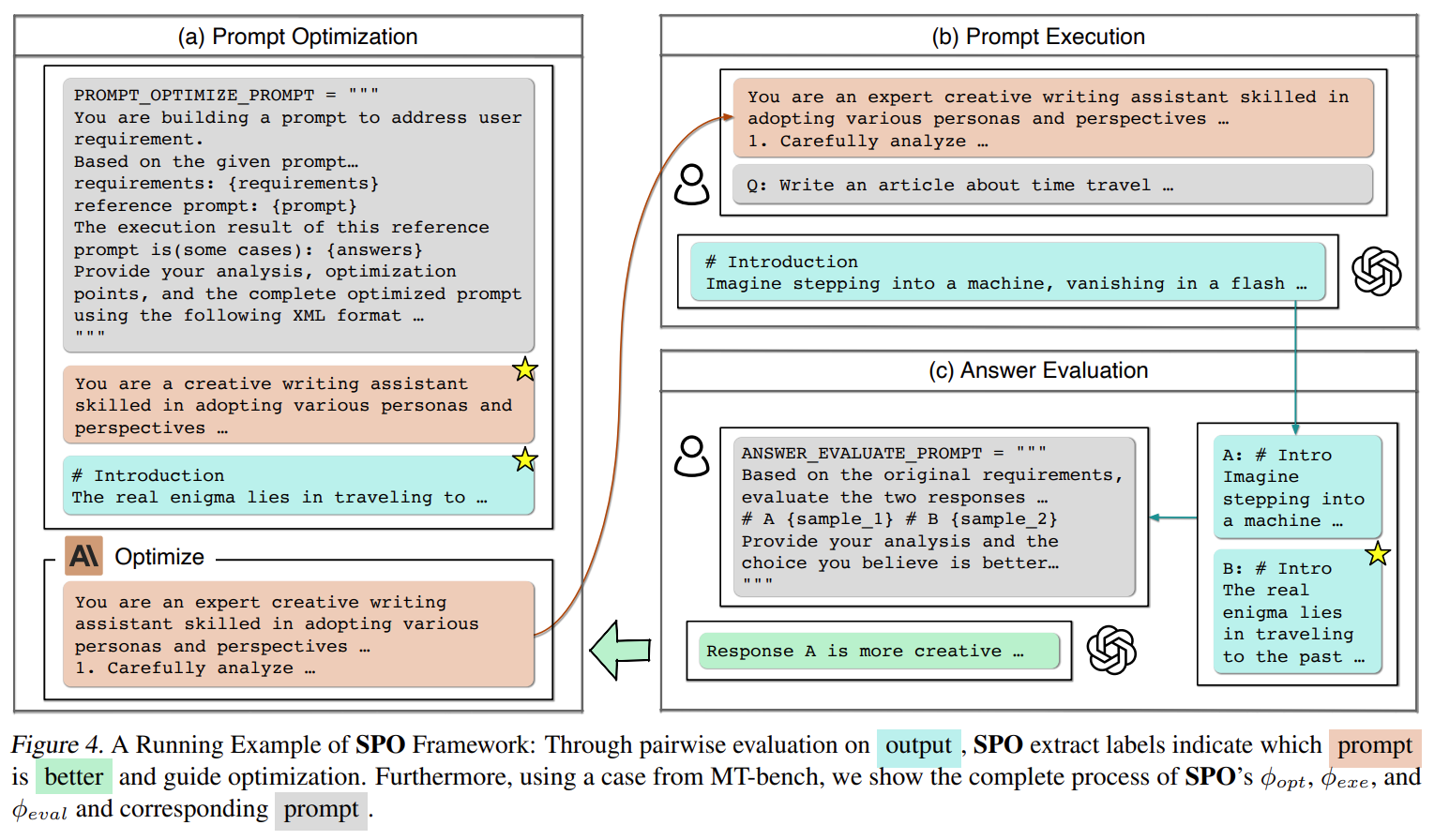
SPO(Self-Supervised Prompt Optimization)是一种基于大语言模型自监督能力的提示优化框架。与传统依赖人工标注或基准答案的方法不同,SPO通过对比不同提示生成的输出质量,自主完成优化迭代。
该框架创新性地将优化过程分解为执行-评估-优化三阶段循环,利用LLM自身对任务需求的理解能力,通过成对比较输出结果获得优化信号。**自监督提示优化(SPO)**相较于传统方法,实现了优秀的性能,使得成本效率高出17.8-90.9倍。🚀
- 修复了在模型配置中已添加的模型,在开始优化时会出现对应模型配置不存在的问题,原因是由于上一笔修改的逻辑BUG导致只会加载的配置文件来解析模型配置,现进行改进如下:
- 配置文件处理改进
- 简化了
SPO_LLM类的初始化流程。 - 修改了
metagpt/ext/spo/utils/llm_client.py的_load_llm_config方法,直接通过前端传参来初始化ModelsConfig类。 - 移除了加载配置时会将配置文件上传到运行环境的步骤,改为直接在前端进行解析,进一步避免了敏感数据泄露的风险。
- 简化了
- 配置文件处理改进
- 优化了界面状态管理,在
