forked from xdit-project/xDiT
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
add scripts for cogvideo and ditfastattn (xdit-project#299)
- Loading branch information
1 parent
542cf6a
commit b9f10ac
Showing
5 changed files
with
186 additions
and
3 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -10,5 +10,4 @@ profile/ | |
| xfuser.egg-info/ | ||
| dist/* | ||
| latte_output.mp4 | ||
| *.sh | ||
| cache/ | ||
| cache/ | ||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -92,6 +92,7 @@ Furthermore, xDiT incorporates optimization techniques from [DiTFastAttn](https: | |
|
|
||
| <h2 id="updates">📢 Updates</h2> | ||
|
|
||
| * 🎉**October 10, 2024**: xDiT applied DiTFastAttn to accelerate single GPU inference for Pixart Models! The scripst is [./scripts/run_fast_pixart.py](./scripts/run_fast_pixart.py). | ||
| * 🎉**September 26, 2024**: xDiT has been officially used by [THUDM/CogVideo](https://github.com/THUDM/CogVideo)! The inference scripts are placed in [parallel_inference/](https://github.com/THUDM/CogVideo/blob/main/tools/parallel_inference) at their repository. | ||
| * 🎉**September 23, 2024**: Support CogVideoX. The inference scripts are [examples/cogvideox_example.py](examples/cogvideox_example.py). | ||
| * 🎉**August 26, 2024**: We apply torch.compile and [onediff](https://github.com/siliconflow/onediff) nexfort backend to accelerate GPU kernels speed. | ||
|
|
@@ -284,7 +285,7 @@ Below is an example of using xDiT to accelerate a Flux workflow with LoRA: | |
| 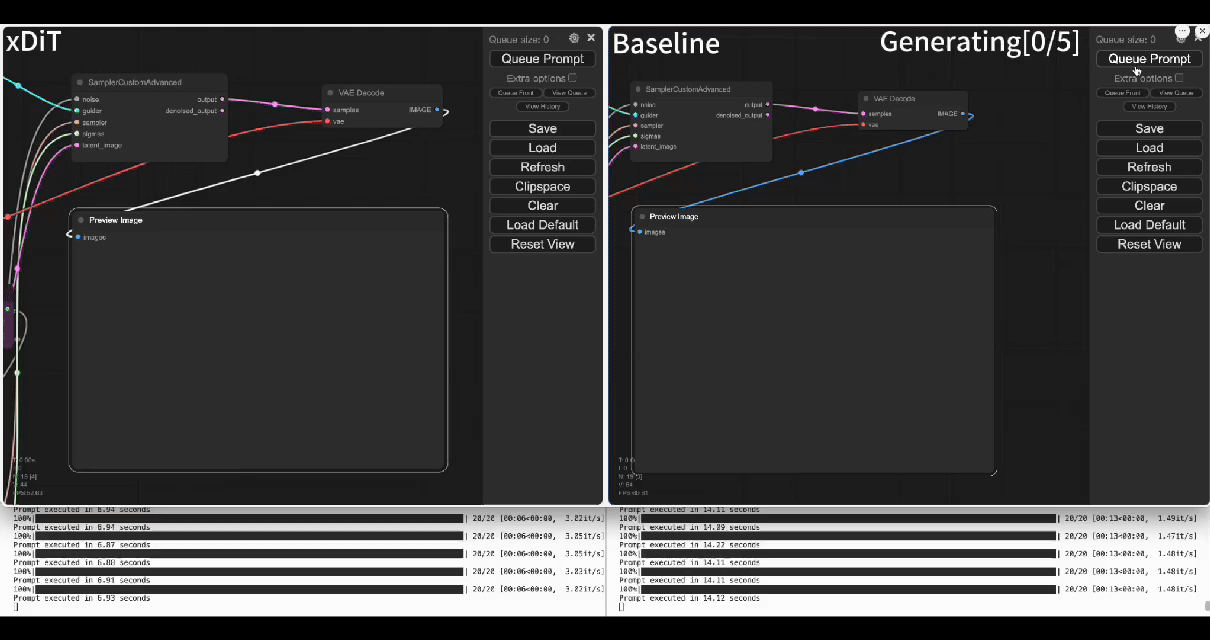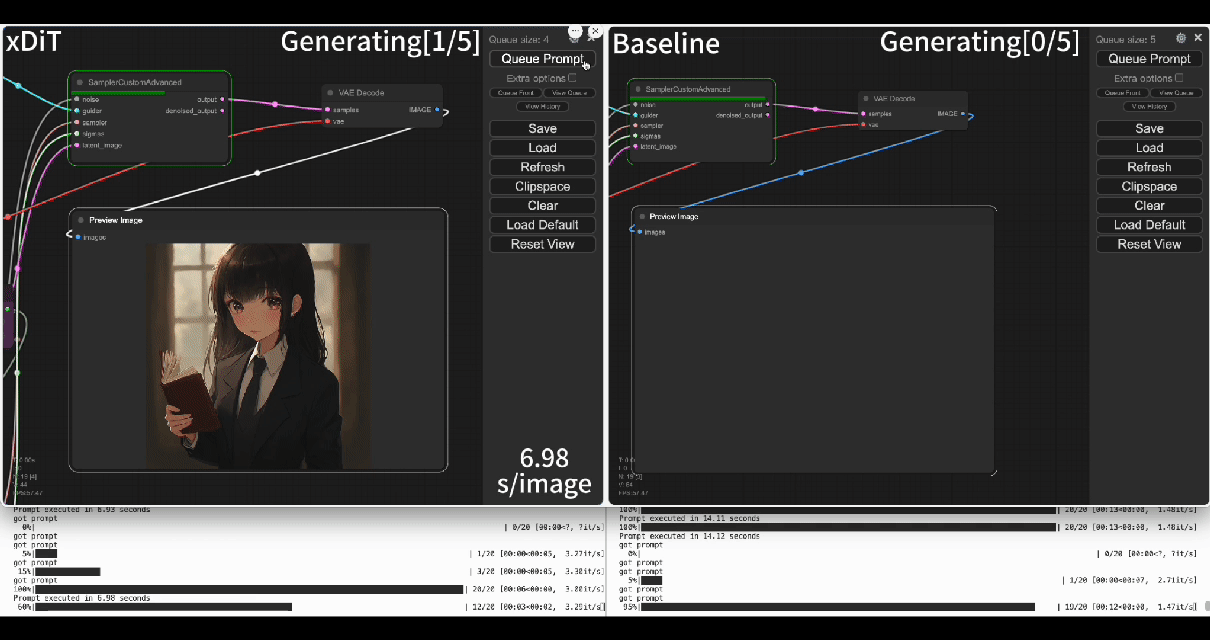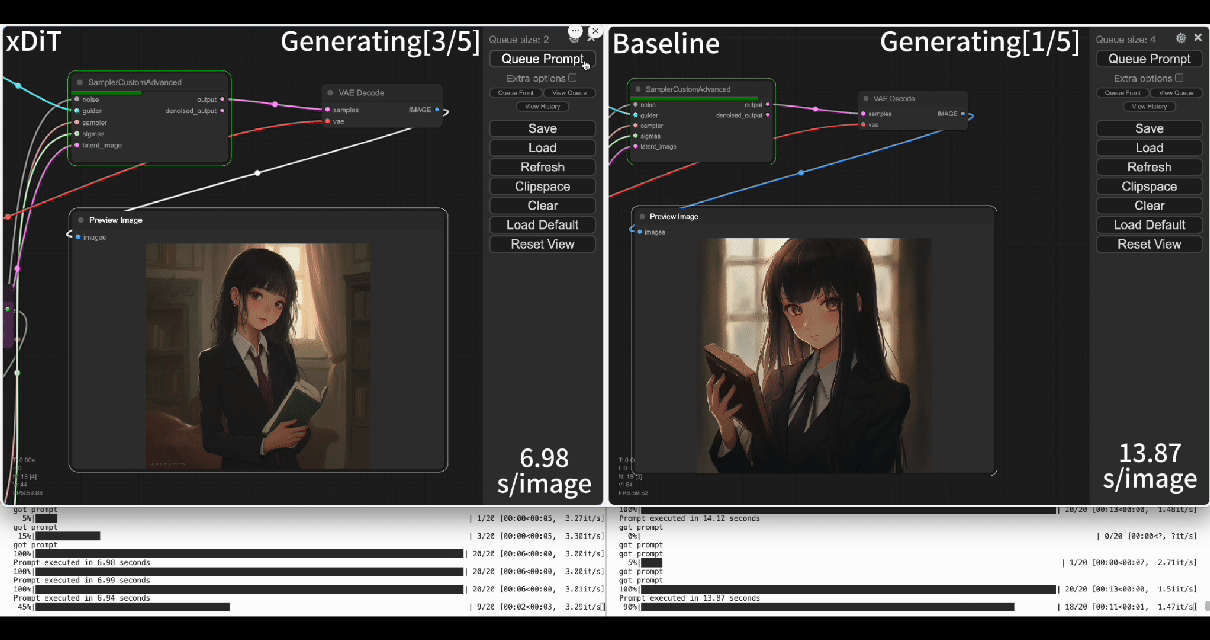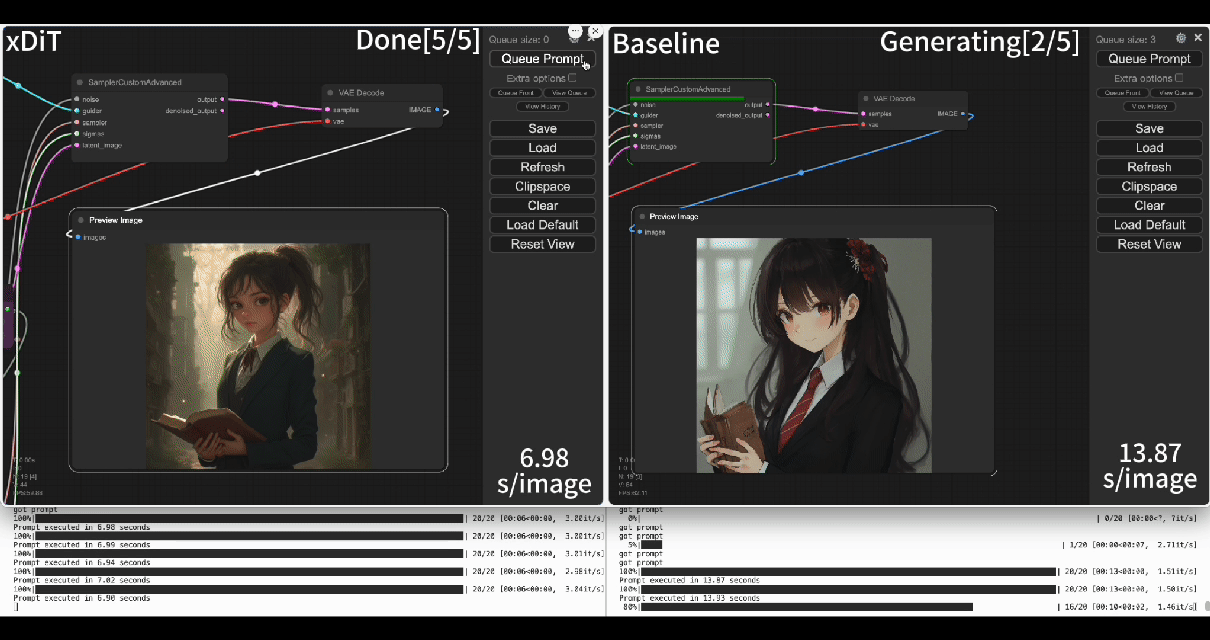 | ||
