



Verdict is a declarative framework for specifying and executing compound LLM-as-a-judge systems. It is
- Plug-and-play across models, prompts, extraction methods, judge protocols — allowing for rapid iteration.
- Concurrency model that can easily coordinate thousands of LLM calls simultaneously.
- Arbitrarily composable dependency graph with primitives from the research literature.
- Rate-limited on the client-side, so you never lose experiment results halfway through.
- Integrated with DSPy for use as a metric in AI system optimization; and more to come soon!
- SOTA-level on a variety of benchmarks with minimal fitting and a fraction of the inference time.
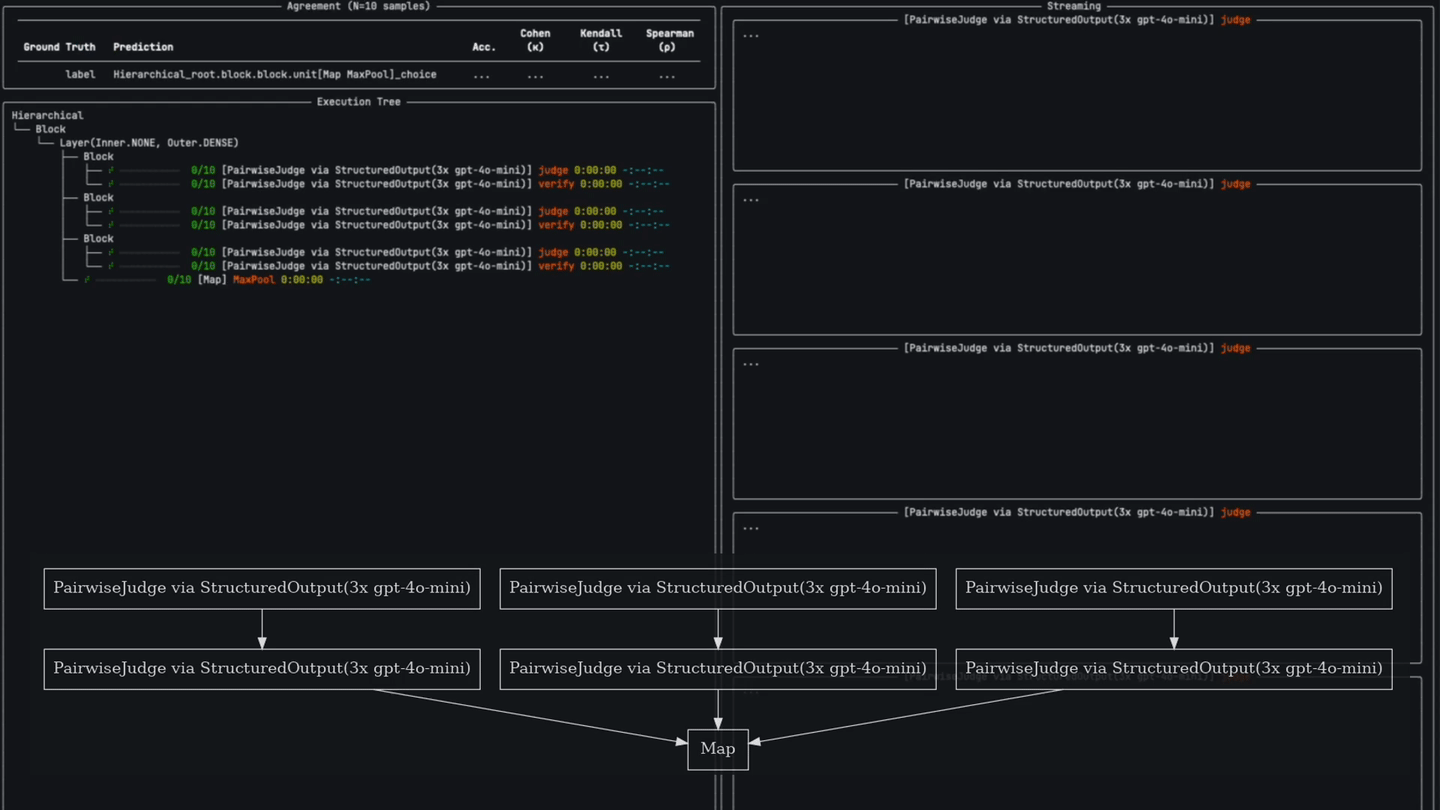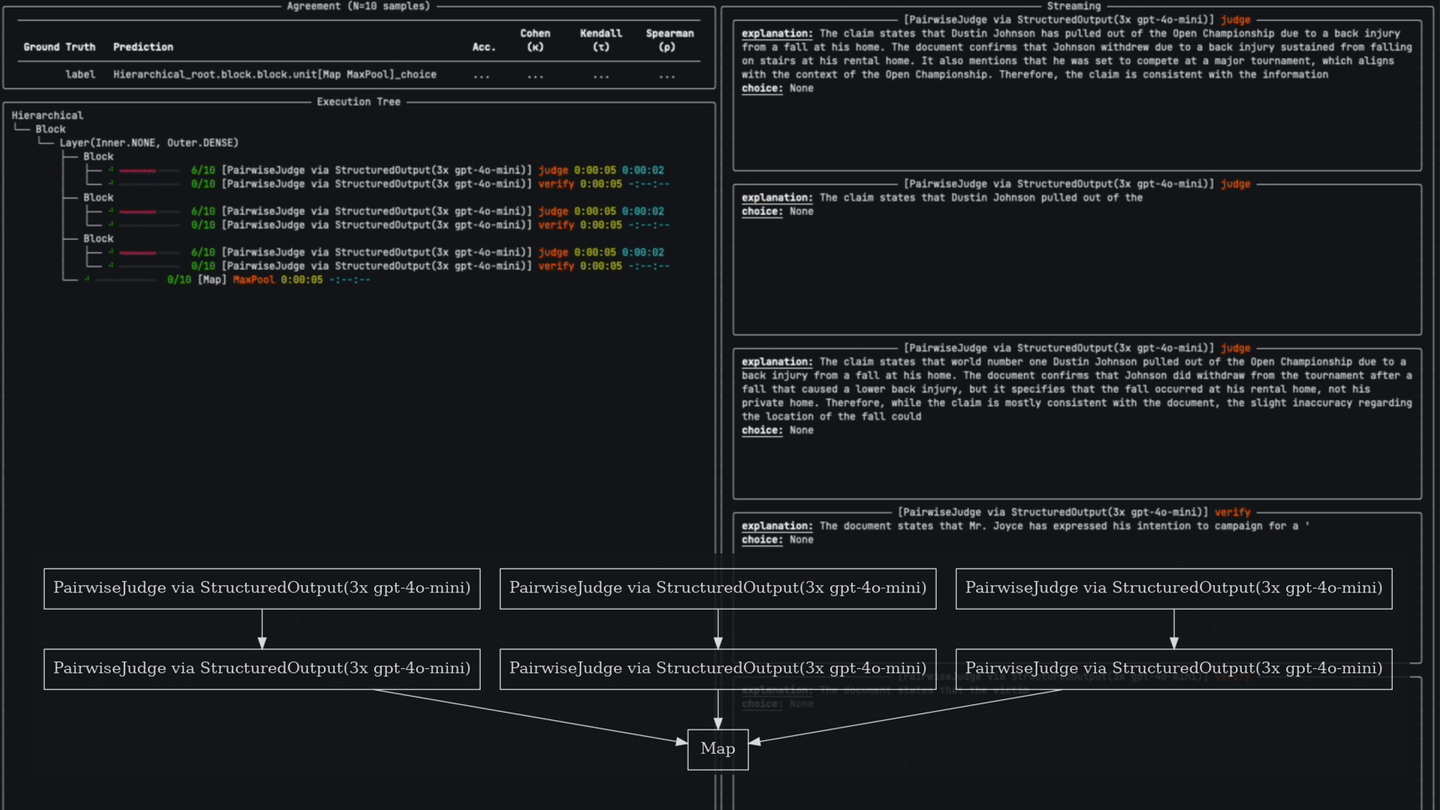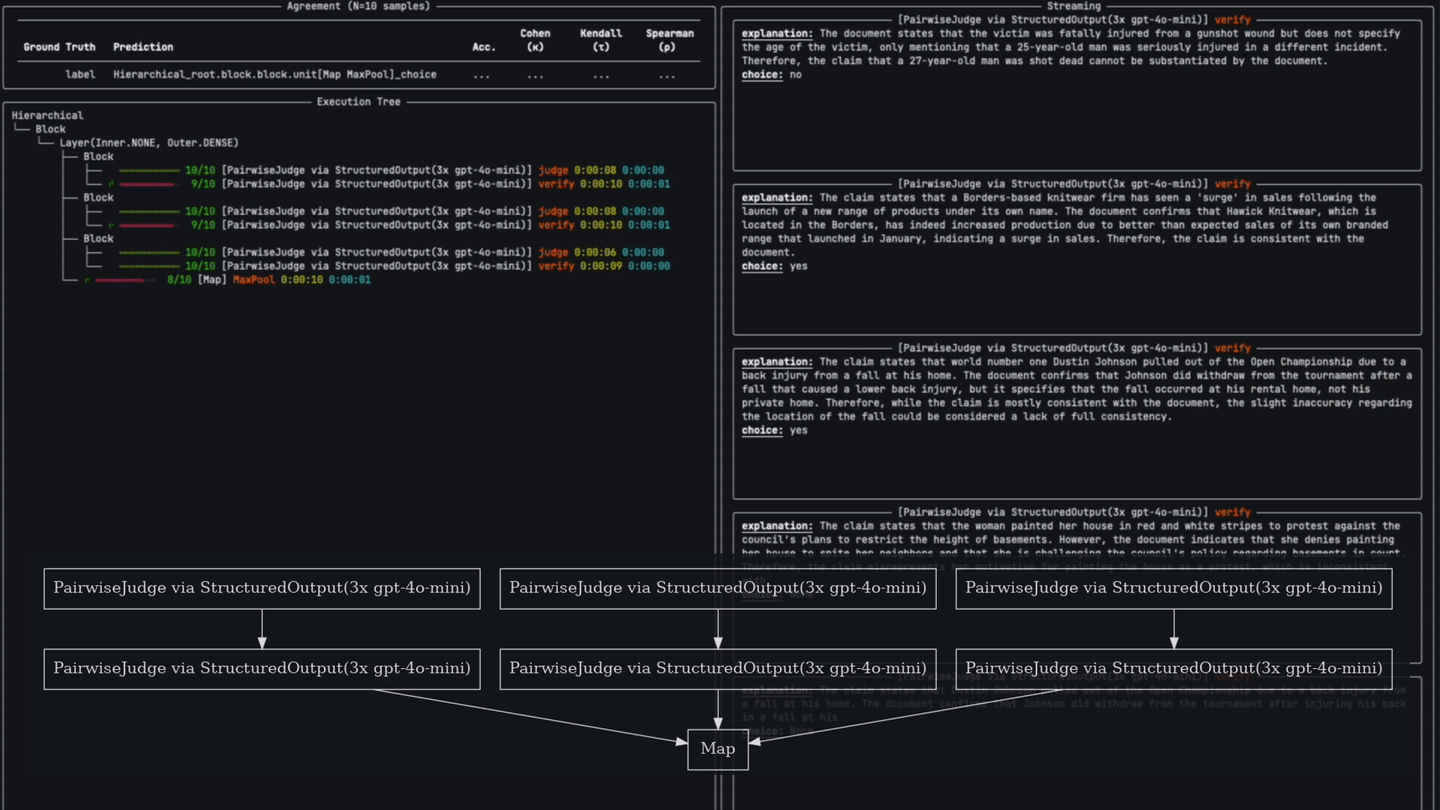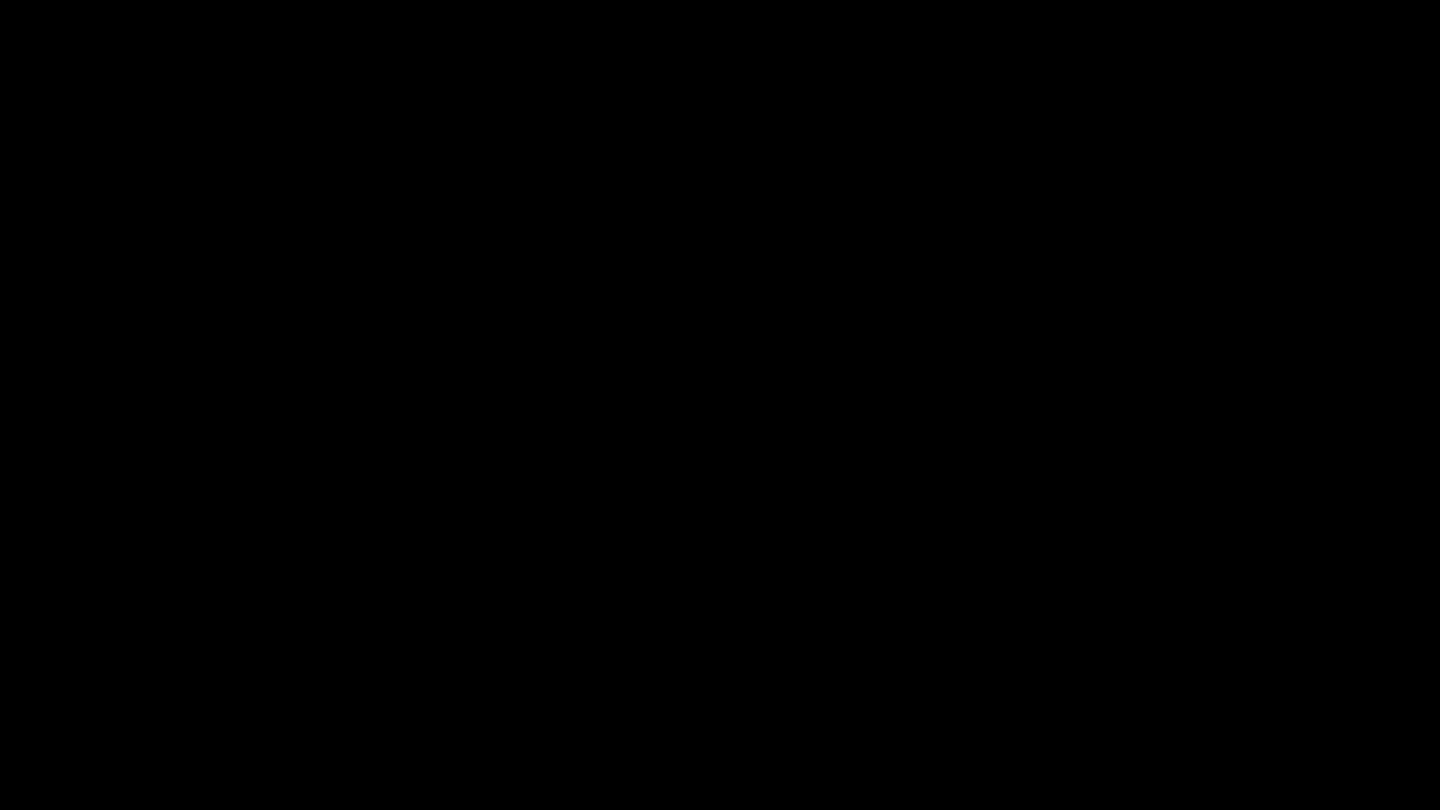
pipeline = Pipeline() \
>> Layer(
# 1. A CategoricalJudgeUnit first decides if a hallucination is present...
CategoricalJudgeUnit(name='Judge', categories=DiscreteScale(['yes', 'no']), explanation=True)
.prompt(JUDGE_PROMPT).via('gpt-4o', retries=3, temperature=0.7) \
# 2. Followed by a CategoricalJudgeUnit that verifies the initial judge's explanation and decision.
>> CategoricalJudgeUnit(name='Verify', categories=DiscreteScale(['yes', 'no']))
.prompt(VERIFY_PROMPT).via('gpt-4o', retries=3, temperature=0.0)