app.py添加了is_optimizing状态来控制在优化提示词时界面的交互。 - 改进了
metagpt/ext/spo/utils/llm_client.py配置文件的处理逻辑,支持保存和加载指定的模型配置文件,避免了在云端部署项目时会导致敏感数据泄漏的问题。(因为原llm_client.py默认通过ModelsConfig类使用的default方法加载模型配置,会默认固定加载config/config2.yaml配置文件,这里增加指定文件路径的逻辑并通过ModelsConfig类的from_home方法加载上传到config/中的yaml配置文件。) - 修复了
app.py在模版配置初始化时问答示例加载不全,以及添加示例后优化时报错的问题。 - 修复了
app.py在模版配置输入问答示例时,由于初始化示例时加载不全的BUG,在Q写完后切换到输入A后出现页面内容重新"刷新"的问题。
在这里特别感谢 UCloud 优云智算提供的 GPU 算力支持!让项目得到了快速的部署和调试运行。

优云智算是 UCloud 优刻得的GPU算力租赁平台,专注于为用户提供灵活的算力资源。支持按天、按小时短期租赁及包月长期租赁,满足各类需求。
结合丰富的公共镜像社区,优云智算提供多种预配置的容器镜像,如LLamaFactory、SD-webUI 和 LLM 等,实现一键部署,5分钟就能快速上手 AI,助力用户快速启动和扩展项目。
