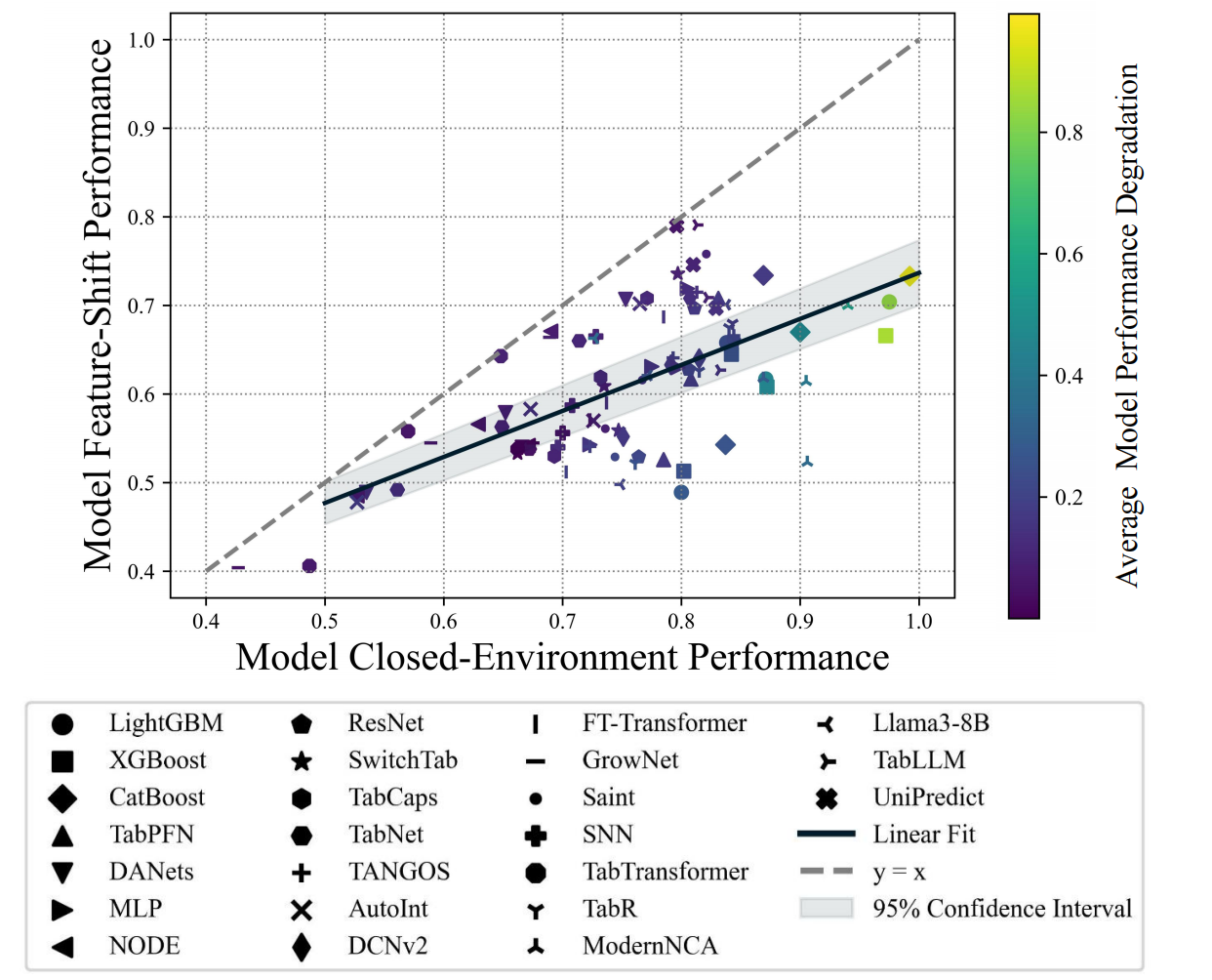
TabFSBench is a benchmarking tool for feature shifts in tabular data in open-environment scenarios. It aims to analyse the performance and robustness of a model in feature shifts.
