
"gestore" means "manager" in Italian.
Report bug
·
Report security issues
·
Appsembler
·
Blog
A set of tools that will help you to
- Export individual objects from DB.
- Import exported objects back.
- Delete objects from the database and all other objects related to it.
Note
Object Import and Delete are not production-ready yet. Use with caution
This idea came out of Appsembler Multi-Cluster UI/UX Workflows. This tool is handy for supporting multiple clusters. Other reasons why having robust Export/Import/Delete functionality on your app would be highly beneficial:
- Frees your site from lots of data you are not using. It's a great idea to export such data to a file system so you can import it later.
- Decreases the overhead for data tools.
- Removes old data to keep your costs down and improve performance of aggregation functions (e.g., data pipelines)
- Deletes obsolete objects as customers churn.
- Data export is beneficial for GDPR reasons
- Some customers want their data now for DR (disaster recovery) reasons, not because they're churning.
- If you are strongly motivated to create a separate cluster for data that already exists on a current one.
- Lowers the risk of objects (e.g., trial users) being able to crack your site isolation and access data from paying customers.
While the functionality might seem the same, these Gestore commands are entirely different from Django commands.
You can use Django's dumpdata commands to back up (export) your models or whole database. And loaddata command helps to import these objects back.
On the other hand, Gestore's exportobjects command will help you export all data across the database that's only related to a given Object. This functionality will make sure that you can import these exported objects successfully later.
Let's assume you want to export a specific Books object:

In Django, you have to export all Books objects dumpdata and load it back later using loaddata. This method is not practical in two situations:
- You only want to export one object, not the whole table.
- Importing that object back might cause some problems as
Authorsobject does not exist the exports file.
Gestore helps you overcome these issues altogether. When you provide it with your object ID, Gestore will scan all objects related to it, so when you import it back, you get it to work as expected.
Start by installing the package from pip
pip install gestoreTo be able to access the management commands, add gestore to your installed apps:
INSTALLED_APPS = [
...
'gestore',
]Now your project should be ready to use gestore to manage objects.
This tool uses BFS to explore all objects in the DB from the given one. In the following GIF, let's assume you want to export object number 3; gestore will fetch its data and process all the objects it's connected to
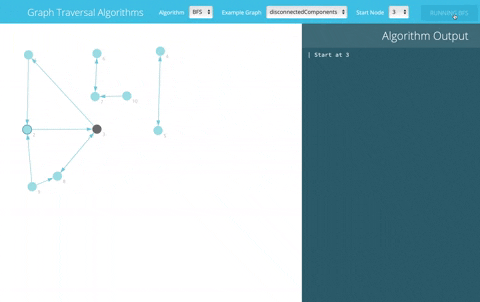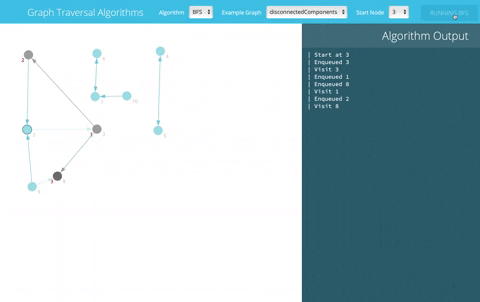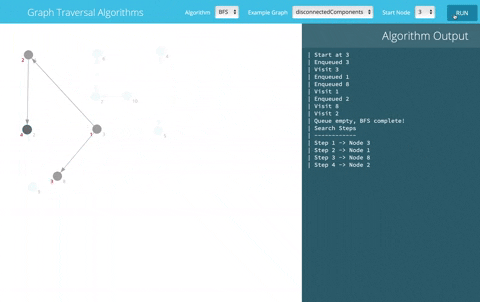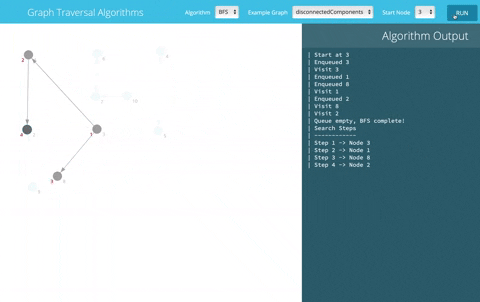
This command will help you export all object-related data once triggered. For every model being processed: we get its data, including linked objects' keys (Foreign, ManyToMany, OneToOne) until we hit a base model that's not connected to any other model (leaf node).