【算力福利速递】神秘通道秒领40枚算力金币解锁20小时顶配4090显卡试驾体验!学生党/职场人亮出大佬身份,立享永久VIP+额外金币补给包,快乐白嫖手慢无~
首先,在镜像发布页可以查看到我制作完成并分享到平台的实例镜像,通过右侧的使用该镜像创建实例可以快速创建一个实例。
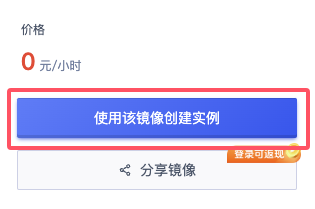
可按需选择配置后再立即部署。
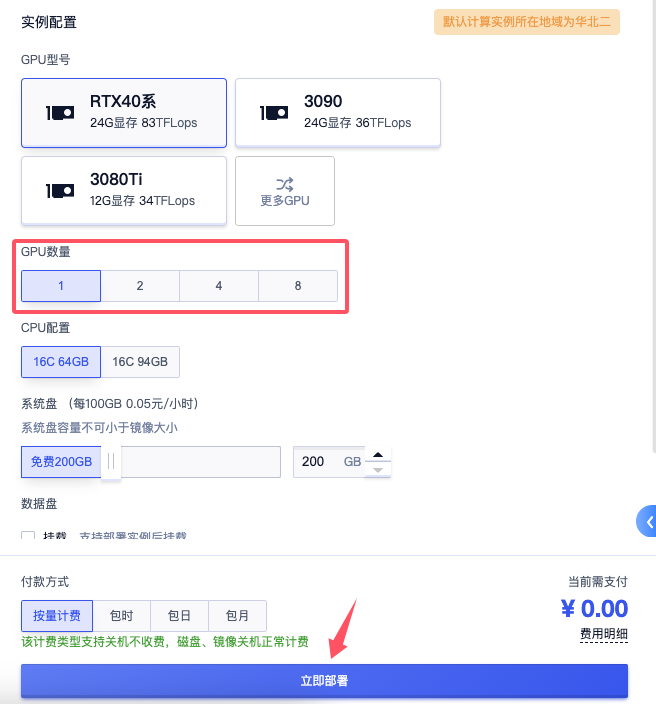
稍等片刻后,实例就会自动创建并启动,通过查看实例列表可查看实例的运行状态,并支持随时关闭或启用。
实例同时提供了一个 JupyterLab 应用作为交互式开发环境,它提供了更现代化和灵活的用户界面,方便我们继续后续的步骤。

启动实例后,你可以通过 JupyterLab 应用的终端输入以下命令来快速启动服务:
python -m streamlit run app.pyWebUI 服务默认通过 8501 端口进行访问,镜像已经配置了端口转发,你可以直接通过https://{公网IP}:8501/访问。
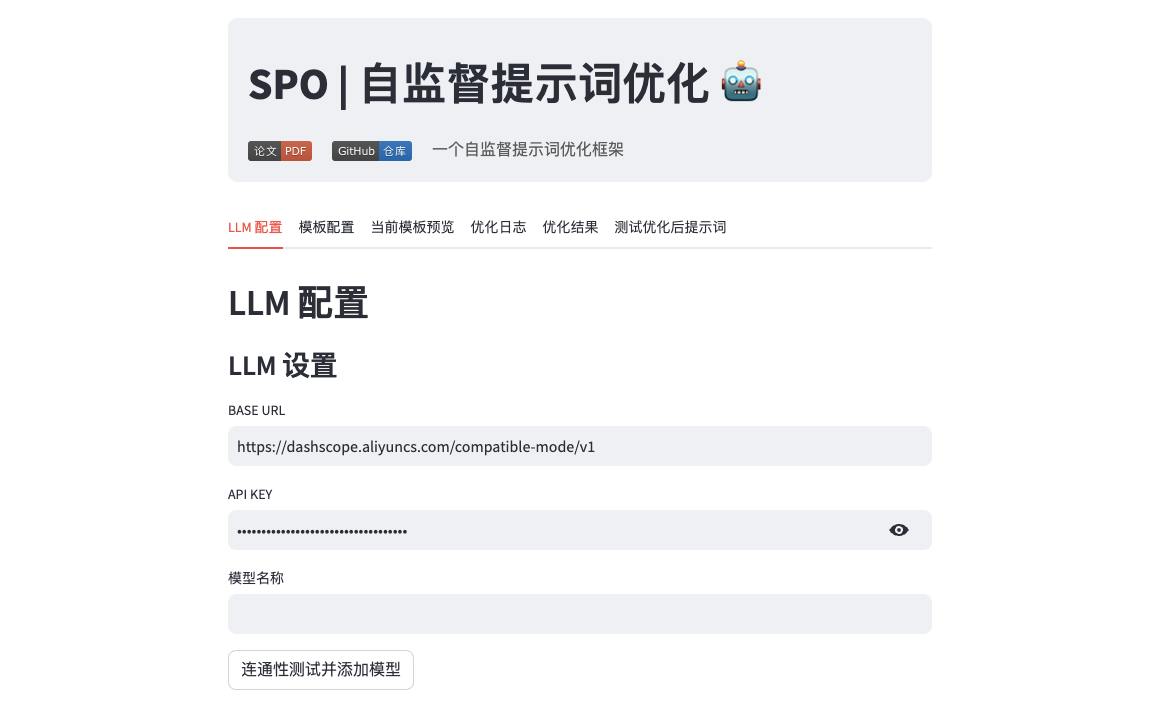
