forked from activepieces/activepieces
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
11 changed files
with
285 additions
and
98 deletions.
There are no files selected for viewing
This file was deleted.
Oops, something went wrong.
2 changes: 1 addition & 1 deletion
2
docs/handbook/engineering/how-we-work.mdx → ...ok/engineering/onboarding/how-we-work.mdx
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,5 +1,5 @@ | ||
| --- | ||
| title: "How We Work?" | ||
| title: "Engineering Workflow" | ||
| icon: 'lightbulb' | ||
| --- | ||
|
|
||
|
|
||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,8 @@ | ||
| --- | ||
| title: "Overview" | ||
| icon: "code" | ||
| --- | ||
|
|
||
| Welcome to the engineering team! This section contains essential information to help you get started, including our development processes, guidelines, and practices. We're excited to have you on board. | ||
|
|
||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,91 @@ | ||
| --- | ||
| title: "Queues Dashboard" | ||
| icon: "gauge-high" | ||
| --- | ||
|
|
||
| The Bull Board is a tool that allows you to check issues with scheduling and internal flow runs issues. | ||
|
|
||
| 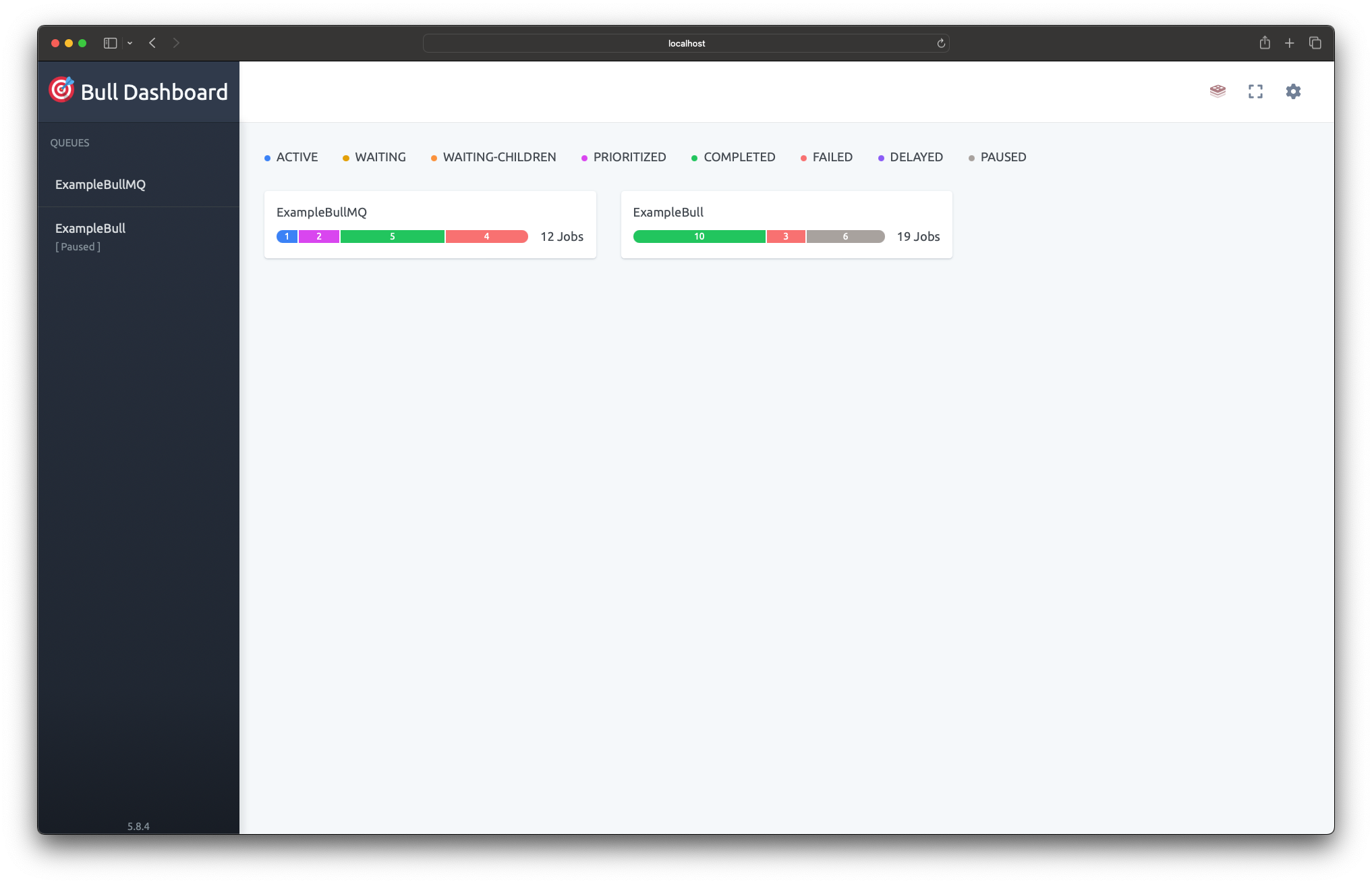 | ||
|
|
||
| ## Setup BullBoard | ||
|
|
||
| To enable the Bull Board UI in your self-hosted installation: | ||
|
|
||
| 1. Define these environment variables: | ||
| - `AP_QUEUE_UI_ENABLED`: Set to `true` | ||
| - `AP_QUEUE_UI_USERNAME`: Set your desired username | ||
| - `AP_QUEUE_UI_PASSWORD`: Set your desired password | ||
|
|
||
| 2. Access the UI at `/api/ui` | ||
|
|
||
|
|
||
| <Tip> | ||
| For cloud installations, please ask your team for access to the internal documentation that explains how to access BullBoard. | ||
| </Tip> | ||
|
|
||
| ## Common Issues | ||
|
|
||
| ### Scheduling Issues | ||
|
|
||
| If a scheduled flow is not triggering as expected: | ||
|
|
||
| 1. Check the `repeatableJobs` queue in BullBoard to verify the job exists | ||
| 2. Verify the job status is not "failed" or "delayed" | ||
| 3. Check that the cron expression or interval is configured correctly | ||
| 4. Look for any error messages in the job details | ||
|
|
||
| ### Flow Stuck in "Running" State | ||
|
|
||
| If a flow appears stuck in the running state: | ||
|
|
||
| 1. Check the `oneTimeJobs` queue for the corresponding job | ||
| 2. Look for: | ||
| - Jobs in "delayed" state (indicates retry attempts) | ||
| - Jobs in "failed" state (indicates execution errors) | ||
| 3. Review the job logs for error messages or timeouts | ||
| 4. If needed, you can manually remove stuck jobs through the BullBoard UI | ||
|
|
||
| ## Queue Overview | ||
|
|
||
| We maintain four main queues in our system: | ||
|
|
||
| #### Scheduled Queue (`repeatableJobs`) | ||
|
|
||
| Contains both polling and delayed jobs. | ||
|
|
||
| <Info> | ||
| Failed jobs are not normal and need to be checked right away to find and fix what's causing them. | ||
| </Info> | ||
|
|
||
| <Tip> | ||
| Delayed jobs represent either paused flows scheduled for future execution or upcoming polling job iterations. | ||
| </Tip> | ||
|
|
||
| #### One-Time Queue (`oneTimeJobs`) | ||
| Handles immediate flow executions that run only once | ||
|
|
||
| <Info> | ||
| - Delayed jobs indicate an internal system error occurred and the job will be retried automatically according to the backoff policy | ||
| - Failed jobs require immediate investigation as they represent executions that failed for unknown reasons that could indicate system issues | ||
