- deep learning model try to classify each image's pixel instead of whole image.
- deep learning model takes input image > based on class trained, try to classify each pixel into a class > output color coded so that easily distinguish one class from another.
cross entropy loss as loss functions
- classify the objects belonging to the same class in the image with single label.
- Combination of segmentation and object detection.
- ratio of pixels that classified / total number of pixels in image
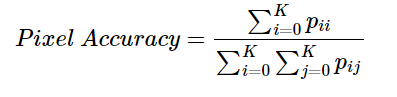
- ratio of correct pixels per class.
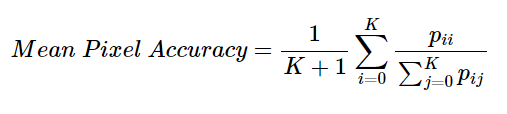
- known as the Jaccard Index is used for both object detection and image segmentation.
- raction of area of intersection of the predicted segmentation of map and the ground truth map to the area of union of predicted and ground truth segmentation maps.
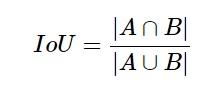
A - predicted B - ground truth
- ratio of the twice the intersection of the predicted and ground truth segmentation maps to the total area of both the segmentation maps.
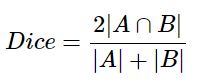
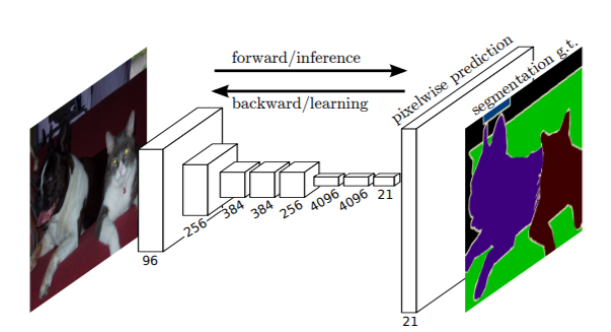
- contains only convolutional layers
- modified the GoogLeNet and VGG16 architectures by replacing the final fully connected layers with convolutional layers
- input is an RGB image
- hence its output a segmentation map of the input image instead of the standard classification scores.
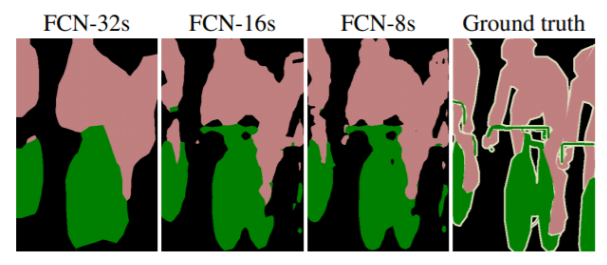
- Disadvantages : model was that it was very slow and could not be used for real-time segmentation
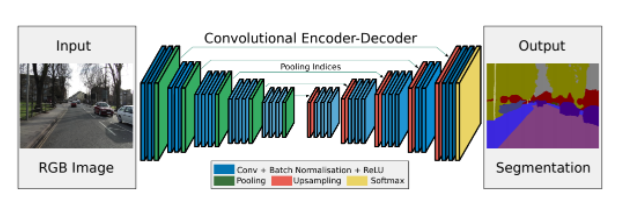
- segmentation model based on the encoder-decoder architecture.
- contains only convolutional layers
- Encoder contains 13 convolutional layers inside VGG16 network.
- Decoder contains upsampling layers and convolutional layers, responsible for the pixel-wise classification of the input image and outputting the final segmentation map.
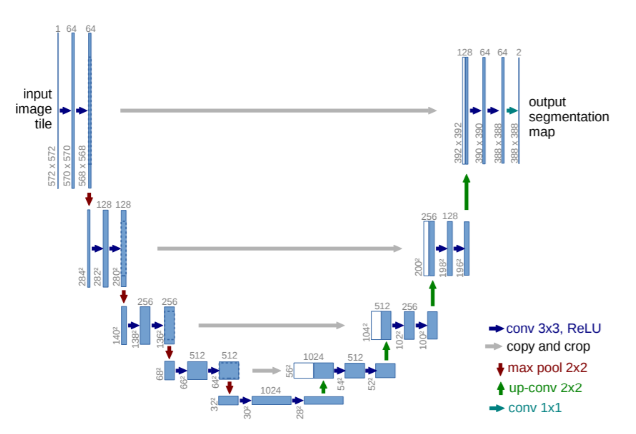
- segmentation model based on the encoder-decoder architecture.
- mainly aimas at segmenting medical images.
- comprises of two parts. One is the down-sampling network part that is an FCN-like network. One is the up-sampling network that increase each dimensions in layers.