| Currently, if you need the xDiT parallel version for ComfyUI, please contact us via this [email]([email protected]). | ||
| Currently, if you need the xDiT parallel version for ComfyUI, please contact us via email [[email protected]]([email protected]). | ||
| ### 2. Launch a Http Service | ||
|
|
||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,38 @@ | ||
| #!/bin/bash | ||
| set -x | ||
|
|
||
| export PYTHONPATH=$PWD:$PYTHONPATH | ||
|
|
||
| # CogVideoX configuration | ||
| SCRIPT="cogvideox_example.py" | ||
| MODEL_ID="/cfs/dit/CogVideoX-2b" | ||
| INFERENCE_STEP=20 | ||
|
|
||
| mkdir -p ./results | ||
|
|
||
| # CogVideoX specific task args | ||
| TASK_ARGS="--height 480 --width 720 --num_frames 9" | ||
|
|
||
| # CogVideoX parallel configuration | ||
| N_GPUS=4 | ||
| PARALLEL_ARGS="--ulysses_degree 2 --ring_degree 1" | ||
| CFG_ARGS="--use_cfg_parallel" | ||
|
|
||
| # Uncomment and modify these as needed | ||
| # PIPEFUSION_ARGS="--num_pipeline_patch 8" | ||
| # OUTPUT_ARGS="--output_type latent" | ||
| # PARALLLEL_VAE="--use_parallel_vae" | ||
| # COMPILE_FLAG="--use_torch_compile" | ||
|
|
||
| torchrun --nproc_per_node=$N_GPUS ./examples/$SCRIPT \ | ||
| --model $MODEL_ID \ | ||
| $PARALLEL_ARGS \ | ||
| $TASK_ARGS \ | ||
| $PIPEFUSION_ARGS \ | ||
| $OUTPUT_ARGS \ | ||
| --num_inference_steps $INFERENCE_STEP \ | ||
| --warmup_steps 0 \ | ||
| --prompt "A small dog" \ | ||
| $CFG_ARGS \ | ||
| $PARALLLEL_VAE \ | ||
| $COMPILE_FLAG |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,68 @@ | ||
| set -x | ||
|
|
||
| # export NCCL_PXN_DISABLE=1 | ||
| # # export NCCL_DEBUG=INFO | ||