| </Info> | ||
|
|
||
| #### Webhook Queue (`webhookJobs`) | ||
|
|
||
| Handles incoming webhook triggers | ||
|
|
||
| <Info> | ||
| - Delayed jobs indicate an internal system error occurred and the job will be retried automatically according to the backoff policy | ||
| - Failed jobs require immediate investigation as they represent executions that failed for unknown reasons that could indicate system issues | ||
| </Info> | ||
|
|
||
| #### Users Interaction Queue (`usersInteractionJobs`) | ||
|
|
||
| Handles operations that are directly initiated by users, including: | ||
| • Installing pieces | ||
| • Testing flows | ||
| • Loading dropdown options | ||
| • Executing triggers | ||
| • Executing actions | ||
| <Info> | ||
| Failed jobs in this queue are not retried since they represent real-time user actions that should either succeed or fail immediately | ||
| </Info> |
94 changes: 94 additions & 0 deletions
94
docs/handbook/engineering/playbooks/database-migration.mdx
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,94 @@ | ||
| --- | ||
| title: "Database Migrations" | ||
| description: "Guide for creating database migrations in Activepieces" | ||
| icon: "database" | ||
| --- | ||
|
|
||
| Activepieces uses TypeORM as its database driver in Node.js. We support two database types across different editions of our platform. | ||
|
|
||
| The database migration files contain both what to do to migrate (up method) and what to do when rolling back (down method). | ||
|
|
||
| <Tip> | ||
| Read more about TypeORM migrations here: | ||
| https://orkhan.gitbook.io/typeorm/docs/migrations | ||
| </Tip> | ||
|
|
||
| ## Database Support | ||
|
|
||
| - PostgreSQL | ||
| - SQLite | ||
|
|
||
| <Tip> | ||
| **Why Do we have SQLite?** | ||
| We support SQLite to simplify development and self-hosting. It's particularly helpful for: | ||
|
|
||
| - Developers creating pieces who want a quick setup | ||
| - Self-hosters using platforms to manage docker images but doesn't support docker compose. | ||
| </Tip> | ||
|
|
||
| ## Editions | ||
|
|
||
| - **Enterprise & Cloud Edition** (Must use PostgreSQL) | ||
| - **Community Edition** (Can use PostgreSQL or SQLite) | ||
|
|
||
| <Tip> | ||
| If you are generating a migration for an entity that will only be used in Cloud & Enterprise editions, you only need to create the PostgreSQL migration file. You can skip generating the SQLite migration. | ||
| </Tip> | ||
|
|
||
|
|
||
| ### How To Generate | ||
|
|
||
| <Steps> | ||
| <Step title="Uncomment Database Connection Export"> | ||
| Uncomment the following line in `packages/server/api/src/app/database/database-connection.ts`: | ||
| ```typescript | ||
| export const exportedConnection = databaseConnection() | ||
| ``` | ||
| </Step> | ||
|
|
||
| <Step title="Configure Database Type"> | ||
| Edit your `.env` file to set the database type: | ||
|
|
||
| ```env | ||
| # For SQLite migrations (default) | ||
| AP_DATABASE_TYPE=SQLITE | ||
| ``` | ||
|
|
||
| For PostgreSQL migrations: | ||
| ```env | ||
| AP_DATABASE_TYPE=POSTGRES | ||
| AP_POSTGRES_DATABASE=activepieces | ||
| AP_POSTGRES_HOST=db | ||
| AP_POSTGRES_PORT=5432 | ||
| AP_POSTGRES_USERNAME=postgres | ||
| AP_POSTGRES_PASSWORD=password | ||
| ``` | ||
| </Step> | ||
|
|
||
| <Step title="Generate Migration"> | ||
| Run the migration generation command: | ||
| ```bash | ||
| nx db-migration server-api name=<MIGRATION_NAME> | ||
| ``` | ||
