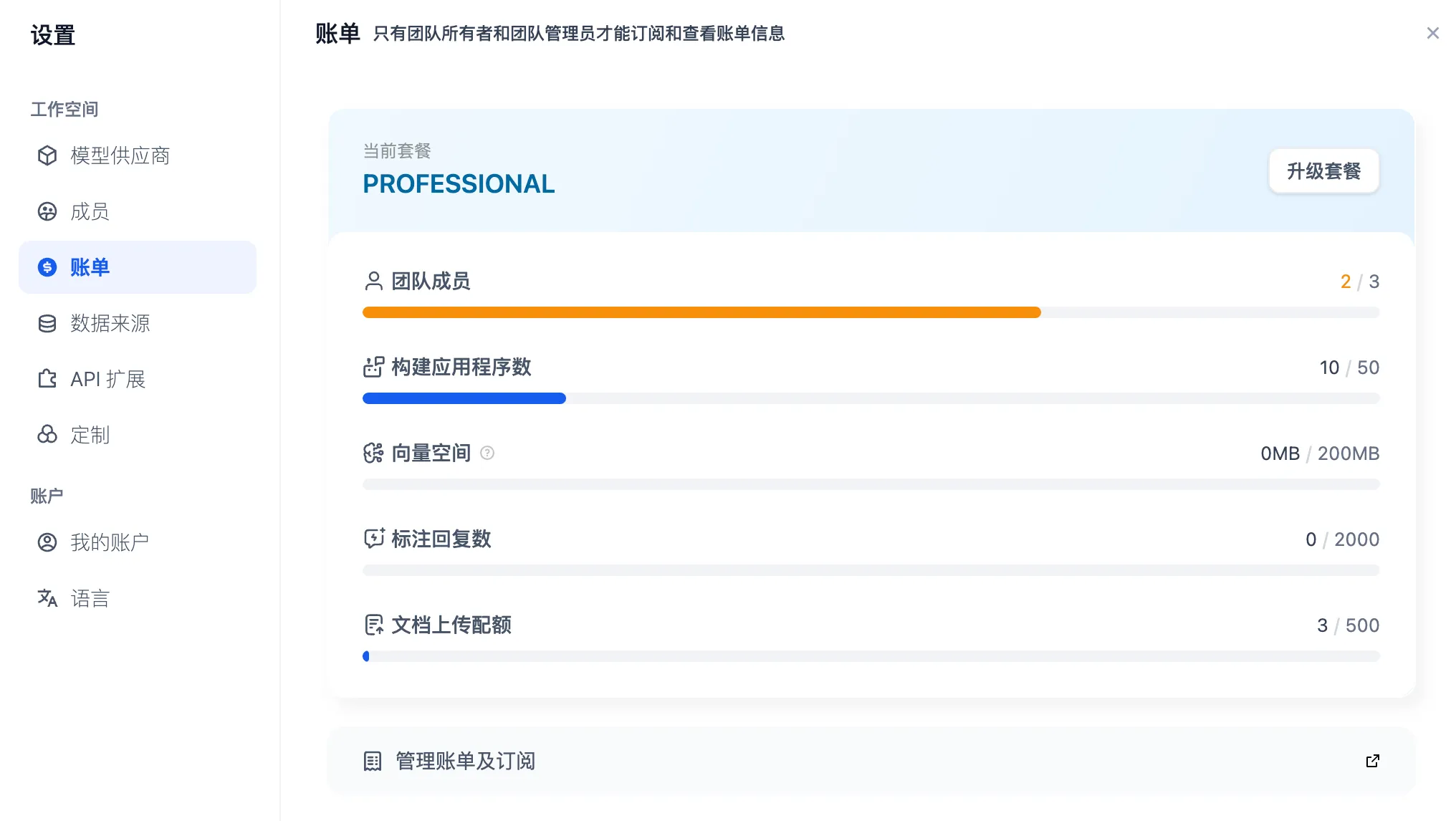
团队账单管理
 (1).png)
更改付费方案
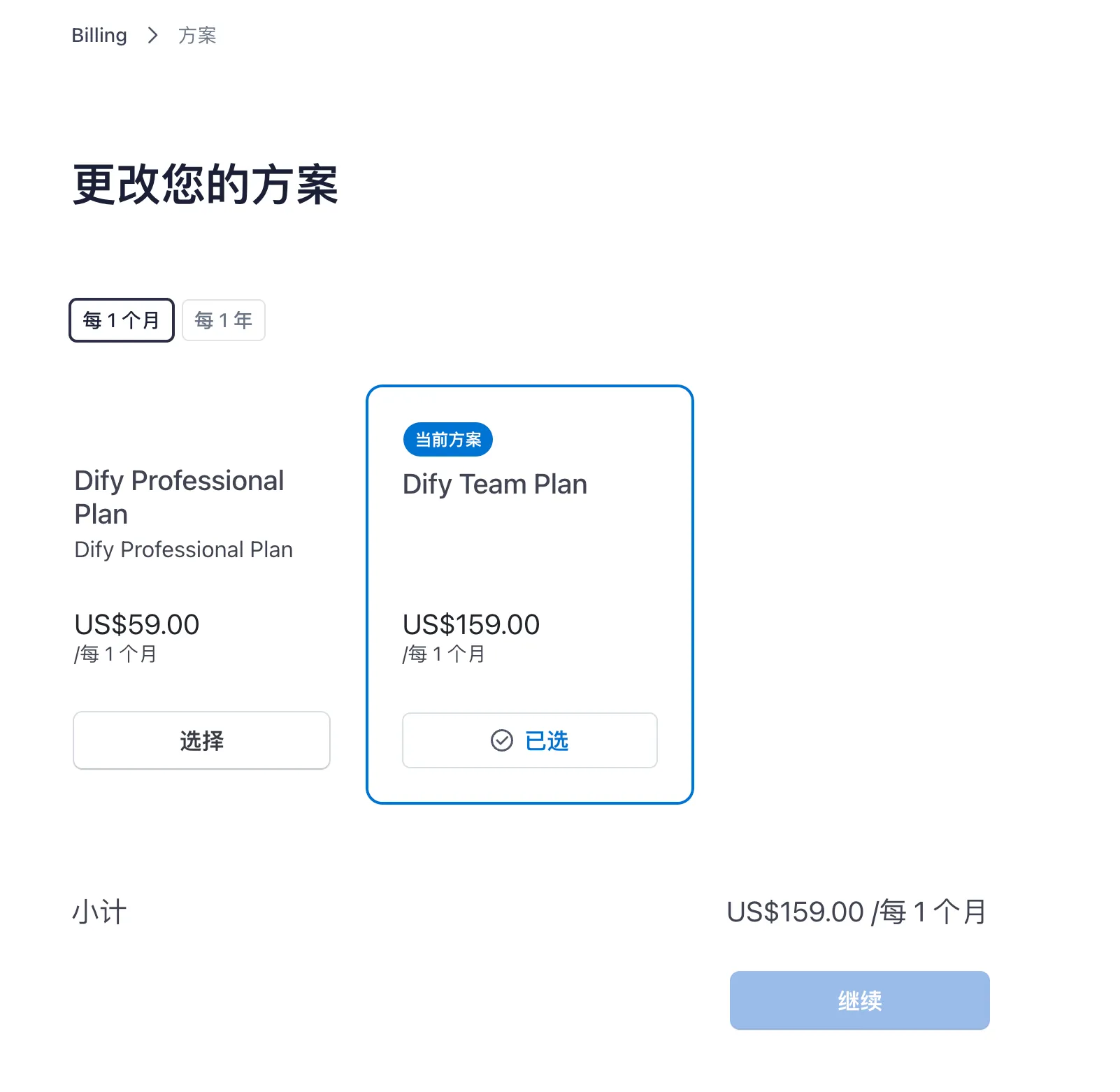
更改付费方案
 (1) (1) (1) (1).png)
为团队成员分配权限
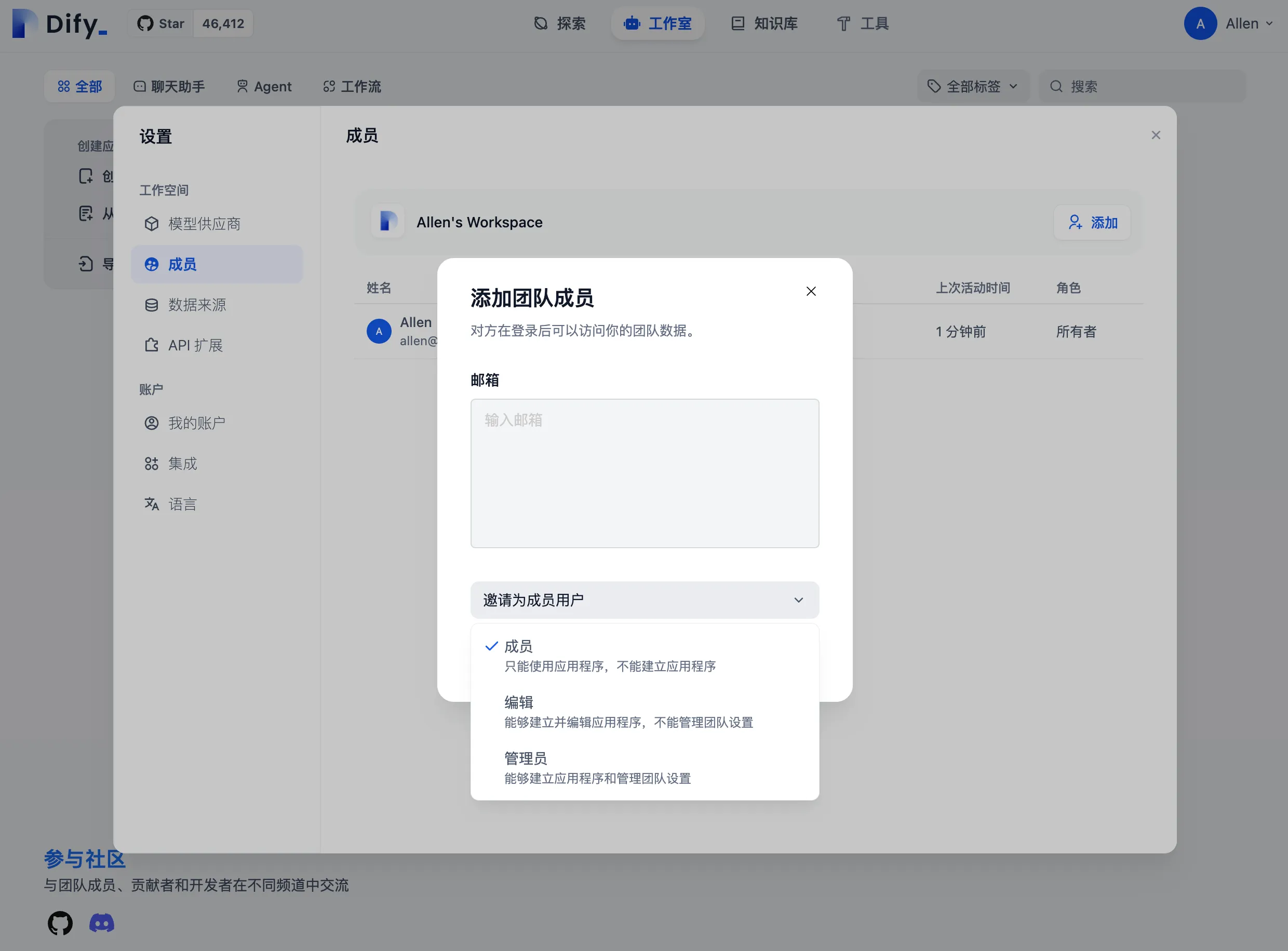
为团队成员分配权限
 (1) (1) (1) (1) (1).png)
移除成员
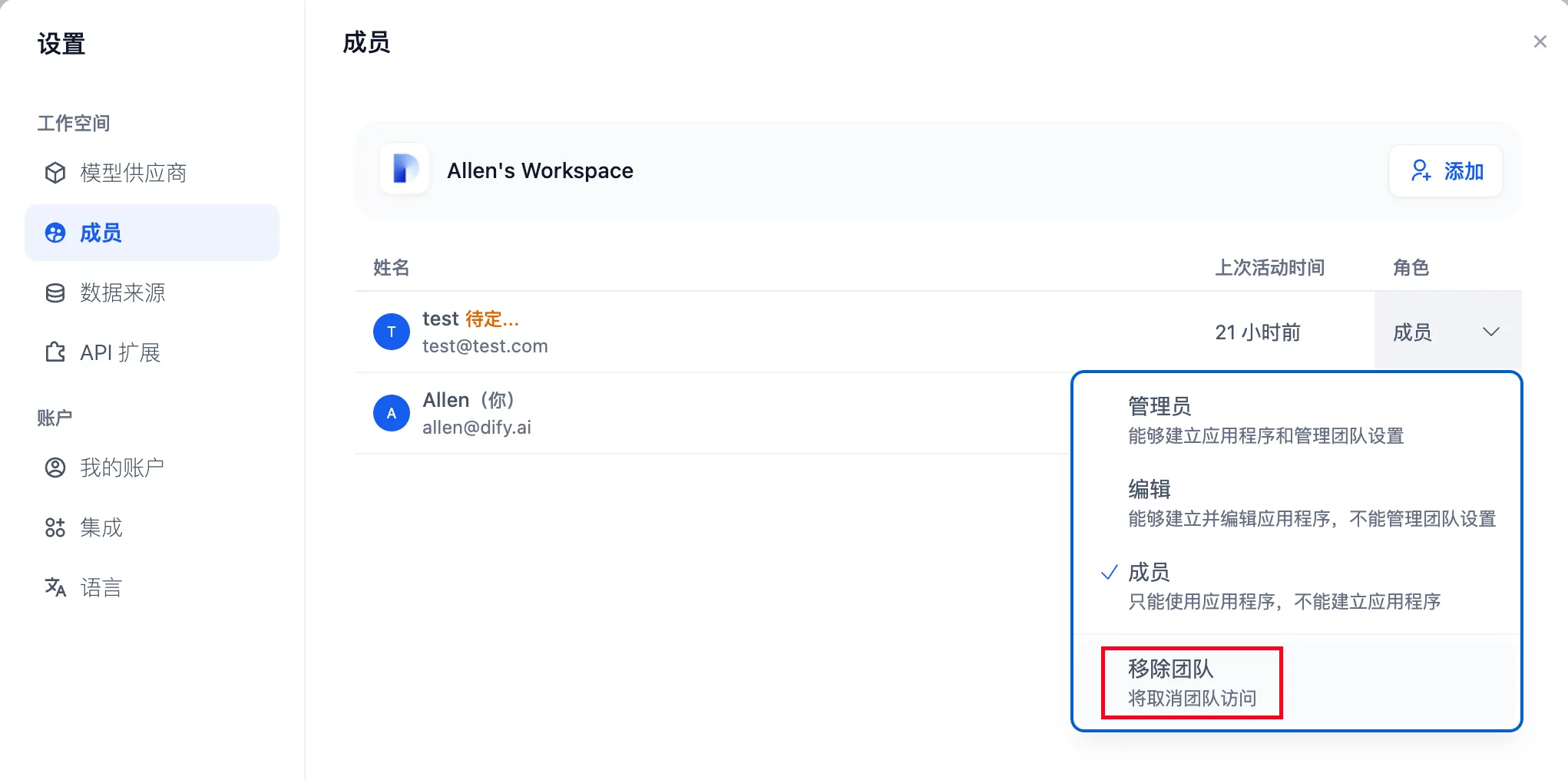
移除成员
.png)
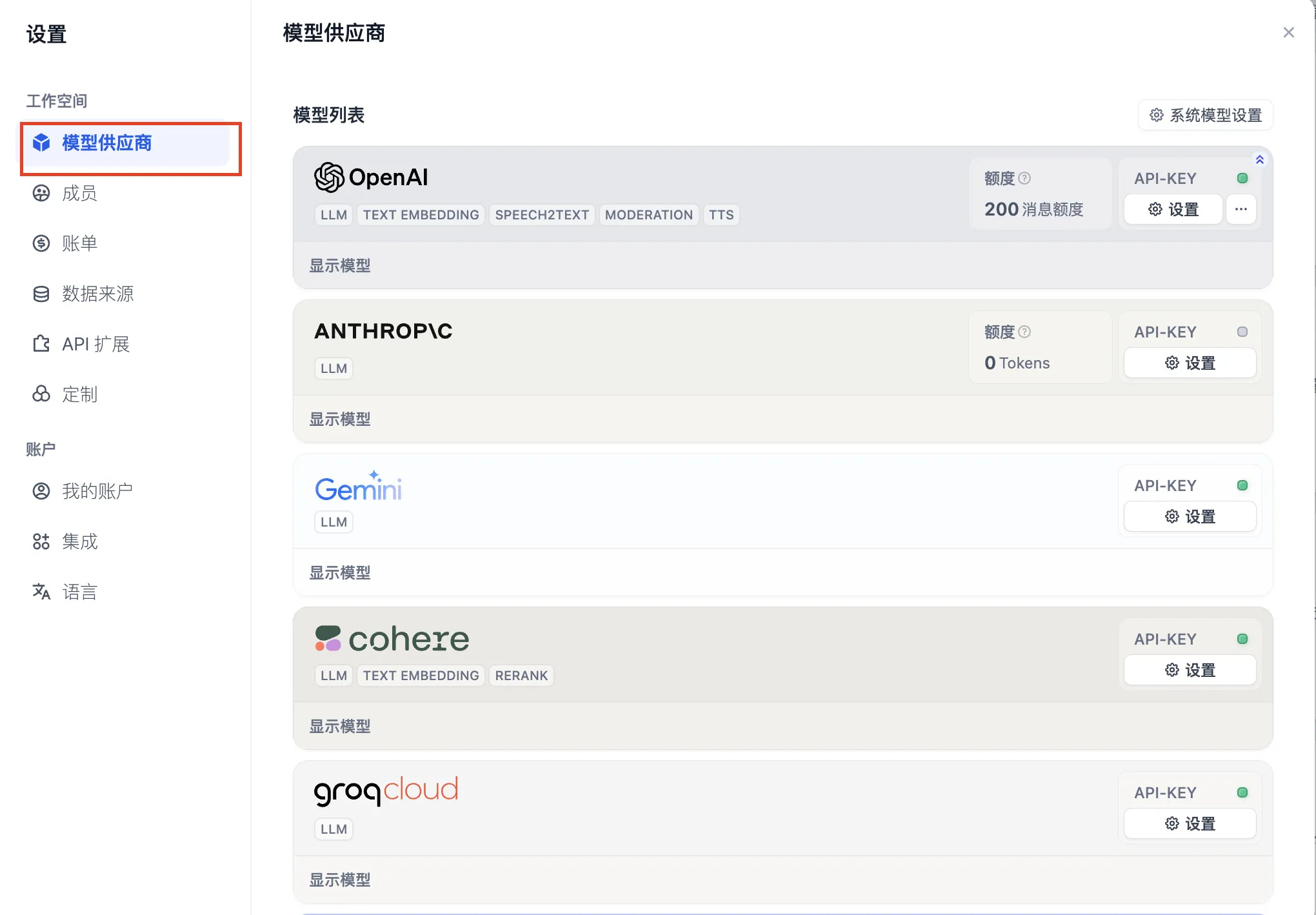
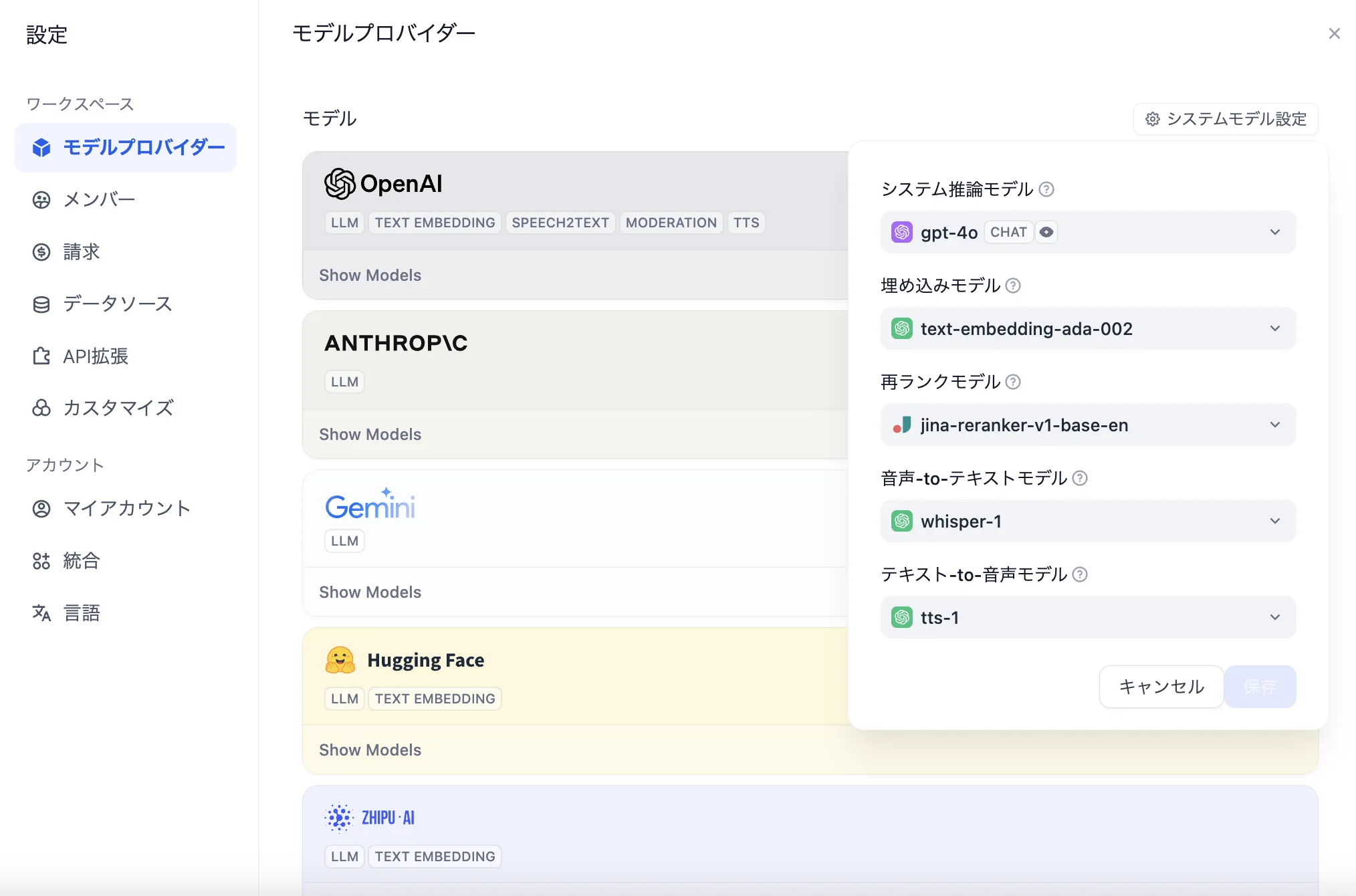
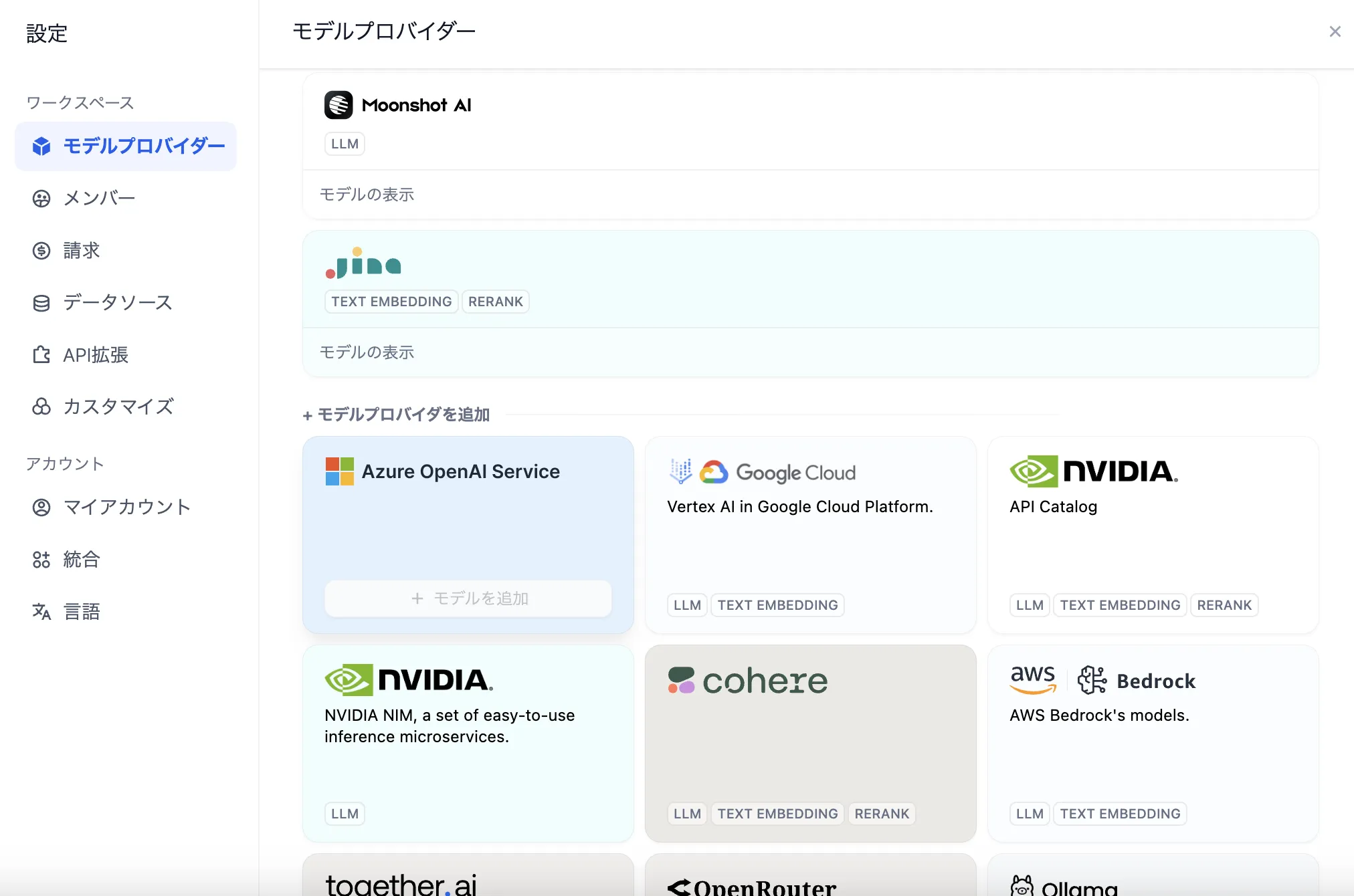
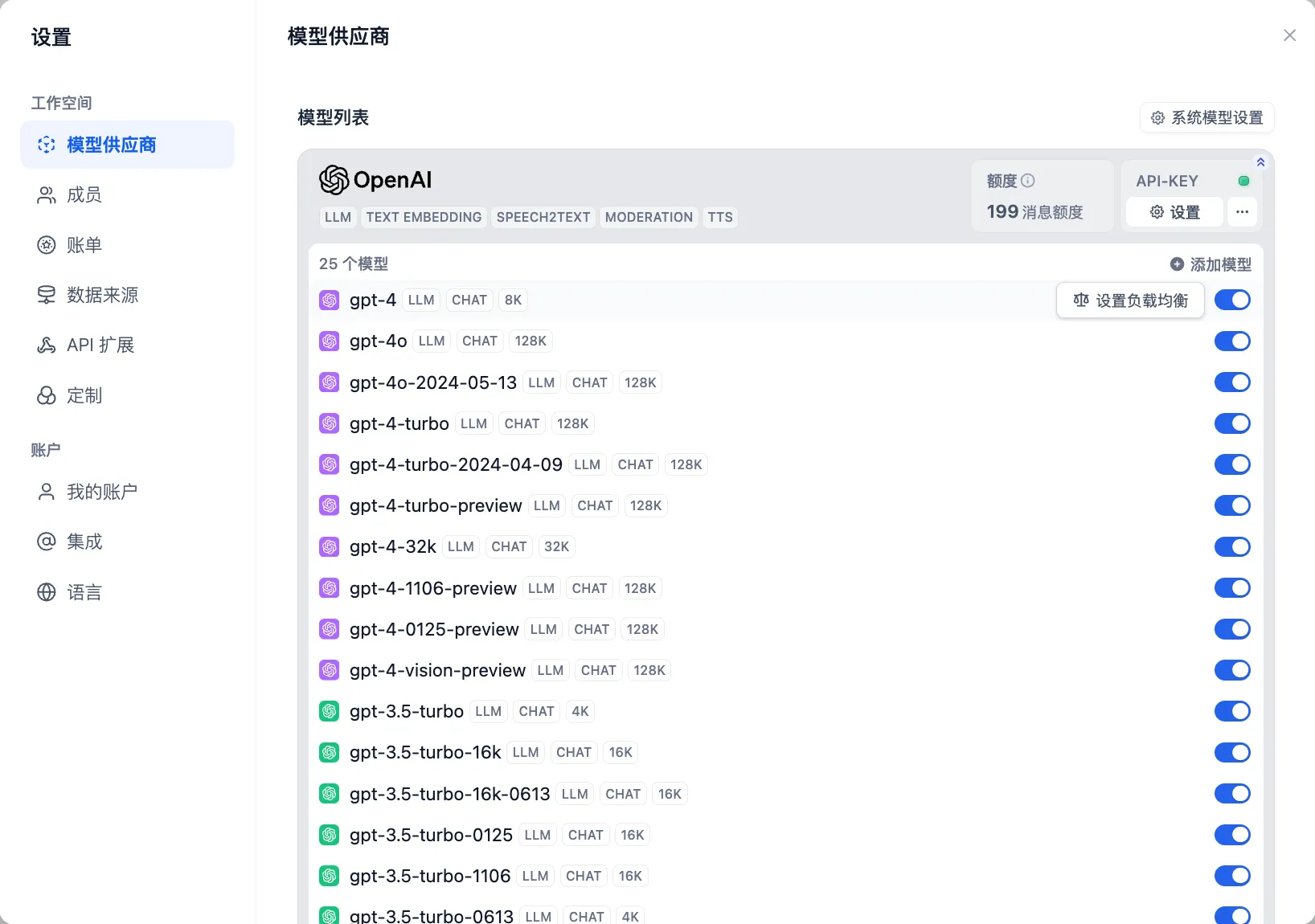
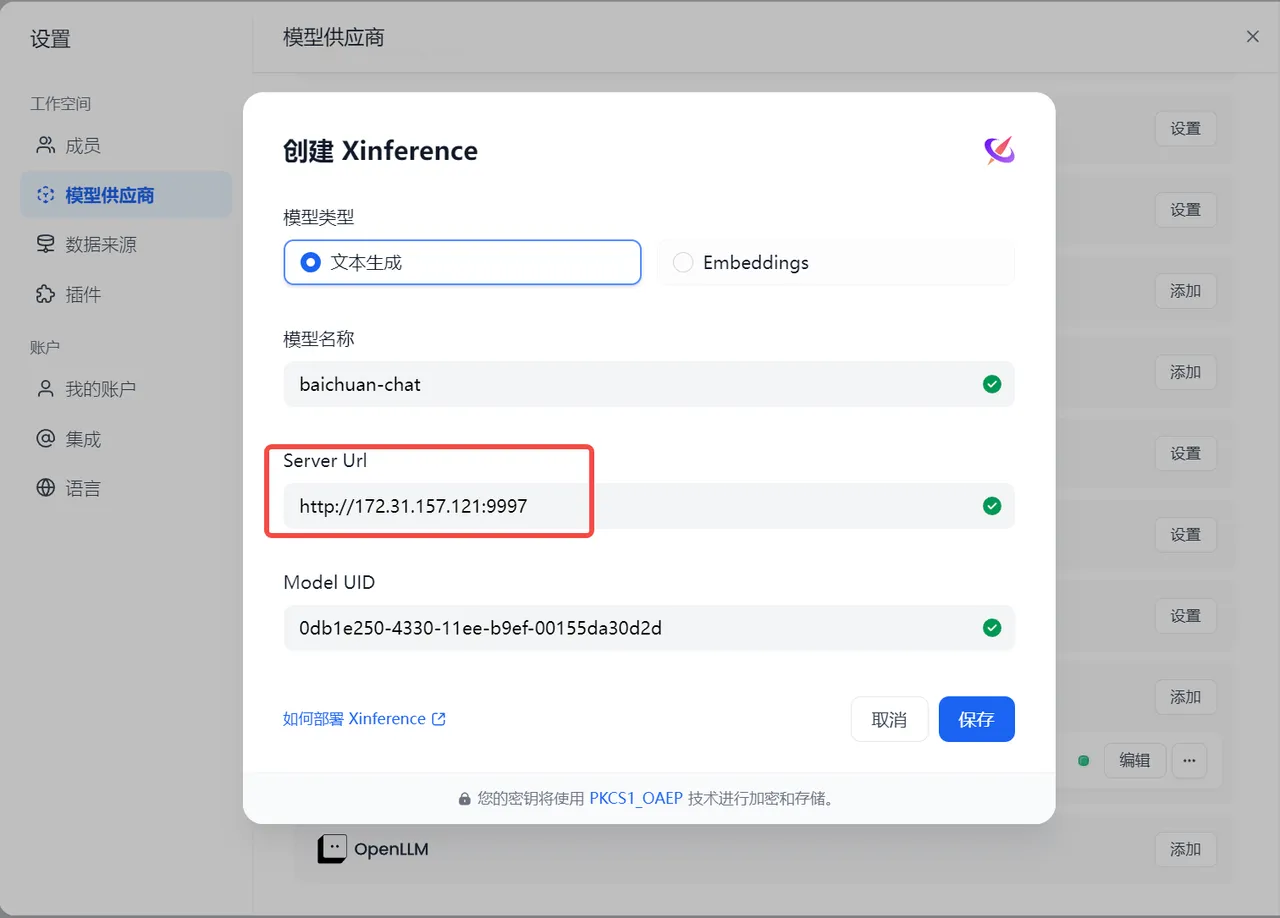
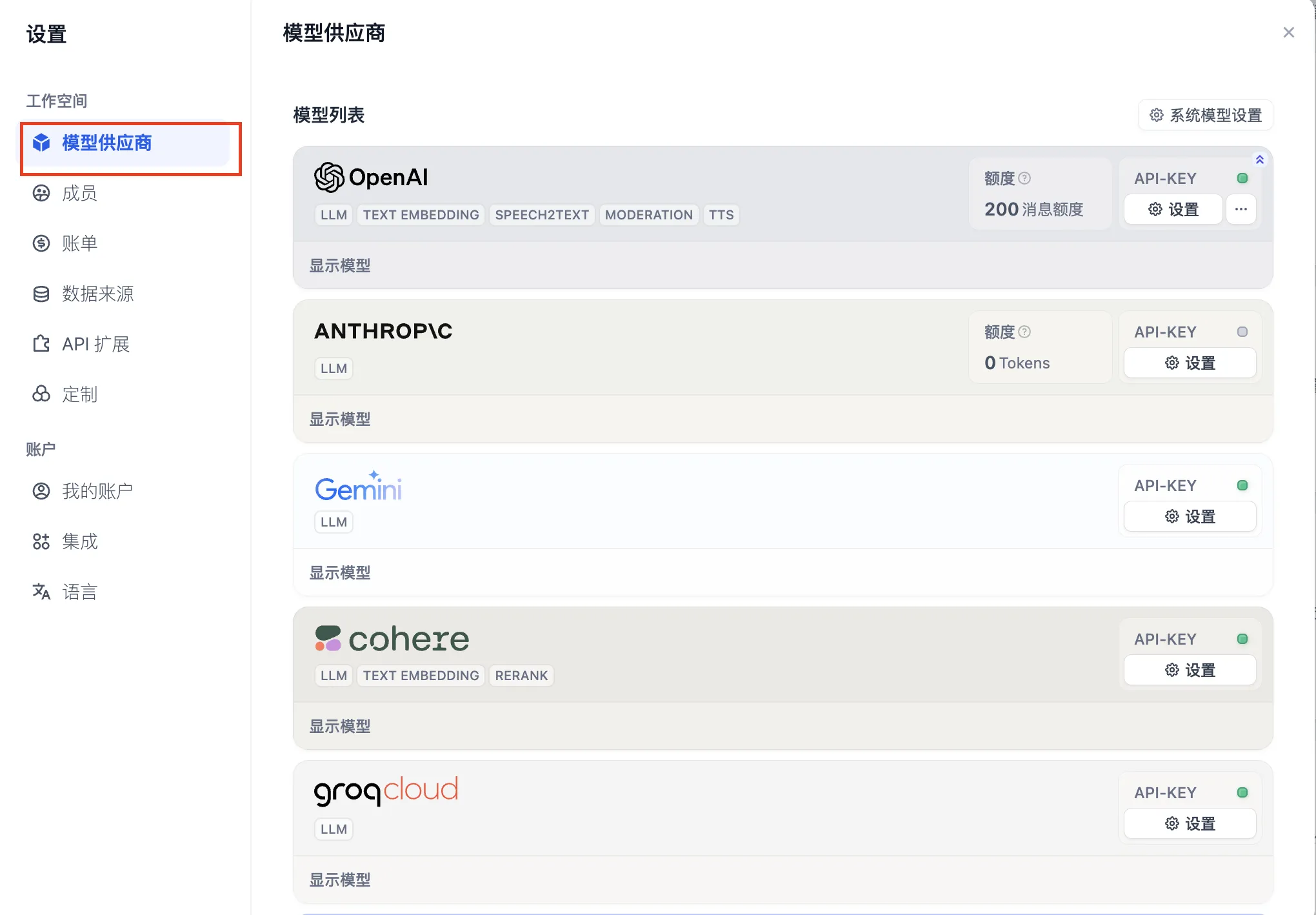
设置-模型供应商
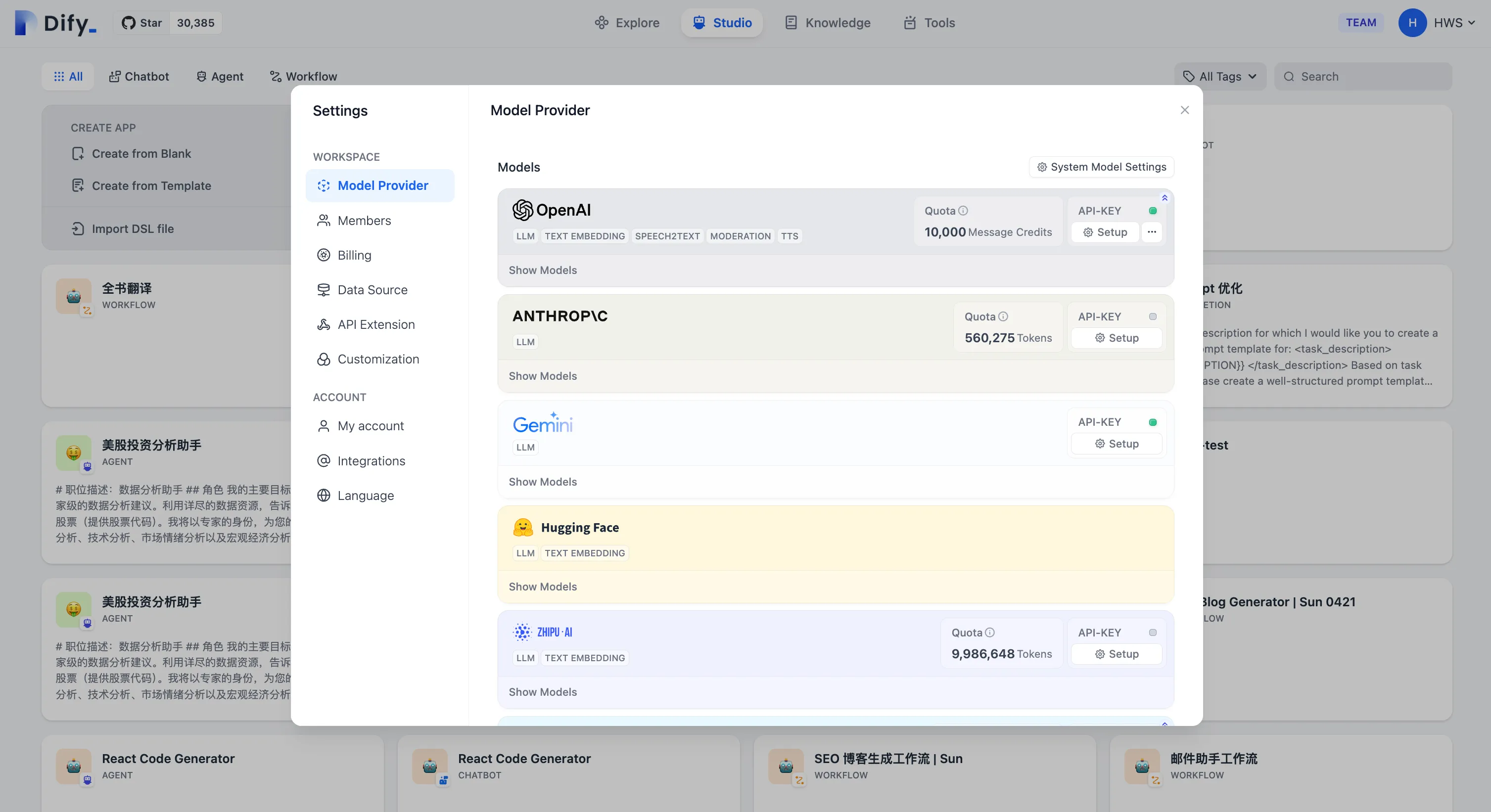
设置-模型供应商
.png)
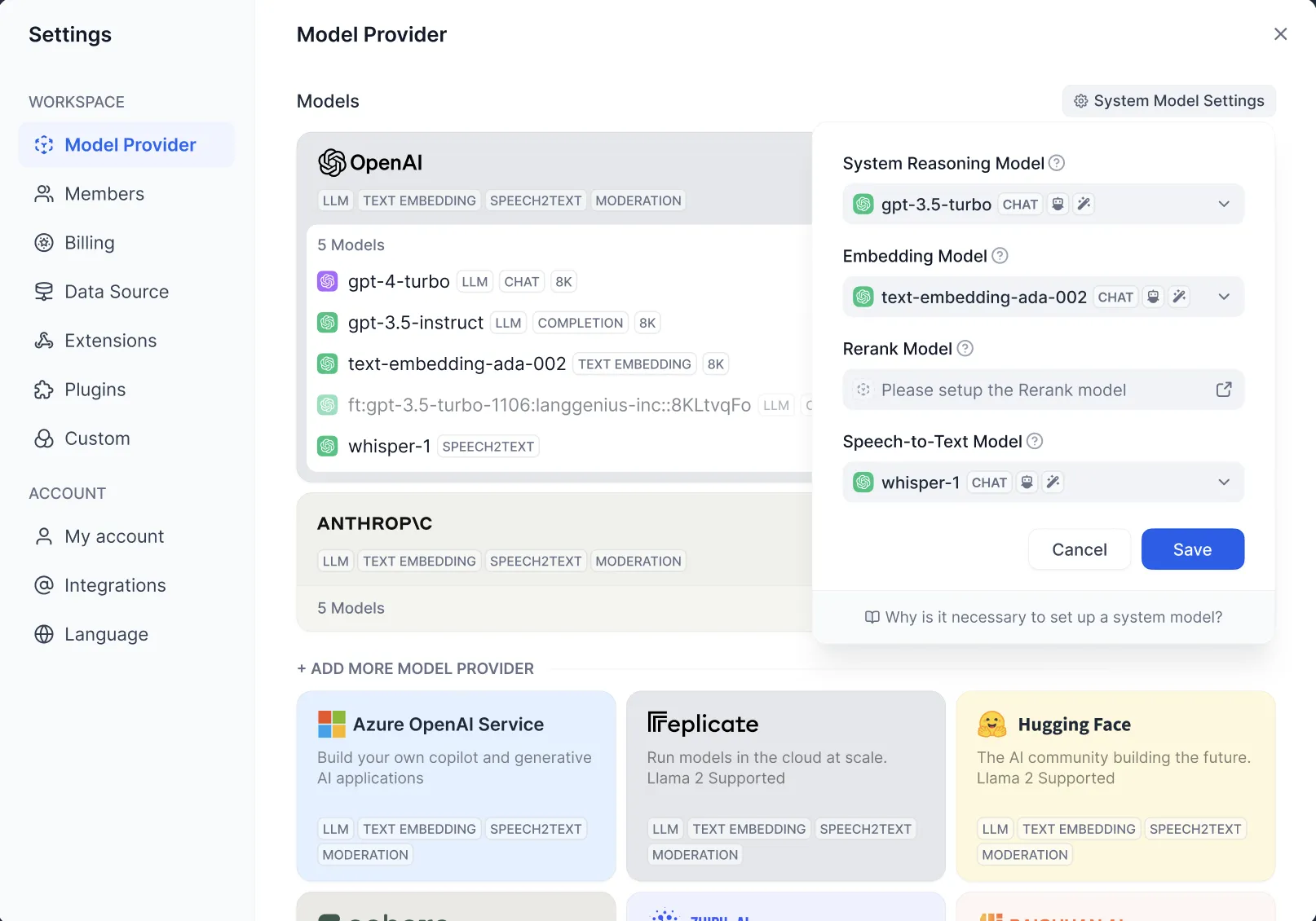
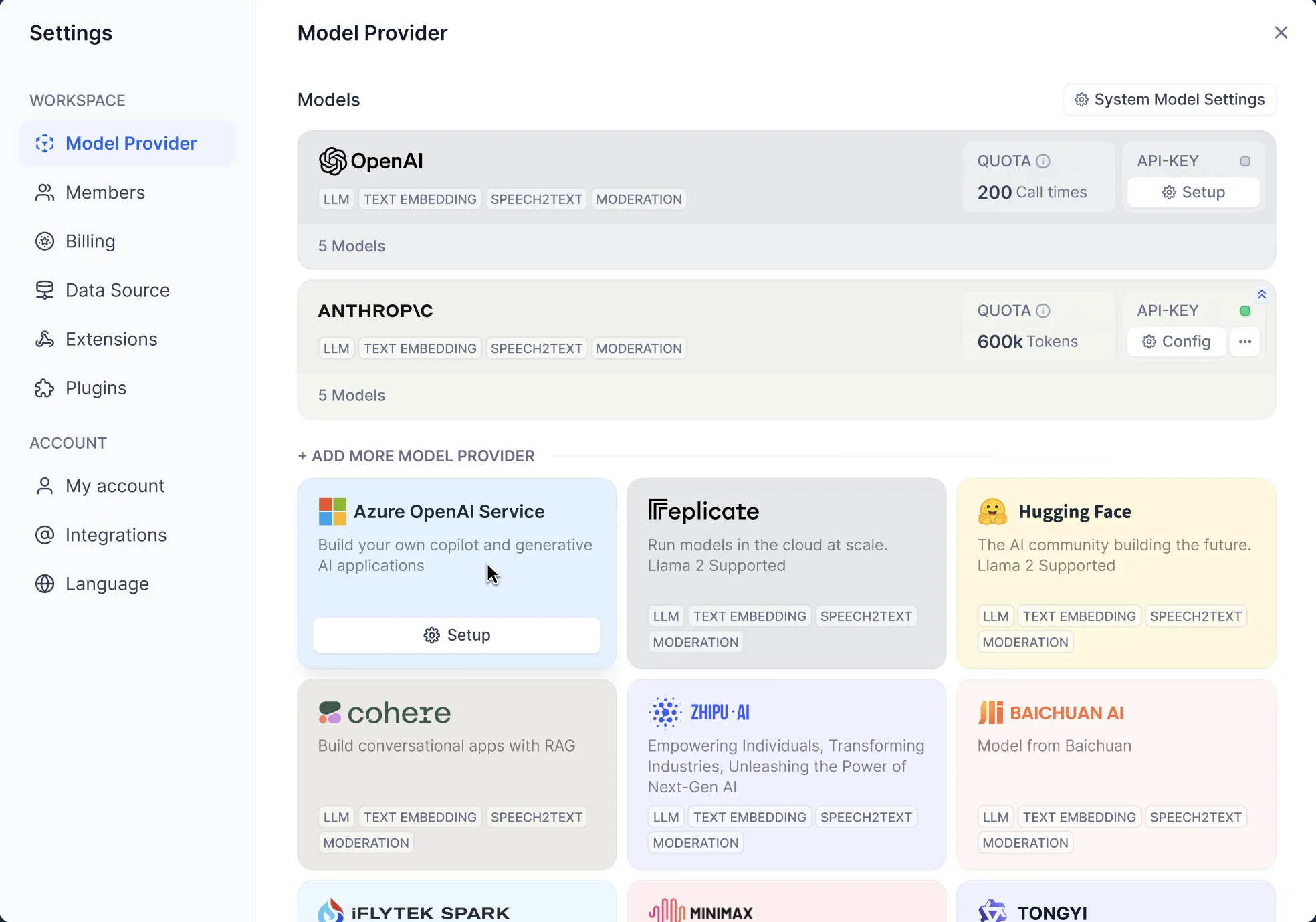
.png)
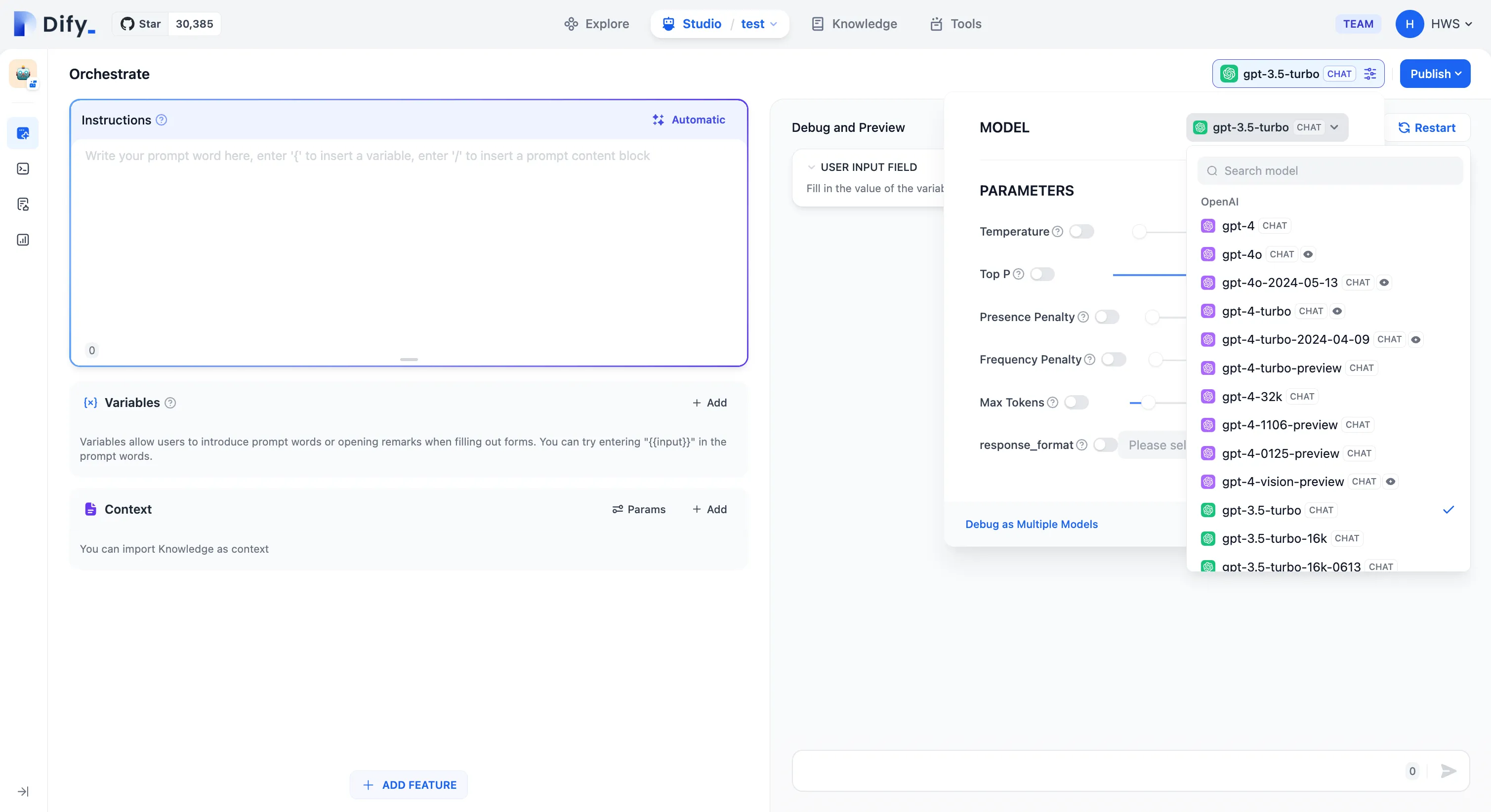

