![]()
Website • Docs • Cube.js Models docs • Docker Hub • Slack community
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale.
- Data modeling and transformations: Flexibly define metrics and dimensions using SQL and Cube data models. Apply transformations and aggregations.
- Semantic layer: Consolidate metrics from across sources into a unified, governed data model. Eliminate metric definition differences.
- Scheduled reports and alerts: Monitor metrics and get notified of changes via configurable reports and alerts.
- Versioning: Track schema changes over time for transparency and auditability.
- Role-based access control: Manage permissions for data models and metrics access.
- Data exploration: Analyze metrics through the UI, or integrate with any BI tool via the SQL API.
- Caching: Optimize performance using pre-aggregations and caching from Cube.
- Teams: Collaborate on metrics modeling across your organization.
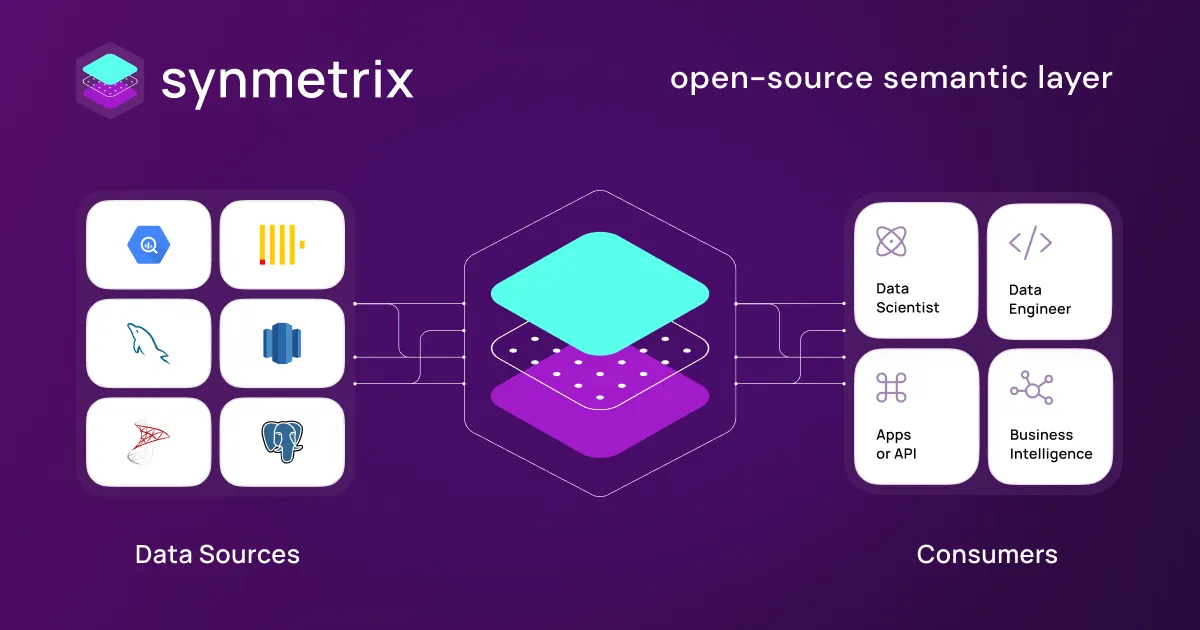
Synmetrix leverages Cube (Cube.js) to implement flexible data models that can consolidate metrics from across warehouses, databases, APIs and more. This unified semantic layer eliminates differences in definitions and calculations, providing a single source of truth.
The metrics data model can then be distributed downstream to any consumer via a SQL API, allowing integration into BI tools, reporting, dashboards, data science, and more.
By combining best practices from data engineering, like caching, orchestration, and transformation, with self-service analytics capabilities, Synmetrix speeds up data-driven workflows from metrics definition to consumption.
-
Data Democratization: Synmetrix makes data accessible to non-experts, enabling everyone in an organization to make data-driven decisions easily.
-
Business Intelligence (BI) and Reporting: Integrate Synmetrix with any BI tool for advanced reporting and analytics, enhancing data visualization and insights.
- Embedded Analytics: Use the Synmetrix API to embed analytics directly into applications, providing users with real-time data insights within their workflows.
- Integrating Synmetrix with Observable: A Quick Guide (Video)
- Guide to Connecting Synmetrix with DBeaver Using SQL API (Video)
- Semantic Layer for LLM: Enhance LLM's accuracy in data handling and queries with Synmetrix's semantic layer, improving data interaction and precision.
Ensure the following software is installed before proceeding:
The repository mlcraft-io/mlcraft/install-manifests houses all the necessary installation manifests for deploying Synmetrix anywhere. You can download the docker compose file from this repository:
Execute this in a new directory
wget https://raw.githubusercontent.com/mlcraft-io/mlcraft/main/install-manifests/docker-compose/docker-compose.yml
Alternatively, you can use curl
curl https://raw.githubusercontent.com/mlcraft-io/mlcraft/main/install-manifests/docker-compose/docker-compose.yml -o docker-compose.yml
NOTE: Ensure to review the environment variables in the docker-compose.yml file. Modify them as necessary.