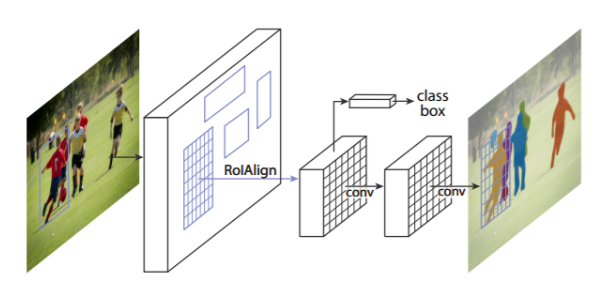
- contains 3 output branches.
- branches for the bounding box coordinates, branches for output classes, and the branches for segmentation map.
-
Medical Imaging
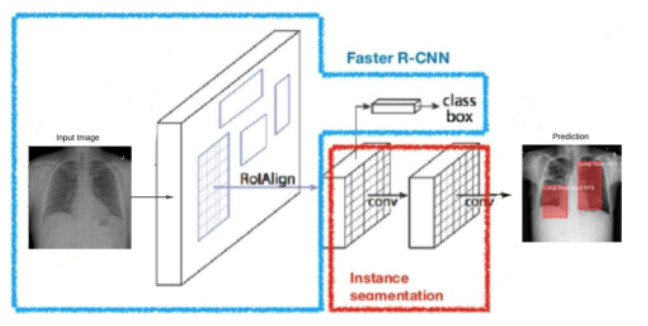
-
Autonomous Driving


- Satellite Imaging
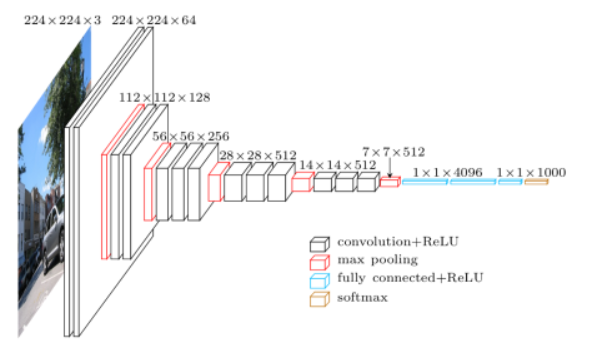
1.CNN takes input as an image “x”, which is a 2-D array of pixels with different color channels(Red,Green and Blue-RGB).
2.Different filters or feature detector applied to the input image to output feature maps.
3.Multiple convolutions are performed in parallel by applying nonlinear function ReLU to the convolutional layer. Feature detector identifies different things like edge detection, different shapes, bends or different colors etc.
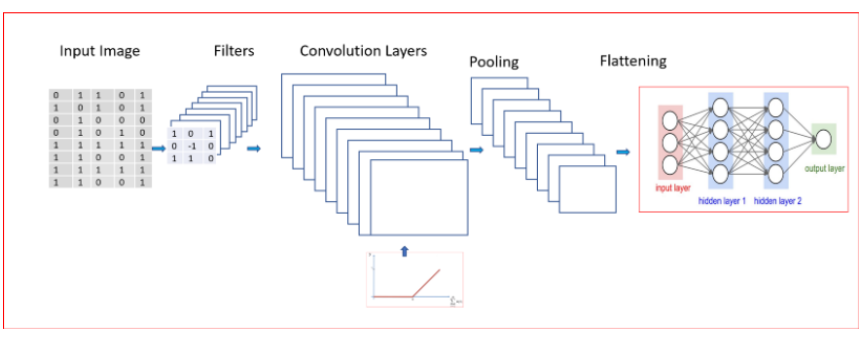
4.Apply Min Pooling, Max Pooling or Average Pooling. Max pooling function provides better performance compared to min or average pooling.
5.Pooling helps with Translational Invariance. Translational invariance means that when we change the input by a small amount the pooled outputs does not change.Invariance of image implies that even when an image is rotated, sized differently or viewed in different illumination an object will be recognized as the same object.
6.Next,flatten the pooled layer to input it to a fully connected(FC) neural network.
7.softmax activation function for multi class classification in the final output layer of the fully connected layer.
8.sigmoid activation function for binary classification in the final output layer of the fully connected layer.
- Don't work well when multiple objects are in the image and draw bounding boxes around all the different objects.
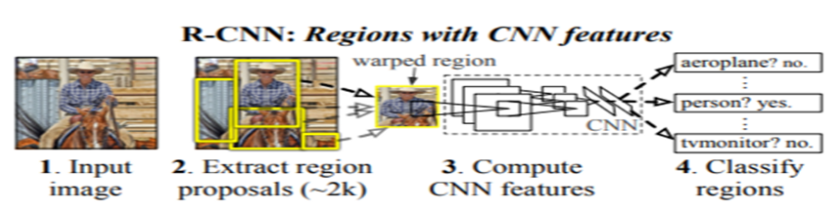
- used for classification as well as objection detection with bounding boxes for multiple objects present in an image
- uses selective search algorithm for object detection to generate region proposals.