TabFSBench offers the following advantages:
- Various Models: Tree-based models, deep-learning models, LLMs and tabular LLMs.
- Diverse Experiments: Single shift, most/least-revelant shift and random shift.
- Exportable Datasets: Be able to export the feature-shift version of the given dataset.
- Addable Components: Supports to add new datasets and models, and export the given dataset under the specific experiment.
If you use the benchmark in your research, please cite the paper:
@article{cheng2025tabfsbenchtabularbenchmarkfeature,
title={TabFSBench: Tabular Benchmark for Feature Shifts in Open Environment},
author={Zi-Jian Cheng and Zi-Yi Jia and Zhi Zhou and Lan-Zhe Guo and Yu-Feng Li},
journal={arXiv preprint arXiv:2501.18935},
year={2025}
}
- [2025-03] Results from TabPFNv2 are added.
- [2025-02] Our project page is released.
- [2025-01] Our code is available now.
- [2025-01] Our paper is accessible now.
If you have any questions, please contact us at [email protected] or submit an issue in the project issue.
Download this GitHub repository.
git clone https://github.com/LAMDASZ-ML/TabFSBench.git
cd TabFSBenchCreate a new Python 3.10 environment and install 'requirements.txt'.
conda create --name tabfsbench python=3.10
pip install -r requirements.txtYou need to input four parameters to use TabFSBench. There are dataset, model, task and degree.
dataset and model: input the full name.
task: You can choose 'single', 'least', 'most' or 'random' as TaskName.
degree: Degree refers to the number of missing columns as a percentage of the total number of columns in the dataset, in the range 0-1. If you want to see the performance of the model at all missing degrees, set Degree to 'all'.
export_dataset: Whether to export the dataset or not. Default is 'False'.
python run_experiment.py --dataset DatasetName --model ModelName --task TaskName --degree Degree --export_dataset True/FalseIn example.sh you can get different kinds of instruction samples.
All the datasets used in TabFSBench are publicly available. You can get them from OpenML or Kaggle. Also you can directly use them from ./datasets.
Datasets used in TabFSBench are placed in the project's current directory, corresponding to the file name.
Each dataset folder consists of:
-
dataset.csv, which must be included. -
info.json, which must include the following two contents (task can be "regression", "multiclass" or "binary", link can be from Kaggle or OpenML, num_classes is optional):{ "task": "binary", "link": "www.kaggle.com", "num_classes": }
TabFSBench is possible to test three kinds of models' performance directly, including tree-based models, deep learning models and tabular LLMs. For LLMs, TabFSBnech provides text files(.json) about the given dataset that can be used directly for LLM to finetune.
- CatBoost: A powerful boosting-based model designed for efficient handling of categorical features.
- LightGBM: A machine-learning model based on the Boosting algorithm.
- XGBoost: A machine-learning model incrementally building multiple decision trees by optimizing the loss function.
We use LAMDA-TALENT to evaluate deep-learning models. You can get details from LAMDA-TALENT.
- MLP: A multi-layer neural network, which is implemented according to RTDL.
- ResNet: A DNN that uses skip connections across many layers, which is implemented according to RTDL.
- SNN: An MLP-like architecture utilizing the SELU activation, which facilitates the training of deeper neural networks.
- DANets: A neural network designed to enhance tabular data processing by grouping correlated features and reducing computational complexity.
- TabCaps: A capsule network that encapsulates all feature values of a record into vectorial features.
- DCNv2: Consists of an MLP-like module combined with a feature crossing module, which includes both linear layers and multiplications.
- NODE: A tree-mimic method that generalizes oblivious decision trees, combining gradient-based optimization with hierarchical representation learning.
- GrowNet: A gradient boosting framework that uses shallow neural networks as weak learners.
- TabNet: A tree-mimic method using sequential attention for feature selection, offering interpretability and self-supervised learning capabilities.
- TabR: A deep learning model that integrates a KNN component to enhance tabular data predictions through an efficient attention-like mechanism.
