이 Repository는 데이터 품질 평가기반 데이터 고도화 및 데이터셋 보정 기술 개발 국책과제의 구성 중 하나이며 데이터의 편향을 보정하는 기술을 개발하는 것을 목적으로 한다.
인공지능 및 빅데이터 기술이 적용되는 분야에서 그동안의 주요한 개발 대상과 목표는 더 높은 정확성을 가진 기술을 개발하는 것이었다. 반면에 그런 연구 방향으로는 해당 기술이 내놓은 판단 결과가 얼마나 신뢰할만 하고 공정한 결과인지는 설명하거나 알기 어렵다.
우리의 현실 세계와 사회에서는 많은 양과 다양한 형태의 데이터들이 끊임없이 생성되는데 그러한 데이터들 중에는 고의적/비고의적으로 일부가 훼손된 데이터, 샘플링에의한 변형, 사회 관습적으로 치우친 패턴, 여러가지 차별들이 담겨있고 구조적, 체계적인 왜곡이 내재되어 있기도 하다. 이러한 데이터 편향(Bias)의 문제는 데이터 자체가 가진 특성이므로 아무리 뛰어난 정확성을 가진 기술이라도 실제 편향을 훌륭하게 재현할 뿐, 편향으로부터 벗어날수는 없다.
나이에 따른 금융권의 대출 심사 판단 결과의 차이, 성별에 따른 진급 심사 결과 차이, 인종에 따른 재범 가능성 평가의 차이 등을 데이터 불공정 편향의 예로 들수 있다.
이와같은 데이터의 치우침, 차별, 체계적 편향은 상황에 따라 실세계를 반영한다는 관점에서 본질적인 의미가 있을수 있지만 법률적, 정치적 또는 윤리적 관점에서는 의도적으로 편향으로 탐지하고 제외하도록 요구될수 있다.
이미 IBM AIF360, Microsoft Fairlearn, Google PAIR, Facebook 등 전세계적으로 데이터 공정성 확보를 위한 여러 관련 연구가 진행되고 있으며 다양한 오픈소스들이 나와있다. 따라서 앞선 연구들을 참조하여 데이터로부터 불필요하다고 판단되는 불공정 편향을 탐지하고 탐지한 편향을 완화 또는 제거하는 알고리즘을 개발하는 것을 목표로 한다.
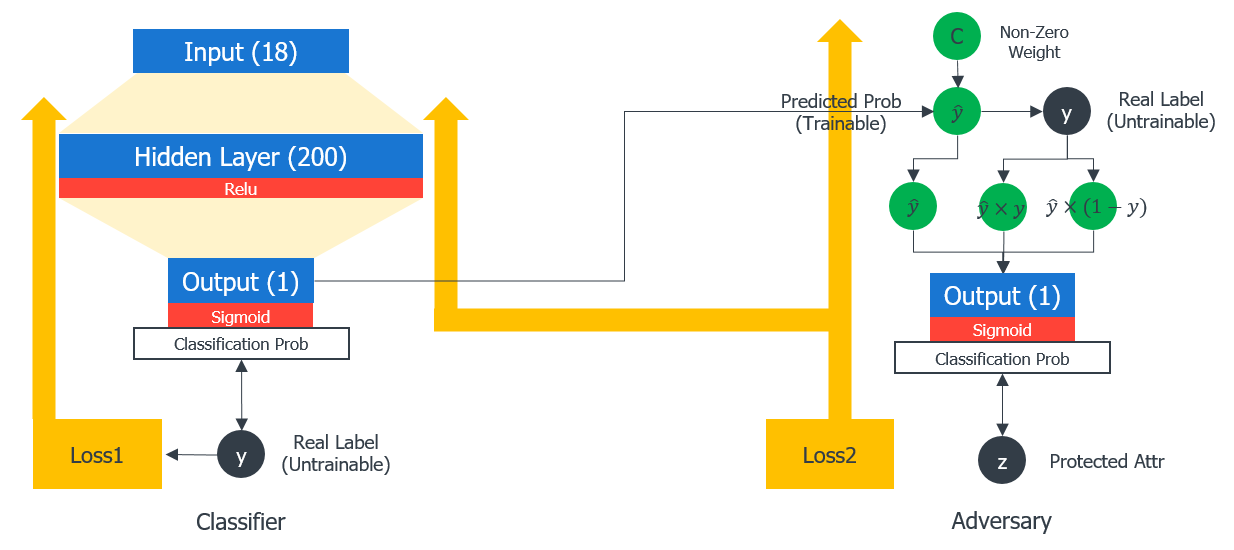
Classification Model의 Classification과 Classification 결과의 공정성 확보를 동시에 수행하는 Deep Learning Classification Model이자 Bias Mitigation Model.
