Design A Google Analytic like Backend System.
Requirement
We need to provide Google Analytic like services to our customers. Pls provide a high level solution design for the backend system. Feel free to choose any open source tools as you want.
The system needs to:
-
handle large write volume: Billions write events per day.
-
handle large read/query volume: Millions merchants want to get insight about their business. Read/Query patterns are time-series related metrics.
-
provide metrics to customers with at most one hour delay.
-
run with minimum downtime.
-
have the ability to reprocess historical data in case of bugs in the processing logic.
Please refer at the end for solution to above specific requirement
Requirement Analysis
- Collection : Collects user-interaction data.
- Configuration: Allows you to manage how the data is processed.
- Processing : Processes the user-interaction data with the configuration data.
- Reporting : Provides access to all the processed data.

Data Collection Backend API Design
Analtics input data includes millions of concurrent event data coming from sources. The volume is huge and it comes in very fast rates from milliions of sources. Hence Data collection API must be higly scalable highly efficient microservice API. We have many architecture options for designing the microservice API. The most common is REST microservice. The REST depends on HTTP/1.1 protocol. We know that HTTP/1.1 highly inefficient when we compare with websocket or HTTP/1.2 protocol implementations. HTTP/1.x was fundamentally built over the principle that only one response can be delivered at a time. This led to response queueing and blocking, slowing down the TCP connection along with whole lot of other problems. Many these problems are solved by HTTP/1.2 though REST doesnt support it yet. Moreover the request response interaction model of HTTP that REST uses makes it poor choice for the data collection backend API.
Another solution is RSocket, is a new binary application-level protocol capable of reactive streaming. Its is transport agnostic and can be used on top of any transport protocol like TCP or even on top of HTTP/2 or WebSocket. From QPS, latency, CPU consumption, and scalability, RSocket performs better than many compteting microservice implementation like REST, grpc etc. RSocket has various interaction which can be used for different Use cases.
- request/response (HTTP Like)
- request/stream (finite stream of many)
- fire-and-forget (Kind of Async)
- event subscription (infinite stream of many)
For our Data collection API, Fire and Forget Model is best suited because its highly async.
Aprt from RSocket API, we also needed following components at the Data collection API
Load Balancer A Load Balancer, usually High Availability Proxy is used as Software Load Balancing solution. It shall be distributed cluster servers deployed across georgraphy to support users across globe with better response. When we use Kubernetes as a container orchestrator and cluster or workload management we have two options for Load balancing - an extenal load balancer (NOT in your kubernetes cluster) like HAProxy using k8s LoadBalancer service and Ingress controller which is just a set of rules to pass to a APIs that is listening for the request. (We would use netify as External HALB which I will discuss later)
API gateway, Service Registration/Discovery Its a gateway and single point of entry for microservices APIs. We have many options Spring cloud Gateway (which itself built on top of Rsocket) or Apache Dubbo. Dubbo provide Automatic service registration and discovery, Load banlacing,Runtime traffic routing and Visualized service monitoring also. Visualized monitoring very important as it helps in querying service metadata, health status and statistics.
Service Mesh
Service mesh is an interservice communication among Microservice APIs. The service mesh is usually implemented by providing a proxy instance, called a sidecar, for each service instance. Istio is most common Service mesh infrastructure tool available in market. It also provide other services to monitor and control microservices.
I am proposing a Data Collection API Architecture is Shown Below

Netifi
I am propsoing to use Netify which simplifies the process of building cloud-native applications and microservices using Rsocket. Applications and services can communicate with each other as peers, without any of them having to keep track of where their peers are to be found, while Netifi takes care of networking concerns like routing, session resumption, application flow control, and predictive load balancing.
Follwing is architecture diagram sourced from netify
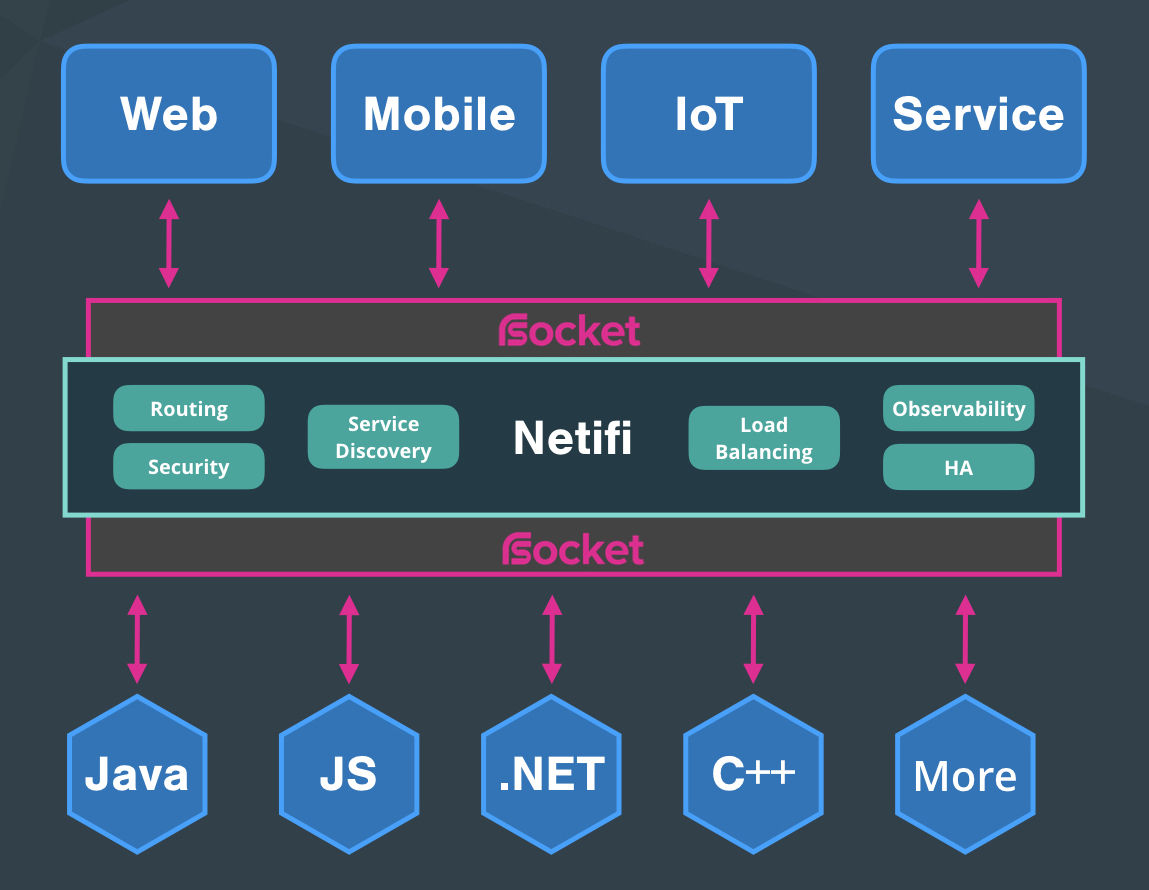
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Netify also provide Service Mesh which is compeltely different from usual sidecar approach. Existing meshes require doubling the size of your infrastructure by requiring you to run proxies for every single service instance that we deploy, increasing operational overhead and cost, while reducing overall performance.