Step 1: Generate initial sub-segmentation. We generate as many regions, each of which belongs to at most one object.
Step 2: Recursively combine similar regions into larger ones. Here we use Greedy algorithm.
- From the set of regions, choose two regions that are most similar.
- Combine them into a single, larger region
- Repeat until only one region remains.

Step 3: Use the generated regions to produce candidate object locations.
- set of candidate detection available to the detector. CNN runs the sliding windows over the entire image however R-CNN instead select just a few windows. R-CNN uses 2000 regions for an image.
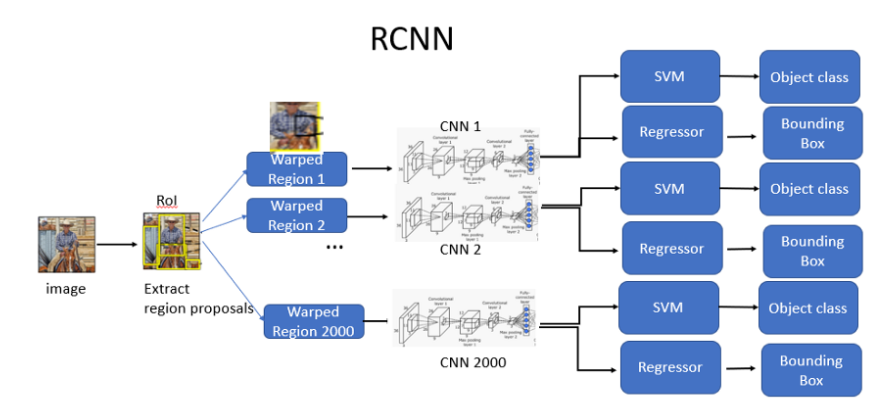
1.Generate category-independent region proposals using selective search to extract around 2000 region proposals. Warp each proposal.
2.Warped region proposals are fed to a large convolutional neural network. CNN acts as a feature extractor that extracts a fixed-length feature vector from each region. After passing through the CNN, R-CNN extracts a 4096-dimensional feature vector for each region proposal
3.Apply SVM(Support Vector Machine) to the extracted features from CNN. SVM helps to classify the presence of the object in the region. Regressor is used to predict the four values of the bounding box.
4.To all scored regions in an image, apply a greedy non-maximum suppression. Non-Max suppression rejects a region if it has an intersection-over union (IoU) overlap with a higher scoring selected region larger than a learned threshold.
Our objective with object detection is to detect an object just once with one bounding box. However, with object detection, we may find multiple detections for the same objects. Non-Max suppression ensures detection of an object only once.
IoU computes intersection over the union of the two bounding boxes, the bounding box for the ground truth and the bounding box for the predicted box by algorithm.
- Non-Max Suppression will remove all bounding boxes where IoU is less than or equal to 0.5
- Pick the bounding box with the highest value for IoU and suppress the other bounding boxes for identifying the same object
-
training is slow and expensive as extract 2000 regions for every image based on selective search.
-
Extracting features using CNN for every image region. For N images, we will have N*2000 CNN features.
-
R-CNN’s Object detection uses three models: •CNN for feature extraction •Linear SVM classifier for identifying objects •Regression model for tightening the bounding boxes
-
Have one deep ConvNet to process the image once instead of 2,000 ConvNets for each regions of the image.
-
Have one single model for extracting features, classification and generating bounding boxes unlike R-CNN that uses three different models
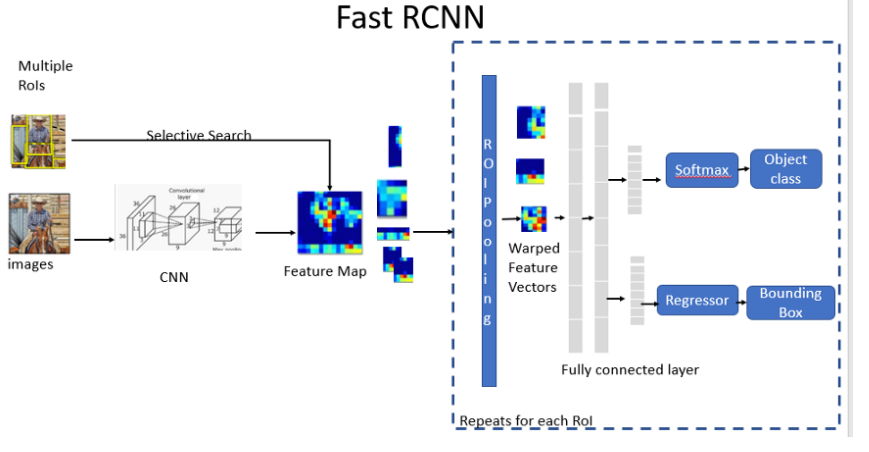
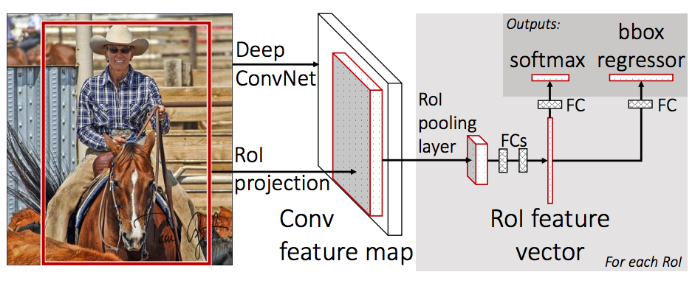
- Fast R-CNN network takes image and a set of object proposals as an input.