| # export NCCL_SOCKET_IFNAME=eth0 | ||
| # export NCCL_IB_GID_INDEX=3 | ||
| # export NCCL_IB_DISABLE=0 | ||
| # export NCCL_NET_GDR_LEVEL=2 | ||
| # export NCCL_IB_QPS_PER_CONNECTION=4 | ||
| # export NCCL_IB_TC=160 | ||
| # export NCCL_IB_TIMEOUT=22 | ||
| # export NCCL_P2P=0 | ||
| # export CUDA_DEVICE_MAX_CONNECTIONS=1 | ||
|
|
||
| export PYTHONPATH=$PWD:$PYTHONPATH | ||
|
|
||
| # Select the model type | ||
| # The model is downloaded to a specified location on disk, | ||
| # or you can simply use the model's ID on Hugging Face, | ||
| # which will then be downloaded to the default cache path on Hugging Face. | ||
|
|
||
| export COCO_PATH="/cfs/fjr2/xDiT/coco/annotations/captions_val2014.json" | ||
| export MODEL_TYPE="Pixart-alpha" | ||
| # Configuration for different model types | ||
| # script, model_id, inference_step | ||
| declare -A MODEL_CONFIGS=( | ||
| ["Pixart-alpha"]="pixartalpha_example.py /cfs/dit/PixArt-XL-2-1024-MS 20" | ||
| ["Pixart-sigma"]="pixartsigma_example.py /cfs/dit/PixArt-Sigma-XL-2-2K-MS 20" | ||
| ) | ||
|
|
||
| if [[ -v MODEL_CONFIGS[$MODEL_TYPE] ]]; then | ||
| IFS=' ' read -r SCRIPT MODEL_ID INFERENCE_STEP <<< "${MODEL_CONFIGS[$MODEL_TYPE]}" | ||
| export SCRIPT MODEL_ID INFERENCE_STEP | ||
| else | ||
| echo "Invalid MODEL_TYPE: $MODEL_TYPE" | ||
| exit 1 | ||
| fi | ||
|
|
||
| mkdir -p ./results | ||
|
|
||
| TASK_ARGS="--height 1024 --width 1024 --no_use_resolution_binning" | ||
| FAST_ATTN_ARGS="--use_fast_attn --window_size 512 --n_calib 4 --threshold 0.15 --use_cache --coco_path $COCO_PATH" | ||
|
|
||
|
|
||
| # By default, num_pipeline_patch = pipefusion_degree, and you can tune this parameter to achieve optimal performance. | ||
