- 1 Capstone Project--Overview
- 1.1 Problem statement: Predicting DNA Plasmid Lab of Origin
- 1.2 Why I chose this project and how I approached it
- 2 Obtaining and Exploring Data
- 3 Modeling
- 3.1 First phase of modeling: Random forest models
- 3.1.1 Initial model: Random forest model from DrivenData blog
- 3.1.1.1 Using DNA sequences as the basis for model features (n-grams)
- 3.1.1.2 The Error Metric: Top 10 Accuracy
- 3.1.1.3 Model run on 4-grams plus original binary features
- 3.1.2 Constructing my own features for random forest models: 3-grams
- 3.1.2.1 Feature Engineering and Model Run: 3 bp Sequences
- 3.1.2.2 Run model on 3-letter DNA sequences
- 3.1.3 Constructing my own features for random forest models: Commonly used sequences
- 3.1.4 Conclusion from running Random Forest models on these features
- 3.1.1 Initial model: Random forest model from DrivenData blog
- 3.2 Second phase of modeling: Neural networks
- 3.2.1 Conceptual approach
- 3.2.2 Preparing data for modeling
- 3.2.2.1 Reducing dataframe size to increase the speed of training models
- 3.2.2.2 Character-level vectorization: values and targets
- 3.2.2.3 Train_test_split on this data for validation
- 3.2.2.4 Compute class weights for training dataset
- 3.2.3 Modeling: Labs submitting at least 200 plasmids each (n = 200)
- 3.2.3.1 Model setup
- 3.2.3.2 Model compile
- 3.2.3.3 Model fit
- 3.2.3.4 Visualizations
- 3.2.3.5 Observations about model: n >= 200 plasmids per lab
- 3.2.4 Model: labs submitting 10 or fewer plasmids each
- 3.2.5 Model: labs submitting between 10 and 50 plasmids each
- 3.2.5.1 Model setup
- 3.2.5.2 Model compile
- 3.2.5.3 Model fit
- 3.2.5.4 Visualizations
- 3.2.5.5 Observations about model for plasmids per lab: 10 <= n <= 50
- 3.2.6 Model: labs summitting 50 or fewer plasmids each
- 3.2.6.1 Model setup
- 3.2.6.2 Model compile
- 3.2.6.3 Model fit
- 3.2.6.4 Visualizations
- 3.2.6.5 Observations about model: n <= 50 plasmids per lab
- 3.1 First phase of modeling: Random forest models
- 4 Results and Conclusions
- 4.1 Summary of results and outcomes for analysis performed October 2020
- 4.2 Summary of revised analysis (performed July 2021)
- 4.2.1 Model run: Sequences from labs submitting 10 or fewer plasmids (449 labs in total)
- 4.2.2 Model run: Sequences from labs submitting between 10 and 50 plasmids (730 labs)
- 4.2.3 Model run: sequences from labs submitting 50 or fewer plasmids (1106 labs in total)
- 4.2.4 Comments on the revised analysis using data subsets with many more targets
- 4.3 So, how did the GEAC competition winners approach the problem?
- 4.4 Final thoughts
This project is focused on exploring modeling techniques to predict the labs-of-origin for DNA constructs called plasmids. Plasmids have been used for decades in molecular cloning applications and are critically important to both research activities and industrial production. However, the increased availability of advanced methods and tools for genetic engineering raises the specter of potential harm due to unintended or malicious activities by a broader range of actors. The development of tools that can correctly identify the lab of origin for a given plasmid is becoming ever more important and urgent.

Source: https://www.nlm.nih.gov/exhibition/fromdnatobeer/img/exhibition-recombinantDNA.jpg
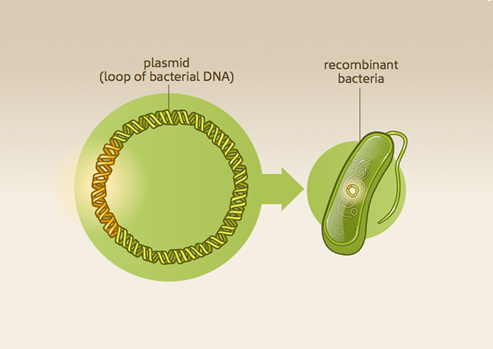{kind=link}
The Genetic Engineering Attribution Challenge (GEAC), a data science competition sponsored by altLabs and hosted by DrivenData, was created to crowdsource potential solutions to this problem. (The competition page can be viewed at https://www.drivendata.org/competitions/63/genetic-engineering-attribution/.) DrivenData and altlabs published a blog with some starter code and guidance to help participants get started and to successfully format competition submissions. Partipicants downloaded training data and test data on which to make predictions for competition submission. The training data set included over 63,000 plasmids submitted by a total of 1,314 labs. Plasmid sequence lengths ranged from a few dozen DNA 'letters' to over 60,000, making this a fairly unusual sequential analysis relative to, say, natural language processing or time series analysis.
![]()

For my Flatiron data science capstone project, I chose to use a dataset from the GEAC competition. It was a fascinating topic that allowed me to revisit and update the molecular biology knowledge I had gained in college. It also pushed me to learn much more about deep learning and AI than I otherwise would have at the end of an already-rigorous data science program!

Source: http://clipart-library.com/clipart/479704.htm
While I did peek at a few abstracts of scientific papers by altlabs and others on this topic, I started off by thinking through the problem, applying what I had learned in the program, asking for guidance from my instructors, and beginning with the the guidance and starter code from the DataDriven/altlabs blog post.
-
The data sets provided by the competition organizers are too large to be hosted on github. The required .csv files at https://www.drivendata.org/competitions/63/genetic-engineering-attribution/page/164/. Login is required, but accounts are free and easy to set up.
-
The DrivenData website for this competition features a blog post that provides guidance and starter code to participants, so that everyone is able to access the data and format submissions properly. The blog is available at https://www.drivendata.co/blog/genetic-attribution-benchmark/.
There are 41 columns in this dataset. Each row corresponds to a plasmid DNA sequence, which is uniquely identified by sequence_id, a 5-character alphanumeric string. In addition to the DNA sequences provided in sequence, there are 39 binary features that provide metadata about the plasmids. All variables are described below.
sequence(type: string): A plasmid DNA sequence. Any Us were changed to Ts and letters other than A, T, G, C, or N were changed to Ns. Possible values: A, T, G, C, or Nbacterial_resistance_ampicillin,bacterial_resistance_chloramphenicol,bacterial_resistance_kanamycin,bacterial_resistance_other,bacterial_resistance_spectinomycin(type: binary): One-hot encoded columns that indicate the antibiotic resistance of the plasmid used for selecting during bacterial growth and cloning.copy_number_high_copy,copy_number_low_copy,copy_number_unknown(type: binary): One-hot encoded columns that indicate the number of plasmids per bacterial cell.growth_strain_ccdb_survival,growth_strain_dh10b,growth_strain_dh5alpha,growth_strain_neb_stable,growth_strain_other,growth_strain_stbl3,growth_strain_top10,growth_strain_xl1_blue(type: binary): One-hot encoded columns that indicate the strain used to clone the plasmid.growth_temp_30,growth_temp_37,growth_temp_other(type: binary): One-hot encoded columns that indicate the temperature the plasmid should be grown at.selectable_markers_blasticidin,selectable_markers_his3,selectable_markers_hygromycin,selectable_markers_leu2,selectable_markers_neomycin,selectable_markers_other,selectable_markers_puromycin,selectable_markers_trp1,selectable_markers_ura3,selectable_markers_zeocin(type: binary): One-hot encoded columns that indicate genes that allow non-bacterial selection (for a plasmid used outside of the cloning organism).species_budding_yeast,species_fly,species_human,species_mouse,species_mustard_weed,species_nematode,species_other,species_rat,species_synthetic,species_zebrafish(type: binary): One-hot encoded columns that indicate the species the plasmid is used in, after cloning.
DrivenData and altlabs published a blog (https://www.drivendata.co/blog/genetic-attribution-benchmark/) providing ideas for how to approach the project and some starter code to explore the data and properly format model predictions for submission. To generate predictions to feed into the function, they constructed a fairly simple random forest model with DNA n-grams ("bag of words"). They then took the model predictions and ran them through the function to generate the predictions in the appropriate format for competition submission.
Note: What follows below is excerpts of code, visualizations, and results. For full technical details, please see the technical notebook in the repo for this project.
| sequence | bacterial_resistance_ampicillin | bacterial_resistance_chloramphenicol | bacterial_resistance_kanamycin | bacterial_resistance_other | bacterial_resistance_spectinomycin | copy_number_high_copy | copy_number_low_copy | copy_number_unknown | growth_strain_ccdb_survival | growth_strain_dh10b | growth_strain_dh5alpha | growth_strain_neb_stable | growth_strain_other | growth_strain_stbl3 | growth_strain_top10 | growth_strain_xl1_blue | growth_temp_30 | growth_temp_37 | growth_temp_other | selectable_markers_blasticidin | selectable_markers_his3 | selectable_markers_hygromycin | selectable_markers_leu2 | selectable_markers_neomycin | selectable_markers_other | selectable_markers_puromycin | selectable_markers_trp1 | selectable_markers_ura3 | selectable_markers_zeocin | species_budding_yeast | species_fly | species_human | species_mouse | species_mustard_weed | species_nematode | species_other | species_rat | species_synthetic | species_zebrafish | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sequence_id | ||||||||||||||||||||||||||||||||||||||||
| 9ZIMC | CATGCATTAGTTATTAATAGTAATCAATTACGGGGTCATTAGTTCA... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 5SAQC | GCTGGATGGTTTGGGACATGTGCAGCCCCGTCTCTGTATGGAGTGA... | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| E7QRO | NNCCGGGCTGTAGCTACACAGGGCGGAGATGAGAGCCCTACGAAAG... | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| CT5FP | GCGGAGATGAAGAGCCCTACGAAAGCTGAGCCTGCGACTCCCGCAG... | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 7PTD8 | CGCGCATTACTTCACATGGTCCTCAAGGGTAACATGAAAGTGATCC... | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| BOQSD | AACAAAATATTAACGCTTACAATTTCCATTCGCCATTCAGGCTGCG... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 5XVVU | AACAAAATATTAACGCTTACAATTTCCATTCGCCATTCAGGCTGCG... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| CVGHF | CCGGTGGTGCATATCGGGGATGAAAGCTGGCGCATGATGACCACCG... | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ZVT1A | CTAGCTAGTCCTGCAGGTTTAAACGAATTCGCCCTTTGCTTTCTCT... | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| U5MR3 | TGGCGAATGGGACGCGCCCTGTAGCGGCGCATTAAGCGCGGCGGGT... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
63017 rows × 40 columns
sequence_lengths = train_values.sequence.apply(len)
sequence_lengths.describe()count 63017.000000
mean 4839.025501
std 3883.148431
min 20.000000
25% 909.000000
50% 4741.000000
75% 7490.000000
max 60099.000000
Name: sequence, dtype: float64
We can see that the vast majority of plasmids are less than about 10,000 base pairs (bp), with a large spike of plasmids of length ~1,000 bp. However, the scale of this graph can be misleading: there are still thousands of plasmids beyond 10,000 bp in length; this can be seen in the following graphs.