首次启动项目时,默认在模型设置中没有预置模型可以选择的,所以你需要先配置 LLM API 和相应的模型名称,这里我以配置阿里百练大模型为例。
配置完成后,点击连通性测试并添加模型并等待测试,测试成功后就会将模型保存到本地配置中,之后你会发现在下方的模型设置*中增加了相应的模型选项,你可以选择使用相同/不同的模型作为优化提示、评估提示和执行提示(测试优化后提示词)的模型。
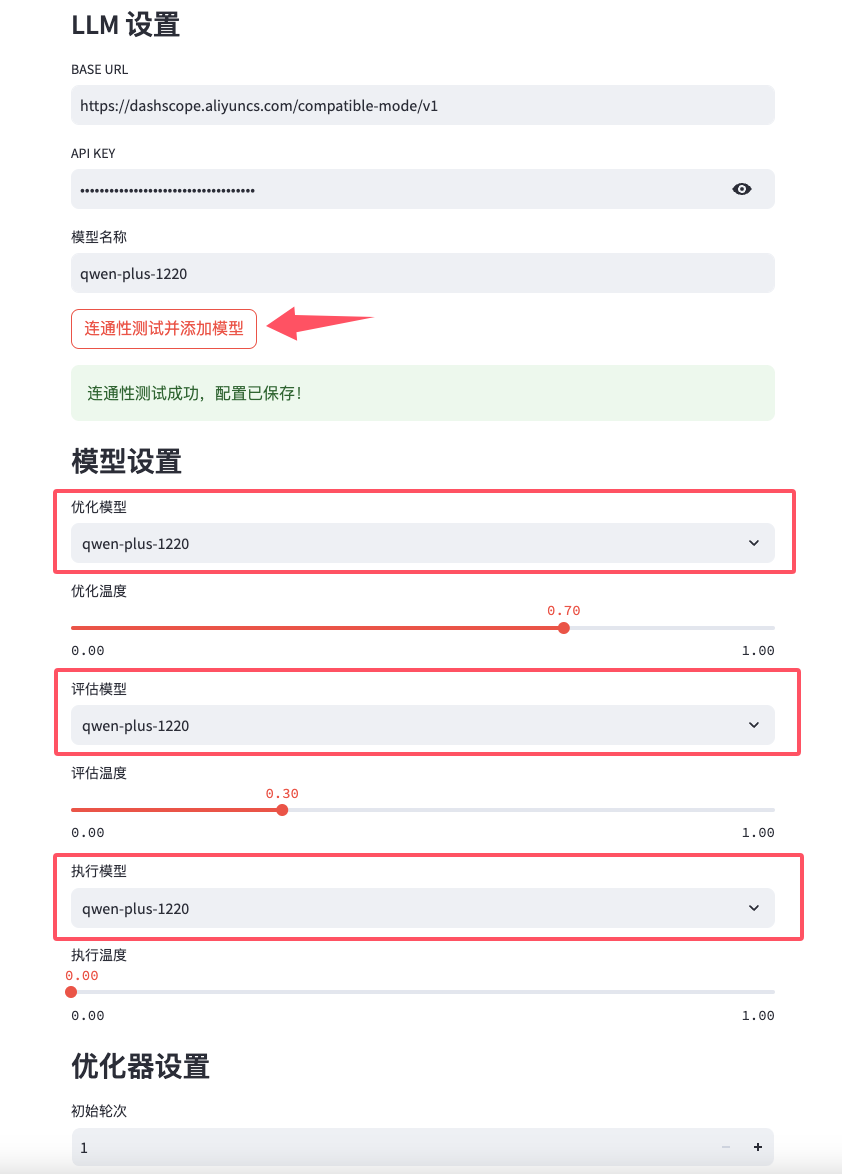
滑动到LLM 配置的最下方,你会发现一个优化器设置,这里的初始轮次和最大轮次,你可以按照需要配置它们的次数。
来到模板配置页,这里提供了一个提示词的配置模板,是SPO框架的核心配置,这决定了你想优化的提示词以及优化的目标。
- 提示词:输入你想要优化的提示词,主要用于优化模型优化提示词。
- 要求:输入提示词优化的目标,或者是一段描述(描述对提示词输出结果的要求),主要用于评估模型评估提示词。
- 问答示例[可选]:可以添加多个Q&A作为示例,可以更好地指导模型优化提示词向目标对齐。

完成模板配置后,你就可以进入优化日志页,点击开始优化执行SPO脚本开始优化提示词了!并且在这个过程中,你可以从页面看到优化的过程和模型输入输出的日志信息。Enjoy it!