, repeat=3) # duplicate this 3x
# 3. Vote to find the most popular response.
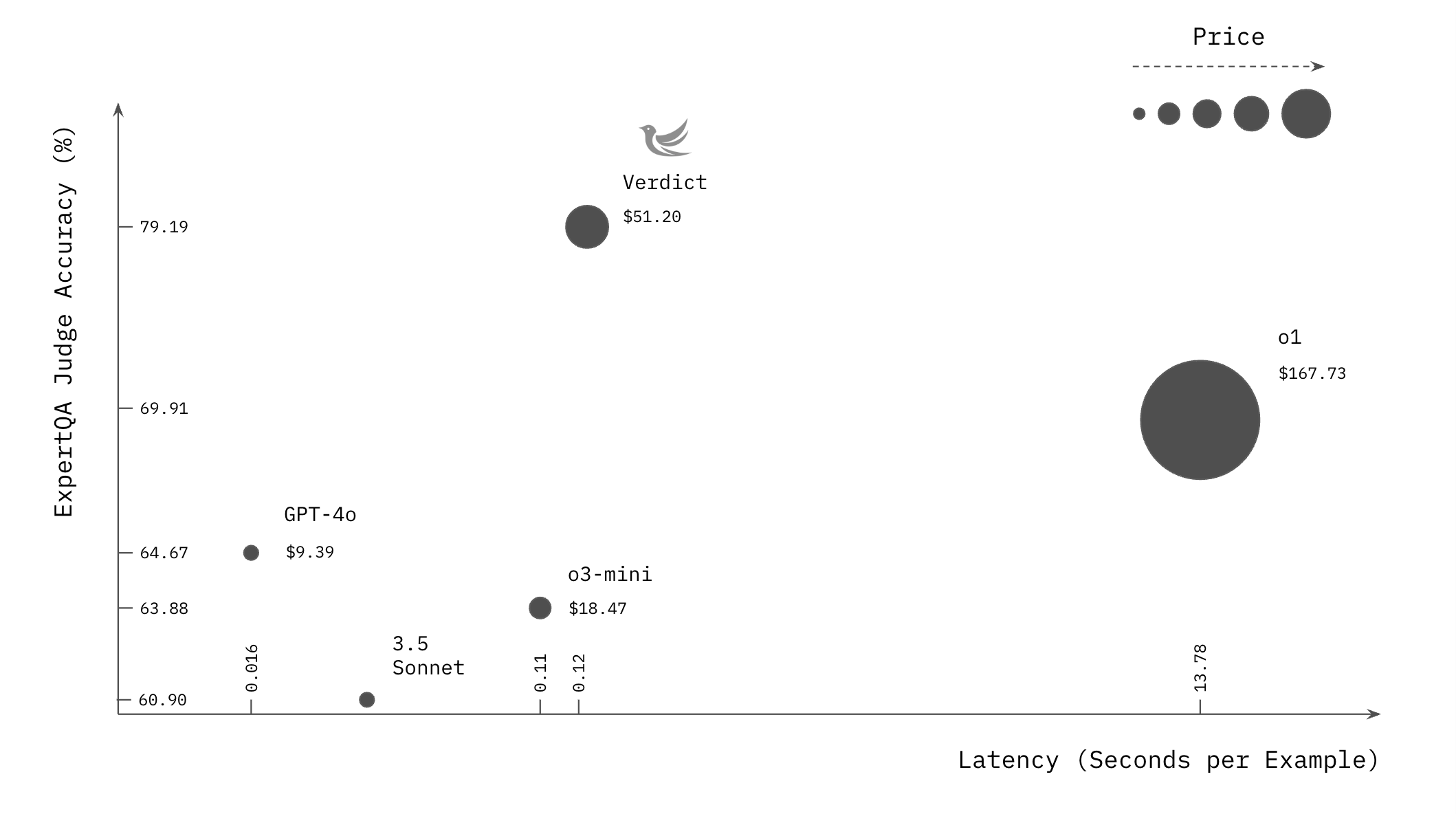
>> MaxPoolUnit()Verdict judges beat out reasoning models like o1 and o3-mini on evaluation tasks for a fraction of the cost and latency.
- Building Judges that Actually Work
- Verdict Scales Up Judge-Time Compute
- A Simple Example of Hierarchical Reasoning
- Verdict for Evaluation, Guardrails, Verification, and Reinforcement Learning
- Learn More
Automated correctness checks using LLMs, a.k.a. LLM-as-a-judge, is a widely adopted practice for both developers and researchers building LLM-powered applications. However, LLM judges are painfully unreliable. Today's LLM judges struggle with inconsistent output formats, mode collapse, miscalibrated confidence, superficial biases towards answer positioning, data frequency, model family, length, style, tone, safety, and numerous other failure modes. This makes the problem of evaluation twice the trouble, as both the evaluator and evaluatee may be unreliable.