Looking just at the distribution of plasmid lengths between 8,000 and 25000 bp, we see there are still many hundreds just in this bandwidth of plasmid length:

(First 5 rows of dataframe)
| 00Q4V31T | 012VT4JK | 028IO5W2 | 03GRNN7N | 03Y3W51H | 09MQV1TY | 0A4AHRCT | 0A9M05NC | 0B9GCUVV | 0CL7QVG8 | 0CML4B5I | 0DTHTJLJ | 0FFBBVE1 | 0HWCWFNU | 0L3Y6ZB2 | 0M44GDO8 | 0MDYJM3H | 0N3V9P9M | 0NP55E93 | 0PJ91ZT6 | 0R296F9R | 0T2AZBD6 | 0URA80CN | 0VRP2DI6 | 0W6O08VX | 0WHP4PPK | 0XPTGGLP | 0XS4FHP3 | 0Y24J5G2 | 10TEBWK2 | 11TTDKTM | 131RRHBV | 13LZE1F7 | 14PBN8C2 | 15D0Z97U | 15S88O4Q | 18C9J8EH | 19CAUKJB | 1AP294AT | 1B9BJ2IP | 1BE35FI1 | 1CIHYCE4 | 1DJ9L58E | 1DTDCRUO | 1EDZ6CA7 | 1HCQTAYT | 1HK4VXP8 | 1IXFZ3HO | 1K11RCST | 1KC6XYO6 | 1KNFJ6KQ | 1KZHNVYR | 1LBGAU5Z | 1NXRMDN6 | 1OQJ21E9 | 1OWZDF82 | 1PA232PA | 1PIGWQFY | 1Q1IUY3G | 1S515B69 | 1TC200QC | 1TI4HS4X | 1UOA7CA1 | 1UREJUSJ | 1UU0CHTK | 1VPOX8VI | 1VQS4WNS | 1X0VC0O1 | 1XU60MET | 1ZC8RPN1 | 20ABQYHS | 20CEB9KE | 216DWMG6 | 21ZFBX5E | 24SL2992 | 25UVYUID | 26KK8UM5 | 27OS3BTP | 28D4D4QM | 298AMR5C | 29D6Q091 | 2AQG6I31 | 2BAFY4GP | 2CJHRNWD | 2FCX4O0X | 2GGU2QA2 | 2GSZMU46 | 2GTLIT33 | 2H37WPKA | 2HNZZYDB | 2JPNC9X6 | 2KDACBQT | 2L336TQL | 2M3CXS8N | 2MCB7LXW | 2MQ2NPMA | 2NEXWXMT | 2PY8K6GU | 2Q33W599 | 2SSVM7H9 | 2TVMHQTW | 2TXY439E | 2VP4JPB9 | 2VTLZHDS | 2VX4F6RC | 2XC1478M | 2XX0N87I | 2Y9L13L4 | 2YCH1PUI | 2YLQA8OZ | 303BN0Z0 | 318RH8P0 | 330L4OIV | 33AR5KVE | 343M819H | 34TE1Q0A | 35MKXPL0 | 36W150XW | 36XLYYGZ | 37VO60SB | 384ASNLB | 38MDETY1 | 38MEQ4SU | 39LLQ2PB | 39TEZ0C3 | 39TPBOL7 | 3BGLF8BC | 3C2VZQ2R | 3C952KY7 | 3D9CMQ4V | 3EARN0Z7 | 3EYBG174 | 3EZXYI3U | 3FPH0N6R | 3FW33G68 | 3GEXBRC0 | 3KCEM7V4 | 3L314D8W | 3LSNTL1N | 3MDRJUI2 | 3MX1D3LD | 3N169DM2 | 3NSJ6N02 | 3O1GIAV7 | 3QP4D23X | 3RK54JUW | 3TLD81QQ | 3TUFYWQN | 3TXFYNKG | 3X2GGDHW | 3XE0BJDW | 3YAQWNBK | 3YEGUN04 | 3YYEC52Y | 40MD0YZ3 | 40ZI3TDN | 443NZOSB | 448QVC4C | 44N2CYI9 | 459BZKP3 | 4648UZGD | 46AZ97U9 | 48F0EUVN | 49571DXY | 49YZILWR | 4CKAV3LS | 4DGGCYVE | 4DGMNDIC | 4E7187A9 | 4GF31RCS | 4GHCND6Z | 4IADYZ8R | 4IDTMY10 | 4J7KEYE2 | 4KSHU5M7 | 4LCFACE1 | 4LQ8L195 | 4M3XG8RC | 4O39WLXM | 4O5RQHEF | 4PKCMX7O | 4QK5ZDHA | 4QU07FT7 | 4RCA1UZG | 4RHLX089 | 4S1LIWGV | 4TIT4L5F | 4U5LAAN5 | 4VHMF1RI | 4WAQ4VFB | 4WRI77CU | 4X2RTV2D | 4Y4DT3SL | 4ZYW54M8 | 50NBGIOB | 52Y9GFGK | 54C6PEBH | 54ZFOPSF | 558GIQ68 | 55HTZ7T0 | 579G0TJI | 57FHO8YC | 57NGF1YS | 58BSUZQB | 5ASQZ0OT | 5AUVXXDU | 5BNUT8AW | 5BTY65G6 | 5CBNCRST | 5FUDT1QA | 5H71LUBY | 5K2PTY6L | 5KXWXV9G | 5LH9NUMK | 5OBD73W0 | 5OF7OYEA | 5OFUVG9U | 5PC2F8NE | 5PR9OSRS | 5Q9ETXJL | 5QLBIUXN | 5QY2HU8J | 5SCOFTY2 | 5SGMS705 | 5V3Z108E | 5W2PCT95 | 5X9VNAN3 | 5Z4CMIY5 | 5ZB8I3T0 | 5ZW05824 | 60HBQEP8 | 62PKSARW | 638UYIQC | 64FFXH4M | 65CCBIXK | 669R7ER0 | 66XSSS3Q | 685KTH3G | 68OY1RK5 | 69M351P4 | 6AT20D5S | 6DBY872A | 6E28DNQK | 6KT0EAKX | 6LQ0W02R | 6NCTAA30 | 6NKNB308 | 6NULQ6KP | 6PS2LHCV | 6PXRABDR | 6QBXXYN4 | 6QUCW04X | 6SBB6IL2 | 6T9SGGS1 | 6TT5CXVI | 6TTWEXT3 | 6UGWNYCX | 6UI9XACW | 6UXF7L28 | 6WD2LIHN | 6WT1F4RJ | 6XVBD39G | 6YSX60MZ | 7039MMH2 | 709K4VRB | 7185O9V8 | 71R7TM8L | 738FBTIL | 73RKEO3U | 747XMBIJ | 74RXUGS4 | 74TS5KG4 | 78QGAL01 | 78XDAJNS | 7ANCD9AK | 7DMNXU84 | 7E63E5RD | 7F905YRZ | 7GWW4637 | 7IHPTKFF | 7KG191H8 | 7MUAYEHW | 7NGLQ1CA | 7O3PWIL0 | 7OV5K86R | 7PWA4ZJN | 7QEORFJN | 7QF2VB5B | 7QWHL2C6 | 7SW79VAJ | 7T28F53W | 7TYZHD5J | 7UU8O65I | 7WKS90AG | 7X3RSRT5 | 7XPDUYJE | 7XU8ACPI | 7YSTNZME | 7ZV0Z1T9 | 81QAZACE | 82NXGO4K | 862RYK1K | 86ET7WW4 | 88E6O06E | 8ABA3MWO | 8BF8ANNO | 8C0T09C6 | 8C9737JL | 8D4D6M5V | 8ECLELF1 | 8EKC599S | 8F0XPAZX | 8FT6HD4D | 8FZMCIFG | 8G29TDOS | 8H6M75LF | 8HI3GY44 | 8HW91I4K | 8HZXGARR | 8IPYO6SS | 8JKDTT0Y | 8K0HZBL0 | 8MUKKVMF | 8MW998Z0 | 8N5EPD5C | 8OBT3FSQ | 8ORZZFA7 | 8RIKS696 | 8SW7WFE6 | 8T12OXHS | 8US76O46 | 8VCFY56I | 8VI1RY3M | 8VLB2R3D | 8WAY3T1E | 8Z6SANMH | 8ZB94ICE | 8ZB99KHH | 904V6V2S | 909V5A2H | 91Y7NKBM | 91Z8RRSB | 92WF5WVN | 93R70J1L | 93WIIL7Y | 97FR69TQ | 97PR85CP | 99A19JAD | 9DBCRJYM | 9DKQF2I2 | 9DRMDPIZ | 9G5XH4HI | 9GDHC3D0 | 9HPM9NFY | 9HRDSOST | 9IVIPDX5 | 9JRKFKVC | 9KHXMSMW | 9KV8R3HP | 9LSH625Y | 9MC0DPDJ | 9MC1YKKZ | 9MEFUZQN | 9MG50RM7 | 9MZBKXJF | 9PWYZMNS | 9QQZ79I6 | 9R765PJF | 9SJCUIKS | 9SSQ1FSY | 9U0DELRD | 9WEGTUIJ | 9WQQKFVK | 9XE0FL8P | 9Y5EWA8O | 9YM3QINZ | 9ZTEQPA4 | A0ADXLZU | A0Z7XCDN | A1738D1Z | A18S09P2 | A1A8EROR | A1J0YXZX | A2A1R52R | A2U1AIC1 | A332O9JW | A3FZPLM1 | A3QUOXIX | A44GW57T | A4BM0B6A | A6RCKKER | A768XIWP | A78F2YFJ | A7CK3WNB | A810BWR5 | A8FZHMOS | A9G8OKRG | AATDRXYQ | AAURK3RG | ABMAPCYN | ABWCZWFU | ACO8WWPF | ADB7SAPN | AG93GZYN | AHMVJ2VP | AL7N3DL2 | AM8AJH2H | AMSPTQVJ | AMV4U0A0 | AOCCEP3S | AOFJN8HX | AOFPYGHC | AOKRU4AF | AOQQU910 | AR433PVR | AS30HPUK | AUCMR8HU | AUUSW2YZ | AUZNSS79 | AV7ONIVD | AWWC1KIV | B131HDBV | B17J3JSX | B1I4L0XW | B25KOPVH | B2BULVFH | B4L9R8JU | B517ID6W | B832TQ6U | B8FC99WI | B8YR9IIK | B9H5SLHK | BBTA1L43 | BBZJCYJ0 | BD9EXLDM | BDQOSDFG | BDSEVK9M | BH7HW7XH | BHKOO62U | BHNI9DCI | BHW9ILRC | BJKTDFN4 | BL2TLVFC | BLC9WIIM | BLFM4YKK | BLNELN02 | BN8BMXPM | BNFZZTKX | BP2X9ITX | BPT27UPE | BQJ79YS3 | BSEEWS00 | BSH6LB19 | BTQL3UFQ | BV6PVSO5 | BV8D4RYV | BWFN4ZI7 | BXMEKONO | BY5IEG4O | BZBNZDNS | C1BIUBL5 | C35C2C2W | C4W63WJ2 | CA0MBQ9S | CAO2H0WE | CAQEITX6 | CB714TAM | CBCQST29 | CBFKYZ9S | CBKRHK4I | CDM3SRRP | CDU1LWN3 | CEATO4LM | CENOJ84D | CFDEOSH4 | CFOET28L | CFQ9PAJA | CHTQ7QLX | CJFLQNE1 | CK1M5UHL | CKDZNQV2 | CLO7VQ12 | CNX48K3H | COEMYLH1 | COVE5WRD | CRP30ATM | CTJGWLX0 | CTLP20Y9 | CWZP8AQK | CY64689U | CYCSYMQ3 | CZUGPH88 | D0EKC82X | D0NFHXL2 | D0YWREJ5 | D10S0UDQ | D1BZRMOB | D2N5DOSQ | D3KJQCYH | D4PJE56U | D4Q1QMRJ | D63K976U | D7L6VZNV | D8MRQA91 | D8OQ3YNK | DD0JBK3T | DE6NAU7D | DEFNZK0A | DEWKAO5I | DGE8LLAJ | DGQ2L6KM | DJW5U56I | DKA65CRR | DLSU0QRX | DN01XVIU | DQGG01WF | DRFCUPZO | DSE2G8LF | DY0KIZZ9 | DZ2XFGQS | E3CE5WE9 | E3CRPQL7 | E3FFACSU | E4EF2K0A | E4T4IQMG | E59C5N01 | E5OB5QF1 | E6G69ESA | E6TPDVWA | E7CPRIYW | E7EZD62E | E8100WU0 | E8GMEHFW | EA2DKNTD | EBF1G8Z7 | ED0OS5OF | EEC8D29F | EFKGYR79 | EI8B4WEC | EJ3T17DB | EJXP2QAW | EKHYS325 | EKXAPD70 | EL9FN1LB | ELF2BN3S | ELX1D1DS | EMJXDINV | EMNH5MYX | EN78WKI4 | EOQAQ9X1 | EPDX32D3 | EQPB3YTZ | ER1IJR80 | ETR2SP13 | EW4ZXWSN | EXQZ5V7S | EYOJGC9T | EZ40BRHE | EZL4HNHH | EZMV5TKG | F0ESSJYM | F0MOWJYA | F1X6DMDH | F3D2JAYU | F3S4VUQI | F50DBVIK | F8I0DT7Z | F8LNIZ27 | FCI1HZ3G | FEBWERSN | FH8TEJI1 | FHR8UUYO | FHZYKEUV | FJTJ4KY0 | FLHGDG0P | FLSWA4NU | FLU9ZT18 | FMJ19E48 | FN1RKQ2M | FN38BX60 | FNKCHGB7 | FNM1Z945 | FPH5H8JT | FQ8V2QHL | FRFT0H8N | FRK40JVP | FRX9XJYW | FSR0IC6I | FVYCRUFK | FWOZ05UZ | FXBIP7LS | FXRWH0M9 | FZ37IFWH | G2P73NZ0 | G4UJDFPK | G57JANUL | G6MP6EIN | G7MXLRV8 | G81LO0AZ | G8QWQL1C | GB45D1XV | GBX3MNVS | GDV3S3ZG | GHG5MDER | GJKR73YA | GJPI1WIV | GKY6ZB15 | GKY7BZOQ | GLOJFBA0 | GLUZC5HC | GM3HKY2J | GS8G1IFF | GSK9JT39 | GSNU5TXL | GT4RHNUE | GTVTUGVY | GUCIE6TT | GUWYJRRS | GWJ0A1IK | GWP6E8FA | GYCOAVYS | GYCY8LCF | GZMPRX5J | H0WSDLJE | H12S8X2Q | H1G4FFR7 | H20JGHP0 | H3D82ATM | H3RWZ7UR | H48Y5BOY | H5Y73UHQ | H9RBDN30 | HB3OQUA5 | HCW1Y9QM | HGN5HD65 | HGPS0FQN | HHSIC4NY | HI7ZNYCK | HJNGSDJ5 | HK78MCH7 | HNGYSI62 | HODOBX62 | HQC2OFGM | HRFD8R1G | HRWBEBRE | HT51BMN1 | HTXABMRS | HV6GZXC3 | HVAG84XI | HVBBJM37 | HVN93I56 | HVXSID0M | HVZMFFNW | HX2XDS73 | HX5NMCPJ | HY9DN23J | HZ5C2E4C | I0J54PBT | I16TS2B4 | I1RQMFZC | I2ATV1DI | I2N7C27Y | I3UODLOR | I5L6E1U2 | I5RNBXF3 | I6B3VKYD | I7FXTVDP | I8U0Q5FP | I9MWC6I3 | IBBLXRDR | ICDP084U | ICRBJL24 | ID37U3DA | IDXJ25FE | IGHBC70Q | IH12MVU4 | IIWFYXGG | IJEA3NUI | IL47R85Z | ILKPIFSA | IM2JLO1B | IMFV7GM3 | IMVSI4VW | INDCDVP0 | INELF20P | INJ6L6NB | IO2FYB6G | IO56YRTG | IOKPSO7K | IOOQONCI | IOPR6B78 | IP9XMFII | IPV1W17S | IPVYEI8G | IQPZXRU2 | IS75OD95 | ISMP5LYF | IUJPYIRX | IYKXT23R | IZD0O5Q0 | IZSQDCWP | J0NVCXDJ | J1UFMOCR | J339EI56 | J3752QSY | J3L1KD1J | J3YKGOCX | J5WRC3DJ | J648LM1S | J70NZZIW | J7PWRE94 | J9M11KX1 | JAEI655A | JB8JTFSG | JC35D8WT | JC6LUZLT | JCHNPTSF | JDENEZ6I | JICWX3AS | JJBJFUAT | JK9C0VN8 | JKUCC6UK | JL1OZP2G | JMJD18BP | JN497K3S | JNB98WP1 | JNU5CAOV | JO1WTZOB | JPI7LZJ3 | JPO7CTQP | JQ4YBT3Z | JQ7Z5Q44 | JQJ499YN | JRBK08H6 | JRDHZ51W | JRRTJ3GV | JS1KUAD6 | JS59HL6M | JSEGAB8K | JT4GYL2P | JUC55NLK | JUYW4QZ1 | JVWQ5HEJ | JWVCJ3UR | JWYYB1L5 | JXDP2C4M | JYZ82A2B | JZ1RSLKQ | JZ2KQL0P | JZS556ZA | JZTRRSKQ | K1DU5H0C | K1K1AESM | K212MH7P | K25LXPOI | K3QD4AHX | K4AGNZ3R | K57LN37R | K83DA8K5 | KB0YFLBH | KD7N9YDF | KDW3ZVWJ | KDZ388UF | KF32BDPB | KFWFMIUK | KG943QKP | KGMINGSB | KH4VOX9Q | KJJYCUJ7 | KKG07XA9 | KKIO1X0Z | KM3OV97R | KMPCXZUY | KMSH5BSO | KRS7ST1L | KSFFKSV7 | KU0G64D0 | KUGU9MQC | KUH39TQR | KV5TCH8S | KVLIE219 | KWH2Y6KA | L0FS3EPM | L27ULB0P | L2HRYP1A | L2UTYYJT | L3OPGJO5 | L3RQSW75 | L3SSKU27 | L5AMS3QT | L657W1BK | L76WWQ74 | L78GOBQS | L905DK46 | LDCSZOKC | LF9AQIHZ | LFQ6YRHV | LGEAIIK8 | LGTP4O86 | LHMKC873 | LHNLO8Q8 | LKC4LOOM | LKR5NGJZ | LKVB0S84 | LL11R5T6 | LM6LV3JB | LNTF6KP8 | LPBA27LH | LPQY1SEL | LQ6K46C8 | LU684LJ9 | LUHRMKEB | LUI0TOT2 | LVXSGLT6 | LWQ8FULT | LXBPBCS3 | LXOZJ3TV | LXPTXE5K | LYY8P69T | M1CZ7MK8 | M2HPA1EK | M2R84KMY | M2W28OUV | M3B15QGL | M3MFQNC7 | M46L0EBU | M4V0NJ97 | M59DNUXD | M9265ASV | M9PHW06O | MB9HHEPN | MBQUJESG | MDCIP8E0 | MEKV5BRI | MEVIH0XF | MFZHQ165 | MGQBELNN | MH0GC0GY | MIUE47ZL | MJR1CR7U | ML1YCDCG | ML5W6LDB | MLGLKKI7 | MMU3QFIP | MNV2YSWZ | MOCIAZ0D | MQKR83SM | MQQTIYIC | MQRIDTFZ | MULMC195 | MUO5QBB6 | MV1CMX4O | MXV7CSHI | MZOM2K35 | N0CP1NI7 | N0FDUY5E | N5LOOJSR | N5X3YG2I | N764BFJU | N7BY4DKZ | N8FNYI0A | N8X63KYC | N9I581ZL | NBCZC85X | ND7I48LA | ND88CY09 | NDDT3NOB | NDZT8PV3 | NHNLVWDR | NIKHJTWP | NIRCF0RK | NK0S2WH6 | NKPC0Z4Q | NKRRLD5O | NMQKJMH3 | NNNIMDVI | NPWC1BXV | NQVW27OC | NR26DCAB | NRRH4BON | NT9Y0D19 | NTLCS343 | NUOEY3LD | NUSJ1NGL | NUYVBFLU | NWE84W10 | NWKWVAIA | NX7I9PQG | NYI75N90 | O1LMIA6M | O3M287V6 | O4VJ2EV7 | O55K40VQ | O5PJEO54 | O69KS0OS | O7NEA7KO | O8E18PJ4 | OAEZWMZR | OAPTL0AF | OB97CO94 | OCJ3W2EF | OEGM98R5 | OERPDTWW | OG01U0FT | OJ9HCGTB | OKI0Z2UO | OKK933IV | OKWROFEH | OL1HWRRD | OL59ZZX5 | OML0TEF3 | ON2CU60C | ON9AXMKF | ONPQ2I44 | OOKK1JHN | OPPRIPN9 | OUA1CRWO | OUJLF506 | OVPHRVOD | OYRI4NVE | P361G1OD | P3Q11IAK | P4H26KKX | P8PW7Q1Q | PEUBDA2B | PFI6E05S | PFNRAGJP | PGWZZALU | PHQEJTNO | PIT16TZ9 | PJYVLL0Z | PKC5LJ6W | PMCWG8N5 | PNWFSSF0 | POKTJVRL | PONI61NE | POZMOX9T | PQZ6Z3YJ | PRU3JF6Y | PRYT0A2P | PS6MZN15 | PSY58O49 | PUECZ8ZI | PV7QTHJV | PW7GT7TE | PXT3AJ7C | PY8VPVM5 | PYX7I7X5 | Q1D88JO2 | Q1M9RXYR | Q21CAL4Z | Q2K8NHZY | Q2LO2OGN | Q35PXLRT | Q3O4J4HB | Q5V3EKJC | QASMCASJ | QC3VEU4P | QEOKKUF1 | QJ5LYZHA | QJJAG1IV | QJMUUPFK | QL3AU1NN | QNE79S52 | QNKGHIRB | QNQQVRNB | QPA31HRW | QQFF3LO5 | QQR3SE8Y | QR91QBR2 | QSLQZQH2 | QT44Y8VV | QTIRUM0G | QUFMTUB3 | QUUKEGL5 | QV09SDY8 | QV71AJ91 | QVAHXT35 | QVAZPYQ8 | QYBCIW4J | QYZ57QTQ | QZ1V5GME | QZ8BT14M | QZD4I9UW | R1BX2NZI | R1OFLDKQ | R2O5C424 | R3AAYF7V | R3QOGZZF | R5B3KVZI | R67AMR4P | R6QNKUC4 | R830GQGO | RASRCD7I | RBL3SN1I | RBLPDV4R | RBMLZBYW | RD5YXSBA | RD62G56Y | RE7IER1C | REKW7MRF | RF45YZMF | RFUY4U4W | RFYO6TO0 | RGD51NW1 | RHH1X0A2 | RHSAJGR1 | RIEIBCRF | RKJHZGDQ | RNSK8HLJ | RP37N5WN | RQUURTUT | RRIG3SH3 | RSMDF425 | RYUA3GVO | RZCRWMTU | RZPGGEG4 | RZPT9APG | RZT9JPDV | S0Z5J1EW | S15Z6XG6 | S2PFIP6S | S2ZYVBUF | S5CBU2AX | S7345IVO | S768X16I | S824JJ06 | SAONBMNO | SBQXQOPV | SBWHI6Y6 | SCKCR39J | SD7VPKVQ | SDNECLRB | SEAEY0CN | SEH3FI81 | SEVOI9NR | SEX60YJE | SFPE2DX4 | SGAZ5VOA | SGIINS2G | SHKNA9S1 | SIUTK5SR | SIUXBYDS | SLG5DZG2 | SLVO27W6 | SM3HAKL8 | SNNICLKQ | SNZP9G8K | SOPNMXWX | SQB9N47Y | SR345GAS | SRZSX1LR | SSVDNEY9 | ST2DCNR0 | SU06AE5D | SUUFTUWK | SW00LEHT | SWHE2RH1 | SYQSKHN2 | SZ0MR59K | T18CGW8H | T3KHULCH | T4J4YRDK | T5R7YFPH | T8R673OI | T9LSOTV6 | T9ZHWQE9 | TBJE6V15 | TBUHVONI | TCKOTGYJ | TD593FIM | TE1TWCPZ | TFTOGJOD | TGPPSF7M | THD393NW | THW6JGC7 | TI21BGNU | TIAPP57M | TJLVHJ87 | TK932JM1 | TKLYRWYO | TNR495LD | TQAA3UHV | TRM5SRRW | TTU1NVDI | TU2W2LCB | TUO2TVTX | TVQC1R4D | TWH1XFPL | TWV05PEP | TYJN7K7A | TYQ2T01H | TZ8JAEO6 | TZL79DYX | U0U7F3EW | U2C1NG0D | U2C2VVY8 | U2OZU4IY | U2VWRM3F | U2ZEEFLD | U3QRAT06 | U47IUY9C | U49ISLNE | U5966IDO | U5ZJCLCX | U69N21WU | U6DS14AT | U6TNOS7M | U74I1JYB | U8FRHWSV | U8SWTHB5 | UAY0HW9A | UBO7MS4D | UBWK5LJH | UBXL2EGE | UC094GDG | UCC4KYQL | UCVUALGM | UEZVPK90 | UFAQZXPY | UFEO02VM | UFTYVG6Y | UH5Z524P | UHU62P41 | UJNF3UO2 | UJSK2U9A | UK4B4I7A | UKG1R822 | ULOHU3PC | ULVU086L | UMDZG9XM | UMM76IOX | UMOD7PGG | UNAGKRY0 | UNE947CO | UO4MVLJS | UP3750KB | UQUIUCVA | URO46KFW | URY1ZVZI | US8KF8X3 | UVXQ3O4K | UWWS6RWO | UXK3D4GF | UYCX4ZJS | UYLJZRPN | UYPE34HA | V04Z48C3 | V1YVL2DL | V3JDHWOB | V4A28VLV | V4RKPN30 | V5C3CWTK | V6X2Z58S | V8MF2IKQ | VAGUTU8C | VB04AEHZ | VDSDXJ71 | VDYHUCQB | VE48SF8D | VFCTUL5J | VFOEJ2CS | VGCXUCRO | VGWO9SBA | VHPX9GYO | VJU9EYFE | VKN3L279 | VKU9G6Y5 | VMU0L6UM | VO0ATBFS | VOT8OKU2 | VRZZPHI4 | VW6ZY2L1 | VYW7T8YY | VZLS9GCK | W184Y53L | W1STLS0T | W2DYAZID | W7WRIFC0 | W9QZOUW7 | WAL364PD | WB78G3XF | WBGCVIO8 | WD8MHX8N | WDNYZZHJ | WG42FGWA | WG7S6W2T | WHLUO40S | WK162QYQ | WK4NBYSB | WKRC8NSD | WKYJ6R7D | WL3FJI96 | WL8VMHWG | WM3Q8LBC | WM9JWC4B | WNEX0Y1X | WP6H3E2T | WQ1DVVYG | WQBN4WGH | WRDZ1CVS | WSHPKJ3H | WTFS8JV2 | WTYMIZ88 | WUARWGNF | WUR2UJYP | WWDAZG6C | WX0HMR4F | WZX61W39 | WZZLL8O4 | X0VJJXGQ | X2PFPX2S | X4WO7LHO | X4YNMN9Z | X6497O49 | X6LFEBK7 | X920R0YN | X9RNN0YD | XCWSW5T9 | XD80LQN2 | XE4D68OI | XHQPAVRU | XLYFD8RW | XOEVMQZT | XP1SRNTB | XP5B8615 | XPQ9IYZC | XR7GR7UE | XRENDLF1 | XSA3Y2H6 | XTKRJ8N6 | XU8GASLQ | XV32YHEZ | XY9JOM6L | XYB5NWR4 | Y060M6TK | Y324NGPN | Y3HA6UDE | Y4G53L4X | Y4X5JU76 | Y575VUS1 | Y5YH740Y | Y620TYKH | Y6EC9YQA | Y73L2QKM | Y81SHRRC | YCD71LRY | YCNWCC0Z | YCY2FFYZ | YDPNP1KR | YE9BU3J3 | YEA0ZZZP | YEZ30YUQ | YFSGJUTL | YGFI5B9G | YGFIQ8SA | YHUR7HZ6 | YHX2594T | YKXRSB4N | YL8AOR9Q | YLS2HEMR | YMHGXK99 | YMWK7JKH | YP4WCV92 | YQ3L8TWE | YQITW66D | YTGT3GEX | YTOOMPZ8 | YW85XPTE | YWQZUSA8 | YWZAEK5A | YXKFDH6S | YY5Y32CI | YZX8R26H | Z1C99MVU | Z1Y066QU | Z6LWLWFZ | Z7YFK3I0 | Z7ZKDLZG | Z80NVAXF | Z8BWVZZX | ZAYLY2YU | ZB6DPIG5 | ZB862XHR | ZBQD50GN | ZC07UYVV | ZCU48L3S | ZEAZQ1QQ | ZEB7PDQK | ZEBTRK7D | ZEJOQQJF | ZELU1VMX | ZFBSIW7Q | ZGY1YZ7P | ZH6LR5MO | ZIGUIE0J | ZIJRW95G | ZK6YBV02 | ZLSXM0KN | ZMCRIYYJ | ZMEZU4BS | ZMUIMBDX | ZOI7FJEN | ZQ5A6IY9 | ZQNGGY33 | ZSHS4VJZ | ZT1IP3T6 | ZU6860XU | ZU6TVFFU | ZU75P59K | ZUI6TDWV | ZWFD8OHC | ZX06ZDZN | ZZJVE4HO |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sequence_id | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9ZIMC | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 5SAQC | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| E7QRO | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| CT5FP | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 7PTD8 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
To make the evaluation of training labels simpler, we'll collapse them into one column, 'lab_ids', shown below (first 5 rows shown for brevity).
| lab_id | |
|---|---|
| sequence_id | |
| 9ZIMC | RYUA3GVO |
| 5SAQC | RYUA3GVO |
| E7QRO | RYUA3GVO |
| CT5FP | RYUA3GVO |
| 7PTD8 | RYUA3GVO |
We can see that there is a huge range in the number of plasmids submitted by labs in the database--from just 1 plasmid submitted to over 8200!
I7FXTVDP 8286
RKJHZGDQ 2732
GTVTUGVY 2672
A18S09P2 1064
Q2K8NHZY 973
...
58BSUZQB 3
G2P73NZ0 3
WB78G3XF 2
0L3Y6ZB2 1
ON9AXMKF 1
Name: lab_id, Length: 1314, dtype: int64
Let's get a sense of what this looks like:

