모든 학습 및 파일은 Google Colab Pro + 환경에서 구동되도록 구현하였음
┣segmentation
┃ ┣ sample_image
┃ ┣ 0.test.ipynb
┃ ┣ 1. DLv3_base.ipynb
┃ ┣ 2. DL_v3+unfreeze_adam0.01_train.ipynb
┃ ┣ 3. DL_v3+unfreeze_sgd0.01_train.ipynb
┃ ┣ 4. DL_v3+freezed_sgd0.01_train.ipynb
┃ ┣ 5. DL_v3+trainableTure_sgd0.001_train.ipynb
┃ ┣ 6. DL_v3+unfreeze_sgd0.01+seblock_train.ipynb
┃ ┣ 7. Last_fulltrain.ipynb
┗ ┗ model_visualization.ipynb
┣arrange.py
┣scrap.py
┣seg.py

- 카드뉴스의 형식으로 기사의 타이틀과 요약문제공
- 왼쪽 이미지에 마우스를 오버하면 우측에 카드뉴스 제공
- 왼쪽 이미지 클릭 시 기사 원문 링크로 이동
-
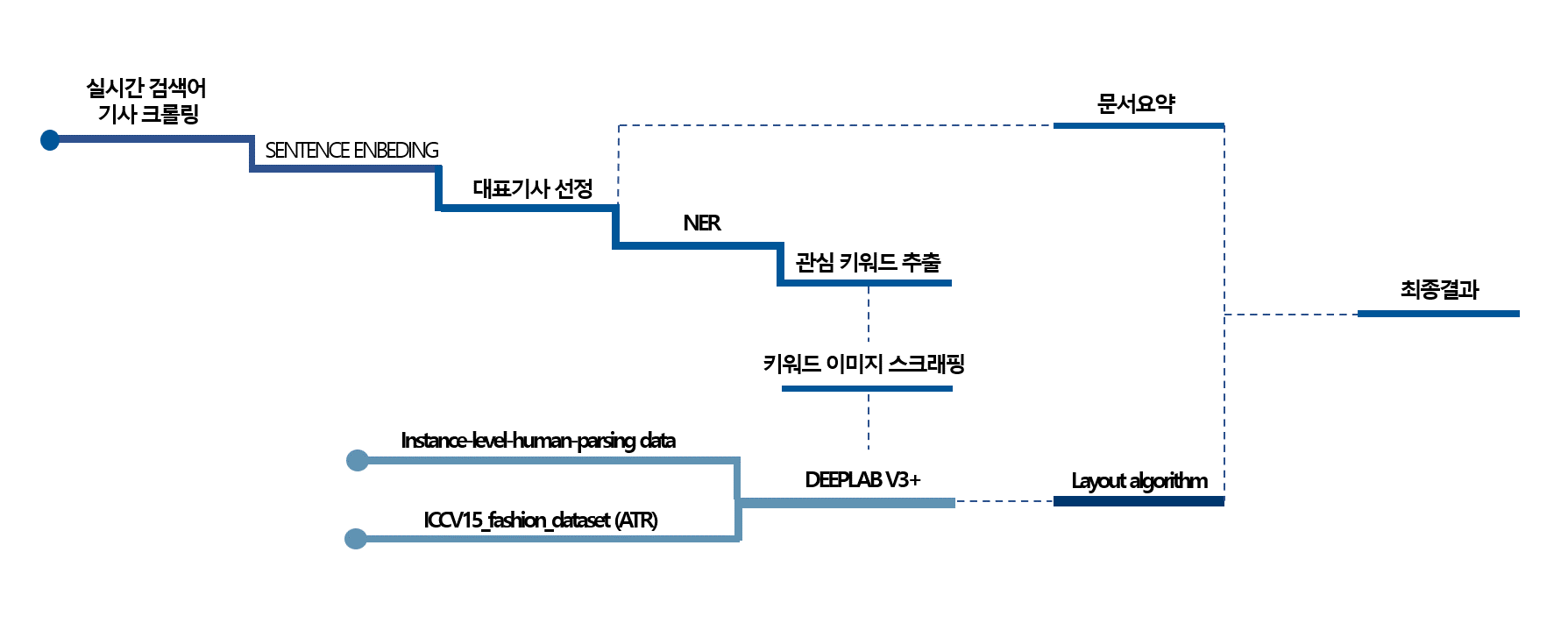
현재 네이버시그널 에서 제공하는 실시간 검색어를 스크래핑
-
각 검색어에 해당하는 기사들 또한 정해진 숫자만큼 크롤링. 기사는 특수문자를 제거한 이후 350자가 넘는 기사들을 대상으로만 크롤링 진행, 검색어당 8개의 기사를 크롤링.
-
크롤링한 8개의 기사의 제목에 Sentence Embedding 실시 -> 각 기사들과 타 기사들 간의 cosine similarity를 계산하여 cosine similarity가 가장 높은 기사는 해당 검색어가 실시간 검색어에 선정된 이유와 가장 밀접한 기사라고 할 수 있는 기사라고 가정하고 해당 기사를 대표기사로 선정
-
3에서 선정한 대표기사와 검색어를 대상으로 NER을 실시하여 실제 이슈 키워드가 무엇인지 파악
-
대표기사의 본문을 대상으로 TEXT SUMMARIZATION을 실시
-
4에서 추출한 키워드의 이미지를 나무위키(인물의 프로필사진 또는 단체의 로고를 고해상도로 제공)에서 스크랩
-
레이아웃 알고리즘으로 이미지 배치
-
위 결과물들을 web으로 전송
- 상세내용은 파일내에 주석으로 작성
-
웹에서 데이터를 스크래핑하는 함수들을 담은 py main에서 실시간 정보를 가지고 오는 데에 사용
-
상세 내용은 파일내에 주석으로 작성
-
크롤링 - Segmentation을 거친 이미지들을 배치 시에 사용한 함수들을 담은 py파일
-
상세 내용은 파일내에 주석으로 작성
-
이미지를 기학습한 모델로 Segmentation하고 후처리를 거친 이미지를 리턴하는 함수 및 이미지 간 구분을 위한 테두리를 생성하는 함수를 담은 py파일
-
상세 내용은 파일내에 주석으로 작성

-
deeplabV3+ 모델을 학습하는데에 사용했던 ipynb파일들
-
visualization.ipynb : 학습결과를 시각화한 파일
-
sample_image : sampleimage들과 그 결과
-
training code에 대한 주석은 1. DLv3_base.ipynb에 모두 작성
-
weight는 깃용량이 제한으로 구글 드라이브로 공유 weight
-
Crowd Instance-level Human Parsing Dataset 을 사용하여 약 50000개의 sementic level의 사람 이미지를 학습함