One promising solution is to scale up judge-time compute — the number of inference tokens used for judging. We do this in a very particular way: by composing judge architectural primitives grounded in the scalable oversight, automated evaluation, and generative reward modeling research.
This is the foundation of Verdict, our library for scaling up judge-time compute.

Verdict provides the primitives (Unit; Layer; Block), composition of primitives, and execution framework for building complex, composable, compound judge protocols. Instead of a single LLM call, Verdict judges synthesize multiple units of reasoning, verification, debate, and aggregation.
Verdict's primary contributions are as follows:
Important
- Verdict provides a single interface for implementing a potpourri of prompting strategies, bias mitigations, and architectures grounded in frontier research. We support insights from the fields of automated evaluation, scalable oversight, safety, fact-checking, reward modeling, and more.
- Verdict naturally introduces powerful reasoning primitives and patterns for automated evaluation, such as hierarchical reasoning verification and debate-aggregation.
- Verdict is fully composable, allowing arbitrary reasoning patterns to be stacked into expressive and powerful architectures.
- Judges built using Verdict require no special fitting but still achieve SOTA or near-SOTA performance on a wide variety of challenging automated evaluation tasks spanning safety moderation, hallucination detection, reward modeling, and more.
Scaling judge-time compute works astonishingly well. For example, Verdict judges achieve SOTA or near-SOTA for content moderation, hallucination detection, and fact-checking.
Say you have an AI agent that you'd like to evaluate on politeness. A first stab may be to simply prompt a Verdict JudgeUnit as follows
Pipeline() \
>> JudgeUnit(DiscreteScale((1, 5))).prompt("""
Evaluate the following customer support interaction on politeness.
{source.conversation}
Respond with a score between 1 and 5.
- 1: Extremely impolite, rude, hostile, or disrespectful
...
- 5: Extremely polite. Consistently respectful, friendly, and courteous.
""").via('gpt-4o-mini', retries=3, temperature=0.4)Chain-of-thought prompting can improve response quality. Most Verdict built-ins simulate this by prepending a reasoning/thinking/explanation to the requested response.
>> JudgeUnit(DiscreteScale((1, 5)), explanation=True).prompt(""" ...As shown by the recent success of reasoning models like the o3-family, complex reasoning chains can provide major boost in model performance. However, these models are far too slow for many automated evaluation applications, particularly real-time guardrails. Rather than have a powerful model solve the meta-problem of deciding how much reasoning to use each time, Verdict allows you to manually specify the structure of a simpler reasoning chain best suited for the task. For example, we may find that a single round of self-contemplation on if the explanation is reasonable is sufficient to match your intended preference alignment. This allows us to replace an o1 call with two gpt-4o-mini calls.
Pipeline() \
>> JudgeUnit(DiscreteScale((1, 5)), explanation=True).prompt("""
...
""").via('gpt-4o-mini', retries=3, temperature=0.4) \
>> JudgeUnit(BooleanScale()).prompt("""
Check if the given explanation correctly references the source conversation.
Conversation: {source.conversation}
Politeness Score: {previous.score}
Explanation: {previous.explanation}
Return "yes" if the explanation correctly references the source, and "no" otherwise.
""").via('gpt-4o-mini', retries=3, temperature=0.0)Applying this principle in various configurations allows us to make informed tradeoffs between performance and inference time. Read on in our Getting Started guide!
Verdict judges can be used anywhere to replace human feedback and verification. Naturally, they apply to at least the following scenarios:
Tip
- Automated Evaluation of AI Applications. Verdict judges enable tailored and automated evaluation of AI applications.
- Run-Time Guardrails. Verdict judges are guardrails that sit on top of AI applications running in production.
- Test-Time Compute Scaling. Verdict judges are verifiers that help rank, prune, and select candidates during test-time compute scaling.
- Reward Modeling & Reinforcement Learning. Verdict judges provide signal in reinforcement learning — particularly in settings where rewards are not verifiable.
To learn more about applying Verdict for your judging use cases, please find us at [email protected].