Obviously, plotting number of plasmids by number of labs contributing that amount is not very useful--other than to show us that a small percentage of labs contribute the majority of plasmids.
Labs can have anywhere from 1 to > 8000 sequences in this data set. Using describe(), we can get a sense of the distribution of the number of sequences submitted by lab.
lab_ids.lab_id.value_counts().describe()count 1314.000000
mean 47.958143
std 262.552258
min 1.000000
25% 9.000000
50% 15.000000
75% 34.000000
max 8286.000000
Name: lab_id, dtype: float64
The key takeaway from these numbers is that, despite the very large maximum number of plasmids submitted (8286 plasmids submitted by just one lab!), the majority of labs have submitted a small number of plasmids. In fact, three-quarters of labs have submitted fewer than 35 plasmids each. On the flip side, a small percentage of labs (just over 50) have contributed the majority of plasmids to this database.
Looking at the top 50 labs, we see a dramatic dropoff in the number of sequences contributed.

Looking at the top 50 labs, we see that they have contributed 31,211 plasmids out of a total of 63,007 plasmids in this data set
lab_ids.lab_id.value_counts()[:50].sum()31211
Looking at just the top 10 labs, we can see that they have contributed just over 30% (just over 21,000) of all plasmids to this data set.
lab_ids['lab_id'].value_counts(normalize=True).sort_values(ascending=False).head(10).sum()
# Ten labs contribute over 30% of all plasmids to the database0.30125204309948106
Sorting labs by their prevalence of sequences in the data, we can see that lab I7FXTVDP is the most heavily represented, contributing 8286 plasmids, or just over 13%, to this data set.
I7FXTVDP 0.131488
RKJHZGDQ 0.043353
GTVTUGVY 0.042401
A18S09P2 0.016884
Q2K8NHZY 0.015440
131RRHBV 0.011267
0FFBBVE1 0.010822
AMV4U0A0 0.010537
THD393NW 0.009918
G8QWQL1C 0.009140
Name: lab_id, dtype: float64
Two key elements of this dataset present challenges: the variability in the length of DNA sequences (from 20 to over 60,000) and the non-uniformity of number of sequence contributions per lab (from 1 sequence to over 8900). Whether using machine learning ensemble methods or neural networks, addressing these issues will be necessary to manage modeling complexity.
(Note: The text and code in this section are adapted from the DrivenData/altlabs blog providing starter code and guidance for beginning the project.)
The DNA sequences in this data set are composed of five characters. G, C, A, and T represent the four nucleotides commonly found in DNA (guanine, cytosine, adenine, thymine). N stand for any nucleotide (not a gap).
One common way to turn strings into useful features is to count n-grams, or continuous subsequences of length n. Here, we'll split up the DNA sequences into four-grams, or subsequences consisting of 4 bases.
With 5 unique bases, we can produce 120 different sequence permutations consisting of 4 bases.
| CTAG | CTAN | CTGA | CTGN | CTNA | CTNG | CATG | CATN | CAGT | CAGN | CANT | CANG | CGTA | CGTN | CGAT | CGAN | CGNT | CGNA | CNTA | CNTG | CNAT | CNAG | CNGT | CNGA | TCAG | TCAN | TCGA | TCGN | TCNA | TCNG | TACG | TACN | TAGC | TAGN | TANC | TANG | TGCA | TGCN | TGAC | TGAN | TGNC | TGNA | TNCA | TNCG | TNAC | TNAG | TNGC | TNGA | ACTG | ACTN | ACGT | ACGN | ACNT | ACNG | ATCG | ATCN | ATGC | ATGN | ATNC | ATNG | AGCT | AGCN | AGTC | AGTN | AGNC | AGNT | ANCT | ANCG | ANTC | ANTG | ANGC | ANGT | GCTA | GCTN | GCAT | GCAN | GCNT | GCNA | GTCA | GTCN | GTAC | GTAN | GTNC | GTNA | GACT | GACN | GATC | GATN | GANC | GANT | GNCT | GNCA | GNTC | GNTA | GNAC | GNAT | NCTA | NCTG | NCAT | NCAG | NCGT | NCGA | NTCA | NTCG | NTAC | NTAG | NTGC | NTGA | NACT | NACG | NATC | NATG | NAGC | NAGT | NGCT | NGCA | NGTC | NGTA | NGAC | NGAT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sequence_id | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9ZIMC | 13 | 0 | 44 | 0 | 0 | 0 | 28 | 0 | 25 | 0 | 0 | 0 | 14 | 0 | 17 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 37 | 0 | 24 | 0 | 0 | 0 | 18 | 0 | 13 | 0 | 0 | 0 | 29 | 0 | 46 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 24 | 0 | 21 | 0 | 0 | 0 | 19 | 0 | 30 | 0 | 0 | 0 | 39 | 0 | 25 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 27 | 0 | 20 | 0 | 0 | 0 | 28 | 0 | 15 | 0 | 0 | 0 | 30 | 0 | 32 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5SAQC | 1 | 0 | 6 | 0 | 0 | 0 | 2 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 2 | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 2 | 0 | 0 | 0 | 2 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| E7QRO | 0 | 0 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 3 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| CT5FP | 6 | 0 | 8 | 0 | 0 | 0 | 3 | 0 | 3 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 6 | 0 | 3 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 5 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 2 | 0 | 0 | 0 | 2 | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 3 | 0 | 0 | 0 | 3 | 0 | 1 | 0 | 0 | 0 | 3 | 0 | 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7PTD8 | 2 | 0 | 4 | 0 | 0 | 0 | 7 | 0 | 4 | 0 | 0 | 1 | 2 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 3 | 0 | 0 | 0 | 2 | 0 | 3 | 0 | 0 | 0 | 2 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 5 | 0 | 3 | 0 | 0 | 0 | 2 | 0 | 6 | 0 | 0 | 0 | 5 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 2 | 0 | 3 | 0 | 0 | 0 | 7 | 0 | 4 | 0 | 0 | 0 | 6 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| BOQSD | 8 | 0 | 28 | 0 | 0 | 0 | 28 | 0 | 24 | 0 | 0 | 0 | 11 | 0 | 20 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 27 | 0 | 14 | 0 | 0 | 0 | 19 | 0 | 22 | 0 | 0 | 0 | 22 | 0 | 33 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 17 | 0 | 20 | 0 | 0 | 0 | 18 | 0 | 22 | 0 | 0 | 0 | 24 | 0 | 16 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 10 | 0 | 27 | 0 | 0 | 0 | 24 | 0 | 13 | 0 | 0 | 0 | 19 | 0 | 30 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 5XVVU | 7 | 0 | 26 | 0 | 0 | 0 | 28 | 0 | 23 | 0 | 0 | 0 | 11 | 0 | 20 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 28 | 0 | 14 | 0 | 0 | 0 | 19 | 0 | 22 | 0 | 0 | 0 | 23 | 0 | 33 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 17 | 0 | 19 | 0 | 0 | 0 | 17 | 0 | 22 | 0 | 0 | 0 | 24 | 0 | 16 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 0 | 26 | 0 | 0 | 0 | 25 | 0 | 13 | 0 | 0 | 0 | 20 | 0 | 28 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CVGHF | 22 | 0 | 50 | 0 | 0 | 0 | 40 | 0 | 33 | 0 | 0 | 0 | 17 | 0 | 19 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 36 | 0 | 23 | 0 | 0 | 0 | 22 | 0 | 21 | 0 | 0 | 0 | 35 | 0 | 42 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 33 | 0 | 22 | 0 | 0 | 0 | 27 | 0 | 33 | 0 | 0 | 0 | 46 | 0 | 23 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 28 | 0 | 33 | 0 | 0 | 0 | 34 | 0 | 16 | 0 | 0 | 0 | 24 | 0 | 45 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ZVT1A | 21 | 0 | 48 | 0 | 0 | 0 | 40 | 0 | 32 | 0 | 0 | 0 | 17 | 0 | 18 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 37 | 0 | 22 | 0 | 0 | 0 | 22 | 0 | 21 | 0 | 0 | 0 | 36 | 0 | 42 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 33 | 0 | 21 | 0 | 0 | 0 | 25 | 0 | 33 | 0 | 0 | 0 | 46 | 0 | 23 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 28 | 0 | 32 | 0 | 0 | 0 | 35 | 0 | 16 | 0 | 0 | 0 | 24 | 0 | 43 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| U5MR3 | 7 | 0 | 35 | 0 | 0 | 0 | 28 | 0 | 23 | 0 | 0 | 0 | 11 | 0 | 23 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 22 | 0 | 13 | 0 | 0 | 0 | 12 | 0 | 8 | 0 | 0 | 0 | 24 | 0 | 17 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 23 | 0 | 14 | 0 | 0 | 0 | 29 | 0 | 28 | 0 | 0 | 0 | 20 | 0 | 15 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 15 | 0 | 28 | 0 | 0 | 0 | 19 | 0 | 4 | 0 | 0 | 0 | 18 | 0 | 22 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
63017 rows × 120 columns
ngram_features.shape(63017, 120)
We now have features for all 120 possible subsequences. Their values show the counts of each 4-gram within the full DNA sequence.
Let's join them with our one-hot endcoded binary features.
all_features = ngram_features.join(train_values.drop('sequence', axis=1))
all_features.head()| CTAG | CTAN | CTGA | CTGN | CTNA | CTNG | CATG | CATN | CAGT | CAGN | CANT | CANG | CGTA | CGTN | CGAT | CGAN | CGNT | CGNA | CNTA | CNTG | CNAT | CNAG | CNGT | CNGA | TCAG | TCAN | TCGA | TCGN | TCNA | TCNG | TACG | TACN | TAGC | TAGN | TANC | TANG | TGCA | TGCN | TGAC | TGAN | TGNC | TGNA | TNCA | TNCG | TNAC | TNAG | TNGC | TNGA | ACTG | ACTN | ACGT | ACGN | ACNT | ACNG | ATCG | ATCN | ATGC | ATGN | ATNC | ATNG | AGCT | AGCN | AGTC | AGTN | AGNC | AGNT | ANCT | ANCG | ANTC | ANTG | ANGC | ANGT | GCTA | GCTN | GCAT | GCAN | GCNT | GCNA | GTCA | GTCN | GTAC | GTAN | GTNC | GTNA | GACT | GACN | GATC | GATN | GANC | GANT | GNCT | GNCA | GNTC | GNTA | GNAC | GNAT | NCTA | NCTG | NCAT | NCAG | NCGT | NCGA | NTCA | NTCG | NTAC | NTAG | NTGC | NTGA | NACT | NACG | NATC | NATG | NAGC | NAGT | NGCT | NGCA | NGTC | NGTA | NGAC | NGAT | bacterial_resistance_ampicillin | bacterial_resistance_chloramphenicol | bacterial_resistance_kanamycin | bacterial_resistance_other | bacterial_resistance_spectinomycin | copy_number_high_copy | copy_number_low_copy | copy_number_unknown | growth_strain_ccdb_survival | growth_strain_dh10b | growth_strain_dh5alpha | growth_strain_neb_stable | growth_strain_other | growth_strain_stbl3 | growth_strain_top10 | growth_strain_xl1_blue | growth_temp_30 | growth_temp_37 | growth_temp_other | selectable_markers_blasticidin | selectable_markers_his3 | selectable_markers_hygromycin | selectable_markers_leu2 | selectable_markers_neomycin | selectable_markers_other | selectable_markers_puromycin | selectable_markers_trp1 | selectable_markers_ura3 | selectable_markers_zeocin | species_budding_yeast | species_fly | species_human | species_mouse | species_mustard_weed | species_nematode | species_other | species_rat | species_synthetic | species_zebrafish | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sequence_id | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9ZIMC | 13 | 0 | 44 | 0 | 0 | 0 | 28 | 0 | 25 | 0 | 0 | 0 | 14 | 0 | 17 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 37 | 0 | 24 | 0 | 0 | 0 | 18 | 0 | 13 | 0 | 0 | 0 | 29 | 0 | 46 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 24 | 0 | 21 | 0 | 0 | 0 | 19 | 0 | 30 | 0 | 0 | 0 | 39 | 0 | 25 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 27 | 0 | 20 | 0 | 0 | 0 | 28 | 0 | 15 | 0 | 0 | 0 | 30 | 0 | 32 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 5SAQC | 1 | 0 | 6 | 0 | 0 | 0 | 2 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 2 | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 2 | 0 | 0 | 0 | 2 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| E7QRO | 0 | 0 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 3 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| CT5FP | 6 | 0 | 8 | 0 | 0 | 0 | 3 | 0 | 3 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 6 | 0 | 3 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 5 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 2 | 0 | 0 | 0 | 2 | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 3 | 0 | 0 | 0 | 3 | 0 | 1 | 0 | 0 | 0 | 3 | 0 | 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 7PTD8 | 2 | 0 | 4 | 0 | 0 | 0 | 7 | 0 | 4 | 0 | 0 | 1 | 2 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 3 | 0 | 0 | 0 | 2 | 0 | 3 | 0 | 0 | 0 | 2 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 5 | 0 | 3 | 0 | 0 | 0 | 2 | 0 | 6 | 0 | 0 | 0 | 5 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 2 | 0 | 3 | 0 | 0 | 0 | 7 | 0 | 4 | 0 | 0 | 0 | 6 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
all_features.shape
# includes all n-grams and binary features in original data set(63017, 159)
The goal for the GEAC competition was to narrow down the field of possible labs-of-origin from thousands to just a few. To that end, predictions were evaluated based on top-ten accuracy--meaning that a prediction was considered "correct" if the true lab-of-origin is in the top ten most likely labs.
There is not a built in evaluation metric for top-k accuracy in scikit-learn, so DrivenData/altlabs provided code for a custom scorer. This was used to determine the final accuracy of the model. The function took in validation data, labels, and an estimator, and returned a score based on the top ten results from each predicton.
(Text in this section is verbatim from DrivenData blog.)
Random forests are often a good first model to try so we'll start there. We'll leave more complicated modeling and feature selection up to you!
It's easy to build a random forest model with Scikit Learn. We're going to create a simple model with a few specified hyperparameters.
We've got our features and our labels, but we still have to address the class imbalance we discovered during data exploration. Luckily, scikit-learn has an easy solution for us. We can set class_weight to "balanced". This will set class weights inversely proportional to the class frequency.