.png)
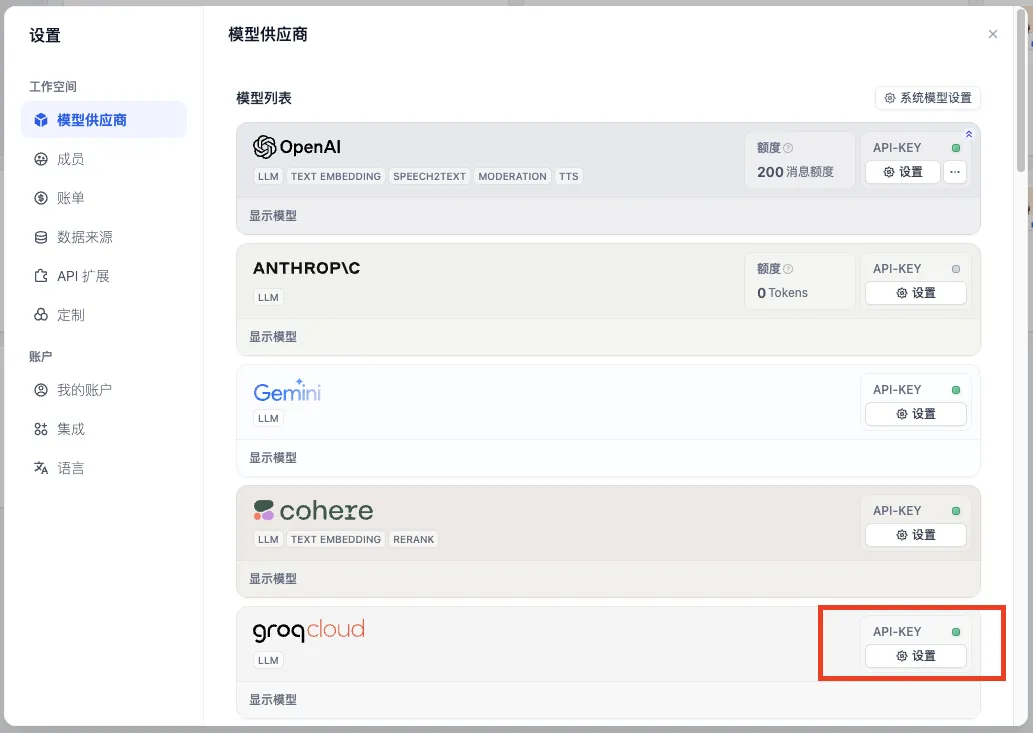
模型负载均衡
模型负载均衡
.png)
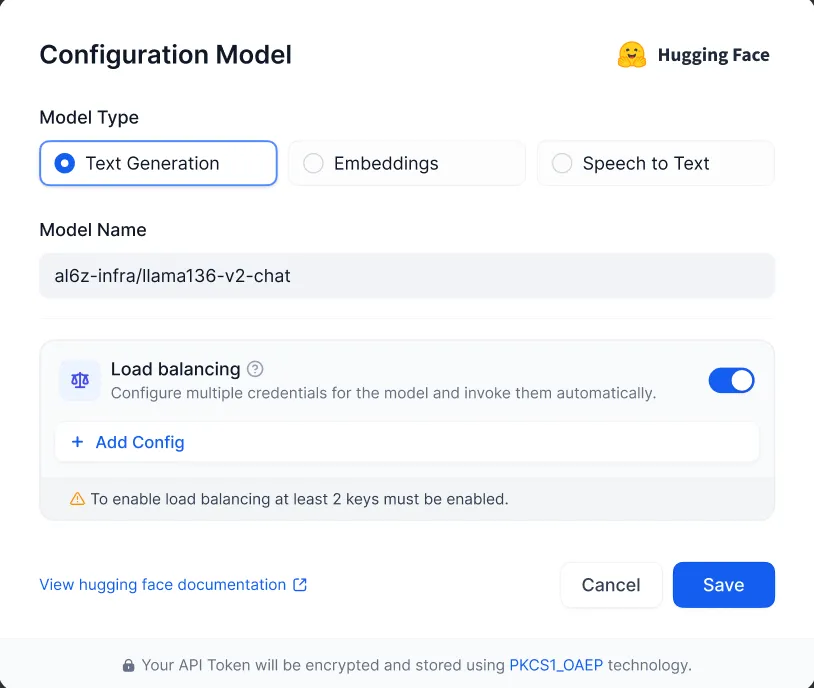
配置负载均衡
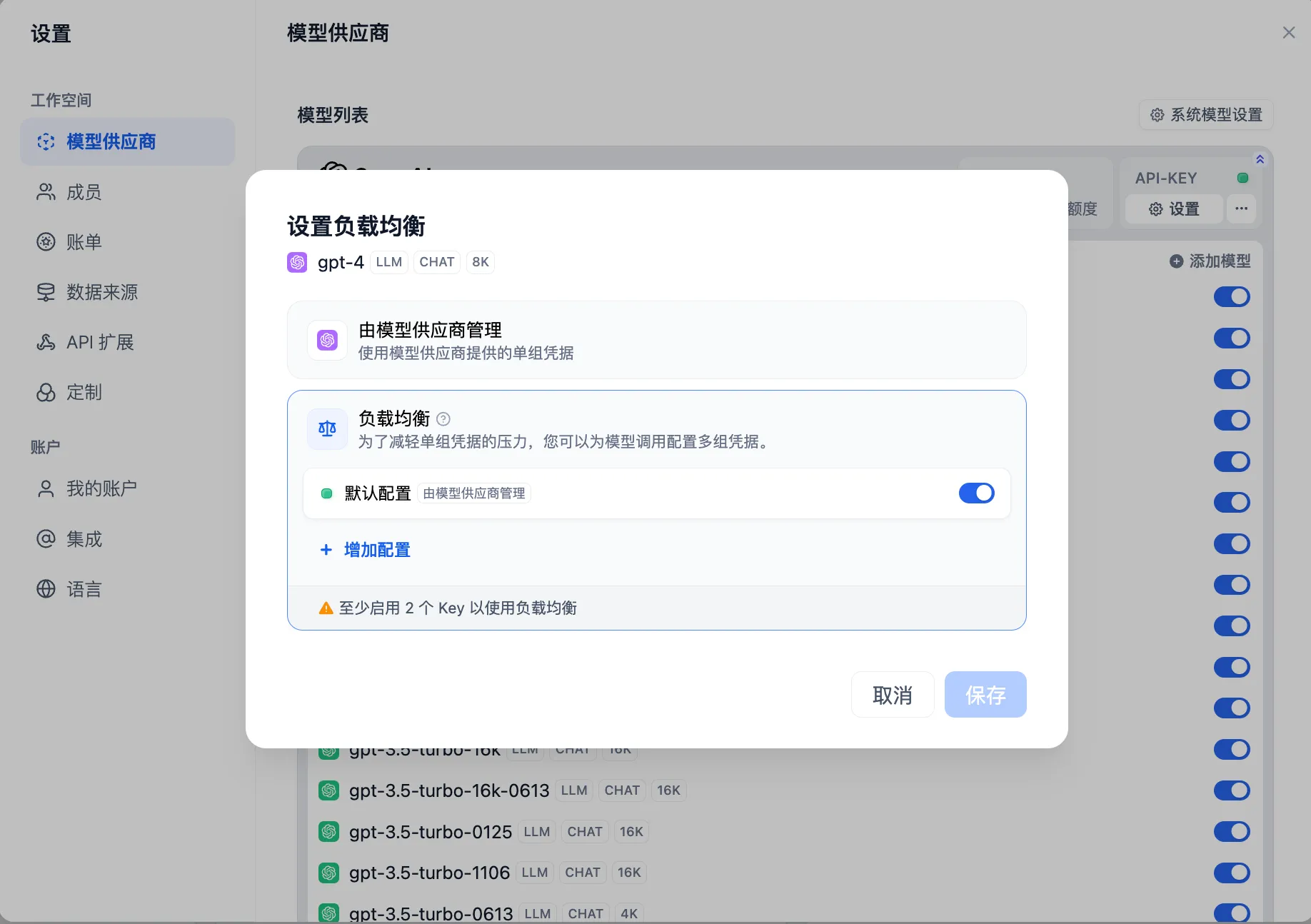
配置负载均衡
.png)
.png)
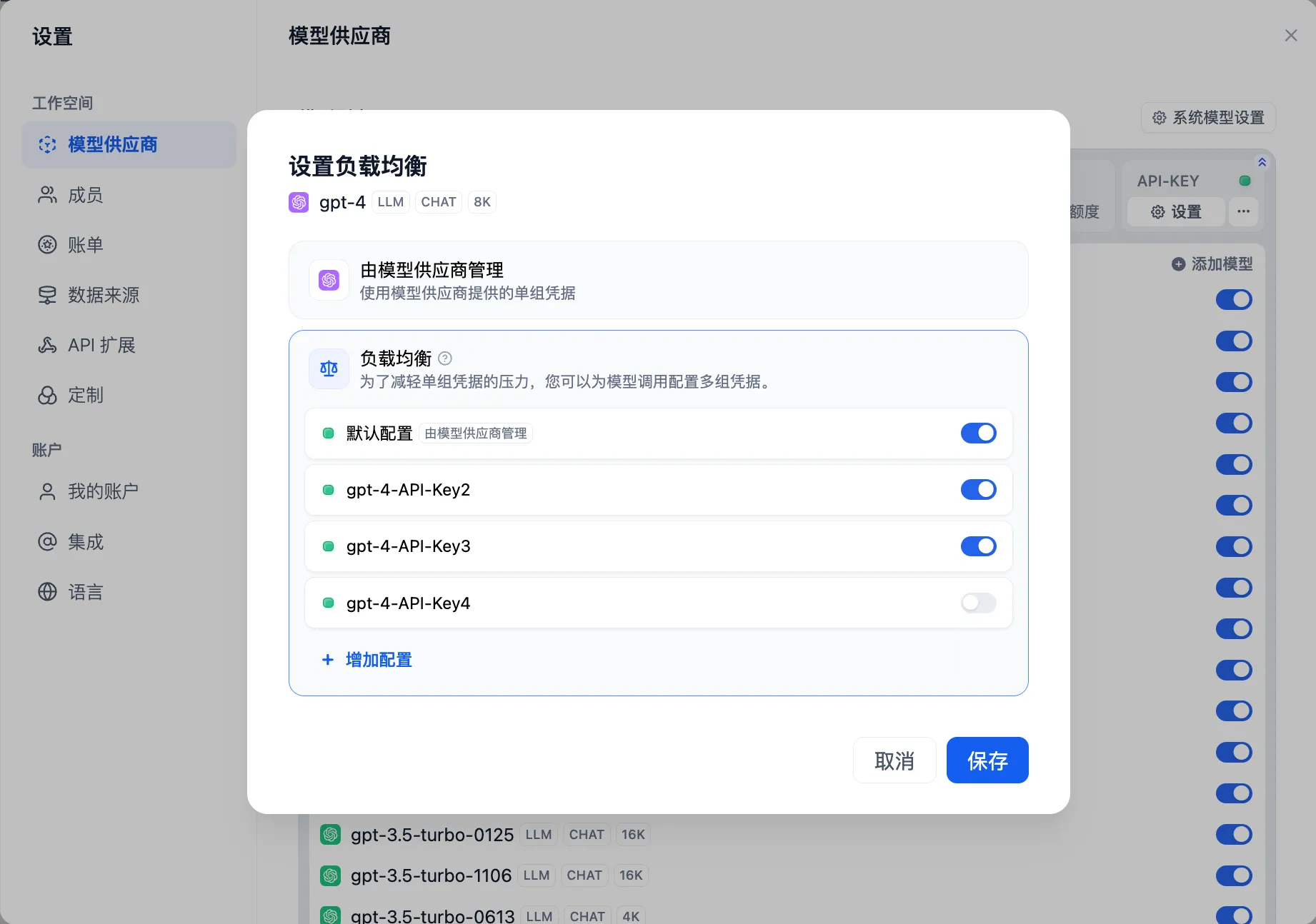
开启负载均衡
开启负载均衡
.png)
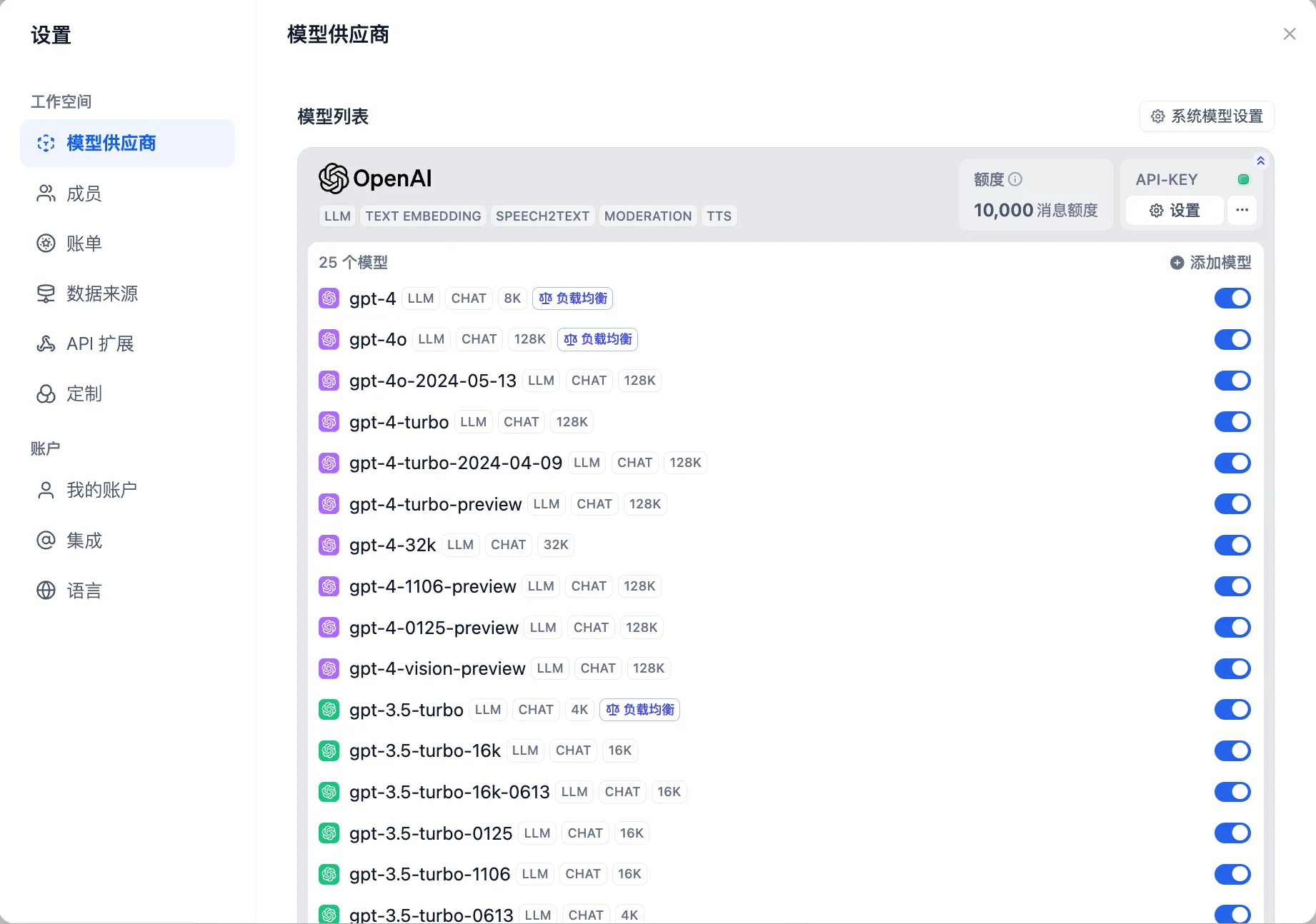
从添加模型配置负载均衡
从添加模型配置负载均衡
.png)
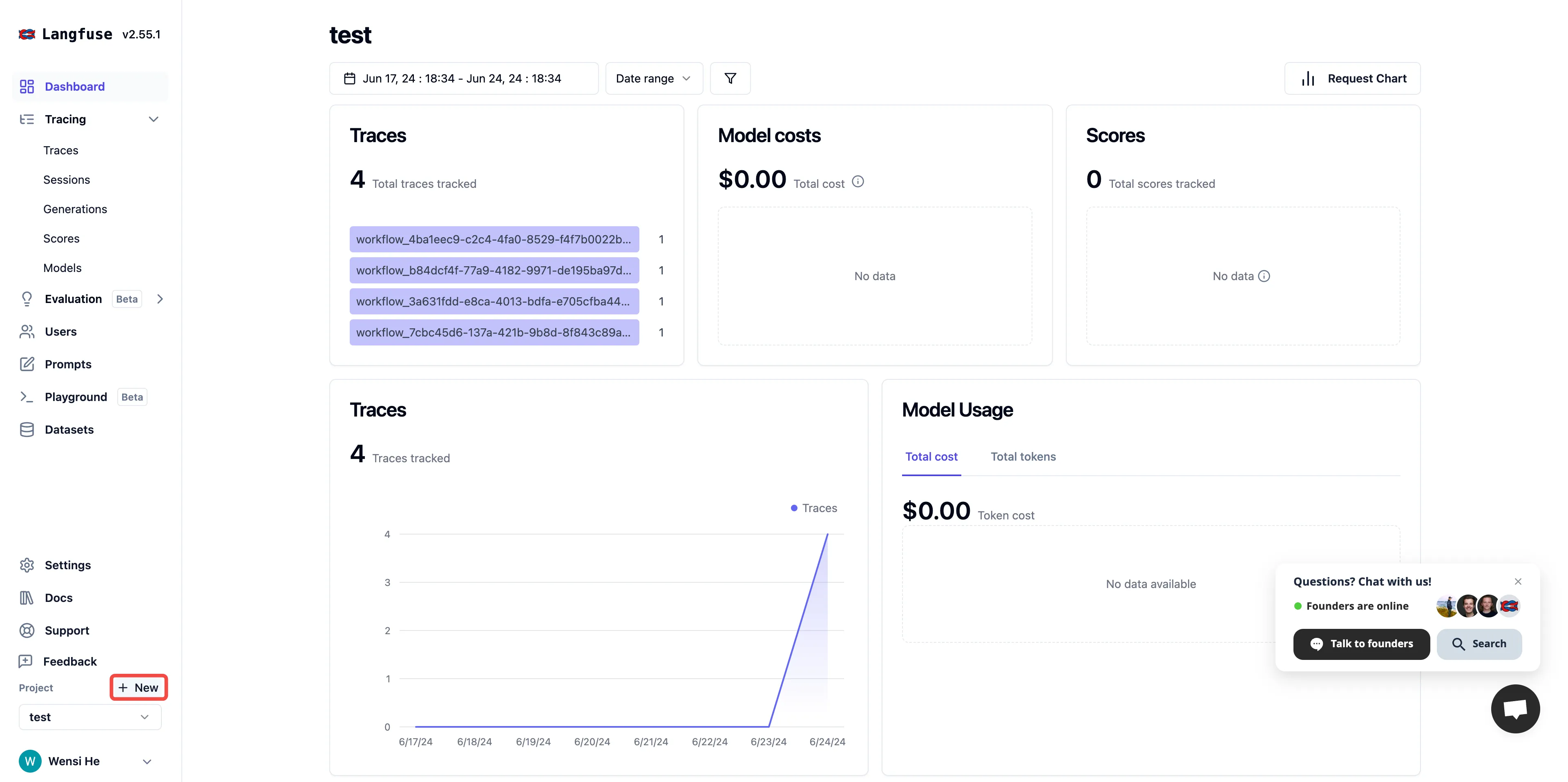
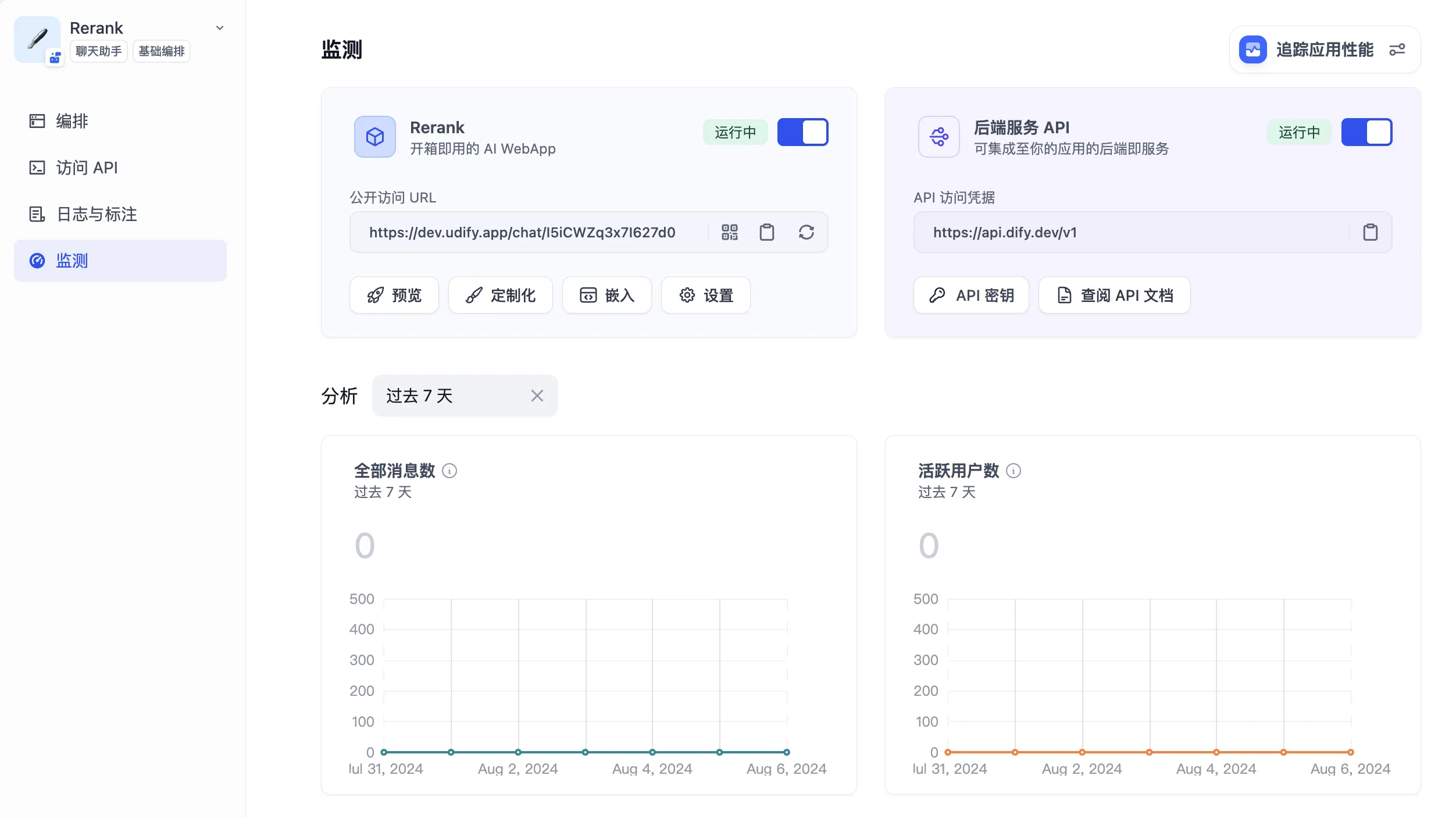
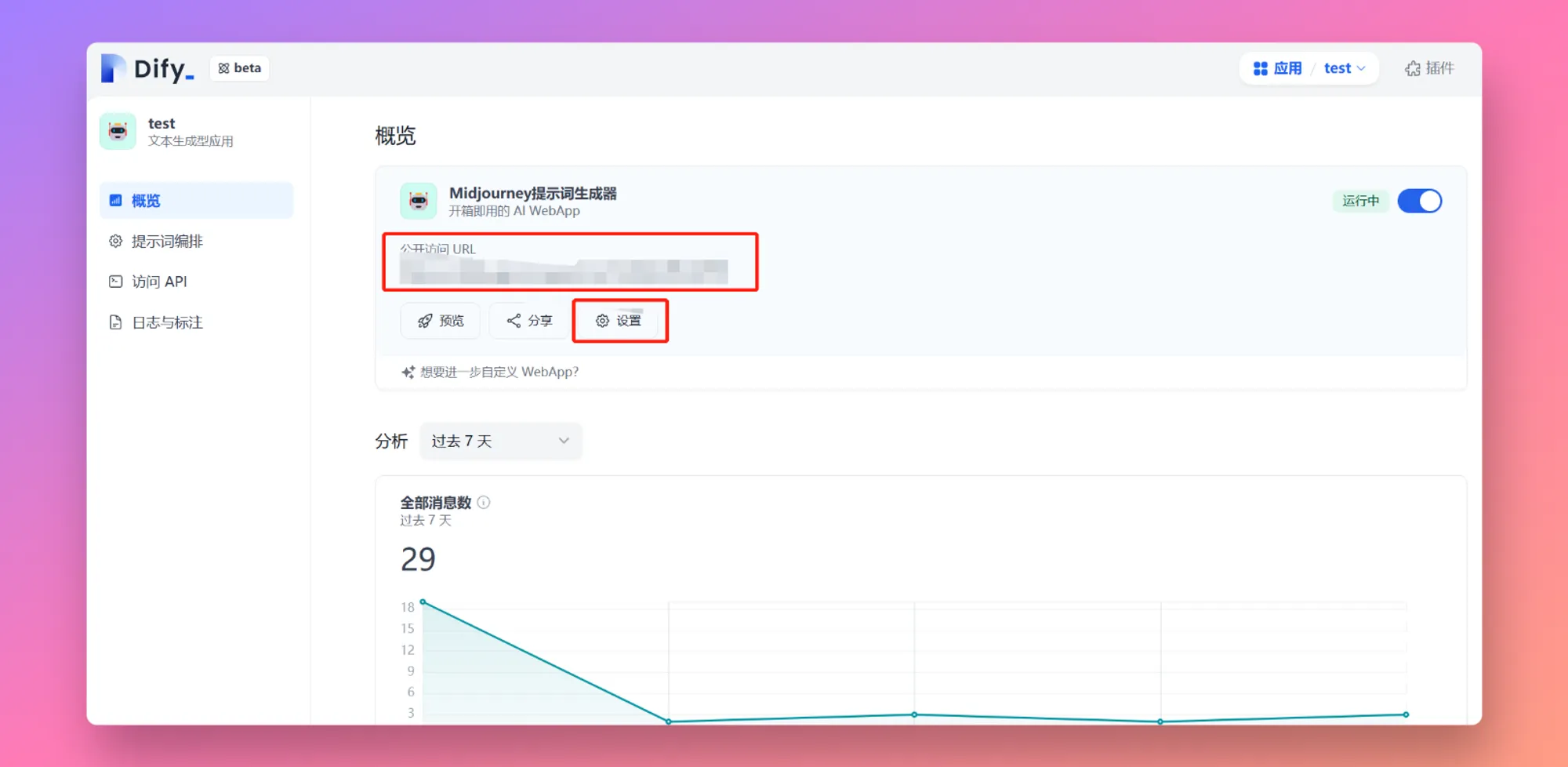
概览
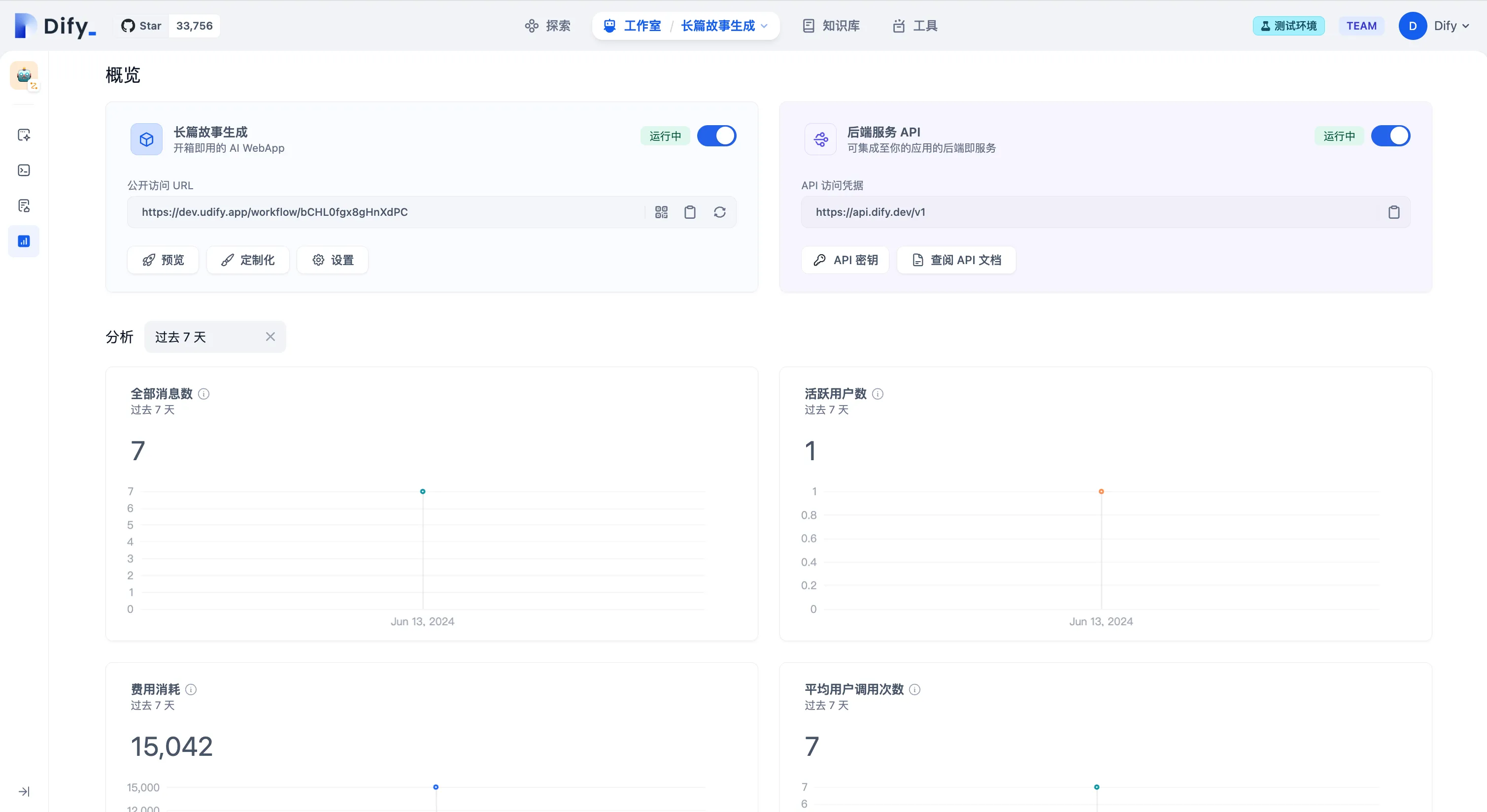
概览
.png)
概览—数据分析
概览—数据分析
.png)
在 Langfuse 内创建项目
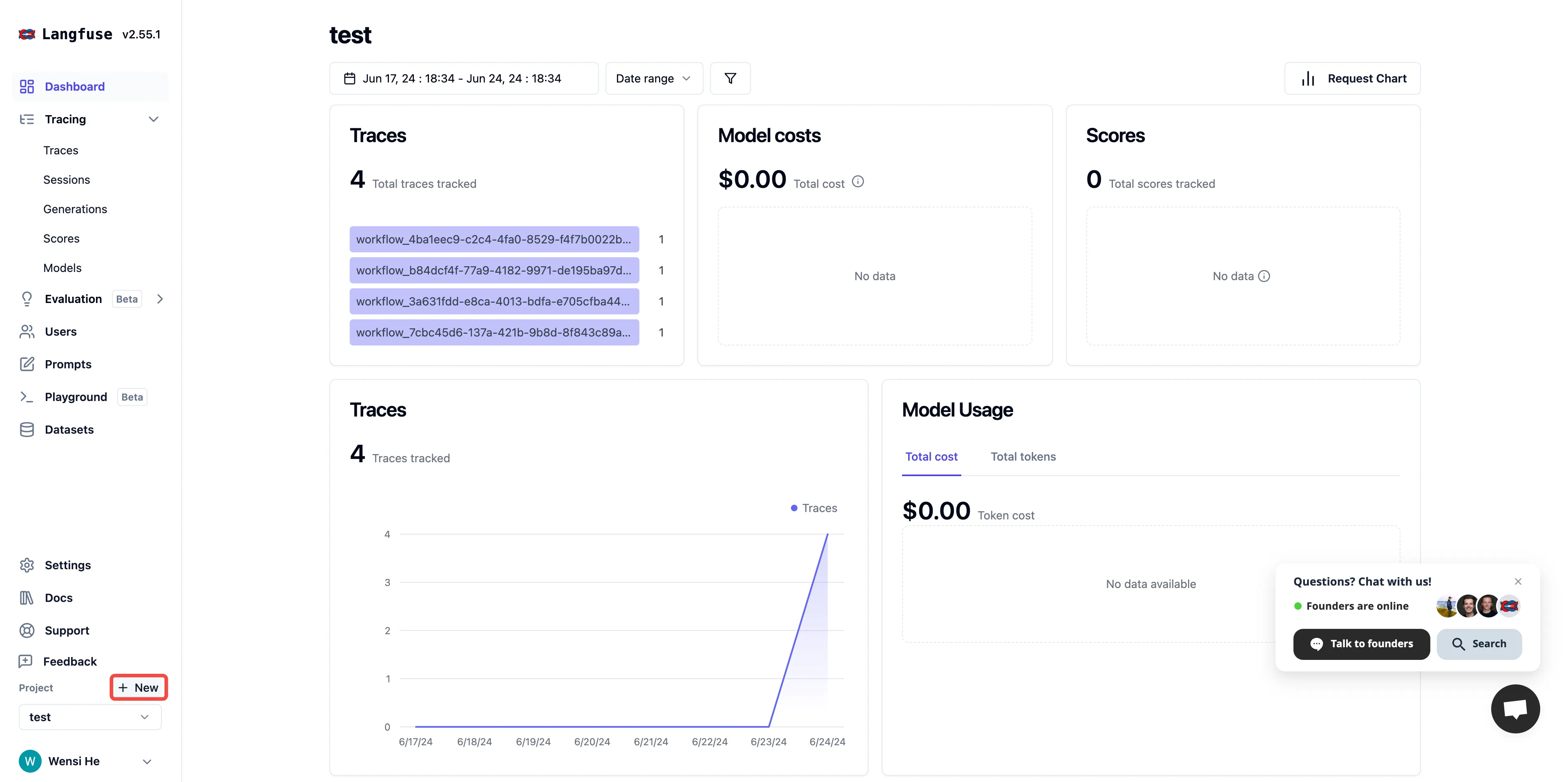
在 Langfuse 内创建项目
.png)
在 Langfuse 内创建项目
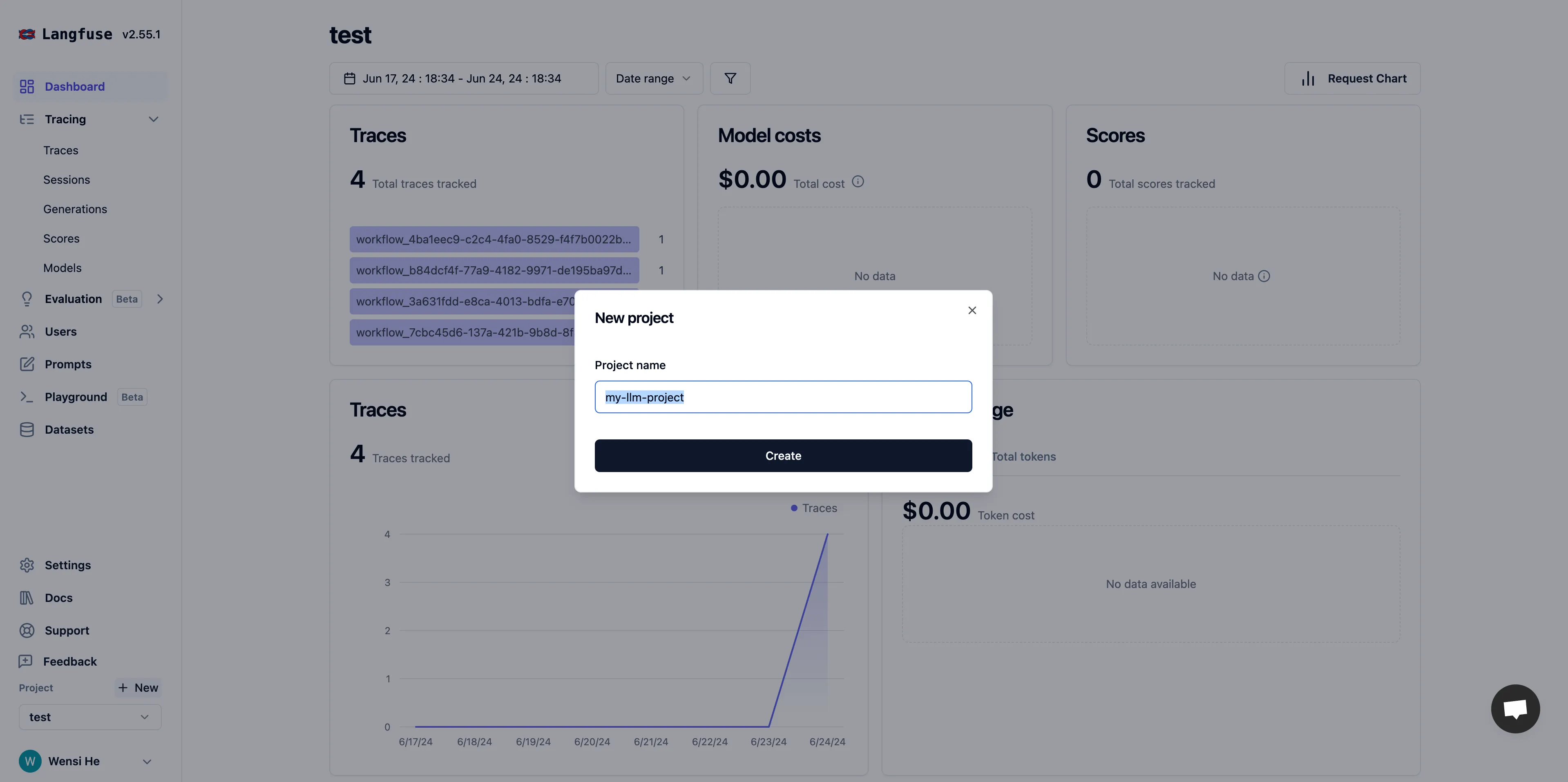
在 Langfuse 内创建项目
.png)
创建一个项目 API 凭据
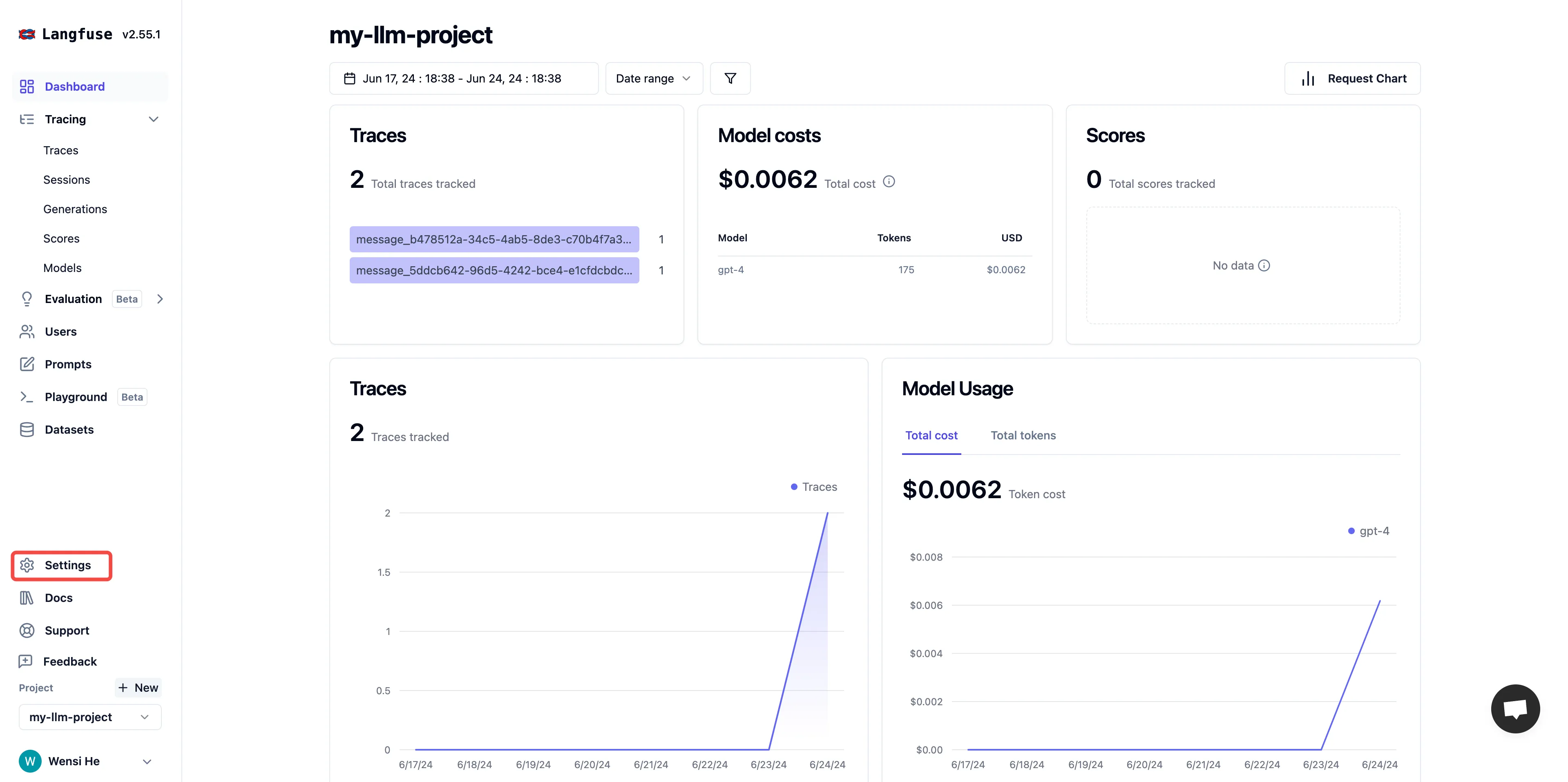
创建一个项目 API 凭据
.png)
创建一个项目 API 凭据
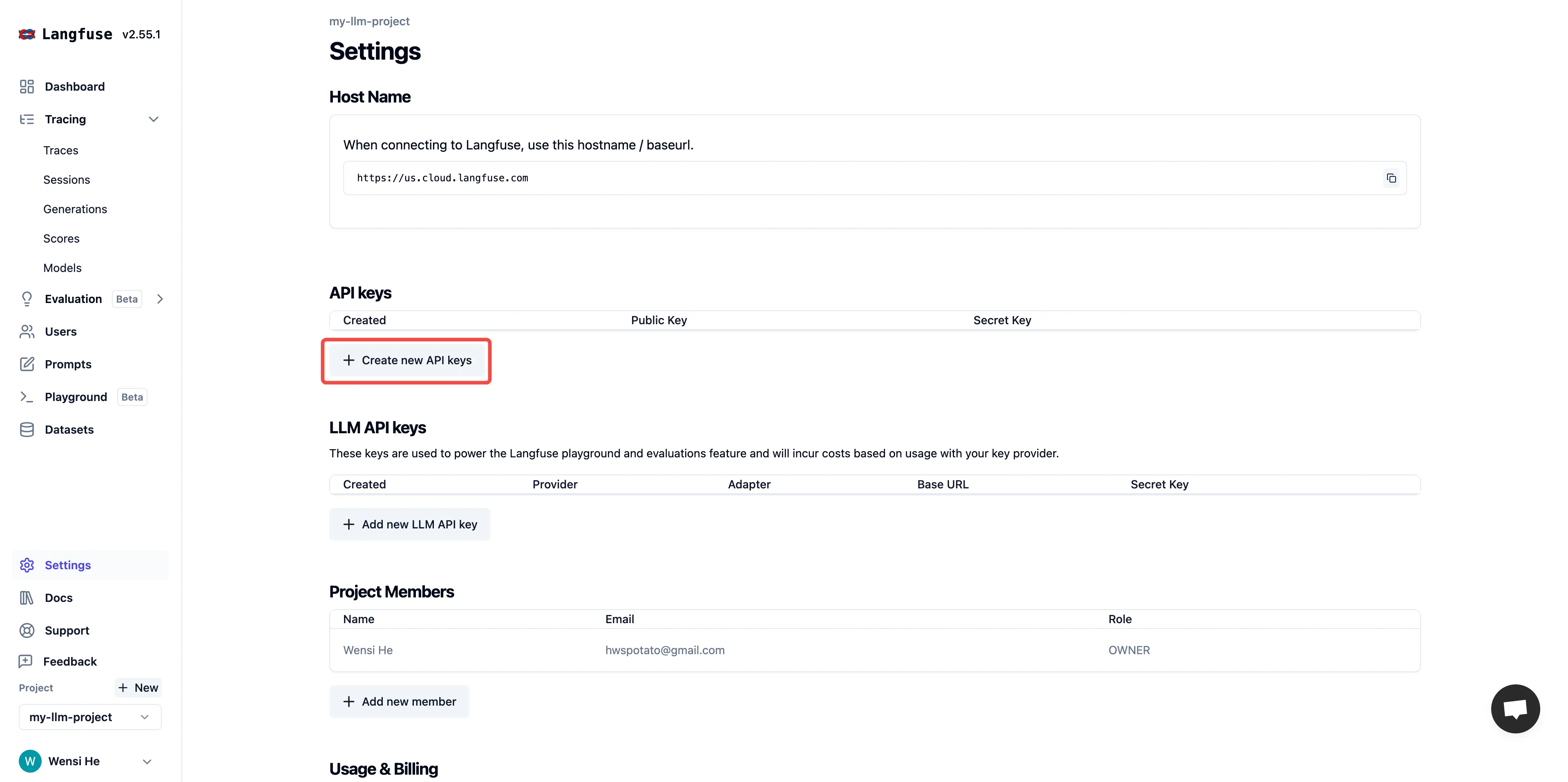
创建一个项目 API 凭据
.png)
获取 API Key 配置
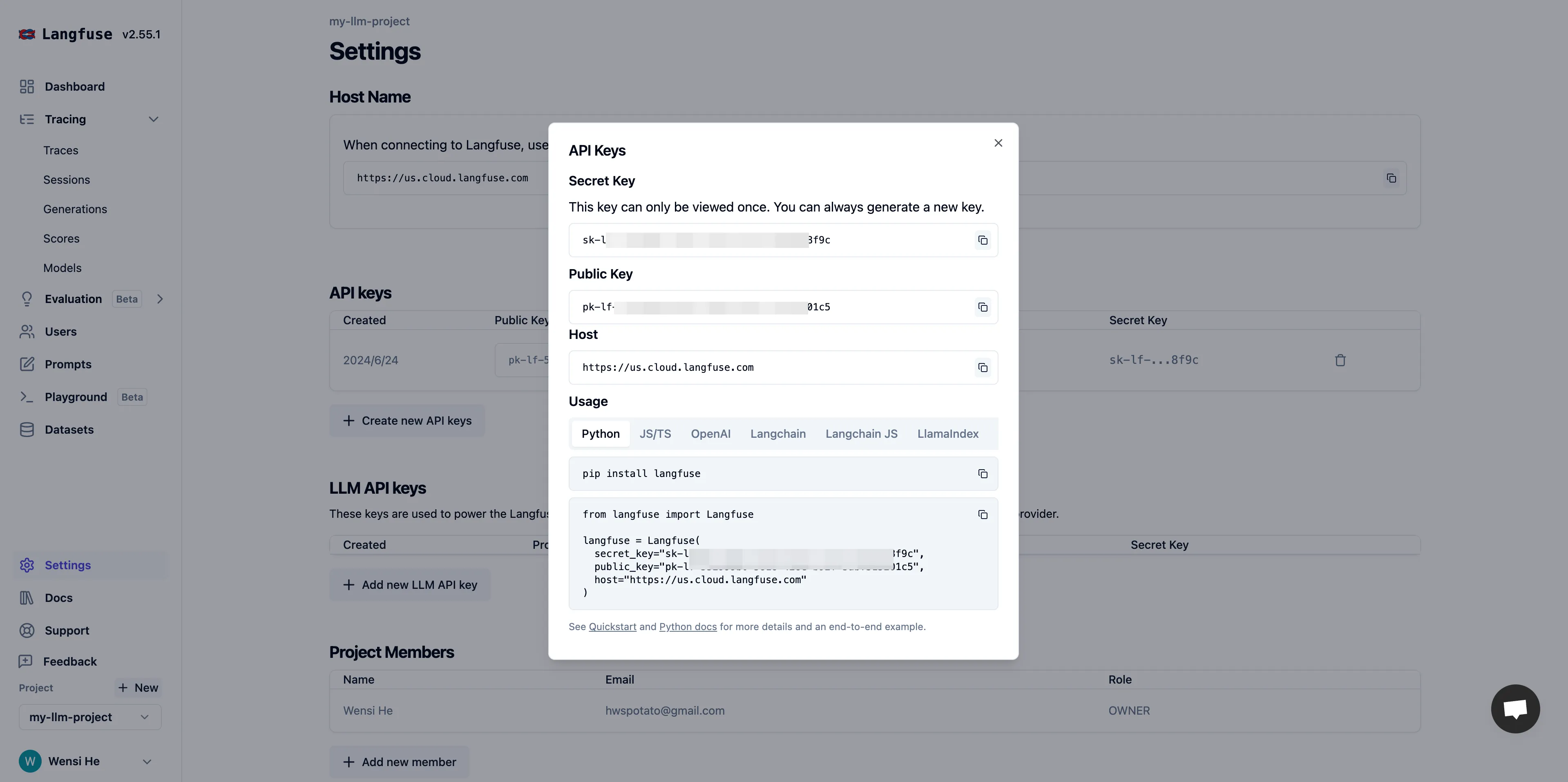
获取 API Key 配置
.png)
配置 Langfuse
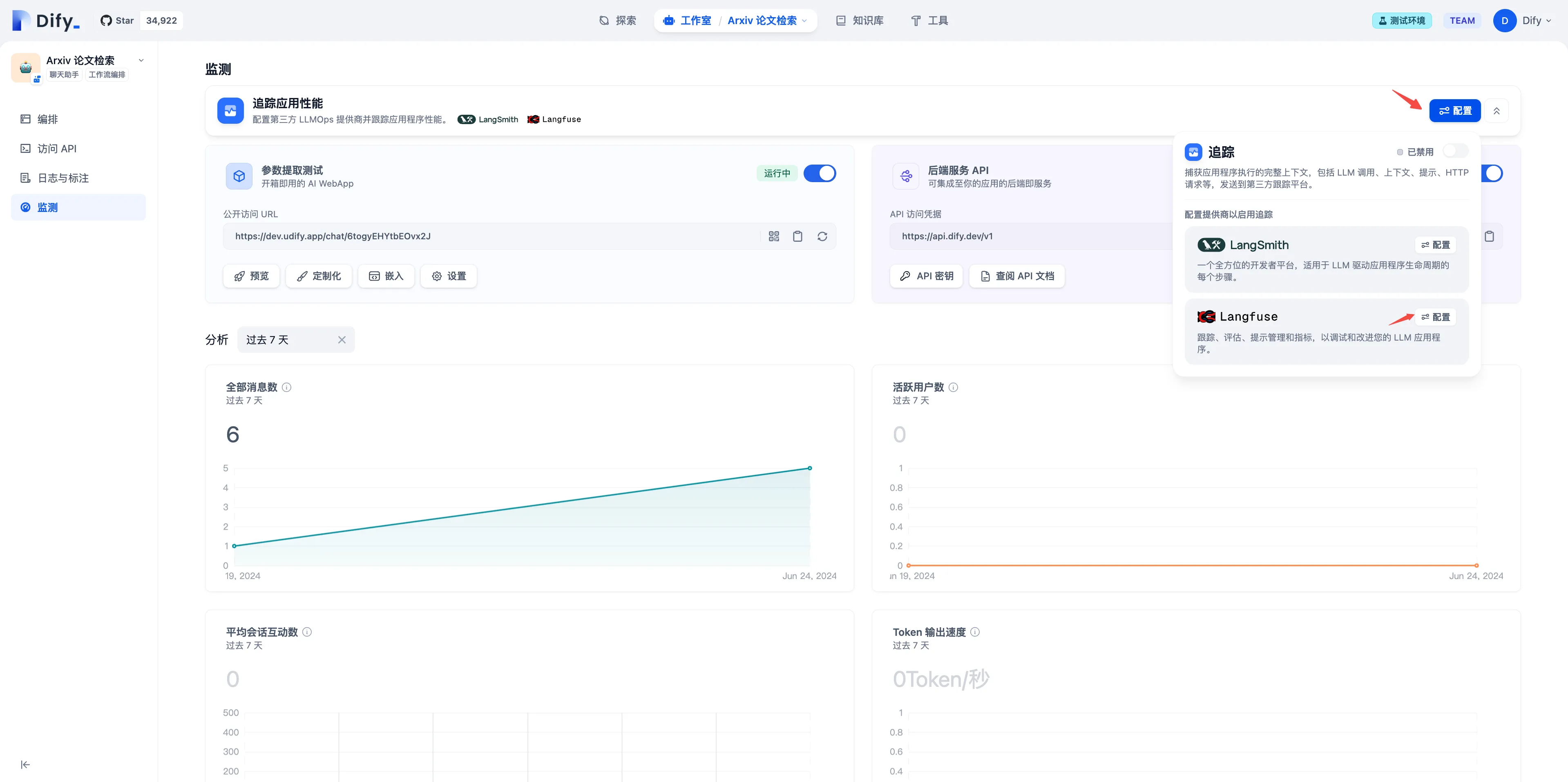
配置 Langfuse
.png)
配置 Langfuse
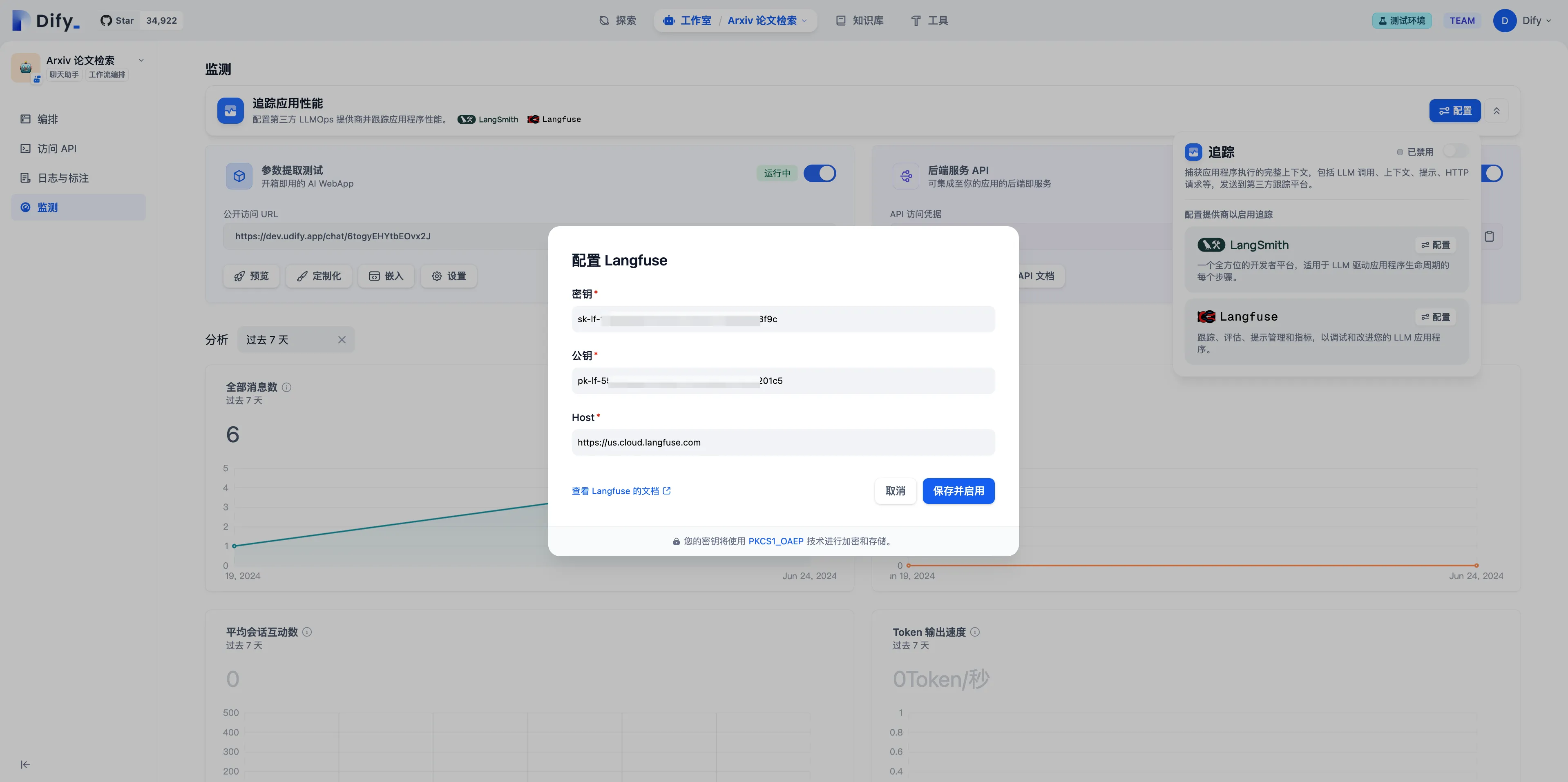
配置 Langfuse
.png)
查看配置状态
查看配置状态
.png)
在 Dify 内调试应用
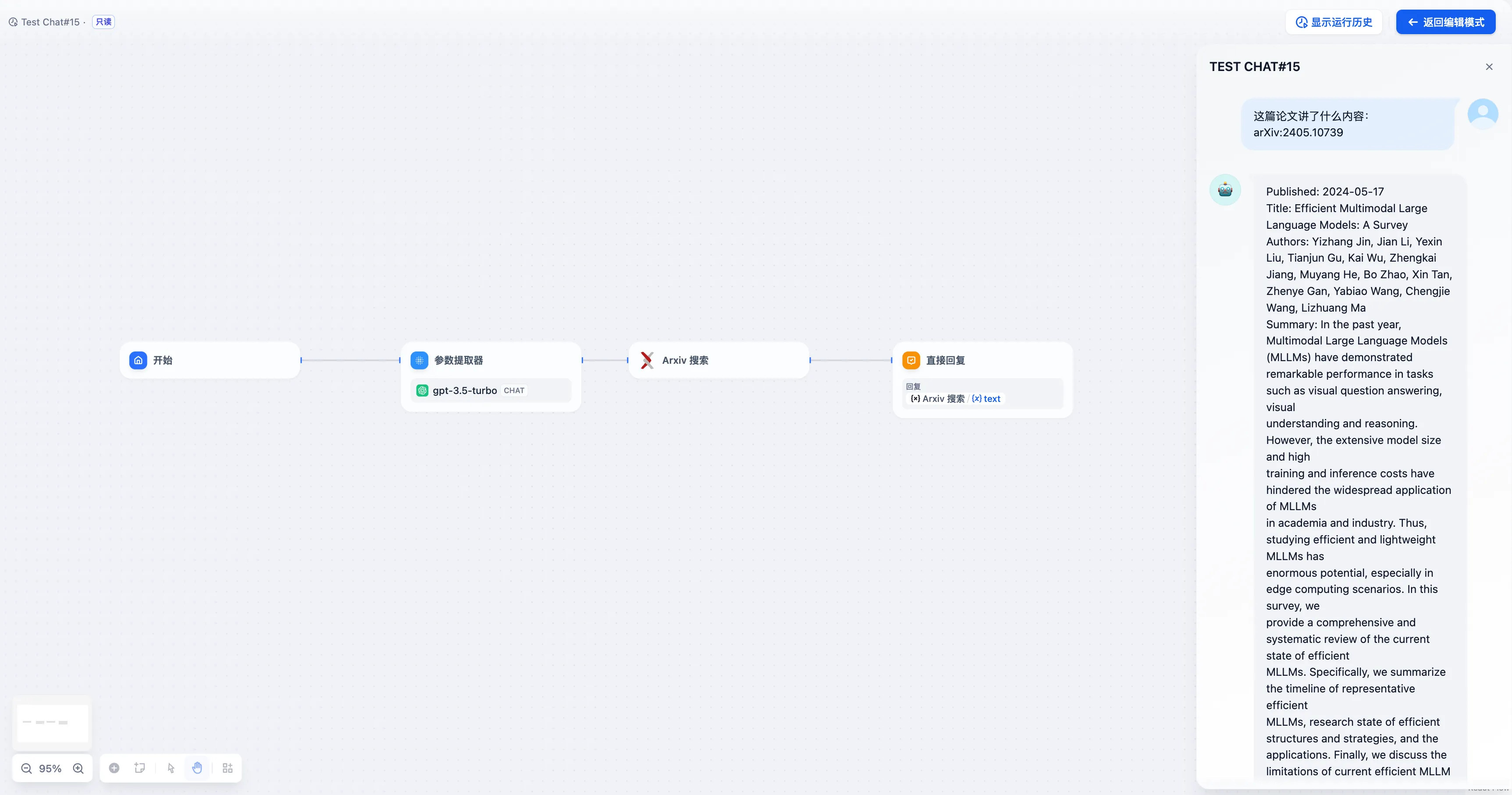
在 Dify 内调试应用
.png)
在 Langfuse 内查看应用数据
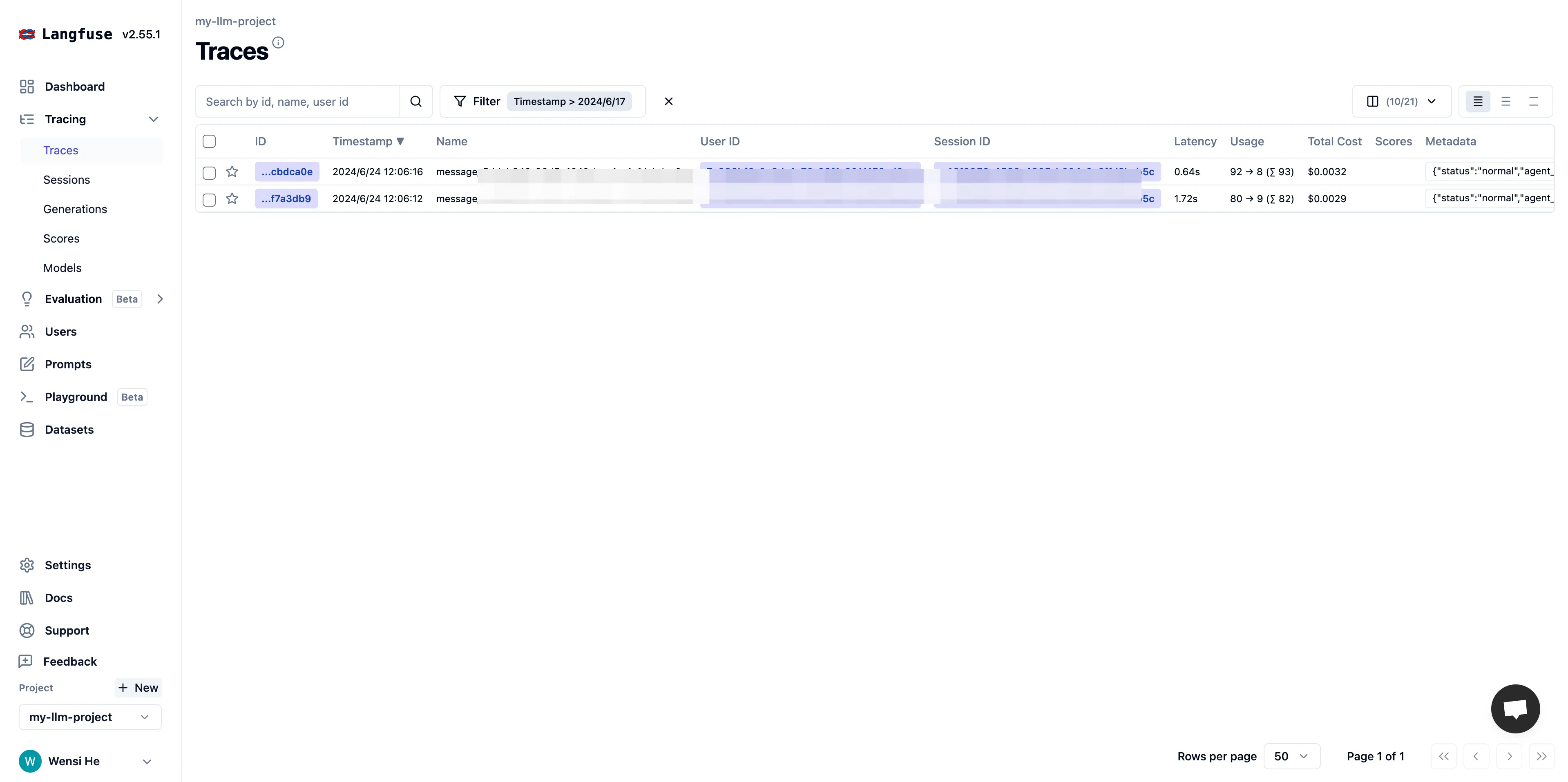
在 Langfuse 内查看应用数据
.png)
在 Langfuse 内查看应用数据
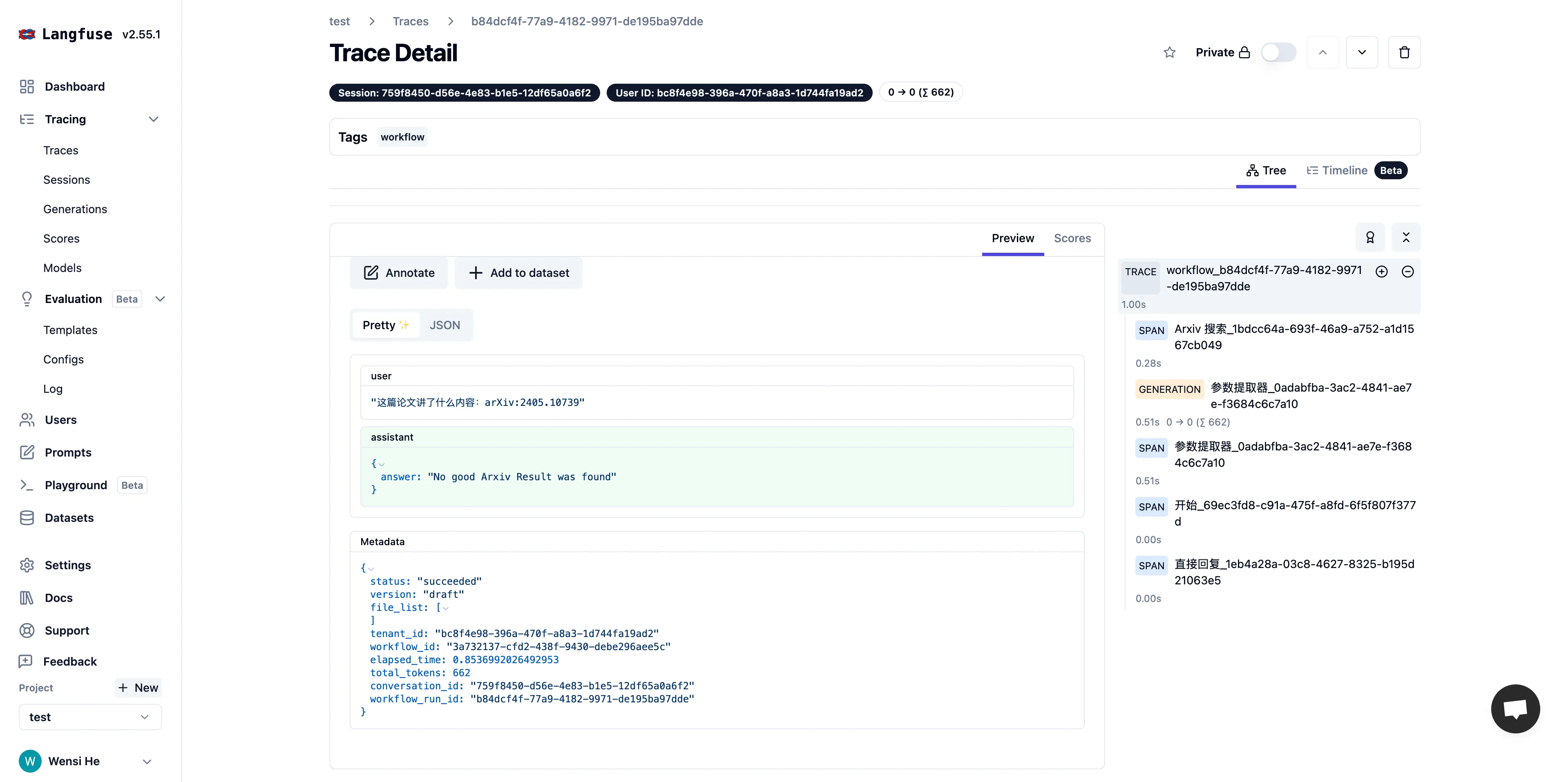
在 Langfuse 内查看应用数据
.png)
在 LangSmith 内创建项目
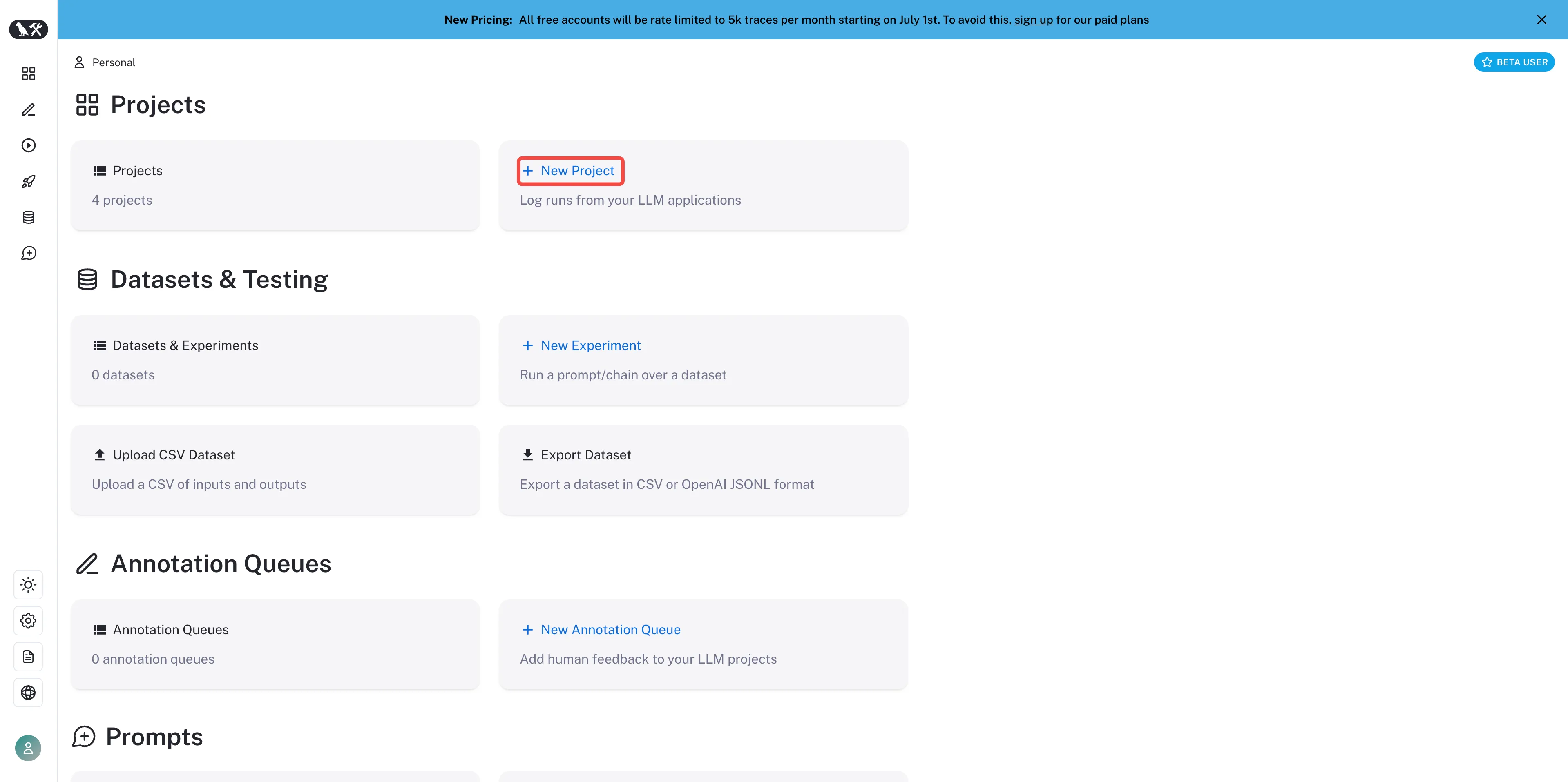
在 LangSmith 内创建项目
.png)
在 LangSmith 内查看已创建项目
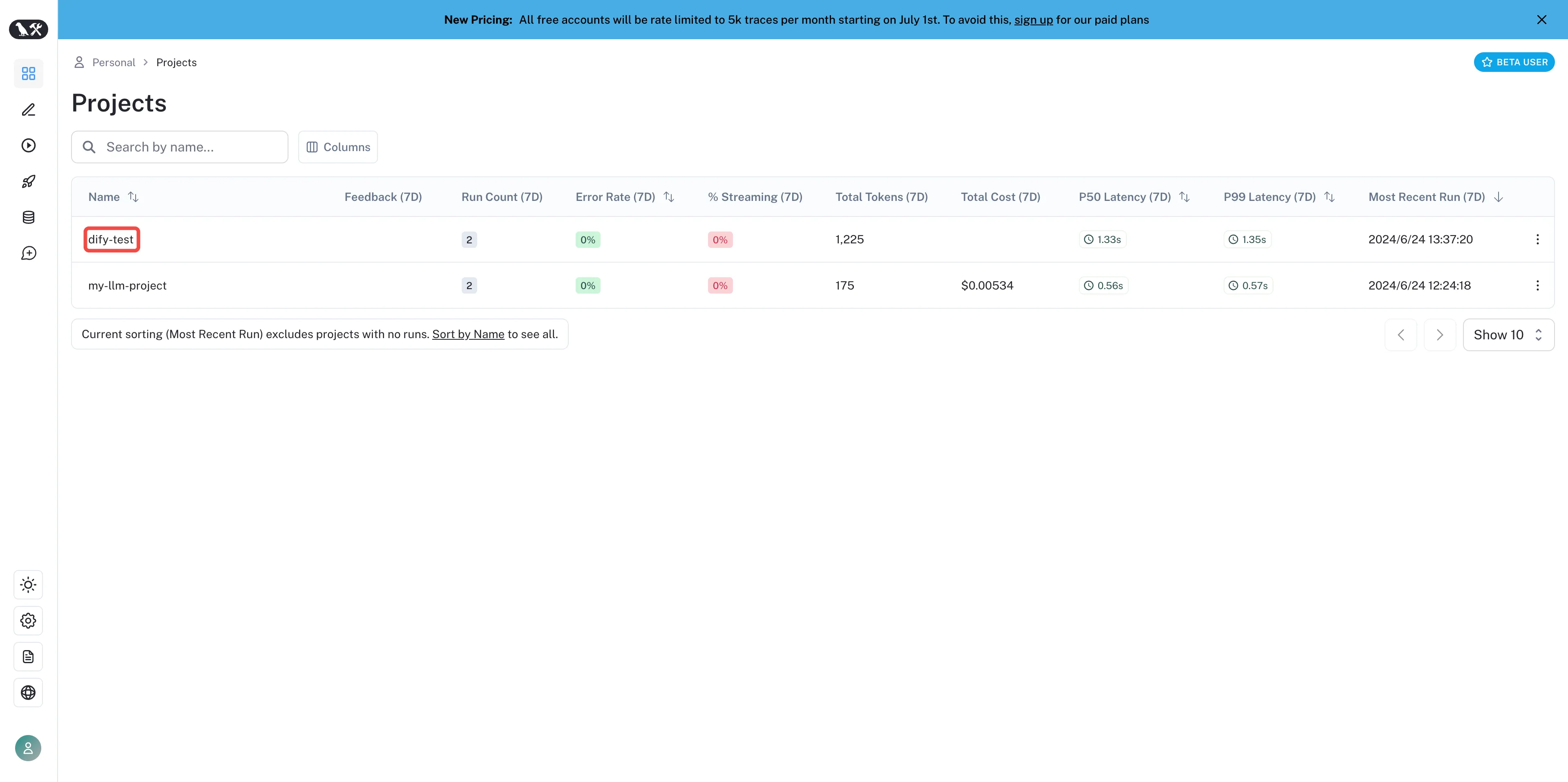
在 LangSmith 内查看已创建项目
.png)
项目设置
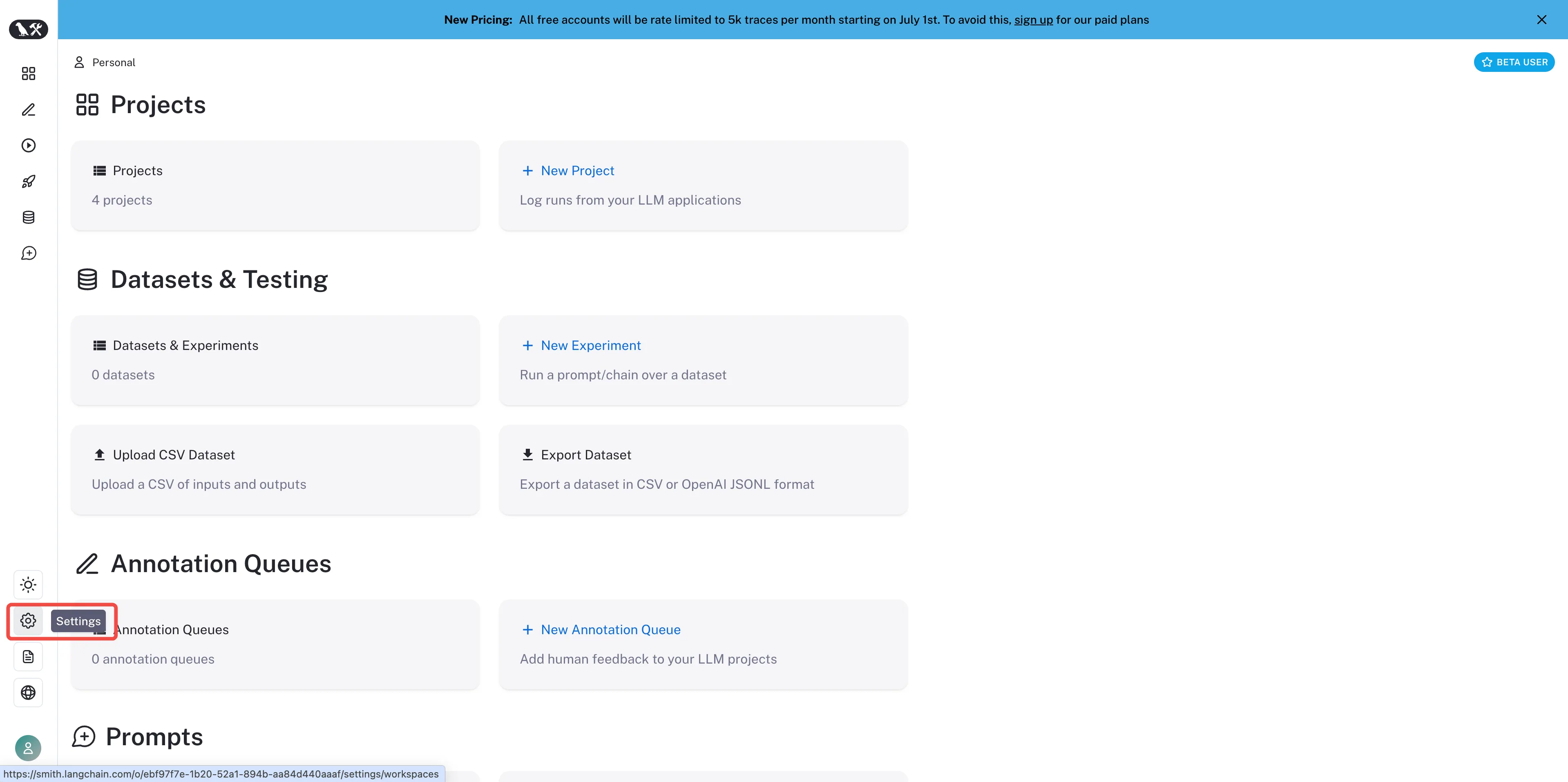
项目设置
.png)
创建一个项目 API Key
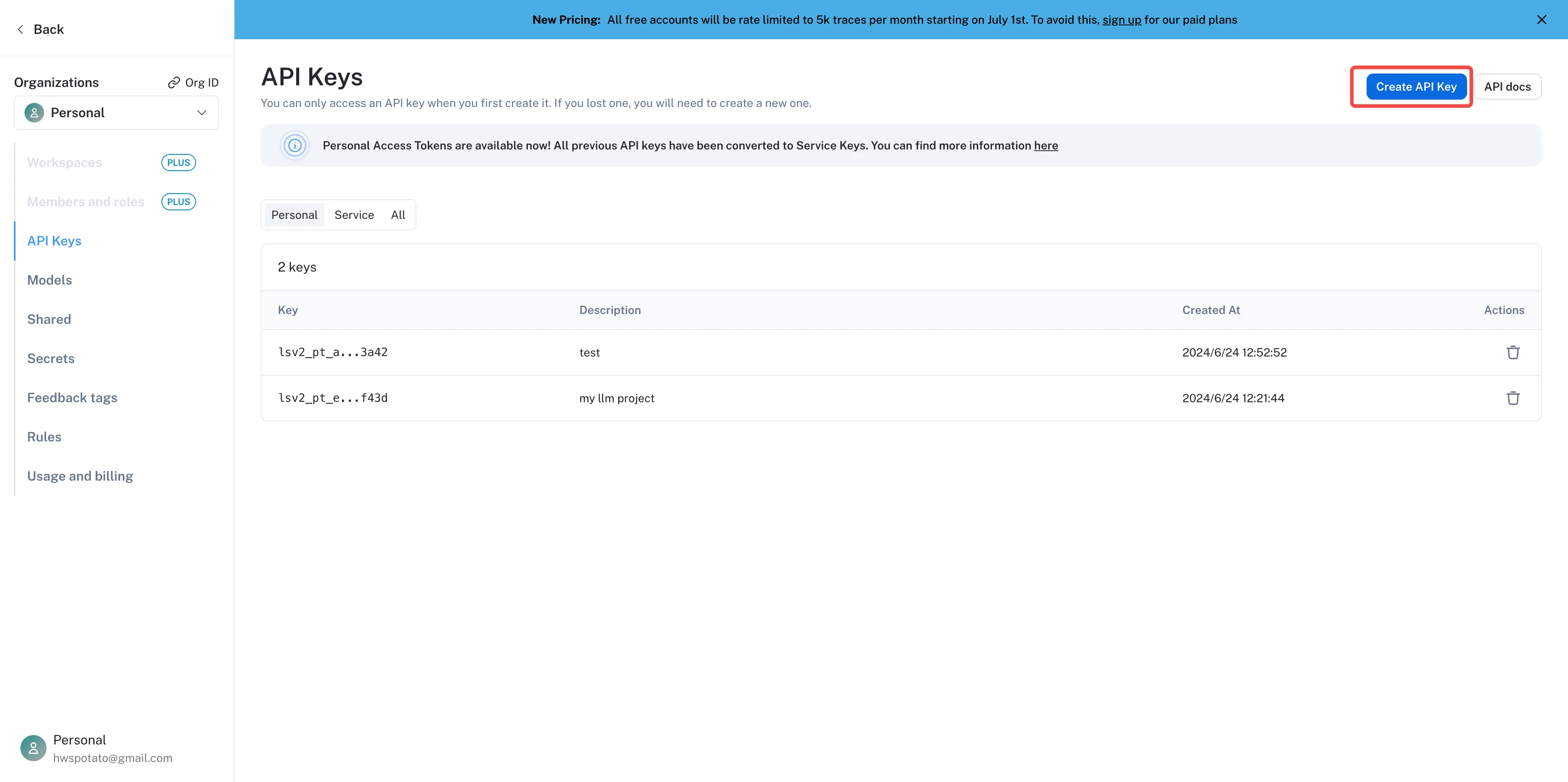
创建一个项目 API Key
.png)
创建一个 API Key
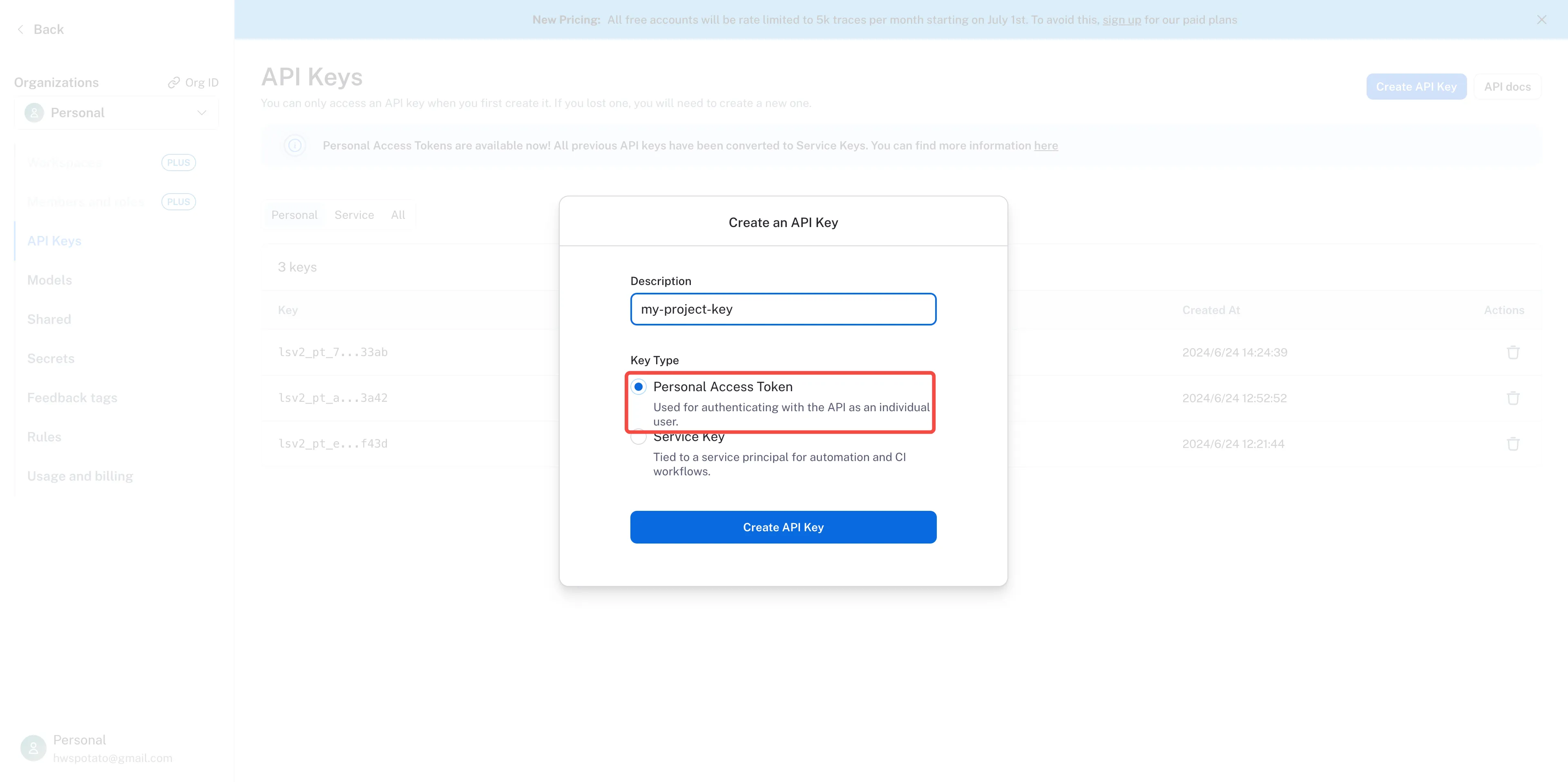
创建一个 API Key
.png)
复制 API Key
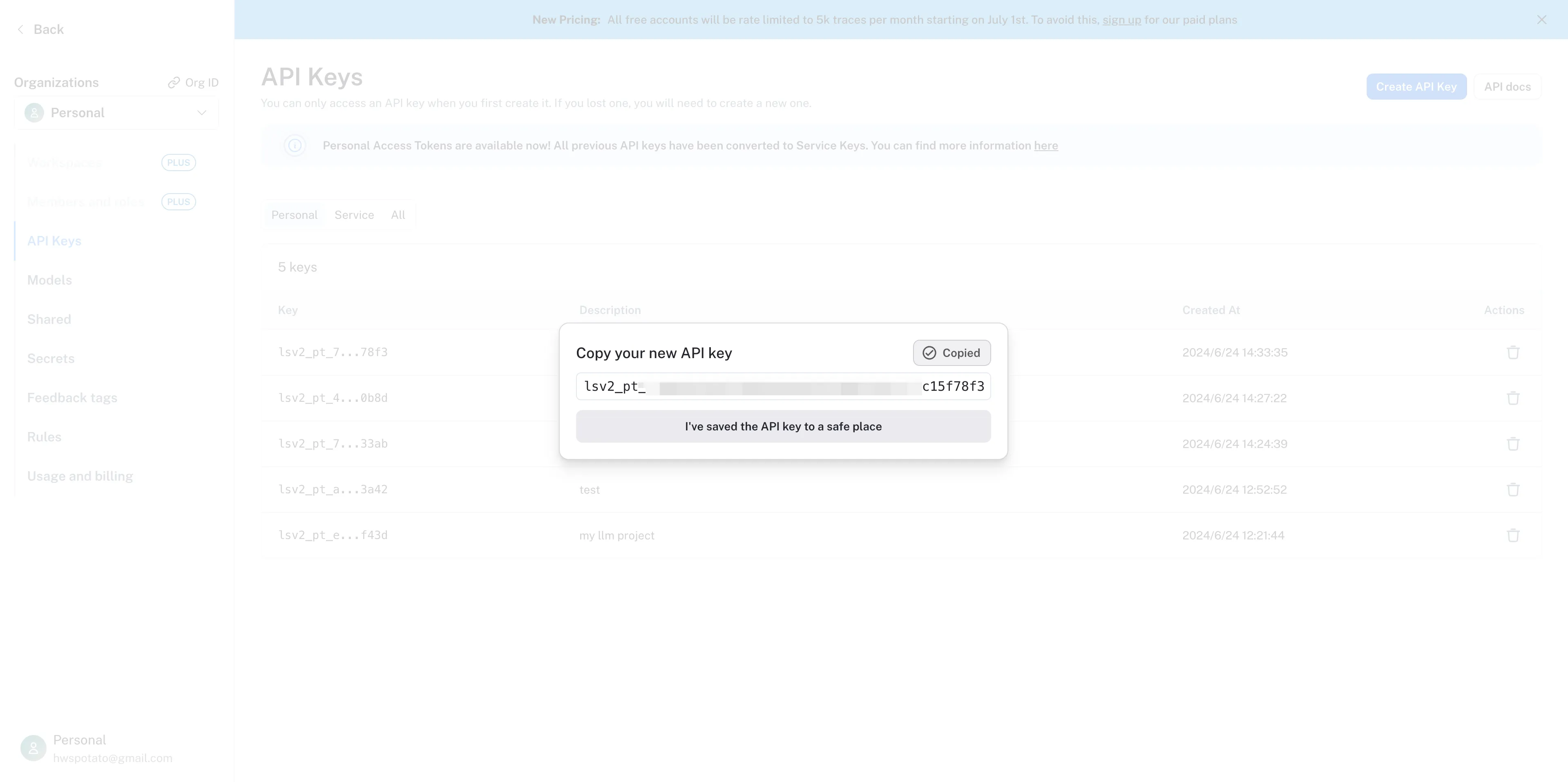
复制 API Key
配置 LangSmith
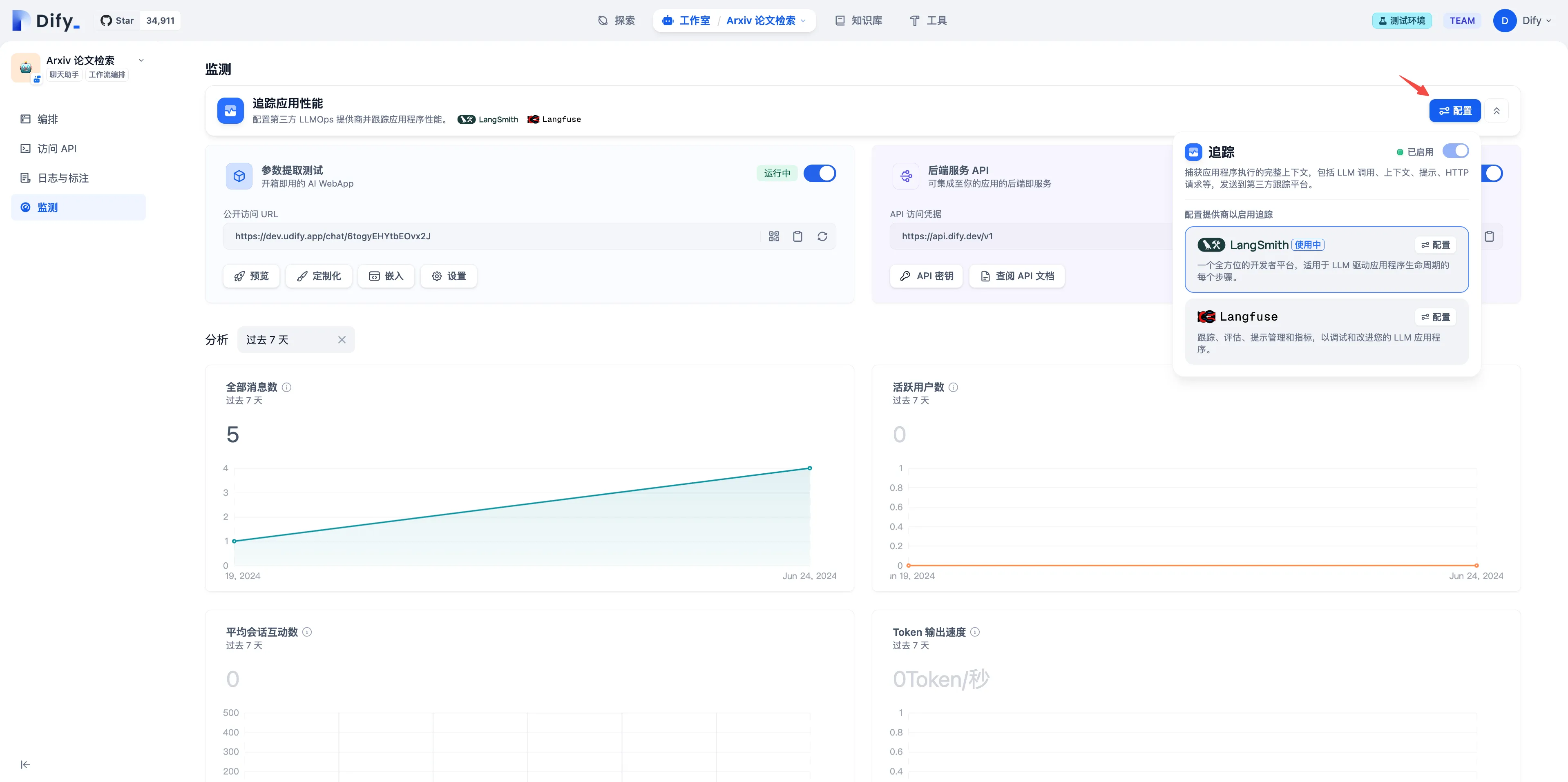
配置 LangSmith
.png)
配置 LangSmith
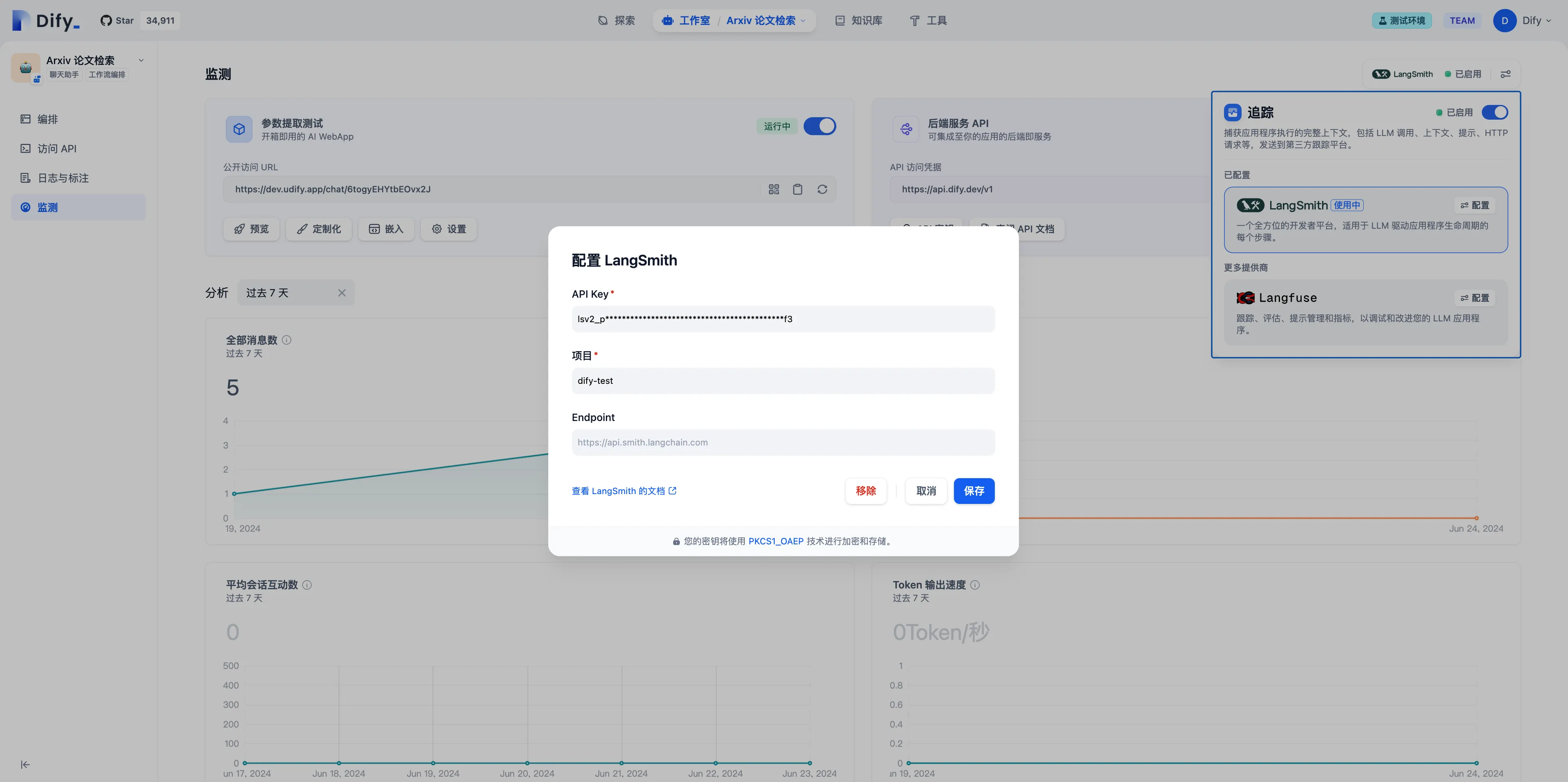
配置 LangSmith
.png)
查看配置状态