我这里为了快速演示,设置最大轮次为3次。在等待结束优化之后,你可以跳转到优化结果页,你将会看到每一轮优化的提示、完成状态和详细的优化结果。
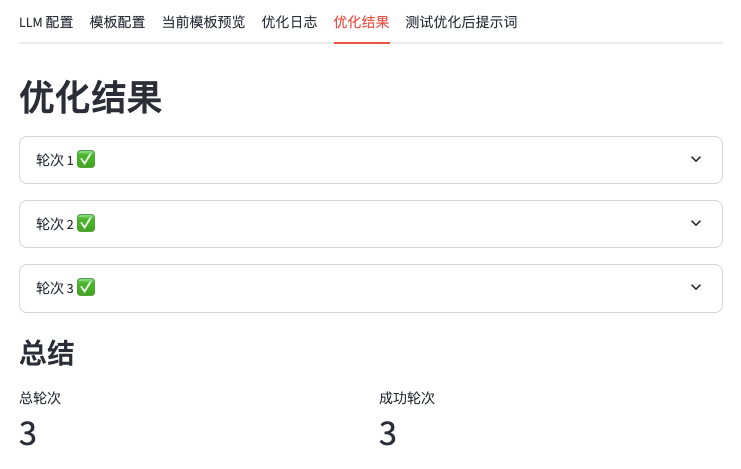
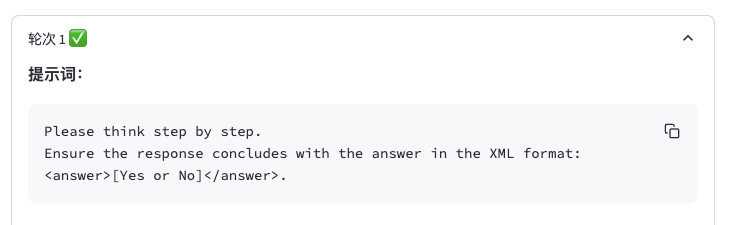
点开对应轮次,你可以看到更加详细的优化结果,这里我先查看开轮次1的优化结果,发现第1轮的提示词是你输入的提示词,它将首当其冲作为提示词,输入到模型中进行优化和评估,为后续优化提示词的进程作准备。
接着,我再查看开轮次3的优化结果,发现不同于第1轮的提示词,当优化进程达到第3轮时,提示词已经变得更加细致完整了,像这样更完善的提示词,能够在测试时更好地指导模型输出,提高目标结果的命中率。

最后,我测试了轮次3的优化结果中的提示词,输入了一个问答示例中不存在的问题(避免拟合),它不仅输出了详细的推理过程,得到了正确的结果,而且非常好地完成我设定的任务目标,最后生成了我要求的输出结果。
优化后的提示词是具备通用性的,即使是在其他的模型或参数量更小的模型中,也能非常准确地指导模型输出预期的结果。

git clone https://github.com/Airmomo/SPO.gitcd SPO/# Windows/macOS/Linux 通用命令
python -m venv myenv
# 如果遇到 python 命令无效,尝试用具体版本号:
python3 -m venv myenv- Windows 系统:
# 常规命令提示符(CMD)
myenv\Scripts\activate.bat
# PowerShell
.\myenv\Scripts\Activate.ps1- macOS/Linux 系统:
source myenv/bin/activatepip install -e .
cd ../项目提供了更加友好的交互体验,可以使用 Streamlit Web 界面来配置LLM和运行优化器。
首先,安装 Streamlit:
pip install "streamlit~=1.42.0"安装
Streamlit后可能会提示存在依赖版本冲突,不会影响正常运行,可以忽略!