- Fast R-CNN uses a single deep ConvNet to extract features for the entire image once.
- Region of interest (RoI) layer is created to extracts a fixed-length feature vector from the feature map for each object proposal for object detection.
- Fully Connected layers(FC) needs fixed-size input. Hence we use ROI Pooling layer to warp the patches of the feature maps for object detection to a fixed size.
- ROI pooling layer is then fed into the FC for classification as well as localization. RoI pooling layer uses max pooling. It converts features inside any valid region of interest into a small feature map.
- Fully connected layer branches into two sibling output layers:
- One with softmax probability estimates over K object classes plus a catch-all “background” class
- Another layer with a regressor to output four real-valued numbers for refined bounding box position for each of the K object classes.
-Fast R-CNN uses single Deep ConvNet for feature extractions. A single deep ConvNet speeds us the image processing significantly unlike R-CNN that uses 2000 ConvNets for each region of the image.
-Fast R-CNN uses softmax for object classification instead of SVM used in R-CNN. Softmax slightly outperforming SVM for objection classification
-Fast R-CNN uses multi task loss to achieve an end to end training of Deep ConvNets increases the detection accuracy.
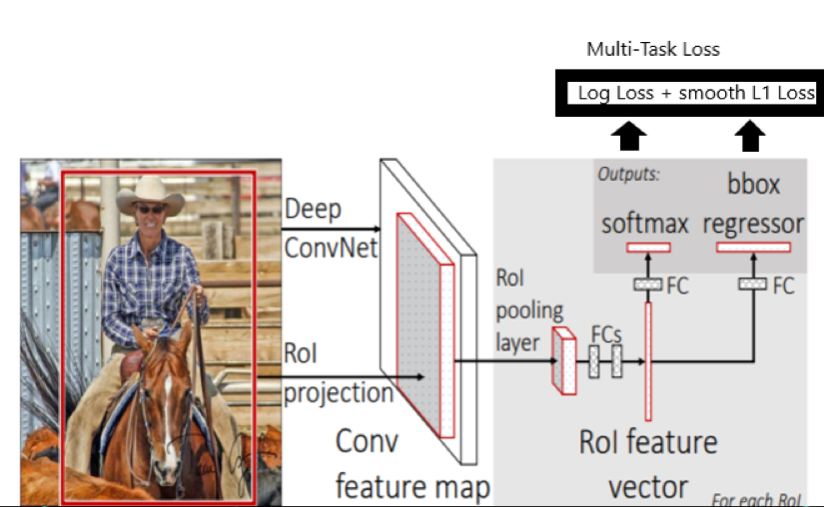
- usesselective search as a proposal method to find the Regions of Interest, which is slow and time consuming process. Not suitable for large real-life data sets.
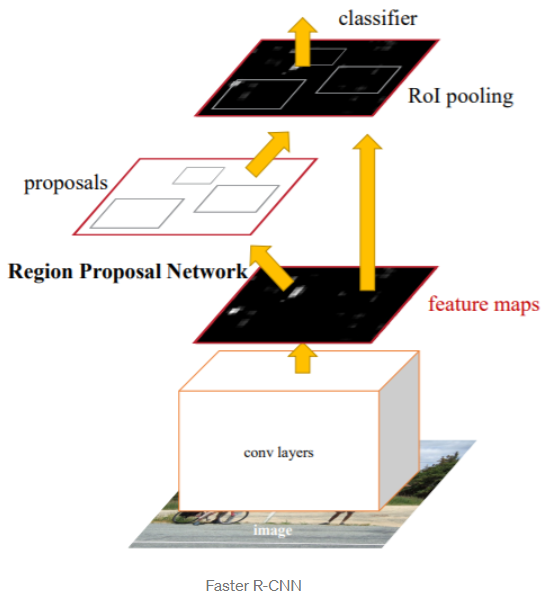
- does not use expensive selective search instead uses Region Proposal Network.