Here sidecar proxy intercepts/manages service to service communication. On the other hand in Netifi we have a virtual point-to-point network between all the microservice API services.No side car required to be deployed in every ervices and then configure TCP/IP configurations. The virtual P2P makes the communciation ligning fast and also secure.

Scalability,fault-tolerance and availability which I have not mentioned above for the the Rsocket microservices achieved through deploying the services Kubernetes cluster which I will explain at the end of the design
Data Processing Design
My proposed design uses Apache Kafka events data collection as it handle high volumes of traffic which is core requirement for google analytical platoform. Different event types in the system shall be maintained in separated Kafka topics, which helps in scaling them separately. Following is the architecture

Kafka brokers cluster shall run multiple data centers across the globe to provide highly available stream pipeline bus.
Now we have data pushed into highly available Kafka System and now we need read this and build Distributed Datasets (Time series dataset). APache spark can be used to process stream data as it provide large number of tranformations and aggregation actions to build our dataset. Spark can use Inmemory database like Redis during the transformation and aggregation action. Once aggregated it can be pushed to a NoSQL data store. Cassandra is best suited for the case. Cassandra is a peer-to-peer architecture ensuring high availability. There is no concept of master slave.

Data Configuration
There are many configuration required for data analtics which can be done via Configuration module. Example include create users and acount, managing reports, configuraing reports, setting user access etc. This can be implemented with simple REST microservices API.
I propose Qurakus(claimed to be Supersonic Subatomic Java) REST framework over Spring because its A Kubernetes Native Java REST stack. Another aspect is we can use GraalVM or OpenJDK HotSpot. Graal is super fast polygot VM running applications written in JavaScript, Python, Ruby, R, JVM-based languages like Java, Scala, Groovy, Kotlin, Clojure, and LLVM-based languages such as C and C++.

Reporting/Data Visualization API
For reports and data visulaization, I am proposing solution involing graphQL as its best suited as we require large types of custom reports and dyanamic reports. Of course graphQL can be agregator and still it can call REST microservice API to gather data from data store. I propose Quarkus REST stack over sporing boot in this implementation this microservice bankend for GraphQL aggregator

Report data shall be cached in MongoDB for faster access. reports accessed repeatedly or static data can be efficiently cached in mongodb.
Other Design considertion
I propose Kubernetes as CD solution it allows to deploy and manage cloud-native miroservices based analtics application helps in scaling application, hot deployment, version management, health monitoring nodes/pods, tracing with help of add on modules
I propose to use countinous integration using github/jenkin. (My personal favourite is GITlab CI)
Solutions for specific Requirement
- handle large write volume: Billions write events per day
At a high level, we need decoupled components, asynchronous communication real-time computations and highly available systems/db for managing large volume write of event data. We also need to map data to in memory db during processing. Rsocket, Kafka Stream, Spark, cassandra and redis infrstructure solution best suited for this.
- handle large read/query volume: Millions merchants want to get insight about their business. Read/Query patterns are time-series related metrics
The solution involves > DB level - Optimizing Data Queries using indexing, Contrlled query scope (like query range), better Retention strategy for reaccessed data, limit caridnality while fetching > Application level - caching (Mongodb)
-
provide metrics to customers with at most one hour delay
Job scheduling in Apache spark should be able do this
-
run with minimum downtime
Kafka, Spark and cassandra all provide high availability along with load balancing and kubernates(Rolling updates) ensure we have have a highly available system with minimum downtime
- have the ability to reprocess historical data in case of bugs in the processing logic
Kafka writes the messages it receives to disk and keeps multiple copies of each message, hence it ensures durability. So in case bugs or failures we can reprocess the data. However, its not the permanent store. So we configure our Kafka cluster to retain information for a few hours and get the data and then push data to permanent store like Google Cloud STorage or Amazon S3.