| Replace `<MIGRATION_NAME>` with a descriptive name for your migration. | ||
| </Step> | ||
|
|
||
| <Step title="Move Migration File"> | ||
| The command will generate a new migration file in `packages/server/api/src/app/database/migrations`. | ||
| Review the generated file and: | ||
|
|
||
| - For PostgreSQL migrations: Move it to `postgres-connection.ts` | ||
| - For SQLite migrations: Move it to `sqlite-connection.ts` | ||
| </Step> | ||
|
|
||
| <Step title="Re-comment Export"> | ||
| After moving the file, remember to re-comment the line from step 1: | ||
| ```typescript | ||
| // export const exportedConnection = databaseConnection() | ||
| ``` | ||
| </Step> | ||
| </Steps> | ||
|
|
||
| <Tip> | ||
| Always test your migrations by running them both up and down to ensure they work as expected. | ||
| </Tip> |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,26 @@ | ||
| --- | ||
| title: "Cloud Infrastructure" | ||
| icon: "server" | ||
| --- | ||
|
|
||
| <Warning> | ||
| The playbooks are private, Please ask your team for an access. | ||
| </Warning> | ||
|
|
||
|
|
||
| Our infrastructure stack consists of several key components that help us monitor, deploy, and manage our services effectively. | ||
|
|
||
| ## Hosting Providers | ||
|
|
||
| We use two main hosting providers: | ||
|
|
||
| - **DigitalOcean**: Hosts our databases including Redis and PostgreSQL | ||
| - **Hetzner**: Provides the machines that run our services | ||
|
|
||
| ## Grafana (Loki) for Logs | ||
|
|
||
| We use Grafana Loki to collect and search through logs from all our services in one centralized place. | ||
|
|
||
| ## Kamal for Deployment | ||
|
|
||
| Kamal is a deployment tool that helps us deploy our Docker containers to production with zero downtime. |
2 changes: 1 addition & 1 deletion
2
docs/handbook/engineering/pre-releases.mdx → ...ndbook/engineering/playbooks/releases.mdx
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,5 +1,5 @@ | ||
| --- | ||
| title: 'Pre-Releases' | ||
| title: 'How to create Release' | ||
| icon: 'flask' | ||
| --- | ||
|
|
||
|
|
||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,30 @@ | ||
| --- | ||
| title: "Setup Incident.io" | ||
| icon: 'bell-ring' | ||
| --- | ||
|
|
||
| Incident.io is our primary tool for managing and responding to urgent issues and service disruptions. | ||
| This guide explains how we use Incident.io to coordinate our on-call rotations and emergency response procedures. | ||
|
|
||
| ## Setup and Notifications | ||
|
|
||
| ### Personal Setup | ||
|
|
||
| 1. Download the Incident.io mobile app from your device's app store | ||
| 2. Ask your team to add you to the Incident.io workspace | ||
| 3. Configure your notification preferences: | ||
| - Phone calls for critical incidents | ||
| - Push notifications for high-priority issues | ||
| - Slack notifications for standard updates | ||
|
|
||
| ### On-Call Rotations | ||
|
|
||
| Our team operates on a weekly rotation schedule through Incident.io, where every team member participates. When you're on-call: | ||
| - You'll receive priority notifications for all urgent issues | ||
| - Phone calls will be placed for critical service disruptions | ||
| - Rotations change every week, with handoffs occurring on Monday mornings | ||
| - Response is expected within 15 minutes for critical incidents | ||
|
|
||
| <Tip> | ||
| If you are unable to respond to an incident, please escalate to the engineering team. | ||
| </Tip> |
Oops, something went wrong.