- First stage is the deep fully convolutional network that proposes regions called a Region Proposal Network(RPN). RPN module serves as the attention of the unified network
- The second stage is the Fast R-CNN detector that extracts features using RoIPool from each candidate box and performs classification and bounding-box regression
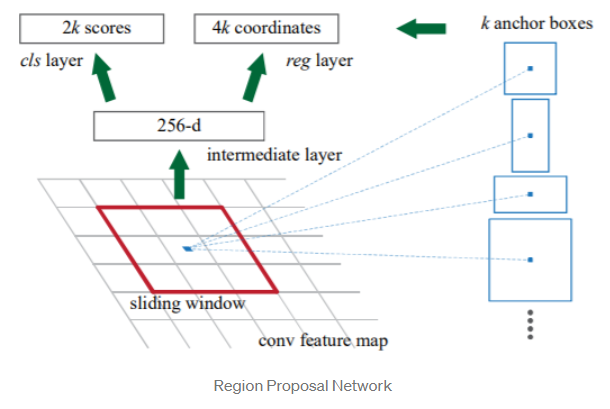
- Region Proposal Network takes an image of any size as input and outputs a set of rectangular object proposals each with an objectness score. It does this by sliding a small network over the feature map generated by the convolutional layer.
- Feature generated from RPN is fed into two sibling fully connected layers ,a box-regression layer for the bounding box and a box-classification layer for object classification.
- RPN is efficient and processes 10 ms per image to generate the ROI’s
-
An anchor is centered at the sliding window in question and is associated with a scale and aspect ratio. Faster R-CNN uses 3 scales and 3 aspect ratio, yielding 9 anchors at each sliding windows.
-
help with translational invariance.
-
At each sliding window location, we simultaneously predict multiple region proposals. The number of maximum possible proposals for each location is denoted as k.Reg layer has 4k outputs encoding the coordinates of k boxes, and the cls layer outputs 2k scores that estimate the probability of object or not object for each proposal.
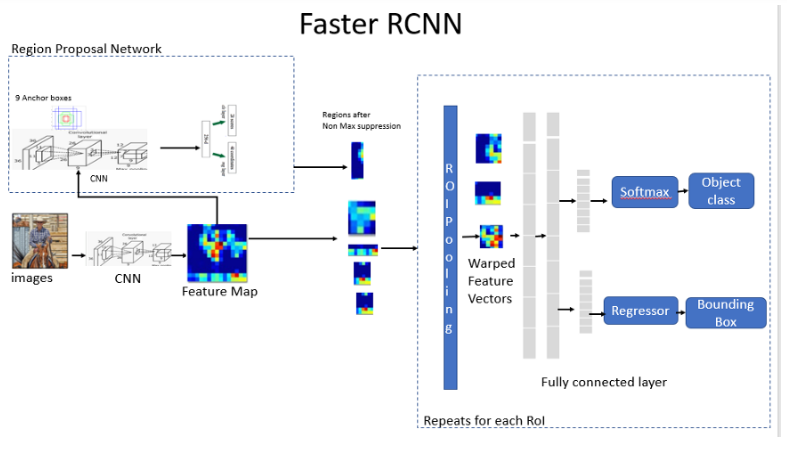
1.Feature Network which generates feature maps from the input image using deep convolutional layer(feature network).
2.Region Proposal Network (RPN) is used to identify different regions which uses 9 anchors for each sliding window. This helps with translational invariance. RPN generate a number of bounding boxes called Region of Interests ( ROIs) with a high probability for the presence of an object.
3.Detection Network is the R-CNN which takes input as the feature maps from the convolutional layer and the RPN network. This generates the bounding boxes and the class of the object.
-Faster R-CNN takes image as an input and is passed through the Feature network to generate the feature map.
-RPN uses the feature map from the Feature network as an input to generate the rectangular boxes of object proposals and the objectness score.
-The predicted region proposals from RPN are then reshaped using a RoI pooling layer. Warped into a fixed vector size.
-Warped fixed-size vector is then fed into two sibling fully connected layers, a regression layer to predict the offset values for the bounding box and a classification layer for object classification.
We started with a simple CNN used for image classification and object detection for a single object in the image.
R-CNN is used for image classification as well as localization for multiple objects in an image.
R-CNN was slow and expensive so Fast R-CNN was developed as a fast and more efficient algorithm. Both R-CNN and Fast R-CNN used selective search to come up with regions in an image.
Faster R-CNN used RPN(Region Proposal Network) along with Fast R-CNN for multiple image classification, detection and segmentation.
- A single convolutional network simultaneously predicts multiple bounding boxes and class probabilities for those boxes.


- inspired by the GoogLeNet model for image classification.
- has 24 convolutional layers followed by 2 fully connected layers.
- YOLO uses a linear activation function for the final layer and a leaky ReLU for all other layers.
- YOLO predicts the coordinates of bounding boxes directly using fully connected layers on top of the convolutional feature extractor. YOLO only predicts 98 boxes per image.