We use a BFS technique to scrape data element by element from the database until we reach a node without any relations. For each processed object, we store its data and its children's data.
The output of
exportobjectscan be used as input forimportobjects.
python manage.py exportobjects [-d] [-o OUTPUT] [-r [ROOT ...]] objectsobjects is a list of objects to be exported. Each of these arguments must match the following syntax: <app_id>.<Model>.<object_id>
python manage.py exportobjects auth.User.10 demoapp.Book.4 -o /path/to/exp.jsonobjectsThe main argument of theexportobjects. Its representation is described above.--debugflag is optional. Use it to prevent any file writing. It is helpful to see the JSON output of the data before writing it on your system.--outputis an optional argument that takes a path string of the location in which you want to store the data exports file.--rootis an optional argument you can use to skip processing certain models. Check thegenerate_objectsfor more info.--bucketIf provided, we will export the objects a GCP bucket in the path provided above (or the auto generated one). This needs settings configurations.
Importing objects is developed in a way that leverages Django's
django.core.serializers.python.Deserializer functionality. In Django, if you are loading a JSON-formatted object into a Model, Django will check the desired table for that object ID and then determines whether to perform either an update or an insert action on that table.
python manage.py importobjects [-d] [-o] pathpython manage.py importobjects /path/to/exp.jsonpath. The main argument of theimportobjects. It should point to an export file on your local system.--debugperforms a dry run. Will not commit or save any changes to the DB.--overrideDANGEROUS. In case of a conflict, this will override objects in the DB with the ones being imported.--bucketIf provided, we will import the objects from the given path in a GCP bucket. This needs settings configurations.
Let's say I have two objects with the same ID. Both of these objects might have the same schema or might be completely different. How can we perform a safe import without sacrificing the current data and without duplicating all objects? In other words, we have primary key collisions on import and need a strategy to prevent these collisions.
As this app is still under development, we now route for two ways to solve this:
- Manual editing: We'll collect all conflicts before committing changes, then we notify the developer about them. The developer will go to the export file, check these objects, compare them with the ones in the database, and modify the import file with the desired values. Once satisfied, they can use the import command again.
- Force replacement: Using the
--overrideflag allows the command to replace all conflicting objects in the DB with the ones being imported. This is a very DANGEROUS approach and should never be considered in a production environment.
- Using UUIDs in our system: It's the industry-standard solution making database IDs unique in distributed systems.
- Changing conflicting objects IDs: This is a good solution to avoid all conflicts. We set an offset value (or auto increment) and add it to the new object being inserted in the database. Instead of
ID=1we end up withID=9001. This approach is nice in case conflicts have been resolved, but might cause data duplicates in case not.
This app is created for the sole purpose of testing and visualizing the manager commands in action. No other functionality is expected out of this app.
We publish new releases using GitHub Actions. The following steps must be followed to post a new release:
- Create a PR to bump the version and get it merged. Version is being stored in gestore/init.py file which both the commands and the setup.py file read its value from.
- Once the PR is merged, go and make a new release out of master using the Draft New Release button:
- Mark dev releases as Pre-release so it's clear on GitHub and PyPI
- In a minute or so, the release will be published into PyPI.
- Go to the GitHub actions tab and select Build and upload Python package.
- Click on it to see build logs.
Until we feel this is production-ready, we will continue only to push releases that contain dev in them.
- Platform state: When exporting data from your project, it's assumed that importing it back will take place in the same project with the same data structures. If you upgrade a library that you're using its models, and these models were changed (fields removed, added, type changed), you will face some problems.
- Object conflicts
- Some data like usernames are unique cluster-wide; if we're importing such data from another cluster, some could be duplicated or overridden.
- Some exported objects might have a similar ID to a different object in the database. This tool will flag these objects for you so you know what to change and what to override.
- Using Buckets: At the moment, we are only supporting GCP Cloud Storage, not only that, but we are using
gsutilto perform this operation for us. I know this sounds stupid, but it was our only way to do so sincegoogle-cloud-storagedoesn't have support for Python 3.5, which is something we have to support at the moment.
Please do not report security issues in public. Please email us on [email protected].