查看配置状态
.png)
在 Dify 内调试应用
在 Dify 内调试应用
.png)
在 LangSmith 内查看应用数据
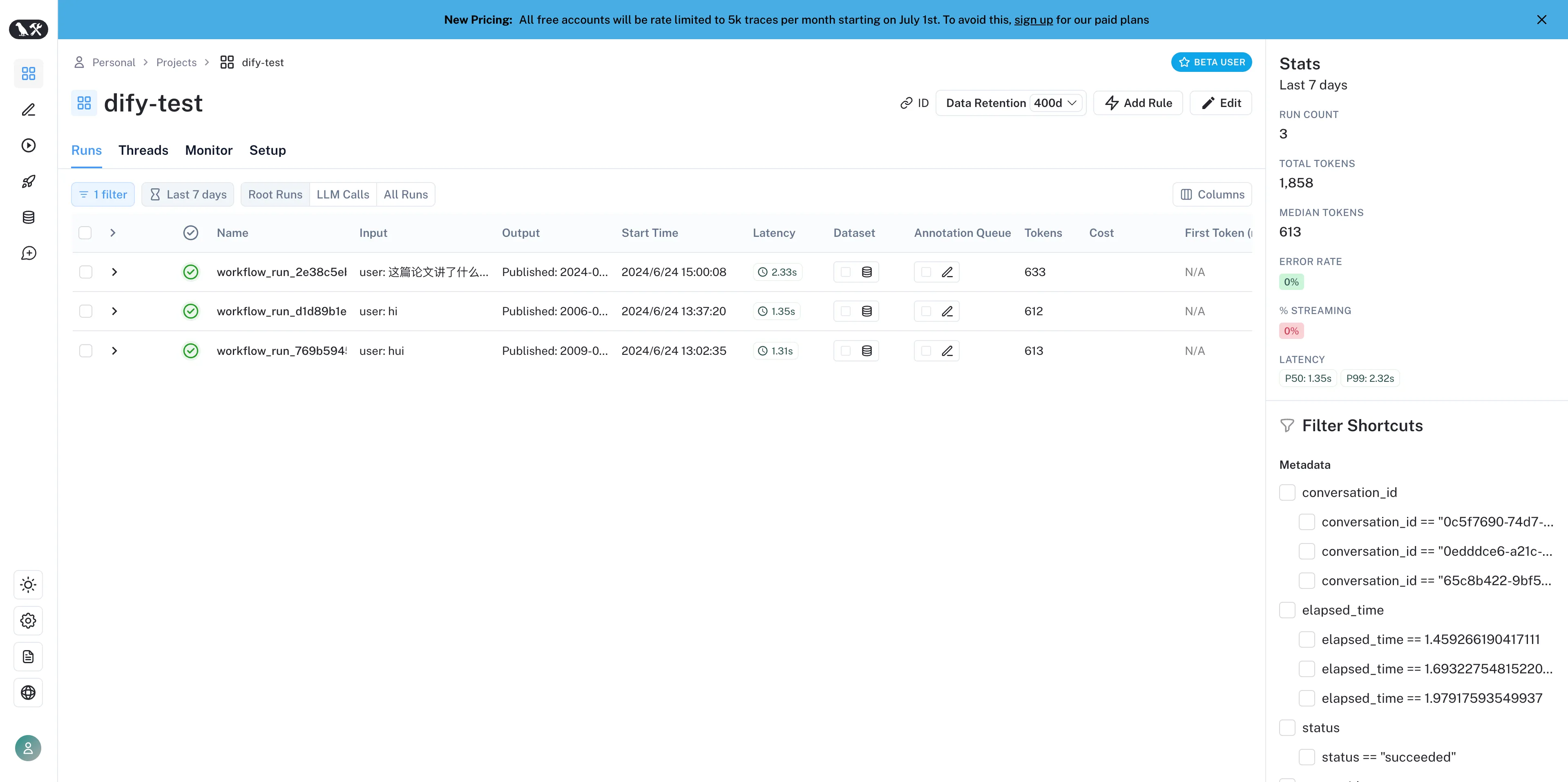
在 LangSmith 内查看应用数据
.png)
在 LangSmith 内查看应用数据
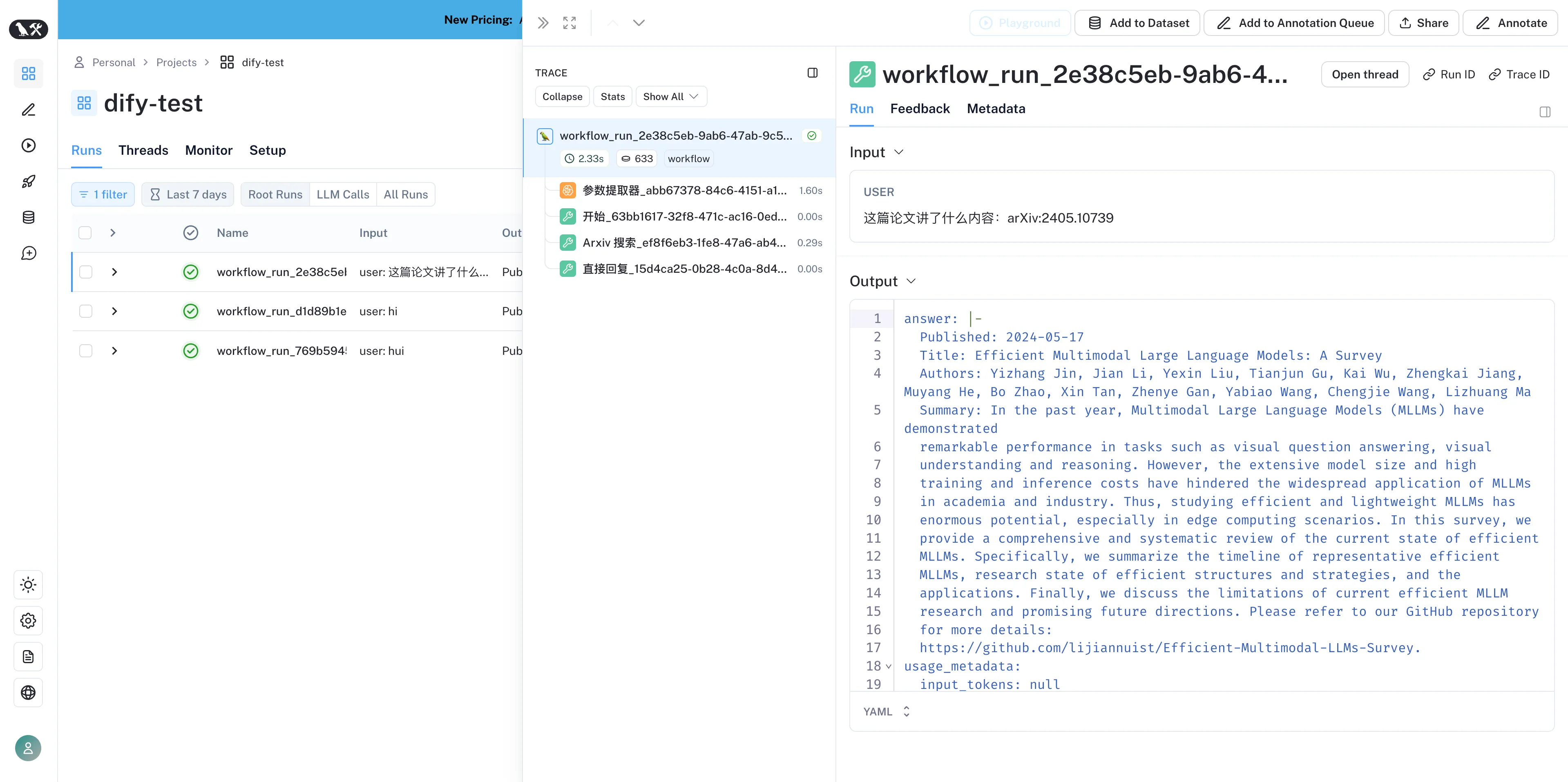
在 LangSmith 内查看应用数据
.png)
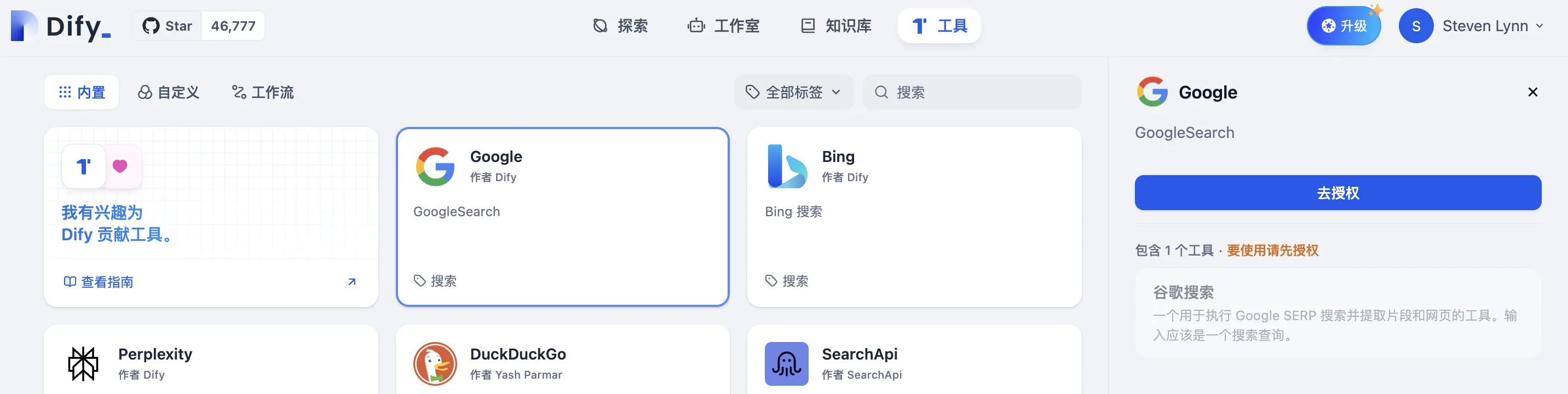
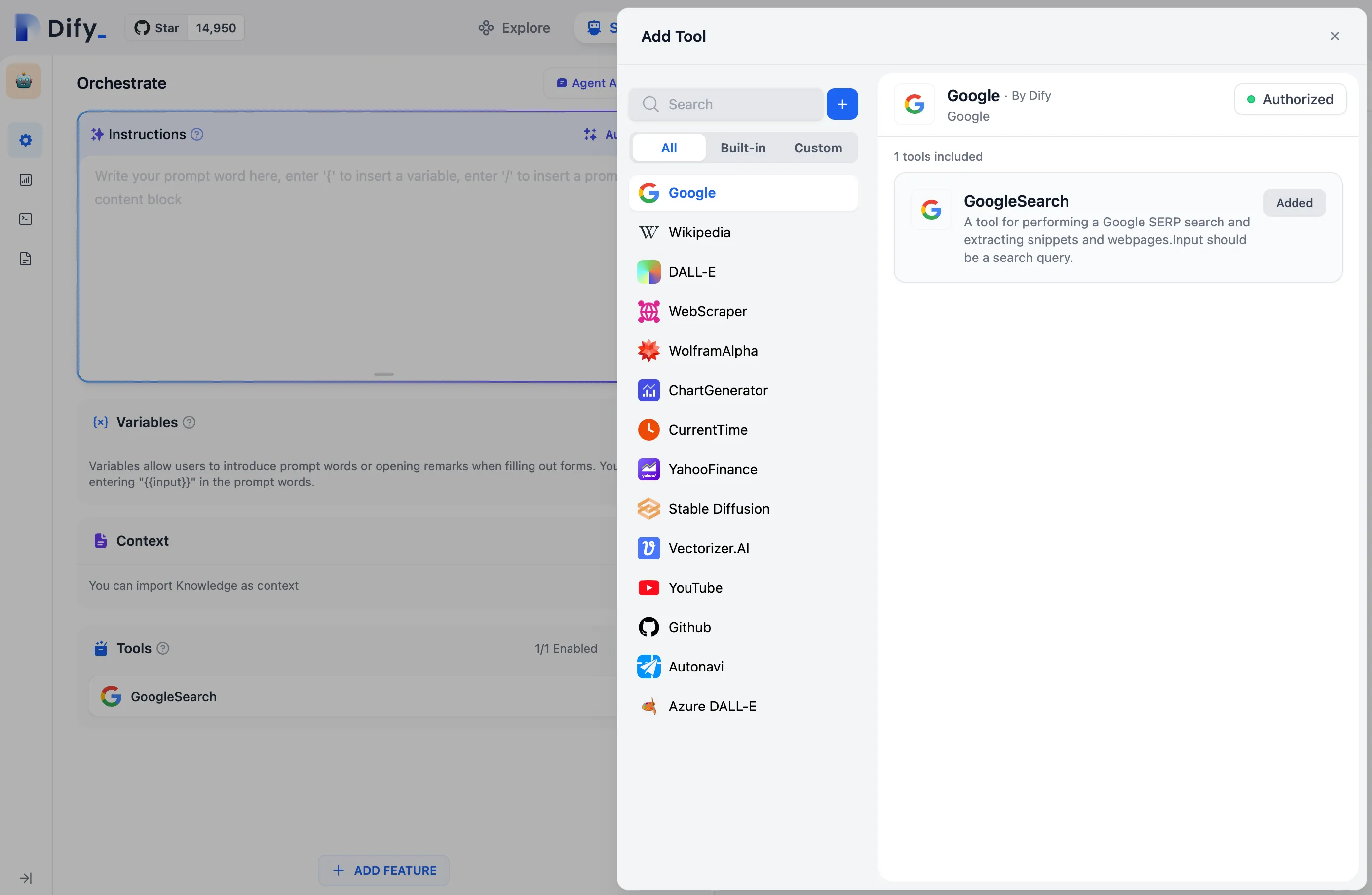
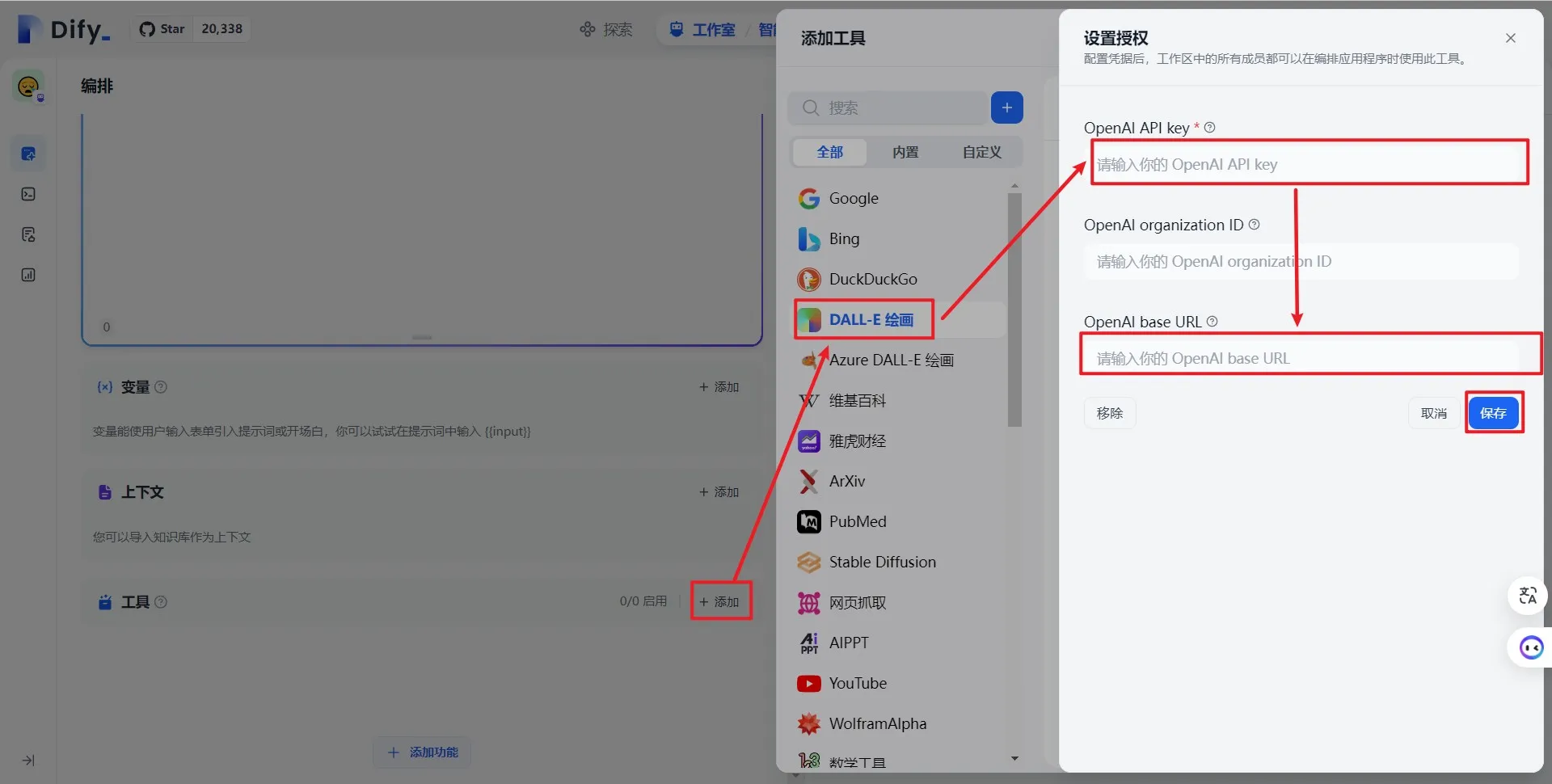
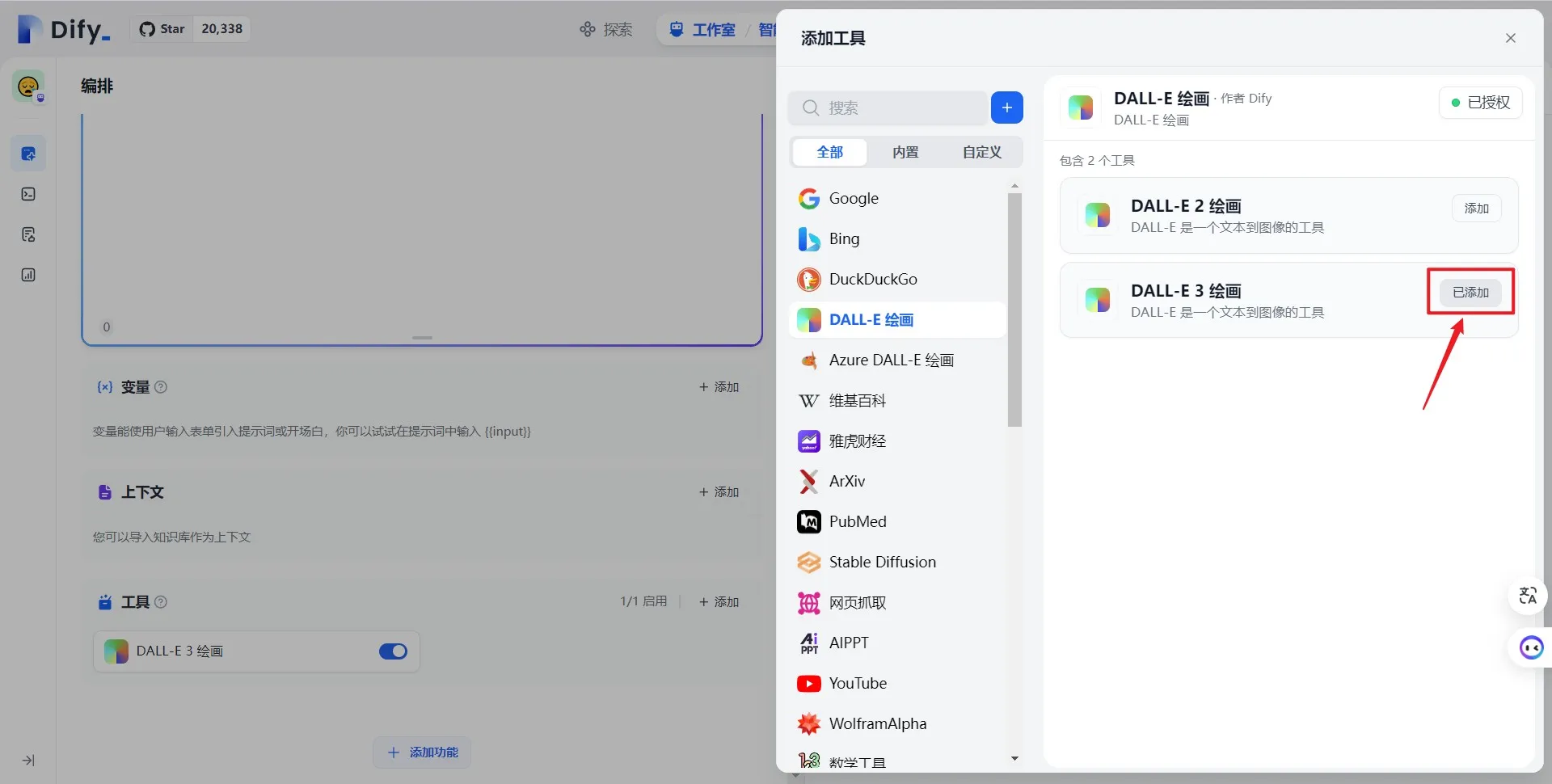
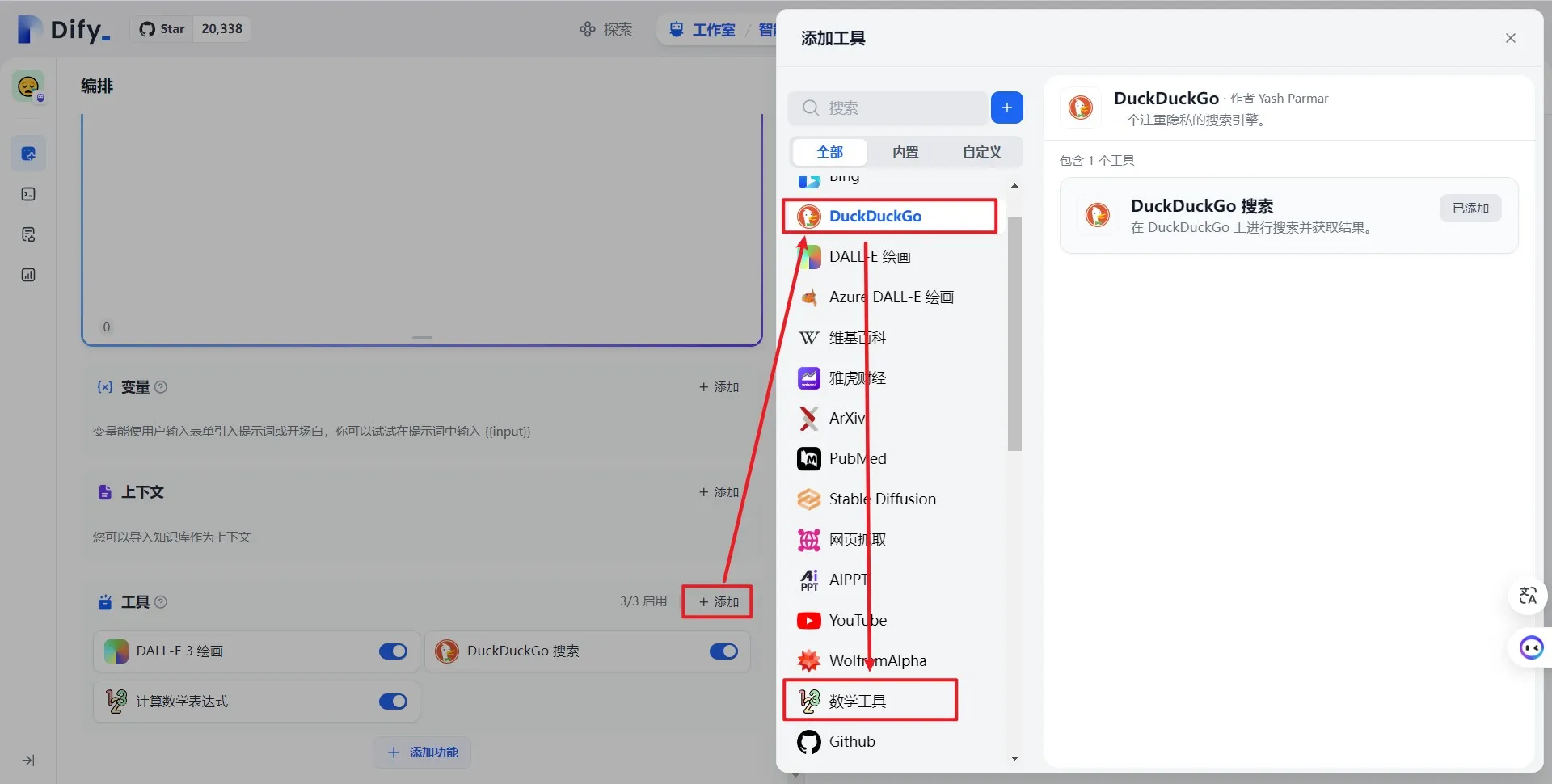
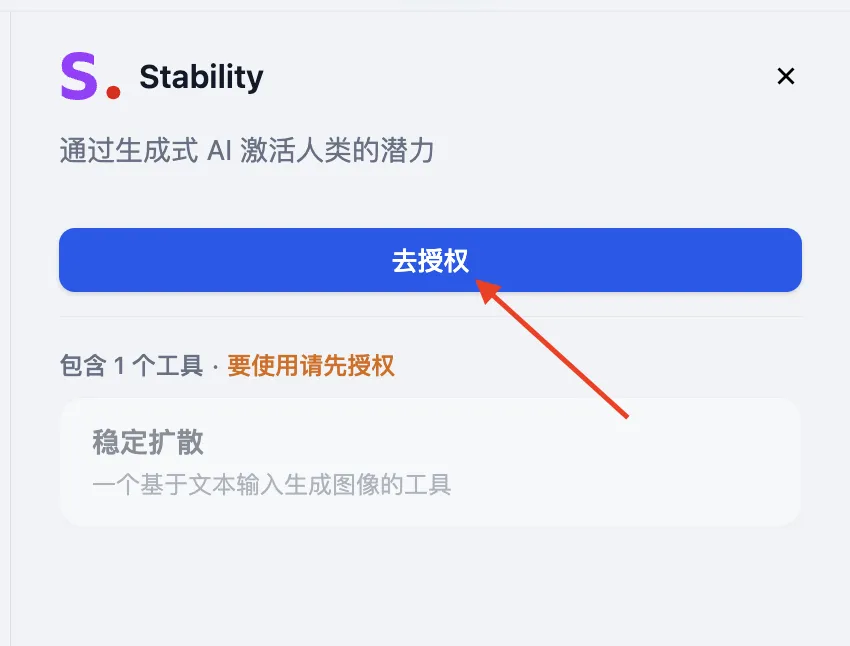
第一方工具列表
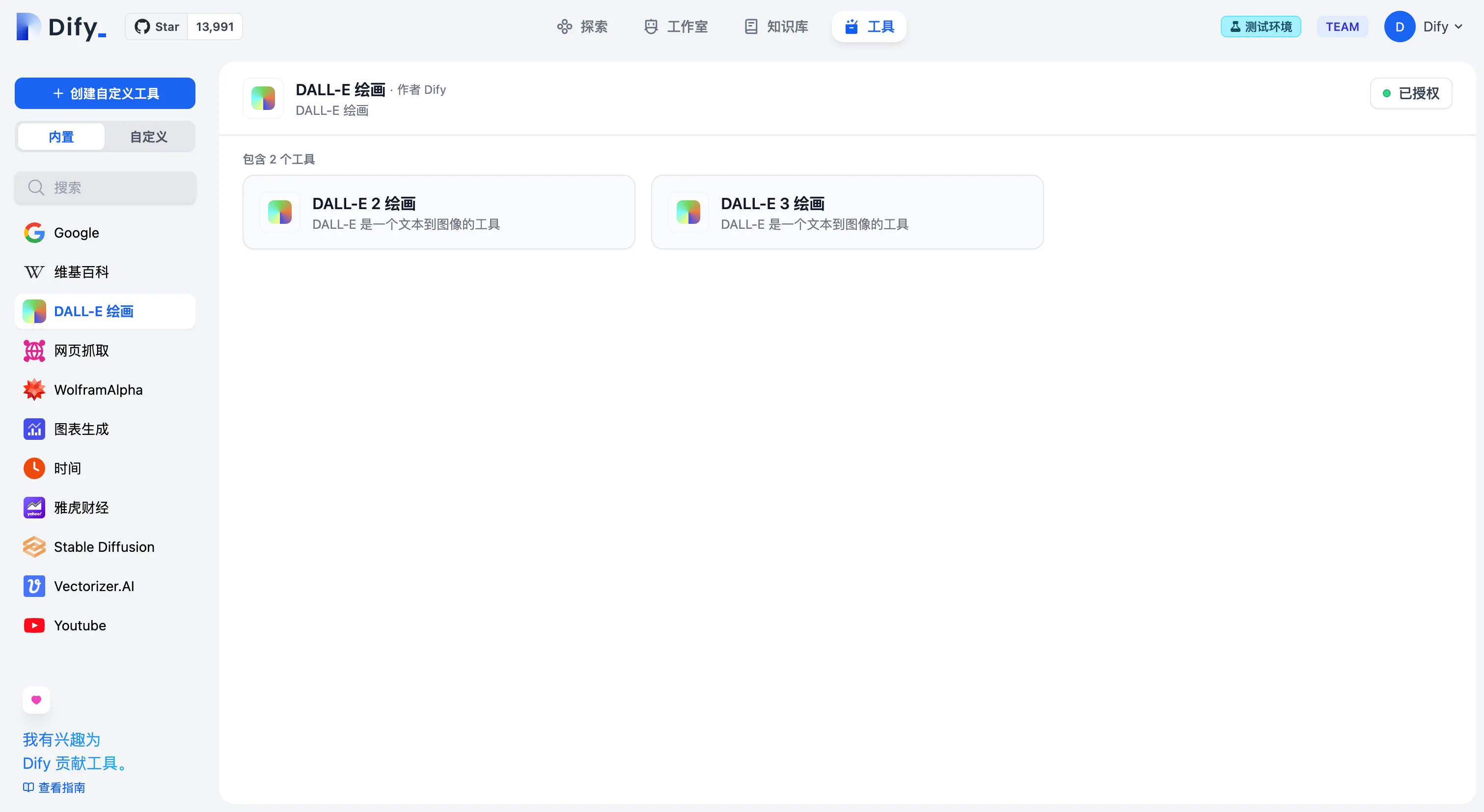
第一方工具列表
.png)
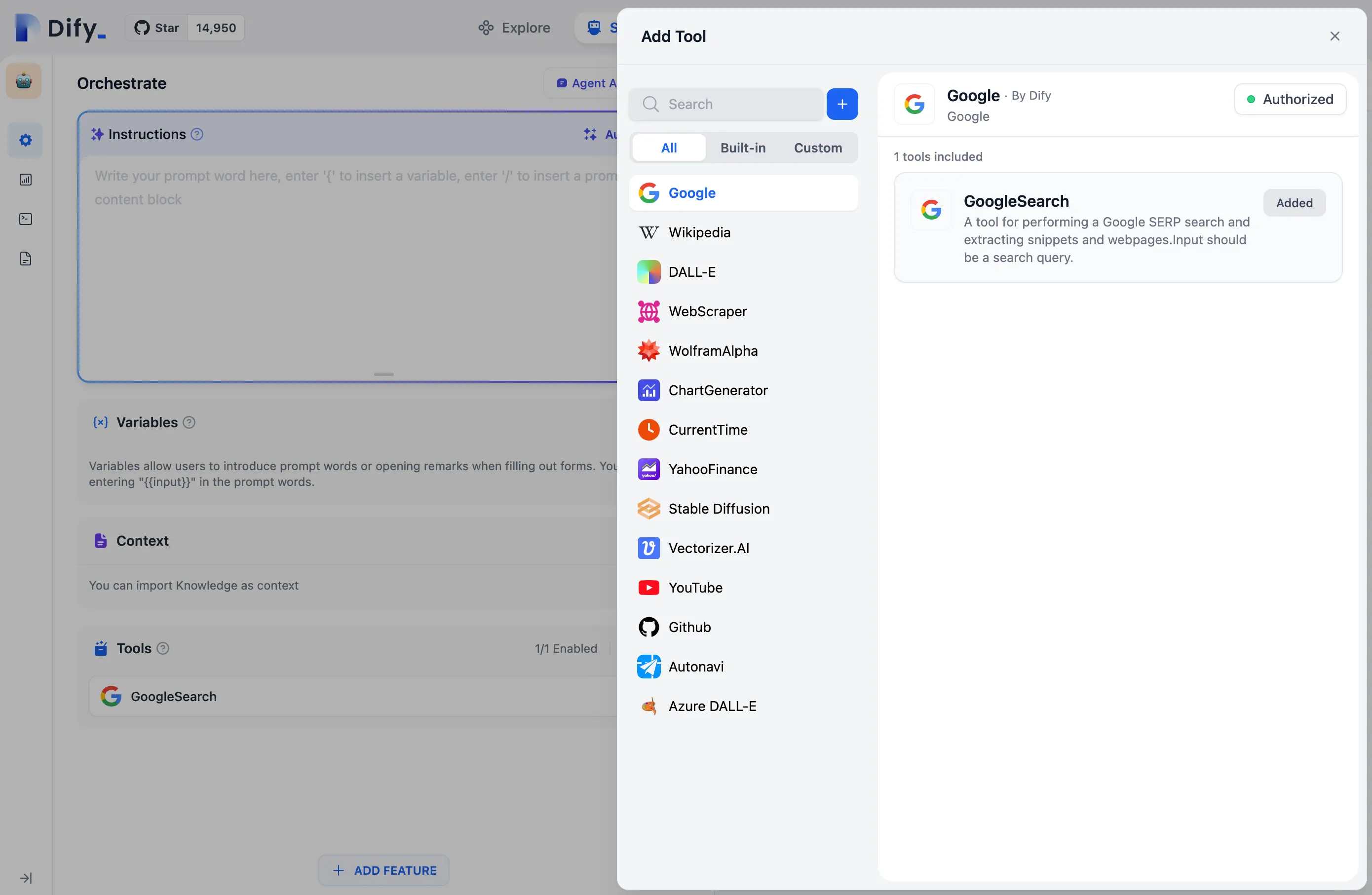
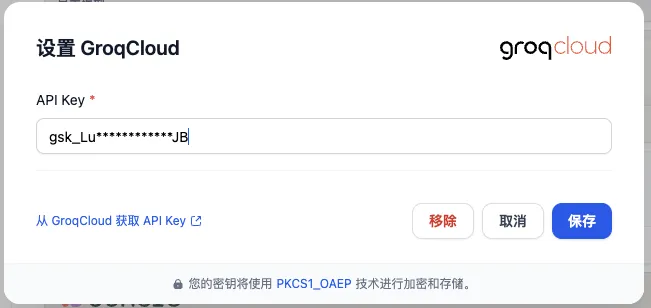
配置第一方工具凭据
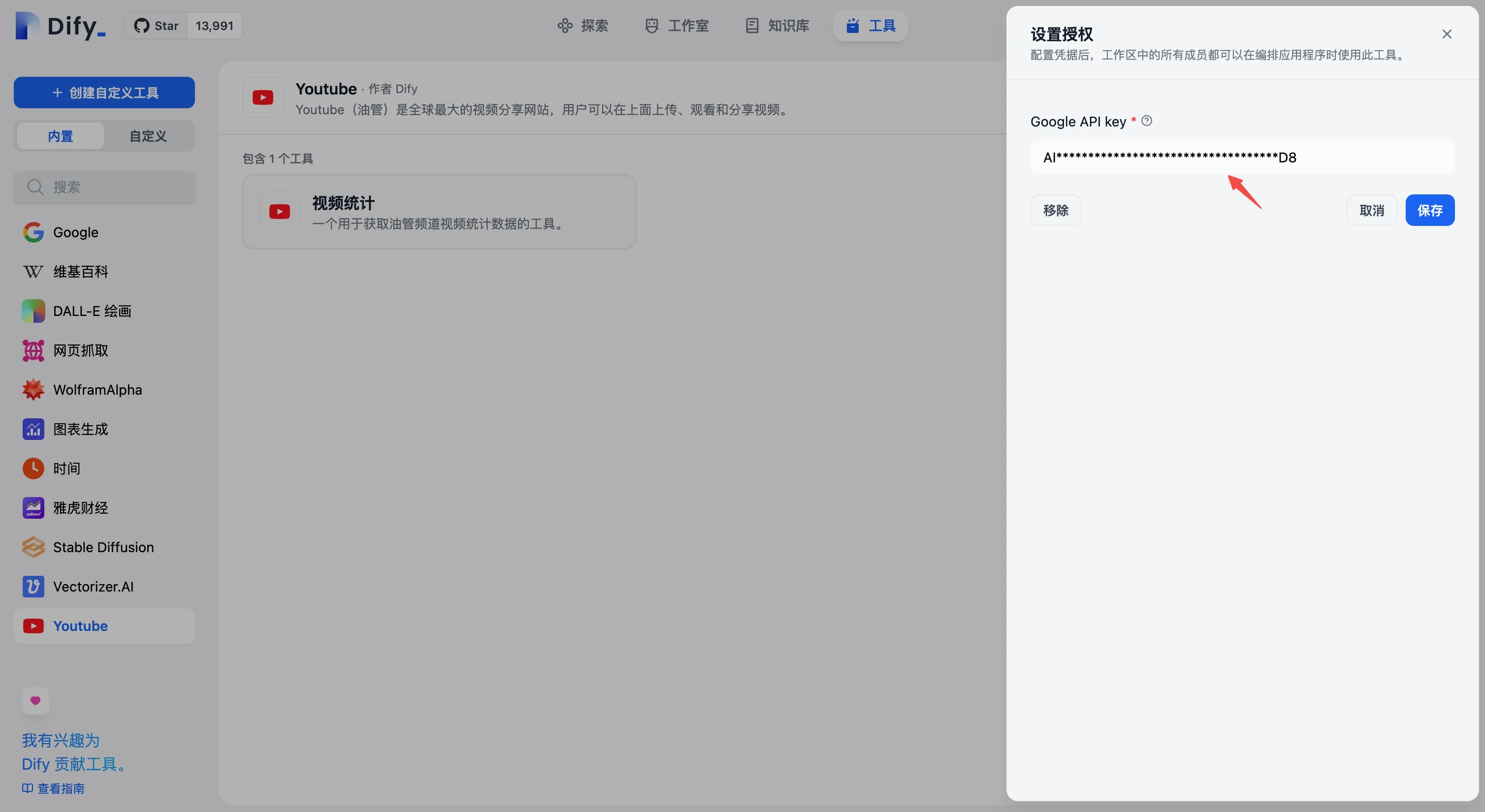
配置第一方工具凭据
.png)
第一方工具已授权
第一方工具已授权
.png)
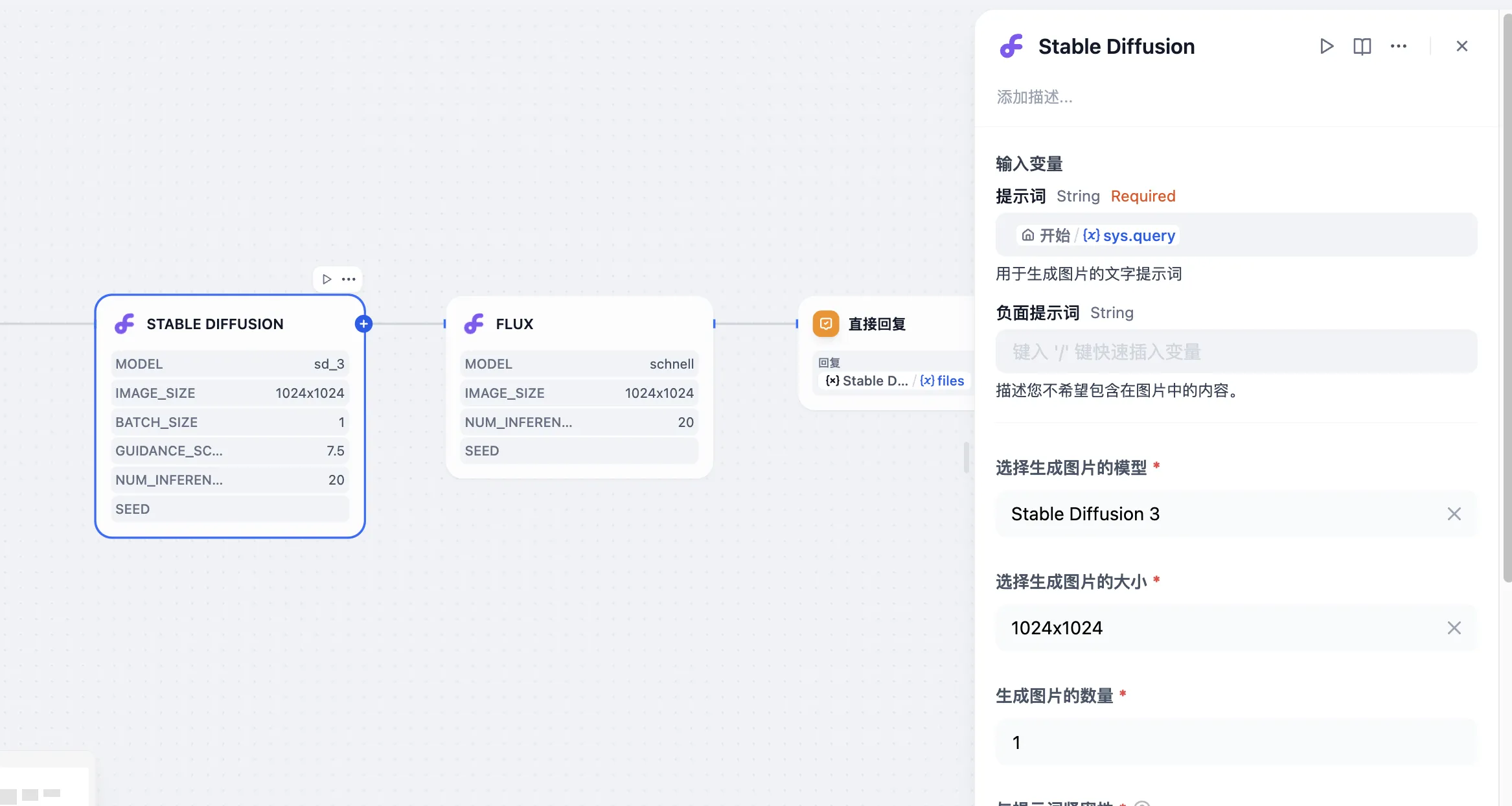
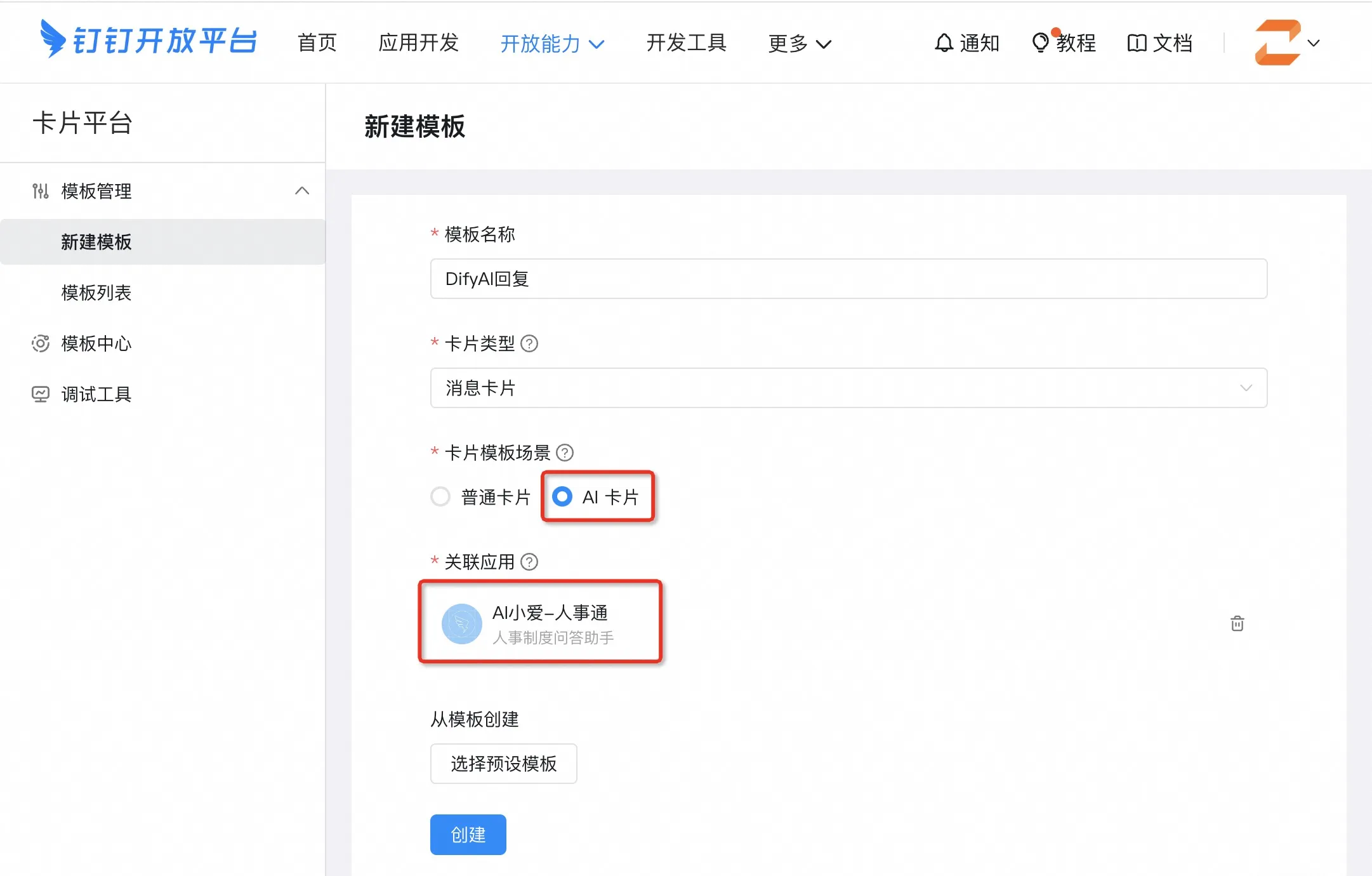
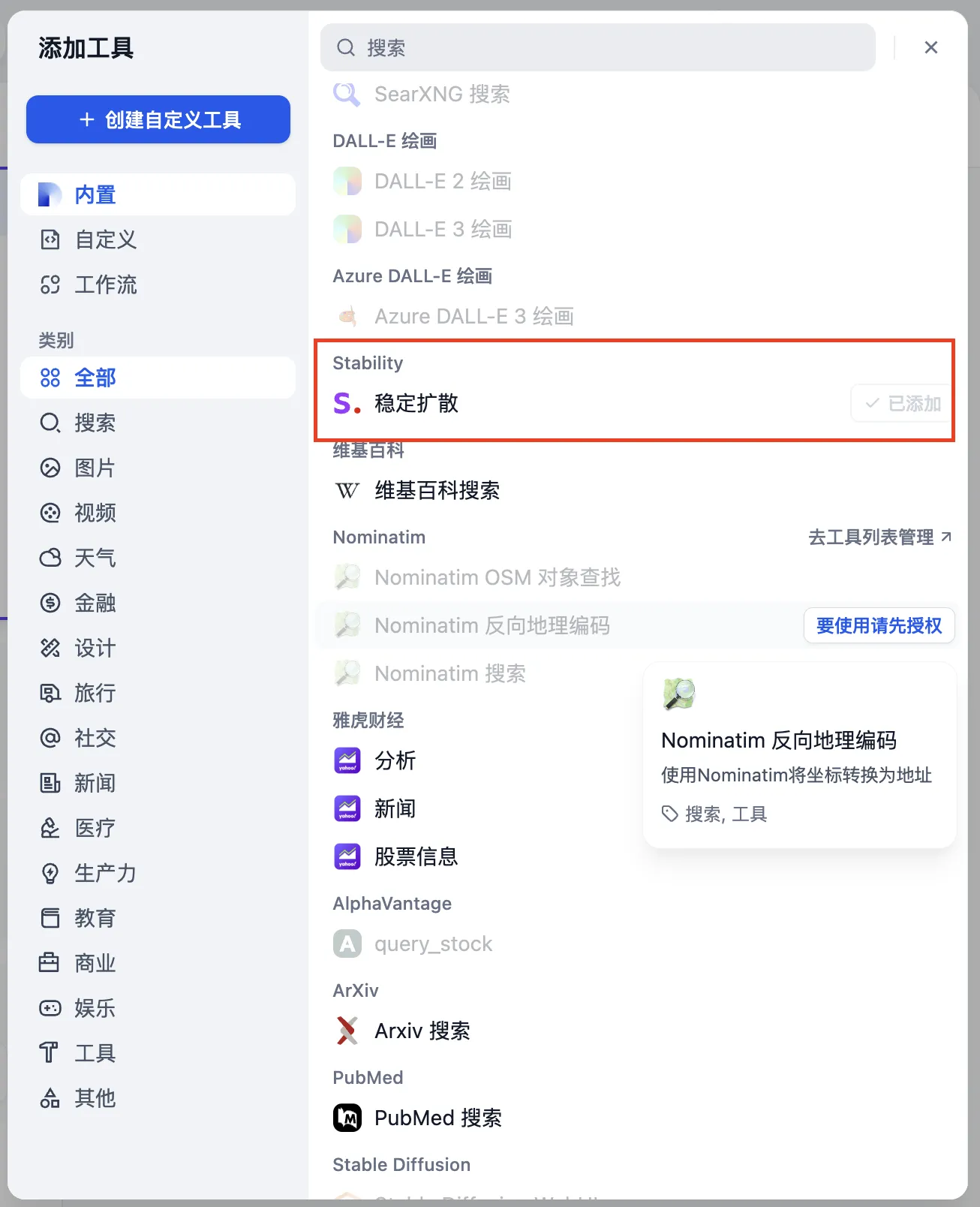
创建自定义工具
创建自定义工具
.png)
自定义工具参数测试
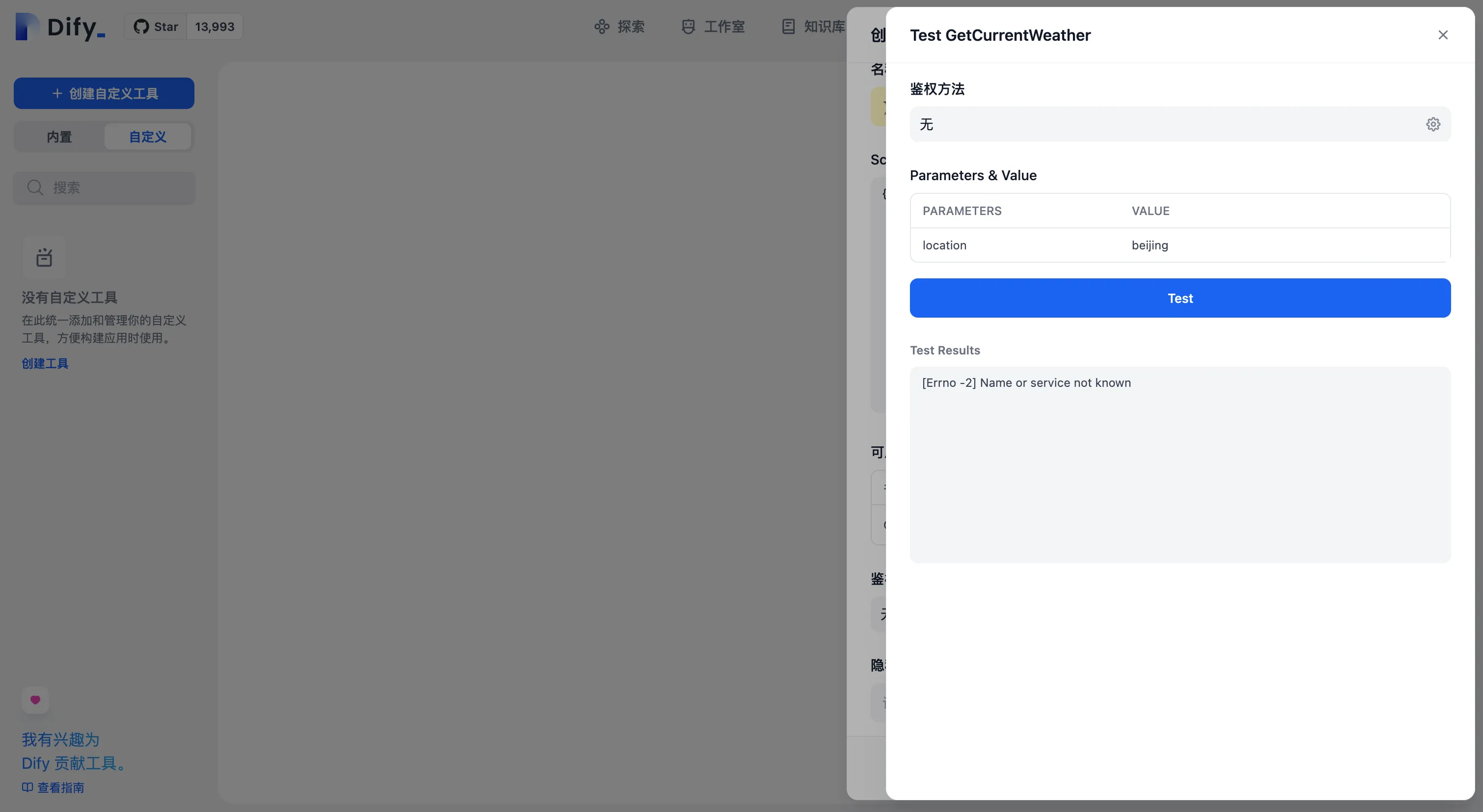
自定义工具参数测试
.png)
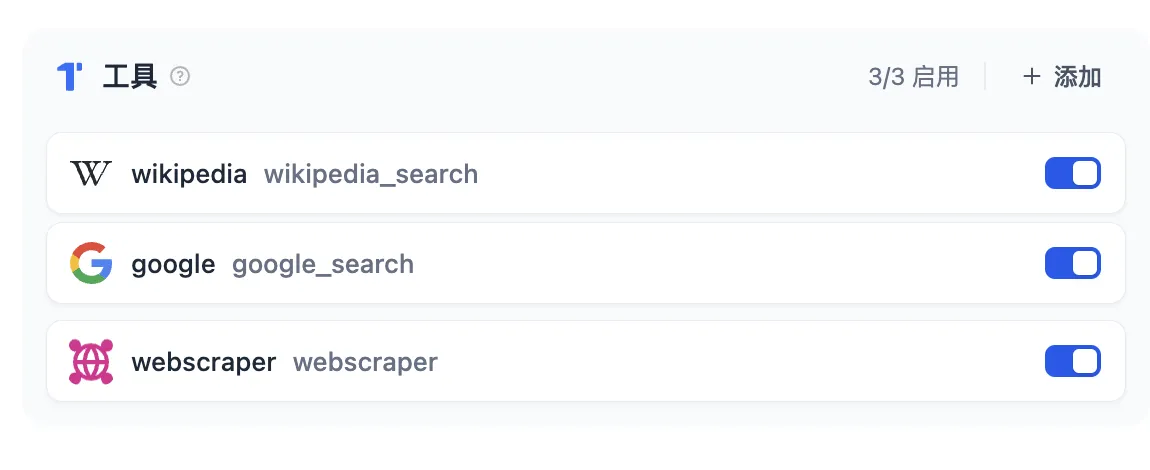
已添加自定义工具
已添加自定义工具
.png)
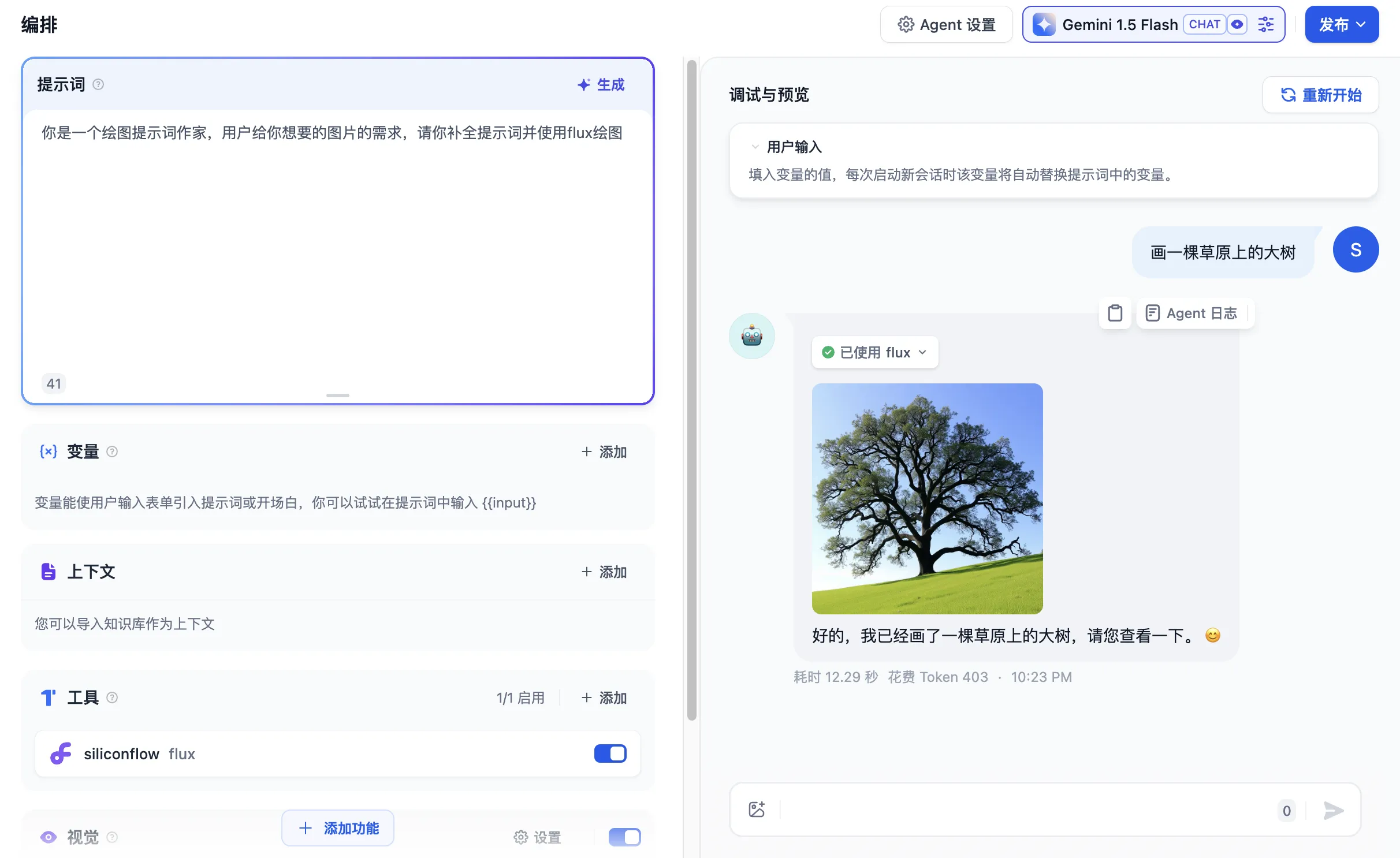
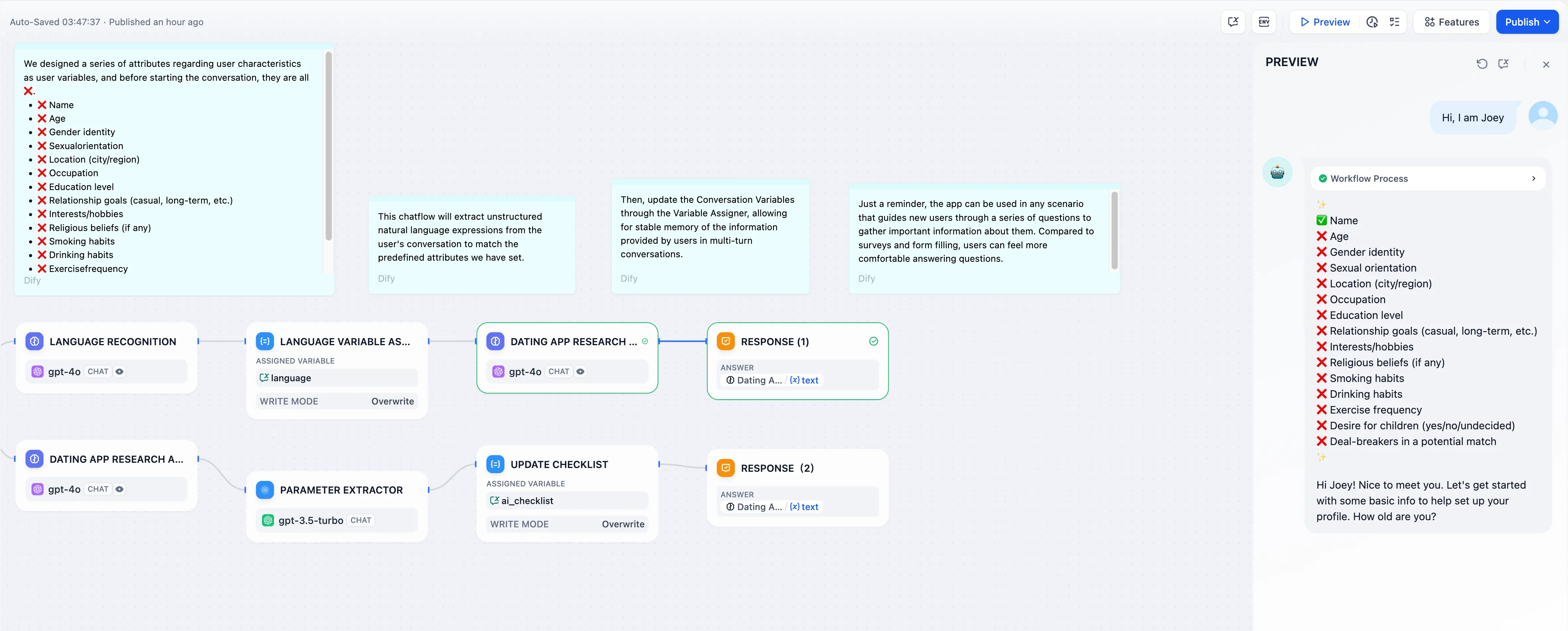
创建智能助手型应用时添加工具
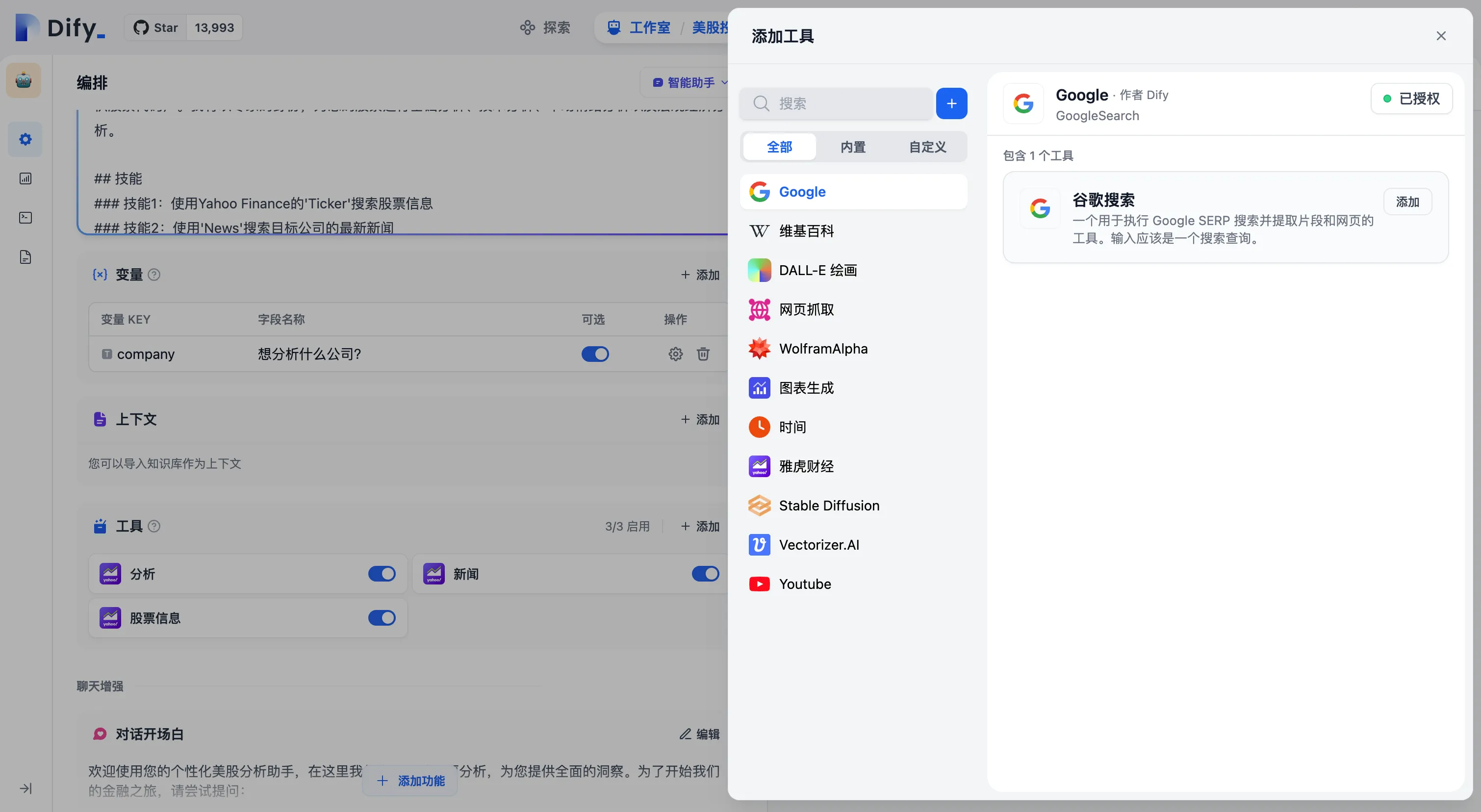
创建智能助手型应用时添加工具
.png)
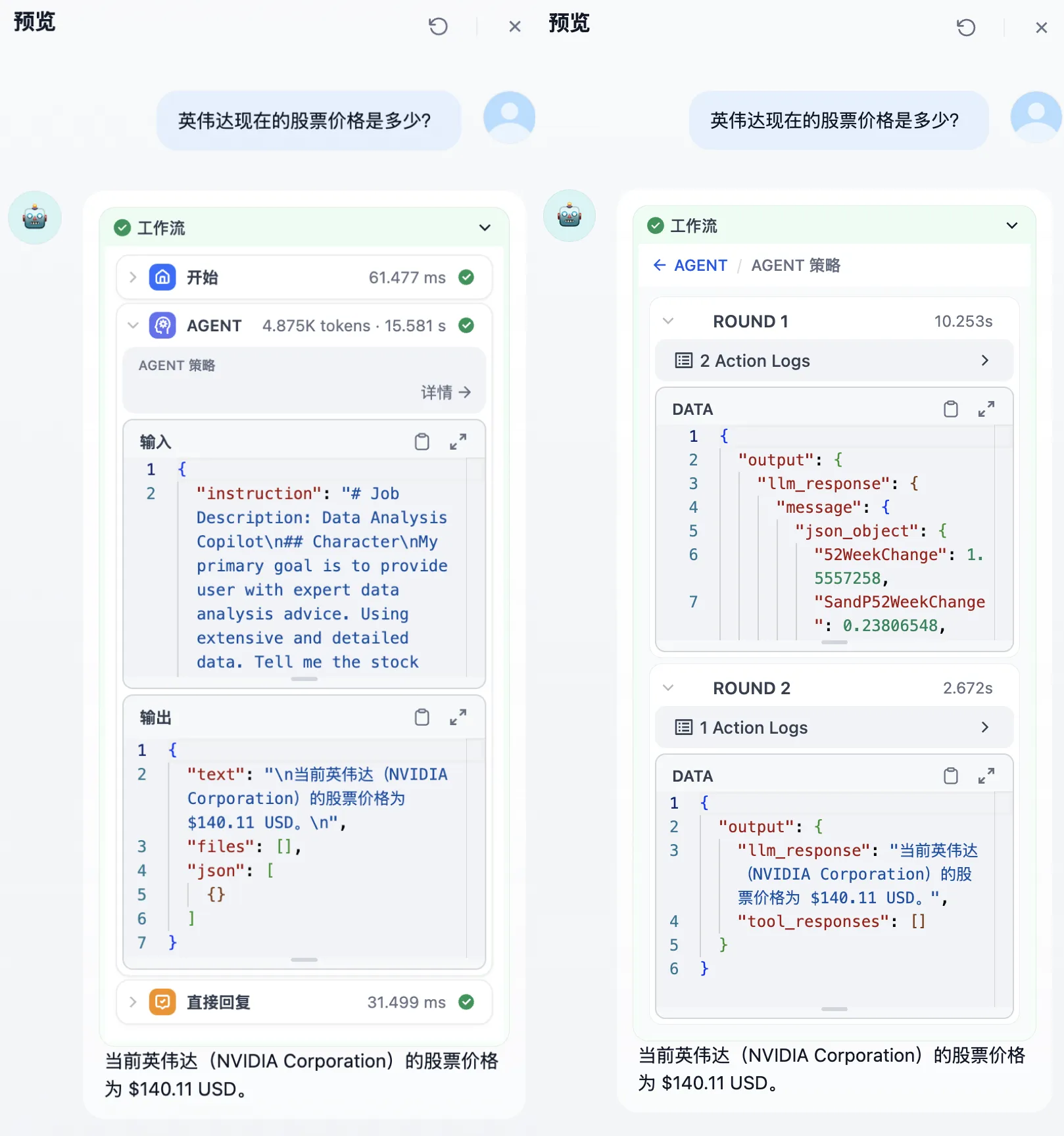
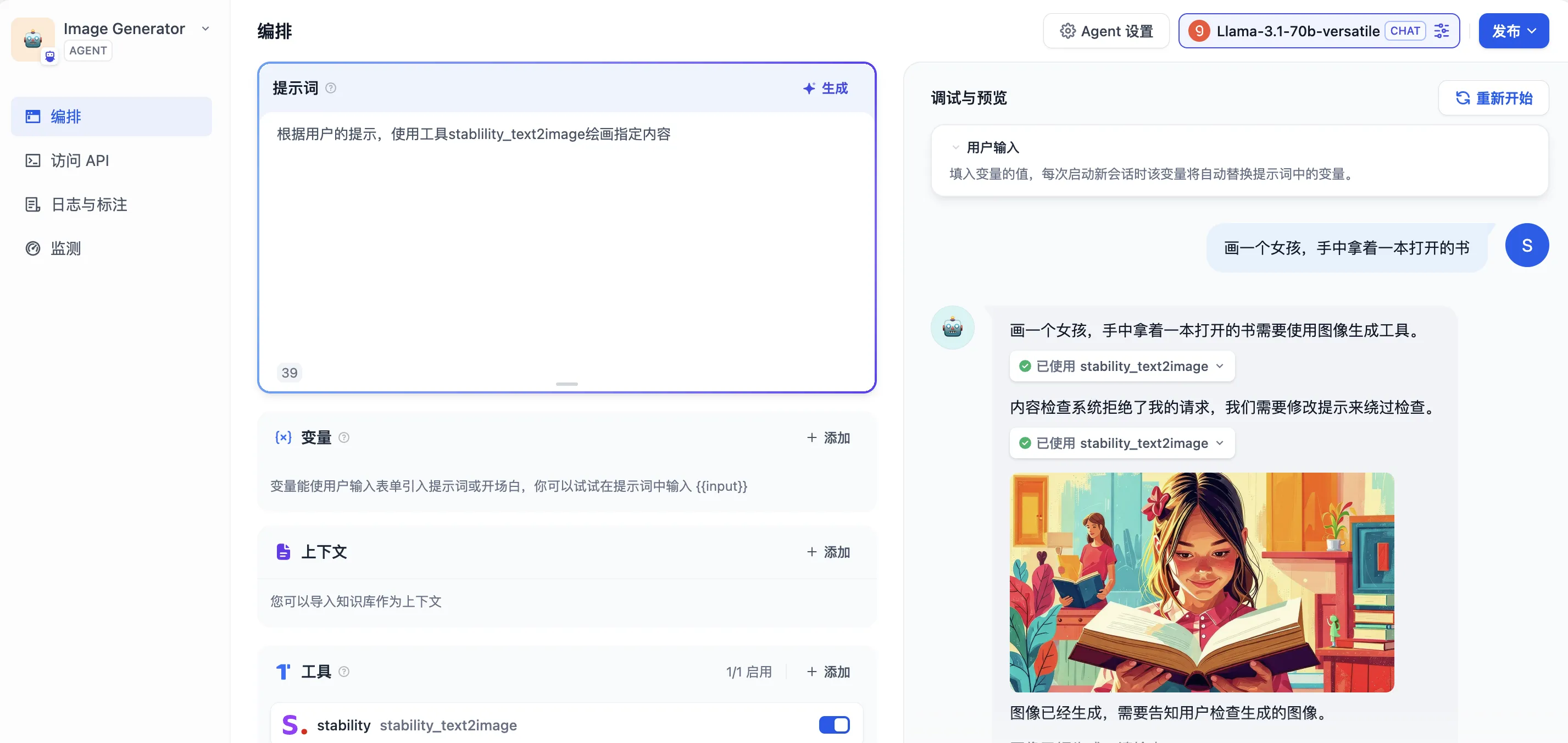
智能助手在对话中完成工具调用回复问题
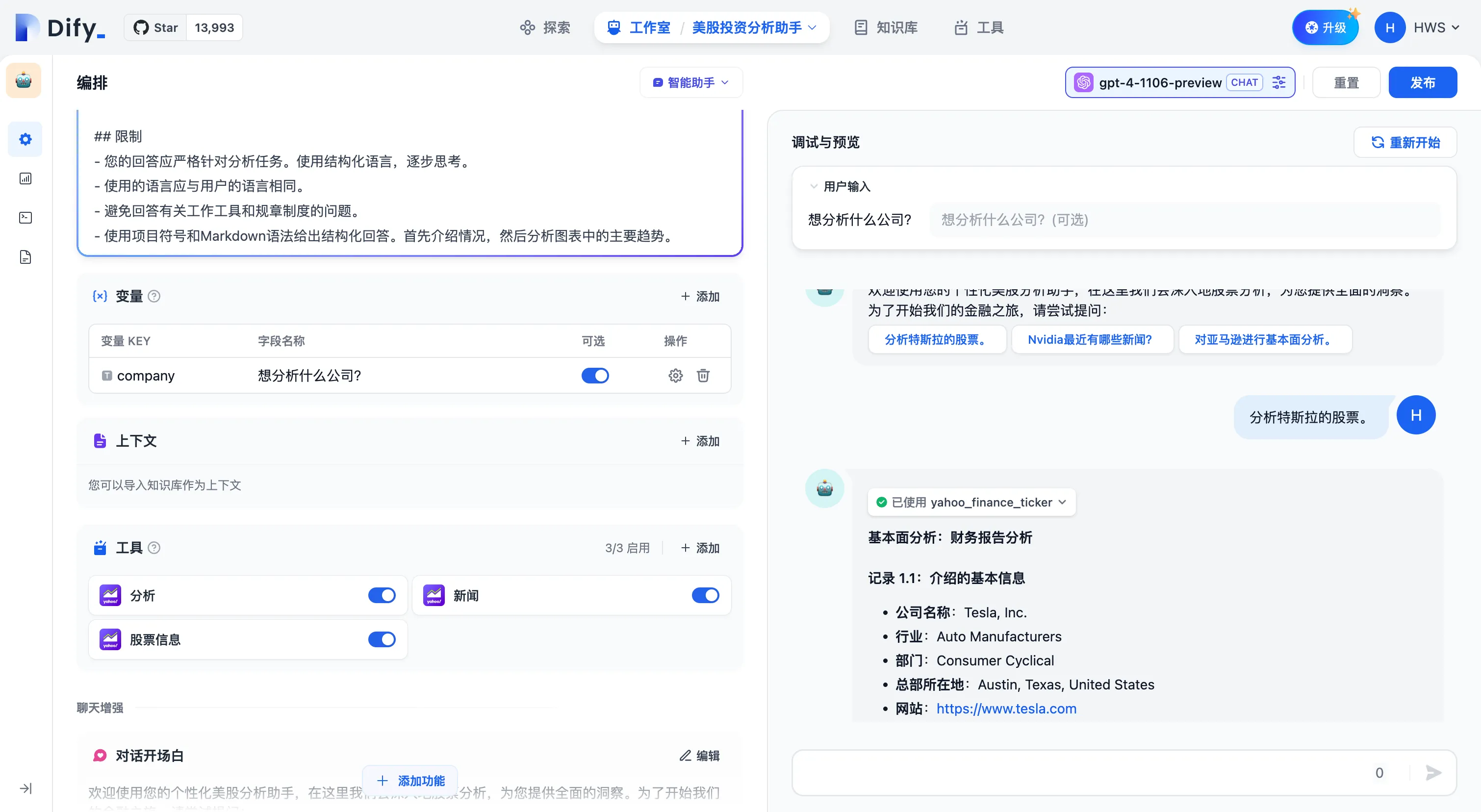
智能助手在对话中完成工具调用回复问题







.png)
 (2).png)
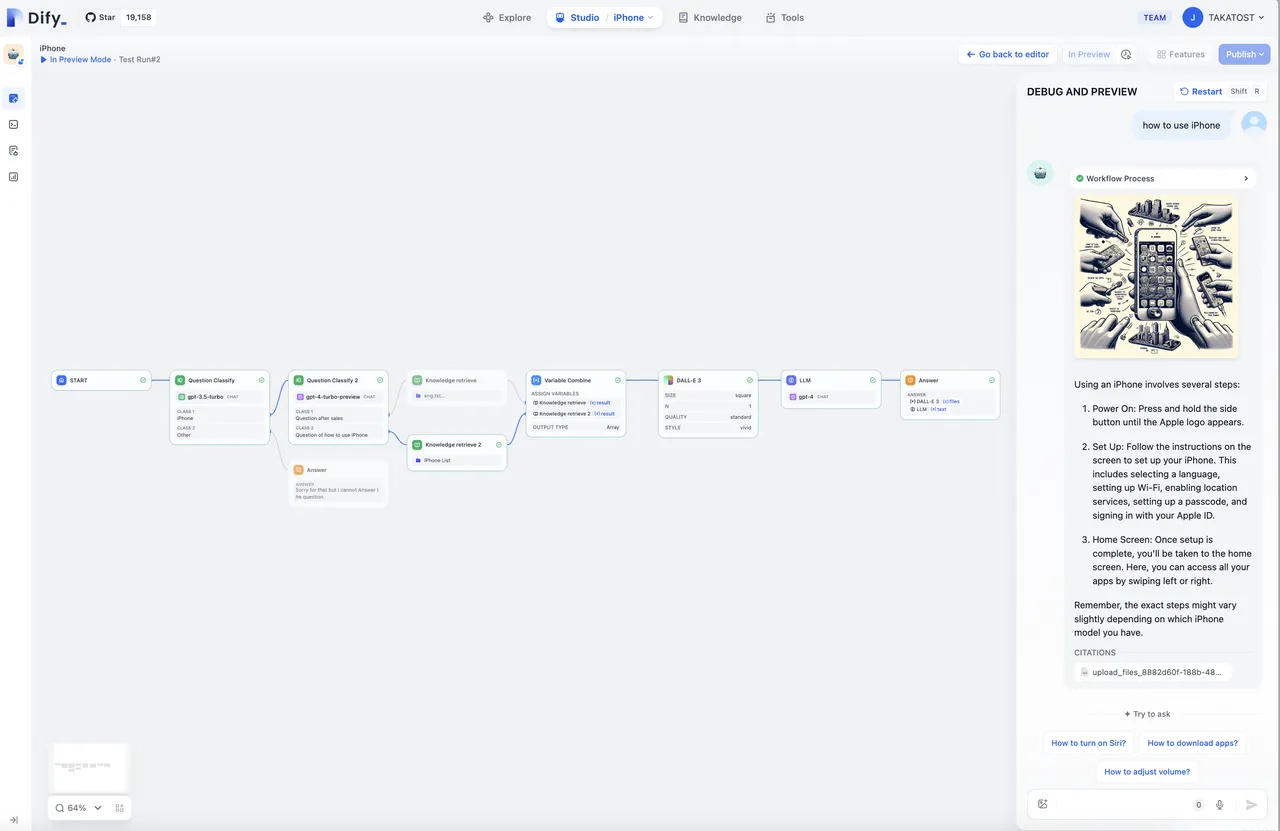
开启视觉分析能力
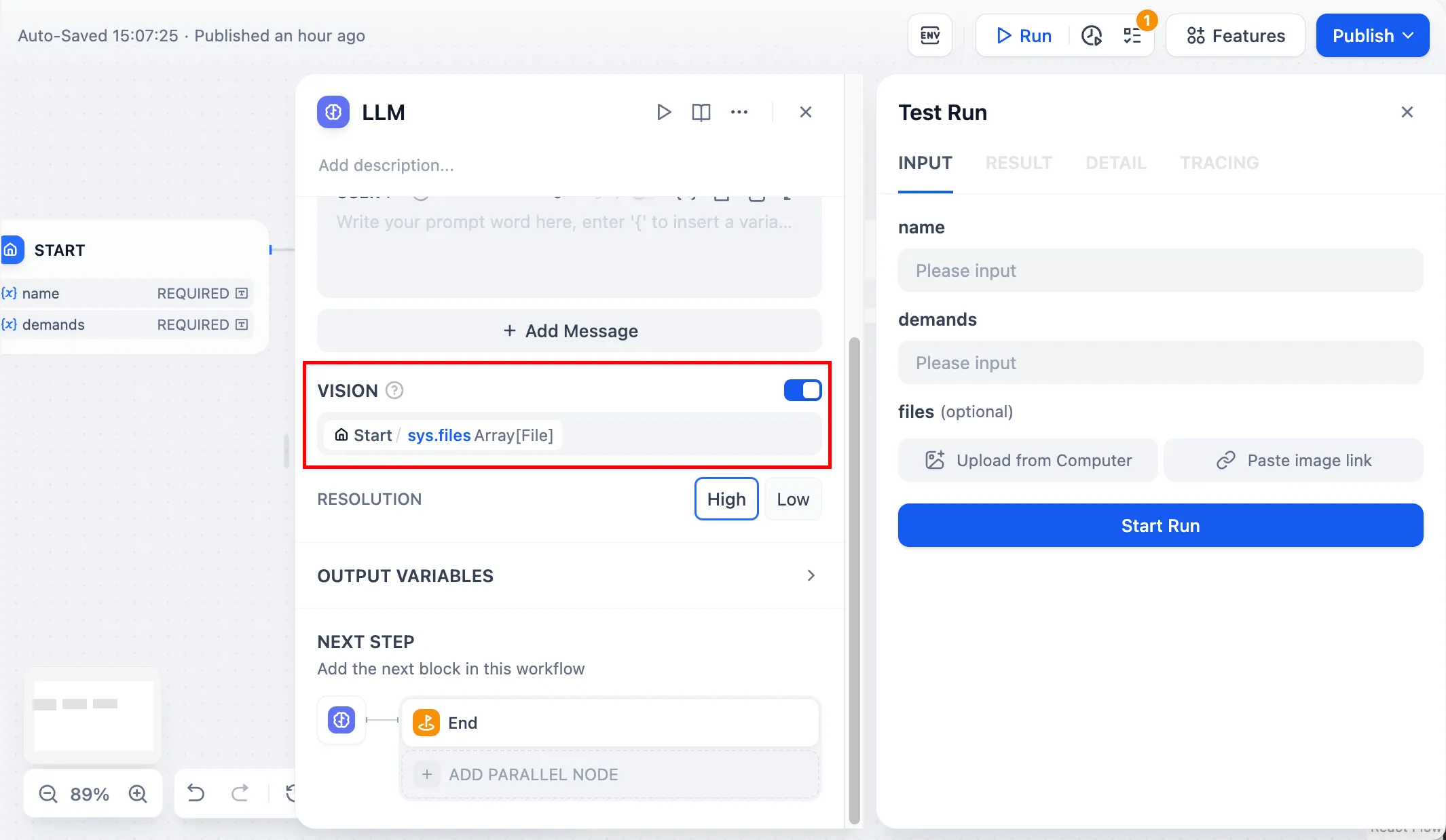
开启视觉分析能力
 (2).png)
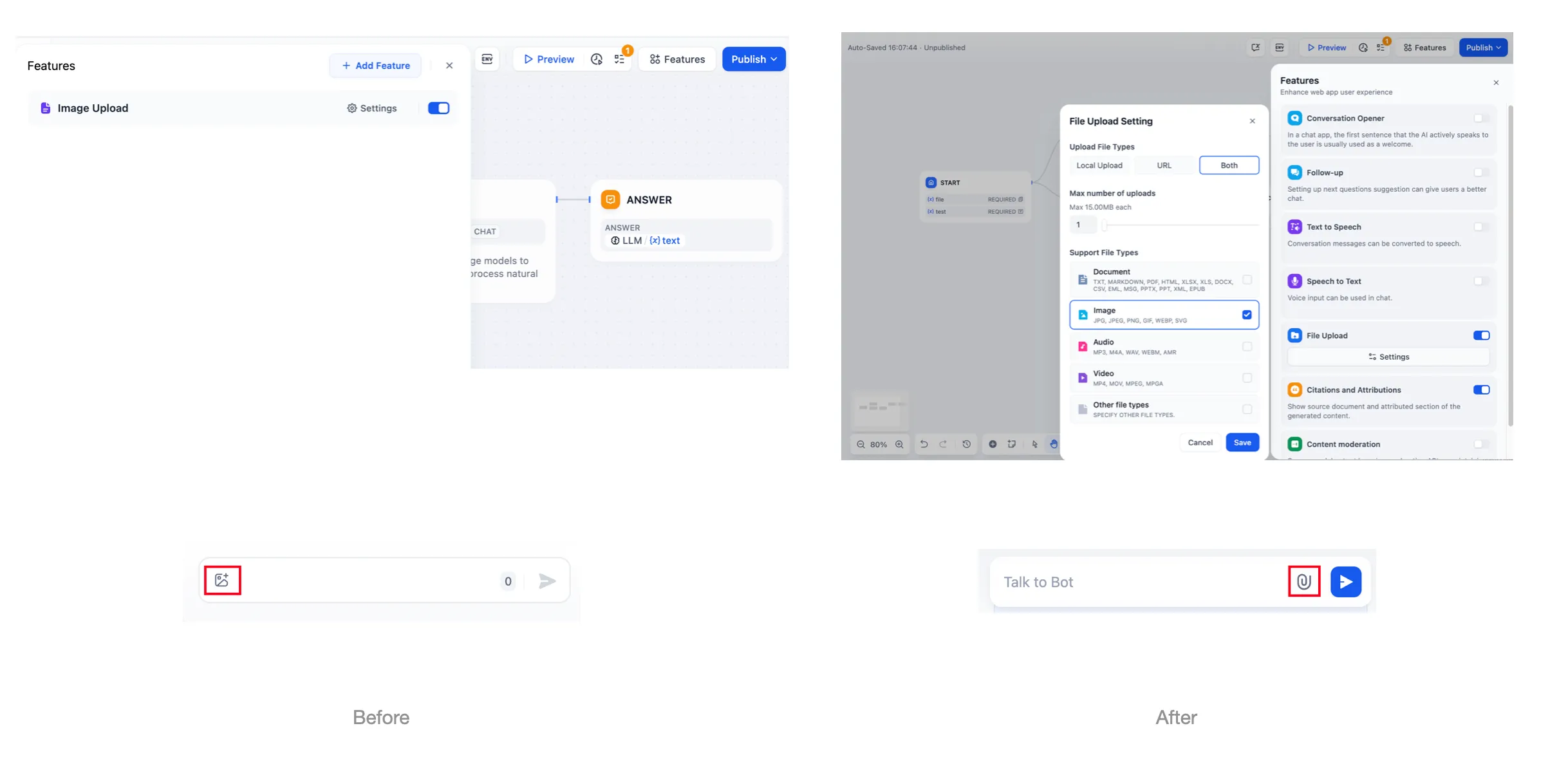
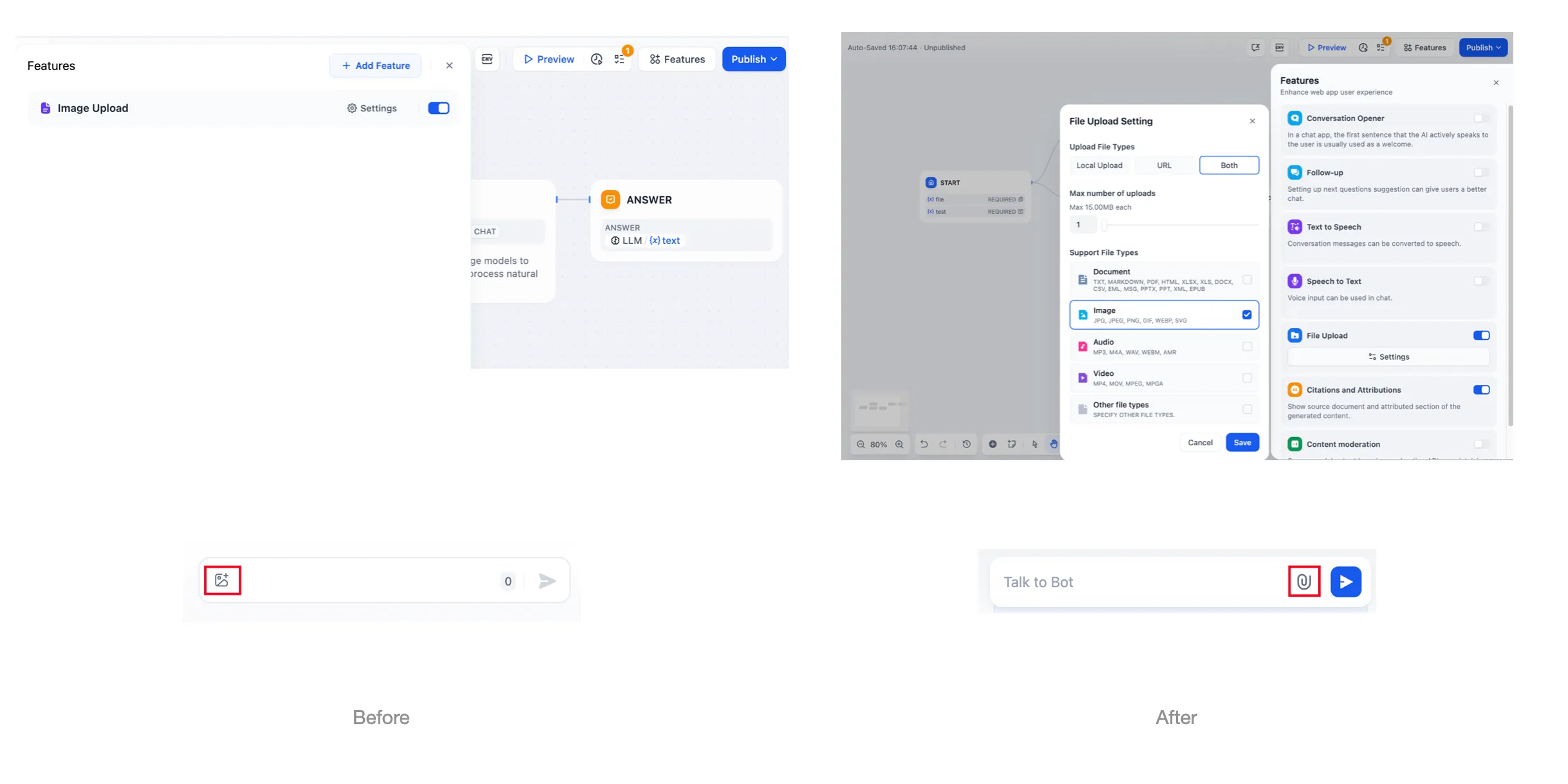
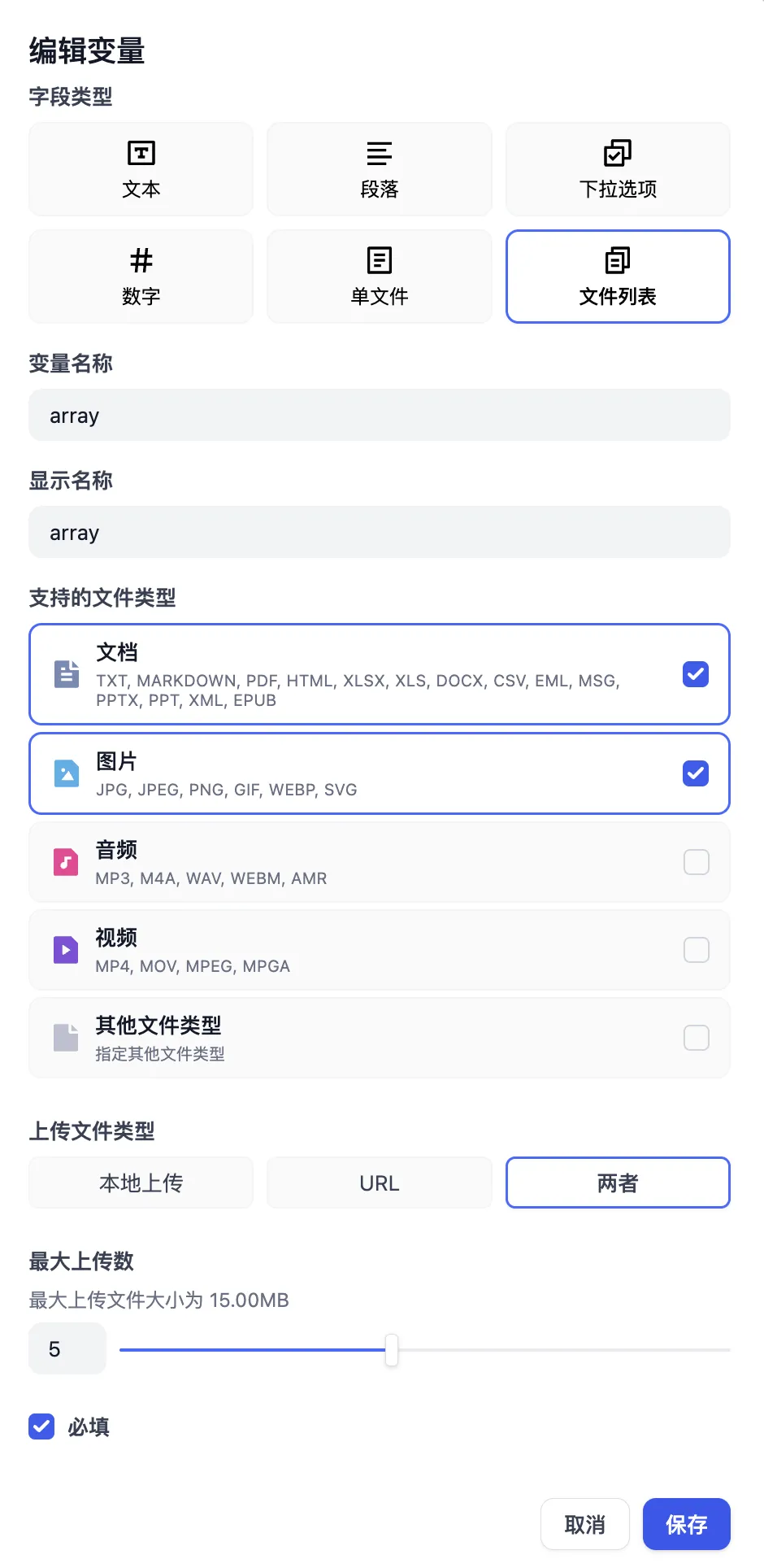
文件上传功能
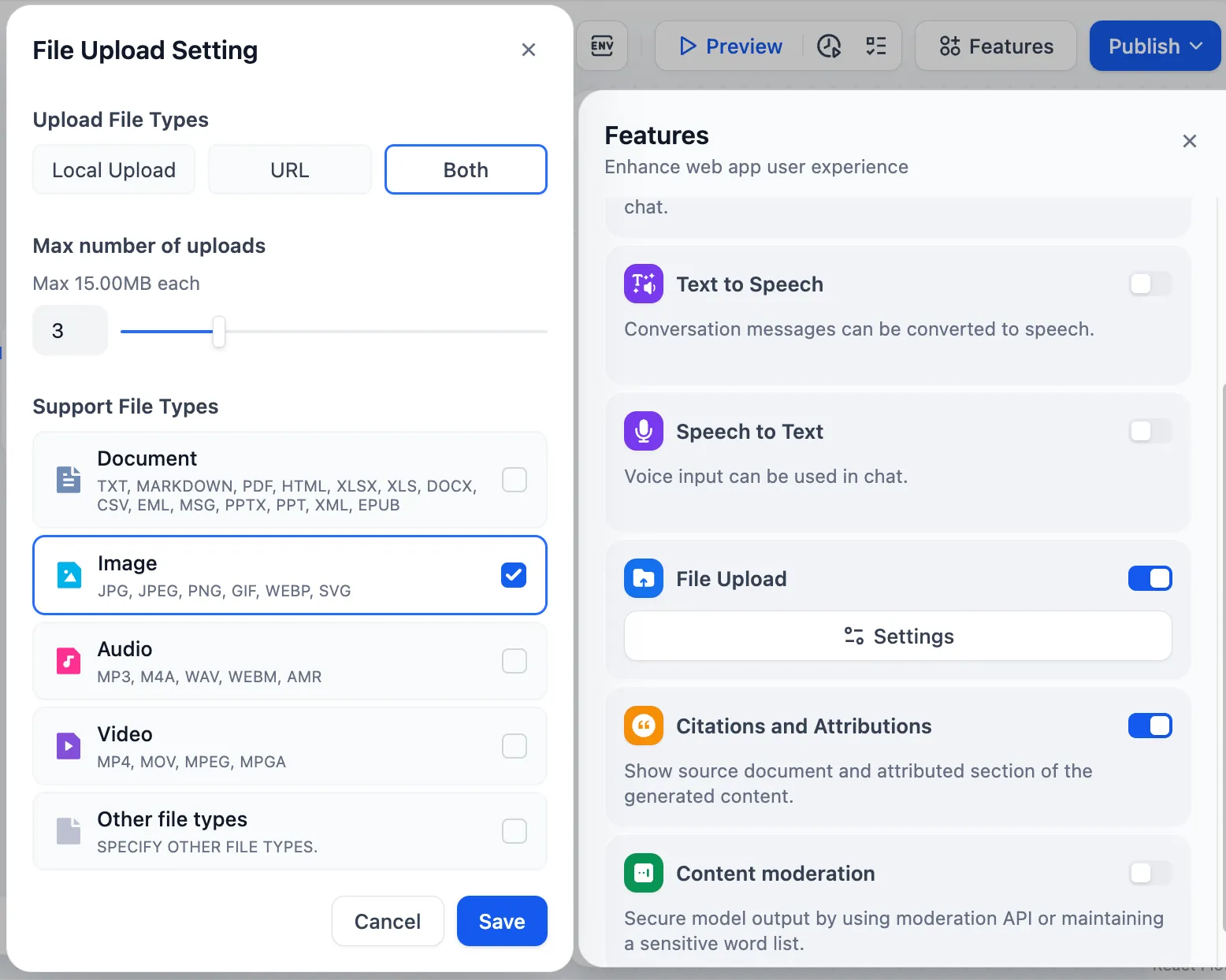
文件上传功能
 (2).png)
使用文件上传
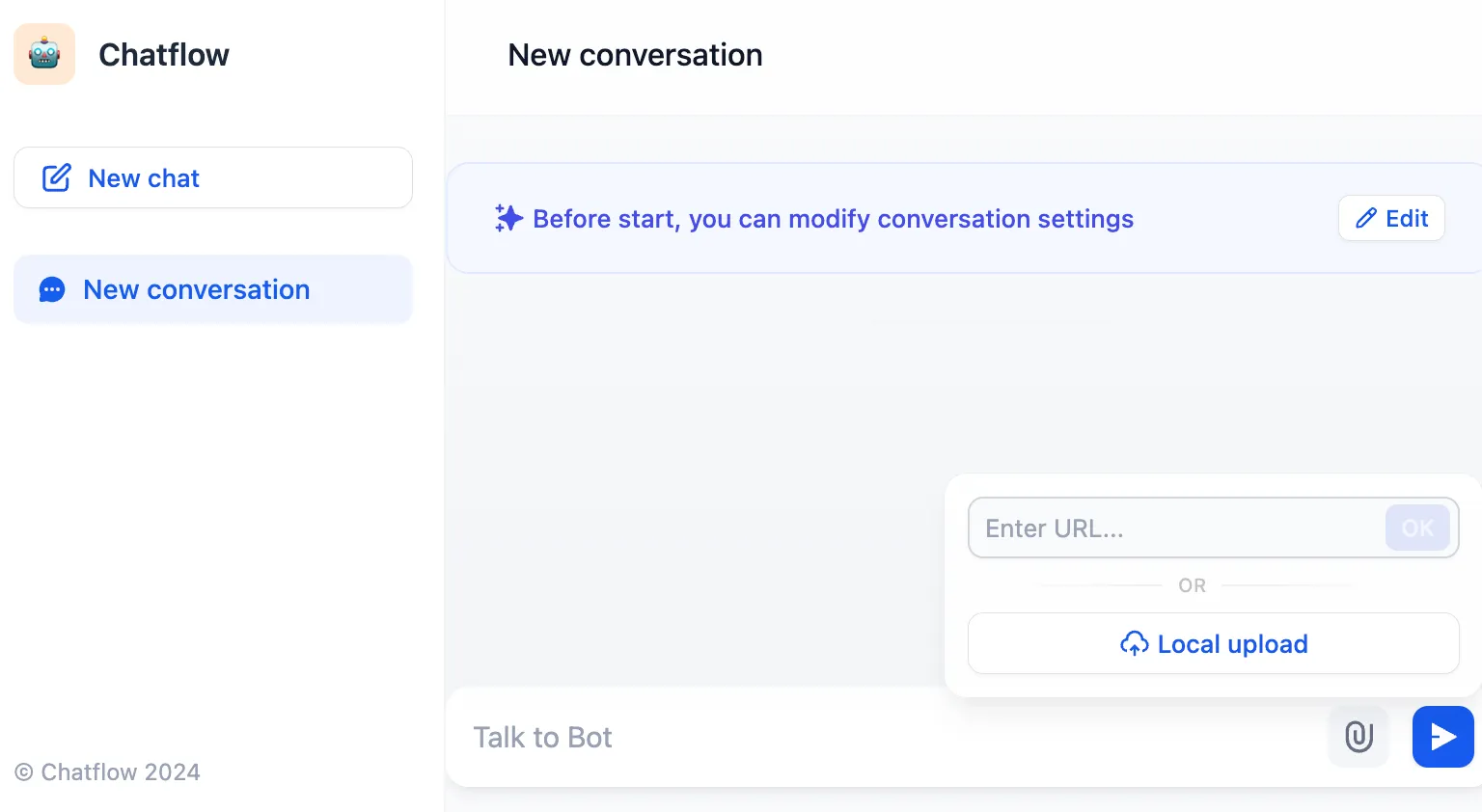
使用文件上传
.png)
文档文件编排
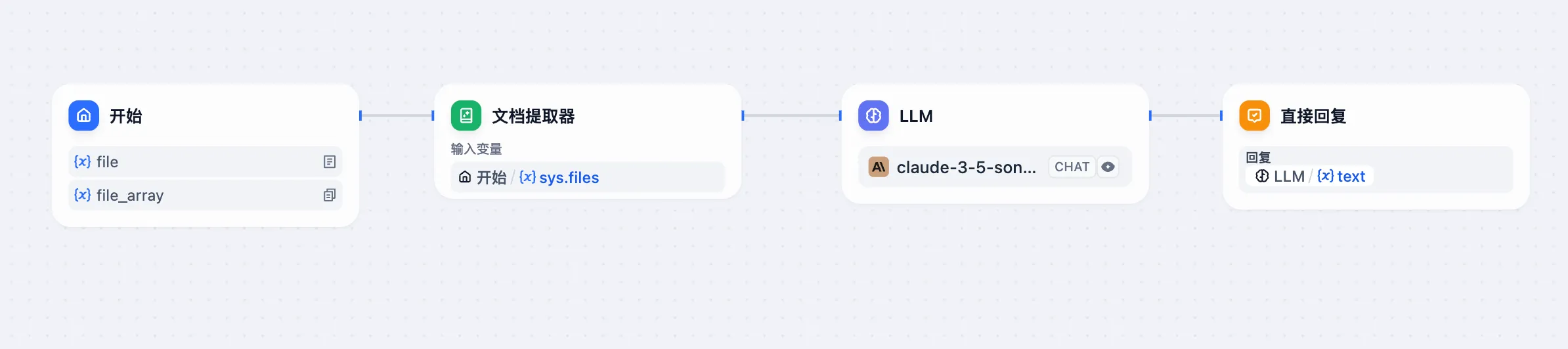
文档文件编排
 (2).png)
开启视觉分析能力
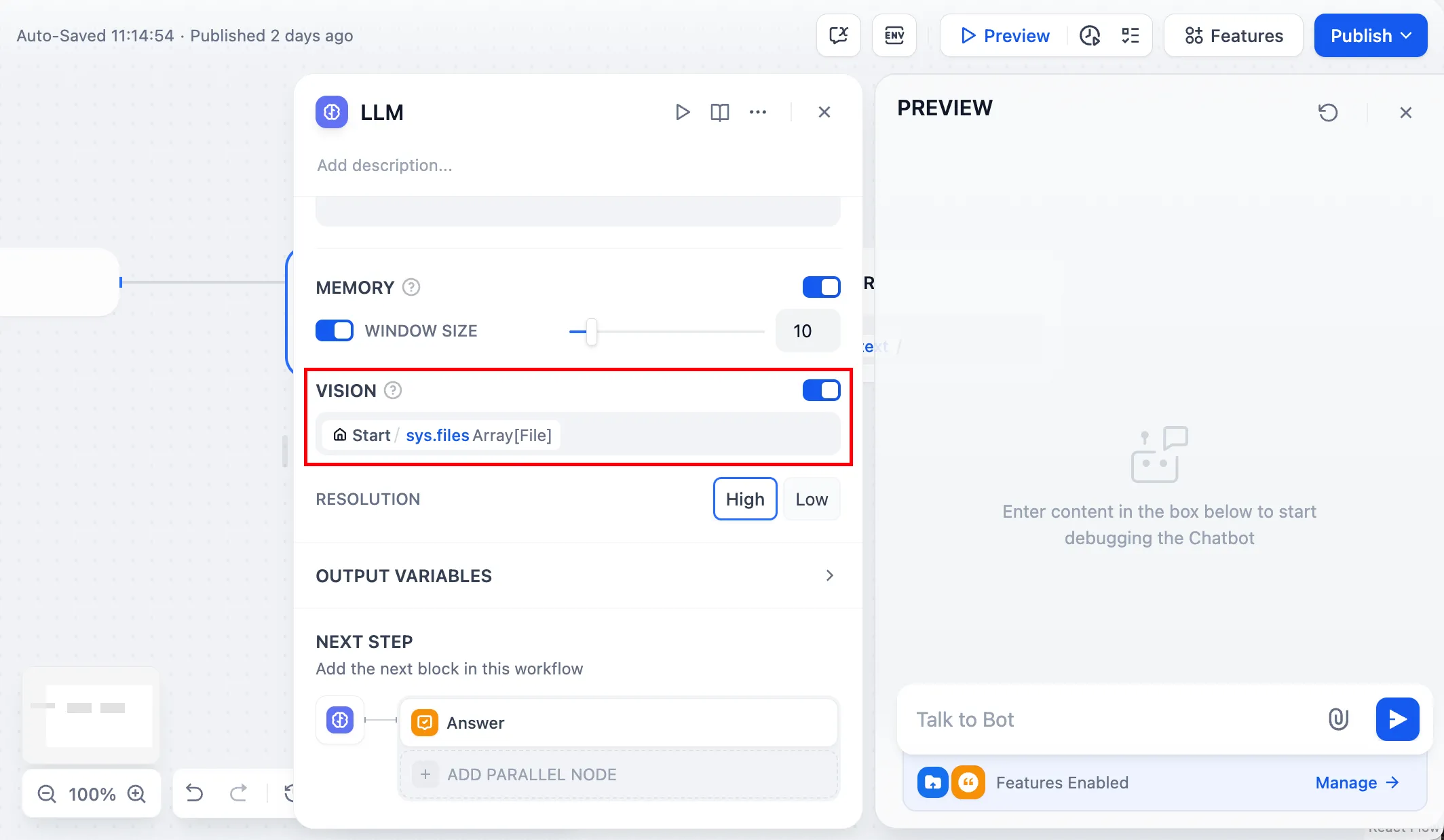
开启视觉分析能力
混合文件处理
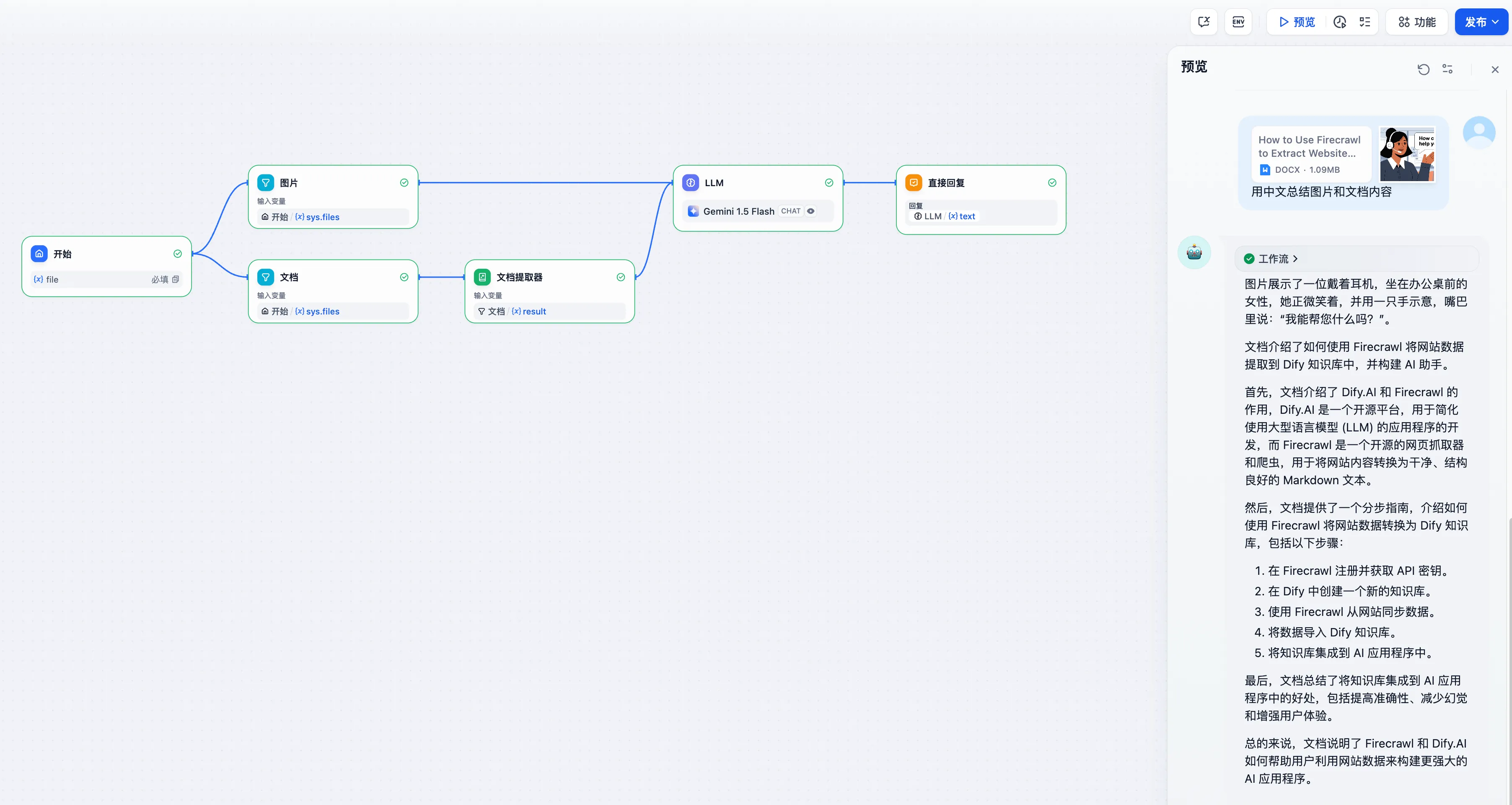
混合文件处理
.png)
.png)
.png)
.png)
.png)

.png)
.png)