- Limitatins : each grid cell only predicts two boxes and can only have one class and this limits the number of nearby objects that the model can predict. struggles with small objects that appear in groups, such as flocks of birds
- uses 9 convolutional layer instead of 24 used in YOLO and also uses fever filters.
- Input size in YOLOv2 has been increased from 224224 to 448448.
- YOLOv2 divides the entire image into 13 x 13 grid. This helps address the issue of smaller object detection in YOLO v1.
- YOLOv2 uses batch normalization which leads to significant improvements in convergence and eliminates the need for other forms of regularization.
- YOLOv2 runs k-means clustering on the dimensions of bounding boxes to get good priors or anchors for the model. YOLOv2 found k= 5 gives a good tradeoff for recall vs. complexity of the model. YOLOv2 uses 5 anchor boxes
- YOLOv2 uses Darknet architecture with 19 convolutional layers, 5 max pooling layers and a softmax layer for classification objects.
- YOLOv2 use anchor boxes to detect multiple objects, objects of different scales, and overlapping objects. This improves the speed and efficiency for object detection.
-Uses 9 anchors
-Uses logistic regression to predict the objectiveness score instead of Softmax function used in YOLO v2
-YOLO v3 uses the Darknet-53 network for feature extractor which has 53 convolutional layers
- Mask R-CNN extends Faster R-CNN.
1.Faster R-CNN has two outputs -For each candidate object, a class label and a bounding-box offset;
2.Mask R-CNN has three outputs -For each candidate object, a class label and a bounding-box offset; Third output is the object mask
- Both Mask R-CNN and Faster R-CNN have a branch for classification and bounding box regression.
- Both use ResNet 101 architecture (Backbone Model) to extract features maps from image.
- Both use Region Proposal Network(RPN) to generate Region of Interests(RoI).This basically predicts if an object is present in that region (or not). In this step, we get those regions or feature maps which the model predicts contain some object.
- The regions obtained from the RPN might be of different shapes.A pooling layer and convert all the regions to the same shape. Next, these regions are passed through a fully connected network so that the class label and bounding boxes are predicted.
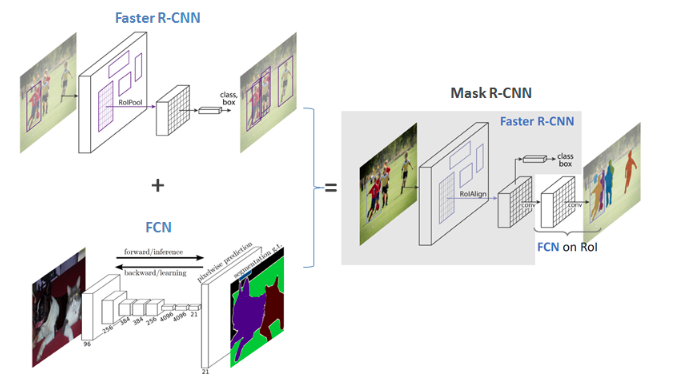
Mask R-CNN model is divided into two parts
1.Region proposal network (RPN) to proposes candidate object bounding boxes.
2.Binary mask classifier to generate mask for every class.
3.Image is run through the CNN to generate the feature maps.
4.Region Proposal Network(RPN) uses a CNN to generate the multiple Region of Interest(RoI) using a lightweight binary classifier. The region that RPN scans over are called anchors. It does this using 9 anchors boxes over the image.The classifier returns object/no-object scores. Non Max suppression is applied to Anchors with high objectness score.
5.The RoI Align network outputs multiple bounding boxes rather than a single definite one and warp them into a fixed dimension.
6.Warped features are then fed into fully connected layers to make classification using softmax and boundary box prediction is further refined using the regression model.
7.Warped features are also fed into Mask classifier, which consists of two CNN’s to output a binary mask for each RoI. Mask Classifier allows the network to generate masks for every class without competition among classes
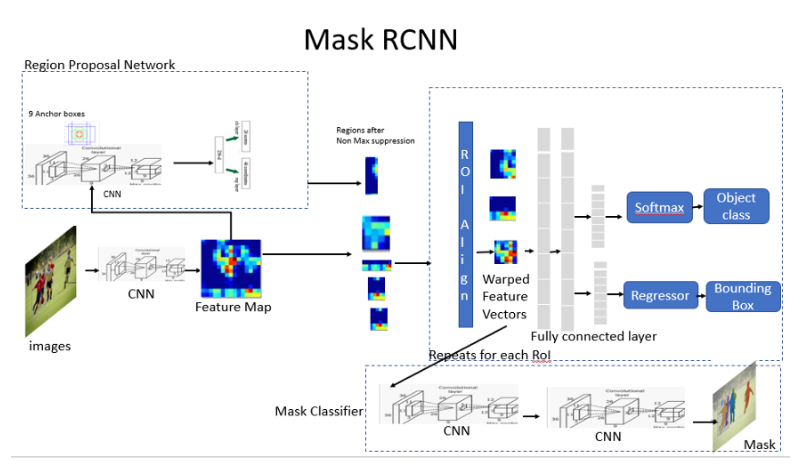
To predict multiple objects or multiple instances of objects in an image, Mask R-CNN makes thousands of predictions. Final object detection is done by removing anchor boxes that belong to the background class and the remaining ones are filtered by their confidence score. We find the anchor boxes with IoU greater than 0.5. Anchor boxes with the greatest confidence score are selected using Non-Max suppression.