| # PIPEFUSION_ARGS="--num_pipeline_patch 8 " | ||
|
|
||
| # For high-resolution images, we use the latent output type to avoid runing the vae module. Used for measuring speed. | ||
| # OUTPUT_ARGS="--output_type latent" | ||
|
|
||
| # PARALLLEL_VAE="--use_parallel_vae" | ||
|
|
||
| # Another compile option is `--use_onediff` which will use onediff's compiler. | ||
| # COMPILE_FLAG="--use_torch_compile" | ||
|
|
||
| torchrun --nproc_per_node=1 ./examples/$SCRIPT \ | ||
| --model $MODEL_ID \ | ||
| $PARALLEL_ARGS \ | ||
| $TASK_ARGS \ | ||
| $PIPEFUSION_ARGS \ | ||
| $OUTPUT_ARGS \ | ||
| --num_inference_steps $INFERENCE_STEP \ | ||
| --warmup_steps 0 \ | ||
| --prompt "A small dog" \ | ||
| $CFG_ARGS \ | ||
| $FAST_ATTN_ARGS \ | ||
| $PARALLLEL_VAE \ | ||
| $COMPILE_FLAG |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,77 @@ | ||
| set -x | ||
|
|
||
| # export NCCL_PXN_DISABLE=1 | ||
| # # export NCCL_DEBUG=INFO | ||
| # export NCCL_SOCKET_IFNAME=eth0 | ||
| # export NCCL_IB_GID_INDEX=3 | ||
| # export NCCL_IB_DISABLE=0 | ||
| # export NCCL_NET_GDR_LEVEL=2 | ||
| # export NCCL_IB_QPS_PER_CONNECTION=4 | ||
| # export NCCL_IB_TC=160 | ||
| # export NCCL_IB_TIMEOUT=22 | ||
| # export NCCL_P2P=0 | ||
| # export CUDA_DEVICE_MAX_CONNECTIONS=1 | ||
|
|
||
| export PYTHONPATH=$PWD:$PYTHONPATH | ||
|
|
||
| # Select the model type | ||
| # The model is downloaded to a specified location on disk, | ||
| # or you can simply use the model's ID on Hugging Face, | ||
| # which will then be downloaded to the default cache path on Hugging Face. | ||
|
|
||
| export MODEL_TYPE="Flux" | ||