然后运行 Web 界面:
python -m streamlit run app.py默认运行在8501端口,启动后会自动打开浏览器并访问http://localhost:8501/.
在运行 PromptOptimizer 之前,需要配置语言模型 (LLM) 的参数。这些参数可以在 config/config2.yaml 文件中设置,你可以参考 examples/spo/config2.example.yaml 文件的格式进行配置。
创建一个迭代模板文件 metagpt/ext/spo/settings/task_name.yaml,模板内容如下:
prompt: |
Please solve the following problem.
requirements: |
...
count: None
qa:
- question: |
...
answer: |
...
- question: |
...
answer: |
...- prompt:迭代的初始提示。
- requirements:期望的效果或结果(例如,生成更多思考或使用更幽默的语言)。
- count:生成提示的目标字数(例如,50)。设置为
None表示不限制字数。 - qa:用于迭代的问答对,通常包含 3 个左右的问答对。
- question:数据集中用于迭代的问题。
- answer:对应的答案,可以包含期望的思考模式或响应,也可以留空。
参考示例:metagpt/ext/spo/settings/Navigate.yaml
PromptOptimizer 提供了三种运行方式,分别是 Python 脚本、命令行接口和 Streamlit Web 界面。
以下是通过 Python 脚本运行 PromptOptimizer 的示例代码:
from metagpt.ext.spo.components.optimizer import PromptOptimizer
from metagpt.ext.spo.utils.llm_client import SPO_LLM
if __name__ == "__main__":
# 初始化 LLM 设置
SPO_LLM.initialize(
optimize_kwargs={"model": "claude-3-5-sonnet-20240620", "temperature": 0.7},
evaluate_kwargs={"model": "gpt-4o-mini", "temperature": 0.3},
execute_kwargs={"model": "gpt-4o-mini", "temperature": 0}
)
# 创建并运行优化器
optimizer = PromptOptimizer(
optimized_path="workspace", # 输出目录
initial_round=1, # 起始轮次
max_rounds=10, # 最大优化轮次
template="Poem.yaml", # 模板文件
name="Poem", # 项目名称
)
optimizer.optimize()运行以下命令以通过命令行接口启动优化器:
python -m examples.spo.optimize可用的命令行选项如下:
--opt-model 用于优化的模型(默认:claude-3-5-sonnet-20240620)
--opt-temp 优化的温度参数(默认:0.7)
--eval-model 用于评估的模型(默认:gpt-4o-mini)
--eval-temp 评估的温度参数(默认:0.3)
--exec-model 用于执行的模型(默认:gpt-4o-mini)
--exec-temp 执行的温度参数(默认:0)
--workspace 输出目录路径(默认:workspace)
--initial-round 初始轮次编号(默认:1)
--max-rounds 最大轮次数量(默认:10)
--template 模板文件名称(默认:Poem.yaml)
--name 项目名称(默认:Poem)
查看帮助信息:
python -m examples.spo.optimize --help优化完成后,结果将存储在 workspace 目录中,结构如下:
workspace
└── Project_name
└── prompts
├── results.json
├── round_1
│ ├── answers.txt
│ └── prompt.txt
├── round_2
│ ├── answers.txt
│ └── prompt.txt
├── round_3
│ ├── answers.txt
│ └── prompt.txt
├── ...
└── round_n
├── answers.txt
└── prompt.txt
文件说明:
- results.json:存储每轮迭代是否成功判断及其他相关信息。
- prompt.txt:对应轮次的优化提示。
- answers.txt:使用该提示生成的输出结果。
If you use SPO in your research, please cite our paper:
@misc{xiang2025spo,
title={Self-Supervised Prompt Optimization},
author={Jinyu Xiang and Jiayi Zhang and Zhaoyang Yu and Fengwei Teng and Jinhao Tu and Xinbing Liang and Sirui Hong and Chenglin Wu and Yuyu Luo},
year={2025},
eprint={2502.06855},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.06855},
}