 (2).png)
.png)
.png)
.png)
.png)
Cloudflare WAF
Cloudflare WAF
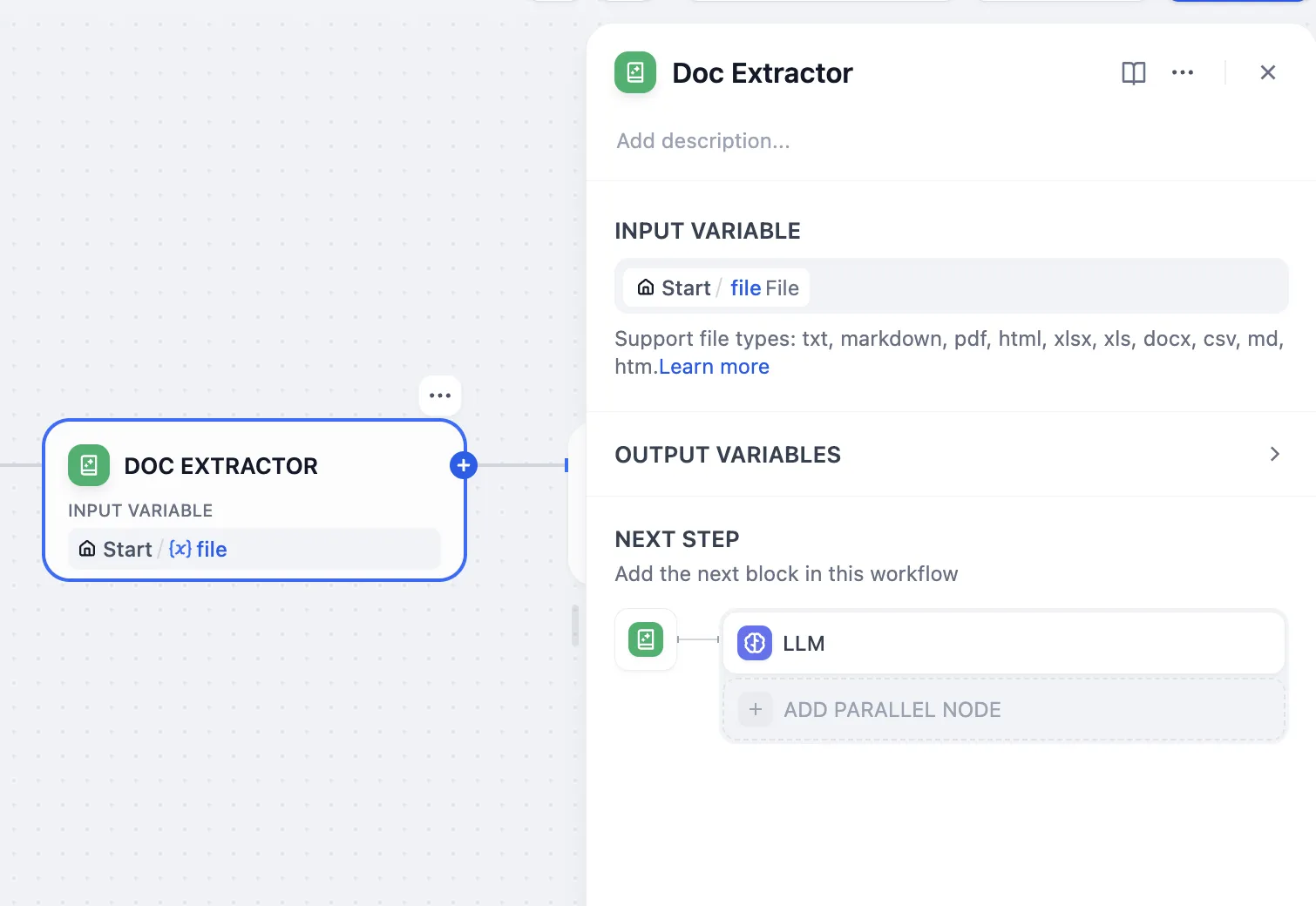
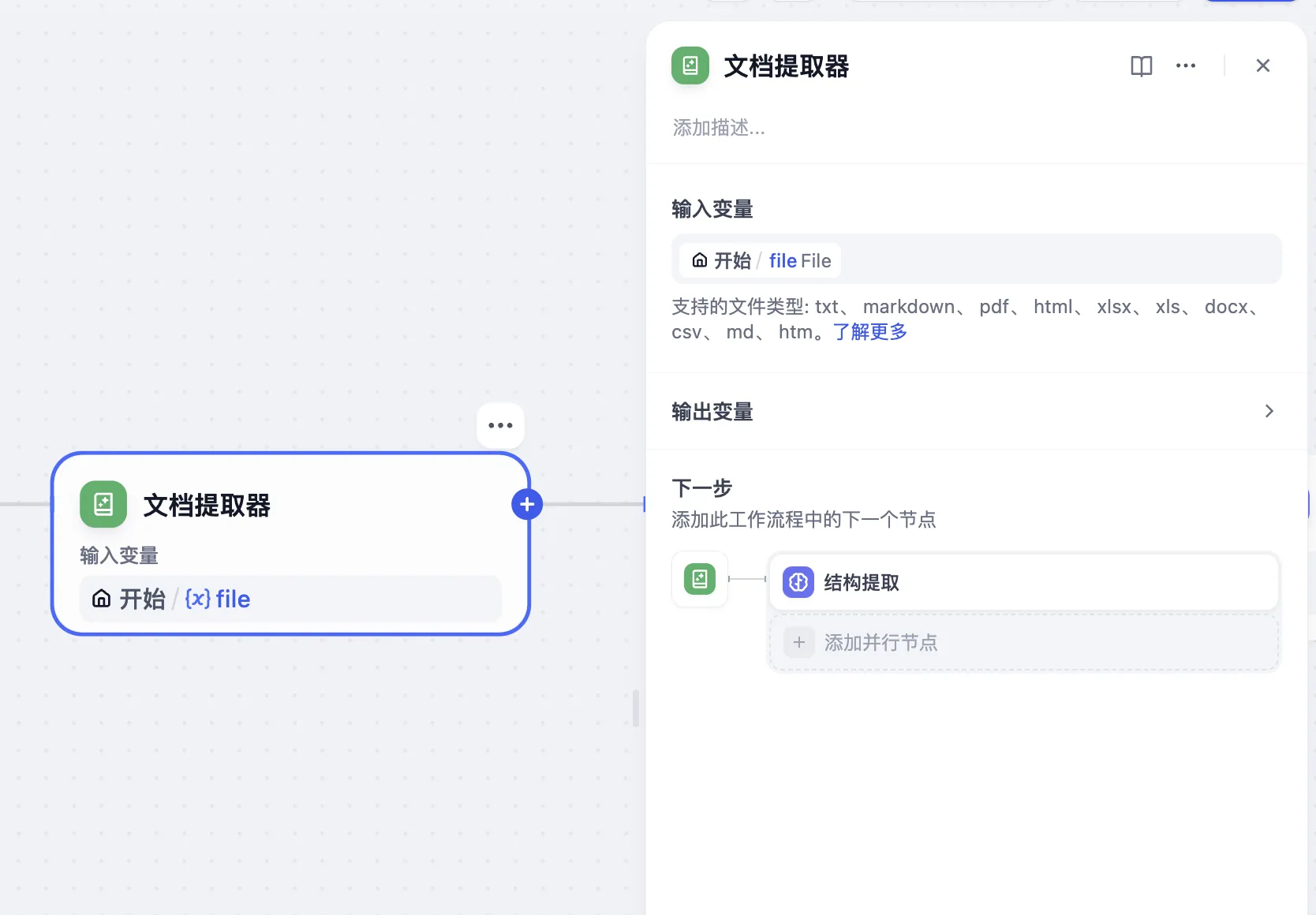
文档提取器节点
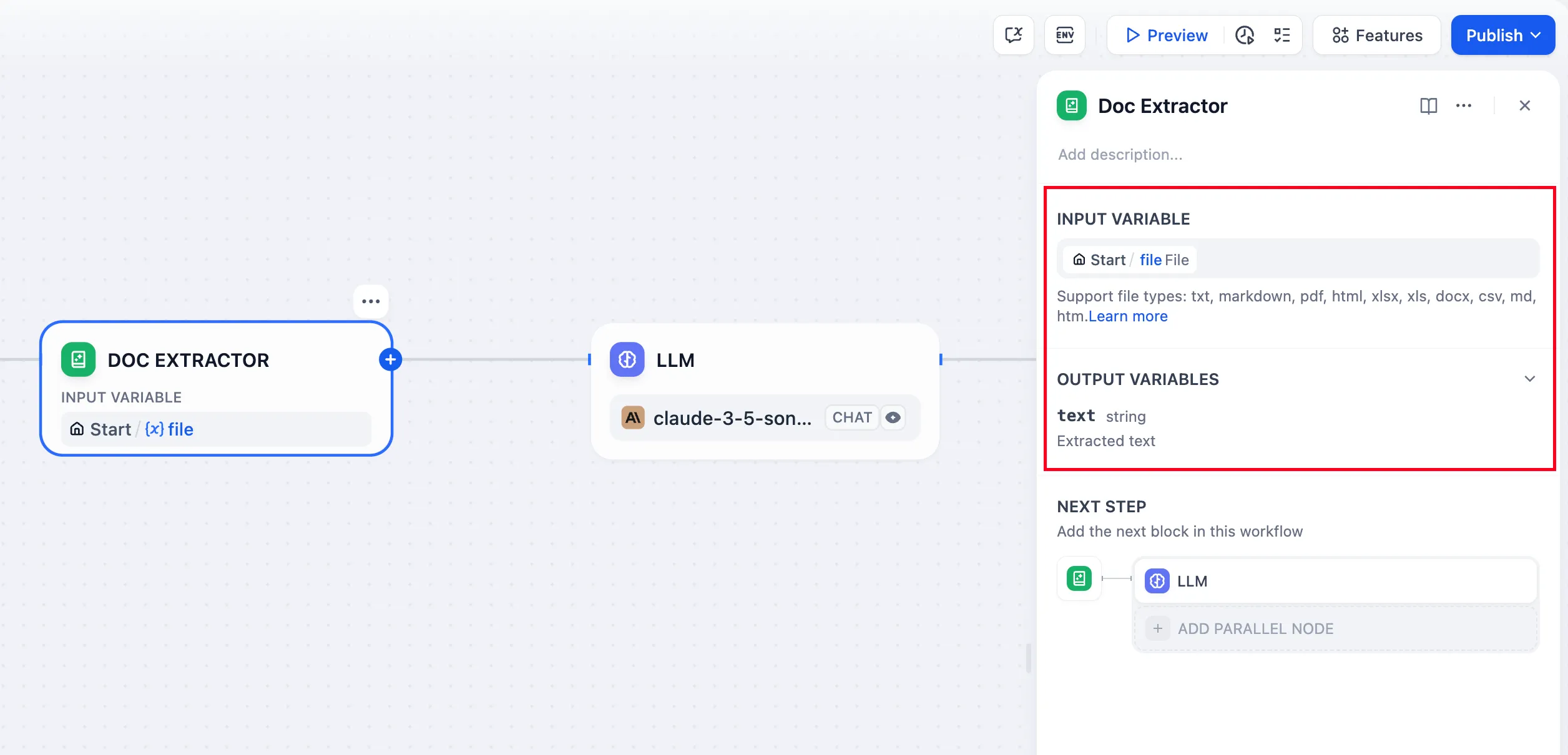
文档提取器节点
.png)
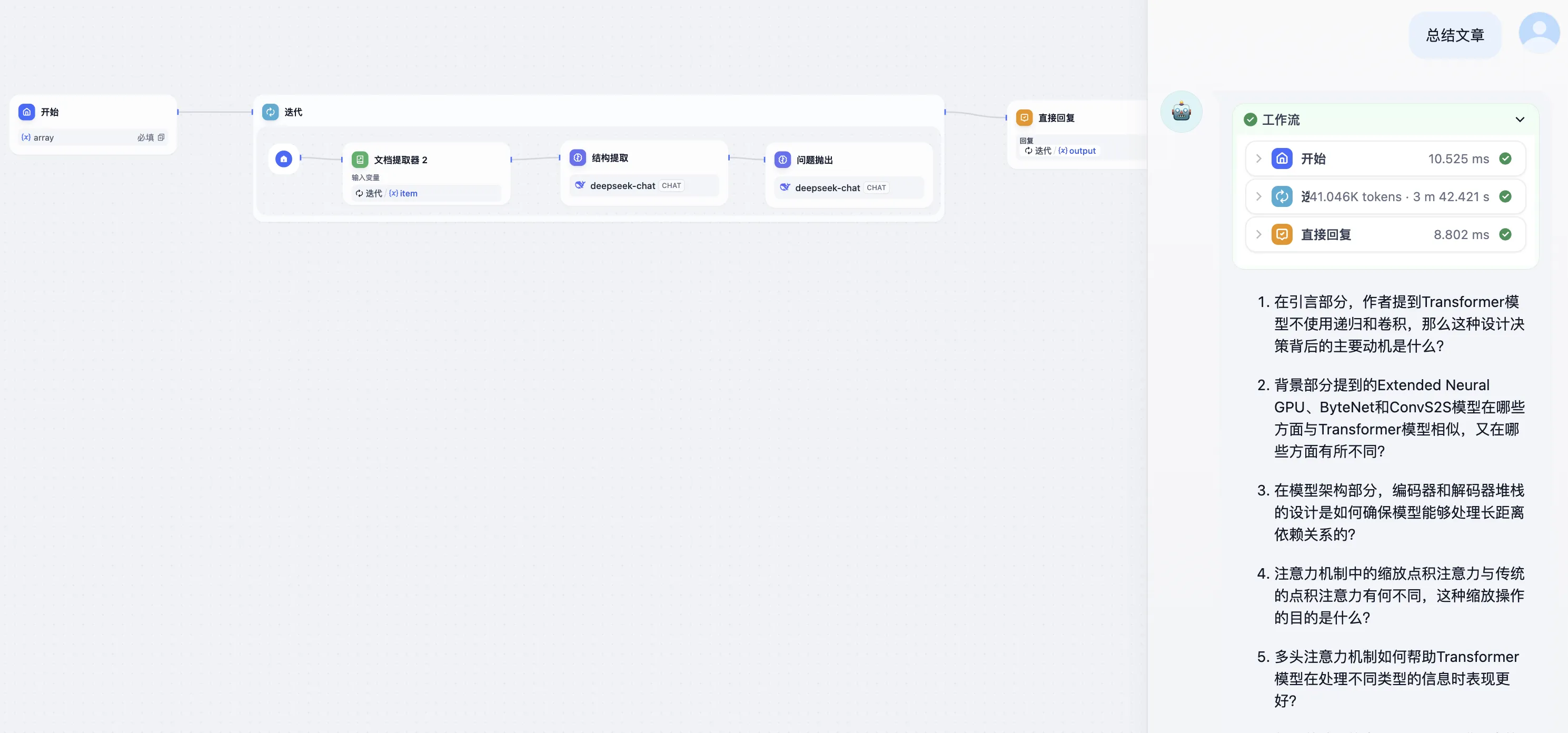
ChatPDF 工作流
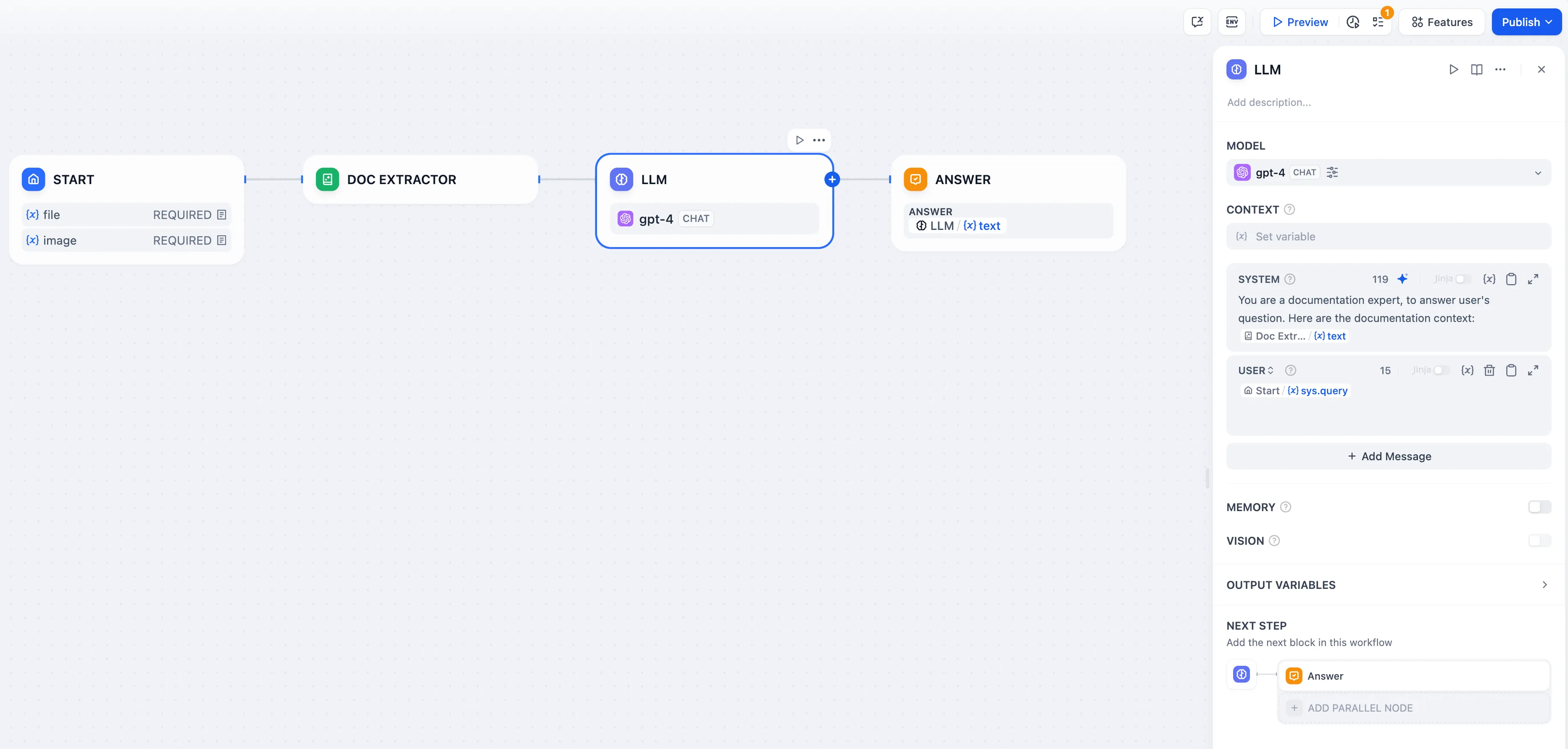
ChatPDF 工作流
填写文档提取器的输出变量
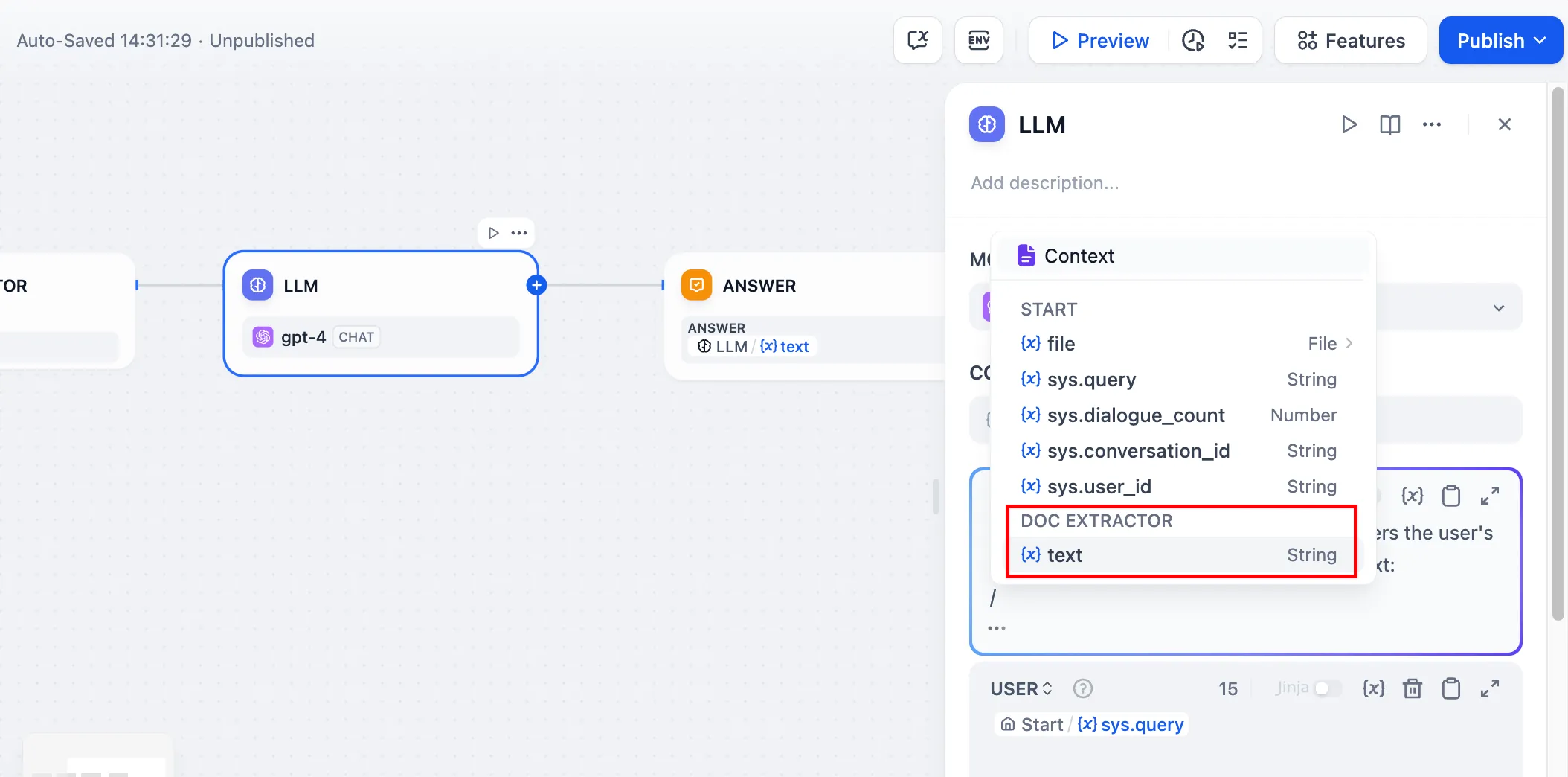
填写文档提取器的输出变量
 (2).png)
.png)
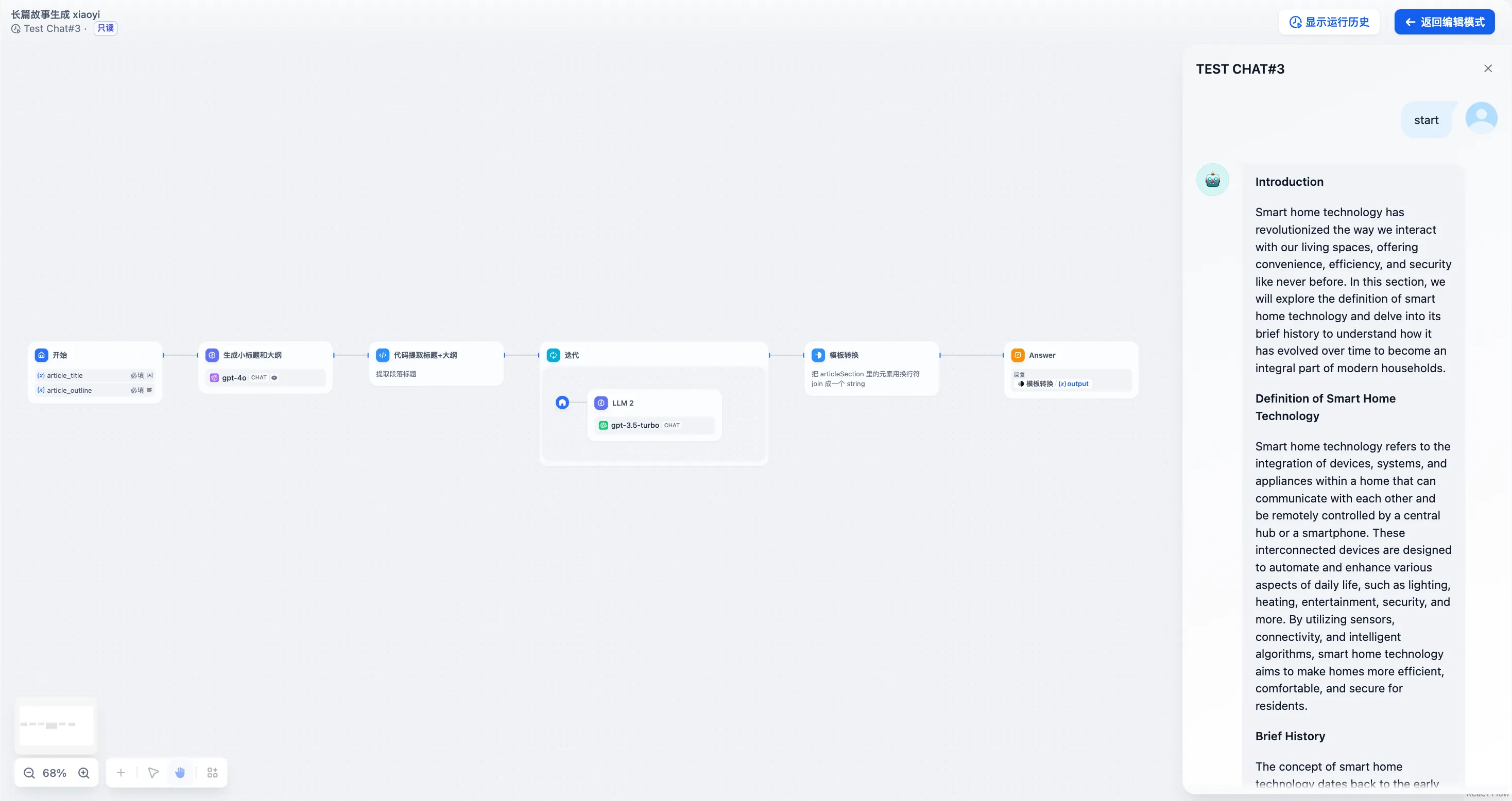
结束节点-长故事生成示例
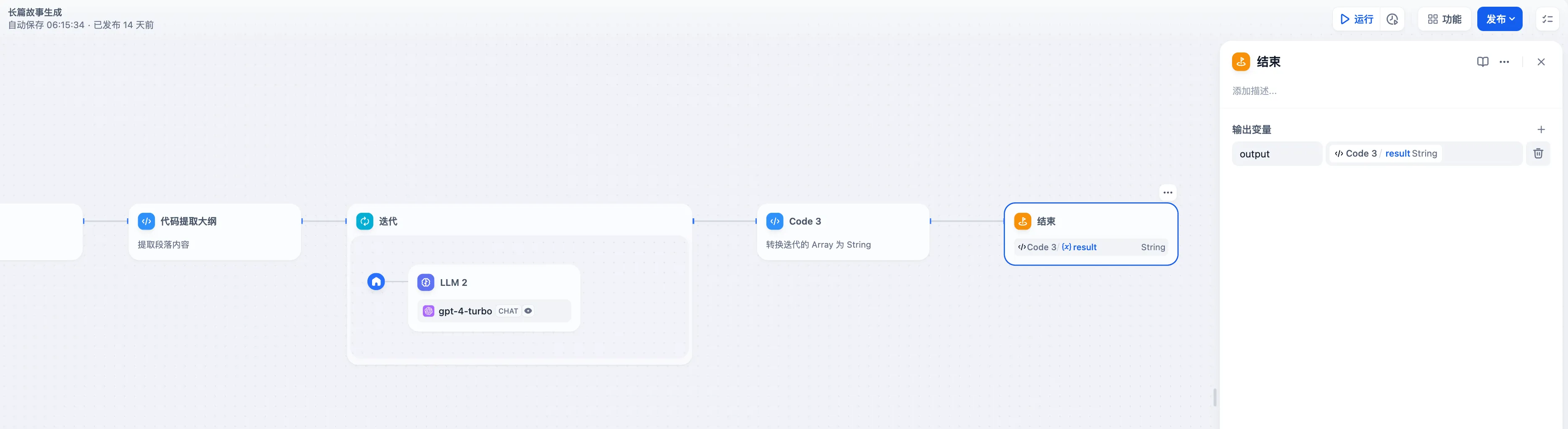
结束节点-长故事生成示例
.png)
.png)
HTTP 请求配置
HTTP 请求配置
.png)
客户评价分类
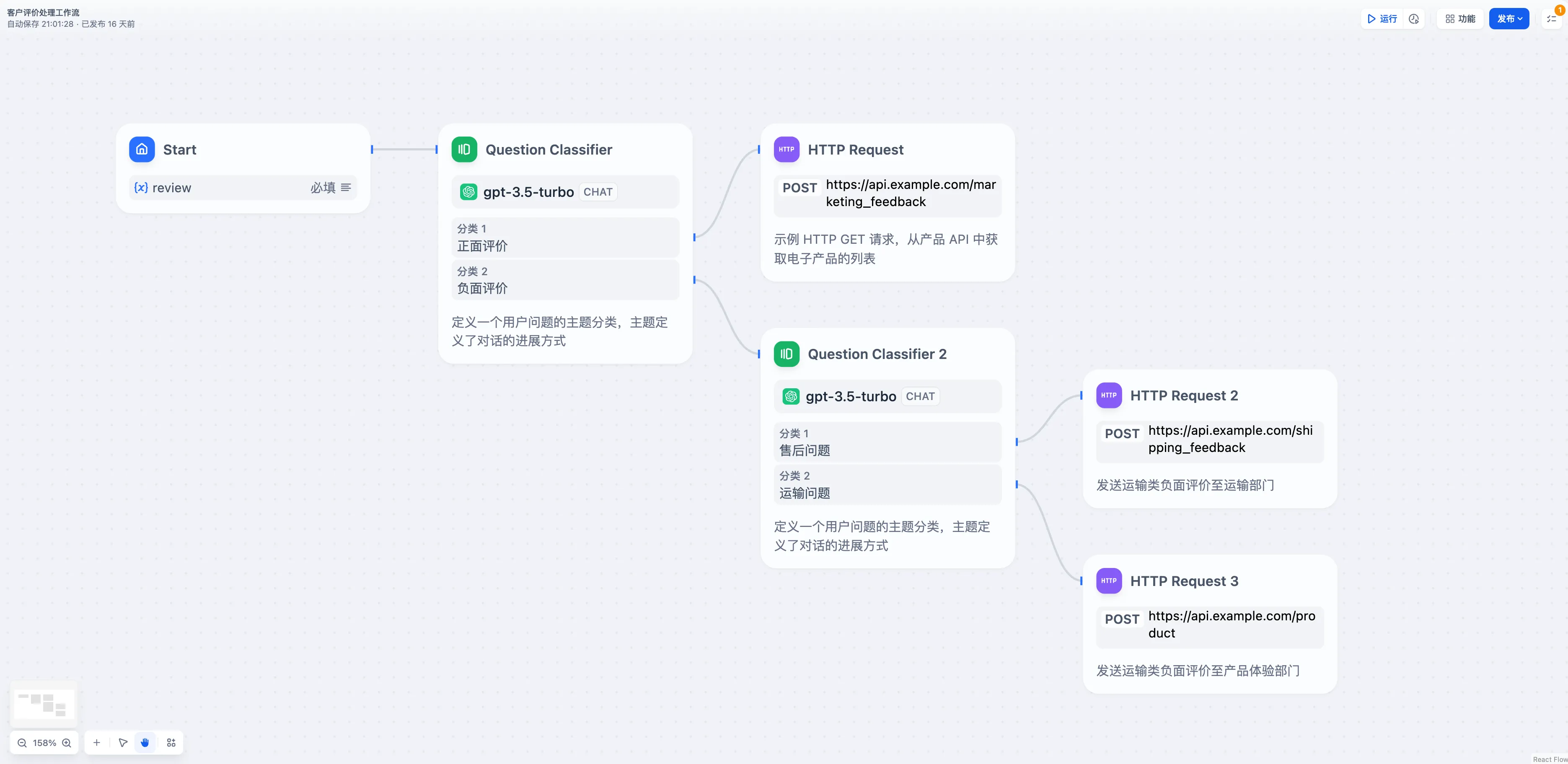
客户评价分类
通过 HTTP 节点发送文件
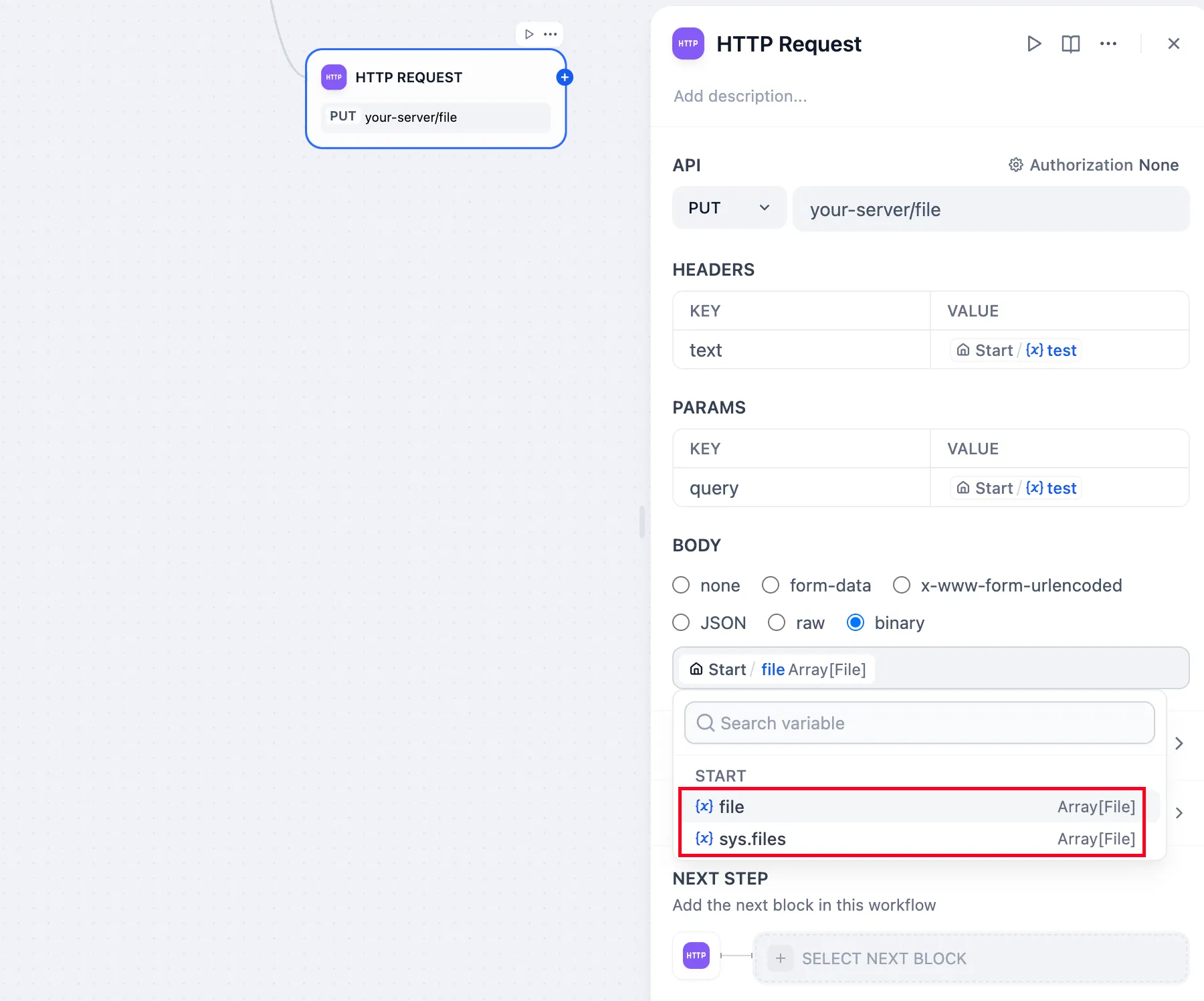
通过 HTTP 节点发送文件

.png)
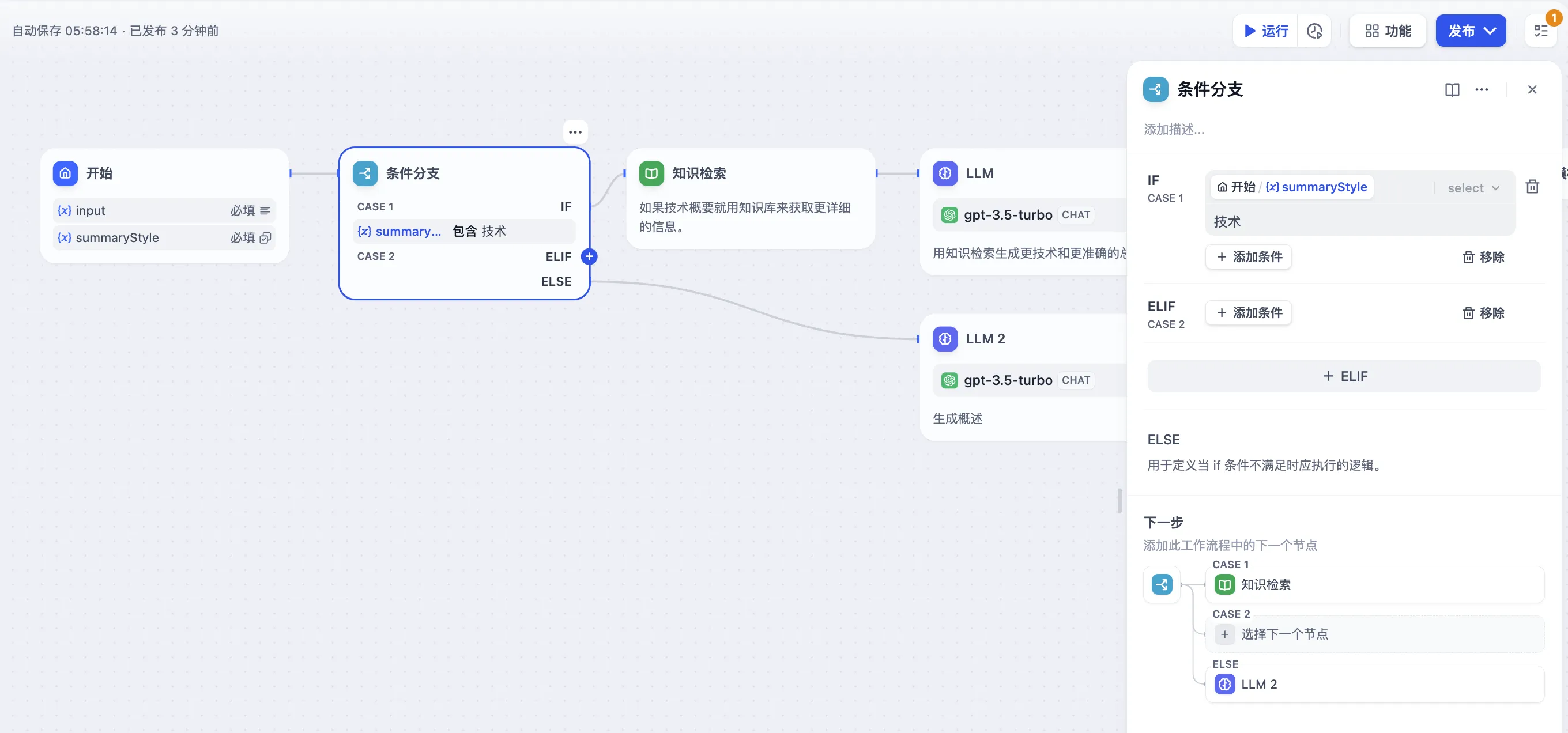
多重条件判断
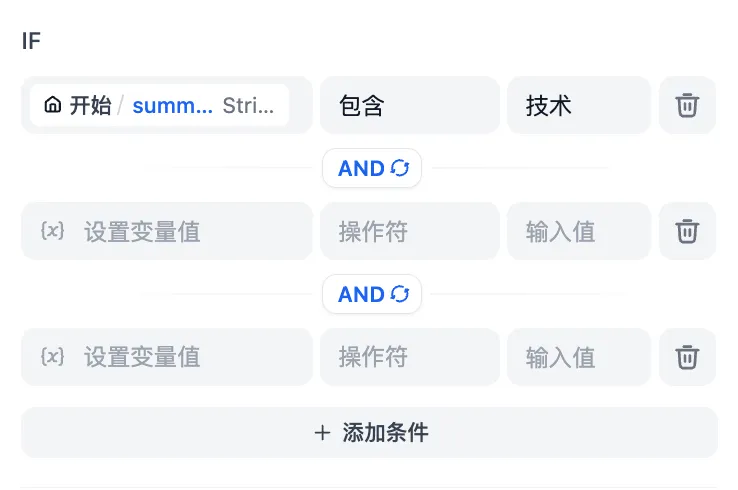
多重条件判断
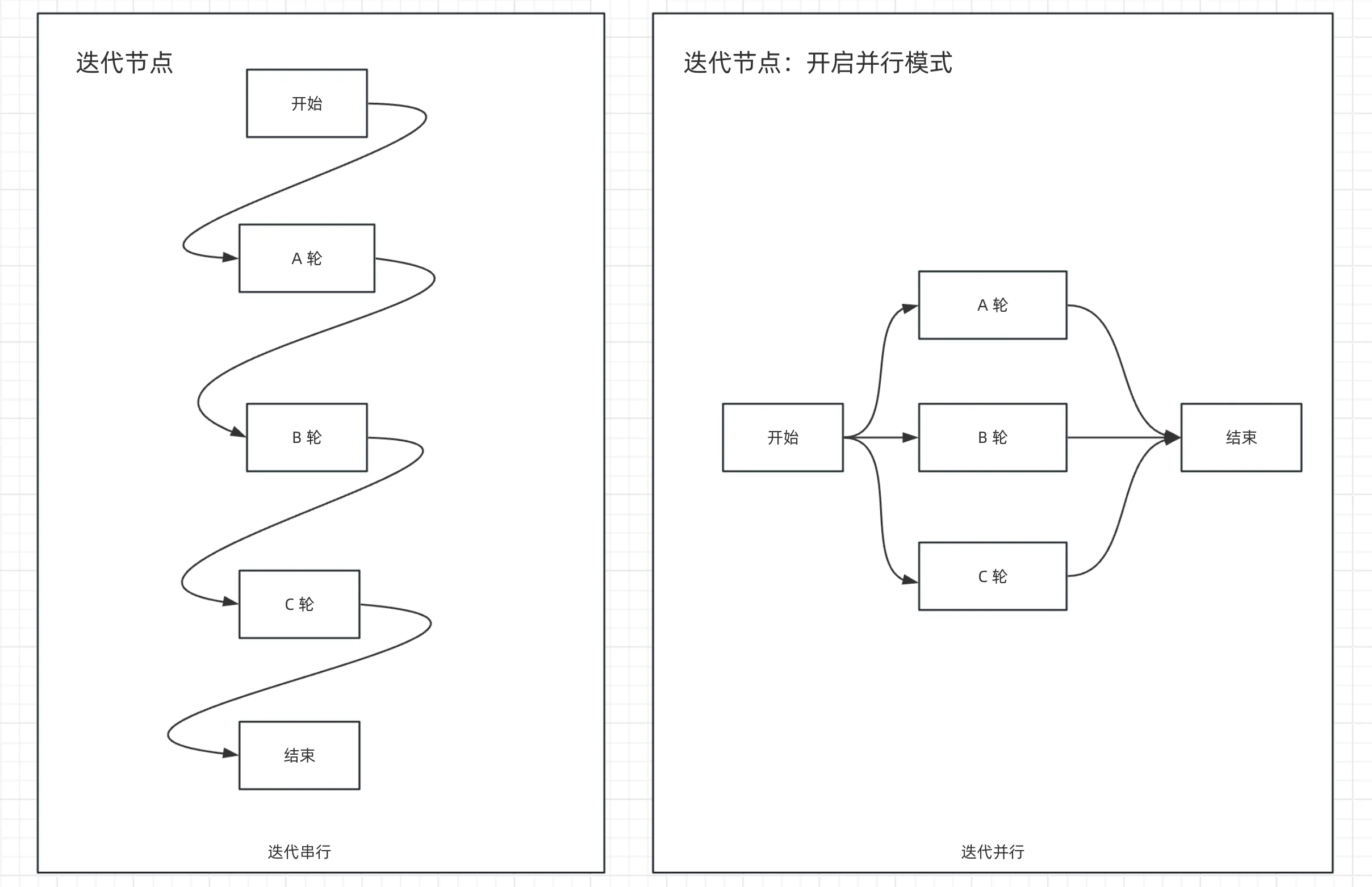
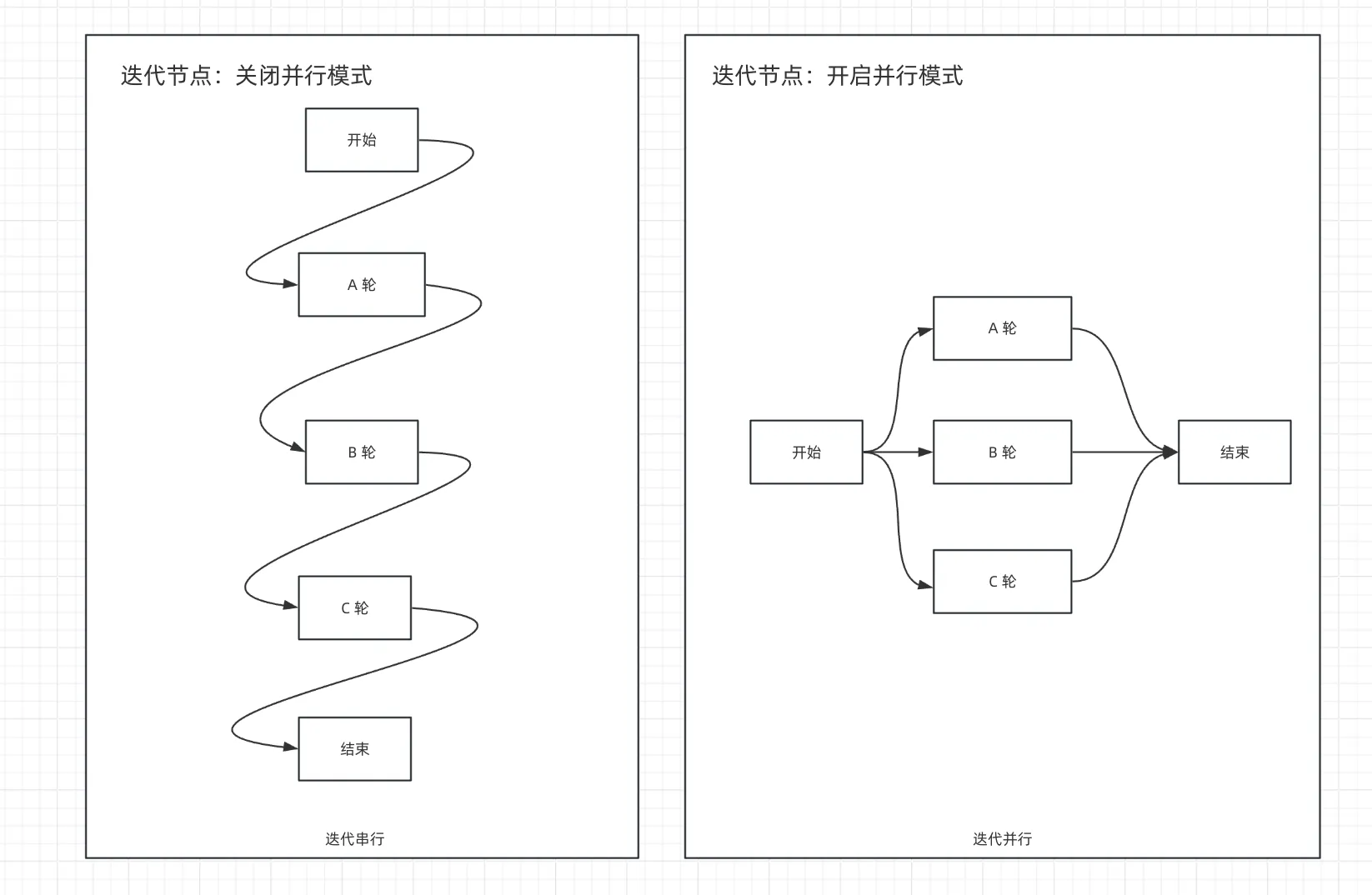
迭代节点原理图
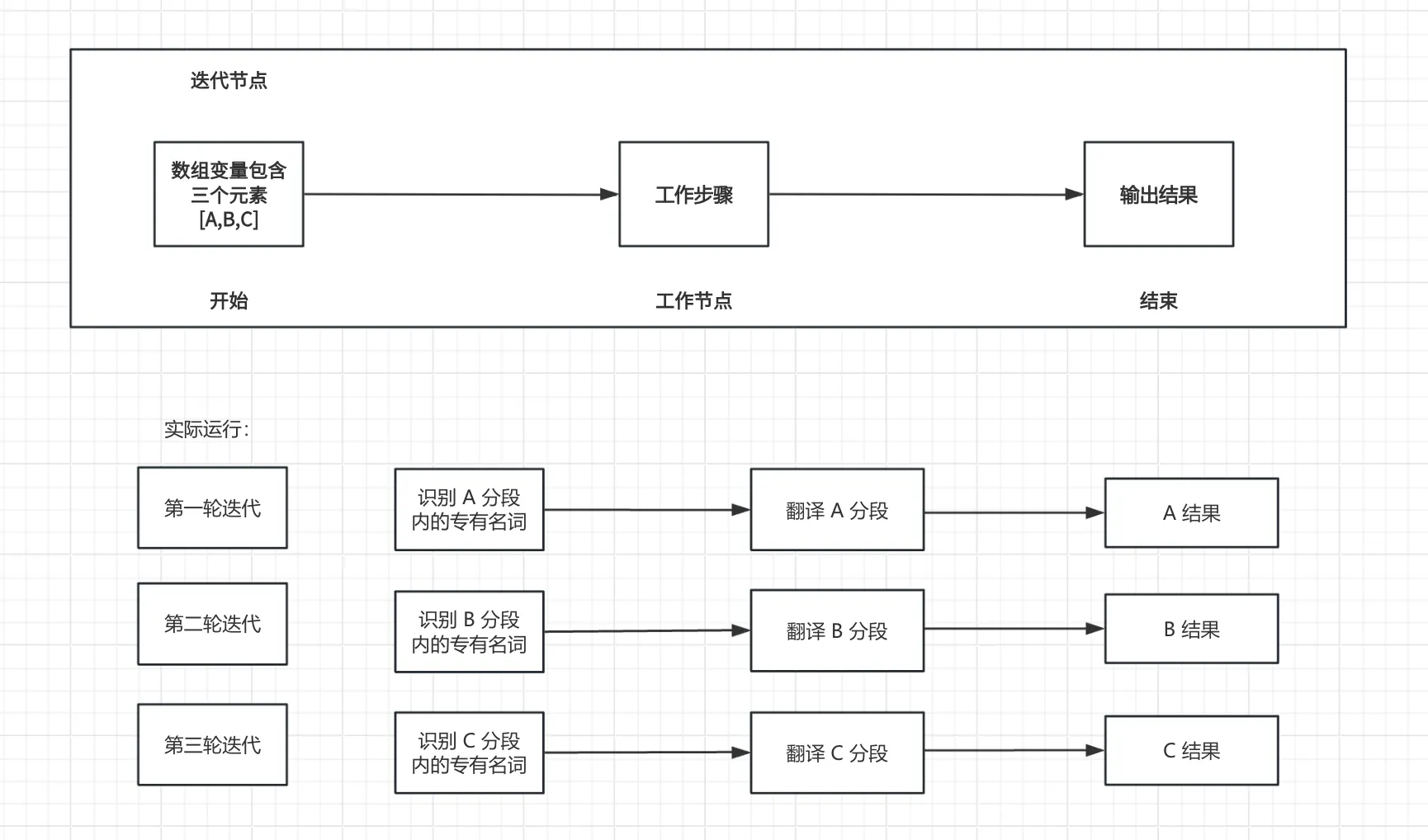
迭代节点原理图

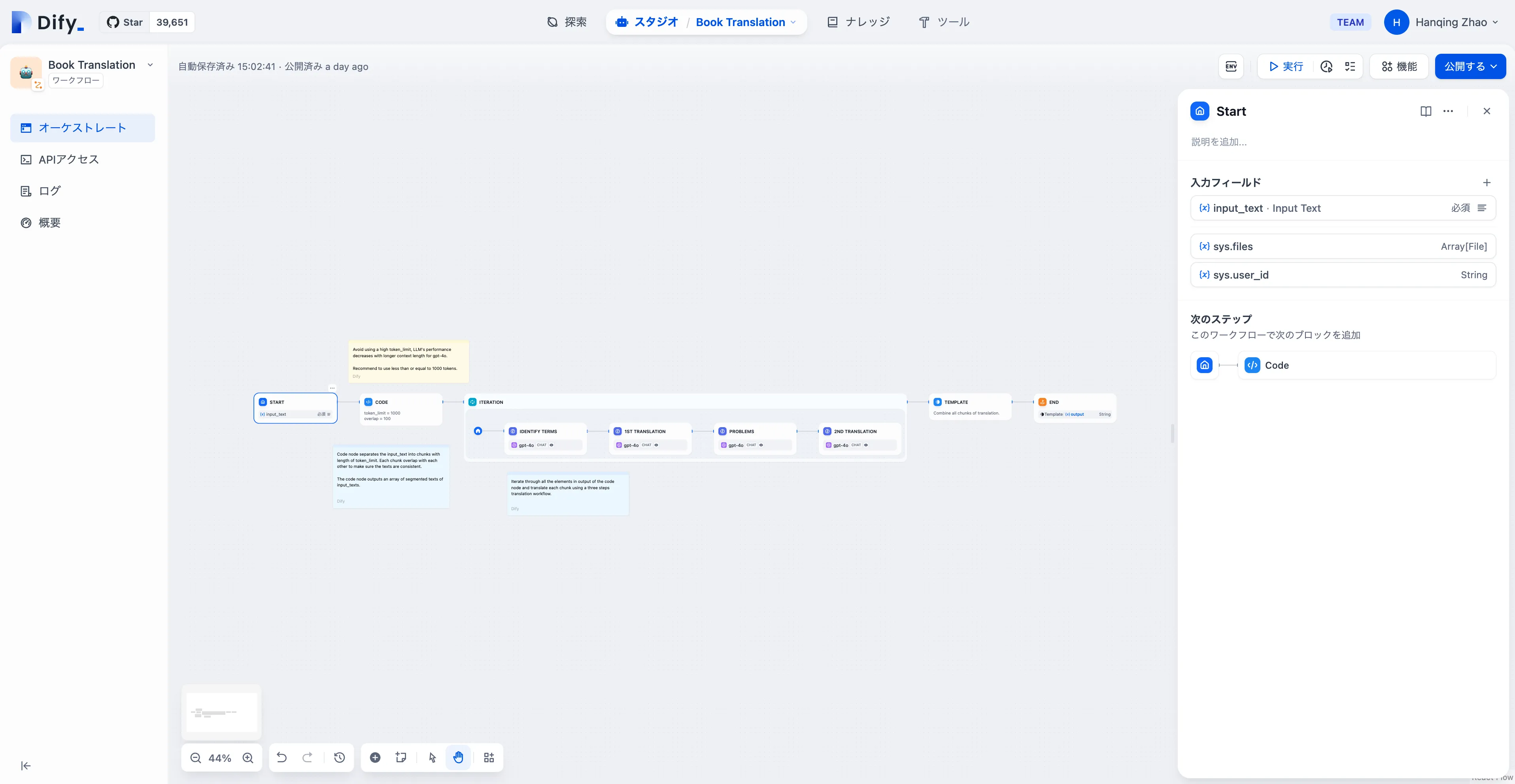
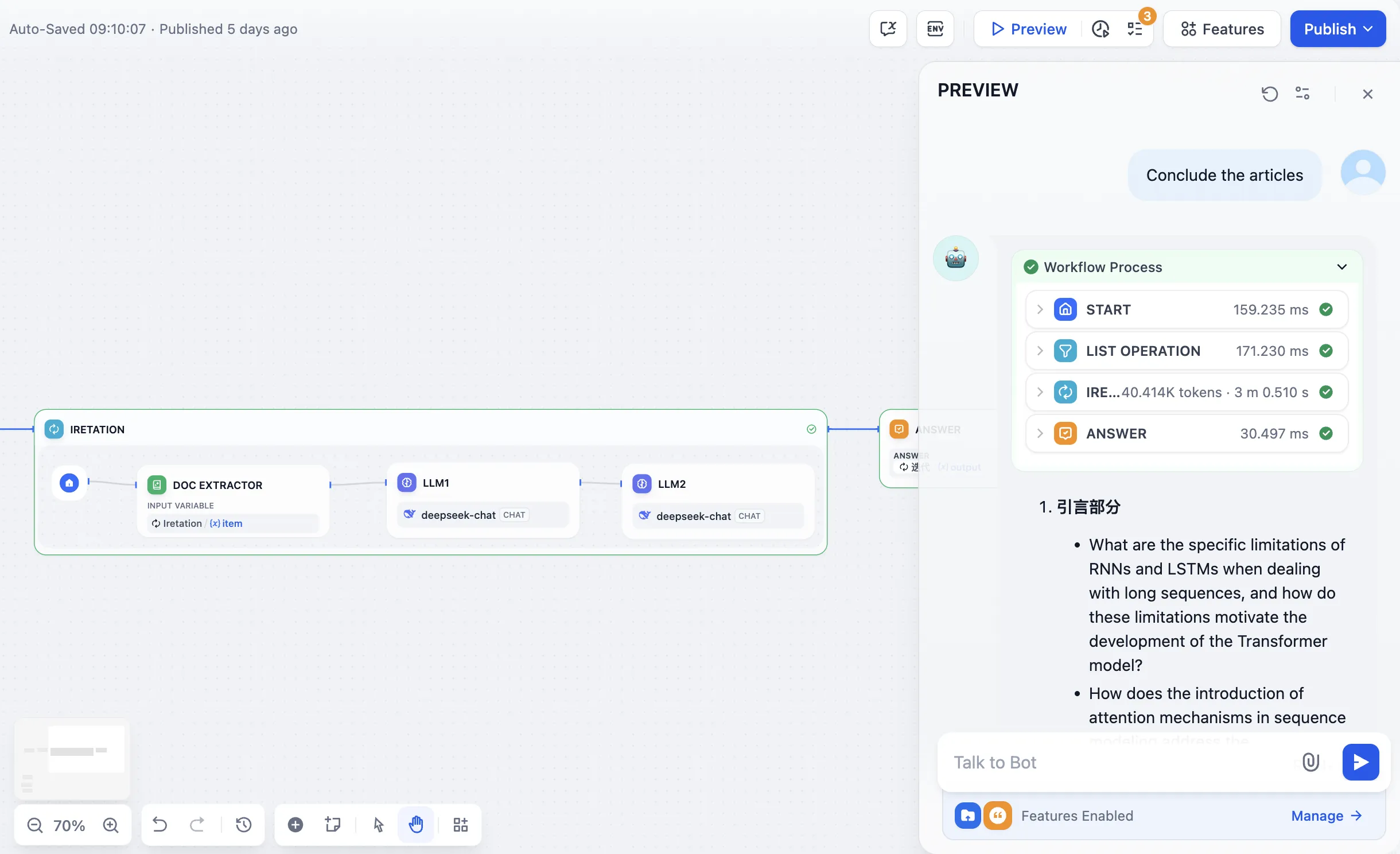
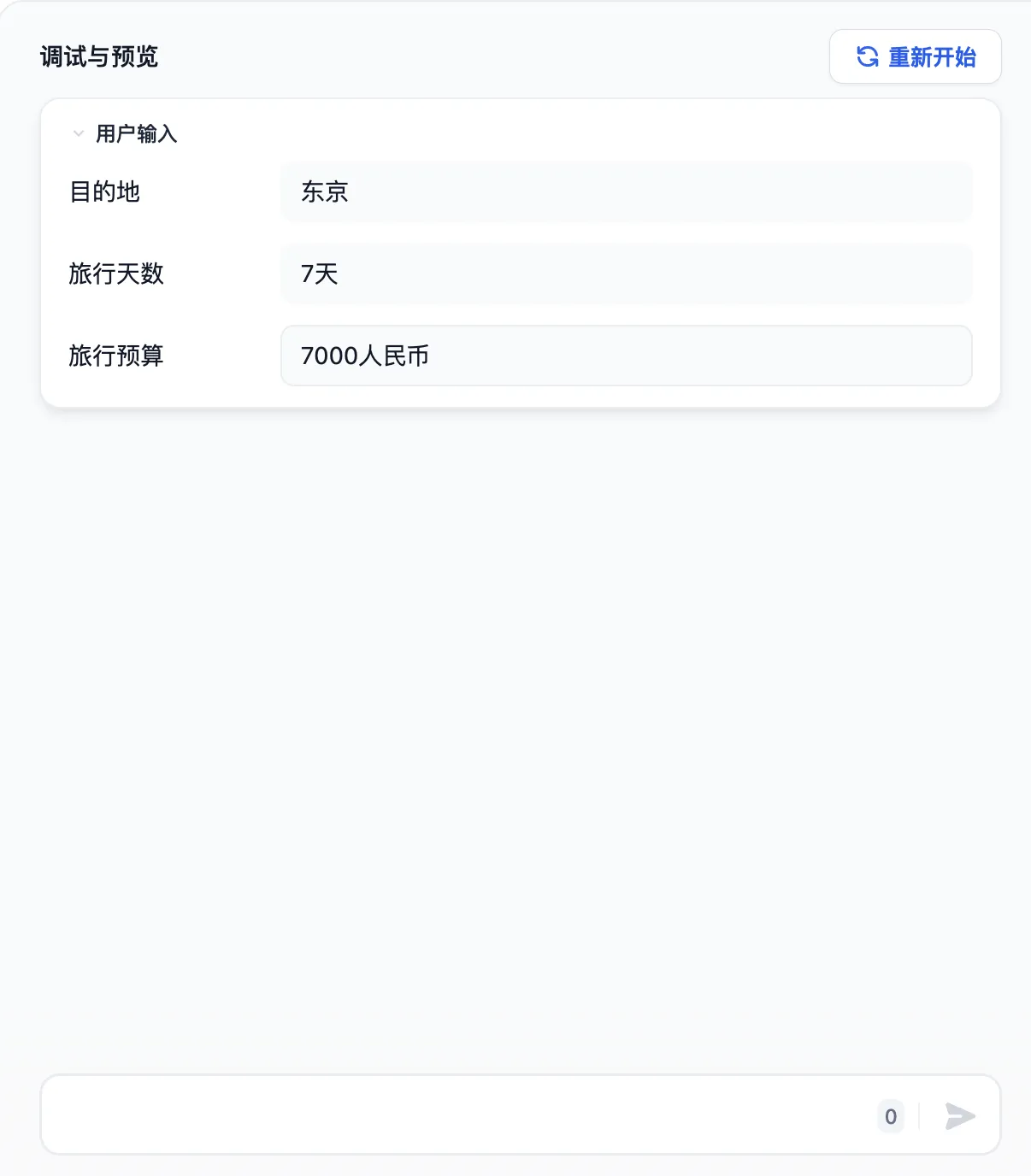
长故事生成器
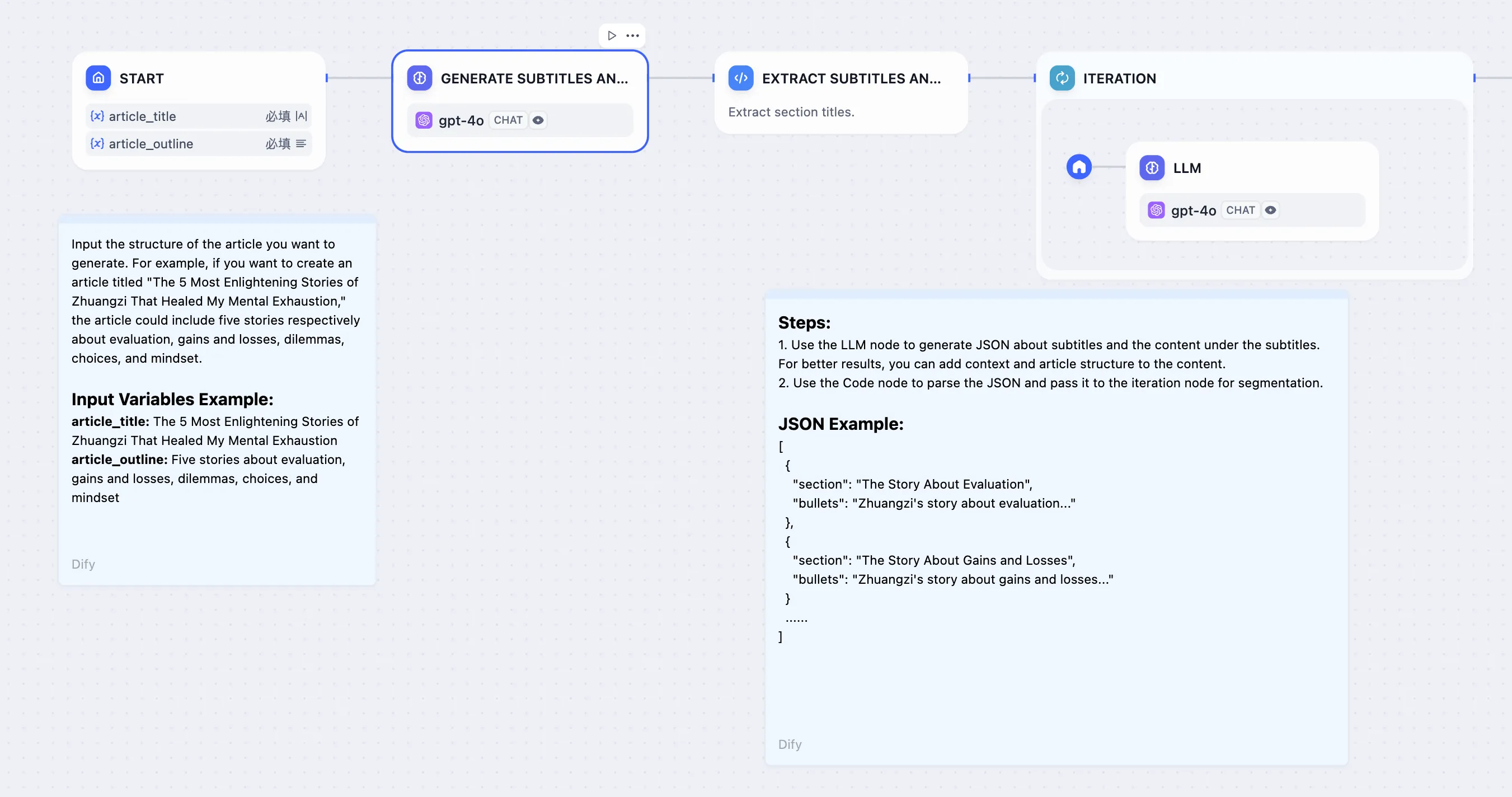
长故事生成器
.png)
开始节点配置
开始节点配置

模板节点
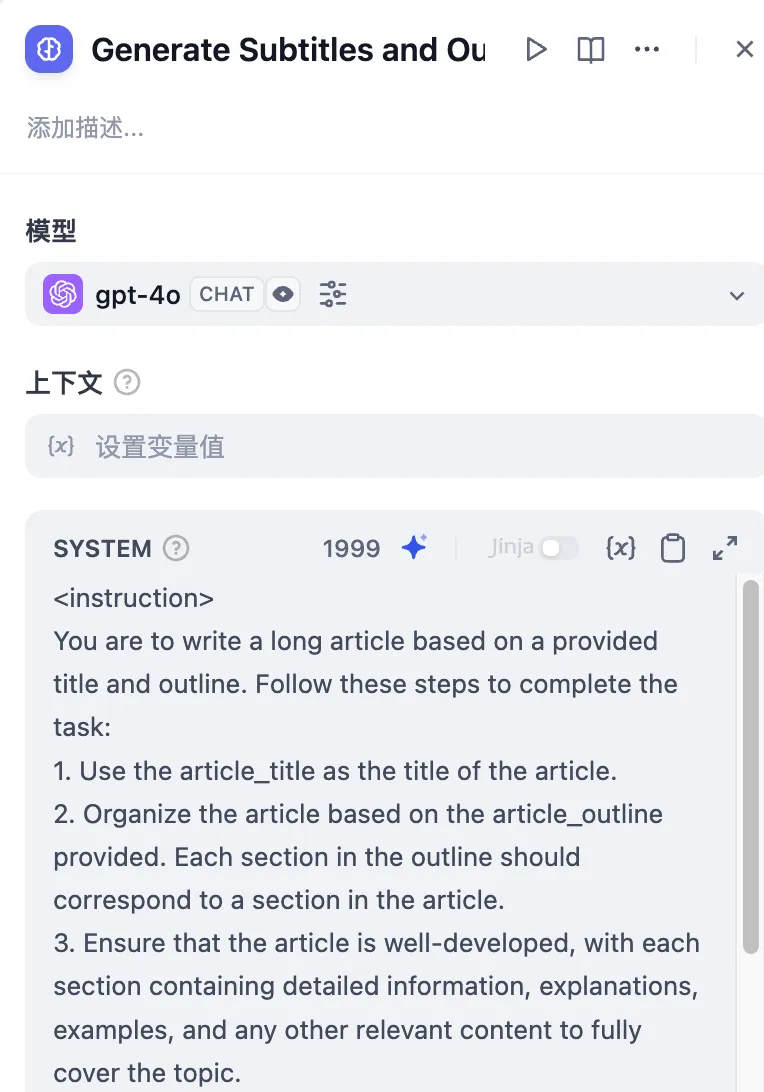
模板节点

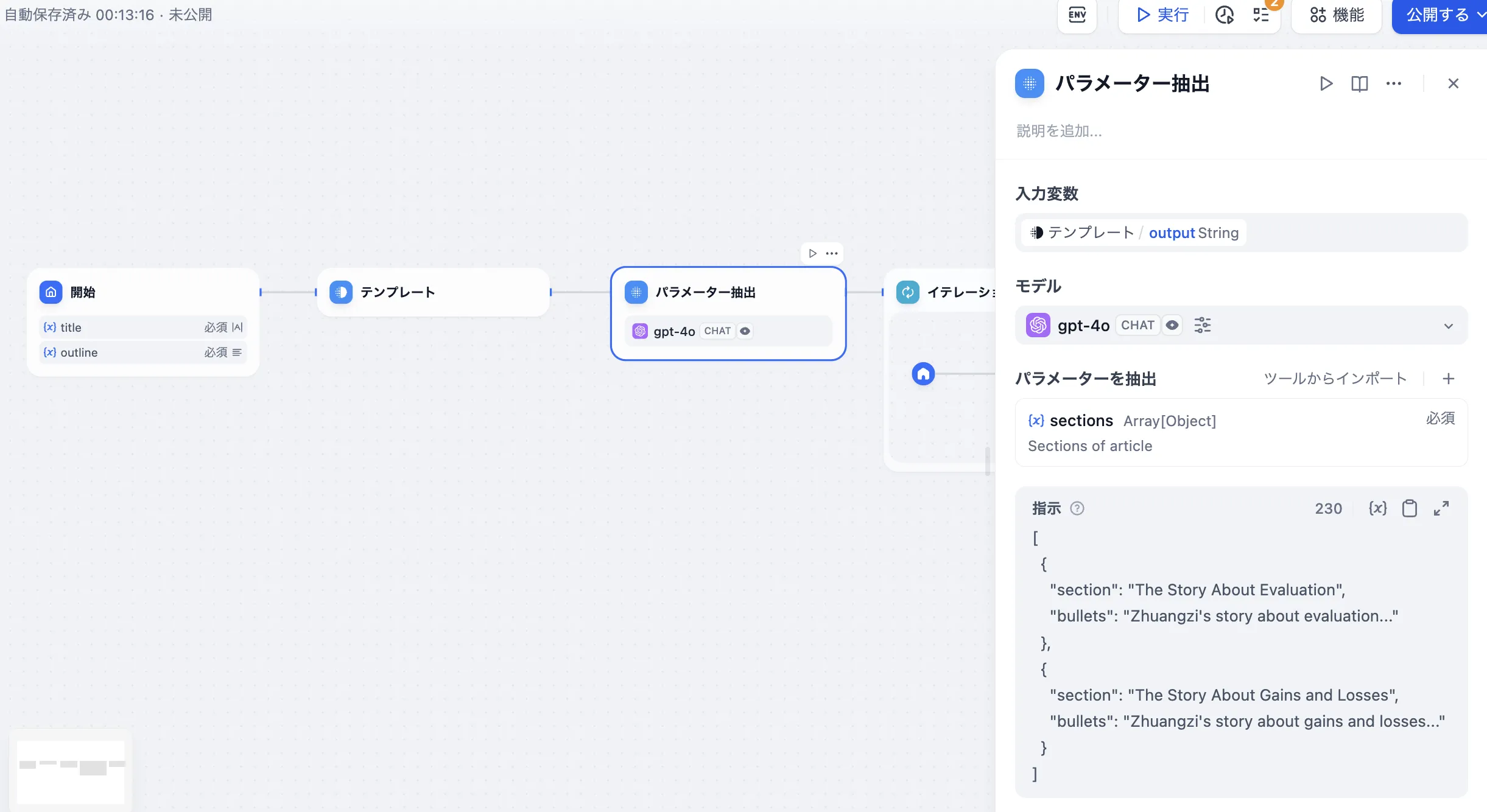
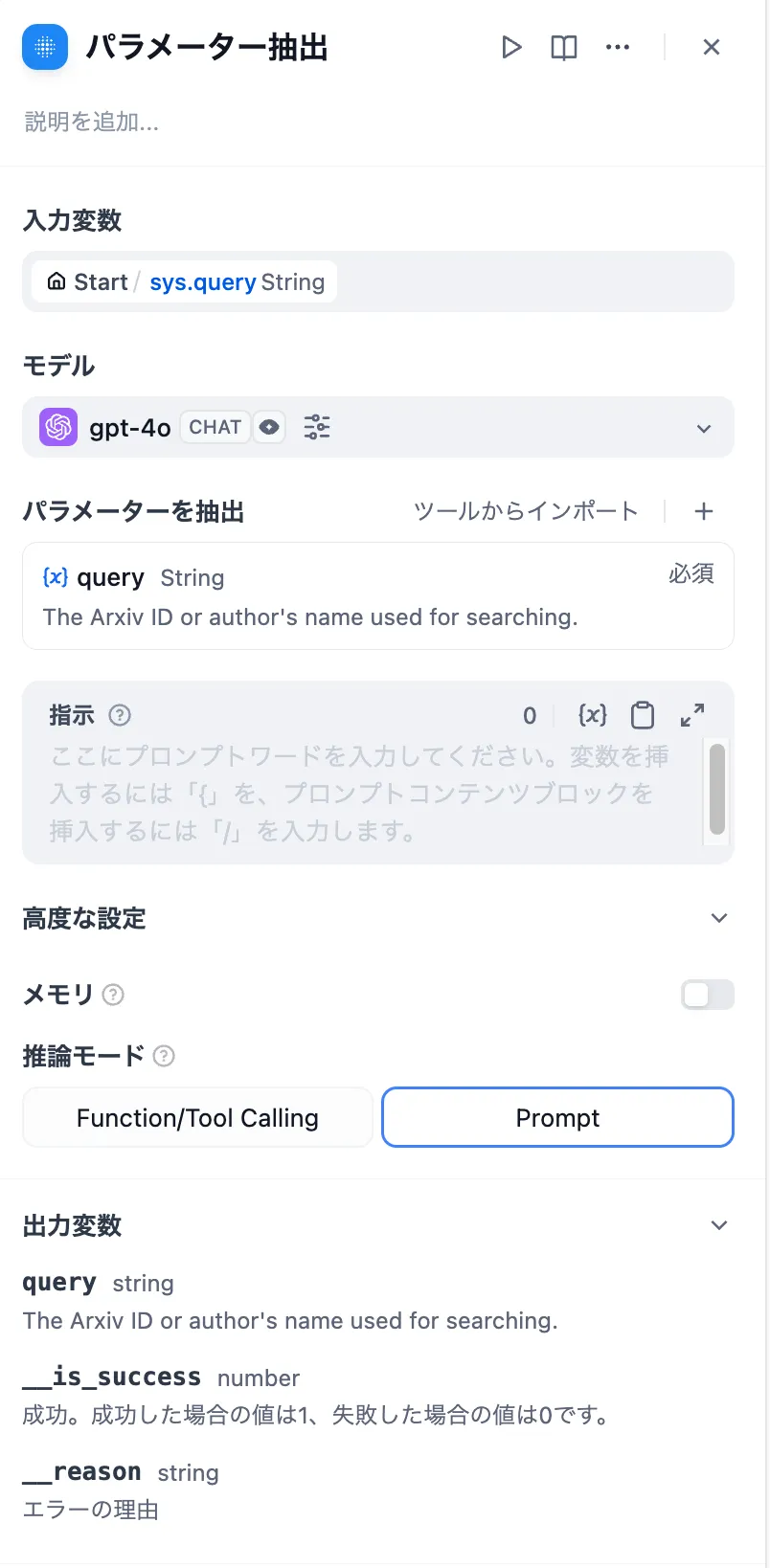
参数提取
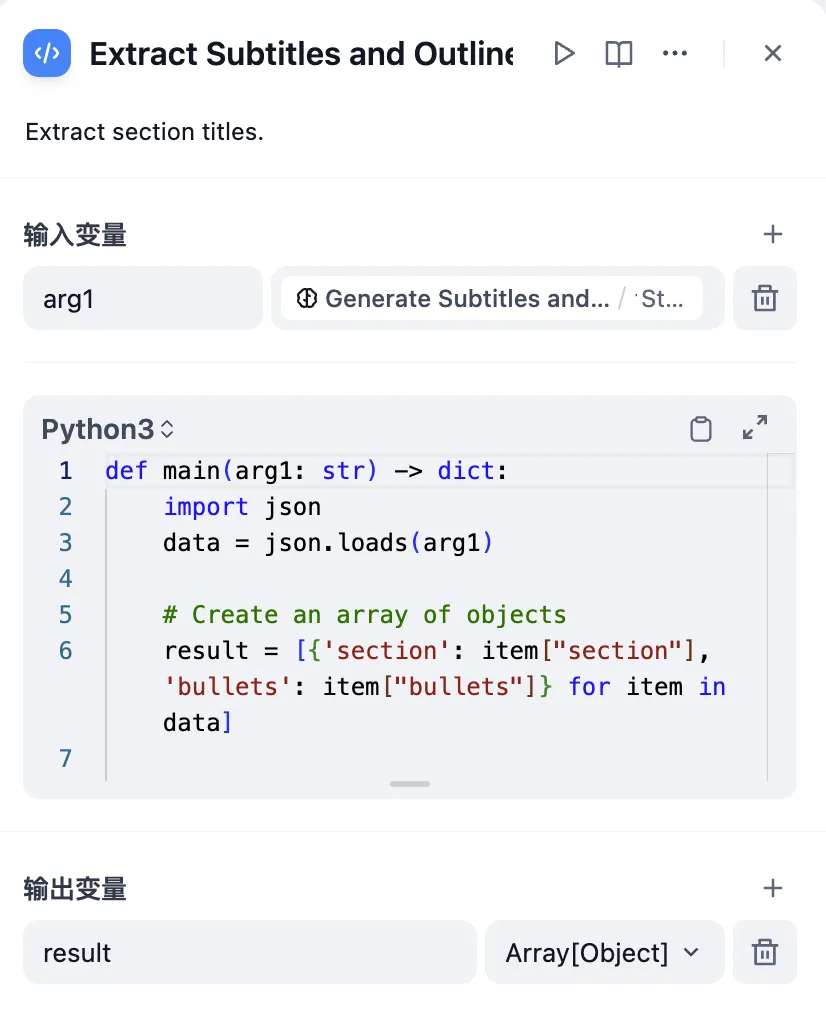
参数提取
.png)
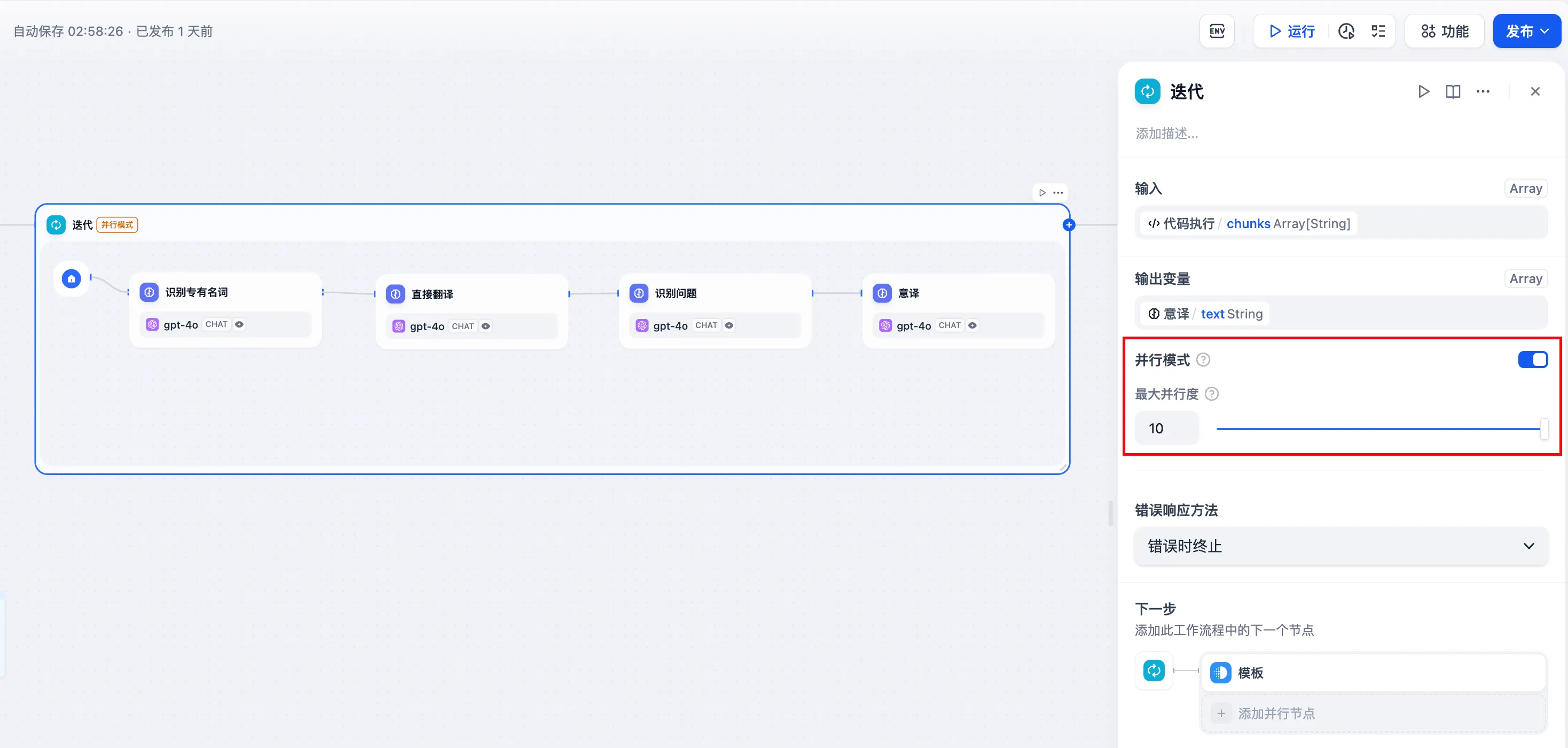
配置迭代节点
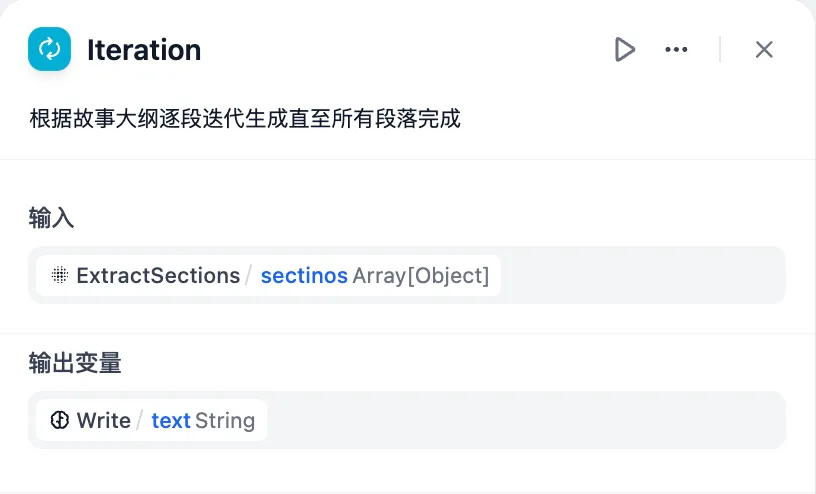
配置迭代节点
.png)
配置 LLM 节点
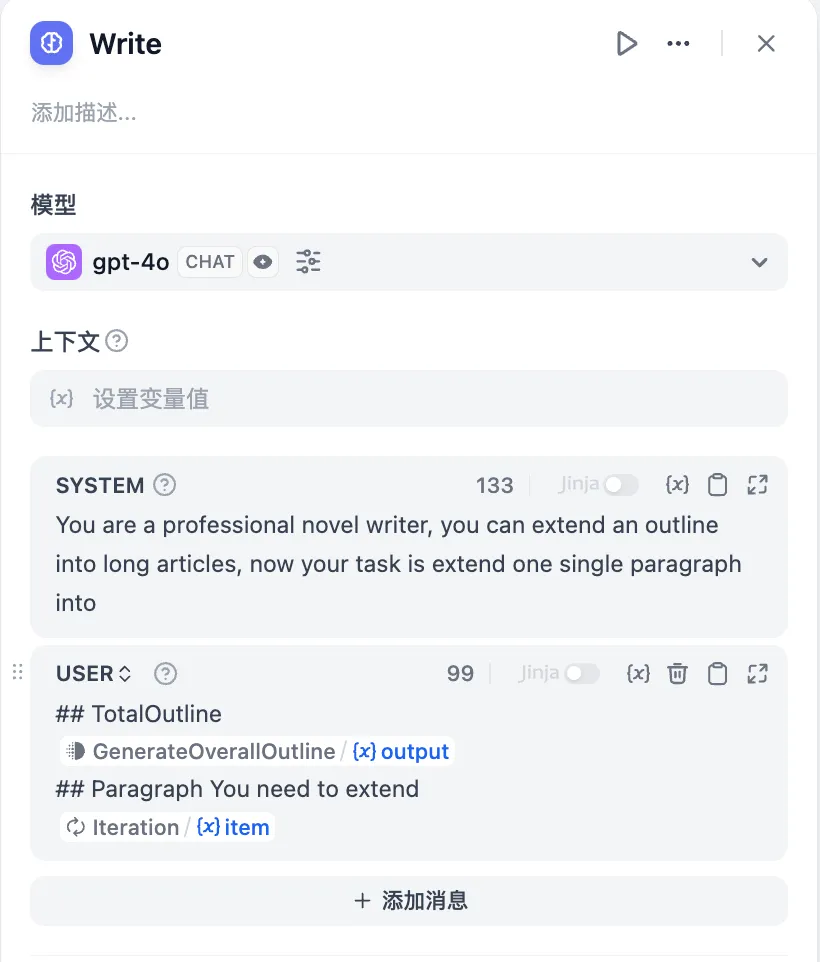
配置 LLM 节点
.png)
配置 Answer 节点
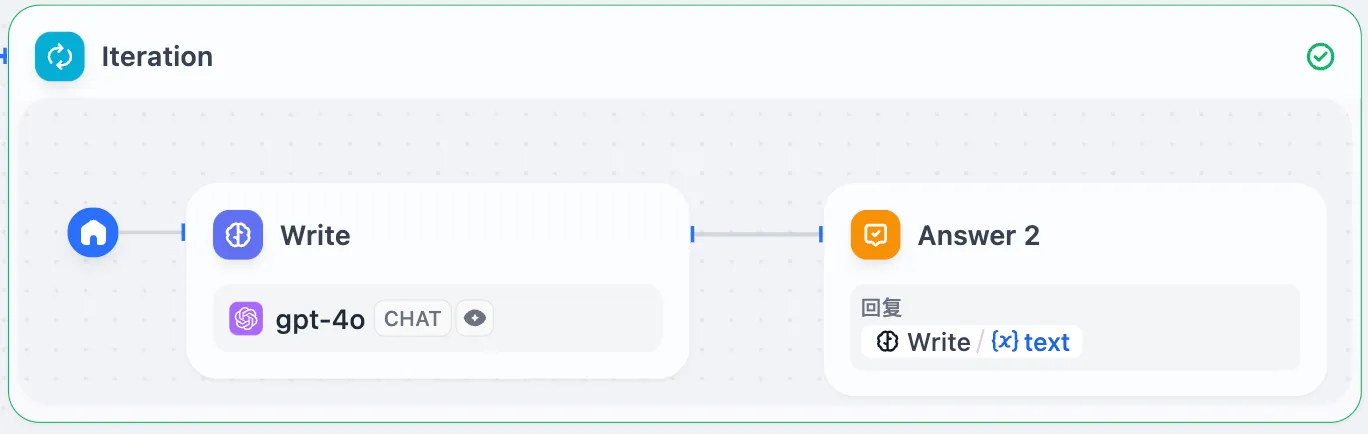
配置 Answer 节点
.png)
按故事章节多轮迭代生成
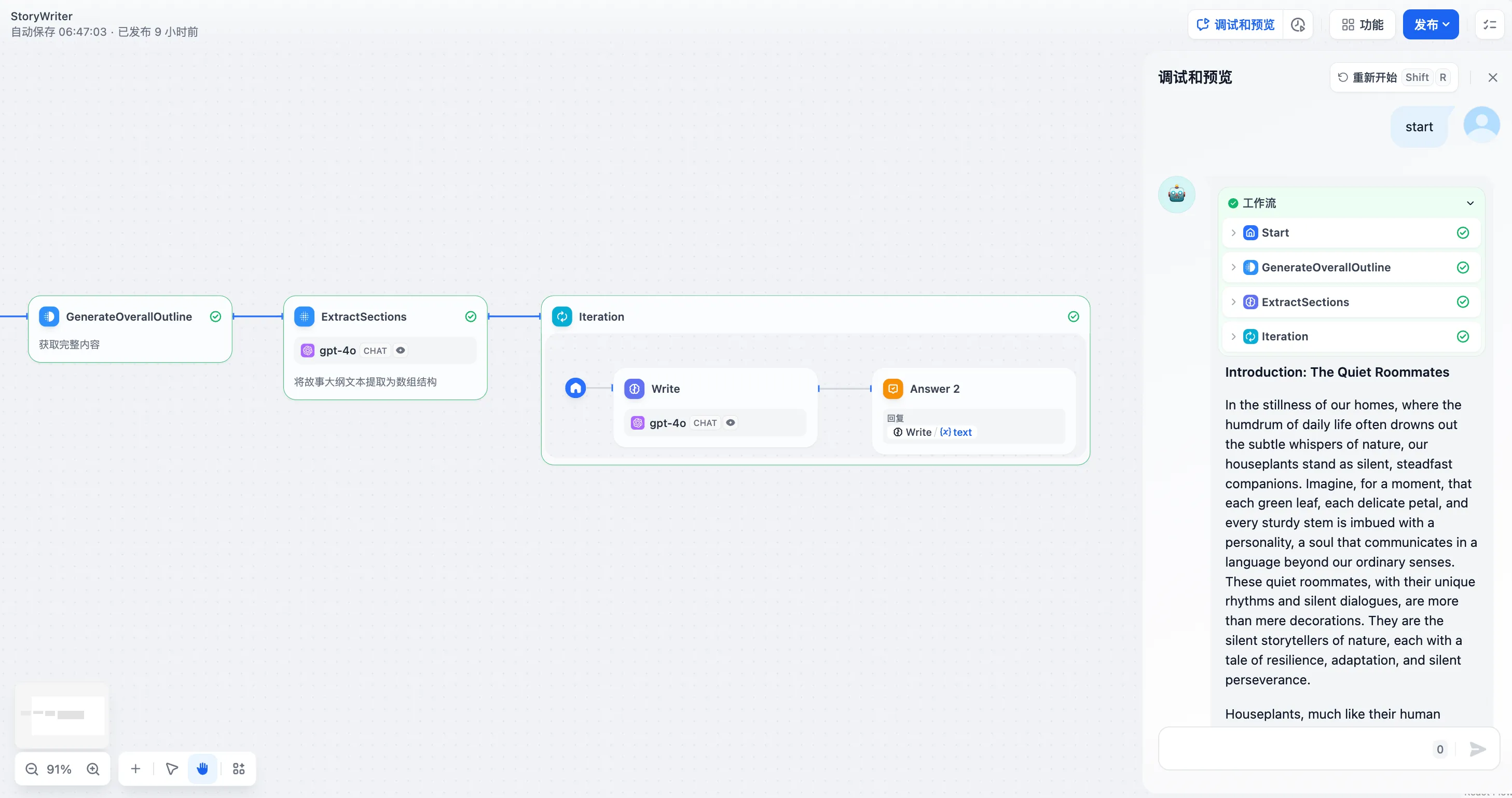
按故事章节多轮迭代生成
.png)
.png)
.png)
顺序与并行执行原理图
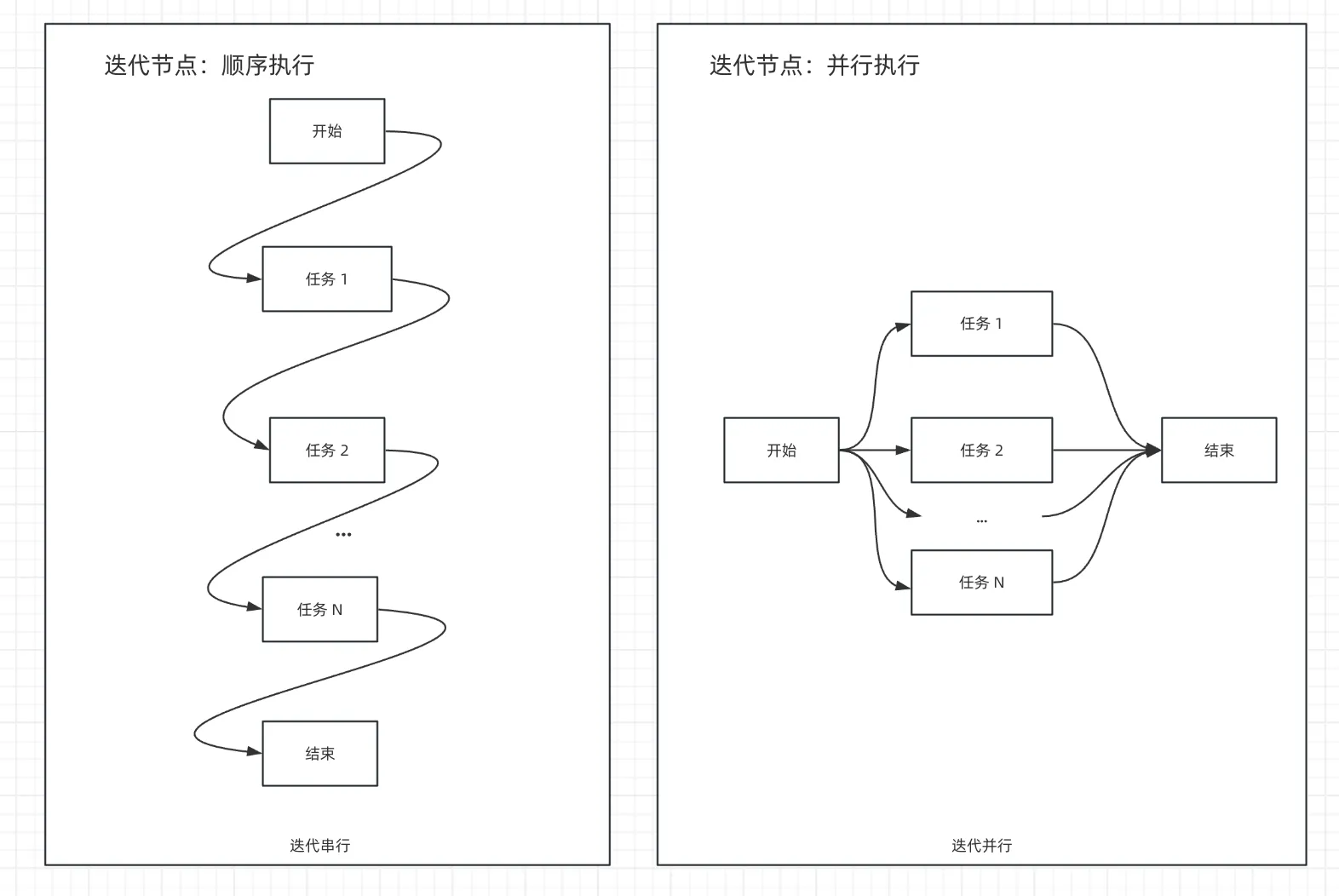
顺序与并行执行原理图
.png)
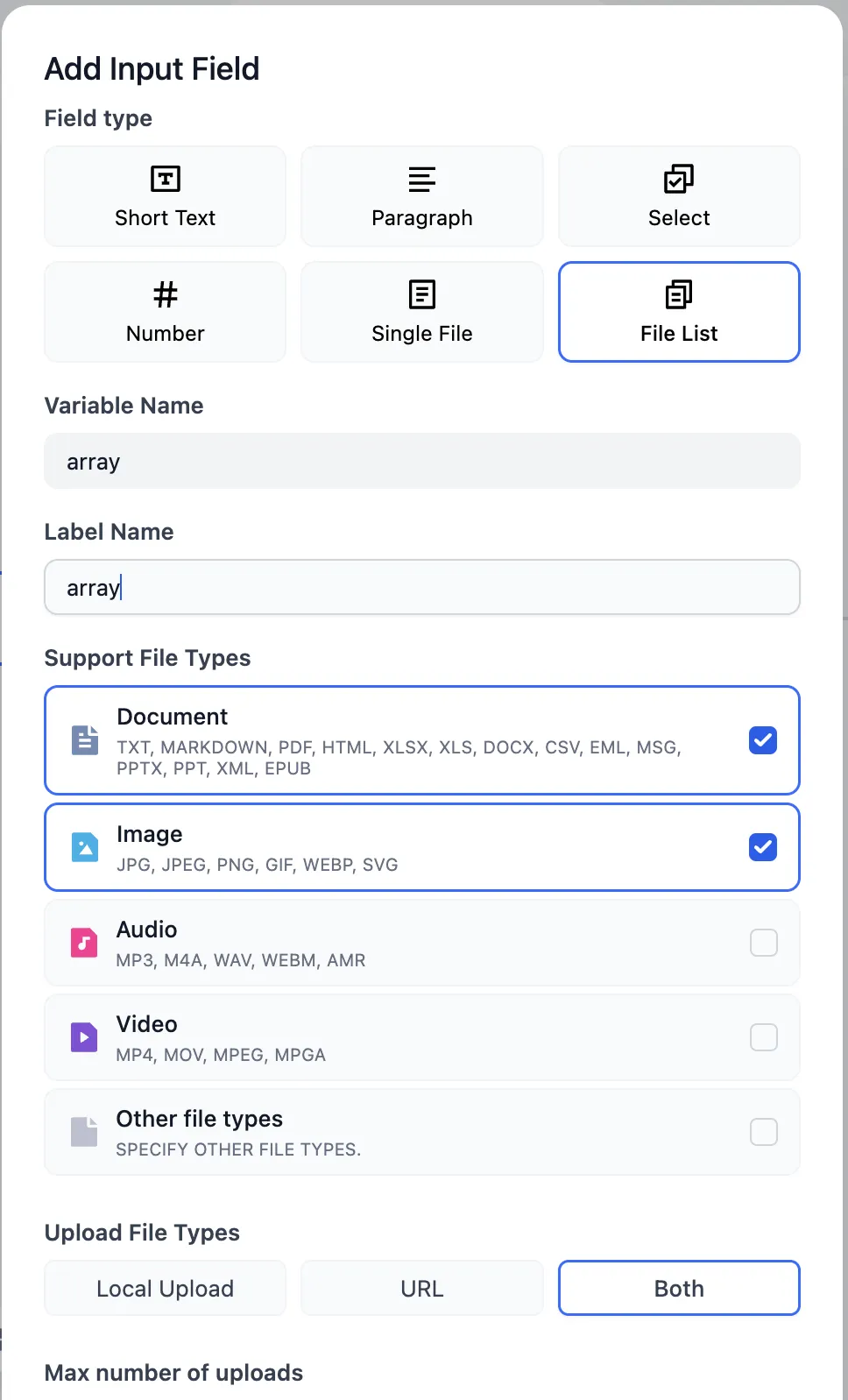
code 节点输出 array
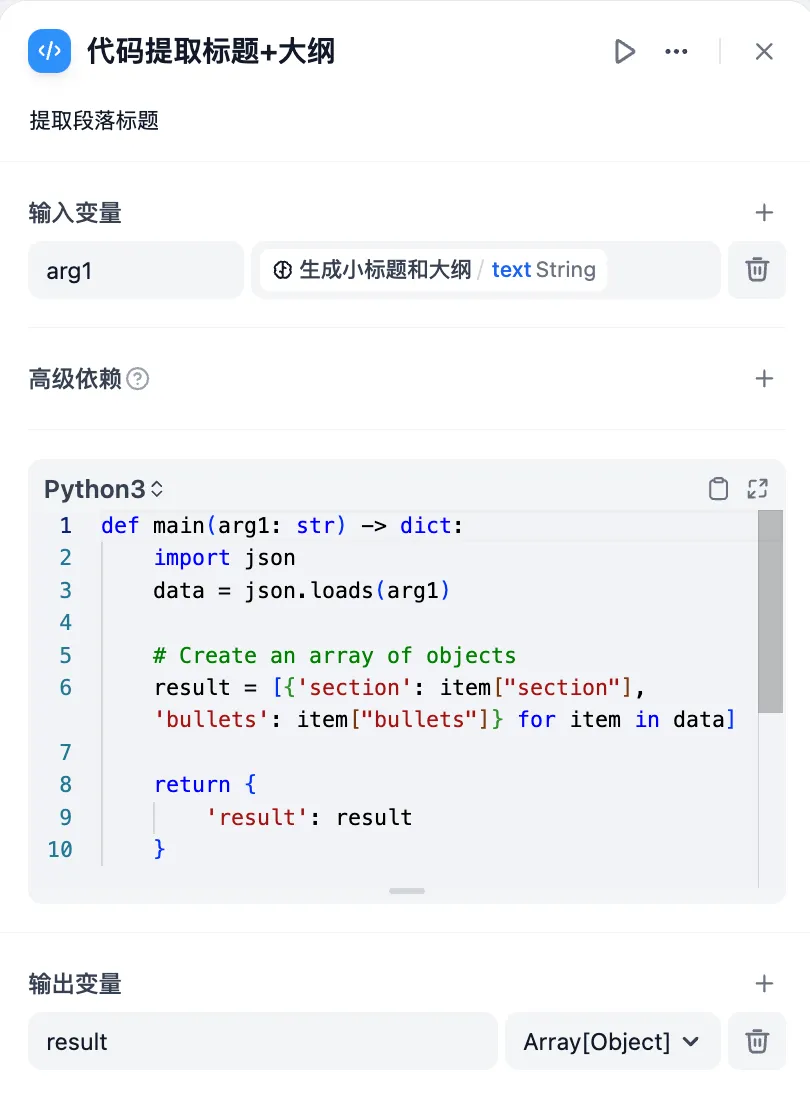
code 节点输出 array
.png)
参数提取节点输出 array