-
Non-Max Suppression will remove all bounding boxes where IoU is less than or equal to 0.5
-
Pick the bounding box with the highest value for IoU and suppress the other bounding boxes for identifying the same object
Backbone Network — implemented as ResNet 101 and Feature Pyramid Network (FPN), this network extracts the initial feature maps which are forward propagated to other components.
Region Proposal Network(RPN)—is used to extract Region of Interest(ROI) from images and Non-max suppression is applied to select the most appropriate bounding boxes or ROI generated from RPN.
ROI Align — wraps Region of Interest(ROI) into fixed dimensions.
Fully Connected Layers — consists of two parallel layers, one uses softmax for classification and the other regression for bounding box prediction.
Mask Classifier — generates a binary mask for each instance in an image.
1.Backbone
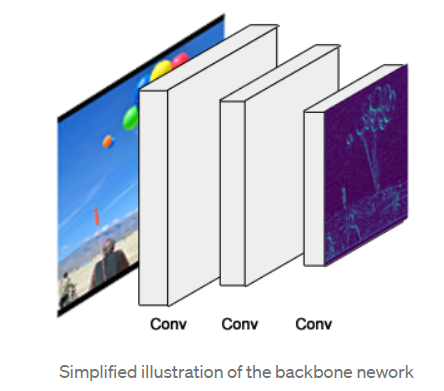
This is a standard convolutional neural network (typically, ResNet50 or ResNet101) that serves as a feature extractor. The early layers detect low level features (edges and corners), and later layers successively detect higher level features (car, person, sky).
2.Region Proposal Network The regions that the RPN scans over are called anchors. RPN doesn’t scan over the image directly (even though we draw the anchors on the image for illustration). Instead, the RPN scans over the backbone feature map.
The RPN generates two outputs for each anchor:
Anchor Class: One of two classes: foreground or background. The FG class implies that there is likely an object in that box.
Bounding Box Refinement: A foreground anchor (also called positive anchor) might not be centered perfectly over the object. So the RPN estimates a delta (% change in x, y, width, height) to refine the anchor box to fit the object better.
Using the RPN predictions, we pick the top anchors that are likely to contain objects and refine their location and size. If several anchors overlap too much, we keep the one with the highest foreground score and discard the rest (referred to as Non-max Suppression).
This stage runs on the regions of interest (ROIs) proposed by the RPN. And just like the RPN, it generates two outputs for each ROI:
Class: The class of the object in the ROI. Unlike the RPN, which has two classes (FG/BG), this network is deeper and has the capacity to classify regions to specific classes (person, car, chair, …etc.). It can also generate a background class, which causes the ROI to be discarded.
Bounding Box Refinement: Very similar to how it’s done in the RPN, and its purpose is to further refine the location and size of the bounding box to encapsulate the object.
Classifiers don’t handle variable input size very well. They typically require a fixed input size. But, due to the bounding box refinement step in the RPN, the ROI boxes can have different sizes. That’s where ROI Pooling comes into play. ROI pooling refers to cropping a part of a feature map and resizing it to a fixed size.

A method named ROIAlign, in which they sample the feature map at different points and apply a bilinear interpolation.
- The mask branch is a convolutional network that takes the positive regions selected by the ROI classifier and generates masks for the regions.
- The generated masks are low resolution: 28x28 pixels. But they are soft masks, represented by float numbers, so they hold more details than binary masks
- The small mask size helps keep the mask branch light. During training, we scale down the ground-truth masks to 28x28 to compute the loss, and during inferencing we scale up the predicted masks to the size of the ROI bounding box and that gives us the final masks, one per object.
-
Pan means “all” and optic means “vision”. Panoptic segmentation, therefore, roughly means “everything visible in a given visual field”.
-
Panoptic segmentation can be broken down into three simple steps:
-
Separating each object in the image into individual parts, which are independent of each other.
-
Painting each separated part with a different color - labeling.
-
Classifying the objects into things and stuff.
Things
- refers to objects that have properly defined geometry and are countable, like a person, cars, animals, etc.
Stuff
- used to define objects that don’t have proper geometry but are heavily identified by the texture and material like the sky, road, water bodies, etc.

In panoptic segmentation, the input image is fed into two networks: a fully convolutional network (FCN) and Mask R-CNN.