# instantiate RF model
rf = RandomForestClassifier(n_jobs=4, n_estimators=150, class_weight='balanced', max_depth=3, random_state=0)
rf.fit(X, y)RandomForestClassifier(class_weight='balanced', max_depth=3, n_estimators=150,
n_jobs=4, random_state=0)
rf.score(X, y)0.16916070266753416
Using the top 10 scorer, we should expect to do better on the competition metric, top-10 accuracy. Let's use our custom defined scorer to see how we did:
top10_accuracy_scorer(rf, X, y)0.38835552311281085
The model got almost 40% top-ten accuracy.
To create predictions and show how these should be formatted for submittal to the GEAC competition, DrivenData and altlabs used the binary features of the data set, as well as creating additional features (n-grams of length 4), to run a random forest model. I was curious about whether 3-grams would be better than 4-grams, so I decided to run the model with the binary features plus all possible 3-grams.
As in the initial model setup outlined in the previous section, the first step here was to create 3-grams out of the possible 5 'letters' (A, G, C, T, and N) and then add the binary features in the original data set. (As a reminder, 'N' represents a place in the sequence where a letter substitution that does not compromise the function of the sequence.) The engineered features plus the binary features give a total of 164 features.
The first 5 rows of the dataframe resulting from the feature engineering process are displayed below:
| CCC | CCT | CCA | CCG | CCN | CTC | CTT | CTA | CTG | CTN | CAC | CAT | CAA | CAG | CAN | CGC | CGT | CGA | CGG | CGN | CNC | CNT | CNA | CNG | CNN | TCC | TCT | TCA | TCG | TCN | TTC | TTT | TTA | TTG | TTN | TAC | TAT | TAA | TAG | TAN | TGC | TGT | TGA | TGG | TGN | TNC | TNT | TNA | TNG | TNN | ACC | ACT | ACA | ACG | ACN | ATC | ATT | ATA | ATG | ATN | AAC | AAT | AAA | AAG | AAN | AGC | AGT | AGA | AGG | AGN | ANC | ANT | ANA | ANG | ANN | GCC | GCT | GCA | GCG | GCN | GTC | GTT | GTA | GTG | GTN | GAC | GAT | GAA | GAG | GAN | GGC | GGT | GGA | GGG | GGN | GNC | GNT | GNA | GNG | GNN | NCC | NCT | NCA | NCG | NCN | NTC | NTT | NTA | NTG | NTN | NAC | NAT | NAA | NAG | NAN | NGC | NGT | NGA | NGG | NGN | NNC | NNT | NNA | NNG | NNN | bacterial_resistance_ampicillin | bacterial_resistance_chloramphenicol | bacterial_resistance_kanamycin | bacterial_resistance_other | bacterial_resistance_spectinomycin | copy_number_high_copy | copy_number_low_copy | copy_number_unknown | growth_strain_ccdb_survival | growth_strain_dh10b | growth_strain_dh5alpha | growth_strain_neb_stable | growth_strain_other | growth_strain_stbl3 | growth_strain_top10 | growth_strain_xl1_blue | growth_temp_30 | growth_temp_37 | growth_temp_other | selectable_markers_blasticidin | selectable_markers_his3 | selectable_markers_hygromycin | selectable_markers_leu2 | selectable_markers_neomycin | selectable_markers_other | selectable_markers_puromycin | selectable_markers_trp1 | selectable_markers_ura3 | selectable_markers_zeocin | species_budding_yeast | species_fly | species_human | species_mouse | species_mustard_weed | species_nematode | species_other | species_rat | species_synthetic | species_zebrafish | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sequence_id | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9ZIMC | 109 | 115 | 163 | 116 | 0 | 107 | 113 | 82 | 137 | 0 | 112 | 103 | 164 | 157 | 0 | 109 | 75 | 101 | 103 | 0 | 0 | 0 | 0 | 0 | 0 | 111 | 92 | 133 | 79 | 0 | 121 | 91 | 65 | 100 | 0 | 82 | 71 | 76 | 52 | 0 | 100 | 85 | 143 | 119 | 0 | 0 | 0 | 0 | 0 | 0 | 146 | 103 | 108 | 94 | 0 | 104 | 84 | 72 | 113 | 0 | 121 | 98 | 109 | 156 | 0 | 150 | 86 | 127 | 126 | 0 | 0 | 0 | 0 | 0 | 0 | 137 | 130 | 132 | 96 | 0 | 82 | 89 | 61 | 94 | 0 | 135 | 102 | 135 | 127 | 0 | 140 | 83 | 125 | 81 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 5SAQC | 11 | 14 | 9 | 2 | 0 | 10 | 12 | 2 | 14 | 0 | 5 | 6 | 7 | 10 | 0 | 0 | 2 | 3 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 7 | 9 | 5 | 1 | 0 | 5 | 6 | 2 | 11 | 0 | 4 | 3 | 1 | 4 | 0 | 9 | 5 | 19 | 14 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 8 | 10 | 2 | 0 | 4 | 4 | 5 | 12 | 0 | 9 | 6 | 9 | 8 | 0 | 10 | 6 | 9 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 9 | 6 | 4 | 3 | 0 | 4 | 2 | 3 | 9 | 0 | 12 | 10 | 15 | 6 | 0 | 2 | 6 | 12 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| E7QRO | 4 | 5 | 4 | 7 | 0 | 2 | 5 | 3 | 11 | 0 | 6 | 1 | 4 | 8 | 1 | 6 | 0 | 10 | 15 | 0 | 1 | 0 | 0 | 0 | 2 | 2 | 3 | 2 | 1 | 0 | 4 | 0 | 0 | 7 | 0 | 4 | 1 | 2 | 2 | 0 | 5 | 3 | 8 | 21 | 3 | 0 | 0 | 1 | 1 | 2 | 3 | 5 | 5 | 4 | 0 | 2 | 2 | 4 | 7 | 0 | 2 | 7 | 10 | 15 | 3 | 13 | 5 | 20 | 94 | 1 | 1 | 1 | 0 | 5 | 5 | 10 | 8 | 7 | 17 | 1 | 0 | 3 | 2 | 15 | 1 | 6 | 6 | 19 | 94 | 3 | 17 | 13 | 99 | 242 | 9 | 0 | 1 | 3 | 8 | 8 | 1 | 0 | 1 | 2 | 2 | 0 | 1 | 0 | 0 | 3 | 0 | 0 | 2 | 3 | 5 | 2 | 0 | 2 | 9 | 5 | 4 | 2 | 6 | 6 | 16 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| CT5FP | 18 | 27 | 20 | 14 | 0 | 13 | 15 | 12 | 25 | 0 | 13 | 18 | 16 | 20 | 0 | 13 | 3 | 10 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 20 | 16 | 14 | 5 | 0 | 10 | 7 | 2 | 20 | 0 | 8 | 4 | 7 | 8 | 0 | 19 | 11 | 22 | 16 | 0 | 0 | 0 | 0 | 0 | 0 | 11 | 9 | 20 | 3 | 0 | 20 | 7 | 8 | 12 | 0 | 10 | 11 | 15 | 24 | 0 | 20 | 15 | 19 | 20 | 0 | 0 | 0 | 0 | 0 | 0 | 30 | 13 | 13 | 14 | 0 | 13 | 10 | 5 | 11 | 0 | 12 | 14 | 22 | 22 | 0 | 17 | 10 | 19 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 7PTD8 | 7 | 19 | 14 | 10 | 1 | 17 | 10 | 12 | 21 | 0 | 8 | 19 | 19 | 17 | 2 | 11 | 8 | 15 | 14 | 0 | 2 | 0 | 0 | 1 | 1 | 17 | 13 | 18 | 8 | 0 | 12 | 7 | 6 | 14 | 0 | 10 | 8 | 15 | 18 | 0 | 17 | 15 | 33 | 27 | 0 | 0 | 0 | 0 | 1 | 0 | 9 | 13 | 15 | 12 | 0 | 13 | 10 | 14 | 25 | 0 | 12 | 12 | 25 | 65 | 0 | 23 | 22 | 56 | 46 | 1 | 2 | 0 | 0 | 1 | 0 | 18 | 15 | 18 | 16 | 0 | 14 | 12 | 19 | 31 | 1 | 18 | 23 | 55 | 49 | 0 | 14 | 33 | 40 | 18 | 3 | 0 | 0 | 0 | 1 | 3 | 0 | 0 | 1 | 1 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 2 | 0 | 1 | 3 | 0 | 1 | 0 | 1 | 2 | 20 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
all_features.shape(63017, 164)
# instantiate RF model
rf = RandomForestClassifier(n_jobs=4, n_estimators=150, class_weight='balanced', max_depth=3, random_state=0)
rf.fit(X, y)RandomForestClassifier(class_weight='balanced', max_depth=3, n_estimators=150,
n_jobs=4, random_state=0)
rf.score(X, y)0.1263944649856388
Using top-10 accuracy scorer:
top10_accuracy_scorer(rf, X, y)0.36160083786914643
We can see that 3-grams did slightly worse than the 4-grams used in the original random forest model (36.2% vs. over 38% for the 4-grams in the DrivenData blog example). My next effort is to use common plasmid marker sequences for features in the model.
Additional sequences include repeats, common restriction enzyme recognition sites, origins of replication, primers, start and stop codons, and more. I created a list of 48 commonly used sequences as a starting point to run a basic model and see whether performance improved. I used these sequences, along with the binary features present in the original data set, in this model run. (Note: I did not create n-gram features for this model run.)
I constructed the following set of 48 sequences based on a list of very commonly-used short sequences in plasmids. More information on this process and list can be found in the technical notebook.
{'AAAA',
'AACGTT',
'AAGCTT',
'AGCGAGTCAGTGAGCGAG',
'AGCT',
'AGCTAAGG',
'ATG',
'CAGCTG',
'CCANNNNNTTG',
'CCCC',
'CCCGGG',
'CCGCAGCCGAACGACCGAGC',
'CCTCTAGAAGCGGCCGCGAATTC',
'CGGCCG',
'CTCGAG',
'CTGCAG',
'CTGGAGNNNNNNNNNNNNNNNN',
'GAATGCN',
'GAATTC',
'GACCGANNNNNNNNNNN',
'GACGGTGCGTC',
'GACGTC',
'GACGTCA',
'GACTGCAGGGTC',
'GAGCTC',
'GATATC',
'GATC',
'GCAACTGACTGAAATGCCTC',
'GCAATGNN',
'GCATAT',
'GCATGC',
'GCGATCNNNNNNNNNN',
'GCGGCCGC',
'GGATCC',
'GGCC',
'GGGAAACGCCTGGTATCTTT',
'GGGG',
'GGTACC',
'GTCGAC',
'NNNN',
'TAA',
'TAG',
'TCCGGA',
'TCGA',
'TCTTTTCGGTTTTAAAGAAAAAGGGCAGGGTGGTGACACCTTGCCCTTTTTTGCCGGA',
'TGA',
'TGGCCA',
'TTTT'}
Adding back binary features from original data set gives us a dataframe of 87 features (first five rows shown):
| AAAA | TTTT | GGGG | CCCC | NNNN | CGGCCG | GAATTC | GACGTCA | AACGTT | GACGGTGCGTC | AGCT | TGGCCA | GGATCC | CTGGAGNNNNNNNNNNNNNNNN | AGCTAAGG | GAATGCN | TCCGGA | GCAATGNN | GCGATCNNNNNNNNNN | GACTGCAGGGTC | GATATC | GGCC | AAGCTT | GGTACC | GCATAT | GCGGCCGC | CTCGAG | CCANNNNNTTG | CAGCTG | CTGCAG | GTCGAC | GATC | CCCGGG | GCATGC | GAGCTC | TCGA | GACCGANNNNNNNNNNN | GACGTC | ATG | TAG | TAA | TGA | AGCGAGTCAGTGAGCGAG | GGGAAACGCCTGGTATCTTT | GCAACTGACTGAAATGCCTC | TCTTTTCGGTTTTAAAGAAAAAGGGCAGGGTGGTGACACCTTGCCCTTTTTTGCCGGA | CCTCTAGAAGCGGCCGCGAATTC | CCGCAGCCGAACGACCGAGC | bacterial_resistance_ampicillin | bacterial_resistance_chloramphenicol | bacterial_resistance_kanamycin | bacterial_resistance_other | bacterial_resistance_spectinomycin | copy_number_high_copy | copy_number_low_copy | copy_number_unknown | growth_strain_ccdb_survival | growth_strain_dh10b | growth_strain_dh5alpha | growth_strain_neb_stable | growth_strain_other | growth_strain_stbl3 | growth_strain_top10 | growth_strain_xl1_blue | growth_temp_30 | growth_temp_37 | growth_temp_other | selectable_markers_blasticidin | selectable_markers_his3 | selectable_markers_hygromycin | selectable_markers_leu2 | selectable_markers_neomycin | selectable_markers_other | selectable_markers_puromycin | selectable_markers_trp1 | selectable_markers_ura3 | selectable_markers_zeocin | species_budding_yeast | species_fly | species_human | species_mouse | species_mustard_weed | species_nematode | species_other | species_rat | species_synthetic | species_zebrafish | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sequence_id | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9ZIMC | 24 | 34 | 20 | 33 | 0 | 1 | 2 | 4 | 0 | 0 | 39 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 33 | 2 | 1 | 0 | 0 | 1 | 0 | 2 | 2 | 1 | 32 | 0 | 3 | 2 | 24 | 0 | 5 | 113 | 52 | 76 | 143 | 0 | 1 | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 5SAQC | 4 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 12 | 4 | 1 | 19 | 0 | 0 | 0 | 0 | 0 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| E7QRO | 2 | 0 | 160 | 0 | 11 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 7 | 2 | 2 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| CT5FP | 3 | 2 | 1 | 3 | 0 | 1 | 0 | 0 | 0 | 0 | 2 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 8 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 7 | 0 | 0 | 0 | 3 | 0 | 0 | 12 | 8 | 7 | 22 | 0 | 0 | 0 | 0 | 0 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 7PTD8 | 3 | 2 | 5 | 2 | 14 | 0 | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 1 | 3 | 0 | 0 | 25 | 18 | 15 | 33 | 0 | 0 | 0 | 0 | 0 | 0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
all_features_sel_seqs.shape(63017, 87)
# instantiate RF model
rf = RandomForestClassifier(n_jobs=4, n_estimators=150, class_weight='balanced', max_depth=3, random_state=0)
rf.fit(X_rf, y_rf)RandomForestClassifier(class_weight='balanced', max_depth=3, n_estimators=150,
n_jobs=4, random_state=0)
rf.score(X_rf, y_rf)0.14135868099084373
top10_accuracy_scorer(rf, X_rf, y_rf)0.3759303045210023
The very simple random forest model included in the starter code gave top-10 lab predictions that were better than chance, but not by much (~38% for the model vs. ~30% by just guessing the 10 most common labs every time).
For this first phase of modeling, I continued with the approach outlined by DrivenData's blog and ran a few models with my own feature engineering: one model used 3-grams (vs. the 4-grams in the original blog) and another included some common sequences (markers) as features but omitted n-grams. (All models used the original binary features.). However, my changes did not improve on the results obtained by the original DrivenData starter model.
A much larger marker library would probably have resulted in better predictions. Having said that, a problem with the random forest approach is that it can't learn from spatial relationships within and among sequences within a plasmid.
- First, the spatial relationships are important if a plasmid is going to work properly
- Second, the way plasmids are constructed from one lab to the next and the markers used will be reflected in the sequence order of a plasmid
With that, let's look at other approaches to predicting plasmid lab-of-origin based on plasmid characteristics and sequence order.
When considering the next modeling approach, I thought about how information is encoded in DNA.
First, and perhaps most obvious, DNA, like written language, encodes information in a linear sequence of units. While not a perfect analogy, DNA information encoding and written language information encoding have some fundamental similarities:
- Base pairs can be represented by 'letters'
- Assemblages of 'letters' code for functional units (analogous to letters in words)
- The order of the 'words' created by the ordering of DNA 'letters', in turn, contains additional information (similar to how a sentence conveys meaning by virtue of how the words within it are ordered)