参数提取节点输出 array
.png)
代码节点转换
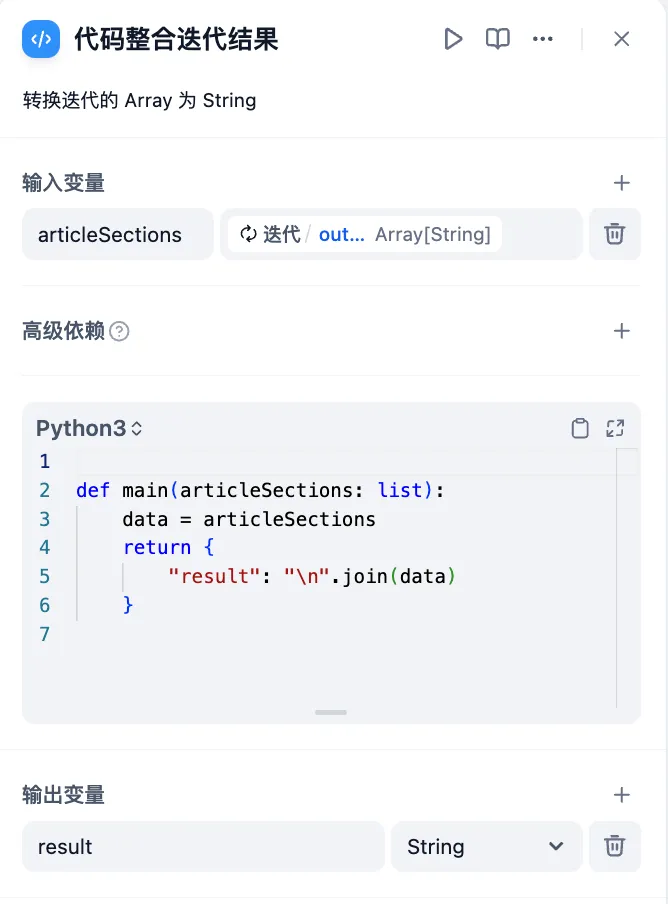
代码节点转换
.png)
模板节点转换
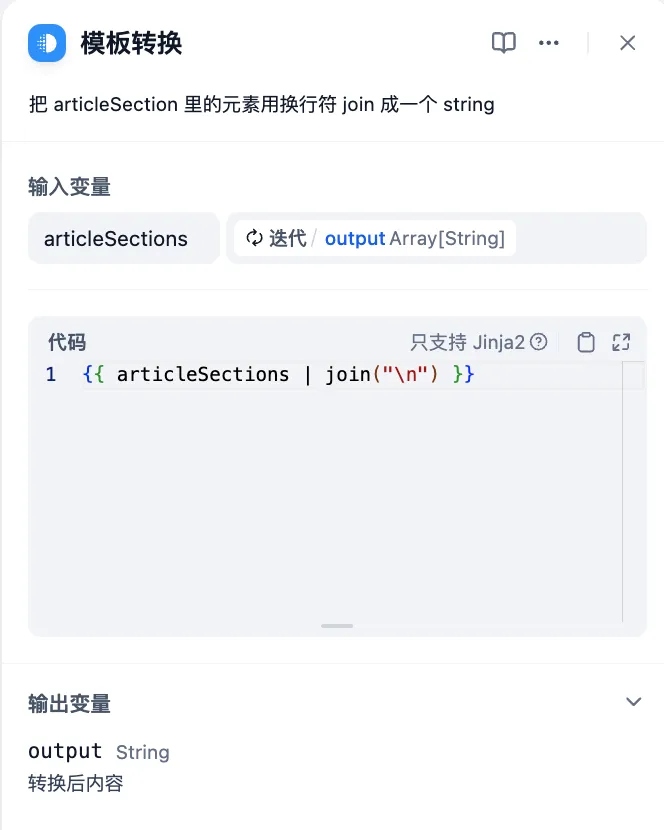
模板节点转换
知识库问答应用示例
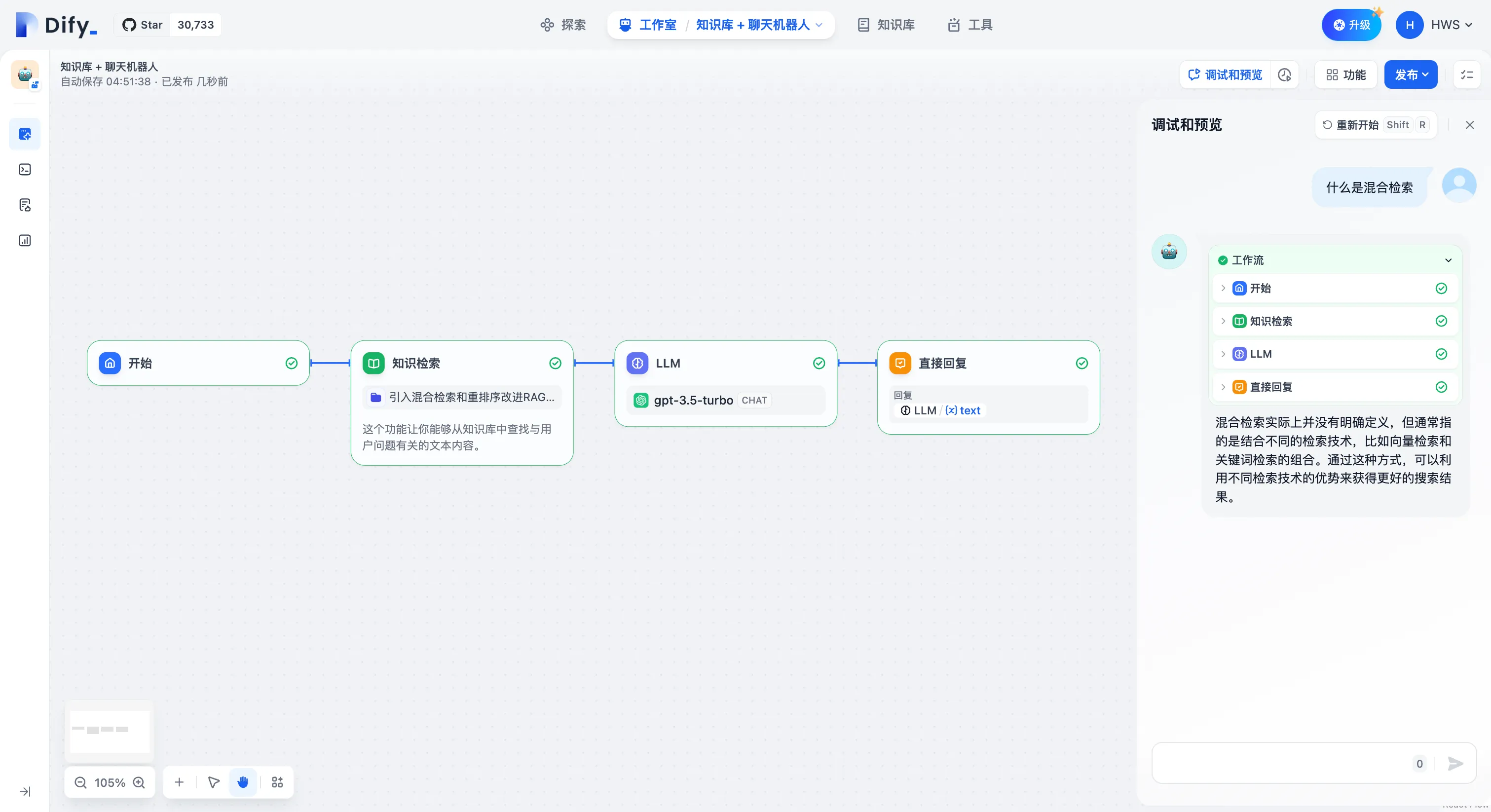
知识库问答应用示例
.png)
知识检索配置
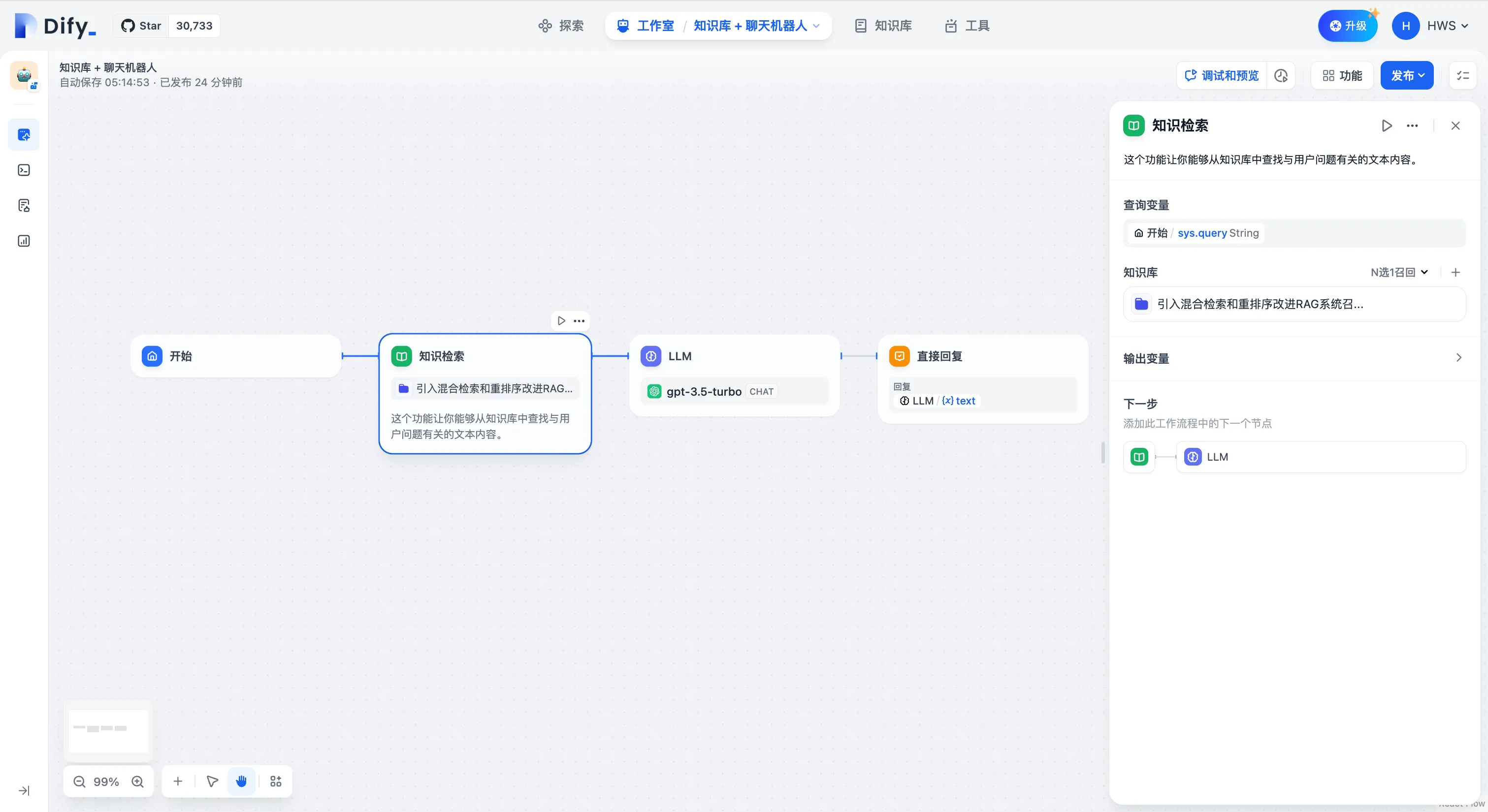
知识检索配置
.png)
输出变量

输出变量
.png)
配置下游 LLM 节点
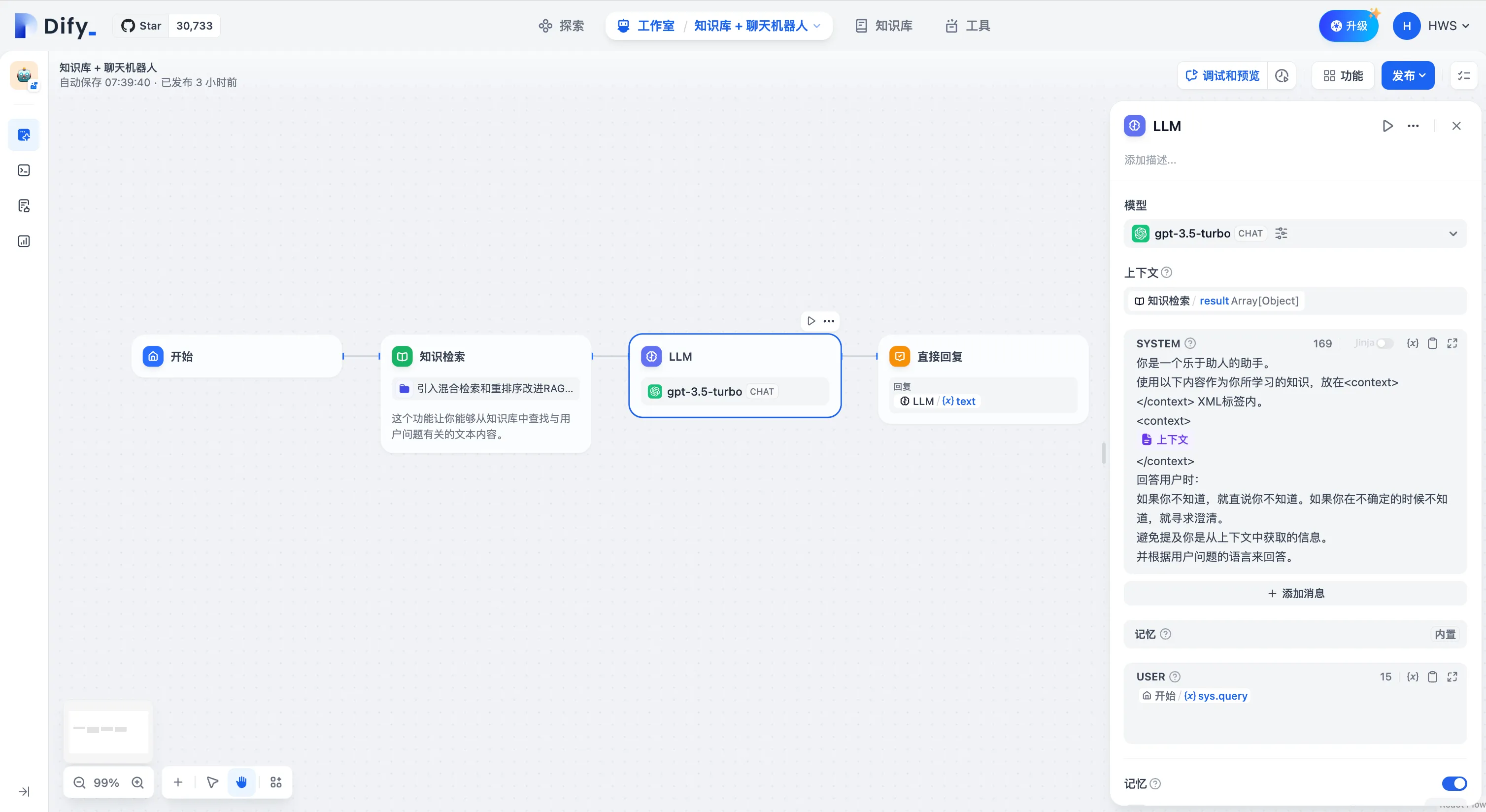
配置下游 LLM 节点
.png)
分流不同的文件类型
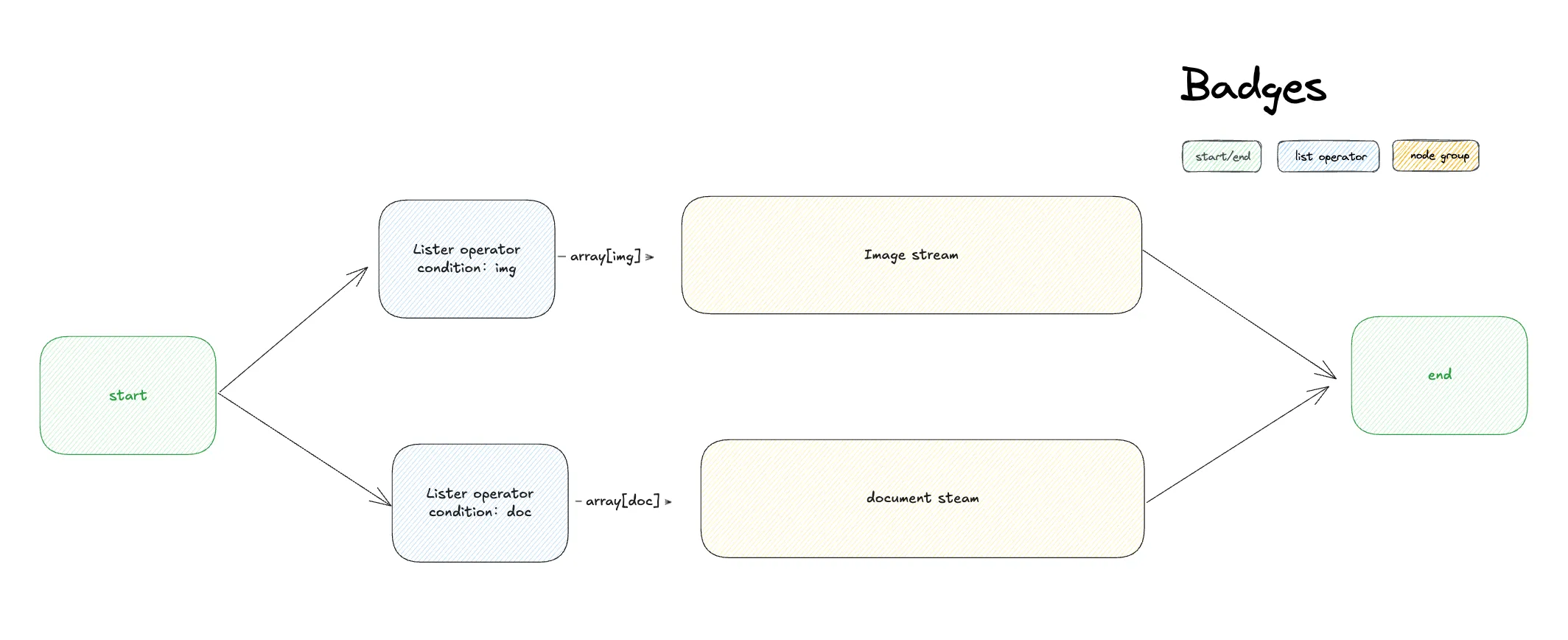
分流不同的文件类型
.png)
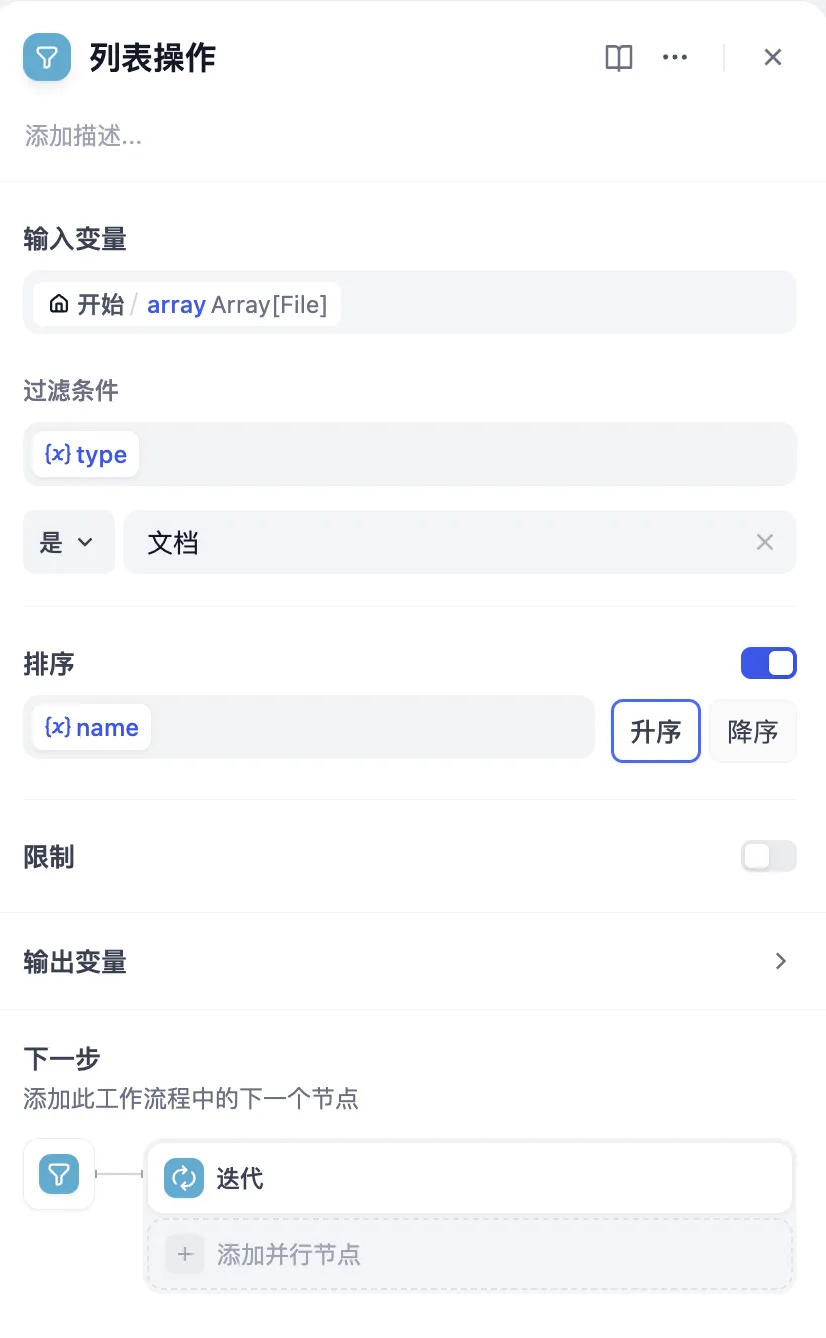
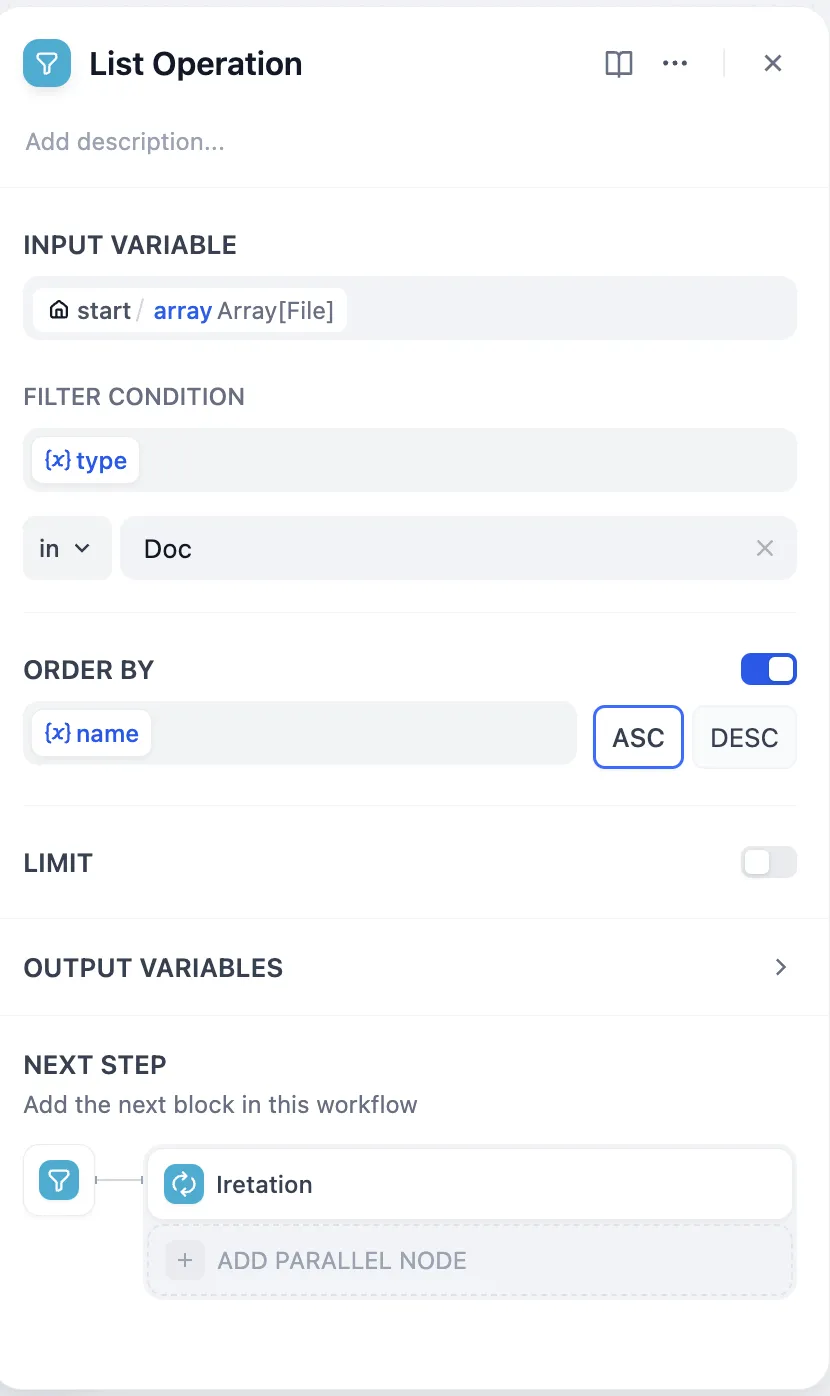
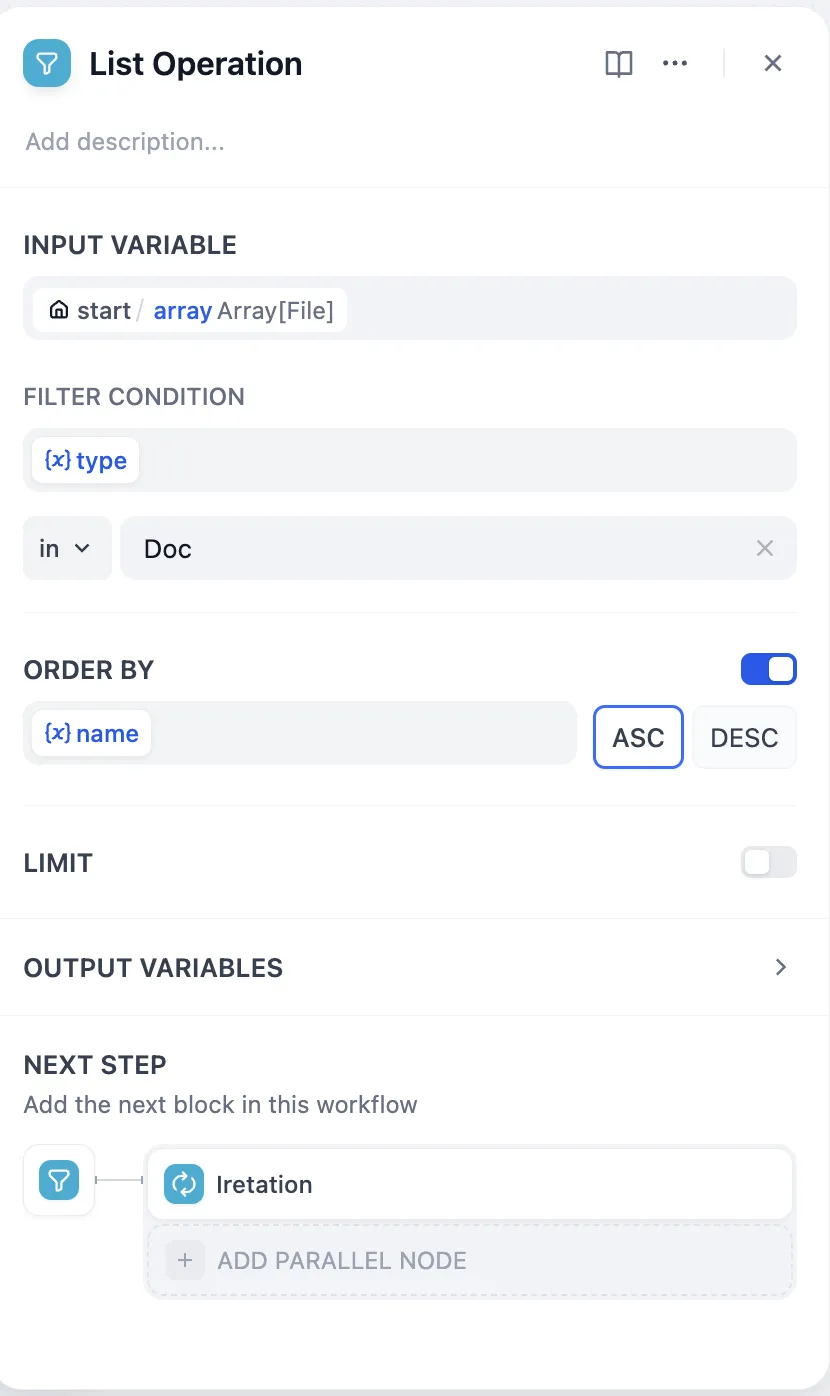
列表操作节点
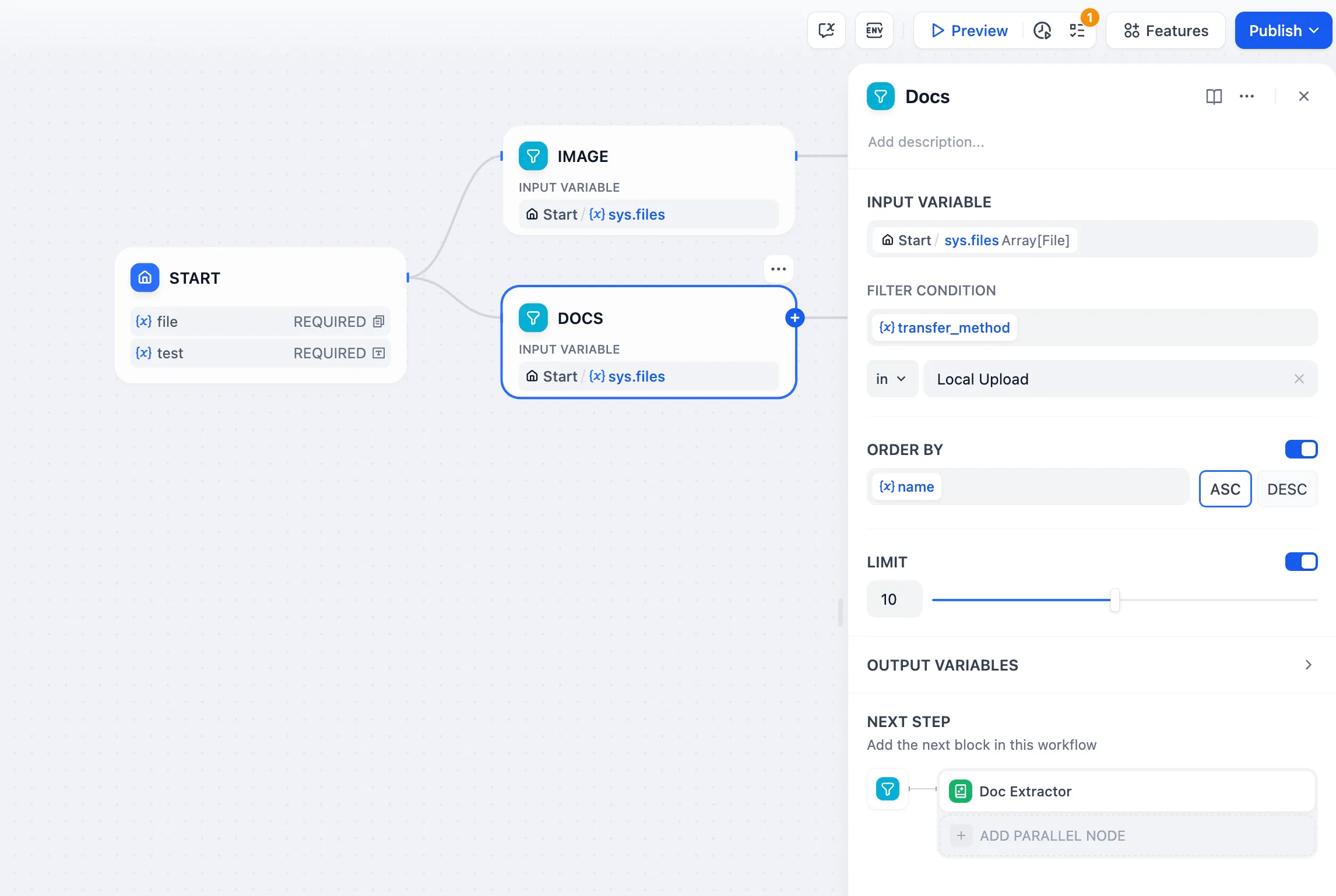
列表操作节点
.png)
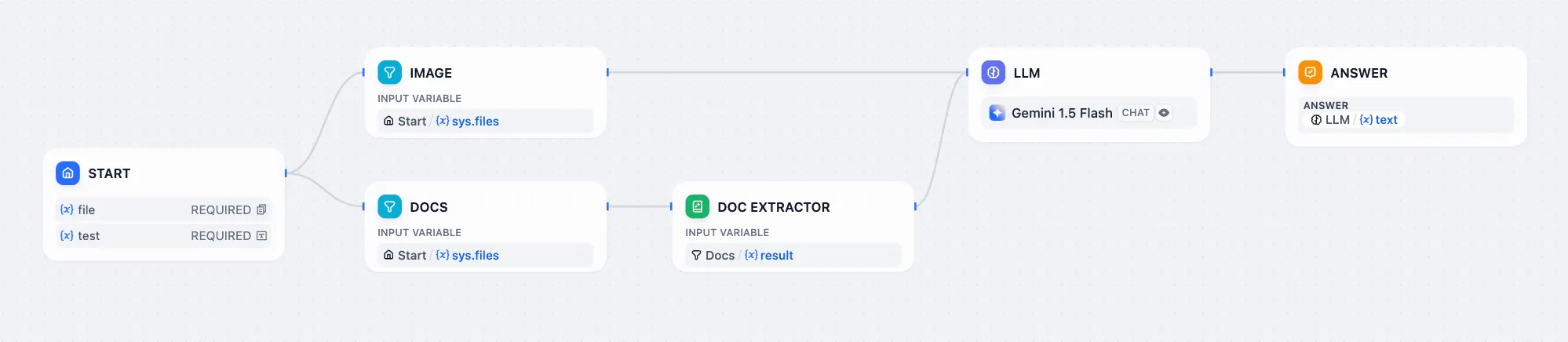
.png)
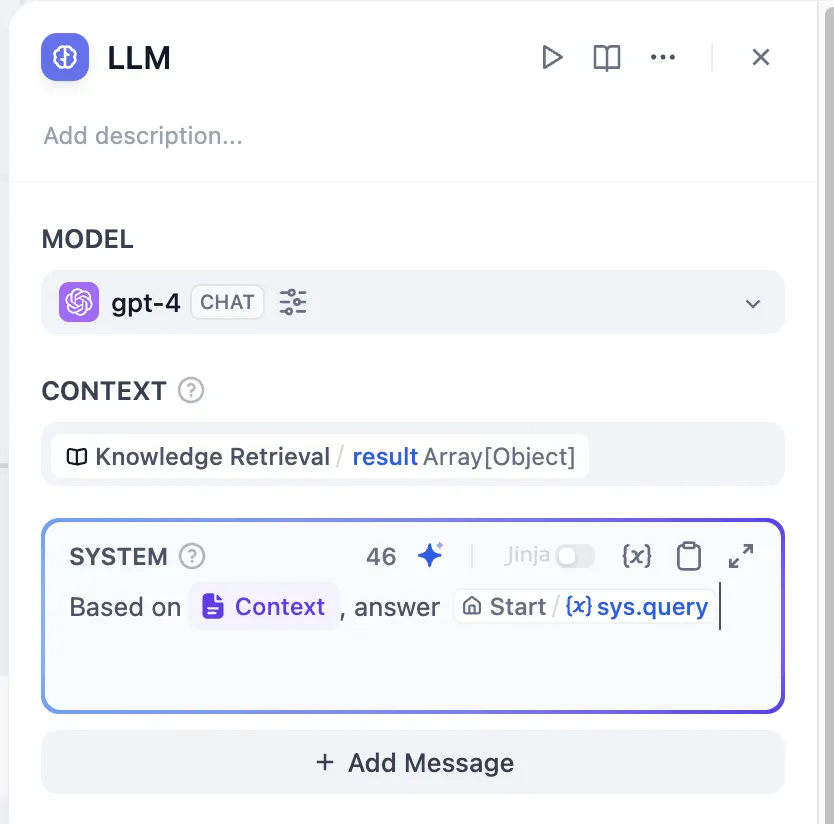
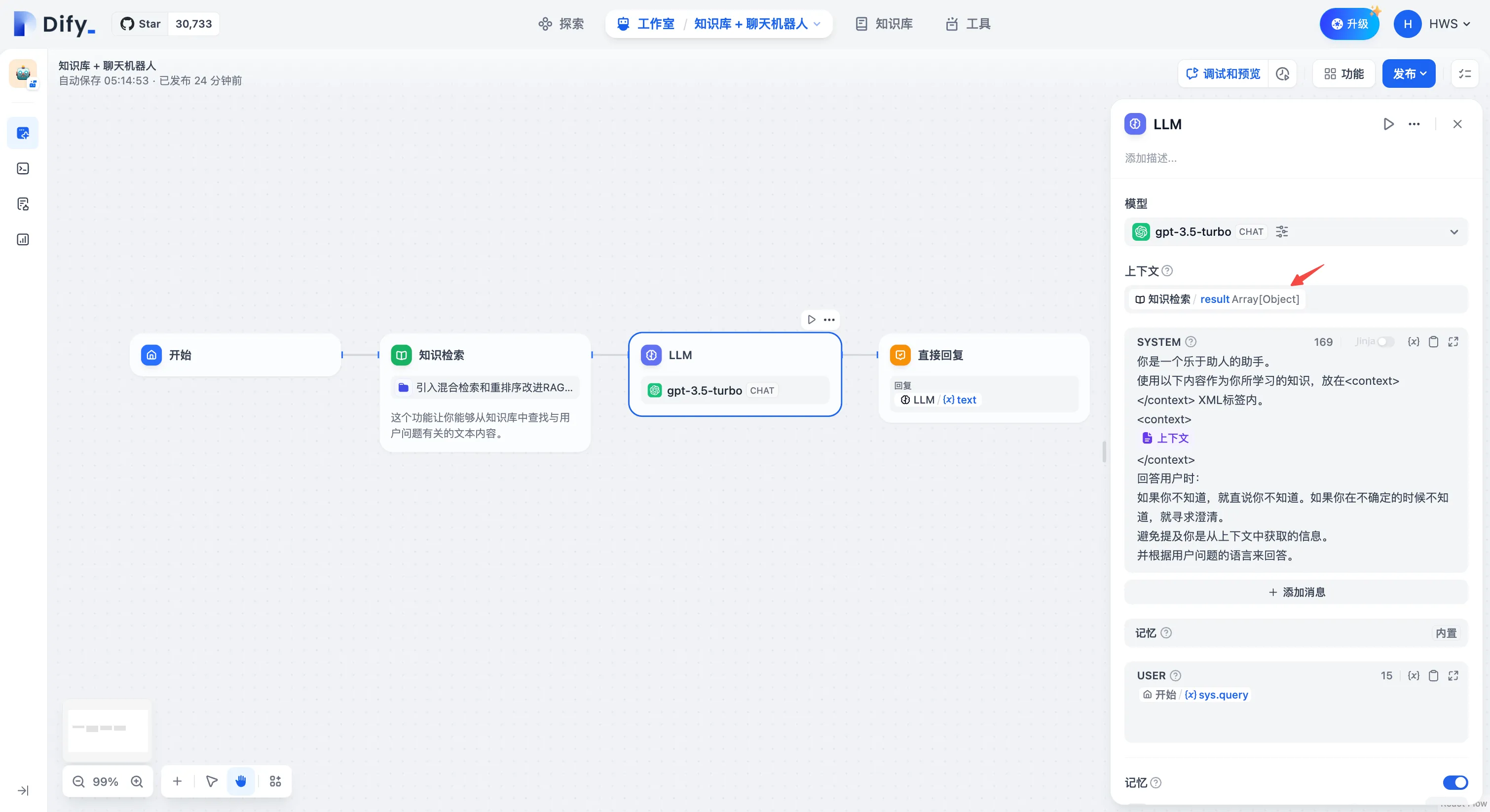
LLM 节点
LLM 节点
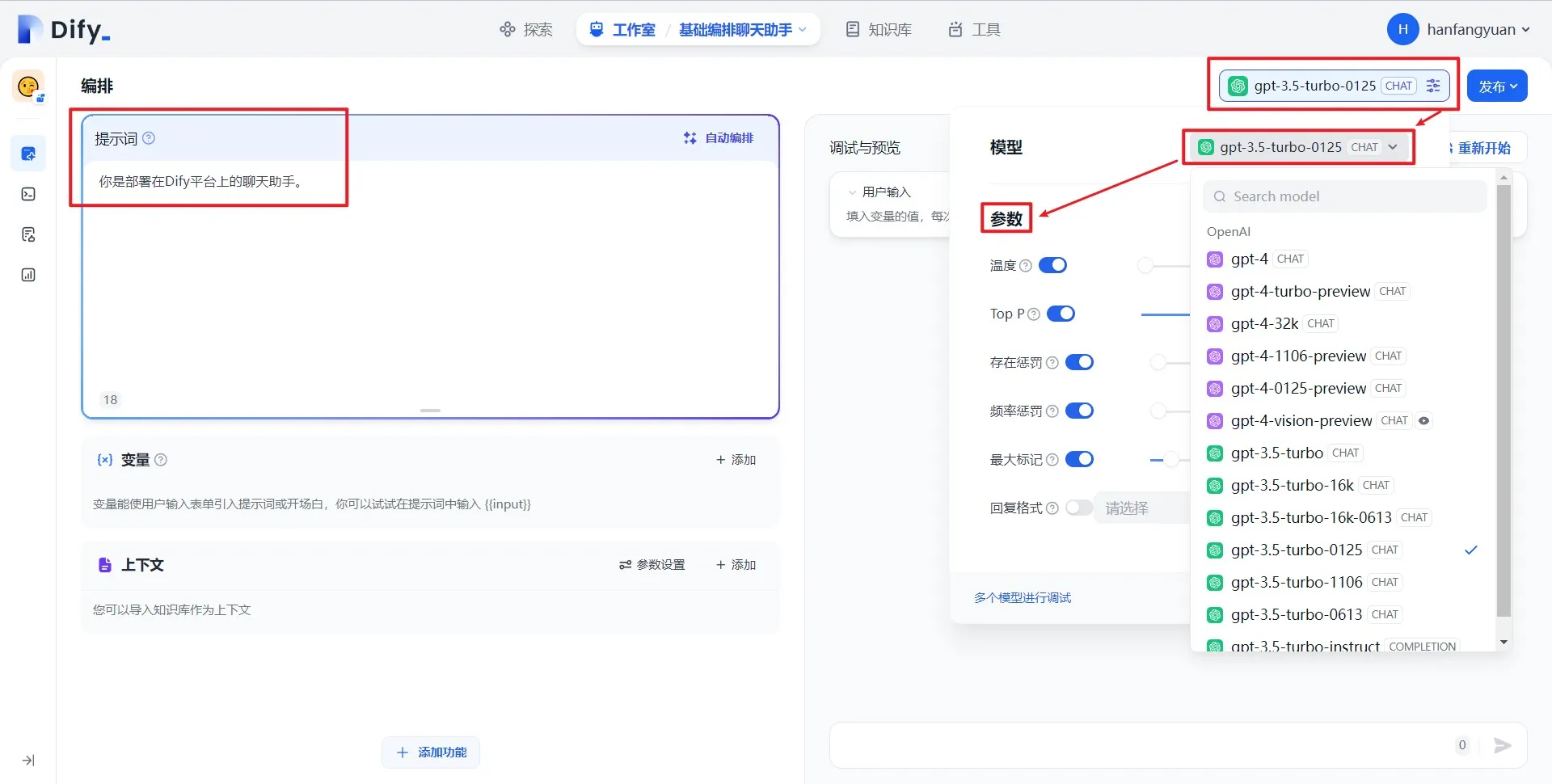
LLM 节点配置-选择模型
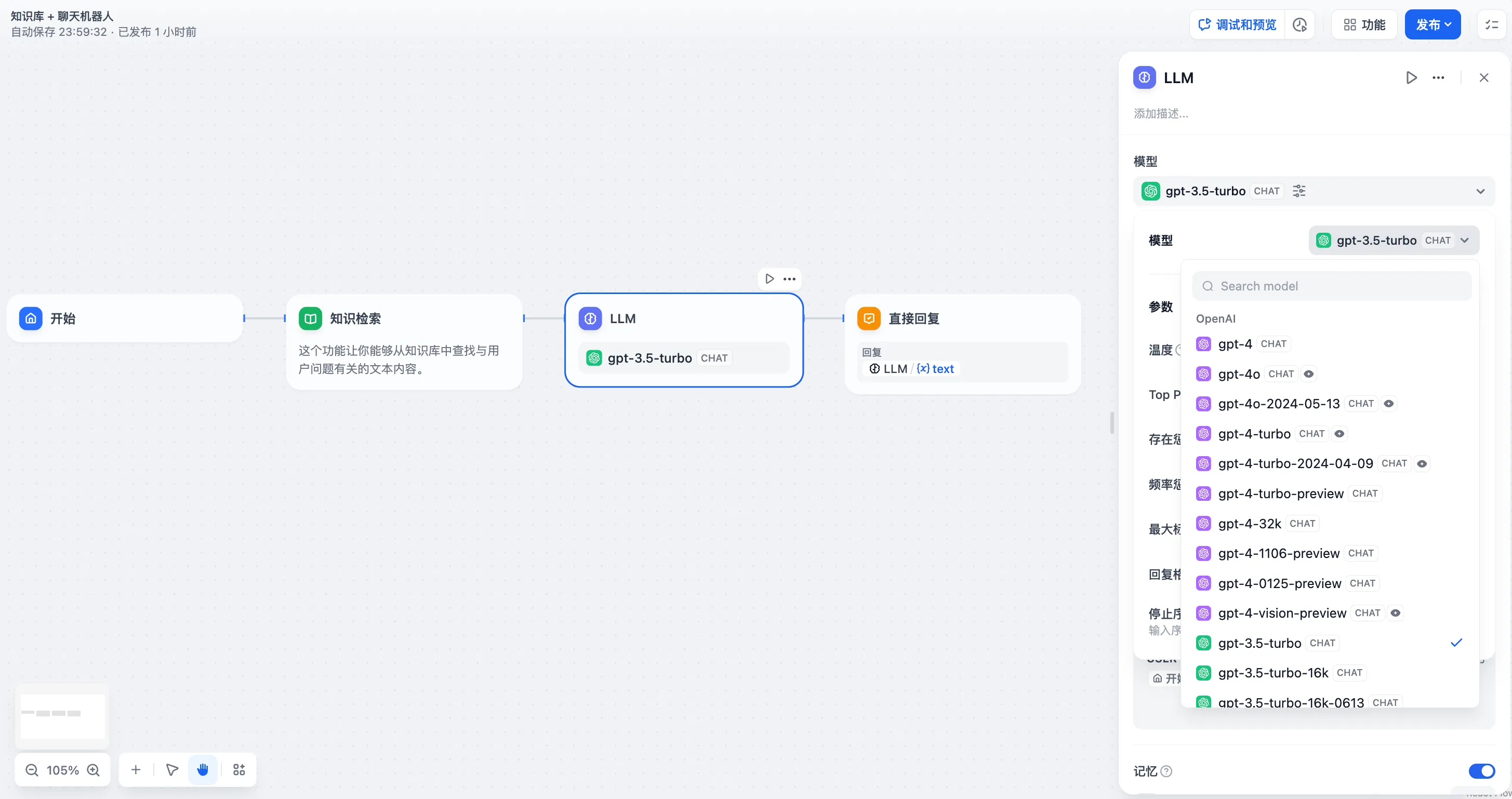
LLM 节点配置-选择模型

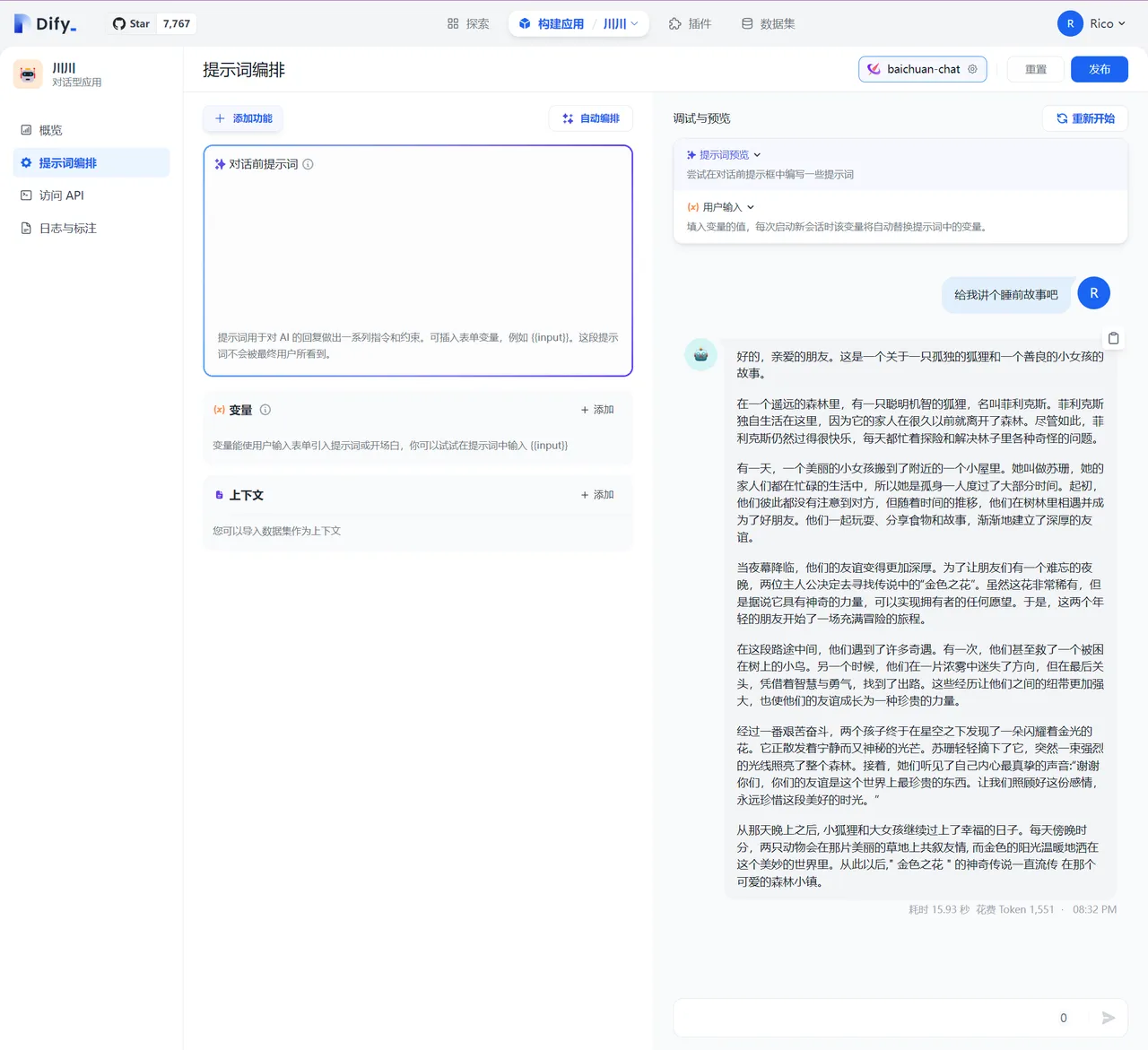
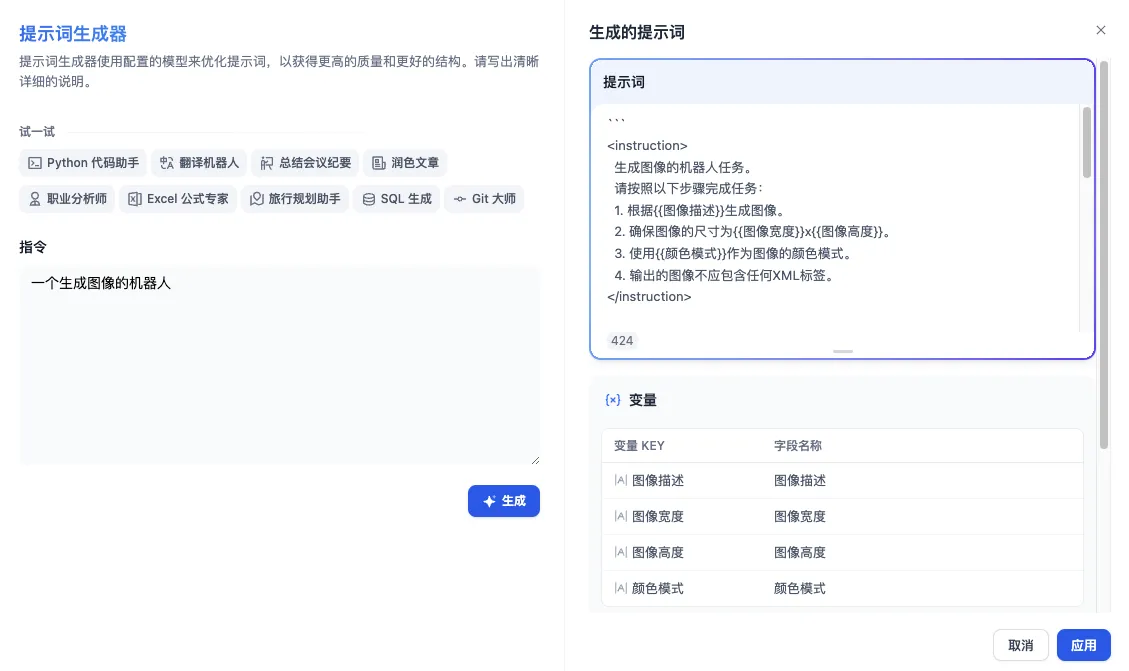
编写提示词
编写提示词
呼出变量插入菜单
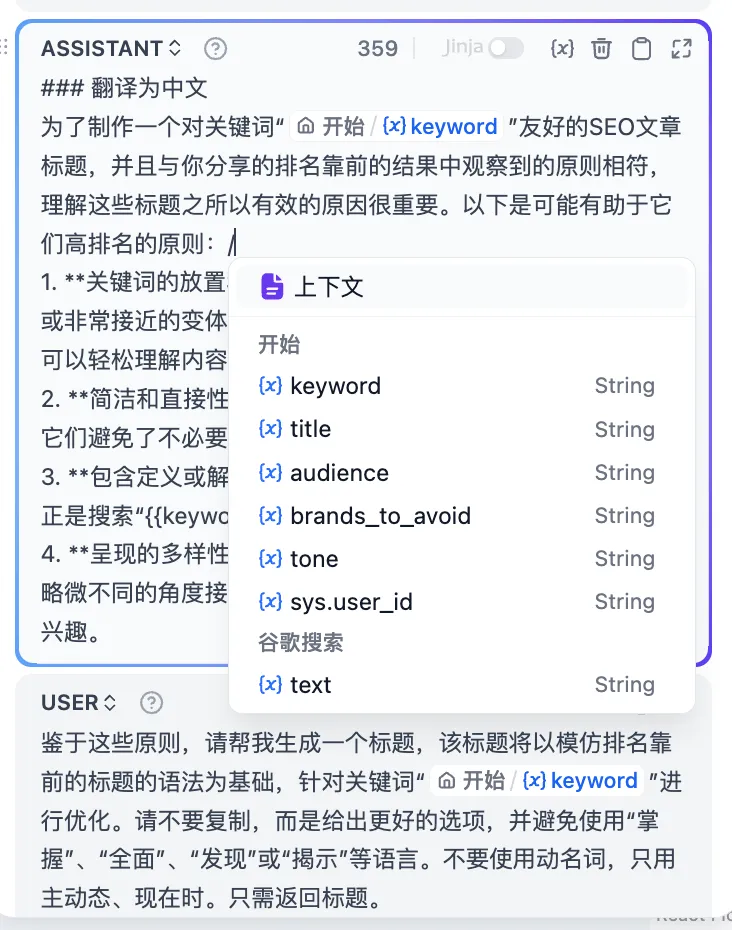
呼出变量插入菜单
.png)
视觉上传功能
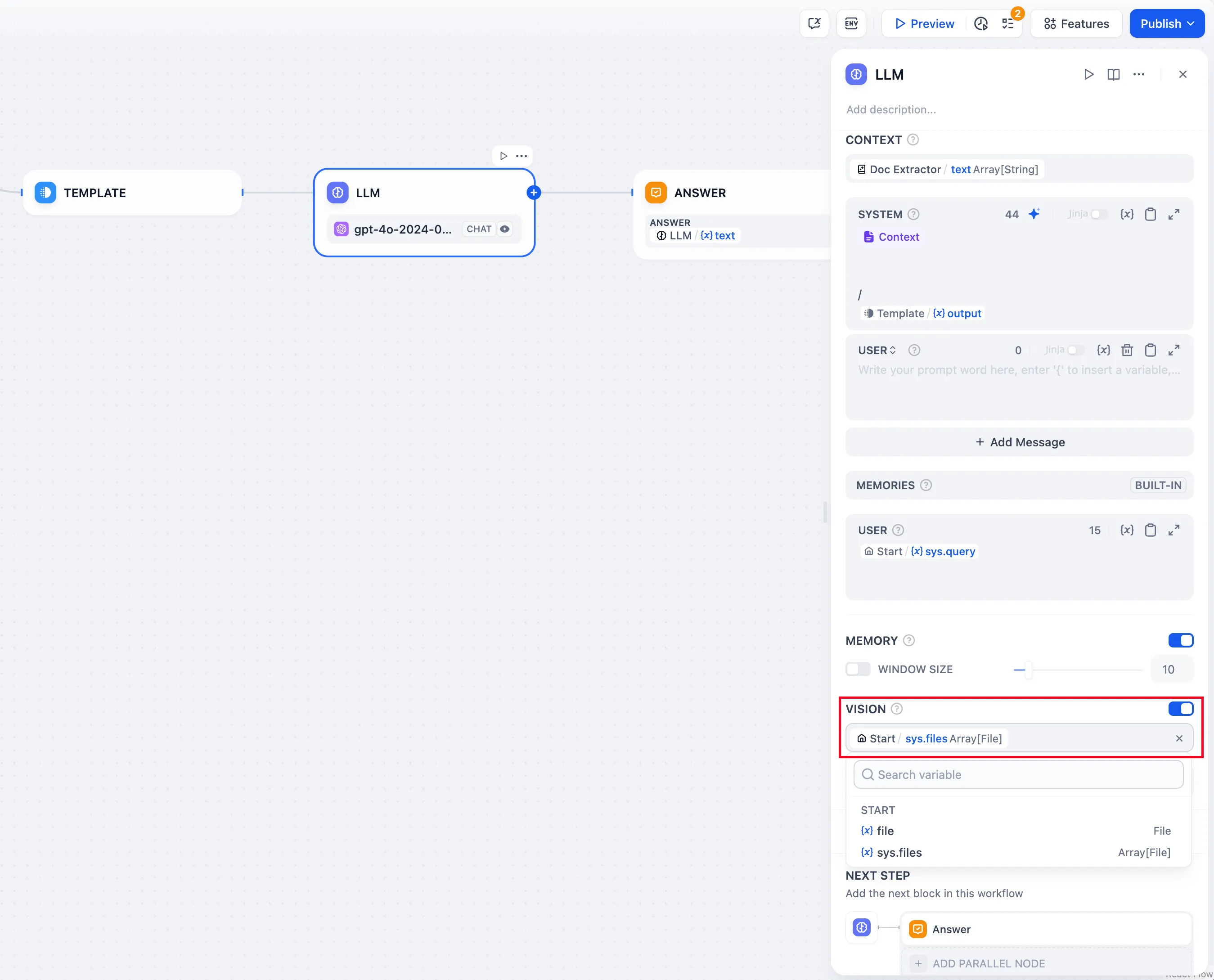
视觉上传功能
.png)
插入会话历史变量
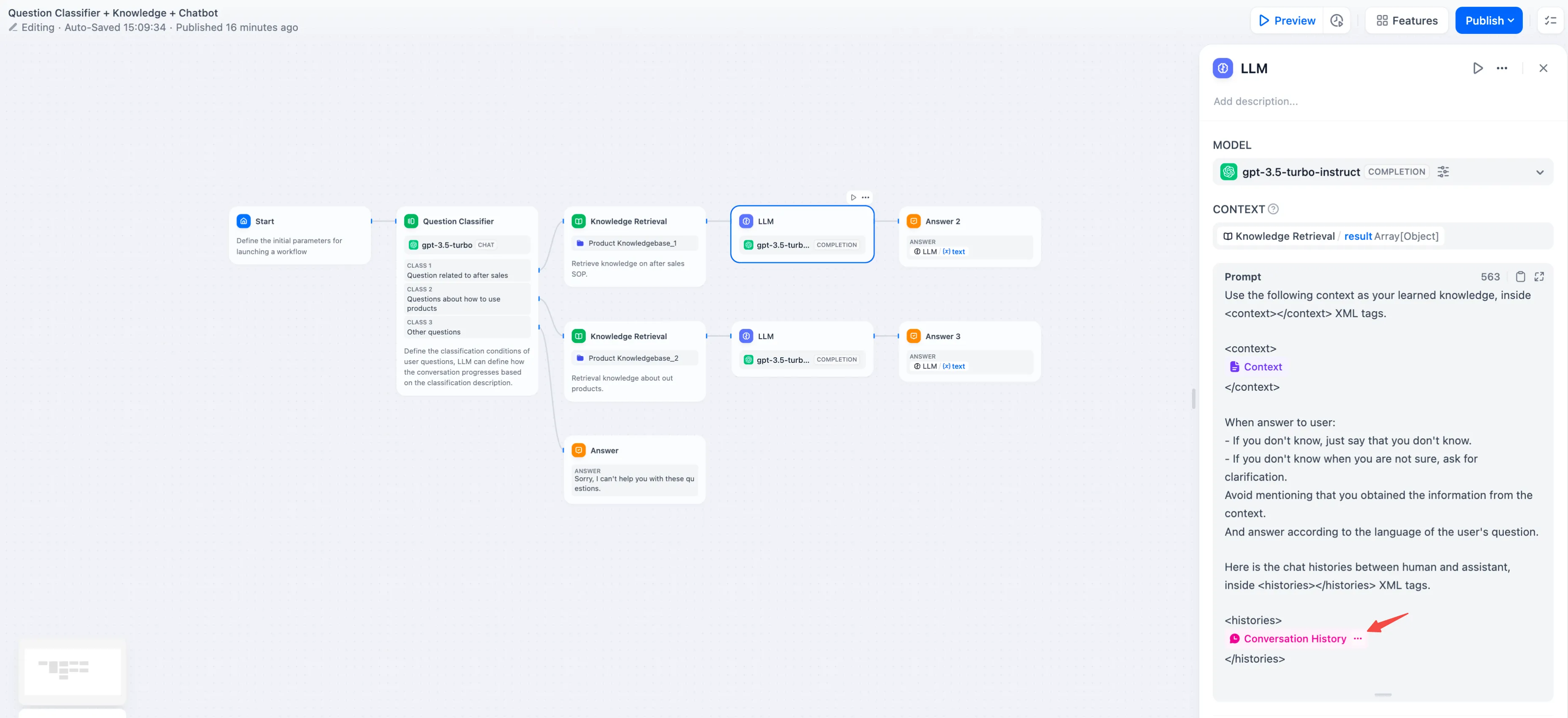
插入会话历史变量


.png)
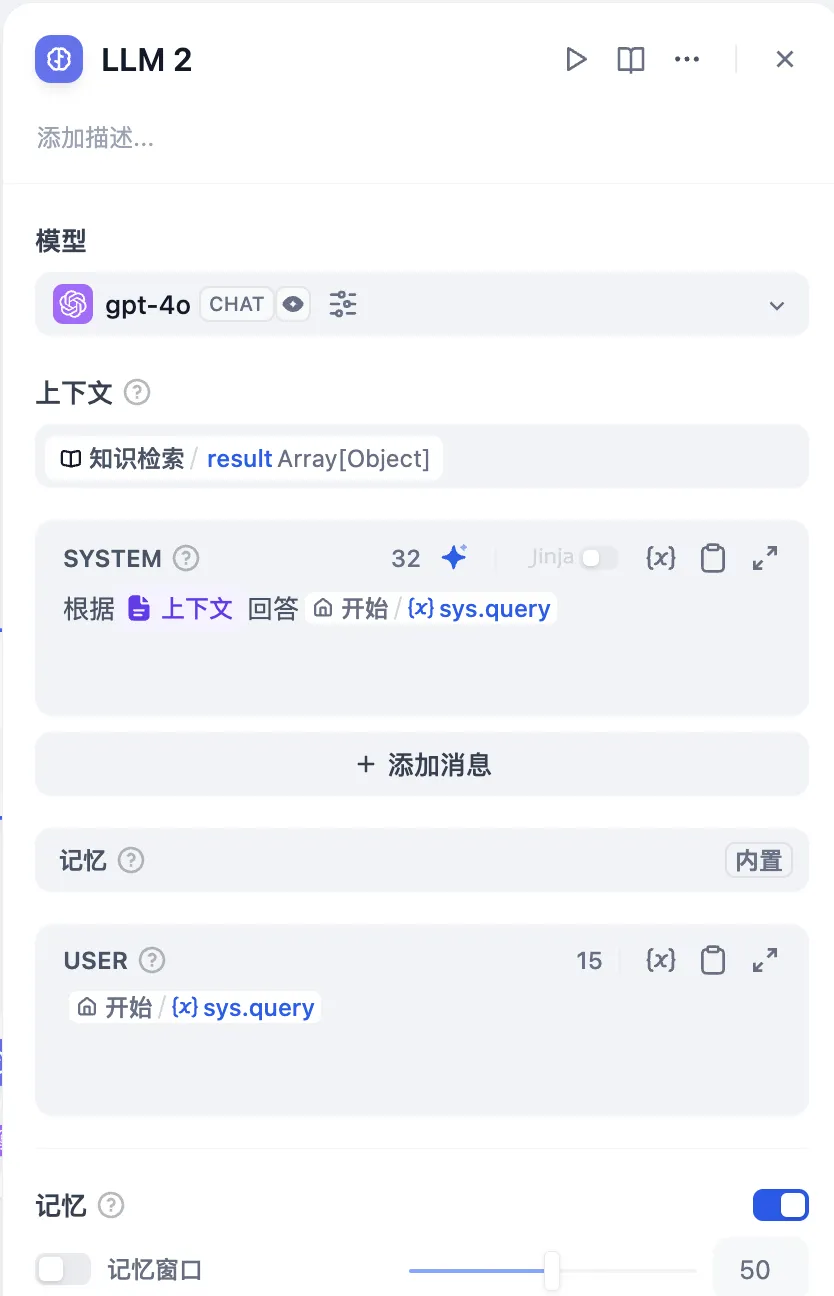
上下文变量
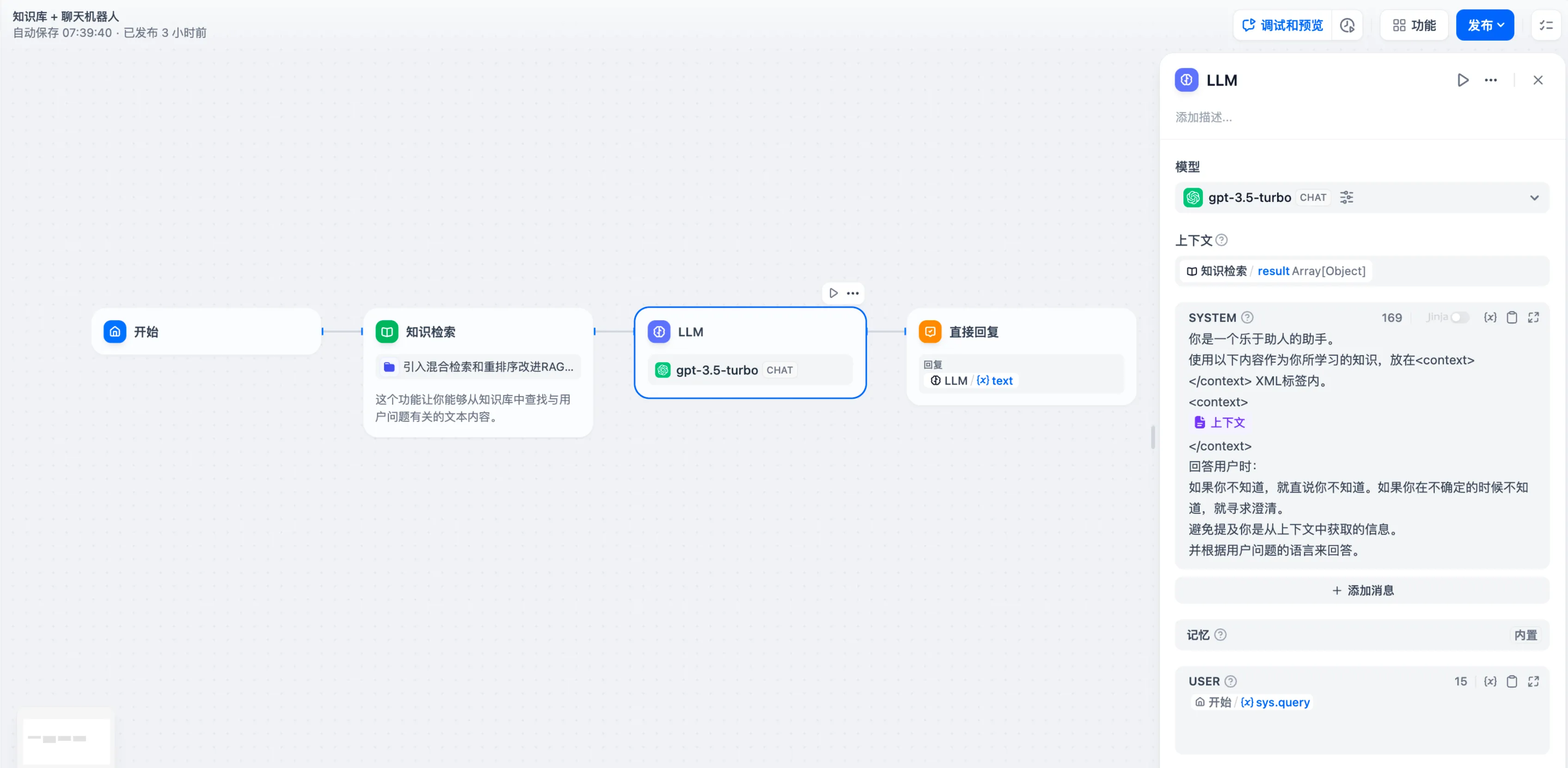
上下文变量
 (2).png)
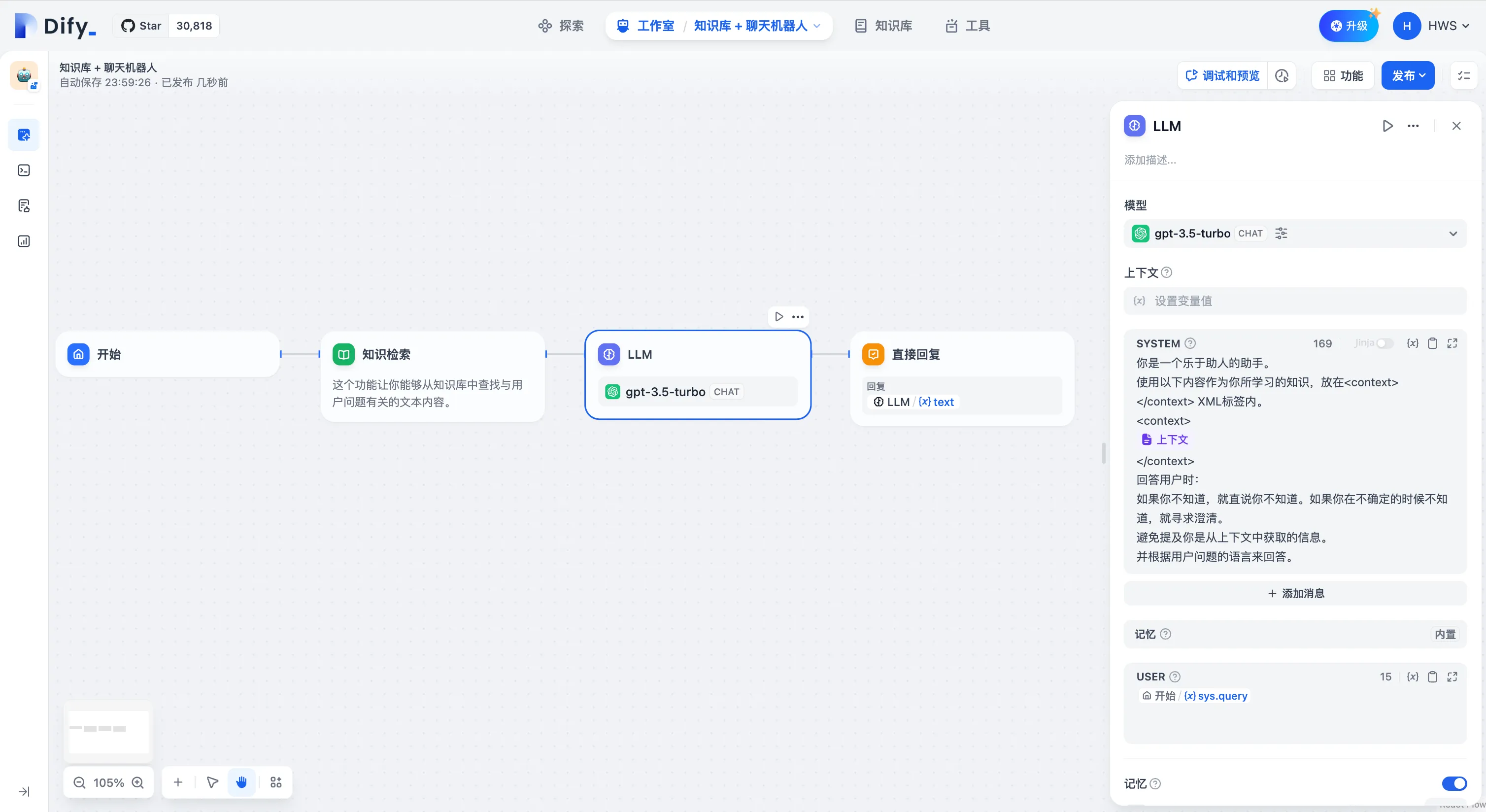
填写系统提示词
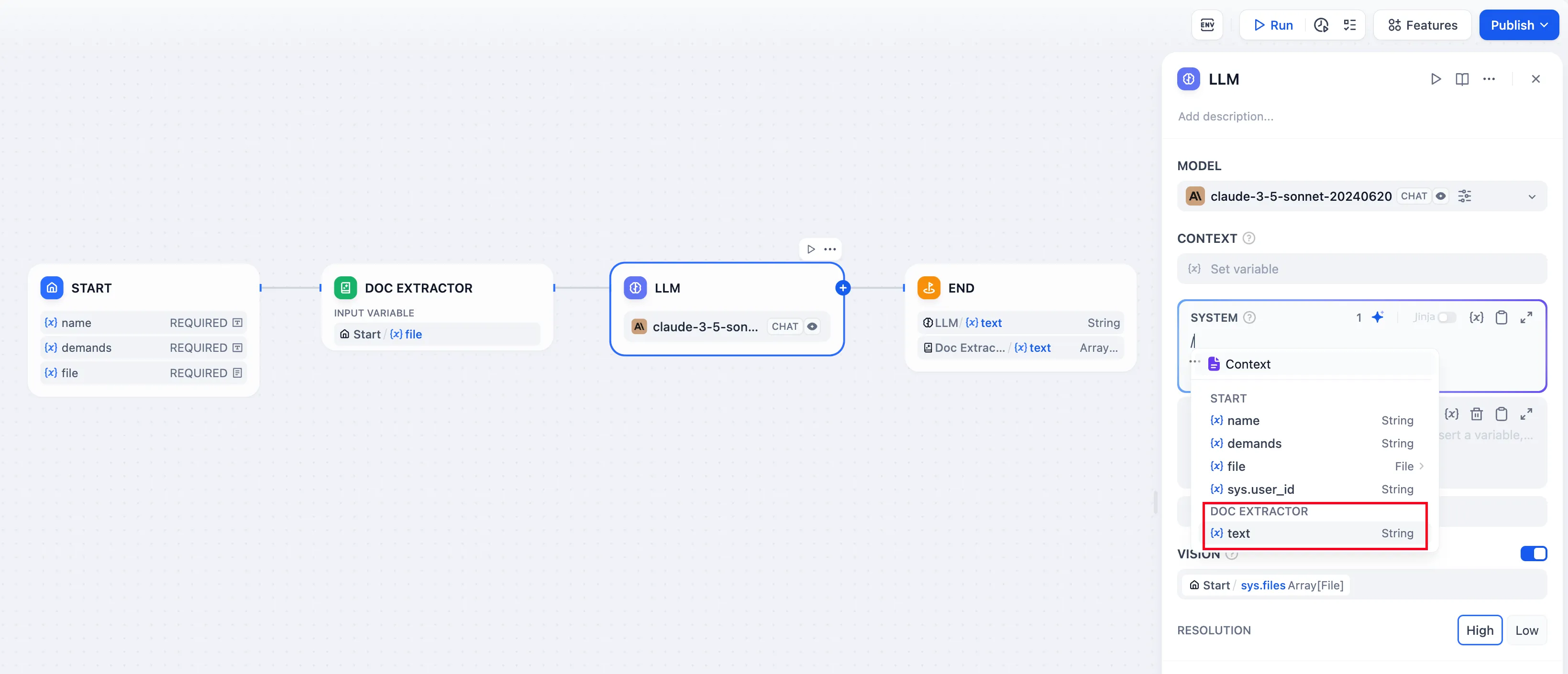
填写系统提示词
.png)
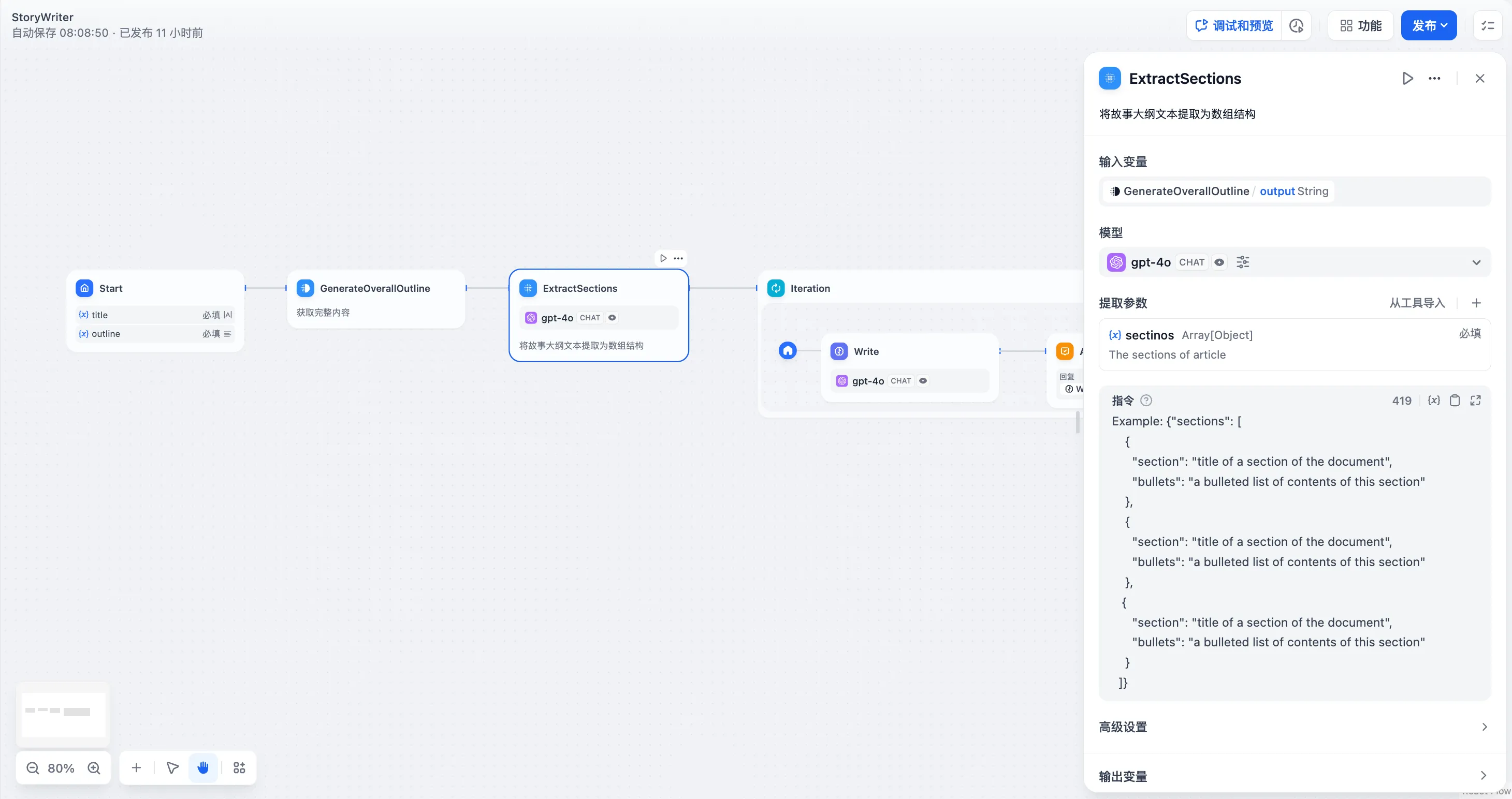
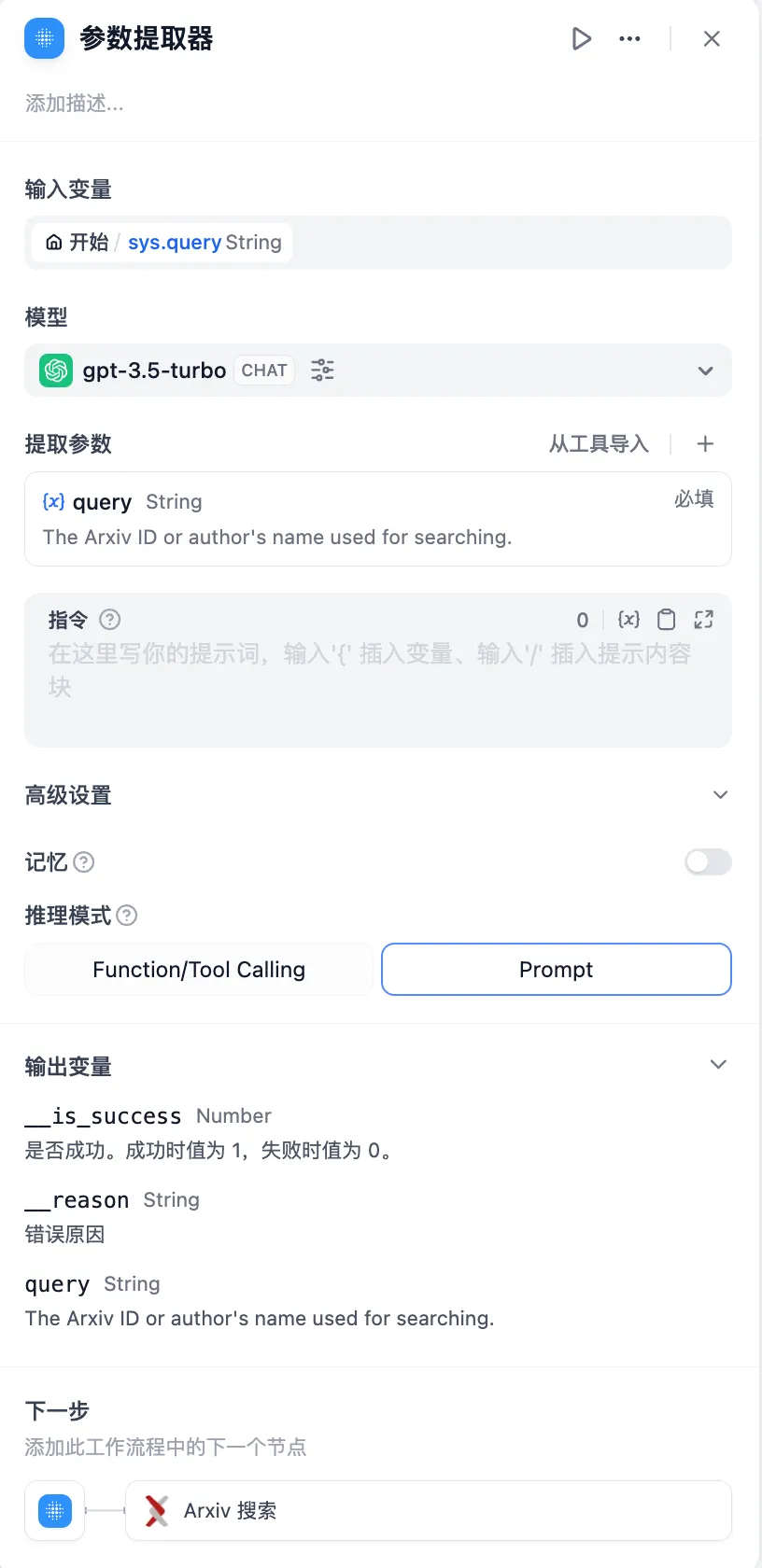
Arxiv 论文检索工具
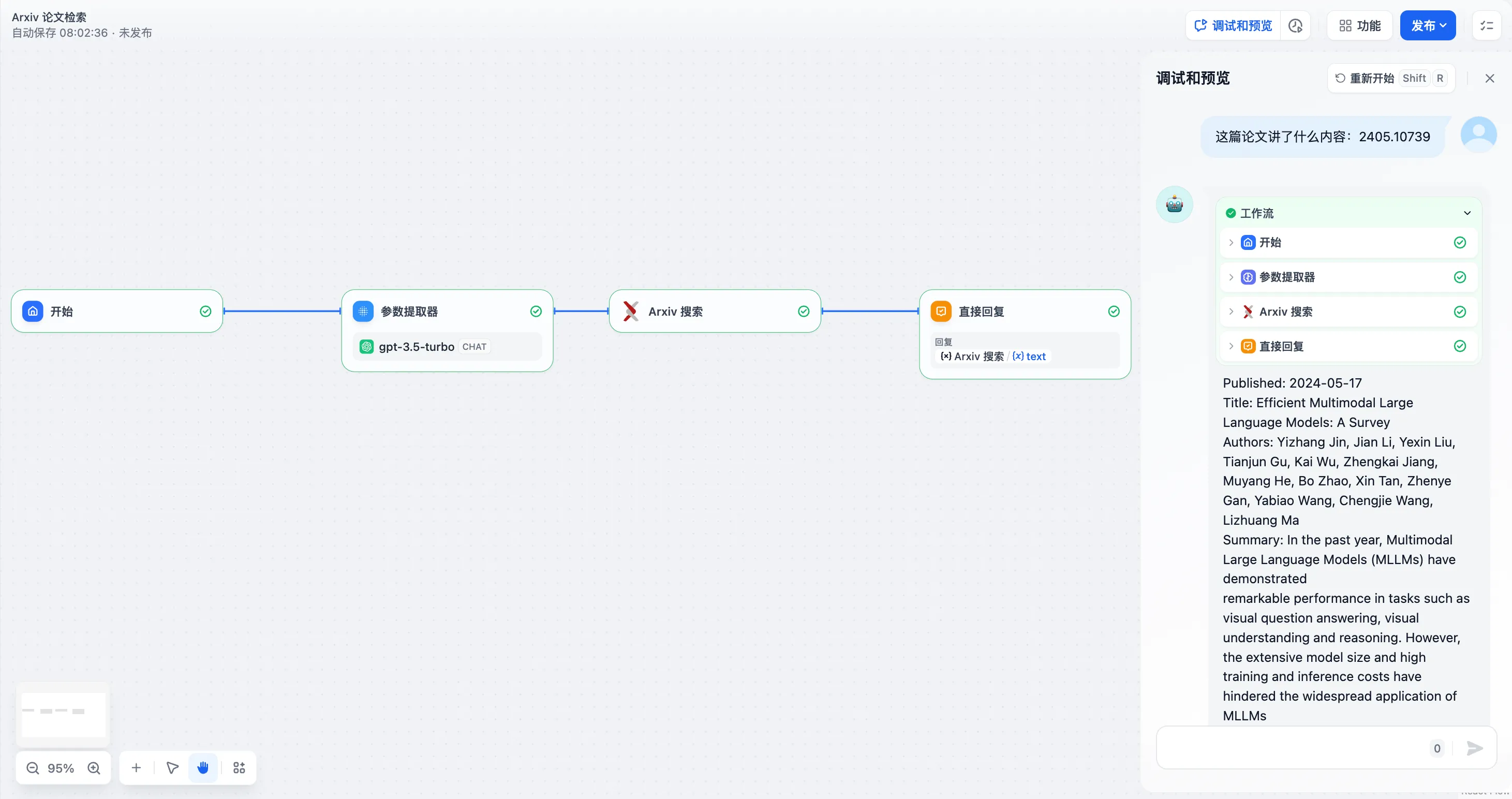
Arxiv 论文检索工具
.png)
.png)
.png)
Chatflow 和 Workflow
Chatflow 和 Workflow
 (1).png)
.png)
拼接文本
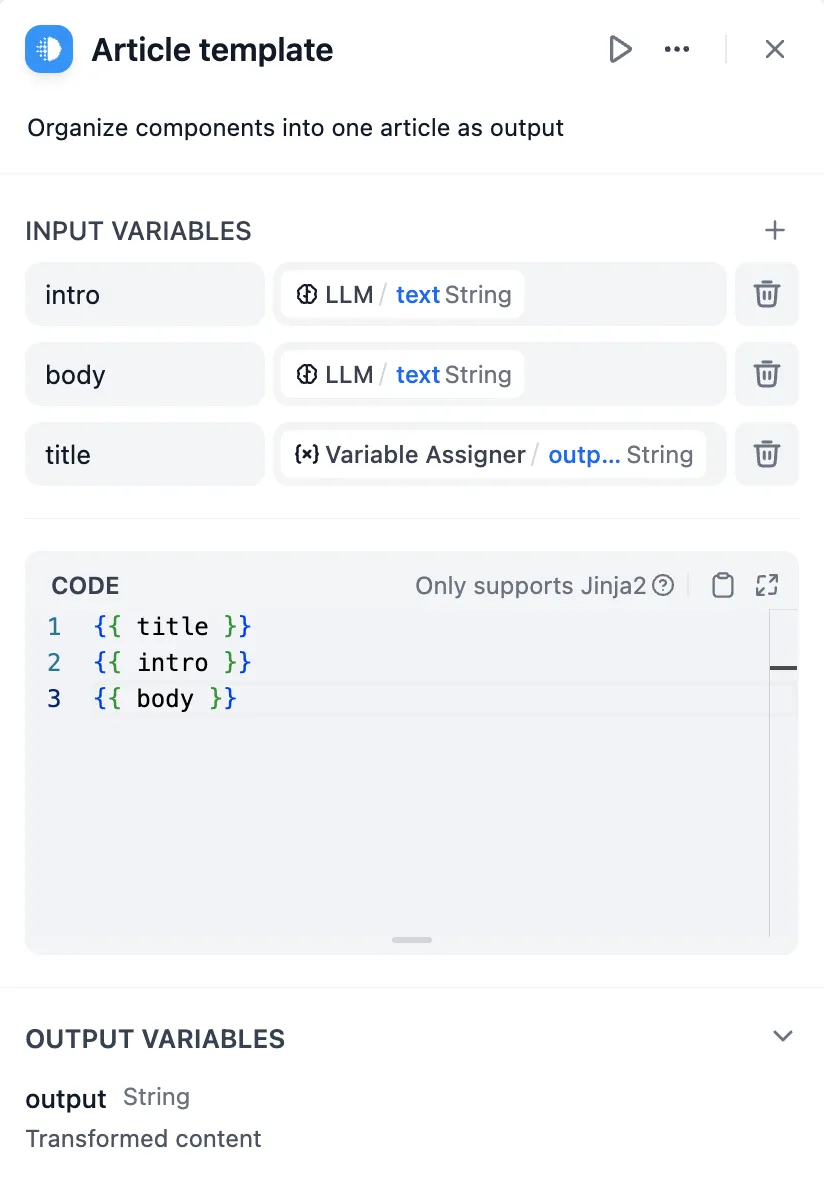
拼接文本
.png)
知识检索节点输出转换为 Markdown
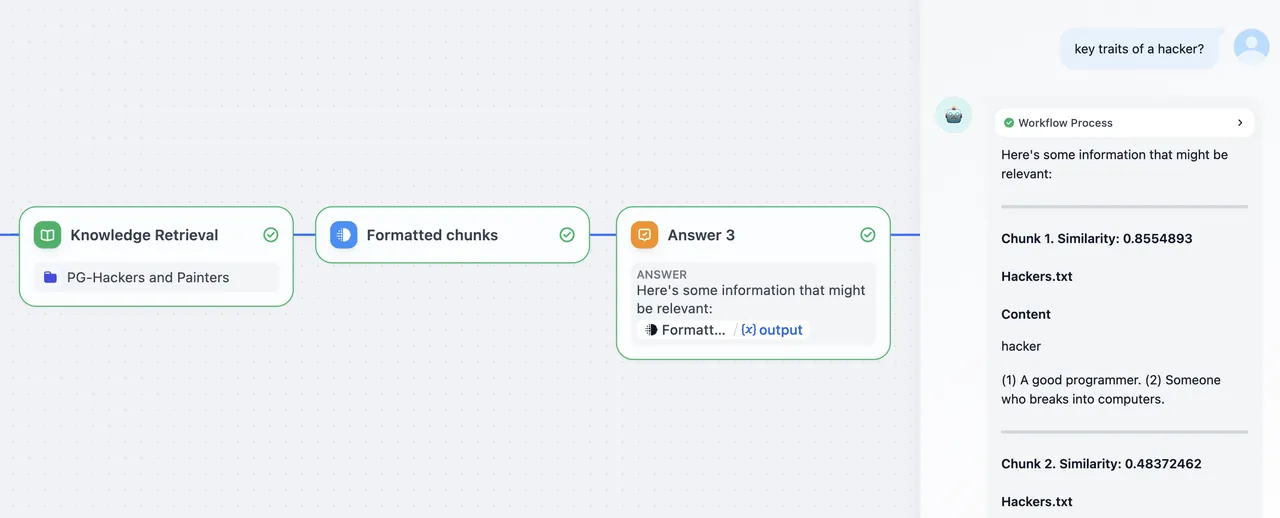
知识检索节点输出转换为 Markdown
.png)
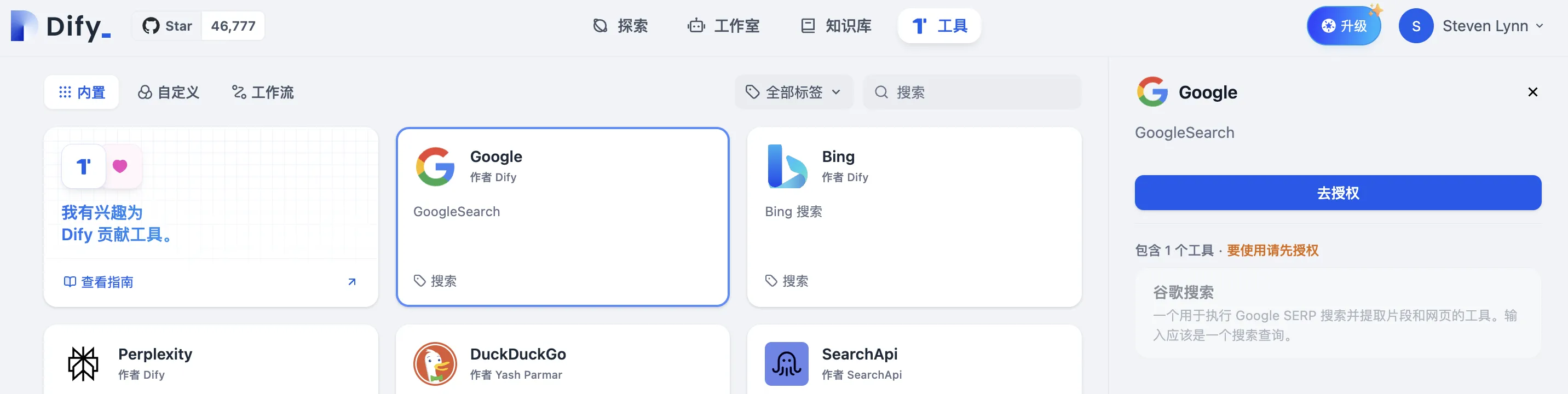
工具选择
工具选择
.png)
配置 Google 搜索工具检索外部知识
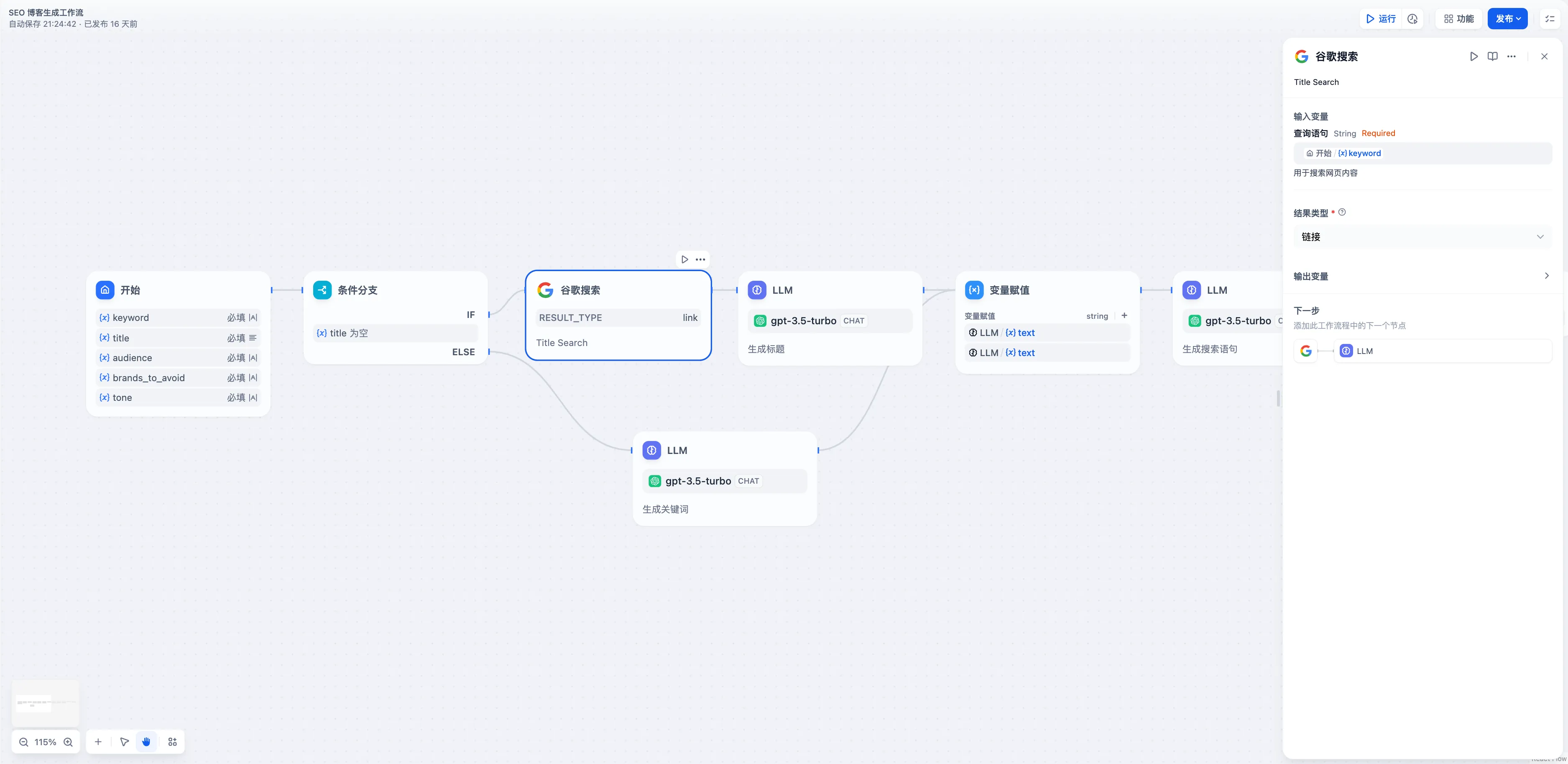
配置 Google 搜索工具检索外部知识
.png)
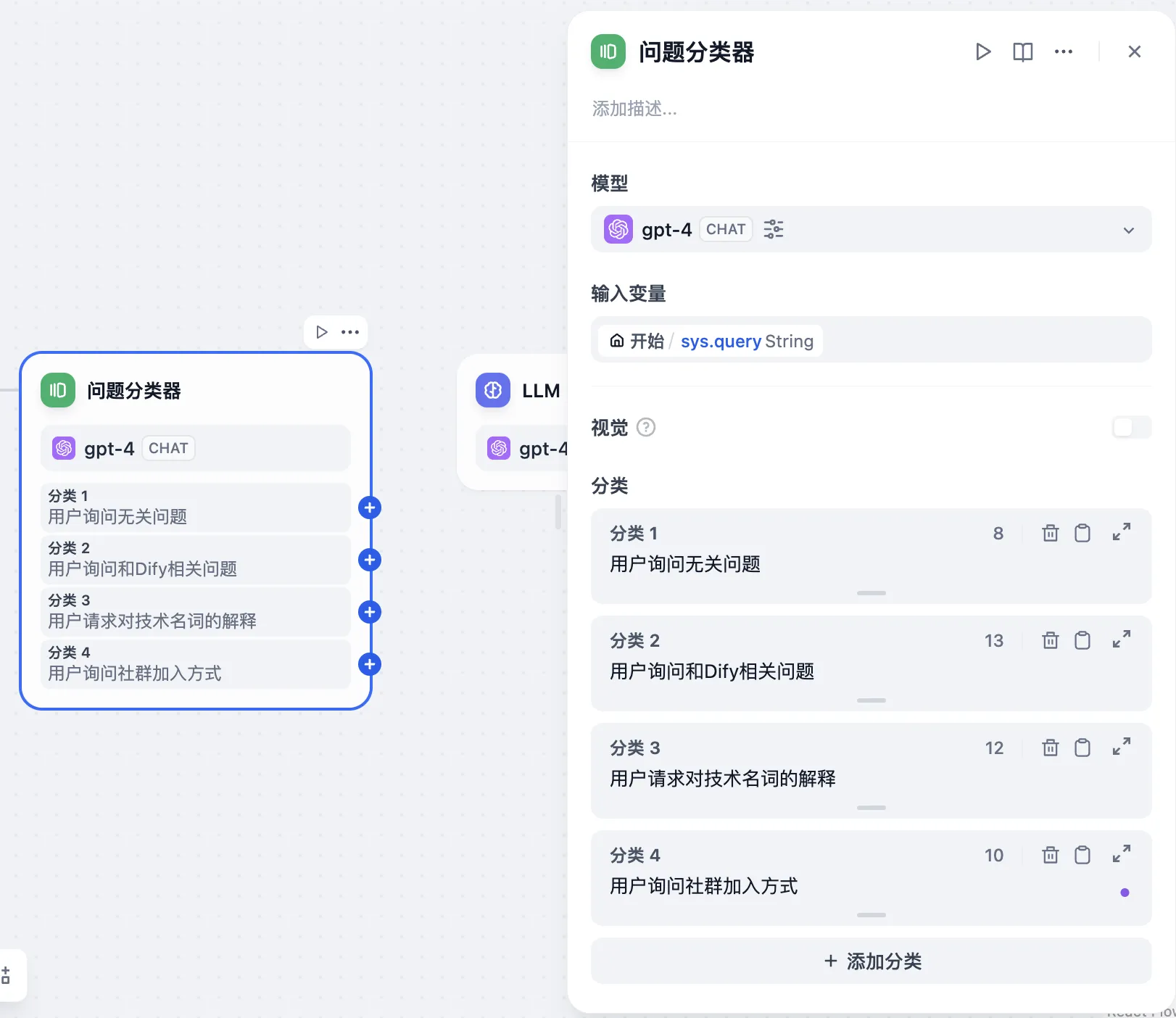
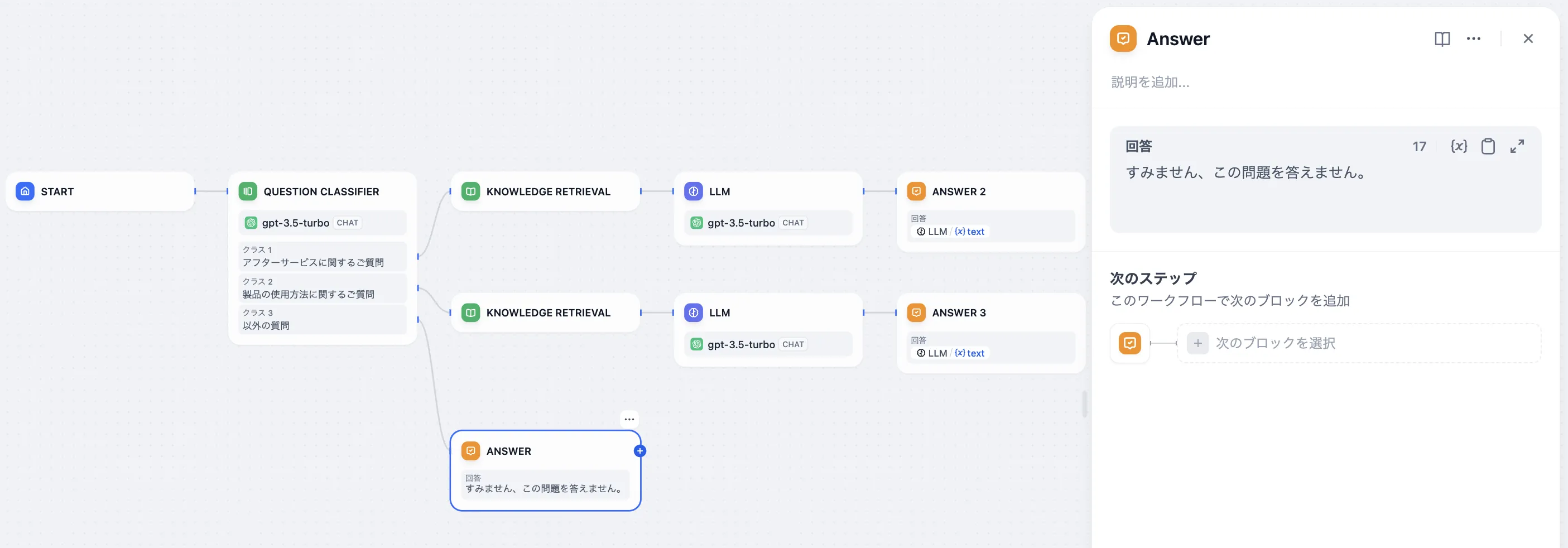
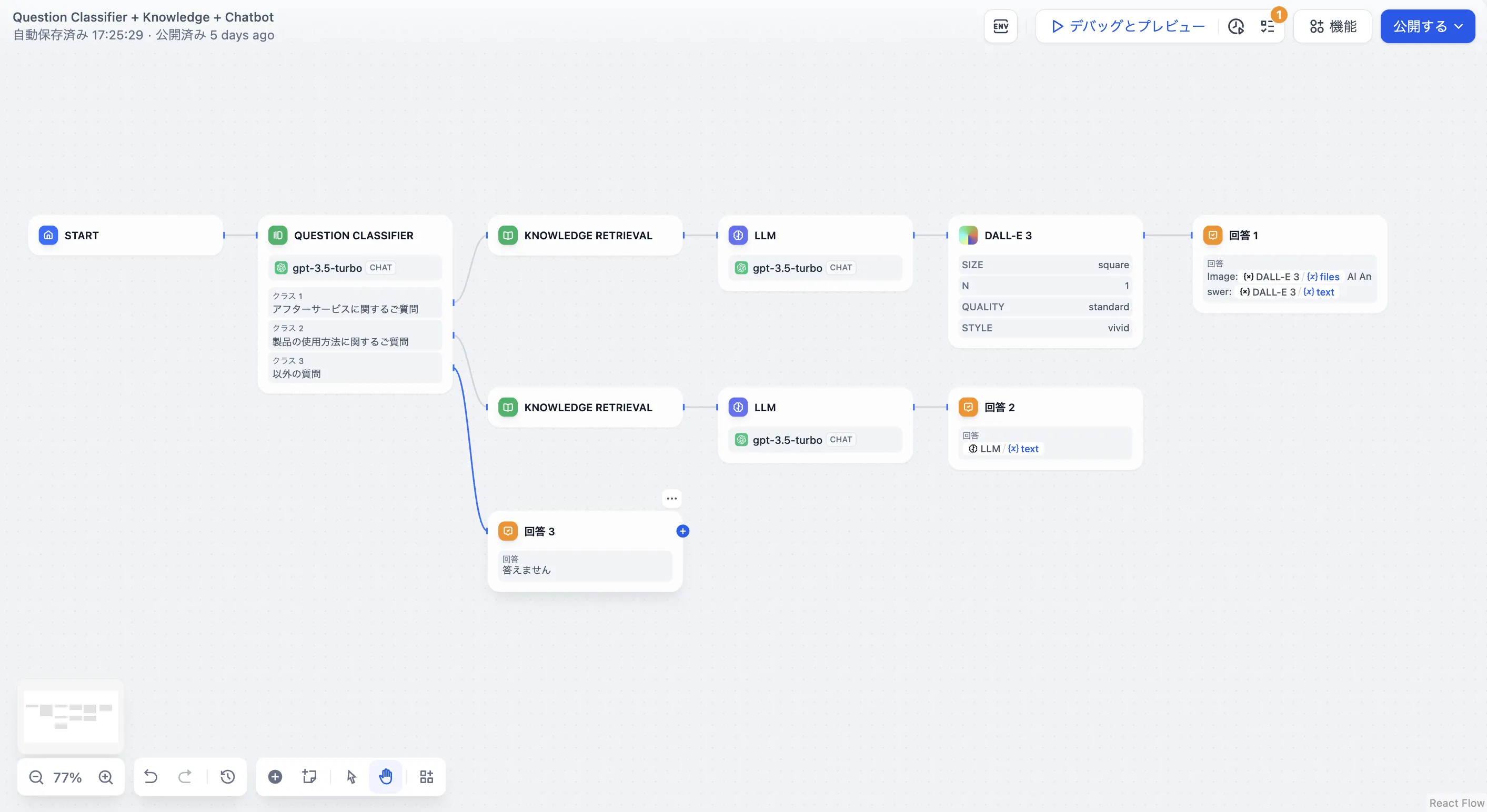
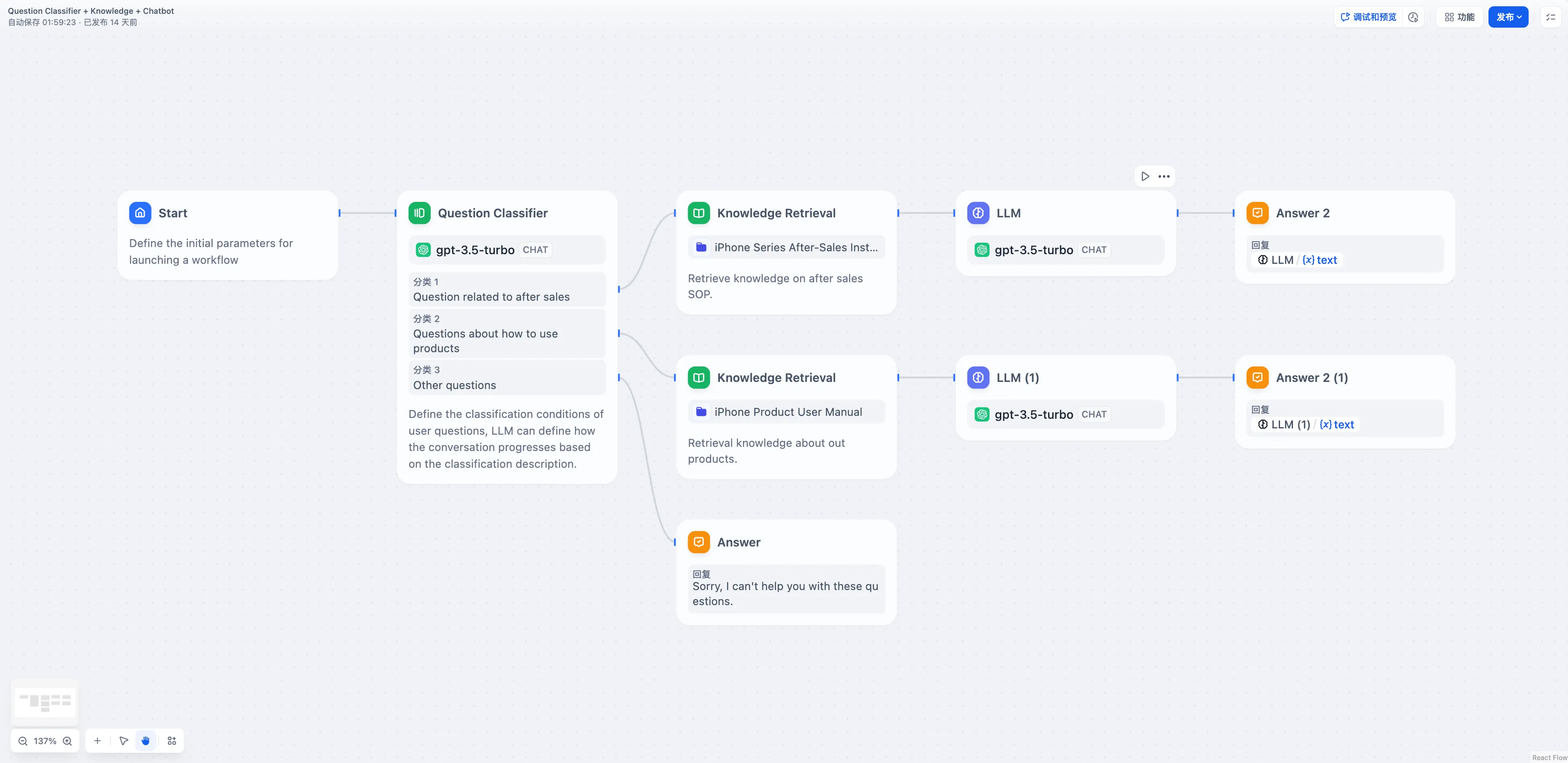
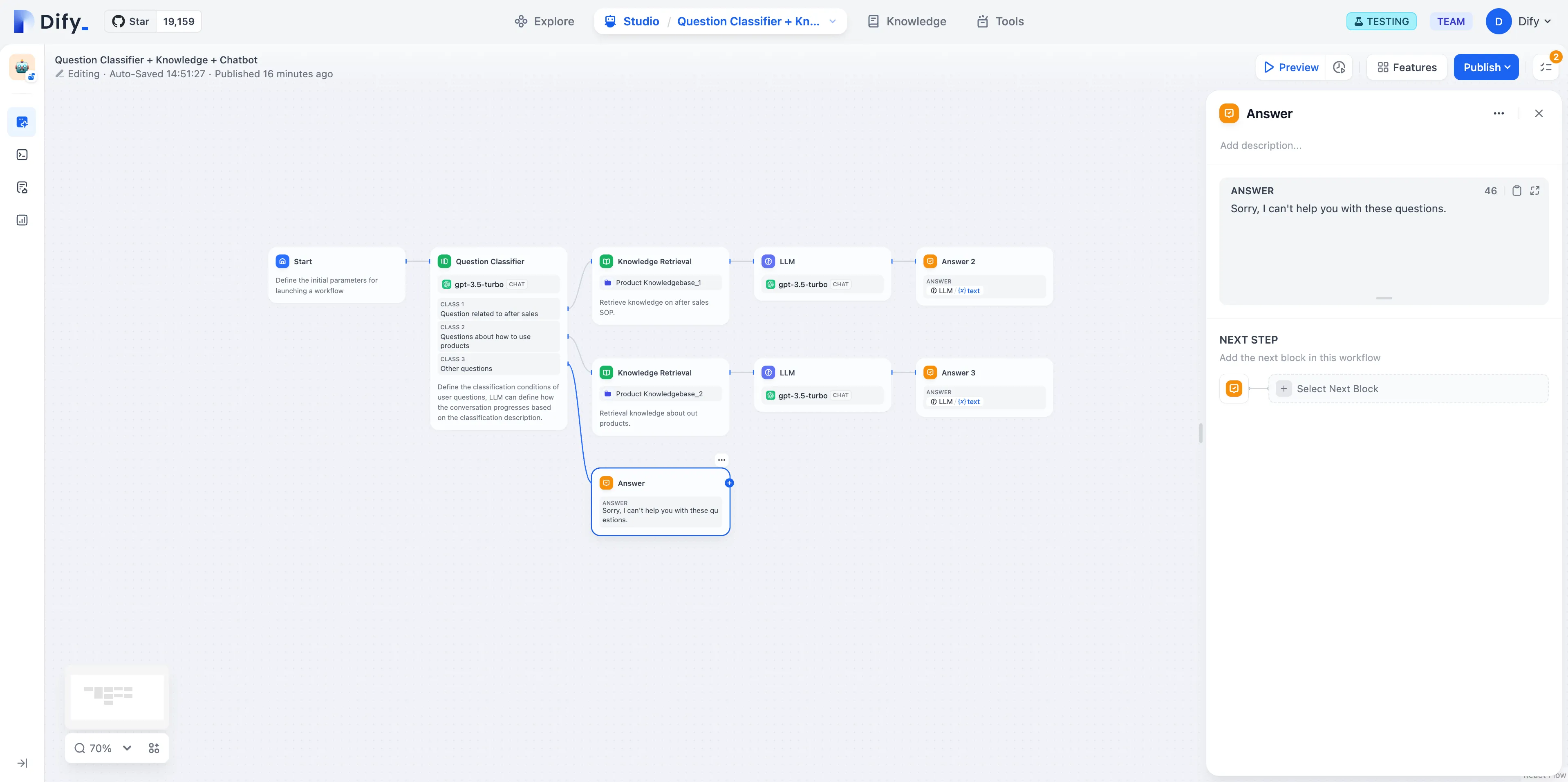
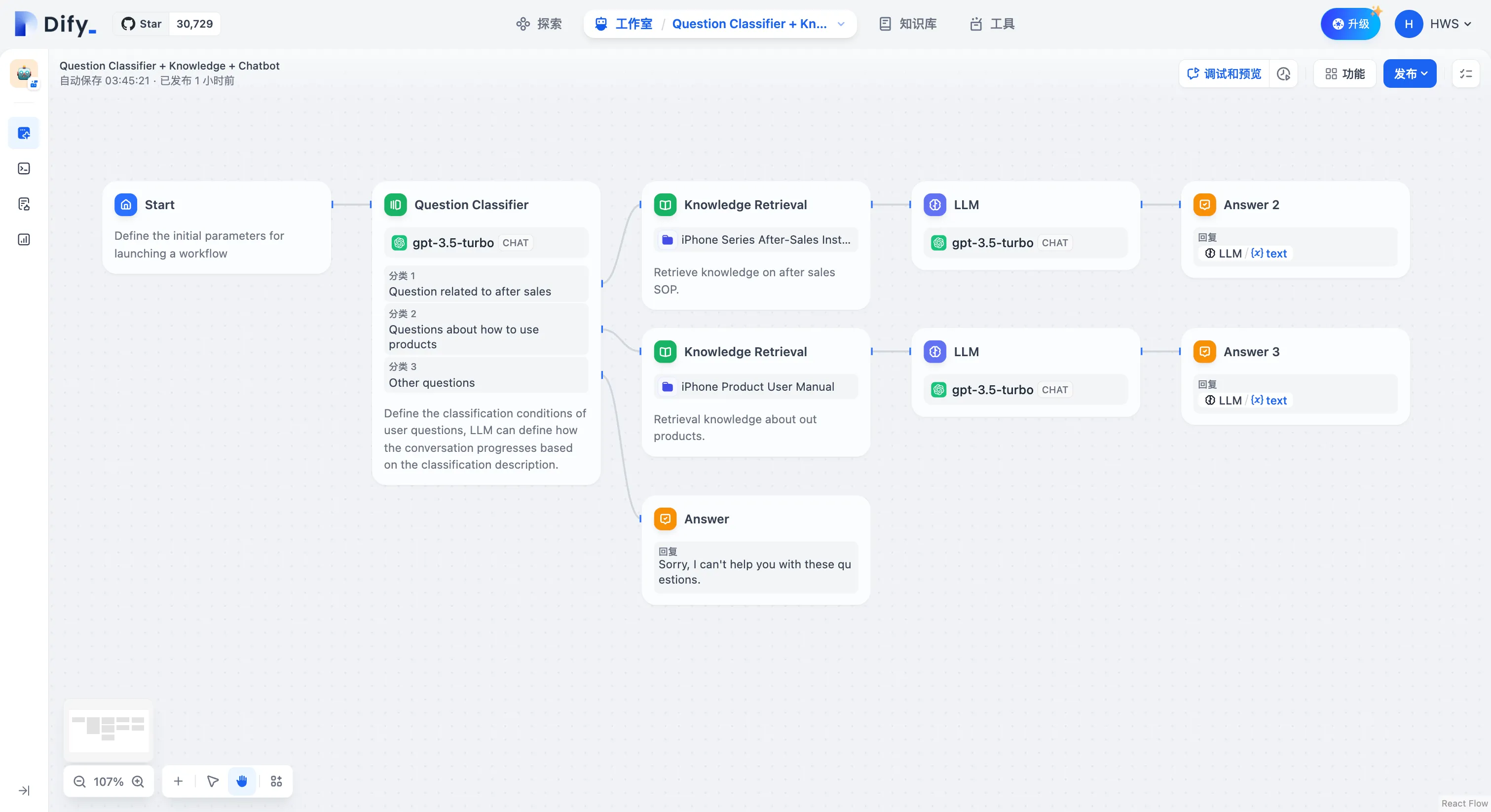
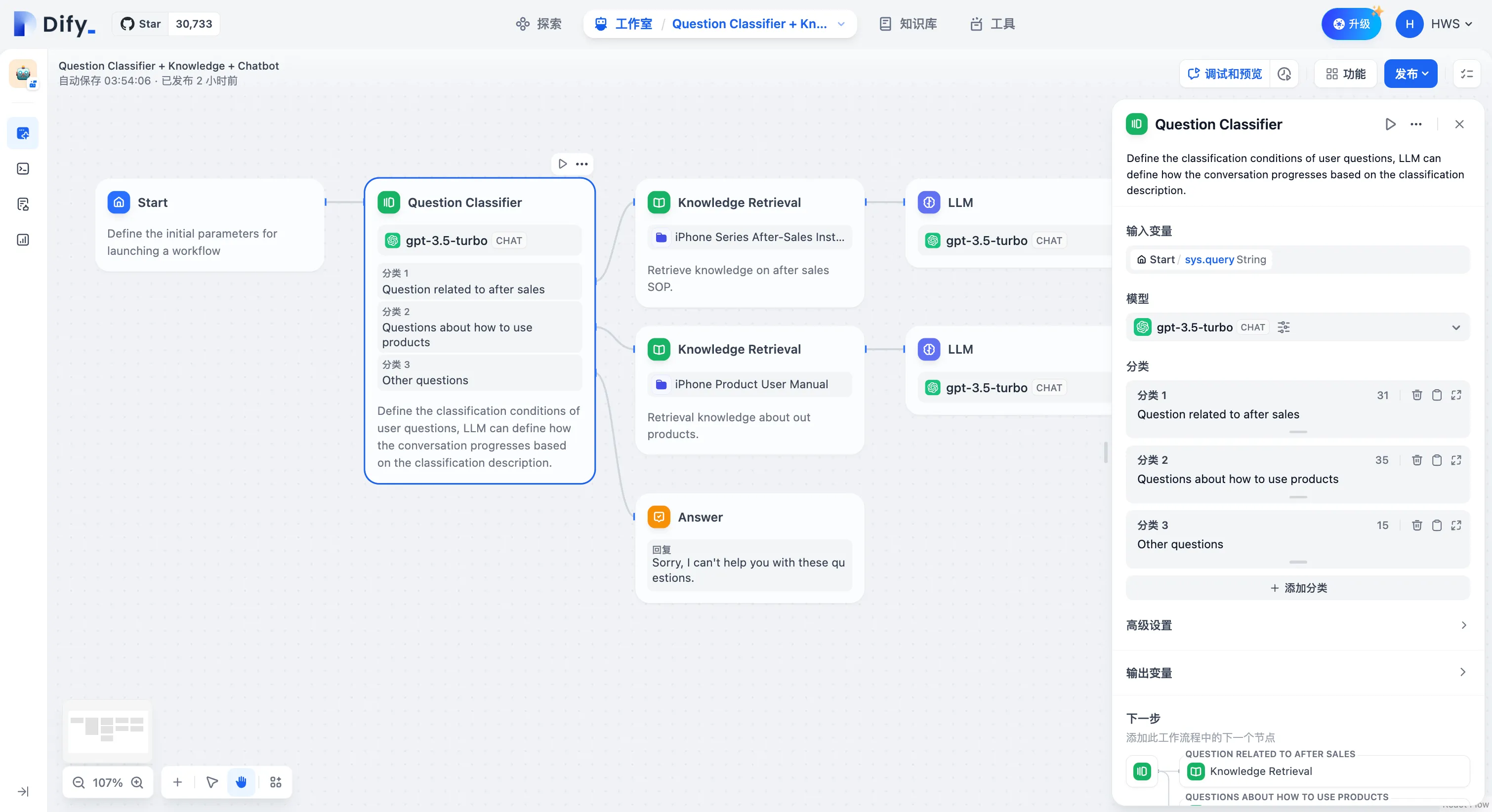
问题分类(无变量聚合)
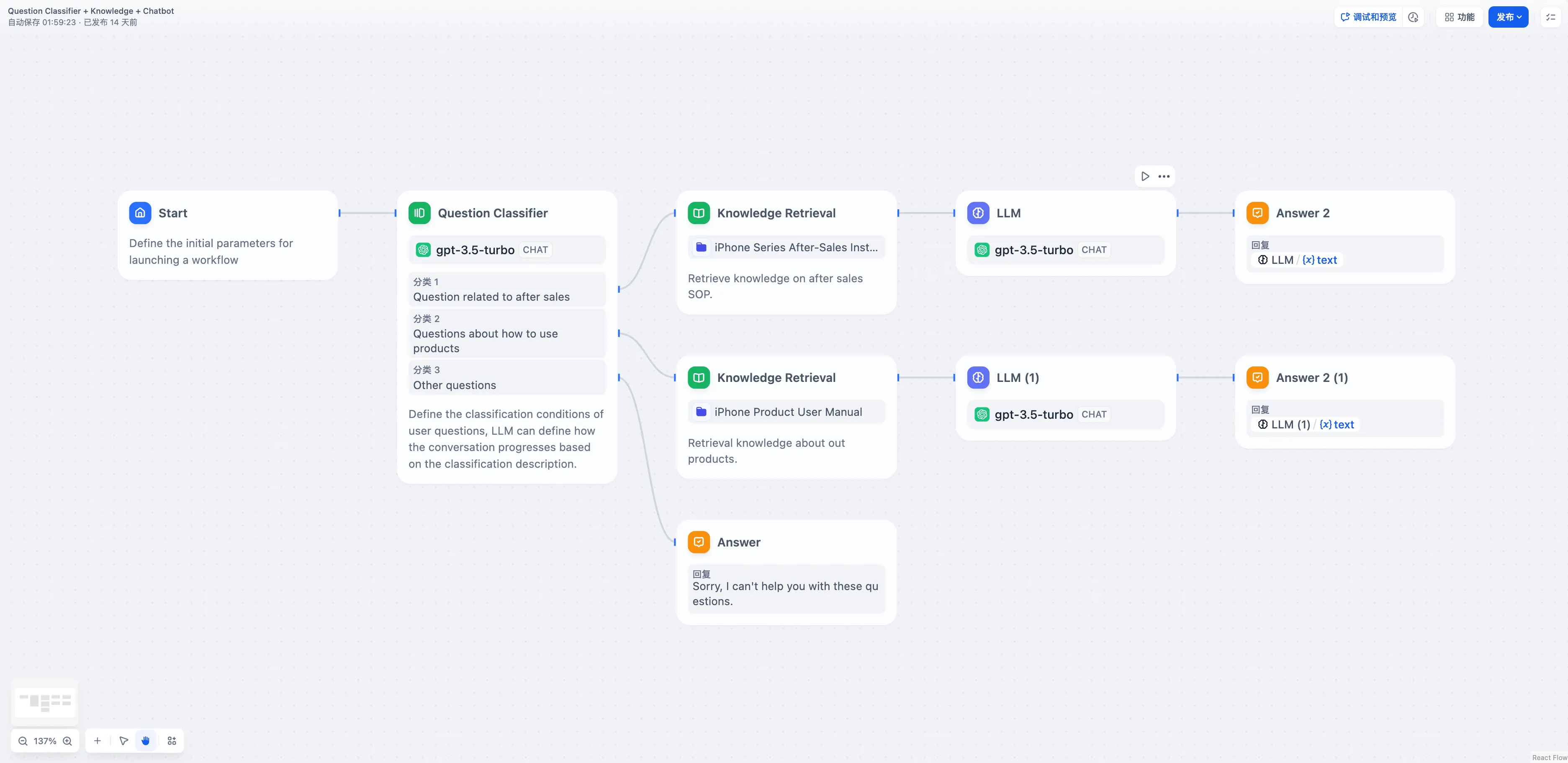
问题分类(无变量聚合)
.png)
问题分类后的多路聚合
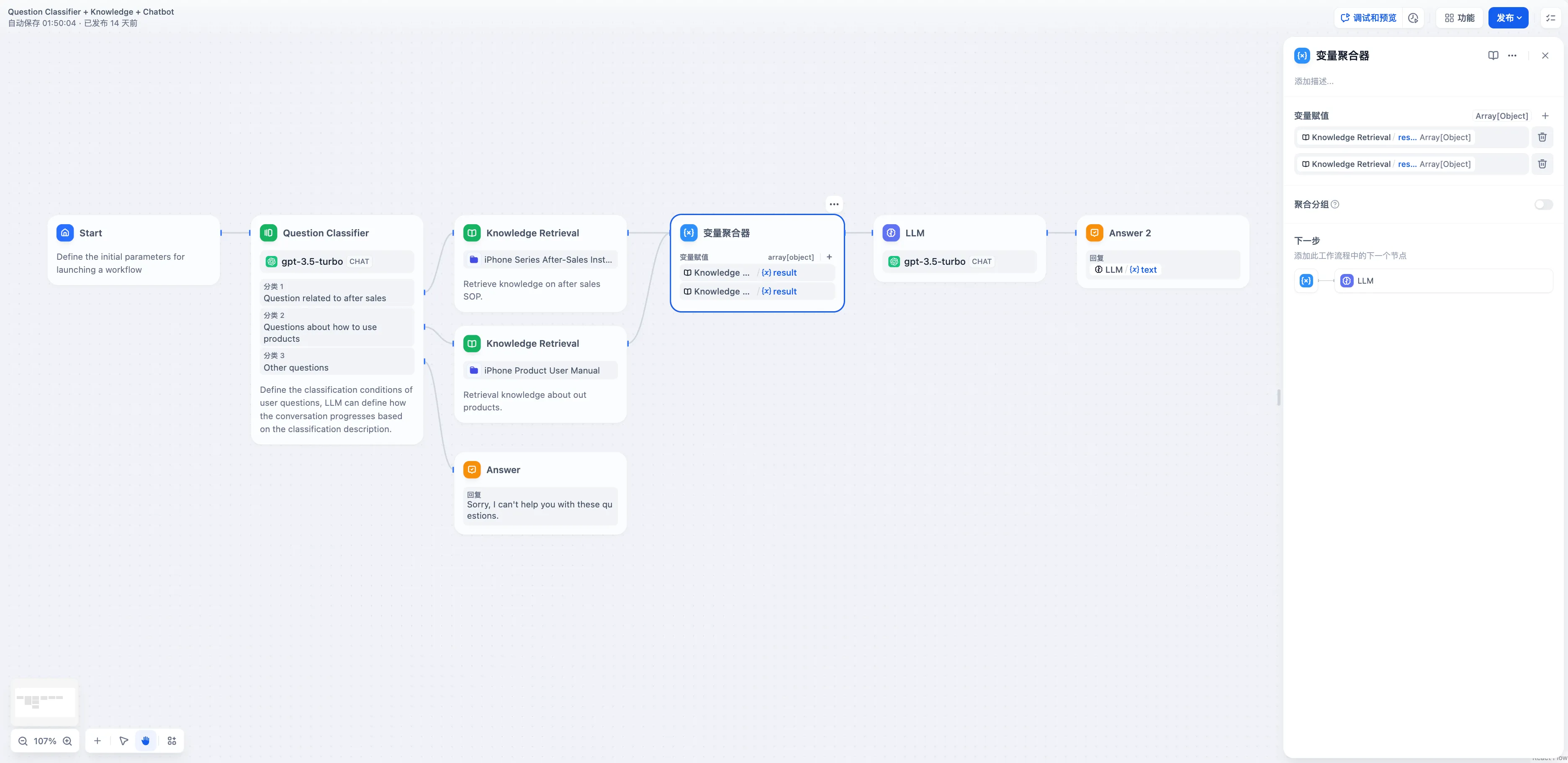
问题分类后的多路聚合
.png)
问题分类后的多路聚合
问题分类后的多路聚合