-
The FCN is responsible for capturing patterns from the uncountable objects - stuff – and it yields semantic segmentations.
-
The FCN uses skip connections that enable it to reconstruct accurate segmentation boundaries. Also, skip connections enable the model to make local predictions that accurately define the global or the overall structure of the object.
-
Likewise, the Mask R-CNN is responsible for capturing patterns of the objects that are countable - things - and it yields instance segmentations. It consists of two stages:
-
Region Proposal Network (RPN): It is a process, where the network yields regions of interest (ROI).
-
Faster R-CNN: It leverages ROI to perform classification and create bounding boxes.
-
The output of both models is then combined to get a more general output.
However, this approach has several drawbacks such as:
- Computational inefficiency
- Inability to learn useful patterns, which leads to inaccurate predictions
- Inconsistency between the network outputs
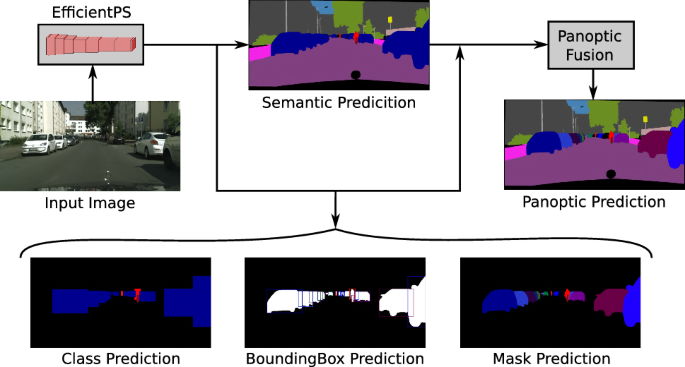
To address these issues, a new architecture called the Efficient Panoptic Segmentation or EfficientPS was proposed, which improves both the efficiency and the performance.
EfficientPS uses a shared backbone built on the architecture called the EfficientNet.
The architecture consists of:
-
EfficientNet: A backbone network for feature extraction. It also contains a two-way feature pyramid network that allows the bidirectional flow of information that produces high-quality panoptic results.
-
Two output branches: One for semantic segmentation and one for instance segmentation.
-
A fusion block that combines the outputs from both branch.

EfficientPS network is represented in red, while the two-way Feature Pyramid Network (FPN) is represented in purple, blue and green. The network for semantic and instance segmentation is represented in yellow and orange, respectively, while the fusion block is represented at the end.
The image is fed into the shared backbone, which is an encoder of the EfficientNet. This encoder is coupled with a two-way FPN that extracts a rich representation of information and fuses multi-scale features much more effectively.
The output from the EfficientNet is then fed into two heads in parallel: one for semantic segmentation and the other for instance segmentation.
The semantic head consists of three different modules, which enable it to capture fine features, along with long-range contextual dependencies, and improve object boundary refinement. This, in turn, allows it to separate different objects from each other with a high level of precision.
The instance head is similar to Mask R-CNN with certain modifications. This network is responsible for classification, object detection, and mask prediction.
The last part of the EfficientPS is the fusion module that fuses the prediction from both heads.
This fusion module is not parameterized—it doesn’t optimize itself during the backpropagation. It is rather a block that performs fusion in two stages.
In the first stage, the module obtains the corresponding class prediction, the confidence score bounding box, and mask logits. Then, the module:
-
Removes all the object instances with the confidence score lower than a threshold value.
-
Once reductant instances are removed, the remaining instances or mask-logits are resized followed by zero-padding.
-
Finally, the mask-logits are scaled the same resolution as the input image.
In the first stage, the network sorts the class prediction, bounding box, and mask-logits with respect to the confidence scores.
In the second stage, it is the overlapping of the mask-logit that is evaluated.
It is done by calculating the sigmoid of the mask-logits. Every mask-logit that has a threshold greater than 0.5, obtains a corresponding binary mask. Furthermore, if the overlapping threshold between the binary is greater than a certain threshold, it is retained, while the others are removed.
A similar thing is done for the output yielded from the semantic head.
Once the segmentations from both heads are filtered, they are combined using the Hadamard product, and voila—we’ve just performed the panoptic segmentation.
-
Medical Imaging
-
Autonomous vehicles
-
Digital Image processing
-
Panoptic segmentation is an image segmentation task that combines the prediction from both instance and semantic segmentation into a general unified output.
-
Panoptic segmentation involves studying both stuff and things.
-
The initial panoptic deep learning model used two networks: Fully convolutional network (FCN) for semantic segmentation and Mask R-CNN for instance segmentation which was slow and yielded inconsistent and inaccurate segmentations due to which EfficientPS was introduced.
-
EfficientPS consists of a shared backbone that enables the network to efficiently encode and combine semantically rich multi-scale features. It is fast and consistent with the output.