The Subtitler is an application that provides real-time subtitling for spoken audio. It uses speech recognition and translation to convert spoken words into subtitles, which are displayed on the screen. This README file explains how to use the Subtitler and provides an overview of its functionality.
pip install requirements.txtClick the image below for the demo:
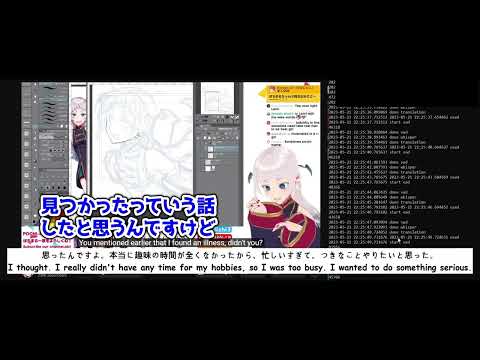
To run the Subtitler, execute the following command:
python main.pyUpon running the command, a Tkinter interface will open, allowing you to configure the parameters for the Subtitler.
- Offset X: The horizontal offset of the subtitle overlay window.
- Offset Y: The vertical offset of the subtitle overlay window.
- Font Size: The size of the subtitle text.
- Color: The color of the subtitle text.
- Background Color: The background color of the subtitle overlay window.
- Sacrificial Color: The color used for transparency in the subtitle overlay window.
- Tk Timeout: The duration (in milliseconds) for which the subtitle overlay window remains visible.
- App Output ID: The ID of the microphone input to use for recording audio.
- Record Timeout: The duration (in seconds) for which audio is recorded in each recording session.
- Phrase Timeout: The maximum duration (in seconds) between phrases before a new phrase is started.
- Pause Threshold: The pause duration (in seconds) between phrases.
- Model Type: The type of speech recognition model to use.
After configuring the parameters, click the "Start" button to begin the Subtitler application. The Subtitler will start listening to the specified microphone input and display real-time subtitles on the screen.
The Subtitler uses the speech_recognition library to record audio from the selected microphone input. It performs voice activity detection (VAD) using the webrtcvad module to detect speech segments in the recorded audio.
Once a speech segment is detected, it is processed using the whisper library to perform speech recognition. The resulting text is then translated from the source language (Japanese by default) to the target language (English by default) using the deep_translator module.
The translated text is displayed as subtitles on the screen using a Tkinter overlay window. The overlay window is transparent and can be positioned and styled using the configuration parameters provided in the Tkinter interface.
To close the Subtitler, you can either click the "Close" button in the Tkinter interface or press Ctrl+C in the terminal window where the Subtitler is running.
Please note the following limitations of the Subtitler:
- The Subtitler currently supports recording audio from a single microphone input. If you have multiple microphone inputs, you can select the desired input using the "App Output ID" parameter in the Tkinter interface.
- The speech recognition and translation accuracy depends on the quality of the audio and the performance of the underlying speech recognition and translation models.
- The Subtitler may not work correctly if the selected microphone input is not properly configured or if there are issues with the audio recording setup.