A comprehensive toolkit for web content aggregation, analysis, and preparation for Large Language Models (LLMs).
- Multi-Format Ingestion
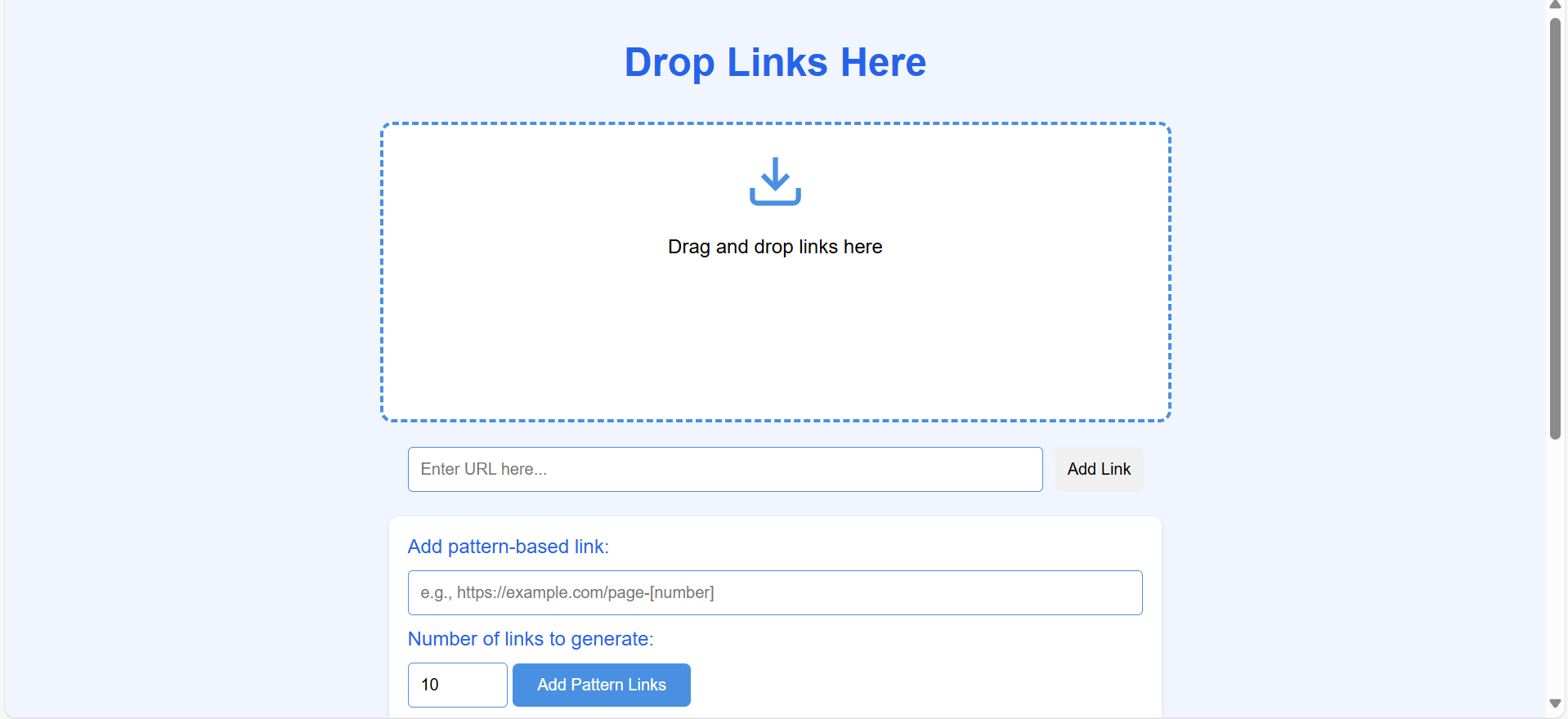
- Drag & Drop URL management
- Bulk content parsing
- Pattern-based URL generation (e.g.,
page-[number])
- Content Processing
- Text-only extraction with smart filtering
- Raw HTML source code retrieval
- Deep parsing with configurable depth
- Output Management
- Individual or bulk content copying
- Editable link management
- Real-time parsing status
- Research Assistant
- ArXiv paper discovery & summarization
- Multi-level explanation styles
- Literature review generation
- Security Scanner
- Automated vulnerability detection
- Code analysis through LLMs
- Progressive scanning controls
- Modern web browser (Chrome 90+, Firefox 88+, Edge 90+)
- Internet connection
git clone https://github.com/seenmttai/urlingest.git
cd urlingest
python3 -m http.server 8000Access via:
- Live Website:
https://urlingest.pages.dev - Local file:
file:///path/to/index.html - Local server:
http://localhost:8000
- Add URLs via drag & drop or manual input
- Choose processing mode:
- Text Mode: Clean content extraction
- Source Mode: Raw HTML inspection
- Configure filters and parsing depth
- Parse and export content to clipboard
- 150+ research categories
- Automatic paper discovery
- Adaptive summarization:
- Technical deep dives
- Layman explanations
- Literature reviews
- Automated vulnerability detection
- Real-time code analysis
- Progressive result reporting
We welcome contributions! Please follow these guidelines:
- Fork the repository
- Create feature branch (
git checkout -b feature/amazing-feature) - Commit changes (
git commit -m 'Add amazing feature') - Push to branch (
git push origin feature/amazing-feature) - Open Pull Request
Distributed under the MIT License. See LICENSE for more information.
- Inspired by Gitingest
- CORS proxy services
- Cloudflare worker and pages