| # Configuration for different model types | ||
| # script, model_id, inference_step | ||
| declare -A MODEL_CONFIGS=( | ||
| ["Flux"]="flux_service.py /cfs/dit/FLUX.1-schnell 4" | ||
| ) | ||
|
|
||
| if [[ -v MODEL_CONFIGS[$MODEL_TYPE] ]]; then | ||
| IFS=' ' read -r SCRIPT MODEL_ID INFERENCE_STEP <<< "${MODEL_CONFIGS[$MODEL_TYPE]}" | ||
| export SCRIPT MODEL_ID INFERENCE_STEP | ||
| else | ||
| echo "Invalid MODEL_TYPE: $MODEL_TYPE" | ||
| exit 1 | ||
| fi | ||
|
|
||
| mkdir -p ./results | ||
|
|
||
| for HEIGHT in 1024 | ||
| do | ||
| for N_GPUS in 1; | ||
| do | ||
|
|
||
| TASK_ARGS="--height $HEIGHT --width $HEIGHT --no_use_resolution_binning" | ||
|
|
||
| PARALLEL_ARGS="--ulysses_degree 1 --ring_degree 1" | ||
|
|
||
|
|
||
|
|
||
| # By default, num_pipeline_patch = pipefusion_degree, and you can tune this parameter to achieve optimal performance. | ||
| # PIPEFUSION_ARGS="--num_pipeline_patch 8 " | ||
|
|
||
| # For high-resolution images, we use the latent output type to avoid runing the vae module. Used for measuring speed. | ||
| # OUTPUT_ARGS="--output_type latent" | ||
|
|
||
| # PARALLLEL_VAE="--use_parallel_vae" | ||
|
|
||
| # Another compile option is `--use_onediff` which will use onediff's compiler. | ||
| # COMPILE_FLAG="--use_torch_compile" | ||
|
|
||
| python ./examples/$SCRIPT \ | ||
| --model $MODEL_ID \ | ||
| $PARALLEL_ARGS \ | ||
| $TASK_ARGS \ | ||
| $PIPEFUSION_ARGS \ | ||
| $OUTPUT_ARGS \ | ||
| --num_inference_steps $INFERENCE_STEP \ | ||
| --warmup_steps 0 \ | ||
| --prompt "A small dog" \ | ||
| $CFG_ARGS \ | ||
| $PARALLLEL_VAE \ | ||
| $COMPILE_FLAG | ||
|
|
||
| done | ||
| done | ||
|
|
||
|
|