A versão em português pode ser vista neste link.
This repository implements of the deep reinforcement learning algothrims DQN and DRQN in python. The Deep Q-Network (DQN) introduced by the article Human-level control through deep reinforcement learning[1] is an algorithm that applies deep neural networks to the problem of reinforcement learning. The reinforcement learning's goal is, basically, how to teach artificial intelligence, called an agent, to map the current state in the environment in actions, in such a way to maximize the total reward at end of the task. In the DQN case, the states are images from the environment's screen. Therefore, the deep neural network is trained while the agent interacts with the environment (via reinforcement learning), in such a way to transform these high dimensional data (images) in actions (buttons to be pressed). The Deep Recurrent Q-Network (DRQN) is a version of the DQN introduced by the article Deep recurrent q-learning for partially observable mdps[2] that replaces the first fully connected layer of the DQN by one of the type recurrent (LSTM). Thereby, the agent trained by this algorithm deals better with partial observable environments, such as the tridimensional maps from ViZDoom.
Although there are numerous scripts that implement the algorithms described above, these implementations are simple and most of the time there is no attention with performance, in other words, how much time that the simulation will take to conclude and consequently the electrical energy spent on the process of training the agent. To optimize the performance of the algorithms, the scripts in this repository take full advantage of vectorized computation by the frameworks Numpy and Tensorflow to reduce the time of simulation spent on training the agents. Furthermore, it was developed a method to reduce considerably the time necessary to the simulation, some examples had concluded the training spending 30% less time. This method consists in doing a simple parallelization of the algorithms DQN and DRQN (more details about the optimizations in performance can be seen in the topic performance).
Another important aspect that should be taken into account besides the performance is the user experience. The scripts in this repository were developed in such a way to give more flexibility in the choice of the simulation's parameters, without the need of changing the main code. The user has total control over the simulation, being able to: define his own neural network architectures, simulate with color frames, specify the size of the frames, choose between any of the Atari 2600 environments offered by the framework GYM or any of the tridimensional maps of ViZDoom platform. Besides that, this repository presents the possibility of visualization the trained agent with the test mode, it is possible to choose to render or not the environment to the user, the continuation of training, transfer learning and others (more details in features).
To the developers and interested people, it is important to emphasize that all the codes in this repository - functions, and classes - are commented out to facilitate understanding.
- Parallel execution mode for the reinforcement learning algothrims (some examples are 30% faster with this mode).
- Bidimensional (OpenAi Gym) and tridimensional environments (ViZDoom) for training and testing the agent.
- Two exclusive maps, for ViZDoom, simulating a mobile robotics problem.
- Configuration of the training/testing of an agent via terminal commands or configuration files .cfg (more information in the sections: examples and documentation-parameters)
- Ease and robustness to define the simulation parameters without the need of changing the main code (See section: CFG files).
- Storage of training information in .csv files (more details here) and neural network's weights as a .h5 file.
- Ease in the creation of network architecture without the need of changing the main code (See section: Defining your own neural network architecture).
- Simulation with colorful or monochromatic frames (more details here).
- Storage of episodes over the training and states over the testing as animated images .gif.
- Pre-trained weights for the ViZDoom map labyrinth (more details here).
During the algorithm development, it was sought the best ways to improve the processing of frames per second. The part that demands the greater amount of time in the processing is the neural networks’ utilization. During the calculation of the neural networks training error, we need the results from both neural networks Q and Q_target for all N samples taken from the replay memory. Thus, this part of the code was thought in a way that it could take full advantage of the vectorized computation, so python for loops were replaced by Numpy vectorization, and later changed to Tensorflow vectorization. Thus, if the user has a GPU, the code will take advantage of the massive parallelism provided by the GPU in order to get the faster execution of the algorithm.
Besides the use of neural networks, the part that uses the most processing resources is the sampling of experiences from the replay memory as the replay memory is fulfilled. For attenuation of this problem, parallel processing (multi-threading) approach was developed for the DQN and DRQN algorithms. The parallel mode basically consists of sampling the experiences from the replay memory in parallel while the decision algorithm is executed. Thus, when we arrive at the training part of the neural network, the computational cost of the samples has already been executed. The following figure demonstrates how the serial (single-threading) and parallel (multi-threading) approaches are performed.