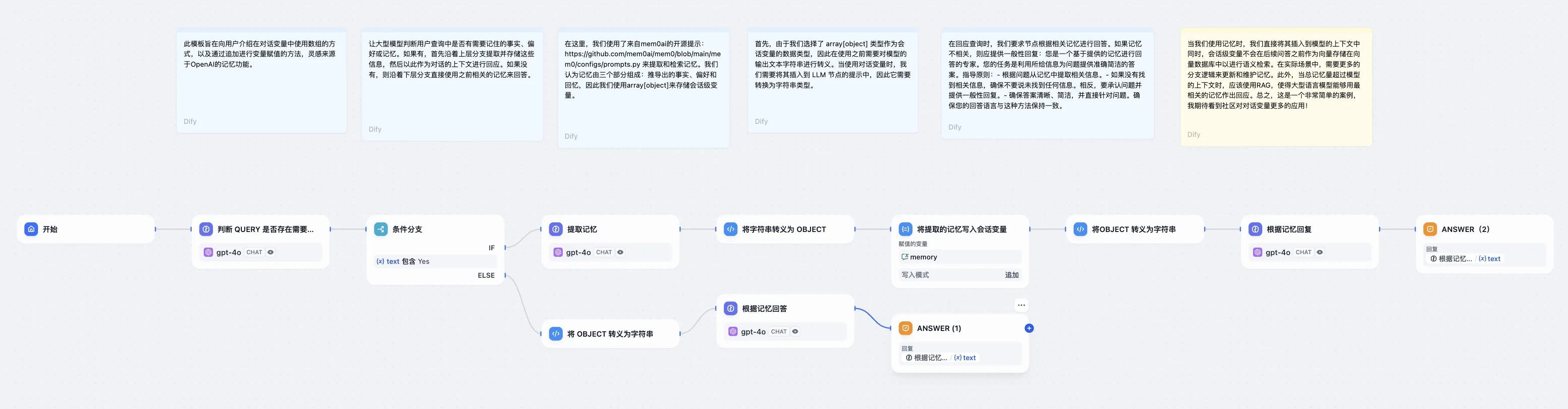

.png)
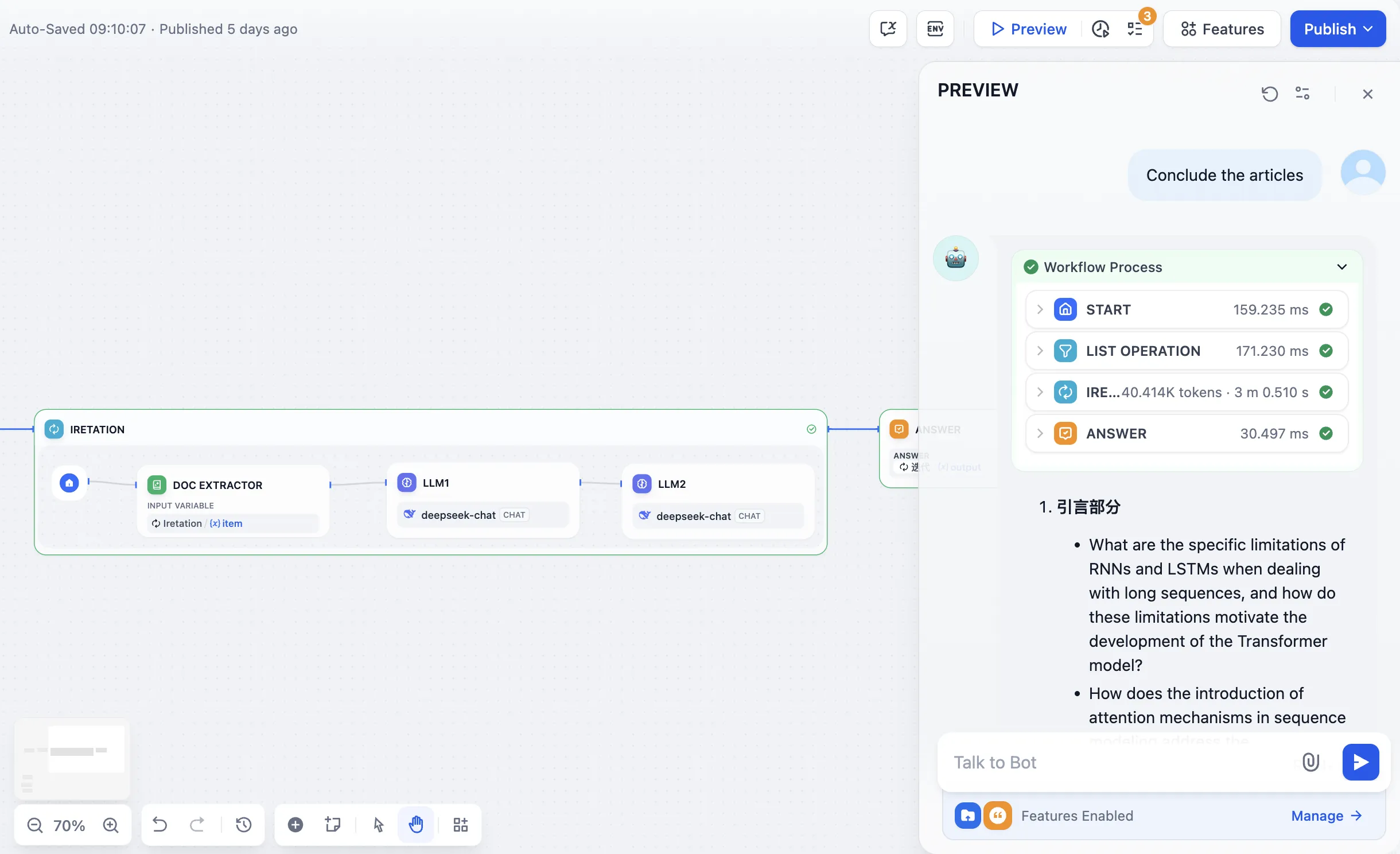
上图为串行节点流、下图为并行节点流
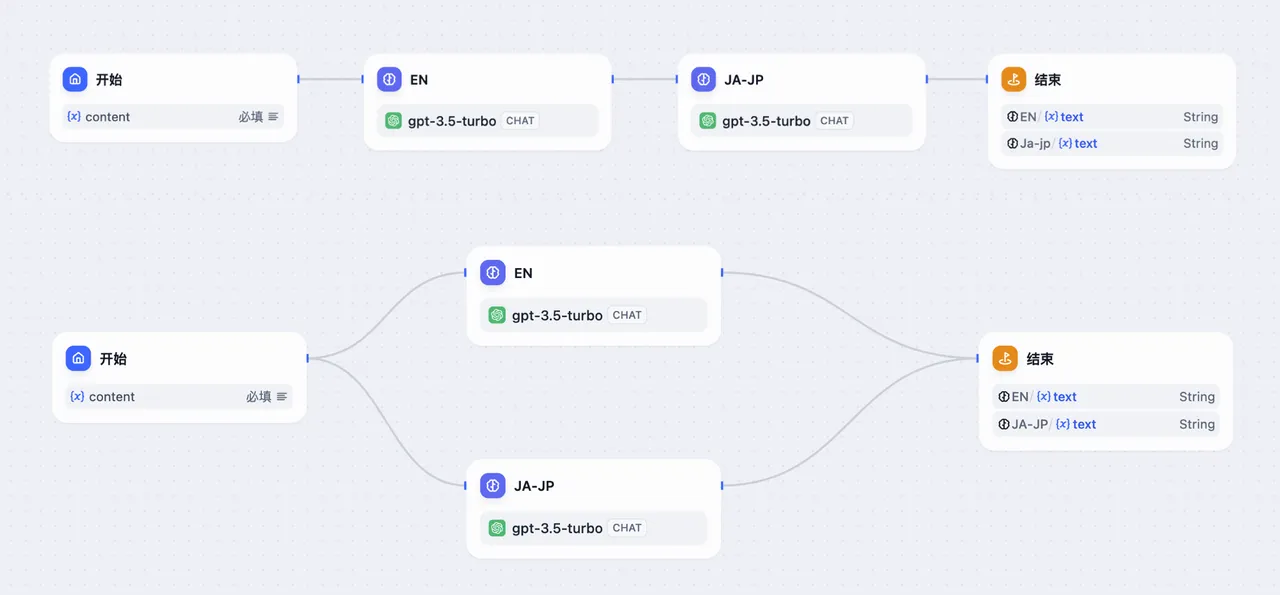
上图为串行节点流、下图为并行节点流
.png)
串行结构

串行结构
.png)
串行结构应用日志
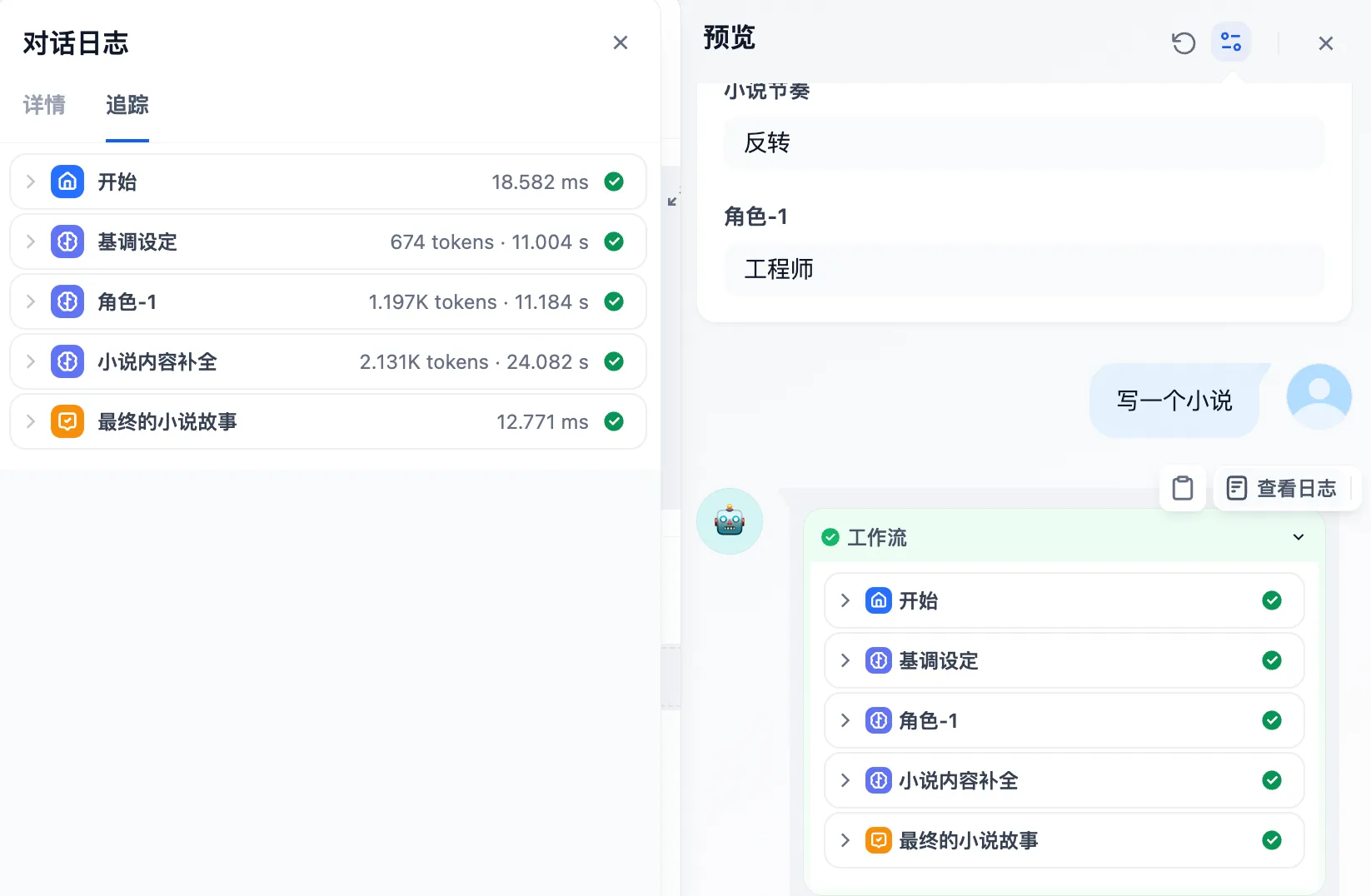
串行结构应用日志
.png)
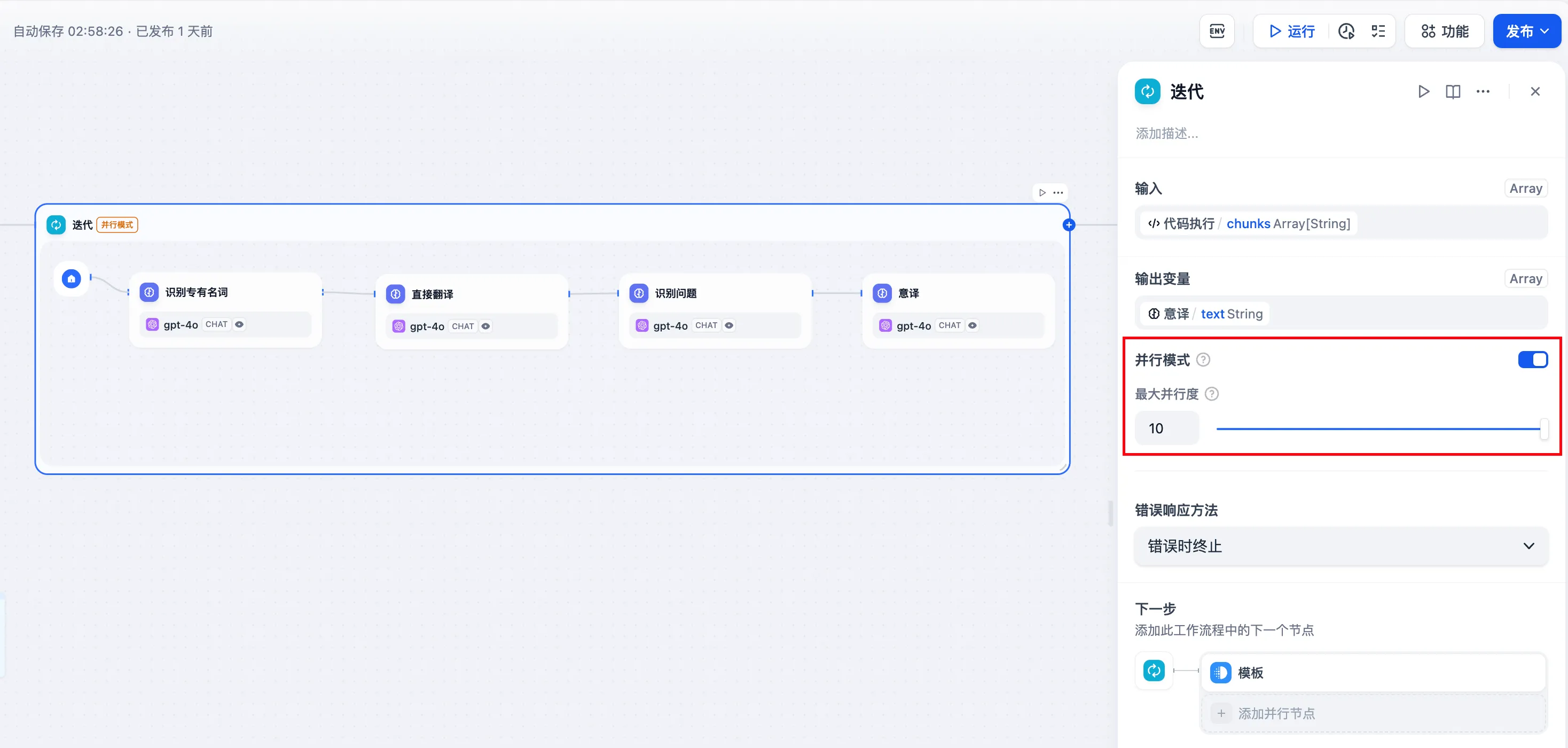
并行设计
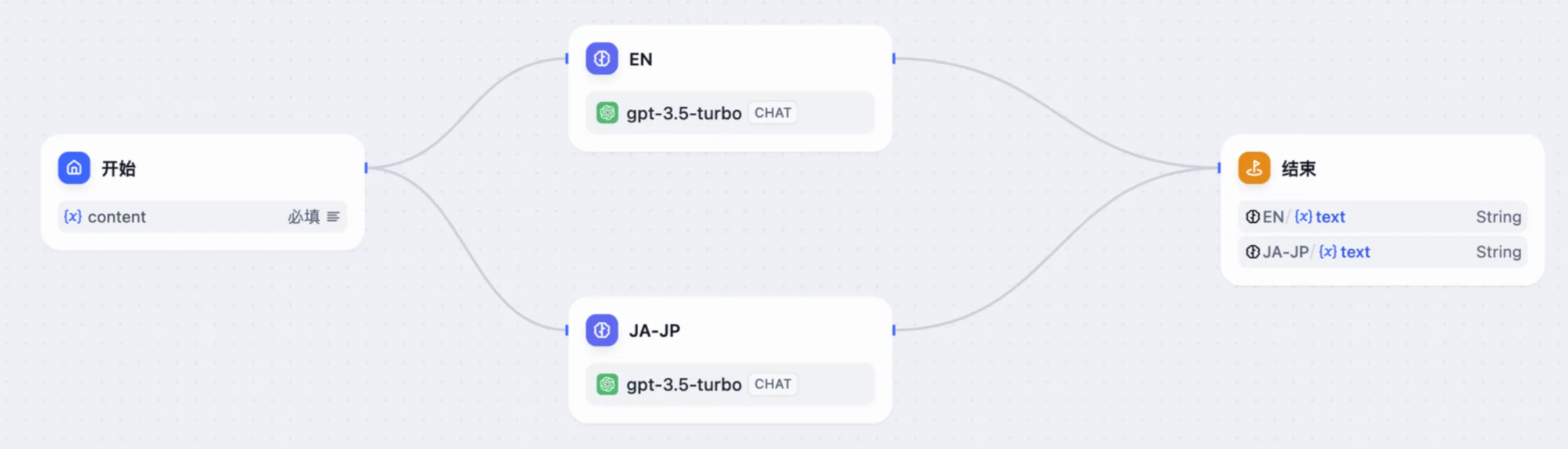
并行设计
.png)
Type 01
Type 01
.png)
Type 02
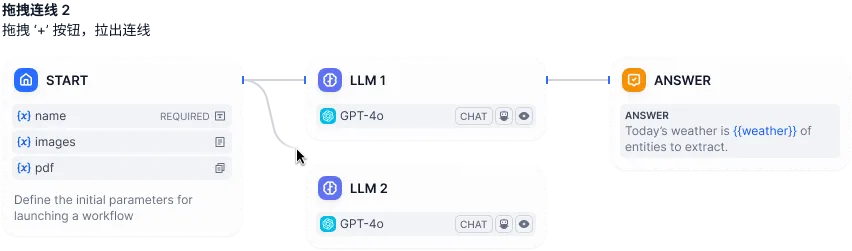
Type 02
.png)
Type 03

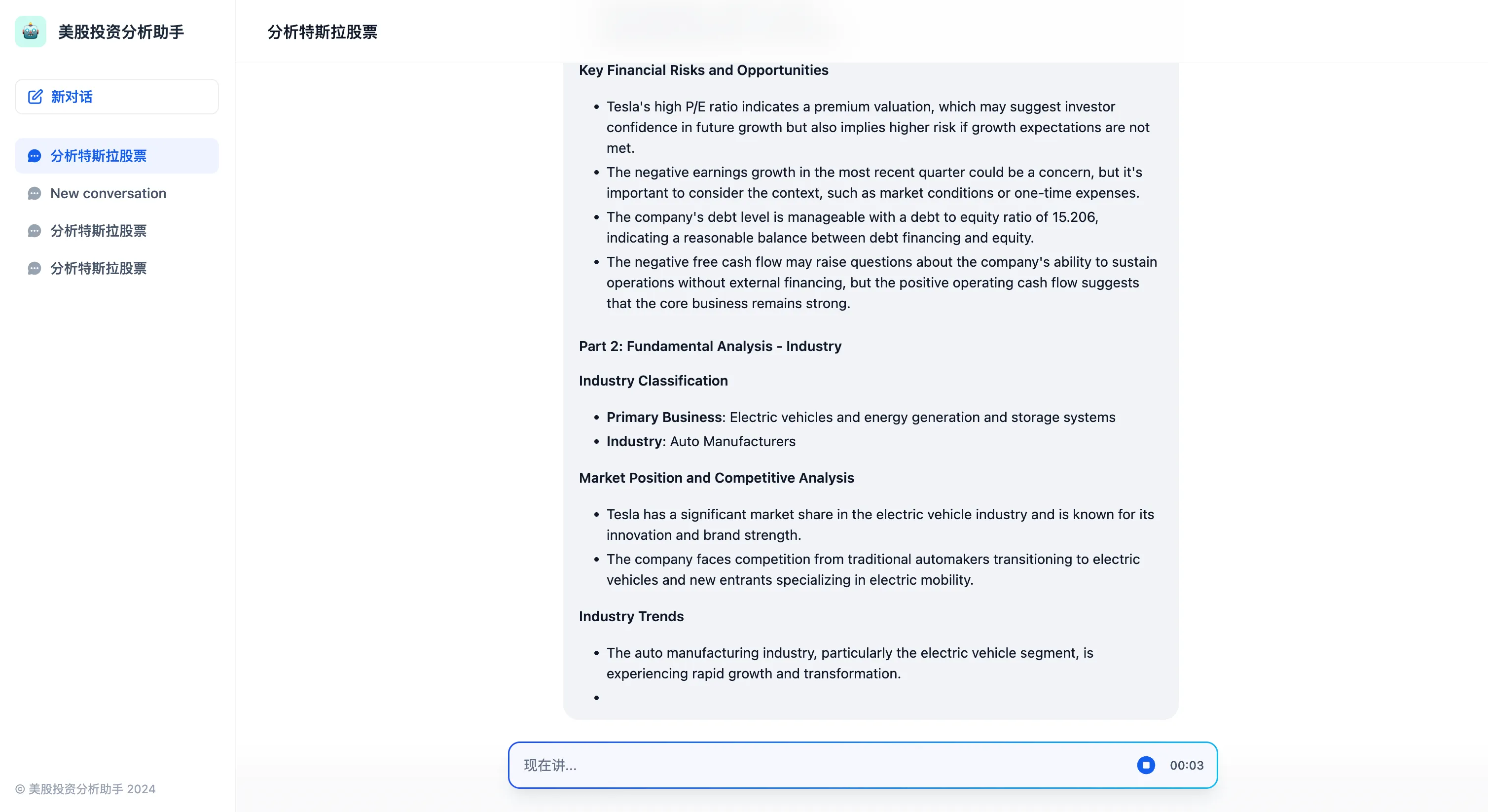
Type 03
.png)
Type 04
Type 04
.png)
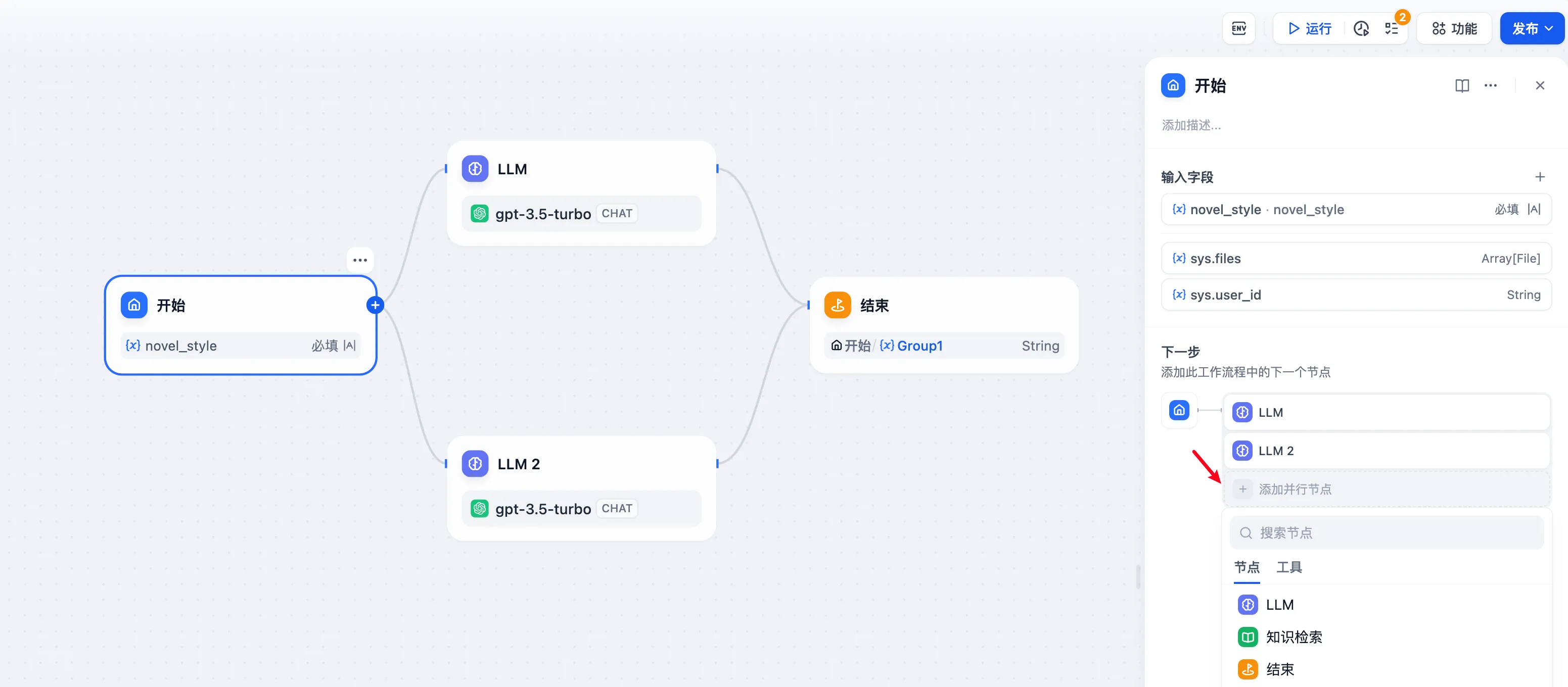
Chatflow 应用中的并行结构
Chatflow 应用中的并行结构
.png)
普通并行
普通并行
.png)
嵌套并行:2 层嵌套关系
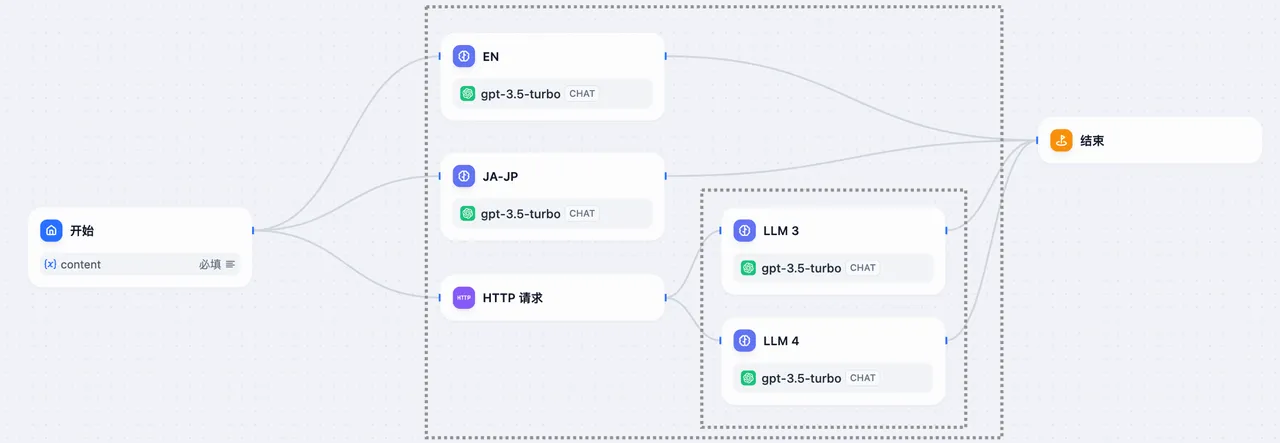
嵌套并行:2 层嵌套关系
.png)
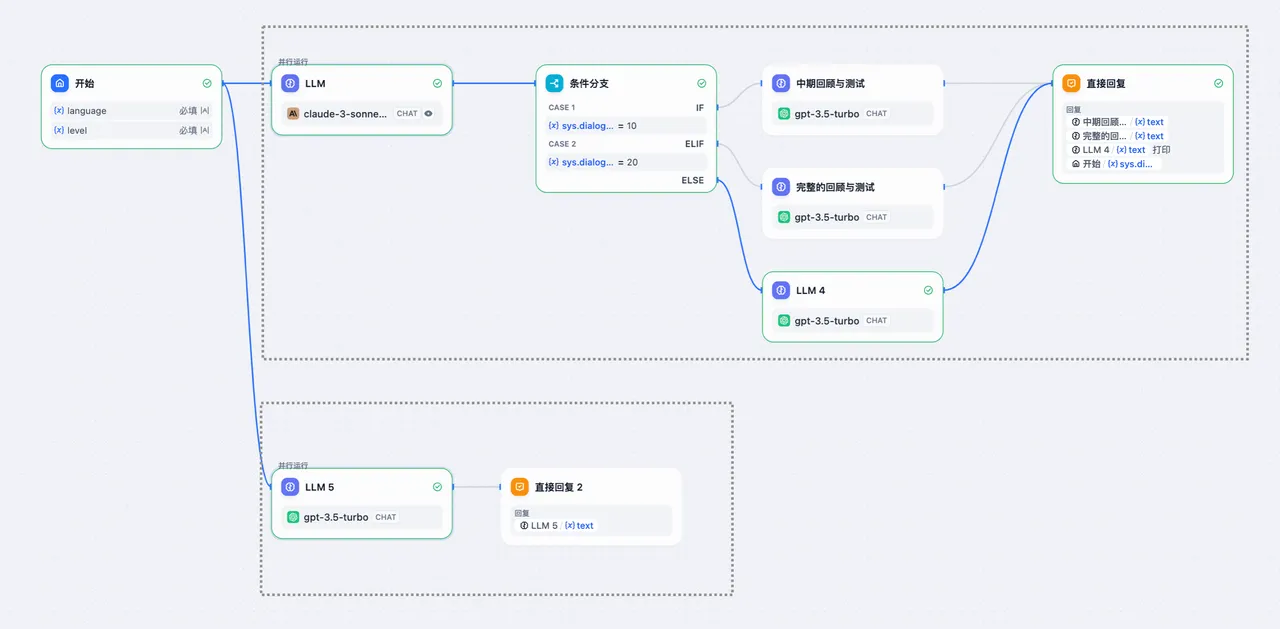
条件分支 + 并行
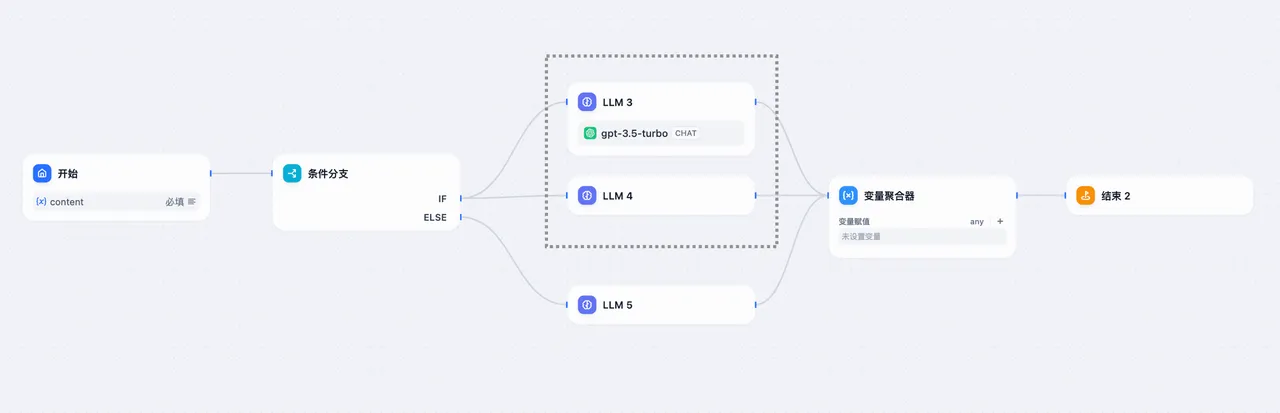
条件分支 + 并行
.png)
迭代分支+并行
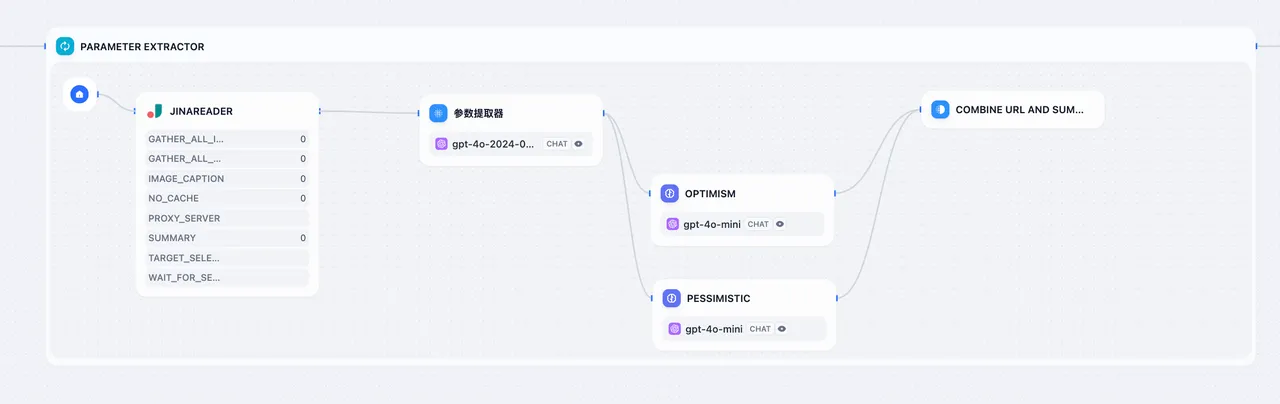
迭代分支+并行
.png)
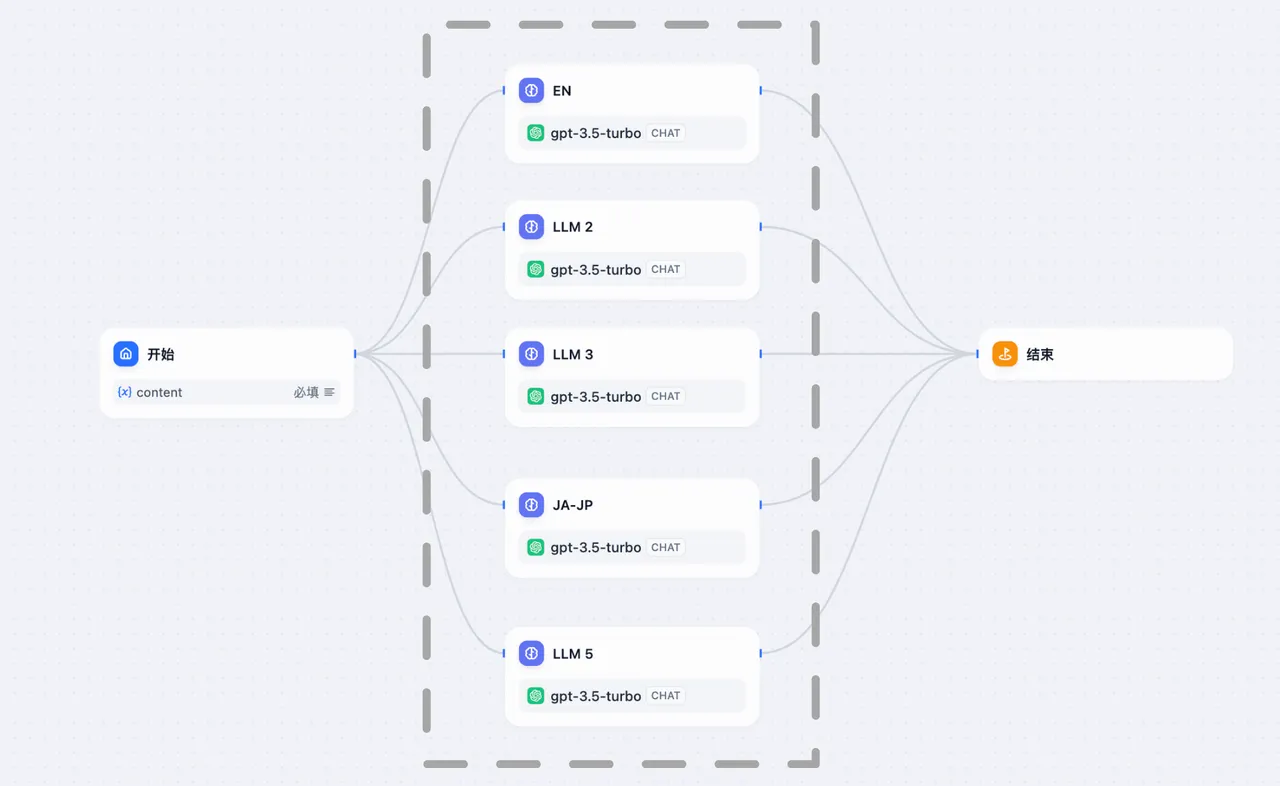
并行结构
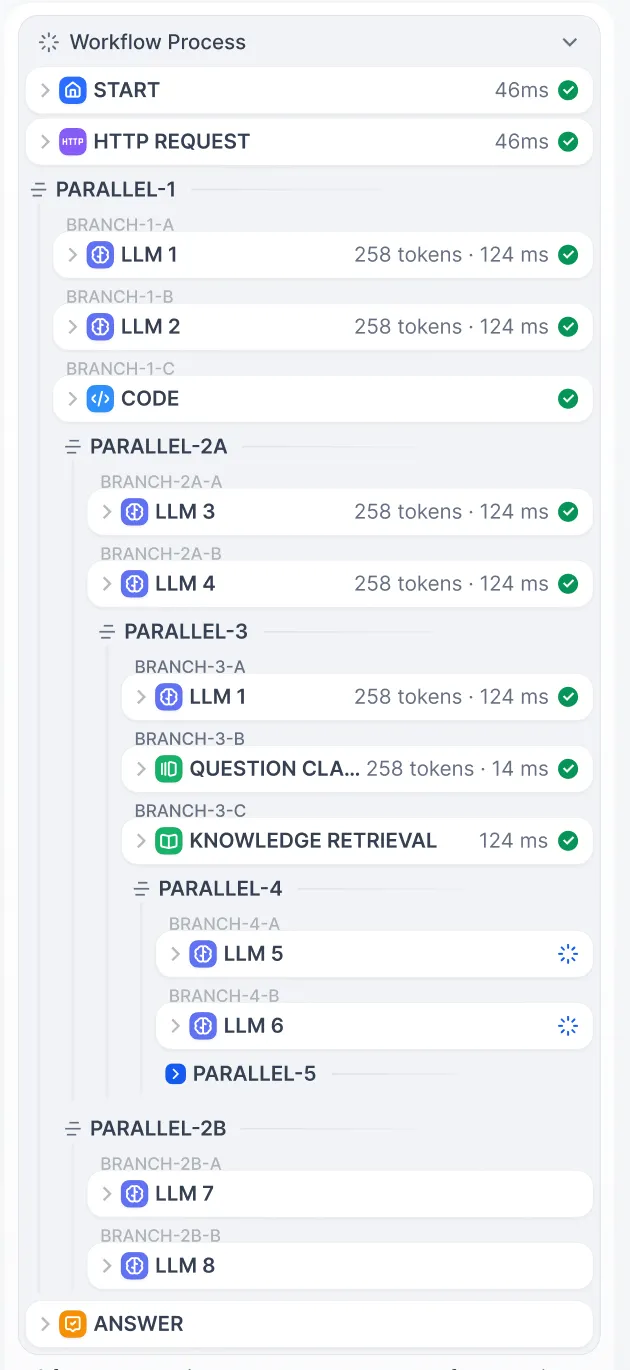
并行结构
Workflow 类型应用系统变量
Workflow 类型应用系统变量
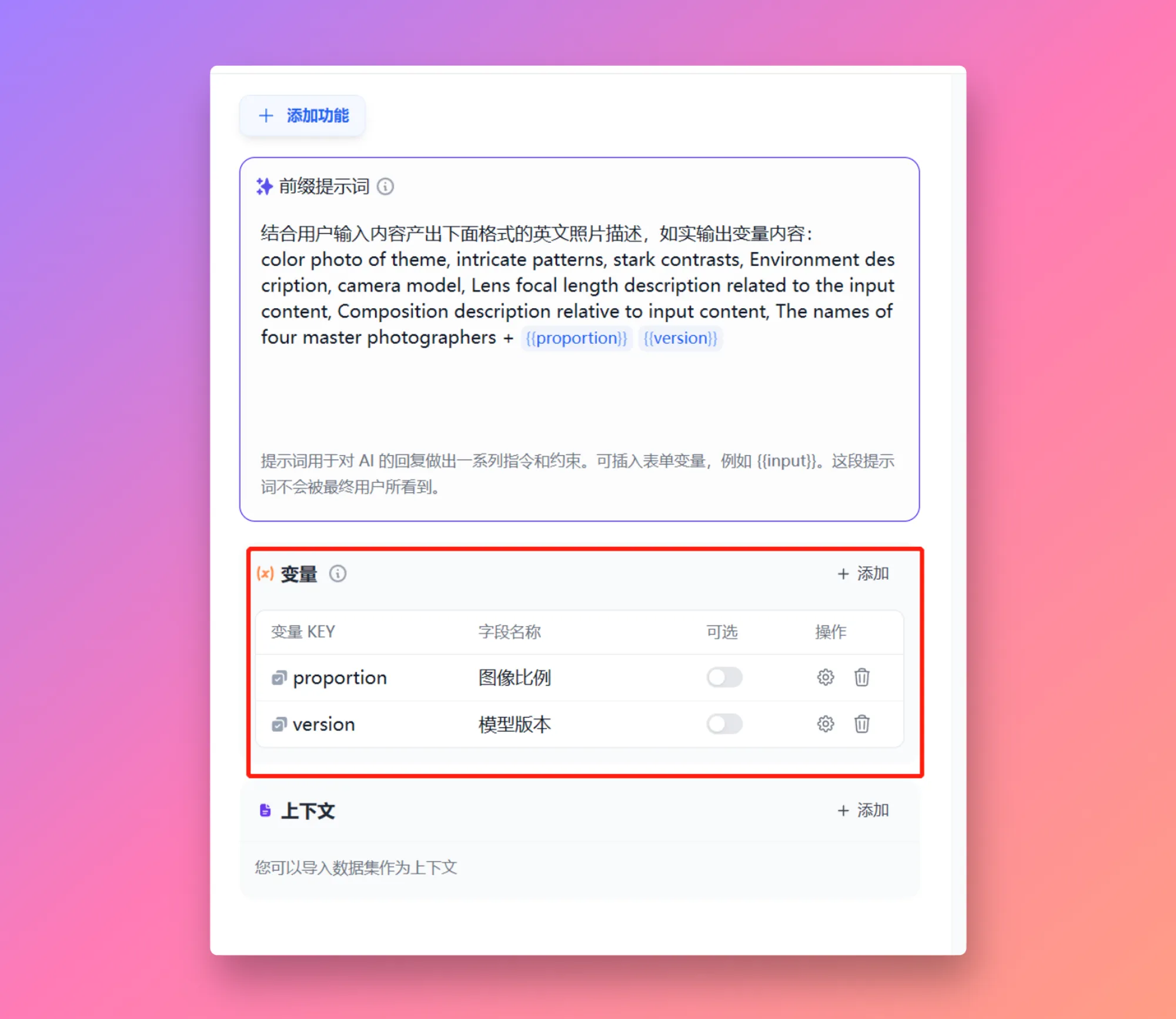
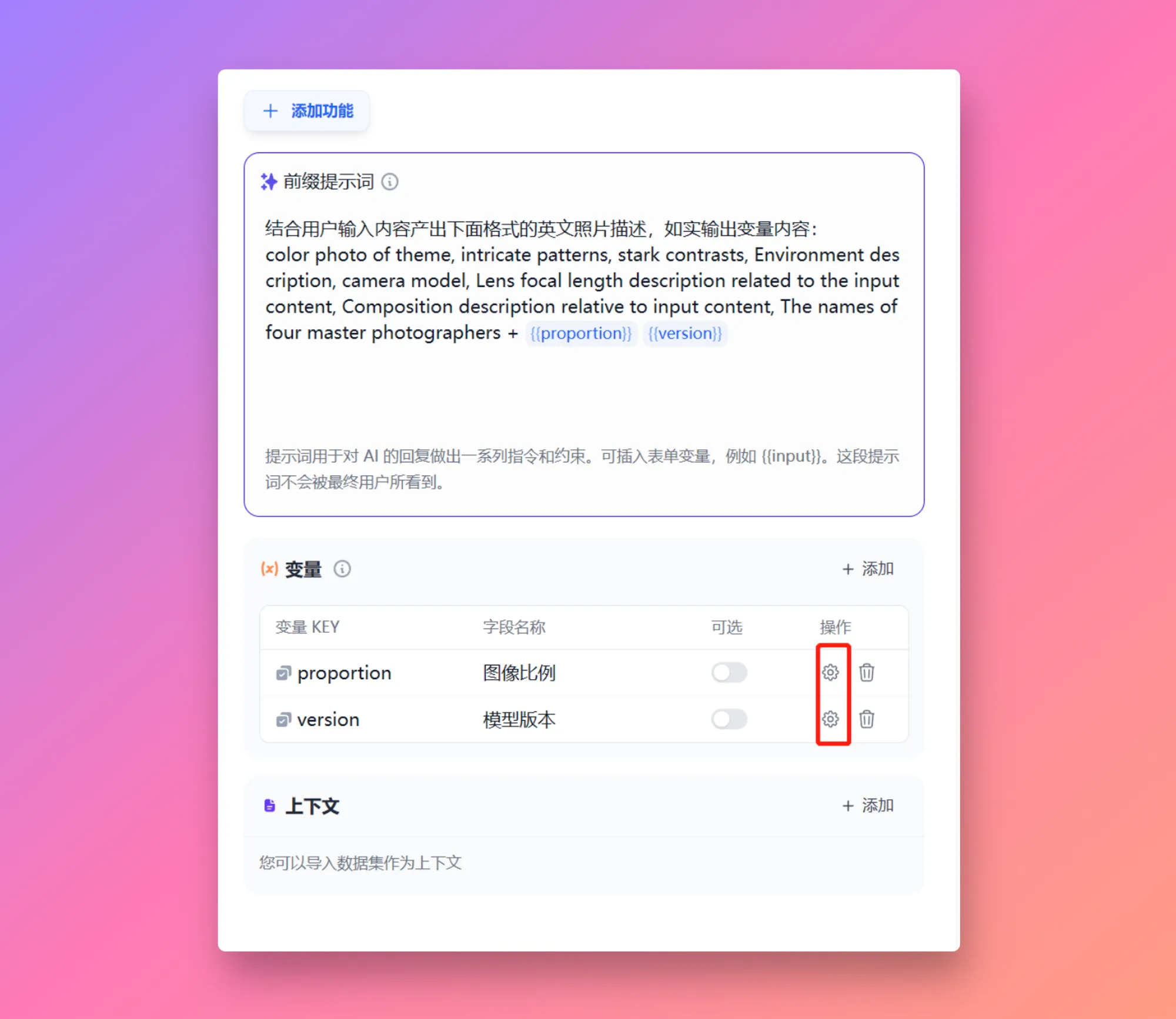
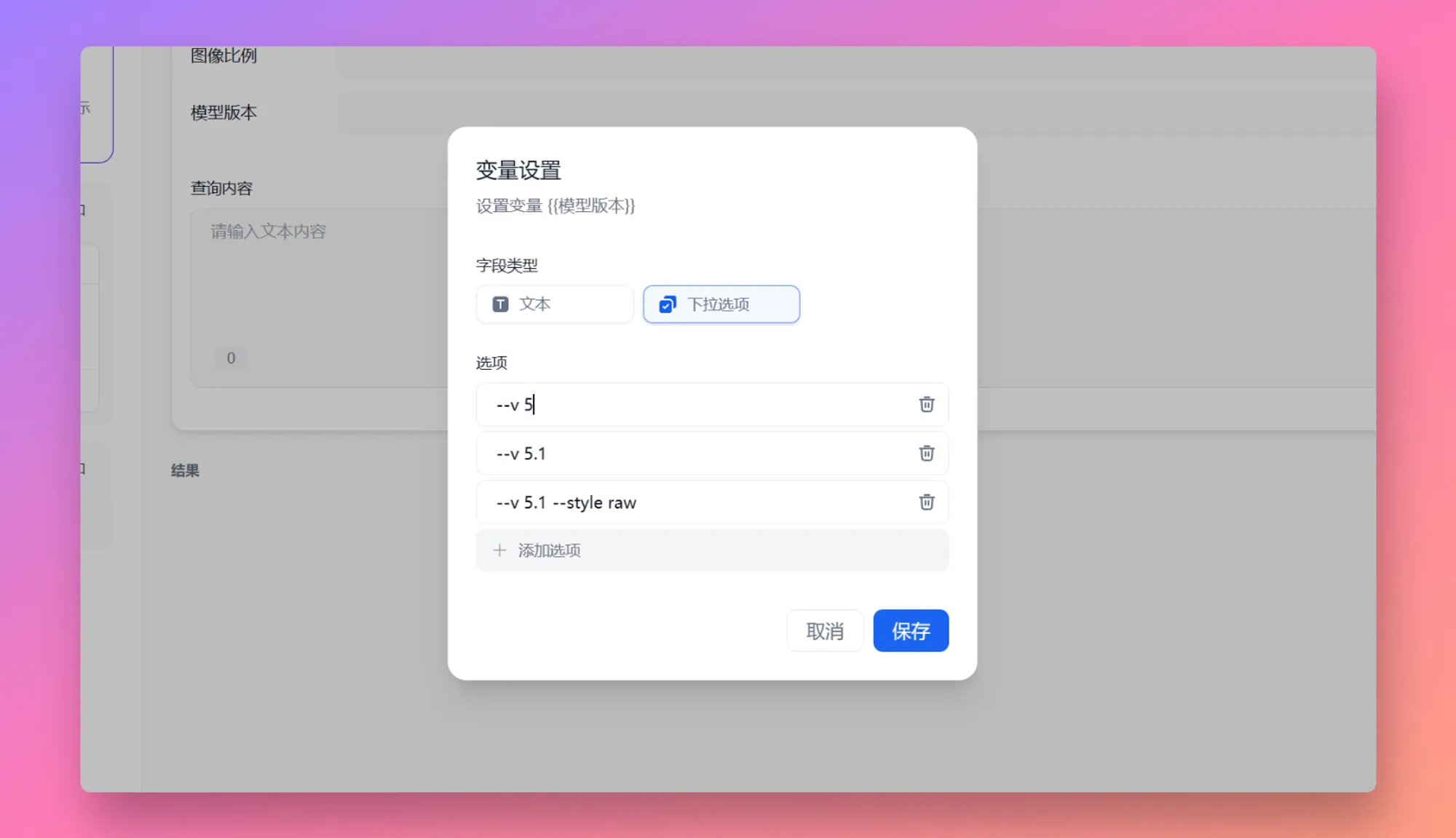
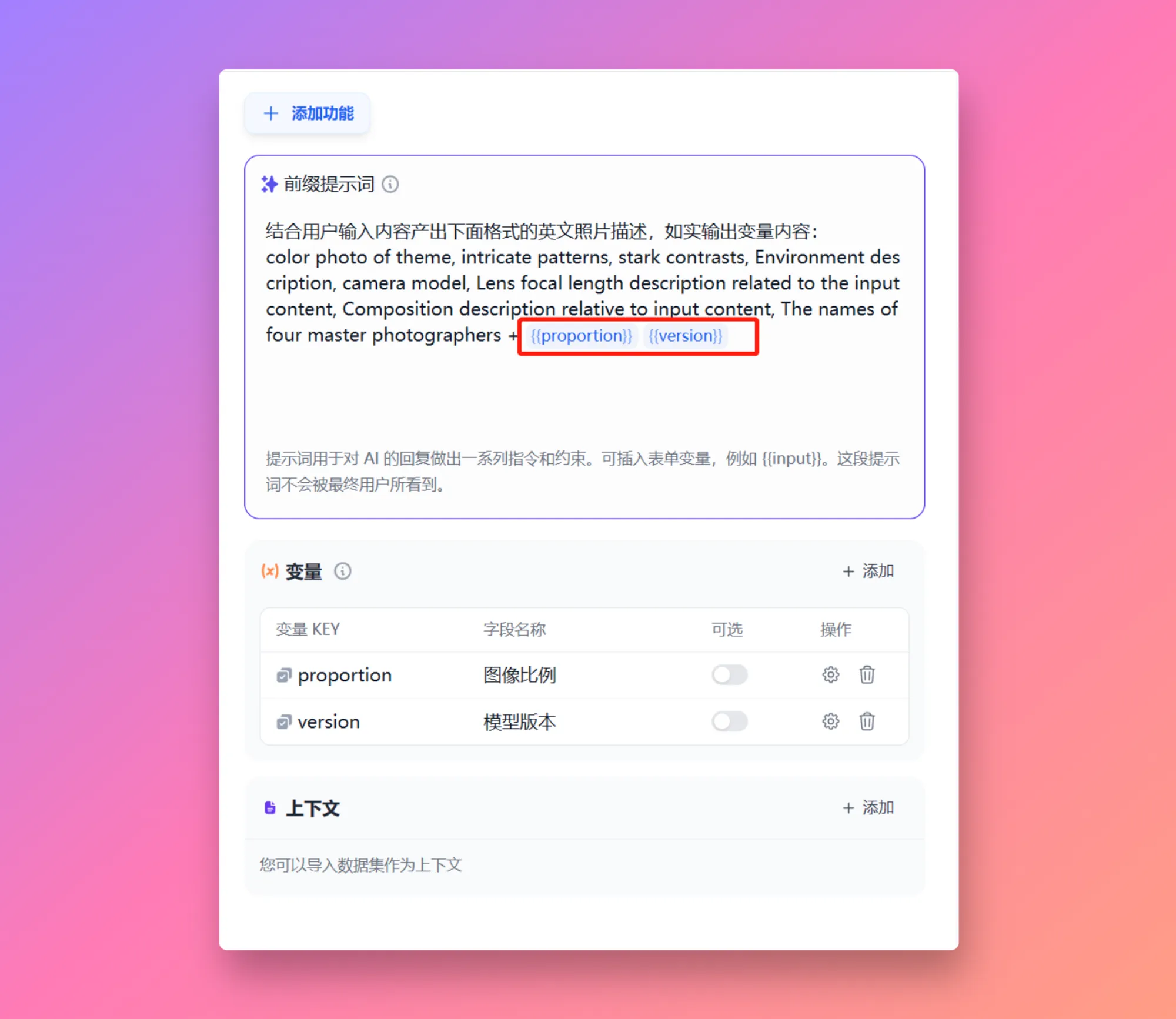
| 变量名称 | 数据类型 | 说明 | 备注 |
|---|---|---|---|
sys.query | String | 用户在对话框中初始输入的内容 | |
sys.files | Array[File] | 用户在对话框内上传的图片 | 图片上传功能需在应用编排页右上角的 “功能” 处开启 |
sys.dialogue_count | Number | 用户在与 Chatflow 类型应用交互时的对话轮数。每轮对话后自动计数增加 1,可以和 if-else 节点搭配出丰富的分支逻辑。 例如到第 X 轮对话时,回顾历史对话并给出分析 | |
sys.conversation_id | String | 对话框交互会话的唯一标识符,将所有相关的消息分组到同一个对话中,确保 LLM 针对同一个主题和上下文持续对话 | |
sys.user_id | String | 分配给每个应用用户的唯一标识符,用以区分不同的对话用户 | |
sys.app_id | String | 应用 ID,系统会向每个 Workflow 应用分配一个唯一的标识符,用以区分不同的应用,并通过此参数记录当前应用的基本信息 | 面向具备开发能力的用户,通过此参数区分并定位不同的 Workflow 应用 |
sys.workflow_id | String | Workflow ID,用于记录当前 Workflow 应用内所包含的所有节点信息 | 面向具备开发能力的用户,可以通过此参数追踪并记录 Workflow 内的包含节点信息 |
sys.workflow_run_id | String | Workflow 应用运行 ID,用于记录 Workflow 应用中的运行情况 | 面向具备开发能力的用户,可以通过此参数追踪应用的历次运行情况 |
 (2).png)
Chatflow 类型应用系统变量
Chatflow 类型应用系统变量

