Website • LinkedIn • Slack • Documentation • Blog • Demo
Play with our demo app!
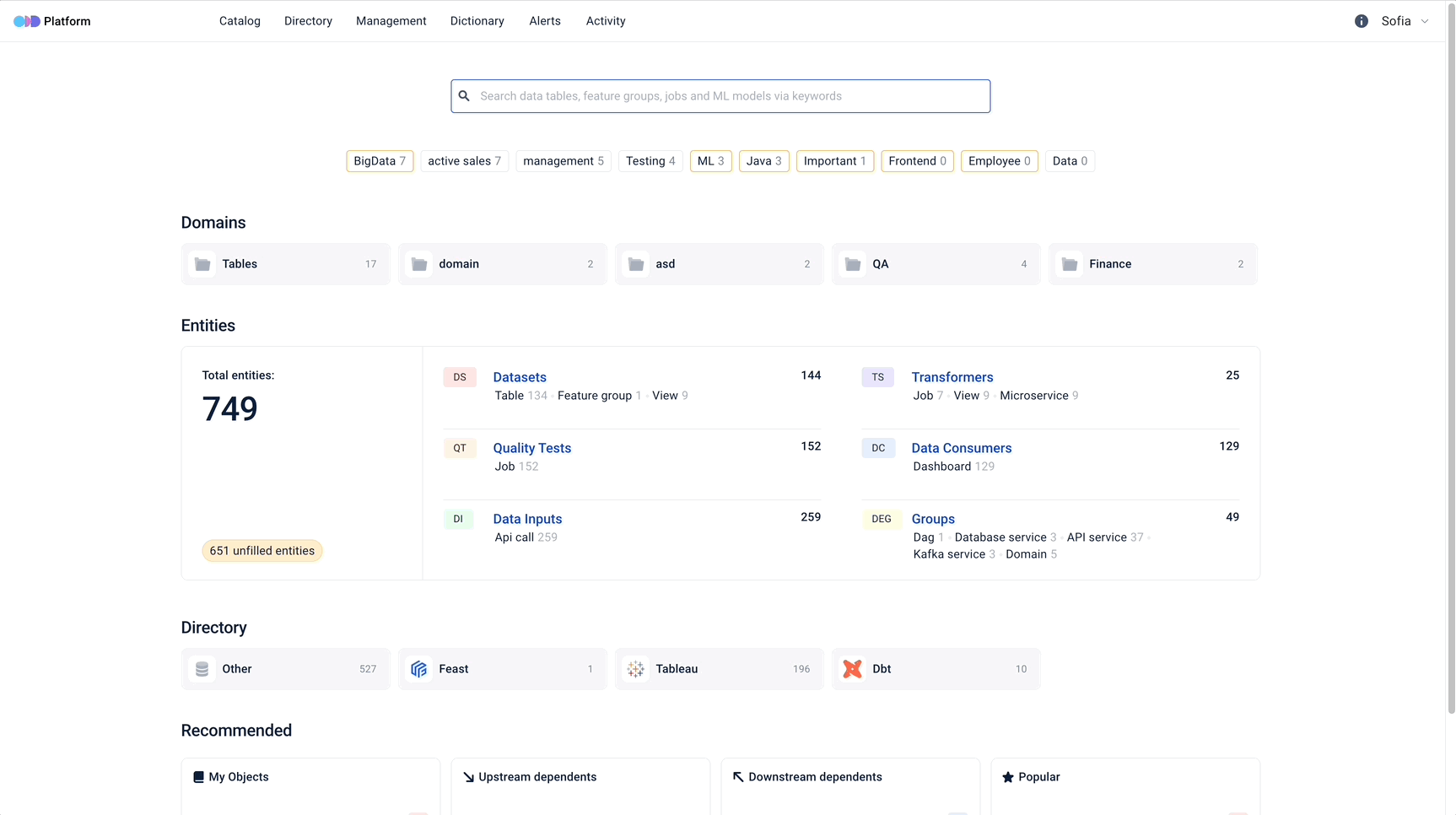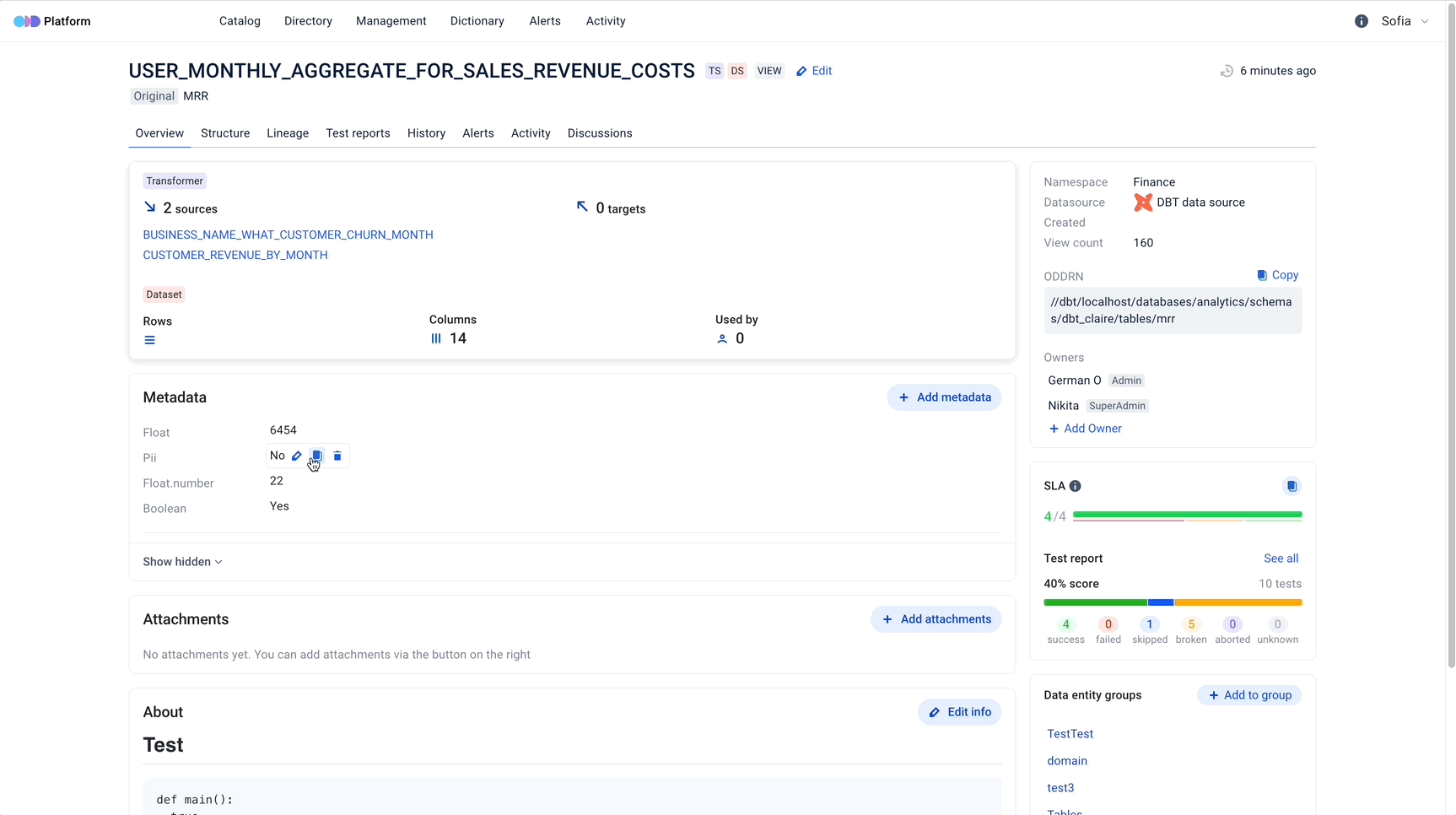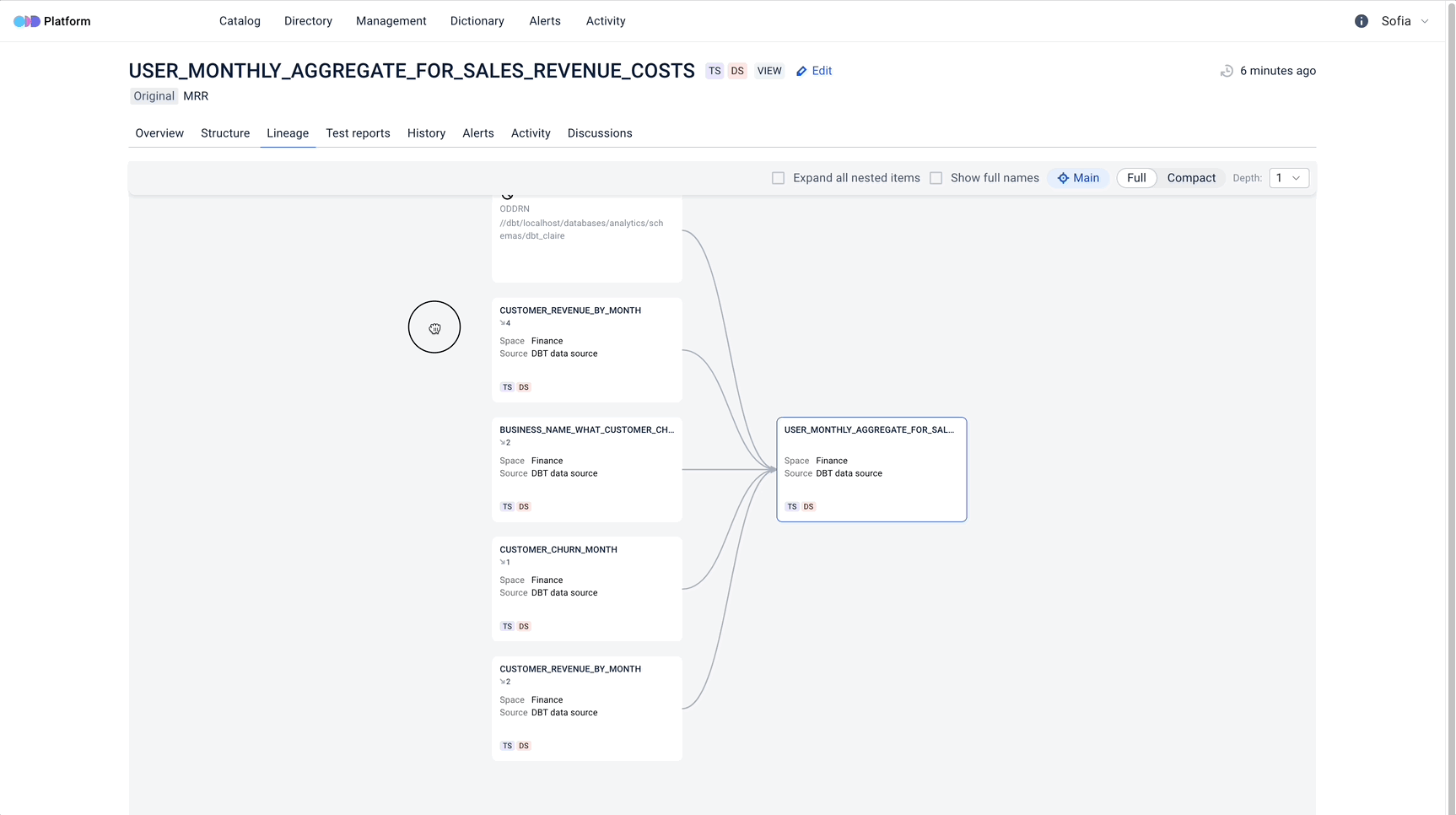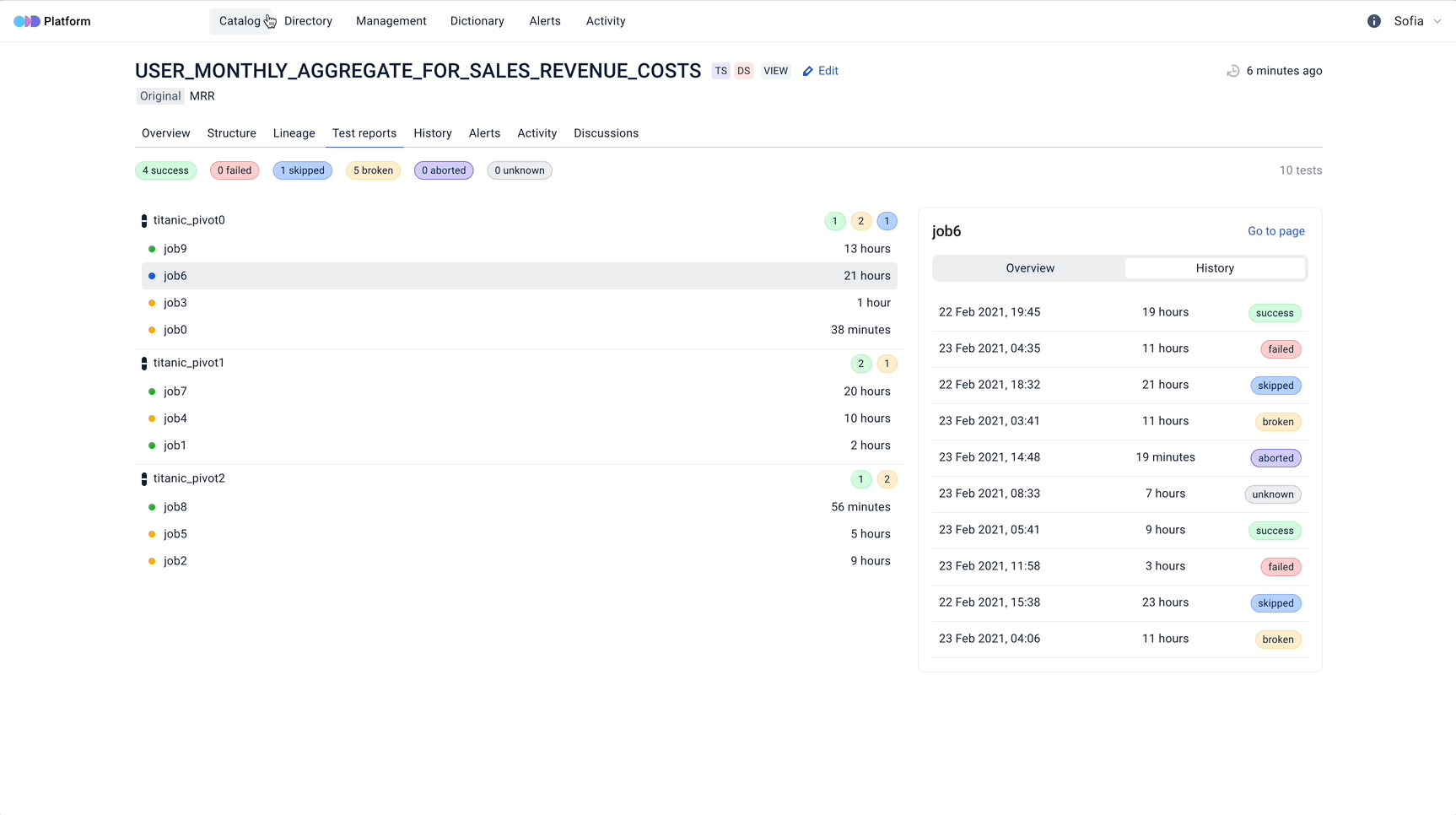
ODD is an open-source data discovery and observability tool for data teams that helps to efficiently democratise data, power collaboration and reduce time on data discovery through modern user-friendly environment.
-
Shorten data discovery phase
-
Have transparency on how and by whom the data is used
-
Foster data culture by continuous compliance and data quality monitoring
-
Accelerate data insights
-
Know the sources of your dashboards and ad hoc reports
-
Deprecate outdated objects responsibly by assessing and mitigating the risks
-
👉 ODD Platform is a reference implementation of Open Data Discovery Spec.