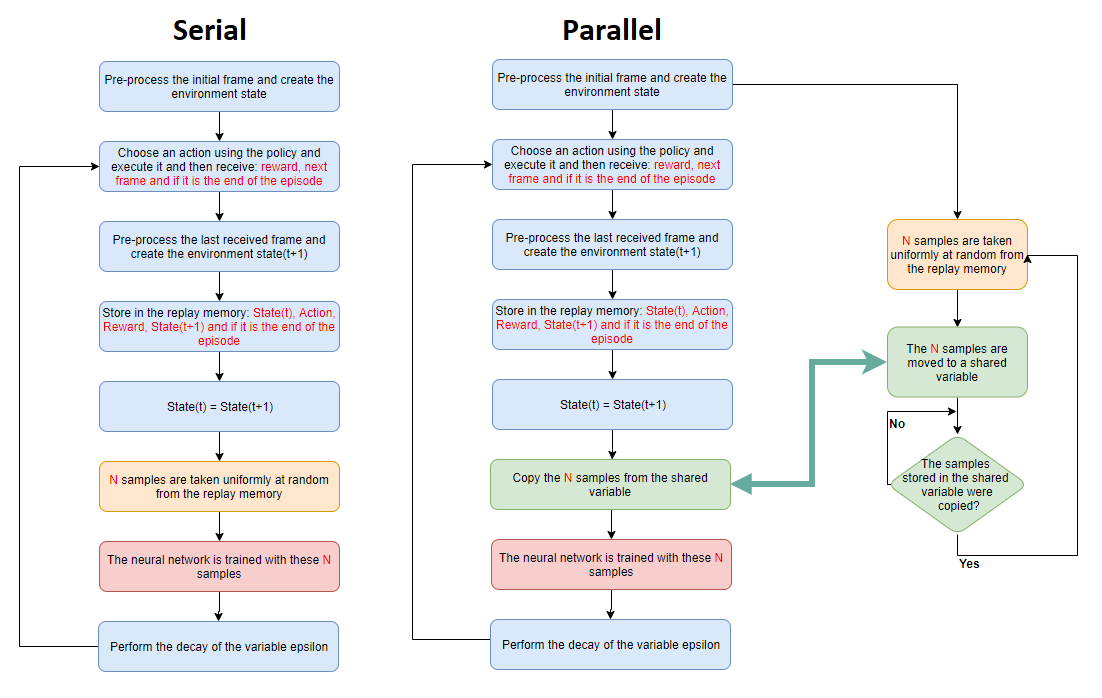
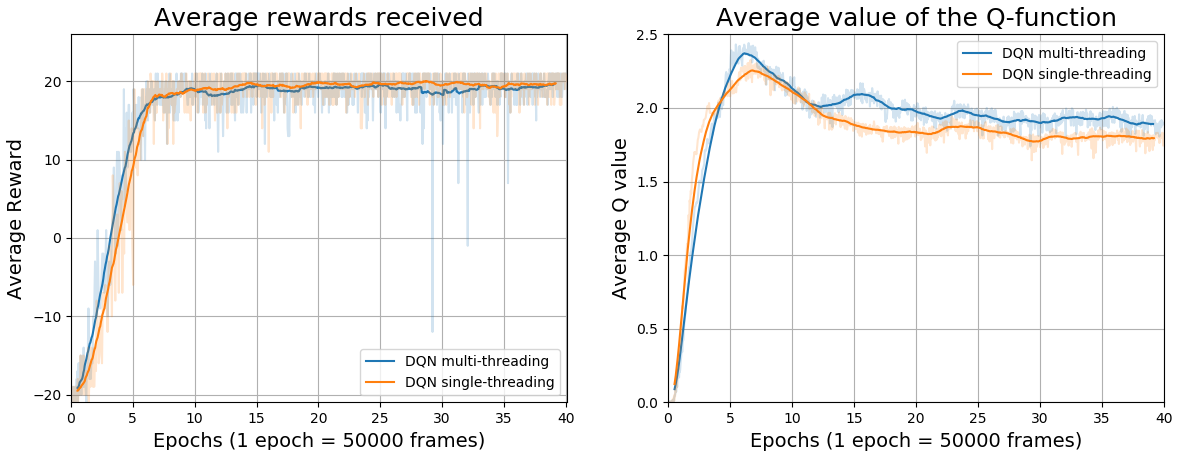
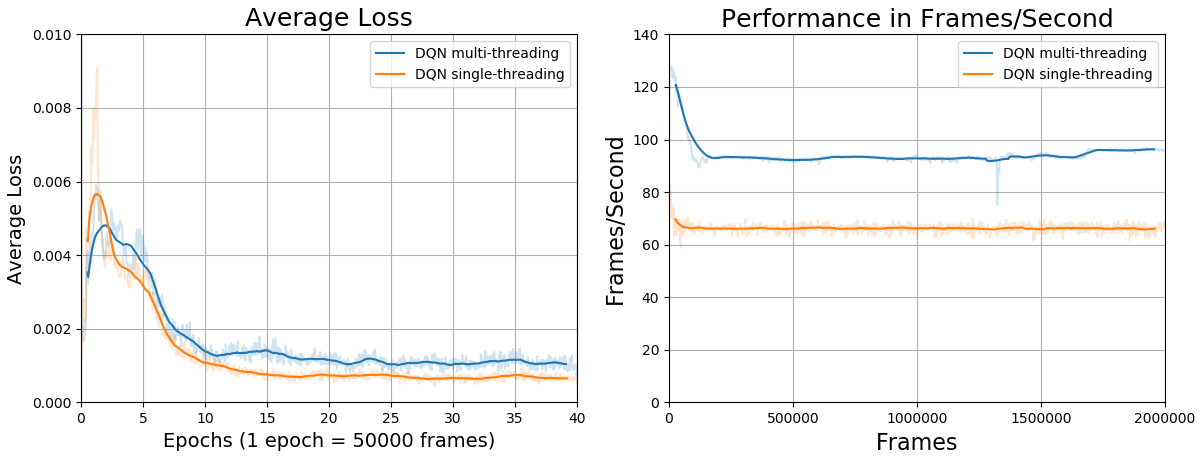
Following, there are some comparative images between the performances in frames/second of the serial mode and the parallel mode for an agent trained in the game of Atari 2600 Pong with 2 million frames. As can be seen, the parallel version takes 30% less simulation time to conclude the training in comparison to the standard version (serial version).
| Type of processing | Average Frames/second | Simulation time |
|---|---|---|
| Serial | 94.9 | 5 hours and 54 minutes |
| Parallel | 66.39 | 8 hours and 23 minutes |
An important point to be emphasized in the parallel approach is the fact that it introduces a sampling delay of one sample in the algorithm. In other words, the experience of one iteration t can only be sampled in the next iteration t + 1. This is due to the fact that the sampling will already have occurred at the time the agent is interacting with the environment. However, as we can see from the training images below, the learning process is minimally affected. In fact, as all experiments are sampled evenly from the replay memory, with a full memory with 100000 experiences, we have that the probability of an experience to be chosen is 0.001%. Thus, it can be concluded that the learning process of the DQN and DRQN algorithms is robust enough so it can’t be affected by this delay of one sampling. Thus, multi-threading mode is recommended for simulations performed using the scripts in this repository due to their faster processing.
- Installation