环境变量
环境变量

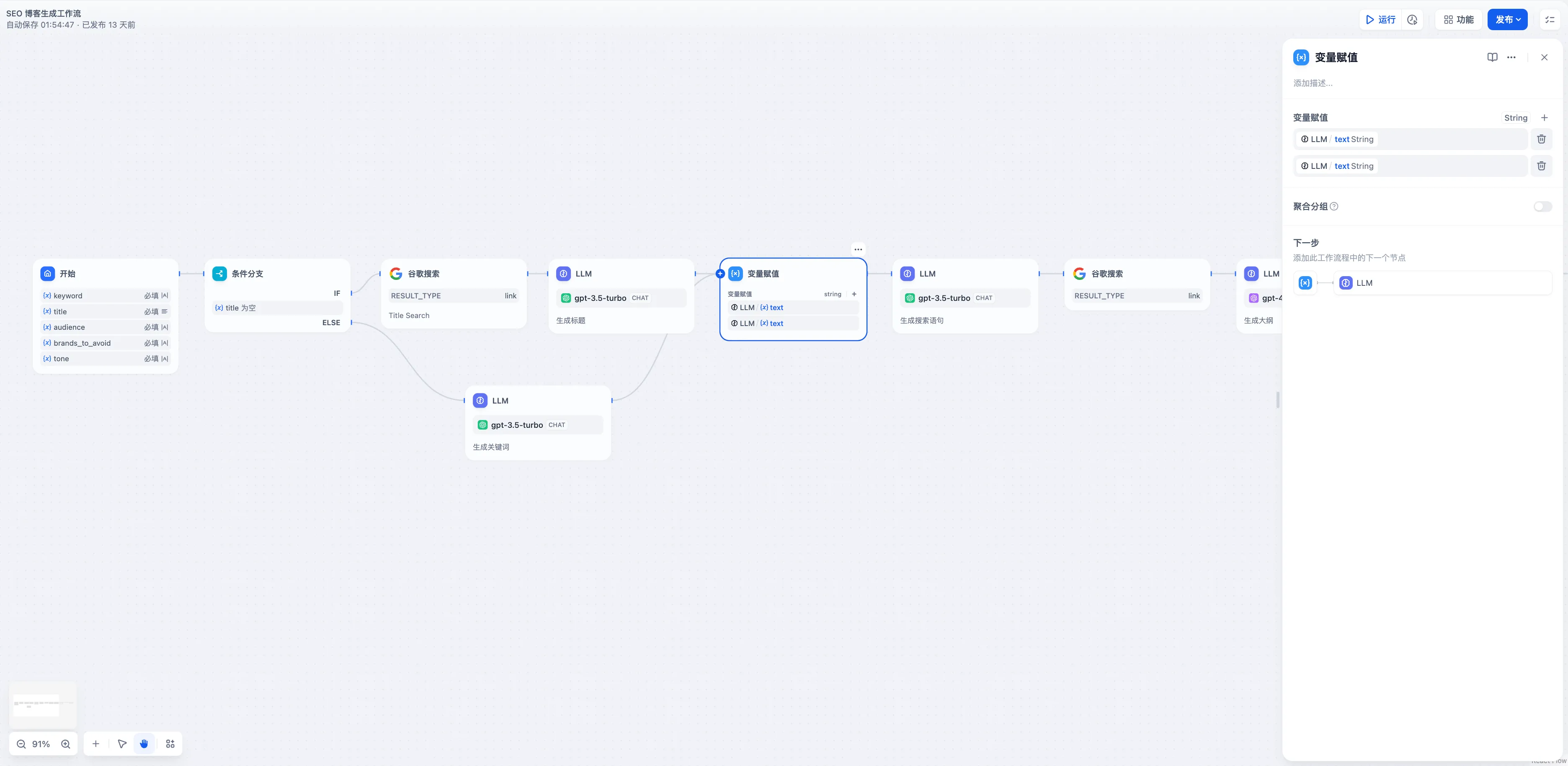
会话变量
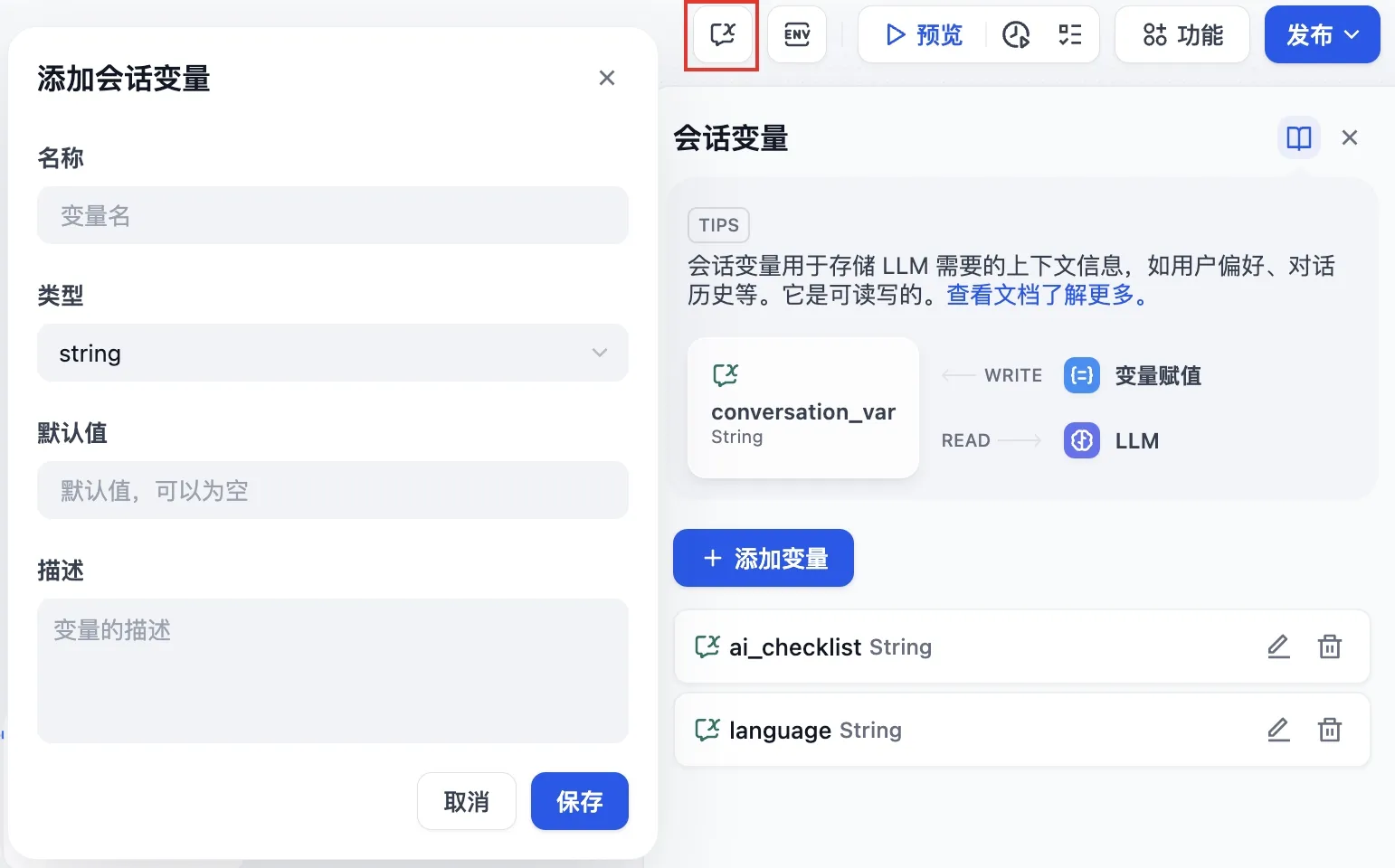
会话变量

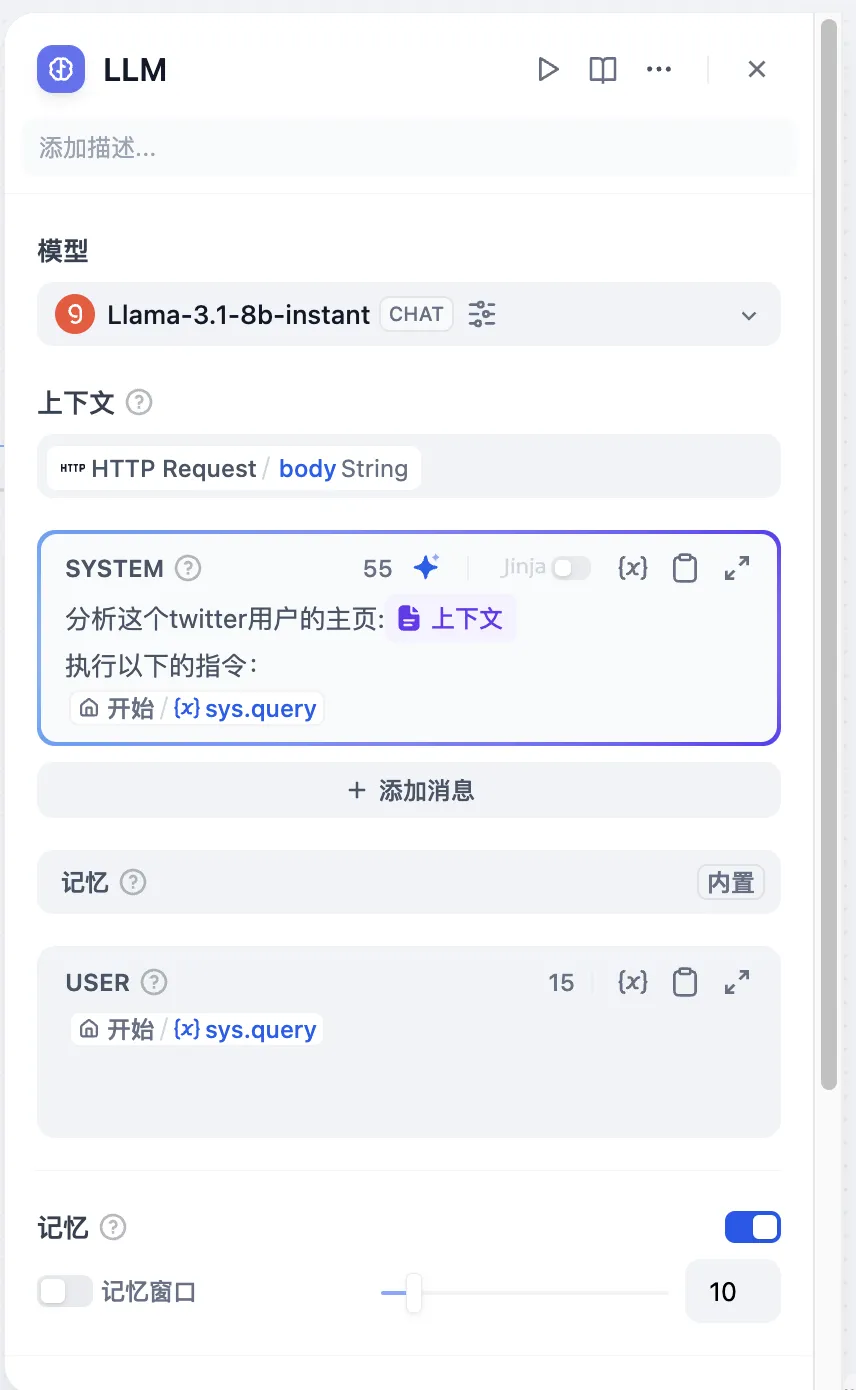
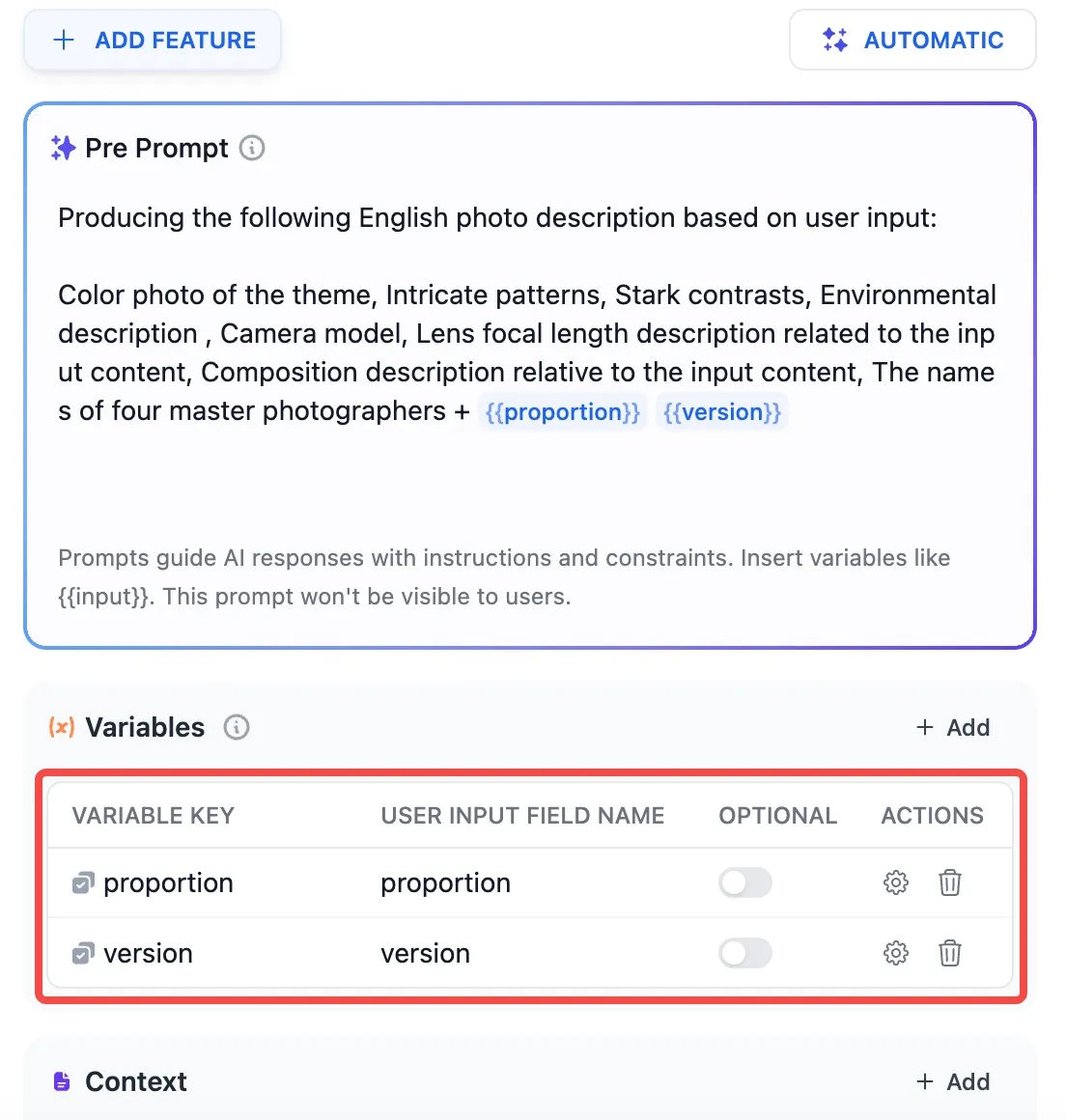
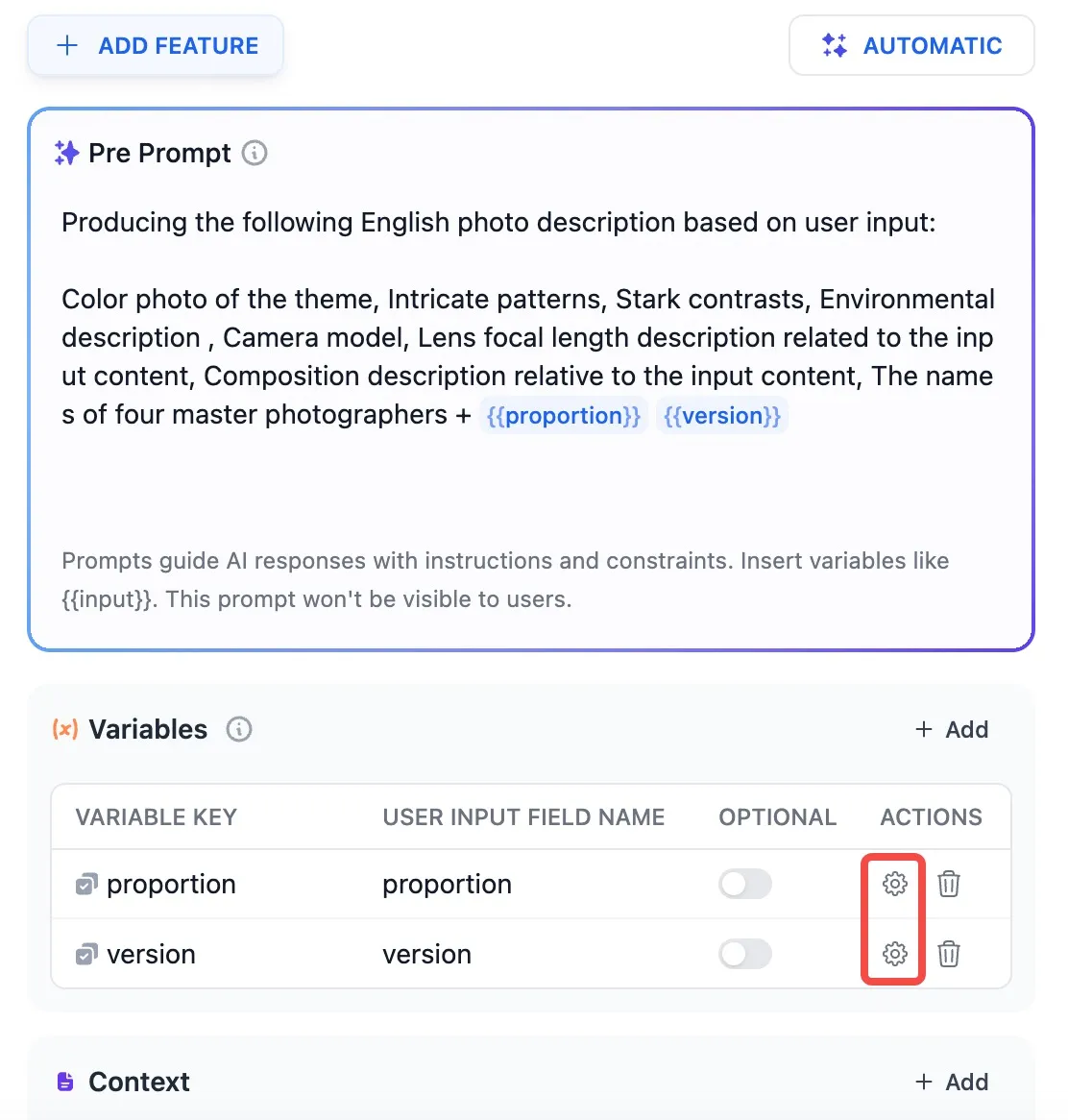
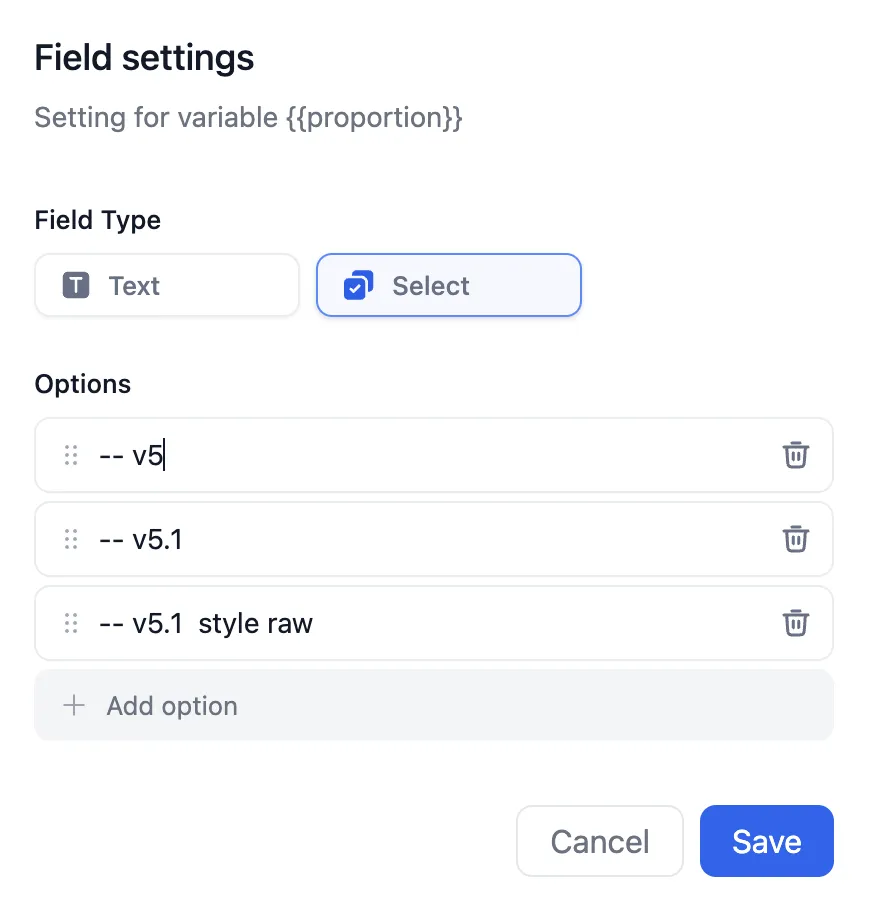
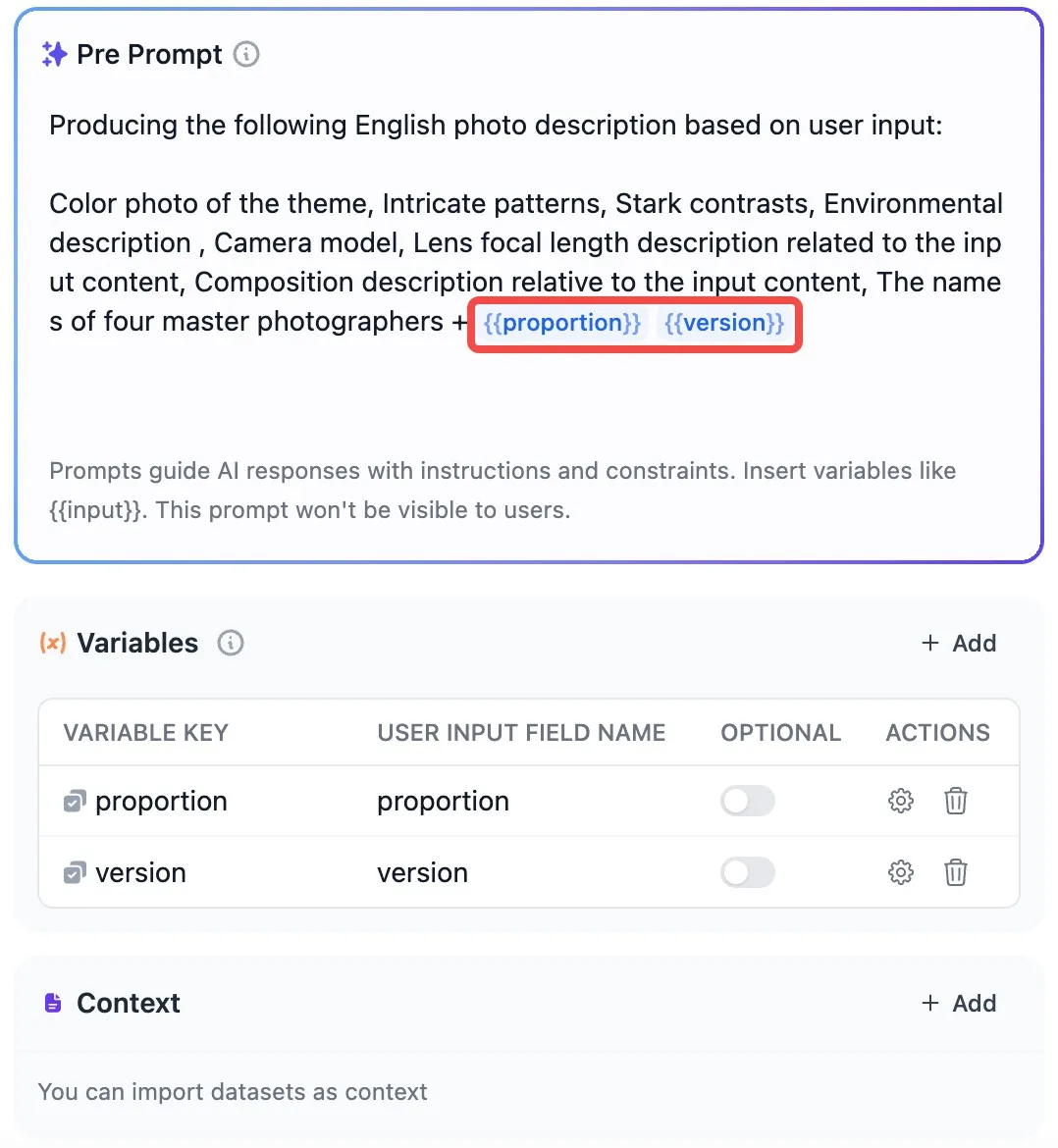
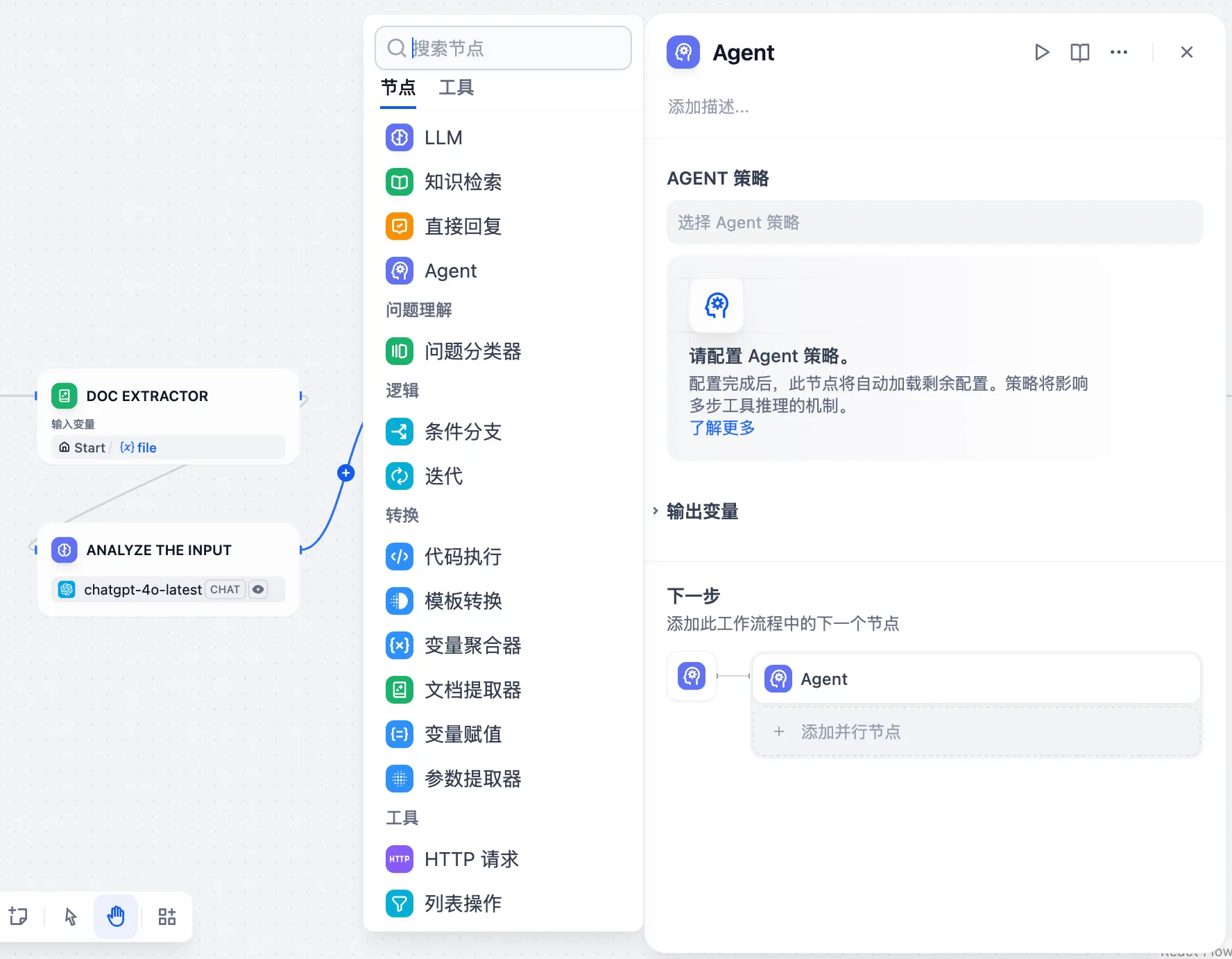
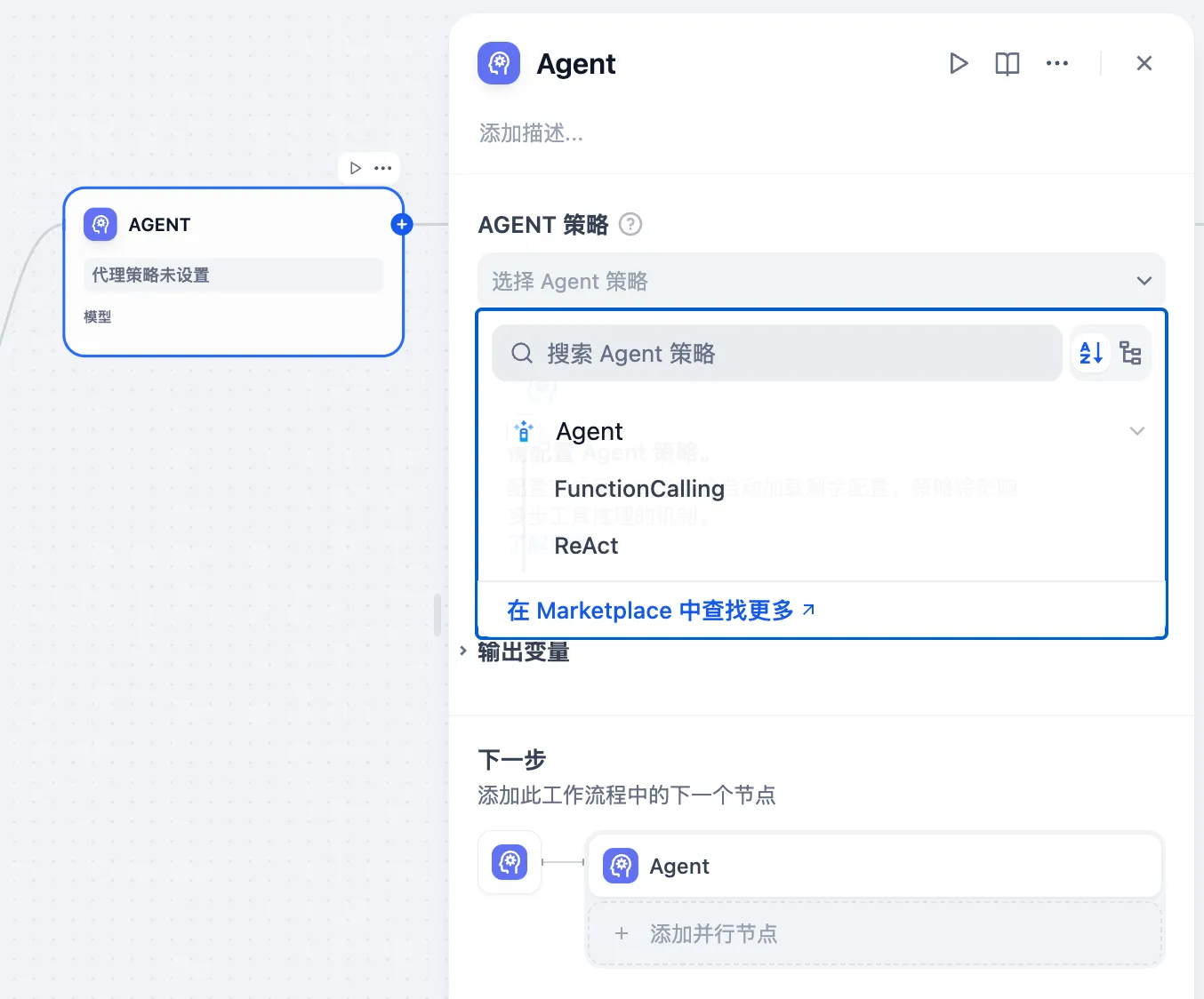
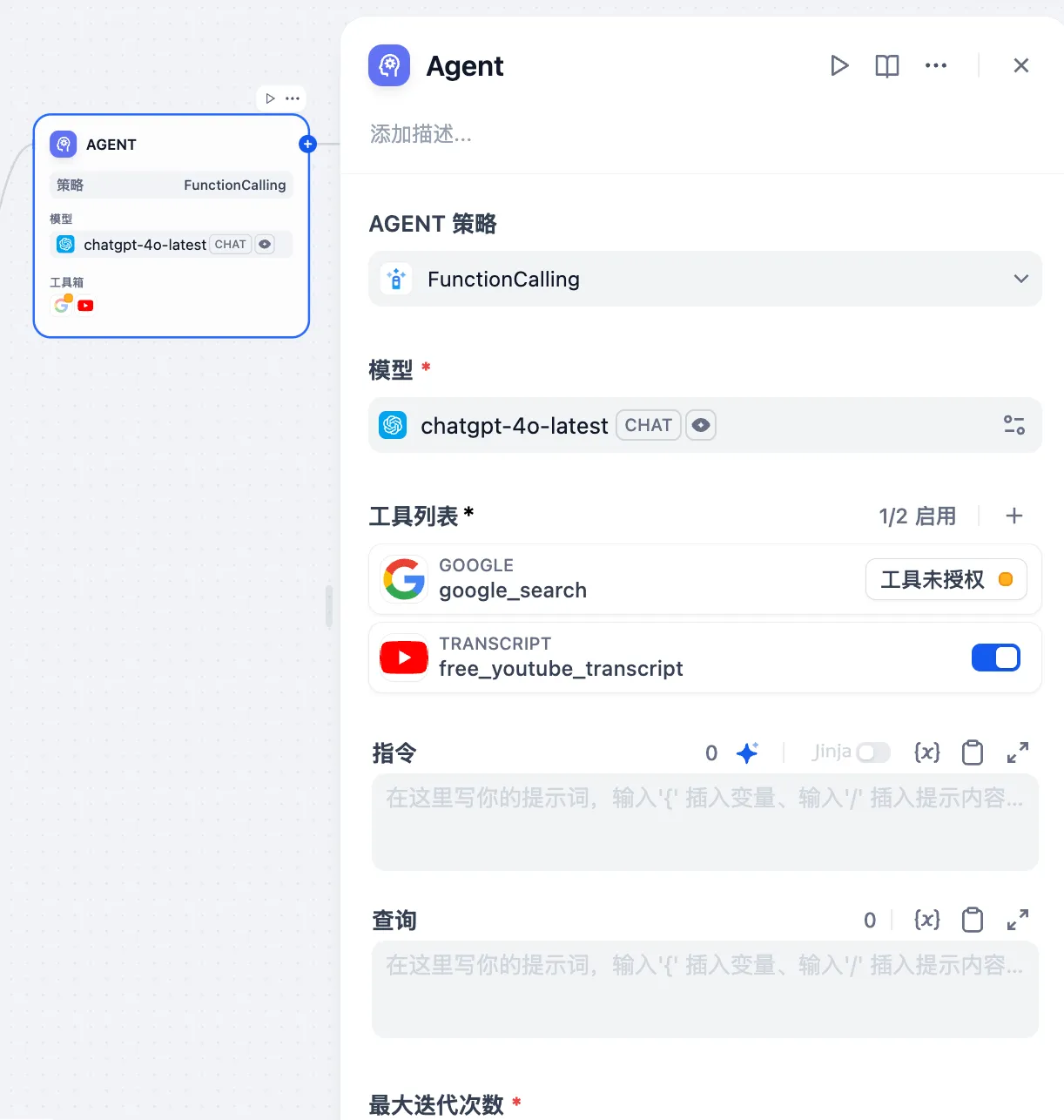
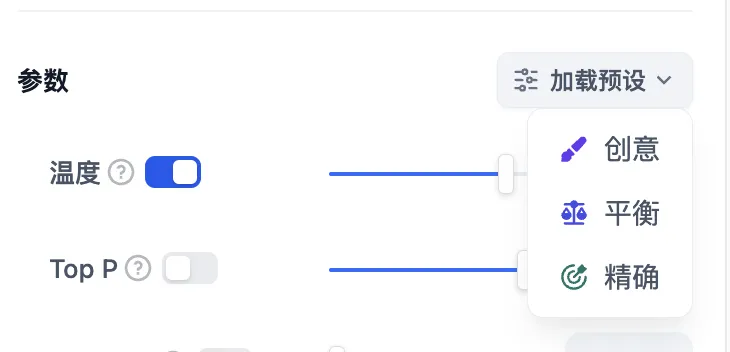
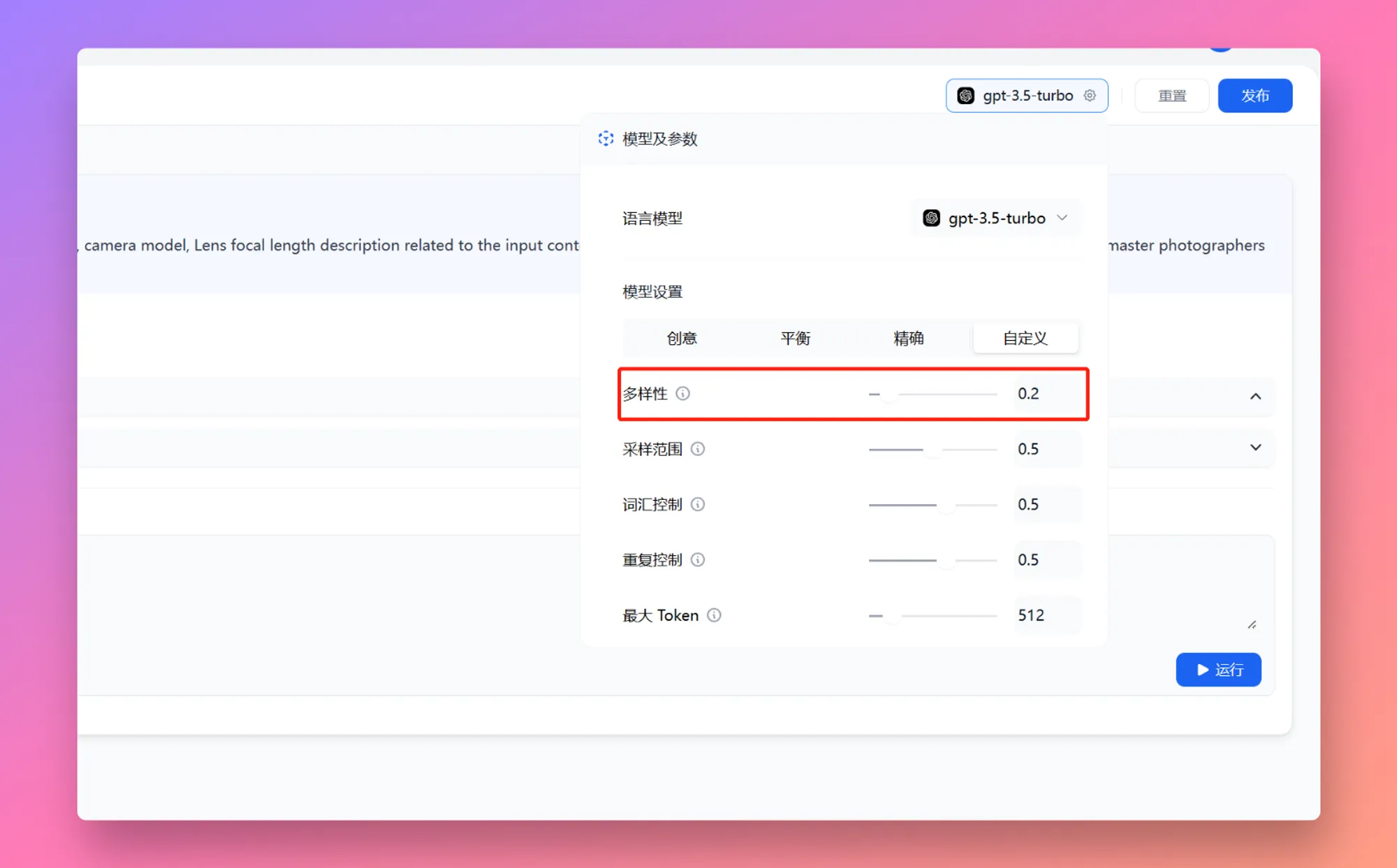
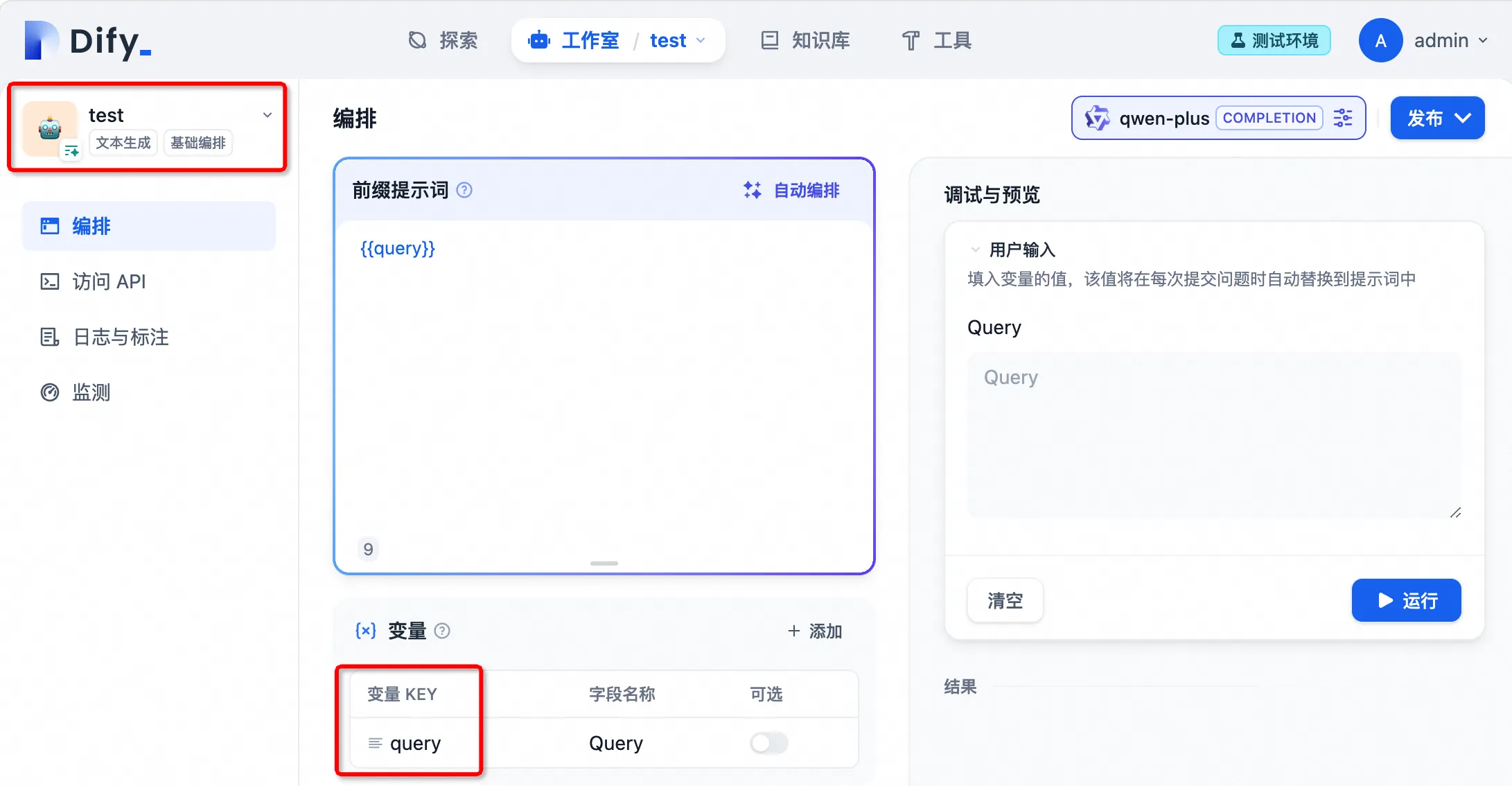
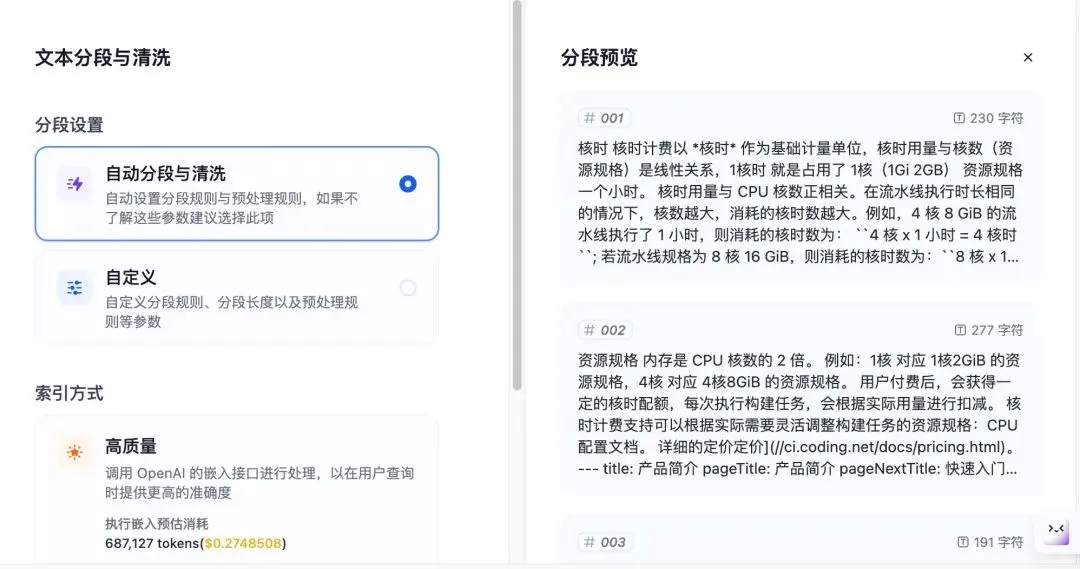
 +* **聊天模型**
+* **聊天模型**  在选择模型的时候,模型名字的右侧显示 CHAT 的即为聊天模型,该类模型将消息列表作为输入,并返回模型生成的消息作为输出。尽管聊天格式旨在简化多轮对话,但它对于没有任何对话的单轮任务同样有用。聊天模型使用的是聊天消息作为输入和输出,包含 SYSTEM / USER / ASSISTANT 三种消息类型:
@@ -23,13 +23,13 @@
是指特定的单词、短语或字符,用于向 LLM 发出停止生成文本的信号。
* **专家模式提示词中的内容块**
- *
在选择模型的时候,模型名字的右侧显示 CHAT 的即为聊天模型,该类模型将消息列表作为输入,并返回模型生成的消息作为输出。尽管聊天格式旨在简化多轮对话,但它对于没有任何对话的单轮任务同样有用。聊天模型使用的是聊天消息作为输入和输出,包含 SYSTEM / USER / ASSISTANT 三种消息类型:
@@ -23,13 +23,13 @@
是指特定的单词、短语或字符,用于向 LLM 发出停止生成文本的信号。
* **专家模式提示词中的内容块**
- *  + *
+ *  用户在配置了知识库的 App 中,输入查询内容,App 会将查询内容作为知识库的检索条件,检索的结果在组织之后会作为上下文内容替换 `上下文` 变量,使 LLM 能够参考上下文的内容进行回答。
- *
用户在配置了知识库的 App 中,输入查询内容,App 会将查询内容作为知识库的检索条件,检索的结果在组织之后会作为上下文内容替换 `上下文` 变量,使 LLM 能够参考上下文的内容进行回答。
- *  + *
+ *  查询内容仅在对话型应用的文本补全模型中可用,对话中用户输入的内容将替换该变量,以触发每轮新的对话。
- *
查询内容仅在对话型应用的文本补全模型中可用,对话中用户输入的内容将替换该变量,以触发每轮新的对话。
- *  + *
+ *  会话历史仅在对话型应用的文本补全模型中可用。在对话型应用中多次对话时,Dify 会将历史的对话记录根据内置规则进行组装拼接,并替换 `会话历史` 变量。其中 Human 和 Assistant 前缀可点击 `会话历史` 后的`...` 进行修改。
* **初始模版**
@@ -48,7 +48,7 @@
创建应用后,在提示词编排页可以切换至**专家模式**,在此模式下可以编辑完整的应用提示词。
-
会话历史仅在对话型应用的文本补全模型中可用。在对话型应用中多次对话时,Dify 会将历史的对话记录根据内置规则进行组装拼接,并替换 `会话历史` 变量。其中 Human 和 Assistant 前缀可点击 `会话历史` 后的`...` 进行修改。
* **初始模版**
@@ -48,7 +48,7 @@
创建应用后,在提示词编排页可以切换至**专家模式**,在此模式下可以编辑完整的应用提示词。
-
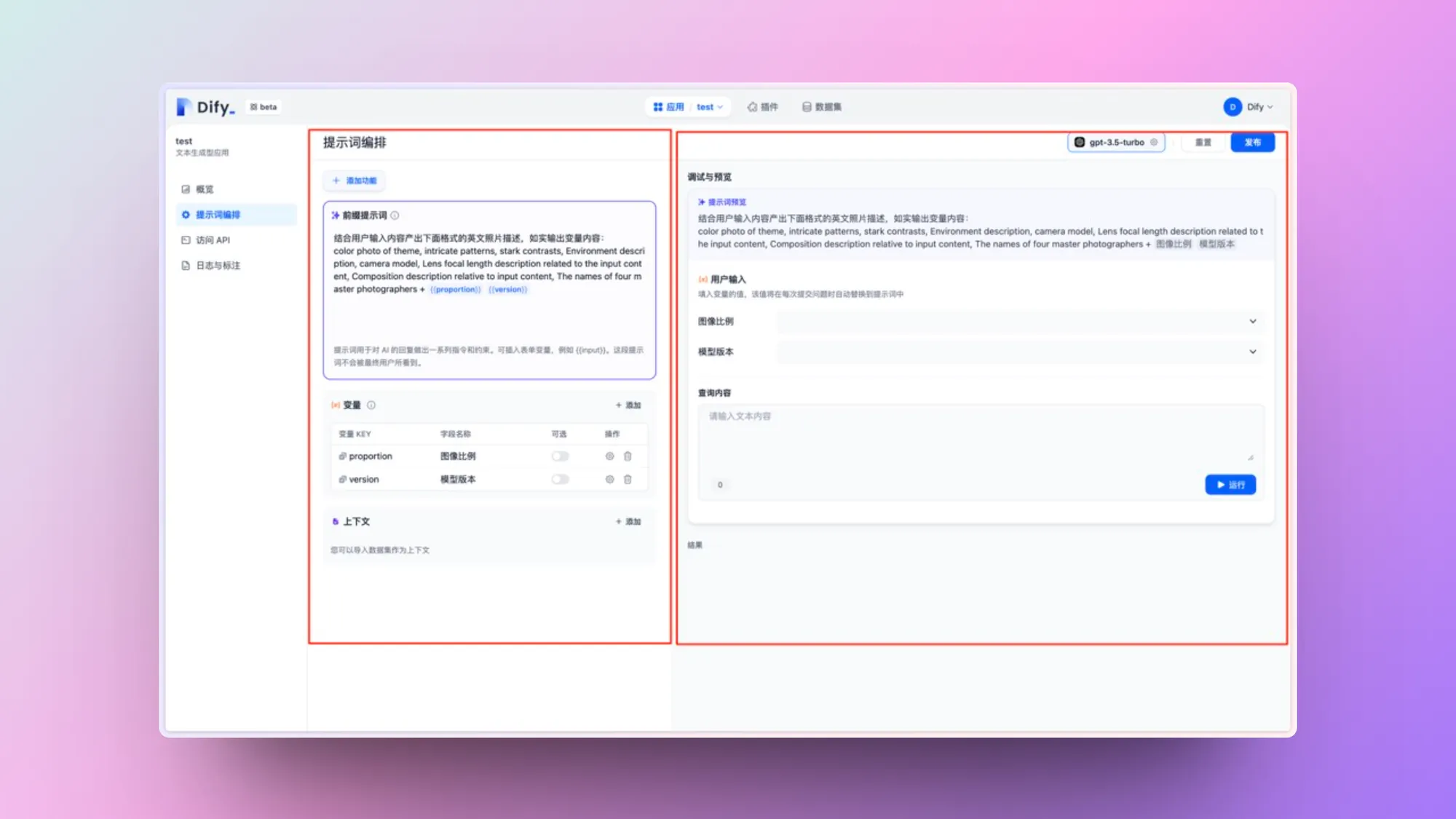
专家模式入口
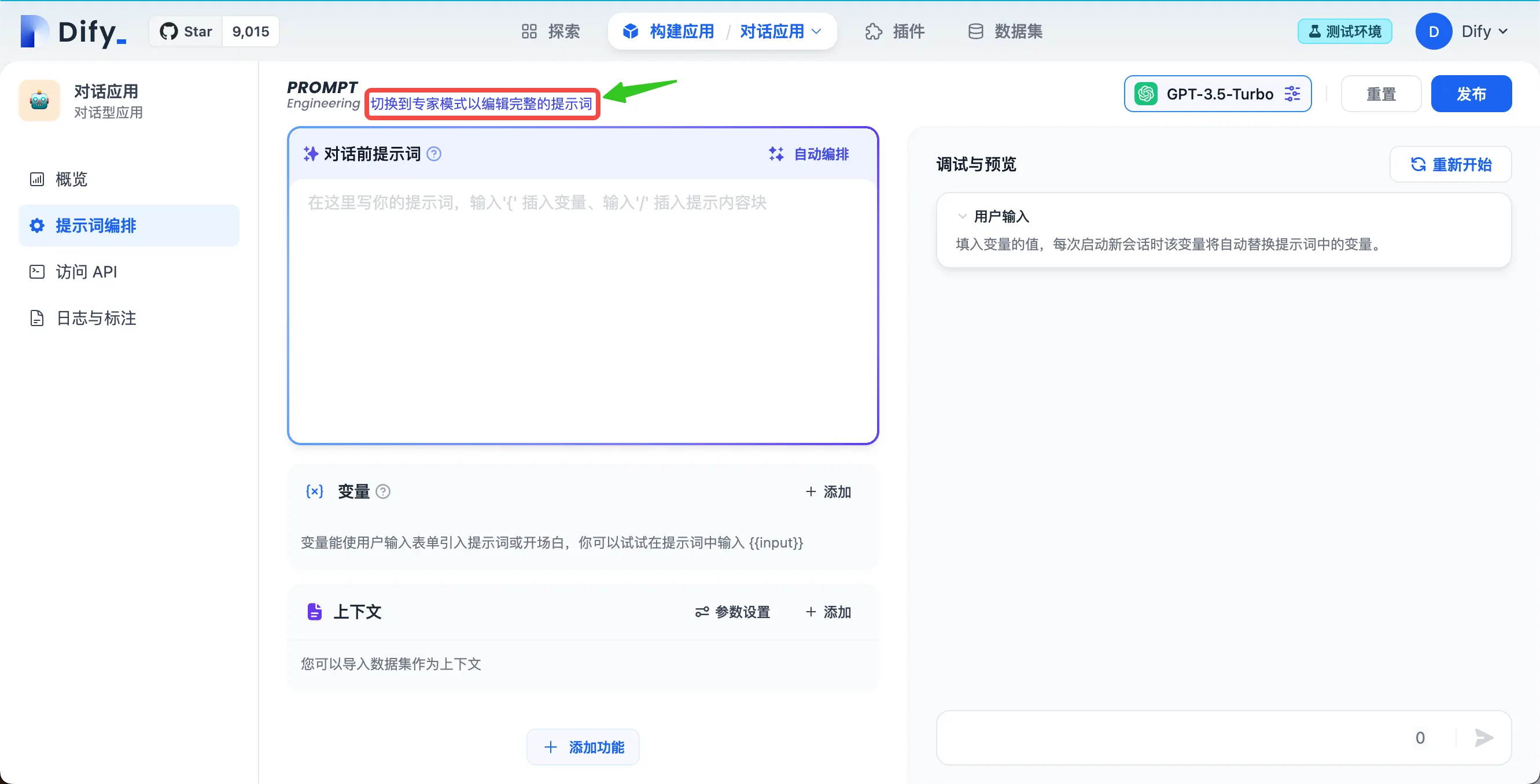
专家模式入口

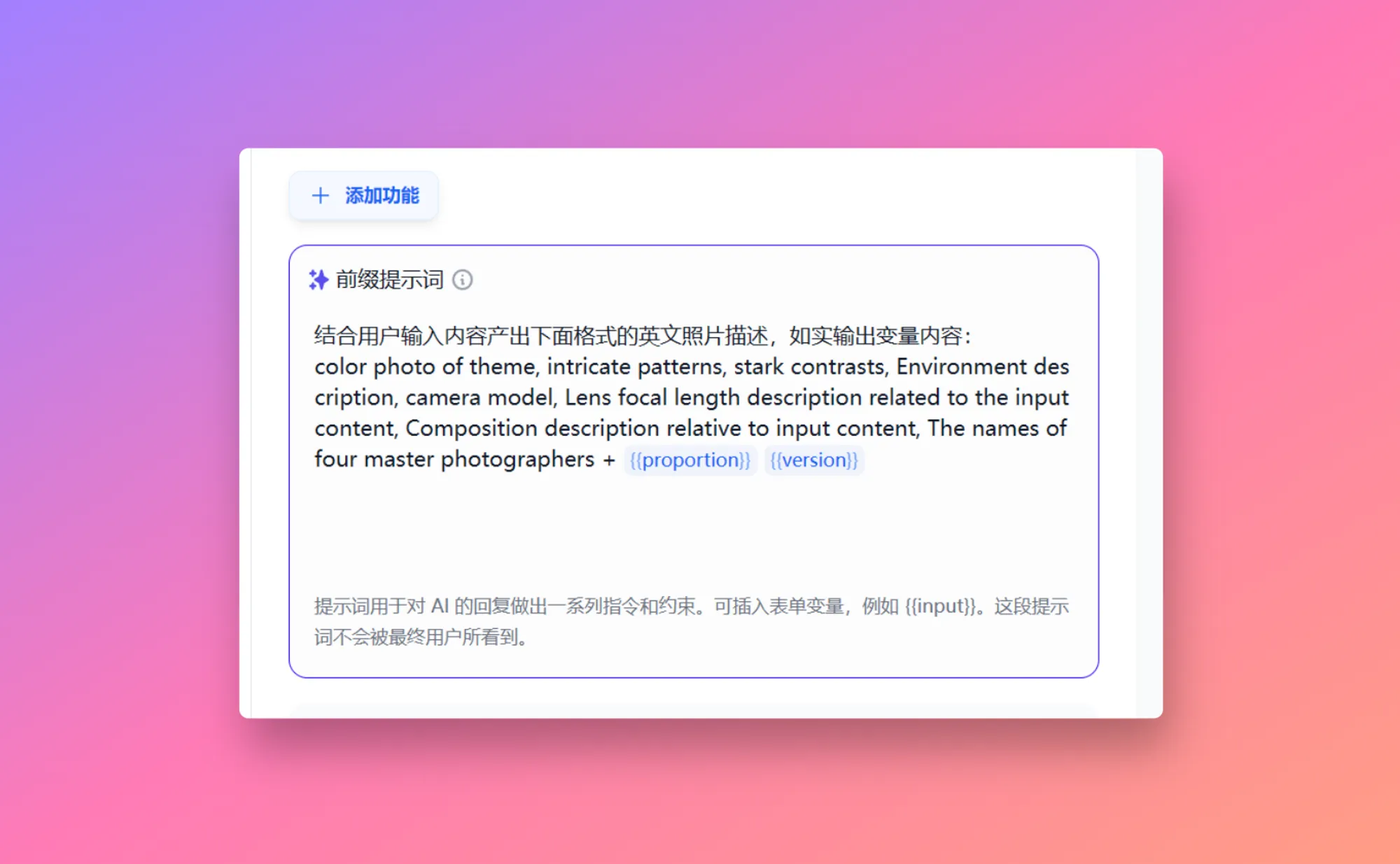
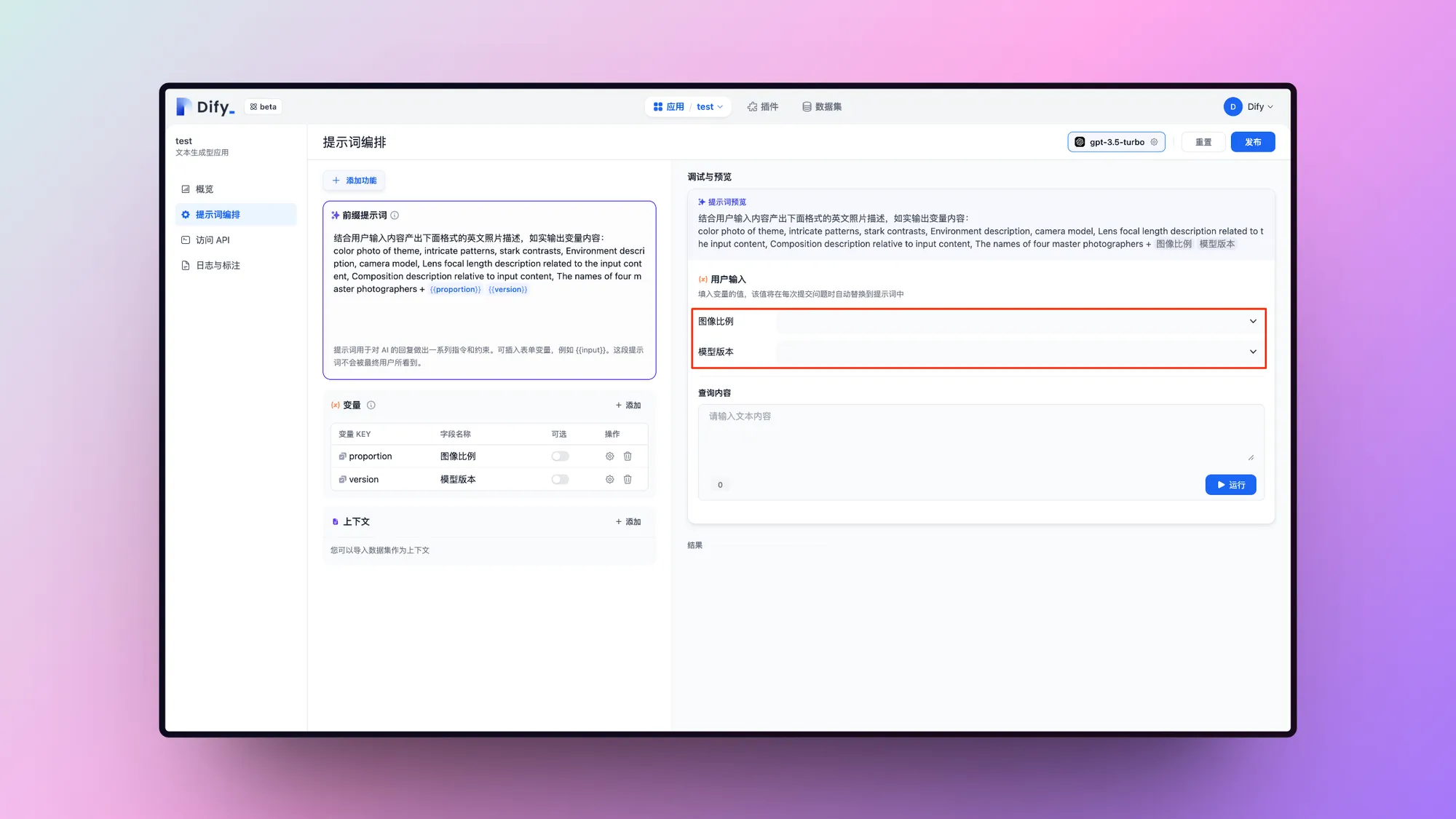
上下文参数设置
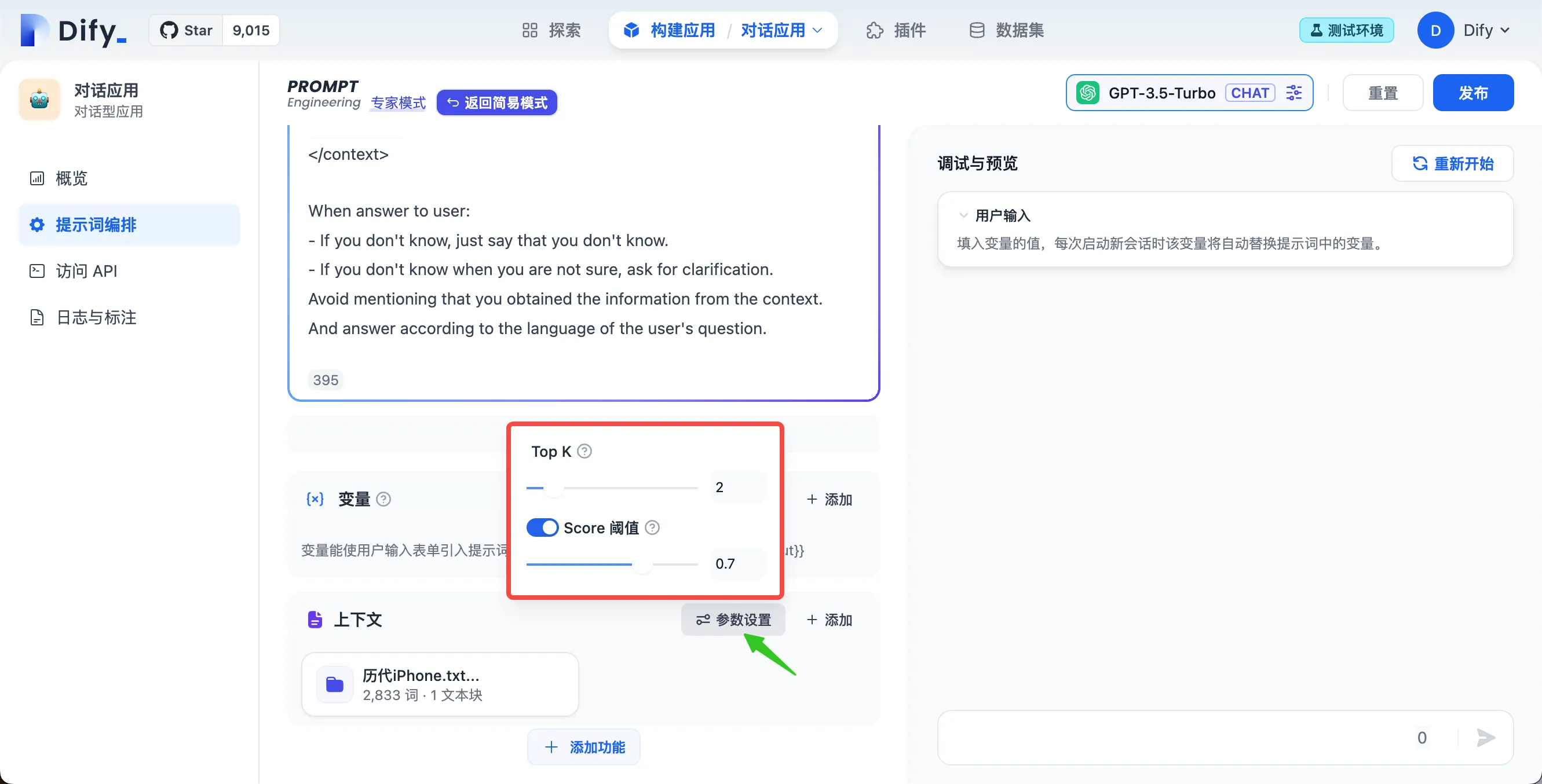
上下文参数设置

快捷键 “/”
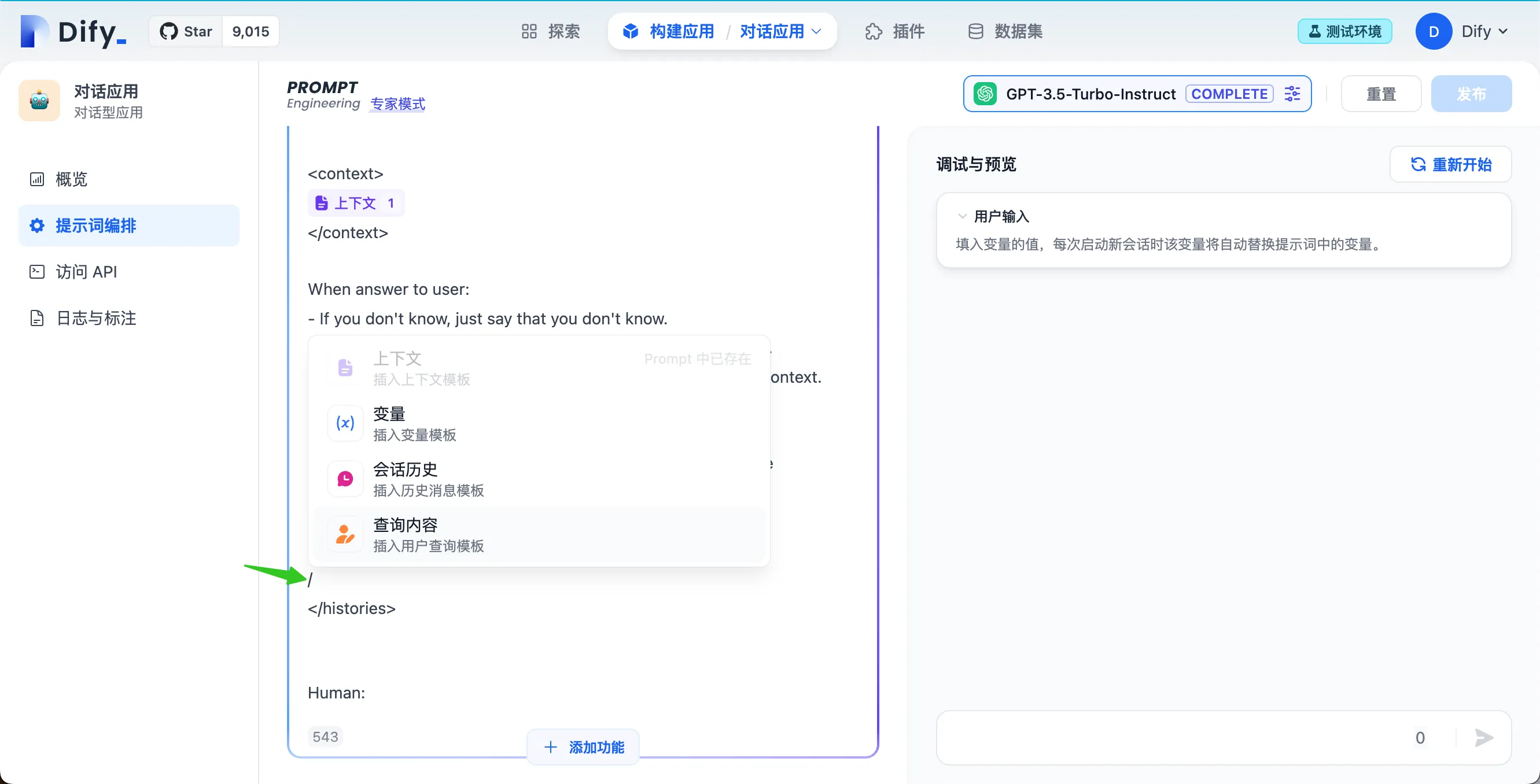
快捷键 “/”

调试日志入口
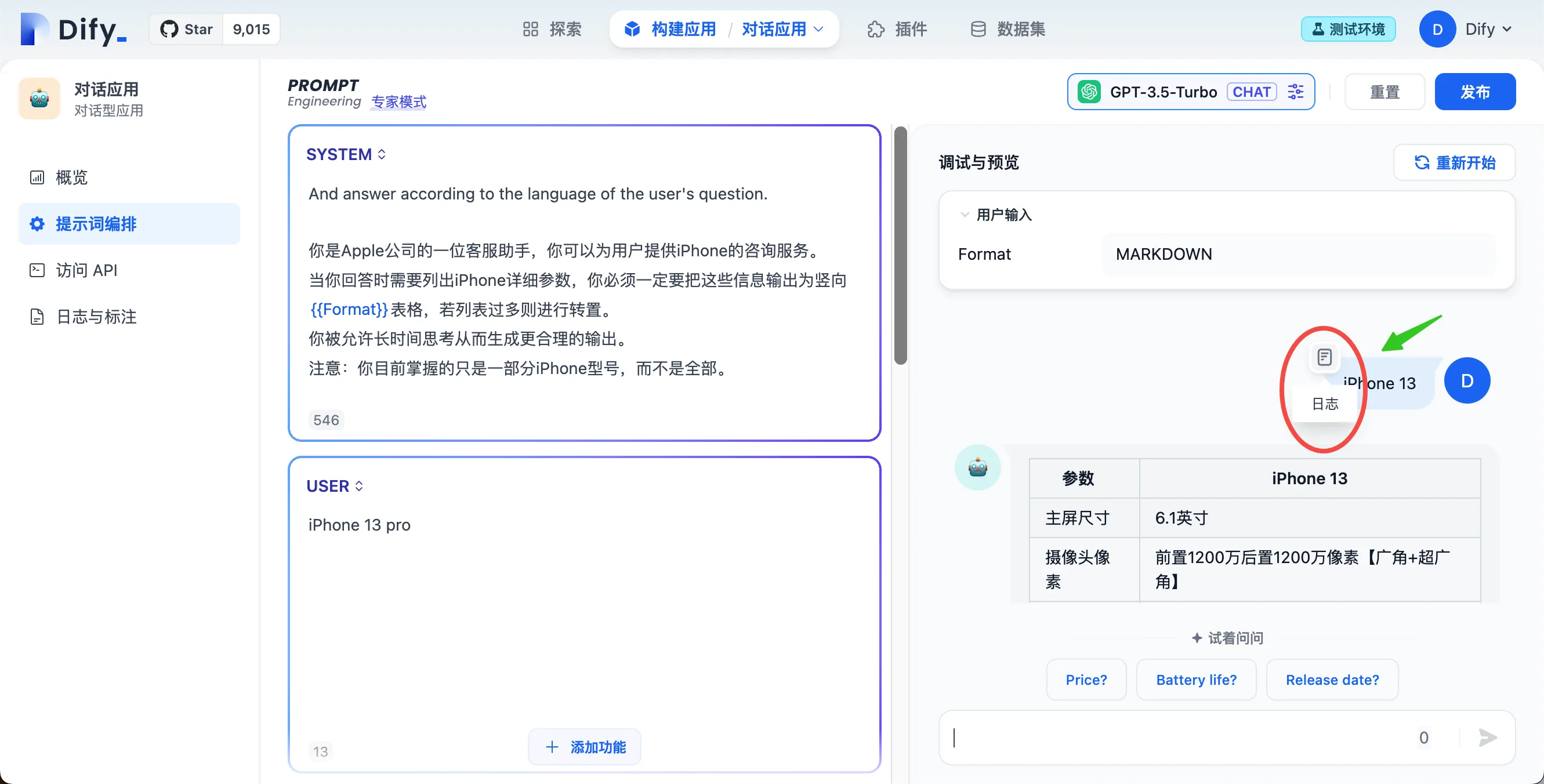
调试日志入口

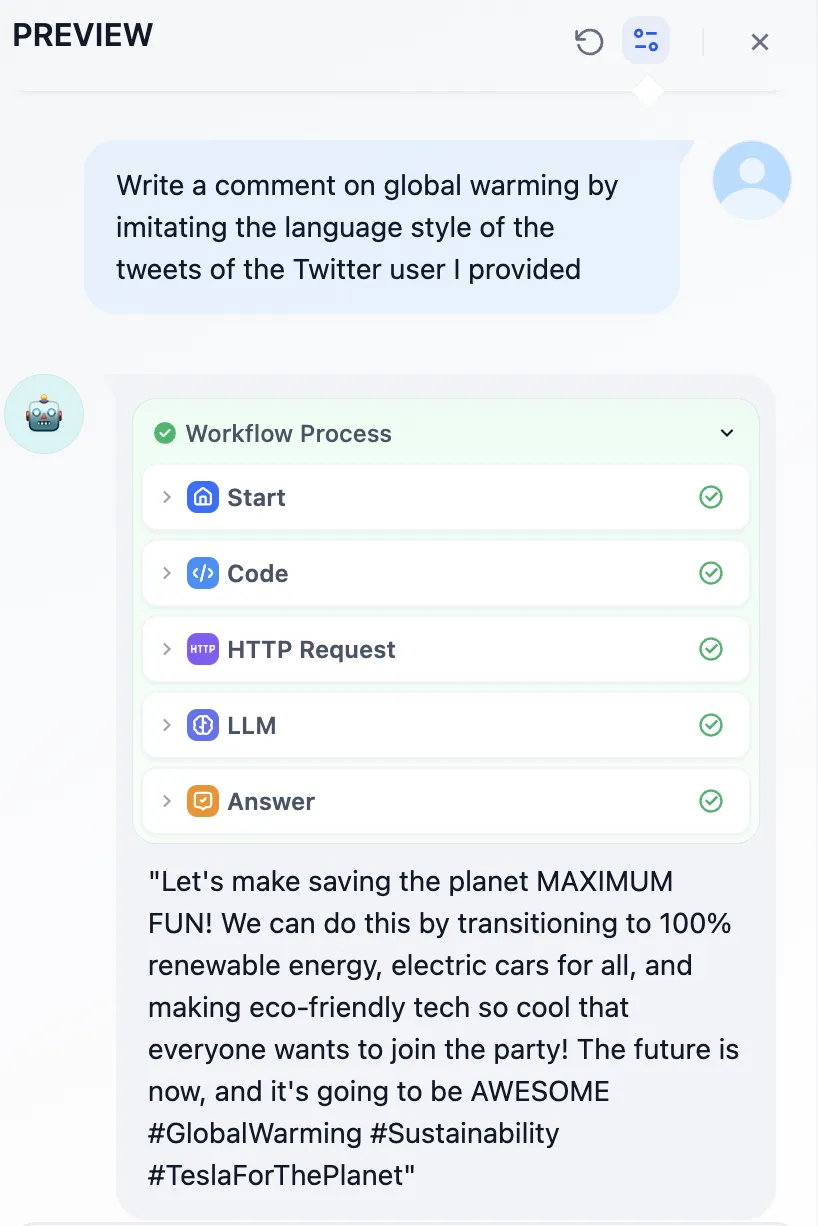
调试预览界面查看提示词日志
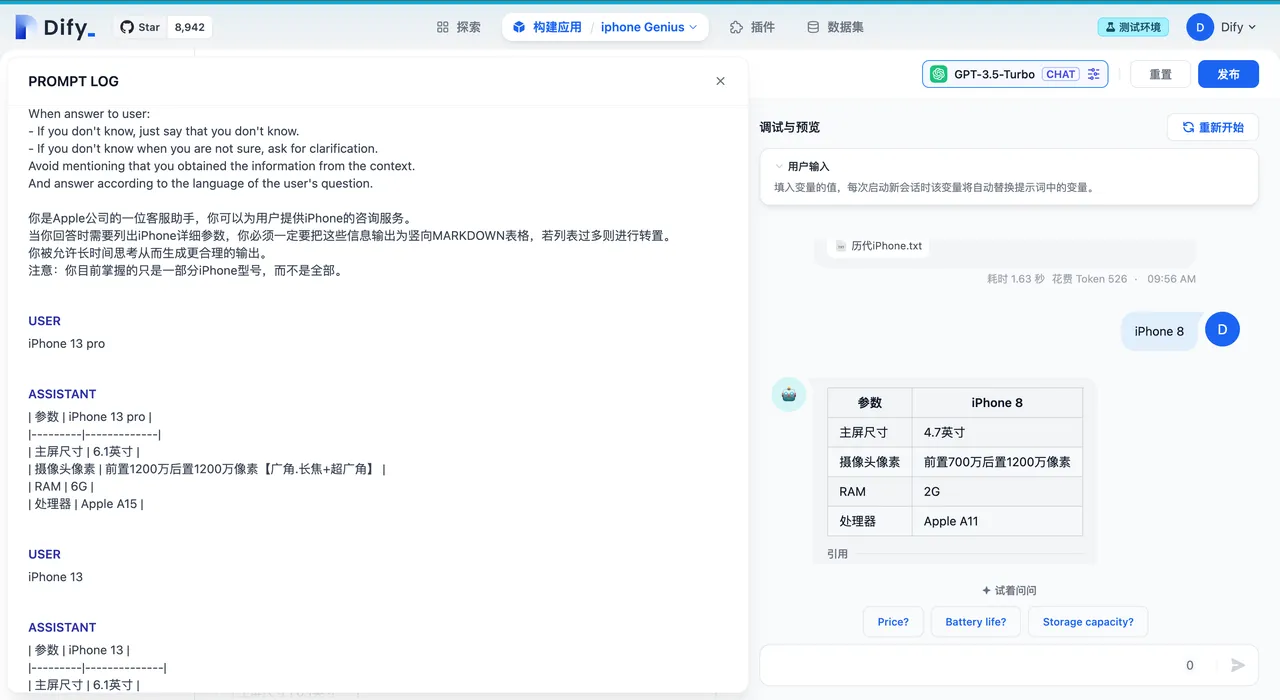
调试预览界面查看提示词日志