- Accumulate scattered data insights in Federated Data catalogue
- Gain observability through E2E Data objects Lineage
- Benefit from cutting-edge E2E microservices Lineage feature in tracking your data flow through the whole data landscape
- Be warned and alerted by Pipeline Monitoring tools
- Store your metadata
- Use ODD-native modern lightweight UI
- Save results of your ML Experiments by automatically logging its parameters
- Manage Tags and Labels to prevent any abuse of the data
- Refer to Tags and Labels to stay compliant with data security standards
- Have full transparency on how and by whom the data is used
- Simplify DQ processes by using ODD and Great Expectations compatibility
- Integrate ODD with any custom DQ framework
docker-compose -f docker/demo.yaml up -d odd-platform-enricher
There are various example configurations (via docker-compose) within docker/examples directory.
Contributing to ODD Platform is very welcome. For basic contributions, all you need is being comfortable with GitHub and Git. The best ways to contribute are:
- Work on new adapters
- Work on documentation
To ensure equal and positive communication, we adhere to our Code of Conduct. Before starting any interactions with this repository, please read it and make sure to follow.
Please before contributing check out our Contributing Guide and issues labeled "good first issue":
OpenDataDiscovery Platform offers comprehensive data source support to meet your needs.
ODD operates the following high-level types of entities:
- Datasets (collections of data: tables, topics, files, feature groups)
- Transformers (transformers of data: ETL or ML training jobs, experiments)
- Data Consumers (data consumers: ML models or BI dashboards)
- Data Quality Tests (data quality tests for datasets)
- Data Inputs (sources of data)
- Transformer Runs (executions of ETL or ML training jobs)
- Quality Test Runs executions of data quality tests
For more information, please check specification.md.
Join our community if you need help, want to chat or have any other questions for us:
- GitHub - Discussion forums and issues
- Slack - Join the conversation! Get all the latest updates and chat to the devs
If you have any questions or ideas, please don't hesitate to drop a line to any of us.
| Team Member | GitHub | |
|---|---|---|
| German Osin | germanosin | |
| Nikita Dementev | DementevNikita | |
| Damir Abdullin | damirabdul | |
| Alexey Kozyurov | Leshe4ka | |
| Pavel Makarichev | vixtir | |
| Roman Zabaluev | Haarolean |
ODD Platform uses the Apache 2.0 License.