- Documentation-parameters
- Configuration files .CFG
- Defining your own neural network architecture
- Information about the exclusive ViZDoom maps
- Information about the pre-trained weights
- Examples
If this repository was useful for your research, please consider citing:
@misc{LVTeixeira,
author = {Leonardo Viana Teixeira},
title = {Development of an intelligent agent for autonomous exploration of 3D environments via Visual Reinforcement Learning},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
url = {https://github.com/vtleonardo/Reinforcement-Learning},
}
To Caio Vinícios Juvêncio da Silva for helping me out with the english translation.
Since this project is maintained and developed in my free time. All bug fixes (including grammar and spelling errors), new examples, ideias of new features and design suggestions and other contributions are welcome!
- [1] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. Nature, 518(7540):529, 2015.
- [2] Matthew Hausknecht and Peter Stone. Deep recurrent q-learning for partially observable mdps. CoRR, abs/1507.06527, 2015.
- [3] Max Lapan. Speeding up dqn on pytorch: how to solve pong in 30 minutes. November 23, 2017. Available at: https://medium.com/mlreview/speeding-up-dqn-on-pytorch-solving-pong-in-30-minutes-81a1bd2dff55. Accessed: November 07, 2018.
- [4] Daniel Seita. Frame Skipping and Pre-Processing for Deep Q-Networks on Atari 2600 Games. November 25, 2016. Available at: https://danieltakeshi.github.io/2016/11/25/frame-skipping-and-preprocessing-for-deep-q-networks-on-atari-2600-games. Accessed: January 04, 2019.