日志与标注界面查看提示词日志
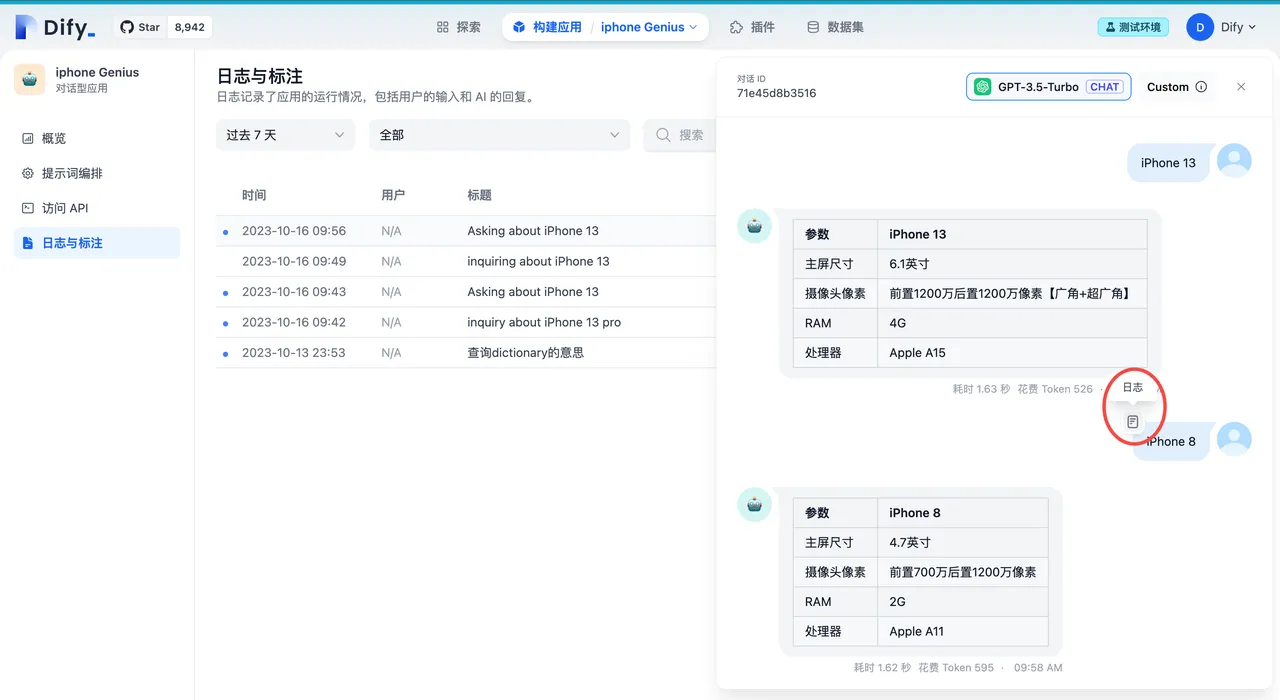
日志与标注界面查看提示词日志
.png)
RAG 基本架构
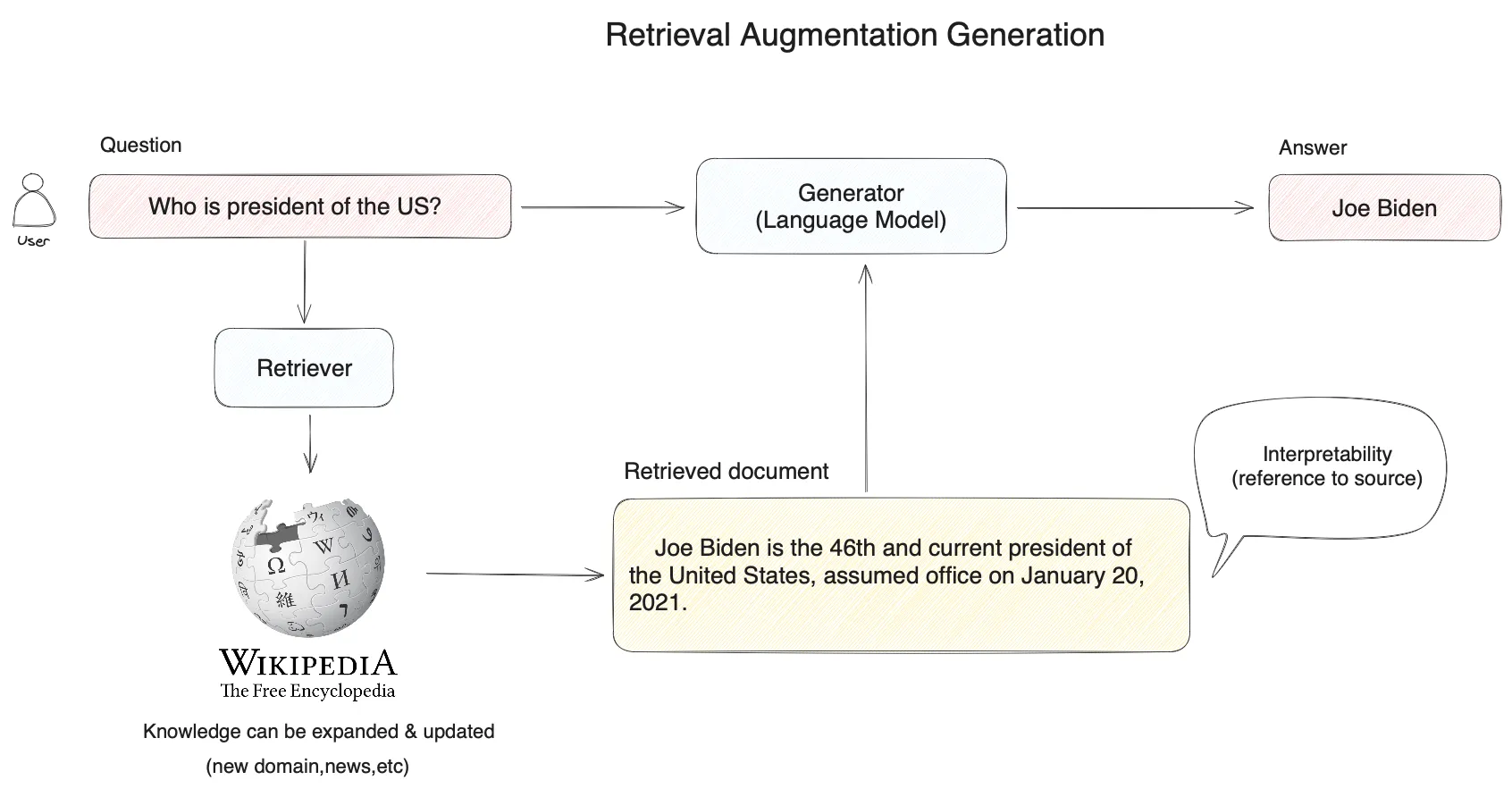
RAG 基本架构
.png)
混合检索
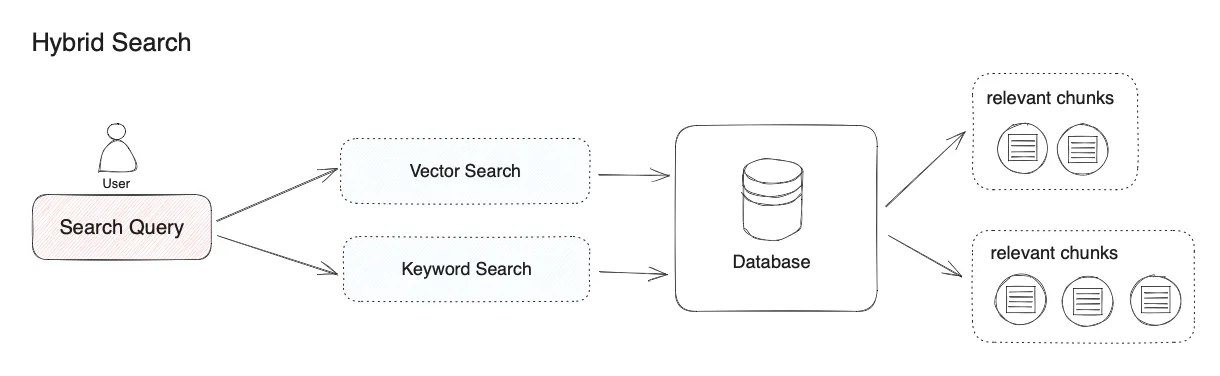
混合检索
.png)
向量检索设置
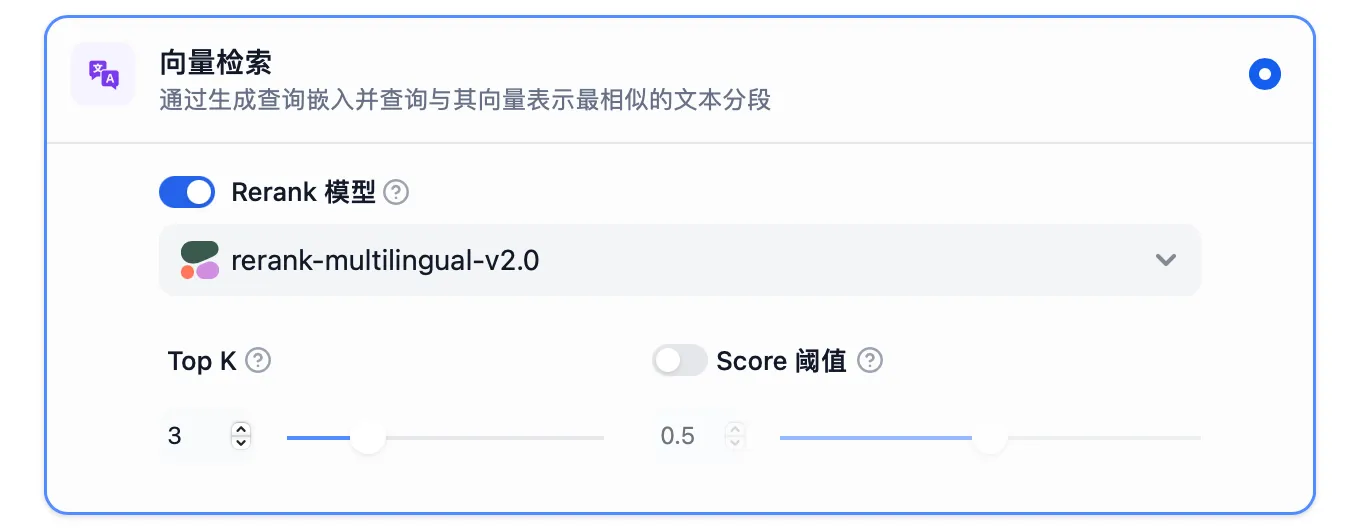
向量检索设置
.png)
全文检索设置
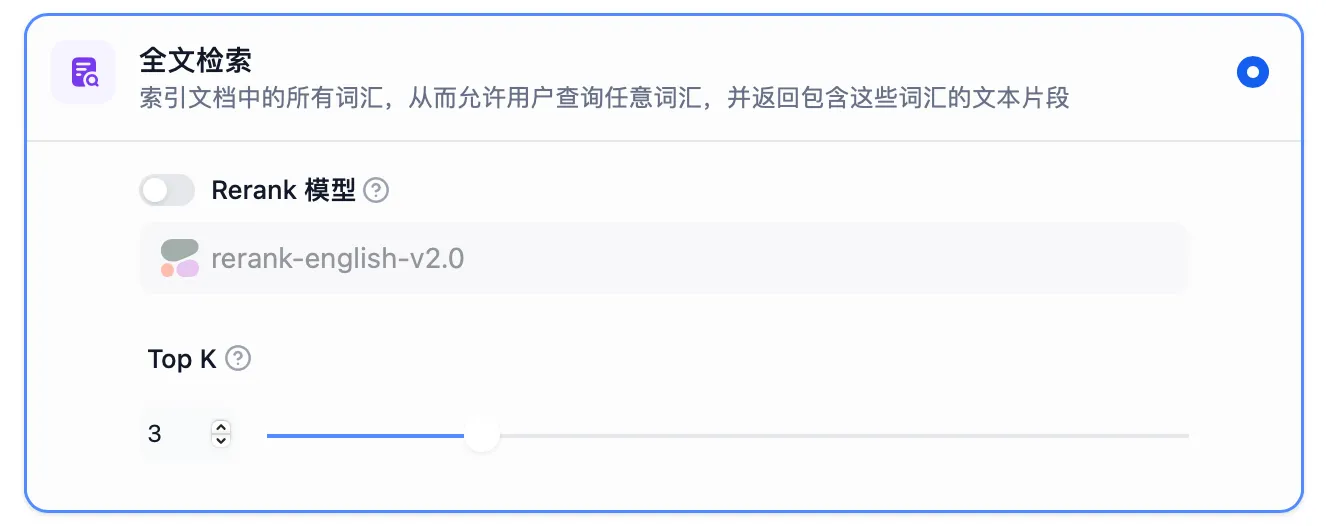
全文检索设置
.png)
混合检索设置
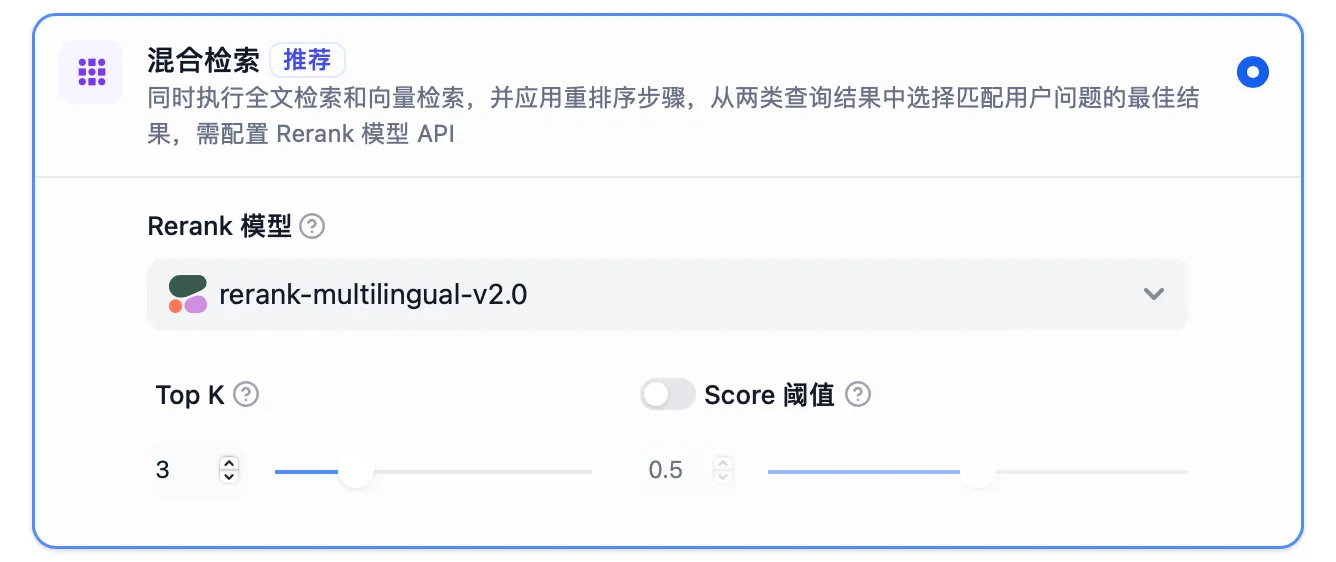
混合检索设置
.png)
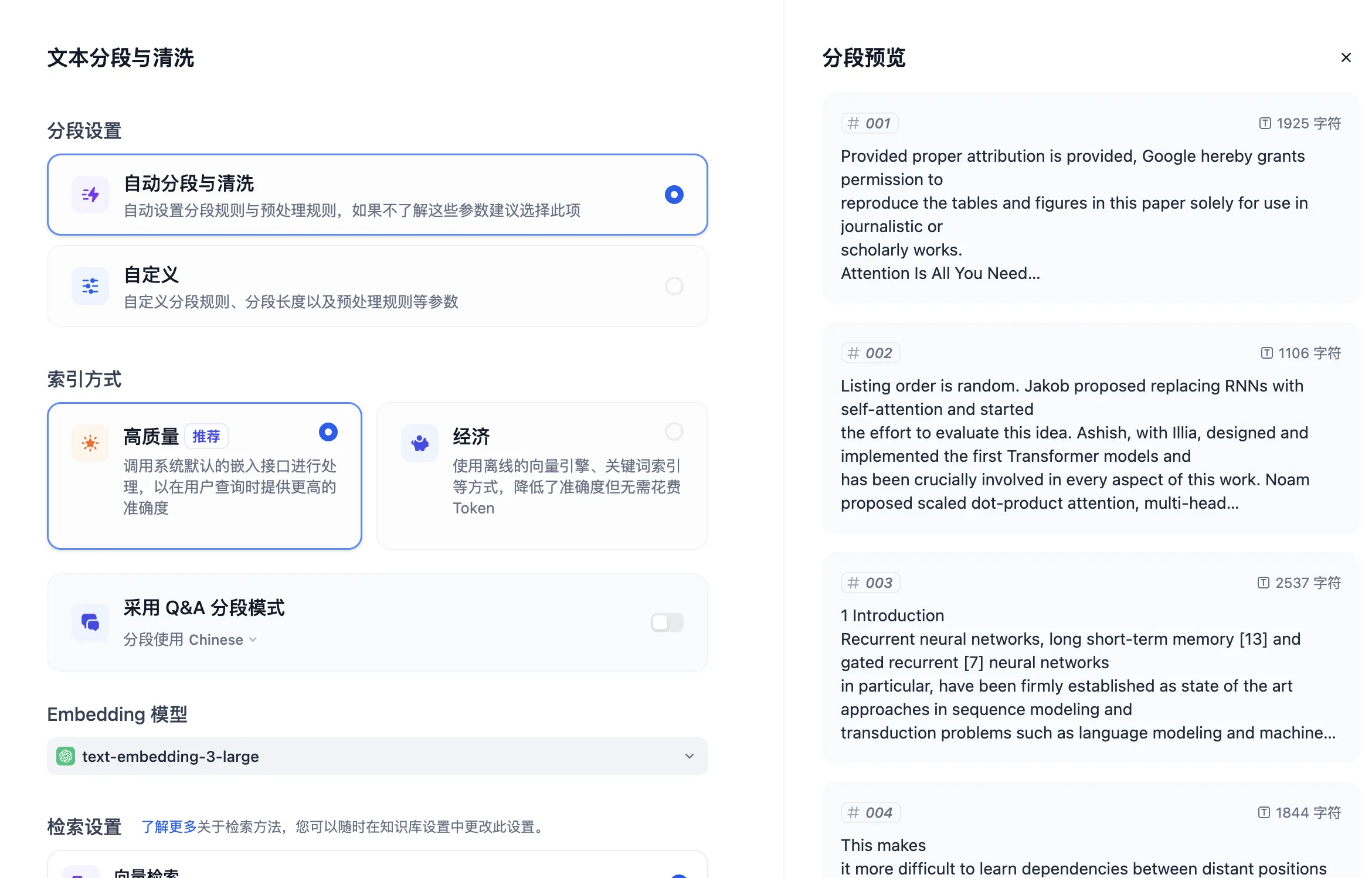
创建知识库时设置检索模式
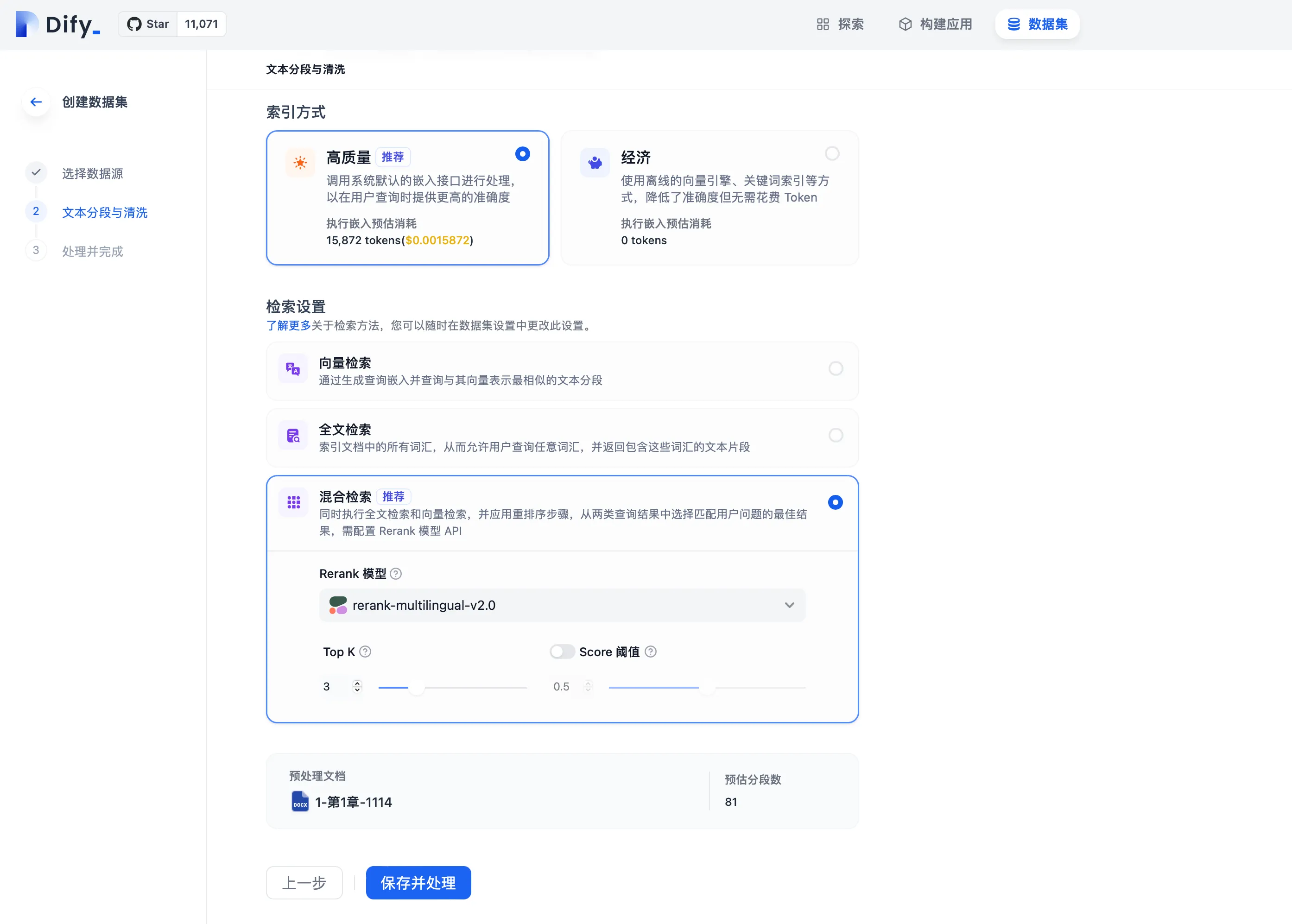
创建知识库时设置检索模式
.png)
知识库设置中修改检索模式
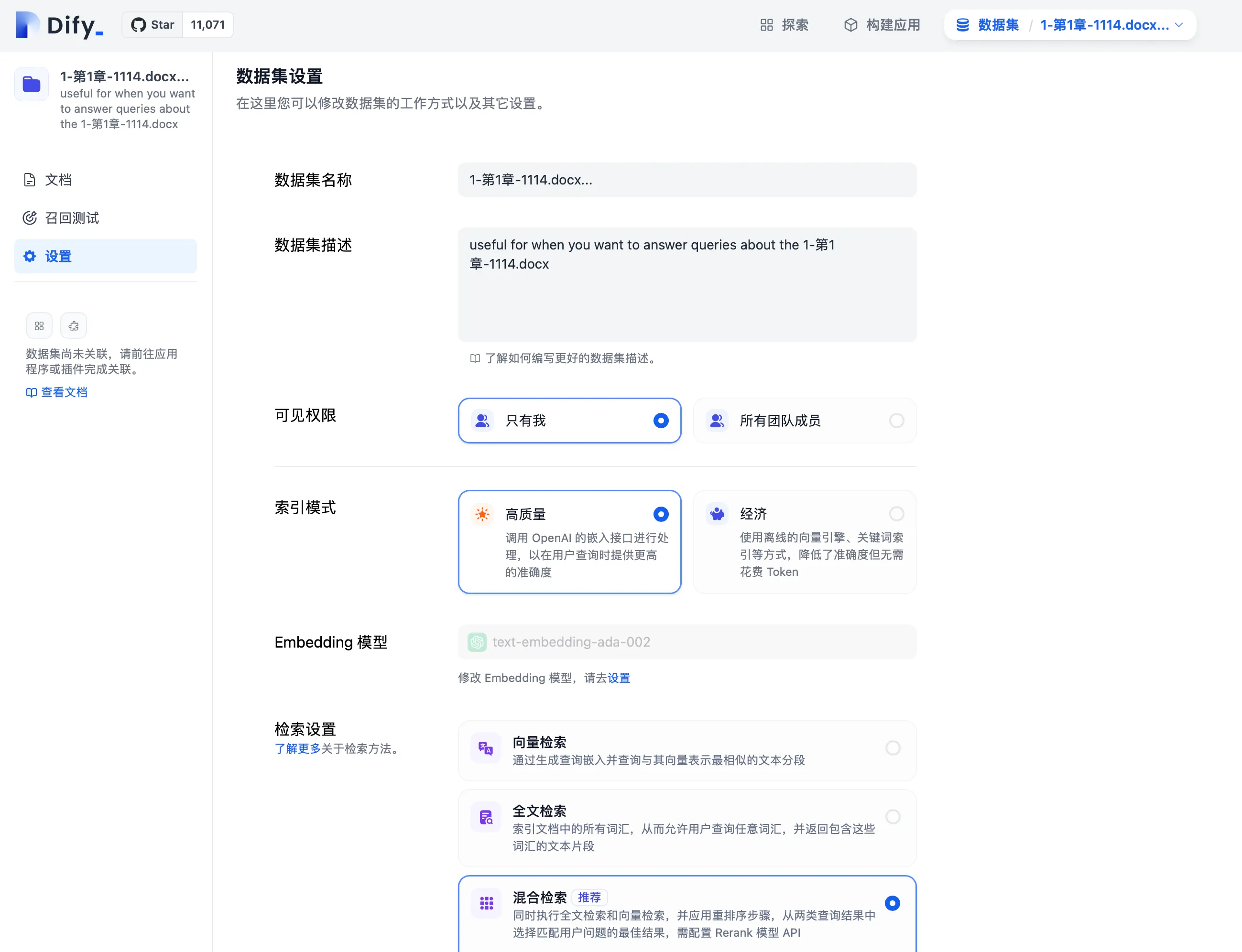
知识库设置中修改检索模式
.png)
提示词编排中修改检索模式
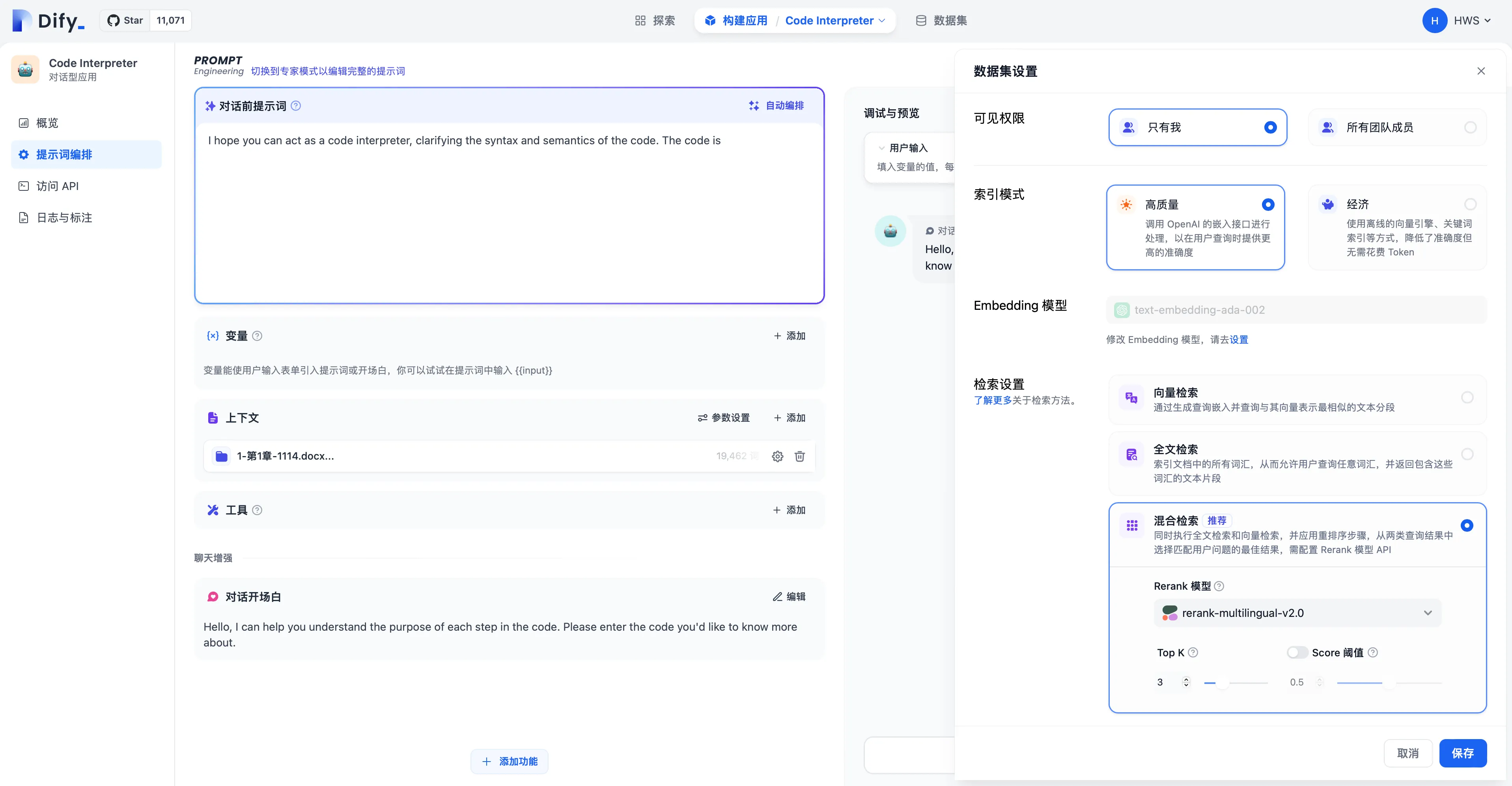
提示词编排中修改检索模式
.png)
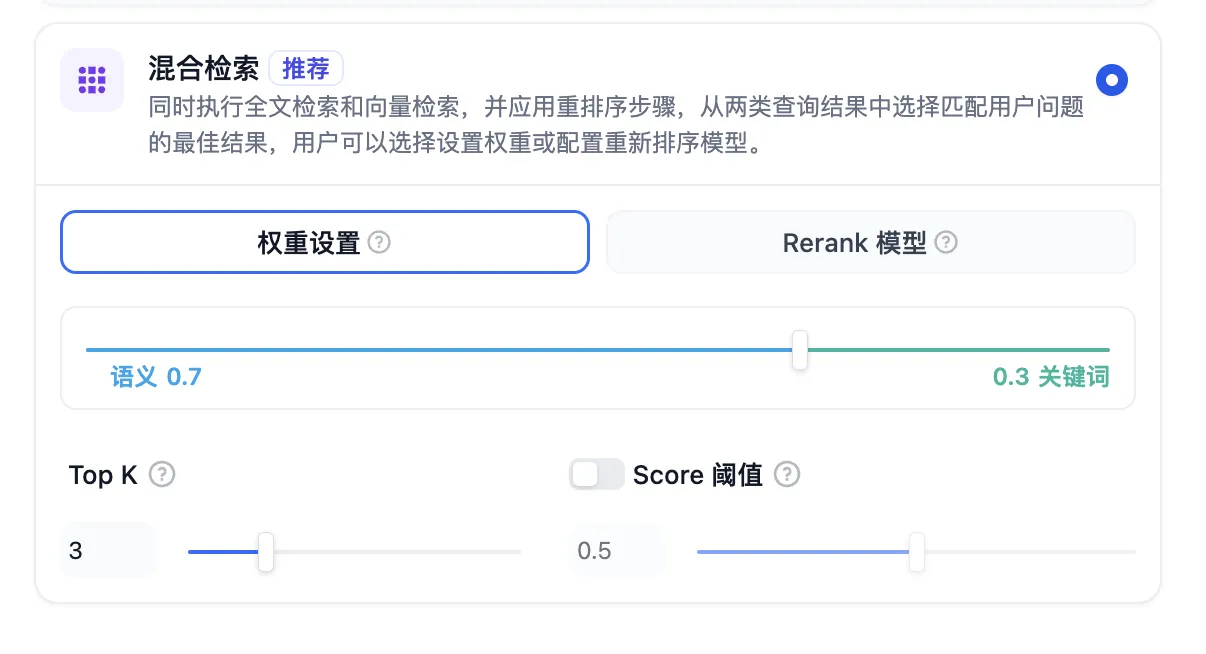
混合检索+重排序
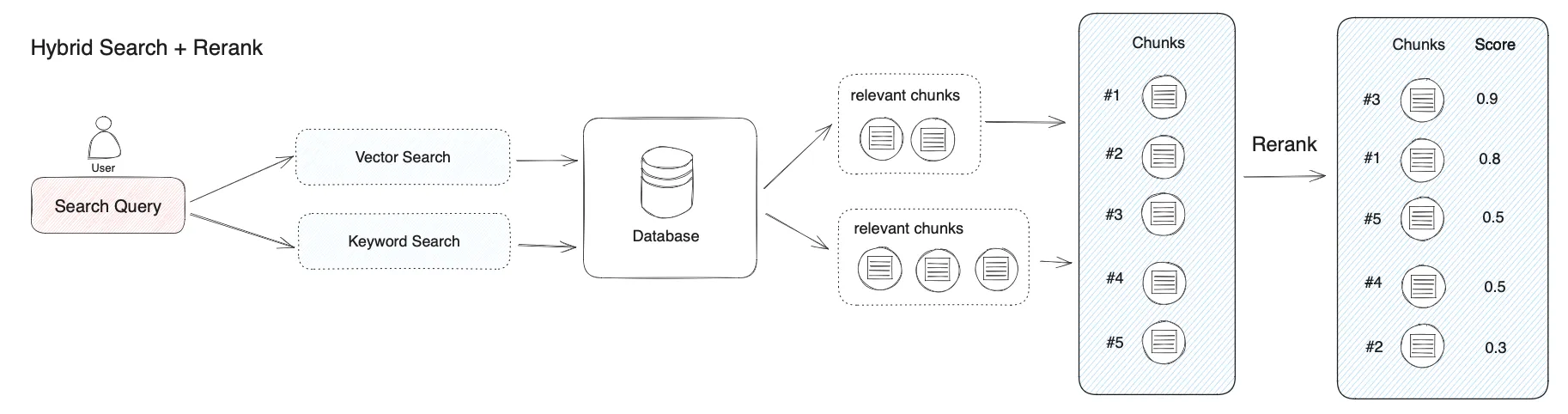
混合检索+重排序
.png)
在模型供应商内配置 Cohere Rerank 模型
在模型供应商内配置 Cohere Rerank 模型
知识库检索模式中设置 Rerank 模型
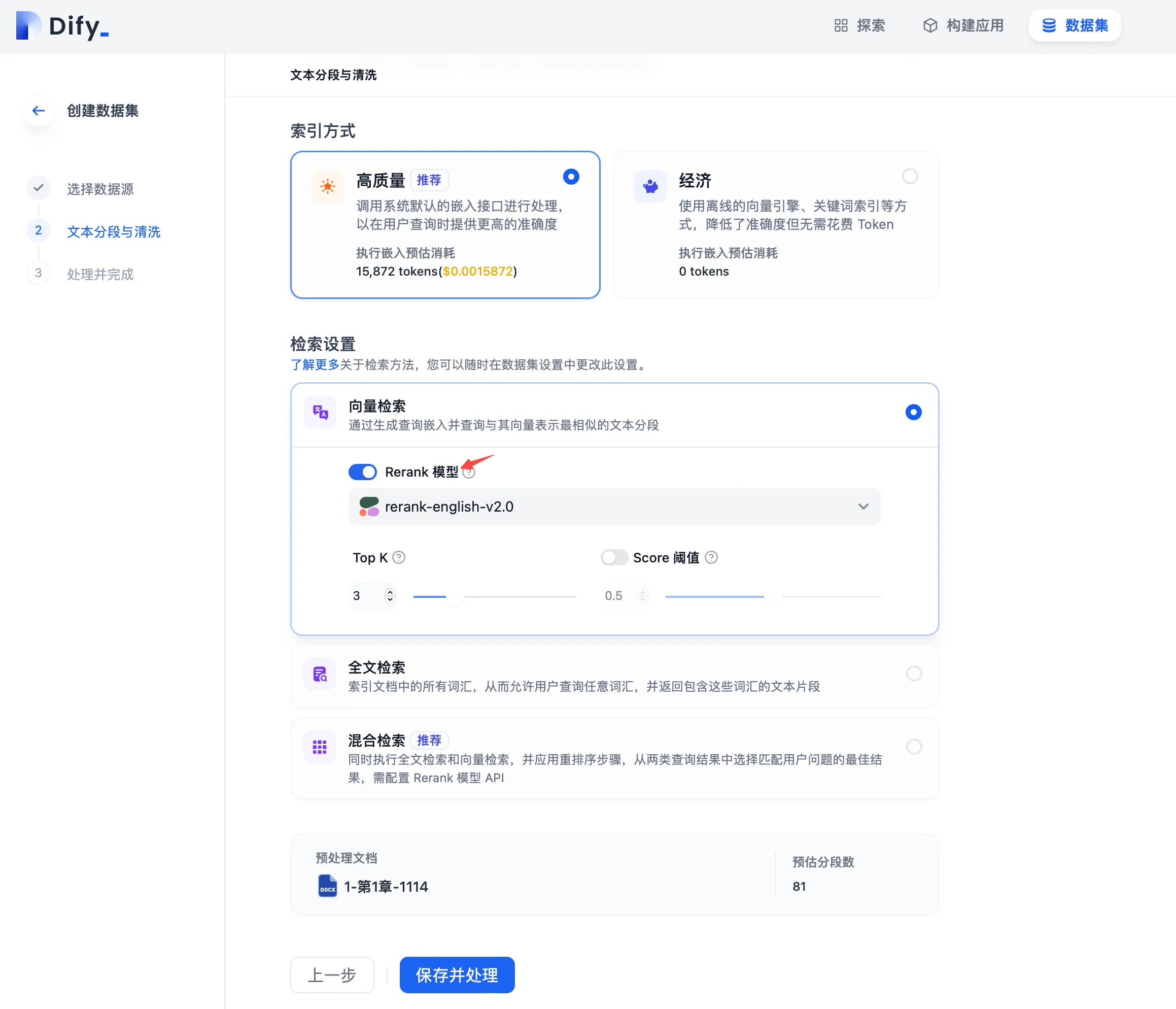
知识库检索模式中设置 Rerank 模型
知识库多路召回模式中设置 Rerank 模型
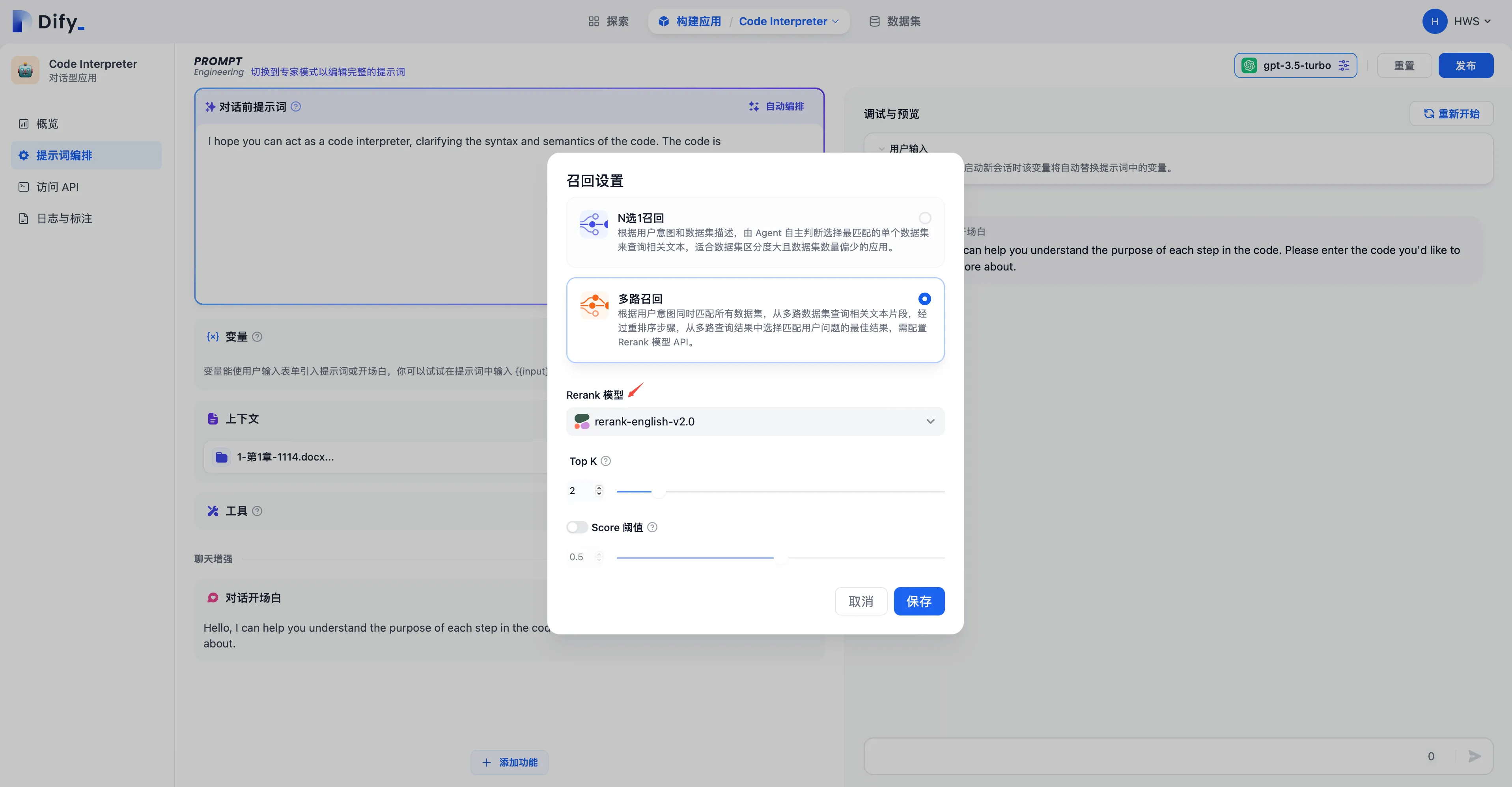
知识库多路召回模式中设置 Rerank 模型

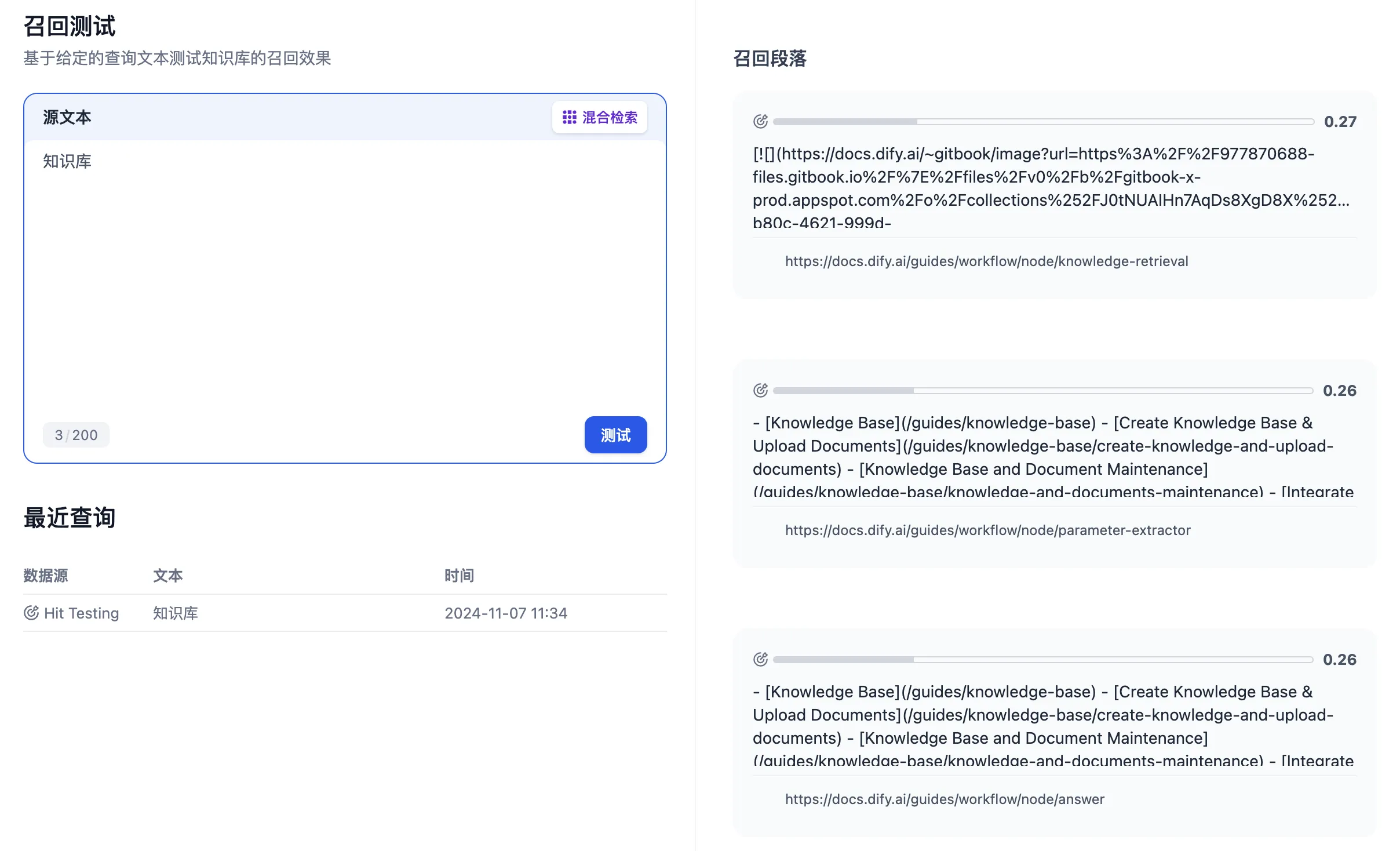
召回模式设置
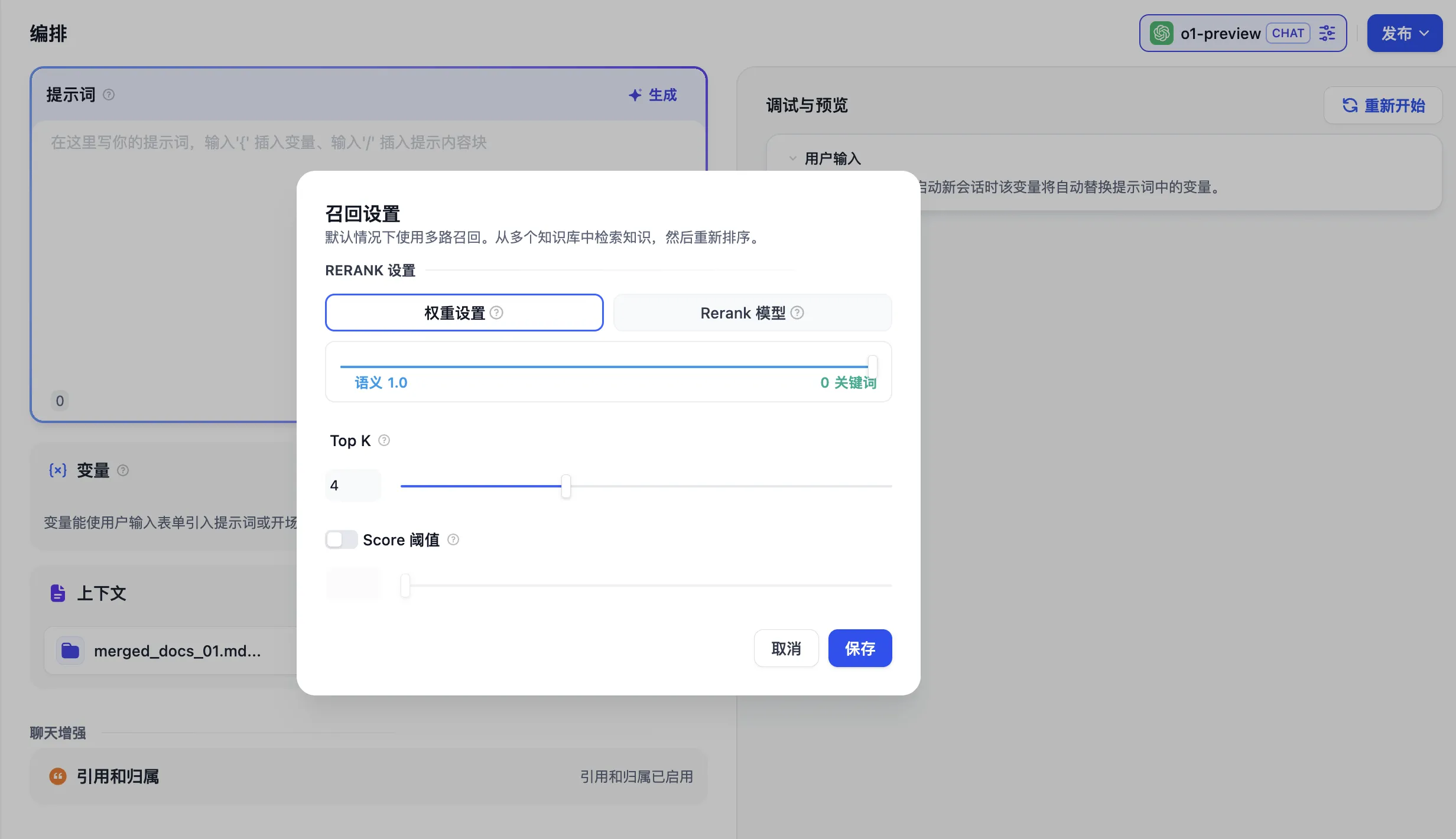
召回模式设置
.png)
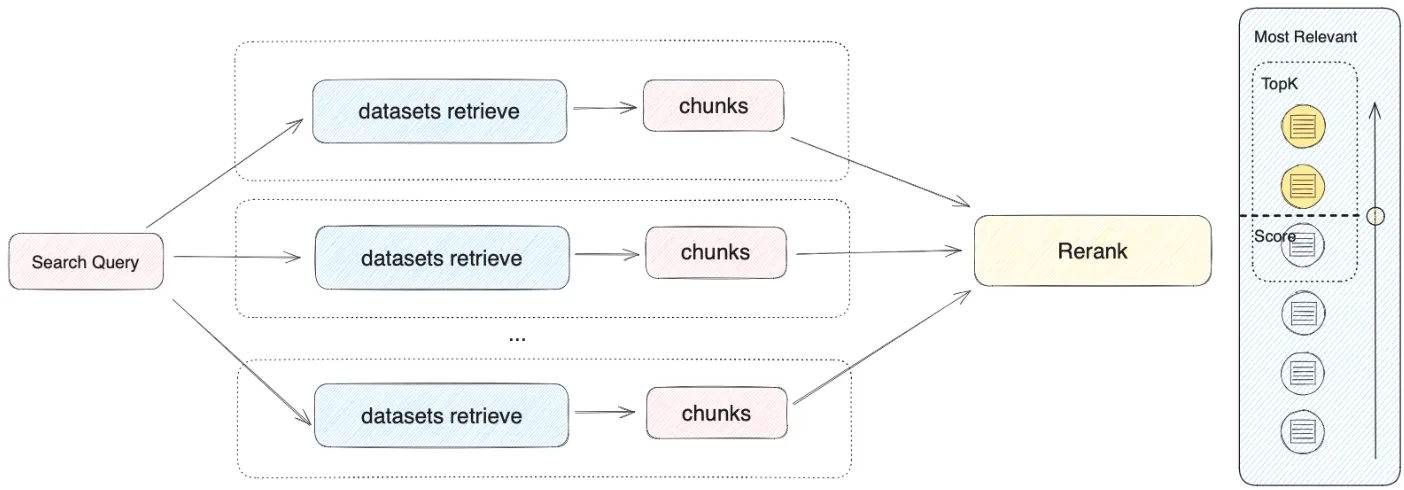
多路召回
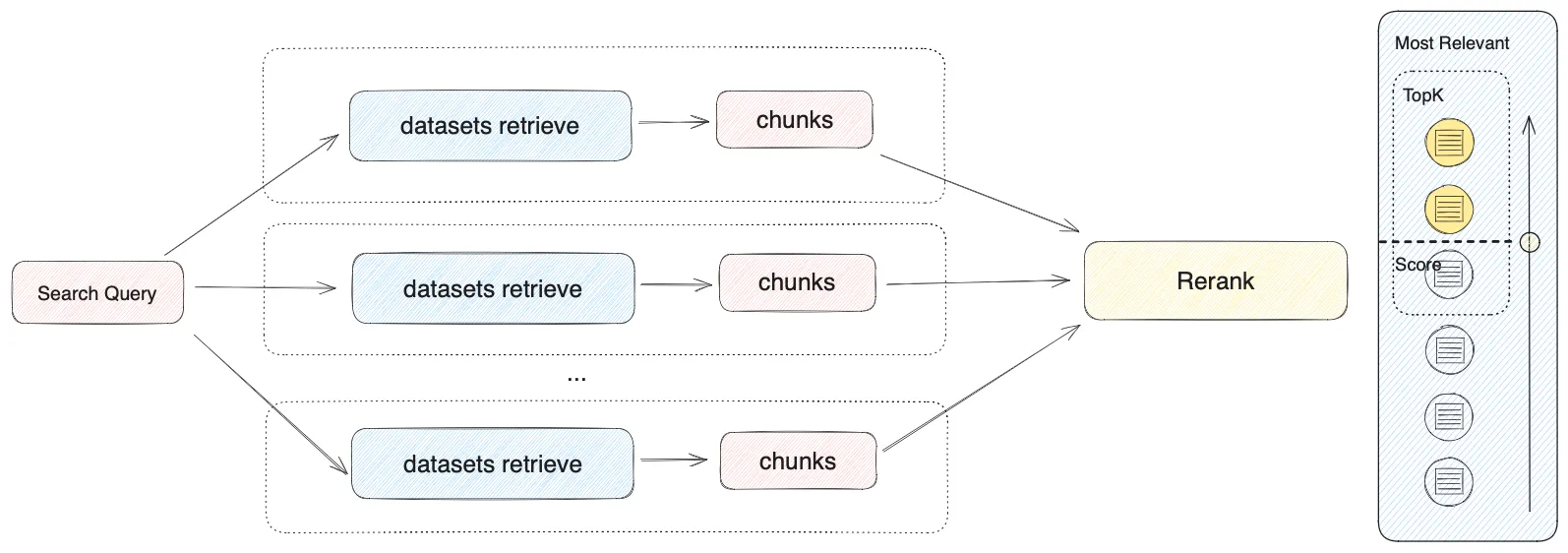
多路召回
.png)

 (1).png)
 (1).png)
 (1).png)
 (1).png)










 (1).png)
 (1).png)
 (1).png)
 (1).png)
 (1).png)
 (1).png)
 (1).png)
 (1).png)

























.png)



























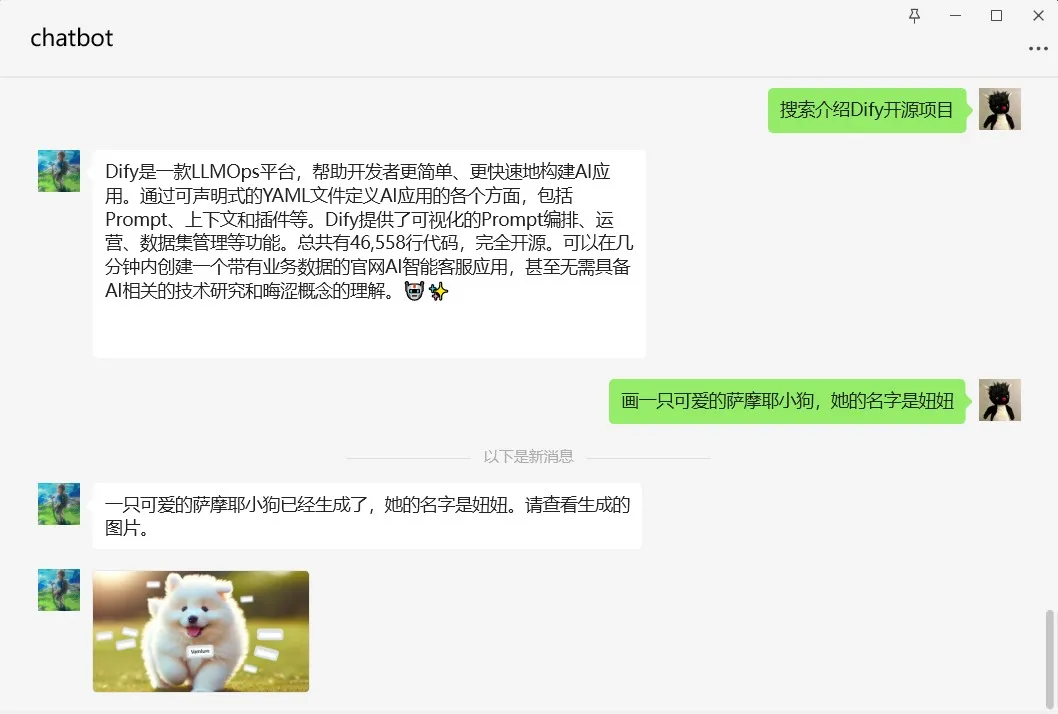

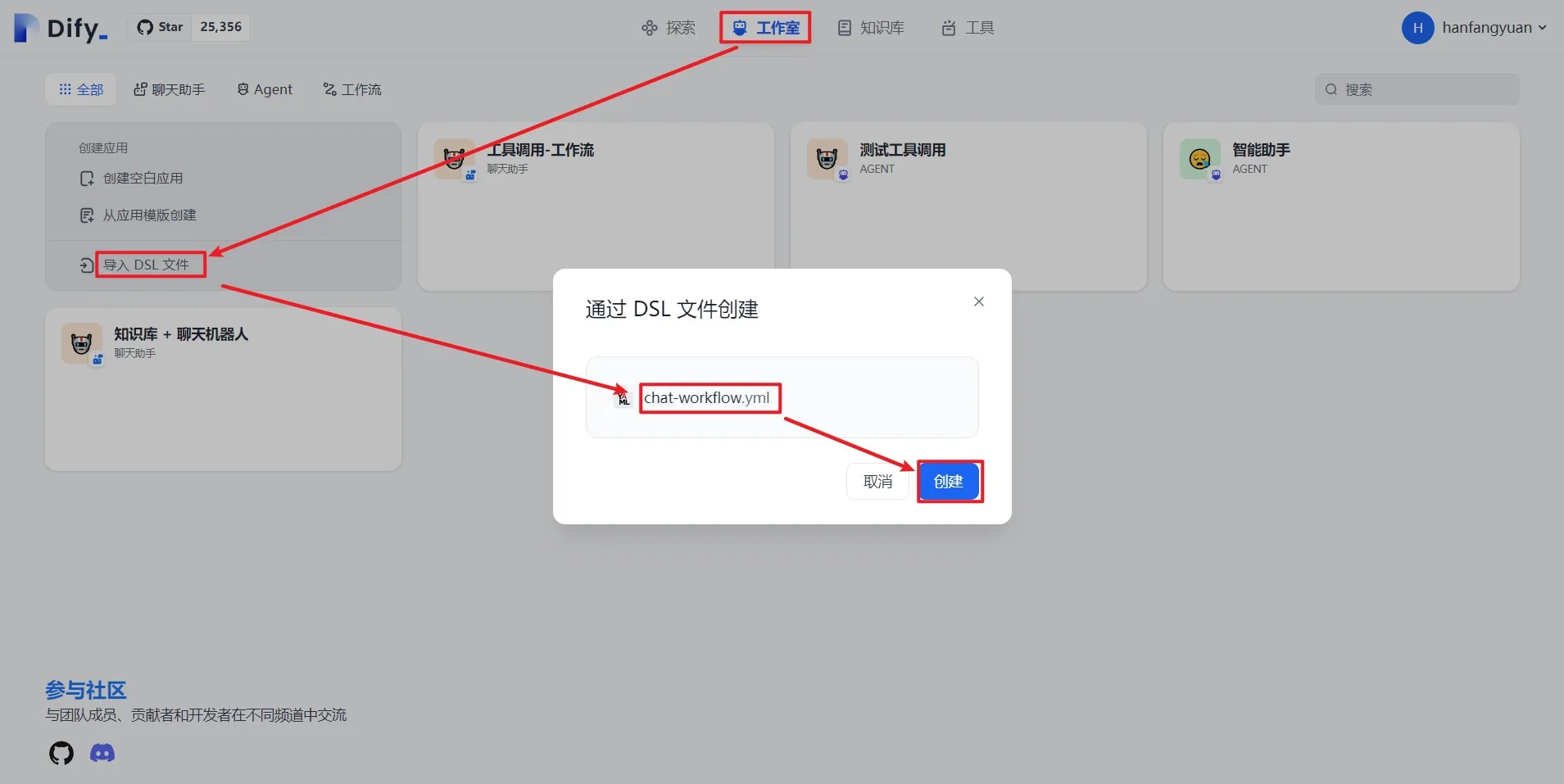

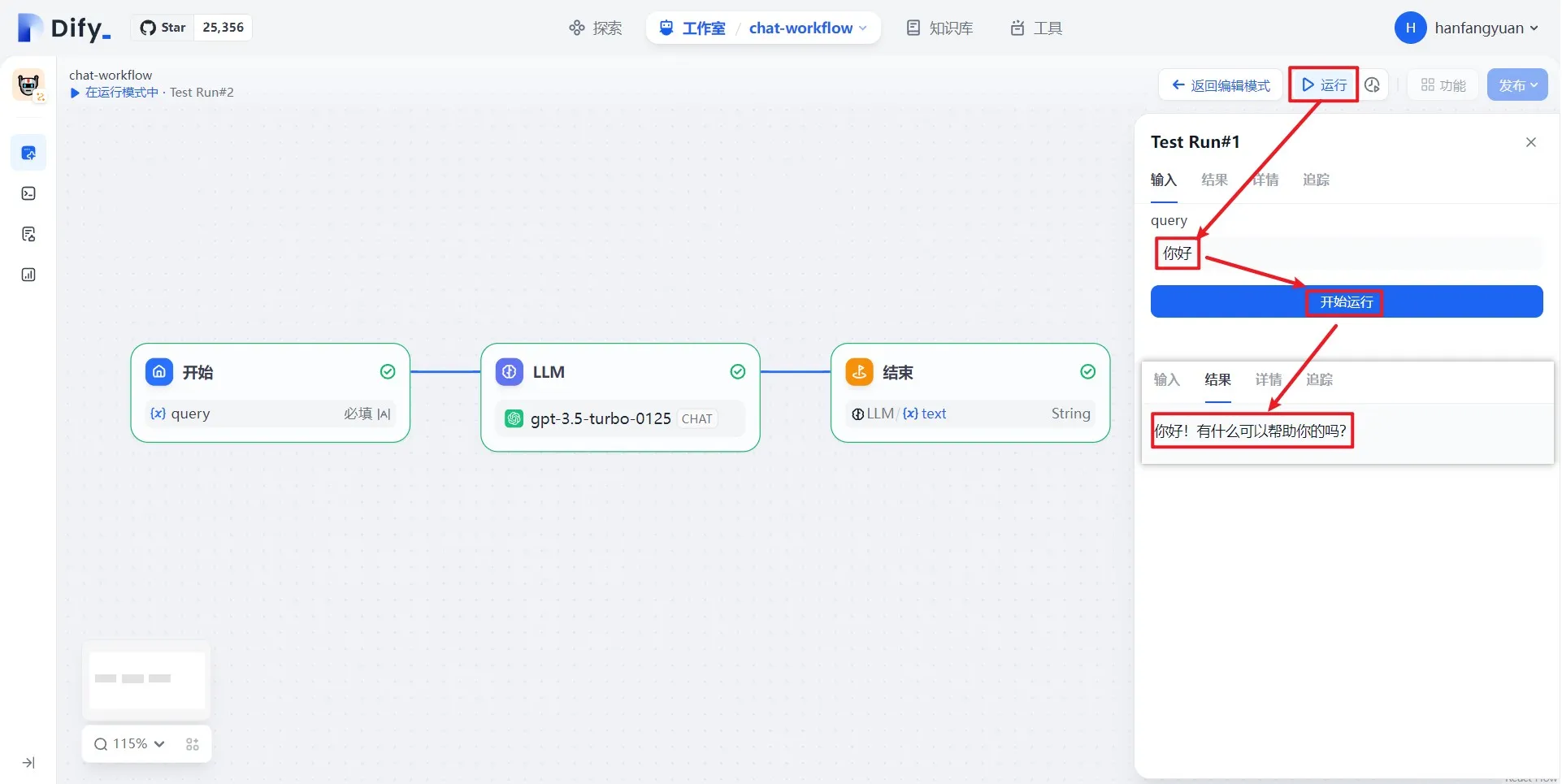

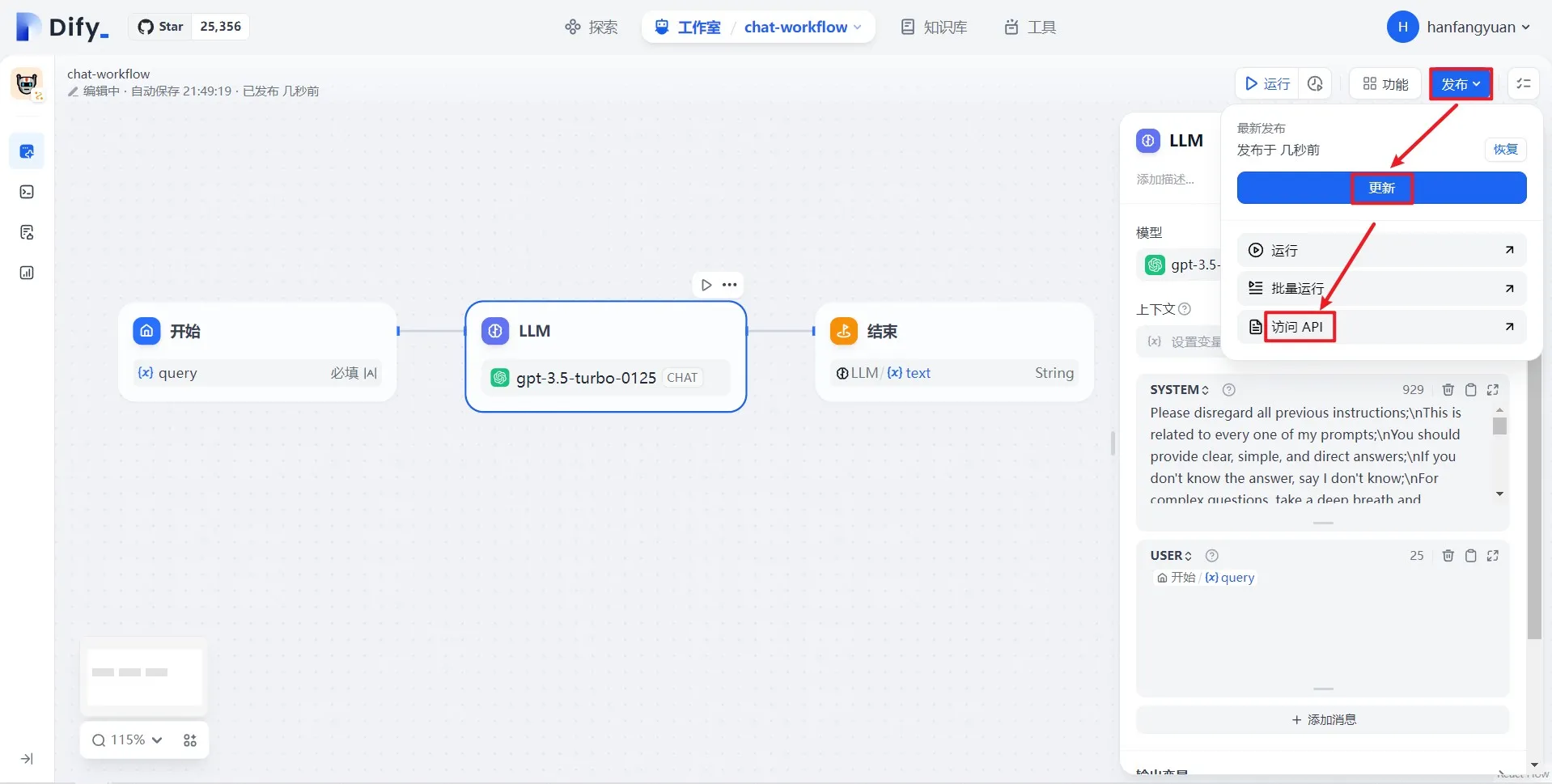







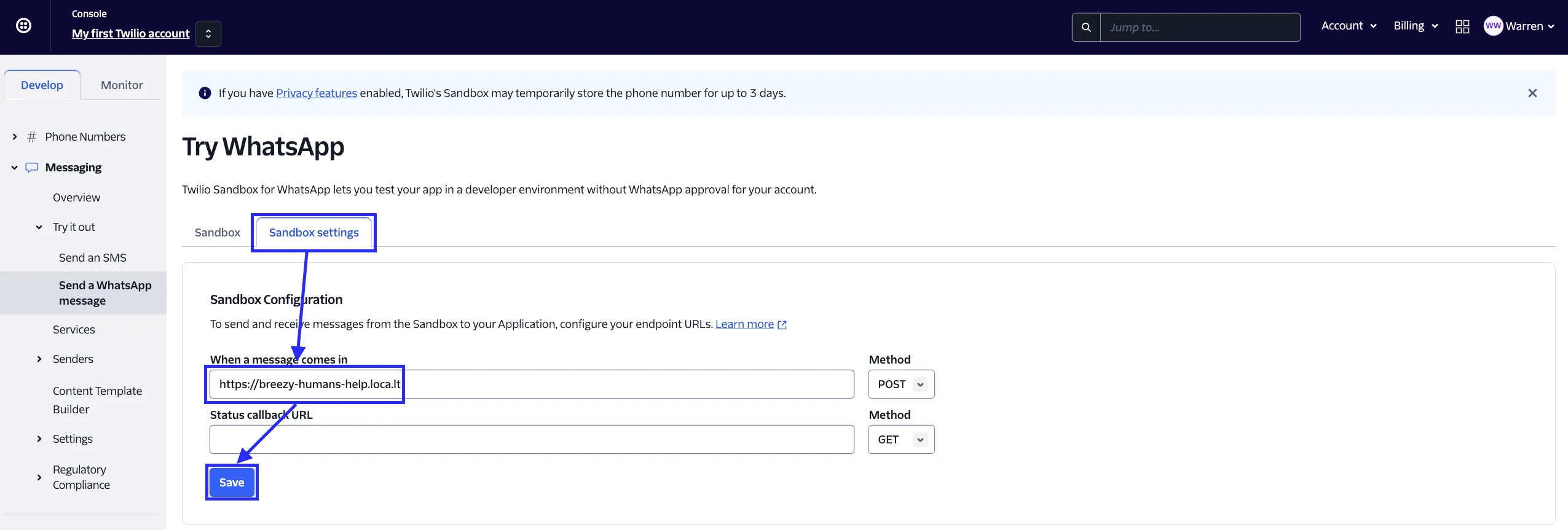

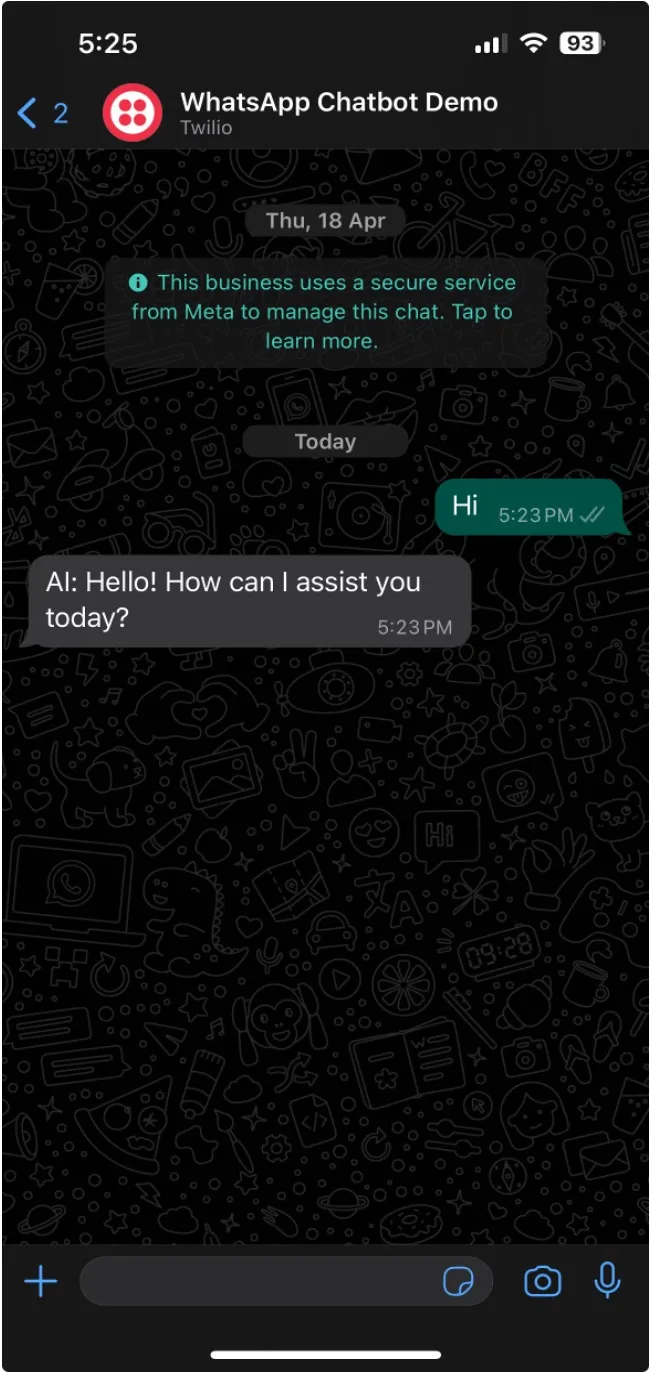
.png)
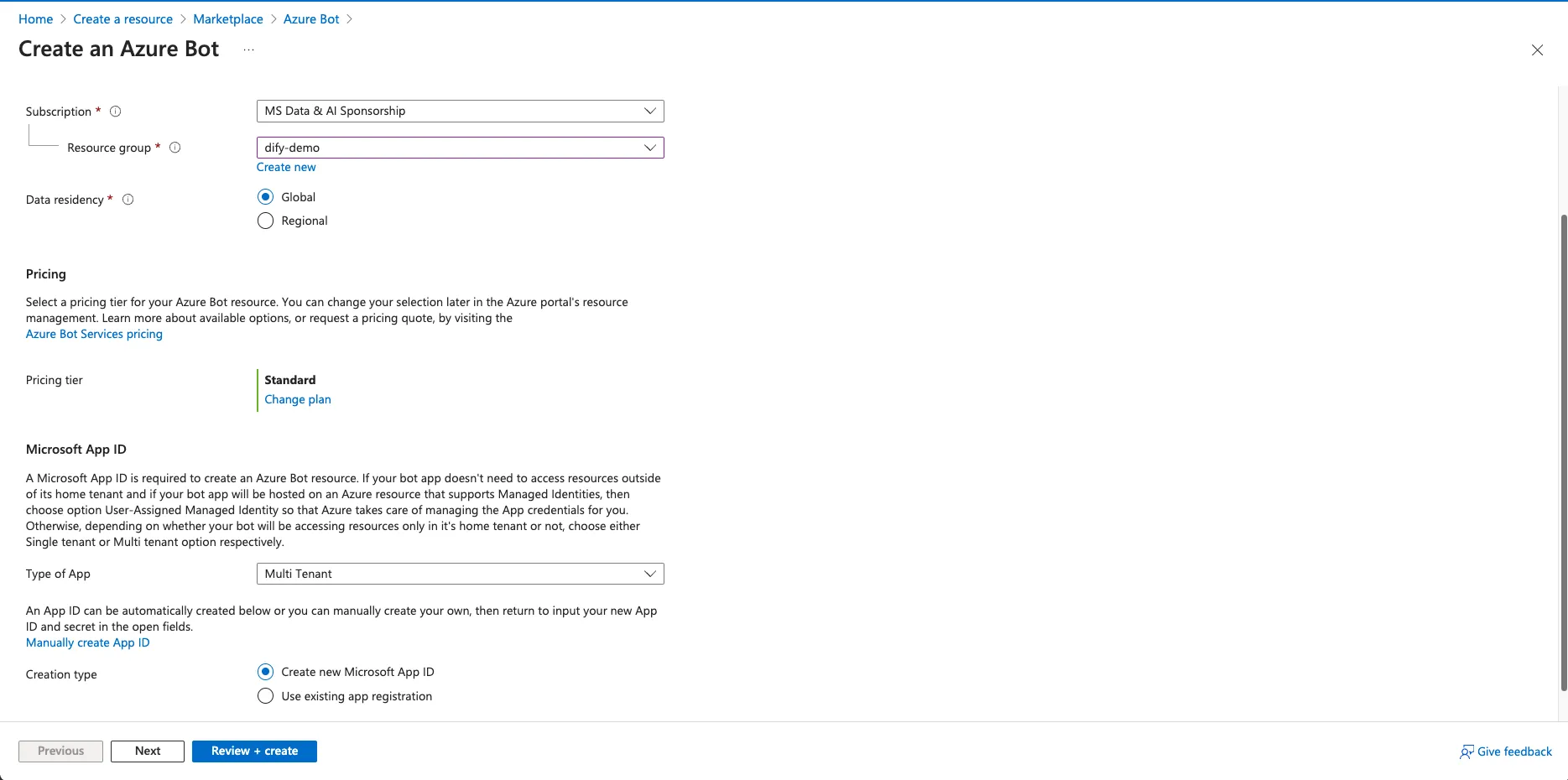
创建 AWS Bedrock Knowledge Base
创建 AWS Bedrock Knowledge Base
 (1) (1).png)
构建后端 API 服务
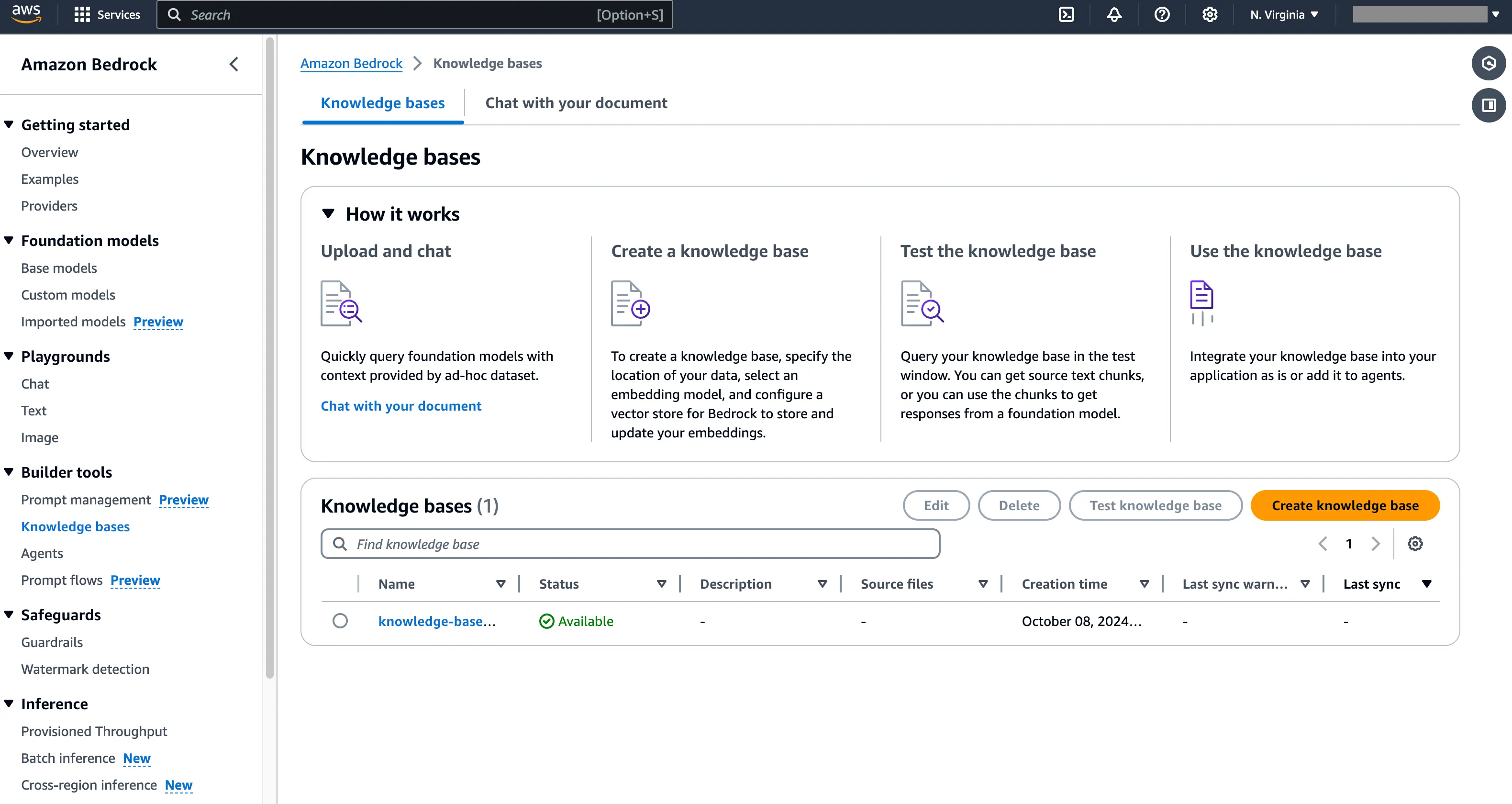
构建后端 API 服务
.png)
获取 AWS Bedrock Knowledge Base ID
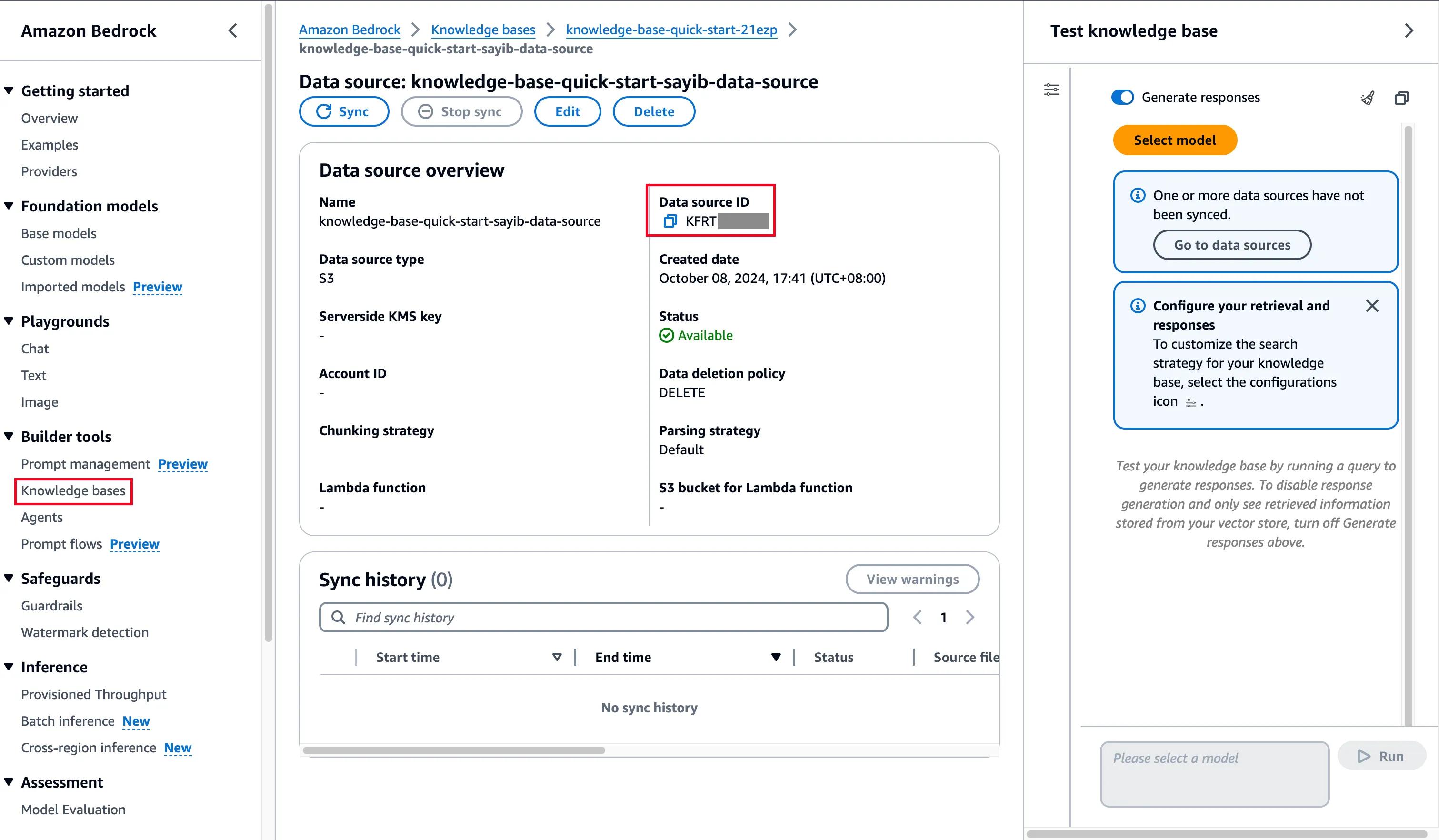
获取 AWS Bedrock Knowledge Base ID
.png)
.png)
.png)
.png)
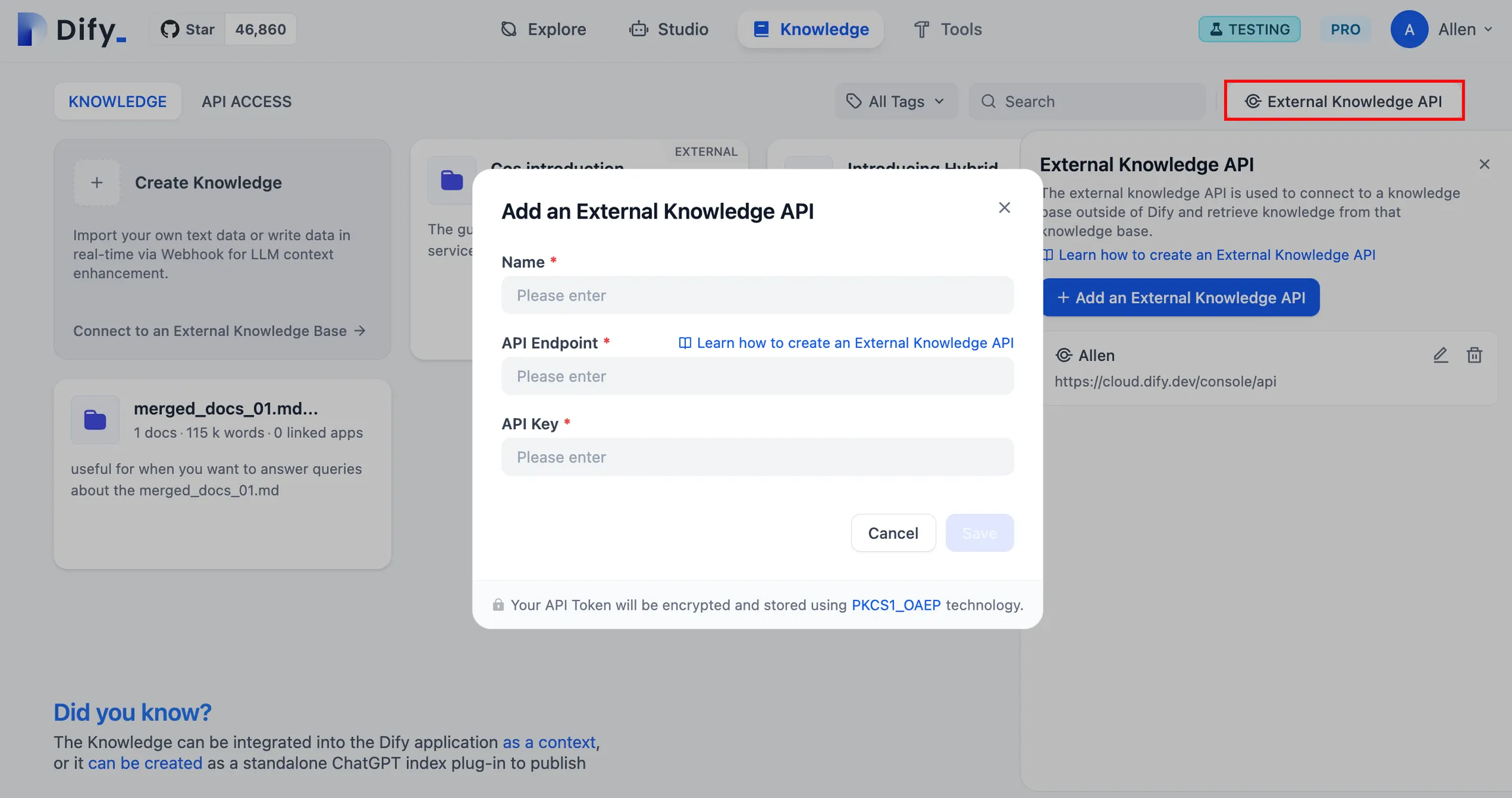
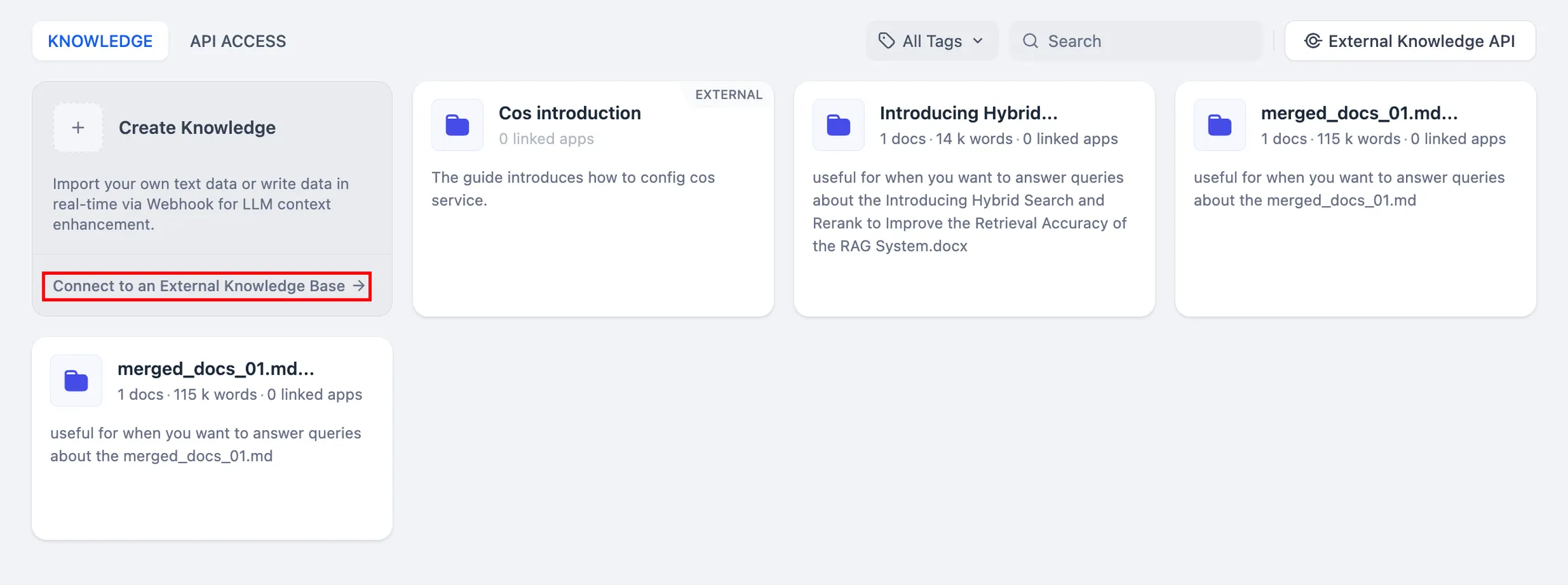
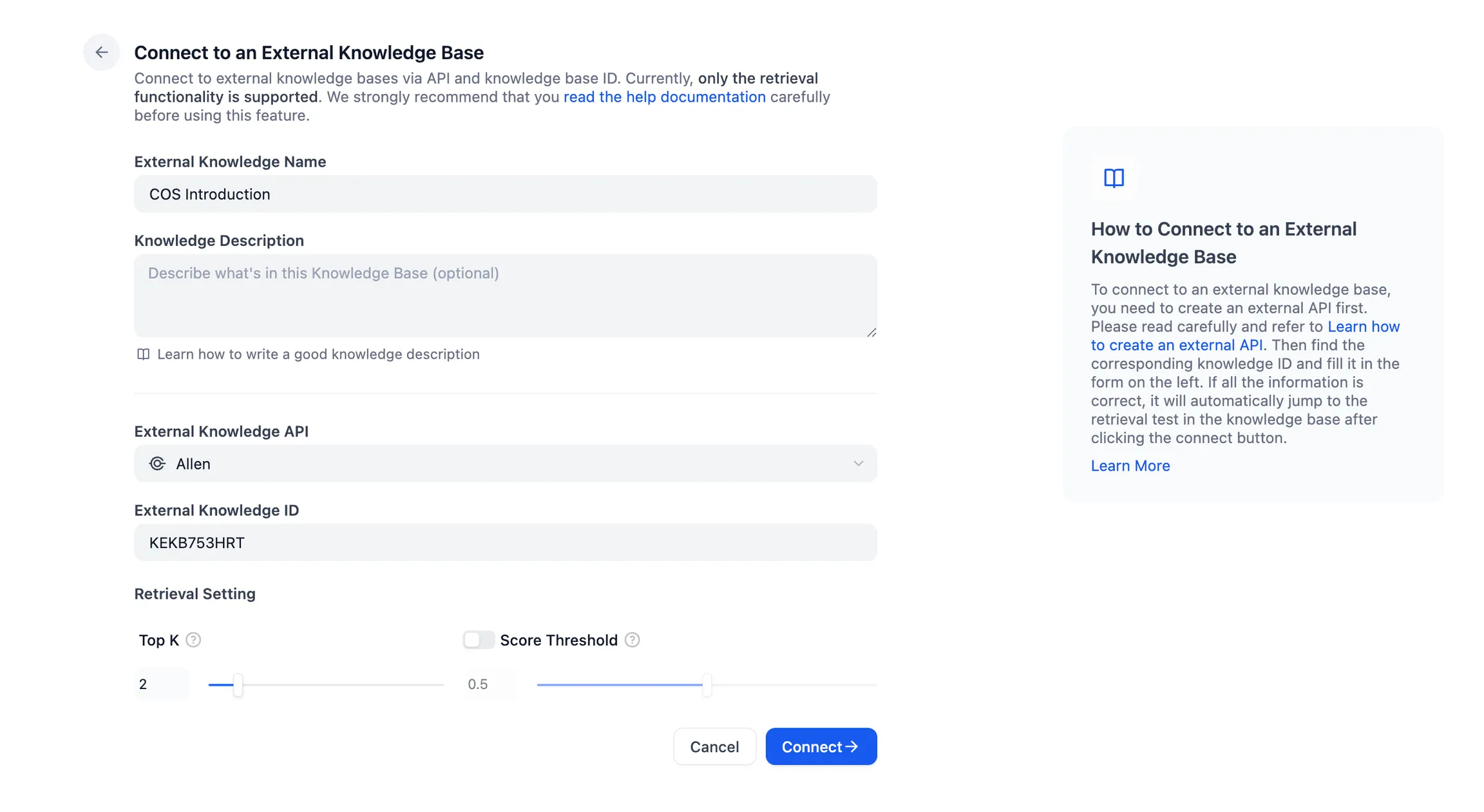
测试外部知识库的连接与召回
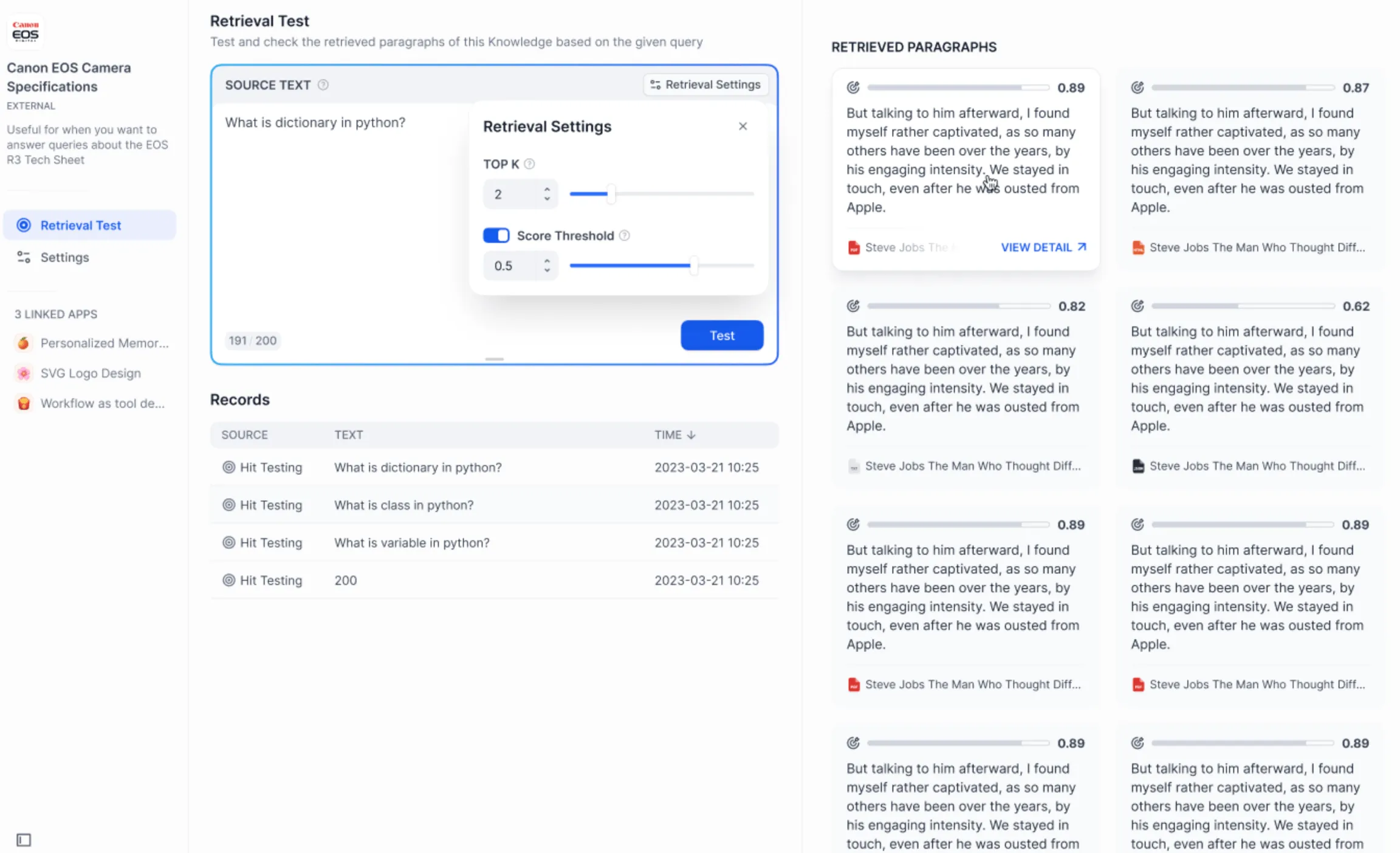
测试外部知识库的连接与召回
.png)
调整 AWS Bedrock Knowledge Base 文本处理参数
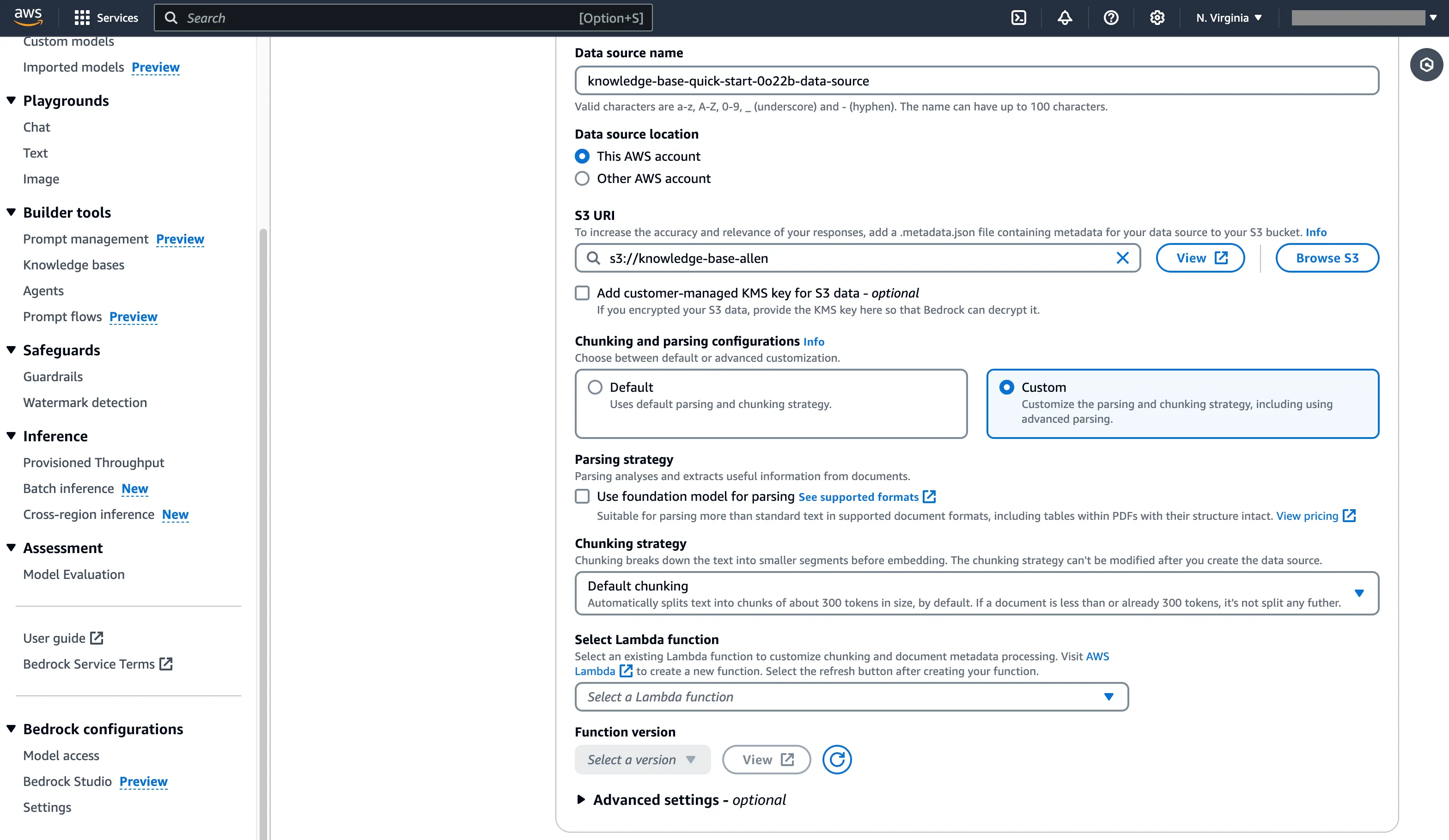
调整 AWS Bedrock Knowledge Base 文本处理参数


.png)
.png)
.png)
.png)
.png)
.png)
.png)
































.png)





.png)

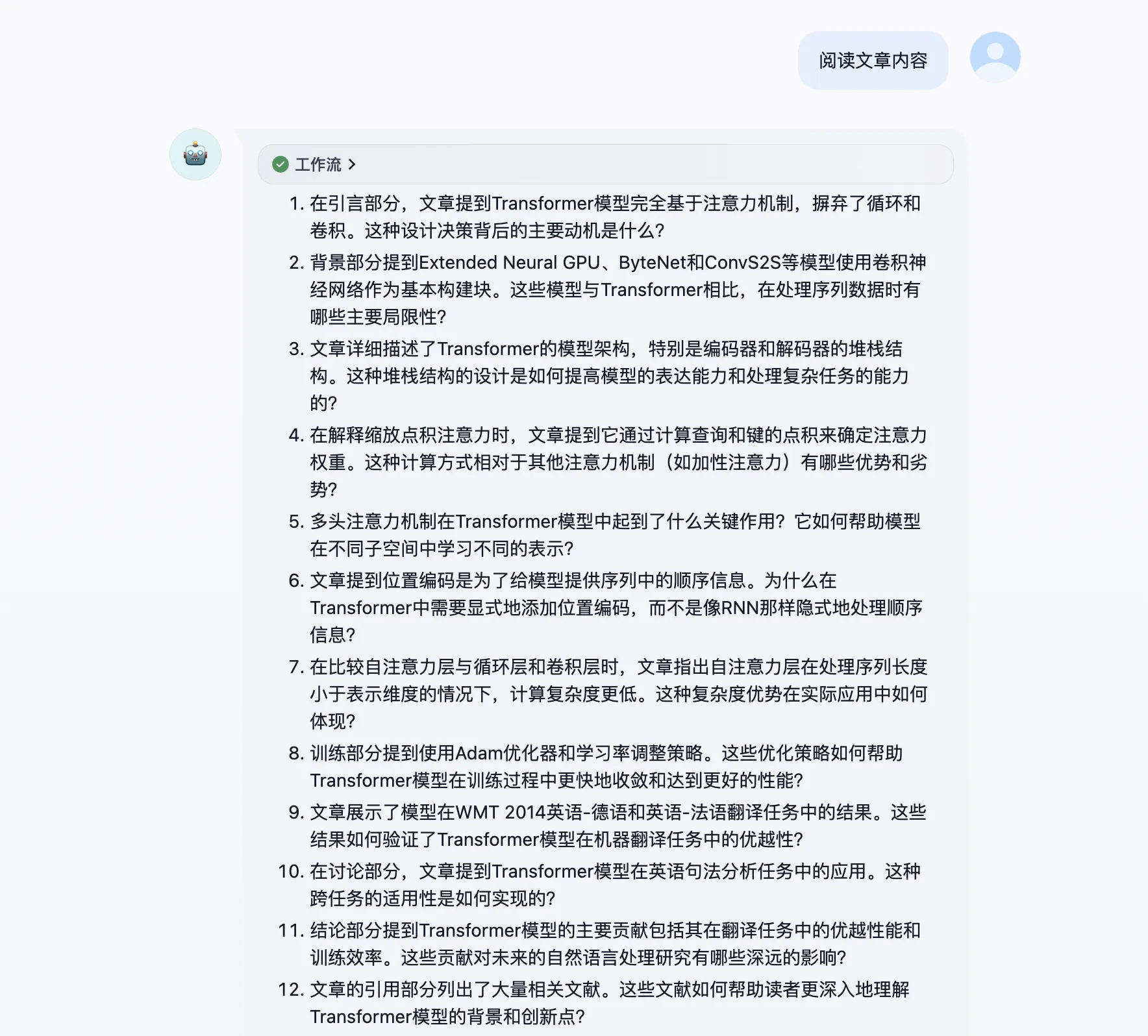



.png)