Source: National Human Genome Research Institute, National Institutes of Health (NIH) at https://www.genome.gov/sites/default/files/inline-images/DNA_Fact-sheet2020.jpg
{kind=link}

Source: National Human Genome Research Institute, National Institutes of Health (NIH) at https://www.genome.gov/genetics-glossary/acgt
Second, and perhaps less obvious, is the similarity of DNA sequence information encoding to image information encoding:
- Analysis of 2D images by neural networks provides analysis of both local spatial features and spatially-distant features that must nevertheless be considered relative to each other
- Researching deep learning approaches brought me to 1D Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs)

Source: Addgene.org https://www.addgene.org/42230/
With all of the above in mind, and with suggestions from my instructors (each of whom saw merits in one approach or the other), I decided to start with 1D CNNs, moving on to Recurrent Neural Networks (RNN) if time allowed.
Given the amount of time neural network models require to run, and to get at least a minimum viable model up and running, I decided to start with a subset of the data that provided a greatly reduced list of targets (labs) but that still contained tens of thousands of sequences for training.
As discussed in the data exploration section, a large proportion of sequences in the original data set were submitted by a small percentage of labs (similar to the 80:20 rule). I wrote a function that allowed me to select plasmids from labs that had submitted at least 'n' number of plasmids to the data base.
For example, when I selected n = 200, I obtained a data set containing over 31,000 plasmids that had been submitted by just 42 labs. This is a huge reduction of targets (labs), down from the original count of 1,314 labs in the data set, while providing plenty of sequences for training.
Model runs were performed on the following subsets of data:
- Plasmids from labs submitting at least 200 plasmids each, producing a data set of ~31,000 plasmids submitted by 42 labs
- Plasmids from labs that had submitted 10 or fewer plasmids each, producing a data set of 3,356 plasmids from 449 labs
- Plasmids from labs that had submitted between 10 and 50 plasmids each, producing a data set of 15,602 plasmids from 730 labs
- Plasmids from labs submitting up to 50 plasmids each, producing a data set of 18,228 sequences from 1106 labs
The next step in preparing the data for analysis in the CNN is to tokenize the base pair letters in the sequences and the lab IDs. These steps include:
- Tokenizing (representing each character as an integer)--before data can be analyzed in a neural network, any non-numerical data type (e.g., string, object) must be converted to numerical form (integer or float)
- Padding or truncating sequences to ensure the same length for each sequence (the default for most model runs is 8,500)
- Vectorizing (encoding integers as binary features)
For demonstration purposes, the preprocessing steps and/or function outputs are displayed here with minimal code for just the first run. All code can be found in the technical notebook for this project.
from sklearn.model_selection import train_test_splitX_train_200_85, X_test_200_85, y_train_200_85, y_test_200_85 = train_test_split(X_200_85, y_200, test_size=0.25, random_state=42)X_train_200_85.shape(22341, 8500)
X_test_200_85.shape(7448, 8500)
y_train_200_85.shape(22341, 42)
y_test_200_85.shape(7448, 42)
Because the number of plasmids submitted by lab varies widely, it's important to address this class imbalance to ensure that the model is actually learning from the features in the data set (as opposed to just picking the more commonly represented classes in the data set).
In Tensorflow 2.0, users can import a dictionary of class weights to address imbalances. I created a function (details in the technical notebook) that creates this dictionary for use in the models. The results for this first model run are shown below as an example.
class_weights = class_weights_dict_tokenized(Y_200)
class_weights{0: 0.08559762307046884,
1: 0.2596127030607265,
2: 0.26544232962646136,
3: 0.6665995345506623,
4: 0.7289433759115157,
5: 0.9989604292421194,
6: 1.0399734673928223,
7: 1.0681655192197361,
8: 1.1348190476190476,
9: 1.2313574735449735,
10: 1.2421399382870486,
11: 1.2848947550034506,
12: 1.2942735488355925,
13: 1.4128723202428382,
14: 1.4474732750242953,
15: 1.4994966274036041,
16: 1.5553989139515456,
17: 1.6807154141277365,
18: 1.8518587591694642,
19: 1.8714034426435482,
20: 1.9325937459452447,
21: 1.975659901843746,
22: 1.9811785049215216,
23: 2.055831608005521,
24: 2.0860644257703083,
25: 2.12991562991563,
26: 2.1363310384394723,
27: 2.223391550977758,
28: 2.348549353516241,
29: 2.4974010731052982,
30: 2.7174785623061486,
31: 2.8715056872951608,
32: 2.9429954554435884,
33: 3.031033781033781,
34: 3.1107978279030912,
35: 3.209329885800474,
36: 3.209329885800474,
37: 3.314307966177125,
38: 3.377437641723356,
39: 3.4099130036630036,
40: 3.4767740429505136,
41: 3.5286661928452974}
This dataset includes sequences from labs submitting at least 200 plasmids to the database. There are over 31,000 plasmids submitted by a total of 42 labs.
(The preprocessing steps outlined in Section 3.2.2, "Preparing data for modeling", were performed prior to model setup)
max_char = 8500
model = Sequential()
embedding_dim = 1
model.add(Embedding(len(word_index) + 1, embedding_dim, input_length=max_char))
model.add(layers.Conv1D(filters=32, kernel_size=12, padding='same', activation='relu'))
model.add(layers.MaxPooling1D(pool_size=2))
model.add(Dropout(0.2))
model.add(layers.Conv1D(filters=32, kernel_size=8, padding='same', activation='relu'))
model.add(layers.MaxPooling1D(pool_size=2))
model.add(Dropout(0.2))
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(len(y_train_200_85[0]), activation='softmax'))Model summary:
Model: "sequential_20"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_20 (Embedding) (None, 8500, 1) 6
_________________________________________________________________
conv1d_37 (Conv1D) (None, 8500, 32) 416
_________________________________________________________________
max_pooling1d_27 (MaxPooling (None, 4250, 32) 0
_________________________________________________________________
dropout_18 (Dropout) (None, 4250, 32) 0
_________________________________________________________________
conv1d_38 (Conv1D) (None, 4250, 32) 8224
_________________________________________________________________
max_pooling1d_28 (MaxPooling (None, 2125, 32) 0
_________________________________________________________________
dropout_19 (Dropout) (None, 2125, 32) 0
_________________________________________________________________
flatten_17 (Flatten) (None, 68000) 0
_________________________________________________________________
dense_34 (Dense) (None, 128) 8704128
_________________________________________________________________
dense_35 (Dense) (None, 42) 5418
=================================================================
Total params: 8,718,192
Trainable params: 8,718,192
Non-trainable params: 0
_________________________________________________________________
None
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])%%time
history = model.fit(X_train_200_85, y_train_200_85, epochs=12, validation_data=(X_test_200_85, y_test_200_85), class_weight = class_weights)history.history['accuracy'][0.3942527174949646,
0.5978693962097168,
0.7053846716880798,
0.7698401808738708,
0.8140637874603271,
0.8448591828346252,
0.8564074635505676,
0.8741327524185181,
0.8858153223991394,
0.875744104385376,
0.8982588052749634,
0.923772394657135]
history.history['val_accuracy'][0.5095327496528625,
0.5477980971336365,
0.5860633850097656,
0.6674275398254395,
0.6721267700195312,
0.6754833459854126,
0.6749463081359863,
0.7152255773544312,
0.6349355578422546,
0.6887755393981934,
0.7075725197792053,
0.7156283855438232]



The 1D CNN models for this data subset (plasmids submitted by the 42 most prolific labs) did a pretty good job predicting plasmid single lab-of-origin (up to ~92% training accuracy and 72% test accuracy). (Note that these results--indeed all CNN results discussed below--are for single lab-of-origin predictions. I figure that train and test accuracies would be extremely high with only 42 labs in the data set if I had used the "top 10" approach.)
For this run, I selected plasmids submitted by labs that have submitted fewer than 10 plasmids to the database.
(Note: The preprocessing steps outlined in Section 3.2.2, "Preparing data for modeling", were performed on this data subset prior to model setup.)
max_char = 8500
model = Sequential()
embedding_dim = 1
model.add(Embedding(len(word_index) + 1, embedding_dim, input_length=max_char))
model.add(layers.Conv1D(filters=32, kernel_size=12, padding='same', activation='relu'))
model.add(layers.MaxPooling1D(pool_size=2))
model.add(layers.Conv1D(filters=32, kernel_size=8, padding='same', activation='relu'))
model.add(layers.MaxPooling1D(pool_size=2))
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(len(y_train_lt_10[0]), activation='softmax'))model.summary()Model: "sequential_26"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_26 (Embedding) (None, 8500, 1) 6
_________________________________________________________________
conv1d_49 (Conv1D) (None, 8500, 32) 416
_________________________________________________________________
max_pooling1d_39 (MaxPooling (None, 4250, 32) 0
_________________________________________________________________
conv1d_50 (Conv1D) (None, 4250, 32) 8224
_________________________________________________________________
max_pooling1d_40 (MaxPooling (None, 2125, 32) 0
_________________________________________________________________
flatten_23 (Flatten) (None, 68000) 0
_________________________________________________________________
dense_46 (Dense) (None, 128) 8704128
_________________________________________________________________
dense_47 (Dense) (None, 449) 57921
=================================================================
Total params: 8,770,695
Trainable params: 8,770,695
Non-trainable params: 0
_________________________________________________________________
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])%%time
history = model.fit(X_train_lt_10, y_train_lt_10, epochs=40, validation_data=(X_test_lt_10, y_test_lt_10), class_weight = class_weights_lt_10)history.history['accuracy'][0.0043702819384634495,
0.02781088650226593,
0.17481128871440887,
0.3976956605911255,
0.5593960881233215,
0.6909018754959106,
0.7620182633399963,
0.8243941068649292,
0.8812077641487122,
0.919348418712616,
0.9451728463172913,
0.9666269421577454,
0.9813269972801208,
0.9876837730407715,
0.9924513101577759,
0.9932458996772766,
0.9936432242393494,
0.9936432242393494,
0.9928486347198486,
0.9924513101577759,
0.9928486347198486,
0.9956297278404236,
0.9952324032783508,
0.9960269927978516,
0.9964243173599243,
0.9964243173599243,
0.9964243173599243,
0.9952324032783508,
0.997218906879425,
0.9964243173599243,
0.997218906879425,
0.9960269927978516,
0.9940404891967773,
0.9928486347198486,
0.9928486347198486,
0.9952324032783508,
0.9964243173599243,
0.997218906879425,
0.9964243173599243,
0.997218906879425]
history.history['val_accuracy'][0.0035756854340434074,
0.04290822520852089,
0.1609058380126953,
0.23718713223934174,
0.27771157026290894,
0.25983312726020813,
0.2824791371822357,
0.3051251471042633,
0.29797378182411194,
0.3051251471042633,
0.31466031074523926,
0.29678186774253845,
0.31823599338531494,
0.31823599338531494,
0.3075089454650879,
0.3098927140235901,
0.3051251471042633,
0.3027413487434387,
0.3063170313835144,
0.31346842646598816,
0.31704410910606384,
0.31823599338531494,
0.31704410910606384,
0.31466031074523926,
0.31704410910606384,
0.31585219502449036,
0.31585219502449036,
0.31704410910606384,
0.3098927140235901,
0.3063170313835144,
0.3098927140235901,
0.31585219502449036,
0.308700829744339,
0.3075089454650879,
0.3110846281051636,
0.31823599338531494,
0.31585219502449036,
0.31823599338531494,
0.31585219502449036,
0.31823599338531494]
loss_viz(history)
acc_viz(history)