논문 Mitigating Unwanted Biases with Adversarial Learning 참조
데이터의 Feature들을 Input으로 받아 Real Label을 예측하는 Classifier 파트와, Classifier 의 Label Prediction 결과와 Real Label을 Input으로 받아 Protected Attribute 값을 예측하는 Adversary 파트로 구성
Classifier 와 Adversary 를 연결하여 학습
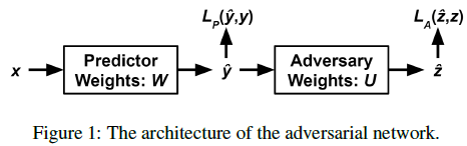
Classifier 는 학습을 통해 Protected Attribute를 포함하는 Feature들로부터 Real Label에 가까운 Label(확률)을 계산하도록 최적화되며, Adversary 는 Real Label에 따라 Classifier 가 예측한 확률값에 발생하는 편향을 살피고 Protected Attribute와의 상관성을 고려해서 Real Protected Attribute를 도출하도록 최적화된다.
모델 학습 중 발생하는 총 Loss에서 Classifier 의 Prediction Failure가 Loss 증가 요인이며, Adversary 의 Prediction Success가 Loss 증가 요인이다. 이렇게 서로 Loss 방향이 반대되는 적대적 학습을 수행하도록 한다.

이런 적대적 학습에 의해 Classifier 는, Adversary 의 Loss를 감소 시켜야 하므로, Classification 예측 결과에 영향을 주는 Feature 중 Protected Attribute 값의 상관을 최소화 하도록 최적화된다.
또 자신의 Loss를 감소 시켜야 하므로, 최종적으로 Classifier 는 최대한 높은 Prediction 정확도를 가지면서 Protected Attribute의 영향로부터 공정성을 가지는 결과를 출력하는 모델이 된다.
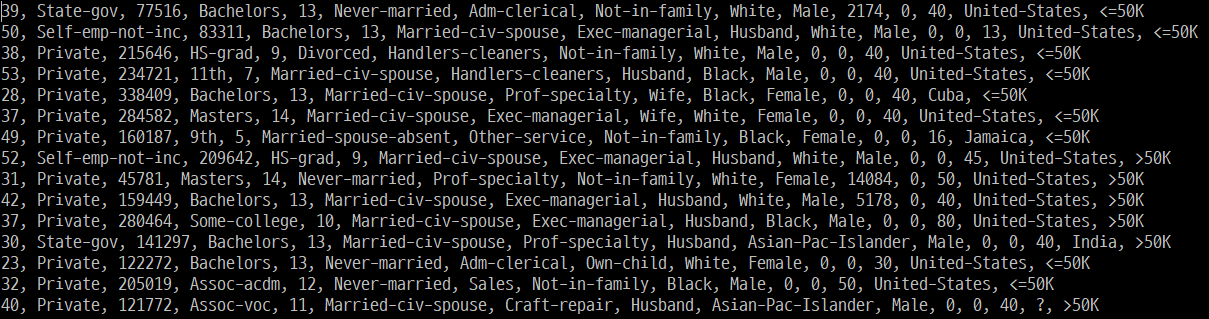
미국 1994 인구조사 자료에 기반하여 특정 개인의 연 수입이 $50K를 초과하는지 예측하는 문제.
14개 Features, 48842 Rows, 결측치 포함
- 각 파일을 다운로드 하여 아래 path에 저장
/data/raw/adult/adult.data
/data/raw/adult/adult.names
/data/raw/adult/adult.test
Reference:
Adult Dataset 을 이용하여 데이터 편향을 측정하고 Adversarial Debiasing 알고리즘을 적용하여 편향을 완화하는 과정을 보여주는 Tutorial.
example_adversarial_debiasing.py 파일을 실행해서 그 결과를 확인해 볼 수 있음.
-
Data
/data/raw/adult/adult.data,/data/raw/adult/adult.test -
Python 3
-
Tensorflow version 1.*
-
Numpy, Pandas
이 성과물은 2020년도 정부(과학기술정보통신부)의 재원으로 정보통신기획평가원의 지원을 받아 수행된 연구임.
(No.2020-0-00512, 데이터 품질 평가기반 데이터 고도화 및 데이터셋 보정 기술 개발)
This work was supported by Institute of Information & communications Technology Planning & Evaluation(IITP) grant funded by the Korea government (MSIT)
(No.2020-0-00512, Data Refinment and Improvement through Data Quality Evaluation)