Execute the following command to start Synmetrix along with a Postgres database for data storage.
docker-compose pull stack && docker-compose up -d
Verify if the containers are operational:
docker ps
Output:
CONTAINER ID IMAGE ... CREATED STATUS PORTS ...
c8f342d086f3 synmetrix/stack ... 1m ago Up 1m 80->8888/tcp ...
30ea14ddaa5e postgres:12 ... 1m ago Up 1m 5432/tcp
The installation of all dependencies will take approximately 5-7 minutes. Wait until you see the Synmetrix Stack is ready message. You can view the logs using docker-compose logs -f to confirm if the process has completed.
First, it's recommended to install Rosetta 2 on your Mac. This will allow Docker to run ARM64v8 containers. Since Docker version 4.25 it allows to run ARM64v8 containers natively, but some users still encounter issues without Rosetta installed.
For ARM64v8, Cubestore requires a specific version. Update the Cubestore version in the docker-compose file to include the -arm64v8 suffix. For instance, use v0.35.33-arm64v8 (refer to the Cubestore tags on Docker Hub for the latest version).
To run the docker-compose file for ARM64v8, use the following command:
docker-compose pull stack && CUBESTORE_VERSION=v0.35.33-arm64v8 docker-compose up -d
Video guide (MacOS, M3 Max processor):
- You can access Synmetrix at http://localhost/
- The GraphQL endpoint is located at http://localhost/v1/graphql
- The Admin Console (Hasura Console) can be found at http://localhost/console
- The Cube Swagger API can be found at http://localhost:4000/docs
-
Admin Console Access: Ensure to check
HASURA_GRAPHQL_ADMIN_SECRETin the docker-compose file. This is mandatory for accessing the Admin Console. The default value isadminsecret. Remember to modify this in a production environment. -
Environment Variables: Set up all necessary environment variables. Synmetrix will function with the default values, but certain features might not perform as anticipated.
-
Preloaded Seed Data: The project is equipped with preloaded seed data. Use the credentials below to sign in:
- Email:
[email protected] - Password:
demodemo
This account is pre-configured with two demo datasources and their respective SQL API access. For SQL operations, you can use the following credentials with any PostgreSQL client tool such as DBeaver or TablePlus:
Host Port Database User Password localhost 15432 db demo_pg_user demo_pg_pass localhost 15432 db demo_clickhouse_user demo_clickhouse_pass - Email:
Demo: app.synmetrix.org
- Login:
[email protected] - Password:
demodemo
| Database type | Host | Port | Database | User | Password | SSL |
|---|---|---|---|---|---|---|
| ClickHouse | gh-api.clickhouse.tech | 443 | default | play | no password | true |
| PostgreSQL | demo-db-examples.cube.dev | 5432 | ecom | cube | 12345 | false |
Synmetrix leverages Cube for flexible data modeling and transformations.
Cube implements a multi-stage SQL data modeling architecture:
- Raw data sits in a source database such as Postgres, MySQL, etc.
- The raw data is modeled into reusable data marts using Cube Data Models files. These models files allow defining metrics, dimensions, granularities and relationships.
- The models act as an abstraction layer between the raw data and application code.
- Cube then generates optimized analytical SQL queries against the raw data based on the model.
- The Cube Store distributed cache optimizes query performance by caching query results.
This modeling architecture makes it simple to create fast and complex analytical queries with Cube that are optimized to run against large datasets.
The unified data model can consolidate metrics from across different databases and systems, providing a consistent semantic layer for end users.
For production workloads, Synmetrix uses Cube Store as the caching and query execution layer.
Cube Store is a purpose-built database for operational analytics, optimized for fast aggregations and time series data. It provides:
- Distributed querying for scalability
- Advanced caching for fast queries
- columnar storage for analytics performance
- Integration with Cube for modeling
By leveraging Cube Store and Cube together, Synmetrix benefits from excellent analytics performance and flexibility in modeling metrics.
| Repository | Description |
|---|---|
| mlcraft-io/mlcraft | Synmetrix Monorepo |
| mlcraft-io/client-v2 | Synmetrix Client |
| mlcraft-io/docs | Synmetrix Docs |
| mlcraft-io/examples | Synmetrix Examples |
For general help using Synmetrix, please refer to the official Synmetrix documentation. For additional help, you can use one of these channels to ask a question:
- Slack / For live discussion with the Community and Synmetrix team
- GitHub / Bug reports, Contributions
- Twitter / Updates and news
- Youtube / Video tutorials and demos
Check out our roadmap to get informed on what we are currently working on, and what we have in mind for the next weeks, months and years.
The core Synmetrix is available under the Apache License 2.0 (Apache-2.0).
All other contents are available under the MIT License.
| Component | Requirement |
|---|---|
| Processor (CPU) | 3.2 GHz or higher, modern processor with multi-threading and virtualization support. |
| RAM | 8 GB or more to handle computational tasks and data processing. |
| Disk Space | At least 30 GB of free space for software installation and storing working data. |
| Network | Internet connectivity is required for cloud services and software updates. |