The data set for the chart above included 3,356 sequences submitted by 449 labs in total. Training accuracy peaked at over 99% and validation accuracy was just under 32%.
For this run, I selected plasmids submitted by labs that have submitted between 10 and 50 plasmids to the database.
(Note: The preprocessing steps outlined in Section 3.2.2, "Preparing data for modeling", were performed on this data subset prior to model setup.)
max_char = 8500
model = Sequential()
embedding_dim = 1
model.add(Embedding(len(word_index) + 1, embedding_dim, input_length=max_char))
model.add(layers.Conv1D(filters=32, kernel_size=12, padding='same', activation='relu'))
model.add(layers.MaxPooling1D(pool_size=2))
model.add(layers.Conv1D(filters=32, kernel_size=8, padding='same', activation='relu'))
model.add(layers.MaxPooling1D(pool_size=2))
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(len(y_train_10_50[0]), activation='softmax'))model.summary()Model: "sequential_29"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_29 (Embedding) (None, 8500, 1) 6
_________________________________________________________________
conv1d_53 (Conv1D) (None, 8500, 32) 416
_________________________________________________________________
max_pooling1d_43 (MaxPooling (None, 4250, 32) 0
_________________________________________________________________
conv1d_54 (Conv1D) (None, 4250, 32) 8224
_________________________________________________________________
max_pooling1d_44 (MaxPooling (None, 2125, 32) 0
_________________________________________________________________
flatten_25 (Flatten) (None, 68000) 0
_________________________________________________________________
dense_50 (Dense) (None, 128) 8704128
_________________________________________________________________
dense_51 (Dense) (None, 730) 94170
=================================================================
Total params: 8,806,944
Trainable params: 8,806,944
Non-trainable params: 0
_________________________________________________________________
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])%%time
history = model.fit(X_train_10_50, y_train_10_50, epochs=20, validation_data=(X_test_10_50, y_test_10_50), class_weight = class_weights_10_50)history.history['accuracy'][0.020083753392100334,
0.18169386684894562,
0.34817537665367126,
0.5128621459007263,
0.6636185050010681,
0.7622425556182861,
0.8371079564094543,
0.8902657628059387,
0.933082640171051,
0.9703444242477417,
0.9813690781593323,
0.9833347201347351,
0.986667811870575,
0.9869241714477539,
0.9845312237739563,
0.9852149486541748,
0.9867532253265381,
0.9841039180755615,
0.988206148147583,
0.9872660040855408]
history.history['val_accuracy'][0.06536785513162613,
0.20353755354881287,
0.2794155478477478,
0.3158164620399475,
0.3094078600406647,
0.32555755972862244,
0.32812100648880005,
0.327095627784729,
0.3391438126564026,
0.34862855076789856,
0.3345296084880829,
0.33606767654418945,
0.3450397253036499,
0.3445270359516144,
0.3409382402896881,
0.3488849103450775,
0.34734684228897095,
0.3350422978401184,
0.35247373580932617,
0.35273006558418274]
loss_viz(history)
acc_viz(history)
Training accuracy peaked at around 99% after epoch 10, but at epoch 4, validation accuracy was approaching its eventual peak at epoch 10 at around 35% accuracy.
For this model run, I selected plasmids based on whether the lab that submitted it had submitted 50 or fewer plasmids to the database. This yielded a data subset with 18,228 plasmids and 1106 labs.
(Note: The preprocessing steps outlined in Section 3.2.2, "Preparing data for modeling", were performed on this data subset prior to model setup.)
max_char = 8500
model = Sequential()
embedding_dim = 1
model.add(Embedding(len(word_index) + 1, embedding_dim, input_length=max_char))
model.add(layers.Conv1D(filters=32, kernel_size=12, padding='same', activation='relu'))
model.add(layers.MaxPooling1D(pool_size=2))
model.add(Dropout(0.2))
model.add(layers.Conv1D(filters=32, kernel_size=8, padding='same', activation='relu'))
model.add(layers.MaxPooling1D(pool_size=2))
model.add(Dropout(0.2))
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(len(y_train_lt_50[0]), activation='softmax'))model.summary()Model: "sequential_22"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_22 (Embedding) (None, 8500, 1) 6
_________________________________________________________________
conv1d_41 (Conv1D) (None, 8500, 32) 416
_________________________________________________________________
max_pooling1d_31 (MaxPooling (None, 4250, 32) 0
_________________________________________________________________
dropout_22 (Dropout) (None, 4250, 32) 0
_________________________________________________________________
conv1d_42 (Conv1D) (None, 4250, 32) 8224
_________________________________________________________________
max_pooling1d_32 (MaxPooling (None, 2125, 32) 0
_________________________________________________________________
dropout_23 (Dropout) (None, 2125, 32) 0
_________________________________________________________________
flatten_19 (Flatten) (None, 68000) 0
_________________________________________________________________
dense_38 (Dense) (None, 128) 8704128
_________________________________________________________________
dense_39 (Dense) (None, 1106) 142674
=================================================================
Total params: 8,855,448
Trainable params: 8,855,448
Non-trainable params: 0
_________________________________________________________________
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])%%time
history = model.fit(X_train_lt_50, y_train_lt_50, epochs=12, validation_data=(X_test_lt_50, y_test_lt_50), class_weight = class_weights_lt_50)history.history['accuracy'][0.001024065539240837,
0.0015360983088612556,
0.0017555409576743841,
0.0018286884296685457,
0.0016823933692649007,
0.0019018360180780292,
0.002121278550475836,
0.0017555409576743841,
0.002121278550475836,
0.0017555409576743841,
0.0017555409576743841,
0.002121278550475836]
history.history['val_accuracy'][0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]



The data set for this run included 18,228 sequences submitted by 1106 labs in total. Model performance was abysmal, with training accuracy peaked at just over 0.2% and validation accuracy was flatlined at 0.000%.
For the analyses completed in October 2020 to satisfy my capstone project requirements, I focused on the end-to-end implementation of a project, creating 1D CNN models with a subset of the GEAC data set. (Note: Flatiron student capstone projects are done independently and all work in the project is my own unless otherwise noted.) Given time constraints, I was unable to also explore RNN models.
The 1D CNN models I developed did a pretty good job predicting plasmid single lab-of-origin (up to ~92% training accuracy and 72% test accuracy) for a subset of labs that had provided nearly 50% (over 31,000) of the sequences in the study data set. (Note that these results were of single lab-of-origin predictions; if I had used the "top 10" approach, I figure that train and test accuracies would be extremely high with only 42 labs in the data set.)
The two graphs below plot the model's performance over 12 epochs for sequences of max length 8,500 and 10,000, respectively.
Accuracy of the best version of 1D CNN model over 12 epochs for sequences of maximum length 8,500. Training accuracy peaked at 92% and validation accuracy peaked at about 72%.

Accuracy of the best version of 1D CNN model over 12 epochs for maximum sequence lengths of 10,000.

Training accuracy peaked at around 93% and validation accuracy peaked at about 70%, just shy of what the model produced with max sequence lengths of 8,500.
Given that I took on this project to satisfy my capstone project requirement, I was really pleased to be able to implement a challenging end-to-end data science project and get good results. Furthermore, I exceeded the capstone requirements and received strong marks for my final assessment, which felt great!
Even so, I hoped to have a chance to revisit these analyses to find out whether these models would perform as well or better when sequences from a greater number of labs was included.
In July 2021, with a new M1 MacBook Air and improved data science/programming skills, I decided to revisit the project to update the code for this project to run Tensorflow 2.5 and python 3.9 natively on the MacBook Air. I purposely chose not to revisit the DrivenData GEAC competition website until updating the code, trying some additional approaches, and expanding my analysis a bit.
Key results are shown below. In a nutshell: the 1D CNN performed reasonably well predicting single lab-of-origin for the subset of sequences (summarized above), but the results using a larger subset of sequences and labs ranged from lackluster to spectacularly awful. (As a reminder, these are single lab-of-origin predictions, rather than top-10 lab probabilities. While I did explore whether it would be possible to set up the 1D CNN model to run with top-10 probability predictions for each epoch, time constraints caused me to cut that effort short.)
The data set for the charts below included plasmids from labs that had submitted 10 or fewer plasmids, resulting in a data set of 3,356 plasmids from 449 labs. Training accuracy peaked at just over 99% and validation accuracy peaked just over 31% around epoch 14 or 15.
Accuracy of the best version of 1D CNN model over 40 epochs for sequences submitted by labs that had submitted 10 or less sequences to the database (max sequence length = 8,500).

However, validation losses were at their minimum at epoch 4, bouncing back up until epoch 15, after which point they declined slightly and then remained around that point through epoch 40.

Slicing the data set to look at plasmids from labs that had submitted between 10 and 50 plasmids each produced a data set of 15,602 plasmids from 730 labs.
Accuracy of the best version of 1D CNN model over 20 epochs for sequences (max sequence length = 8,500).

Training accuracy peaked at around 99% after epoch 10, but at epoch 4, validation accuracy was approaching its eventual peak at epoch 10 at around 35% accuracy. It is interesting that the validation accuracy was so similar for this model run and the previous run, despite the data sets being significantly different. But in both cases, the validation accuracy isn't great (though certainly is much better than chance).
Selecting a subset of data consisting of plasmids from labs submitting 50 or fewer plasmids each resulted in 18,228 sequences from 1106 labs. Training accuracy peaked at just over 0.2% and validation accuracy was flatlined at 0.000%. This is a chart that "only a mother could love".
Accuracy of the best version of 1D CNN model over 12 epochs for sequences submitted by labs that had submitted 50 or less sequences to the database (max sequence length = 8,500).

So, why were these analyses (especially the last one) so much worse than the original analyses on the data set of plasmids from the top 42 labs? Possible causes for the poor performance on these data subsets could include:
- These data subsets had fewer plasmids but many more labs compared to the original data subset (~31,000 sequences and 42 labs)
- The binary features in the original data set were not included in these modeling runs
- My neural network models were focused on predicting single lab-of-origin for each plasmid, as opposed to predicting the top 10 most likely labs for each plasmid
Furthermore, I knew that additional approaches, such as variable batch length processing, using an RNN with LSTM, and/or including a large library of commonly-used plasmid marker sequences, were likely to improve results. However, I was sure of one thing: whatever the winners of the competition developed would be quite a bit more advanced than what I could do in the time available.
After updating the code in my notebook and running additional analyses, I checked out the summary of the winning GEAC competition projects at https://www.drivendata.co/blog/genetic-engineering-attribution-winners/. The algorithms employed by the winner (a computational biologist) were really sophisticated--so much so that I might have decided to pursue a simpler project if the outcomes of the competition were available as reference when I started! But I learned so much about various modeling approaches (most especially 1DCNN and RNN with LSTM), coding in Tensorflow 2.5--even getting the conda environment set up for the M1 MacBook Air, which was a complicated effort--that I figure it was worth it. All in all, it has been a very interesting project, and I am excited to apply what I've learned to new challenges.
As I mentioned in the first section, my goal for this project was to submit it as my capstone. The complexity of this analysis exceeded the requirements for the capstone, but I love tackling complex problems and this one definitely held my interest. Even so, I might not have taken it on at all if I had seen the work published after the conclusion of the competition. The problem is even more challenging than I thought it would be, and I feel like I bit off more than I could chew. At least I started with a subset of the data, so that I could get the models up and running and have reasonably good results. I certainly learned a lot during this project--and gained a newfound appreciation for working up from simpler projects to more complex ones.