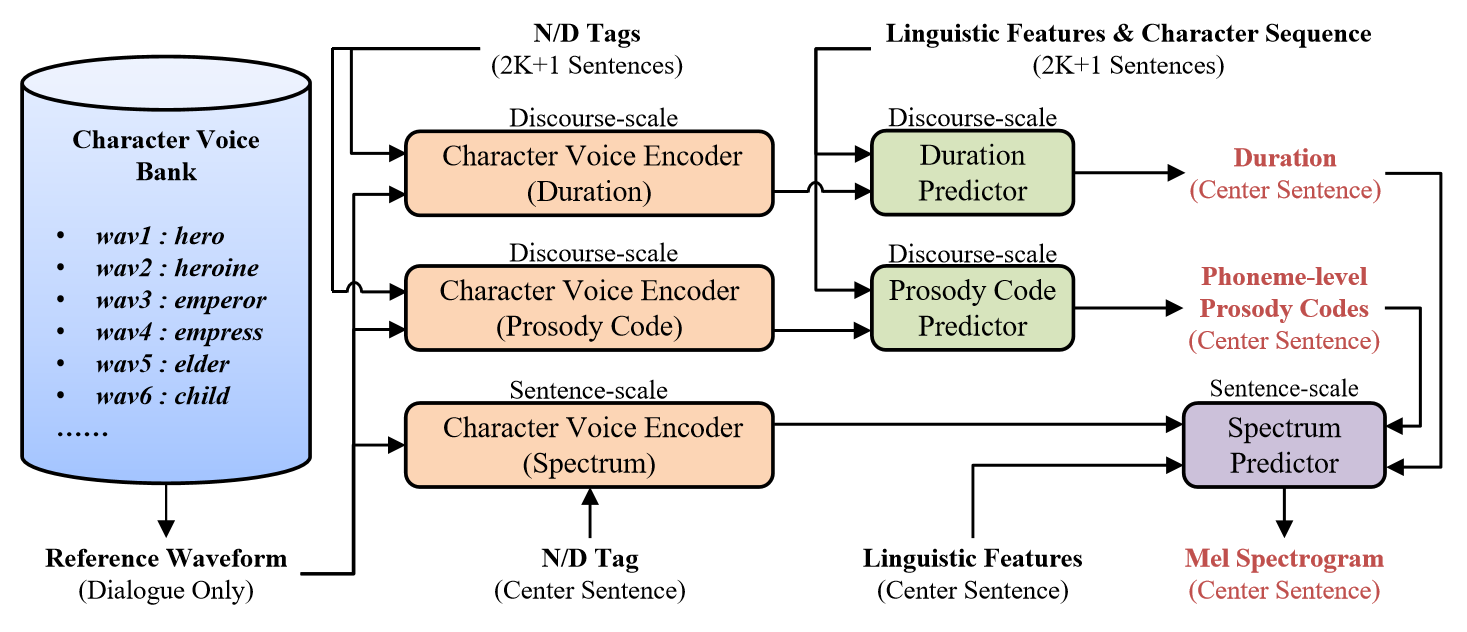
Conventional speech synthesis techniques have made significant strides towards achieving human-like performance. However, the domain of audiobook speech synthesis still presents notable challenges. On one hand, the speech in audiobooks exhibits rich prosody expressiveness, posing substantial difficulties in prosody modeling. On the other hand, the reader of audiobooks uses different voices to perform dialogues of different characters, which has been inadequately explored in existing speech synthesis methods. To address the first challenge, we integrate discourse-scale prosody modeling into the conventional autoencoder-based framework and introduce generative adversarial networks (GANs) for prosody code prediction. Regarding the second challenge, we further explore a character voice encoder based on the pretrained speaker verification model, integrating it into our proposed method. Experimental results validate that the proposed method enhances the prosodic expressiveness of synthesized audiobook speech. Moreover, it demonstrates the capacity to produce distinctive voices for different audiobook characters without compromising the naturalness of the synthesized speech.
Audio samples: https://nqwu.github.io/prosodygan
Due to copyright reasons, we cannot publicly release our training data or pre-trained models. If you need to fully run the training pipeline, the following additional preparations are required:
Prepare a dataset with complete chapter content, split into sentences, and transcribe each sentence's text. The corresponding speech waveform for each sentence should be stored in data_path/wav and named as x_y_z.wav, where:
xis the chapter label,yis the sentence number within the chapter (integer),zis the dialogue label for the sentence (1 for narration, 2 for dialogue).
For example, the first sentence in Chapter 1 (if it is narration) should be named 0001_0001_1.wav.
Then, split the data into three files: train.txt, valid.txt, and test.txt. Each line in these files corresponds to one sentence, formatted as: filename(x_y_z)|text.
Note: The chapters in the training set can be in random order, but sentences from the same chapter must be adjacent and ordered correctly.
Use a frontend tool to convert the text into phoneme sequences, then use the MFA tool with a frame shift of 0.01s to extract phoneme-level durations for each sentence. The result should be saved as a .npy file in data_path/duration, with filenames following the pattern x_y_z.npy.
Prepare the frontend, vocoder, pre-trained BERT network, and pre-trained ECAPA-TDNN network. Modify the code where indicated by ### comments to integrate these modules.
Modify the configuration files in the Configs/ directory to set the paths for data_path, train_data, and valid_data, then run the training steps as follows:
-
Train the duration predictor and spectrum predictor:
python main.py --config ./Configs/0_train_duration.yml python main.py --config ./Configs/0_train_spectrum.yml
-
Extract prosody codes and save them in
data_path/psd_code:python main.py --config ./Configs/1_extract_prosody_code.yml
-
Train the prosody code predictor:
python main.py --config ./Configs/2_train_prosody.yml
Run inference using the following command:
python main.py --config ./Configs/3_test_all.ymlThis project uses parts of the code from the following repositories:
StyleTTS: https://github.com/yl4579/StyleTTSfastspeech2: https://github.com/ming024/FastSpeech2fairseq: https://github.com/facebookresearch/fairseq