- ModernNCA: A deep tabular model inspired by traditional Neighbor Component Analysis, which makes predictions based on the relationships with neighbors in a learned embedding space.
- AutoInt: A token-based method that uses a multi-head self-attentive neural network to automatically learn high-order feature interactions.
- Saint: A token-based method that leverages row and column attention mechanisms for tabular data.
- TabTransformer: A token-based method that enhances tabular data modeling by transforming categorical features into contextual embeddings.
- FT-Transformer: A token-based method which transforms features to embeddings and applies a series of attention-based transformations to the embeddings.
- TANGOS: A regularization-based method for tabular data that uses gradient attributions to encourage neuron specialization and orthogonalization.
- SwitchTab: A self-supervised method tailored for tabular data that improves representation learning through an asymmetric encoder-decoder framework. Following the original paper, our toolkit uses a supervised learning form, optimizing both reconstruction and supervised loss in each epoch.
- TabPFN: A general model which involves the use of pre-trained deep neural networks that can be directly applied to any tabular task. TabFSBench uses the first version of TabPFN and supports to evaluate TabPFNv2 by updating the version.
- Llama3-8B: Llama3-8B is released by Meta AI in April 2024.
- Due to memory limitations, TabFSBench only provides json files for LLM fine-tuning and testing (
datasetname_train.json / datasetname_test_i.json, i means the degree of feature shifts), asking users to use LLM locally. - TabFSBench provides the context of Credit Dataset. Users can rewrite background, features_information, declaration and question of
llm()in./model/utils.py.
- Due to memory limitations, TabFSBench only provides json files for LLM fine-tuning and testing (
- TabLLM: A framework that leverages LLMs for efficient tabular data classification.
- UniPredict: A framework that firstly trains on multiple datasets to acquire a rich repository of prior knowledge. UniPredict-Light model that TabFSBench used is available at Google Drive. After downloading the model, place it in
./model/tabularLLM/files/unified/modelsand rename it tolight_state.pt.
TabFSBench provides two methods to evaluate new model on feature-shift experiments.
- Export the dataset. Set export_dataset as True, then can get a csv file of a given dataset in a specific experiment.
- Import model python file.
- Add the model name in
./run_experiment.py. - Add the model function in the
./model/utils.pyby leveraging parameters like dataset, model, train_set and test_sets.
- Add the model name in
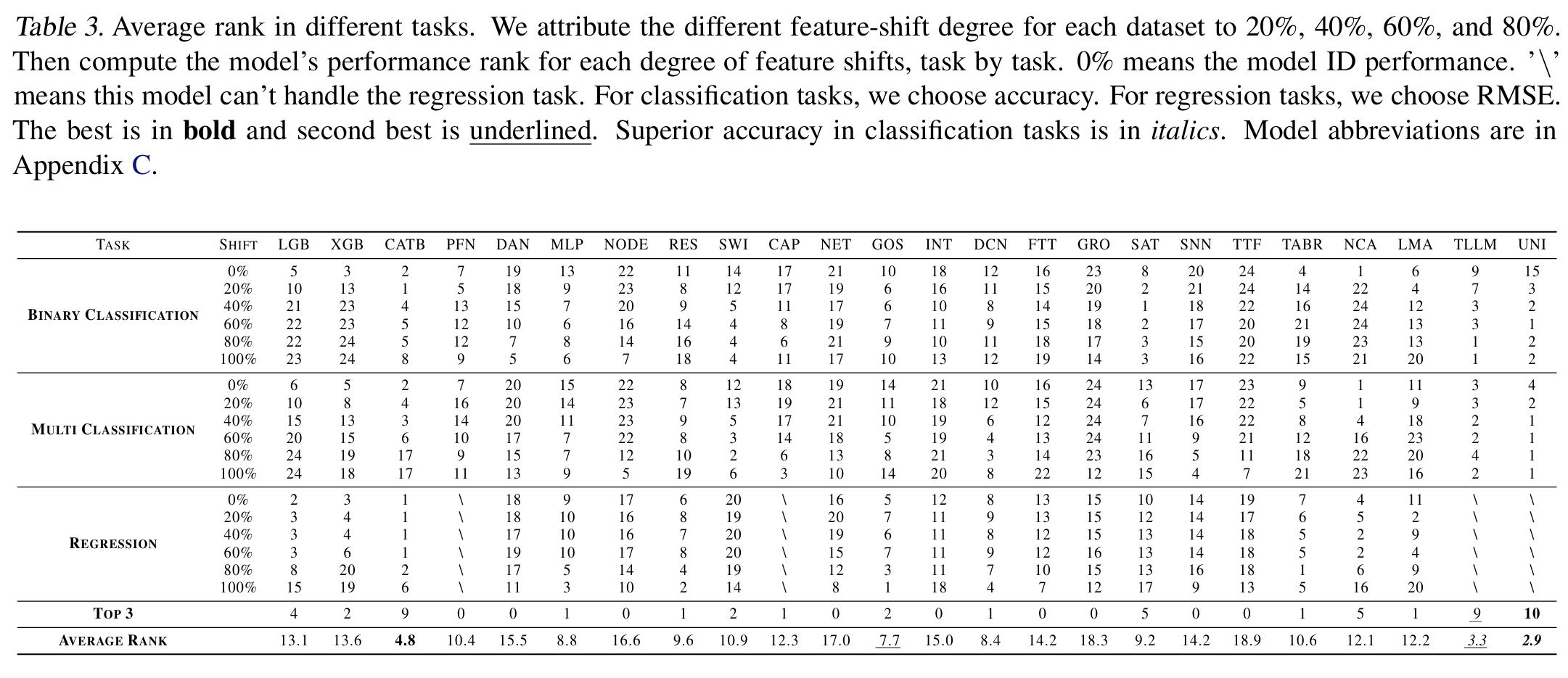
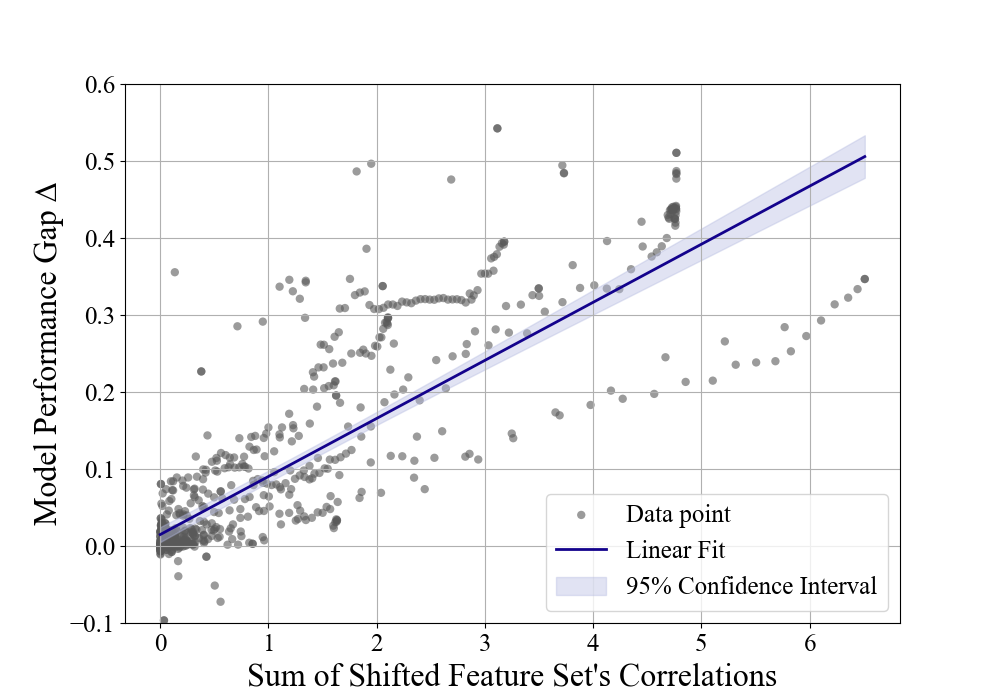
We use